
Nous sommes très heureux de lancer officiellement Octolis en ce mois de janvier 2022.
Pour ne pas connaître la même déconvenue que le concepteur de ce labyrinthe, nous avons développé Octolis en nous appuyant très tôt sur des feedbacks clients.
Cela fait quasiment un an que nous avons des clients qui utilisent la première version du produit, dont de belles marques comme KFC ou Le Coq Sportif. On est resté discrets, et on a énormément travaillé pendant des mois avec quelques clients pour améliorer notre produit, encore et encore.
Et maintenant, il est temps d’ouvrir les portes, Octolis est désormais accessible à toutes les entreprises qui le souhaitent !
Nous avons beaucoup à dire sur les raisons qui nous ont poussées à lancer Octolis. Si vous n’avez pas le temps de tout lire, voici ce que pouvez retenir en quelques mots :
- Nous sommes convaincus que la montée en régime des datawarehouses cloud modernes va profondément changer les organisations. Quand toutes les données de l’entreprise sont stockées dans un entrepôt, je peux utiliser cet entrepôt pour alimenter toutes mes équipes, tous mes outils. Octolis, c’est en quelque sorte le logisticien de vos données.
- Nous allons donner aux PME les moyens de devenir vraiment “data driven”. Pas pour créer des reportings à peine utilisés, pas pour faire un énième POC de machine learning qui ne sera jamais mis en production, mais pour améliorer les actions du quotidien.
- Nous avons développé la solution de data management qu’on aurait aimé avoir dans nos précédentes expériences. Une solution suffisamment simple pour être utilisée par des marketers, et ouverte/souple pour les équipes tech/data.
Le problème classique du silotage des données
Clément et moi, nous sommes rencontrés chez Cartelis, où nous avons été consultants data pendant des années. On a eu la chance de travailler pour des entreprises avec des tailles et des niveaux de maturité digitale très variées, de belles start-up comme Openclassrooms, Blablacar ou Sendinblue, mais aussi des entreprises plus traditionnelles comme RATP, Burger King ou Randstad.
Dans quasiment toutes les entreprises pour lesquelles nous avons travaillé, il y avait de gros challenges autour de la réconciliation des données clients.
Le problème est assez simple en apparence. Toutes les équipes aimeraient disposer d’un maximum d’informations sur chaque client dans les outils qu’elles utilisent au quotidien. Les équipes commerciales veulent voir dans leur logiciel CRM si le client a utilisé le produit récemment pour le relancer au bon moment, les équipes marketing veulent mettre en place des messages automatisés après qu’un client se soit plaint auprès du service client ou qu’il ait visité une page spécifique du site internet, le service client veut prioriser les tickets clients en fonction de la taille et du risque de perdre un client, etc.
Les outils qui permettent d’interagir avec les prospects / clients sont de plus en plus puissants, mais ils sont sous-exploités car on a du mal à les alimenter avec toutes les données dont on a besoin. La raison principale, c’est qu’on a des données intéressantes partout. Les parcours clients sont complexes, les interactions entre l’entreprise et ses clients reposent sur de plus en plus de canaux et d’outils différents (application mobile, chat automatisé, marketing automation, retargeting publicitaire, service client, etc.), cela génère une quantité phénoménale de données potentiellement utilisables pour personnaliser la relation client.
Pour répondre à ce challenge, la plupart des entreprises commencent de manière pragmatique par mettre en place des tuyaux entre les outils. Pour chaque projet, on met en place de nouveaux tuyaux grâce à des outils simples en apparence comme Zapier ou Integromat. Évidemment, cela devient très vite un gros sac de nœuds, difficile à maintenir et à faire évoluer.
Ensuite vient le moment où on juge qu’il est temps de centraliser toutes les données clients au même endroit. On liste les nombreux avantages (connaissance client complète, accélération des projets, ..) pour justifier du ROI potentiel, on définit un budget cible, et on prend son souffle pour se lancer dans un gros projet “Référentiel Clients (Unique)” ou “Base clients 360” qui fait peur.
La grosse question, c’est de savoir quelle forme va prendre ce fameux référentiel clients complet. Les options envisagées la plupart du temps sont principalement :
- Une solution déjà existante : CRM ou ERP
- Une base de données sur mesure
- Une solution logicielle dédiée à cet objectif, une “Customer Data Platform”
En réalité, la source de vérité unique existe déjà dans beaucoup d’entreprises, ça s’appelle un “datawarehouse”.
