Si vous envisagez de déployer une CDP dans votre entreprise, vous allez être confronté(e) à un choix. Vous avez (grosso modo*) 2 options d’architecture : la CDP packagée Vs la CDP composée.
D’un côté, la CDP packagée, tout-en-un, gérant l’ensemble de la chaîne de traitement & valorisation des données : collecte, déduplication, nettoyage, unification, segmentation/audiences, orchestration et parfois activation & BI.
De l’autre, la CDP composée qui consiste à construire sa CDP avec une combinatoire d’outils interconnectés et inter-opérables. Grosso modo, un Data Warehouse + un outil de Data Ops pour la normalisation et l’unification des données sans oublier les outils d’activation et l’outil de BI.
*Attention, cette séparation n’est pas si absolue qu’on pourrait le penser. Comme toujours, la réalité est plus nuancée. Les solutions CDP modernes, comme Octolis, cherchent le meilleur des deux mondes. On vous donne plus de détails en conclusion 🙂
Arpit Choudhury, un expert en infrastructure data, fondateur notamment d’Astorik, a publié un excellent article consacrée aux différences entre CDP packagée et CDP composée. L’article est en anglais. Parce qu’il nous a beaucoup plu et que nous voulions vous le partager, nous vous en proposons ici une traduction en français. Si vous prévoyez un projet CDP, cet article est vraiment à lire. Bonne lecture ! [Voici le lien vers l’article d’origine]

Arpit Choudhury
Martech expert & Fondateur de Databeats
Arpit Choudhury a travaillé pour de belles startups Martech comme Make ou Hightouch, avant de devenir entrepreneur. Il est aujourd’hui reconnu comme l’un des meilleurs experts sur le sujet des CDP. Arpit travaille désormais principalement sur DataBeats, une communauté et un centre de ressources pour les professionnels des technologies marketing.
Introduction
La CDP – une vraie bête de foire, n’est-ce pas ?
Je pense que c’est un peu comme l’Hydre dans la mythologie grecque – le monstre aquatique qui se voit pousser deux têtes chaque fois qu’on lui en coupe une.
Chaque tentative de tuer la CDP l’a rendue plus fort, plus de gens en parlent et de plus de en plus de fournisseurs affirment qu’ils sont en fait une CDP déguisé – la CDP est officiellement antifragile.
J’ai été personnellement fasciné par la CDP. Au cours des trois dernières années, j’ai passé une quantité ridicule de temps à écrire sur la CDP et à suivre son évolution, de packagée à composée. Si vous avez suivi les discussions sur la CDP composée par rapport à la CDP packagée, vous avez certainement entendu les deux côtés de l’argument et vous n’avez pas besoin d’un autre article d’opinion expliquant pourquoi une approche est meilleure que l’autre.
Il est temps de publier un guide impartial qui propose une décomposition complète de la CDP en ses composants, qui, comme les têtes d’Hydra, ne cessent de se multiplier.
Ce guide a pour but d’aider les gens à prendre des décisions d’achat de CDP basées sur une compréhension claire des différents composants d’un CDP, de l’objectif de chaque composant et des composants nécessaires pour trouver le chemin le plus efficace pour mettre les données au travail avant qu’elles ne deviennent périmées ou inutilisables.
Commençons par les définitions.
Les définitions de la CDP
L’essor de l’entrepôt de données a conduit à l’émergence de l’ETL inversé à la fin de l’année 2020, puis à l’idée que la combinaison de ces deux technologies a permis aux entreprises de construire – ou plus exactement d’assembler – une plateforme de données clients au-dessus de l’entrepôt de données.
C’est ainsi que l’idée d’une CDP composée est apparue début 2021 et a pris de l’ampleur en 2022. Mais qu’est-ce qu’une CDP composée ? S’agit-il d’une architecture ? Est-ce une approche ? Un ensemble d’outils intégrés ? Ou s’agit-il d’une solution produite comme une CDP packagée ?
