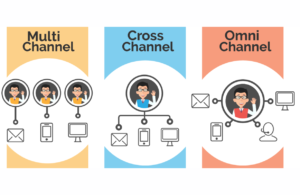
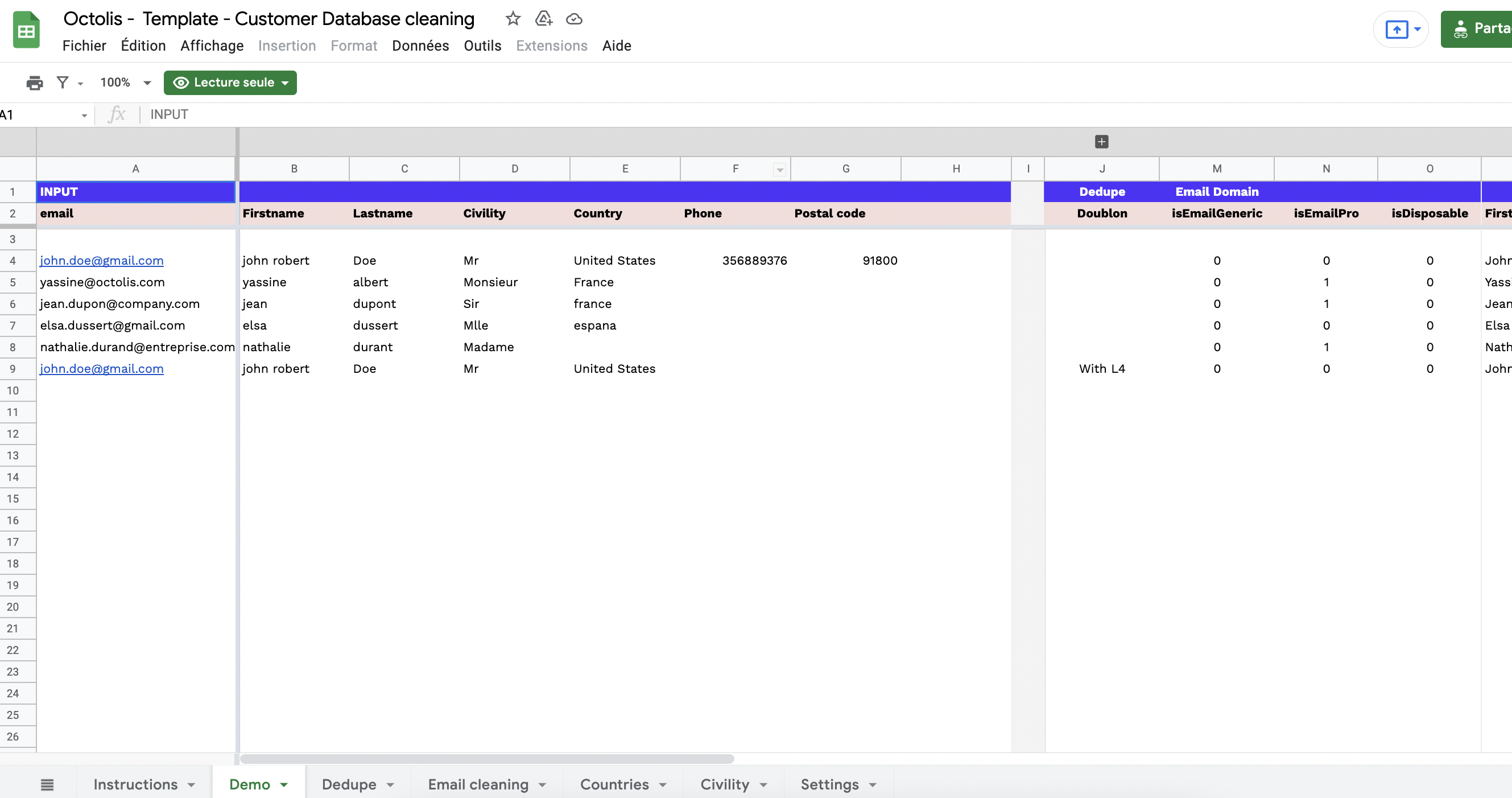
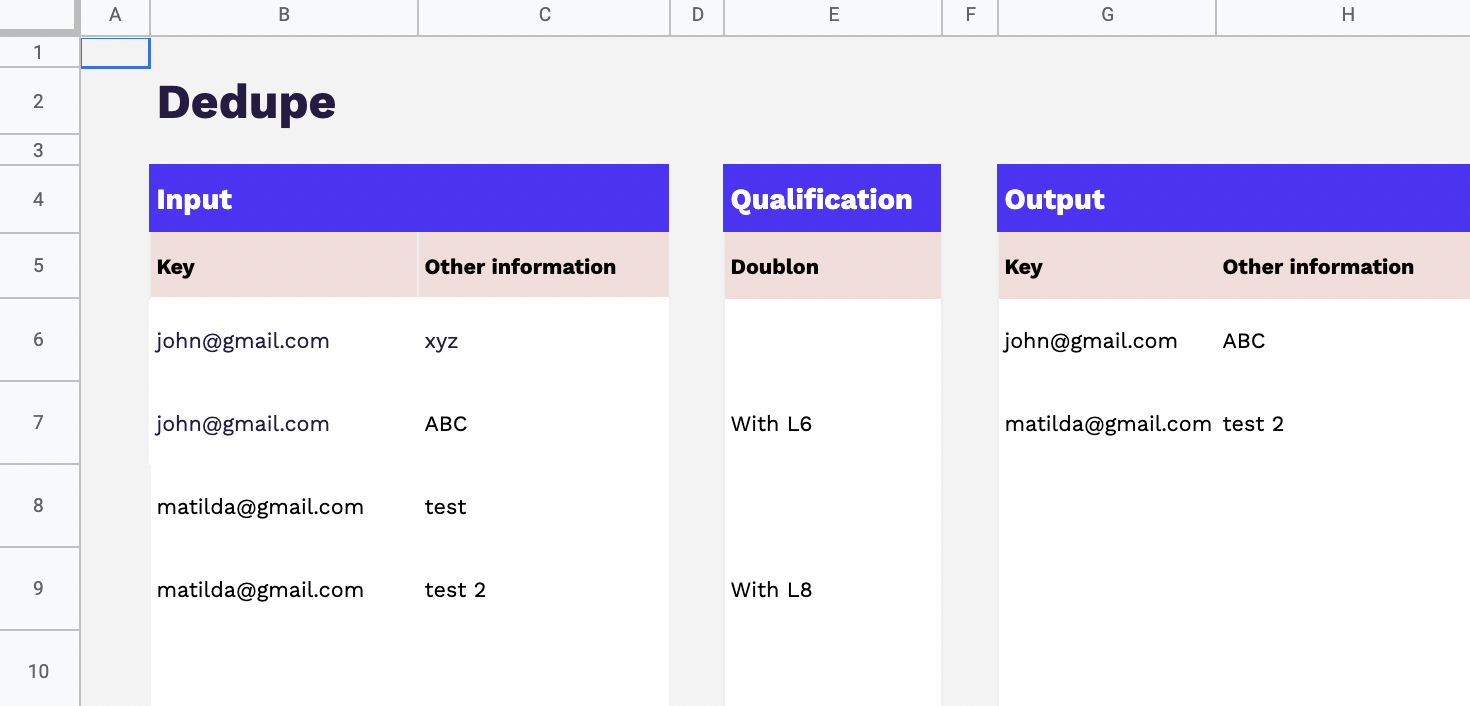
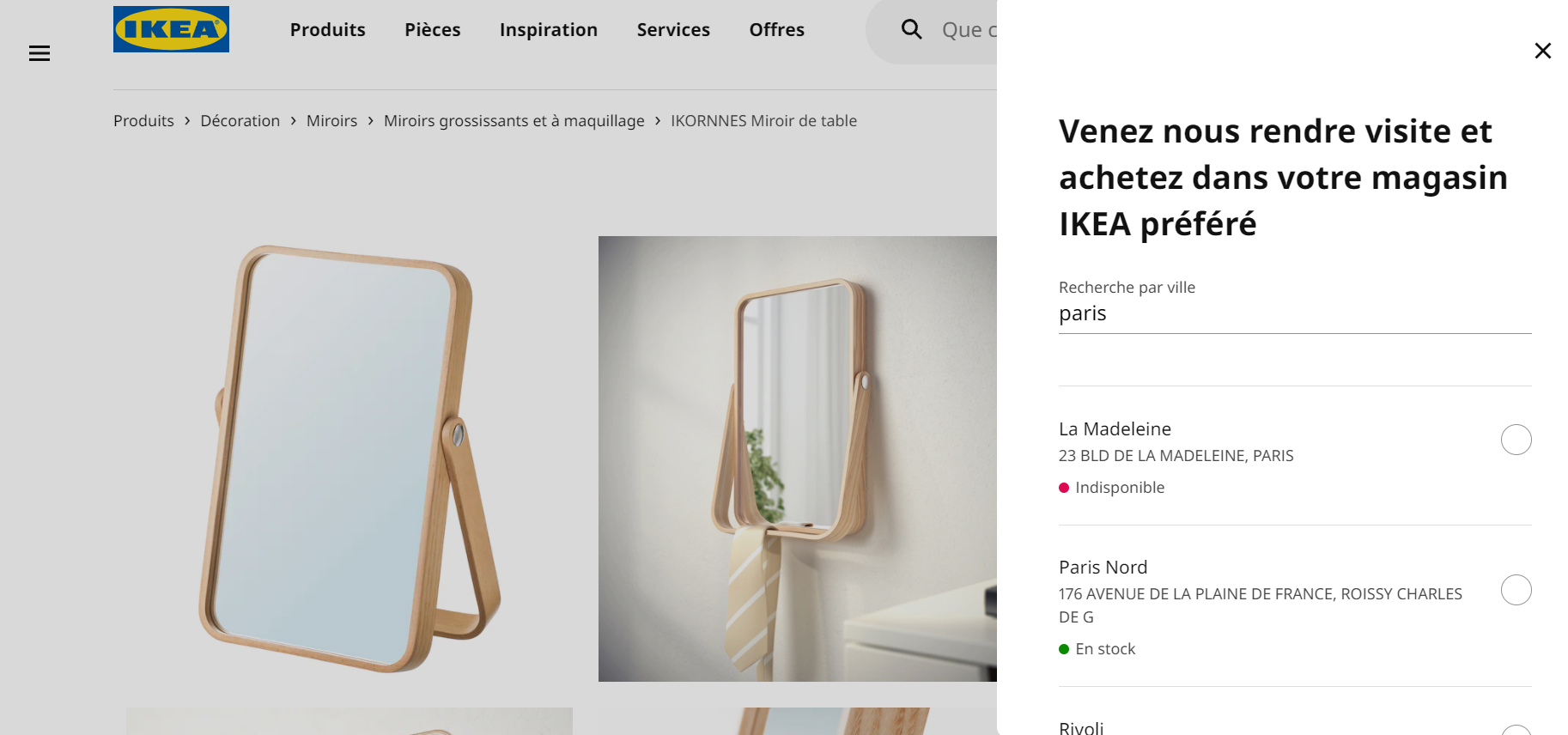
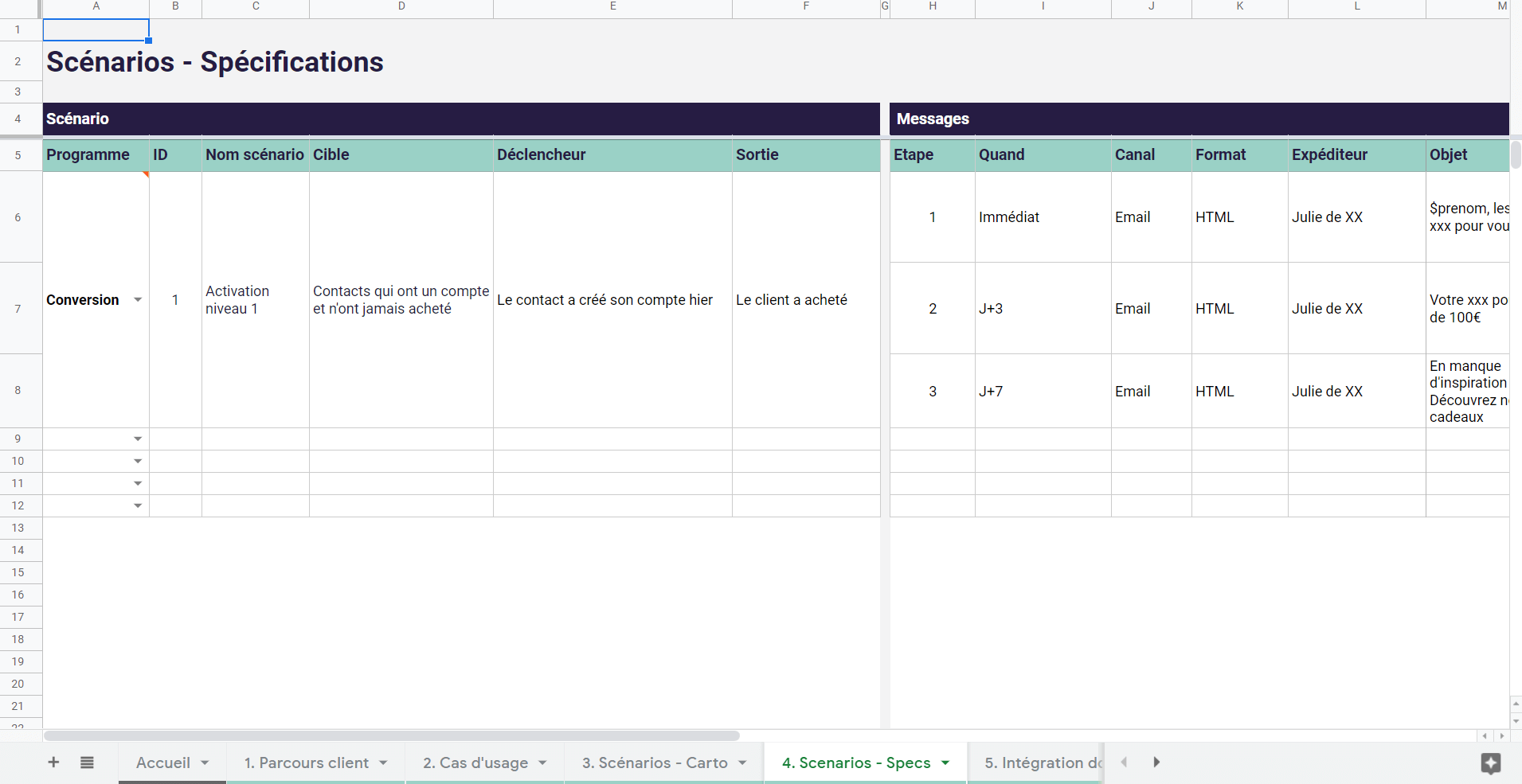
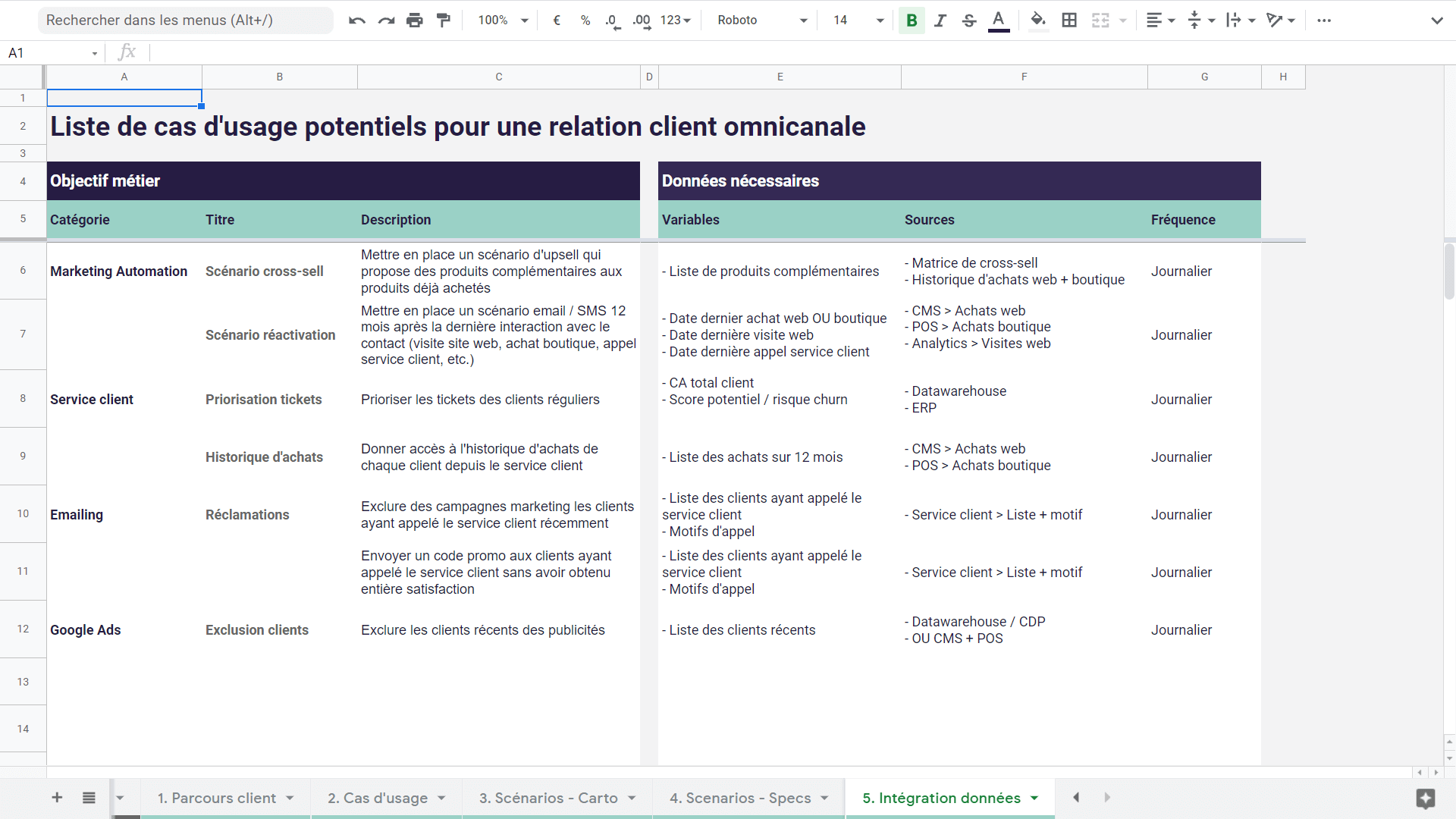
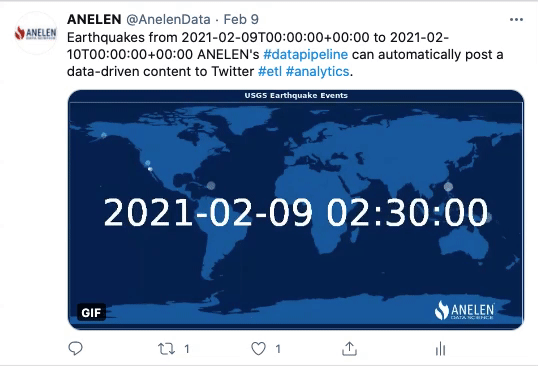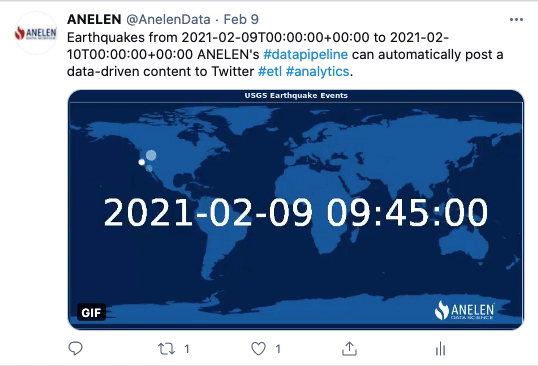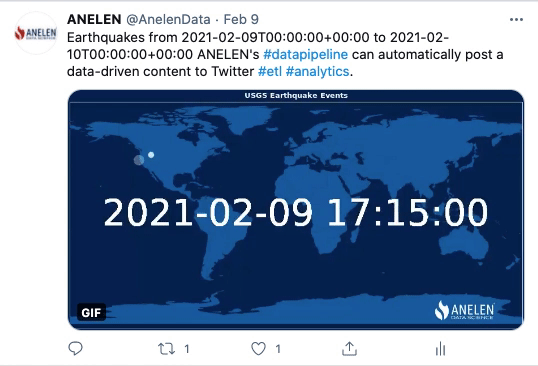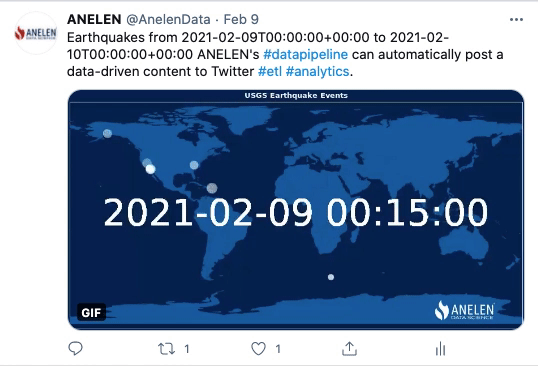
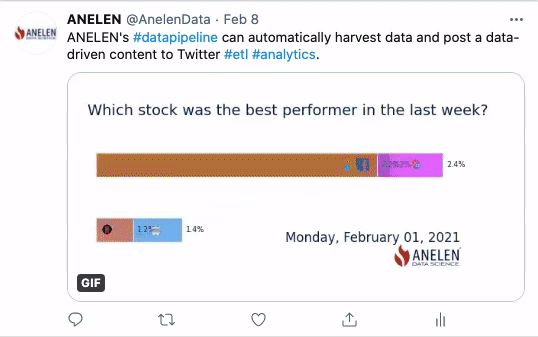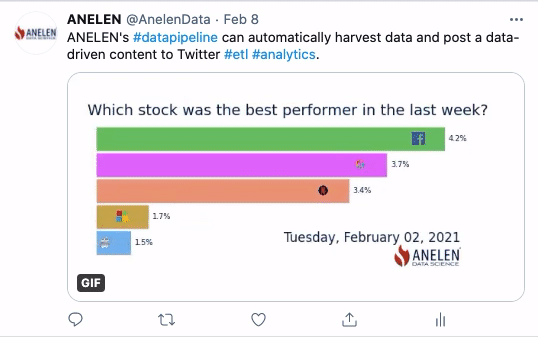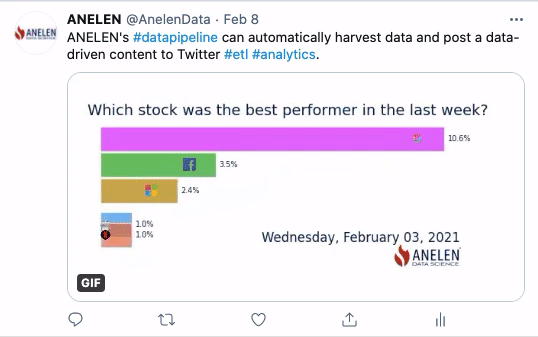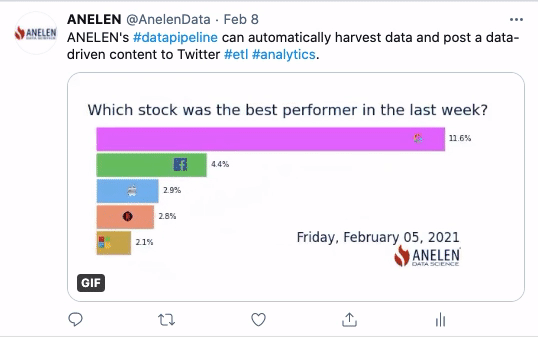
Toute entreprise souhaitant devenir plus mature en matière d’exploitation des données clients rencontre tôt ou tard le sujet épineux de la déduplication des données.
L’unification et la déduplication des données clients sont la condition nécessaire pour pleinement exploiter vos données clients, que ce soit pour l’activation omnicanale de vos parcours clients ou pour le reporting/BI.
Pour faire simple, la déduplication des données est une problématique qui se pose dès lors que vous souhaitez unifier les données en provenance de différentes sources dans une plateforme unique (de type Customer Data Platform, par exemple).
Le sujet est complexe, mais de plus en plus à l’ordre du jour dans les entreprises en raison de la multiplication des canaux, des points de contact et des outils qui engendre naturellement une dissémination des données et des duplications.
On va vous présenter dans ce guide les principaux enjeux autour de la déduplication des données et les principales méthodes de déduplication.
L’essentiel à retenir sur la déduplication des données clients
La déduplication des données clients est une étape essentielle pour unifier les informations provenant de différentes sources et créer une vue client 360 complète et cohérente.
Les données dupliquées peuvent entraîner des incohérences, des erreurs d’analyse, des coûts supplémentaires, une perte de confiance des clients, des problèmes de conformité et une perte d’opportunités commerciales.
La normalisation et le nettoyage des données sont des étapes préalables indispensables avant la déduplication pour garantir des données cohérentes et fiables.
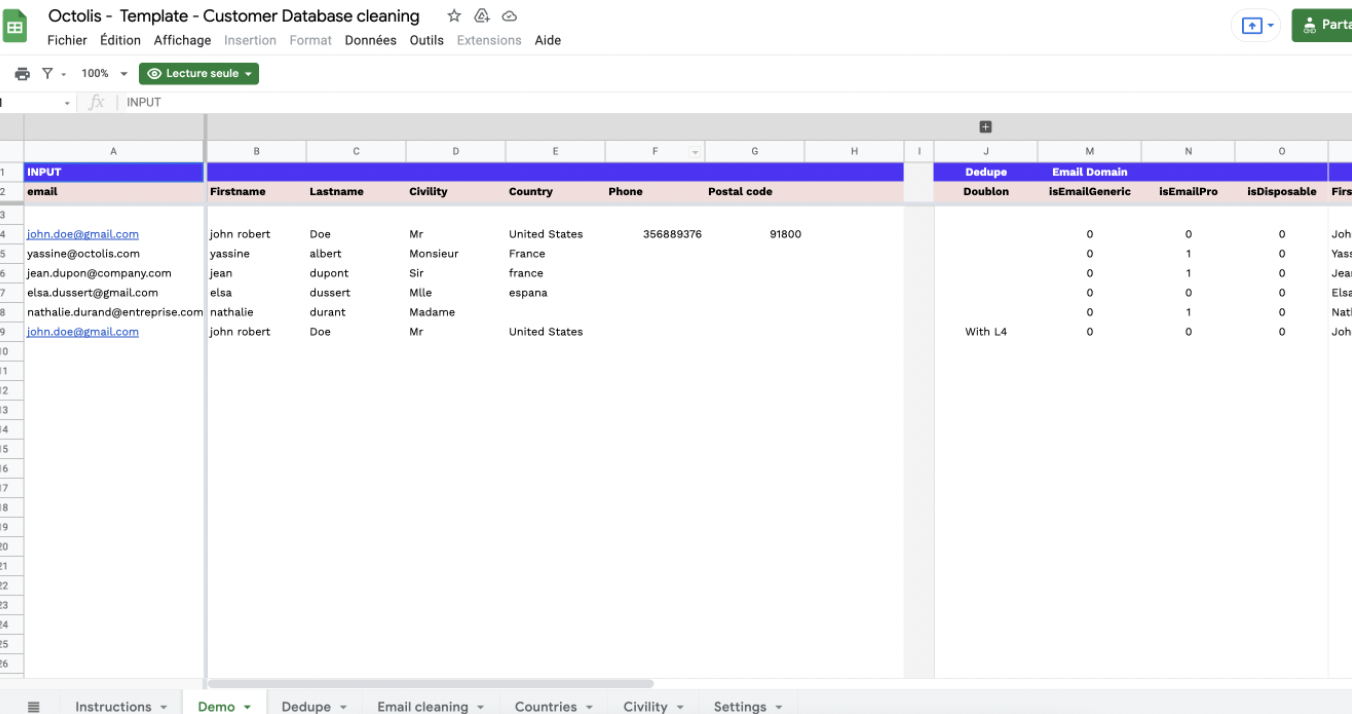
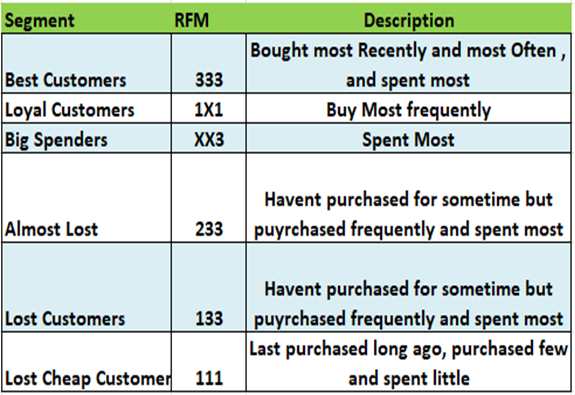
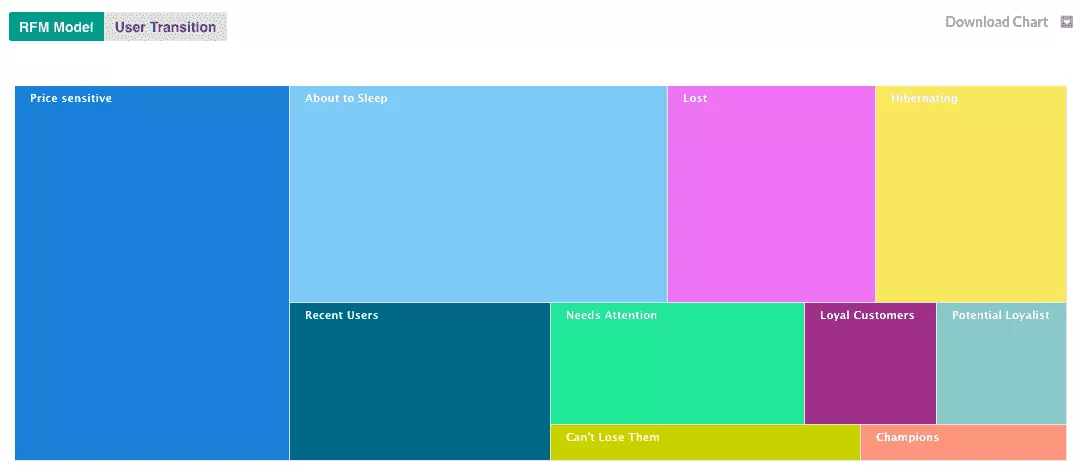
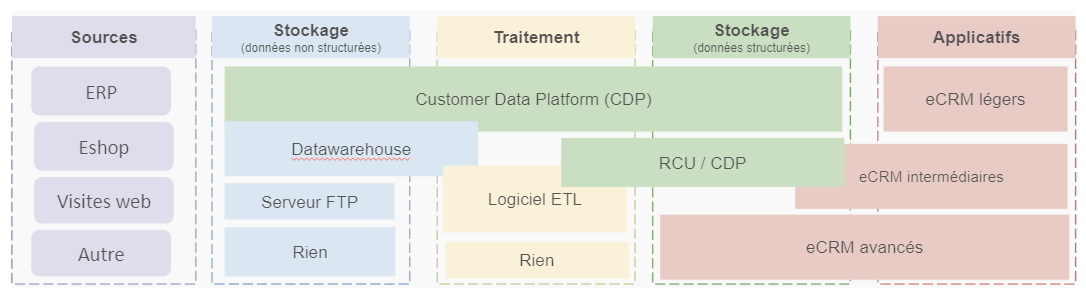
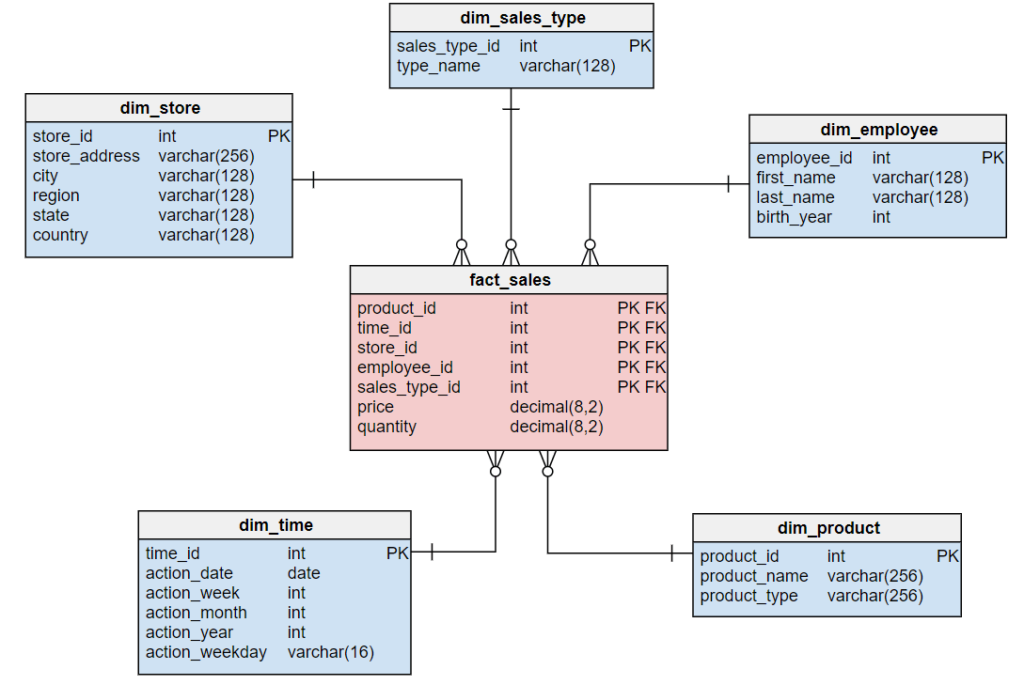
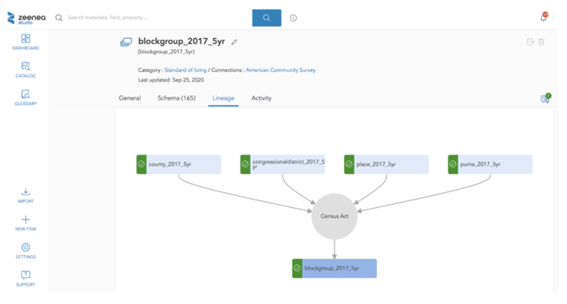
Le graph d’identités est une table visuelle qui permet de visualiser tous les identifiants utilisés par les clients et les données associées à ces identifiants.
Il existe deux approches pour dédupliquer les données : le matching déterministe, basé sur des règles précises, et le matching probabiliste, utilisant des méthodes statistiques pour détecter des correspondances potentielles.
Pour commencer, qu’est-ce que la déduplication des données ?
Définition simple de la déduplication des données
La déduplication des données clients est le processus de fusion des informations clients provenant de différentes sources pour créer une vue client 360 unifiée. Elle vise à résoudre les problèmes de doublons et d’incohérences causés par la dissémination des données dans plusieurs outils, l’utilisation d’identifiants clients différents, les erreurs humaines de saisie et les problèmes de synchronisation entre les systèmes.
L’objectif est d’agréger toutes les données au même endroit, dans une base de référence, pour obtenir une vision complète et précise du client, essentielle pour des décisions stratégiques et des actions marketing ciblées.
Déduplication vs Dédoublonnage des données
Le dédoublonnage et la déduplication des données sont deux concepts qu’il est important de bien distinguer :
Le dédoublonnage concerne la suppression ou la fusion des doublons présents à plusieurs endroits au sein d’une même base de données. En d’autres termes, il s’agit de traiter les enregistrements en double qui peuvent résulter d’erreurs de saisie, de duplications accidentelles ou de mises à jour mal synchronisées. L’objectif du dédoublonnage est d’éliminer les redondances pour garantir que chaque enregistrement dans la base de données est unique, ce qui permet d’améliorer la qualité et l’exactitude des données.
En revanche, la déduplication des données clients fait référence à un problème plus complexe. Elle se produit lorsque les données clients sont réparties dans plusieurs outils ou bases de données différentes, ce qui entraîne la dissémination des informations clients. Dans ce cas, le défi consiste à rassembler ces données dispersées en un seul endroit, généralement dans un référentiel central ou une base de données globale, afin de créer une vue client 360 unifiée. L’objectif de la déduplication des données clients est donc d’agréger toutes les données éparses pour obtenir une vision complète, holistique et cohérente des clients, en éliminant les silos de données et en consolidant les informations issues de diverses sources.
En résumé, le dédoublonnage concerne la gestion des doublons au sein d’une même base de données, tandis que la déduplication des données clients concerne la consolidation des informations clients disséminées dans plusieurs outils ou bases de données différentes pour créer une vue globale et unifiée des clients.
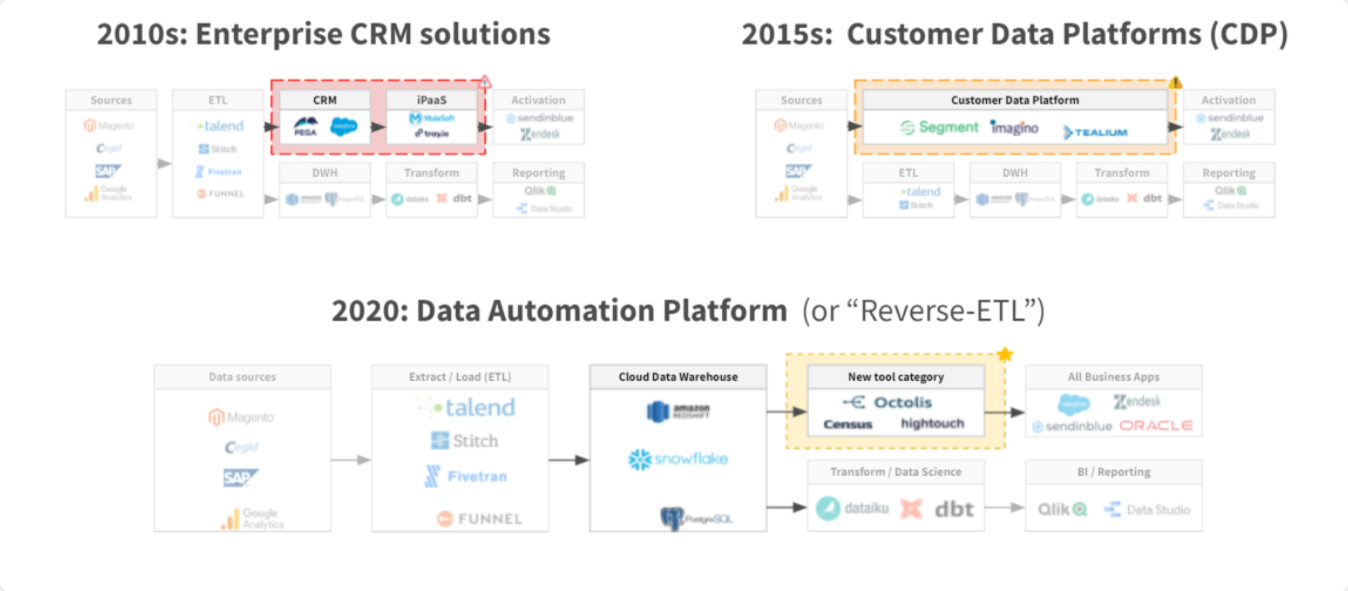
L’enjeu derrière la déduplication des données : l’unification de données multi-sources
L’enjeu majeur derrière la déduplication des données réside dans la nécessité de faire face à la croissance exponentielle des outils et technologies utilisés par les entreprises, en particulier dans le domaine du marketing et de la relation client (MarTech). Avec la multiplication des canaux et des points de contact clients, les entreprises sont confrontées à un afflux massif de données clients provenant de sources diverses.
Au cœur de cette problématique se trouve l’unification des données clients, qui est devenue le principal défi depuis plusieurs années. L’objectif est de rassembler toutes ces données éparpillées dans une base de données centrale ou un référentiel client, pour créer une vue client 360 complète et cohérente. Cette vue unifiée permet aux entreprises de mieux comprendre leurs clients, d’identifier leurs besoins et leurs préférences, et d’offrir des expériences personnalisées et pertinentes.
La déduplication des données joue un rôle crucial dans ce processus d’unification. Elle consiste à identifier et à éliminer les doublons d’informations clients qui peuvent exister dans les différentes sources de données. En effet, lorsque les données clients proviennent de multiples canaux et outils, il y a souvent des risques de redondance et d’incohérence dans les enregistrements.
Cependant, il est essentiel de noter que la déduplication n’est qu’une étape parmi d’autres dans le processus d’unification des données. L’unification va au-delà de la simple suppression des doublons, car elle implique également la normalisation, la consolidation et la synchronisation des informations clients provenant de diverses sources.
Ainsi, l’enjeu majeur derrière la déduplication des données réside dans la création d’une vue client complète, permettant aux entreprises de mieux exploiter leurs données, de mieux comprendre leurs clients, et ce afin de prendre des décisions stratégiques plus éclairées et d’offrir des expériences clients plus personnalisées et satisfaisantes.
Quelques cas d’usage concrets de la déduplication des données
La déduplication des données joue un rôle essentiel dans de nombreux cas d’usage concrets, permettant aux entreprises d’améliorer leurs opérations et d’optimiser leur relation client. Voici quelques exemples pratiques :
Amélioration de la qualité des données clients : La déduplication aide à éliminer les doublons et les incohérences dans les informations clients, garantissant ainsi que chaque enregistrement est précis et à jour. Cela contribue à améliorer la qualité globale de vos données, ce qui est essentiel pour des prises de décision fiables et des actions marketing ciblées.
Unification des profils clients : En consolidant les données clients provenant de diverses sources, la déduplication permet de créer une vue client 360 complète et cohérente. Cela permet aux équipes marketing et aux équipes de service client de disposer d’une image précise et unifiée de chaque client, favorisant ainsi une meilleure compréhension de leurs besoins et de leurs préférences.
Optimisation de l’expérience client : Grâce à cette connaissance approfondie des clients, les entreprises peuvent offrir des expériences clients plus personnalisées et pertinentes. La déduplication des données permet de mieux cibler les clients avec des offres et des communications adaptées, améliorant ainsi la satisfaction et la fidélité des clients.
Réduction des coûts opérationnels : En éliminant les doublons de données clients, les entreprises évitent les inefficiences et les redondances dans leurs opérations. Cela peut entraîner des économies de temps et de ressources, en simplifiant les processus et en améliorant l’efficacité générale de l’entreprise.
Prise de décision éclairée : Une déduplication réussie permet d’obtenir des données fiables et cohérentes, ce qui est essentiel pour prendre des décisions stratégiques éclairées. Les dirigeants peuvent compter sur des informations précises pour établir des objectifs, identifier les opportunités de croissance et anticiper les tendances du marché.
Conformité et sécurité des données : La déduplication contribue à garantir que les informations clients sont correctes et à jour, ce qui est crucial pour respecter les réglementations de protection des données telles que le RGPD. En évitant les doublons, les entreprises minimisent également les risques liés à la sécurité des données.
Amélioration de l’efficacité des campagnes marketing : En éliminant les doublons, les entreprises peuvent mieux segmenter leur base de clients et cibler les audiences appropriées. Cela permet d’optimiser les campagnes marketing en évitant de solliciter plusieurs fois les mêmes clients, améliorant ainsi le retour sur investissement de votre dispositif data.
Les risques associés aux données dupliquées
Les données dupliquées peuvent entraîner de nombreux risques pour les entreprises, notamment :
Incohérence des données : Divergence entre les enregistrements dans différents systèmes, rendant difficile la compréhension des informations clients.
Erreurs dans l’analyse des données : Comptage multiple de clients dupliqués dans les rapports, faussant ainsi les résultats et pouvant conduire à des décisions commerciales erronées.
Coûts supplémentaires : Stockage et gestion de données en double, entraînant des coûts inutiles pour l’entreprise.
Perte de confiance des clients : Erreurs dans les communications avec les clients, entraînant de la frustration et une perte de confiance envers l’entreprise.
Problèmes de conformité : Risque de non-conformité avec les réglementations de protection des données, exposant l’entreprise à des sanctions légales et des amendes.
Perte d’opportunités commerciales : Difficulté à obtenir une vue complète des clients, entraînant une perte d’opportunités commerciales et une baisse de compétitivité sur le marché.
La méthode pour dédupliquer vos données clients
Les préalables à la déduplication des données : normalisation & nettoyage
Avant de se lancer dans le processus de déduplication des données, deux étapes essentielles sont à prendre en compte : la normalisation et le nettoyage des données.
Normalisation des données : La normalisation consiste à uniformiser les données en les formatant de manière cohérente et standardisée. Cela implique de convertir les informations dans un format commun, tel que les codes postaux, les numéros de téléphone ou les dates, afin de faciliter la comparaison et l’identification des doublons. La normalisation garantit que les données sont cohérentes et comparables, créant ainsi une base solide pour le processus de déduplication.
Nettoyage des données : Le nettoyage des données est une étape cruciale pour éliminer les erreurs, les incohérences et les valeurs manquantes dans les enregistrements. Cela peut inclure la correction des fautes de frappe, la suppression des caractères spéciaux, la remplissage des valeurs manquantes ou la mise à jour des informations obsolètes. Le nettoyage des données garantit que les enregistrements sont fiables et précis, ce qui est essentiel pour éviter des doublons involontaires et pour obtenir des résultats de déduplication précis.
En résumé, la normalisation et le nettoyage des données sont des préalables indispensables avant de se lancer dans la déduplication. Ces étapes permettent de s’assurer que les données sont cohérentes, comparables et exemptes d’erreurs, créant ainsi un terrain propice à une déduplication réussie et efficace.
La création du graph d’identités (Identity Graphs)
Le graph d’identités est une table visuelle qui regroupe les identifiants utilisés sur les points de contact et par les outils de l’entreprise, offrant une vue globale des clients et des données associées à ces identifiants. Certains logiciels offrent des représentations visuelles pour faciliter la compréhension des interrelations complexes entre les différents points de contact.
Les éléments du graph d’identités comprennent :
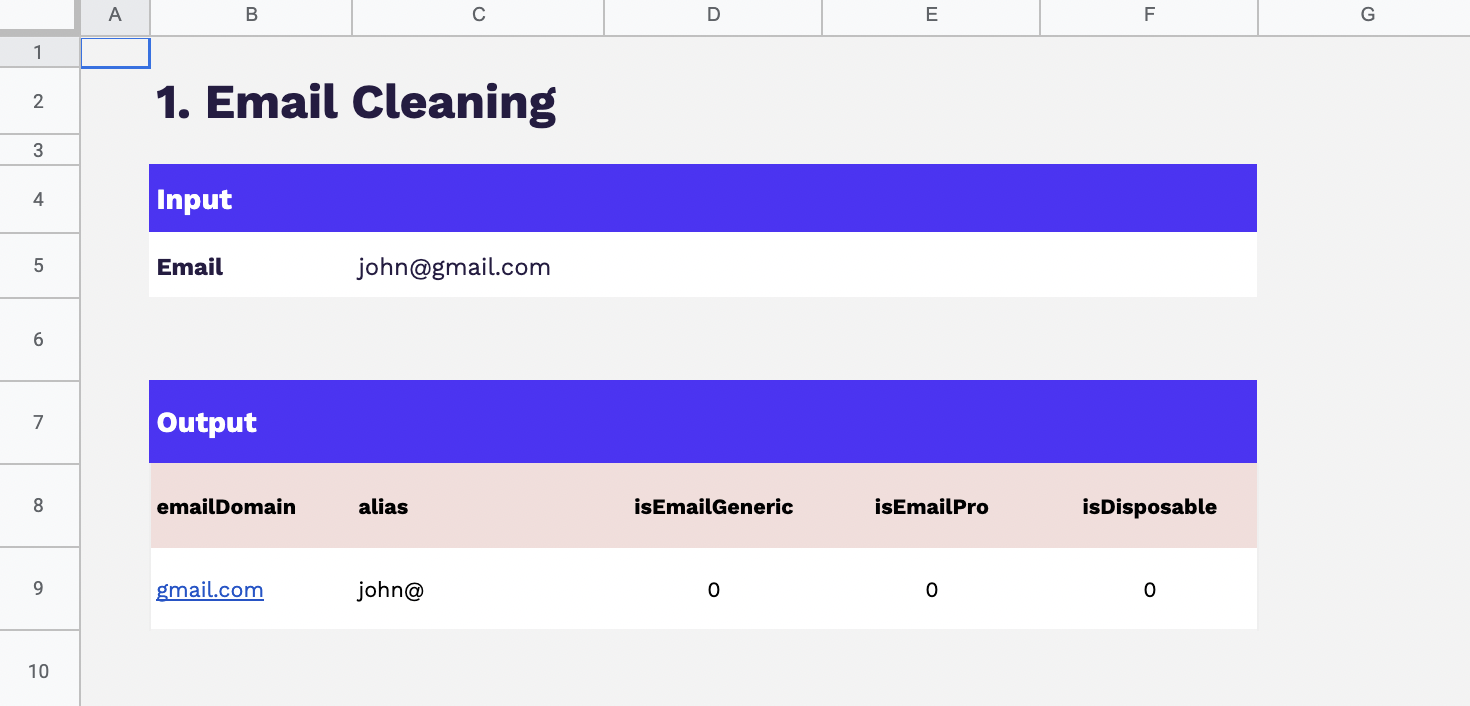
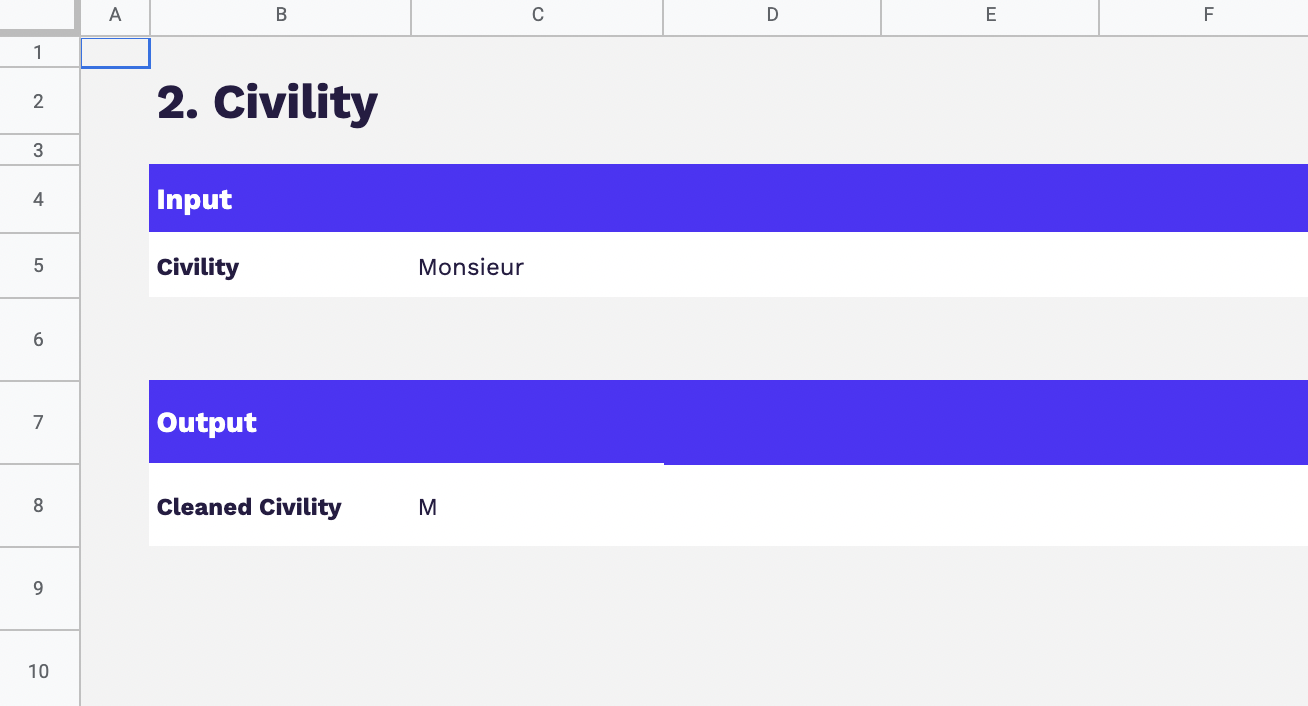
Email
Cookie ID
Numéro client
Nom Prénom
Téléphone
Autres identifiants utilisés par l’entreprise
Il permet de visualiser les types de données rattachés à chaque identifiant, tels que les données démographiques, les préférences, les historiques d’achats, etc. L’objectif est d’obtenir une vue complète et unifiée des clients pour améliorer les expériences personnalisées, la satisfaction client et les décisions stratégiques basées sur des données précises.
