The CRM solution has long been used as the main customer base by companies. The CRM software, whether “Sales” CRM like Salesforce, or a “Marketing” CRM like Splio or Adobe Campaign, was used both as a customer base and as a customer relationship management tool.
Then a new family of software appeared: the Customer Data Platforms (or CDP), designed to play the role of customer database instead of the CRM. CRM softwares has structural limitations when it comes to database management. CRMs do not handle behavioral data, real-time data or multi-source reconciliation (which is essential for unified data). These limitations explain the rise of CDPs.
With the multiplication of tools, data sources and the growing importance of behavioral data, more and more companies are choosing to manage their customer base independently of their main CRM software. This new paradigm of decoupling the customer base and activation tools is made possible by the latest generation of CDP.
📕 Contents
When looking to build or improve your CRM ecosystem, you need to ask yourself this key question: which system or tool should play the role of the primary customer base? Some companies still believe that CRM is able to play this role. Others, on the other hand, choose to equip themselves with a CDP. Most companies are a bit confused and don’t know what to think. If you are one of them, don’t worry, we have written this article for you.
In this publication, we will start by helping you to better understand the differences between CRM and CDP. We will then take the time to outline the requirements for a customer base to act as a customer repository. This will lead us to discuss the various reasons why we believe that CRM software is no longer suitable for this role.
Understanding the differences between CRM and CDP
First of all, it should be remembered that CDP and CRM are not competing solutions, but complementary ones. A company that is equipped with a CDP usually also has a CRM.
To begin, here is a table summarising the main differences between CRM and CDP:
| CRM | CDP | |
|---|---|---|
| Rôle | Gérer la relation clients : les interactions commerciales (gestion des leads), marketing (campagnes et scénarios) et servicielles (support client)) | Gérer la base de données clients : réconciliation des données autour d’un ID client, hub data pour les autres systèmes |
| Utillisateurs | Profils métiers | Profils martech ou data |
| Ingestion de données | Batch ou manuel | Temps réel ou presque |
| Réconciliation / déduplication | Basée généralement sur l'email | Réconciliation déterministe ou probabiliste basée sur plusieurs clés |
| Transformation de données | Basique ou inexistante | Avancée : normalisation, enrichissement, segmentation, scoring, création d'audiences... |
CRM definition – Customer Relationship Management
A CRM software is used to centralise the management of customer interactions. There are four families of CRM:
The CRM is therefore a tool before being a database. Except that, as we recalled in the introduction, CRM has in fact been playing the role of a database for a long time. It stores :
Vendors have all developed connectors for CRM to accommodate other types of data, for example transactional data and, with much less success, behavioural/web browsing data. This has contributed to the evolution of CRM from an activation and interaction management tool to a primary customer repository.
Reminder – Customer Data Platform definition
A Customer Data Platform is a technology that is used to unify customer data, prepare it according to business use cases and, finally, redistribute it to other business systems (activation tools and reporting tools). It is basically a data management tool.
A CDP is used to carry out 4 main activities:
The CDP Institute has identified some criteria for a solution to qualify as a Customer Data Platform:
Focus on the main differences
Let’s summarise the main differences between CRM and CDP here:
What does it take to properly manage your core customer base?
The formulation of the differences between CRM and CDP already gives some clues to the question we set out to address in this article: which tool or system should play the role of the main database. Let’s continue our investigation. We will now define the main characteristics that a customer database must have in order to play the role of master DB or “Single Customer Repository”.
The main customer base must be exhaustive
The database should centralise all customer data that is of known or potential interest to the business. A company can store different types of data:
There are many ways to categorise different types of customer data. It does not matter here. The main thing to remember is that a customer database, in order to be exhaustive and play its role as a master database, must be able to handle all types of data: hot data as well as hot data, third party data as well as personal data, online data as well as offline data, web logs as well as phone numbers.
The main customer base must be unified
The main customer database is intended to aggregate all the customer data collected via the company’s various data sources. This aggregation necessarily produces duplicates, which can have 2 origins:
In both cases, the problem is basically the same: there is no identity resolution.
It is essential to be able to unify the data that reaches the main customer base. How can this be done? By setting up more or less complex deduplication rules, enabling data to be matched and records to be merged.
The main customer base must be clean
A clean database meets 4 conditions. The data it stores must be :
A customer database, in order to play the role of a main database, must therefore offer :
The main customer base should act as a hub with other systems
The main customer base must be able to easily feed the company’s other systems, whether they are operational/activation tools (sales CRM, marketing CRM/marketing automation, customer service CRM, advertising platforms…) or analysis tools (BI, reporting, data science…).
It should be easy to “wire” to the destination tools, whether via native connectors, a robust API, webhooks or manual exports.
The structural limitations of most CRM / marketing solutions to play the role of customer base
Most CRM/marketing software are not designed to play the role of the main customer database, for the good reason that it is customer relationship management software, not customer data management tools.
Rigid data model
The data model proposed by CRM solutions is more or less rigid, often more than less. As a reminder :
The consequence is that updating the data model of a CRM is difficult, unless you have a very advanced (and usually very expensive) CRM like Salesforce. First limitation.
No multi-source reconciliation
In most CRMs, the email is the key. This means that if the same individual registers with two different emails, this will create two lines within the CRM, even if the individual has registered with the same phone, the same first name x surname, the same postcode…
The consequence is that this generates duplicates in the Contacts table, as we saw earlier, but also some difficulties in associating the contact with all its touchpoints. If, for example, an customer writes to the customer service department with a different email than the one they registered with, and if I cannot reconcile the contacts and the customer service tickets using several keys, then it will not be possible to associate the individual with the customer ticket.
To do this, the CRM must be able to manage multi-source deduplication rules. It is with this type of rule that we could tell the tool: “If two contacts have a different email address but the same postal address + the same first name, then the two contacts must be deduplicated and merged”.
No or little normalization & data cleansing
In a CRM tool, the possibilities for data cleansing are very limited:
Therefore, data normalisation and cleansing must be done on the front end of CRM, using custom scripts that are complex to maintain.
No computed fields & scoring
A CRM tool is like Excel but without the formulas… In most CRM solutions it is not possible to add computed fields. Some CRM tools propose computed fields by default (average basket, cumulative, etc.) which are impossible to modify.
However, the ability to create computed fields is essential, especially when it comes to implementing marketing automation scenarios. For example, in order to exclude customers who have recently expressed dissatisfaction, we need a “status of the last customer ticket” or “number of customer tickets over the last X days” field. Creating this type of computed field (scoring or otherwise) is very difficult, and often impossible in a CRM.
No direct access to the database for reporting
A main customer database is used to activate customers, to “act”, but also to analyse the data and to do reporting. Reporting on a CRM database is not easy, because the reports available in the tool are very quickly limited.
Let’s take the example of automated scenarios. In order to measure their impact, we need to use cohort analysis. For example, if we want to deploy a new upsell scenario that consists of sending a sequence of messages 1 month after the first purchase, we will need to look at each monthly cohort of new buyers to see if the number of purchases after 2 months has increased.
How do you do this in CRM software? There is only one solution: export the data to a database/datawarehouse, and then connect your reporting tool to the database in question. It is not possible to connect the reporting tool directly to the CRM software, you have to go through the database…
History’s direction is the decoupling of the customer base and the activation of customer data
From the “software CRM” to the “ecosystem CRM”
CRM today refers to the management of all interactions and activations with identified customers. In most companies, CRM is no longer operated by a single software, as in the past, but by a set of tools, a combination of solutions:
CRM has become an environment, an ecosystem of software. This is one of the reasons why it is no longer really possible to use CRM as a customer repository: a company uses customer tools, but needs a master customer base.
The benefits of managing a customer base separately
If you have read all of the above, you are probably beginning to realise the benefits of managing a customer base separately.
Having a separate customer base allows you to :
Small presentation of the approach proposed by Octolis
We have been Data / CRM consultants for many years. We have often been confronted with the limits of CRM in the course of our missions. Some of our clients had a unique customised Customer Repository, which was very flexible, but every change required technical intervention. Other clients had first generation CDP solutions, you have a nice interface to manipulate the data, but the downside is that you don’t have control over the data, and less flexibility on the data model.
It seemed obvious to us that we needed to reconcile the two approaches. A custom database, controlled/hosted by mature customers, completed with a software interface on top.
This is the way the story goes. The democratisation of datawarehouses is encouraging this hybrid approach. CDPs are leading the way, but we are starting to see other types of SaaS software that use the customer’s data warehouse as a foundation.
Some of our clients already have a main client base: in this case, we “plug” Octolis into this base. If you do not yet have a main database, Octolis will create one for you.
