Avoir la volonté de mettre la data au cœur d’une stratégie commerciale et produit est une chose, être en mesure de construire une équipe data solide, capable de diffuser efficacement ses analyses dans les différentes strates de l’entreprise, en est une autre.
La construction d’une équipe data est une étape complexe pour une organisation. Cela implique la mobilisation de compétences diverses, un recrutement avisé, ainsi qu’une connaissance précise des besoins et des objectifs à atteindre.
Dans cet article nous abordons les étapes clés de cette construction : définition des besoins en fonction des objectifs et de la maturité data, choix du modèle d’intégration avec les autres équipes et bien sûr les profils à privilégier.
📕 Sommaire
#1 Définir les besoins data de l’organisation
Toutes les entreprises ne sont pas égales face à leurs données, certaines ont saisi l’importance de cette matière dans leur croissance, d’autres ont accumulé plus de retard et sont aujourd’hui incapables de les exploiter.
En amont de la constitution d’une équipe data, il est important pour une entreprise d’évaluer son degré de maturité, pour ainsi mieux définir les étapes à suivre vers le Graal et l’organisation “data driven”.
Quelle est la maturité data de votre entreprise ?
La maturité data peut se définir par l’ensemble des moyens, connaissances et actions visant à améliorer la performance globale de l’entreprise grâce aux données.
Tout d’abord, est définie comme donnée toute information utilisée par l’entreprise pour automatiser ou numériser des processus. Les données sont issues de sources diverses (CRM, équipements, capteurs) et leur volume est amené à augmenter dans les années à venir.
Les 5 piliers de la maturité data
Dans son enquête menée en Novembre 2021 auprès de 179 entreprises en Ile-de-France, l’Observatoire de la Maturité Data a établi un rapport qui met en exergue plusieurs points clés.
Pour évaluer la maturité data d’une organisation, l’observatoire a défini 5 piliers pour situer la maturité des entreprises sur le sujet.
- Le Potentiel data : Désigne la richesse et diversité des données disponibles au sein de l’entreprise afin de déterminer le potentiel de valorisation.
- La stratégie data : Qui vise à évaluer la capacité de l’entreprise à générer de la valeur grâce à son patrimoine
- L’organisation et la gouvernance : Permettent d’évaluer l’organisation et les règles permettant d’optimiser l’efficacité de la gestion des données dans l’entreprise (Ethique des données, RGPD, Cybersécurité)
- Les compétences : Moyens humains et compétences internes mobilisés pour la valorisation des données dans l’entreprise.
- La culture data : Reflète tous les aspects liés à la sensibilité des acteurs de l’entreprise vis-à-vis de l’usage des données et la connaissance des enjeux.
La maturité d’une organisation est évaluée au niveau de la quantité de données qu’elle possède, mais également à travers sa stratégie, sa gouvernance, sa capacité à instaurer une culture data et à susciter l’adhésion des collaborateurs pour la valoriser.
Les 7 profils de maturité data
Sur la base de ces piliers, nous ressortons 7 niveaux de maturité qui ont été déterminés pour permettre à une organisation de se situer.
- Niveau 0: Pas digitalisé
- Niveau 1: Sans outil de pilotage
- Niveau 2: Pilotage classique
- Niveau 3: Pilotage évolué (BI)
- Niveau 4: Pilotage prédictif
- Niveau 5: Management orienté data
- Niveau 6: Full Data Driven
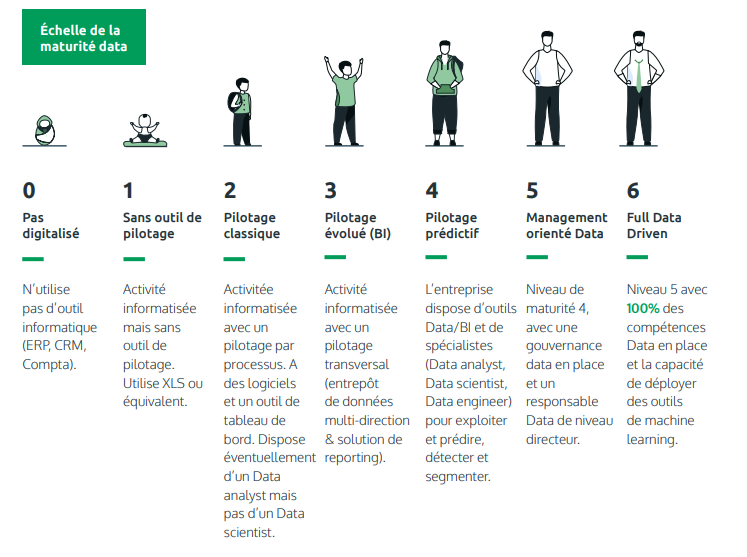
Source : Observatoire de la Maturité Data
Aujourd’hui, les entreprises prennent conscience de leur retard et mettent en place les outils de pilotage et via les outils de reportings. Cependant, à peine 7% des entreprises interrogées sont suffisamment matures pour passer l’étape du pilotage prédictif impliquant des compétences en Data Science.