Si vous recherchez « Composable CDP » sur Google, vous constaterez qu’aucun article n’offre une définition concise de ce terme. Changeons cela.
Qu’est-ce qu’une CDP packagée ?
Une plateforme de données clients (CDP) packagée est une solution tout-en-un produite avec des capacités de collecte et de stockage de données provenant de sources multiples, de transformation et d’unification des données, de résolution des identités, de création d’audiences et de synchronisation des données vers des destinations en aval. En outre, certaines CDP packagées offrent également des outils permettant de définir des règles de qualité des données, de mettre en œuvre des protocoles de gouvernance des données et de se conformer aux réglementations en matière de protection de la vie privée.
Il y a deux éléments clés à prendre en compte :
- Une CDP packagée doit stocker une copie des données qu’elle collecte afin de résoudre les identités (résolution d’ID) et de construire des profils d’utilisateurs unifiés. Cependant, la méthodologie de résolution d’identité utilisée – probabiliste ou déterministe – varie d’un fournisseur à l’autre.
- Un fournisseur de CDP packagé permet généralement aux entreprises de créer leurs propres packages en combinant les capacités de base et les outils complémentaires.
Qu’est-ce qu’une CDP composée ?
Une plateforme de données clients composée (CDP) est un ensemble d’outils intégrés qui sont assemblés à l’aide de logiciels libres ou propriétaires afin d’exécuter certaines ou toutes les fonctions d’une plateforme de données clients packagée.
Il y a deux éléments clés à prendre en compte :
Maintenant que les définitions sont connues, examinons plus en détail les différents composants d’un CDP.
Les composantes d’une CDP
L’un des principaux problèmes posés par le terme « Customer data Platform » est qu’il a été utilisé et détourné par divers fournisseurs de logiciels dans des contextes différents. De nombreux éditeurs ont même positionné une fonctionnalité de leur produit comme une CDP, simplement parce que cette fonctionnalité permet aux utilisateurs de gérer les données clients qui ont été intégrées dans ce produit.
J’aimerais énumérer quelques mises en garde avant de présenter un aperçu complet de chaque composante d’une CDP :
Entrons dans le vif du sujet.
1. La collecte de données comportementales : l’infrastructure de données clients (IDC)
Une IDC est un outil spécialisé qui offre un ensemble de SDK pour collecter des données comportementales ou des données d’événements à partir de sources de données de première partie.
Votre produit principal – applications web, applications mobiles, appareils intelligents ou une combinaison des deux – alimenté par un code propriétaire est une source de données de première partie, et les données comportementales permettent de comprendre comment votre produit est utilisé et d’identifier les points de friction.
Ces données sont un prérequis pour une CDP et sans ces données, une CDP n’est pas une CDP. Les données comportementales provenant de vos sources de données de première partie servent de base à une CDP.
Il y a deux éléments clés à prendre en compte ici :
Pour en savoir plus sur les capacités et les fournisseurs d’IDC (dont certains font partie d’offres plus larges de CDP), voici.
P.S. : Bien que j’aie été un fervent partisan du terme IDC, avec le recul, je pense que le terme « Client » devrait être remplacé par « Audience » car les données collectées ne concernent pas uniquement les clients – en fait, la collecte de données est initiée bien avant qu’un utilisateur ou une organisation ne devienne un client. Si la notion d’Audience plutôt que de Client vous parle, vous apprécierez la lecture de cet article.