Le choix des clés de déduplication
Les clés de déduplication sont les identifiants sélectionnés pour unifier les enregistrements similaires et éliminer les doublons dans le graph d’identités. Il est recommandé d’utiliser des clés d’unification qui sont spécifiques, persistantes et uniques pour chaque client. Les clés d’unification servent à identifier de manière fiable et précise les clients, garantissant ainsi que les enregistrements pertinents sont regroupés ensemble.
En univers Retail / Ecommerce, deux clés fréquemment utilisées pour la déduplication sont :
Email : L’email est l’un des identifiants les plus répandus dans le commerce électronique. Il est souvent unique pour chaque client et offre une méthode fiable pour unifier les données clients.
Nom + prénom + adresse : Cette combinaison de données démographiques est également largement utilisée pour identifier les clients de manière précise. En utilisant le nom, le prénom et l’adresse, les entreprises peuvent regrouper les enregistrements associés à un même individu, même si les autres identifiants sont différents.
Il est important de noter que différentes entreprises peuvent avoir des besoins spécifiques en matière de clés de déduplication en fonction de leurs données et de leur secteur d’activité. Par conséquent, il est possible d’utiliser des règles en cascade avec une priorisation pour la déduplication.
Les règles en cascade permettent de hiérarchiser l’utilisation des différentes clés de déduplication dans le processus de déduplication. Par exemple, on peut commencer par utiliser l’email comme clé principale, puis en cas d’absence d’email, utiliser la combinaison du nom, du prénom et de l’adresse comme clé de secours.
Matching déterministe Vs matching probabiliste
Le processus de déduplication des données peut être réalisé à l’aide de deux approches distinctes : le matching déterministe et le matching probabiliste. Ces approches peuvent être utilisées de manière complémentaire pour obtenir des résultats plus précis.
Matching déterministe : Le matching déterministe repose sur des règles de correspondance claires et précises pour identifier les doublons. Cela signifie que les enregistrements sont comparés en utilisant des clés d’identifications spécifiques et uniques, telles que l’email, le numéro de téléphone ou le numéro de client. Si deux enregistrements ont la même clé d’identification, ils sont considérés comme des doublons et sont fusionnés pour former un seul enregistrement. Le matching déterministe garantit une déduplication précise, car les correspondances sont basées sur des critères stricts.
Matching probabiliste : Le matching probabiliste, en revanche, utilise des méthodes statistiques et algorithmiques pour évaluer la similarité entre les enregistrements. Plutôt que de se baser sur des clés d’identification uniques, le matching probabiliste examine les similitudes entre les enregistrements en utilisant des techniques telles que le calcul de la similarité de chaînes de caractères ou le calcul de la distance entre les valeurs. Cela permet d’identifier des correspondances potentielles même lorsque les clés d’identification ne sont pas exactement les mêmes. Le matching probabiliste est plus flexible, mais peut entraîner un risque plus élevé de fausses correspondances.
Ces deux approches peuvent être utilisées de manière complémentaire pour obtenir des résultats plus robustes. Par exemple, le matching déterministe peut être utilisé en priorité pour les enregistrements avec des clés d’identification claires et uniques, tandis que le matching probabiliste peut être utilisé pour détecter des correspondances potentielles lorsque les clés d’identification sont manquantes ou inexactes.
Dans le cadre de l’identity resolution, qui vise à créer une vue client unifiée, le choix entre le matching déterministe et le matching probabiliste dépend des besoins spécifiques de l’entreprise et de la qualité des données disponibles. Une combinaison judicieuse de ces deux approches peut permettre une déduplication précise et complète, conduisant à une meilleure compréhension des clients et à des actions marketing plus efficaces.
Les outils pour dédupliquer vos données clients
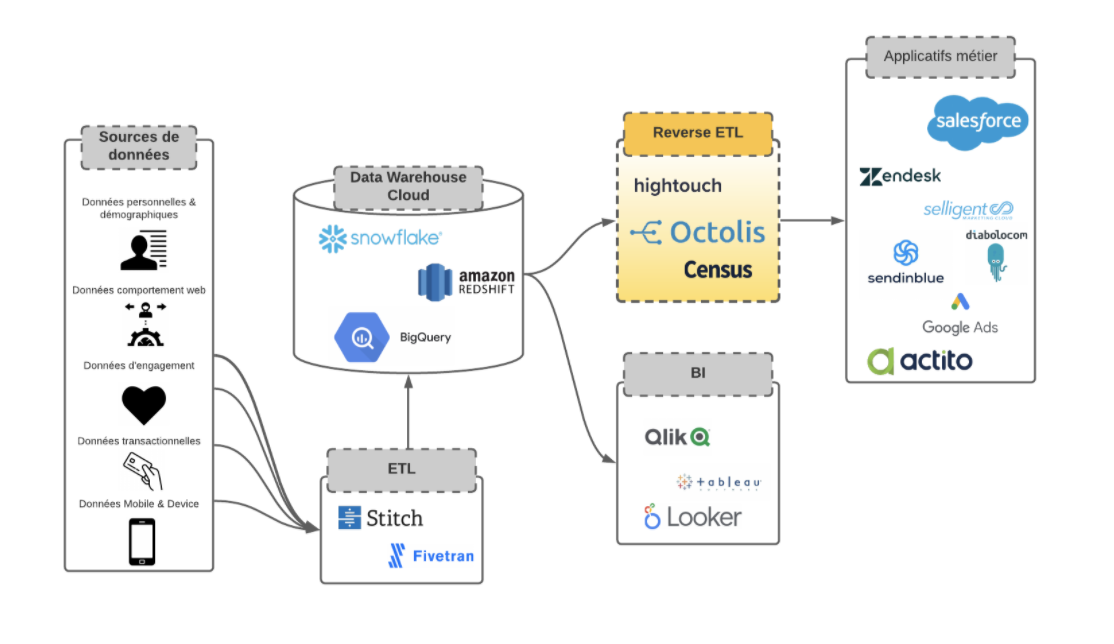
Pour dédupliquer les données clients, plusieurs solutions et types d’outils sont disponibles, chacun offrant des fonctionnalités spécifiques adaptées aux besoins des entreprises.
Data Warehouses avec SQL : Certains Data Warehouses utilisent des requêtes SQL pour effectuer la déduplication des données. En combinant le pouvoir du SQL avec des outils additionnels tels que Zingg et Truelty, ces plateformes permettent aux entreprises de gérer efficacement leurs données clients et de supprimer les doublons.
Customer Data Platforms (CDP) : Les CDP offrent une approche globale de l’unification des données clients, incluant généralement des fonctionnalités de déduplication. Cependant, leur personnalisation peut parfois être assez limitée en termes de règles de déduplication, ce qui peut ne pas convenir à toutes les entreprises ayant des besoins spécifiques.
Outils de préparation des données et de qualité des données spécialisés : Il existe également des outils dédiés à la préparation des données et à l’amélioration de leur qualité. Ces outils sont conçus spécifiquement pour gérer les problématiques de déduplication, de nettoyage et de normalisation des données, offrant une approche plus personnalisable et flexible pour répondre aux besoins spécifiques de chaque entreprise.
Chaque type d’outil a ses avantages et ses inconvénients, et le choix dépendra des besoins, de la taille et des ressources de l’entreprise. Les Data Warehouses avec SQL peuvent être une option solide pour les entreprises ayant déjà des infrastructures de données en place et des compétences en SQL. Les CDP sur l’étagère peuvent être une solution rapide et simple pour les entreprises cherchant une approche globale, tandis que les outils de préparation et de qualité des données spécialisés offrent une personnalisation plus poussée et une meilleure adaptabilité aux besoins spécifiques.
Conclusion
En résumé, la déduplication des données et l’identity resolution sont des processus cruciaux pour obtenir une vue client complète et exploiter efficacement les informations clients. Les entreprises doivent s’appuyer sur des outils adaptés, des clés d’unification appropriées et une approche équilibrée entre le matching déterministe et probabiliste pour assurer la fiabilité, la précision et la cohérence de leurs données clients.
Consultant CDP : rôle, comment le choisir et combien ça coûte
Mener à bien un projet CDP ne s’improvise pas. La preuve ? Beaucoup de projets échouent et on finit par se retrouver avec une CDP qui ne répond pas aux attentes et qui, sous-exploitée, ne fait qu’ajouter une pile (de complexité) à une stack data mal maîtrisée.
Assez logique si on prend la peine d’y réfléchir. Il est loin d’être évident, quand on n’a pas l’expertise en interne, de choisir seul la bonne Customer Data Platform, de gérer son déploiement dans l’entreprise et de réussir à l’exploiter efficacement.
C’est là qu’intervient le consultant CDP. Expert indépendant des éditeurs, sa mission est de vous guider dans la structuration et la réussite de votre projet Customer Data Platform. Il peut intervenir à toutes les étapes, selon vos attentes : cadrage du besoin, sélection de la CDP la mieux adaptée, pilotage de l’installation, déploiement des premiers cas d’usage…
Le but de cet article est simple : répondre aux principales questionsque vous vous posez (ou que vous devriez vous poser) à propos des consultants CDP : leur rôle dans un projet CDP, leur périmètre d’accompagnement ainsi que leur coût. Nous vous partagerons aussi de précieux conseils pour choisir votre consultant CDP et éviter les erreurs de casting. Si vous souhaitez vous équiper d’une CDP et que vous envisagez l’intérêt d’un accompagnement, c’est l’article que vous devez lire.
Un consultant CDP est un expertindépendant des éditeurs qui connaît parfaitement les Customer Data Platforms et accompagne les entreprises dans le choix et le déploiement de la plateforme la mieux adaptée au besoin.
Le périmètre d’accompagnement d’un consultant CDP, qui s’adapte aux attentes de ses clients, comprend la formalisation des objectifs du projet, la qualification des besoins métiers et des cas d’usage, la définition de l’organisation cible, la sélection de l’outillage CDP approprié et le pilotage du déploiement de la CDP.
Il existe 3 types de consultant CDP : les consultants très orientés métiers, les consultants orientés tech et les consultants CDP polyvalents.
Lors du choix d’un consultant CDP, recherchez un professionnel avec une solide expérience et une expertise avérée dans le domaine, des compétences techniques solides en CDP, une compréhension approfondie de vos besoins métiers spécifiques, de bonnes compétences en communication et des références vérifiables
5 erreurs à éviter lors du choix de votre consultant expert en Customer Data Platform (CDP) : négliger l’expérience et l’expertise, ignorer l’alignement avec vos besoins métiers, sous-estimer les compétences techniques, ignorer la communication et la collaboration, et ne pas demander de références ou de recommandations.
Comprendre le rôle du Consultant CDP
Un consultant CDP est un expert en Data Marketing et en MarTech (technos marketing) qui connaît parfaitement le marché des Customer Data Platforms et le fonctionnement de ces technos. Il peut travailler à son compte ou au sein d’un cabinet de conseil. Son rôle : aider les entreprises dans le cadrage des besoins (fonctionnels et techniques), le choix, le déploiement et la bonne exploitation de leur CDP.
Le périmètre d’accompagnement d’un consultant CDP en résumé
Le consultant CDP peut vous accompagner à toutes les étapes de votre projet CDP, mais s’adapte avant tout à vos besoins d’accompagnement. Son périmètre d’intervention est donc variable, fixé en début de collaboration.
Cadrage du projet & expression du besoin. La première étape sur laquelle il peut intervenir, c’est le cadrage du projet et des besoins de l’entreprise. Il est important en effet, dans un projet CDP, de formaliser les objectifs du projet en identifiant les résultats souhaités. Ensuite, il est essentiel de qualifier les besoins métiers et les cas d’usage, en analysant les processus métiers nécessitant une optimisation grâce à la CDP et en examinant les besoins en termes de collecte, gestion et exploitation des données clients. Le consultant CDP est en mesure de traduire vos objectifs et vos besoins métiers en exigences fonctionnelles et techniques.
Définition de l’organisation cible. C’est une étape cruciale sur laquelle le consultant CDP peut apporter une grande valeur ajoutée. Cette étape est souvent négligée, à tort. Votre future CDP a vocation à s’intégrer dans un système IT existant, celui de votre entreprise – système que vous allez peut-être vouloir/devoir faire évoluer. Le consultant CDP peut vous présenter les différentes options d’architecture possibles.
Sélection de la CDP. Une fois l’architecture IT cible définie, l’étape qui suit est celle du choix de la plateforme CDP. Le consultant CDP vous présentera les différentes familles de CDP du marché et vous conseillera celle qui répond le mieux à vos besoins, à vos attentes et aux caractéristiques de votre entreprise et de son organisation.
Déploiement. Enfin, le consultant CDP intervient généralement en phase de déploiement : installation et mise en place des premiers use cases. Il pilote l’implémentation de la Customer Data Platform dans votre organisation et supervise le travail de l’intégrateur ou de l’éditeur.
3 profils de consultants experts en Customer Data Platforms
Les consultants CDP très orientés métier : Ces consultants se concentrent principalement sur les aspects métier liés à l’utilisation de la CDP. Leur expertise réside dans la compréhension des besoins de l’entreprise, la sélection de la solution CDP appropriée et l’accompagnement des utilisateurs. Ils sont impliqués dans la phase de cadrage du projet, aidant à définir les objectifs et les exigences spécifiques de l’entreprise. Pendant la phase de déploiement technique, ils jouent un rôle d’Assistance à la Maîtrise d’Ouvrage (AMOA), supervisant le déploiement exécuté par un intégrateur ou l’éditeur de la CDP, avec la participation de la DSI ou de l’équipe IT de l’entreprise.
Les consultants CDP techniques : Ces consultants sont axés sur les aspects techniques de la mise en place de la CDP. Une fois que la CDP a été sélectionnée, ils sont responsables de la gestion et de l’intégration de la plateforme au sein de l’organisation.Leur expertise technique leur permet de gérer efficacement le déploiement de la CDP, y compris la configuration, l’intégration avec les systèmes existants, la gestion des flux de données, et la mise en place des règles de collecte et de traitement. Ils travaillent en étroite collaboration avec les équipes IT de l’entreprise pour garantir une intégration fluide de la CDP dans l’infrastructure existante.
Les consultants CDP polyvalents : Ce profil de consultant combine à la fois une expertise métier et une expertise technique. Ils peuvent prendre en charge à la fois les aspects métier et les aspects techniques de la mise en place de la CDP. Ils sont capables de comprendre les besoins spécifiques de l’entreprise, de recommander la meilleure solution CDP, de piloter le déploiement technique et de fournir un soutien continu.Leur polyvalence leur permet d’avoir une vision globale du projet et de s’adapter aux besoins changeants de l’entreprise tout au long du processus de mise en place de la CDP.
Le périmètre d’accompagnement du consultant CDP plus en détail
Formaliser les objectifs
Dans cette première étape, le consultant CDP travaille en étroite collaboration avec l’entreprise pour formaliser les objectifs du projet. Il s’agit d’identifier les résultats souhaités et les indicateurs clés de performance (KPI) qui guideront la mise en place de la Customer Data Platform (CDP). Un KPI récurrent dans l’évaluation des CDP est le ROI par exemple. Sur ce sujet, découvrez notre article : « Comment mesurer le ROI de votre Customer Data Platform (CDP)« .
Le consultant analyse les besoins spécifiques de l’entreprise, tels que l’amélioration de la connaissance client, l’optimisation des campagnes marketing ou l’amélioration de l’expérience client. En travaillant de manière concertée, le consultant aide à définir des objectifs réalistes et alignés sur la stratégie globale de l’entreprise.
Qualifier les besoins métiers et les cas d’usage (data & métiers)
Dans cette étape, le consultant CDP se concentre sur la compréhension approfondie des besoins métiers de l’entreprise. Il réalise une analyse approfondie des cas d’usage, à la fois du point de vue des données et du métier. Le consultant échange avec les différentes parties prenantes pour identifier les processus métier qui nécessitent une optimisation grâce à la CDP.
Il examine également les besoins en termes de données, tels que la collecte, la gestion et l’exploitation des données clients. Grâce à cette qualification minutieuse, le consultant est en mesure d’identifier les solutions CDP adaptées, celles disposant des fonctionnalités répondant aux besoins métiers et cas d’usage de l’entreprise.
Définir l’organisation cible : architecture IT/Data & architecture projet
L’étape de définition de l’organisation cible implique la collaboration étroite du consultant CDP avec les équipes IT et les parties prenantes de l’entreprise. Le consultant évalue l’architecture informatique existante et identifie les éventuelles lacunes ou les besoins en termes d’infrastructure et de flux de données pour soutenir la CDP.
Il travaille en parallèle sur l’architecture projet, déterminant les rôles et les responsabilités des différentes parties prenantes dans la mise en place de la CDP. Cette étape permet de définir une organisation cible solide, favorisant une collaboration harmonieuse et efficace entre les équipes métiers, IT et le consultant.
Sélectionner l’outillage CDP
Le consultant CDP apporte son expertise dans le processus de sélection de l’outil CDP le plus approprié pour l’entreprise. En fonction des besoins métiers, des contraintes techniques et des objectifs fixés, le consultant évalue différentes solutions disponibles sur le marché.
Il réalise une analyse comparative, en prenant en compte des critères tels que la compatibilité avec l’infrastructure existante, les fonctionnalités offertes, la convivialité de l’interface et la capacité à répondre aux besoins spécifiques de l’entreprise. Le consultant accompagne l’entreprise dans le processus de sélection, en recommandant la solution CDP qui correspond le mieux aux exigences et aux objectifs fixés.
La phase de sélection s’effectue le plus souvent dans le cadre d’un appel d’offres / RFP dont le consultant prend en charge le pilotage.
Le consultant CDP vous aidera à bien comprendre le marché des Customer Data Platforms. Il vous rappellera certainement qu’il existe en réalité plusieurs familles de CDP assez différentes. C’est parce que le marché des CDP est à ce point foisonnant qu’il peut faire sens de se faire conseiller par un consultant CDP…
Le déploiement de la Customer Data Platform
Lors du déploiement de la CDP, le consultant CDP joue un rôle essentiel en tant que chef d’orchestre. Il travaille en étroite collaboration avec les équipes techniques internes, les intégrateurs ou les éditeurs de la CDP pour s’assurer d’une mise en place efficace et sans heurts. Si le consultant CDP dispose de compétences techniques avancées, il peut prend en charge tout ou partie le travail d’intégration, en collaboration avec la DSI de l’entreprise et l’éditeur de la CDP.
Le consultant supervise les différentes phases du déploiement, de la configuration initiale à l’intégration des sources de données, en passant par la définition des règles de collecte et de traitement des données.
Tout au long du processus, le consultant CDP s’assure de la qualité des données, de la conformité aux normes de confidentialité et de sécurité, et apporte son expertise pour maximiser l’exploitation de la CDP dès sa mise en production.
Coût d’un consultant CDP
Les consultants CDP, qu’ils soient rattachés à des cabinets de conseil ou en freelance, facturent la plupart du temps au temps passé, sur la base d’un tarif journalier. En début de mission, l’entreprise et le consultant définissent en général d’un commun accord un nombre de jours d’accompagnement à ne pas dépasser (budget capé).
Les tarifs journaliers moyens (TJM) varient selon le type de consultants, son niveau d’expérience, sa seniorité et la structure (agence ou freelance).
Pour vous donner quelques ordres d’idées…
Les consultants techniques ont un TJM compris entre 700 et 1 000 euros.
Les consultant métiers ou polyvalents ont un TJM compris entre 900 et 1 300 euros.
Les tarifs des freelances sont en général 20% à 30% moins élevés que ceux des consultants en cabinets de conseil.
Nombre de jours facturés :
Cadrage du besoin : 3 à 8 jours.
Sélection de la CDP (pilotage de l’appel d’offres) : 5 à 10 jours.
Déploiement : 10 à 50 jours, suivant le niveau d’implication du consultant en phase de déploiement…
Un exemple de cabinet de conseil intervenant sur des projets CDP : Cartelis.
Quelques conseils pour choisir votre consultant CDP
Une fois le rôle, les compétences et le périmètre d’action du consultant CDP compris, il est maintenant temps de sauter le pas et d’engager un véritable consultant ! Pour cela, pas de panique, voici quelques conseils pour faire le meilleur des choix !
Expérience et expertise : Recherchez un consultant CDP avec une solide expérience et une expertise avérée dans le domaine. Vérifiez leurs références, demandez des exemples de projets similaires et assurez-vous qu’ils comprennent les enjeux de la gestion des données clients.
Compétences techniques : Choisissez un consultant possédant des compétences techniques solides en CDP, notamment en intégration de données, en gestion des flux de données et en sécurité des données. Assurez-vous qu’ils maîtrisent les outils et les technologies CDP couramment utilisés.
Compréhension des besoins métiers : Optez pour un consultant capable de comprendre vos besoins métiers spécifiques et d’aligner la solution CDP en conséquence. Cherchez quelqu’un qui peut apporter des conseils stratégiques et qui a une connaissance approfondie des cas d’utilisation liés à votre secteur d’activité.
Bonnes compétences en communication : Sélectionnez un consultant avec d’excellentes compétences en communication pour une collaboration fluide et efficace. Assurez-vous qu’ils peuvent expliquer des concepts complexes de manière claire et travailler harmonieusement avec votre équipe interne.
Références et recommandations : Demandez des références et des recommandations vérifiables pour évaluer la réputation et la satisfaction des clients précédents. Cela vous donnera un aperçu de la qualité de leur travail et de leur capacité à fournir des résultats concrets.
5 erreurs à ne pas faire dans le choix de votre consultant expert en Customer Data Platform
Avant de vous lancer, il est important de ne pas tomber dans les principaux écueils que les recruteurs rencontrent dans leur choix de consultant CDP. Voici la liste des principales erreurs à ne pas faire de la recherche de votre expert CDP.
Négliger l’expérience et l’expertise : Évitez de choisir un consultant qui manque d’expérience ou qui n’a pas une expertise solide dans le domaine de la CDP. Assurez-vous de vérifier leurs antécédents, leurs références et leurs compétences spécifiques en CDP.
Ignorer l’alignement avec vos besoins métiers : Ne commettez pas l’erreur de choisir un consultant qui ne comprend pas pleinement vos besoins métiers spécifiques. Assurez-vous de sélectionner quelqu’un qui peut s’adapter à votre secteur d’activité et proposer des solutions personnalisées en fonction de vos cas d’utilisation.
Sous-estimer les compétences techniques : Évitez de choisir un consultant qui manque de compétences techniques nécessaires pour mettre en œuvre une solution CDP. Assurez-vous qu’ils possèdent une solide expertise en intégration de données, en gestion des flux de données et en sécurité des données.
Ignorer la communication et la collaboration : Ne négligez pas l’importance d’une bonne communication et d’une collaboration harmonieuse avec le consultant. Choisissez quelqu’un qui peut expliquer clairement les concepts techniques et travailler efficacement avec votre équipe interne.
Ne pas demander de références ou de recommandations : Évitez de choisir un consultant sans vérifier ses références ou sans demander des recommandations de clients précédents. Les retours d’expérience peuvent vous donner une idée précieuse de la qualité de leur travail et de leur capacité à fournir des résultats concrets.
En conclusion, choisir le bon consultant expert en Customer Data Platform (CDP) est essentiel pour le succès de votre projet. En tenant compte de critères tels que l’expérience, les compétences techniques, la compréhension des besoins métiers, la communication et les références, vous pourrez prendre une décision éclairée et trouver le consultant qui correspond le mieux à vos besoins spécifiques.
L’accompagnement d’un consultant expert en CDP tout au long du processus, de la formalisation des objectifs à la sélection de l’outillage CDP, est précieux. L’expertise et le soutien des consultants CDP vous permettront de maximiser les avantages de votre plateforme de gestion des données clients, d’améliorer la connaissance client, d’optimiser les campagnes marketing et d’offrir une expérience client exceptionnelle. N’hésitez pas à revenir sur notre blog pour n’importe quelle question liée de près ou de loin aux CDP !
Il existe 2 familles de logiciels pour gérer des campagnes SMS Marketing :
Les plateformes marketing tout-en-un (type Brevo ou ActiveCampaign), qui gèrent tous les canaux dont le SMS.
Les solutions 100% dédiées à la gestion de campagnes SMS, comme AllmySMS ou Primotexto.
Nous allons vous présenter les meilleurs logiciels dans ces 2 catégories. Nous vous présenterons aussi les fonctionnalités clés des logiciels de SMS Marketing pour vous aider à construire votre grille d’analyse.
Les avantages du marketing par SMS sont nombreux, le principal étant le fort taux d’ouverture moyen (comparé aux campagnes emails).
Les fonctionnalités clés des logiciels de SMS Marketing sont : la gestion des contacts, la personnalisation des messages, la planification des envois, la gestion de scénarios automatisés (Marketing Automation), la gestion des réponses, le suivi de la performance des campagnes, etc.
2 familles de logiciels de SMS Marketing
Il existe 2 familles de logiciels de SMS Marketing : les plateformes marketing omnicanales qui permettent de gérer les campagnes marketing sur tous les canaux ET les solutions 100% dédiées à la gestion des campagnes SMS.
Le choix entre une solution spécialisée de SMS Marketing et une plateforme marketing omnicanale dépend des besoins et des objectifs spécifiques de chaque entreprise :
Les solutions 100% SMS Marketing offrent une approche spécialisée pour les entreprises qui souhaitent se concentrer exclusivement sur ce canal de communication. Ces solutions permettent la création de listes de contacts ciblées, la personnalisation des messages, la planification des envois, ainsi que le suivi des performances et les rapports d’analyse détaillés. Cependant, ces solutions présentent des limitations en termes d’intégration avec d’autres canaux de communication.
Les plateformes marketing omnicanales offrent une approche plus globale en intégrant plusieurs canaux de communication, y compris l’emailing, le SMS, WhatsApp et les notifications push. Les entreprises peuvent ainsi orchestrer des campagnes cohérentes et personnalisées, en envoyant un email initial suivi d’un SMS pour maximiser les chances d’engagement des destinataires. Ces plateformes offrent également des fonctionnalités avancées telles que la segmentation des contacts, l’automatisation des envois et l’analyse des résultats.
Les meilleurs logiciels pour faire du marketing par SMS
Brevo
Brevo (anciennement Sendinblue) offre une solution de SMS Marketing complète qui vous permettra de mener à bien votre campagne marketing. Grâce à cette plateforme, vous disposerez de toutes les fonctionnalités nécessaires pour promouvoir efficacement vos offres. Vous pouvez rédiger votre message personnalisé, sélectionner le groupe de contacts approprié, et programmer la date et l’heure d’envoi. De tous les logiciels de SMS Marketing, Brevo offre le meilleur contrôle sur votre campagne et vous pouvez adapter votre approche en fonction des besoins de votre audience.
La force de Brevo réside dans la personnalisation des SMS : vous pouvez segmenter vos contacts et ajouter des attributs spécifiques tels que leur nom, leur adresse, etc. Cela vous permet de créer des messages ciblés et pertinents, augmentant ainsi l’impact de vos communications. De plus, Brevo vous offre une analyse détaillée des résultats de votre campagne en temps réel. Vous pouvez suivre les performances, mesurer le taux de réponse et prendre des décisions éclairées pour optimiser vos prochaines actions marketing.
Solution complète de SMS Marketing
Fonctionnalités pour promouvoir efficacement vos offres
Personnalisation des SMS
Analyse détaillée des résultats en temps réel
Offres & Tarifs
Offre Gratuite : 0€/mois
Offre Starter : à partir de 19€/mois
Offre Premium : 49€/mois
Offre entreprise : sur demande
ActiveTrail
ActiveTrail est un des logiciels de SMS Marketing qui offre une interface conviviale pour gérer facilement vos listes de diffusion et créer des segments. Ce logiciel vous permet de préparer des campagnes SMS automatisées, même sans connaissances en développement, à condition d’avoir une parfaite maîtrise de votre stratégie marketing, car aucune assistance au démarrage n’est proposée. Les guides disponibles sur le site se concentrent exclusivement sur la prise en main de la plateforme.
Interface ergonomique pour gérer les listes de diffusion et constituer des groupes
Préparation de campagnes SMS automatisées sans connaissances en développement
Aucune assistance au démarrage, guides disponibles pour la prise en main de la plateforme
Offres & Tarifs
Basic : 8€ / mois, paiement annuel
Plus : 11€ / mois, paiement annuel
Premium : 298€ / mois, paiement annuel
ActiveCampaign
ActiveCampaign est un acteur renommé dans le domaine de l’email marketing : avec une interface complète, intuitive et facile à prendre en main, ce logiciel professionnel propose une solution de SMS marketing de qualité à des tarifs compétitifs, notamment sur le marché américain et canadien.
Grâce à ActiveCampaign, vous bénéficiez d’un outil puissant pour mener des campagnes SMS efficaces. Vous pouvez cibler votre audience, personnaliser vos messages et programmer l’envoi pour atteindre vos contacts au bon moment. Que vous souhaitiez promouvoir vos produits, informer vos clients ou envoyer des rappels, ActiveCampaign vous offre les fonctionnalités nécessaires pour maximiser l’impact de vos campagnes SMS.
Avec son expertise éprouvée dans le domaine de l’email marketing, ActiveCampaign apporte son savoir-faire et sa fiabilité au monde des SMS marketing. Profitez de cette solution professionnelle pour atteindre votre public cible, accroître votre portée et développer votre activité à l’échelle internationale.
Interface complète, intuitive et facile à prendre en main
Ciblage de l’audience, personnalisation des messages et programmation de l’envoi
Expertise éprouvée dans l’email marketing, fiabilité et savoir-faire appliqués au SMS marketing
Offres & Tarifs
Plus : $49
Professional : $149
Enterprise : Forfait sur-mesure
OVHcloud
OVH Cloud propose des services de marketing par SMS conçus pour renforcer vos relations clients. Grâce à la fonctionnalité SMS automatisée, vous pouvez envoyer facilement des messages à un large groupe de destinataires, garantissant ainsi une communication inclusive et efficace. Avec la possibilité de recevoir des réponses directes, vos clients peuvent engager une conversation bidirectionnelle, favorisant ainsi l’interaction et la fidélisation. De plus, la fonctionnalité de regroupement des SMS via Internet permet aux entreprises d’envoyer des messages en masse de manière rapide et pratique.
En choisissant les services de marketing par SMS d’OVH, vous disposez d’une solution complète pour maintenir des relations significatives avec vos clients. L’automatisation des SMS, la fonctionnalité de réponse et le regroupement des messages par Internet simplifient et améliorent vos campagnes de communication. Avec OVH Cloud, vous pouvez optimiser vos efforts de marketing par SMS et consolider votre relation avec vos clients.
Fonctionnalité SMS automatisée pour envoyer des messages à un large groupe de destinataires
Possibilité de recevoir des réponses directes pour favoriser l’interaction
Regroupement des SMS via Internet pour l’envoi en masse rapide et pratique
Offres & Tarifs
100 SMS : 6€
1000 SMS : 58€
10 000 SMS : 540€
500 000 SMS : 24 500€
AllmySMS
AllMySms est une suite complète de SMS marketing qui offre une gamme d’outils puissants pour vous aider à promouvoir efficacement votre entreprise. Avec cette plateforme, vous pouvez facilement créer et gérer des campagnes SMS personnalisées et envoyer des messages ciblés à votre public. De plus, AllMySms permet l’intégration avec des modules CRM, vous permettant ainsi de synchroniser vos données client et de gérer vos contacts de manière plus efficace.
Une des fonctionnalités clés d’AllMySms est l’attribution d’un numéro virtuel, vous permettant d’avoir un numéro dédié pour vos campagnes SMS. Cela renforce la crédibilité et la reconnaissance de votre entreprise, et facilite la communication bidirectionnelle avec vos clients.
Création et gestion facile de campagnes SMS personnalisées
Intégration avec des modules CRM pour synchroniser les données client
Attribution d’un numéro virtuel dédié pour renforcer la crédibilité et faciliter la communication avec les clients.
Offres & Tarifs
Prix unique : 0.045€ HT / SMS
Klaviyo
Klaviyo est un logiciel d’emailing et de marketing automation basé sur le cloud, offrant une multitude de fonctionnalités pour améliorer les campagnes d’email des entreprises. Klaviyo offre également des fonctionnalités avancées en matière de SMS, en complément de ses capacités d’email marketing. Le logiciel permet de segmenter vos contacts en fonction de leurs comportements et de leurs préférences, vous permettant ainsi d’envoyer des messages SMS personnalisés et pertinents.
Klaviyo propose des fonctionnalités d’automatisation des SMS, vous permettant de déclencher des messages en fonction d’événements spécifiques, tels que l’abandon de panier ou la confirmation de commande. Grâce à son interface ergonomique et à ses fonctionnalités avancées, Klaviyo vous offre une solution complète pour intégrer les SMS dans votre stratégie marketing et maximiser votre impact auprès de votre audience.
Logiciel d’emailing et de marketing automation basé sur le cloud
Offre des fonctionnalités avancées en matière de SMS en complément de l’email marketing
Permet de créer et envoyer des campagnes SMS ciblées et personnalisées
Propose des fonctionnalités d’automatisation des SMS pour déclencher des messages en fonction d’événements spécifiques.
Offres & Tarifs
Les prix de Klaviyo dépend du nombre de contacts, mais une offre gratuite existe.
Digitaleo
Digitaleo offre une solution complète qui va au-delà de la simple gestion de campagnes SMS allant de l’email marketing aux réseaux sociaux, en passant par le SMS marketing.
Digitaleo vous fait bénéficier de nombreux avantages, tels que la personnalisation des campagnes SMS, la possibilité de récupérer les réponses, la modification du nom de l’expéditeur et une interface conviviale avec une prévisualisation du message. Vous pouvez également tester vos SMS avant de les envoyer et planifier des scénarios de marketing automation pour des événements tels que les anniversaires ou les rappels.
Digitaleo offre de nombreuses fonctionnalités supplémentaires, telles que la création de landing pages, l’email marketing, les messages vocaux, la communication print et le référencement local.
Solution complète allant de l’email marketing aux réseaux sociaux, en passant par le SMS marketing
Personnalisation des campagnes SMS avec récupération des réponses et modification du nom de l’expéditeur
Interface conviviale avec prévisualisation du message et possibilité de tester avant l’envoi
Fonctionnalités supplémentaires telles que la création de landing pages, l’email marketing, les messages vocaux, la communication print et le référencement local.
Offres & Tarifs
Les tarifs ne sont pas publics, ce qui signifie qu’il est nécessaire de contacter l’entreprise pour obtenir des informations précises sur les coûts associés à l’utilisation de la plateforme.
Primotexto
Primotexto est le logiciel de marketing SMS idéal pour les professionnels à la recherche d’une solution clé en main pour leurs campagnes SMS marketing. Avec une interface conviviale et des fonctionnalités complètes, cet outil simplifie la gestion de vos envois de SMS. Que ce soit pour des campagnes promotionnelles, des alertes ou des notifications, Primotexto couvre l’ensemble de vos besoins.
Le logiciel propose des fonctionnalités avancées en matière de valorisation des ventes. Vous pouvez facilement mettre en place des promotions flash, assurer un suivi client efficace grâce à des confirmations de rendez-vous et des rappels de livraison. Ces services ajoutent une valeur considérable à votre entreprise et vous permettent de répondre aux attentes de votre clientèle.
Primotexto se démarque par son engagement éthique. Il offre une gestion des désabonnements, préservant ainsi votre image de marque et respectant les exigences de confidentialité des utilisateurs. Avec Primotexto, vous bénéficiez d’un outil flexible et puissant pour vos campagnes SMS marketing, quel que soit votre secteur d’activité.
Offres & Tarifs
Packs prépayés : à partir de 0.035€ HT / SMS
Tarifs sur mesure : par devis
Spot Hit
Spot-Hit est une plateforme appréciée pour sa particularité « multicanal », offrant une grande diversité de canaux de communication tels que les SMS, les MMS, les messages vocaux, les e-mails et même les courriers postaux. Cette approche permet d’établir des contacts variés avec les clients, en identifiant le canal avec lequel ils sont le plus réactifs. Spot-Hit se positionne ainsi comme une solution proche des meilleurs logiciels d’envoi de SMS en masse.
Avec des outils de création en ligne gratuits et une interface intuitive, la plateforme facilite la structuration de vos messages. Cependant, il est crucial de bien quantifier vos besoins et de prendre en compte les tarifs variables en fonction du mode de transmission choisi. De plus, l’utilisation de l’API pour propulser votre SMS marketing nécessite des compétences en développement, ce qui peut représenter un coût supplémentaire si vous ne les possédez pas.
Identification de la réactivité des clients avec différents canaux de communication
Outils de création en ligne gratuits et interface intuitive pour structurer les messages
Tarifs variables en fonction du mode de transmission, prise en compte des besoins et coûts supplémentaires avec l’API.
Offres & Tarifs
de 100 à 10 000 SMS : 0.059 €
de 10 000 à 100 000 SMS : 0.054 €
plus de 100 000 : 0.049 €
Sarbacane
Sarbacane propose un logiciel de prospection par SMS qui présente de nombreux avantages. En utilisant ce logiciel, vous bénéficiez d’un pilote marketing éprouvé qui garantit un taux de délivrabilité supérieur à la concurrence. L’envoi de SMS en masse s’intègre parfaitement aux autres outils marketing, offrant ainsi une solution complète qui facilite la gestion et la cohérence de vos communications.
L’un des principaux atouts de ce logiciel de SMS en masse, qui se démarque parmi les solutions de SMS marketing sur le marché, est son interface entièrement en français. Cependant, Sarbacane propose de multiples langues pour accompagner l’expansion de votre marché. En termes de tarification, compte tenu de la praticité des automatisations et des nombreux services offerts, vous obtenez un retour sur investissement satisfaisant tout en bénéficiant d’un outil haut de gamme et fiable.
De plus, Sarbacane propose de nombreux services inclus tels que la formation, les guides personnalisés et un support réactif par chat, e-mail et téléphone.
Logiciel de prospection par SMS avec un pilote marketing éprouvé pour un taux de délivrabilité supérieur
Intégration avec d’autres outils marketing pour une gestion et une cohérence optimales des communications
Interface entièrement en français et prise en charge de plusieurs langues pour une expansion internationale
Services inclus tels que la formation, les guides personnalisés et un support réactif par chat, e-mail et téléphone.
Offres & Tarifs
Une offre unique à 69€
SMS Factor
SMS Factor offre une variété d’options d’envoi de SMS en masse qui répondent aux besoins spécifiques des entreprises. Par exemple, l’envoi de SMS par Internet permet de distinguer les textos marketing des alertes. Les rendez-vous peuvent être adaptés à votre clientèle ou à votre patientèle, ouvrant ainsi l’utilisation des messages courts à des secteurs souvent négligés par d’autres fournisseurs de logiciels. De plus, la possibilité d’envoyer des SMS depuis votre boîte mail simplifie l’organisation, tandis que l’API SMS s’intègre parfaitement à votre CRM.
Cependant, il convient de noter que le fonctionnement en packs prépayés, qui constitue la majorité des offres de SMS Factor, exige que vous connaissiez précisément vos besoins avant de passer une commande. Cela peut être risqué pour une entreprise en expansion, car si de nouveaux prospects sont ajoutés à la liste des contacts par la suite, vous devrez opter pour un deuxième pack pour le même envoi. Et quelle entreprise ne rêve pas de convaincre de plus en plus de consommateurs ?
Possibilité d’envoyer des SMS par Internet pour différencier les textos marketing des alertes
Adaptation des rendez-vous à différents secteurs souvent négligés par d’autres fournisseurs de logiciels
Fonctionnalités telles que l’envoi de SMS depuis votre boîte mail et l’intégration de l’API SMS à votre CRM
Fonctionnement en packs prépayés qui nécessite une bonne connaissance de vos besoins
Offres & Tarifs
Pack prépayés : Le tarif est dégressif en fonction de la consommation de SMS
Paiement mensuel : sur devis.
SendPulse
SendPulse offre de nombreux avantages pour vos campagnes SMS. Vous pouvez envoyer entre 200 et 500 SMS par seconde, planifier l’heure d’envoi des SMS et personnaliser vos messages. L’interface intuitive et simple facilite la gestion de vos campagnes, et vous pouvez intégrer facilement des formulaires de collecte d’abonnés sur vos sites web. Les SMS peuvent également être intégrés dans des scénarios de marketing automation, et vous avez la possibilité d’envoyer des campagnes à des segments spécifiques de contacts.
En plus du SMS marketing, SendPulse propose de nombreux autres services tels que l’emailing, les chatbots et les notifications web push. De plus, une API est disponible pour la gestion des SMS transactionnels. Cependant, il est important de noter que la plateforme est en anglais et qu’un abonnement au logiciel d’emailing est nécessaire pour utiliser l’option SMS. Malgré cela, SendPulse offre une solution complète pour vos besoins en marketing digital, combinant l’emailing et le SMS marketing pour atteindre efficacement votre audience cible.
Envoi rapide et personnalisé de SMS à une vitesse élevée (200 à 500 SMS par seconde)
Gestion facile des campagnes grâce à une interface intuitive
Intégration de formulaires de collecte d’abonnés sur les sites web
Combinaison du SMS marketing avec d’autres services tels que l’emailing, les chatbots et les notifications web push.
Offres & Tarifs
Standard : 5,60€/mois
Pro : 6,72€/mois
Entreprise : 9,41€/mois
SMSmode
SMSMode est un logiciel d’envoi de SMS en masse qui offre une couverture mondiale pour vos campagnes de communication. Doté de l’API Rest, SMSmode est très apprécié des développeurs pour la réalisation de notifications SMS. Cependant, il est important de maîtriser les compétences requises pour tirer pleinement parti de cette plateforme et de bien évaluer les tarifs en combinant un forfait illimité avec un nombre précis d’envois.
SMSMode est membre de la French Tech, de la GSMA et de la Mobile Marketing Association France. Fort de plus de 10 000 comptes clients actifs, SMSMode envoie plus de 300 millions de SMS par an. Principalement destiné aux grandes entreprises qui envoient des milliers de SMS commerciaux et transactionnels chaque mois, SMSMode compte des clients tels que Doctolib, TripAdvisor et Century 21. C’est une plateforme professionnelle reconnue pour répondre aux besoins des entreprises à grande échelle.
Requiert des compétences pour tirer parti de la plateforme et évaluer les tarifs
Membre de la French Tech, GSMA et Mobile Marketing Association France
Destiné aux grandes entreprises, envoie plus de 300 millions de SMS/an
Offres & Tarifs
Basique : 9€
Classique : 69€
Médium : 159€
Premium : 499€
Comprendre le marketing par SMS
Qu’est-ce que le marketing par SMS ?
Le marketing par SMS consiste dans l’envoi de messages texte promotionnels à des clients, offrant une communication directe et personnalisée, ainsi qu’un fort taux de lecture. En envoyant des offres spéciales, des remises, des rappels de rendez-vous ou des mises à jour de produits, les entreprises peuvent atteindre les clients de manière instantanée et efficaces. Les messages peuvent être personnalisés en fonction des préférences et des comportements des clients, ce qui permet d’offrir un contenu plus pertinent et attrayant.
Cependant, il est crucial que le marketing par SMS soit réalisé dans le respect des réglementations en matière de consentement et de confidentialité des données. Les utilisateurs doivent donner leur accord préalable pour recevoir des messages SMS promotionnels, et il doit être facile pour eux de se désabonner s’ils ne souhaitent plus recevoir ces messages. Les entreprises doivent également veiller à protéger les données personnelles des utilisateurs et à respecter les réglementations en vigueur pour éviter toute violation de la vie privée.
Avantages du marketing par SMS
Haut taux de lecture : les messages SMS ont un taux de lecture élevé, la plupart des messages étant lus dans les quelques minutes suivant leur réception. Cela garantit que un fort taux de ciblage du public visé.
Communication directe : Le marketing par SMS permet d’établir une communication directe avec les clients, car les messages sont envoyés directement sur les téléphones portables.
Réactivité : Les SMS sont généralement considérés comme plus réactifs que d’autres canaux de communication, car ils sont souvent consultés rapidement après réception. Cela vous permet d’obtenir des réponses et des actions rapides de la part de vos clients.
Personnalisation : Vous pouvez personnaliser vos messages SMS en fonction des préférences et des comportements des clients. Cela vous permet de fournir un contenu plus ciblé et pertinent, ce qui augmente les chances d’engagement et de conversion. À cet effet, nous vous conseillons dans notre article à utiliser vos données CRM pour cibler intelligemment votre clientèle.
Grande portée : La majorité des personnes possèdent un téléphone portable et ont accès aux messages texte. Cela signifie que vous pouvez atteindre un large public avec votre message, indépendamment du type de téléphone ou de smartphone qu’ils utilisent.
Facilité d’interaction : Les SMS permettent une interaction facile avec les clients. Vous pouvez inclure des liens vers des sites web, des codes de réduction ou des appels à l’action qui incitent les clients à prendre des mesures immédiates.
Automatisation possible : Il est possible d’automatiser l’envoi de messages SMS en utilisant des outils de gestion de campagnes ce qui facilite la planification et l’exécution de vos campagnes de marketing par SMS.
Les fonctionnalités clés des logiciels de SMS Maketing
Gestion des contacts
La fonctionnalité de gestion des contacts vous permet de gérer et d’organiser votre liste de contacts de manière efficace. Vous pouvez importer et exporter des contacts, ajouter de nouvelles entrées, mettre à jour les informations existantes et segmenter votre liste en fonction de critères spécifiques. Cette fonctionnalité facilite la création de groupes cibles pour vos campagnes de marketing par SMS. Vous pouvez également gérer les désabonnements, les numéros invalides ou les doublons dans votre liste de contacts. Une gestion optimisée des contacts garantit que vos messages atteignent le bon public et en améliore la pertinence.
Personnalisation des messages
La personnalisation des messages est une fonctionnalité qui vous permet de créer des messages SMS personnalisés pour chaque destinataire. Vous pouvez inclure des informations spécifiques dans vos messages, comme le nom du destinataire, son historique d’achat ou toute autre donnée pertinente que vous avez collectée. La personnalisation renforce l’engagement et l’attention des destinataires en leur offrant une expérience plus individualisée. Les messages personnalisés montrent aux destinataires que vous les considérez comme des individus uniques, ce qui renforce la relation client et augmente le taux de conversion.
Planification des envois
La fonctionnalité de planification des envois permet aux utilisateurs de programmer l’envoi des messages SMS à une date et une heure spécifiques. Cela offre une meilleure gestion des campagnes en permettant de préparer les messages à l’avance et de les envoyer au moment le plus opportun. Par exemple, vous pouvez planifier l’envoi d’un message promotionnel pour coïncider avec une période de vente spéciale ou programmer des rappels de rendez-vous pour éviter les oublis. Cette fonctionnalité vous permet de gagner du temps et d’optimiser la diffusion de vos messages en fonction de votre public cible.
Gestion de scénarios automatisés (Marketing Automation)
L’automatisation des campagnes est une fonctionnalité puissante qui permet d’envoyer des messages SMS en fonction de déclencheurs prédéfinis. Vous pouvez configurer des scénarios automatisés, tels que l’envoi d’un message de bienvenue aux nouveaux abonnés, l’envoi d’un message d’anniversaire à un client ou l’envoi d’un suivi après une interaction spécifique. Cela permet d’établir des communications personnalisées et opportunes, tout en réduisant la charge de travail manuelle.
L’automatisation des campagnes garantit une cohérence dans les communications et améliore l’engagement des clients en offrant des messages pertinents et opportuns.
Suivi des performances
La fonctionnalité de suivi des performances fournit des statistiques détaillées et des rapports sur les taux d’ouverture, de clics et de conversion de vos campagnes de marketing par SMS. Ces données vous permettent d’évaluer l’efficacité de vos messages et de mesurer leur impact sur vos objectifs marketing. Vous pouvez identifier les campagnes les plus performantes, les tendances de comportement des utilisateurs et les opportunités d’amélioration. En suivant ces indicateurs clés, vous pouvez ajuster vos stratégies et optimiser vos campagnes pour obtenir de meilleurs résultats.
Gestion des réponses
La gestion des réponses est une fonctionnalité qui facilite la réception, le suivi et la réponse aux messages des destinataires. Elle permet de gérer les réponses des utilisateurs en regroupant les messages dans une interface centralisée, ce qui facilite la gestion des conversations et des interactions. Vous pouvez répondre directement aux messages des clients, traiter les demandes d’informations supplémentaires ou résoudre les problèmes. Cette fonctionnalité favorise l’engagement et la satisfaction des clients en offrant un moyen pratique et efficace de communiquer avec eux.
Segmentation des audiences
La segmentation des audiences permet de diviser votre liste de contacts en segments spécifiques en fonction de critères tels que l’emplacement géographique, les préférences d’achat, les comportements passés, etc. Cela vous permet d’envoyer des messages plus ciblés et pertinents à des groupes spécifiques de clients. En personnalisant vos communications en fonction des caractéristiques et des intérêts de chaque segment, vous augmentez les chances d’engagement et de conversion. La segmentation des audiences vous aide à maximiser l’impact de vos messages en adaptant votre contenu aux besoins de chaque groupe.
Intégrations avec d’autres outils
La fonctionnalité d’intégration avec d’autres outils permet de connecter votre logiciel de marketing par SMS à d’autres outils de marketing ou de gestion des clients, tels que votre CRM ou votre plateforme de commerce électronique. Cette intégration assure une synchronisation et une cohérence des données entre les différents systèmes, ce qui facilite la gestion des contacts, l’automatisation des campagnes et le suivi des résultats. Par exemple, vous pouvez synchroniser les informations de contact entre votre logiciel de marketing par SMS et votre CRM pour une vue complète de l’expérience client.
Gestion des désabonnements des logiciels de SMS Marketing
La gestion des désabonnements est une fonctionnalité essentielle pour se conformer aux réglementations en matière de consentement et offrir une expérience utilisateur transparente. Elle permet aux destinataires de se désabonner facilement des messages SMS promotionnels en suivant un processus de désinscription clair. Les outils de gestion des désabonnements garantissent que les demandes de désabonnement sont traitées rapidement. En respectant les préférences des utilisateurs, vous maintenez une relation de confiance avec votre public et favorisez le respect de la vie privée des individus.
Le guide complet pour réussir la migration de votre CRM
Les migrations CRM sont souvent retardées, et certaines sont des échecs. Pour une raison simple : les entreprises pour la plupart n’anticipent pas assez la difficulté de ce type de projet. La migration CRM ne se réduit pas à un simple import/export de données de l’ancien CRM vers le nouveau, car chaque CRM a un modèle de données qui lui est propre.
Surtout, la migration CRM ne doit pas être envisagée comme un simple projet techno. Un projet de migration CRM doit être l’occasion de repenser votre stratégie, d’identifier les nouveaux cas d’usage que vous voulez déployer avec votre future plateforme, de rationaliser votre SI client, de moderniser votre architecture IT. La migration CRM doit découler d’une vision stratégique.
Dans ce guide pratique, nous allons passer en revue les différentes étapes à suivre pour mener à bien votre projet de migration CRM. Le contenu des étapes peut évidemment varier, mais les grands jalons sont globalement assez standardisés.
📕 Le guide complet pour réussir la migration de votre CRM étape par étape :
L’essentiel à retenir pour réussir la migration de votre CRM :
Définissez clairement les raisons et objectifs de la migration, en identifiant les lacunes de votre CRM actuel et les améliorations souhaitées.
Constituez une équipe projet compétente avec des rôles bien définis pour assurer une coordination efficace.
Effectuez un état des lieux de votre organisation CRM actuelle, en cartographiant les cas d’usage et les flux de données pour comprendre vos besoins et défis.
Choisissez une nouvelle solution CRM en tenant compte de vos cas d’usage cibles et de l’architecture CRM souhaitée, en envisageant des solutions complémentaires si nécessaire.
Préparez la migration en nettoyant vos données, en supprimant les doublons et les informations obsolètes, et configurez le nouveau CRM en adaptant le modèle de données.
Formez convenablement les utilisateurs au nouveau CRM pour faciliter une adoption réussie et maximiser les avantages de la nouvelle solution.
En suivant ces points clés, vous augmenterez vos chances de mener à bien la migration de votre CRM et de bénéficier d’un système adapté à vos besoins métier.