Historiquement le datawarehouse est une base de données qui sert de socle pour des analyses, et non pour des usages opérationnels. Les solutions utilisées comme datawarehouses étaient construites pour supporter de grosses requêtes ponctuelles, avec des données mises à jour une fois par jour au mieux. Désormais, les datawarehouses modernes peuvent supporter tout type de requêtes, en quasi-temps réel, à un prix beaucoup plus compétitif, sans effort de maintenance, et ça change tout.
La stack data moderne définit un nouveau paradigme
Le gros changement des dernières années, c’est la montée en régime d’une nouvelle génération de datawarehouse cloud (Snowflake, Google BigQuery, Firebolt, ..). L’introduction en bourse record de Snowflake en 2020, avec une valorisation qui continue d’augmenter, est le reflet financier de cette rupture majeure. Cela fait pourtant des années qu’Oracle, IBM ou Microsoft proposent des solutions de type “Data warehouses” (ou Data Lakes), qu’est ce qui a changé concrètement ?
La nouvelle génération de datawarehouses cloud dispose de 3 avantages majeurs :
- Rapidité / puissance : on peut accéder à une puissance de calcul phénoménale par rapport aux standards de 2010 en quelques clics.
- Prix : le découplage entre le stockage et le traitement des données a réduit significativement le coût de stockage. On paie à l’usage, en fonction des requêtes réalisées, mais stocker de gros volumes de données ne coûte quasiment plus rien.
- Accessibilité : la mise en place et la maintenance sont beaucoup plus simples, il n’est plus nécessaire d’avoir un régiment d’ingénieurs réseau pour gérer un datawarehouse.
Voici un très bon article sur le sujet des datawarehouse écrit par nos amis de Castor si vous souhaitez en savoir plus.
Grâce à ces innovations, l’adoption des datawarehouses cloud explose, et c’est tout un nouvel écosystème qui est en train de se structurer autour.
- Des outils “Extract Load (Transform)” comme Airbyte ou Fivetran pour alimenter le datawarehouse avec les données présentes dans tous les applicatifs internes.
- Des outils comme DBT pour transformer les données directement dans le datawarehouse.
- Des outils comme Dataiku pour faire des projets de data science directement dans votre datawarehouse.
- Des outils de reporting comme Metabase ou Qlik
- Et désormais des outils d’activation (ou reverse ETL dans la novlangue martech) comme Octolis pour enrichir les outils opérationnels à partir des données du datawarehouse.
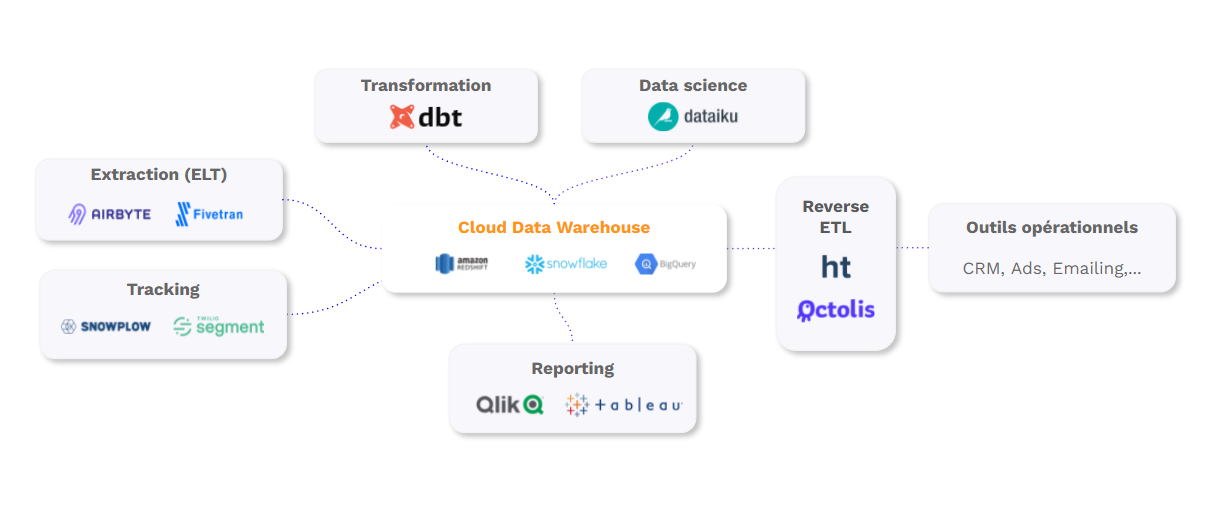
Si le sujet de la stack data moderne vous intéresse, on a écrit un article plus complet sur le sujet.