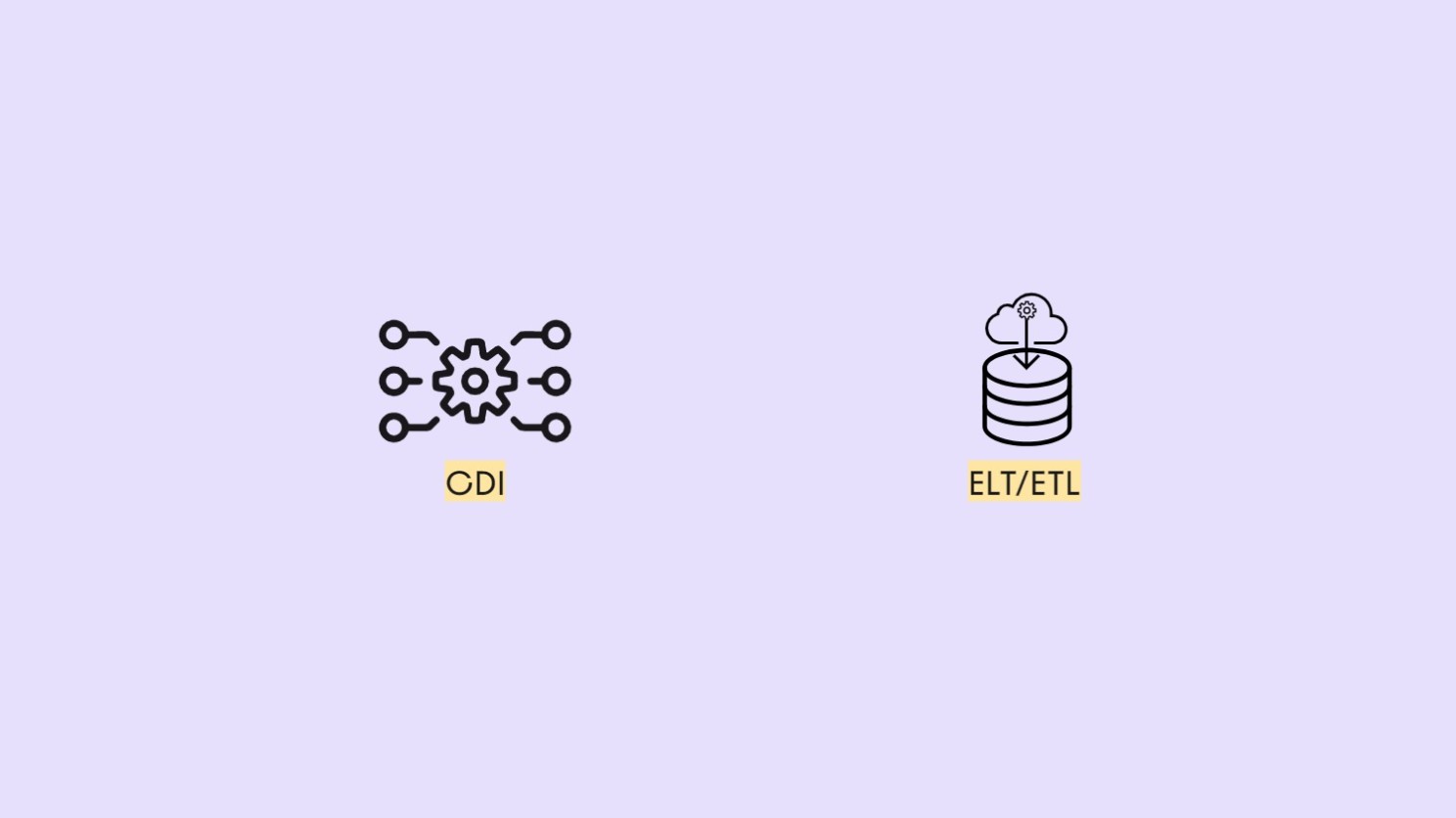
2. L’ingestion des données : ELT (ou ETL)
Une solution ELT/ETL autonome est conçue pour extraire tous les types de données d’un catalogue croissant de sources de données secondaires (outils tiers) et les charger dans des Cloud Data Warehouse.
Les sources de données secondaires comprennent les outils tiers avec lesquels les utilisateurs interagissent directement ou indirectement – outils utilisés pour l’authentification, les paiements, les expériences in-app, l’assistance, le retour d’information, l’engagement et la publicité.
