Êtes-vous vraiment certain d’avoir le contrôle sur vos données clients ? Si vous lisez ces lignes, c’est peut-être qu’un doute vous assaille. Et vous avez raison de douter, car il y a des chances que vous n’ayez pas la maîtrise de vos données.
Si vos données clients sont stockées dans vos logiciels (CRM, CDP, Marketing Automation), vous n’avez pas un accès complet aux données et vous n’êtes pas libre de gérer les règles de sécurité et de confidentialité de manière aussi fine qu’il le faudrait. Vous êtes prisonnier des modèles de données proposés (imposés…) par les éditeurs. Vous êtes enfermé dans leur écosystème. Rassurez-vous, si vous êtes dans ce cas vous n’êtes pas le seul. La plupart des organisations acceptent de stocker leurs données dans leurs applicatifs Saas.
Il est temps que les choses changent et que vous repreniez le contrôle de vos données clients.
Comment faire ? C’est le sujet de cet article.
📕 Sommaire
Les 3 dimensions clés du contrôle des données
Commençons par préciser de quoi on parle. Qu’est-ce que ça veut dire concrètement avoir le contrôle de ses données ? Il y a 3 dimensions clés associées au contrôle des données. Avoir le contrôle sur ses données, c’est :
- Avoir un accès complet à ses données.
- Pouvoir gérer la sécurité des données (droits & permissions).
- Gestion de la confidentialité des données.
Revenons en détail sur chacun de ces points, en nous appuyant sur des exemples d’outils : Google Analytics, Snowflake et Amazon S3.
| Critères | Google Analytics | Snowflake | AWS S3 | Data center 'in-house' |
|---|---|---|---|---|
| Accessibilité des données | 🔒 | 🔒🔒 | 🔒🔒🔒 | 🔒🔒🔒 |
| Sécurité des données | 🔒 | 🔒🔒 | 🔒🔒 | 🔒🔒🔒 |
| Contrôle de la confidentialité | 🔒 | 🔒🔒 | 🔒🔒 | 🔒🔒🔒 |
#1 Accessibilité des données (Niveau d’ouverture des données)
Première dimension de contrôle des données : l’accessibilité, le niveau d’accès à vos données. Il varie suivant les outils et systèmes utilisés. Si l’on prend les exemples de Google Analytics, de Snowflake et de AWS 3, il y a un point commun : dans les trois cas, les données sont hébergées dans le cloud, mais le niveau d’accessibilité des données n’est pas du tout identique.
Les données stockées dans Google Analytics ne sont accessibles qu’au travers des tableaux de bord et rapports auxquels Google vous donne accès. Il n’y a pas moyen d’accéder aux données sous-jacentes qui sont utilisées pour construire les dashboards. Vous ne pouvez pas faire de requête SQL sur la base de données Google Analytics. Donc, clairement, le niveau d’accès aux données sur Google Analytics est très faible. Vous n’avez pas le contrôle de vos données !
Dans une infrastructure cloud comme Snowflake, vous pouvez interagir avec vos données via des requêtes SQL complexes, en bénéficiant de toute la puissance de calcul offerte par un DWH Cloud moderne. Par contre, vous ne pouvez pas exécuter de Spark jobs.
Ce serait possible techniquement, mais très coûteux à faire dans la pratique. C’est en revanche faisable avec Amazon S3 qui, de ce fait, est la solution qui offre le meilleur niveau d’accès aux données. Non seulement, vous pouvez connecter S3 à vos outils de BI et exécuter des requêtes SQL, mais vous pouvez extraire les données et les charger dans Spark ou vos autres applications.
La question de l’accès aux données englobe aussi celle de la portabilité des données, c’est-à-dire de la capacité d’extraire les données de l’outil où elles sont stockées pour les héberger ailleurs, dans une autre base, un autre outil. En matière de portabilité, c’est Amazon S3 qui remporte la palme. Vous pouvez facilement basculer vos données d’Amazon S3 vers Google Cloud par exemple. À l’inverse, les données de Google Analytics ne peuvent être extraites vers d’autres systèmes dans leur état brut.
