A Data Engineer cryopreserved in 2010 and woken up by mischief today would no longer understand much about modern stack data.
Remember, in only a few years, the way of collecting, extracting, transporting, storing, preparing, transforming, redistributing, and activating data has completely changed.
We changed the world, and opportunities to generate business through data have never been greater.
What does the modern data stack look like?
We can start with a macro diagram.
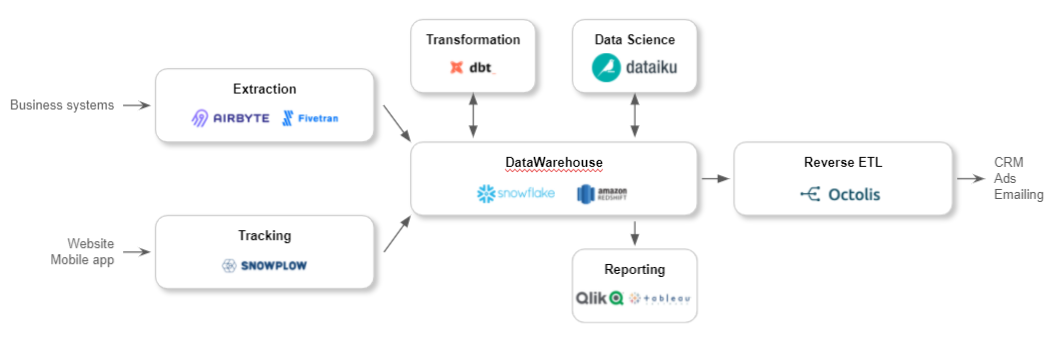
The most striking development is the centralized place occupied (gradually) by the Cloud Data Warehouse, which has become the pivotal system of the IT infrastructure. From this flow all other notable transformations:
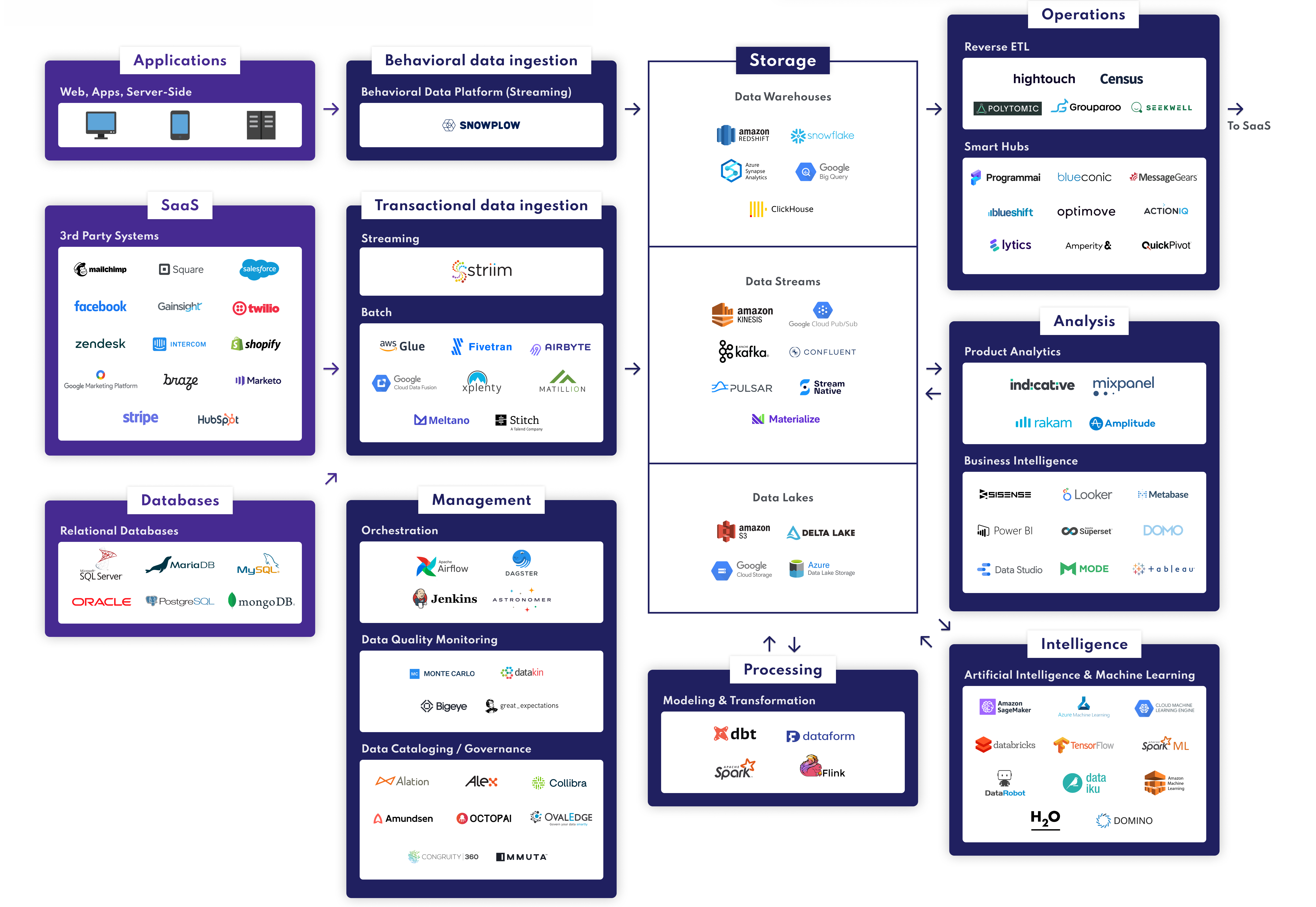
Let’s get to the heart of the matter.