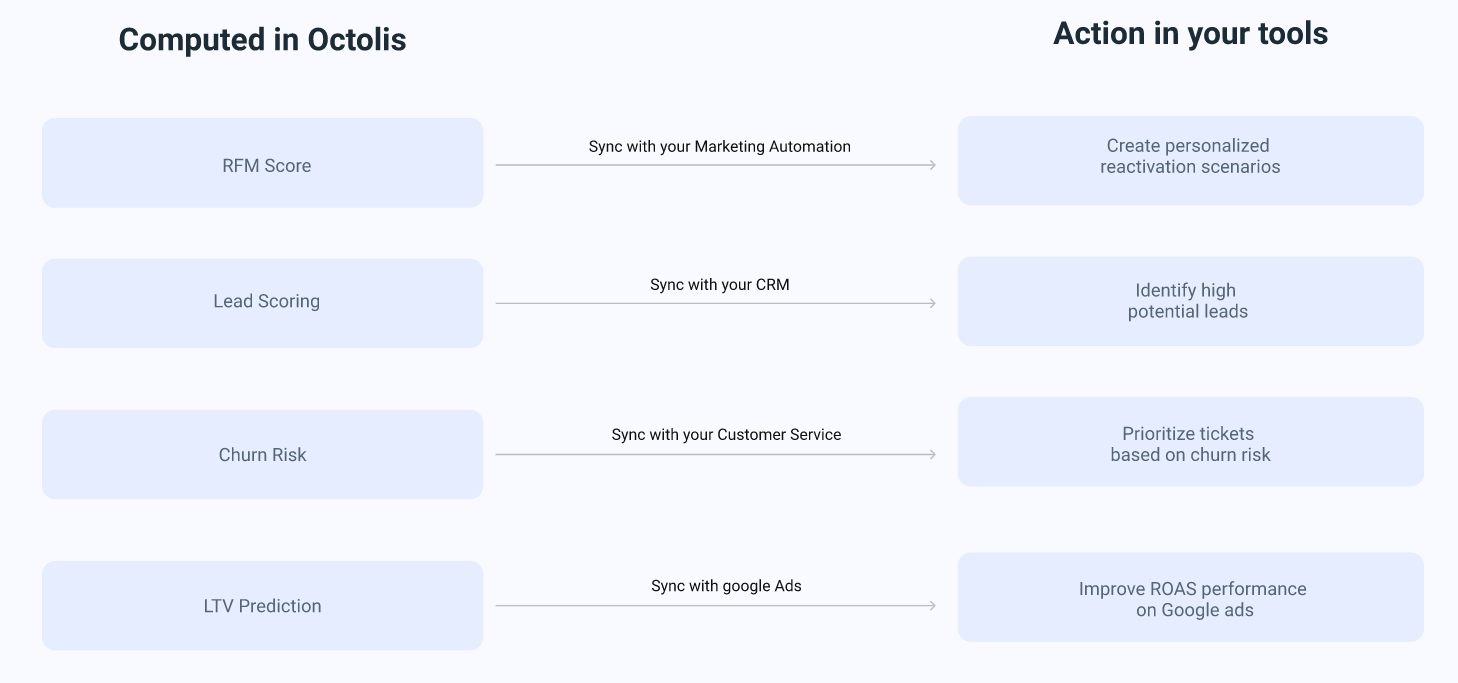
We wanted to create a self-service software interface, accessible to business profiles, usable by both marketing profiles (in “no code”) and data teams in SQL. As a new generation CDP, Octolis allows you to manage the 4 functions that we presented above: Connection, Preparation, Structuring, Synchronisation.