Il y a deux éléments clés à prendre en compte ici :
Si vous souhaitez explorer les offres des principaux fournisseurs d’ELT, voici.
3. Le stockage des données
Comme nous l’avons déjà mentionné, les fournisseurs de CDP packagées stockent une copie des données qu’ils collectent dans un magasin ou un Data Warehouse interne. Les clients peuvent en outre envoyer une copie des données à leur propre Data Warehouse ou Data Lake par le biais d’intégrations de destination.
Le Data Warehouse, comme vous le savez déjà, est le composant central d’une CDP composée – la pièce maîtresse à laquelle tous les autres composants se connectent.
Il y a deux considérations essentielles à prendre en compte ici :
4. La résolution d’identité et l’API de profil
La résolution d’identité est le processus d’unification des enregistrements d’utilisateurs capturés à travers de multiples sources. Elle nécessite un ensemble d’identifiants (ID) utilisés pour faire correspondre et fusionner les enregistrements d’utilisateurs provenant de différentes sources, ce qui permet aux entreprises d’obtenir une vue d’ensemble de chaque utilisateur ou client.
La résolution d’identité a plusieurs cas d’utilisation, mais elle contribue principalement aux efforts de personnalisation et de protection de la vie privée.
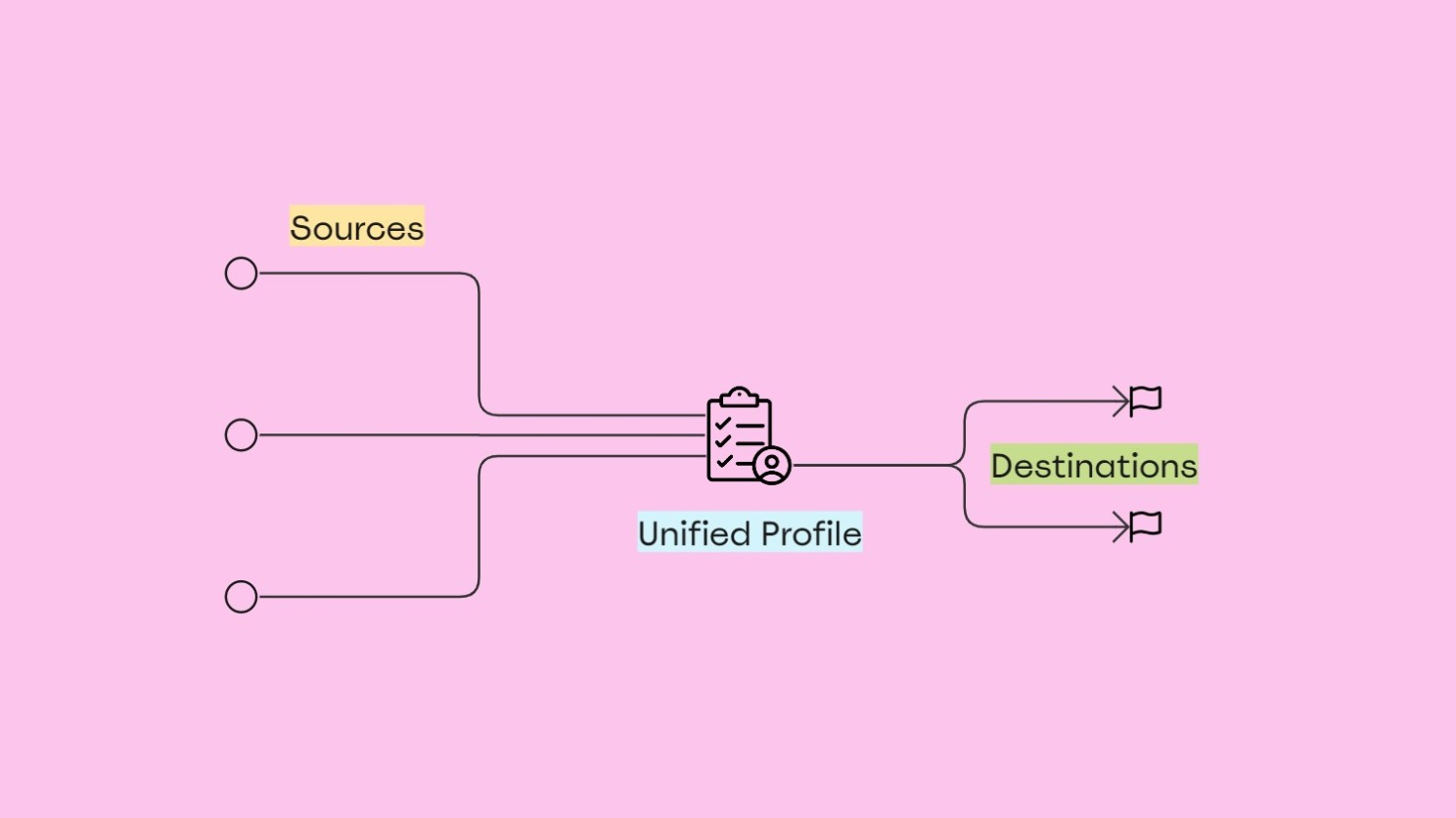
Il y a deux éléments clés à prendre en compte ici :