We’ll introduce you to the modern data stack outlines; we chose two angles:
🌱 The changes behind the modern data stack
Modern data stack defines the set of tools and databases used to manage the data that feed business applications.
The Stack data’s architecture has undergone profound transformations in recent years, marked by:
The rise of the Cloud DataWarehouses (DWH)
Data Warehouse technology is as old as the world, or almost. In any case, it’s not a new word. And yet, we’ve seen a dramatic transformation of the Data Warehousing landscape over the past decade.
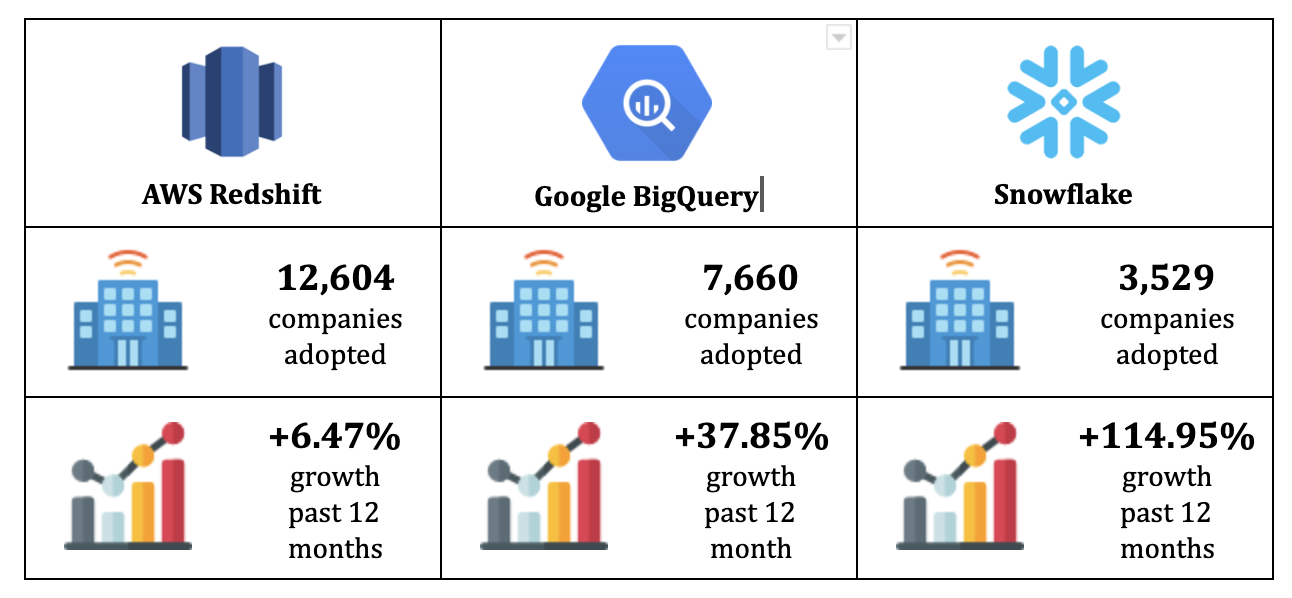
Traditional DWH solutions gradually give way to cloud solutions: the Cloud Data Warehouse. We can precisely date this evolution: October 2012, the date of marketing Amazon’s Cloud DWH solution: Redshift. There’s a clear before and an after, even if Redshift is losing ground today.