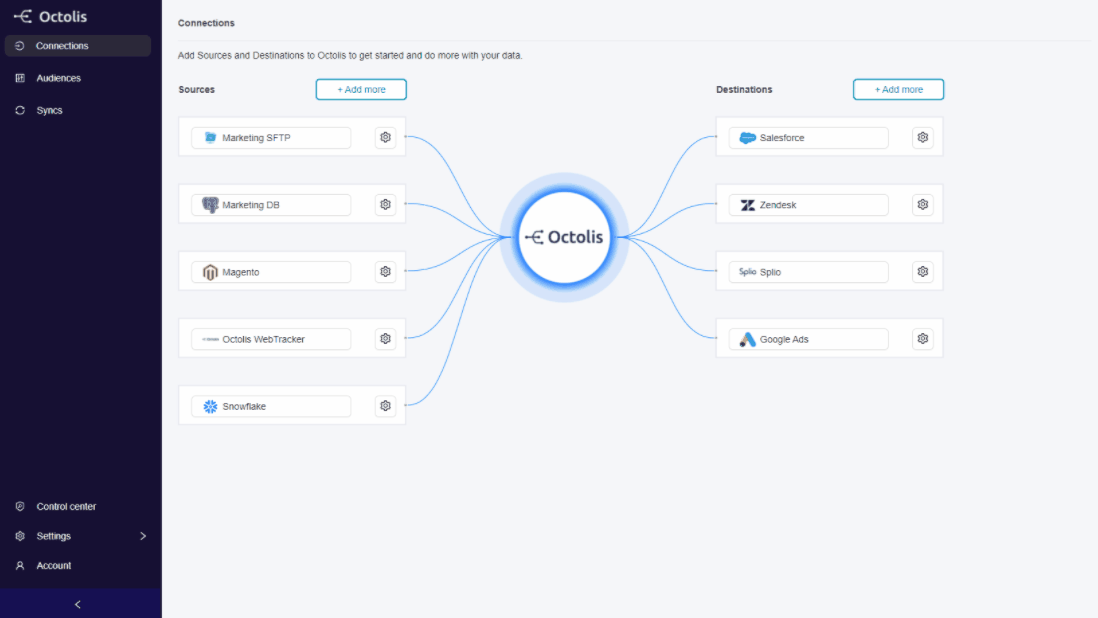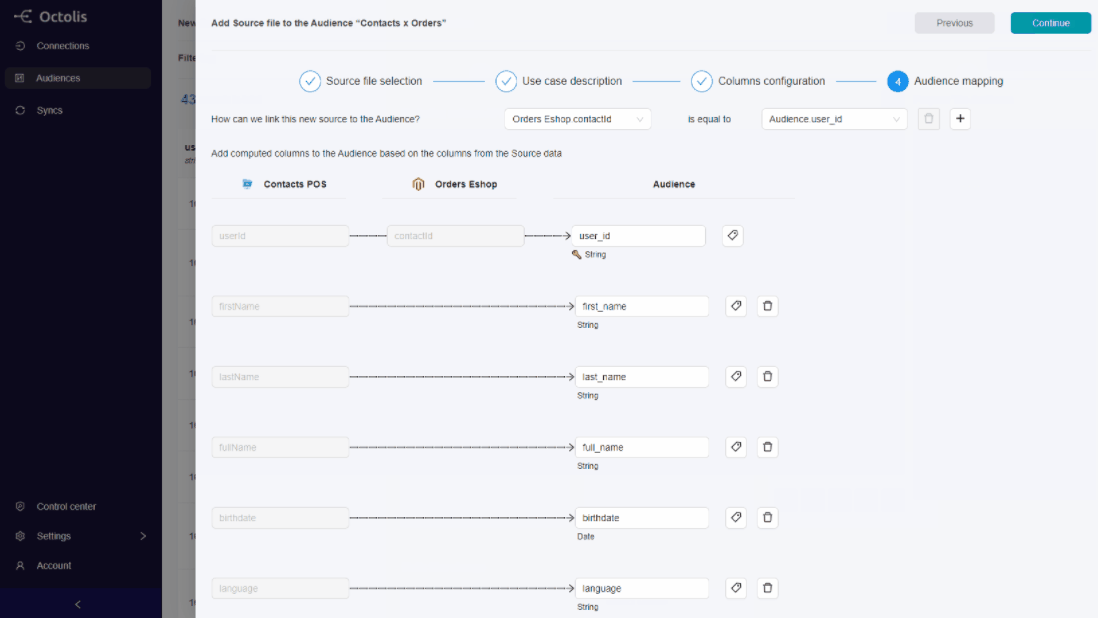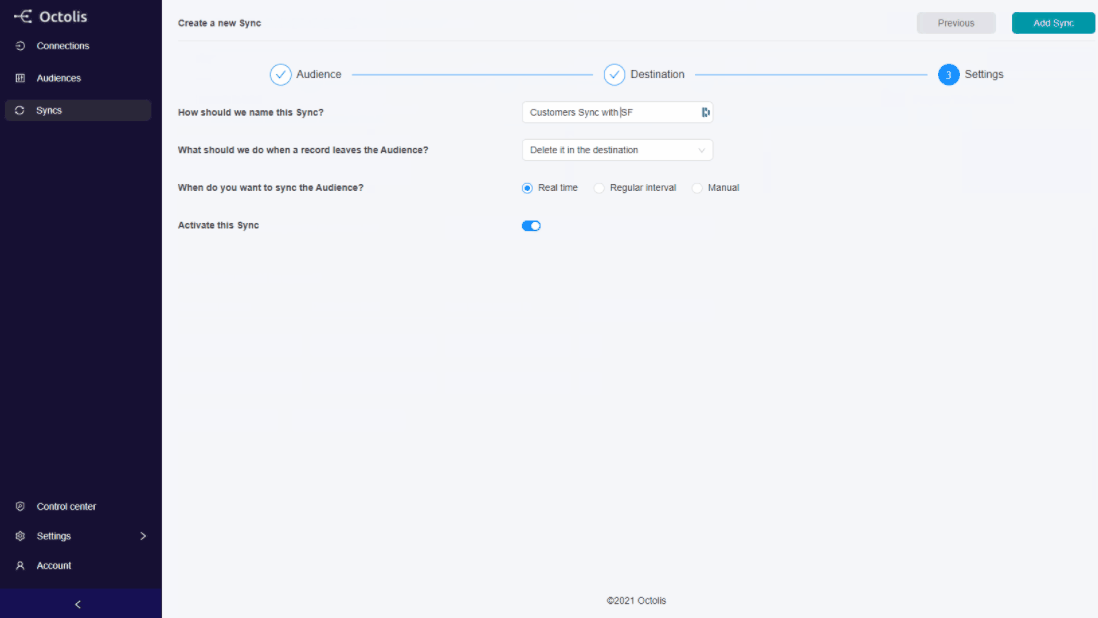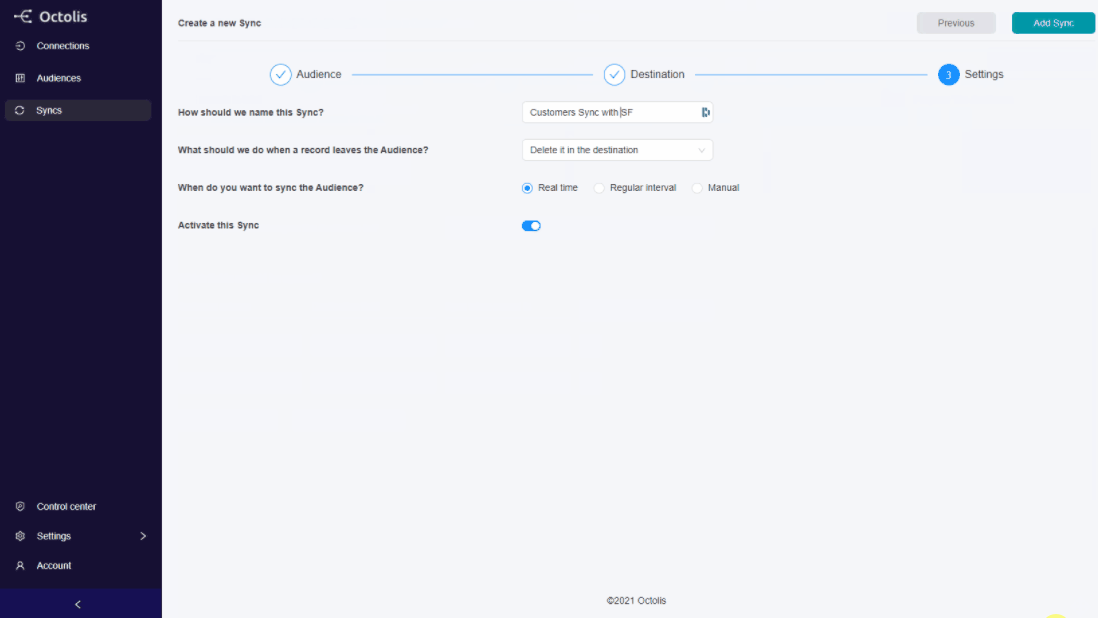
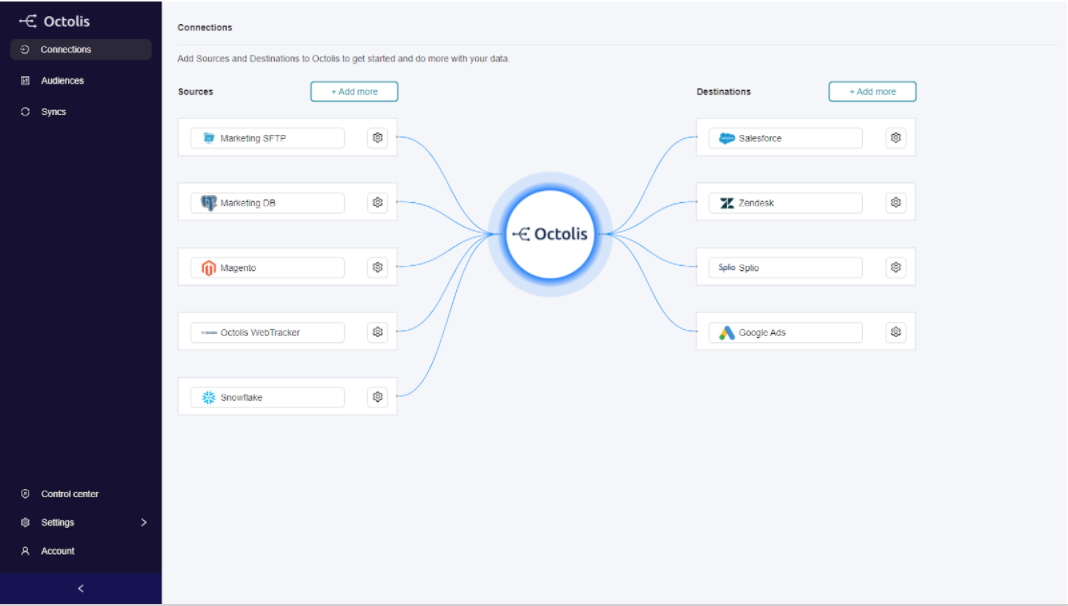
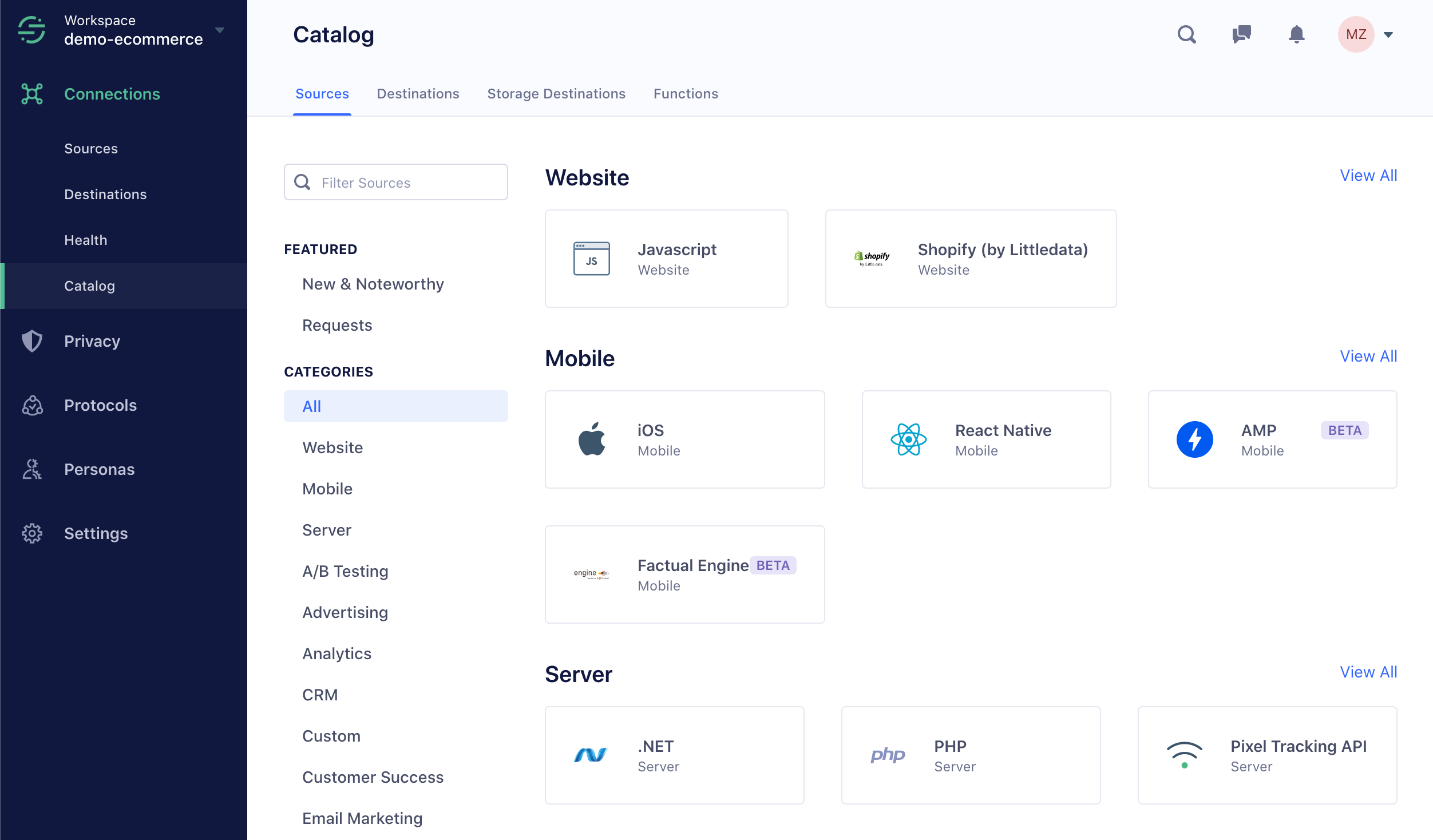
Here is a very quick overview of the solution. You are first asked to connect the different data sources. Among these data sources, of course, is the independent customer database.