5. Le Visual Audience Builder (et la modélisation des données)
Autre prérequis d’une CDP, un générateur d’audience visuelle est précisément ce qu’il semble être – une interface glisser-déposer pour construire des audiences ou des segments en combinant des données provenant de diverses sources.
Dans le cadre de l’approche composée, cette capacité est offerte par les outils ETL inversés, désormais appelés outils d’Activation des Données.
Il y a deux éléments clés à prendre en compte :
P.S. : Je pense qu’il faudrait un meilleur terme pour décrire cette catégorie d’outils car l’ETL inversé n’est qu’une fonctionnalité et l’activation des données est un cas d’utilisation qui peut également être réalisé à l’aide d’une CDP packagée.
6. L’ETL inversé
Comme vous le savez déjà, l’ETL inversé fait référence au processus de déplacement des données du Data Warehouse vers des destinations en aval – généralement des outils tiers, mais il peut également s’agir d’une base de données interne.
Les entreprises construisent des pipelines ETL inversés depuis un certain temps ; cependant, l’utilisation du terme « ETL inversé » n’a commencé qu’après la productisation de l’ETL inversé au début de 2020 (j’ai entendu le terme pour la première fois en août 2020 de la part de Boris Jabes).
Nous sommes en 2023 et l’ETL inversé est désormais une fonctionnalité ou une composante de la CDP.