#2 Sécurité des données (gestion et contrôle des accès & permissions)
La deuxième dimension du contrôle des données, c’est la sécurité. Le niveau de sécurité des données se mesure à la capacité que vous avez de gérer les accès à vos données. Si vous gérez tout, alors le niveau de sécurité des données est au top. Si vous choisissez une solution cloud, qu’il s’agisse de Google Analytics et d’une infrastructure cloud comme Amazon S3, vous n’avez pas de contrôle complet sur la sécurité des données. Vous êtes limité par les fonctionnalités de gestion d’accès & de droits proposées par la solution.
Sur Google Analytics, vous pouvez gérer les accès basés sur l’utilisateur, mais vous ne pouvez pas mettre en place un contrôle d’accès basé sur les attributs, contrairement à ce qui est possible avec Amazon S3. Si vous stockez vos données sur vos propres machines, vous pouvez créer des mécaniques de gestion des droits et des permissions 100% sur-mesure. Le niveau de contrôle sur la sécurité des données sera toujours inférieur avec une solution SaaS/Cloud qu’avec une solution auto-hébergée. Plus les données que vous stockez sont sensibles, plus il est important de bien s’informer sur les politiques appliquées par les éditeurs cloud…
Les besoins en matière de gestion de la sécurité ne sont pas les mêmes d’une entreprise à l’autre. Une entreprise qui a une petite base clients et qui collecte peu de données sur ses clients aura typiquement moins de gêne à héberger ses données dans une infrastructure cloud comme Snowflake ou Amazon S3 qu’une grande banque qui stocke de gros volumes de données très sensibles.
#3 Gestion de la confidentialité
La gestion de la confidentialité est la troisième dimension du contrôle des données.
La sécurité des données, dont nous avons parlé plus haut, c’est la question de savoir qui a accès à vos données. La confidentialité des données, c’est la question de l’usage des données et celle de savoir si l’usage que vous voulez faire des données est légal et consenti par l’utilisateur.
Reprenons nos 3 exemples pour illustrer cette dimension : Google Analytics, Snowflake et Amazon S3. Dans ces trois entreprises, il y a des collaborateurs qui ont accès à vos données brutes. Par contre, ce qu’ils peuvent faire ou font avec vos données varie :
- Google Analytics. Il y a forcément des salariés de Google qui ont accès aux rapports que vous avez configurés dans Analytics. Il est très probable que Google utilise « vos » données Google Analytics pour créer un profil utilisateur et à des fins marketing. Même si l’on ne sait pas très bien ce que Google fait de vos données visiteurs/clients, il n’y a aucun doute sur le fait qu’il les utilise.
- Snowflake et AWS3. Il y a des chances que des salariés au sein de ces entreprises aient un accès plus ou moins limité à vos données brutes, mais leurs capacités d’analyse sont plus limitées. Il faudrait qu’ils soient capables de faire du reverse engineering pour utiliser vos données. Ils n’ont pas la capacité de relier les données clients entre elles et de créer un profil utilisateur comme peut le faire Google. Par ailleurs, signalons que, dans S3, vous avez la possibilité de crypter vos données.
En matière de confidentialité, c’est à des solutions d’infrastructure cloud comme Snowflake ou AWS 3 que va le point, clairement.
Absence de contrôle des données = risque
Le couplage données <> applicatifs, un héritage des éditeurs de CRM/CDP
Les données clients sont exploitées par les solutions CRM, les logiciels de Marketing Automation et autres Customer Data Platforms. Elles en constituent le carburant. Ce qui caractérise ces logiciels, c’est le couplage données <> applicatifs. En clair, vos données sont stockées dans les applicatifs, dans vos logiciels. Il n’y a pas de séparation de la couche de données et de la couche logicielle.