Le datawarehouse moderne devient un socle pour l’analyse et l’opérationnel
Il est désormais possible d’utiliser le datawarehouse comme un référentiel opérationnel. On peut assez facilement construire l’équivalent d’une Customer Data Platform dans un datawarehouse, c’est ce que certains experts appellent l’approche Headless CDP.
C’est une tendance de plus en plus populaire dans les entreprises matures, qui aura un impact significatif sur l’ensemble de la chaîne de valeur du SaaS. Dans cet article, David Bessis, le fondateur de Tinyclues, insiste sur le fait que cette évolution va limiter la dépendance aux solutions logicielles complètes proposées par Adobe / Salesforce / Oracle. Cela peut expliquer pourquoi Salesforce a investi significativement dans Snowflake d’ailleurs…
Les avantages d’utiliser le datawarehouse comme socle des outils opérationnels sont nombreux.
- Limiter le travail d’intégration / traitement de données, on importe les données à un seul endroit, on les transforme une seule fois, et elles servent partout ensuite.
- Garder le contrôle des données, et faciliter le passage d’une solution logicielle à l’autre.
- Aligner l’analyse et l’action, ce sont les mêmes données qui servent pour les reportings et pour alimenter les outils. Quand un analyste calcule une fréquence d’achat, cela peut aussi servir dans les outils CRM ou emailing.
Cela permet d’accélérer de nombreux projets qui étaient compliqués jusqu’à présent. On pense forcément aux cas d’usages classiques d’une “Customer Data Platform” :
- vision 360 de chaque prospect / client avec toutes les interactions associées à chaque individu
- segmentations / scorings avancés utilisables dans les outils marketing
- utilisation des données “first party” dans les campagnes d’acquisition pour cibler des profils similaires à vos meilleurs clients, relancer les non-ouvreurs emails ou utiliser la LTV comme indicateur de succès des campagnes.
Mais on peut penser aussi à des cas d’usages moins centrés sur les données clients, comme par exemple :
- enrichir un moteur de recommandations produit du stock produit disponible ou de la marge par produit.
- créer des “events web” à partir des appels téléphoniques ou des achats offline pour avoir une vision complète des parcours clients dans les outils d’analytics web.
- générer des alertes Slack quand une campagne Adword est mal paramétrée ou un lead mal complété sur Salesforce.
Jusqu’à présent, les entreprises qui utilisaient leur datawarehouse pour des usages opérationnels mettaient en place des connecteurs sur mesure pour envoyer les données du datawarehouse vers les outils métiers. Ces connecteurs peuvent être assez complexes à mettre en place car il faut gérer des problèmes de format de données, des flux en “batch” ou en temps réel, des quotas API, etc. Et puis il faut maintenir ces connecteurs une fois qu’ils sont mis en place.
Une nouvelle catégorie d’outils est en train d’émerger pour faciliter la synchronisation des données du datawarehouse aux outils métiers. Même si le terme ne fait pas encore consensus, c’est le concept de “Reverse ETL” qui est le plus souvent utilisée pour parler de cette nouvelle catégorie d’outils.
Octolis permet à toutes les PME de s’équiper pour exploiter leurs données dans leurs outils existants
La plupart des start-up matures ou des grandes entreprises disposant d’une belle équipe d’ingénieurs data ont déjà mis en place ce type d’architecture, mais on en est encore très loin dans la plupart des entreprises de taille moyenne.
Cela va s’accélérer à pleine vitesse dans les prochaines années. L’écosystème autour de la “stack data moderne” a beaucoup mûri, et les décideurs sont de plus en plus conscients que la maturité data est un axe prioritaire dans les prochaines années.
Le blocage est souvent humain, les compétences en ingénierie data sont rares et chères.
Octolis veut devenir la solution de référence pour les PME / ETI qui veulent passer un gros palier dans l’exploitation de leurs données sans disposer d’une équipe d’ingénieurs data.
On propose une solution clé en main qui permet de :
- Centraliser les données de différents outils dans un datawarehouse
- Croiser et préparer ses données facilement, pour avoir de belles tables de référence avec les clients, achats, produits, contrats, magasins, etc.
- Synchroniser les données avec les outils opérationnels : CRM, Marketing Automation, Ads, Service client, Slack, etc.
