Are you sure you have control over your customer data? If you’re reading these lines, a doubt probably assails you. And you’re right to doubt it because you may not be in control of your data.
Suppose your customers’ data are stored in your software (CRM, CDP, Marketing Automation). In that case, you don’t have full access to data, and you’re not free to manage security and confidentiality rules finely. You’re a prisoner of data models proposed (imposed) by editors. You’re locked into their ecosystem.
Rest assured, you’re not alone in this case. Most organizations agree to store their data in their SaaS applications.
It’s time for things to change and for you to take back control of your customer data.
How to do it? This is the subject of this article.
📕 Summary
The 3 key dimensions of data control
What does it actually mean to have control over your data? Having control over your data means:
- Full access to your data.
- Ability to manage data security (rights & permissions).
- Data privacy management.
Let’s go back in detail on each of these points, based on examples of tools: Google Analytics, Snowflake, and Amazon S3.
| Critères | Google Analytics | Snowflake | AWS S3 | Data center 'in-house' |
|---|---|---|---|---|
| Accessibilité des données | 🔒 | 🔒🔒 | 🔒🔒🔒 | 🔒🔒🔒 |
| Sécurité des données | 🔒 | 🔒🔒 | 🔒🔒 | 🔒🔒🔒 |
| Contrôle de la confidentialité | 🔒 | 🔒🔒 | 🔒🔒 | 🔒🔒🔒 |
#1 Data accessibility (Level of data openness)
The first dimension of data control is the level of access to your data. It changes according to the tools and systems used. If we take examples like Google Analytics, Snowflake, and AWS 3, there’s one thing in common. In all three cases, the data are hosted in the cloud, but the level of data accessibility is not identical at all.
Data stored in Google Analytics are only accessible through dashboards and reports that Google gives you access. There’s no way to access the underlying data used to build the dashboards. You cannot make an SQL query on the Google Analytics database. So clearly, the level of access to data on Google Analytics is very low. You don’t have control of your data!
In a cloud infrastructure like Snowflake, you can interact with your data through complex SQL queries, taking advantage of all the computing power offered by a modern DWH Cloud. However, you cannot run Spark jobs.
This would be technically possible but very expensive in practice. On the other hand, it is feasible with Amazon S3, which, therefore, is the solution that offers the best level of access to data. Not only can you connect S3 to your BI tools and run SQL queries, but you can extract data and load it into Spark or your other applications.
The data access issue also encompasses data portability, i.e., the ability to extract data from one tool and host it in another database and tool.
In terms of portability, Amazon S3 wins the prize. For example, you can easily switch your data from Amazon S3 to Google Cloud. Conversely, you cannot extract data from Google Analytics to other systems in its raw state.
#2 Data security (management and control of access & permissions)
The second dimension of data control is security. The level of data security is measured by your ability to manage access to your data. If you manage everything, then the level of data security is at the top. If you choose a cloud solution, be it Google Analytics and cloud infrastructure like Amazon S3, you don’t have complete control over data security. You’re limited by the access & rights management features offered by the solution.
On Google Analytics, you can manage user-based access, but you cannot set up attribute-based access control, as is the case with Amazon S3. If you store your data on your machines, you can create 100% tailor-made rights and permissions management mechanisms.
The level of control over data security will always be lower with a SaaS/Cloud solution than with a self-hosted solution. The more sensitive the data you store, the more important it is to be well informed about the policies applied by cloud publishers.
Security management needs are not the same for all companies. A company with a small customer base and collects little data about its customers will typically have less trouble hosting its data in a cloud infrastructure like Snowflake or Amazon S3 than a big bank that stores large volumes of highly sensitive data.
#3 Privacy management
Privacy management is the third dimension of data control.
Data security, which we talked about above, is about who has access to your data. Data confidentiality is about the use of the data and whether it’s legal and approved by the user.
Let’s take our 3 examples to illustrate this dimension: Google Analytics, Snowflake, and Amazon S3. In these three companies, certain employees have access to your raw data. What they do or can do with your data, however, isn’t the same:
- Google Analytics. There are Google employees with access to the reports you configured in Analytics. Google likely uses “your” Google Analytics data to create a user profile for marketing purposes. Even if what Google does with your visitor/customer data is unclear, there is no doubt that they use it.
- Snowflake and AWS3. It appears likely that employees within these companies have more or less limited access to your raw data, but their analytical capabilities are more limited. They should be able to do reverse engineering to use your data. They can’t link customer data together and create a user profile as Google can. In addition, note that, in S3, you can encrypt your data.
When it comes to privacy, the focus is clearly on cloud infrastructure solutions like Snowflake or AWS 3.