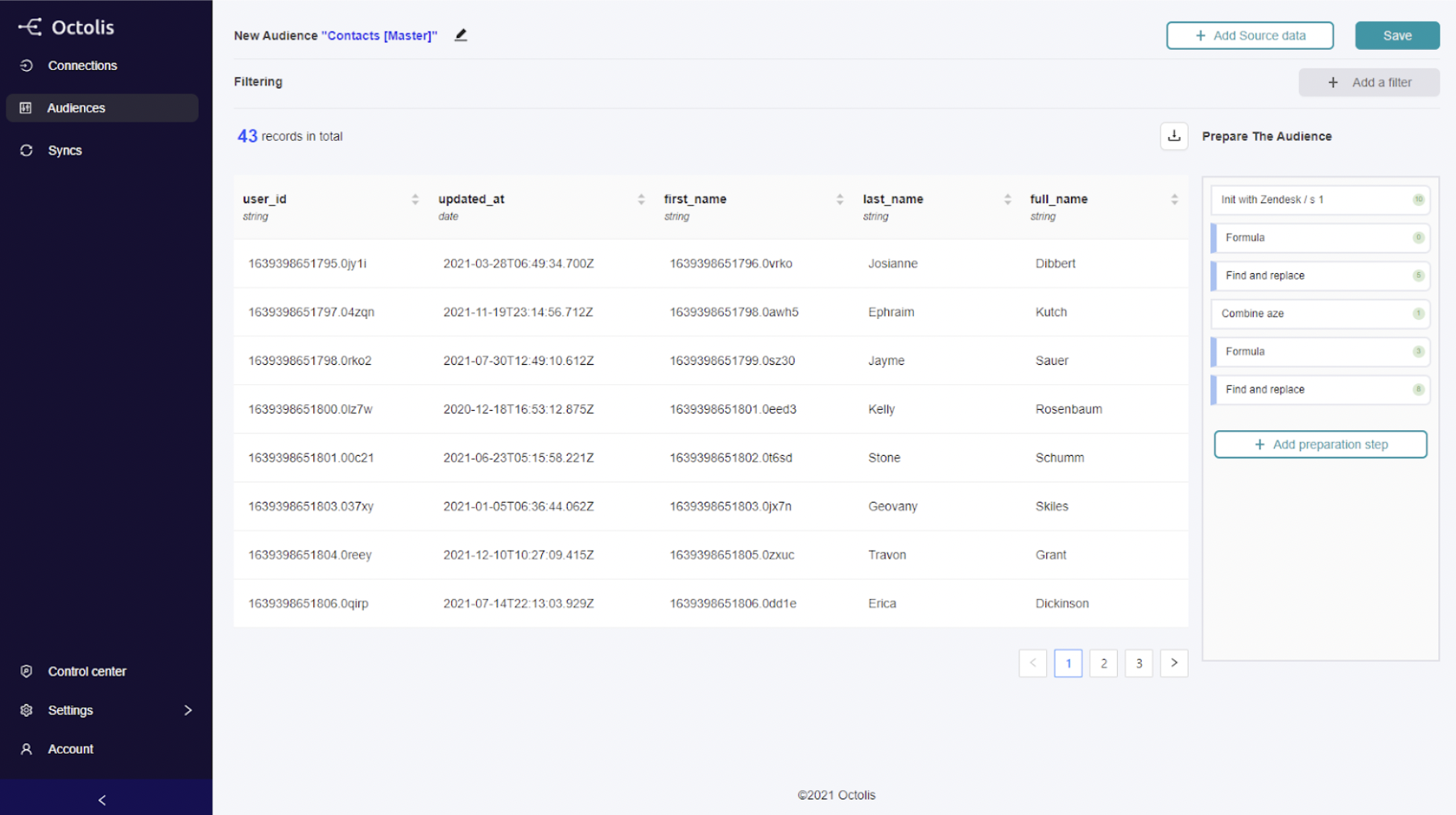
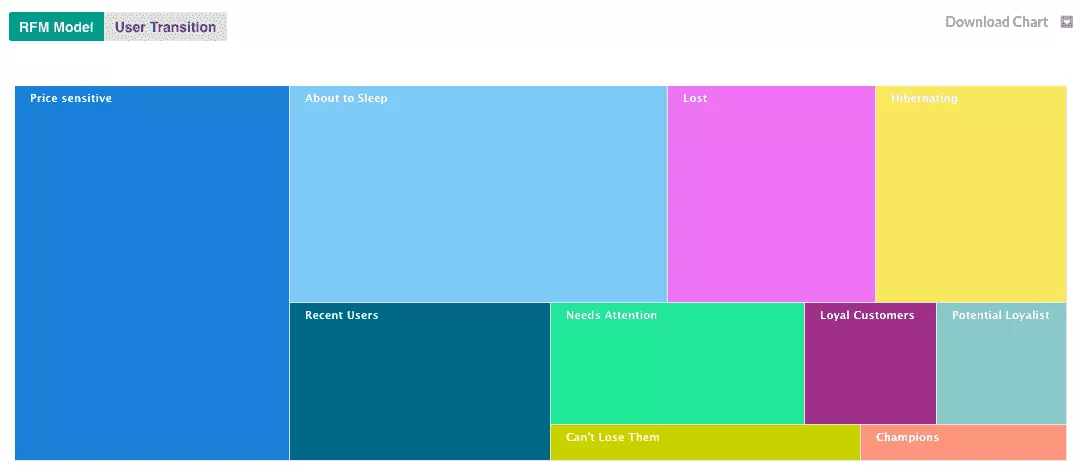
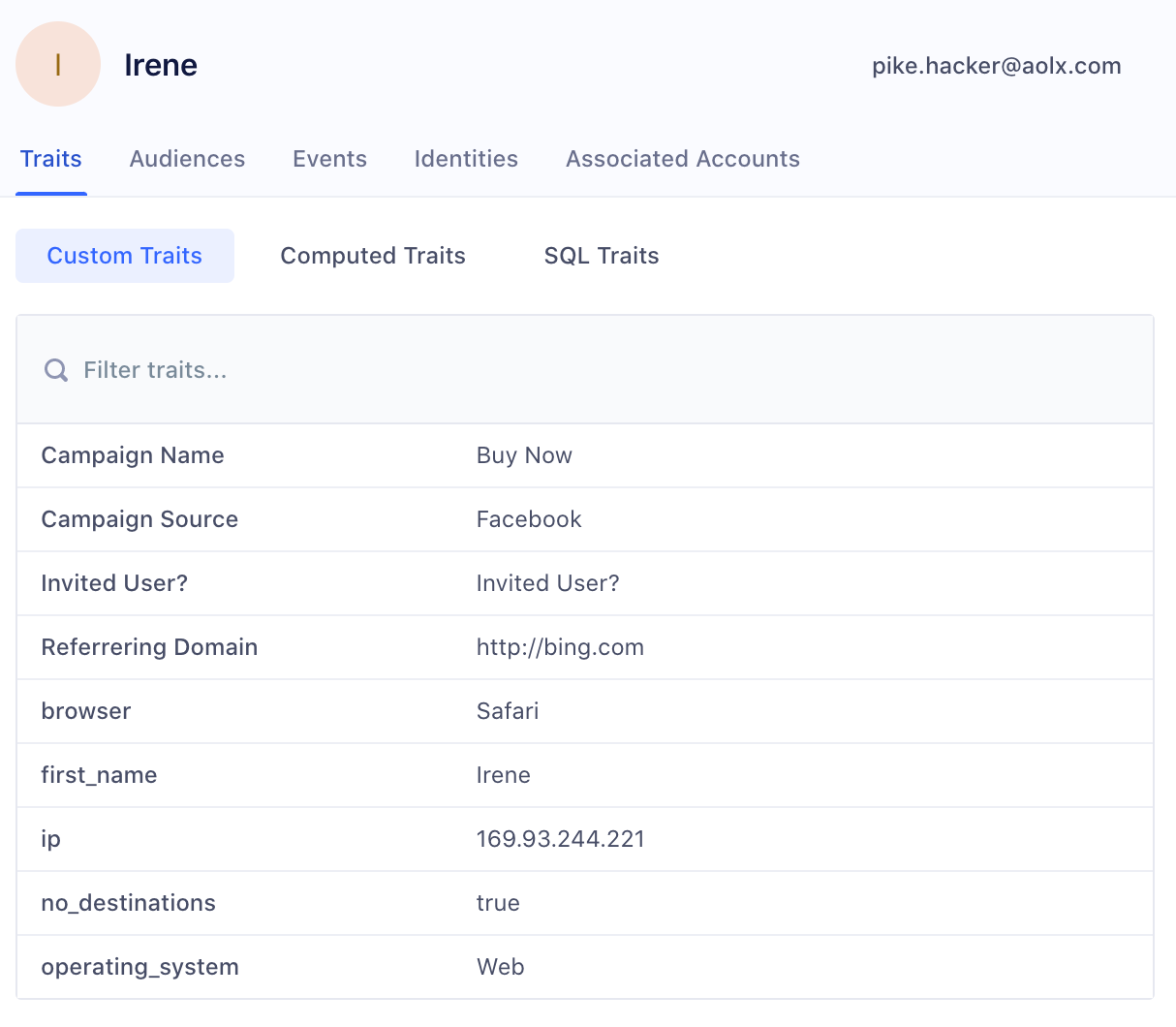
It is on the “Audiences” menu that you prepare and structure the data: deduplication rules, normalisation, construction of audiences and segments, creation of calculated fields (indicators, scorings, etc.).