The main impetus that birthed the modern data stack came from Amazon, with Redshift. All the other solutions on the market that followed owe a debt to the American giant: Google BigQuery, Snowflake, and a few others. This development is linked to the difference between MPP (Massively parallel processing) or OLAP systems like Redshift and OLTP systems like PostgreSQL. But this discussion deserves a whole article that we’ll probably produce one day.
In short, Redshift can process SQL queries and perform joins on huge data volumes 10 to 10,000 times faster than OLTP databases.
But note that Redshift is not the first MPP database. The first ones appeared a decade earlier, but on the other hand, Redshift is:
In recent years, BigQuery and especially Snowflake have risen in power. These two solutions now have the best offers on the market, both in terms of price and computing power. Special mention for Snowflake, which offers a very interesting pricing model since storage billing is independent of computing billing.
But because we have to give back to Caesar his due – Caesar being Redshift here, let’s remember these few figures:
What changes with Cloud Data Warehouse?
The advent of Redshift and other Cloud Data Warehouse solutions that followed have made it possible to improve on several levels:
The transition from ETL solutions to EL(T)
Extract-Transform-Load = ETL while Extract-Load-(Transform) = EL(T).
Listing these acronyms makes the difference quite easy to understand:
What are the underlying issues of such an inversion? It’s quite simple.
Transformations consist of:
That is the challenge.
Transforming before Loading helps to evacuate part of the data and therefore, avoids overloading the master database too much.
Indeed, that is why all traditional Data Warehouse solutions worked with heavy ETL solutions. It was vital to sort before loading into the DWH with limited storage capacities.
With Cloud Data Warehouses, storage cost has become a commodity, and computing power has increased dramatically.
Result: No need to transform before loading.
The DWH On-Premise – ETL On-Premise combination gradually gives way to the modern Cloud DWH – EL(T) Cloud combination.
Loading data into the Data Warehouse before any transformations avoids asking strategic and business questions when extracting and integrating data into the DWH.
Pipeline management’s cost is considerably reduced; we can afford to load everything into the DWH “without getting carried away” – and thus, we do not deprive ourselves of future use cases for the data.
The trend toward self-service Analytics
We have talked about the Cloud Data Warehouse, which is becoming the backbone of the modern data stack. Upstream, we have the EL(T) tools that connect the multiple data systems and the data warehouse. Data Warehouse Cloud data is then used for BI, data analysis, dashboarding, and reporting.