C’est le mode de fonctionnement traditionnel des éditeurs de CRM et de CDP. Les données sont collectées, stockées et activées par et dans le logiciel. Le CRM, ou la CDP, est à la fois base de données (avec accès restreint aux données) et outil d’activation. Le développement du modèle SaaS dans l’univers du CRM n’a pas changé grand-chose à cette situation : le couplage reste la règle. Traditionnel ou SaaS, même combat. Même chose pour les Customer Data Platforms dont on parle tant depuis quelques années.
Pourquoi stocker les données clients dans les logiciels (CRM, CDP…) est problématique ?
Le fait que les données clients soient stockées dans les applicatifs pose problème pour plusieurs raisons. Ce caractère problématique, pour des raisons évidentes, est rarement évoqué par les éditeurs, pas plus que par les intégrateurs et autres ESN qui profitent de la prison dont ce couplage est synonyme.

Le « Guantanamo numérique », évoqué par Louis Naugès, où les ESN jouent le rôle de gardiens des DSI emprisonnés.
Les données clients sont votre actif le plus précieux. Or, les éditeurs CRM, CDP, Marketing Automation ne vous donnent qu’un accès restreint à ces données. Vous êtes prisonnier des modèles de données imposés par le logiciel, vous ne vous pouvez pas accéder à vos données dans leur état brut et les organiser dans le modèle de données de votre choix. Vous êtes limité par les choix d’infrastructure faits par l’éditeur de la solution.
Les conséquences sur le plan métier sont plus graves qu’elles ne le semblent. Le manque de flexibilité des modèles de données proposées par ces éditeurs réduit la capacité de vos équipes marketing à adapter les scores et les règles de traitement aux spécificités de votre activité. Des campagnes moins ciblées ou une personnalisation moins importante, peut être fatal dans la course à la relation client ultime et omnicanal que mènent les marques aujourd’hui.
L’autre conséquence directe de ce manque de flexibilité réside dans le manque de progression et de maturité de vos équipes dans l’exploitation des données clients. Vos équipes métiers ne vont pas apprendre à imaginer des cas d’usage en dehors du cadre proposé par votre CRM ou CDP et vous passerez à côté d’opportunités au sein de votre parcours client.
D’autre part, l’accès à votre base de données clients, organisée et stockée dans votre CRM/CDP, est payant. Vous devez payer pour visualiser et utiliser vos données ! Vous devez payer des droits d’accès. Comme chacun sait, le modèle économique des solutions classiques d’activation des données clients (CRM, Marketing Automation, ERP, CDP) est la tarification au nombre d’utilisateur. Même un utilisateur qui n’a besoin d’accéder à la base de données de manière très ponctuelle devra s’acquitter d’un abonnement.
En fait, vous êtes enfermé dans un écosystème donné qui vous coupe de l’extérieur. Cet écosystème, c’est celui construit par l’éditeur. Il peut être vaste : pensons aux CRM qui proposent des dizaines de modules différents. Mais ça n’en reste pas moins un cadre rigide.
L’exemple de BlackBerry
Pour illustrer, prenons l’exemple de BlackBerry. On doit cet exemple à David Bessis, qui le décrit dans un bel article Medium consacré à la montée en puissance des technologies data ouvertes. Grosso modo, BlackBerry étaient les rois du monde de 2001 à 2008. Et puis est arrivé l’iPhone, en 2007. Et puis un peu plus tard encore, Android. Et patatra, BlackBerry s’est effondré.
Entre 2008 et 2012, la part de marché de BlackBerry a été divisée par 20. Il y a plusieurs raisons à cela, mais la principale est la suivante : BlackBerry a été construit comme une boîte noire. Personne ne pouvait créer d’applications BlackBerry, c’était BlackBerry qui avait la main sur l’écriture du code…contrairement à iOS et Android qui se sont tout de suite positionnés comme des plateformes ouvertes.
À l’instar de BlackBerry, les éditeurs CRM / CDP sont des plateformes fermées qui freinent le développement et l’enrichissement de vos cas d’usage data. Pensez-y, comme vous seriez plus libres si vous pouviez disposer de vos données dans une base indépendante de votre CRM/CDP pour pouvoir l’exploiter dans d’autres outils, pour d’autres finalités !