Le schéma ci-dessous nous montre la répartition des entreprises sur l’échelle de maturité.

Source : Observatoire de la Maturité Data
L’importance du patrimoine Data
Le patrimoine data, aussi appelé Capital Data (ou capital données) désigne l’ensemble des informations que possède une organisation.
La naissance de solutions basées sur le Machine Learning et Deep Learning a transformé tous les actifs d’une entreprise en source de données potentielle et exploitable. Il est donc important d’avoir une lecture structurée du capital d’informations, et de bien définir les typologies et sources de données (notamment en distinguant les données structurées des non-structurées).
Le croisement des données permet de faire ressortir des informations qui peuvent être précieuses. Pour ceci, il est important de les classer selon certaines caractéristiques:
- Les données CRM
- Les données volatiles / données persistantes
- Les données sémantiques (tweets, posts sur les réseaux sociaux)
- Données externes vs données propriétaires
Avoir une vision de clair de ce patrimoine est incontournable pour définir son niveau de maturité.
Objectifs à atteindre grâce aux données
Les cas d’usage potentiels sont très nombreux, et au regard de ces possibilités, l’identification de ces cas est une étape clé. Il est donc primordial de prioriser les objectifs à atteindre.
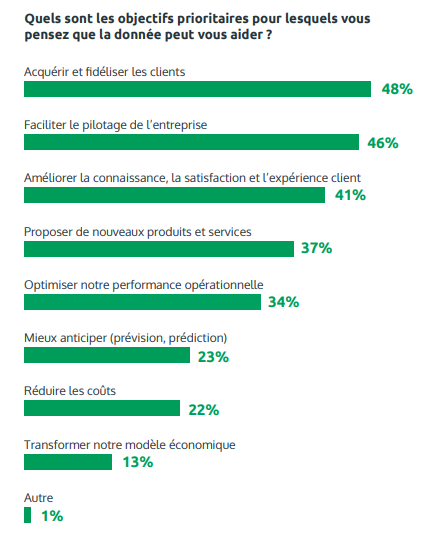
Source : Observatoire de la Maturité Data
À travers le graphique ci-dessus, on dégage 4 types d’objectifs :
- Métiers ou Business : Acquérir, fidéliser, améliorer l’expérience client.
- Prise de décision : Pilotage, anticiper.
- Productivité : Performance opérationnelle, réduction des coûts.
- Rupture : Transformer les modèles économiques
La nature des objectifs que vous allez poursuivre via la construction de votre équipe data va impacter le choix des différents profils qui la constitueront.
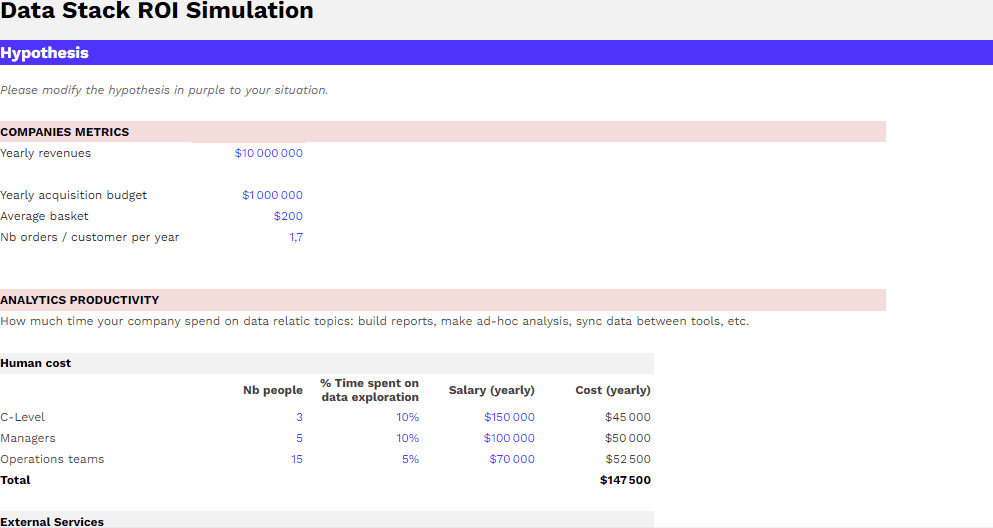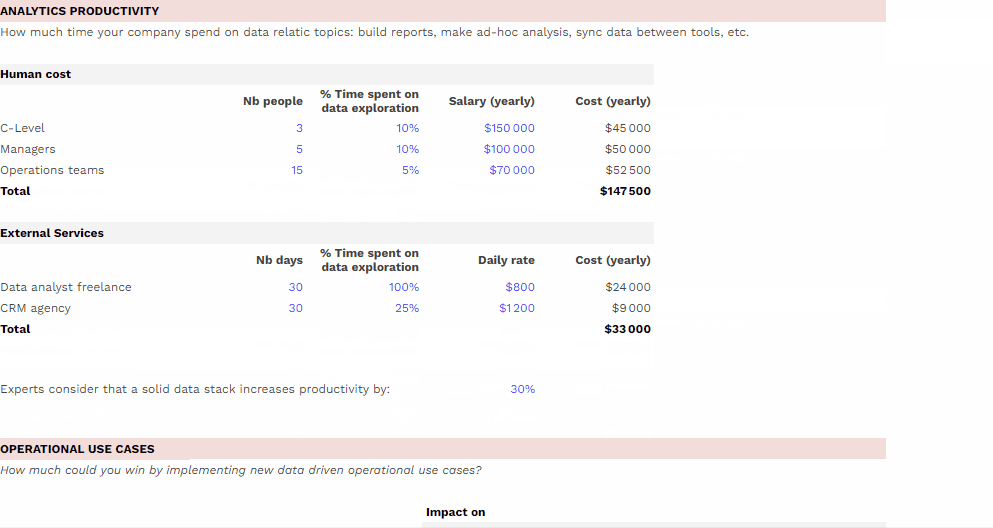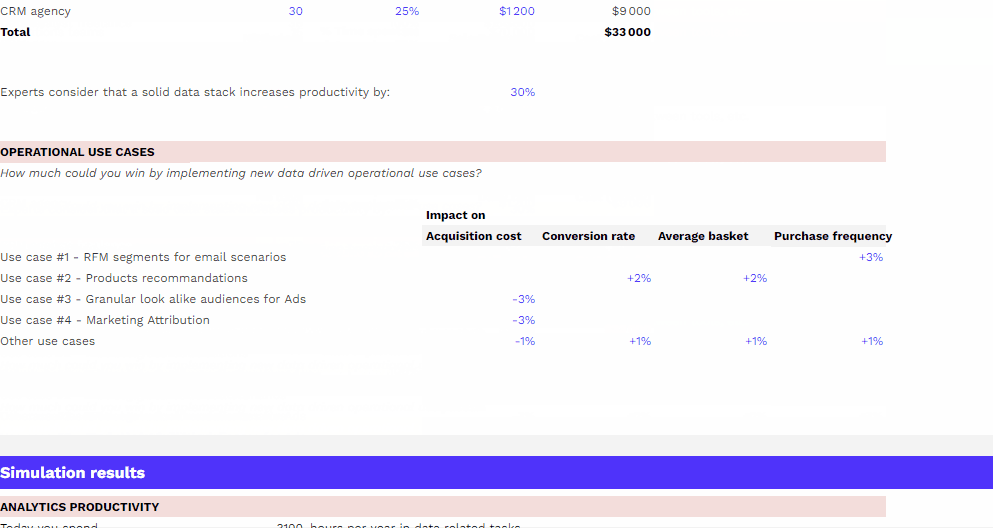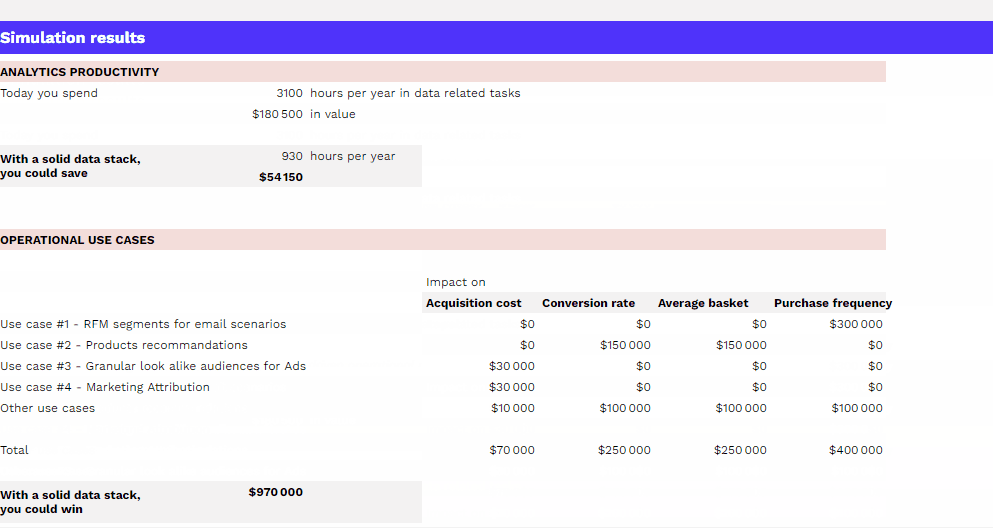
Comment mesurer le ROI de mon dispositif data ?