The advent of Cloud DWH has contributed to “cloudify” not only integration solutions (ETL/ELT) but also BI solutions.
Today, we have dozens of cloud-based BI solutions vendors on the market that are affordable and designed for business users. These easy-to-use solutions offer native connectors with the main Cloud Data Warehouses on the market.
Power BI, Looker, or Tableau are reference Cloud BI solutions:

🔎 Zoom on modern data stack’s bricks
We will now review the main bricks that make up the modern data stack in more detail, starting from the diagram presented in the introduction.
Typical diagram of a modern data stack
We appreciate this modern data stack diagram proposed by a16z.
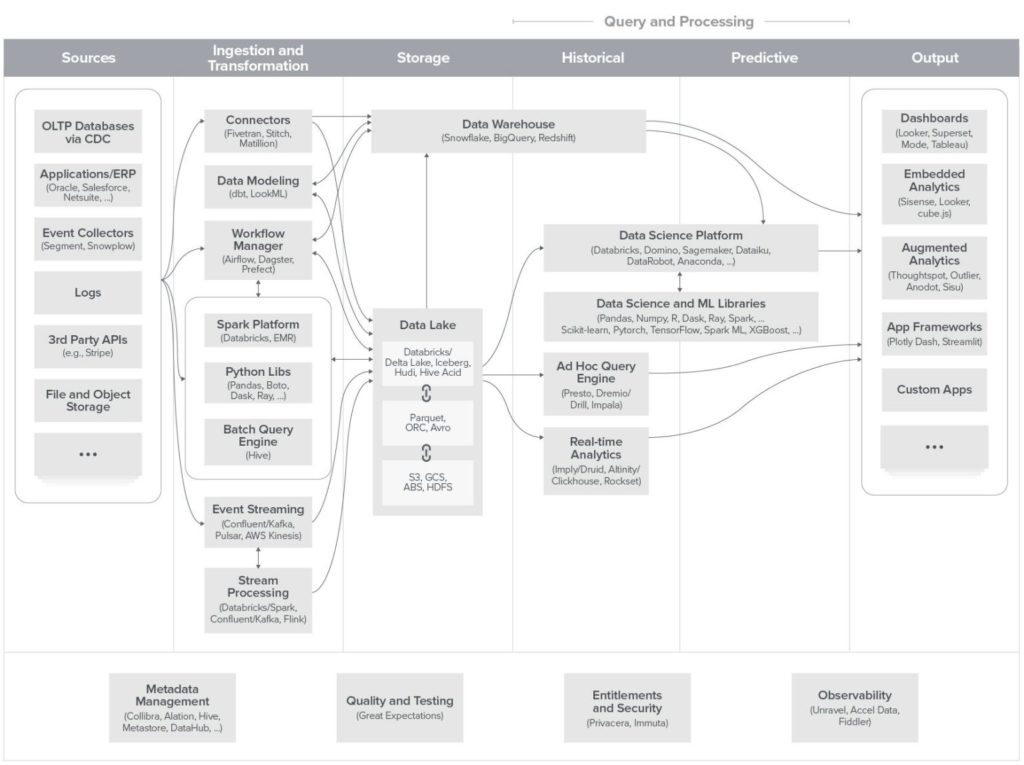
From left to right, we find:
The Data Lake is a bathtub in which all data is poured in bulk without any transformations or processing, in its raw state. This Data Scientists’ tool serves for very advanced data use cases such as Machine Learning.
The Data Warehouse remains a “warehouse” organizing data in a structured way, even if its capacities to integrate semi-structured data are clearly increasing. These capabilities’ development elsewhere makes DWH increasingly pivotal – unlike the “pure” Data Lake, which increasingly plays a secondary role. We shall return to it.
Let’s now review each of these bricks of the modern data stack.
The Cloud Data Warehouse
The Cloud DWH is the foundation of the modern data stack, the pivotal solution around which all other tools revolve.
It stores structured and semi-structured enterprise data and is not just a database. It’s also a data laboratory, a veritable machine. It is a place of data preparation and transformation via one main tool: SQL, even if Python is increasingly used (but that is another subject).
The Cloud Data Warehouse is sometimes built downstream of a Data Lake which serves, as a catch-all, a tub of data stored in its raw state.
We can well use both Data Lake and Cloud Data Warehouse. You don’t necessarily have to choose between the two technologies. To be honest, they fulfill different roles and can be complementary…even if it’s a safe bet that the two technologies are called to merge.
Also, note that some actors, such as Snowflake, offer integrated Cloud Data Warehouse and Data Lake solutions. It’s a possible article’s title: Are Data Lake and Cloud Data Warehouse destined to merge? Though it’s not the subject of this article, it is a debate that stirs many expert heads!
However, the entire modern data stack is organized around the Cloud Data Warehouse, connected or merged with the Data Lake.
EL(T) solutions
As seen in the first section of the article, EL(T) solutions prevail over traditional ETL tools. This evolution reflects a transformation in the data integration process, a significant evolution in building the data pipeline.
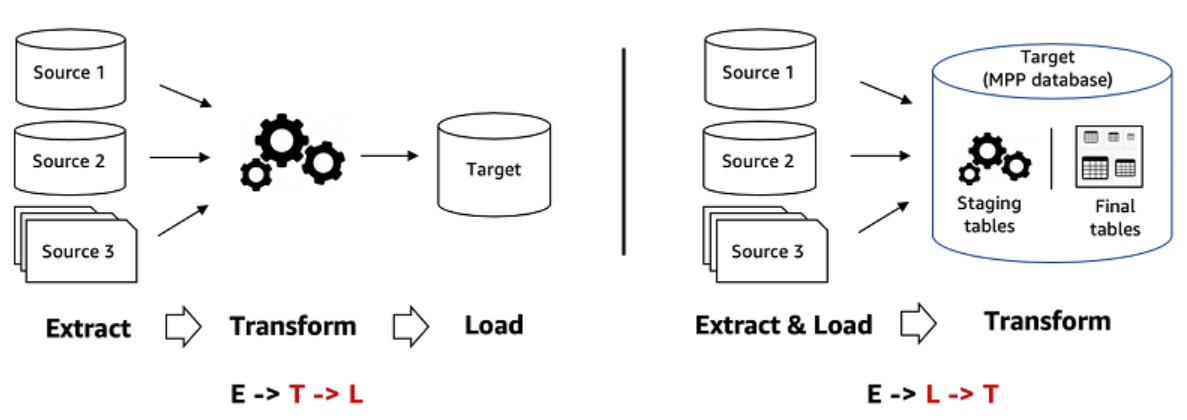
A question you may have asked yourself: Why put “T” into parentheses?