#1 Cadrer le projet – Définir les raisons & objectifs de la migration CRM
Avant de se lancer dans une migration CRM, il est essentiel de cadrer le projet en définissant clairement les raisons et les objectifs qui motivent ce changement. Comme pour tout projet, une qualification précise des raisons de la migration est nécessaire pour orienter les efforts et garantir sa réussite. Voici quelques raisons courantes qui peuvent justifier une migration CRM :
Le CRM actuel n’offre pas les fonctionnalités souhaitées : Il se peut que votre système CRM actuel ne réponde pas aux besoins spécifiques de votre entreprise. Vous pourriez avoir identifié des fonctionnalités manquantes qui sont essentielles pour améliorer vos processus de vente, votre suivi des clients ou votre gestion des campagnes marketing.
Le modèle de données du CRM est inadapté : Chaque entreprise a des besoins uniques en matière de gestion de la relation client. Si le modèle de données de votre CRM actuel ne correspond pas à votre structure organisationnelle ou à vos flux de travail spécifiques, il peut être difficile d’exploiter pleinement son potentiel. Une migration vers un nouveau CRM permettrait alors d’adopter un modèle de données plus adapté à vos besoins.
Le CRM actuel n’est plus dimensionné à votre taille/activité : Votre entreprise peut avoir connu une croissance significative depuis la mise en place de votre CRM actuel. Si celui-ci n’est plus dimensionné pour gérer efficacement votre volume croissant de données et d’activités, une migration vers une solution plus évolutive et puissante peut être nécessaire.
Il est important de prendre le temps de formuler précisément les défis et les problèmes rencontrés avec le CRM actuel. Cela permet de mieux comprendre les lacunes du système et d’identifier les améliorations souhaitées. Par exemple, vous pourriez constater que votre CRM actuel ne dispose pas de fonctionnalités suffisamment robustes pour suivre efficacement vos prospects tout au long du cycle de vente. Dans ce cas, l’objectif de la migration pourrait être d’améliorer le suivi des prospects et d’optimiser le processus de vente global.
En définissant clairement les raisons et les objectifs de la migration CRM, vous pourrez orienter efficacement les étapes suivantes du projet et maximiser les avantages de votre nouveau système CRM.
#2 Construire une équipe projet
La constitution d’une équipe projet compétente est essentielle pour mener à bien la migration de votre CRM. Voici les différents acteurs qui devraient idéalement faire partie de votre équipe projet :
Chef de projet : Le chef de projet est chargé de la planification, de la coordination des différentes étapes ainsi que de la gestion des ressources. Il peut être issu de l’organisation interne ou être un consultant externe spécialisé dans les migrations CRM.
Sponsor : Le sponsor est un membre de la direction ou une personne ayant le pouvoir de prendre des décisions stratégiques. Il soutient le projet, en assure le financement et s’assure que les objectifs de la migration CRM sont alignés sur les objectifs de l’entreprise. Le sponsor joue un rôle crucial pour obtenir l’engagement et les ressources nécessaires.
Équipe IT/Data : Cette équipe est responsable de la gestion technique du projet de migration CRM. Ils doivent s’assurer que l’infrastructure technique est en place, gérer les aspects de sécurité des données, coordonner les intégrations avec d’autres systèmes et garantir la disponibilité du nouveau CRM.
Utilisateurs du CRM : Il est important d’inclure des représentants des différentes équipes qui utiliseront le CRM au quotidien, tels que les équipes commerciales, marketing et service client. Leurs retours d’expérience et leurs besoins spécifiques sont essentiels pour garantir que le nouveau système répondra aux exigences opérationnelles de l’entreprise.
Consultant CRM (facultatif) : Si nécessaire, l’ajout d’un consultant CRM externe peut être bénéfique pour apporter une expertise supplémentaire, fournir des conseils sur les meilleures pratiques, les fonctionnalités à prendre en compte, et aider à la configuration et à la personnalisation du nouveau CRM.
Pour construire une équipe projet efficace, voici quelques conseils pratiques :
Attribution des rôles : Chaque personne de l’équipe projet devrait se voir attribuer un ou plusieurs rôles clairement définis. Une matrice RACI peut être utilisée pour spécifier les responsabilités de chaque membre de l’équipe projet.
Organiser le travail en équipe : Utilisez un outil de gestion de projet pour faciliter la collaboration et le suivi des tâches. Il est également recommandé d’organiser des instances de pilotage régulières, telles que des réunions hebdomadaires ou des comités de pilotage (COPIL), pour faire le point sur l’avancement du projet, discuter des problèmes éventuels et prendre des décisions.
Communication et collaboration : Assurez-vous d’établir une communication claire et ouverte au sein de l’équipe projet. Une communication transparente favorisera la coordination, l’alignement des objectifs et la résolution rapide des problèmes.
Formation et support : Assurez-vous aussi que les membres de l’équipe projet disposent des compétences et des connaissances nécessaires pour réussir leur mission. Organisez des séances de formation adaptées aux besoins de chaque membre de l’équipe, en mettant l’accent sur la familiarisation avec le nouveau CRM, ses fonctionnalités et ses processus. Prévoyez par ailleurs un support continu tout au long du projet, que ce soit sous la forme d’un point de contact dédié ou d’un système d’assistance pour répondre aux questions et résoudre les problèmes rencontrés par l’équipe.
En suivant ces conseils supplémentaires, vous créerez un environnement propice à la collaboration, à l’efficacité et à la réussite de votre équipe projet lors de la migration de votre CRM.
#3 Faire un état des lieux de l’organisation CRM actuelle
Pour réussir votre projet de migration CRM, il est essentiel de commencer par faire un état des lieux de l’organisation CRM actuelle. Cette étape permet de comprendre en détail comment le CRM est actuellement utilisé dans l’entreprise, quels sont les cas d’usage existants et quels sont les flux de données en place. Voici les deux volets clés à explorer dans cette partie :
Cartographier les cas d’usage actuels (volet métier)
Pour avoir une vision claire de l’utilisation actuelle du CRM, il est important de réaliser un audit des processus internes et de définir les cas d’usage actuels. Vous pouvez organiser des ateliers avec les utilisateurs du CRM pour recueillir leurs retours, comprendre les défis rencontrés, les besoins spécifiques et les axes d’amélioration.
Construisez une grille des cas d’usage actuels en documentant pour chaque cas, son objectif ainsi que les fonctionnalités CRM utilisées et les points critiques identifiés. Impliquer les utilisateurs finaux du CRM dans cette étape est essentiel pour garantir leur adhésion au projet et éviter de modifier le CRM à leur insu.
Vous pouvez vous référer à l’article suivant pour obtenir des conseils supplémentaires sur la cartographie des cas d’usage actuels d’un CRM.
Cartographier les flux de données (volet technique)
Comprendre l’architecture CRM actuelle est essentiel afin de réaliser au mieux votre migration. Il est nécessaire d’analyser les différents systèmes de données, y compris les sources, les outils et les bases de données qui alimentent le CRM. Identifiez les flux de données entre ces systèmes, en mettant particulièrement l’accent sur les flux entre le CRM et les sources de données qui le nourrissent. Cette cartographie vous permettra de visualiser les interactions existantes et de comprendre comment les données circulent dans l’organisation.
En effectuant une analyse approfondie des cas d’usage actuels et des flux de données, vous serez en mesure de mieux comprendre l’état actuel de votre organisation CRM. Cette connaissance approfondie servira de base solide pour la planification et la conception de votre nouveau CRM, en vous assurant de répondre aux besoins métier tout en garantissant une intégration harmonieuse des flux de données.
#4 Choisir la nouvelle solution CRM
Définir les cas d’usage cibles
Pour choisir la meilleure solution CRM possible, il est essentiel de définir les cas d’usage cibles. Voici les étapes clés :
Analysez les cas d’usage actuels et identifiez les améliorations nécessaires.
Impliquez les parties prenantes pour recueillir leurs besoins spécifiques.
Priorisez les cas d’usage en fonction de leur importance stratégique.
Identifiez les nouvelles fonctionnalités à intégrer.
Documentez les cas d’usage cibles avec leurs objectifs et exigences.
La définition claire des cas d’usage cibles vous aidera à choisir une solution CRM qui répondra aux besoins de votre entreprise, tout en tenant compte des coûts associés.
Traduire les cas d’usage cibles en fonctionnalités cibles
Pour aligner les cas d’usage cibles avec la nouvelle solution CRM, suivez ces étapes :
Analyse détaillée : Comprenez les exigences spécifiques de chaque cas d’usage cible.
Correspondance des fonctionnalités : Associez les fonctionnalités de la nouvelle solution CRM aux cas d’usage cibles.
Hiérarchisation : Classez les fonctionnalités cibles par ordre d’importance.
Documentation : Documentez clairement les caractéristiques et les bénéfices des fonctionnalités cibles.
Validation : Obtenez les retours des parties prenantes pour valider les fonctionnalités proposées.
Grille des fonctionnalités CRM cibles (construites après la grille des cas d’usage et sur sa base). Source : Cartelis
En traduisant les cas d’usage cibles en fonctionnalités spécifiques, vous pourrez choisir la solution CRM qui répondra le mieux à vos besoins opérationnels et vous aidera à atteindre vos objectifs métier.
Définir l’architecture CRM cible
Lors d’une migration, il est crucial de ne pas se limiter au simple changement de logiciel, mais également de prendre en compte la réorganisation de l’architecture CRM, qui englobe l’ensemble des outils et systèmes utilisés pour gérer le CRM. Voici quelques points importants à considérer :
Choix de l’architecture : Déterminez si vous optez pour un gros CRM tout-en-un ou une combinaison d’une base de données client indépendante et d’un logiciel CRM plus léger. Il existe différentes configurations possibles, donc il est essentiel de trouver celle qui correspond le mieux à vos besoins et à votre infrastructure existante.
Exploitation des données en ligne : l’importance croissante de l’exploitation des données online telles que celles provenant des réseaux sociaux sont mal gérées par la plupart des CRM standards. La migration CRM peut être l’occasion de repenser votre architecture IT pour mieux exploiter ces données. Une option recommandée est de combiner une solution d’unification/préparation des données, telle qu’une Customer Data Platform (CDP), avec un logiciel CRM.
Réflexion stratégique : Profitez de la migration CRM pour prendre du recul et réfléchir à l’architecture optimale qui répondra à vos besoins spécifiques. Vous pouvez envisager des développements sur l’architecture de données, en mettant l’accent sur la collecte, la gestion et l’utilisation des informations clients de manière efficace et sécurisée.
Evolution de l’architecture des systèmes d’information client au fil du temps. De l’approche CRM monolithique à l’approche Data Warehouse centric.
En définissant une architecture CRM cible adaptée, vous pourrez maximiser l’exploitation des données clients, améliorer votre marketing relationnel et tirer le meilleur parti de votre solution CRM dans le cadre de la migration.
Pré-sélectionner les logiciels CRM éligibles
Pour choisir la meilleure solution CRM lors de votre migration, vous devez suivre une approche méthodique. Tout d’abord, identifiez les fonctionnalités et les exigences qui sont cruciales pour votre activité. Ensuite, menez une évaluation approfondie des différentes options de solutions CRM disponibles sur le marché.
Prenez en compte des critères tels que l’adéquation avec vos besoins, la convivialité, les performances et la réputation du fournisseur. N’hésitez pas à demander des démonstrations et des tests pour mieux comprendre comment chaque solution CRM répondra à vos besoins opérationnels.
Parallèlement à l’évaluation des solutions, évaluez également les aspects financiers. Considérez les coûts liés à l’acquisition de la solution CRM, tels que les licences, la formation et le support technique. Assurez-vous que ces coûts sont compatibles avec votre budget et qu’ils offrent un bon retour sur investissement.
Sélectionner la nouvelle solution CRM
Une fois un certain nombre de solutions présélectionnées, prenez en compte les retours d’expérience d’autres utilisateurs. Consultez les avis et les témoignages pour avoir une idée plus concrète de la performance et de la satisfaction des utilisateurs actuels de chaque solution CRM.
Grille de comparaison des CRM. Source : Cartelis
En suivant cette approche réfléchie, vous serez en mesure de sélectionner la nouvelle solution CRM qui répondra le mieux aux besoins de votre entreprise et qui facilitera une migration réussie vers un système CRM plus performant.
#5 Préparer la migration de votre ancien CRM à votre nouveau CRM
La préparation de la migration de votre ancien CRM vers le nouveau système CRM implique plusieurs étapes clés :
Premièrement, vous devez préparer les données. Cela inclut le nettoyage des données de votre CRM actuel en supprimant les doublons et les informations obsolètes. L’objectif est d’importer des données propres et de qualité dans le nouveau système CRM. Profitez-en également pour faire le tri et supprimer les données inutiles ou non utilisées, de faire véritable un « ménage de printemps » dans vos données.
Il est important de noter que plus le modèle de données diffère entre l’ancien et le nouveau CRM, plus vous devrez effectuer des travaux de retraitement et de préparation des données.
Ensuite, vous devez configurer le nouveau CRM. Cette étape implique les paramétrages et la personnalisation ou l’adaptation du modèle de données, dans la mesure du possible. Il est essentiel de comprendre la rigidité des modèles de données CRM et de considérer la possibilité de découpler la base de données (BDD), ce qui permettrait une plus grande flexibilité.
En suivant ces étapes de préparation, vous serez en mesure de migrer vos données de manière efficace et de configurer votre nouveau CRM selon vos besoins spécifiques.
#6 Effectuer la migration CRM
La migration CRM est une étape critique qui nécessite une expertise technique. Il est fortement recommandé de faire appel à un intégrateur spécialisé dans le nouveau CRM pour minimiser les risques d’échec. Cette étape comprend plusieurs chantiers importants.
Tout d’abord, il faut mettre en place les flux de données de manière progressive pour assurer une transition fluide. Ensuite, l’import des données dans le nouveau CRM est essentiel. Cela implique d’effectuer des opérations de correspondance (matching) des données entre les systèmes.
La phase de tests est également cruciale. Par exemple, pour les flux de données, il est recommandé de commencer par connecter une première source de données pour vérifier son bon fonctionnement. Il est essentiel d’identifier les sources de données qui seront utilisées pour tester le nouveau système et de procéder à des tests rigoureux à chaque étape.
En résumé, la migration CRM doit être réalisée avec soin et précision, en s’appuyant sur l’expertise d’un intégrateur spécialisé. La mise en place progressive des flux de données, l’import des données et les tests rigoureux sont des éléments clés de cette étape.
#7 Former les utilisateurs au nouveau CRM
La formation des utilisateurs est une étape essentielle pour assurer une adoption réussie du nouveau CRM. Voici quelques points importants à prendre en compte :
Identifier les besoins de formation : Commencez par évaluer les besoins spécifiques de chaque utilisateur en termes de compétences et de connaissances nécessaires pour utiliser efficacement le nouveau CRM. Certaines équipes, telles que les équipes de vente, de marketing ou de service client, peuvent avoir des besoins différents en fonction des fonctionnalités qu’elles utiliseront le plus.
Concevoir un programme de formation adapté : Sur la base des besoins identifiés, élaborez un programme de formation structuré et adapté à chaque groupe d’utilisateurs. Cela peut inclure des sessions de formation en classe, des tutoriels en ligne, des vidéos explicatives ou des guides d’utilisation.
Privilégier une approche pratique : Lors de la formation, mettez l’accent sur des exercices pratiques et des exemples concrets pour permettre aux utilisateurs de se familiariser avec les fonctionnalités clés du nouveau CRM. Encouragez-les à explorer et à expérimenter par eux-mêmes pour renforcer leur confiance dans l’utilisation du système.
Assurer un suivi et un support continus : La formation ne se termine pas une fois que les utilisateurs maîtrisent les bases du nouveau CRM. Prévoyez un suivi régulier et un support technique pour répondre aux questions, résoudre les problèmes et aider les utilisateurs à tirer le meilleur parti du CRM dans leur travail quotidien.
En conclusion, la formation des utilisateurs est une étape cruciale pour garantir une transition en douceur vers le nouveau CRM. En identifiant les besoins de formation, en concevant un programme adapté, en privilégiant une approche pratique, en offrant un soutien continu et en favorisant l’engagement des utilisateurs, vous maximiserez les chances de réussite de la migration CRM.
Conclusion
La migration d’un CRM est un processus complexe et crucial pour une organisation. Il est essentiel de suivre les bonnes étapes et de prendre les bonnes décisions pour garantir le succès du projet. Dans cet article, nous avons exploré les différentes étapes clés pour réussir la migration de votre CRM.
Tout d’abord, il est important de cadrer le projet en définissant clairement les raisons et les objectifs de la migration. Comprendre les besoins de l’entreprise et des utilisateurs permet de choisir la nouvelle solution CRM adaptée. Ensuite, la construction d’une équipe projet solide, avec des rôles bien définis, favorise une collaboration efficace et une gestion optimale du projet.
L’état des lieux de l’organisation CRM actuelle permet de comprendre les cas d’usage actuels et de cartographier les flux de données, préparant ainsi le terrain pour la migration. Le choix de la nouvelle solution CRM doit être fait en fonction des cas d’usage cibles et de l’architecture CRM souhaitée. Il est recommandé de s’appuyer sur des experts et de considérer l’exploitation des données en ligne. La préparation de la migration implique le nettoyage des données de l’ancien CRM, la configuration du nouveau CRM et la réalisation de tests approfondis pour assurer une transition en douceur.
Enfin, la formation des utilisateurs au nouveau CRM est essentielle pour favoriser une adoption réussie. En concevant un programme de formation adapté et en offrant un soutien continu, les utilisateurs pourront exploiter pleinement les fonctionnalités du CRM.
En suivant ces étapes et en mettant en place une approche méthodique, vous augmentez vos chances de réussir la migration de votre CRM et de bénéficier des avantages d’un système adapté à vos besoins.
La ressource que nous avons conçue pour vous aujourd’hui, va vous faciliter la vie et booster votre business. Notre outil Indicateurs Analyse Produit va vous aider à :
Avoir une définition plus claire quant aux indicateurs les plus pertinents dans votre analyse produit, avec une piste d’amélioration pour chaque indicateur.
Un dashboard (que vous pouvez lier à vos données) qui affichera vos KPIs, votre top 10 des produits qui vous rapportent le plus, votre performance par catégorie de produits, et bien plus encore.
Un data sample (avec une structure holistique, produite grâce au logiciel Octolis) dans lequel vous pourrez intégrer vos données, tout en respectant le format de ce dernier.
Comme son nom l’indique, l’analyse produit consiste à collecter et analyser des données provenant de différentes sources de vente pour comprendre les comportements des clients et les tendances d’achat, avec pour finalité : l’optimisation de l’expérience client et de la stratégie de ventes, en se basant sur des informations précises et actualisées.
Les avantages d’une bonne analyse produit
Effectuer une bonne analyse produit ne peut être que bénéfique pour votre business.
Voici les principaux avantages de l’approche :
Compréhension des clients : Elle permet de mieux comprendre les préférences et les habitudes d’achat des clients pour personnaliser les offres et améliorer leur expérience.
Décisions stratégiques : Grâce à l’analyse produit, les retailers peuvent prendre des décisions éclairées en identifiant les tendances émergentes et les opportunités de croissance.
Optimisation des opérations : L’analyse produit vous aide à optimiser les opérations en identifiant les inefficacités, améliorant la gestion des stocks et ajustant les prix pour maximiser les ventes et minimiser les coûts.
Cependant, pour effectuer une analyse produit rigoureuse, la liste d’indicateurs clés est assez longue, et peut porter à confusion vu le nombre de facteurs qui entrent en jeu. Mais, heureusement pour vous, on a minutieusement sélectionné les indicateurs les plus pertinents à évaluer, et on vous les a regroupés en 5 catégories principales :
Revenus : Croissance des revenus, revenus totaux, revenus annuels…
Marge : Marge brute, marge totale…)
Commandes et clients : Nombre de commandes, % premières commandes, Nombre de clients avec 2+ commandes…)
Comportements utilisateur : Taux de rebond, taux de satisfaction client, taux de clics…)
Comment structurer votre reporting produit ?
Vous n’avez toujours pas su choisir les bons indicateurs pour votre analyse ?
Voici notre tableau résumé qui vous guide avec les questions importantes que vous devez vous poser pour mieux choisir vos indicateurs clés.
Indicateurs clés : Tableau résumé
Catégorie
Indicateurs
Revenus
- Croissance des revenus / Global - Croissance des revenus / Catégorie de produits - Croissance des revenus / Canal de vente - Revenus totaux - Revenus des 365 derniers jours
Marge
- Marge brute - Marge totale - % Marge brute - Marge brute des 365 derniers jours
Commandes et clients
- Nombre de commandes - Nombre de commandes total - Nombre de commandes total des 365 derniers jours - Nombre de commandes retour - Nombre de commandes saison été - Nombre de commandes saison automne - Nombre de commandes saison hiver - Nombre de commandes saison printemps - Nombre de clients - Nombre de clients depuis 365 jours - Taux de rétention - Nombre de premières commandes - Nombre de premières commandes depuis 365 jours - Taux de premières commandes - Nombre de clients avec 2+ commandes de ce produit - Taux de clients avec avec 2+ commandes de ce produit - Nombre de commandes en ligne - Nombre de commandes en magasin
Performance commerciale
- Taux de conversion - Coût d'acquisition client (CAC) - Valeur vie client (VVC) - Taux d'attrition - Temps de vie moyen (LTV) - Délai moyen d'inter-achat - Panier moyen - Taux d'un produit par rapport au panier moyen - Taux de vente croisée - Taux de retour produit - Taux de complétion des fiches produits - Temps moyen de mise en marché
Comportements utilisateur
- Taux de satisfaction client - Taux d'abandonnement - Temps moyen de traitement des commandes - Taux de rebond par page produit - Taux de clics sur le bouton "Ajouter au panier" - Nombre de vues par page produit - Taux de traffic source - Taux de clics sur les images du produit - Taux de clics sur le bouton "Acheter maintenant" - Taux de clics sur les liens de produits associés - Taux de clics sur les liens de produits similaires - Taux de clics sur les liens de produits complémentaires
Il est vrai que toutes les questions qu’on vous a présentées sont du même degré d’importance. Mais un reporting produit bien structuré, ne veut pas forcément dire qu’il devrait tout inclure. Ayez donc la liberté de choisir les indicateurs qui vous conviennent au mieux, et soyez le plus pertinent possible dans votre choix.
Impact sur le revenu
Croissance des revenus / Global : Taux de croissance des revenus globaux sur une période donnée.
Croissance des revenus / Catégorie de produits : Taux de croissance des revenus par catégorie de produits sur une période donnée.
Croissance des revenus / Canal de vente : Taux de croissance des revenus par canal de vente sur une période donnée.
Revenus totaux : Le montant total des revenus générés par la vente du produit.
Revenus des 365 derniers jours : Le montant total des revenus générés par la vente du produit au cours des 365 derniers jours.
Impact sur la marge
Marge brute : Le montant de la marge brute générée par la vente du produit.
Marge totale : Le montant total de la marge générée par la vente du produit.
Taux de marge brute : Le pourcentage de la marge brute par rapport au prix de vente.
Marge brute des 365 derniers jours : Le montant de la marge brute générée par la vente du produit au cours des 365 derniers jours.
Impact sur les commandes et les clients
Nombre de commandes : Le nombre total de commandes passées pour le produit.
Nombre de commandes total : Le nombre total des produits vendus.
Nombre de commandes retour : Le nombre de commandes qui ont été renvoyées par les clients. Cet indicateur peut-être décliné par raison de renvoi.
Nombre de commandes saison été : Le nombre total de produits vendus au cours de l’été.
Nombre de commandes saison automne : Le nombre total de produits vendus au cours de l’automne.
Nombre de commandes saison hiver : Le nombre total de produits vendus au cours de l’hiver.
Nombre de commandes saison printemps : Le nombre total de produits vendus au cours du printemps.
Taux de complétion des fiches produits : Le taux de complétion de la fiche produit.
Nombre de clients : Le nombre total de clients qui ont acheté le produit.
Nombre de clients depuis 365 jours : Le nombre de clients qui ont acheté le produit au cours des 365 derniers jours.
Taux de rétention : Le pourcentage de clients de l’année d’avant qui reviennent.
Nombre de premières commandes : Le nombre total de premières commandes pour le produit. Cet indicateur permet d’identifier les produits qui ont le plus d’impact sur le recrutement de nouveaux clients.
Taux de premières commandes : Le pourcentage de premières commandes par rapport au nombre total de commandes.
Nombre de premières commandes depuis 365 jours : Le nombre total de premières commandes pour le produit au cours des 365 derniers jours.
Nombre de clients avec 2+ commandes de ce produit : Le nombre de clients qui ont acheté le produit au moins deux fois.
Taux de clients avec 2+ commandes de ce produit : Le pourcentage de clients qui ont acheté le produit au moins deux fois par rapport au nombre total de clients qui ont acheté le produit.
Nombre de commandes en ligne : Le nombre de commande en ligne pour un produit spécifique.
Nombre de commandes en magasin : Le nombre de commande en magasin pour un produit spécifique.
Impact sur la performance commerciale
Taux de conversion : Le pourcentage de visiteurs de la page du produit qui effectuent un achat.
Coût d’acquisition client (CAC) : Le coût total dépensé pour attirer un client pour un produit (par exemple : publicité, marketing, coûts de vente).
Valeur vie client (VVC) : Le montant total de revenus générés par un client sur la durée de sa relation commerciale avec l’entreprise.
Taux d’attrition : Le taux de clients qui ont cessé d’acheter le produit au cours d’une période donnée.
Temps de vie moyen (LTV) : La durée moyenne de la relation commerciale avec les clients pour ce produit.
Délai moyen d’inter-achat : La durée moyenne entre deux achats d’un même produit.
Panier moyen : Le montant moyen dépensé par client sur une commande pour un certain produit.
Taux d’un produit par rapport au panier moyen : La place qu’occupe un produit dans un panier moyen (en prix ou volume). Il est possible de combiner cet indicateur avec certains types de paniers moyens.
Taux de vente croisée : Le nombre de produits qui partagent un panier avec une autre catégorie de produit.
Taux de retour produit : Le pourcentage de nombre de produits retournés par rapport aux produits vendus.
Temps moyen de mise en marché : Temps pris en moyenne pour mettre un produit sur le marché.
Taux de complétion des fiches produits : Le nombre des fiches produits complétées par rapport au nombre total des fiches produits.
Temps moyen de mise en marché : La moyenne du temps de mise en marché de tous les produits.
Impact sur le comportement utilisateur
Taux de satisfaction client : Le pourcentage de clients satisfaits du produit, mesuré par des enquêtes de satisfaction ou des commentaires sur le produit.
Taux d’abandonnement : Le taux d’abandon d’un panier contenant un certain produit ou catégorie de produit.
Temps moyen de traitement des commandes : La durée moyenne entre la réception d’une commande et la livraison du produit.
Taux de rebond par page produit : Le pourcentage de visiteurs qui quittent la page du produit sans effectuer aucune action (par exemple : cliquer sur une autre page du site).
Taux de clics sur le bouton « Ajouter au panier » : Le pourcentage de visiteurs qui ont cliqué sur le bouton « Ajouter au panier ».
Nombre de vues par page produit : Le nombre total de fois que la page du produit a été consultée.
Taux de traffic source : Le pourcentage de clients qui sont venus par une source extérieure.
Taux de clics sur les images du produit Le pourcentage de visiteurs qui ont cliqué sur les images du produit pour les agrandir.
Taux de clics sur le bouton « Acheter maintenant » : Le pourcentage de visiteurs qui ont cliqué sur le bouton « Acheter maintenant ».
Taux de clics sur les liens de produits associés : Le pourcentage de visiteurs qui ont cliqué sur les liens de produits associés à celui en cours de visualisation.
Taux de clics sur les liens de produits similaires : Le pourcentage de visiteurs qui ont cliqué sur les liens de produits similaires à celui en cours de visualisation.
Taux de clics sur les liens de produits complémentaires : Le pourcentage de visiteurs qui ont cliqué sur les liens de produits complémentaires à celui en cours de visualisation.
Le rôle de l’analyse produit en E-Commerce / Retail
Connaissance produits : définition et objectifs
On a beau entendre le mot “Produit” et “Analyse”, et directement croire que la notion Analyse Produit est standard, peu importe son contexte d’utilisation.
Dans le monde du retail, on évite assez souvent d’utiliser le terme “Product Analytics” -qui, en soi, représente l’analyse des parcours utilisateurs sur les applications et les sites web et souvent remplacé par la notion de “Retail Analytics”.
De ce fait, l’analyse ou connaissance produit en retail permet de prendre des décisions éclairées sur les prix, les stocks, le marketing, le merchandising, et toute sorte d’opérations en magasin, grâce à des algorithmes prédictifs provenant de sources internes (historique d’achats des clients, par exemple) et des référentiels externes (comme les données du marché ou mêmes les prévisions météorologiques).
Pourquoi faire une l’analyse produit ?
Vos objectifs principaux en tant qu’ bon E-commerçant ou Retailer, c’est d’optimiser toute sorte d’opération liée à la vente, afin de réduire les coûts et d’améliorer les marges. Pour vous montrer comment l’analyse produit peut vous aider à atteindre vos objectifs, on commence déjà par vous présenter ses bienfaits :
Réduction des ruptures de stock et du besoin de remises : Vu son pouvoir inégalé à vous renseigner sur les tendances de la demande, l’analyse produit vous permet de disposer d’un stock suffisant, sans pour autant avoir un excédent d’inventaire qui nécessiterait des remises importantes. Par exemple, l’analyse peut aider à prédire à quelle vitesse la demande diminue pour des articles de mode influencés par la popularité des influenceurs sur les réseaux sociaux.
Amélioration de la personnalisation : L’analyse produit fournit beaucoup d’informations aux retailers quant aux préférences de leurs clients et les aide ainsi à acquérir davantage de demande que leurs concurrents. Par exemple, en utilisant l’historique des achats, un libraire peut informer les clients qui ont montré de l’intérêt pour l’histoire américaine de la disponibilité en pré-commande d’un nouveau livre de l’historien Ron Chernow.
Amélioration de la fixation de prix : L’analyse produit est un outil primordial pour votre stratégie de pricing. En effet, elle vous aide à fixer les prix optimaux de vos produits en synthétisant divers facteurs tels que les paniers d’achat abandonnés, les informations sur les prix pratiqués par la concurrence, et le coût des marchandises vendues. Ainsi, les détaillants peuvent maximiser leurs profits en évitant de fixer des prix supérieurs au seuil du marché ou inférieurs à ce que les clients seraient prêts à payer.
Amélioration de l’allocation des produits : L’analyse permet aux détaillants de décider comment allouer les produits dans différentes régions géographiques, centres de distribution et magasins, ce qui réduit les coûts de transport inutiles. Par exemple, un détaillant d’articles de sport peut utiliser l’analyse pour constater que même une différence de deux degrés de température affecte les ventes de sous-vêtements thermiques et peut allouer davantage de ces articles à un centre de distribution proche des zones prévues pour connaître des températures plus froides pendant un hiver donné.
Analyse produit : Les bonnes pratiques
Exploiter pleinement les données client
Vu la multitude d’interactions que vos clients ont avec votre marque, il est naturel que vous ayez accès à un volume important de données vous informant sur leur parcours d’achat, et leur comportement.
Un bon retailer aura tendance à combiner ses données clients provenant de plusieurs sources (tels que leurs propres programmes de fidélité, les systèmes de points de vente, les historiques d’achats, etc.) avec des données complémentaires achetées auprès de courtiers. Les détaillants font également une distinction entre les « clients » (les personnes qui ont déjà fait affaire avec eux) et les « consommateurs » (qui comprennent ceux qui pourraient être de bons prospects).
Les données de ces derniers peuvent contribuer à éclairer la « modélisation d’audiences looka like » – par exemple, un détaillant identifie Mark comme un excellent client, puis recherche d’autres personnes ayant des attributs similaires et les cibles avec des offres spéciales.
Utiliser des outils de visualisation
Les outils de visualisation tels que les graphiques, les tableaux et les tableaux de bord, couramment utilisés dans les logiciels de Business Intelligence, sont essentiels pour comprendre les données et prendre des décisions éclairées. Ils permettent également aux utilisateurs métier d’accéder aux analyses très facilement, sans pour autant dépendre des équipes data pour générer des rapports et exécuter des requêtes.
Analyser plusieurs sources de données
L’analyse de plusieurs sources de données peut aider les détaillants à obtenir une vue plus holistique de leur activité, d’autant plus que les mesures sont souvent interdépendantes. Une telle approche permet d’avoir une vision plus globale des opérations, et de prendre d’agir sur différents facteurs en même temps.
Par exemple, les détaillants peuvent corréler les analyses en magasin avec les analyses des attributs des produits pour déterminer comment optimiser l’aménagement d’un magasin physique afin de transformer les visiteurs en clients payants. L’analyse des stocks peut aider à s’assurer que le retailer dispose d’un stock suffisant pour soutenir l’aménagement du magasin.
Les détaillants doivent également être attentifs au fait que différentes applications peuvent avoir des définitions différentes des types de données, ce qui pourrait conduire à des analyses incorrectes si elles ne sont pas corrigées. C’est un argument en faveur de l’utilisation d’une plateforme unique pour l’analyse de données de vente au détail plutôt que d’adopter des applications dites « best-of-breed ».
Suivre les indicateurs clés de performance (KPI)
Le suivi des indicateurs clés de performance aide les détaillants à mesurer leurs performances et à identifier les domaines d’amélioration. Les bons détaillants ont tendance à adopter un suivi hebdomadaire de leurs KPIs, en comparant et en évaluant leur évolution d’une semaine à une autre, ce qui leur permet d’avoir une certaine agilité par rapport à leurs opérations et être réactifs face à leur marché et aux éventuels problèmes auxquels ils pourront faire face.
Dans leur suivi, ils ont tendance à présenter un review de ce qui s’est passé, suivi d’une analyse plus approfondie du “pourquoi” des choses.
Prioriser vos objectifs
Tout ce qui peut être mesuré, ne devrait pas obligatoirement l’être. Il est vrai que les données sont multiples, voire même infinies. Mais il est essentiel de discerner entre ce qui doit être mesuré, et ce qui ne doit pas forcément l’être. Lors de la priorisation de vos objectifs, l’idéal c’est d’adopter une approche “less is more”. Plus vous êtes concis dans le choix de vos objectifs, moins vous risquez d’accabler les décideurs avec des recommandations excessives. En tant que retailer, vous devez commencer par identifier les opportunités à haute priorité qui peuvent avoir un impact immédiat sur votre activité.
Pour conclure, les cinq bonnes pratiques qu’on partage avec vous sont interreliées. On vous recommande donc de les suivre toutes, en respectant cet ordre:
Commencez par un objectif, puis choisissez deux ou trois objectifs sous-jacents. Les KPIs qui mesureraient votre progrès à ce niveau sont des KPIs “précurseurs”.
Par exemple: Objectif principal: Vous rapprocher de vos clients. Vous pourrez choisir comme KPIs sous-jacents :
KPI #1 : Augmenter la CLV (ou Customer Lifetime Value) de 20%.
KPI #2 : Atteindre un taux de conversion de 15% (year-to-year).
KPI #3 : Optimiser les niveaux de stock pour soutenir les objectifs clients.
Les outils de visualisation vous permettront de présenter votre progrès aux dirigeants de votre entreprise et d’initier des actions correctives, sans pour autant les bombarder d’informations excessives et incohérentes.
Pour aller plus loin – Les opinions d’expert métier
Afin de vous fournir un contenu de qualité, on se tourne très souvent vers les experts du métier pour qu’ils challengent nos ressources, et partagent avec nous leur expertise sur le sujet.
En préparant cet article, nous avons sollicité Grégoire Mialet– le Managing Partner de la boîte C-Ways, Faustine Caradeux – la Growth Marketing Manager d’Unifai, et Thomas Bertail – le Regional Marketing Manager d’Akeneo – qui nous ont tous les deux beaucoup assistés sur la sélection des meilleurs indicateurs pour votre analyse produit, et qu’on remercie beaucoup d’ailleurs pour leur aide précieuse.
Lors de nos échanges avec eux, on a soulevé beaucoup de questions sur les bonnes pratiques de l’analyse produit. Et comme petit cadeau pour nous avoir suivis jusque-là, on a décidé de partager avec vous les pro tips qu’on a récoltés :
Tip #1 : Sur quelle durée baser mon analyse ?
Il faut avoir en tête qu’une analyse produit est généralement basée sur une durée de 12 mois. Le problème, c’est que l’on veut parfois avoir un retour sur un produit qui a été lancé il y a moins de 12 mois. Par exemple, dans le cas d’un lancement d’un nouveau produit qui a été lancé il y a quelques mois. Il faut donc être vigilant sur les périodes de comparaison. Si cela ne fait que quelques mois et qu’on veut déjà réaliser une analyse, alors une solution est de comparer avec des produits similaires qui viennent de la même famille.
Tip #2 : Faut-il analyser produit par produit ou des ensembles ?
Souvent, on a une logique de bestseller quand on analyse ses produits. On veut savoir, : Quel est le produit que mon entreprise vend le plus ? Quel est le produit qui me ramène le plus de clients (produit recrutant) ou quel est le produit qui fait rester mes clients (produit fidélisant) ? De ce fait, on regarde les produits qui m’apportent le plus de revenus, clients… C’est important mais il ne faut pas hésiter à analyser aussi quels sont mes produits associés, c’est-à-dire, quels sont mes produits que mes clients associent ensemble. Bien comprendre et optimiser ces associations permet de booster ses ventes. En conclusion, il ne faut donc pas oublier de regarder des ensembles de produits plutôt qu’un par un.
Tip #3 : Quels sont vos conseils pour améliorer les performances de ses produits ?
Il y a beaucoup d’indicateurs importants à prendre en compte mais un en particulier que je ne vois pas assez souvent est le taux de retour par produit. Cet indicateur est critique car il est directement lié à la satisfaction client. De plus, c’est l’indicateur qui tire la sonnette d’alarme et qui est une des têtes de lance de la satisfaction client. Il faut, bien sûr, une fois le nombre de retour calculé, conduire des recherches sur les raisons de ces retours et les catégoriser. Une raison ne va pas demander les mêmes changements qu’une autre.
Au-delà de l’analyse effectuée sur un produit en particulier, Il y a une erreur commise par des entreprises, surtout en e-commerce. Ils ne réfléchissent pas assez à comment présenter leurs produits. Ils ne regardent pas l’entièreté de la fiche produit et, de ce fait, si la fiche produit n’est pas optimale, les performances ne le seront pas non plus.
Tip #4 : L’importance cruciale des fiches produit
Un point qui est souvent négligé est la complétion des fiches produits. Or, il y a de nombreux bénéfices à bien compléter l’information sur ces produits. Ainsi, des fiches produits complètes ont un taux de conversion 56% plus élevé que celles qui sont pauvres en informations. En plus de convertir mieux, la complétion de vos fiches produits vous garantit :
Une meilleure expérience client
Un meilleur référencement
Un nombre de retours produits réduit
On a pu donc observer que les consommateurs préfèrent payer un peu plus cher pour un produit qui offre davantage d’informations plutôt que d’acheter un produit plus bon marché avec moins d’informations. Des attributs complets aident les clients à prendre des décisions d’achat éclairées et les rassurent dans leurs achats. De cette façon, on remarque 65% des consommateurs pourraient acheter un produit différent de celui qu’ils envisageaient au départ faute d’informations à la hauteur. Et inversement, 2 acheteurs sur 3 ont déjà abandonné un achat par manque d’informations.
En plus de compléter la fiche produit, il faut s’assurer que les données utilisées dans la fiche produit sont de bonne qualité. Il faut donc prévoir et anticiper des erreurs de classification des produits, qui pourraient entraîner des problèmes tels que des produits publiés dans la mauvaise catégorie ou des dimensions incorrectes, ce qui peut nuire à la satisfaction des clients.
Voilà, nous avons fait le tour de la ressource. N’hésitez pas à l’utiliser et à nous partager vos retours & suggestions 🙂
Dashboard Indicateurs Analyse Produit – Télécharger notre Template
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Pour mesurer efficacement la performance de votre dispositif CRM, vous devez choisir soigneusement vos KPIs. Certains sont bien connus, d’autres moins. Comme il existe beaucoup de KPI CRM et pour vous aider à y voir plus clair, nous allons vous présenter les indicateurs les plus pertinents classés en 4 catégories : acquisition client, expérience/satisfaction client, valeur client, service client.
Pour chaque indicateur, on vous donne la définition, l’objectif et la méthode de calcul. C’est parti !
Les différentes familles de KPIs pour piloter la relation clients et la performance client
Les entreprises s’appuient de plus en plus sur la gestion de la relation client (CRM) pour optimiser leurs stratégies de vente, renforcer la fidélité des clients et améliorer leur rentabilité. L’une des clés pour réussir dans cette démarche consiste à identifier et à suivre les bons indicateurs de performance clés (KPIs) de leur CRM.
Ces KPIs offrent des informations précieuses sur différents aspects de la performance de votre entreprise, notamment l’acquisition de clients, la satisfaction et l’expérience client, ainsi que la rentabilité client. Pour apprendre à mieux connaître ses clients, il est aussi importer de ne pas se contenter d’observer ces KPIs mais de les analyser, comme vous le permet notre ressource d’analyse de données clients dans notre article sur le reporting client et son outil de reporting gratuit.
Dans cet article, nous explorerons en détail les trois principales familles de KPIs CRM, qui sont essentielles pour évaluer et améliorer vos résultats commerciaux.
#1 Les KPIs d’acquisition client
La première famille de KPIs CRM se concentre sur la mesure de la performance en matière d’acquisition de clients. Ces KPIs vous permettent d’évaluer l’efficacité de vos efforts de prospection, de marketing et de ventes pour attirer de nouveaux clients.
Ils peuvent inclure des indicateurs tels que le nombre de nouveaux prospects générés, le taux de conversion des leads en clients, le coût d’acquisition par client, ou encore le taux de croissance du chiffre d’affaires lié à de nouveaux clients. En suivant ces KPIs, vous pouvez ajuster vos stratégies d’acquisition et allouer vos ressources de manière optimale pour maximiser votre base de clients.
#2 Les KPIs de satisfaction et d’expérience client
La deuxième famille de KPIs CRM se concentre sur la satisfaction et l’expérience client. Ces KPIs vous aident à évaluer la qualité de vos interactions avec les clients, ainsi que leur niveau de satisfaction globale. Ils peuvent inclure des mesures telles que le taux de satisfaction client, le temps moyen de réponse aux demandes des clients, le nombre de plaintes ou d’évaluations négatives, ainsi que des indicateurs spécifiques à votre secteur d’activité.
En comprenant et en surveillant ces KPIs, vous pouvez identifier les domaines à améliorer pour offrir une meilleure expérience client, renforcer la fidélité et favoriser le bouche-à-oreille positif.
#3 Les KPIs de rentabilité des clients
Enfin, la troisième famille de KPIs CRM se concentre sur la rentabilité des clients. Ces KPIs vous aident à mesurer la valeur que chaque client apporte à votre entreprise. Ils peuvent inclure des mesures telles que le chiffre d’affaires moyen par client, la marge bénéficiaire par client, la valeur à vie du client (Customer Lifetime Value – CLV), ou encore le taux de rétention des clients.
En suivant ces KPIs, vous pouvez identifier vos clients les plus rentables, adopter des stratégies de fidélisation efficaces et optimiser vos efforts marketing pour maximiser la valeur globale de votre base de clients.
En utilisant les bonnes métriques pour mesurer la performance de votre CRM, vous pouvez prendre des décisions éclairées, améliorer votre efficacité opérationnelle et accroître votre succès commercial global. Pour que vos KPIs soient les plus précis et pertinents possibles, il est important de recueillir un maximum de données pertinentes sur vos clients. Voici plus de 20 méthodes pour collecter plus de données clients.
8 KPIs CRM pour mesurer l’acquisition client
#1 Nombre de nouveaux prospects générés
Définition : Il s’agit du nombre total de nouveaux clients potentiels que votre entreprise a réussi à attirer pendant une période donnée.
Objectif : Mesurer l’efficacité de vos efforts de génération de prospects et suivre la croissance de votre base de prospects.
Formule : Nombre de nouveaux prospects générés = Nombre total de nouveaux contacts ajoutés dans votre base de prospects.
#2 Taux de conversion des leads en clients
Définition : Il calcule le pourcentage de leads (prospects qualifiés) qui se transforment en clients réels.
Objectif : Évaluer l’efficacité de votre entonnoir de conversion et identifier les opportunités d’amélioration.
Formule : Taux de conversion des leads en clients = (Nombre de clients / Nombre de leads) x 100.
#3 Coût d’acquisition par client (CAC)
Définition : Il évalue le coût moyen nécessaire pour acquérir un nouveau client. Il prend en compte les dépenses liées au marketing, à la publicité, aux promotions et à d’autres activités d’acquisition.
Objectif : Mesurer l’efficacité de vos investissements en acquisition client et optimiser votre budget marketing.
Formule : Coût d’acquisition par client = Coûts totaux d’acquisition / Nombre de nouveaux clients acquis.
#4 Taux de croissance des clients
Définition : Il mesure le pourcentage de croissance de votre base de clients sur une période donnée.
Objectif : Suivre la progression de votre entreprise dans l’acquisition de nouveaux clients et évaluer la santé de votre entreprise.
Formule : Taux de croissance des clients = ((Nombre de nouveaux clients – Nombre de clients au début de la période) / Nombre de clients au début de la période) x 100.
#5 Taux de conversion des visiteurs en leads
Définition : Il évalue le pourcentage de visiteurs de votre site web ou de vos canaux de marketing qui deviennent des leads (prospects qualifiés).
Objectif : Mesurer l’efficacité de vos efforts pour transformer les visiteurs en prospects qualifiés et identifier les opportunités d’optimisation.
Formule : Taux de conversion des visiteurs en leads = (Nombre de leads / Nombre total de visiteurs) x 100.
#6 Coût par lead (CPL)
Définition : Il calcule le coût moyen pour générer un lead (prospect qualifié).
Objectif : Évaluer l’efficacité de vos campagnes marketing et comparer différentes sources de leads.
Formule : Coût par lead = Coûts totaux de marketing / Nombre de leads générés.
#7 Taux de recommandation des clients
Définition : Il mesure le pourcentage de clients existants qui recommandent votre entreprise à d’autres personnes.
Objectif : Évaluer la satisfaction des clients et la viralité de votre entreprise.
Formule : Taux de recommandation des clients = (Nombre de clients recommandant votre entreprise / Nombre total de clients) x 100
#8 Taux d’abandon de panier
Définition : Il évalue le pourcentage de visiteurs de votre site e-commerce qui ajoutent des produits à leur panier mais ne finalisent pas leur achat.
Objectif : Identifier les obstacles ou les problèmes qui empêchent les clients de finaliser leurs achats et améliorer l’expérience utilisateur.
Formule : Taux d’abandon de panier = (Nombre d’abandons de panier / Nombre total d’ajouts de panier) x 100.
8 KPIs CRM pour mesurer l’expérience client / la satisfaction client
#1 Taux de satisfaction client
Définition : Il mesure le pourcentage de clients satisfaits parmi votre base de clients.
Objectif : Évaluer la satisfaction globale des clients et identifier les domaines d’amélioration.
Formule : Taux de satisfaction client = (Nombre de clients satisfaits / Nombre total de clients) x 100.
#2 Temps moyen de réponse aux demandes des clients
Définition : Il mesure le temps moyen que vous mettez pour répondre aux demandes et aux problèmes des clients.
Objectif : Évaluer votre réactivité envers les clients et fournir un service client efficace.
Formule : Temps moyen de réponse aux demandes des clients = Somme des temps de réponse / Nombre total de demandes.
#3 Nombre de plaintes ou d’évaluations négatives
Définition : Il surveille le nombre de retours négatifs ou de plaintes émis par les clients.
Objectif : Identifier les problèmes ou les insatisfactions des clients pour pouvoir y remédier rapidement.
Formule : Nombre de plaintes ou d’évaluations négatives = Nombre total de plaintes ou d’évaluations négatives reçues.
#4 Taux de rétention client
Définition : Il mesure le pourcentage de clients qui restent fidèles à votre entreprise sur une période donnée.
Objectif : Évaluer la fidélité des clients et mesurer la capacité de votre entreprise à les retenir.
Formule : Taux de rétention client = ((Nombre de clients à la fin de la période – Nombre de nouveaux clients acquis) / Nombre de clients au début de la période) x 100.
#5 Net Promoter Score (NPS)
Définition : Il évalue la propension des clients à recommander votre entreprise à d’autres personnes.
Objectif : Mesurer la satisfaction et la loyauté des clients, ainsi que le potentiel de recommandation.
Formule : NPS = Pourcentage de promoteurs – Pourcentage de détracteurs.
#6 Taux d’engagement client
Définition : Il mesure le niveau d’engagement et d’interaction des clients avec votre entreprise.
Objectif : Évaluer la relation et l’implication des clients, ainsi que l’efficacité de vos stratégies d’engagement.
Formule : Taux d’engagement client = (Nombre d’interactions des clients / Nombre total de clients) x 100.
#7 Taux de résolution au premier contact
Définition : Il mesure le pourcentage de demandes ou de problèmes des clients résolus dès le premier contact.
Objectif : Évaluer l’efficacité de votre service client et améliorer la satisfaction en résolvant les problèmes rapidement.
Formule : Taux de résolution au premier contact = (Nombre de demandes résolues dès le premier contact / Nombre total de demandes) x 100.
#8 Taux de fidélité client
Définition : Il mesure le pourcentage de clients qui sont fidèles et continuent de faire des achats réguliers auprès de votre entreprise.
Objectif : Évaluer la fidélité des clients et mesurer la rétention à long terme.
Formule : Taux de fidélité client = (Nombre de clients fidèles / Nombre total de clients) x 100.
8 KPIs CRM pour mesurer la valeur client
#1 Valeur vie client (Customer Lifetime Value – CLV)
Définition : Il mesure la valeur financière totale que chaque client apporte à votre entreprise tout au long de sa durée de vie.
Objectif : Évaluer la rentabilité des clients et orienter les décisions commerciales axées sur la valeur à long terme.
Formule : CLV = (Revenu moyen par transaction x Nombre de transactions par an x Durée de vie du client).
#2 Panier moyen
Définition : Il mesure la valeur moyenne des achats effectués par chaque client lors d’une transaction.
Objectif : Évaluer la valeur d’achat des clients et suivre les tendances de dépenses.
Formule : Panier moyen = Revenu total des ventes / Nombre total de transactions.
#3 Taux de réachat
Définition : Il mesure le pourcentage de clients qui effectuent des achats répétés après leur premier achat.
Objectif : Évaluer la fidélité et la récurrence des achats chez les clients.
Formule : Taux de réachat = (Nombre de clients qui effectuent des achats répétés / Nombre total de clients) x 100.
#4 Taux de rétention de la valeur client
Définition : Il mesure le pourcentage de valeur client que vous êtes capable de retenir sur une période donnée.
Objectif : Évaluer la capacité à maintenir et à maximiser la valeur des clients existants.
Formule : Taux de rétention de la valeur client = (Valeur client à la fin de la période / Valeur client au début de la période) x 100.
#5 Part de portefeuille client
Définition : Il mesure la part de dépenses ou de revenus totaux attribuée à votre entreprise par un client par rapport à ses dépenses totales dans votre secteur.
Objectif : Évaluer l’importance de votre entreprise dans le portefeuille d’achat d’un client.
Formule : Part de portefeuille client = (Revenu client avec votre entreprise / Revenu client total dans votre secteur) x 100.
#6 Taux d’attrition client
Définition : Il mesure le pourcentage de clients perdus au cours d’une période donnée.
Objectif : Évaluer la fidélité et la rétention des clients, identifier les problèmes de satisfaction et de rétention.
Formule : Taux d’attrition client = (Nombre de clients perdus / Nombre total de clients au début de la période) x 100.
#7 Valeur de rétention client
Définition : Il mesure la valeur financière des clients que vous avez réussi à retenir sur une période donnée.
Objectif : Évaluer l’impact financier de la rétention client et mesurer la rentabilité des efforts de fidélisation.
Formule : Valeur de rétention client = Valeur totale des clients retenus – Valeur totale des clients perdus.
#8 Taux de pénétration du marché
Définition : Il mesure la part de marché que vous détenez dans votre industrie par rapport au marché total disponible.
Objectif : Évaluer votre position concurrentielle et votre capacité à capturer une part significative du marché.
Formule : Taux de pénétration du marché = (Revenu de votre entreprise / Revenu total du marché) x 100.
8 KPIs CRM pour mesurer votre service client
#1 Temps de réponse moyen
Définition : Il mesure le temps moyen que votre équipe met pour répondre aux demandes et aux problèmes des clients.
Objectif : Évaluer l’efficacité et la rapidité de votre service client.
Formule : Temps de réponse moyen = Somme des temps de réponse / Nombre total de demandes.