Une solution, même s’il s’agit d’une suite de logiciels, ne peut pas tout faire. S’enfermer dans l’écosystème d’un éditeur, c’est forcément passer à côté de certains usages de la donnée clients.
Comment la stack data moderne permet de reprendre le contrôle de vos données ?
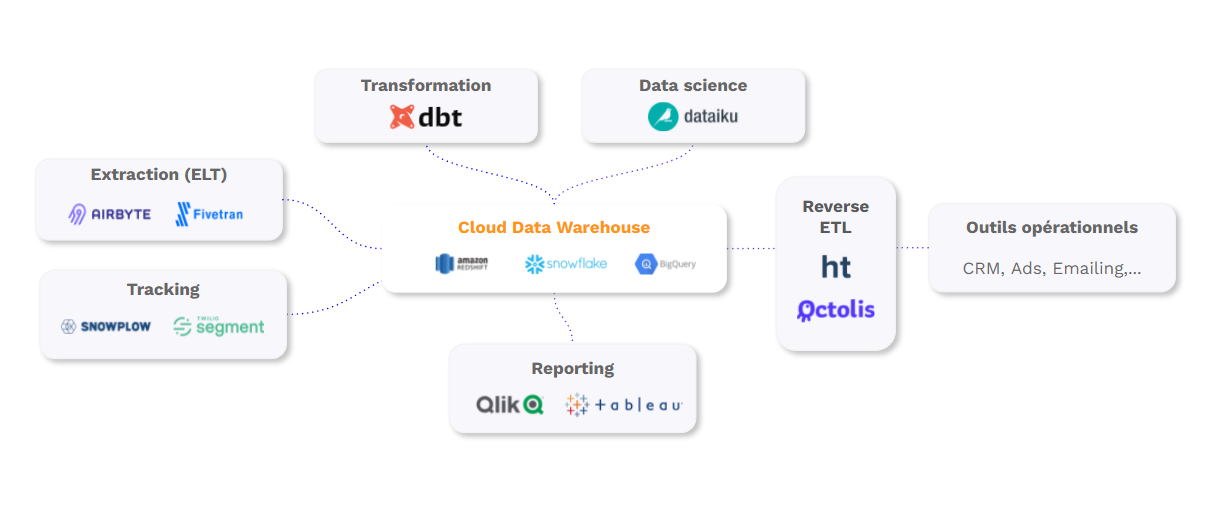
Nous avons montré qu’il y avait un problème : le couplage des données et des applicatifs qui les utilisent. La conséquence, c’est le manque de contrôle des données, de vos données clients. La solution, c’est ce dont nous allons parler maintenant : la Stack Data Moderne. Le terme est barbare, jargonneux, on vous l’accorde, mais la réalité qu’il désigne est simple. C’est une nouvelle manière d’organiser les données, une organisation tripartite :
- Un Datawarehouse Cloud qui sert de socle data de l’entreprise. C’est la base de données principale de l’entreprise qui permet d’unifier les données structurées et semi-structurées.
- Les outils métiers qui exploitent les données à des fins d’analyse mais aussi et surtout à des fins d’activation. En clair, les outils de BI de type Tableau ou PowerBI mais aussi et surtout les outils de type CRM, Marketing Automation, Google/Facebook Ads, Diabolocom…
- Un ETL et/ou un Reverse ETL qui permet de faire circuler la donnée entre le Datawarehouse et les autres systèmes de l’entreprise : les logiciels.
Le Datawarehouse moderne comme socle opérationnel
Précisons que nous ne parlons pas ici des Datawarehouses de la nouvelle génération, en plein essor depuis le début des années 2010 : les Datawarehouses cloud. On pense à des noms comme BigQuery (Google), Snowflake, Redshift (Amazon) ou Azure (Microsoft)… Ces infrastructures cloud se sont démocratisées et sont désormais accessibles aux PME, aux startups…
Alors, de quoi parle-t-on ? Un Datawarehouse moderne est une base de données cloud qui sert à stocker toutes les données structurées ou semi-structurées de l’entreprise. Plus qu’un simple entrepôt, un Datawarehouse est une machine de guerre qui permet d’exécuter des requêtes SQL et de réaliser des opérations de jointure sur des volumes énormes de données…le tout beaucoup plus rapidement que les bases de données transactionnelles (OLTP).