Lack of data control = risk
The coupling data <> applications, a legacy of CRM/CDP publishers
Customer data is used by CRM solutions, Marketing Automation software, and other Customer Data Platforms. They are the fuel. What characterizes these programs is the coupling data <> applications. Clearly, your data is stored in applications, in your software. There’s no separation between the data layer and the software layer.
That’s how CRM and CDP editors traditionally operate. Data is collected, stored, and activated by and within the software. The CRM, or the CDP, is both a database (with restricted access to data) and an activation tool.
The development of the SaaS model in CRM has not changed much in this situation: coupling remains the rule. Traditional or SaaS, same fight. The same goes for the Customer Data Platforms discussed so much for a few years.
Why is storing customer data in software (CRM, CDP, etc.) problematic?
Customer data stored in applications is problematic for several reasons rarely mentioned by publishers, integrators, and other ESNs (Enterprise Social Networks) who take advantage of the prison implied by this coupling.

The “Digital Guantanamo”, evoked by Louis Naugès, where ESN play the role of guardians of the imprisoned CIOs.
Customer data is your most valuable asset. However, CRM, CDP, and Marketing Automation publishers only give you restricted access to this data. You’re a prisoner of the data models imposed by the software; you can’t access your data in their raw state and organize them in the data model of your choice. You are limited by the infrastructure choices of the solution vendor.
The business consequences are more serious than they appear. Lacking flexibility of data models reduces the ability of your marketing teams to adapt the scores and processing rules to your business specifics. Less targeted campaigns or less personalization can be fatal in the race for the ultimate omnichannel customer relationship led by brands today.
The other direct consequence of this low flexibility is that your teams lack progress and maturity in exploiting customer data. Your business teams will not learn to imagine use cases outside the framework offered by your CRM or CDP, and you will miss opportunities within your customer journey.
Discover business use cases
To help you imagine what you can do with full control over your data, we have put together a library of concrete use cases, don’t hesitate to consult it.
On the other hand, access to your customer database, organized and stored in your CRM/CDP, is chargeable. You must pay access fees to view and use your data! As everyone knows, the economic model of classic solutions for activating customer data (CRM, Marketing Automation, ERP, CDP) is based on pricing by several users. Even a user who only needs access to the database on a very occasional basis will have to pay a subscription.
In fact, you are locked into a specific ecosystem, built by the publisher, that cuts you off from outside. It can be vast: think of CRMs that offer dozens of different modules. But it is still a rigid framework.
The BlackBerry example
To illustrate, let’s take the example of BlackBerry. We owe this example to David Bessis, who describes it in a beautiful Medium article dedicated to the rise of open data technologies. Broadly, BlackBerry was the king of the world from 2001 to 2008. And then came the iPhone, in 2007. And then a bit later, Android. And boom, BlackBerry collapsed.
Between 2008 and 2012, BlackBerry’s market share was divided by 20. There are several reasons for this, but the main one is this: BlackBerry was built like a black box. Nobody could create BlackBerry applications; BlackBerry had a stronghold on writing the code…unlike iOS and Android, which immediately positioned themselves as open platforms.
Like BlackBerry, CRM / CDP publishers are closed platforms that hinder the development and enrichment of your data use cases. Think about it, how freer you would be if you could have your data in a database, independent of your CRM/CDP, to use it in other tools for other purposes!
A solution, even if it’s a suite of software, cannot do everything. Locking yourself into a publisher’s ecosystem inevitably means missing out on specific uses of customer data.
How does modern stack data allow you to regain control of your data?
We showed a problem: the coupling of data with applications. The consequence is lacking control of your customer data. Let’s now talk about the solution: Modern Stack Data.
The term is barbaric, jargon, we grant you, but it designates a simple reality. It is a new way of organizing data, a tripartite organization:
- A Cloud Datawarehouse which serves as the company’s database. It is the main enterprise database that helps unify structured and semi-structured data.
- Business tools that exploit data for analysis and manly activation purposes. BI tools such as Tableau or PowerBI and, above all, tools such as CRM, Marketing Automation, Google/Facebook Ads, Diabolocom, etc.
- An ETL and/or a Reverse ETL allows data to circulate between the Datawarehouse and the other company systems: the software.
The modern Data warehouse as an operational base
Note that we are not talking here about the new generation Data warehouses, which have been booming since the beginning of the 2010s: cloud Data warehouses. We think of names like BigQuery (Google), Snowflake, Redshift (Amazon), or Azure (Microsoft) that have become democratized and are now accessible to SMEs and startups.
So, what are we talking about?
A modern Data warehouse is a cloud database used to store all of the company’s structured or semi-structured data. More than just a warehouse, a Data warehouse is a war machine that allows you to execute SQL queries and perform operations on huge volumes of data…all much faster than transactional databases ( OLTP).
We are convinced today:
- That the data must be stored in a separate database from the software.