Impact sur la productivité des équipes et sur les performances marketing, simulez gratuitement le ROI de votre dispositif data grâce à notre template.
#2 Intégrer l’équipe data à votre organisation
En amont de la constitution de l’équipe data, une bonne démarche consiste à identifier, au sein de l’organisation, les personnes dont les postes sont en lien avec l’exploitation des données. Il ne s’agit peut-être pas uniquement des personnes ayant le terme « données » dans leur titre, mais de tout employé qui n’a pas peur de l’analyse des données ou qui possède déjà des compétences en SQL, comme les Business Ops par exemple.
Si vous ne prenez pas le temps de localiser soigneusement les personnes qui travaillent déjà sur les données, vous risquez de vous retrouver avec une structure d’équipe de données mal structurée, peu susceptible de répondre aux besoins de votre entreprise.
Aussi, avant de choisir le modèle d’intégration de votre équipe data, gardez en tête que cette structure doit être le plus évolutive possible.
Modèles d’intégration centralisé
Le modèle centralisé place l’équipe Data au centre des activités des autres fonctions. C’est une structure qui se présente sous forme de plateforme de données centralisée, où l’équipe chargée des données a accès à la data et fournit des services à l’ensemble des autres fonctions dans le cadre de leurs projets.
Dans le modèle centralisé, l’équipe data est dirigée par le responsable des données, et elle entretient une relation similaire à celle d’un consultant avec son client.
L’équipe chargée des données peut appuyer les autres équipes tout en travaillant sur son propre agenda et le responsable des données dispose d’une vue panoramique de la stratégie de l’entreprise, et peut affecter les personnes chargées des données aux projets les plus adaptés à leurs compétences.

Source : Castordoc – How to build your data team
Aussi, ce modèle offre plus de possibilités pour développer les talents et les compétences du fait de la grande variété de projets et du travail en équipe qui favorise les acquisitions de compétences. Cependant, il implique pour le responsable des données de veiller à ne pas déconnecter l’équipe data des autres unités opérationnelles car les data analysts, scientists et engineers ne sont pas immergés dans les activités quotidiennes.
Ce modèle est particulièrement adapté aux entreprises en pleine croissance car sa flexibilité lui permet de s’adapter aux besoins changeants de celles-ci.
Modèle Décentralisé
Contrairement au modèle centralisé, qui place l’équipe data au centre des activités, le modèle décentralisé préconise le recrutement des profils nécessaires pour chaque unité opérationnelle, mais qui garde tout de même la plateforme data centralisée. L’équipe constituée répond directement au responsable de l’unité et les profils data recrutés sont impliqués dans les problématiques spécifiques à leur entité d’appartenance, avec peu d’interactions avec les autres équipes data.