You can synchronise the data prepared and transformed in Octolis in your tools and in your main database at any time.






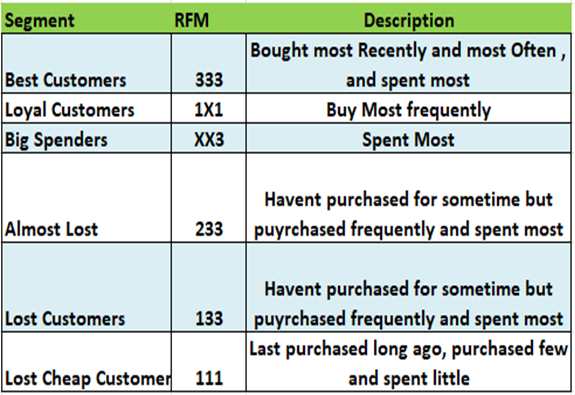
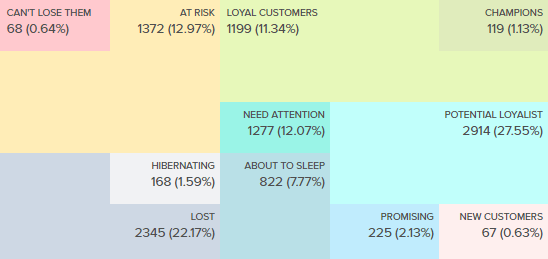
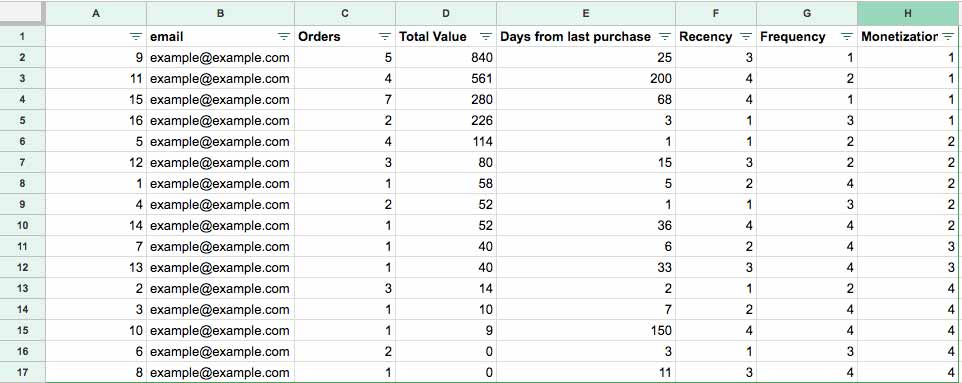
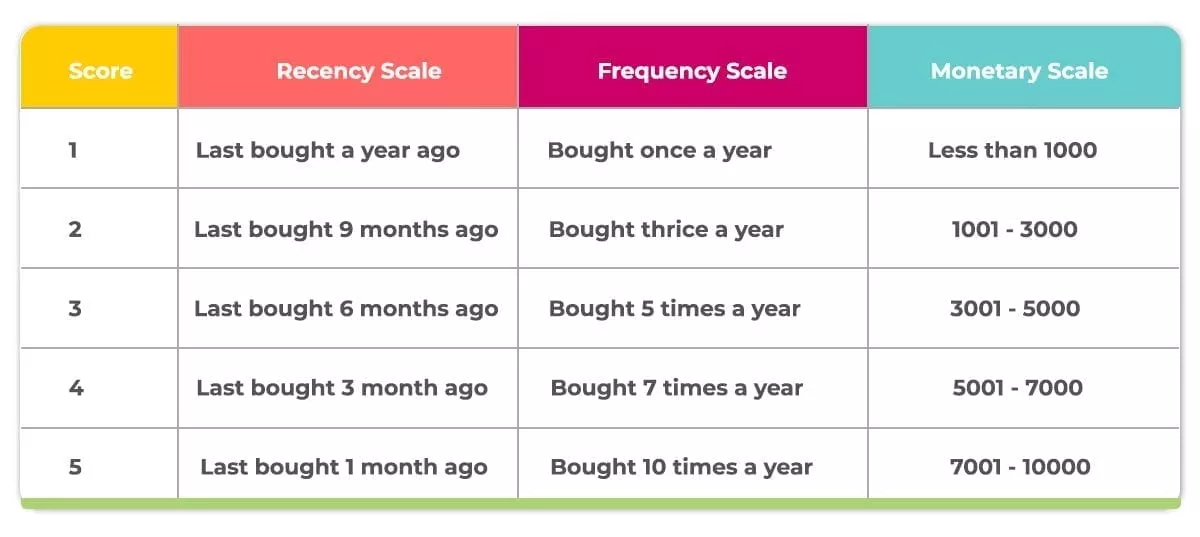

