
We are delighted to announce the official launch of Octolis in January 2022.
To avoid the disappointment experienced by the creator of that labyrinth, we have based the development of Octolis on our clients’ feedback.
We’ve had customers using the product’s first version for almost a year now, including major brands like KFC and Le Coq Sportif. We’ve been quiet while working hard with a few customers for months to improve our product, over and over again.
And now, the time has come! Octolis is now available to all companies who want it!
We have a lot to say about why we launched Octolis. But if you don’t have time to read it all, here’s what you can take away in a nutshell:
- We believe that the growth of modern cloud data warehouses will profoundly transform organizations. When all the company’s data is stored in a warehouse, you can use this warehouse to manage all your teams and sync all your tools. Octolis acts as a sort of data logistician.
- We will enable small businesses (SMBs) to become genuinely “data-driven”. Not to create reports that are barely used, not to create yet another machine learning POC that will never be put into practice, but to improve everyday operations.
- We have developed the data management solution we wish we had in our previous experiences. It’s a simple enough solution to be used by marketers and flexible enough for tech/data teams.
The standard issue of data silos
Clément and I met at Cartelis, where we have been data consultants for years. We had the chance to work for companies of various sizes and levels of digital awareness, from great start-ups like Openclassrooms, Blablacar, or Sendinblue, to more traditional companies like RATP, Burger King, or Randstad.
In almost all the companies we worked for, there were significant challenges around customer data reconciliation.
The problem is simple, all teams would like to have as much information about their customer as possible, within the tools they use daily.
For example, sales teams want to see in their CRM software if the customer has used the product recently so they can trigger a follow-up at the right time. Marketing teams want to set up fully automated messages after a customer has complained to customer service or visited a specific page on the website. And customer service wants to prioritize client tickets based on the potential risk of losing a customer, just to name a few.
The tools that allow you to interact with your prospects/customers are more and more powerful, but they are under-exploited because it is difficult to sync them with all the data you need. The main reason is that we have valuable data everywhere. Interactions between the company and its customers happen on several channels and tools (e.g., mobile application, automated chat, marketing automation, advertising retargeting, customer service, etc.). These sources generate a phenomenal amount of data that businesses can use to personalize customer relationships.
Most companies start by trying to bind all of their tools to address this challenge; new connections are then established with apparently simple-looking tools like Zapier or Integromat, but shortcomings start to become evident when trying to manage them all at once or trying to scale.
Then comes the moment when we judge that it is time to centralize all customer data in the same place, we list the many advantages (customer knowledge, project acceleration, etc.) to justify the potential ROI, then fix a specific budget and finally, decide to launch a complex “Unified Customer Repository” or a “360° customer database” project, which can be pretty daunting and intimidating, to say the least.
The big question is, what format will this customer repository take? The main options considered most of the time are:
- An already existing solution: CRM or ERP
- A tailored made database (usually with an in-house team for support)
- A software solution dedicated to this objective: “Customer Data Platform.”
However, this can be easily and cost-effectively solved with the new generation of data warehouses.
Historically, a data warehouse was a database that supported analysis, not operational uses. Solutions were built to support large punctual queries, with data updated once a day at most. Now, modern data warehouses can support all types of queries, in almost real-time, at a more competitive price, and with no maintenance effort. This changes everything.
The modern data stack creates a new paradigm
In the last few years, the major shift has been the emergence of a new generation of cloud data warehouses like Snowflake, Google BigQuery, Firebolt. Snowflake’s historic IPO in 2020 – with a valuation that continues to increase – is the financial reflection of this significant breakthrough, and yet, Oracle, IBM, and Microsoft have been offering data warehousing solutions for years. So what has changed?
The new generation of cloud data warehouses provides 3 significant advantages:
- Speed/power: Phenomenal computing power compared to 2010 standards can be achieved in a few clicks.
- Price: Decoupling storage and data processing has significantly reduced storage costs. Depending on the queries you make, you pay per use, but storing large volumes of data costs almost nothing.