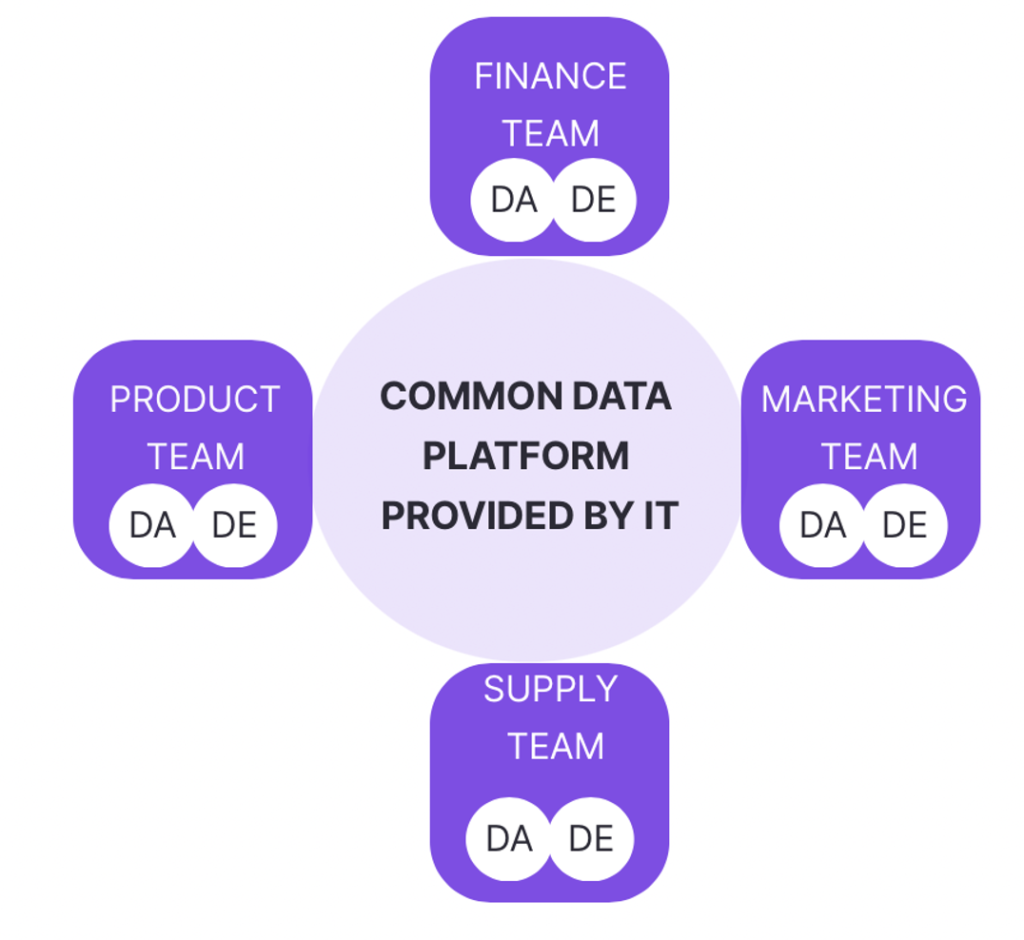
Source : Castordoc – How to build your data team
L’avantage de ce modèle est que chaque unité peut appliquer la méthodologie agile car les membres étant en lien direct avec le responsable, l’équipe data est plus réactive et est dédiée à des fonctions spécifiques. Par ailleurs, les données étant disponibles directement au sein des équipes de l’unité, cela permet à l’équipe data d’accéder directement aux ressources dont elles ont besoin.
Modèle Fédéré / Centre d’excellence
Enfin, il y a le modèle fédéré, qui est plus adapté aux entreprises à la maturité data avérée. Dans ce modèle, les profils chargés d’effectuer les tâches relatives aux données sont intégrés dans les unités commerciales. Mais sont pilotées par un groupe centralisé (centre d’excellence) qui assure le soutien et la formation. Bien que les Data Analysts et data scientists soient déployés dans les différents départements, il y a toujours un responsable de données pour superviser le projet en cours. Cela assure la priorisation des projets et la qualité des services.
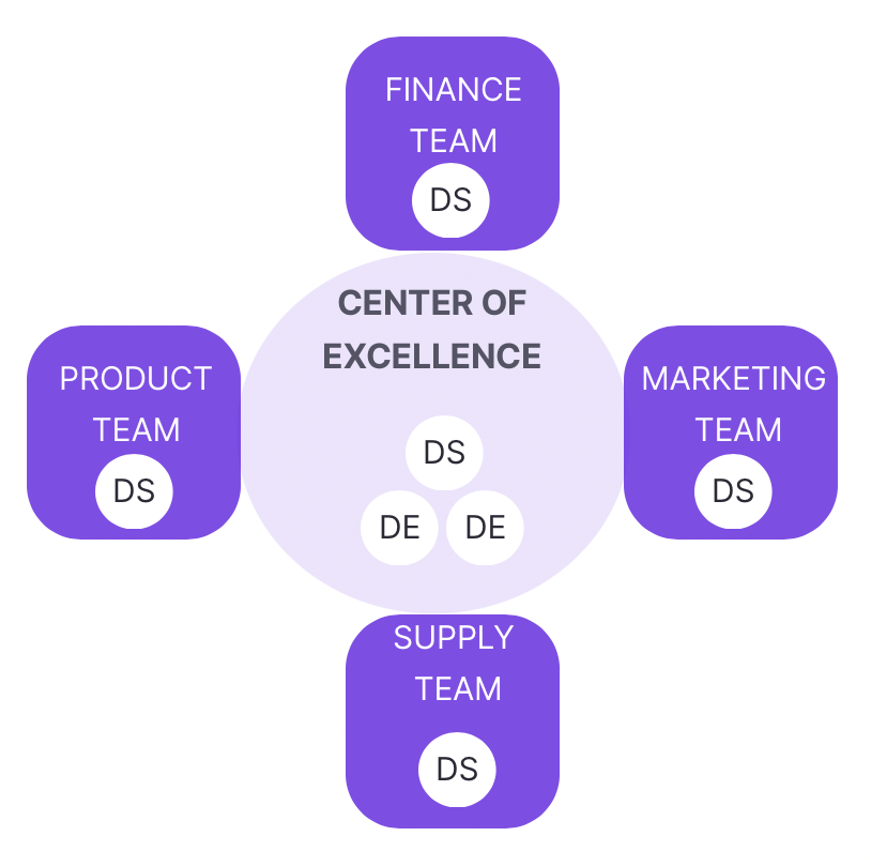
Source : Castordoc – How to build your data team
Le modèle fédéré convient aux grandes entreprises disposant d’une feuille de route claire et qui sont « data driven ». Cependant, il implique une équipe data plus importante car il y a des profils dans le centre d’excellence ainsi que dans les unités.