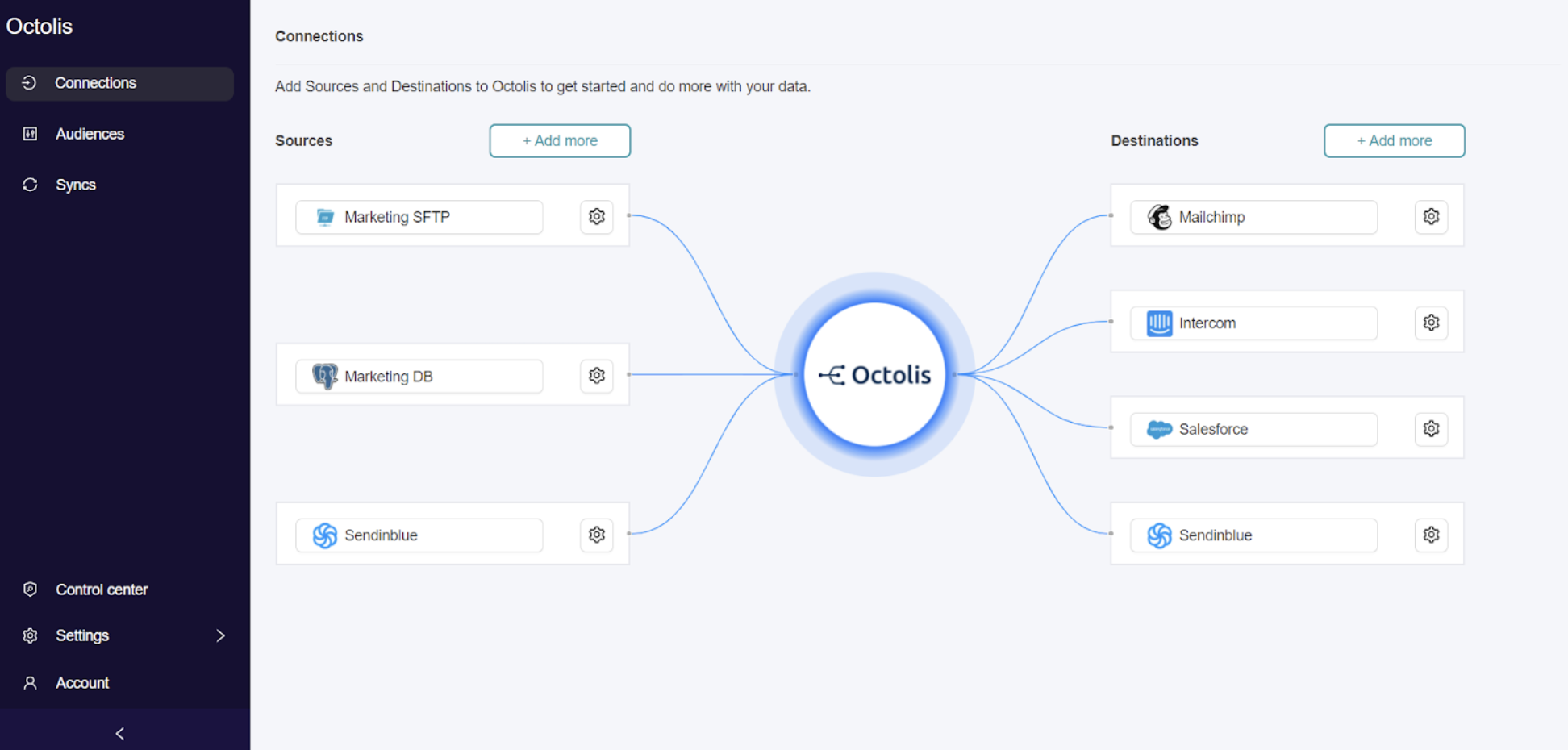
Nous sommes convaincus chez Octolis qu’il est possible de donner de l’autonomie aux équipes marketing tout en laissant un certain niveau de contrôle aux équipes IT.
L’interface du logiciel Octolis est suffisamment simple pour qu’un marketer puisse croiser / préparer des données, et les envoyer où il en a besoin. Cette simplicité ne signifie pas qu’il s’agit d’une boîte noire. Les données sont hébergées dans la base de données ou le datawarehouse de chaque client, accessible par les équipes IT à tout moment, sur laquelle on branche un outil de reporting.
Avec Octolis, une PME peut disposer d’un socle solide pour monter ses reportings, et surtout pour accélérer tous ses projets marketing / sales.
Le potentiel est énorme, les cas d’usages sont innombrables, et nous nous levons très motivés tous les matins pour améliorer encore et encore le produit et aider nos clients à exploiter pleinement le potentiel de leurs données !