For a simple and good reason, the tool used to build the data pipeline between the source systems and the Cloud Data Warehouse no longer needs to transform the data.
EL(T) Cloud solutions (Portable, Fivetran, Stitch Data, etc.) are primarily used to organize piping. This is their main role. It is now Cloud Data Warehouse solutions and third-party tools that support the transformation phases.
A Cloud DWH solution helps transform data tables with a few lines of SQL.
We’ll have to talk about this evolution again: Most Data Preparation and Data Transformation operations can now be performed in the Cloud Data Warehouse itself, using SQL.
Data Engineers (in Java, Python, and other Scala) are increasingly leaving Data transformations to Data Analysts and business teams using SQL. This also raises a real question: What role for the Data Engineer tomorrow? Its role in the organization and maintenance of modern data stack is not assured.
The goal of a modern data stack is to empower the end-users of the data. It’s increasingly at the service of the business teams and the marketing stack they handle.
The modern data stack breaks down barriers between data and marketing; it is the sine qua non of efficient Data-Marketing, the condition for becoming truly “data-driven.”
Preparation/transformation solutions
In a modern data stack, data preparation, and transformation take place:
Or the most frequent case, by the DWH, reinforced by third-party tools.
Data preparation or transformation is the art of making data usable. This phase consists of answering a simple question: How to transform raw data into a data set that the business can use?
Data transformation is a multifaceted process involving different processing types:
Preparation and transformation tools are also used to maintain Data Quality. Because data “transformation” refers to operations of a different nature, it’s not surprising that the modern data stack hosts several tools belonging to this large multifaceted family.
Data management solutions (Data governance)
Cloud Data Warehouse’s accessibility and usability by a large number of users is, of course, a positive thing. The potential problem is the chaos these expanded accesses can cause in terms of Data Management.
To avoid falling into this trap, the company must absolutely:
Issues around Data Governance are more topical than ever
The first reason we have just mentioned is open access to and editing data stack solutions.
The second reason is the explosion of data volumes which requires the implementation of strict governance rules.
The third reason is the strengthening of the rules governing the use of personal data. The famous GDPR in particular…
Data governance is a sensitive subject that organizations generally deal with inadequately. It’s not the sexiest subject, but it clearly needs to be integrated into the roadmap.
Reverse ETL solutions
Let’s end with a whole new family of data solutions, much sexier and with a promising future: the Reverse ETL. We will soon publish a complete article on the Reverse ETL, its role, and its place in the modern data stack. Let’s summarize here in a few words the issues and functionalities offered by these new kinds of solutions.
The challenge is straightforward: Data from various and varied data sources goes up in the Cloud Data Warehouse but still has a lot of trouble going back down into the management activation tools: CRM, Marketing Automation, ticketing solutions, e-commerce, etc.
Reverse ETL is the solution that organizes and facilitates the transfer of DWH data into the tools used by operational teams.
With a Reverse ETL, data from the Cloud Data Warehouse is no longer just used to feed the BI solution; it is also used to benefit the business teams in their daily tools.
This is why we speak of “Reverse ETL”.
Where the ETL (or ELT) moves the data up in the DWH, the Reverse ETL does the opposite. It pushes the data down from the DWH into the tools.
The Reverse ETL is the solution that connects the data stack and the marketing stack in a broad sense. It’s at the interface of the two.
An example? With a Reverse ETL, you can feed web activity data (stored in the DWH) into the CRM software to help sales reps improve their prospect/customer relationship. But it is one use case among many others… The multiple cases are likely to increase in the coming months and years.
Census, HighTouch, and of course Octolis are three examples of Reverse ETL.
🏁 Conclusion
Infrastructures, technologies, practices, and even Data marketing professions have evolved at an incredible speed in the broadest sense. We’ve seen the central place this modern data stack gives to the Cloud Data Warehouse. Everything revolves around this point of gravity.
Certain recent developments and particularly including the fashion for on-the-shelf Customer Data Platforms, somewhat distort the understanding of what’s really going on.
But make no mistake, the arrow of the future is clearly pointing toward Data Warehouses (which no longer have anything to do with their On-Premise ancestors).
Towards the Cloud DWH side…and the whole ecosystem of tools revolving around it: EL(T), BI Cloud solutions…and of course Reverse ETL.