#3 Constitution de l’équipe Data
Les métiers incontournables d’une équipe Data
Pour avoir une bonne compréhension des trois principaux profils en Data Science, envisageons ceux-ci dans le déroulement d’un projet type en data.
Un projet data se décline par 4 étapes principales:
- La collecte de données : extraire et réunir les données pertinentes au projet
- L’exploration : Comprendre la donnée qui a été collectée
- L’exploitation : Valoriser les données à disposition dans un but prédictif. Cette étape recourt au Machine Learning et Deep Learning
- La Mise en production (phase d’industrialisation): Mise en production des modèles et ainsi faire passer le projet à grande échelle.
Le Data Analyst
- Missions
Le Data Analyst explore les données dans le but d’avoir une visibilité sur le passé, et d’analyser les tendances et les corrélations pour aider à la prise de décision. Ses missions s’articulent autour des tâches qui ont trait à l’extraction, l’analyse, et la présentation des données.
- L’extraction des données depuis une base grâce à SQL
- Analyse des données (en Python ou R)
- Création de dashboards avec les outils de Business Intelligence (Tableau, Power BI)
- Optimisation des processus grâce au Machine Learning
- Intervention dans le projet data
Bien que le périmètre d’intervention du Data Analyst puisse varier en fonction de la structure dans laquelle il évolue, on le trouvera très souvent dans la phase d’exploration, car le gros de son travail sera de comprendre la data à disposition et de lui donner du sens. Le Data Analyst consacre donc une grande partie de son temps à explorer les données, les analyser et les présenter au management.
Pour avoir une vision plus exhaustive sur les compétences d’un Data Analyst, vous pouvez vous référer à notre article dédié au sujet.
Le Data Scientist / Machine Learning Engineer
Le Data Scientist est la « star » dans l’univers de la Data. Son profil est très prisé et il joue un rôle central dans l’ensemble du pipeline d’un projet data. Selon le type de structure dans laquelle il évolue, son rôle peut se concentrer sur la création des modèles de prédiction (Machine Learning).
Par la nature transverse de son métier, les missions du Data Scientist sont très variées, mais le plus souvent, on retrouve les tâches suivantes:
- Développement des algorithmes de Machine Learning pour optimiser un processus ou automatiser une tâche.
- Présentation des résultats d’analyse
- Recueil des données pour alimenter la database ou pour construire un algorithme.
- Exploration et Nettoyage des données pour les rendre utilisables.
Intervention dans le projet data
Dans une organisation de plus petite taille, et notamment dans une startup, le data scientist occupe un rôle de couteau suisse, ses taches s’étendent de l’exploration des données à la mise en production. Dans une structure plus importante et au sein d’une équipe avec divers profils, son rôle est plus spécifique et il est fréquent que le Data Scientist soit assigné aux seules missions de construction des modèles de Machine Learning.
Il est à souligner que l’arrivée à maturité d’un grand nombre d’entreprises en matière d’intelligence artificielle a favorisé la mutation du profil de data scientist. En effet, les entreprises matures sont passées du stade du POC (Proof of Concept) à la phase d’industrialisation et doivent par conséquent couvrir tout le cycle de vie d’un modèle de Machine Learning, de sa conception à son monitoring en passant par le déploiement. Par conséquent, le rôle du Data Scientist est voué à se transformer et inclure l’étape de la mise en production, ce qui le rapproche du Data Engineer.
Le Data Engineer
- Mission et compétences
Le Data Engineer travaille dans divers contextes pour construire des systèmes servant à collecter, gérer et transformer les données « brutes » (raw data) en informations exploitables que le Data Analyst et Data Scientist peut exploiter. L’objectif est d’accroître l’accessibilité aux données afin qu’une organisation puisse reposer dessus pour évaluer et optimiser ses performances. Ses principales missions sont :
- L’industrialisation / monitoring des algorithmes de Machine Learning développés par les data scientists
- La centralisation et standardisation des données récoltées dans un Data Lake
- La conception et implémentation du pipeline ETL.