Nous sommes convaincus aujourd’hui :
- Que les données doivent être stockées dans une base de données distincte des logiciels.
- Que le Datawarehouse cloud est de loin la solution la plus puissante et la plus économique pour faire office de base de données maîtresse.
Dans cette optique, le Datawarehouse a vocation à devenir la clé de voûte, la solution pivot du système d’information de l’entreprise moderne. Dans cet article sur la Stack Data Moderne, nous revenons plus en détail sur nos convictions vis-à-vis des infrastructures cloud de type Datawarehouse et les principaux avantages de ces solutions. Découvrez aussi notre article « Pourquoi vous devez utiliser votre Data Warehouse pour jouer le rôle de Customer Data Platform« .
ETL & Reverse ETL
On peut se représenter la Stack Data Moderne de cette manière :
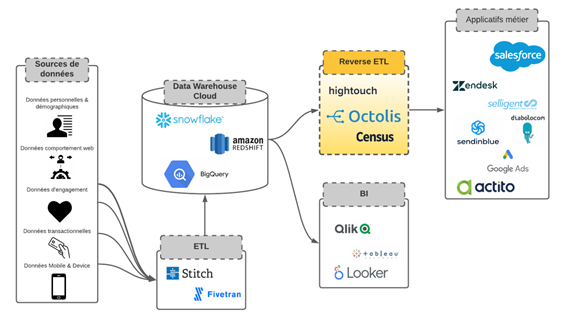
L’ETL et le Reverse ETL sont les outils qui permettent de mieux faire circuler la donnée dans le système d’information et dans les outils, tout en en gardant le contrôle. Plus précisément :
- L’ETL (Extract – Transform – Load) est la technologie qui se connecte aux sources de données, les transforme et les charge dans le Datawarehouse cloud. Deux exemples d’ETL ? Stitch Data & Fivetran.
- Le Reverse ETL est une famille de solutions plus récente qui permet de redistribuer les données du Data Warehouse aux outils métiers (CRM, Marketing Automation, ecommerce…), sous forme de segments, d’agrégats, de scorings. Il est la pièce maîtresse qui permet de mettre les données du datawarehouse au service des équipes métiers. Un exemple de Reverse ETL ? Octolis !
C’est cette architecture data moderne, articulant Data Warehouse Cloud et ETL/Reverse ETL, qui assure le plus haut niveau de contrôle des données :
- Les données sont stockées dans une base de données indépendante des logiciels. En clair, elles ne sont stockées ni dans vos applicatifs métiers, ni dans votre ETL, ni dans votre Reverse ETL, mais dans votre entrepôt de données.
- Vous pouvez créer des modèles de données sur-mesure répondant à vos besoins et cas d’usage spécifiques.
- Les performances de calcul de votre BDD sont bien meilleures que ce qu’offrent les éditeurs de CRM/CDP.
- Vous contrôlez de manière centralisée et granulaire les accès et les permissions à la base de données (le DWH).
Conclusion
Les entreprises doivent prendre conscience des risques et des coûts qu’il y a à stocker les données clients dans des logiciels, aussi puissants soient-ils (CDP). Aujourd’hui, il est possible et souhaitable que vous repreniez le contrôle sur vos données clients. Nous avons vu que cela passait par une nouvelle organisation de vos données, ce qu’on appelle de manière un jargonneuse la « stack data moderne » : vos données clients sont hébergées et consolidées dans un Data Warehouse et redistribuées à vos logiciels via une solution de type « Reverse ETL » comme Octolis.
La souveraineté des données est une condition nécessaire (bien que non suffisante) pour déployer des cas d’usage des données innovants et ROIstes. En clair, reprendre le contrôle de vos données clients est la première étape pour devenir réellement data-driven.