#2 Taux de résolution au premier contact
Définition : Il mesure le pourcentage de demandes ou de problèmes des clients résolus dès le premier contact avec votre service client.
Objectif : Évaluer l’efficacité de votre équipe à résoudre les problèmes des clients dès le premier échange.
Formule : Taux de résolution au premier contact = (Nombre de demandes résolues dès le premier contact / Nombre total de demandes) x 100.
#3 Taux de satisfaction du service client
Définition : Il mesure le pourcentage de clients satisfaits de l’assistance et du support reçus de votre service client.
Objectif : Évaluer la qualité de votre service client et la satisfaction des clients.
Formule : Taux de satisfaction du service client = (Nombre de clients satisfaits / Nombre total de clients interrogés) x 100.
#4 NPS du service client
Définition : Il évalue la propension des clients à recommander votre service client à d’autres personnes.
Objectif : Mesurer la satisfaction et la fidélité des clients à l’égard de votre service client.
Formule : NPS du service client = Pourcentage de promoteurs – Pourcentage de détracteurs.
#5 Taux d’abandon des appels
Définition : Il mesure le pourcentage d’appels de clients abandonnés avant d’avoir été résolus.
Objectif : Évaluer l’efficacité de votre service client en termes de disponibilité et de gestion des appels.
Formule : Taux d’abandon des appels = (Nombre d’appels abandonnés / Nombre total d’appels reçus) x 100.
#6 Temps moyen de traitement des demandes
Définition : Il mesure le temps moyen nécessaire pour résoudre les demandes et les problèmes des clients.
Objectif : Évaluer l’efficacité et l’efficience de votre équipe de service client.
Formule : Temps moyen de traitement des demandes = Somme des temps de traitement / Nombre total de demandes.
#7 Taux de résolution des problèmes
Définition : Il mesure le pourcentage de problèmes des clients résolus avec succès par votre service client.
Objectif : Évaluer l’efficacité de votre équipe à résoudre les problèmes rencontrés par les clients.
Formule : Taux de résolution des problèmes = (Nombre de problèmes résolus / Nombre total de problèmes) x 100.
#8 Nombre de rappels ou d’appels de suivi
Définition : Il mesure le nombre d’appels de suivi ou de rappels nécessaires pour résoudre les problèmes des clients.
Objectif : Évaluer la qualité de service et la résolution complète des problèmes dès le premier contact
Formule :Nombre de rappels ou d’appels de suivi = Nombre total de rappels ou d’appels de suivi effectués.
30+ exemples d’analyses clients pertinentes en ecommerce/retail
L’analyse de vos clients et de leurs données est le levier le plus puissant pour améliorer vos performances, votre marketing et vos produits. L’analyse est la base de l’amélioration continue. Particulièrement dans des secteurs comme le Retail et le Ecommerce. Nous allons vous présenter dans cet article les analyses clients les plus utilisées par les professionnels du marketing et les Data Analysts. On les a classés en 5 catégories : segmentation client, campagnes marketing, expérience client, catalogue produits et stratégie de pricing.
7 exemples d’analyses clients pour comprendre comment se répartissent vos clients (votre segmentation client)
#1 L’analyse RFM
L’analyse RFM est une méthode précieuse pour évaluer la valeur de vos clients dans le domaine du e-commerce et de la vente au détail. En utilisant trois critères clés (récence, fréquence et montant), vous pouvez segmenter vos clients en différents groupes en fonction de leur comportement d’achat. Par exemple, vous pourrez identifier vos meilleurs clients récents et fréquents, les clients prometteurs, les clients dormants et les clients perdus.
Cette segmentation vous permettra de mieux comprendre vos clients et d’adapter vos stratégies marketing en conséquence. Vous pourrez cibler vos efforts de fidélisation et de réactivation de manière plus précise pour maximiser le retour sur investissement. Vous saurez quels clients sont les plus louables et pourrez héberger vos ressources sur eux.
En résumé, l’analyse RFM est un outil puissant pour optimiser vos performances dans le secteur de l’e-commerce et de la vente au détail. Elle vous aidera à mieux connaître vos clients, à fidéliser les plus précieux et à élaborer des stratégies de croissance plus efficaces.
Guide ultime sur la Segmentation RFM
Pour aller plus loin, découvrez notre guide complet sur la segmentation RFM, avec une méthode pas à pas pour la mettre en place au sein de votre entreprise.
#2 La segmentation comportementale
La segmentation comportementale consiste à regrouper vos clients en fonction de leurs comportements d’achat et de leurs interactions avec votre marque.
En analysant les préférences et les habitudes spécifiques de chaque groupe, vous pourrez personnaliser vos offres, vos recommandations et vos campagnes marketing. Cela vous permettra de créer des messages ciblés et pertinents, d’améliorer l’expérience client et d’augmenter votre taux de conversion.
La segmentation comportementale vous permet de créer des groupes distincts, tels que les acheteurs impulsifs, les clients fidèles ou ceux qui recherchent des réductions. Vous aurez la capacité d’adapter vos stratégies marketing pour répondre aux besoins uniques de chaque groupe.
De plus, en analysant les schémas comportementaux, vous pourrez détecter les tendances émergentes et identifier de nouvelles opportunités commerciales. Cela vous permettra de rester compétitif sur le marché en ajustant vos produits, services et campagnes marketing en conséquence.
La segmentation comportementale est un outil essentiel pour comprendre vos clients et personnaliser vos interactions. Grâce à cette approche, vous pourrez optimiser votre marketing, améliorer l’expérience client et saisir de nouvelles opportunités dans le secteur de l’e-commerce et de la vente au détail.
#3 La segmentation démographique
Il s’agit d’une méthode que vous pouvez utiliser dans le domaine de l’e-commerce et de la vente au détail pour regrouper vos clients en fonction de leurs caractéristiques démographiques telles que l’âge, le sexe, le niveau d’ l’éducation, le revenu, etc.
Cette approche vous permettra de mieux comprendre les préférences et les besoins spécifiques de chaque segment démographique, et ainsi personnaliser vos offres, vos produits et vos messages marketing pour répondre de manière précise aux attentes de chaque groupe démographique.
En segmentant démographiquement vos clients, vous pourrez améliorer leur expérience en proposant des produits et des communications adaptés à leurs caractéristiques, tout en optimisant vos campagnes publicitaires en ciblant les segments les plus pertinents pour votre entreprise.
L’analyse des schémas démographiques vous permettra de prendre des décisions stratégiques éclairées, telles que l’ajustement de votre assortiment de produits, la tarification adaptée à chaque segment et l’adaptation de votre communication pour répondre aux exigences spécifiques de chaque groupe démographique.
Utiliser la segmentation démographique est essentiel pour mieux comprendre vos clients et personnaliser vos stratégies marketing, optimiser vos offres, cibler vos campagnes publicitaires et améliorer votre performance globale dans le secteur de l’e-commerce et de la vente au détail.
#4 La segmentation géographique
La segmentation géographique consiste à diviser votre base de clients en fonction de leur localisation géographique, telle que la région, la ville ou le pays.
En utilisant la segmentation géographique, vous pouvez mieux comprendre les comportements d’achat et les préférences des clients dans différentes régions. Cela vous permet de personnaliser vos offres, vos promotions et votre communication pour répondre aux besoins spécifiques de chaque segment géographique.
La segmentation géographique vous aide à adapter votre stratégie marketing en fonction des particularités régionales, telles que les tendances de consommation, les saisons et les habitudes culturelles. Cela vous permet d’optimiser vos efforts de marketing local et de mieux répondre aux attentes des clients dans chaque région.
En analysant les données géographiques, vous pouvez identifier les opportunités de croissance dans de nouvelles régions et déterminer les zones géographiques les plus louables pour votre entreprise. Vous pouvez également ajuster votre logistique, vos prix et vos promotions en fonction des besoins spécifiques de chaque segment géographique.
Outil stratégique essentiel pour les entreprises de l’e-commerce, cette méthode vous permettra de mieux comprendre les comportements d’achats locaux, de personnaliser les offres et la communication, d’optimiser la logistique et de saisir de nouvelles opportunités de croissance dans différentes Régions.
#5 L’analyse de la valeur à vie des clients (customer lifetime value)
Cette analyse permet d’évaluer la valeur financière globale qu’un client peut générer tout au long de sa relation avec votre entreprise dans le domaine de l’e-commerce ou du retail.
Elle vous donne une vision claire de la rentabilité de chaque client et vous aide à prendre des décisions stratégiques éclairées.
En utilisant cette analyse, vous pourrez identifier vos clients les plus précieux, comprendre leurs habitudes d’achat, personnaliser votre offre pour répondre à leurs besoins spécifiques et mettre en place des actions marketing ciblées pour les fidéliser.
Cela vous permettra d’optimiser votre retour sur investissement marketing, d’augmenter la valeur à vie de vos clients et d’augmenter votre rentabilité globale à long terme.
#6 L’analyse psychographique
L’analyse psychographique consiste à étudier les motivations, les valeurs, les attitudes et les comportements des consommateurs. Elle vise à comprendre les facteurs psychologiques qui influencent les décisions d’achat des clients.
En utilisant cette analyse, vous pourrez segmenter votre audience en fonction de traits psychologiques communs, ce qui vous permettra de mieux cibler vos messages et vos offres. Vous pourrez également adapter votre stratégie de marketing et de communication en fonction des préférences et des besoins spécifiques de chaque segment.
Cela vous permettra d’établir des relations plus solides avec vos clients, de renforcer leur engagement et de favoriser leur fidélité à long terme.
En fin de compte, l’analyse psychographique vous permettra de personnaliser votre approche et d’améliorer l’expérience globale de vos clients, ce qui se traduira par une meilleure performance commerciale.
#7 La segmentation de la fidélité client
La segmentation de la fidélité client dans le domaine du e-commerce ou du retail implique de regrouper vos clients en différents segments en fonction de leur niveau de fidélité envers votre entreprise.
Cette méthode vous permet de mieux comprendre les comportements et les besoins spécifiques de chaque groupe de clients fidèles. En utilisant cette segmentation, vous serez en mesure de personnaliser vos offres, vos programmes de fidélité et vos communications afin de répondre aux attentes de chaque segment.
L’objectif est de renforcer la satisfaction et l’engagement de vos clients fidèles, à encourager leurs achats répétés et à maximiser leur valeur à vie. De plus, vous pourrez identifier les clients en voie de fidélisation et mettre en place des initiatives spécifiques pour les encourager à devenir des clients fidèles.
Au final, la segmentation de la fidélité client vous permettra d’améliorer la rétention des clients, d’optimiser votre rentabilité et d’établir des relations solides à long terme avec votre clientèle fidèle.
5 exemples d’analyses clients pour optimiser vos campagnes marketing
#8 Le test A/B
Il s’agit d’un moyen permettant de comparer deux versions différentes d’un élément marketing, comme une page web, un email ou une publicité, afin de déterminer laquelle est la plus performante.
Cette méthode vous permet d’obtenir des données réelles sur l’impact de chaque version sur les comportements des clients. En utilisant le test A/B, vous pourrez tester différentes variations, telles que des titres, des images, des couleurs ou des appels à l’action, pour identifier les éléments qui ont généré les meilleurs résultats. Cela vous aidera à optimiser vos campagnes, à améliorer les taux de conversion et à augmenter vos ventes.
De plus, l’A/B testing vous fournira des informations précieuses sur les préférences et les réactions de vos clients, ce qui vous permettra d’affiner votre stratégie marketing pour mieux les engager.
En fin de compte, cette approche vous permettra de prendre des décisions éclairées, d’optimiser l’expérience client et de maximiser votre succès dans le domaine du commerce en ligne ou de la vente au détail.
#9 L’analyse du tunnel de conversion
L’analyse du tunnel de conversion consiste à étudier les différentes étapes que les visiteurs parcourent depuis leur arrivée sur votre site jusqu’à la finalisation d’un achat, dans le but d’optimiser ce processus.
Cette méthode vous permet de comprendre où se manifestent les éventuels obstacles ou points de friction, ainsi que les opportunités d’amélioration pour augmenter les conversions.
En utilisant l’analyse du tunnel de conversion, vous pourrez identifier les étapes du parcours client où se produiront les abandons les plus fréquents, vous permettant de mettre en place des actions correctives. Vous pourrez ainsi améliorer l’expérience utilisateur, augmenter le taux de conversion et maximiser vos ventes.
De plus, cette analyse vous fournit des informations précieuses sur le comportement de vos clients, vous permettant d’adapter votre stratégie marketing à chaque étape du tunnel de conversion pour maximiser son efficacité. Cela vous aidera donc à optimiser votre processus d’achat, à renforcer votre rentabilité en ligne ou en magasin, et à atteindre vos objectifs commerciaux.
#10 L’analyse du ROI des campagnes
L’analyse du ROI (Return on Investment) des campagnes vise à évaluer la performance et la rentabilité de vos différentes campagnes marketing et publicitaires. Son objectif principal est de mesurer le retour financier généré par vos investissements.
En utilisant cette analyse, vous pourrez déterminer quelles campagnes ont été les plus efficaces et les plus louables, ce qui vous permettra de prendre des décisions éclairées quant à l’allocation de vos ressources.
Vous pourrez ainsi mettre en œuvre vos efforts sur les stratégies qui permettent d’obtenir les meilleurs résultats et d’optimiser vos investissements futurs.
De plus, cette analyse vous fournira des informations précieuses sur les canaux, les segments de clientèle et les messages qui ont eu le plus d’impact, vous permettant d’affiner vos futures campagnes et d’améliorer votre rentabilité globale.
En somme, l’analyse du ROI des campagnes vous aide à maximiser vos revenus, à optimiser votre stratégie marketing et à obtenir un meilleur retour sur vos investissements.
#11 La cartographie des parcours clients
La cartographie des parcours clients consiste à analyser et représenter graphiquement les différentes étapes par lesquelles les clients passent lors de leur interaction avec votre entreprise. Son objectif principal est de vous permettre de visualiser de manière claire et détaillée les itinéraires empruntés par les clients, du premier contact à l’achat et au-delà.
En utilisant la cartographie des parcours clients, vous pourrez identifier les points de contact clés, les moments forts ainsi que les éventuels obstacles rencontrés par les clients tout au long de leur parcours. Cela vous permettra d’optimiser chaque étape pour offrir une expérience fluide, personnalisée et sans friction, ce qui améliorera la satisfaction client et favorisera la fidélité.
De plus, cette analyse vous permet de mieux comprendre les motivations et les besoins des différents segments de votre clientèle, vous permettant ainsi d’adapter vos stratégies marketing et de proposer des offres et des interactions plus applicables.
En résumé, la cartographie des parcours clients vous permettra donc d’optimiser l’expérience client, d’augmenter les taux de conversion et de développer une relation solide avec votre clientèle.
Dans le domaine du commerce électronique, le taux de désabonnement mesure la proportion de clients qui se désengagent de votre entreprise en se désabonnant de vos communications ou en annulant leur abonnement. Son objectif est d’évaluer la rétention et la fidélité des clients.
En analysant le taux de désabonnement, vous pouvez repérer les tendances et les motifs derrière les désabonnements, ce qui vous permet de prendre des mesures pour améliorer la satisfaction et réduire les départs.
Cela vous aidera à adapter vos stratégies de fidélisation, à renforcer les relations avec vos clients et à maintenir leur engagement à long terme.
7 exemples d’analyses pour mesurer l’expérience de vos clients et leur satisfaction
#13 Les enquêtes de satisfaction client
La satisfaction client joue un rôle essentiel dans la compréhension et l’évaluation du degré de satisfaction de votre clientèle à l’égard de vos produits ou services.
Elle vous permet de générer des données via des questionnaires ou des sondages afin de mesurer la perception et les opinions de vos clients. Avec l’aide de cette analyse, vous pouvez mettre en évidence les points forts de votre offre, ainsi que les aspects à améliorer pour accroître la satisfaction de votre clientèle.
En examinant les résultats de ces enquêtes, vous serez en mesure de détecter les problèmes récurrents, de repérer les tendances émergentes et d’ajuster votre stratégie pour mieux répondre aux attentes changeantes de vos clients.
En utilisant les informations obtenues grâce à cette analyse, vous serez en mesure de prendre des décisions éclairées pour améliorer l’expérience client, renforcer la fidélité de votre clientèle et optimiser les performances globales de votre entreprise.
#14 Le NPS (score net de promotion)
Le NPS en e-commerce est un indicateur clé qui permet de mesurer la satisfaction et la fidélité des clients envers votre entreprise. Il consiste à poser une question simple aux clients : « Sur une échelle de 0 à 10, dans quelle mesure recommanderiez-vous notre entreprise à votre entourage ? ».
En fonction des réponses, les clients sont classés en trois catégories : les promoteurs (note 9-10), les passifs (note 7-8) et les détracteurs (note 0-6).
Le NPS est alors calculé en soustrayant le pourcentage de détracteurs du pourcentage de promoteurs. Ce score permet d’évaluer la satisfaction globale des clients et d’identifier les leviers d’amélioration.
Grâce au NPS, vous pourrez mesurer l’impact de vos actions sur la satisfaction client, identifier les domaines à renforcer et prendre des mesures concrètes pour améliorer l’expérience client et fidéliser votre clientèle.
#15 L’écoute des médias sociaux
L’écoute des médias sociaux est une méthode qui consiste à surveiller et à analyser les conversations et les mentions relatives à votre entreprise sur les plateformes de médias sociaux.
Elle permet de comprendre ce qui se dit sur votre marque, vos produits ou services, ainsi que sur vos concurrents.
Grâce à cette méthode, vous pouvez favoriser des informations précieuses sur les préoccupations, les attentes et les avis de votre public cible. L’écoute des médias sociaux vous permet d’identifier les tendances émergentes, de détecter les problèmes potentiels et d’ajuster votre stratégie en conséquence.
En utilisant les données recueillies grâce à cette méthode, vous serez en mesure de prendre des décisions éclairées, d’optimiser vos campagnes marketing, d’améliorer l’expérience client et de renforcer votre présence sur les réseaux sociaux.
#16 Le CSAT (note de satisfaction client)
Le CSAT en e-commerce a pour objectif de mesurer la satisfaction des clients vis-à-vis de leur expérience d’achat. Il se base sur une simple question posée aux clients : « Sur une échelle de 1 à 5, commentez-vous votre satisfaction par rapport à votre expérience d’achat ? ».
Les clients sont invités à attribuer une note de 1 à 5, allant de très insatisfait à très satisfait.
Le CSAT est calculé en fonction du pourcentage de clients satisfaits (notes 4-5) par rapport au nombre total de réponses. En utilisant le CSAT, vous pouvez évaluer la satisfaction de vos clients, identifier les points forts et les axes d’amélioration de votre expérience d’achat, et mettre en place des actions concrètes pour augmenter la satisfaction client.
En surveillant régulièrement le CSAT, vous pourrez suivre l’évolution de la satisfaction client dans le temps et ajuster vos stratégies en conséquence.
#17 Le CES (client score d’effort)
Le CES est un indicateur utilisé pour évaluer l’effort fourni par les clients lors de leur expérience d’achat. Il se base sur une question clé posée aux clients : « Dans quelle mesure avez-vous dû fournir des efforts pour effectuer votre achat ? ». Les clients sont invités à répondre sur une échelle de 1 à 7, allant de « Aucun effort » à « Un effort considérable ».
Cet indicateur est calculé en calculant les réponses des clients. Grâce au CES, vous pouvez mesurer l’effort perçu par vos clients, identifier les points de friction dans le processus d’achat, et prendre des mesures pour réduire leur effort. En utilisant régulièrement le CES, vous pourrez suivre l’évolution de l’effort client au fil du temps et optimiser leur expérience d’achat.
Ainsi, par l’étude des résultats du CES, vous pourrez mettre en place des améliorations spécifiques pour simplifier et rendre plus fluide le parcours d’achat de vos clients.
#18 Le VOC (Voix du client)
Le VOC (Voice of the Customer) est une approche essentielle pour diffuser et analyser les avis, les besoins et les attentes des clients. Il consiste à collecter les feedbacks des clients à travers divers canaux de communication tels que les sondages, les commentaires et les avis.
Grâce au VOC, vous pouvez obtenir des informations précieuses directement des clients pour mieux comprendre leur perception de votre entreprise et de vos produits.
En utilisant le VOC, vous pouvez identifier les domaines de forces de votre offre et les améliorer, vous permettant ainsi de prendre des décisions stratégiques adaptées aux besoins réels des clients.
De ce fait, les retours de cet outil vous permettent d’optimiser l’expérience client, d’augmenter la satisfaction et de fidéliser votre clientèle.
#19 L’analyse du service client
Celle-ci revêt une importance cruciale dans votre entreprise, car elle permet d’évaluer et d’améliorer l’expérience de vos clients.
Elle consiste à collecter, analyser et interpréter les données relatives aux interactions avec vos clients, que ce soit par le biais des appels, des e-mails ou des chats en direct. Grâce à cette analyse, vous serez en mesure d’identifier les problèmes récurrents, de mesurer l’efficacité de votre équipe de service client et de repérer les points forts et les faiblesses de votre processus. Cela vous permettra de former votre équipe de manière ciblée, d’anticiper les besoins des clients et de leur offrir une expérience personnalisée, tout en résolvant rapidement leurs problèmes.
En utilisant l’analyse du service client, vous pourrez également suivre l’impact de vos actions d’amélioration, mesurer la fidélité des clients et évaluer leur niveau de satisfaction globale. En comprenant les attentes et les besoins de vos clients grâce à cette analyse, vous serez en mesure de prendre des décisions stratégiques éclairées pour optimiser leur expérience. De surcroît, vous favoriserez la croissance de votre entreprise et maintiendrez une relation solide avec votre base de clients fidèles.
Par conséquent, l’analyse du service client vous permettra d’offrir un service exceptionnel, de fidéliser vos clients et de vous démarquer dans un marché concurrentiel.
7 exemples d’analyses pour améliorer votre catalogue produits
#20 L’analyse de la performance produit
Cette analyse de produits permet d’évaluer et d’optimiser les résultats de vos produits au sein de votre activité commerciale. En l’utilisant, vous pourrez mesurer la performance de chaque produit, identifier les forces et les faiblesses, et découvrir des opportunités d’amélioration.
Cette analyse vous aide à évaluer les ventes, les marges bénéficiaires, la demande et la satisfaction client liées à chaque produit, ce qui vous permet de prendre des décisions éclairées sur l’approvisionnement, la tarification, la promotion et l’optimisation de votre assortiment.
De plus, elle vous permet de segmenter votre catalogue en fonction de la performance de chaque produit, afin de vous concentrer sur les produits les plus louables et de mettre en place des stratégies spécifiques pour améliorer ceux qui ont des résultats les moins satisfaisants.
L’objectif de l’analyse de la performance produit est de maximiser les ventes, la rentabilité et la satisfaction client grâce à des décisions stratégiques basées sur des données précises et fiables. Cela vous aidera donc à comprendre quels produits rencontrent le plus de succès, quelles sont les tendances du marché et quelles sont les préférences de votre clientèle. De ce fait, vous serez en mesure d’ajuster votre offre, de cibler vos efforts de marketing et d’adapter votre stratégie globale pour atteindre les meilleurs résultats. L’analyse de la performance produit vous permet donc d’évaluer, d’optimiser et de développer votre activité.
#21 L’analyse des avis clients
Celle-ci consiste à résoudre et analyser les avis et retours d’expérience des clients concernant vos produits ou services. Son objectif est d’évaluer la satisfaction des clients, d’identifier les forces et les faiblesses de votre offre, et d’obtenir des informations précieuses pour améliorer votre activité.
En analysant les avis clients, vous pouvez découvrir les préférences, attentes et tendances des clients, ce qui vous permet d’adapter votre offre et d’améliorer leur expérience globale. De plus, cette analyse vous aide à identifier les problèmes récurrents et à prendre des mesures correctives pour améliorer la qualité de vos produits et services.
En répondant aux commentaires des clients, vous pouvez également développer une relation de confiance et renforcer votre réputation en ligne.
Par conséquent, vous allez ainsi pouvoir optimiser la satisfaction client, fidéliser vos clients et prendre des décisions stratégiques ciblées sur les besoins réels de votre clientèle.
#22 L’analyse des recommandations produits
L’examen des produits recommandés implique l’analyse des données et des comportements des clients afin de fournir des suggestions personnalisées et applicables.
L’objectif principal est d’améliorer l’expérience d’achat en proposant des produits qui correspondent aux intérêts de chaque client. Avec l’utilisation de cette analyse, vous pouvez appréhender les préférences, les habitudes d’achat et les comportements des clients, ce qui permet de suggérer des produits adaptés à leurs goûts et à leurs besoins.
En utilisant l’analyse des produits recommandés, vous pouvez optimiser la pertinence de vos suggestions, augmenter les ventes croisées et encourager les clients à acheter des produits complémentaires.
De plus, cette analyse vous permet de personnaliser l’expérience client, d’accroître la fidélité et d’améliorer la satisfaction globale.
Dans l’ensemble, l’analyse des recommandations vous aide à affiner les suggestions pour chaque client, à stimuler les ventes et à créer une expérience d’achat personnalisée et satisfaisante.
#23 L’analyse concurrentielle
Dans le cadre de l’e-commerce/retail, l’analyse concurrentielle implique d’étudier vos concurrents et le marché. Son objectif est de comprendre les stratégies, les forces et les faiblesses de vos rivaux.
Cette analyse vous permet d’identifier les opportunités et les menaces présentes sur le marché, afin de prendre des décisions éclairées.
En évaluant la performance de vos concurrents, vous pouvez comparer votre offre, vos prix et vos services pour vous démarquer et trouver des axes d’amélioration.
En définitive, l’analyse concurrentielle vous aide à vous positionner stratégiquement et à optimiser votre compétitivité dans le secteur de l’e-commerce/retail.
#24 Les tests utilisateurs
Les tests utilisateurs dans le domaine de la vente au détail sont des méthodes d’évaluation qui sont cohérentes à observer et qui permettent de réagir aux retours des utilisateurs lorsqu’ils interagissent avec votre site web ou vos produits.
L’objectif principal de ces tests est de comprendre comment les utilisateurs interagissent avec votre plateforme, d’identifier les problèmes d’utilisabilité et d’améliorer l’expérience client.
En utilisant les tests utilisateurs, vous pouvez observer directement les comportements des utilisateurs, donner leurs avis et obtenir des informations précieuses sur leurs préférences et leurs besoins. Ces tests vous permettent également de détecter les obstacles et les points de friction dans le processus d’achat. Ainsi, vous pourrez mieux optimiser votre conversion et améliorer votre satisfaction client.
Enfin, les tests utilisateurs vous permettent de prendre des décisions fondées sur des données réelles et d’apporter des modifications ciblées pour améliorer l’ergonomie, la convivialité et la performance globale de votre plateforme.
#25 L’analyse des prix des produits
Pour utiliser l’analyse des prix des produits en e-commerce/retail, il est important de comprendre en quoi elle consiste et comment elle peut vous être bénéfique. Cette analyse implique d’étudier les prix pratiqués sur le marché pour des produits similaires ou concurrents, dans le but de déterminer le positionnement optimal de votre prix.
Grâce à cette analyse, vous pouvez identifier des opportunités de tarification, ajuster vos prix en fonction de la demande et de la concurrence, et améliorer votre rentabilité.
Elle vous permet également de surveiller les variations de prix sur le marché, d’anticiper les tendances et les comportements des consommateurs, et de prendre des décisions éclairées en matière de tarification.
En résumé, l’analyse des prix des produits vous offre des insights précieux pour optimiser votre stratégie commerciale et rester compétitif sur le marché de l’e-commerce/retail.
#26 L’analyse des caractéristiques des produits
L’analyse des caractéristiques des produits a pour mieux appréhender en détail les spécifications, les fonctionnalités et les attributs comprenant de vos produits, afin de ce que vos clients apprécient le plus et recherchent les détails.
En utilisant cette analyse, vous serez en mesure de déterminer les atouts clés de vos produits, d’identifier les améliorations potentielles et de saisir de nouvelles opportunités.
En comparant vos produits avec ceux de vos concurrents, cette analyse vous permettra de mettre en évidence vos avantages compétitifs et de positionner votre offre de manière stratégique.
Grâce à cette analyse approfondie, vous serez de ce fait en mesure de prendre des décisions éclairées quant au développement de produits, au marketing et à la communication, en répondant de manière précise et efficace aux attentes et aux besoins de vos clients.
6 exemples d’analyses pour améliorer votre stratégie de pricing
#27 L’analyse de la sensibilité des prix
L’analyse de la sensibilité des prix est un outil essentiel pour comprendre comment les variations de prix peuvent influencer les décisions d’achat des clients. Grâce à cette analyse, vous pourrez déterminer la plage de prix idéale pour maximiser vos revenus tout en maintenant la satisfaction de vos clients.
En évaluant l’élasticité de la demande pour vos produits, vous saurez commenter vos clients réagissent aux changements de prix, ce qui vous aidera à ajuster votre stratégie tarifaire de manière optimale.
Vous serez en mesure d’identifier les segments de clients les plus sensibles aux prix, vous permettant ainsi d’adapter vos promotions et votre marketing en conséquence. Grâce à cette analyse, vous pourrez également évaluer l’impact de vos actions promotionnelles sur vos ventes et déterminer la rentabilité de vos produits à différents niveaux de prix.
Cette analyse vous donnera donc des insights précieux pour prendre des décisions éclairées en matière de tarification et de maximisation de vos revenus.
#28 La tarification dynamique
La tarification dynamique est une stratégie astucieuse qui vous permet de moduler vos prix en fonction des variations du marché et de la demande. Grâce à cette approche, vous pourrez ajuster vos tarifs en temps réel, en tenant compte de différents paramètres tels que la disponibilité des produits, les fluctuations saisonnières et la concurrence.
En exploitant des données et des algorithmes avancés, la tarification dynamique vous offre la possibilité d’identifier les moments propices pour augmenter ou réduire vos prix, optimisant ainsi vos revenus.
De plus, cette méthode vous permet de vous adapter rapidement aux évolutions de la demande et de maintenir votre compétitivité sur le marché. En surveillant attentivement les réactions des clients face à vos ajustements tarifaires, vous serez en mesure d’affiner continuellement votre stratégie de tarification, en vous rendant efficaces sur des informations concrètes.
Ainsi, la tarification dynamique vous offre la flexibilité nécessaire pour optimiser vos prix selon les conditions du marché, augmenter vos revenus et permettre votre position concurrentielle.
#29 La discrimination par les prix
Il s’agit d’une approche qui vous permet de décortiquer les différentes stratégies tarifaires. Avec cette méthode, vous allez explorer les subtilités des prix et découvrir si des facteurs tels que la segmentation de la clientèle ou les préférences individuelles qui influencent vos tarifs.
En utilisant cette analyse, vous serez en mesure de sculpter votre prix de manière ciblée, en harmonie avec les attentes de chaque segment de clientèle.
Grâce à cette compréhension approfondie des réactions de vos clients aux différents niveaux de prix, vous pourrez ajuster votre stratégie tarifaire pour optimiser à la fois vos revenus et la satisfaction de votre clientèle.
En scrutant attentivement les résultats de cette analyse, vous pourrez prendre des décisions éclairées quant à l’implémentation de politiques de tarification différenciées. Ceci donne naissance à une expérience d’achat sur mesure pour chaque client, tout en maximisant vos profits.
En résumé, cette méthode peut vous permettre de propulser votre entreprise vers de nouveaux sommets de succès économique et de satisfaction client.
#30 La modélisation de l’optimisation des prix
La modélisation est une approche potentiellement puissante puisqu’elle peut vous permettre de maximiser vos revenus en ajustant stratégiquement vos tarifs.
En utilisant cette modélisation, vous allez pouvoir explorer et analyser différentes variables, telles que la demande, la concurrence, les coûts et les préférences des clients, pour déterminer les prix optimaux de vos ou services. Vous pourrez identifier les relations complexes entre ces facteurs et prendre des décisions éclairées pour optimiser vos marges bénéficiaires. Par l’analyse des données intelligentes et l’utilisation des algorithmes avancés, cette modélisation vous permettra de créer des stratégies tarifaires et dynamiques. Celles-ci seront adaptées aux fluctuations du marché et aux attentes changeantes des clients.
La modélisation de l’optimisation des prix vous offre de ce fait les outils nécessaires pour maximiser votre rentabilité. Vous êtes en mesure de prendre une longueur d’avance sur vos concurrents et d’offrir une valeur optimale à vos clients. Et tout cela en maintenant un équilibre subtil entre vos objectifs financiers et la satisfaction de votre clientèle.
#31 L’élasticité-prix
L’élasticité-prix est un concept qui vous permet de comprendre comment la demande d’un produit ou d’un service réagit aux variations de son prix. En utilisant l’élasticité-prix, vous pourrez évaluer la sensibilité des consommateurs aux changements de prix et ajuster votre stratégie tarifaire en conséquence. Cette mesure va vous offrir des informations précieuses sur la réaction des clients face aux variations de prix (qu’il s’agisse d’une augmentation ou d’une réduction).
Grâce à cette élasticité-prix, vous pourrez prendre des décisions afin de maximiser vos revenus en identifiant les gammes de prix les plus avantageuses, en présentant le bon équilibre entre rentabilité et volume des ventes, et en anticipant les répercussions de vos ajustements tarifaires.
En analysant les données et en calculant l’élasticité-prix, vous pourrez adapter votre offre en fonction de la demande du marché, optimiser vos marges bénéficiaires et rester compétitif.
L’élasticité-prix est un outil essentiel qui vous permettra de prendre des décisions stratégiques éclairées en matière de tarification, en comprenant comment les variations de prix influent sur la demande de vos produits ou services.
#32 Le test de prix
Le test de prix est une méthode utilisée pour évaluer la réaction des clients à différents niveaux de prix pour un produit ou un service donné. En menant des expériences de test de prix, vous pourrez mesurer l’élasticité-prix et comprendre comment la demande fluctue en fonction des variations tarifaires. Cela vous permettra d’optimiser votre stratégie de tarification en identifiant les prix les plus appropriés pour maximiser vos revenus.
Le test de prix consiste à proposer des prix différents à des groupes de clients ou à des segments spécifiques du marché, puis à analyser les résultats pour déterminer l’impact sur la demande et les performances commerciales.
En utilisant le test de prix, vous pourrez ajuster votre prix de manière itérative et obtenir des données concrètes sur la sensibilité des consommateurs aux changements tarifaires. Cela vous aidera à prendre des décisions éclairées en matière de tarification.
En évaluant les résultats du test de prix, vous pourrez ajuster vos stratégies tarifaires, identifier les prix optimaux qui maximisent à la fois vos revenus et votre rentabilité, et anticiper les réactions des clients face aux changements de prix.
#33 L’analyse de la concurrence
L’analyse de la concurrence dans une stratégie de tarification vise à comprendre comment vos concurrents positionnent leurs prix sur le marché. En réalisant cette analyse, vous pourrez évaluer la compétitivité de vos prix par rapport à ceux de vos concurrents.
L’analyse de la concurrence consiste en effet à examiner les prix pratiqués par vos concurrents, ainsi que les stratégies de tarification qu’ils utilisent. Vous pourrez ainsi identifier les écarts de prix, les opportunités de différenciation et les marges de manœuvre pour ajuster vos propres prix. L’analyse de la concurrence vous permettra également d’identifier les facteurs clés qui influencent les décisions de prix de vos concurrents, tels que la qualité perçue, les promotions, les remises ou les niveaux de service. En comprenant ces facteurs, vous pourrez donc affiner votre propre stratégie de tarification pour être compétitif sur le marché.
L’analyse de la concurrence dans une stratégie de tarification vous aide ainsi à évaluer la position de vos prix par rapport à ceux de vos concurrents. Vous pouvez identifier des opportunités de différenciation et ajuster votre stratégie de tarification pour être compétitif sur le marché.
L’art de gérer une Base de Données Clients [Guide & Logiciels]
Votre base de données clients est le système qui permet de stocker et d’organiser de manière structurée l’ensemble de vos données clients. Socle de l’analyse et de l’activation, son rôle est fondamental dans votre capacité à exploiter vos données clients.
Problème ? La multiplication des interactions avec vos clients, tout au long du parcours d’achat rend cette démarche plus complexe. Vos données clients sont stockées dans des systèmes et des formats différents, ce qui implique un travail d’unification et de normalisation en amont de leur exploitation d’un point de vue marketing.
A quoi correspond exactement la notion de base de données clients ? Quels sont les principaux enjeux associés ? Vers quels outils se tourner pour poser les bases d’une bdd clients saine et scalable ?
On répond à toutes ces questions dans le guide ci-dessous ! Bonne lecture 🙂
📕 Guide complet sur la gestion de votre Base de Données Clients
L’essentiel à retenir sur les bases de données clients
Une base de données clients est un système permettant de stocker et organiser les données clients de l’entreprise afin de mieux connaitre ses clients et ainsi améliorer vos performances. Des données clients fiables et structurées servent de socle à l’analyse et à l’activation grâce à des campagnes marketing plus performantes.
Pour être exploitable, une BDD doit être bien organisée, cohérente et mise à jour régulièrement. Tout l’enjeu d’une bonne BDD est de centraliser les données constamment tout en les gardant les plus à jour possibles dans un environnement intégralement sécurisé et structuré.
Construire sa BDD implique de déterminer les objectifs, identifier les sources des données et adopter la solution logicielle adéquate à ses besoins.
Pour commencer, c’est quoi une base de données clients ?
Définition d’une base de données clients
Une base de données clients est un système servant à stocker et à organiser de manière structurée les données clients de l’entreprise.
Mais qu’est-ce que sont concrètement les données clients ? C’est ce que nous allons voir maintenant. Un peu plus loin dans l’article, nous vous présenterons les principaux systèmes possibles pour organiser ces données clients et construire votre base de données clients.
Parce qu’on définit aussi une chose par sa finalité, une BDD clients a deux types d’usage principaux étant :
L’analyse / la Business Intelligence / la connaissance client : la finalité principale d’une BDD client est de mieux connaître ses clients. Entre autre, les données de la BDD servent à alimenter des reportings, qui peuvent avoir des fins stratégiques / business mais aussi comptables / financières / juridiques…
L’activation : une BDD Clients peut être utilisée par les équipes marketing, les commerciaux, le service client pour personnaliser les actions, mieux cibler les clients et ainsi être plus compétitif.
Quelles données contient une BDD Client ?
Comme vous pouvez l’imaginer, les données clients incluent l’ensemble des données liées au profil de chaque client. Par exemple, une entreprise connait les données minimum requises comme le nom, le prénom, l’âge, le sexe, l’email, l’adresse et le téléphone de chaque client. Pourtant, les données clients sont beaucoup plus riches que des simples données personnelles ou de contact comme celles-ci, car les données clients incluent aussi l’ensemble des données transactionnelles (historiques d’achats, informations de facturation, etc.), les données d’engagement web / marketing de chaque client et bien d’autres encore.
En bref, les données clients sont l’ensemble de données qui, combinées, permettent d’avoir une compréhension précise et solide de chaque consommateur (profil, comportement d’achat, parcours client…). Pour avoir les idées un peu plus au clair, on peut regrouper ces types de données en plusieurs familles :
Type de données
Présentation
Exemples de données
Données de profil
Ensemble de données qui sont utilisées pour reconnaître un individu
Ces données peuvent inclure des informations personnelles (nom, adresse, sexe), démographiques (localisation, profession, revenu) ainsi que ses centres d'intérêts et hobbies
Les données de profil sont en général les premières données qu'une entreprise récupère sur ses clients
Age
Adresse email
Date de naissance
Données d’engagement
Ensemble des données qui permettent de savoir comment vos clients interagissent avec votre marque via les différents points de contact de leur parcours.
Ces données révèlent à quel point le client est réactif sur les différents points de contact.
Elles permettent d'avoir une visibilité claire sur votre relation avec chacun d’entre eux.
Visites web
Nombre de post likés
Nombre d'emails ouverts, cliqués...
Données comportementales
Données enregistrées à partir du comportement que le client a face à votre marque (visite du site web / application mobile, clics, ouvertures de mails)
Si cette donnée représente souvent une valeur moindre qu'une donnée transactionnelle (liée à une action moins engageante), elle présente, en revanche, l'intérêt d'être collectée plus tôt dans le parcours client.
Elles permettent de traduire l'intérêt que le client montre à votre marque.
Comportement "on site" : pages consultées, durée des sessions, ajouts au panier, clics...
Si on a surtout parlé de données clients B2C jusqu’ici, il est important de garder en tête que la typologie B2B est assez différente. En B2B, on distingue deux niveaux : le client-entreprise et le client-interlocuteur dans l’entreprise. Les données clients relatives à l’entreprise, aussi communément appelées « données firmographiques », sont une spécificité du B2B et incluent des informations comme le SIRET, l’effectif salarié, les données financières, le secteur d’activité, etc. Bref toutes les infos qui permettent de qualifier une entreprise.
Les caractéristiques d’une bonne base de données clients
Pour considérer qu’une BDD est solide, elle doit remplir les critères suivants :
La complétude : pour maximiser la pertinence de votre BDD, vous devez d’abord vous assurer de bien identifier les champs dont vous aurez besoin . Ces champs peuvent inclure, par exemple, des informations telles que le nom, l’adresse e-mail, l’adresse postale, le numéro de téléphone, l’âge, le sexe, le domaine d’activité, etc. Assurez-vous ensuite de bien les compléter afin de bien cerner le profil de chaque client.
La vision clients unifiée : intrinsèquement liée à la complétude des informations clients, une vision clients unifiée implique la constitution des fiches clients 360. Dans ce contexte, la BDD doit centraliser le maximum de données clients (indice de complétude) mais de façon intelligente et ordonnée (gare aux doublons !). Ainsi, n’importe quelle équipe de votre entreprise pourra accéder et utiliser rapidement l’ensemble des informations collectées sur le client pour personnaliser au mieux le service.
La propreté : pour être exploitables, les données doivent être régulièrement mises à jour et nettoyées. Il faut également faire attention au format qui doit être uniformisé pour chaque catégorie. La propreté passe également par la cohérence entre les informations : vos données ne doivent pas entrer en conflit en présentant par exemple des informations contradictoires.
L’exploitabilité : que ce soit pour faire des analyses ou améliorer la relation clients, l’intérêt d’une BDD clients réside dans ce qu’on en fait. Cela implique donc une interface user-friendly, adaptée pour les utilisateurs métiers (préférer ici une Customer Data Platfom à un data lake) avec une segmentation de données bien réfléchie (par exemple, par zone géographique, par centre d’intérêt, etc.). L’exploitabilité de la BDD passe également par la mise en place de flux / connecteurs entre la BDD et les outils utilisés par les équipes.
La sécurité : bien gérer sa BDD réside également dans la bonne gestion de son accès. Les droits d’accès utilisateurs doivent être accordés uniquement aux équipes susceptibles d’en avoir besoin. Par ailleurs, des mesures doivent être mises en place pour lutter contre la perte et la fuite de données, mais également pour analyser régulièrement le niveau de qualité des données.
Le respect des règlementations : une base de données étant, par définition, un nid d’informations personnelles sur ses clients, elles se doivent de respecter les différentes réglementations portant sur les données personnelles comme la Loi Informatique et Libertés (LIL) et le Règlement général sur les données personnelles (RGPD).
Votre BDD réunit toutes ces caractéristiques ? Il ne vous reste plus qu’à l’exploiter intelligemment pour en récolter les fruits !
Comment centraliser la quasi totalité des données clients ?
Dans un contexte d’explosion des données comportementales web, beaucoup d’entreprises peinent à articuler intelligemment ces données et ensuite les exploiter.
L’idée de la centralisation des données est donc de donner une vision exhaustive de chaque client, afin de mettre en place les actions marketing les plus pertinentes possibles et adapter son discours en fonction de leurs préférences / intérêts / comportements d’achat.
Pour centraliser intelligemment ses données, il suffit de :
Déterminer le périmètre de ses données : chaque entreprise brassant un nombre colossal de données internes, externes, privées et publiques, la première étape est donc d’identifier toutes les sources disséminées au sein de l’organisation. Ces silos de données peuvent prendre la forme de logiciels CRM et ERP, de systèmes hérités ou encore de tableurs.
Articuler la gestion des données autour d’objectifs concrets : pour éviter de se laisser submerger par la quantité de données disponibles, il est en général recommandé de déterminer au préalable les enjeux professionnels que vous souhaitez atteindre et les problèmes que vous souhaitez résoudre.
Fédérer ses collaborateurs : le succès d’une stratégie de gestion des données passe par la mobilisation des équipes à tous les niveaux. La gestion des données n’étant plus le domaine réservé des services informatiques et financiers, vous devez sensibiliser vos collaborateurs à la qualité des données puisque ce seront eux qui collecteront et exploiteront au quotidien ces données.
Si les logiciels CRM ont longtemps été incapables de gérer les données issues du digital, les Customer Data Platforms se sont positionnées comme une alternative pertinente et complète.
Comment créer une vision clients unifiée ?
On entend concrètement par une « vision clients unifiée » :
La capacité à dédupliquer / dédoublonner les données importées des différences sources de l’entreprise (les interactions des clients avec votre entreprise, les données de navigation sur votre site web, les interactions sur les réseaux sociaux, les transactions d’achat, les données de comportement, etc.).
La capacité à pouvoir visualiser simplement, dans une fiche client, et exploiter l’ensemble des données relatives à un client.
On peut trouver ci-dessous un exemple de fiche client 360 qui permet de comprendre parfaitement le profil d’un client en un clic :
Dans le cas où vous avez plusieurs systèmes hétérogènes, il existe des solutions pour assurer l’unification de vos données clients :
Choisir les produits d’un même éditeur, de sorte que tous les programmes soient intégrés nativement.
Développer votre propre code pour forcer les systèmes à communiquer entre eux.
Utiliser des interfaces de programmation d’application (API) : ces solutions permettent à deux sources de données hétérogènes de se « parler » le même langage informatique, afin d’échanger des informations sans avoir à copier des données.
Chaque approche a ses avantages et ses inconvénients : le tout est de savoir laquelle vous conviendra le mieux en fonction du profil de votre entreprise et de l’industrie dans laquelle elle évolue.
Comment assurer la data quality dans le temps ?
Assurer la data quality de sa BDD, c’est tout sauf sorcier ! Comme mentionné plus haut, une bonne BDD centralise des données à jour, pertinentes et cohérentes.
Pour assurer la data quality de sa BDD dans le temps, il suffit donc de la maintenir régulièrement à jour. Les données, par définition, se détériorent pour l’essentiel d’entres elles avec le temps : certaines deviennent obsolètes. Par exemple, un client n’aura pas forcément les mêmes centres d’intérêt à 20 ans qu’à 40 ans !
Pour assurer cette mise à jour régulière de ses données, privilégiez la mise en place d’un process rigoureux pour maintenir l’exploitabilité de votre BDD clients.
Assurer la data quality de sa BDD implique donc deux choses : un process permettant son exploitabilité, ainsi que des outils permettant de la nettoyer régulièrement.
Comment limiter la dépendance aux profils tech pour modifier la BDD ?
Pendant longtemps, la gestion d’une BDD était compliquée, dû au fait que celle-ci était maintenue par la DSI (Direction des Services d’Information). Ainsi, l’accès aux données par les différentes équipes était compliqué, ce qui rendait le système très lent et peu user-friendly.
Aujourd’hui, les nouvelles technologies permettent de déléguer la gestion d’une BDD aux utilisateurs métier (marketing, sales, etc.), grâce à l’avènement de BDD no code / low code, avec notamment l’émergence de Customer Data Platforms. Si les paramétrages initiaux se font encore par la DSI / l’IT, sa gestion quotidienne est assurée par les utilisateurs métier qui deviennent ainsi autonomes dans la manipulation des données.
Ce nouveau système permet donc une exploitation optimisée de la BDD !
Comment s’assurer que la BDD est sécurisée tout en facilitant l’exploitation par les équipes marketing ?
Déléguer la gestion d’une BDD aux équipes métier est une bonne chose, car elle permet une plus grande autonomie et donc une plus grande efficacité des utilisateurs métier.
Néanmoins, ceci n’est pas sans risque : qui dit plus de gestionnaires potentiels dit donc un plus grand risque de mauvaises manipulations, de désorganisation de la base, des soucis de cohérence… Pour contrer cela, il s’agit donc de mettre en place des process solides / des gardes fous pour s’assurer que la BDD reste propre, cohérente et sécurisée.
Comment construire une base de données clients ?
La construction d’une base de données clients est en fait assez intuitive. Il suffit, pour cela, de suivre quelques étapes essentielles.
#1 – Définir les objectifs de la BDD Clients
Définir les objectifs de sa BDD Clients est essentiel puisqu’elle permet de déterminer son utilisation future. Par conséquent, les objectifs détermineront les données à collecter et les actions à entreprendre pour ce faire.
Les objectifs de la BDD client peuvent être variés, mais ils ont tous en commun l’objectif final d’améliorer et de développer les relations avec les clients. Pour identifier ces objectifs, on peut envisager de déterminer :
Les objectifs globaux de l’entreprise : pour être efficace, la BDD client doit être alignée avec les objectifs globaux de l’entreprise. Il est donc important de déterminer les objectifs généraux de l’entreprise (augmentation des ventes, amélioration du service client, etc.).
Les objectifs spécifiques de la BDD client, qui doivent être liés aux objectifs globaux. Par exemple, l’objectif spécifique pourrait être d’augmenter la fidélité des clients en améliorant leur expérience d’achat.
Les critères de la BDD client : on entend par « critères » les informations à collecter pour alimenter la BDD client. Ils peuvent inclure des informations de base telles que le nom, l’adresse et l’adresse e-mail du client, ou des informations plus détaillées telles que les achats précédents du client ou ses préférences.
Lorsque l’on fixe les objectifs de sa BDD client future, il est aussi important de se poser quelques questions comme :
Quoi : quels indicateurs de performance vais-je regarder ? (taux de conversion, NPS, taux de réachat…)
Quand : sur quels points de contacts vais-je interroger mes clients ? (en sortie de site, sur les pages produits…)
Qui : quelles sont les données dont je vais avoir besoin ? (URL de la page, ID client, magasin concerné…)
Comment : quel dispositif vais-je mettre en oeuvre afin de collecter ces données ? (questionnaire post-achat, pop-in en sortie de site, questionnaire post-contact…
#2 – Définir les données qu’elle va accueillir / les sources de données
Une fois les objectifs identifiés, il est important de définir les sources de données pour les collecter de manière efficace. Parmi les sources, on peut imaginer des formulaires en ligne, des bons de commandes, des jeux concours, des enquêtes, etc.
De manière générale, pour obtenir des informations sur vos clients, il vous faut être proactif. Le recueil de données doit être fait soit discrètement, soit avec incitation mais toujours avec discernement. Si vous communiquez un sondage à un client afin de mieux le connaitre, gardez à l’esprit que vous êtes en train de lui demander quelque chose. Préférez alors une formulation agréable pour votre client, comme par exemple : « Afin que nous puissions en apprendre davantage sur vous et vous fournir un service plus adapté à vos besoins personnels, veuillez remplir… ». Vous pouvez également envisager d’offrir une réduction sur leur prochain achat à vos clients récurrents s’ils remplissent votre enquête ou participent à votre jeu concours.
Les sources sont multiples, il faut juste savoir comment bien les utiliser !
#3 – Choisir une solution logicielle adaptée
Savoir reconnaitre une solution logicielle adaptée à vos besoins n’est pas toujours chose facile. Pour vous faciliter la tache, nous vous conseillons de prendre en compte ces quelques critères de base :
La notoriété de la plateforme, qui donnera un indicateur sur ses performances.
La pertinence et la richesse des fonctionnalités de base de données clients en fonction de vos objectifs et de l’industrie dans laquelle votre entreprise s’inscrit.
La facilité d’utilisation de l’outil (ergonomie, graphisme).
La possibilité de se connecter depuis différents appareils : ordinateur, tablette, smartphone…
Encore un peu perdu ? Voici d’autres critères un peu plus poussés qui pourront vous aiguiller dans votre choix :
L’évolutivité de la plateforme : plus vous collectez de données clients, plus votre entreprise se développe et vos besoins évoluent. Assurez-vous que la solution choisie puisse se synchroniser et s’intégrer avec d’autres outils essentiels au développement de votre activité. Une solution basée sur le Cloud est souvent recommandée.
La protection de vos données : assurez-vous que le logiciel de base de données clients propose un système de gestion des droits d’accès et plusieurs méthodes de protection des données (suppression automatique en cas de piratage, sauvegarde automatique…).
La cohérence de vos données et la facilité de leur utilisation : vous serez amené à collecter différentes données provenant de différentes sources, il faut que le logiciel choisi puisse les supporter.