- Accessibility: Implementation and maintenance are more straightforward. It’s no longer necessary to have a team of network engineers to manage a data warehouse.
If you want to know more about data warehouses, here is an excellent article about it written by our friends at Castor.
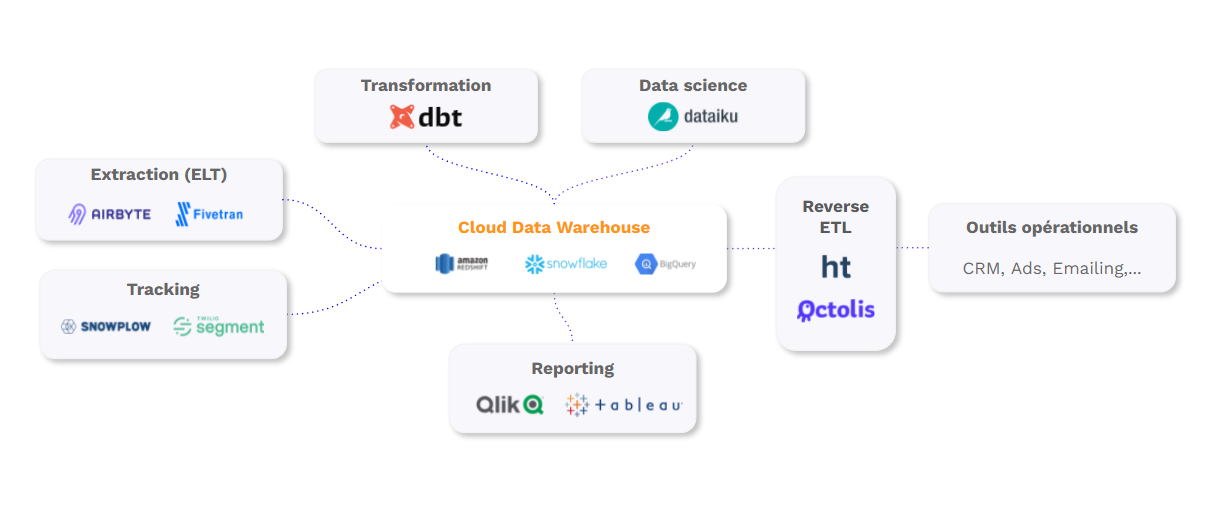
Thanks to these innovations, cloud data warehouse adoption is booming, and a whole new ecosystem is emerging around it, including:
- Extract Load (Transform) tools like Airbyte or Fivetran to sync the data warehouse with data from all internal applications.
- Tools like DBT to transform data directly into the data warehouse.
- Tools like Dataiku to perform data science projects directly in your data warehouse.
- Reporting tools like Metabase or Qlik
- And now software activation tools (or reverse ETL) like Octolis to enrich operational tools with data from the data warehouse.
You can learn more about the modern data stack in this article.
The modern data warehouse becomes a foundation for analysis and operations
It is now possible to use the data warehouse as an operational repository because it’s easy to build in it a Customer Data Platform equivalent. Some experts call this the Headless CDP approach. It is a growing trend in mature enterprises, which will significantly impact the entire SaaS value chain.
In this article, David Bessis, the founder of Tinyclues, insists that this shift will limit the dependency on full-featured software solutions offered by Adobe, Salesforce, or Oracle. This may explain why Salesforce has invested significantly in Snowflake…
- There are many advantages to using the data warehouse as the foundation for operational tools.
- Limit data integration/processing work: We import the data in one place, transform it once, and use it everywhere afterwards.
- Keep control of the data, and facilitate the transition from one software solution to another.
Align analysis and action; the same data is used to report and populate the tools. When an analyst calculates a purchase frequency, this can also be used in CRM or emailing tools.
This allows companies to speed up many previously complex projects. For instance, the classic use cases of a “Customer Data Platform”:
- 360-degree view of each prospect/customer including all the interactions associated with each individual.