- That the Cloud Data warehouse is by far the most powerful and economical solution to act as a master database.
With this in mind, the Data warehouse is intended to become the keystone, the pivotal solution of the modern company’s information system.
In this article on the Modern Stack Data, we go more into detail about our convictions regarding Data warehouse-type cloud infrastructures and the main advantages of these solutions. Also, discover our article “Why you should use your Data Warehouse to play the role of Customer Data Platform.”
ETL & Reverse ETL
We can represent Modern Stack Data in this way:
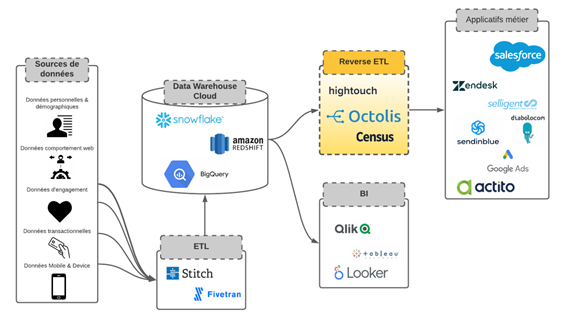
ETL and Reverse ETL are the tools that allow data to circulate better in the information system and tools while maintaining control. More specifically:
- ETL (Extract – Transform – Load) is the technology that connects to data sources, transforms them, and loads them into the Datawarehouse cloud. Two examples of ETL? Stitch Data & Fivetran.
- The Reverse ETL is a more recent family of solutions that allows data to be redistributed from the Data Warehouse to business tools (CRM, Marketing Automation, e-commerce, etc.), in the form of segments, aggregates, and scorings. It is the centerpiece that allows business teams to access data from the data warehouse. An example of Reverse ETL? Octolis!
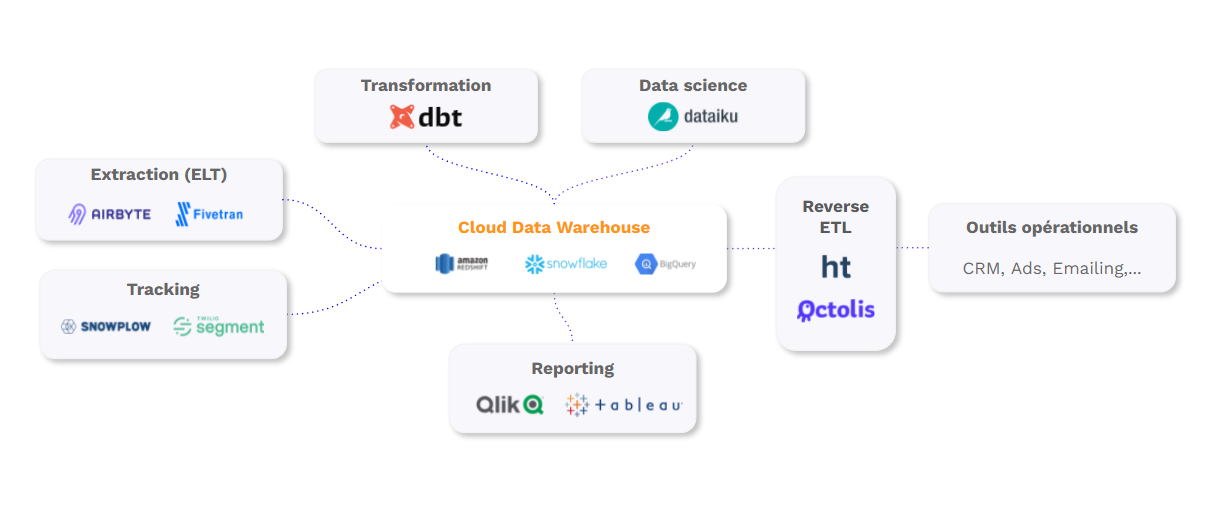
It is this modern data architecture, linking Data Warehouse Cloud and ETL/Reverse ETL, which ensures the highest level of data control:
- Data are kept in a software-independent database. They are stored neither in your business applications, ETL, nor your Reverse ETL, but your data warehouse.
- You can create custom data models to meet your specific needs and use cases.
- The calculation performance of your database is much better than that offered by CRM/CDP editors.
- You centrally and granularly control access and permissions to the database (the DWH).
Conclusion
Companies need to be aware of the risks and costs of storing customer data in software, no matter how powerful CDPs are. Today, it is possible and desirable to regain control over your customer data.
We have seen that this requires a new organization of your data called the “modern data stack”: your customer data is hosted and consolidated in a Data Warehouse and redistributed to your software via a “Reverse ETL” like Octolis.
Data sovereignty is a necessary (although not sufficient) condition for deploying innovative, and ROIst data use cases. Taking back control of your customer data is the first step to becoming truly data-driven.