Nous reviendrons un peu plus tard dans l’article sur les différents logiciels disponibles pour la tenue de sa BDD clients.
#4 – Connecter les sources de données à la BDD pour faire remonter les données dans la BDD
L’un des enjeux principaux d’une bonne BDD est de centraliser l’ensemble des informations provenant de sources multiples.
Après avoir extrait des données pertinentes, il vous faut choisir une méthode d’intégration de ces données avant de les connecter à la BDD. Les méthodes peuvent varier en fonction du système utilisé pour stocker la BDD et des fonctionnalités disponibles. Parmi les méthodes que l’on retrouve couramment, on peut envisager l’utilisation d’une API (Application Programming Interface soit une interface de programmation), l’importation de fichiers CSV ou encore l’intégration avec des outils ETL (Extract, Transform, Load).
Une fois la méthode d’intégration choisie, connectez les sources de données à la BDD. Cela implique généralement la configuration des paramètres de connexion, tels que l’adresse IP, le nom d’utilisateur, le mot de passe, les clés d’API, etc.
Il ne vous reste plus qu’à importer les données extraites dans la BDD !
#5 – Normaliser et dédupliquer les données
Pour qu’une BDD soit pertinente, il faut à tout prix éviter les doublons et nettoyer un maximum ses données car les informations erronées peuvent vous couter très cher ! Selon Forbes, les données « polluées » coûtent aux entreprises 12% de leur chiffre d’affaires global, soit environ 3.1 billions de dollars par an…
C’est pourquoi, il vous faut étudier régulièrement les données que votre entreprise collecte. Déterminez quelles sont celles que vous utilisez vraiment. Déterminez ensuite celles qui manquent, celles qui ne vous servent pas, et identifiez comment vos données peuvent être polluées.
Avez-vous des champs obsolètes dans de nombreuses entrées ? Avez-vous beaucoup de doublons ? Supprimez-le ! Assurez-vous que les fondements de votre base de données clients ne soient pas erronés afin de ne pas construire votre connaissance clients sur de mauvaises bases !
Si vous souhaitez en savoir plus sur comment nettoyer correctement sa base de données clients, n’hésitez pas à jeter un oeil à notre guide dédié à ce sujet.
#6 – Structurer le modèle de données : la manière dont les données vont s’organiser dans la BDD : les champs, les colonnes, les tables…
La clé d’une BDD saine est l’organisation. Une BDD désorganisée est une BDD illisible, opaque et donc peu user-friendly, surtout lorsqu’elle contient plusieurs dizaines de leads.
Ce faisant, optez pour une base de données segmentée et organisée autour des caractéristiques qui vont permettre de bien connaitre et comprendre les particularités, les besoins et les centres d’intérêts de chaque client. Cette organisation est primordiale puisqu’elle permettra d’identifier plus rapidement les contacts et ainsi mener des opérations de communication ciblées !
Enfin, petite précision qui semble négligeable mais qui fait une grande différence : prenez garde au format de chaque catégorie. Veillez à bien respecter le format afin de garder une lecture aussi limpide que possible.
#7 – Mettre en place des process et règles d’utilisation pour garantir sécurité et santé de la BDD
Une BDD est une mine d’or si elle est toutefois bien gérée. Du fait de la multiplicité des acteurs susceptibles de l’utiliser (utilisateurs métier), de la variété des informations ainsi que de la mise à jour quotidienne nécessaire de ces données, la base de données clients nécessite une politique d’utilisation stricte pour garantie sa sécurité et sa pertinence.
C’est pourquoi, on peut envisager :
De définir en premier lieu les politiques de sécurité qui régissent son accès et son utilisation. Cela peut inclure l’accès restreint aux utilisateurs autorisés, l’utilisation de mots de passe forts, la limitation des privilèges d’accès en fonction des rôles et des responsabilités, etc. Ces politiques visent à protéger les données clients contre les accès non autorisés et les atteintes à la confidentialité.
De gérer les droits d’accès : vous devez mettre en place un système de gestion des droits d’accès qui permet de contrôler qui peut accéder à la base de données et quelles actions ils peuvent effectuer. Cela peut impliquer la création de profils utilisateur avec des autorisations spécifiques ainsi que la définition de rôles et de groupes d’utilisateurs.
De sauvegarder régulièrement les données en créant des copies de sauvegarde et les stocker dans des emplacements sécurisés. Testez régulièrement les procédures de récupération pour vous assurer qu’elles fonctionnent correctement. Envisagez de faire également des mises à jour régulières de votre BDD.
Et voilà, il ne vous reste plus qu’à récolter les fruits de votre travail ! A ce propos, n’hésitez pas à établir des indicateurs de performance pour mesurer l’efficacité de votre BDD. Votre taux de conversion a augmenté ? Vous avez obtenu de nouveaux clients ? Tant mieux ! Votre service client ne s’est pas suffisamment amélioré ? Laissez-vous peut-être encore un peu de temps ou revisitez votre BDD pour la rendre plus pertinente…!
Zoom sur les logiciels de bases de données clients
S’il existe une multitude de logiciels de bases de données clients, toutes ne sont pas nécessairement pertinentes : certaines sont plus adaptées aux entreprises nouvellement créées, tandis que d’autres sont particulièrement appréciées par les grandes entreprises. Par exemple, une entreprise fraichement créée a peu de clients et donc peu de data : on peut donc envisager de construire sa BDD clients sur Excel.
Malheureusement, Excel montre vite des limites. S’ouvrent alors plusieurs options :
Un logiciel CRM : hyper utilisé depuis les années 1990 par les entreprises pour gérer leurs données clients, les CRM permettaient de centraliser efficacement toutes ces données sur une même plateforme. Le CRM reste un outil traditionnel pour la gestion d’une BDD clients.
Un logiciel CDP : apparus dans un contexte de digitalisation massive des parcours clients et l’explosion des volumes de données web/comportementales que les logiciels CRM ne savaient pas gérer, les CDP ont connu un fort intérêt depuis le milieu des années 2010. Leur point fort ? Ils permettent la construction d’une BDD Clients 360 en offrant la capacité de centraliser et unifier à la fois les données offline (transactionnelles notamment) et online (données du site web notamment).
Un Data Warehouse : bien qu’elles existent depuis longtemps, la nouvelle génération de Data Warehouse apparue dans les années 2010 a permis un regain d’intérêt pour cet outil. Très concrètement, les DW offrent une approche moderne dans la gestion d’une BDD Clients, en combinant un Data Warehouse (pour le stockage) et un outil de Data Ops (pour le traitement des données) qui peut, par ailleurs, être une CDP (comme Octolis).
Si vous souhaitez en savoir plus sur l’évolution de ces outils dans la gestion de données clients, n’hésitez pas à jeter un œil à notre guide complet dédié à ce sujet.
Les logiciels CRM
De l’anglais Customer Relationship Management, un logiciel de CRM est une boîte à outils vous permettant de gérer au mieux votre base de données clients. Concrètement, cet outil vous permet de comprendre la relation que chaque client a avec votre marque et par conséquent optimiser la qualité de la relation client, ainsi que des outils marketing précieux pour fidéliser sa clientèle et maximiser son chiffre d’affaires.
Historiquement outil de référence pour la centralisation de données clients, le logiciel CRM représente pour les équipes commerciales, marketing et service client un gain en temps et en efficacité considérable !
Logo
Présentation
Cette pépite française a développé en quelques années une suite marketing complète grâce à un excellent rapport qualité / prix. La plateforme Brevo, anciennement appelée SendinBlue, comporte une solution de campagnes Email / SMS, un module de Marketing Automation très complet, un module Landing page, etc.
Splio est un CRM marketing très orienté retail. Made in France, Splio est bon aussi bien sur la partie gestion de base de données que sur la partie activation des données (campagnes, automation). L'outil propose des campagnes marketing et de fidélisation centralisées et est excellent quant au développement de l'engagement client.
Lancé en 2000 par une équipe belge, Actito est un logiciel CRM marketing qui s’adresse essentiellement aux PME et aux ETI. Très complet, Actito présente les 4 fonctionnalités clés des CRM marketing : la base de données, la gestion de campagnes marketing, l’automation et le reporting. Il propose une interface intuitive ainsi que de nombreuses intégrations supplémentaires.
Lancé au début des années 2000, Emarsys est un CRM marketing destiné principalement aux acteurs du e-commerce et du Retail en général. Il permet de créer des campagnes marketing omnicanales et de créer des scenarios complexes de Marketing Automation basés sur le comportement des clients en ligne. Le logiciel se démarque par son interface intuitive ainsi que son moteur de recommandation puissant.
Fondée en Belgique en 1990, Selligent s’adresse aux grandes entreprises, notamment dans les secteurs du tourisme, de l’automobile, de l’édition et des services financiers. Le logiciel excelle aussi bien sur le volet base de données que sur les fonctionnalités de gestion de campagnes et de reporting CRM. Le logiciel est unique pour son moteur d'IA proposant de nombreuses recommandations ainsi que son outil de retargeting comportemental avancé.
Les Customer Data Platforms (CDP)
Dans la même logique que le CRM, la Customer Data Platform (CDP) désigne une solution marketing centralisée qui récolte, unifie et rend accessible les données client (identitaires, comportementales, transactionnelles) issues de différents outils et canaux de contact.
Contrairement au CRM, les solutions CDP vous permettent d’avoir une vue d’ensemble de la manière dont la totalité des clientset plateformes interagissent avec votre marque. Les plateformes CDP suivent le comportement général des clients afin de déterminer comment les audiences et segments interagissent avec votre marque, et vous donnent ainsi une idée du parcours client dans son intégralité.
En traitant, en nettoyant et en contextualisant les données en temps réel, la CDP leur donne un sens. Elle construit des profils clients précis, cohérents et complets dans une base de données accessible aux différentes équipes de l’entreprise, qui profitent d’une data toujours plus pertinente et exploitable pour optimiser leurs futures actions de marketing ou de vente !
Logo
Présentation
Solution Bordelaise fondée en 1999, NP6 a évolué en une véritable Customer Data Platform (CDP) afin de proposer une plateforme unique permettant d’harmoniser le dialogue client sur tous les canaux. Elle combine unification des données clients, marketing automation et activation cross-canal.
Fondée en 2021, Octolis est une Customer Data Platform orientée Data Management, dont les fonctionnalités les plus avancées sont celles relatives à la préparation des données : normalisation, déduplication, scoring… Elle s'adresse aux PME souhaitant passer d’un marketing multicanal à un marketing omnicanal.
Lancée en 2020, la solution CDP d'Oracle, très orientée Data Management, est destinée aussi bien aux organisations B2B qu’aux organisations B2C. Le logiciel offre des fonctionnalités de Data Management puissantes (unification, segmentation, scoring), un modèle de données très souple et user-friendly, des algorithmes d’intelligence artificielle (IA) solides ainsi que de nombreuses autres fonctionnalités.
Editeur implanté de longue date en Asie, Insider a développé une CDP qui vient en support des solutions d’orchestration de l’expérience client qu'il propose. La CDP s'adresse en priorité aux grands groupes et offre des fonctionnalités d'activation avancées, une excellente gestion du mobile et des réseaux sociaux, ainsi qu'une très bonne gestion du temps réel et des données web.
Lancée en 2019, la CDP d'Adobe propose aux ETI et grandes entreprises une gestion en temps réel des données à l'aide d'une plateforme ouverte, API-first et capable de se connecter à n’importe quel système tiers. Cette CDP vise en priorité les clients B2C ou B2B, ayant une bonne maturité en matière de gestion des données et de pratique marketing-ventes.
Les Data Warehouses
Dans le même état d’esprit qu’une CDP, un Data Warehouse, « entrepôt de données » en français, permet de collecter et conserver les informations de toute une société. On lui trouve quatre caractéristiques propres :
L’orientation sujet : les données sont classées et définies par domaine et thème, et il est ainsi plus simple de rechercher un sujet désiré dans la base.
L’intégration de données : on parle ici d’ETL (extract, transform and load) c’est-à-dire d’extraction (sortir les données de la plateforme pour les analyser), de transformation (nettoyer les données) ou encore de chargement (insertion des données). Grosso modo, il s’agit de manier les informations au sein de la base.
Leur caractère non-volatile : une fois inscrite dans la base de données, l’information est immuable et ne peut pas être modifiée.
Leur attrait « time-variant » : le Data Warehouse se concentre et analyse les transformations temporelles, pour ainsi déceler et mettre en avant les grandes tendances.
Plus simplement, le système Data Warehouse permet d’étudier et comparer les informations passées et présentes de l’entreprise. Par rapport à une CDP, le Data Warehouse vous permettra d’adopter une vue d’ensemble de l’organisation et se prête ainsi plus à une veille stratégique. Cependant, un DW n’est pas actualisé et mis à jour en temps réel comme une CDP et peut donc être moins efficace concernant l’analyse des données clients. C’est pourquoi il peut être intéressant d’ajouter les services d’une CDP légère comme Octolis !
Outils
Présentation
Data Warehouse proposée sous la forme d’un SaaS, Snowflake propose une grande flexibilité liée au Cloud permettant une gestion et un partage facile de données en temps réel et en toute sécurité, sur n'importe quel format. La DW offre de nombreuses fonctionnalités liées au stockage de base de données, au traitement de requêtes, et aux services Cloud.
En tant que solution Google prête à l'emploi, BigQuery est facile d'utilisation grâce à son intégration avec les autres services de Google et sa forte capacité d'analyse. La solution offre des prédictions, des perspectives et des fonctions d'intelligence, faisant d'elle une solution évolutive et viable à long terme.
Infrastructure Microsoft lancée en 2018, ce Data Warehouse cloud est adapté aux organisations qui recherchent un accès facile aux solutions d'entrepôt de données, grâce à son intégration intuitive avec Microsoft SQL Server. La plateforme offre en plus de l'entreposage de données d'entreprise, une plateforme d'analyse unifiée, le choix du langage pour interroger les données et la surveillance des données de bout en bout.
Lancée en 2012, la partie Data Warehouse d'Amazon propose un excellent rapport qualité-prix pour l'entreposage de données dans le cloud.
La solution utilise un matériel conçu par AWS et le machine learning pour offrir le meilleur rendement réel, quelle que soit l'échelle.
Favori parmi les ingénieurs et les analystes de données, Firebolt offre une grande vitesse d'exécution et une grande performance face à un volume conséquent de données. Conçu pour une utilisation moderne, Firebolt peut traiter des données semi-structurées, et son architecture de stockage et de calcul découplée le rend facilement évolutif.
Conclusion
Comme vous avez pu le constater, gérer une base de données clients est une chose, savoir faire le bons choix en fonction de ses besoins en est une autre !
Une BDD client regroupe un ensemble de données complètes sur chacun de vos clients et permet d’avoir une vision 360.
Cette forte connaissance client vous permet alors d’améliorer considérablement votre service client, mieux cibler vos campagnes marketing et personnaliser d’autant plus l’expérience d’achat. Cela se traduit en général par une plus forte fidélisation des clients et un chiffre d’affaires boosté.
Créer sa base de données clients nécessite de la rigueur dans la détermination des objectifs, des sources, le choix de la solution logicielle et sa structure globale. L’entretien, la sécurisation et la mise à jour des données sont également essentiels pour garder une BDD pertinente et exploitable.
Une solution intelligente et adoptée par de plus en plus d’entreprises est d’utiliser une Data Warehouse, complétée d’une CDP légère comme Octolis.
Zoom sur 15+ exemples de segmentation marketing | Ressource à télécharger
Le succès d’une entreprise dépend largement de sa capacité à comprendre et à satisfaire les besoins de ses clients. Or, pour comprendre ses clients, il faut bien les connaître et les distinguer, ce que permet précisément la segmentation marketing, qui est donc essentielle pour toute stratégie commerciale efficace.
Pour rappel, la segmentation marketing permet de diviser le marché en groupes homogènes de consommateurs ayant des besoins et des comportements similaires, afin de mieux cibler ses actions marketing.
Mais comment réussir à segmenter efficacement son marché ? C’est là que notre ressource entre en jeu ! Nous avons conçu une ressource présentant en détail les principaux modèles de segmentation marketing.
Grâce à cette ressource, vous pourrez découvrir les différentes méthodes de segmentation et choisir celle qui convient le mieux à votre entreprise. Vous y trouverez également des conseils pratiques pour mettre en place votre stratégie de segmentation et atteindre vos objectifs marketing, alors ne manquez surtout pas cette opportunité de booster vos ventes et de fidéliser votre clientèle en réussissant votre segmentation !
L’essentiel à retenir sur la segmentation marketing
Pour vous rafraîchir la mémoire, voici l’essentiel à savoir sur la segmentation marketing:
La segmentation marketing consiste à diviser un marché en groupes homogènes de consommateurs ayant des besoins et des comportements similaires, afin de mieux cibler les actions marketing.
Les bénéfices de la segmentation marketing sont nombreux : une meilleure compréhension des besoins des clients, une personnalisation plus efficace des offres, une augmentation de la satisfaction et de la fidélité des clients, une réduction des coûts marketing, etc.
Il existe plusieurs modèles de segmentation marketing, tels que la segmentation géographique, démographique, comportementale, psychographique, etc. Nous les décrivons en détail dans notre article.
Pour réussir sa stratégie de segmentation marketing, il est important de bien définir ses critères de segmentation, d’adapter son offre à chaque segment, de mesurer les résultats et de faire évoluer sa stratégie en fonction des feedbacks clients.
Si vous souhaitez en savoir plus sur la segmentation marketing et découvrir comment l’appliquer à votre entreprise, téléchargez notre ressource présentant les principaux modèles de segmentation marketing et les conseils pratiques pour réussir votre stratégie.
Qu’est ce qu’une segmentation marketing ? [Définition]
La segmentation marketing est l’art de segmenter sa base clients à des fins de ciblage marketing.
C’est est une technique qui permet de diviser un marché en plusieurs segments homogènes, regroupant des consommateurs ayant des besoins, des attentes et des comportements similaires. Cette approche permet aux entreprises de mieux comprendre les caractéristiques de chaque segment et de développer des offres adaptées à leurs besoins spécifiques.
En d’autres termes, la segmentation marketing est l’art de personnaliser ses actions marketing en fonction des différentes caractéristiques des clients. Cela peut inclure des critères tels que l’âge, le sexe, le niveau de revenu, la localisation géographique, les centres d’intérêt, le comportement d’achat, etc. L’objectif final est de maximiser la pertinence et l’efficacité des messages marketing en proposant des offres qui répondent de manière ciblée aux besoins de chaque segment.
Pourquoi faire de la segmentation marketing ?
Voici 5 principaux bénéfices de la segmentation marketing, illustrés pour deux types d’entreprises différentes :
#1 Pour mieux comprendre vos clients
La segmentation marketing permet aux entreprises de mieux comprendre les besoins de leurs clients et d’adapter leurs offres en conséquence. Pour une entreprise de mode, par exemple, la segmentation en fonction de l’âge et du sexe permettrait de proposer des vêtements adaptés aux goûts et aux besoins de chaque segment.
Pour une entreprise de vente en ligne, la segmentation en fonction des comportements d’achat permettrait de proposer des produits complémentaires ou des offres promotionnelles personnalisées.
#2 Pour personnaliser plus efficacement vos offres
En segmentant leur marché, les entreprises peuvent proposer des offres personnalisées et mieux ciblées à chaque segment. Pour une entreprise de restauration, par exemple, la segmentation en fonction des centres d’intérêt (végétariens, amateurs de cuisine épicée, etc.) permettrait de proposer des menus adaptés à chaque groupe de clients.
Pour une entreprise de cosmétiques, la segmentation en fonction des types de peau permettrait de proposer des produits spécifiques répondant aux besoins de chaque segment.
#3 Pour augmenter la satisfaction et la fidélité de vos clients
La segmentation marketing permet de proposer des offres personnalisées et adaptées aux besoins de chaque segment, ce qui augmente la satisfaction et la fidélité des clients. Pour une entreprise de loisirs, par exemple, la segmentation en fonction des centres d’intérêt (sports, musique, arts, etc.) permettrait de proposer des activités qui correspondent aux goûts de chaque segment, augmentant ainsi leur satisfaction et leur fidélité à long terme.
Pour une entreprise de services financiers, la segmentation en fonction des niveaux de revenus et des besoins en matière d’investissement permettrait de proposer des offres adaptées à chaque segment, augmentant ainsi leur satisfaction et leur fidélité.
#4 Pour réduire les coûts marketing
La segmentation marketing permet de mieux cibler les actions marketing, ce qui réduit les coûts liés aux campagnes publicitaires.
Pour une entreprise de e-commerce, par exemple, la segmentation en fonction des comportements d’achat permettrait de cibler des offres promotionnelles uniquement aux segments les plus susceptibles de convertir, réduisant ainsi les coûts de publicité inutiles.
Pour une entreprise de tourisme, la segmentation en fonction de la localisation géographique permettrait de cibler des publicités spécifiques à chaque marché, réduisant ainsi les coûts publicitaires inutiles.
#5 Pour augmenter les ventes et vos revenus
En proposant des offres personnalisées et mieux ciblées, la segmentation marketing permet d’augmenter les ventes et les profits de l’entreprise.
Pour une entreprise de téléphonie mobile, par exemple, la segmentation en fonction des niveaux d’utilisation permettrait de proposer des forfaits adaptés à chaque segment, augmentant ainsi le nombre de clients et les revenus de l’entreprise.
Pour une entreprise de bijouterie, la segmentation en fonction des occasions d’achat (mariage, anniversaire, etc.) permettrait de proposer des offres adaptées à chaque segment, augmentant ainsi les ventes et les profits.
La segmentation RFM consiste à classer les clients en groupes en fonction de la récence de leur dernier achat, de la fréquence de leurs achats, et de leur montant total dépensé.
Cela permet d’ identifier les clients les plus rentables pour l’entreprise et de cibler efficacement les campagnes marketing pour maximiser les résultats.
Comment fonctionne le framework RFM ?
Le framework RFM est basée sur trois critères : la récence (R) du dernier achat, la fréquence (F) des achats et le montant (M) des dépenses. Il permet de classer les clients en groupes en fonction de leur comportement d’achat.
Comment utiliser le framework RFM ?
Les 3 dimensions du framework RFM sont :
Récence (Recency) : Cette dimension mesure la période de temps écoulée depuis le dernier achat d’un client. Les clients plus récents sont généralement considérés comme plus engagés et plus susceptibles de réaliser de nouveaux achats.
Fréquence (Frequency) : Cette dimension évalue la fréquence d’achat d’un client sur une période donnée. Les clients qui achètent fréquemment sont considérés comme plus fidèles et peuvent nécessiter une approche marketing différente de ceux qui achètent moins souvent.
Montant (Monetary) : Cette dimension examine le montant total dépensé par un client sur une période donnée. Les clients qui dépensent davantage peuvent être considérés comme des clients à valeur élevée et peuvent justifier des stratégies de fidélisation spécifiques.
En combinant ces trois dimensions, vous pouvez créer des segments RFM pour mieux comprendre le comportement de vos clients et adapter vos stratégies marketing en conséquence.
Exemple d’utilisation
Dans le cadre de réactivation de clients passifs, c’est l’une des méthodes les plus utilisées pour créer un ou plusieurs segments de clients passifs. Chaque segment fait ensuite l’objet d’un scénario de réactivation personnalisé.
#2 La segmentation PMG
La segmentation PMG s’appuie sur la loi de Pareto qui stipule que 20 % de vos clients génèrent 80 % de votre chiffre d’affaires. Il faut donc axer ses efforts en priorité sur cette minorité de clients.
Comment fonctionne le framework PMG ?
Le framework PMG est basée sur trois critères : le profil (P) des clients, leurs motivations (M) d’achat et leurs habitudes de consommation (G). Il permet de regrouper les clients ayant des caractéristiques similaires.
Comment utiliser le framework PMG ?
Pour les gros clients, on peut les transformer en ambassadeurs en les invitant à des ventes privées, en leur demandant leurs avis sur de nouvceaux produits ou en leur faisant des offres de parrainages. Au contraire, pour les petits clients c’est l’occasion de faire revenir les clients ou diversifier leurs achats grâce à des offres promos ciblées.
#3 La segmentation promophilie
La segmentation promophilie évalue la sensibilité aux promotions, en fonction de la proportion d’achats réalisés avec une promotion rapporté à l’ensemble de la base sous la forme de déciles.
Comment utiliser le framework promophilie ?
On parle de clients promophiles pour caractériser les clients qui achètent principalement des produits disposant de remises commerciales. Il peut être très utile d’identifier les promophiles afin de les cibler dans certaines campagnes promotionnelles, ou au contraire de les exclure.
Pour modifier les critères du framework, vous pouvez ajuster le poids des critères comme le volume de remise sur le CA cumulé ou le nombre d’achats avec remise, ou pour calculer ce score uniquement pour les clients ayant réalisé plus de 3 achats.
#4 La segmentation par cycles de vie
La segmentation marketing par cycles de vie consiste à diviser les clients d’une entreprise en groupes en fonction de leur position dans le cycle de vie du produit ou du service offert.
Comment fonctionne le framework cycles de vie ?
Le cycle de vie du client décrit la manière dont les relations avec les clients se renforcent au fil du temps, au fur et à mesure qu’ils envisagent, achètent, utilisent et deviennent fidèles à un produit ou à un service.
Il y a 5 étapes dans la vie du client : le reach, l’acquisition, la conversion, la rétention et la fidélisation.
Comment utiliser le framework cycles de vie ?
On adapte la stratégie marketing à la phase de vie du client :
Ce framework divise les clients en différents champs grâce aux sonnées du service client comme le niveau de satisfation, le nombre tickets sur 3 mois ou les motifs de contacts.
Comment fonctionne le framework satisfaction client ?
On utilise le NPS (Net Promoter Score), qui est un indicateur de fidélisation de la clientèle très répandu qui aide les entreprises à mesurer la satisfaction et la fidélité de leurs clients.
Il est calculé en soustrayant le pourcentage de détracteurs (clients qui ne recommanderaient pas votre marque) du pourcentage de promoteurs (clients qui recommanderaient fortement votre marque).
Comment utiliser le framework satisfaction client ?
Pour les promoteurs : Utilisez vos promoteurs pour créer du contenu généré par les utilisateurs : Encouragez vos promoteurs à partager leurs expériences positives avec votre marque sur les médias sociaux ou d’autres canaux.
Détracteurs : Répondez à leurs préoccupations : Tendez la main aux détracteurs et répondez à leurs préoccupations. Cela vous permet non seulement de fidéliser le client, mais aussi de montrer que vous êtes déterminé à améliorer l’expérience client de votre marque.
#6 La segmentation RFE
La segmentation RFE fonctionne comme un RFM à la différence que les transactions sont remplacés par toutes formes de points de contacts (pages visitées, ouverture email, clic email, ..) auxquels on associe un nombre de points, exemple : +1 ouverture email, +3 visite site web, +5 clic email, etc.
Comment fonctionne le framework RFE ?
Le framework suit la même logique que la segmentation RFM (Récence, Fréquence, Montant), mais on s’intéresse ici à l’Engagement plutôt que le Montant.
L’idée est de considérer chaque interaction client comme l’équivalent d’un achat, et c’est l’intensité de l’engagement qui joue le rôle du montant.
On peut considérer par exemple qu’une ouverture d’email vaut 1, une page visitée vaut 5, etc. Une approche vraiment flexible pour définir les actifs, passifs, inactifs.
Comment utiliser le framework RFE ?
Par exemple, on peut imaginer la démarche suivante :
Pour les petits clients passifs : Vous pouvez créer un scénario de réactivation simple avec 2 messages emails (produits populaires, code promo…).
Pour les petits clients passifs : Vous pouvez créer un scénario de réactivation multicanal avec envoi d’emails, puis retargeting Google / Facebook Ads, puis finir avec un envoi de courrier ou un appel téléphonique sortant.
#7 La segmentation par affinité produits
La segmentation par affinités produits consiste à regrouper les clients en fonction de leur intérêt et de leur comportement d’achat pour des produits similaires ou liés entre eux. Cette segmentation permet aux entreprises de mieux comprendre les préférences et les habitudes d’achat des clients, ce qui leur permet de personnaliser leur marketing et de cibler les offres de produits en fonction des intérêts spécifiques des différents segments.
Comment construire le framework affinité produits ?
La construction d’un modèle de ce type nécessite plusieurs étapes :
Identifier les catégories de produits complémentaires. On construit la matrice ci-contre en excluant les clients ayant réalisé un seul achat.
Mettre en place une matrice de recommandation de catégories. On construit la matrice ci-contre en excluant les clients ayant réalisé un seul achat.
L’objectif est de construire le tableau qui permet de définir pour chaque client, quelles sont les catégories de produits à recommander en fonction des catégories de produits dans lesquelles il a déjà acheté.
La première matrice doit nous servir de base pour ce travail. Si on observe que 30% des clients ayant acheté dans la catégorie A ont aussi acheté un produit de la catégorie C, alors qu’ils sont 5% à avoir acheté dans la catégorie D, on a envie de recommander la catégorie C aux clients ayant acheté dans la catégorie A.
Comment exploiter ce framework ?
L’objectif est la diversification produit : Augmenter le nombre de catégories différentes dans lequel un client a acheté au moins un produit.
On peut aussi le formaliser différemment, l’objectif est d’augmenter la part de clients qui ont acheté au moins un produit dans plus de N catégories.
#8 Segmentation par canal préférentiel
La segmentation par canal préférentiel est principalement pertinente pour les marques omnicanales.
Cette segmentation consite à associer à un client son canal de préférence afin de le pousser vers les autres afin d’en faire un client encore plus fidèle.
Comment fonctionne la segmentation par canal préférentiel ?
Ce framework consiste à classer les clients en groupes en fonction de leur préférence pour un canal de vente en ligne ou en boutique mais également dans quelle boutique.
On va donc identifier :
Les clients web / boutique / mixte
Les clients qui achètent : dans un magasin uniquement ou « multi-boutiques »
Comment utiliser le framework canal préférentiel ?
Vous pouvez utiliser ce framework pour :
Améliorer votre scénario de relance de panier abandonné en y intégrant les achats en magasin. Ne pas envoyer l’email de relance aux clients qui ont finalement acheté en magasin, mais de leur envoyer à la place un email post-transactionnel.
Inciter à l’achat les visiteurs du site web pendant leur recherche sur votre site. Mettre en avant le fait que la livraison est gratuite si c’est le cas, que les retours sont gratuits, si c’est le cas, en améliorant la visibilité des produits qui correspondent aux préférences, habitudes, comportements navigationnels des visiteurs, etc.
#9 La segmentation RFI
La segmentation RFI permet de détecter pour chaque client si celui-ci est en avance, dans les temps ou en retard par rapport à son rythme d’achat individuel.
Comment fonctionne le framework RFI ?
La segmentation RFI ne concerne les clients ayant effectué au moins 3 achats. Et permet d’ajuster ses campagnes marketing en fonction du rythme d’achat du client.
Comment utiliser le framework RFI ?
Vous pouver regrouper les clients en plusieurs segments : achat récent, bientôt atteint, en retard ou en retard important et inactif (voir illustration sur la diapositive suivante).
Cette segmentation est particulièrement efficace pour les catégories de produits consommés de manière récurrente.
Ajustement des critères:
Un client ayant effectué un achat au cours des 7 derniers jours est considéré par défaut comme un achat récent
Un client n’ayant effectué aucun achat au cours des 1 dernières années est inactif.
La segmentation adaptable par département
Garder en tête cette formule générale : “Temps écoulé depuis le dernier achat – temps habituel pour acheter à nouveau, divisé par l’écart type du temps pour acheter à nouveau”
#10 La segmentation par période d’achats préférés
La segmentation par période d’achats préférés consiste à regrouper les clients en fonction de leur tendance à effectuer des achats à des moments spécifiques de l’année ou de la semaine. Cette segmentation vous permet de mieux comprendre les habitudes d’achat saisonnières ou hebdomadaires de vos clients, afin de planifier votre inventaire et votre marketing en conséquence.
Comment fonctionne le framework période d’achat préférée ?
Le framework période d’achat préférée consiste à classer les clients en groupes en fonction des périodes pendant lesquelles ils sont plus enclins à effectuer des achats. Il permet de mieux comprendre les habitudes d’achat des clients et de proposer des offres et des produits qui répondent à leurs besoins.
Comment utiliser le framework période d’achat préférée ?
Vous pouvez par exemple mettre en place 2 types de scores :
Jours d’achats préférés, c’est à dire la liste des jours d’achats qui représentent plus de 30% des achats
Mois d’achats préférés, c’est à dire la liste des mois d’achats qui représentent plus de 30% des achats.
Ensuite vous pouvez prévoir des campagnes pour pousser des offres spécifiques sur les périodes clés et adapter les jours d’envoi des campagnes et préparer des scénarios à visée transactionnelles
#11 La segmentation par niveaux de prix
C’est une segmentation basée sur le montant moyen du panier d’achat. L’évaluation des clients est faite ici en fonction de leur panier moyen, ce qui permet d’adapter les stratégies d’upsell et de cross-sell en fonction des comportements d’achat.
Comment fonctionne le framework niveau de prix ?
Le framework niveau de prix consiste à classer les clients en groupes en fonction de leur préférence pour les produits de différentes gammes de prix. Il permet de mieux comprendre le comportement d’achat des clients en termes de prix et de proposer des offres et des produits qui répondent à leurs besoins.
Comment utiliser le framework niveau de prix ?
La segmentation par classes de niveau de prix moyen vous permet de classer les clients en 4 segments selon le type de montant dépensé pour chaque famille de produits achetée :
Discount
Moyen –
Moyen +
Premium…
Cet indicateur permet donc, par exemple, d’identifier les acheteurs haut de gamme, y compris parmi les segments RFM occasionnels.
L’art de choisir votre segmentation marketing
Il est préférable de se concentrer sur quelques segmentations clés plutôt que d’en utiliser trop. Cela permet de mieux cibler les efforts marketing sur les segments les plus pertinents et les plus rentables pour l’entreprise, et d’éviter de disperser les ressources.
En outre, utiliser trop de segmentations différentes peut rendre les campagnes marketing complexes et difficiles à gérer, et peut conduire à des messages contradictoires ou confus pour les clients.
Les conseils :
Inutile d’utiliser beaucoup de segmentation différentes. Mieux vaut se concentrer sur 1 ou 2 segmentations.
Commencer simple par exemple avec des classiques comme la segmentation PMG / RFM avec peu de segments au début.
Définir les actions possibles sur chaque segment et déterminer les actions à mettre en oeuvre sur chaque segment. Vous pouvez prendre l’exemple de la segmentation RFM, dans cet article, on détaille les actions possibles sur chaque segment RFM :
Suivre les différentes compositions de chaque segment (Il est important de suivre l’évolution de chaque segment de marché car les besoins, les préférences et les comportements des clients peuvent changer au fil du temps, en réponse à des facteurs tels que l’évolution des tendances, des technologies, de la concurrence, ou des conditions économiques), cela suppose d’ailleurs d’avoir une segmentation client dynamique, mise à jour en temps réel, ce que permet de faire Octolis.
Analyser la performance par segment pour mesurer l’impact des actions.
Il est donc important de prendre le temps d’analyser les données disponibles et de réfléchir à la manière dont les différentes segmentations peuvent être utilisées pour atteindre les objectifs de l’entreprise.
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Le coût d’un projet Data Warehouse peut varier de 1 à 100, alors forcément impossible de donner une réponse toute faite. Nous allons vous partager les infos clés à connaître pour comprendre ce qui impacte le coût d’un Data Warehouse : les différents postes de coûts à anticiper, la différence importante à faire entre coût de stockage et coût de computing, batch et streaming de données…
En fin d’article, on a voulu vous présenter le prix des principales solutions data warehouse cloud du marché : BigQuery, Snowflake, Azure, Redshift (mais, spoiler alert, n’oubliez jamais que le coût d’un Data Warehouse ne se réduit jamais au seul coût de la licence…)
Poste de coût
Présentation & Estimation
Coûts de stockage
20 à 25 dollars par téraoctet par mois pour le cloud. Pour un stockage en local, la mise de départ débute à 3 500 $ et les coûts mensuels peuvent dépasser les 1 000 $ par mois.
Licence d'exploitation
Le coût des licences est calculé en fonction de la taille de la base de données, de votre utilisation (computing) et des services consommés (intégrations, cleansing...). Le coût peut varier de quelques milliers d'euros par an à plusieurs dizaines (voire centaines) de milliers d'euros par an.
Coût en ressource humaines
La construction d'un data warehouse peut impliquer des coûts significatifs en termes de ressources humaines. Ces coûts peuvent varier en fonction de la taille et de la complexité du projet, ainsi que du niveau d'expertise technique nécessaire.
Coût des outils connexes
Ce sont les coûts des outils supplémentaires nécessaires pour gérer et optimiser et utiliser vos données : ETL, outil de reporting, outil de Data Ops...
L’essentiel à retenir sur le coût d’un Data Warehouse
La création et la gestion d’un data warehouse peuvent être coûteuses pour une entreprise. Ces coûts peuvent varier considérablement en fonction de plusieurs facteurs clés.
Taille du Data Warehouse. La taille du data warehouse est l’un des principaux facteurs qui influenceant les coûts. Plus il est grand, plus il nécessitera de ressources. Cela implique une augmentation des frais de stockage, des coûts d’acquisition de matériel et de logiciels supplémentaires, et des coûts de maintenance.
Coût du matériel et des logiciels. Le choix du matériel et des logiciels utilisés pour votre data warehouse est un autre facteur important pouvant affecter votre budget. Les coûts peuvent varier considérablement selon les fournisseurs et les technologies utilisées. Il est donc important de sélectionner le bon fournisseur et la bonne technologie pour répondre aux besoins de l’entreprise.
Coût de la gestion des données. La gestion des données implique de nombreux coûts dus à la collecte, au nettoyage, à la normalisation et à la sécurité des données. Ces coûts peuvent également inclure les frais d’audit et de conformité réglementaire.
Coût de la main-d’œuvre. La main-d’œuvre est un autre élément important des coûts associés au développement d’un data warehouse. Les entreprises doivent disposer de personnel qualifié pour configurer, maintenir et mettre à jour le data warehouse. Il faut inclure dans le budget des coûts dus à la formation, au recrutement et aux salaires du personnel.
Évolutivité. L’évolutivité est un facteur clé à prendre en compte dans la création et la gestion d’un data warehouse. Les entreprises doivent être en mesure de faire face à la croissance continue de leurs données et d’adapter leur infrastructure de données en conséquence. Les coûts peuvent être dus à l’ajout de matériel et de logiciels supplémentaires, ainsi qu’à la mise à niveau de l’infrastructure existante.
En résumé, la création et la gestion d’un data warehouse peuvent être coûteuses pour une entreprise. Ces coûts dépendent de la taille du data warehouse, du choix du matériel et des logiciels, des coûts de main-d’œuvre, de la gestion des données et de l’évolutivité. Les entreprises doivent prendre en compte ces facteurs clés pour anticiper les coûts et déterminer la meilleure stratégie pour la mise en place et la gestion de leur data warehouse.
Découvrez notre article sur l’évolution du SI Client vers une approche data warehouse centric.
Estimer le coût du déploiement de votre Data Warehouse
Le coût de la licence
Une composante importante du coût total est la licence d’exploitation. La plupart des fournisseurs proposent une licence annuelle ou pluriannuelle, dont le coût dépend des besoins spécifiques de l’entreprise. Le prix varie en fonction de la taille du data warehouse, du nombre d’utilisateurs, des fonctionnalités nécessaires, la durée de la licence, de la région d’hébergement…
Pour un data warehouse de taille moyenne, le coût d’une licence annuelle s’élève généralement à quelques milliers d’euros. Les frais de maintenance peuvent être inclus dans le coût de la licence, ou facturés séparément. Il est important de noter que le coût des licences peut également varier en fonction du fournisseur.
Source : Snowflake.
Il est donc nécessaire de comparer les offres et de choisir un fournisseur qui répond aux besoins spécifiques de l’entreprise, tout en offrant des prix compétitifs et des fonctionnalités adaptées. Certains fournisseurs de plateformes cloud proposent même des programmes de tarification qui permettent de réaliser des économies en fonction de la quantité d’utilisation.
Le coût des outils connexes : ETL, BI…
En plus des coûts de licence et de la plateforme cloud, il faut considérer les coûts des outils supplémentaires nécessaires pour gérer et optimiser le data warehouse et utiliser vos données. Ces outils supplémentaires incluent des outils d’intégration de données pour charger et transformer les données, des outils de gestion des métadonnées, et des outils de BI pour permettre aux utilisateurs de requêter et d’analyser les données.
Le coût de ces outils supplémentaires peut varier là aussi en fonction du fournisseur et de la quantité de données traitées. Par exemple, les outils d’intégration de données peuvent coûter environ 20 000 par an. Les outils de gestion des métadonnées et d’analyse peuvent coûter entre 5 000 et 50 000 dollars par an en fonction de la complexité de l’environnement et du volume de données traitées. Il existe 4 types de facturations principaux que nous vous présentons ci-dessous.
Le coût des ressources humaines
La construction d’un data warehouse peut impliquer des coûts significatifs en termes de ressources humaines. Ces coûts peuvent varier en fonction de la taille et de la complexité du projet, ainsi que du niveau d’expertise technique nécessaire. Voici quelques-unes des ressources humaines qui peuvent être impliquées dans la construction d’un data warehouse :
Chef de projet : les responsables de la gestion globale du projet. Il travaille avec les parties prenantes pour comprendre les exigences commerciales, développer un plan de projet et assurer la coordination de l’équipe de projet.
Architecte de données : les responsables de la conception du data warehouse, y compris la modélisation de données, la définition de la structure de stockage des données et la conception de l’architecture globale.
Analyste de données : ils analyses des données pour identifier les tendances et les modèles. Ils peuvent être nécessaires pour aider à la conception des modèles de données, la rédaction des spécifications et la validation des données.
Ingénieur en informatique : ils permettent la mise en œuvre de l’architecture technique du data warehouse. Ils peuvent être nécessaires pour travailler sur la mise en place de bases de données, la configuration de serveurs et la gestion des interfaces de programmation d’applications (API).
Testeur : Les testeurs assurent la qualité du data warehouse. Ils travaillent avec l’équipe de développement pour tester les données et les fonctionnalités pour s’assurer qu’elles répondent aux exigences spécifiées.
Formateur : Les formateurs sont responsables de la formation des utilisateurs sur l’utilisation du data warehouse. Le coût des formateurs dépend du niveau d’expertise requis et de la méthode de formation choisie. En outre, il est important de considérer les coûts de formation qui peuvent varier en fonction de la complexité du data warehouse et du nombre d’utilisateurs.
En fin de compte, le coût total des ressources humaines nécessaires pour construire un data warehouse dépendra des spécificités de chaque projet. Cependant, il est important de comprendre que la construction d’un data warehouse peut nécessiter une équipe de personnes qualifiées et spécialisées pour garantir un projet réussi qui répond aux besoins commerciaux.
Le coût de la maintenance du Data Warehouse
La maintenance d’un data warehouse est également un coût important à prendre en compte. Cela peut inclure des coûts pour le personnel de maintenance, des mises à jour logicielles, des réparations matérielles, etc.
En résumé, il est important de considérer l’ensemble des coûts liés à la mise en place et à la gestion d’un data warehouse, y compris les coûts de licence, les coûts de la plateforme cloud, les coûts des outils supplémentaires et les coûts de formation. En prenant en compte tous ces facteurs, les entreprises peuvent élaborer un budget réaliste pour leur projet de data warehouse et s’assurer que leur investissement est rentable.
Comprendre la facture de votre Data Warehouse
Le prix du stockage
La première composante de la facture de votre data warehouse est le prix du stockage. Ce coût du stockage dépendra de plusieurs facteurs, notamment la quantité de données stockées, la fréquence d’accès aux données, le type de stockage utilisé, etc. Le stockage peut être effectué en interne, en utilisant des disques durs, ou via un stockage en cloud, en utilisant des services de stockage tels que Amazon S3, Google Cloud Storage ou Microsoft Azure Blob Storage. Le site Light IT propose une analyse détaillée des différents providers clouds.
Si vous optez pour un stockage en cloud, les coûts seront souvent basés sur la quantité de données stockées et la fréquence d’accès aux données. Les fournisseurs de cloud peuvent également facturer des coûts supplémentaires pour les opérations de lecture et d’écriture, les transferts de données et les frais de gestion. En revanche, si vous optez pour un stockage en interne, vous devrez prendre en compte les coûts de l’achat de disques durs, de la maintenance, de l’espace physique nécessaire, etc.
Les frais de stockage peuvent varier en fonction de la quantité de données stockées et du type de stockage utilisé. Pour un stockage cloud, les coûts peuvent varier de 20 à 25 dollars par téraoctet par mois. Pour un stockage sur site, les coûts incluent d’abord la mise de départ, qui débute à 3 500 $. Les coûts mensuels peuvent varier, et inclus l’électricité, la maintenance… Ils peuvent dépasser les 1 000 $ par mois.
Le prix des ressources de calcul (compute)
La deuxième composante de la facture de votre data warehouse est le prix des ressources de calcul. En effet, le traitement des données nécessite souvent des ressources de calcul importantes pour effectuer des requêtes complexes et générer des rapports.
Le coût des ressources de calcul dépendra de plusieurs facteurs, notamment la quantité de données à traiter, la complexité des requêtes, la fréquence d’exécution des requêtes, etc. Les ressources de calcul peuvent être fournies par des serveurs internes ou des services de cloud computing tels que Amazon EC2, Google Compute Engine ou Microsoft Azure Virtual Machines.
Si vous optez pour un service de cloud computing, les coûts seront souvent basés sur la quantité de ressources utilisées, la durée d’utilisation, la complexité des requêtes et les frais de gestion. Les fournisseurs de cloud peuvent également proposer des options de tarification à la demande ou réservées, qui peuvent permettre de réduire les coûts. En revanche, si vous optez pour des serveurs internes, vous devrez prendre en compte les coûts de l’achat de serveurs, de la maintenance, de l’espace physique nécessaire, etc.
En résumé, le coût des ressources de calcul est une composante importante de la facture de votre data warehouse. Il est important de comprendre les coûts associés à chaque option de traitement disponible et de déterminer celle qui convient le mieux aux besoins de votre entreprise.
La tendance moderne : la décorrélation du stockage et du compute
La tendance moderne en matière de data warehouse est la décorrélation du stockage et du compute. Cette tendance permet de séparer la gestion du stockage des données de la gestion du traitement de ces données, deux tâches distinctes qui peuvent être effectuées de manière indépendante. La décorrélation de ces tâches permet de traiter les données sans avoir à les déplacer vers un emplacement centralisé, ce qui peut être bénéfique en termes de coûts et de performances.
Cette tendance se manifeste souvent par l’utilisation de services de cloud computing tels que Amazon Redshift, Google BigQuery ou Microsoft Azure Synapse Analytics. Ces services offrent une séparation du stockage et du traitement, ce qui permet d’optimiser les coûts en payant uniquement pour les ressources de traitement nécessaires. En effet, avec cette approche, le stockage des données peut être effectué dans un emplacement centralisé et économique, tandis que le traitement peut être effectué de manière distribuée et à la demande, en fonction des besoins de l’entreprise.
Batch VS Streaming
Le quatrième point à considérer est le choix entre le traitement par lot (batch) ou le traitement en continu (streaming) des données.
Le traitement par lot est le traitement de grands volumes de données en une seule fois, généralement sur une période donnée, comme une journée ou une semaine. Cette approche est souvent utilisée pour des tâches d’analyse historique ou de génération de rapports réguliers, qui n’ont pas besoin d’une réponse en temps réel. Le traitement par lot peut être moins coûteux que le traitement en continu, car il peut être effectué en dehors des heures de pointe et ne nécessite pas de ressources en continu.
En revanche, le traitement en continu est le traitement de données en temps réel, au fur et à mesure de leur arrivée. Cette approche est souvent utilisée pour des tâches qui nécessitent une réponse en temps réel, comme la surveillance des données, les alertes et les notifications. Le traitement en continu peut être plus coûteux que le traitement par lot, car il nécessite des ressources en continu.
Le choix entre le traitement par lot et le traitement en continu dépendra des besoins de votre entreprise. Si vous avez besoin d’analyser de grands volumes de données historiques de manière régulière, le traitement par lot peut être une option plus économique. Si vous avez besoin d’une réponse en temps réel, le traitement en continu peut être plus approprié. Il est important de noter que certains services de data warehouse proposent des options hybrides combinant le traitement par lot et le traitement en continu. Ces options peuvent être utiles pour les entreprises qui ont besoin de répondre à des besoins variés.
Structure de prix des principaux Data Warehouses du marché
Tableau de synthèse
Data Warehouse
Coût
Snowflake
Stockage : 270 à 500 $ par TB/an
Calcul : 17 280 $ par an
Google BigQuery
Système principalement "pay as you go", mais possibilité d'avoir une tarification mensuelle prévisible.
Amazon Redshift
Stockage : 295 $ par TB/an
Calcul : 18 848 $ par an
Azure Analytics
Stockage : 120 $ par téraoctet traité
Calcul : 6 600 $ par an
Google BigQuery
BigQuery est un data warehouse basé sur le cloud qui fait partie de la Google Cloud Platform. L’un des principaux avantages de BigQuery est son modèle de tarification « pay-as-you-go », qui permet aux utilisateurs de ne payer que pour les ressources informatiques qu’ils utilisent. Il s’agit donc d’une option rentable pour les entreprises de toutes tailles. BigQuery propose également des tarifs forfaitaires pour les clients qui souhaitent une tarification mensuelle prévisible.
BigQuery offre plusieurs fonctionnalités qui en font un outil puissant pour l’analyse des données, notamment la prise en charge du langage SQL et le flux de données en temps réel. Il s’intègre également à d’autres services de Google Cloud Platform, tels que Google Cloud Storage, Dataflow et Dataproc. En outre, BigQuery offre plusieurs fonctions de sécurité, de contrôles d’accès et d’audit. Il est également conforme à plusieurs normes et réglementations du secteur, telles que SOC 2, HIPAA et GDPR.
Dans l’ensemble, le modèle de tarification « pay-as-you-go » de BigQuery, ses puissantes fonctionnalités et sa sécurité robuste en font un choix populaire pour l’entreposage et l’analyse de données dans le cloud. Son intégration avec d’autres services de Google Cloud Platform le rend facile à utiliser et offre une expérience utilisateur simple.
Snowflake
Snowflake est un data warehouse moderne basé sur le cloud qui offre une architecture distincte pour le stockage de masse et le calcul. Il propose une variété de fonctionnalités pour la gestion, l’analyse, le stockage et la recherche de données. L’un des principaux avantages de Snowflake est qu’il offre des ressources informatiques dédiées, ce qui garantit de meilleures performances et des temps de traitement des requêtes plus rapides. Ce datawarehouse est strcturé en 3 couches :
Snowflake propose plusieurs modèles de paiement, dont le stockage à la demande et le stockage de capacité, qui sont basés sur la quantité de données stockées dans l’entrepôt. En outre, il existe quatre modèles de tarification qui offrent différents niveaux de fonctionnalité : Standard, Enterprise, Business Critical et Virtual Private Snowflake.
Le modèle Standard offre les fonctionnalités de base de l’entrepôt de données, notamment le stockage, le traitement et l’interrogation des données. Ensuite, le modèle Enterprise comprend des fonctionnalités avancées telles que le partage de données, le voyage dans le temps et l’échange sécurisé de données.
Le modèle Business Critical est conçu pour les charges de travail critiques et offre des fonctionnalités supplémentaires telles que le clonage sans copie et l’échange de données accéléré.
Enfin, le modèle Virtual Private Snowflake offre un environnement dédié et isolé aux clients qui exigent une sécurité et une conformité maximales.
Dans l’ensemble, les modèles de tarification flexibles et les ressources informatiques dédiées de Snowflake en font un choix populaire pour les besoins d’entreposage de données modernes. La plateforme offre une gamme de caractéristiques et de fonctionnalités qui peuvent répondre aux besoins des entreprises de toutes tailles et de tous secteurs, des startups aux grandes entreprises.
Amazon Redshift
Amazon Redshift est un entrepôt de données basé sur le cloud qui fait partie de la plateforme Amazon Web Services (AWS). Il s’agit d’une solution évolutive et entièrement gérée pour l’entreposage et l’analyse de données.
Redshift utilise un format de stockage et une architecture de traitement massivement parallèle qui lui permet de traiter rapidement et efficacement de grands ensembles de données. Il offre plusieurs fonctionnalités qui en font un outil puissant, notamment l’intégration avec d’autres services AWS tels que S3, Lambda et Glue. Redshift offre également plusieurs fonctionnalités de sécurité et la conformité à plusieurs normes et réglementations sectorielles telles que SOC 2, PCI DSS et HIPAA.