- Advanced segmentation/scorings that can be used in marketing tools.
- Use “first party” data in acquisition campaigns to create and target best customers look alike audiences, follow-up after no response, or use LTV as an indicator of campaign success.
Other examples include use cases that are less focused on customer data, such as:
- Enriching a product recommendation engine with available product stock or margin per product.
- Creating “web events” from phone calls or offline purchases to have a complete view of customer cycles in web analytics tools.
- Generating Slack alerts when an Adword campaign is incorrectly set up or a lead is poorly completed in Salesforce.
Until now, companies that used their data warehouse for operational purposes set up custom connectors to send data to their different business tools. These connectors can be quite complex to implement because they deal with data format incompatibility issues, batch or real-time flows, API quotas, and more; and you also have to keep these connectors in place once they are set up.
A new category of tools is emerging to facilitate data synchronization from the data warehouse to business tools. Even if the term has not yet been agreed upon, the concept of “Reverse ETL” is most often used to refer to these tools.
Octolis allows all SMEs to effortlessly exploit the data from their existing tools
Unlike medium-sized companies, most mature start-ups or large companies with data engineers have already implemented this type of architecture. This will grow at full speed in the next few years.
The ecosystem around the “modern data stack” has matured a lot, and decision-makers are increasingly aware that data maturity is a priority in the coming years.
But the barrier is often human; data engineering skills are rare and expensive.
Octolis wants to become the benchmark solution for small and medium-sized companies that wish to take their data to the next level without having a team of data engineers.
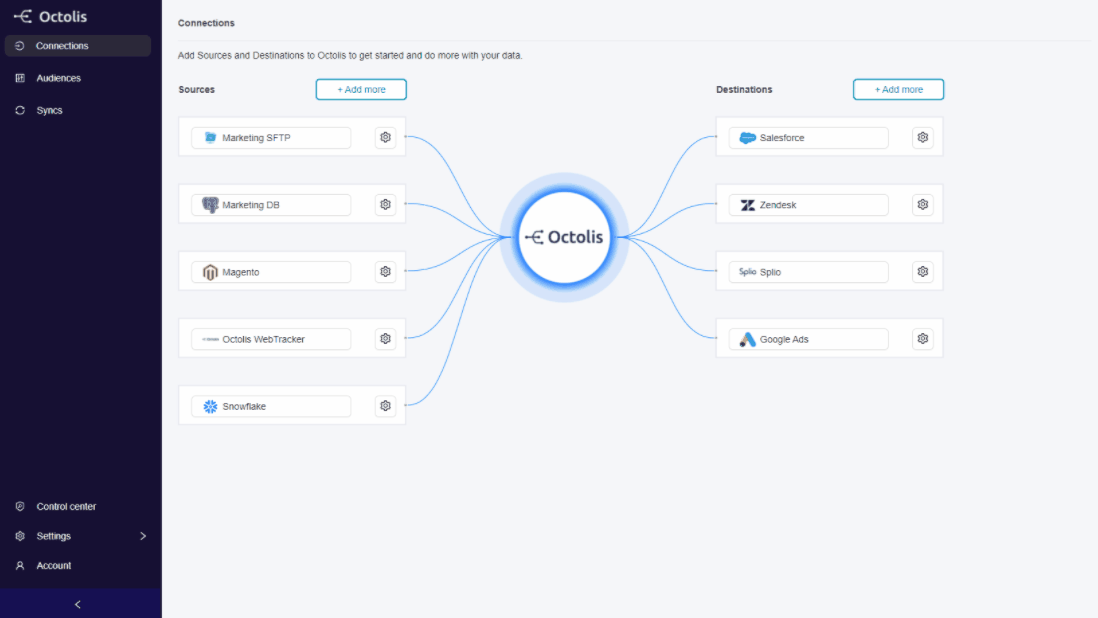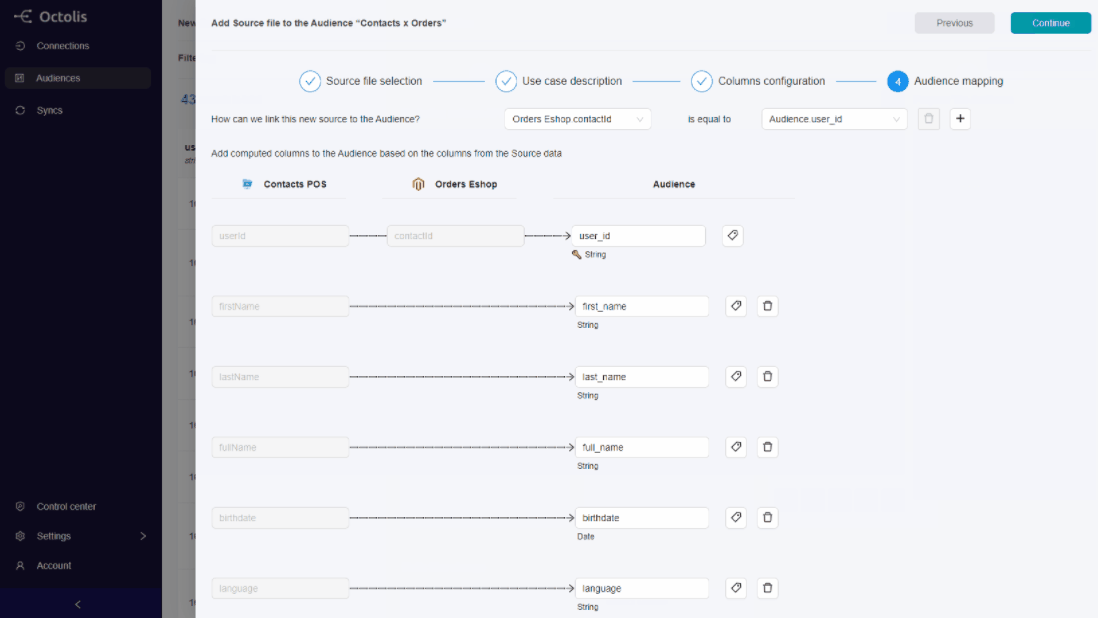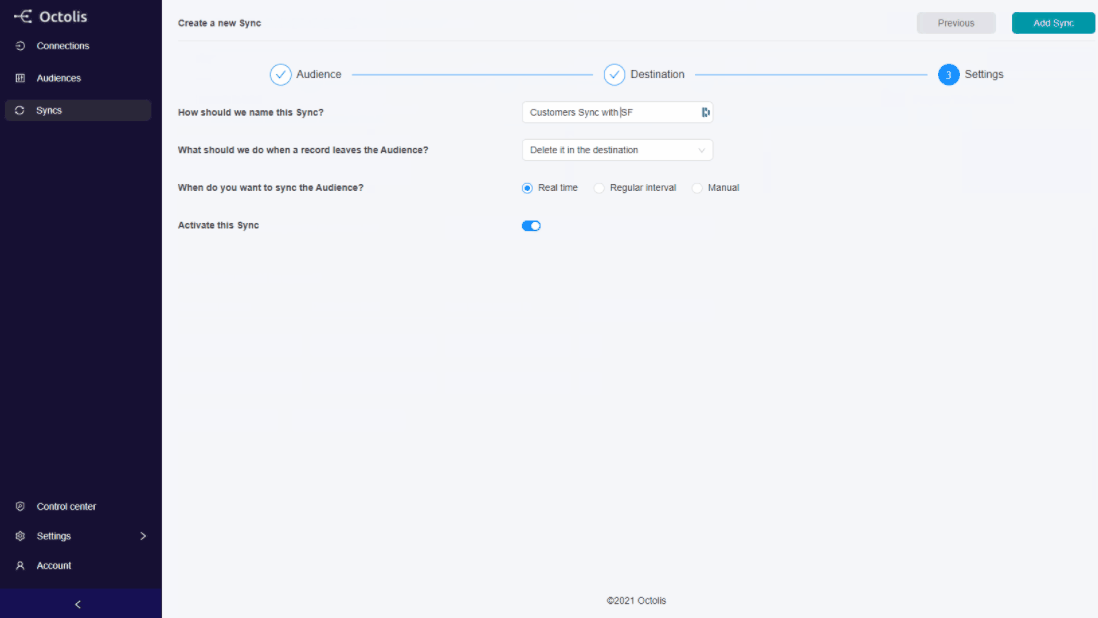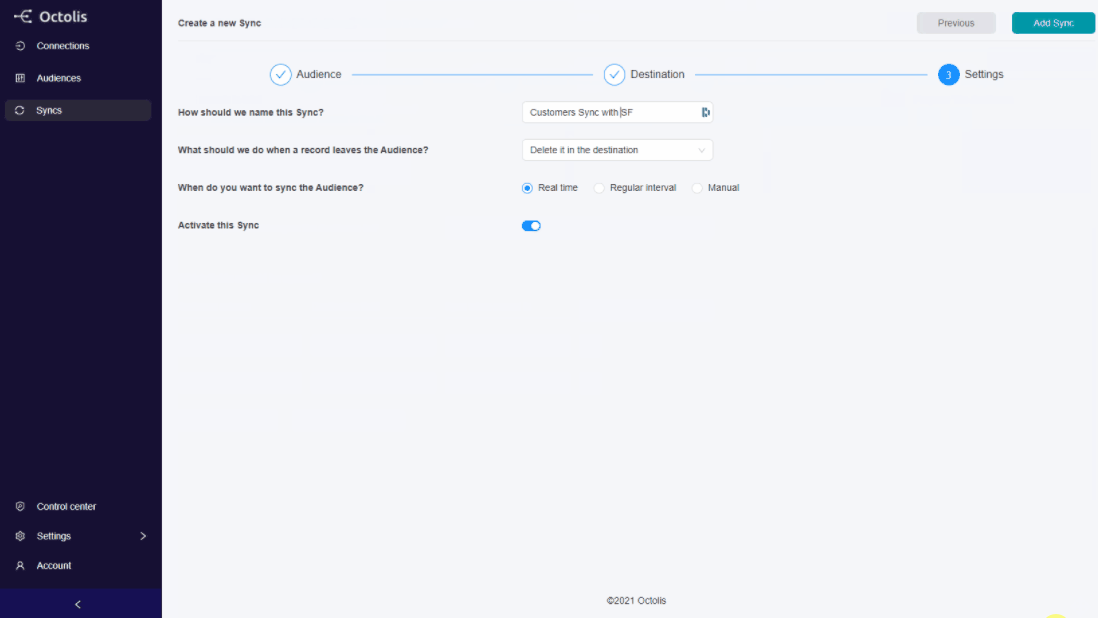
We offer a turnkey solution that allows to:
Centralize data from different tools in a data warehouse
Cross-reference and prepare data efficiently, to have nice reference tables with customers, purchases, products, contracts, stores, etc.
Synchronize data with operational tools: CRM, Marketing Automation, Ads, Customer Service, Slack, etc.
At Octolis, we believe companies can give autonomy to marketing teams while leaving a certain level of control to IT teams.
The Octolis software interface is simple enough for a marketer to cross-reference/prepare data and send it wherever needed. But this simplicity does not mean that it’s a black box, the data is accessible by the IT teams at any time, hosted in each client’s database or data warehouse, and connected to a reporting tool.
With Octolis, an SME can have a solid base to set up its reporting and accelerate all its marketing/sales projects.
The potential is enormous, and the use cases are innumerable. We get up every morning highly motivated to further improve the product and help our clients fully exploit their data’s potential!