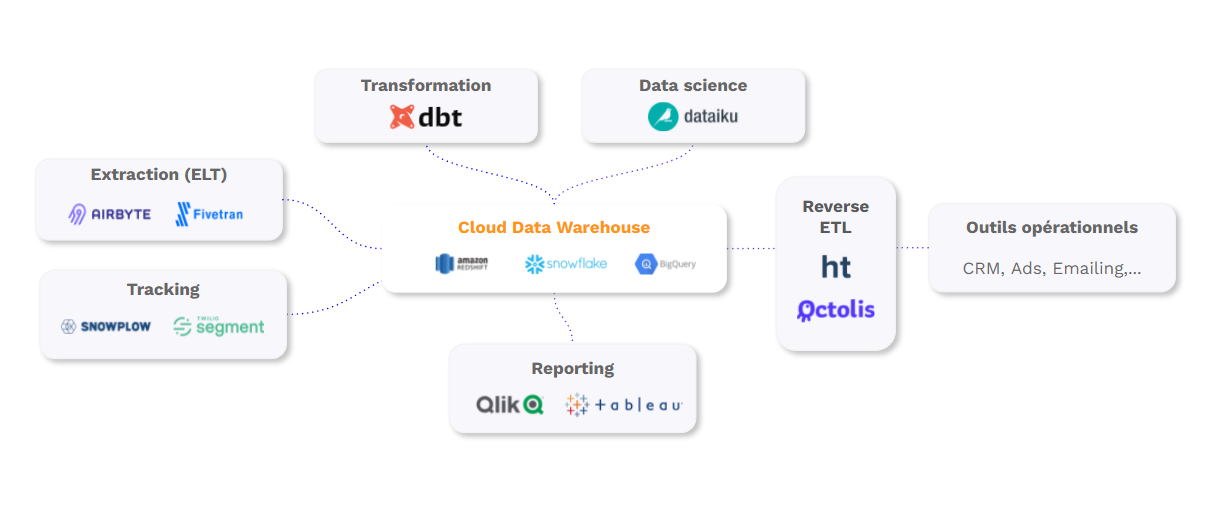

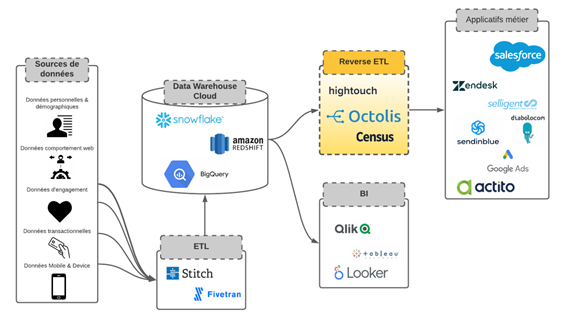
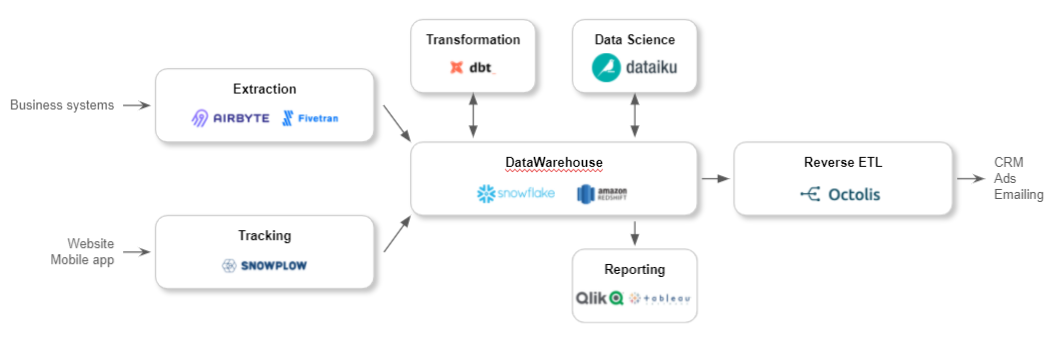
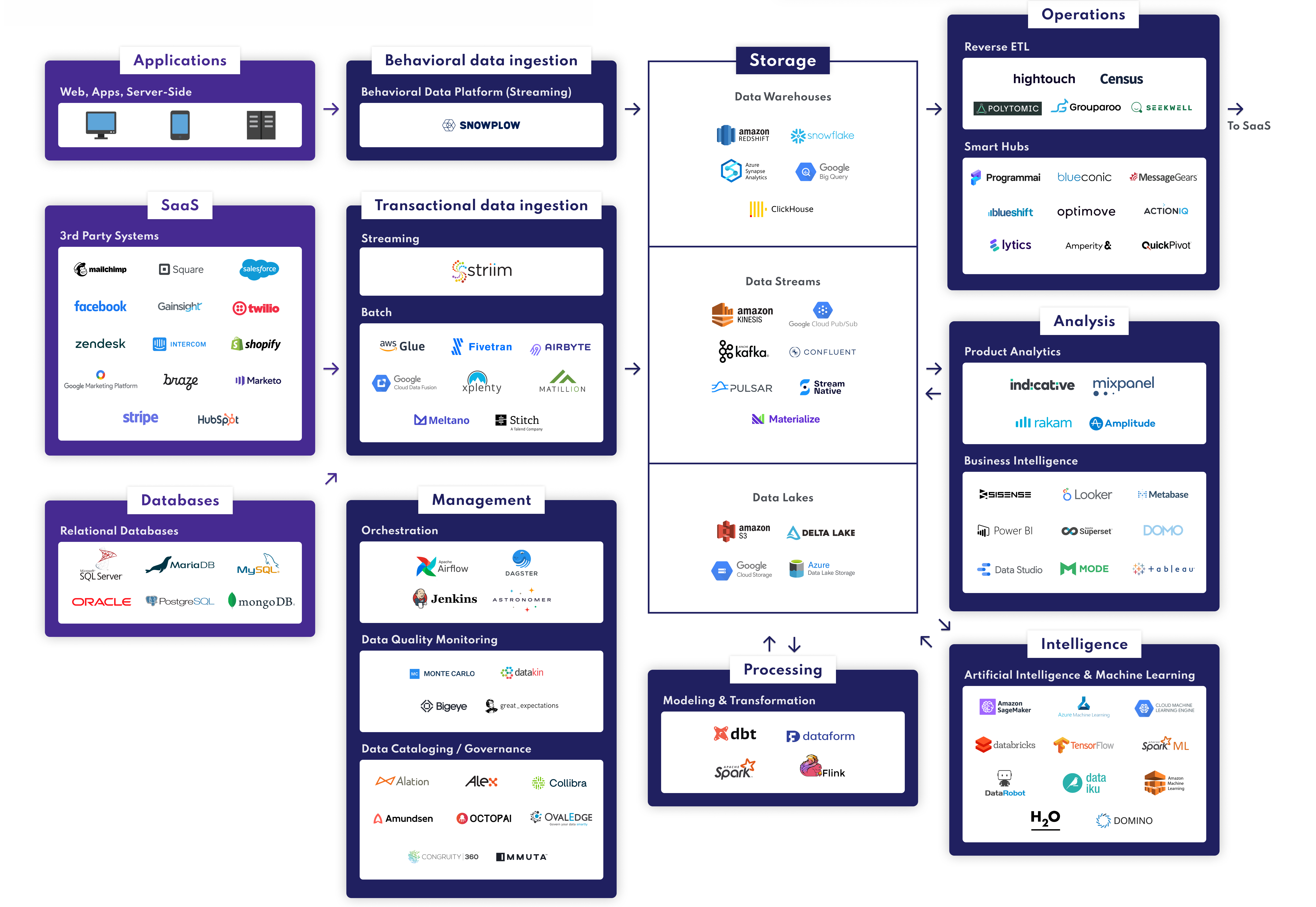

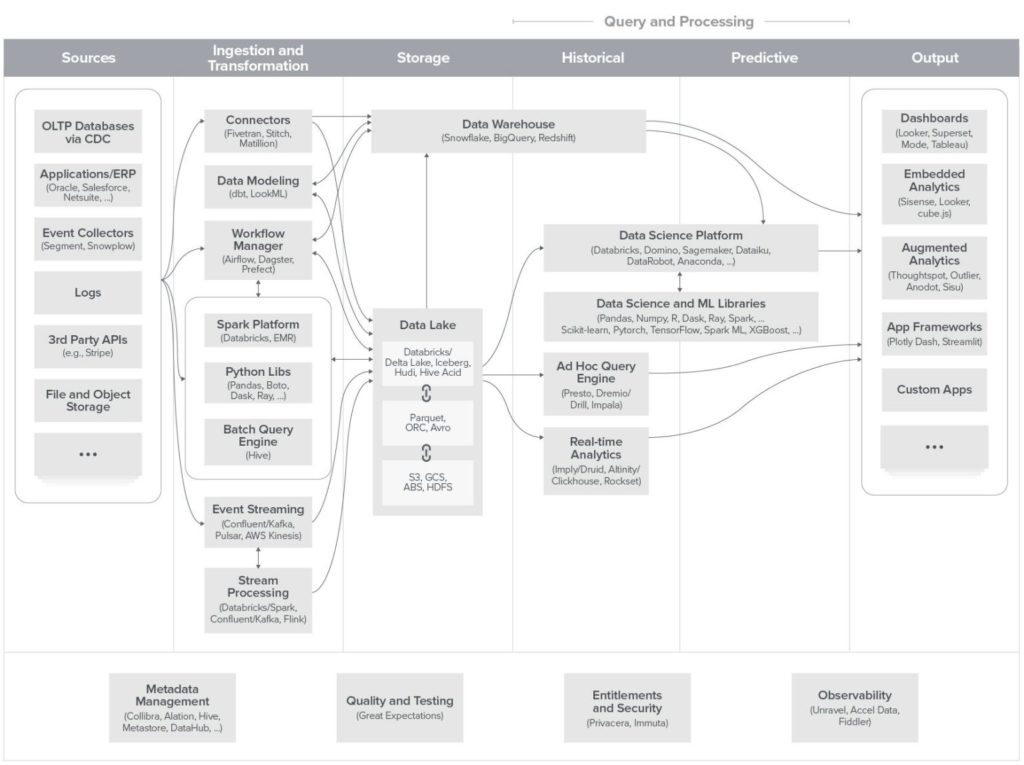
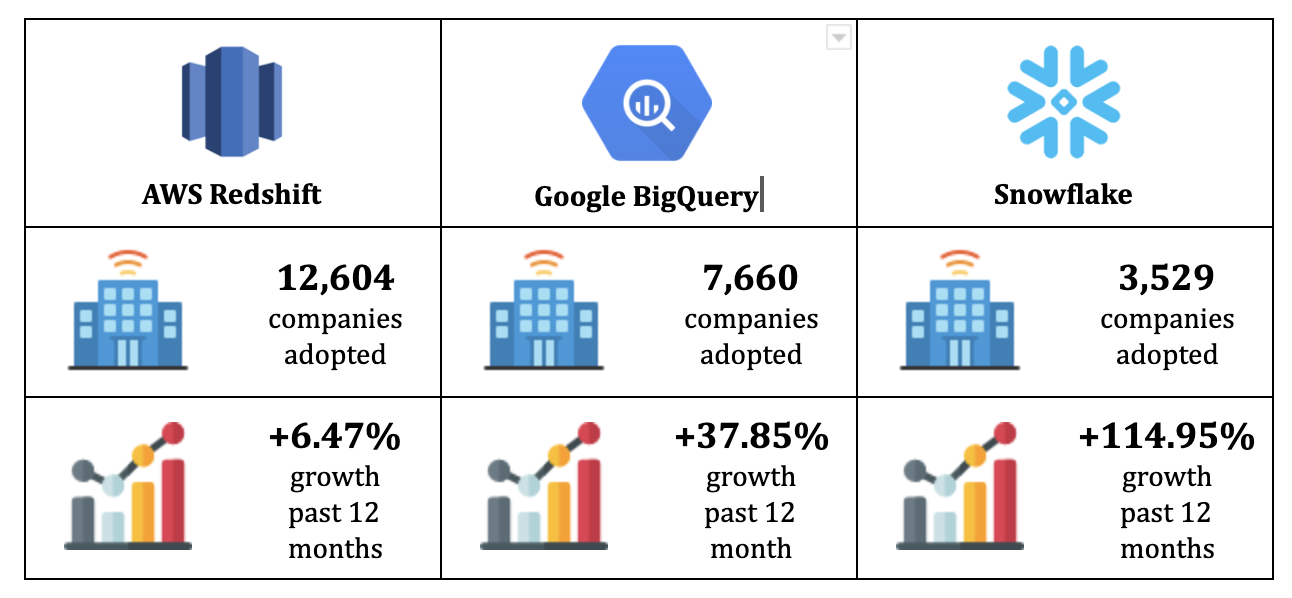