L’un des principaux avantages de Redshift est sa compatibilité avec un large éventail d’outils de BI et d’analyse, notamment Tableau, Power BI et Looker. Cela permet aux entreprises d’intégrer facilement Redshift dans leurs flux de travail analytiques existants.
Redshift propose plusieurs modèles de tarification, notamment la tarification à la demande, qui permet aux utilisateurs de ne payer que pour les ressources qu’ils utilisent, et la tarification des instances réservées, qui offre des réductions importantes aux clients qui s’engagent à utiliser Redshift pendant une certaine période. En outre, Redshift offre un éventail de types de nœuds, allant des petits nœuds avec quelques téraoctets de stockage aux grands nœuds avec des pétaoctets de stockage.
Dans l’ensemble, l’évolutivité de Redshift, sa flexibilité tarifaire et sa compatibilité avec les outils d’analyse les plus courants en font un choix populaire pour l’entreposage de données et l’analyse dans le cloud. Son intégration avec d’autres services AWS et sa conformité aux normes de l’industrie en font une solution sûre et fiable pour les entreprises de toutes tailles.
Microsoft Azure
Azure Synapse Analytics, anciennement connu sous le nom d’Azure SQL Data Warehouse, est une solution d’entreposage de données basée sur le cloud proposée par Microsoft Azure. Il s’agit d’un service entièrement géré et hautement évolutif qui s’intègre à d’autres services Azure et offre de bonnes performances sur de grands ensembles de données.
L’un des principaux avantages d’Azure Synapse Analytics est sa capacité à traiter des données structurées et non structurées, y compris des données provenant d’Azure Data Lake Storage. Il offre plusieurs options de tarification, notamment le paiement à l’utilisation, le calcul provisionné et les instances réservées, ce qui permet aux clients de choisir le modèle qui correspond le mieux à leurs besoins.
Azure Synapse Analytics permet l’intégration avec d’autres services Azure tels qu’Azure Data Factory, Azure Stream Analytics et Azure Databricks. Un autre avantage de ce data warehouse est son intégration avec Power BI, qui permet aux entreprises de créer facilement des tableaux de bord et des rapports interactifs pour mieux comprendre leurs données. Il prend également en charge plusieurs langages de programmation, notamment SQL, .NET et Python, ce qui le rend flexible et facile à utiliser pour les data scientist et engineer.
Dans l’ensemble, Azure Synapse Analytics est une solution puissante et flexible pour l’entreposage de données et l’analyse dans le nuage. Son intégration avec d’autres services Azure et sa compatibilité avec les outils d’analyse les plus courants en font un choix populaire pour les entreprises de toutes tailles. Ses options tarifaires et ses fonctions de sécurité en font une solution rentable et sûre pour la gestion et l’analyse de grands ensembles de données.
La gestion des coûts est un élément crucial lors de la mise en place d’un data warehouse pour les entreprises. Il est important de comprendre les différents postes de coûts associés à la construction, l’hébergement et la maintenance.
Les entreprises doivent choisir la bonne plate-forme de data warehouse en fonction de leurs besoins spécifiques, en tenant compte des coûts de licence, des frais de gestion et des coûts de stockage et de traitement des données.
Les options de pricing flexibles offertes par les fournisseurs de cloud computing peuvent aider les entreprises à s’adapter à l’évolution de leurs besoins en matière de données et à maîtriser leurs dépenses. En somme, une planification minutieuse, une évaluation des coûts et un choix judicieux de plate-forme peuvent aider les entreprises à améliorer leur efficacité et leur rentabilité en matière de gestion de données.
Pourquoi vous devez utiliser vos données CRM dans vos campagnes Ads
Les données CRM sont encore trop peu utilisées dans les campagnes publicitaires. Il y a pourtant de nombreux cas d’usage possibles, bien au-delà de l’approche lookalike qui vient souvent en tête dès qu’on parle de ce sujet. Nous allons dans cet article vous montrer différentes manières d’utiliser les données clients pour booster la performance de vos campagnes Ads. On va voir d’ailleurs que les données CRM ne sont pas seulement exploitables dans les campagnes d’acquisition, mais aussi pour créer des campagnes de cross-sell intelligentes.
L’essentiel à retenir sur l’exploitation des données CRM dans vos campagnes Ads
Les données CRM sont une mine d’or à exploiter car elles permettent de bien comprendre les profils et comportements de ses clients et donc d’améliorer considérablement la fidélisation client.
Les bénéfices de l’exploitation de ces données vont bien au-delà la simple fidélisation et sont complémentaires aux campagnes Ads : en ciblant plus intelligemment une bonne clientèle cible, les données permettent de booster l’efficacité des campagnes marketing tout en diminuant les coûts associés à sa mise en place.
L’exploitation des données CRM permet également une meilleure compréhension du parcours d’achat clients et donc une plus grande marge de manœuvre sur ses campagnes marketing.
4 raisons d’utiliser les données CRM dans vos campagnes publicitaires
1 – Améliorer le ciblage de vos campagnes d’acquisition
Comme expliqué plus haut, les données CRM sont la source de la connaissance client. En effet, une meilleure connaissance client permet une meilleure compréhension des caractéristiques de sa clientèle cible / ses meilleurs clients.
Comprendre et lister les caractéristiques communes à ces meilleurs clients est un levier crucial pour une meilleure efficacité de campagnes Google Ads / Facebook Ads, en améliorant le ciblage client. C’est ce qu’on appelle la méthode LookAlike.
Très concrètement, la méthode LookAlike (« sosie ») consiste à cibler des prospects ayant des comportements semblables à ceux des clients actuels d’une entreprise ou d’une marque. Pour ce faire, une entreprise doit leverager ses données clients afin de :
Identifier sa clientèle cible / ses meilleurs clients.
Déterminer leurs caractéristiques sociodémographiques / culturelles et leurs centres d’intérêt afin d’analyser leurs comportements et habitudes de consommation.
Rechercher et identifier une nouvelle audience plus large, dont le profil ressemble à celui de sa clientèle cible, en veillant bien à ce que ces nouveaux prospects soient pertinents par rapport à son image de marque et à ses objectifs.
En créant ces audiences « Lookalike », cette méthode permet d’améliorer considérablement le ciblage des campagnes Google Ads / Facebook Ads puisqu’elle permet de toucher des prospects ayant statistiquement plus de chances d’être convertis en clients, et ainsi booster le taux de conversion et par conséquent le retour sur investissement de ces campagnes publicitaires. Très utilisée en publicité digitale, cette méthode est toutefois rendue possible par la capacité d’ultra-ciblage des audiences des plateformes comme Google Ads ou Facebook Ads.
Cette approche peut également être utilisée en conjonction avec d’autres méthodes de ciblage publicitaire telles que le ciblage par intérêt ou le ciblage géographique pour maximiser l’efficacité de la campagne publicitaire.
2 – Optimiser vos budgets Ads
Acquérir de nouveaux clients via des campagnes publicitaires est devenu de plus en plus cher, notamment via Google et Facebook. En effet, en raison de la concurrence croissante entre les annonceurs et des mises à jour régulières de leur offre publicitaire, les plateformes de publicité en ligne sont de moins en moins abordables.
C’est pourquoi, il est crucial de segmenter finement sa base clients afin de retargeter son audience et ainsi de ne pas dépenser inutilement des budgets conséquents !
On trouve deux effets positifs sur le budget marketing grâce au ciblage :
Une diminution des coûts : qui dit une audience ciblée dit une audience par définition plus étroite, à laquelle on offre un contenu publicitaire adapté. En évitant de dépenser de l’argent pour des audiences qui sont moins susceptibles de se convertir, votre campagne marketing se fera par conséquent à moindre coût. Par ailleurs, la précision du ciblage client peut également permettre d’optimiser le choix des canaux de communication, les messages diffusés et les horaires de diffusion, qui sont autant de facteurs qui ont un impact sur les coûts de marketing ! En faisant en sorte que la publicité soit plus efficace, vous pourrez économiser sur plusieurs postes de dépenses, comme la production de publicités, l’achat d’espaces publicitaires ou encore les coûts des agences de publicité.
Une augmentation des revenues : une audience bien ciblée se montrera plus réceptive à l’offre et générera un meilleur taux de conversion !
3 – Augmenter la LTV de vos clients
Grâce à vos données CRM organisées et riches, vous avez une vision client 360°. Concrètement, cela signifie que l’ensemble de vos équipes opérationnelles ont la capacité de visualiser à n’importe quel moment toutes les informations récoltées sur un client (profil, informations de contact, préférences, historique des interactions, comportement sur les réseaux sociaux, programmes et offres souscrits…) et ainsi les éclairer dans leurs prises de décision et actions, qu’elles soient marketing, commerciales ou servicielles.
Cette vision 360 a de nombreux avantages, parmi lesquels on compte :
Une meilleure maitrise de la pression marketing en évitant d’intégrer à une campagne marketing un client déjà existant ou pire, un client qui vient de se plaindre au service clients.
La capacité d’adapter le discours aux appétences des vos clients et ainsi doper votre CA grâce au cross-selling.
La capacité d’adapter vos moyens de communication en fonction de chaque client. En comprenant à quels canaux un client est le plus sensible, vous capterez plus facilement son attention et ainsi augmenterez l’efficacité de votre campagne.
Globalement, l’utilisation de vos données CRM permettront d’améliorer la satisfaction de vos clients, et ainsi les poussera à acheter chez vous plus souvent ou sur une plus longue période !
4 – Disposer d’une vision plus précise du parcours d’achat
Nous avons vu jusqu’ici que l’utilisation des données CRM dans les campagnes Ads permettait de les booster considérablement. Seulement, ce n’est pas la seule façon de leverager ces données !
Une autre manière d’utiliser intelligemment les données CRM est de les associer avec les données issues des Ads dans des reportings, afin de recréer le parcours d’achat client et ainsi avoir une vision complète de l’expérience d’achat.
Prenons un exemple. Imaginons qu’un client achète un complément alimentaire après avoir cliqué sur une annonce Google Ads. Plusieurs cas sont possibles : intéressé depuis longtemps par l’achat de complément alimentaire sans toutefois connaitre votre entreprise, le client aurait vu la publicité Google Ads et se serait directement engagé dans l’achat. Dans ce cas, le mérite de la conversion serait revenu à Google Ads.
En revanche, l’histoire serait tout autre si l’on réalisait que le client avait reçu la semaine précédant l’achat un emailing lui présentant l’offre et qu’il était déjà allé consulter la page produit sur votre site web. Le cas échéant, Google Ads n’a presque aucun mérite dans cette transaction !
C’est pourquoi l’élaboration d’un modèle multi-touch est intéressante à envisager. En effet, ce modèle permet d’inclure les différents points de contact du voyage de l’acheteur, leur attribuer à chacun un crédit fractionné et ainsi mettre en évidence l’influence de chaque canal sur une vente.
Combiner les données CRM avec les données issues des Ads permet donc de savoir comment chaque parcours d’achat s’est réalisé et avoir ainsi une vision plus juste de l’impact / poids des campagnes Ads sur la performance et de l’utilisation des canaux marketing. D’où l’importance d’utiliser une plateforme de type CDP pour unifier toutes les données (CRM, online, ecommerce, ads…) !
5 cas d’usage concrets des données CRM dans les campagnes Ads
1 – Créer des audiences similaires aux Top Clients (approche Lookalike)
Comme expliqué plus haut, l’une des façons les plus intéressantes de leverager les données clients est d’identifier une audience source, dans le but d’acquérir d’autres clients semblables.
Comment déterminer cette audience ? On distingue deux « degrés » d’audience :
La « basique » : généralement, on utilise par facilité les visiteurs ayant réalisé une conversion, ou ceux ayant une certaine page, car ce sont des segments faciles à déterminer depuis l’interface de Google ou Facebook.
Les « meilleurs clients« , que vous déterminez sur l’ensemble des informations à votre disposition (achats en magasin, achats en ligne…). Les achats offline ou le niveau de marge généré par un client ne sont pas disponibles dans Google / Facebook, mais ces informations existent dans votre Datawarehouse, votre ERP, etc.
A partir du profil de votre audience source, Google / Facebook se chargent d’étudier les caractéristiques de cette audience à partir de nombreux critères (âge, sexe, lieu géographique, habitudes, centre d’intérêts, comportements, historique de navigation…) pour identifier des profils d’individus « proches ».
Comme mentionné plus haut, le but est d’améliorer les performances en ciblant des personnes qui ont plus de chances de devenir de bons clients. Un autre intérêt de l’élaboration d’une audience voisine de votre clientèle cible par Facebook ou Google est que cela vous permet un gain de temps considérable et vous évite toute erreur lors de la création des audiences.
2 – Utiliser la LTV comme valeur de conversion de vos campagnes Google Ads au ROAS
Google et Facebook utilisent des stratégies d’enchères automatisées très spécifiques, leur laissant la possibilité de fixer librement le montant des enchères tout en se chargeant d’atteindre les objectifs fixés (clics, conversions, CPA cible, etc.). De manière générale, les annonceurs qui obtiennent les meilleures performances sont ceux qui ont appris à nourrir et piloter l’IA de Google / Facebook le plus efficacement possible.
L’enjeu principal devient donc de nourrir correctement l’IA de Google et Facebook avec les bons indicateurs, surtout si vous avez des interactions en dehors du site web. Dans ce cadre, le critère idéal est la Life Time Value (LTV), la valeur de vie client (i.e la somme des revenus générés par un client), quel que soit le canal de vente. Il peut s’agir de la LTV actuelle ou encore de la LTV estimée à partir des premiers points de contact.
Or Google / Facebook ne peuvent pas toujours connaitre cette LTV, car une partie du revenu de ce client est peut-être générée offline, ou avant la campagne publicitaire. C’est pourquoi, le calcul de la LTV incombe le plus souvent aux entreprises elles-mêmes.
Pour cela, plusieurs approches sont possibles. Si la règle du 80/20 s’applique généralement très bien, de plus en plus d’entreprises disposent des compétences en data science pour monter un modèle prédictif solide de la LTV. Certaines entreprises se basent sur un GSheet avec le potentiel de récurrence des premiers produits achetés, d’autres sur le « Lead Scoring » du CRM, d’autres sur les pages visitées du site web (un prospect qui visite la catégorie A ou la page Pricing B a peut être plus de valeur).
Tout est faisable pour évaluer la LTV, mais il faut rester simple au départ, et se donner les moyens de faire évoluer le dispositif facilement !
3 – Recibler les contacts CRM non-ouvreurs email avec des Ads
Beaucoup de clients refusent de donner leur mail, de peur d’être submergés par des pubs, tandis que d’autres l’ayant transmis se montrent complètement passifs. De toute évidence, le mail ne semble pas être le moyen de communication favoris des clients. Pour autant, il est prouvé qu’en utilisant une bonne stratégie marketing, la relance des non-ouvreurs peut augmenter votre taux d’ouverture jusqu’à 30% !
Pour ce faire, il suffit de :
créer un segment de contacts n’ayant pas ouvert un email depuis un certain temps, en ajoutant si possible d’autres critères basés sur d’autres sources de données.
synchroniser cette audience avec Google / Facebook Ads.
Néanmoins, tous les outils CRM / Marketing automation ne permettent pas de réactiver les non ouvreurs emails via une campagne Ads. C’est pourquoi un partenaire comme Octolis vous facilitera grandement la vie.
Source : Codeurblog
4 – Améliorer votre stratégie de cross-selling
En plus de vous donner des informations sur les profils des clients, les données CRM vous donnent des informations sur les comportements d’achats et donc les ventes. Par exemple, il se peut qu’en analysant vos données vous vous rendiez compte que les clients ayant acheté le produit A achètent généralement le produit B.
Or, cette information est précieuse puisqu’elle peut être exploitée dans les Ads. En identifiant les combinaisons de produits les plus souvent achetées, vous pouvez créer des ensembles de produits et ainsi en informer vos publics cibles. Si nous reprenons notre exemple plus haut, proposez dans des Ads le produit B aux clients qui ont acheté le produit A et vous verrez vos ventes exploser. C’est ce qu’on appelle du cross-selling.
Cette méthode est extrêmement utile lorsque vous avez identifié des tendances au sein de votre clientèle. Elle est également utile pour l’up-selling qui consiste à faire du remarketing et de la vente incitative d’articles de plus grande valeur lorsque votre client est sur le point d’acheter à nouveau.
5 – Exclure les clients existants des campagnes Ads
Savoir qu’un client a déjà acheté un produit pour lequel vous êtes sur le point de lancer une campagne marketing peut être utile. En effet, si vous souhaitez créer une campagne Ads pour promouvoir le produit A, il est préférable d’exclure les clients qui ont déjà acheté ce produit (sur le site ou en boutique) de l’audience de la campagne.
Dans ce cas, l’information est contenue dans les données CRM, et plus précisément dans les données transactionnelles. A partir de celles-ci, vous pourrez déterminer les clients ayant déjà acheté le produit en question et ainsi les exclure de ces campagnes Ads.
Encore une fois, c’est un nouvelle usage des données CRM pour améliorer ses campagnes Ads. Cette approche a une multiplicité d’avantages, parmi lesquels on compte une meilleure gestion de la pression marketing, un marketing plus ciblé et intelligent ainsi qu’une réduction intelligente des coûts.
En somme, bien exploiter ses données CRM va bien au-delà de la simple connaissance de ses clients. Si de toute évidence elles permettent une meilleure expérience client et donc une plus grande fidélisation, elles montrent tout leur potentiel quand elles sont associées aux campagnes Ads :
En exploitant les informations sur ses meilleurs clients, les campagnes marketing peuvent être mieux ciblées sur des prospects voisins à ceux déjà acquis, notamment via Google Ads / Facebook Ads. En ciblant mieux ses campagnes Ads, cela permet de réduire les coûts et d’augmenter ses chances de conversion.
En évitant d’intégrer à une campagne marketing un client déjà existant, l’entreprise peut mieux maitriser la pression marketing.
Au-delà des profils clients, elles permettent de mieux comprendre leur parcours et comportement d’achat, et ainsi faire des choix en conséquence en privilégiant par exemple des canaux plus pertinents. C’est pourquoi il est essentiel d’avoir, pour une bonne centralisation des données client, une plateforme CDP. Si ce n’est pas déjà le cas, n’hésitez pas à jeter un œil à notre guide dédié aux différentes typologies de CDP qui existent sur le marché.
Au vu de la quantité de données client amassées chaque jour, bien gérer et, surtout, bien exploiter ses données clients est devenu un art, et demande un minimum d’organisation. Pour ce faire, Octolis travaille au quotidien avec tout type d’entreprises dans la collecte et la valorisation de ces données pour assurer une performance exemplaire. Vous pêchez un peu sur vos données clients ? Contactez-nous sans plus tarder !
Webinar : Pourquoi faut-il moderniser son dispositif CRM en 2023 ?
L’avènement des data warehouses a profondément transformé l’industrie en permettant aux entreprises de centraliser toutes leurs données et de les rendre accessibles rapidement pour étoffer la connaissance client et faciliter les activations. Avec la grande ambition de délivrer une relation client hyper-personnalisée, en temps réel.
C’est également la promesse des CDP qui proposent des solutions clés en main pour répondre à ces enjeux.
Autrefois dominée par une poignée d’acteurs, les marchés du CRM et du Marketing Automation sont désormais constitués d’une myriade de solutions, qui peuvent se combiner pour répondre aux grandes problématiques de chaque annonceur avec parfois beaucoup plus de flexibilité qu’une solution full-stack.
Dans ce webinar, les experts CRM et Data d’Unnest et d’Octolis s’associent pour vous permettre d’appréhender ces nouveautés et de construire au mieux votre propre dispositif.
Ce que vous allez découvrir :
Les architectures CRM les plus courantes, avec leurs forces et faiblesses.
Les facteurs qui ont favorisé l’adoption rapide du modèle data warehouse centric.
Sur quels critères évaluer la pertinence de votre dispositif CRM (pour différentes tailles d’entreprise).
Les architectures idéales pour des activités spécifiques (pure players, retail omnicanal,…).
Les intervenants :
Nathan BENZINEB – Lead CRM et Marketing Automation @Unnest
Yassine HAMOU TAHRA – Co-founder et CEO @Octolis
Replay & présentation
Les ressources
Téléchargez gratuitement les ressources évoquées au cours du webinar :
Si vous êtes une PME à la recherche d’un outil de reporting pour créer et partager des dashboards personnalisés alimentés avec les données de votre entreprise, nous vous recommandons 3 outils : Metabase, Power BI et Looker.
Ces outils répondent à la plupart des cas d’usage des entreprises de taille moyenne (notamment dans le Retail). Si Metabase et Looker sont un peu plus basiques que Power BI, ils partagent tous les 3 l’avantage d’être simples à prendre en main et assez flexibles. A noter que Metabase et Looker ont une version gratuite assez généreuse.
Metabase
PowerBI
Looker
Prise en main
⭐⭐⭐
⭐⭐
⭐⭐⭐
Intégration des données
⭐
⭐⭐
⭐⭐⭐
Préparation & Modélisation des données
⭐⭐
⭐⭐⭐
⭐
Capacité d'exploration
⭐⭐⭐
⭐⭐
⭐
Dashboards sur mesure
⭐⭐
⭐⭐⭐
⭐⭐
Collaboration & partage
⭐⭐
⭐⭐
⭐⭐⭐
Support client
⭐⭐
⭐⭐⭐
⭐
Sécurité & Gouvernance des données
⭐⭐
⭐⭐⭐
⭐
Rapport qualité/prix
⭐⭐⭐
⭐⭐
⭐⭐⭐
Metabase vs Power BI vs Looker : L’essentiel à retenir
Finalement, vous vous demandez quel outil de reporting vous conviendrait le plus mais vous ne savez pas vers lequel vous tourner.
3 bons outils. Les 3 outils de BI proposés vous permettront de créer, personnaliser et partager des tableaux de bord à partir de vos données clients, produits, web, transactionnelles, etc. Tous les trois sont simples d’utilisation et abordables en termes de prix (voire gratuits), c’est pourquoi ils sont idéaux pour se lancer dans la BI quand on est une TPE/PME. En permettant une analyse de données plus poussée que l’utilisation de tableurs tels qu’Excel ou Google Sheets, ces outils de visualisation vous permettront un gain de temps considérable, ce qui explique pourquoi certaines entreprises décident de les préférer à Excel.
Nous vous recommandons plutôt Looker si vous êtes un grand utilisateur de l’écosystème Google. Grâce à sa forte compatibilité avec l’organisation Google Workspace, l’outil de BI permet facilement d’automatiser la gestion et la migration des éléments entre les deux écosystèmes. A l’aide de ses 600 connecteurs partenaires, Looker Studio est aussi en mesure d’accéder à une grande variété de sources de données, sans codage ni logiciel.
Nous vous recommandons plutôt PowerBI si vous avez des besoins un peu plus avancés. Grâce à une mise à jour en temps réel des données, Power BI permet de visualiser des chiffres à jour et avoir une vue de chaque élément dans son grand ensemble pour prendre une décision plus éclairée.
Metabase est un outil de Business Intelligence destiné à aider les entreprises à analyser et visualiser leurs données de manière efficace. Riche en fonctionnalités et intuitive, cet outil facilite la création de tableaux de bord personnalisés et la visualisation de données à l’aide de graphiques, tableaux ou encore de cartes géographiques.
Dans la plupart des cas, Metabase est compatible avec une grande majorité de PME, start-ups, développeurs ou encore analystes de données tant elle propose une grande variété de sources de donnée comme MySQL, PostgreSQL, Amazon Redshift, Google BigQuery… Dans ce cadre, Metabase permet à ses utilisateurs de partager facilement leurs rapports avec des collègues et des clients en temps réel grâce à un lien sécurisé.
👍👎 Points forts et limites
Comme tout outil, Metabase a ses points forts, et ses points faibles.
Ses points forts :
Interface utilisateur intuitive et facile à utiliser pour les débutants.
Open source et utilisation gratuite.
Prise en charge d’une grande variété de sources de données, telles que MySQL, PostgreSQL, Amazon Redshift, Google BigQuery, etc.
Grande facilité dans la manipulation des filtres, ce qui rend la plateforme très flexible.
Possibilité de créer des tableaux de bord personnalisés avec une grande variété d’options de visualisation de données telles que les graphiques, les tableaux et les cartes géographiques.
Capacité à partager des rapports en temps réel avec des collègues et des clients via un lien sécurisé.
Ses points faibles :
Certaines fonctionnalités avancées ne sont pas disponibles dans la version open source comme dans la version payante (analyse prédictive, comparative, outils de planification stratégique), ce qui peut limiter les capacités des utilisateurs avancés.
Les performances peuvent être lentes lors de l’analyse de grandes quantités de données.
L’outil peut manquer de certaines fonctionnalités de sécurité avancées pour les grandes entreprises.
L’interface utilisateur peut être trop simpliste pour certains utilisateurs avancés de Business Intelligence.
Le serveur peut parfois avoir du mal à se charger ou bloquer pendant le téléchargement des données.
Le support technique peut être limité pour les utilisateurs de la version open source.
🎯A qui s’adresse Metabase ?
Metabase convient à beaucoup de clients, en particulier ceux qui cherchent une solution de Business Intelligence abordable, personnalisable et facile à utiliser. Petites et moyennes entreprises, start-ups et organisations à but non lucratif lui font confiance car elles peuvent bénéficier de la plate-forme de visualisation de données sans avoir besoin de faire appel à un soutien informatique externe. En outre, certains développeurs utilisent Metabase pour créer rapidement des visualisations de données pour les projets en cours.
Cependant, certaines entreprises ayant des exigences de sécurité avancées peuvent trouver que la version open source de Metabase ne répond pas à leurs besoins. Dans ces cas, la version payante, Metabase Enterprise, peut offrir plus de fonctionnalités.
💶 Prix
Metabase est entièrement gratuit à utiliser, ce qui le rend accessible à tous ! La gratuité de la plateforme permet à de nombreuses entreprises de faire des économies sur leur budget de Business Intelligence tout en bénéficiant d’un outil de reporting complet.
Si vous recherchez plus de fonctionnalités notamment du point de vue de la sécurité, il existe une version payante, appelée Metabase Enterprise, qui offre des fonctionnalités avancées telles que la sécurité renforcée, l’intégration LDAP et l’accès prioritaire au support technique.
En somme, cette plateforme de Business Intelligence est particulièrement utile pour les utilisateurs qui n’ont pas de compétences techniques approfondies ou qui ont un budget limité pour les solutions de Business Intelligence. Les clients ayant souscrit à la version payante sont de même généralement contents de la plateforme, la qualifiant de fonctionnelle et d’excellent rapport qualité-prix.
Power BI
👉Présentation
Comme Metabase, Power BI est une plateforme de Business Intelligence cloud qui permet aux entreprises de toute taille de se connecter à des sources de données, de les préparer, les visualiser, les modéliser et les analyser.
Interface intuitive et facile à manipuler, elle permet de créer des tableaux de bord interactifs et des rapports de données à partir d’une grande variété de sources de données, telles que Excel, SQL Server, Salesforce et bien d’autres encore. Power BI s’engage également à assurer la protection des données que ce soit sur la plateforme qu’en dehors. Elle continue ainsi de fonctionner lorsqu’un rapport est partagé en dehors d’une organisation ou exporté vers d’autres formats tels qu’Excel, PowerPoint et PDF.
Comme Metabase, Power BI est une plateforme de Business Intelligence cloud, ce qui signifie que les données sont stockées dans le cloud plutôt que sur des serveurs locaux. Ainsi, plusieurs utilisateurs peuvent travailler sur les mêmes données en temps réel, et surtout de façon sécurisée !
👍👎 Points forts et limites
Power BI recèle une multitude d’avantages :
Interface intuitive et facile à utiliser pour les débutants, maximisant l’expérience utilisateur. Microsoft propose également de nombreux cours gratuits et payants sur son site web pour apprendre tous les outils de Microsoft Power BI.
Large gamme de visualisations et de graphiques personnalisables.
Accès à une grande variété de sources de données autres que Microsoft, telles que SQL Server, Excel, Salesforce ou encore Teams.
Plateforme cloud permettant une collaboration en temps réel et un partage de rapports sécurisé.
Disponible en version gratuite pour les petites entreprises et les utilisateurs individuels. La version payante, Power BI Pro, offre des fonctionnalités plus avancées pour les entreprises de toutes tailles et reste abordable pour un grand nombre d’entreprises (27.50$ / utilisateur / mois).
Intégration de fonctionnalités de data prep qui permettent de préparer / nettoyer les données.
Une amélioration quotidienne du logiciel basée sur les mauvais commentaires.
Mais le logiciel connait aussi des limites :
La version gratuite a des limites telles que la quantité de données pouvant être stockées, la qualité de l’assistance technique ou encore les fonctionnalités de partage.
Les fonctionnalités avancées telles que l’accès à des ensembles de données plus volumineux nécessitent un abonnement payant.
Une connaissance de base en langage de requête DAX est nécessaire pour des modélisations de données plus avancées.
Il peut y avoir des problèmes de performance lors de l’importation et analyse de grands volumes de données.
L’intégration avec des sources de données tierces peut nécessiter un travail supplémentaire de configuration.
La plateforme cloud peut soulever des inquiétudes en matière de sécurité pour certaines entreprises, en particulier celles soumises à des réglementations strictes en matière de sécurité des données.
🎯A qui s’adresse Power BI ?
Power BI est conçu pour les entreprises de toute taille. Les utilisateurs typiques de la plateforme comprennent des analystes commerciaux, des décideurs, des chefs d’entreprise et des professionnels de la BI.
Power BI est également adapté aux utilisateurs individuels qui souhaitent créer des rapports personnalisés pour leurs propres besoins. Par exemple, les propriétaires de petites entreprises peuvent utiliser Power BI pour analyser leurs ventes et leurs stocks, ou les professionnels de la finance pour suivre les tendances de leurs investissements.
Les entreprises qui utilisent déjà d’autres outils Microsoft tels que Excel, SharePoint et Teams peuvent bénéficier de l’intégration transparente de Power BI dans ces environnements. Cela permet une utilisation plus efficace des données existantes et une collaboration plus facile entre les différents départements de l’entreprise.
💶 Prix
Comme Metabase, Power BI est disponible en plusieurs versions : une version gratuite, une version Pro et une version Premium.
Gratuite et facile d’accès, la première version permet aux utilisateurs de se connecter à leurs données et créer des rapports et des tableaux de bord pour leur propre utilisation. Les limites se font vite ressentir puisqu’ils ne peuvent pas utiliser les fonctionnalités de collaboration ou de partage avec d’autres personnes, ni publier du contenu dans les espaces de travail de personnes tierces.
Plus avancée, la version Pro permet aux utilisateurs de créer du contenu, mais aussi de lire celui que d’autres ont publié sur le service Power BI Pro, et d’interagir avec ces derniers. Les fonctionnalités de partage de contenu et de collaboration sont donc incluses et exclusives aux utilisateurs de la version Pro.
Enfin, la licence Premium Par Utilisateur (PPU) fournit au titulaire de la licence toutes les fonctionnalités de Power BI Pro plus l’accès à la plupart des fonctionnalités basées sur la capacité Premium. Ainsi, une licence Power BI PPU déverrouille l’accès à une variété de fonctionnalités, capacités et types de contenu qui sont disponibles seulement à travers Premium. Par exemple, pour collaborer et partager du contenu dans un espace de travail PPU, tous les utilisateurs doivent avoir une licence PPU.
Si la version gratuite n’offre aucune fonctionnalité de partage, les utilisateurs Pro et PPU peuvent, quant à eux, partager du contenu et collaborer avec des utilisateurs de licence gratuite si le contenu est enregistré dans des espaces de travail hébergés dans une capacité Premium.
Un peu perdu sur les différentes options ? Le tableau ci-dessous récapitule les fonctionnalités de base de chaque type de licence :
Looker Studio
👉 Présentation
Anciennement appelé Google Data Studio, Looker Studio est un outil de DataViz, c’est-à-dire de visualisation de données en ligne. Conçu pour aider les entreprises et individus à transformer leurs données en informations exploitables, Looker studio permet à ses utilisateurs de créer des rapports personnalisés à partir de modèles préexistants ou non, et partager ces rapports avec d’autres membres de l’équipe.
Facile à prendre en main grâce à sa fonction de « glisser-déposer », la plateforme permet à l’utilisateur de créer des graphiques (tableaux croisés dynamiques, barres, secteurs, cartes, nuages de points, etc.) à partir de données importées. Par ailleurs, la richesse des filtres permet à chaque utilisateur de sélectionner une plage de dates et d’accéder à des données précises. Actualisées automatiquement et en temps réel, ces données permettent un gain de temps considérable dans l’analyse !
Pour ce faire, Looker Studio peut se connecter à une grande variété de sources de données comme Google Analytics, Google Ads, Google Sheets, ainsi que des sources de données tierces telles que Salesforce, Facebook et Twitter. Ceci permet donc aux utilisateurs de combiner différentes sources pour créer des rapports unifiés et fournir une vue d’ensemble complète de leurs activités commerciales.
Enfin, Looker Studio permet également de partager les rapports créés avec d’autres membres de l’équipe via un lien ou incorporés dans un site Web ou une application, avec la possibilité de configurer les autorisations et ainsi contrôler leur accès et modification. Un outil plutôt complet in fine !
Looker Studio est également reconnu pour ses nombreux avantages :
Entièrement gratuit, le logiciel est accessible à une large gamme d’utilisateurs et d’entreprises.
Interface intuitive et facile d’utilisation, les utilisateurs peuvent créer des rapports sans avoir besoin de compétences techniques avancées.
Couplage fort avec les nombreux logiciels de la suite Google, tout en permettant la connexion à une centaine de sources de données tierces telles que Salesforce, Facebook et Twitter.
Les utilisateurs peuvent personnaliser leurs rapports grâce à une multitude de fonctionnalités qui facilitent l’interprétation des reportings.
Les utilisateurs peuvent facilement partager leurs rapports avec d’autres membres de l’équipe et les modifier en temps.
Tout rapport Looker Studio peut être inclus dans n’importe quelle page Web ou n’importe quel intranet.
Cependant, il y a aussi quelques inconvénients à considérer :
Certaines visualisations de données avancées ne sont pas disponibles dans Looker Studio, ce qui peut limiter la capacité des utilisateurs à créer des rapports personnalisés avec des visualisations complexes.
Looker Studio est un produit Google et dépend donc de ses services tels que Google Drive et Google Cloud Platform. Si ces services sont en panne ou subissent des perturbations, cela peut affecter l’utilisation du logiciel.
La tarification et les coûts opérationnels peuvent s’accumuler rapidement si plusieurs utilisateurs accèdent aux rapports ou si l’utilisation des fonctionnalités augmente.
🎯A qui s’adresse Looker ?
Looker Studio s’adresse à tout type d’entreprises, qui cherchent un outil de reporting facile d’utilisation et permettant :
De visualiser ses données.
De mettre en commun une grande variété de sources sans besoin de programmation.
Departager et collaborer ces rapports.
💶 Prix
Si Looker Studio existe en version gratuite, il existe aussi en version professionnelle. Connue sous le nom de Looker Studio Pro, cette version propose de nombreuses fonctionnalités supplémentaires comme :
La possibilité d’une intégration avec Dataplex (un data fabric pour gérer, surveiller et assurer la gouvernance des données ainsi que la visibilité des métadonnées).
L’arrivée d’un support d’accompagnement.
Des fonctions de gestion d’entreprise, des capacités de collaboration en équipe et de SLA (Accords de service).
Une collaboration renforcée entre Looker Studio et les outils des concurrents, dont Tableau et PowerBI.
Un accès aux Looker Model directement depuis LS via un connecteur natif intégré.
L’idée de proposer une version payante plus aboutie que Looker Studio vise à corriger deux défauts de la version gratuite :
Éviter les risques de coupures de sources de données : en effet, ces dernières seront désormais disponibles au niveau “Organisation” et non plus au niveau “Individuel”. Ainsi, les sources de données ne seront pas perdues même si la personne qui les a créés initialement quitte l’entreprise.
Une meilleure gestion des droits et des rapports grâce aux “Teams Workspaces” : les membres d’un workspace auront automatiquement accès au contenu créé, et les autorisations spécifiques sur les espaces de travail dépendent du rôle qui leur sera attribué : gestionnaire, gestionnaire de contenu ou contributeur.
Si les rumeurs annoncent une tarification abordable de 10$ / mois environ pour souscrire à cet abonnement, il est nécessaire de demander au service commercial pour se positionner sur un prix.
De toute évidence, si Metabase, Power BI et Looker Studio permettent l’exploitation et une bonne visualisation des données, qu’ils soient en version gratuite ou payante, ils ne remplacent pas un outil d’intégration de données à proprement dit comme une CDP (Customer Data Plateform) ou encore un ETL (Extract, Transform and Load). Si vous n’avez pas encore de CDP et que le sujet vous intéresse, n’hésitez pas à consulter notre topo sur l’implémentation et l’utilisation d’une CDP spécialement conçu pour vous !
CDP packagée VS CDP composée : quelle option choisir ?
Si vous envisagez de déployer une CDP dans votre entreprise, vous allez être confronté(e) à un choix. Vous avez (grosso modo*) 2 options d’architecture : la CDP packagée Vs la CDP composée.
D’un côté, la CDP packagée, tout-en-un, gérant l’ensemble de la chaîne de traitement & valorisation des données : collecte, déduplication, nettoyage, unification, segmentation/audiences, orchestration et parfois activation & BI.
De l’autre, la CDP composée qui consiste à construire sa CDP avec une combinatoire d’outils interconnectés et inter-opérables. Grosso modo, un Data Warehouse + un outil de Data Ops pour la normalisation et l’unification des données sans oublier les outils d’activation et l’outil de BI.
*Attention, cette séparation n’est pas si absolue qu’on pourrait le penser. Comme toujours, la réalité est plus nuancée. Les solutions CDP modernes, comme Octolis, cherchent le meilleur des deux mondes. On vous donne plus de détails en conclusion 🙂
Arpit Choudhury, un expert en infrastructure data, fondateur notamment d’Astorik, a publié un excellent article consacrée aux différences entre CDP packagée et CDP composée. L’article est en anglais. Parce qu’il nous a beaucoup plu et que nous voulions vous le partager, nous vous en proposons ici une traduction en français. Si vous prévoyez un projet CDP, cet article est vraiment à lire. Bonne lecture ! [Voici le lien vers l’article d’origine]
Arpit Choudhury
Martech expert & Fondateur de Databeats
Arpit Choudhury a travaillé pour de belles startups Martech comme Make ou Hightouch, avant de devenir entrepreneur. Il est aujourd’hui reconnu comme l’un des meilleurs experts sur le sujet des CDP. Arpit travaille désormais principalement sur DataBeats, une communauté et un centre de ressources pour les professionnels des technologies marketing.
Je pense que c’est un peu comme l’Hydre dans la mythologie grecque – le monstre aquatique qui se voit pousser deux têtes chaque fois qu’on lui en coupe une.
Chaque tentative de tuer la CDP l’a rendue plus fort, plus de gens en parlent et de plus de en plus de fournisseurs affirment qu’ils sont en fait une CDP déguisé – la CDP est officiellement antifragile.
J’ai été personnellement fasciné par la CDP. Au cours des trois dernières années, j’ai passé une quantité ridicule de temps à écrire sur la CDP et à suivre son évolution, de packagée à composée. Si vous avez suivi les discussions sur la CDP composée par rapport à la CDP packagée, vous avez certainement entendu les deux côtés de l’argument et vous n’avez pas besoin d’un autre article d’opinion expliquant pourquoi une approche est meilleure que l’autre.
Il est temps de publier un guide impartial qui propose une décomposition complète de la CDP en ses composants, qui, comme les têtes d’Hydra, ne cessent de se multiplier.
Ce guide a pour but d’aider les gens à prendre des décisions d’achat de CDP basées sur une compréhension claire des différents composants d’un CDP, de l’objectif de chaque composant et des composants nécessaires pour trouver le chemin le plus efficace pour mettre les données au travail avant qu’elles ne deviennent périmées ou inutilisables.
Commençons par les définitions.
Les définitions de la CDP
L’essor de l’entrepôt de données a conduit à l’émergence de l’ETL inversé à la fin de l’année 2020, puis à l’idée que la combinaison de ces deux technologies a permis aux entreprises de construire – ou plus exactement d’assembler – une plateforme de données clients au-dessus de l’entrepôt de données.
C’est ainsi que l’idée d’une CDP composée est apparue début 2021 et a pris de l’ampleur en 2022. Mais qu’est-ce qu’une CDP composée ? S’agit-il d’une architecture ? Est-ce une approche ? Un ensemble d’outils intégrés ? Ou s’agit-il d’une solution produite comme une CDP packagée ?
Si vous recherchez « Composable CDP » sur Google, vous constaterez qu’aucun article n’offre une définition concise de ce terme. Changeons cela.
Qu’est-ce qu’une CDP packagée ?
Une plateforme de données clients (CDP) packagée est une solution tout-en-un produite avec des capacités de collecte et de stockage de données provenant de sources multiples, de transformation et d’unification des données, de résolution des identités, de création d’audiences et de synchronisation des données vers des destinations en aval. En outre, certaines CDP packagées offrent également des outils permettant de définir des règles de qualité des données, de mettre en œuvre des protocoles de gouvernance des données et de se conformer aux réglementations en matière de protection de la vie privée.
Il y a deux éléments clés à prendre en compte :
Une CDP packagée doit stocker une copie des données qu’elle collecte afin de résoudre les identités (résolution d’ID) et de construire des profils d’utilisateurs unifiés. Cependant, la méthodologie de résolution d’identité utilisée – probabiliste ou déterministe – varie d’un fournisseur à l’autre.
Un fournisseur de CDP packagé permet généralement aux entreprises de créer leurs propres packages en combinant les capacités de base et les outils complémentaires.
Qu’est-ce qu’une CDP composée ?
Une plateforme de données clients composée (CDP) est un ensemble d’outils intégrés qui sont assemblés à l’aide de logiciels libres ou propriétaires afin d’exécuter certaines ou toutes les fonctions d’une plateforme de données clients packagée.
Il y a deux éléments clés à prendre en compte :
Une CDP composée possède certaines ou toutes les capacités d’une CDP packagée, en fonction de la manière dont elle est composée ou assemblée.
Une CDP composée est assemblée à l’aide de logiciels libres, de solutions gérées de logiciels libres ou d’outils SaaS propriétaires.
Maintenant que les définitions sont connues, examinons plus en détail les différents composants d’un CDP.
Les composantes d’une CDP
L’un des principaux problèmes posés par le terme « Customer data Platform » est qu’il a été utilisé et détourné par divers fournisseurs de logiciels dans des contextes différents. De nombreux éditeurs ont même positionné une fonctionnalité de leur produit comme une CDP, simplement parce que cette fonctionnalité permet aux utilisateurs de gérer les données clients qui ont été intégrées dans ce produit.
J’aimerais énumérer quelques mises en garde avant de présenter un aperçu complet de chaque composante d’une CDP :
Tous les fournisseurs de CDP packagées n’offrent pas l’ensemble de ces composants.
Plusieurs fournisseurs de CDP établis offrent des capacités ou des composants supplémentaires.
Au sein de chaque composante, les fonctionnalités spécifiques peuvent varier d’un fournisseur à l’autre.
Vous n’avez pas nécessairement besoin de tous ces composantes pour composer une CDP.
Entrons dans le vif du sujet.
1. La collecte de données comportementales : l’infrastructure de données clients (IDC)
Une IDC est un outil spécialisé qui offre un ensemble de SDK pour collecter des données comportementales ou des données d’événements à partir de sources de données de première partie.
Votre produit principal – applications web, applications mobiles, appareils intelligents ou une combinaison des deux – alimenté par un code propriétaire est une source de données de première partie, et les données comportementales permettent de comprendre comment votre produit est utilisé et d’identifier les points de friction.
Ces données sont un prérequis pour une CDP et sans ces données, une CDP n’est pas une CDP. Les données comportementales provenant de vos sources de données de première partie servent de base à une CDP.
Il y a deux éléments clés à prendre en compte ici :
La capacité IDC d’une CDP packagée permet de synchroniser les données directement avec des outils tiers en aval, sans qu’il soit nécessaire de stocker une copie des données dans votre propre data warehouse.
Les IDC autonomes prennent en charge du Data Warehouse en tant que destination principale et, par rapport à la composante IDC des CDP packagées, les IDC autonomes (tels que Snowplow) offrent moins d’intégrations de destinations tierces.
Pour en savoir plus sur les capacités et les fournisseurs d’IDC (dont certains font partie d’offres plus larges de CDP), voici.
P.S. : Bien que j’aie été un fervent partisan du terme IDC, avec le recul, je pense que le terme « Client » devrait être remplacé par « Audience » car les données collectées ne concernent pas uniquement les clients – en fait, la collecte de données est initiée bien avant qu’un utilisateur ou une organisation ne devienne un client. Si la notion d’Audience plutôt que de Client vous parle, vous apprécierez la lecture de cet article.
Éléments de collecte de données d’un PDC : IDC et ELT/ETL
2. L’ingestion des données : ELT (ou ETL)
Une solution ELT/ETL autonome est conçue pour extraire tous les types de données d’un catalogue croissant de sources de données secondaires (outils tiers) et les charger dans des Cloud Data Warehouse.
Les sources de données secondaires comprennent les outils tiers avec lesquels les utilisateurs interagissent directement ou indirectement – outils utilisés pour l’authentification, les paiements, les expériences in-app, l’assistance, le retour d’information, l’engagement et la publicité.
Il y a deux éléments clés à prendre en compte ici :
Une CDP packagée qui offre des fonctionnalités ELT – des intégrations à la source avec des outils tiers – ingère d’abord les données dans son propre magasin de données, et peut en outre synchroniser les données avec un Data Warehouse via des intégrations de destination.
Les capacités d’ELT des fournisseurs de CDP packagées sont très limitées par rapport aux solutions d’ELT conçues à cet effet. Si vous avez besoin de données dans une CDP à partir d’une source qui n’est pas prise en charge de manière native par le fournisseur de CDP, vous devrez construire votre propre pipeline ou utiliser un outil d’ELT pour envoyer les données vers votre Data Warehouse, puis les synchroniser à nouveau avec la CDP à l’aide des intégrations de source proposées par les fournisseurs de CDP.
Si vous souhaitez explorer les offres des principaux fournisseurs d’ELT, voici.
3. Le stockage des données
Comme nous l’avons déjà mentionné, les fournisseurs de CDP packagées stockent une copie des données qu’ils collectent dans un magasin ou un Data Warehouse interne. Les clients peuvent en outre envoyer une copie des données à leur propre Data Warehouse ou Data Lake par le biais d’intégrations de destination.
Le Data Warehouse, comme vous le savez déjà, est le composant central d’une CDP composée – la pièce maîtresse à laquelle tous les autres composants se connectent.
Il y a deux considérations essentielles à prendre en compte ici :
Le Data Warehouse a toujours été utilisé pour stocker des données relationnelles provenant d’outils tiers et pour visualiser ces données à l’aide d’un outil de BI. Par conséquent, pour assembler une CDP composée, même les entreprises qui ont déjà un entrepôt en place doivent ingérer des données comportementales à partir de leurs sources de première partie à l’aide d’un IDC.
Une CDP packagée peut être utilisée parallèlement à un Data Warehouse. En fait, il est de plus en plus fréquent que les clients des CDP packagées stockent une copie de leurs données dans leur propre Data Warehouse en vue d’une utilisation ultérieure. En outre, les entreprises adoptent une approche hybride dans laquelle elles exploitent les capacités prêtes à l’emploi d’une CDP packagée pour certains cas d’utilisation tout en assemblant une CDP composée pour les cas d’utilisation avancés qui s’appuient sur des modèles de données personnalisés.
4. La résolution d’identité et l’API de profil
La résolution d’identité est le processus d’unification des enregistrements d’utilisateurs capturés à travers de multiples sources. Elle nécessite un ensemble d’identifiants (ID) utilisés pour faire correspondre et fusionner les enregistrements d’utilisateurs provenant de différentes sources, ce qui permet aux entreprises d’obtenir une vue d’ensemble de chaque utilisateur ou client.
La résolution d’identité a plusieurs cas d’utilisation, mais elle contribue principalement aux efforts de personnalisation et de protection de la vie privée.
La résolution d’identité crée des profils unifiés qui peuvent être synchronisés en aval à l’aide de l’API de profil.
Il y a deux éléments clés à prendre en compte ici :
Une CDP packagée offre une capacité de résolution d’identité prête à l’emploi et crée des profils d’utilisateur unifiés. Les clients utilisant une CDP peuvent ensuite synchroniser ces profils unifiés avec un Data Warehouse ou des outils tiers à l’aide des API disponibles. Par ailleurs, comme nous l’avons déjà mentionné, un fournisseur de CDP utilise soit la méthodologie probabiliste, soit la méthodologie déterministe pour résoudre les identités.
Dans l’approche composée, les entreprises doivent gérer la résolution des identités dans leur propre Data Warehouse en écrivant le code d’unification à l’aide de SQL. Grâce à la flexibilité offerte par cette approche, l’analyste peut utiliser la méthodologie de résolution d’identité qui fonctionne le mieux en fonction des points de données disponibles.
5. Le Visual Audience Builder (et la modélisation des données)
Autre prérequis d’une CDP, un générateur d’audience visuelle est précisément ce qu’il semble être – une interface glisser-déposer pour construire des audiences ou des segments en combinant des données provenant de diverses sources.
Dans le cadre de l’approche composée, cette capacité est offerte par les outils ETL inversés, désormais appelés outils d’Activation des Données.
Il y a deux éléments clés à prendre en compte :
Une CDP packagée crée automatiquement les modèles de données sous-jacents à partir des données qu’il stocke, ce qui permet aux équipes non spécialisées dans les données de créer des audiences sans aucune dépendance. Cependant, ces modèles sont rigides et les clients ne peuvent pas créer des modèles personnalisés en fonction de leurs besoins spécifiques.
Un outil d’ETL inversé/d’activation des données exige que les équipes chargées des données construisent et exposent des modèles de données (à l’aide de SQL) au-dessus des données présentes dans le Data Warehouse, afin de permettre aux équipes non chargées des données de créer des audiences à l’aide du générateur d’audience visuelle. Cette approche donne aux entreprises une flexibilité totale sur leurs modèles et la possibilité d’incorporer des entités personnalisées.
P.S. : Je pense qu’il faudrait un meilleur terme pour décrire cette catégorie d’outils car l’ETL inversé n’est qu’une fonctionnalité et l’activation des données est un cas d’utilisation qui peut également être réalisé à l’aide d’une CDP packagée.
6. L’ETL inversé
Comme vous le savez déjà, l’ETL inversé fait référence au processus de déplacement des données du Data Warehouse vers des destinations en aval – généralement des outils tiers, mais il peut également s’agir d’une base de données interne.
Les entreprises construisent des pipelines ETL inversés depuis un certain temps ; cependant, l’utilisation du terme « ETL inversé » n’a commencé qu’après la productisation de l’ETL inversé au début de 2020 (j’ai entendu le terme pour la première fois en août 2020 de la part de Boris Jabes).
Nous sommes en 2023 et l’ETL inversé est désormais une fonctionnalité ou une composante de la CDP.
Qu’il s’agisse de la Data Warehouse de la CDP ou de la Data Warehouse du client, le déplacement des données vers l’aval est un ETL inversé.
Il y a deux considérations essentielles à prendre en compte ici :
La capacité d’une CDP packagée à déplacer des données vers des destinations en aval, souvent appelée orchestration, est essentiellement un ETL inversé où les données sont déplacées à partir de l’entrepôt de données de la CDP et non de la Data Warehouse du client. Aujourd’hui, la plupart des CDP packagées prennent également en charge la Data Warehouse du client en tant que source de données.
Dans l’approche composée, les entreprises qui aiment tout construire en interne peuvent créer leurs propres pipelines ou tirer parti de l’ETL inverse packagé offert par les outils d’activation de données (comme Census ou Hightouch) ainsi que par certains IDC (comme RudderStack).
7. La qualité des données
Composante sous-estimée mais importante, la qualité des données (QD) aide les entreprises à s’assurer que les données qui alimentent leurs CDP ne sont pas bizarres. Les outils de QD aident les entreprises à maintenir la validité, l’exactitude, la cohérence, la fraîcheur et l’exhaustivité des données.