- Monitoring des flux de données.
A retenir dans cet ensemble de missions, le processus ETL constitue le coeur du métier du Data Engineer. En effet, l’Extraction, la Transformation et le chargement (Load) des données sont les principales étapes qui permettent à une organisation de devenir « data driven ».
Les compétences du Data Engineer sont surtout techniques, elles comprennent la maîtrise des langages de programmation, la connaissance d’une ou plusieurs plateformes Cloud, ainsi que les outils de standardisation d’environnement.
Dans le cadre d’un projet data classique, le Data Engineer intervient principalement en amont lors de l’implémentation du processus ETL.
Son rôle comprend aussi la phase finale d’un projet data, à savoir la mise en production. Dans cette phase, il est chargé d’industrialiser le modèle et d’assurer sa scalabilité.
Postes plus spécifiques : Machine Learning Scientist, Data Architect, Cloud Data Engineer.
Bien que le Data Analyst, Scientist et Engineer soient les trois profils les plus connus et les plus recherchés, les besoins des entreprises mettent en lumière des profils parfois moins classiques, mais qui répondent aux lacunes de compétences pour la réalisation d’un projet.
Ainsi, lorsqu’une entreprise dispose de profils techniques comme le Data Engineer et le Data Scientist, mais qu’elle a besoin d’un profil scientifique plus pointu dans un domaine précis (Computer vision, time series), ou pour améliorer ses algorithmes de Machine Learning, elle peut recruter un Machine Learning Scientist, dont le rôle premier sera d’effectuer les travaux de recherche sur les algorithmes avant leur mise en production.
Le Cloud Data Engineer est un autre exemple de profil à considérer lorsqu’une entreprise repose sa stratégie data sur le Cloud Computing.
Le processus de recrutement
Multiplicité des entretiens et variation selon les profils.
Les entreprises font passer quatre à cinq entretiens dans la plupart des cas. Les recrutements comprennent en général plusieurs tests, des questions théoriques pour vérifier les connaissances indispensables chez le candidat. Des tests techniques, et des entretiens opérationnels avec les pairs. Ainsi, la multiplicité des entretiens peut rendre le processus plus ou moins long. Celui-ci peut durer quelques jours à plusieurs semaines.
La structure de l’entreprise détermine ensuite la forme des entretiens. Lorsqu’il s’agit de cabinets de conseils, il est coutume de faire passer un entretien « conseil » pour évaluer la capacité de consultant du candidat. Mais dans une startup, le processus contient un premier entretien RH, suivi d’un ou deux tests techniques, et un test « fit » pour valider la compatibilité du candidat avec la culture de l’entreprise.
Tests techniques
Cette phase vise à tester les compétences en programmation et la maîtrise des outils exigés pour le profil recherché. Afin de contrôler cela, une première vérification via le CV est nécessaire, pour voir si le candidat a déjà mis en pratique les éléments qu’il a mentionnés.
Des questions techniques simples peuvent être posées durant l’entretien pour vérifier le niveau attendu, et un exercice de programmation permet d’évaluer l’expérience et le savoir faire. Aussi, il est courant de tester les connaissances du candidat en Machine Learning (exemple : Différence entre Machine Learning Supervisé, et Non Supervisé)
Suivant le profil souhaité, le recruteur peut tester le candidat sur la maîtrise d’une technologie inhérente au poste (SQL ou Tableau pour le Data Analyst par exemple, ou la programmation en Scala pour le Data Engineer).
L’importance des soft skills
En dépit de leurs aspects très techniques, les postes en Data accordent une grande importance pour le savoir-être des candidats et leur capacité à communiquer avec des interlocuteurs non spécialistes. Ainsi, un Data Scientist par exemple, doit être capable d’expliquer les outils qu’il a développés et les méthodes mises en œuvre en sachant adapter son discours à une audience qui n’a pas le bagage technique.
Parmi les soft skills, notons quelques-unes des compétences incontournables :
- Curiosité intellectuelle : Chercher à en savoir davantage que ce que les résultats montrent en surface.
- Connaissance métier : Il est important que le profil recruté connaisse les métiers et le domaine d’activité dans lequel il opère.
- Communication efficace : Comme mentionné ci-dessus, un profil spécialisé est amené à communiquer avec un interlocuteur qui n’a pas le bagage technique, une communication « vulgarisée » permet de fluidifier les échanges et le déroulement des projets, et d’obtenir des résultats plus facilement.