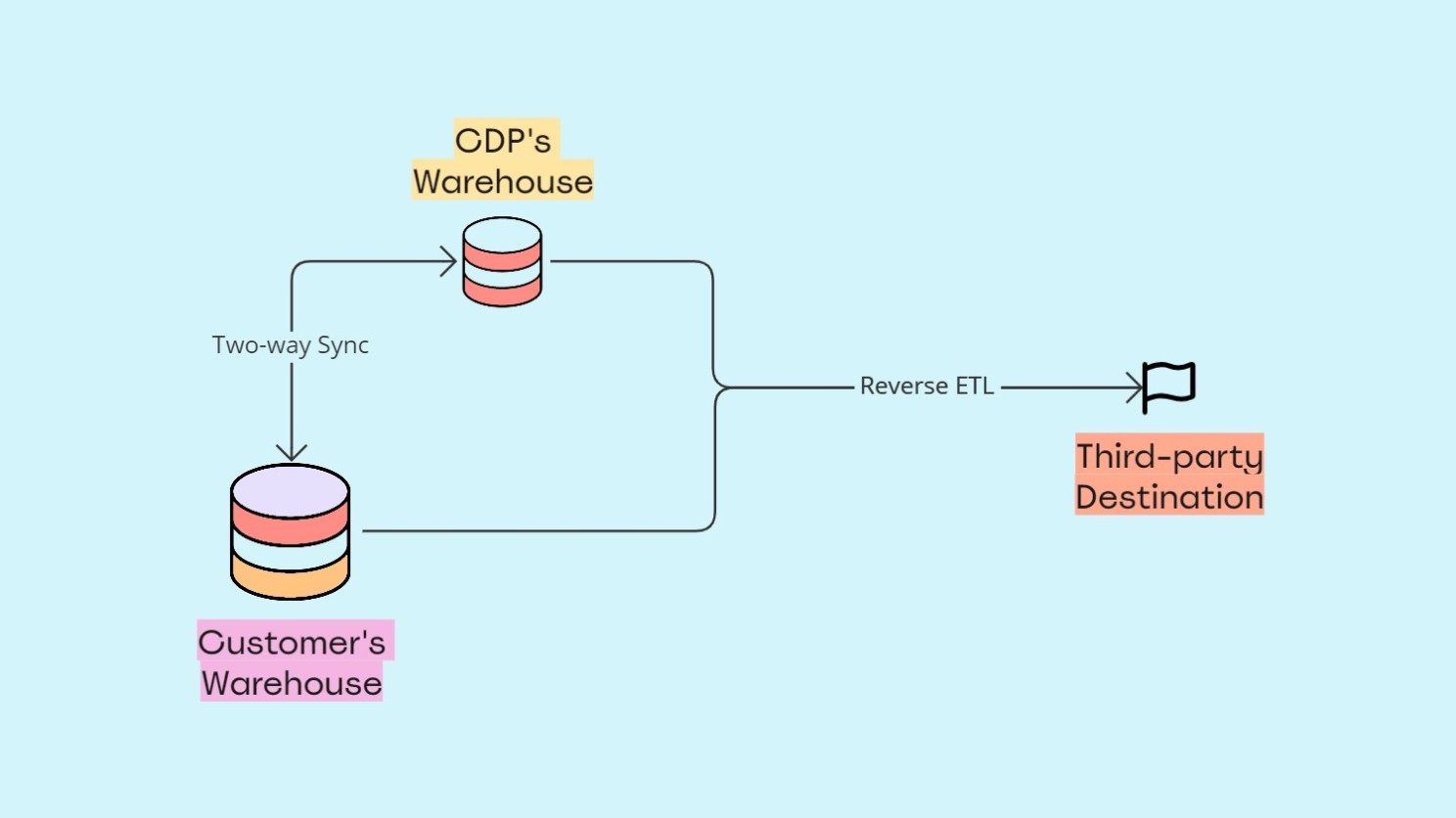
Il y a deux considérations essentielles à prendre en compte ici :
7. La qualité des données
Composante sous-estimée mais importante, la qualité des données (QD) aide les entreprises à s’assurer que les données qui alimentent leurs CDP ne sont pas bizarres. Les outils de QD aident les entreprises à maintenir la validité, l’exactitude, la cohérence, la fraîcheur et l’exhaustivité des données.
La qualité des données est une catégorie très vaste qui comprend une pléthore d’outils permettant de détecter les problèmes et de maintenir la qualité de différents types de données. Cependant, les données comportementales constituent la base d’une CDP et il faut donc des outils pour s’assurer que les données sont valides, exactes et fraîches.
Il y a deux éléments clés à prendre en compte ici :
- Une CDP packagée offre généralement des fonctions de qualité des données permettant d’effectuer des tests sur les données comportementales collectées. Il permet également aux équipes d’élaborer des plans de suivi en collaboration.