La qualité des données est une catégorie très vaste qui comprend une pléthore d’outils permettant de détecter les problèmes et de maintenir la qualité de différents types de données. Cependant, les données comportementales constituent la base d’une CDP et il faut donc des outils pour s’assurer que les données sont valides, exactes et fraîches.
Il y a deux éléments clés à prendre en compte ici :
Une CDP packagée offre généralement des fonctions de qualité des données permettant d’effectuer des tests sur les données comportementales collectées. Il permet également aux équipes d’élaborer des plans de suivi en collaboration.
Dans l’approche composée, la composante QD peut provenir de l’outil IDC ou d’une solution QD distincte (comme Great Expectations) qui peut, au minimum, valider les données entrantes.
8. Gouvernance des données et respect de la vie privée
Un autre élément extrêmement important et pourtant sous-représenté d’une CDP est la capacité à mettre en place des contrôles de gouvernance et des flux de travail de conformité.
Il est juste de dire que c’est quelque chose dont les entreprises ont besoin de toute façon, qu’elles utilisent une CDP ou non. Cependant, si une entreprise utilise une CDP – qu’elle soit packagée ou composée – elle doit s’assurer de certaines choses, telles que :
La collecte des données n’est lancée qu’après que l’utilisateur a consenti à ce que les données soient collectées à des fins spécifiques telles que le marketing ou l’analyse.
Seules les données nécessaires à un outil tiers sont envoyées à cette destination spécifique. Par exemple, les IIP telles que l’adresse électronique ne sont envoyées à un outil tiers qu’après que l’utilisateur final a explicitement consenti à recevoir des courriels envoyés à l’aide de cet outil tiers.
Si un utilisateur refuse la collecte de données, aucune autre donnée le concernant ne doit être collectée auprès de sources de première et de tierce parties.
Si un utilisateur souhaite être oublié (GDPR) ou refuser que ses données soient vendues (CCPA), les demandes d’effacement doivent être envoyées aux outils tiers en aval desquels ses données ont été envoyées plus tôt.
Les membres de l’équipe interne ne doivent pouvoir accéder aux données sensibles ou aux IIP que s’il est nécessaire qu’ils accèdent à ces données, avec des autorisations granulaires basées sur les rôles.
Il ne s’agit là que de quelques-unes des capacités clés de la composante de gouvernance et de conformité d’une CDP et, comme vous pouvez le constater, il n’est pas facile de créer cette composante en interne.
Il y a deux éléments clés à prendre en compte ici :
Les capacités de gouvernance et de conformité des CDP packagées varient considérablement et seuls les principaux fournisseurs de CDP proposent des kits d’outils complets.
Dans le cadre de l’approche composée, il est possible d’exploiter certaines de ces fonctionnalités offertes par certains fournisseurs d’IDC ou d’intégrer des outils autonomes spécialement conçus pour la gouvernance et la conformité.
Conclusion (Octolis)
Nous espérons que cet article vous a aussi intéressé(e) que nous et que vous comprenez bien maintenant la différence entre les deux approches – même si, comme nous le disions en introduction, il faut nuancer un peu les choses. C’est la seule réserve que nous aurions vis-à-vis de l’article de Arpit Choudhury qui, par ailleurs, nous a vraiment stimulés !
En effet, ce que l’on observe depuis 2022, c’est la réduction du fossé entre les 2 approches. Les CDP modernes réunissent le meilleur des deux mondes.
Octolis, une CDP packagée ou une CDP composée ? Le meilleur des deux mondes !
La plateforme que nous proposons, Octolis, fonctionne en surcouche d’un Data Warehouse indépendant. Le but ? Que le client reste maître de sa base de données. Data Warehouse + Octolis = CDP 2.0. Mais nous intégrons dans le même temps toutes les fonctions de traitement des données associées classiquement aux CDP packagée. Octolis est donc à la fois (composante d’une) CDP composée et CDP packagée (tout-en-un). Si vous êtes curieux d’en savoir plus sur notre vision de la CDP, sur Octolis, sur les architectures data modernes, n’hésitez pas à entrer en contact avec nous !
Analytics Ecommerce – Panorama des meilleurs outils
Honnêtement, pas simple de choisir son ou ses outil(s) d’analytics ecommerce. D’abord parce qu’il en existe des dizaines d’excellents et des centaines de très bons. Ensuite, parce que l’offre est très variée. Quoi de commun entre un Matomo et un Hotjar ? Pas grand-chose, et pourtant ce sont tous les deux de super outils pour piloter la performance ecommerce.
Pour vous aider à vous y retrouver et à choisir le ou les logiciel(s) qui correspond(ent) à vos besoins, nous allons vous présenter notre petite sélection. Nous avons classé les outils en 3 familles : les solutions tout-en-un, les outils de web analytics et les outils pour collecter/préparer vos données en vue de l’analyse. Remarque : ce tableau sert de menu, le texte est cliquable, profitez-en, n’hésitez pas à l’utiliser pour naviguer sur ce trèèès long article :).
Plateformes permettant de connecter l'ensemble des données de votre écosystème (CMS, analytics web, ads...) et de créer des tableaux de bord personnalisables ou sur-mesure.
Ces outils se concentrent sur l'analyse du trafic du site web, du comportement de navigation des visiteurs et des conversions sur le site. Exemple : Matomo, Google Analytics...
On trouve aussi dans cette vaste famille des solutions 100% ecommerce (comme Shopify Analytics) ou spécialisées sur un type d'analyse en particulier (par exemple, les cartes de chaleur pour CrazzyEgg et Hotjar).
Les outils qui permettent de collecter et de travailler les données clients & ecommerce en vue de l'analyse. Si ces plateformes sont centrées sur la préparation des données, certaines d'entre elles proposent des fonctionnalités natives de reporting.
Les meilleurs outils analytics ecommerce all-in-one
L’utilisation de tableaux de bord pour visualiser les données est une méthode moderne et efficace pour analyser et organiser les données de marketing. Ces outils simplifient le processus d’analyse en rassemblant toutes les données et en les présentant en un seul endroit. Cet article présente les meilleurs outils analytics ecommerce all-in-one.
Un bon tableau de bord associe plusieurs caractéristiques. Tout d’abord, la personnalisation est essentielle car elle vous permet de représenter clairement les priorités de votre business. De plus, la capacité à accéder au tableau de borddepuis n’importe quel device permet de suivre l’évolution des données à tout instant. Enfin, il est crucial que le tableau de bord soit capable de prendre en charge différentes sources de données et de s’adapter à l’évolution de votre business.
Glew.io
Glew fait parti des meilleurs outils analytics ecommerce avec plus de 180 intégrations et les présente sous la forme de plus de 200 KPI prêts à l’emploi, avec des rapports personnalisés pour répondre à vos besoins spécifiques. Bref, Glew fait parler vos données!
L’installation rapide et facile de Glew en fait un atout majeur et un outil facile d’utilisation, rapide et efficace, qui ne nécessite pas des ressources techniques importantes. Le processus de configuration simplifié facilite l’utilisation et la capacité à générer des données avancées sur la performance des canaux. De plus, en tant que Retailer, la segmentation native des clients vous aidera à optimiser vos stratégies marketing.
Glew.io intègre un large éventail de fonctions, notamment l’automatisation du marketing, la publicité, l’expédition, le support client, l’inventaire et les abonnements. Il s’agit donc d’un outil polyvalent qui peut être personnalisé pour répondre à vos besoins spécifiques de sorte de personnaliser vos besoins.
Glew fournit des données avancées sur les performances des canaux qui peuvent aider vous aider à déterminer des indicateurs tels que la lifetime value (LTV), le coût d’acquisition des clients (CAC) et le chiffre d’affaires par canal. Cela vous permet, Retailers, d’optimiser vos stratégies marketing et de prendre des décisions basées sur des données. En outre, Glew vous fournit des feedbacks et des visualisations personnalisés pour vous aider à prendre des décisions. Ainsi, vous êtes en mesure d’utiliser Glew de manière efficace et d’atteindre les résultats souhaités.
Enfin, Glew génère nativement plus de 30 segments de clients, ce qui facilite le filtrage des données sur la base d’indicateurs tels que les AOV (valeur moyenne de commande) élevés et faibles, les clients récurrents, etc. Cela vous perme de mieux comprendre leur base et d’adapter leurs efforts marketing en conséquence. Enfin, Glew offre un support client dédié afin de vous aider à tirer le meilleur parti de l’outil.
Les principaux points forts de l’outil :
Collecte et stockage automatiques de données provenant de sources multiples.
Suivi et analyse des données sur plusieurs plateformes en temps réel
Créez des rapports et des tableaux de bord personnalisés
Segmentez les données pour identifier les tendances et les opportunités au sein des différents segments de clientèle.
Obtenez des informations sur le comportement des clients
Mettez en place des alertes automatisées pour surveiller les performances
La Formule Starter de ce service est gratuite, tandis que la Formule Pro est proposée à $79 par mois. Pour la Formule « Custom reporting », un devis peut être fourni selon les besoins spécifiques.
Woopra est un des outils analytics ecommerce destiné à vous à développer des techniques de marketing. Cette solution collecte des données à partir de sources multiples, notamment les interactions sur le site web, les médias sociaux, les campagnes d’e-mailing, etc. Ensuite, Woopra créer un profil unique pour chaque utilisateur, cartographie ses interactions et le met à votre disposition.
Les outils de Woopra permettent d’extraire des informations des données collectées, notamment des feedbacks sur le parcours et les tendances clients. La plateforme offre également des outils de personnalisation et d’automatisation pour vous aider à agir sur vos données.
L’un des principaux atouts de Woopra consiste en sa capacité à s’intégrer à une grande variété d’outils tiers, notamment les plateformes publicitaires, les CRM, les plateformes d’automatisation du marketing, les plateformes d’e-commerce, etc.
Si Woopra est plus onéreux que d’autres solutions concurrentes, ses fonctionnalités plus approfondies et sa capacité d’intégration et d’automatisation en font un investissement utile pour ceux qui cherchent à exploiter les données de leurs clients à des fins de personnalisation et d’amélioration de l’engagement. En utilisant ces informations, vous pourrez personnaliser votre communication et donc être plus performant.
Enfin, Woopra met en place une série de profils clients, qui fournissent des informations sur le comportement des clients, tel que leur historique d’achats par exemple. Cette fonctionnalité offre une vue complète du parcours client, ce qui peut vous aider dans votre prise de décision et dans votre compréhension de l’expérience du client de manière globale.
Points forts :
Suite complète d’outils d’analyse et de suivi axés sur le parcours de l’utilisateur
Outils de création de profils permettant la collecte centralisée de données provenant de diverses sources
Des profils d’utilisateurs uniques permettent de suivre les interactions individuelles et collectives sur plusieurs appareils.
Outils d’analyse comprenant des rapports sur le parcours, les tendances, l’attribution, les cohortes et la rétention.
Segmentation comportementale personnalisée et capacités d’analyse du comportement
Accès complet à toutes les données sans échantillonnage
Outils de personnalisation et d’automatisation pour exploiter les données
Woopra propose différents niveaux de tarification pour répondre aux besoins de chaque entreprise. La Formule « Core » est gratuite, la Formule « Pro » est disponible à un coût de $999, et la Formule « Entreprise » est proposée sur devis.
Heap
Heap est une plateforme d’analyse spécialement conçue pour les applications web. Sa capacité à enregistrer chaque interaction (clics, soumissions, transactions, etc.) est un outil précieux pour ceux qui souhaitent exploiter au mieux les données. Son interface visuelle ergonomique simplifie l’analyse du comportement des utilisateurs, ce qui vous permettra d’identifier les taux de conversion avec les clients.
Ce qui distingue Heap, c’est qu’il s’intègre de manière transparente dans les applications construites sur Rails ou Node.js, ce qui simplifie sa mise en œuvre. Ainsi, vous pouvez commencer à collecter des données auprès de leurs utilisateurs immédiatement!
L’une des caractéristiques les plus remarquables de Heap est sa capacité à enregistrer de façon automatisée les actions des utilisateurs mais également les paramètres qui déterminent cette action. Il fait parti de cet gamme d’outils analytics ecommerce permet vous permet de créer des cohortes basées sur ces actions et d’obtenir des informations plus approfondies sur le comportement de leurs clients. Heap est également très flexible, pour vous permettre de sélectionner des données à partir de n’importe quel appareil, qu’il s’agisse d’un ordinateur de bureau, d’une tablette ou d’un téléphone portable.
En outre, Heap fournit automatiquement des informations exploitables en fonction des tendances et des comportements des utilisateurs, ce qui vous permet de mieux comprendre votre audience et d’optimiser votre site ou votre application en conséquence.
Dans l’ensemble, Heap est un des outils analytics ecommerce qui fournit des données actualisées, fiables et précises afin que les analyses qu’il effectue puissent être réalisées rapidement et avec précision de sorte qu’en tant que Retailer vous êtes certains que les informations reçues en temps réel sont exactes.
Points forts :
Suivi en temps réel des actions sur votre site
Analyse du parcours client et des cohortes pour améliorer l’expérience utilisateur.
Visualisation des données afin de comprendre facilement les données et les tendances
Capacité à fournir automatiquement des informations exploitables basées sur les données de comportement des utilisateurs
Heap propose différentes options de prix : une formule gratuite pour les business jusqu’à 10k par mois avec la Formule « Free », une option gratuite calibrée pour les start-up avec la Formule « Growth », une formule sur devis pour la Formule « Pro » et la Formule « Premier ».
SavvyCube propose des outils analytics ecommerce et de reporting pour vous aider à développer votre activité de e-commerce. L’un des principaux atouts de SavvyCube est sa capacité à produire des feedbacks très détaillés pour savoir d’où viennent les clients mais également pour savoir quelles zones de votre site sont consultés. Vous pouvez également suivre les ventes, les performances des produits et le comportement des clients, le tout à partir d’un seul et même outil.
L’intégration de SavvyCube avec les plateformes d’e-commerce vous garantit l’accès à toutes les données dont vous avez besoin pour optimiser votre activité. Grâce à des fonctionnalités telles que le dashboard, l’analyse des ventes, l’analyse des produits et l’analyse des clients, vous pouvez visualiser et analyser ces données sous toutes les coutures.
En outre, SavvyCube vous permet de décomposer des séries de données brutes provenant de diverses sources en fonction de certains indicateurs clés de performance. Vous pouvez également utiliser la fonction “Email Reports” pour recevoir des mises à jour régulières sur les performances de votre business.
SavvyCube propose des outils analyses du profil client qui vous permet de mieux comprendre le comportement et les caractéristiques démographiques de vos clients. Ces informations sont utiles pour personnaliser les offres et les communications.
Parmi les outils analytics ecommerce, SavvyCube est idéal pour les équipes marketing et les agences de conseil numérique qui cherchent à mieux exploiter les données clients afin d’optimiser leurs performances. Ses capacités de reporting, sa facilité d’utilisation et son intégration avec les plateformes d’e-commerce les plus répandues en font un choix fiable.
Points forts :
Des rapports personnalisés permettent une analyse approfondie des performances de l’entreprise.
L’analyse des clients permet de mieux comprendre leur comportement et leurs caractéristiques démographiques.
Les intégrations avec des plateformes telles que PayPal, Shopify et Google Analytics améliorent les capacités de la plateforme.
La plateforme peut consolider les données provenant de plusieurs systèmes d’analyse.
Des rapports réguliers envoyés par courriel permettent aux utilisateurs de se tenir au courant des performances de leur magasin.
Les prix de SavvyCube commencent à $45 par mois pour la formule « Starter », suivie de la formule « Growth » à $99, de la formule « Professional » à $199 et de la formule « Advanced » à $499.
Databox
Les outils analytics ecommerce de visualisation des données vous permettent en tant que Retailer de surveiller leurs principaux indicateurs de performance en un lieu centralisé. Avec plus de 70 intégrations disponibles, y compris Google Sheets et Excel, Databox vous permet de facilement rassembler et synchroniser toutes vos données directement sur un tableau de bord, qui est mis à jour en temps réel. L’outil propose également des centaines de modèles de tableaux de bord prédéfinis que vous pouvez utiliser ou modifier en fonction de leurs besoins.
Databox permet de créer, d’éditer et de gérer facilement n’importe quel contenu, ce qui en fait une solution efficace pour l’analyse des données. De plus, cette solution facilite la personnalisation des modèles prédéfinis, ce qui peut vous aider à concentrer vos efforts de marketing et à améliorer la cartographie du parcours client.
Dans l’ensemble, Databox est un excellent outil : son suivi des données en temps réel et ses fonctions de reporting fournissent des informations qui aident à prendre des décisions informées. Databox s’intègre aisément avec diverses sources de données et ses tableaux de bord personnalisables en font une solution efficace pour la gestion et l’analyse des données.
En outre, des feedbacks réguliers envoyés par e-mail vous informant en fournissant des informations utiles sur les tendances des ventes et le comportement des clients, ce qui rend plus facile la collaboration et la communication entre les équipes et les parties prenantes.
En conclusion, avec sa capacité à rassembler et synchroniser des données en un lieu centralisé, ainsi qu’à fournir des feedbacks réguliers, les outils analytics ecommerce de Databox offre des informations précieuses pour vous aider à prendre des décisions informées. Databox est une solution efficace pour la gestion et l’analyse des données. Dans l’ensemble, Databox est un excellent outil pour les Retailers qui cherchent à mieux exploiter les données de leurs clients et à améliorer leur stratégie de marketing et de vente.
Points forts :
Contrôles personnalisables pour répondre aux besoins spécifiques de chaque entreprise.
Application mobile performante et facile à utiliser qui permet de surveiller les performances en temps réel
Gestion souple des données provenant de différentes sources
Interface utilisateur agréable pour la création de tableaux de bord et la visualisation des données
Plusieurs options de visualisation des données y compris des graphiques, des tableaux et des cartes thermiques.
Databox propose une formule gratuite en dessous de 4 data-connections, tandis que les plans payants commencent à partir de $72 pour la formule « Starter », $135 pour la formule « Professional » et $231 pour la formule « Performer ».
BeProfit
BeProfit appartient aux outils analytics ecommerce de suivi des bénéfices conçu pour la vente en ligne. L’outil est spécialement conçu pour les commerçants Shopify, leur permettant de suivre leurs bénéfices, leurs dépenses et d’autres indicateurs clés à partir d’un tableau de bord ergonomique. Grâce à ses fonctions de reporting avancées et à son interface intuitive, BeProfit peut vous aider à prendre de meilleures décisions fondées sur des données.
L’une des principales caractéristiques de BeProfit est sa capacité à s’intégrer à un large éventail de plateformes, notamment Amazon et eBay. Les commerçants peuvent ainsi facilement connecter tous leurs canaux de vente et suivre leurs bénéfices et leurs dépenses en un seul endroit. L’outil permet également aux utilisateurs de personnaliser leurs rapports et de visualiser leurs données dans une variété de formats, y compris des graphiques, des diagrammes et des tableaux.
Un autre avantage de BeProfit est sa capacité à suivre les dépenses et à calculer la rentabilité. L’outil permet aux utilisateurs de suivre toutes leurs dépenses, y compris les frais d’expédition, les dépenses publicitaires et même le coût des marchandises vendues. Les commerçants peuvent ainsi se faire une idée précise de leurs marges bénéficiaires réelles et identifier les domaines dans lesquels ils peuvent réduire leurs coûts et améliorer leur rentabilité.
BeProfit offre également des fonctions avancées de prévision et de définition d’objectifs, permettant aux commerçants de fixer des objectifs et de suivre leurs progrès au fil du temps. Cette fonction peut s’avérer particulièrement utile pour si vous cherchez à développer leurs activités et à augmenter leurs bénéfices. L’outil offre également une gamme d’alertes et de notifications personnalisables, aidant les commerçants à rester au fait de leurs indicateurs commerciaux et à prendre les mesures qui s’imposent.
Enfin, BeProfit est disponible à un prix très abordable, ce qui le rend facilement accessible. Dans l’ensemble, BeProfit est un des outils analytics ecommerce que l’on trouve sur le marché qui est complet.
Points forts :
Utilise des outils d’analyse avancés pour obtenir des informations approfondies sur les performances marketing et le CLTV.
Affiche les produits et services les plus vendus et utilise l’attribution UTM pour déterminer le retour sur investissement et les taux de conversion sur toutes les plateformes et tous les sites web.
Décompose les données et les compresse dans des diagrammes et des graphiques pertinents.
Accédez aux données à tout moment via le mobile, le web ou l’application et collaborez avec vos collègues en temps réel.
Le tableau de bord entièrement personnalisable vous permet de saisir des dépenses et des revenus variables, de créer des rapports uniques et d’ajouter des catégories et des préférences.
Permet de suivre les coûts des transporteurs, les méthodes de production, les coûts et les frais.
Synchronisation automatique avec les plateformes publicitaires telles que Google, Facebook, Instagram, Snapchat, Tiktok, Pinterest et Bing.
Les utilisateurs peuvent choisir entre trois plans tarifaires pour cet outil, avec un tarif de départ de 25 $ pour la formule Basic, 75 $ pour la formule Pro, et 150 $ pour la formule Ultimate
Les meilleurs outils analytics web
Les outils analytics web sont des logiciels utilisés pour suivre et analyser le comportement des visiteurs d’un site web, fournissant des informations sur la manière dont les utilisateurs interagissent avec un site web, telles que les pages visitées, le temps passé sur chaque page, leurs actions et leurs informations démographiques. En utilisant des outils d’analyse web, les entreprises peuvent mieux comprendre le trafic de leur site web et utiliser ces informations pour prendre des décisions fondées sur des données afin d’améliorer leur présence en ligne.
En plus des outils de suivi de performance de base, comme Google Analytics, il existe des outils plus avancés tels que Hotjar, qui permettent d’analyser en détail le comportement des visiteurs, notamment en utilisant des « heatmaps ». Les données collectées par les outils de web analytics vous aideront, en tant que Retailer, à améliorer l’UX de votre site internet, le taux de conversion et, in fine, vos revenus ecommerce
Google Analytics
Google Analytics offre un large éventail de fonctionnalités qui permettent aux data et CRM managers de mieux comprendre le comportement de leurs clients sur leur site web et de prendre des décisions informées sur la base de ces données.
L’un des principaux atouts de Google Analytics est son interface ergonomique, qui facilite la navigation et l’analyse des données. Google Analytics offre une grande variété de feebacks qui donnent un aperçu du trafic sur le site web, du comportement des utilisateurs et des taux de conversion. La plateforme fournit également des informations en temps réel, ce qui permet de consulter les données les plus récentes et de prendre des décisions rapides sur la base de ces données.
Un autre point fort de Google Analytics est sa capacité à suivre et à analyser plusieurs canaux, y compris les réseaux sociaux. Cela permet aux retailers de comprendre le parcours du client à travers plusieurs touchpoints, et de prendre des décisions en fonction des informations disponibles sur la manière d’optimiser leurs stratégies de marketing.
Google Analytics offre également des fonctionnalités avancées telles que le suivi des objectifs, le suivi du eCommerce et les reporting personnalisés, ce qui permet aux gestionnaires de données et de CRM d’adapter leurs feedbacks à leurs besoins spécifiques. Ils peuvent également créer des tableaux de bord personnalisés, ce qui leur permet de voir rapidement les données les plus importantes d’un seul coup d’œil.
L’utilisation de Google Analytics est gratuite pour les PME/ETI. Toutefois, pour les business plus conséquents, Google propose une version premium de Google Analytics, appelée Google Analytics 360, qui offre des fonctionnalités supplémentaires telles que l’analyse avancée des données, le traitement des données et l’intégration avec d’autres produits Google.
Points forts :
Aperçu complet des performances
Recevez divers rapports sur la façon dont les clients interagissent avec votre site et vos applications.
Points d’accès multiples aux données et outils d’organisation – grâce aux outils de filtrage et de manipulation des données,
vous pouvez facilement visualiser vos données, les personnaliser et les segmenter.
Gestion des données et contrôle de l’accès des utilisateurs
Grâce aux outils analytiques qui vous fournissent des informations précieuses, vous pouvez mettre en œuvre les résultats pour configurer votre site web et vos applications.
Google Analytics fonctionne parfaitement avec les autres solutions Google.
Google Analytics propose deux plans tarifaires : gratuit et 360. Le coût de Google Analytics 360 est de 135,000 euros par an.
Matomo est un des outils analytics ecommerce qui se pose en alternative à Google Analytics. Il s’agit d’une plateforme open-source mise à jour par une communauté d’utilisateurs. Matomo est actuellement utilisé par plus d’un million de sites web dans plus de 190 pays, ce qui en fait une plateforme d’analyse de choix pour les entreprises qui cherchent à obtenir des informations sur les visiteurs de leur site web.
L’un des principaux avantages de Matom réside dans le contrôle total sur les données qu’il propose : vous pouvez ainsi personnaliser la plateforme pour répondre à vos besoins.
De plus, la plateforme offre une série de fonctionnalités remarquables qui aide à comprendre comment les utilisateurs interagissent avec votre site web. Matomoo fournit des feedbacks au sujet des visiteurs de votre site web : leur provenance géographique, la façon dont ils ont trouvé votre site et la langue parlée. Vous pouvez également suivre le comportement des utilisateurs, notamment les pages qu’ils ont visitées, les liens sur lesquels ils ont cliqué et les fichiers qu’ils ont téléchargés.
Matomo propose également des “heatmaps” qui montrent où les utilisateurs cliquent le plus sur votre page, ce qui vous permet de voir l’efficacité de votre mise en page et d’identifier les problèmes éventuels. L’enregistrement des sessions est également disponible, ce qui vous permet de rejouer en différé l’historique d’interaction avec vos pages, et même de suivre les adresses IP des utilisateurs pour une meilleure étude de marché.
Dans l’ensemble, Matomo est une plateforme d’analyse web puissante qui fournit des informations approfondies sur les visiteurs de votre site web et sur vos campagnes marketing. Avec ses options de prix flexibles, ses fonctionnalités personnalisables et sa communauté d’utilisateurs, c’est un excellent choix pour les gestionnaires de données et de CRM qui travaillent dans le commerce de détail et qui souhaitent mieux exploiter les données des clients.
Points forts :
Open-source pour personnaliser et contrôler les données.
Matomo des feedbacks très détaillées (localisation, l’utilisation des moteurs de recherche, mots-clés, la langue parlée et les pages visitées).
Utilisation de heatmaps pour vous à mieux comprendre les données
Fonction d’enregistrement des sessions clients
Le plan tarifaire de Matomo est gratuit pour les serveurs auto-hébergés. Pour les entreprises souhaitant être hébergées sur le Cloud Matomo, les prix vont de 19 euros (50 hits) à 13 900 euros par mois (100 millions de hits et plus).
Shopify Analytics
Shopify Analytics est un outil d’analyse tout-en-un qui vous aide à prendre des décisions en fonction des données pour votre e-commerce. Il vous permet de suivre les indicateurs clés de performance (KPI) et d’obtenir des informations sur les performances de votre site.
L’un des grands atouts de Shopify Analytics est sa simplicité d’utilisation. Vous pouvez y accéder directement depuis votre tableau de bord Shopify et il ne requiert aucune compétence technique ni de codage. Il s’intègre également de manière transparente avec d’autres outils et applications Shopify, ce qui en fait une solution d’analyse intégrée pour votre site.
Shopify Analytics offre une série de fonctionnalités clés pour vous aider à mieux comprendre vos propres clients et à optimiser votre activité. Ces fonctionnalités incluent des feedbacks personnalisés, une analyse en entonnoir, le suivi du profil client et une analyse en temps réel. Vous pouvez également définir des objectifs et des alertes pour ne pas perdre de vue vos KPIs.
Un autre point fort de Shopify Analytics est son adaptabilité. Que vous soyez au début de votre activité ou dans un stade plus avancé de votre business, Shopify Analytics peut vous fournir les données et les informations dont vous avez besoin pour développer votre activité.
En somme, Shopify Analytics parmi les outils analytics ecommerce existant, ce dernier est performant si vous souhaitez prendre des décisions sur la base de données complètes! Sa facilité d’utilisation, sa gamme de fonctionnalités et son évolutivité en font un choix populaire pour les détaillants de toutes tailles. Grâce à Shopify Analytics, vous pouvez mieux connaître vos clients, optimiser votre activité et favoriser votre croissance au fil du temps.
Points forts :
Système d’inventaire pour la gestion et le développement de votre business
Vente multiplateforme et disponible sur plus de 3 000 applications disponibles
Shopify dispose d’une incroyable bibliothèque d’applications et d’extensions tierces pour vous aider à faire passer votre boutique au niveau supérieur.
Shopify est disponible 24 heures sur 24, 7 jours sur 7, pour vous aider si vous vous retrouvez dans une situation délicate.
Les utilisateurs peuvent choisir entre trois plans tarifaires pour cet outil, avec un tarif de départ de 36 euros pour la formule de base, 105 euros pour la formule médium, et 384 euros pour la formule Ultimate.
Piwik PRO
Piwik Pro est une solution anlytics pour analyser et améliorer l’expérience de vos clients à chaque étape de leur relation avec votre entreprise.
L’un des points forts de Piwik Pro réside dans ses fonctionnalités de confidentialité et de sécurité des données. La solution est validée par la CNIL et offre un outil « Consent Manager » qui vous permet de créer et d’implémenter des demandes de consentement, afin que les visiteurs puissent adapter leur collecte de données à leurs décisions. Cela garantit que vos balises de suivi ne sont déclenchées que lorsque les visiteurs acceptent de les utiliser.
Un autre point fort de Piwik Pro est son contrôle total sur les données que vous collectez. Avec Piwik Pro, vous pouvez choisir l’emplacement des données et ses options d’hébergement pour répondre aux besoins de confidentialité les plus stricts et aux protocoles internes. Piwik offre une liberté de choix concernant l’utilisation des données qui n’est pas disponible avec Google Analytics. L’anonymisation des données avec Piwik vous permet de rester conforme et d’obtenir des informations précieuses sur les visiteurs qui ont refusé ou ignoré vos demandes de consentement.
La solution offre plusieurs fonctionnalités pour améliorer votre commerce de détail. Avec Piwik Pro, vous pouvez cartographier votre parcours client, importer et exporter des données, créer des rapports et des analyses personnalisables, mettre en place des systèmes d’alerte et de notification, et gérer les balises sans l’intervention d’une équipe technique. Cela signifie que vous pouvez optimiser votre expérience client avec des données et des informations précises.
Piwik Pro est disponible en version gratuite (limitée) et premium (sur devis) de sa plateforme. La solution offre une interface conviviale, ce qui facilite l’adaptation à la plateforme. Cependant, il est important de noter que Piwik Pro n’est pas connecté à Google Tag Manager et qu’il est impossible de récupérer les données de Google Analytics. En conclusion, Piwik Pro est une excellente alternative à Google Alternative pour les data managers qui souhaitent s’orienter vers une solution analytics différente.
Points forts :
Cartographie du parcours client qui permet de suivre le comportement des visiteurs sur le site web
Importation/exportation de données à partir de différentes sources pour créer des rapports personnalisés.
Rapports et analyses personnalisables en fonction des besoins de chaque Retailers
Systèmes d’alerte et de notification intégré et système de gestion des tags sans intervention de l’équipe technique
Plateforme approuvée par la CNIL,ce qui garantit la conformité avec les réglementations de protection des données en Europe.
Piwik est gratuit de base, mais les options supplémentaires sont payantes et le tarif dépend de la taille de votre entreprise ainsi que du type d’option.
Snowplow
Snowplow Analytics est un formidable analytic web tool qui offre un maximum de flexibilité, de souplesse et de maîtrise des datas. Il est conçu pour les analystes qui ont besoin de maîtriser totalement leurs données, de la collecte au format des données, en passant par la logique commerciale. Snowplow Analytics est une source de données numériques qui offre des possibilités inégalées de modifier et de travailler directement avec vos données dans vos data warehouse.
L’un des principaux avantages de Snowplow Analytics est sa transparence. Contrairement à de nombreux outils d’analyse web, Snowplow Analytics ne comporte aucune boîte noire. Cela signifie que les utilisateurs ont une visibilité totale sur la manière dont les données sont collectées et agrégées, ce qui leur donne un contrôle total sur les données relatives aux événements. Avec Snowplow, vous pouvez construire vos propres modèles, définir vos propres agrégations et faire vos propres choix.
Cette solution offre un service très configurable qui permet la récupération d’un jeu de données complet. Même avec des contraintes telles que l’ITP et les bloqueurs de publicité, Snowplow peut être configuré pour construire une représentation claire du parcours client à travers les plateformes et les canaux de votre organisation. Chaque événement est capturé, traité et envoyé à l’entrepôt de données, ce qui vous offre un contrôle total sur leurs données.
Snowplow Analytics aide les organisations à renforcer la confiance dans leurs données grâce à de nombreux outils d’assurance qualité, tels que Snowplow Micro. Il permet de surveiller et de récupérer les événements défaillants grâce aux schémas de données personnalisables sous-jacents de Snowplow. Grâce aux schémas personnalisables de Snowplow, vous pouvez disposer d’un format unique pour toutes vos sources, qu’elles soient web, mobiles, côté serveur ou autres.
En somme, Snowplow Analytics est une plateforme analytics à code source ouvert qui permet de collecter des données à partir de plusieurs plateformes en vue d’une analyse avancée des données.
Points forts :
Assure le suivi anonyme des visiteurs de votre site web, en préservant leur vie privée.
Snowplow permet de collecter des données à grande échelle en temps quasi réel
Suivi et marquage côté serveur,, ce qui permet de collecter des données supplémentaires sur le comportement des utilisateurs.
Contournement des bloqueurs de publicité avec un domaine personnalisé
Propriété totale des données par les utilisateurs
Snowplow Analytics propose trois tarifs : une version gratuite mais limitée en open source, un tarif “BDP Cloud” qui commence à 1350$ par mois et une version BDP Entreprise sur devis.
AT Internet
AT Internet est une plateforme pionnière du digital analytics qui offre plusieurs solutions de tracking de données dont Analytics Suite Delta. Cette solution analytics vise à fournir des données de qualité, conformes au RGPD : toutes les données d’audience sont traitées et stockées entièrement au sein de l’Union européenne et les utilisateurs en restent propriétaires.
De plus, AT internet prévoit également un traitement illimité des données ; le prix de la solution évolue en fonction de la quantité de données traitées. Une des valeurs ajoutées d’AT Internet est la possibilité d’importer des données provenant d’outils tiers : elle collabore avec 63 partenaires. Les feedbacks et les analyses sont ainsi enrichis et consolidés.
AT Internet vous permet de bénéficier d’un enrichissement automatique (ex : géolocalisation et type d’appareil) pour optimiser la qualité de vos données. Il est également possible de personnaliser les règles de traitement des données pour une gestion avancée et plus sécurisée.
En ce qui concerne les fonctionnalités, AT Internet offre un grand nombre de fonctionnalités identiques à celles de Google Analytics, mais aussi des fonctionnalités supplémentaires : AT Internet propose de récupérer les données que vous possédez déjà dans Google Analytics et une interconnexion avec Google Tag est possible.
En conclusion, AT Internet offre une solution de tracking de données complète et sécurisée avec Analytics Suite Delta, qui permet une analyse consolidée et une personnalisation avancée des règles de traitement des données.
Points forts :
Rapports de données en temps réel
Audit des tags et évaluation systématique et complète des tags présents sur votre site et des données qu’ils collectent
Paramètres sur mesure pour configurer des paramètres sur mesure afin de répondre à des besoins spécifiques,
Rapports d’audience et rapports personnalisés afin de mesurer la performance de votre site web
Fonctionnalités de suivi telles que le suivi de la navigation des utilisateurs, le suivi des événements personnalisés, et le suivi des objectifs
Il faudra débourser au minimum 355€/mois pour bénéficier des services de l’outil dans sa version la plus “soft”. Les versions les plus avancées sont sur devis.
Kissmetrics
KISSmetrics est une plateforme BI (Business Intelligence) qui vous permet d’améliorer, de contrôler et de déterminer les paramètres qui vous semblent importants. Le système offre une grande souplesse en ce qui concerne les données personnalisées, ainsi que des API qui facilitent les intégrations.
KISSmetrics est conçu autour d’une fonctionnalité de suivi approfondi des données et est capable de fournir vous fournir des informations détaillées sur vos performances business. Il automatise les mises à jour et compare les mesures essentielles pour aider les utilisateurs à comprendre comment se comporter par rapport aux objectifs fixés. Le suivi approfondi vous permet d’obtenir des informations significatives sur les clients, afin de mieux les comprendre avant même qu’ils n’effectuent un achat.
De plus, la solution KISSmetrics mémorise et conserve les informations relatives à chaque client, qu’il s’agisse de clients référencés au hasard ou de clients réguliers, une fois qu’ils ont été marqués par le système, leurs informations sont conservées. En fonction de cela, le système utilise les informations stockées afin d’améliorer le processus de génération de leads.
KISSmetrics propose une solution intégrée, sans utiliser d’autres applications et services tiers. Cependant, le système offre la possibilité de le connecter à de nombreuses applications qui existent déjà dans l’écosystème logiciel des utilisateurs.
Points forts :
Outil de suivi des données en temps réel
Périodes de conversion illimitées pour un suivi sur le temps long
Rapports de cohorte pour comprendre le comportement des clients sur le long terme
Création de profils clients pour chaque client
Segmentation des données et création de cohortes
Exportation de données facile et sûre
Support multiplateforme et cross-plateforme/appareil
KISSmetrics propose trois plans tarifaires : une version “Silver” à $299 par mois, une version “Gold” à $499 par mois et une version “Custom” sur devis.
Hotjar
Hotjar est une plateforme d’analyse web et de feedback utilisateur qui offre une variété d’outils analytics ecommerce pour optimiser votre site web. Elle combine des fonctionnalités telles que des cartes thermiques, des enregistrements de visiteurs et des sondages pour donner aux utilisateurs une compréhension complète de l’utilisation de leur site web.
L’une des principales caractéristiques de Hotjar est sa heatmap, qui fournit des représentations visuelles de l’endroit où les utilisateurs cliquent, défilent et survolent une page web. Cela permet vous permet d’identifier les zones de votre site web qui retiennent le plus l’attention et d’optimiser la mise en page en conséquence.
Hotjar propose également des enregistrements de visiteurs afin de visionner les enregistrements de sessions d’utilisateurs pour mieux comprendre comment les utilisateurs interagissent avec leur site web. Cela peut s’avérer particulièrement utile pour identifier les problèmes d’ergonomie ou les zones de confusion sur le site web.
Une autre fonctionnalité caractéristique de Hotjar est la possibilité de réaliser des sondages, qui peuvent être utilisés pour recueillir les commentaires des visiteurs d’un site web en temps réel. Ces sondages peuvent vous aider à mieux comprendre les besoins et les préférences de leur public cible, ce qui leur permet de prendre des décisions fondées sur des données sur la manière d’améliorer leur site web.
L’intérêt de Hotjar réside dans sa capacité à offrir une large gamme d’outils pour l’optimisation des sites web en une seule plateforme. En fournissant une vue d’ensemble de la manière dont les utilisateurs interagissent avec un site web, vous pouvez prendre des décisions plus éclairées sur la manière d’améliorer leur site web et de mieux répondre aux besoins de leur public cible.
Points forts :
Présence de Heatmap
Enregistrement des visiteurs
Entonnoirs de conversion et analyse des formulaires
Sondages d’opinion afin d’avoir un retour d’information
Hotjar propose quatre plans tarifaires, avec une formule gratuite à 0 euro, “standard” à 32 euros, “plus” à 80 euros et une formule “scale” 171 euros.
Crazy Egg
Crazy Egg est une solution d’optimisation de site web hébergée dans le cloud, conçue pour vous aider à comprendre comment vos clients se comportent sur votre site web. Il donne la possibilité de visualiser et comprendre le comportement des utilisateurs qui vous donne la possibilité de savoir ce que font vos clients au moment même. Grâce à la fonctionnalité Heatmap, vous pourrez voir précisément où vos clients cliquent le plus sur les pages de votre site web. Crazy Egg vous aide à suivre la façon dont les utilisateurs interagissent avec leur site web.
Crazy Egg offre une gamme de fonctionnalités vous permettant d’optimiser la conception de votre site web et d’améliorer l’engagement des utilisateurs. Une autre caractéristique de Crazy Egg consiste en sa technologie de capture d’écran, qui permet d’obtenir un historique de la visite d’un utilisateur sur un site web.
Avec Crazy Egg, vous avez également la possibilité de connaître l’origine des visiteurs de votre site. Qu’ils viennent de votre page Facebook, de Twitter ou d’autres sources, vous savez mieux lesquelles de vos plateformes de médias sociaux contribuent le plus à augmenter le trafic vers votre site. Crazy Egg vous permet également de consulter des rapports d’analyse en vous donnant une vue sur les données brutes : tous les outils analytics ecommerce ne sont pas en mesure de le faire !
Crazy Egg propose également des scroll map, qui montrent jusqu’où les utilisateurs font défiler une page web avant de s’en désintéresser et de la quitter. Cette fonctionnalité peut être utilisée pour optimiser l’emplacement du contenu important sur une page et améliorer l’engagement client et le taux de conversion.
Enfin, Crazy Egg est un outil simple d’utilisation qui assure une analyse facile des données et une grande interprétation des données. Crazy Egg s’intègre ainsi à une série d’outils tiers, dont Google Analytics, pour une vision plus complète des performances du site web.
Points forts :
Heatmap afin de cibler les lieux d’interaction
Scrollmap pour voir où les utilisateurs passent le plus de temps
Fonction d’enregistrement pour rejouer les sessions d’utilisateur
Analyse du trafic et suivi des erreurs pour améliorer l’expérience utilisateur
Crazy Egg propose quatre plans tarifaires, avec une formule “basic” à $29, “standard” à $49, “plus” à $99 et une formule “pro” $249 qui varient en fonction de vos besoins.
Glassbox
Plateforme d’analyse de l’expérience client, Glassbox vous aidera à analyser le comportement et le parcours des clients sur votre site. C’est un des outils analytics ecommerce qui propose une fonction de relecture de session qui vous permet d’enregistrer et de rejouer les sessions des clients, offrant ainsi une visibilité totale sur les parcours clients, et permettant d’identifier rapidement les problèmes qui peuvent survenir lors de la navigation sur le site. Grâce à cette fonctionnalité, vous pouvez découvrir les erreurs de site web, les problèmes d’interface utilisateur et résoudre les problèmes rapidement pour améliorer l’expérience client.
En outre, Glassbox dispose d’outils d’enquête et de feedback, ce qui vous permet de recueillir des informations directes auprès de leurs clients. Glassbox fournit également des informations précieuses sur le comportement des clients, tels que la manière dont ils naviguent sur le site web, les pages qu’ils visitent et les produits qu’ils consultent. Ces données collectées peuvent être utilisées pour optimiser la conception et le contenu du site web, améliorer l’offre de produits et l’expérience globale du client.
L’interface simple et ergonomique de Glassbox en fait un des outils analytics ecommerce les plus simple à prendre en main. La plateforme offre des options de prix personnalisables, y compris des abonnements mensuels et annuels, ce qui la rend accessible.
Un autre avantage majeur de Glassbox est l’amélioration de ses fonctions de sécurité. En enregistrant les interactions des utilisateurs et en mettant en évidence toute activité suspecte, Glassbox identifie pour vous les vulnérabilités potentielles en matière de sécurité et à prendre des mesures proactives pour prévenir les atteintes à la sécurité de votre site internet.
En bref, Glassbox est une plateforme d’analyse de l’expérience client avec une fonction de relecture de session qui vous permet en tant que Retailer d’identifier rapidement les problèmes et d’améliorer l’expérience globale du client.
Points forts :
Amélioration de l’expérience utilisateur
Augmentation des taux de conversion
Sécurité renforcée
Résolution efficace des problèmes
Prise de décision basée sur les données et insights détaillés sur le comportement des utilisateurs.
Glassbox propose ses prix sur devis.
Les outils pour collecter/préparation les données clients & ecommerce
Il y a beaucoup de données à analyser en e-commerce : les données web, mais aussi les données des publicités, les données transactionnelles, les données produits, etc. Pour mener des analyses poussées, il faut d’abord consolider toutes ces données. C’est la vocation des outils de “Data Prep”, qui interviennent donc en amont du travail d’analyse à proprement parler. Les données, une fois consolidées, préparées, normalisées, enrichies, sont connectées et envoyées à un outil de reporting. Nous allons vous présenter 3 outils analytics ecommerce de reporting.
Les outils analytics ecommerce de reporting doivent collecter et intégrer des données provenant de diverses sources telles que les médias sociaux, les plateformes publicitaires et les services d’analyse web. Cela permet d’avoir une vue d’ensemble du comportement et des préférences clients et donc de prendre des décisions fondées sur des données. Supermetrics est là pour ça!
Le tableau de bord de Supermetrics permet de créer des rapports personnalisés et d’automatiser le transfert des données. Vous gagnerez ainsi du temps dans la gestion des données et de la relation client.
Une autre force de Supermetrics est sa flexibilité. Il prend en charge un large éventail de plateformes, notamment Google Analytics, Facebook, Instagram et LinkedIn, afin d’intégrer des données provenant de sources multiples dans une seule plateforme. Cela permet non seulement de gagner du temps, mais aussi de garantir l’exactitude et la cohérence des données.
Supermetrics est conçu pour être rapide. Vous pouvez interroger directement les sources de données, en extrayant uniquement les données dont vous avez besoin et accéder à n’importe quel champ disponible dans cette source de données. Si vous avez besoin d’un moyen rapide de transférer des données, Supermetrics est un musthave.
En somme, Supermetrics se présente comme un puissant outil de traitement et de reporting de données, qui s’avère être d’une grande aide pour optimiser l’exploitation des données clients. Les fonctionnalités clés de cette plateforme incluent notamment l’intégration de données, la création de rapports personnalisés ainsi que l’automatisation des tâches. Les atouts de Supermetrics résident dans sa souplesse, son niveau de précision élevé ainsi que sa facilité d’utilisation
Points forts :
Collecte et intègre des données provenant de diverses sources
Offre un tableau de bord facile à utiliser pour créer des rapports personnalisés et automatiser le transfert des données
Fournit une vue d’ensemble du comportement et des préférences des clients, ce qui permet de prendre des décisions fondées sur des données.
Prend en charge un large éventail de plateformes
Excellent support client et des ressources pour aider les utilisateurs
Supermetrics propose un plan tarifaire sur mesure calibré pour chaque plateforme sur laquelle vous souhaitez exporter vos data.
Octolis
La mise en place d’une architecture de données moderne est devenue une priorité pour les entreprises. Les grandes entreprises et les start-ups matures ont déjà mis en place une telle architecture, mais cela reste encore rare pour les entreprises de taille moyenne. Octolis vous aide à franchir ce palier en leur proposant une solution clé en main sur le marché des outils analytics ecommerce.
Octolis est une solution de préparation de données qui permet de connecter toutes les sources de données, les combiner, effectuer des calculs de base ou basés sur SQL, et synchroniser les données en temps réel. De plus, chaque audience peut être alimentée en temps réel avec autant de destinations que nécessaire grâce à Octolis. Les données peuvent ensuite être synchronisées avec les outils opérationnels tels que CRM, marketing automation, ads, service client, Slack, etc.
Octolis offre une grande flexibilité dans l’accès aux données, en permettant la connexion à toutes les sources de données, quel que soit leur format ou leur emplacement. L’utilisateur peut donc facilement importer des données à partir de fichiers Excel, CSV, de bases de données SQL, et même de systèmes opérationnels tels que des CRM ou des ERP. Octolis propose aussi des fonctionnalités de nettoyage des données pour garantir que les données collectées soient fiables et exploitables. L’enrichissement des données est une autre fonctionnalité importante d’Octolis, permettant d’ajouter de nouveaux champs ou d’améliorer le taux de complétude de la base de données.La fonctionnalité d’exportation des données, permettant de les synchroniser en temps réel avec les outils de destination tels que les outils d’analyse ou d’activation, fait également d’Octolis un outil complet et efficace pour la préparation de données.
L’interface du logiciel Octolis est conçue pour être suffisamment simple pour que les marketeurs puissent croiser et préparer les données sans avoir besoin de l’aide des équipes IT. Toutefois, cela ne signifie pas que le logiciel est une boîte noire. Les données sont hébergées dans la base de données ou le datawarehouse de chaque client, accessible par les équipes IT à tout moment, sur laquelle on branche un outil de reporting.
Le blocage pour la mise en place de ces architectures de données modernes est souvent d’ordre humain, car les compétences en ingénierie data sont rares et chères. Octolis veut devenir la solution de référence pour les PME/ETI qui veulent franchir ce palier sans disposer d’une équipe d’ingénieurs data. Grâce à Octolis, les PME peuvent disposer d’un socle solide pour monter leurs reportings et accélérer leurs projets marketing/sales. Le potentiel de la solution est énorme et les cas d’usages sont innombrables.
Points forts :
Synchronisation en temps réel.
Souplesse dans l’accès aux données
Enrichissement des données
Nettoyage des données
Interface ergonomique
Hébergement sur le datawarehouse de chaque client
Solution clé en main pour les PME/ETI qui veulent mettre en place une architecture de données moderne sans disposer d’une équipe d’ingénieurs data.
Octolis propose deux formules tarifaires, un formule “standard” à 700 euros et une formule sur devis avec des fonctionnalités plus avancées.
Funnel
Funnel.io est une plateforme cloud dédiée à l’intégration de données, conçue pour vous aider, Retailers, à consolider, harmoniser et optimiser leurs données de marketing, de publicité et de vente. Il fait parti des outils analytics ecommerce très complet.
Funnel automatise votre reporting marketing en remplaçant votre tableur marketing par un logiciel. Funnel collecte automatiquement les données de toutes vos plateformes publicitaires et les relie aux données de conversion de votre compte Google Analytics. Cela permet aux spécialistes du marketing d’avoir une vue d’ensemble toujours à jour de tous leurs efforts de marketing. Funnel propose trois solutions en fonction de l’endroit où vous souhaitez visualiser vos données.
Avec la solution Dashboard de Funnel, vous pouvez visualiser vos données et créer des tableaux de bord et des rapports personnalisés qui peuvent être facilement partagés entre les personnes et les équipes. Elle contient également un puissant outil d’analyse pour l’exploration des données et le regroupement des données pour les marchés, les catégories de produits, etc. Grâce aux dimensions personnalisées, vous pouvez classer vos données publicitaires comme vous le souhaitez, que ce soit par marché, tactique, source de trafic ou catégorie de produits.
Vous êtes satisfait de Google Analytics mais il vous manque des données sur les coûts des canaux non Google ? En disposant des données de coûts dans Google Analytics, vous pouvez facilement comparer les performances de tous vos canaux de marketing. Funnel envoie les données de coûts à Google Analytics tous les jours, dès que vous l’activez.
L’API de Funnel rend toutes les données que Funnel extrait et structure disponibles pour les systèmes internes ou d’autres solutions de BI. Grâce aux intégrations de Funnel à Google BigQuery, Google Data Studio et Amazon Redshift, vous pouvez obtenir vos données publicitaires vers n’importe quel entrepôt de données ou solution de visualisation que vous souhaitez. Funnel est également un partenaire certifié de Google BigQuery.
Points forts :
Excellente interface
Configuration facile à mettre en œuvre
Tableau de bord simple
Données historiques sur 2 ans
Plus de 500 connecteurs de données
Funnel.io propose trois plans tarifaires pour répondre aux différents besoins : le plan Essentials, au prix de 359 €, le plan Plus, au prix de 899 € et le plan Enterprise, à partir de 1799 €, propose des solutions personnalisées en fonction des exigences et du budget spécifiques.
Comprendre le modèle de données d’un CRM – Zoom sur 3 approches
Les entreprises qui veulent s’équiper d’un logiciel CRM ont tendance à faire l’erreur de se concentrer, dans les appels d’offres, sur l’étude et la comparaison des fonctionnalités. C’est négliger un élément déterminant : le modèle de données.
Le modèle de données conditionne en grande partie ce que vous allez pouvoir faire avec votre CRM.
En deux mots, le modèle de données décrit la manière dont vos informations clients sont organisées dans la base de données du CRM. La majorité des CRM proposent (imposent) un modèle de données fermé, ce qui signifie que vous n’allez pas pouvoir ajouter de nouvelles tables, créer tous les types d’attributs que vous voulez, construire toutes les relations entre objets que vous imaginez. Cela peut être très contraignant et compromettre la mise en oeuvre de certains de vos cas d’usage.
Modèle de données CRM
Description de l'approche
Multi-tables “fermé”
L'approche la plus courante. Le modèle de données du CRM est composé d'un ensemble prédéfini de tables (clients ; commandes : etc.), avec des capacités de personnalisation très limitées.