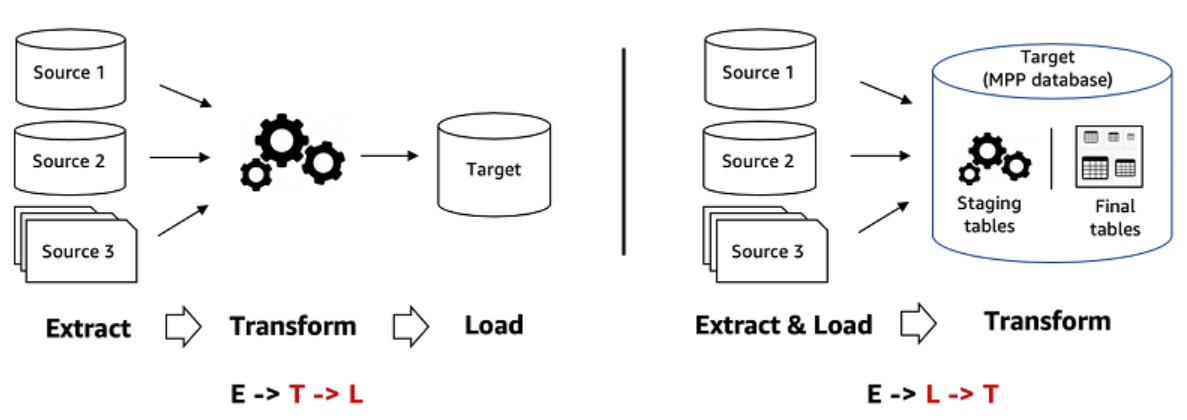
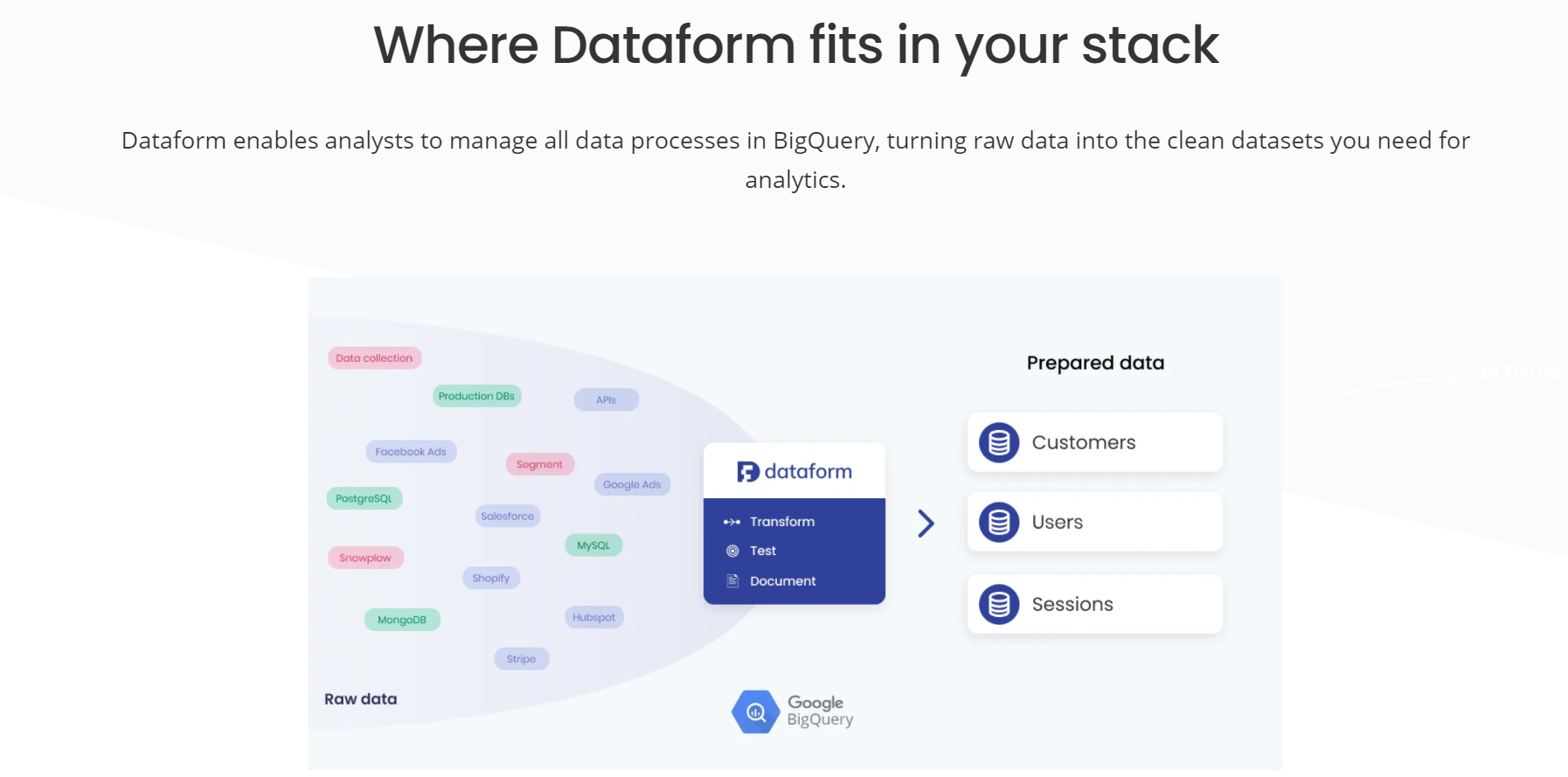
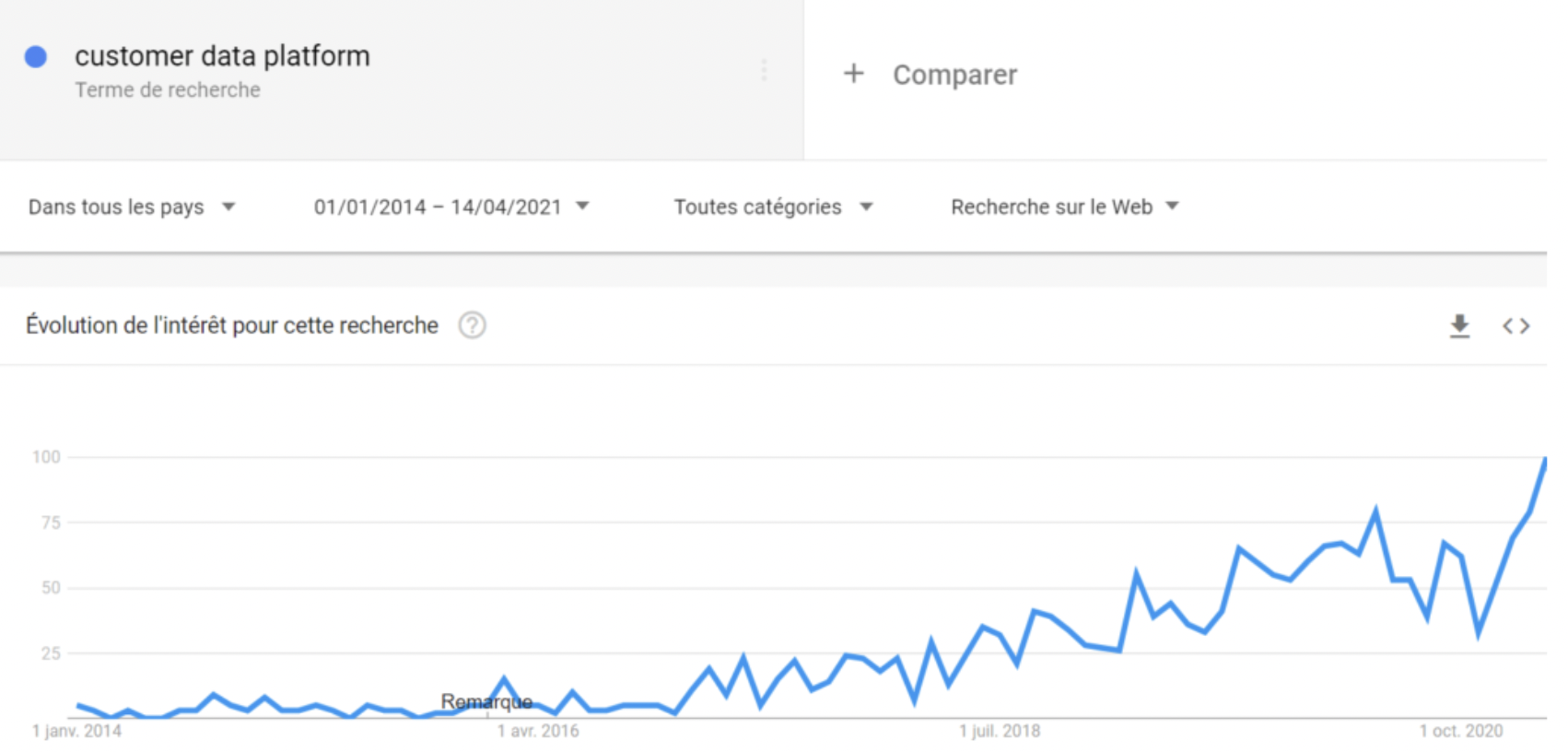

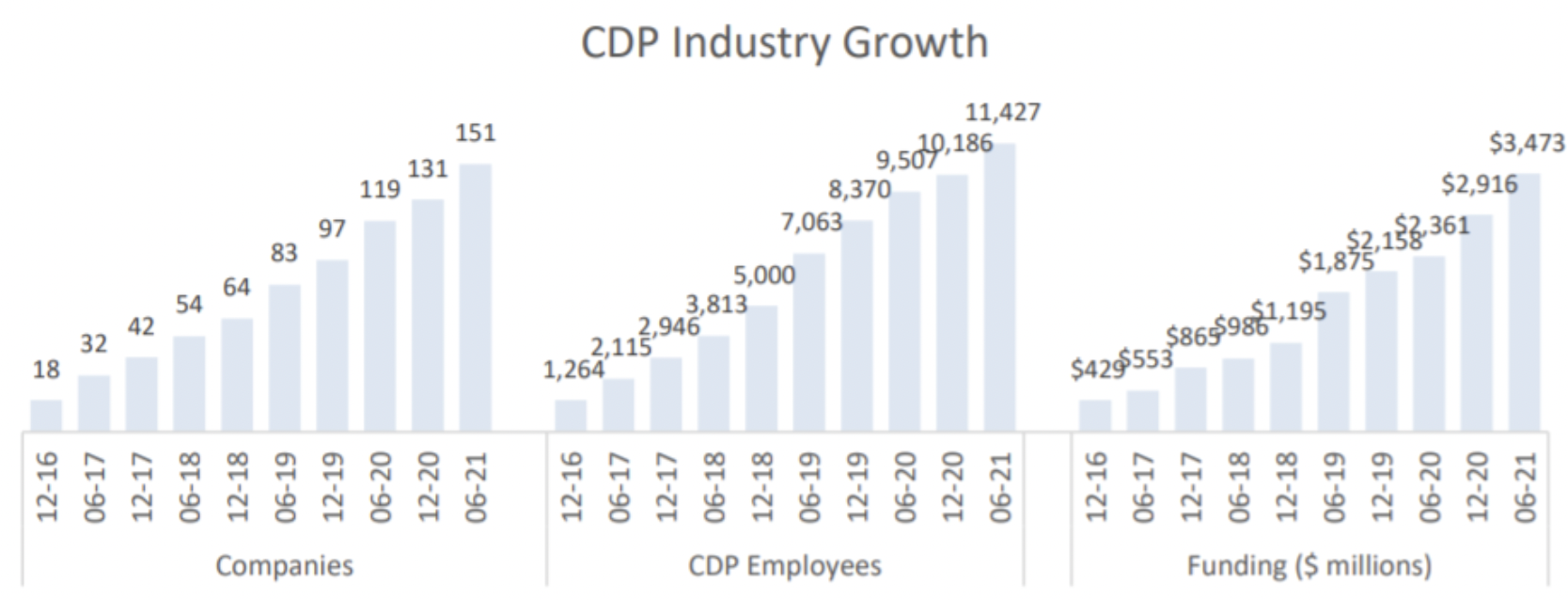
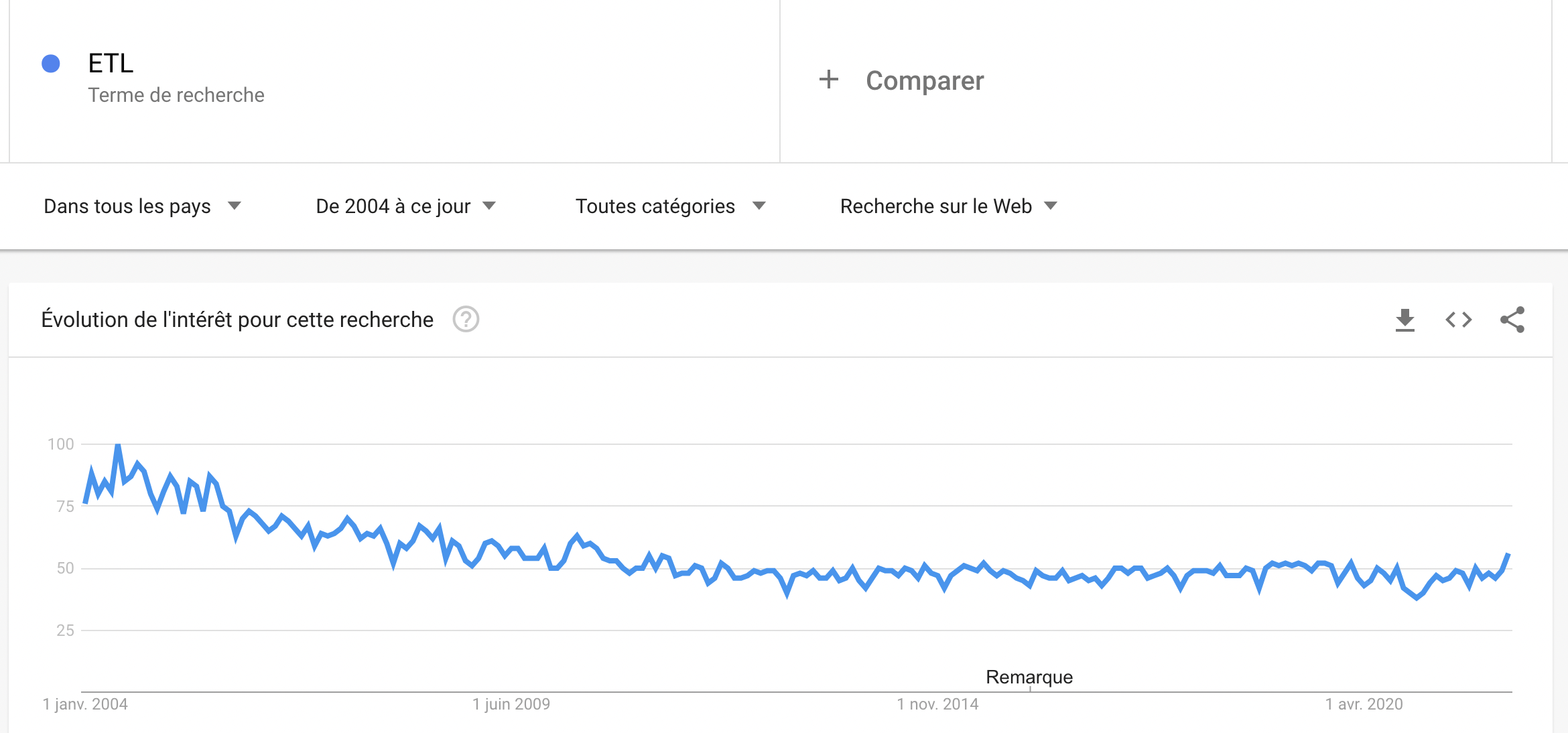

 Reverse ETL is a flexible data integration solution for synchronizing DWH data with applications used by marketing, sales, digital team, and customer service, to name a few.
Reverse ETL is a flexible data integration solution for synchronizing DWH data with applications used by marketing, sales, digital team, and customer service, to name a few.