- Dans l’approche composée, la composante QD peut provenir de l’outil IDC ou d’une solution QD distincte (comme Great Expectations) qui peut, au minimum, valider les données entrantes.
8. Gouvernance des données et respect de la vie privée
Un autre élément extrêmement important et pourtant sous-représenté d’une CDP est la capacité à mettre en place des contrôles de gouvernance et des flux de travail de conformité.
Il est juste de dire que c’est quelque chose dont les entreprises ont besoin de toute façon, qu’elles utilisent une CDP ou non. Cependant, si une entreprise utilise une CDP – qu’elle soit packagée ou composée – elle doit s’assurer de certaines choses, telles que :
Il ne s’agit là que de quelques-unes des capacités clés de la composante de gouvernance et de conformité d’une CDP et, comme vous pouvez le constater, il n’est pas facile de créer cette composante en interne.
Il y a deux éléments clés à prendre en compte ici :
Conclusion (Octolis)
Nous espérons que cet article vous a aussi intéressé(e) que nous et que vous comprenez bien maintenant la différence entre les deux approches – même si, comme nous le disions en introduction, il faut nuancer un peu les choses. C’est la seule réserve que nous aurions vis-à-vis de l’article de Arpit Choudhury qui, par ailleurs, nous a vraiment stimulés !
En effet, ce que l’on observe depuis 2022, c’est la réduction du fossé entre les 2 approches. Les CDP modernes réunissent le meilleur des deux mondes.
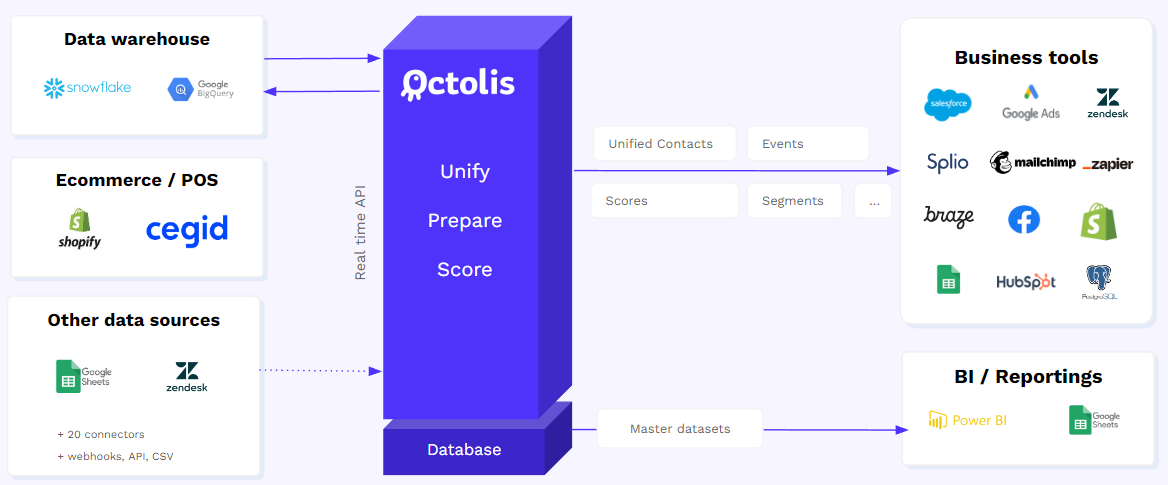
La plateforme que nous proposons, Octolis, fonctionne en surcouche d’un Data Warehouse indépendant. Le but ? Que le client reste maître de sa base de données. Data Warehouse + Octolis = CDP 2.0. Mais nous intégrons dans le même temps toutes les fonctions de traitement des données associées classiquement aux CDP packagée. Octolis est donc à la fois (composante d’une) CDP composée et CDP packagée (tout-en-un). Si vous êtes curieux d’en savoir plus sur notre vision de la CDP, sur Octolis, sur les architectures data modernes, n’hésitez pas à entrer en contact avec nous !