Enjeux RH: Formation continue et Turnover
Recruter et intégrer l’équipe data au sein d’une organisation est une étape clé, mais la nature évolutive du domaine, et les aspirations personnelles et professionnelles des candidats obligent les entreprises à considérer la veille technologique et la montée en compétences comme des enjeux clés pour leur compétitivité.
Formation Continue et Upskilling
Compte tenu du caractère innovant de la Data Science, les plans de formation classiques se révèlent peu efficaces. En effet, un Data scientist est régulièrement amené à lire les papiers scientifiques et autres documentations pour rester au fait des dernières découvertes, de nouveaux algorithmes, ou de nouvelles pratiques.
Par conséquent, les formations courtes et régulières s’avèrent plus adaptées pour suivre le rythme des changements.
Dans le cas d’un pur player, il n’est pas rare que l’organisation ait en son sein un département R&D pour rester à la pointe. Quantmetry, un cabinet de conseil spécialisé en data et pure player en IA, dédie près de 20% de la masse salariale à la R&D et ce, pour permettre à ses collaborateurs de prendre part à des projets en partenariat avec le monde académique.
Aussi, la démarche de formation peut se faire à l’initiative de l’employé. Il est nécessaire pour un bon profil de mettre en place une activité de veille sur les technologies. Notamment à travers les blogs d’entreprises actrices dans le Big Data, ou des publications dans les revues universitaires.
Un autre moyen pour se former à travers la pratique consiste à participer aux compétitions en Data Science. Cette approche permet de participer à des événements et de s’améliorer au contact des autres par le partage de connaissances.
La démarche de formation peut se faire à l’initiative du management en proposant des formations courtes à intervalles réguliers. Mais c’est une approche qui peut être coûteuse et chronophage car elle rogne sur l’emploi du temps du salarié. Cependant, il est nécessaire que le Data Analyst / Scientist / Engineer soit proactif et se forme régulièrement seul.
Turnover
La Data Science a connu une évolution fulgurante durant les dernières années, le volume de données a explosé et les besoins des entreprises avec.
Ce faisant, les métiers de la data sont en tension et les entreprises peinent à recruter les profils nécessaires.
Par conséquent, les candidats se retrouvent en position de force et ont plus de facilités pour orienter leur carrière professionnelle et leurs prétentions salariales.
Ainsi, cet état de fait implique pour les entreprises de gérer la rotation des effectifs, et tenter de maintenir un taux de turnover au minimum.
Ainsi, 365 Data Science, un organisme de formation en ligne spécialisé dans le domaine, a dressé dans cet article le portrait robot du Data Scientist en 2021 (Notre constat est extensible au profil de Data Analyst et Data Engineer).

Les résultats les plus intéressants de l’enquête révèlent que le Data Scientist « type » est employé depuis environ un an, avec une moyenne de 6 ans d’expérience préalable dans le domaine. Aussi, les professionnels interrogés ont changé d’entreprise deux fois ou plus depuis 2017.
Les raisons de ce turnover sont multiples, mais nous pouvons avancer quelques hypothèses pour l’expliquer.
- Le manque d’engagement des employés est l’une des principales causes de la rotation du personnel. Lorsqu’un employé ne ressent pas l’impact de son rôle, estime que son salaire est insatisfaisant, ou est affecté par son environnement de travail, il est plus simple dans un marché en tension d’avoir de meilleures opportunités.
- Un décalage entre les attentes du profil recruté et les missions quotidiennes: Si le recruteur ne définit pas correctement les rôles dans la description du poste, cela peut induire en erreur le candidat et ce dernier se verra octroyer des tâches qui sont en décalage avec ses compétences.
- Opportunités: L’évolution constante du domaine et l’apparition de nouveaux défis incitent les professionnels à suivre le rythme et à rechercher de nouvelles opportunités. Sans possibilité de développement professionnel, les profils en Data Science n’auront aucune difficulté à changer d’employeur jusqu’à trouver l’entreprise qui correspond à leurs besoins.
La rétention des profils est donc primordiale, et les entreprises doivent accompagner leurs offres avec des avantages pour fidéliser les employés:
- Équilibre vie privée / vie professionnelle.
- Télétravail : Comme le montre une étude menée par Microsoft, 70% des employés souhaitent un environnement de travail plus flexible.
- Opportunités : formations pour acquérir une compétence spécifique, implication des employés dans la définition des objectifs de développement professionnel dans l’entreprise, possibilité de promotion. Autant de mesures qu’une entreprise peut prendre afin qu’un profil recruté soit impliqué et motivé pour contribuer à sa croissance.