Multi-tables “ouvert”
Dans ce type de modèle de données, vous avez la possibilité de créer de nouvelles tables. Mais le modèle est en général semi-ouvert, au sens où il est rarement possible de croiser les tables comme on veut ou d'utiliser des champs calculés dans les nouvelles tables.
Event-centric
Toutes les informations sont représentées par un évènement consistant en une interaction et les attributs associés tels que la date, le produit ou le canal de communication. Ce modèle offre beaucoup plus de souplesse.
Nous allons revenir dans cet article sur la définition d’un modèle de données CRM et vous présenter les 3 principales approches utilisées par les éditeurs CRM. Nous terminerons par quelques conseils pour vous aider à choisir le modèle de données le plus approprié à votre besoin.
Tout d’abord, il est nécessaire de rappeler qu’un CRM est avant tout une base de données permettant de gérer des interactions avec des clients, d’envoyer des emails et, notamment en B2B, de collecter, organiser et analyser des données sur les clients. Cependant, l’organisation de la base de données du CRM est sensiblement différente selon le type d’activité : B2C ou B2B. Malgré cela, le socle d’un CRM reste une base de données constituée de tables, de façon similaire à un fichier Excel avec des onglets.
Néanmoins, et contrairement à un fichier Excel, l’utilisateur n’a pas toujours la possibilité de créer ses propres onglets et bénéficie de moins de flexibilité quant à l’organisation des données. Cette organisation prédéfinie des données et la manière dont les données sont organisées dans un CRM correspond à ce que l’on appelle un “modèle de données”. L’éditeur du CRM fixe ce modèle de données, même s’il laisse parfois une certaine souplesse et quelques marges de manœuvre.
Exemple de modèle de données CRM. Chaque rectangle correspond à une table (= l’équivalent d’un onglet Excel). Les flèches figurent les relations intertables. Source : Soft Builder
Le modèle de données du CRM est la structure fondamentale sur laquelle les données sont stockées et organisées. Plus ou moins souple et plus ou moins rigide, il permet aux entreprises de mieux comprendre leurs clients et leurs besoins, et leur fournit les informations nécessaires pour améliorer leurs produits et services, ou pour créer des profils détaillés de leurs clients. Ces profils peuvent être utilisés pour cibler les clients et leur offrir des produits et services plus adaptés à leurs besoins.
Ce modèle de données est composé de plusieurs éléments différents, tels que les personnes, les objets, les événements et les relations entre ces éléments. Ces éléments sont liés entre eux par des liens qui peuvent être définis par l’utilisateur dans le cas d’un système souple. Ces liens peuvent ensuite être analysés pour fournir des informations précieuses sur les clients et leurs achats. Concrètement, le modèle de données est constitué de différentes tables qui sont liées d’une certaine manière, selon certains schémas. On y trouve souvent, par exemple :
Une table contacts,
Une table achats,
Une table organisant les données d’interactions sur le site web.
L’organisation des données est un sujet critique dans un CRM, bien que fréquemment négligé. En effet, la capacité à organiser les données détermine la flexibilité dont l’utilisateur disposera pour segmenter et trier les informations.
Les 3 principales approches de modèle de données CRM
Il existe 3 principaux types d’approches pour structurer le modèle de données au sein d’un CRM.
L’approche multi-tables “fermée”
L’approche multi-tables « fermée » est la plus courante, et on peut la retrouver sur la plupart des éditeurs CRM. C’est un modèle multi-tables, ce qui signifie que le modèle ne repose pas sur une table unique avec les contacts, mais intègre aussi un certain nombre de tables supplémentaires, contenant par exemple les achats, les tickets de caisse, les boutiques… Dans ce modèle, les tables sont prédéfinies par l’éditeur CRM. On ne peut pas créer de nouvelles tables, et en cela, c’est un modèle “fermé”.
Les modèles de données fermés peuvent contenir 3, 4, 5+ tables. Il n’est pas possible d’en créer de nouvelles.
Ainsi, dans un modèle CRM classique pour du B2B, les tables seront constituées de leads, d’entreprises, de clients, de factures et d’interactions. Dans un modèle B2C, les tables seront constituées de contacts, de commandes, de tickets de caisse, de boutiques et d’interactions. Cependant, l’utilisateur n’a pas la possibilité de créer de nouvelles tables et doit donc se contenter des tables pré-existantes. Il n’est par exemple pas possible de créer une nouvelle table “Abonnements” afin gérer des données d’abonnement. Il faut nécessairement considérer les abonnements comme des commandes, et ceux-ci apparaîtront alors dans la table « Orders ».
De la même manière, les « avis clients » entreront dans la table des interactions, au même titre que les autres événements sur le site web (pages vues, etc.). L’utilisateur est ainsi obligé de s’adapter au modèle de données rigide du CRM.
L’approche multi-tables “ouverte”
Ce modèle permet de créer de nouvelles tables d’une manière similaire à la création de nouveaux onglets dans un tableau Excel. Il est théoriquement possible d’ajouter n’importe quel type de table pour ensuite les organiser d’une façon personnalisable. Actito est un exemple d’éditeur proposant ce modèle ouvert, permettant à l’utilisateur de créer de nouvelles tables dans son modèle de données, depuis le Datamart Studio.
Datamart Studio proposé par Actito, dans lequel vous pouvez ajouter et configurer de nouvelles tables de données.
Dans les faits cependant, il n’est pas toujours possible de créer toutes les tables que l’on souhaite. Il est même parfois impossible de les relier entre elles de la façon désirée ou d’ajouter des champs calculés dans les nouvelles tables. Les modèles “ouverts” ne sont donc pas toujours aussi complets qu’il pourrait sembler. Or, lors de la sélection d’un CRM, l’un des principaux éléments à analyser au moment de l’appel d’offres est justement le degré d’ouverture du modèle.
L’approche event-centric
Cette approche a été popularisée il y a une dizaine d’années, notamment par des éditeurs comme Segment ou Klaviyo, Sendinblue… L’idée fondamentale derrière ce type de modèle de données est qu’il n’est pas nécessaire d’avoir une multitude de tables pour représenter tout un business model.
Toute interaction peut être représentée par un événement. Dans la base de données, chaque interaction est associée à une date et contient certaines propriétés. L’intérêt majeur de cette approche est que les propriétés des événements n’ont pas besoin d’être définies à l’avance. Par exemple, il est possible de créer un event nommé “vue produit” et faire en sorte que les attributs de l’événement soit le nom du produit, son prix, sa catégorie, sa couleur.
Le modèle event-centric associe donc des contacts à des événements. Le modèle de données correspond alors à une table de contacts avec l’ensemble des événements associés à chaque contact. Ces événements peuvent avoir une structure différente selon l’event. De plus, il est possible de s’appuyer sur les propriétés de l’événement avec plus ou moins de fonctionnalités selon l’éditeur logiciel.
Ce que rend possible l’approche event-centric
La plupart des logiciels permettent par exemple de réagir aux événements en mettant en place des scénarios prédéfinis. Ainsi, l’entrée d’un event type A dans la base de données entraine le déclenchement d’une action. Cette action peut elle-même être modifiée selon les propriétés X ou Y de l’event A. Par exemple, une demande de devis par un client entraîne automatiquement une première prise de contact, par SMS ou par email selon le choix du client. Certains CRM plus avancés permettent d’utiliser les propriétés des événements comme variables de personnalisation dans un template avec un important niveau de granularité.
De plus, ces events peuvent servir de fondement pour la segmentation client. Là encore, l’efficacité du CRM pour cette fonctionnalité varie grandement selon l’éditeur. Des éditeurs très matures tels que Braze sont vraiment excellents et vont permettre de réaliser des segmentations sur n’importe quelle propriété de tous les événements. Il est par exemple possible de développer un segment en sélectionnant tous les clients ayant consulté un produit d’une catégorie A avec la couleur XYZ. Il est même possible d’actualiser ces segments selon une temporalité pré-définie.
Notez aussi que les acteurs qui ont une approche event-centric comme Klaviyo ont aussi souvent une autre approche supplémentaire. Cela permet principalement de récupérer le catalogue produit qui est extrait depuis un PIM ou depuis un CMS.
Conseils pour choisir le modèle de données CRM le plus pertinent
Les 3 types de modèles définis ci-dessus offrent chacun un certain nombre d’avantages et d’inconvénients. Comme pour toute autre brique du SI, le choix mal avisé d’un outil peut avoir des conséquences très néfastes et à long terme pour votre entreprise. Dès lors, il faut s’assurer que le CRM que vous choisissez repose sur un modèle de données pertinent pour votre activité.
Simplicité Vs Flexibilité
Essentiellement, le choix consiste en un dilemme entre simplicité du CRM et flexibilité du modèle de données. Plus le modèle de données est figé et prédéfini, plus il sera simple d’utiliser le CRM et de travailler avec la base de données. Cependant, cette simplicité au sein du logiciel peut trouver de nombreuses limites dans les cas d’usages de l’entreprise. Un modèle fermé peut être extrêmement éloigné des besoins d’une entreprise au business model complexe. L’entreprise a alors intérêt à se tourner vers un modèle plus souple. On peut ainsi résumer ce dilemme dans un graphique en deux dimensions :
Dilemme de la complexité d’un modèle de données CRM
Puisque le modèle en multi-table fermé est contraint par de nombreuses limites, la mise en place d’un modèle « event-centric » pourrait paraitre comme une bonne solution par défaut qui couvrirait les besoins supplémentaires qui pourraient apparaitre avec le temps. Cependant, adopter une telle solution peut nécessiter de mettre en place une CDP (Customer Data Plateform) en amont, et de revoir son dispositif data. Cela représente donc de nombreuses exigences et implique de nombreux efforts – inutiles si cela ne répond pas à un besoin réel de l’entreprise.
Comment procéder pour choisir son modèle ?
Pour savoir quelle approche est la plus pertinente dans votre métier, il faut alors partir de vos besoins. Vous pouvez suivre cette liste d’étapes pour définir le modèle vous correspondant le mieux :
Lister les “Entités” sur lesquels vous aurez besoin de segmenter.
Lister des exemples de segmentation :
Lister les variables dont vous aurez besoin pour vos principaux scénarios / campagnes.
Demander à l’éditeur d’expliquer comment vos exemples peuvent être réalisés avec sa solution OU essayer de le faire vous-même.
Anticiper le travail de préparation de données qui peut être nécessaire, notamment dans un modèle event centric qui suppose.
Une fois ce travail de reflexion fait, vous pouvez comparer vos besoins aux fonctionnalités proposées par les éditeurs de CRM. Il ne s’agit pas seulement de prendre en compte les informations nécessaire au suivi de l’activité, mais aussi d’inclure les variables dont vous aurez besoin pour vos différentes campagnes CRM ou marketing. Après avoir défini clairement ces éléments, vous devez vous informer quant au travail de transformation nécessaire pour les intégrer dans le CRM.
Le niveau de complexité de ce travail varie grandement. Il est parfois indispensable de transformer certaines informations en objets JavaScript dans le cadre de modèle de données event-centric. En utilisant conjointement un CRM efficace et un pipeline de transformation des données, il est possible de réaliser un très grand nombre de tâches. Il est toutefois nécessaire d’avoir suffisament prévu ces use-cases en amont et d’avoir anticiper toutes les difficultés majeures.
En définitive, il faut donc précisement définir ses besoins pour choisir un CRM au modèle de données capable d’y répondre. Cela permet aussi d’éviter des manipulations et des transformations complexes des données et du SI qui seraient inutiles l’entreprise. Négliger la phase de réflexion peut s’avérer coûteux et très pénalisant pour votre activité.
Vous allez sérieusement monter en compétences et gagner en efficacité dans la gestion de vos campagnes emails, croyez-nous. Nous avons conçu (avec amour) un modèle aux petits oignons de planning de campagnes email qui va vous aider tout à la fois à :
Gérer et suivre la production de vos différentes campagnes.
Organiser vos campagnes emails dans un planning / calendrier (+ en classant les campagnes par catégories : NL, promos…).
Adopter une approche business-driven, en associant toutes vos campagnes à des objectifs mesurables.
Nous savons d’expérience que les responsables marketing galèrent souvent à organiser et gérer les campagnes emails. Le suivi est loin d’être toujours optimal et les logiciels emailing malheureusement ne répondent pas à ce besoin. On s’est aperçus, curieusement, qu’il n’existait pas vraiment sur internet de modèles téléchargeables permettant de construire un planning de campagnes email. C’est ce qui nous a motivés à créer ce template qui, on l’espère, vous plaira. Cesse de bavardage, on vous explique comment fonctionne notre template et comment l’intégrer dans vos process.
Planning Campagnes Email : ce que contient notre ressource
Notre ressource se décompose en plusieurs onglets qui permettent de gérer vos campagnes emails à tous les niveaux et à toutes les étapes de production : conception – planification – analyse. On vous détaille dans la suite de l’article le fonctionnement de chacun de ces onglets.
Onglet
Description
Campagnes
Vue générale sur les campagnes envoyées ou planifiées : - Statut de production. - Brief : nom de la campagne, date d’envoi, segment, objet, brief message. - Résultats : ouvertures, clics, nbre de ventes, CA…
Planning
Vue planning des campagnes, avec la liste des campagnes en ligne et les semaines/mois en colonne. Le planning est généré automatiquement à partir des données complétées dans l'onglet "Campagnes".
Calendrier
Vue calendrier, permettant de visualiser facilement les campagnes prévues chaque mois. Le planning est généré automatiquement à partir des données complétées dans l'onglet "Campagnes".
Segments
- Liste et définition des segments utilisés dans les campagnes : tous les contacts, Optins NL, contacts réactifs, etc. - Suivi de l'évolution du nombre de contacts par segment.
Dashboard
Reporting de suivi de l'état de la base (nombre de contacts, segmentation) et de la performance des campagnes. Le dashboard est généré automatiquement à partir des données renseignées dans les onglets d'édition.
Settings
Paramétrage de la ressource : mois de départ, définition des statuts de production...
Programmes
Description des programmes relationnels auxquels se rattachent les campagnes : nom, objectifs, indicateurs, cible...
Ressources
Ensemble de guides, bonnes pratiques & outils pour monter en compétences sur les sujets email marketing.
Planning des campagnes email marketing : guide d’utilisation de la ressource
Commencer par définir vos réglages
Tout d’abord, il faut définir le mois à partir duquel commence le calendrier des campagnes.
Ensuite, vous êtes invités à personnaliser les différents statuts pour suivre l’avancement de la production des campagnes. Ces différents statuts se définissent en fonction de votre activité, de votre pipeline de clients et de votre processus de vente. Brief à rédiger, brief prêt, design prêt, etc. A vous de définir le nom et le nombre des étapes en fonction de votre activité.
Segmenter votre base de contacts
Vous décrivez sur cet onglet les différents segments que vous allez activer dans le cadre de vos campagnes :
Dans la partie de gauche en rouge, vous pouvez gérer la segmentation de vos différents clients. Figurent donc le classement des segments en catégories, les noms des différents segments et leurs descriptions. On propose des segments classiques par défaut, mais bien sûr à vous de renseigner l’onglet avec vos propres segments.
Dans la partie de droite en bleu vous renseignez le nombre de contacts pour chaque segment, et son évolution au cours des mois. Vous pouvez automatiser la complétion de ces champs en utilisant Zapier/Make, ou…en nous contactant, on vous expliquera comment faire :).
Un petit rappel sur la segmentation…Envoyer un même message à tous les contacts n’est pas jamais la meilleure stratégie pour une campagne marketing efficace. En effet, chaque contact est unique et a des besoins, des intérêts et des comportements différents. C’est pourquoi il est important de segmenter ses contacts pour mieux cibler les campagnes. En segmentant vos contacts, vous pouvez créer des messages plus pertinents et personnalisés qui seront plus susceptibles d’attirer l’attention de vos contacts et de les inciter à interagir avec votre entreprise
La segmentation consiste à diviser sa liste de contacts en groupes distincts en fonction de caractéristiques communes telles que l’emplacement géographique, l’âge, le sexe, les centres d’intérêt, le comportement d’achat, etc. En segmentant votre liste de contacts, vous pouvez personnaliser vos messages et créer des campagnes plus ciblées et plus efficaces.
Il existe plusieurs approches possibles pour segmenter vos contacts comme la segmentation démographique, la segmentation comportementale ou encore la segmentation psychographique ou basée sur les préférences. Pour segmenter de manière efficace et optimiser vos campagnes, n’hésitez pas à consulter notre article sur la segmentation client. On vous présente les principales méthodes de segmentation.
Consulter des ressources pour monter en compétences
Nous vous avons concocté une liste d’articles, de guides, de tutos, de stats et d’outils sur l’email marketing qui devraient vous intéresser. Vous en faites bien sûr ce que vous voulez :).
Parmi les différentes ressources que nous vous proposons pour gérer au mieux votre campagne email nous avons inclus:
Les KPIs de références par industrie
Des exemples de campagnes d’email pour vous inspirer
Une checklist d’envoi d’email
Un template de pilotage de performance de vos emailings
Et bien d’autres ressources…qu’on vous laisse découvrir !
Organiser vos campagnes dans des programmes relationnels
Cet onglet permet de lister vos différents programmes relationnels. Par exemple, vous pouvez avoir un programme newsletter, un programme promotions, un programme nouveautés. Ces programmes permettent de catégoriser les différents types de campagnes que vous allez déployer. Sur l’importance d’associer vos campagnes à des programmes relationnels, nous vous recommandons la lecture de cet article publié par nos amis de chez Cartelis. Construire un plan marketing relationnel, créer des programmes relationnels et associer à ces programmes des campagnes et des scénarios est une bonne démarche à suivre pour structurer votre stratégie d’email marketing.
Pour chaque programme, vous êtes invité à définir un objectif, des KPIs et une cible. Cela permet de bien garder en tête la finalité des campagnes et les objectifs poursuivis ! Cela vous permet de garder l’oeil du stratège même quand vous êtes plongés dans la production.
Lister et décrire le contenu de toutes vos campagnes
L’onglet Campagnes est l’onglet le plus important de notre ressource. Il est composé de 4 volets : Avancements, Brief campagne, Résultats et Statistiques.
La section Avancement décrit l’état de la campagne : brief prêt, design prêt, planifiée, envoyée.
La partie Brief campagne permet de savoir quel est le contenu du mail, son objet, à quel programme il appartient et toutes les autres infos importantes sur lui.
La section Résultats, quant à elle, donne les différentes statistiques importantes sur la campagne de mail, comme le nombre de destinataires, de cliques ou le CA qui en a découlé.
Enfin, le volet Statistiques donne des insights plus poussés comme le taux de délivrabilité, de réactivité ou de conversion.
L’onglet Campagnes est l’onglet d’édition principale de votre campagne. Les autres onglets (notamment les vues planning et calendrier) sont générés automatiquement à partir des données renseignées sur cet onglet. C’est là que vous allez lister l’ensemble des campagnes à lancer sur l’année, détailler leur contenu, suivre l’avancement de leur prod et analyser leurs résultats. Un onglet très complet !
Visualiser votre planning des campagnes (vue “planning”)
L’onglet planning permet de suivre de manière simple et intuitive l’avancement dans le temps de la campagne marketing sur un rétro-planning automatique. Chaque campagne est pilotable grâce aux différents paramètres réglés dans la partie campagnes.
En quelques mots, c’est un premier mode de visualisation de la distribution des campagnes dans le temps. Cet onglet est généré automatiquement et ne nécessite aucune action de votre part.
Visualiser votre planning des campagnes (vue “calendrier”)
De la même manière que l’onglet Planning permet de visualiser vos campagnes dans le temps, l’onglet Calendrier permet de faire la même chose mais cette fois sous forme d’un calendrier. C’est un deuxième mode de visualisation de la distribution des campagnes dans le temps. Comme précédemment, cet onglet est généré automatiquement et ne nécessite aucune action de votre part.
Analyser les performances de vos campagnes grâce au Dashboard
Le volet Dashboard permet d’avoir une vue claire sur l’évolution de votre base de contacts et de vos campagnes d’emails. Elle contient à la fois les statistiques principales et des graphiques d’évolution pour mieux piloter vos campagnes. Généré automatiquement à partir des données renseignées dans les autres onglets, l’onglet Dashboard permet d’avoir une vue synthétique et générale sur la performance de votre dispositif marketing.
Voilà, nous avons fait le tour de la ressource. N’hésitez pas à l’utiliser et à nous partager vos retours & suggestions 🙂
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Le CRM a longtemps constitué le pivot du SI Client, avant que les Customer Data Platforms viennent changer le jeu dans les années 2015. Aujourd’hui, une nouvelle approche s’impose, plus souple, souvent moins coûteuse également, mettant au centre du SI Client le Data Warehouse. Nous allons retracer ensemble l’évolution des architectures IT utilisées par les entreprises pour collecter, stocker, transformer et exploiter les données clients.
Voici un schéma retraçant l’évolution du SI Client du début des années 2010 à aujourd’hui :
📕 L’évolution du SI Client de la révolution digitale à nos jours :
Si le SI Client a toujours été un ensemble plus ou moins connecté d’outils, de bases de données et de fichiers, la manière d’organiser ces différentes composantes au service du stockage, du traitement et de la valorisation des données a beaucoup évolué.
Le SI client a une double fonction qui offre deux 2 leviers d’actions :
La fonction d’activation : Un SI Client sert in fine à animer une relation clients efficace à travers une variété d’outils de la grande famille du « CRM » (dans lequel on inclut le marketing automation, le helpdesk…).
La fonction décisionnelle : Le SI Client sert également à mieux connaître ses clients (grâce aux données), à générer de la connaissance client, à faire des analyses, de la BI…
Révolution digitale : des solutions monolithiques aux écosystèmes
La révolution digitale qui s’est opérée il y a une bonne vingtaine années a fait évoluer de manière significative l’organisation du SI Client. Il y a une véritable scission entre l’avant et l’après.
1995 – 2010 = Une solution monolithique pour gérer une relation clients principalement offline
À partir du milieu des années 1990 jusqu’au milieu/fin des années 2000, les logiciels CRM sont la clef de voute du SI Client, et parfois même l’unique composante de ce système. Le logiciel CRM sert à centraliser toutes les données collectées sur les clients. À l’époque, les CRM n’avaient pas la légèreté des outils type SaaS d’aujourd’hui, ils étaient assez lourds et peu flexibles. Les principaux éditeurs de ces logiciels étaient Salesforce, Siebel, SAP, Oracle… De véritables mastodontes qui commercialisaient des solutions très onéreuses. Les coûts liés à ces solutions étaient élevés : coût de la licence logiciel bien sûr, mais aussi et surtout un coût élevé d’implémentation et de maintenance.
De ce fait, les outils CRM ont d’abord été réservés aux plus grandes entreprises, et présentaient de nombreuses limites :
Faible flexibilité : Difficile à adapter aux besoins spécifiques de l’entreprise et proposant peu d’intégrations à des outils tiers.
Faible accessibilité : Installés localement, ces logiciels n’étaient pas accessibles en dehors de l’entreprise. On parle ici de logiciels “On Premise”, installés sur les serveurs de l’entreprise, à l’opposé de l’approche moderne basée sur le cloud et le modèle SaaS.
Pas de gestion des données online : données comportementales, web, trafic, etc.
Faible collaboration : pas ou peu de fonctionnalités de partage de données.
Principaux acteurs formant un oligopole : Siebel, SAP, Oracle…
2010 – Aujourd’hui = Multiplication des outils et montée en puissance de l’approche “Best of Breed”
La multiplication des outils MarTech / Data Tech
Au cours de la dernière décennie, le nombre d’outils MarTech & DataTech a augmenté de plus de 6 000 % ! On assiste en parallèle de ce développement à une diversification importante du marché des technologies CRM & Marketing. Il y a désormais près de 10 000 solutions stables sur le marché, chacune proposant ses spécificités. Le site Chief Martec présente une étude approfondie de l’évolution de ces outils depuis les années 2010.
Une nouvelle approche du SI Client
Grâce à cette multiplication des services, l’approche moderne consiste à présent à construire son SI Client à partir de briques outils modulaires et spécialisées sur un type de relation ou de support d’interaction. On peut ainsi citer :
Les CRM Marketing, aussi appelés plateformes de “Marketing Automation” pour gérer la relation clients digital : campagnes marketing, scénarios relationnels sur les points de contact digitaux.
Le CRM Commercial pour gérer la relation clients offline, surtout utilisé en B2B. Le CRM Commercial permet d’historiser les échanges avec les prospects et les clients, de centraliser toutes les infos sur les clients dans des fiches clients.
Les logiciels de Helpdesk qui sont utilisés par le service client, par les conseillers, et qui permettent de gérer les tickets clients, les demandes et réclamations…
Il existe de nombreux autres cas d’usages tels que les plateformes publicitaires, des logiciels e-commerce, des plateformes de gestion des réseaux sociaux, etc.
Les nouveaux défis technologiques
L’organisation des SI clients autour d’une multiplicité d’outils a fait apparaitre de nouveaux défis technologiques :
Une dissémination de l’information : les données ont tendance à être éparpillées à travers les différents outils et bases de données de l’entreprise. Il n’y a plus de vision globale ni de lieu de centralisation des données.
Un challenge : l’unification des données clients. Ce sujet est de plus en plus prégnant dans les structures SI, et représente la clef d’une exploitation efficace des données clients.
Résumé de l’évolution du SI Client
L’histoire du SI client est donc celle d’une série de tentatives qui ont été faites et de multiples technologies qui ont été développées afin de répondre au challenge de la centralisation, de l’unification et d’une meilleure utilisation des données. Plusieurs solutions se sont imposées au cours de cette histoire :
2010 – 2015 : Le CRM est utilisée comme base de données clients principale.
À partir de 2015 : montée en puissance des Customer Data Platforms (CDP). De plus en plus de SI Clients s’organisent autour de CDP qui concurrencent ainsi la place autrefois dévolue au CRM.
À partir des années 2020 : montée en puissance d’une nouvelle approche consistant à utiliser une infrastructure Data Warehouse moderne comme pivot du SI Client.
2010 – 2015 : Le CRM comme base clients principale
Durant la première moitié des années 2010, la tendance était d’utiliser le logiciel CRM comme base de données clients principale. Le CRM s’est ainsi imposé comme plateforme pivot du SI Client. Pour autant, utiliser un même outil en tant que base de données et logiciel d’activation ne fait plus nécessairement sens aujourd’hui et peut même complexifier le SI clients.
Description du SI Client CRM-centric
Les différentes sources de données (e-commerce, ERP, Google Analytics, magasins, etc.) viennent alimenter le logiciel CRM via un outil “ETL” (Extract – Transform – Load) qui permet de gérer les flux et d’intégrer les données au bon format. Ce processus permet de centraliser les données clients dans le CRM. Elles sont ensuite exportées vers les outils d’activation (emailing, marketing automation…) par APIs ou via des connecteurs natifs développés par les éditeurs.
En parallèle, les sources de données clients sont également chargées, toujours via un ETL, dans un data warehouse, un entrepôt de données qui permet d’organiser les données dans des tables. Le data warehouse n’a alors qu’une fonction : il sert à faire de la Business Intelligence, à créer des reportings grâce à des outils directement connectés au data warehouse.
Les limites de l’approche CRM-centric
Alors que l’utilisation des CRM comme bases de données est encore très présente dans les entreprises, de nombreuses limites à cette pratique apparaissent. Nous avons traité ce sujet de façon exhaustive dans notre article CRM vs CDP. En résumé, voici les principales limites de cette approche :
Les CRM imposent un modèle de données rigide.
Le CRM gère mal les données comportementales web et ne peut donc pas raisonnablement être utilisé comme référentiel client.
La réconciliation multi-sources est complexe, voire impossible, ce qui exige souvent de dupliquer des données.
Les fonctionnalités de normalisation et de nettoyage des données sont rares et peu efficaces.
Il n’est pas possible de créer des champs calculés et des scorings dans un logiciel CRM.
Il n’est pas possible d’utiliser la BDD clients du CRM pour créer des reportings et faire de la BI.
Ces deux derniers points conduisent à une gestion complexe de la data : il existe désormais 2 sources de vérité, 2 bases de données clients qui ne sont pas gérées par les mêmes équipes :
Le CRM qui sert pour l’activation (utilisé par le marketing, les commerciaux, le service client).
Le Data Warehouse qui sert à faire de la Data Analysis (utilisé par l’équipe IT / data).
À partir de 2015 – La montée en régime des Customer Data Platforms
C’est en 2015 qu’apparait une nouvelle famille d’outils : les Customer Data Platforms (CDP). Il s’agit de plateformes qui permettent d’ingérer facilement toutes les données (online et offline) de l’entreprise et de les unifier afin de créer des agrégats que l’on peut ensuite synchroniser dans les outils d’activation (marketing – ventes – service client – publicité). Entre 2015 et 2020, la CDP apparaît comme la solution miracle pour unifier toutes les données clients.
Description du SI Client CDP-centric
Les CDP sont des logiciels Saas prêts à l’emploi et à être intégré à votre dispositif data marketing actuel. Ils reposent sur des briques fonctionnelles pré-construites qui facilitent le déploiement et permettent une prise en main rapide par les équipes métiers. Les CDP offrent ainsi une réponse à la problématique de la réconciliation des données clients. En clair, il s’agit d’une vue d’ensemble, qui relie toutes les informations relatives à un client donné. Cette vision à 360° de vos clients vous permet de contrôler la pression marketing et vos échanges.
Vos données clients sont donc centralisées, normalisées, enrichies et ce, continuellement. En synchronisant les données évoquées en temps réel (ou presque), une CDP vous permet d’accéder à une vision exhaustive et à jour de vos clients. Une Customer Data Platform ne se contente pas d’ingérer des données, mais les restructure, ajoute des champs calculés tels que des tendances ou des modèles de scoring, puis les rend exploitables par vos autres outils et systèmes à travers des segments ou des agrégats.
Les limites de l’approche CDP-centric
Les CDP ont été un temps la promesse d’une révolution dans le SI clients. Cependant, des limites à cette approche ont très rapidement fait leur apparition. Nous détaillons les avantages et inconvénients des CPD dans cet article. Voici les principales limites que nous trouvons aux CDP.
Tout d’abord, il apparait clairement que les Customer Data Platforms ne sont pas des plateformes mais en réalité des suites de logiciels qui consitituent un environnement rigide.
Les CDP ne sont pas des sources de vérité unique, mais un point de convergence de différentes sources. Cela peut conduire à des contradictions lors de requêtes, comme l’apparition de multiples points de contact pour un client.
La promesse de développer un software qui s’intègre dans la stack data et qui s’utilise sans avoir besoin de faire recours aux fonctions IT de l’entreprise n’a pas pu être tenue et constitue finalement un challenge supplémentaire pour les équipes marketings.
Les CDP ne sont pas des outils flexibles. Ils imposent leurs modèles de données et ne laissent que peu de marges de manœuvre dans la personnalisation de la plateforme.
Les CDP sont des solutions coûteuses.
Ces limites font qu’il est aujourd’hui bien plus pertinent d’adopter une approche se concentrant sur les Data Warehouse.
Pourquoi le SI client moderne doit être “Data Warehouse centric”
Description du SI Client Data Warehouse-centric
Historiquement, le data warehouse est une base de données qui regroupe les informations nécessaires aux analyses. Ces solutions devaient pouvoir supporter des requêtes ponctuelles, mais volumineuses, avec un rythme de mise à jour modéré. Désormais, les data warehouses modernes peuvent supporter tout type de requêtes, en quasi-temps réel, à un prix beaucoup plus compétitif et sans effort de maintenance. C’est d’ailleurs parce que la datawarehouse moderne a pris une telle importance qu’Octolis a centré son offre autour de ce sujet. Octolis permet ainsi d’utiliser les données du data warehouse pour les cas d’usage opérationnels et de créer à partir de là une vision client 360.
La nouveauté majeure concernant les datawarehouse est l’irruption des data warehouse cloud sur le marché depuis les années 2020. Cette nouvelle génération de datawarehouses cloud dispose de 3 avantages majeurs :
Rapidité / puissance : Les serveurs mis à disposition donnent accès à une puissance de calcul phénoménale.
Prix : la facturation se fait à l’usage et le coût de stockage a été significativement réduit.
Accessibilité : la mise en place et la maintenance sont beaucoup plus simples.
Schéma d’un SI Client organisé autour d’un Cloud Data Warehouse.
L’approche Data Warehouse centric décrit l’architecture du SI Client moderne
Adopter une approche data warehouse centric permet de solutionner la plupart des problèmes et limites rencontrées par les approches du passé. C’est pour cette raison qu’elle s’impose, aussi bien auprès des entreprises mid-market que des grands groupes, dans le Retail et dans bien d’autres secteurs.
Ce n’est pas un hasard d’ailleurs si certaines CDP ont fait évoluer leur offre pour permettre à l’utilisateur d’utiliser son Data Warehouse comme base de données principale et indépendante connectée à la CDP en streaming. C’est l’approche sur laquelle nous avons basé Octolis.
Construire un dispositif CRM pour fidéliser vos clients [Méthode]
L’expérience nous a appris qu’il n’était pas possible de fidéliser durablement ses clients sans mettre en place un dispositif CRM solide et structuré. S’il y a de la place pour l’imagination, il n’y en a pas pour l’improvisation ! Trop de projets CRM échouent par manque de cadrage et par défaut de pilotage.
Nous allons vous présenter dans cet article les principales étapes à suivre pour bâtir un dispositif CRM performant et évolutif : définition des objectifs CRM, cartographie des parcours clients, construction du plan marketing relationnel, définition des process internes, plan de collecte des données, etc.
Les prérequis pour construire un dispositif CRM sur des bases solides
Formuler les objectifs du dispositif CRM
Il est tout d’abord nécessaire que vous définissiez les objectifs de votre démarche. Quelle est la raison vous poussant à procéder au déploiement d’un CRM au sein de votre structure ? Vous devez définir des objectifs précis et ne pas vous réduire à l’outil en lui-même. L’idée est de pouvoir garder une certaine prise de recul par rapport à un moyen (votre CRM), qui doit être au service de votre activité. De ce fait, bien définir vos objectifs permet de placer votre CRM au cœur de la stratégie générale que vous souhaitez donner à votre organisation.
Voici quelques exemples typiques d’objectifs CRM :
Améliorer votre productivité
Automatiser votre Marketing Client
Harmoniser votre expérience Clients
Améliorer la satisfaction ou le suivi commercial de vos clients
A vous de définir les vôtres !
Il peut être utile de procéder à un listage et un classement des objectifs de votre organisation, afin de pouvoir être en mesure de les prioriser lors de la mise en pratique.
Une fois vos objectifs établis, il convient de s’attarder à analyser l’état de votre parcours client.
Cartographier le parcours des clients existants & cibles
La cartographie des parcours clients consiste à recenser l’ensemble des points de contact entre votre entreprise et vos clients, à toutes les étapes et sur tous les canaux.
Ce travail permet d’obtenir une vue globale sur beaucoup de points d’interaction entre votre entreprise et vos clients, et d’identifier les moments de tension et les moments de dialogue et d’écoute.
La construction de cette cartographie suppose une bonne compréhension des étapes du parcours clients, des points de contact ainsi que des moments clés de la relation , que l’on peut appeler « moments de vérité ».
Ci-dessus un exemple d’extrait de parcours clients, où vous pouvez notamment observer que les étapes et phases de ce parcours sont disposées en colonnes, lorsque les canaux sont eux formés en ligne. C’est une des méthodes classiques pour représenter ses parcours clients. L’intersection d’une étape et d’un canal correspond à un point de contact. Cette représentation sous forme de matrice va vous permettre d’identifier tous vos points de contact. Voici un autre mode de représentation des parcours clients :
Cette méthode des parcours clients vous est donc utile pour identifier vos points de contact existants, mais également imaginer les points de contacts cibles que vous aimeriez voir apparaître, qui ne sont pas présents dans votre analyse. Avec le parcours clients, il va vous être possible d’identifier les manquements et ainsi d’imaginer de nouvelles dispositions afin de conquérir les clients cibles.
Cette cartographie peut se produire en interne ou via un prestataire externe (qui se basera sur vos informations : documentation, accès outils, interviews…) ou bien encore, être un mix entre l’interne et l’externe (par exemple sous forme d’ateliers combinant vos acteurs clés comme vos équipes Marketing, votre DSI, votre Service Clients etc. et votre partenaire).
Enfin, il n’existe bien souvent pas seulement un mais plusieurs parcours clients. Une enseigne de retail, par exemple, en possède au moins deux grands : un parcours magasin et un parcours digital, et chacun peut faire l’objet d’une cartographie distincte. Il est cependant recommandé de prioriser 2 ou 3 parcours maximum pour chaque organisation, au risque de se perdre dans les analyses et objectifs.
Une fois vos objectifs établis et votre cartographie des parcours clients effectuée, cette dernière va pouvoir servir de base et de fondement solide à l’ensemble du travail de construction de votre plan marketing relationnel.
Construire le plan relationnel (programmes, campagnes & scénarios)
Un plan de marketing relationnel est, à l’instar d’un plan de communication, un outil qui va vous permettre de définir et détailler la stratégie marketing de votre organisation. Il est lui-même construit à l’aide de différents éléments et outils. Son objectif est de structurer et d’apporter de la cohérence à la stratégie de votre structure. Il va en effet pouvoir vous permettre de poser vos idées, afin de mieux les organiser et de pouvoir en déduire une vision globale, avec un calendrier donné.
Un plan de marketing relationnel se construit au regard de l’environnement de votre entreprise et de vos clients. En d’autres termes, il vous faut donc identifier une série d’objectifs, avec des outils et un calendrier concordant, afin de pouvoir déployer des actions qui seront à la fois efficaces et rentables. Cette communication va vous demander de la réflexion et une très bonne connaissance des enjeux et autres tenants et aboutissants liés à votre activité.
Le plan relationnel comprend plusieurs composantes que sont :
Les programmes relationnels
Nous pouvons définir le plan relationnel comme un plan d’actions, dont le but va être de décliner et qualifier différents types d’actions qui pourront être exécutées, dans le but d’atteindre les objectifs CRM fixés au sein de votre entreprise.
Il est possible de répertorier ces actions en deux catégories :
Les scénarios relationnels comprennent des scénarios de longue durée, et se déclenchent en fonction de l’activité et du comportement de vos clients (par exemple la réponse à un formulaire) ou d’un événement particulier (anniversaire de votre client par exemple).
Les campagnes marketing sont elles ponctuelles (par exemples les soldes ou la Saint Valentin). Le canal des mails est évidemment historiquement privilégié, mais d’autres canaux peuvent et doivent également être mobilisés, comme les sms, les notifications push ou encore les réseaux sociaux.
L’ensemble des ces actions sont organisées dans ce que l’on appelle des « programmes relationnels » ou « programmes marketing ». Ceux-ci vont vous permettre d’organiser de manière logique vos actions.
Un plan relationnel peut notamment contenir un programme d’activation, de bienvenue, de parrainage, de réactivation ou encore de satisfaction client.
Un programme est caractérisé par :
Un objectif principal. Par exemple, le programme de réactivation aura pour objectif la réactivation de vos clients inactifs. Chaque objectif doit être mesurable par un KPI (exemple : le nombre de clients réactivés ou le chiffre d’affaires généré après 30 jours de mise en place d’actions de réactivation). D’autres objectifs secondaires sont également possibles.
Une cible ou un moment clé dans le parcours clients (exemple : la phase d’activation).
L’ensemble des actions relationnelles pour atteindre l’objectif du programme (scénarios et campagnes).
Les axes de communication
Les axes de communication, c’est le style que vous allez utiliser pour dialoguer avec vos clients.
Les axes de communication vont donner le ton aux campagnes promotionnelles et c’est autour d’eux que les outils de communication, les messages, l’affichage, les stratégies, les supports médiatiques et les activités seront développés.
Afin de faire un bon choix, il vous faut identifier votre public cible. Le ton d’une campagne ne sera pas le même si vous souhaitez par exemple atteindre des adolescents ou des personnes âgées, ces deux clientèles ayant un profil psychologique totalement différent. Par exemple, pour des personnes âgées, l’axe de communication pourrait porter sur la sécurité.. Cependant, il serait intéressant de miser davantage sur l’audace pour des jeunes. Bien qu’il soit possible de rejoindre plusieurs clientèles à la fois, il est plus compliqué de viser un champ moins spécifique de prospects.
L’axe de communication établit devra être plus réfléchi, en restant fidèle à son identité tout en gardant une certaine cohérence.
Les scénarios de marketing automation
Un scénario relationnel peut se définir comme un ensemble d’actions se déclenchant de manière automatisée, selon différents déclencheurs (triggers). Il doit contenir :
Un objectif (lié à l’objectif du programme dans lequel le scénario s’inscrit). Exemple : augmenter le taux de complétion profil, lié à l’objectif du programme d’augmentation du taux de qualification des prospects.
Un point de départ (élément déclencheur du scénario). Il en existe deux :
Ceux associés au comportement de votre client (exemple : inscription à un service en ligne.)
Ceux associés à un événement pour votre client. (exemple : son anniversaire).
Une mécanique, pouvant ressembler à un arbre décisionnel, avec des chemins différents selon les choix du client (exemple : tel type de mail si abandon de panier, tel type de mail si confirmation de panier).
L’ensemble de ces scénarios doit faire l’objet d’une cartographie.
Le planning des campagnes
Comme nous l’avons déjà défini, les campagnes sont des actions marketing ponctuelles pouvant être déterminé :
Par un événement classique du calendrier : la Saint-Valentin, Noël, le Nouvel an, les Soldes, Halloween, le Black Friday etc.
Par un événement spécifique à l’activité de votre entreprise : un nouveau produit ou une nouvelle offre par exemple.
Plusieurs canaux peuvent être utilisés, comme les e-mail ou les SMS notamment. Vos campagnes peuvent être déclinées par cible, par marque ou encore par segment client, et également en fonction d’une localisation géographique ou d’une échelle (locale ou nationale notamment).
Une fois les grandes lignes de la construction de votre plan marketing relationnel abordées, il est important que vous vous attardiez sur la réflexion touchant à l’ensemble des process de ce plan, afin que son exécution opérationnelle devienne la plus fluide et efficace possible.
Mettre en place des process internes clairs
Définir les conventions internes (nommage, etc.)
Le plan marketing relationnel doit contenir et définir l’ensemble des conventions utilisées par l’entreprise.
Le vocabulaire utilisé (exemple : la définition de « client »)
Les règles de segmentation (exemple : une définition claire des segments que l’on souhaite cibler)
Les règles de gestion des option (exemple : A quelle fréquence collecter des opinions clients)
Les règles de gestion de la pression marketing
Les expéditeurs ou les adresses IP utilisés selon les types de communication
Définir les process RGPD
Le règlement général sur la Protection des Données est rentré en application le 25 mai 2018. Il a pour but d’imposer des règles en ce qui concerne le traitement de données personnelles, afin de redonner le pouvoir au consommateur en responsabilisant les entreprises. Les données clients étant des données personnelles, les actions marketing doivent s’y conformer. Il faut donc définir des règles d’utilisation afin d’encadrer leur utilisation. Par exemple, la mise en place de garanties solides en matière de sécurité et de confidentialité des données avec les sous-traitants est nécessaire.
Définir des process de création des campagnes
Vos process et traitements doivent être organisés et documentés.
L’idée principale est de répartir les rôles. Il s’agit principalement d’assigner vos tâches à des personnes ou équipes précises, de définir le timing de prise de décisions et de mise en place des actions, et également de définir les règles de création générales ( comme les templates ). Il est nécessaire de bien encadrer les process de création et de gestion afin que l’animation et le pilotage de votre Plan Relationnel se déroule de manière fluide et organisée.
Plus concrètement, vos process doivent notamment reposer sur une définition claire de vos règles métiers, ainsi que de vos process de création des campagnes, comme de vos axes de communication (ton des messages…). Vous pouvez également anticiper la liste de vos adresses d’envoi, la typologie de vos templates, la nomenclature des paramètres de tracking (UTM) etc.
Définir des process de formalisation des scénarios
Vos scénarios doivent faire l’objet d’une formalisation. On trouve trois niveaux de formalisation différents :
La cartographie visuelle des scénarios, permettant une vision globale de l’ensemble des scénarios déployés. Il va servir de référence pour la diffusion de l’information en interne entre vos différentes équipes, afin de garder une compréhension claire de l’ensemble du dispositif.
Un document de spécification bien plus détaillé, avec des scénarios relationnels et des déclencheurs.
Il est également possible d’ajouter une modélisation bien plus détaillée de chaque scénario, dont vous pouvez observer un exemple ci-dessous.
Il ne faut pas oublier que vos scénarios de Marketing Automation sont vivants, et destinés à évoluer au fil du temps, selon vos expériences et l’évolution de votre activité. Une revue et une mise à jour peut avoir lieu tous les 3 mois ou tous les 6 mois par exemple.
Mettre en place une gestion de la pression marketing
Gérer la pression marketing, c’est globalement l’art d’envoyer un message à vos contacts lorsque ceux-ci sont prêts à le recevoir. Certains contacts peuvent rester engagés lorsque vous leur envoyez 2 messages par semaine alors que pour d’autres, une surcharge de communication sera rédhibitoire pour maintenir une relation client. L’impact d’une gestion optimisée de votre pression marketing est donc très important pour votre activité.
La pression marketing observe une double dimension :
Une dimension Objective. Il s’agit du volume de sollicitations marketing qui sont adressées à un contact sur une période donnée. Elle ne permet pas vraiment de connaître la perception de vos contacts vis-à-vis de vos sollicitations marketing car le constat peut avoir différentes sources.
Une dimension Subjective. Il s’agit ici d’une perception subjective de vos contacts quant à la nature et au volume de sollicitations que vous leur adressez. C’est un ressenti psychologique bien plus complexe à appréhender que la dimension objective et qui ne dépend de surcroit pas entièrement de votre influence propre. Le niveau de pression marketing ressenti par vos contacts sera par exemple influencé par les sollicitations reçues d’autres marques que la vôtre.
Ainsi, un écart peut apparaitre. Une pression marketing peut par exemple être considérée comme « très » importante d’un point de vue objectif et « trop » importante du point de vue subjectif, faisant de la gestion de la pression marketing une opération complexe.
En définitive, la gestion de la pression marketing est donc fort complexe. Gérer efficacement la pression marketing consiste à trouver, pour chacun de vos contact, le bon dosage dans le volume de sollicitations auquel vous l’exposez. Pour atteindre cet objectif, votre approche doit être centrées sur vos données, que vous devez exploiter au mieux, afin d’en déduire les actions qui seront les plus utiles selon les profils et les réactions antérieures de vos prospects.
A sursolliciter sa base, il est fort possible de dégrader son actif client. Le phénomène général de fatigue marketing des consommateurs est réel, et il faut donc que vous réussissiez à trouver un équilibre, entre le volume d’envois et la capacité d’attention / de réceptivité de vos contacts.
Pour cela, 4 approches pourront vous aider à améliorer le calibrage de votre pression marketing.
Limiter le nombre de messages reçus par segment
Attribuer un poids par nature de communication
Mettre en place un moteur de vos priorités (Une fonctionnalité offerte par des solutions avancées)
Exploiter un centre de préférences pour réduire les désabonnements
Votre plan de marketing relationnel est à présent bien défini et organisé, vous pouvez donc passer à l’action concrète de collecte de vos données, qui vont vous permettre de mettre en route l’ensemble des actions que vous avez anticipées et organisées précédemment, dans le but d’atteindre vos objectifs initiaux.
Construire le plan de collecte
Il s’agit d’un document permettant d’identifier les données à collecter et de déployer des programmes afin de collecter ces données.
La donnée client est la base de l’amélioration de votre relation clients. Elle va vous permettre de personnaliser les moments de contact avec eux, le contenu de vos messages, ainsi que vos offres et vos choix de canaux. C’est elle qui va vous permettre de cibler les campagnes de marketing client afin de « faire tourner » vos scénarios de Marketing Automation. Sans données clients, votre plan de marketing client ne peut exister. Bien souvent, vous serez amené à exploiter des données que vous ne possédez pas au sein de votre entreprise initialement, et que vous devrez donc collecter auprès de vos clients.
Vous devrez donc, dans un premier temps, procéder à un inventaire des données qui sont à disposition au sein de votre entreprise, puis identifier vos données manquantes afin de mettre en place les actions que vous souhaitez lancer (programmes, scénarios…).
C’est ici tout l’intérêt de l’élaboration d’un plan de collecte, qui va pouvoir :
Définir les données clients que votre entreprise doit collecter afin de faire vivre ses programmes relationnels et marketing. (Il pourra s’agir de données socio-démographiques, transactionnelles, comportementales…)
Définir les mécaniques de collecte de vos données cibles. Il sera notamment utile d’identifier quels points de contact pourront être transformés en points de collecte d’informations sur votre client, mais également quels scenarios anticiper etc.).
Une fois le dispositif de collecte mis en place, le gros de votre organisation est fait. Il reste cependant une étape cruciale : celle du suivi et de la mesure de la performance de l’ensemble des décisions que vous venez de prendre, afin de mesurer leur efficacité et de pouvoir être en mesure d’apporter des modifications adéquates au besoin.
Construire un dispositif de pilotage cohérent est nécessaire, afin de développer des reportings adaptés à vos différents utilisateurs, visant à mesurer au mieux l’impact de vos actions CRM sur l’ensemble de vos clients (leur satisfaction, leur rétention, leur fréquence d’achat etc.) ainsi que sur votre entreprise (notamment vos KPIs financiers).
Sur ce sujet, nous vous recommandons la lecture de notre article : [Interview croisée] – Comment piloter son dispositif CRM ?« . Nous avons interrogé 4 experts qui nous ont partagé leurs bonnes pratiques pour piloter au mieux la performance de ses actions CRM. Vous y découvrirez différentes approches permettant de mesurer les résultats de votre dispositif CRM. Voici un petit extrait de l’échange que nous avons eu avec l’un de ces 4 experts, Grégoire Mialet, CEO et cofondateur de C-ways.
Conclusion : l’enjeu de l’unification des données clients
Il faut bien prendre conscience que les données clients sont le carburant de votre dispositif CRM. Elles ont tendance, aujourd’hui encore, à être éparpillées dans le système d’information des entreprises. C’est problématique, car cela complique leur accès et leur exploitation. Plus vos données seront organisées et centralisées, plus facilement vous pourrez les exploiter pour faire vivre votre plan relationnel.
C’est pour cette raison qu’un projet CRM ambitieux doit traiter l’enjeu de l’unification des données clients. Il existe aujourd’hui des plateformes no code permettant de gérer la consolidation, la déduplication, l’unification et la préparation des données – à l’instar d’Octolis.
Notre plateforme a été conçue pour gérer de manière simple et efficace toute la chaîne de traitement des données : unification – préparation – orchestration omnicanale. Octolis a été conçu pour vous permettre d’exploiter le plein potentiel de vos données clients. N’hésitez pas à entrer en contact avec notre équipe pour en savoir plus :).
Ecommerce : comment construire son budget marketing ?
Le budget marketing en ecommerce représente en moyenne 10% à 15% des revenus de l’entreprise. Cela varie bien sûr suivant le secteur d’activité et le stade de développement de l’entreprise, c’est un ordre de grandeur. Comment répartir et utiliser efficacement ce budget ? C’est ce que nous allons voir. Nous avons un petit cadeau pour vous : un modèle Excel gratuit pour construire votre budget marketing ecommerce 🙂
Cette ressource va vous aider à construire vos hypothèses, à élaborer votre budget prévisionnel et à comparer ce dernier au budget constaté. Nous vous expliquons ici comment en faire un bon usage. Nous allons aussi vous partager les 4 règles d’or à suivre pour construire son budget marketing ecommerce.
3/ Prendre le temps d’analyser la stratégie de vos concurrents. C’est bien souvent en copiant/adaptant les bonnes pratiques appliquées par ses concurrents que l’on réussit. Il existe des tas d’outils pour espionner la stratégie marketing, SEO, publicitaire, social media de vos concurrents.
Avant tout chose, voici quelques ordres de grandeur pour un budget marketing ecommerce classique
Part des revenus allouée au budget marketing
La part allouée au budget marketing représente en moyenne 10% du revenu des entreprises. Dans le monde du ecommerce, le marketing peut facilement représenter 15% des revenus.
La ventilation de ce budget varie en fonction de nombreux éléments :
Tout d’abord, la phase de vie de l’entreprise. Il apparaît logique qu’au lancement d’une activité d’e-commerce, une grande part des investissements soit consacrée à l’acquisition. Progressivement, au fur et à mesure de la croissance de l’entreprise, les investissements deviennent de plus en plus importants dans le marketing relationnel et plus généralement la fidélisation de vos clients (avec notamment la mise en place de scénarios, etc.).
Les caractéristiques du secteur. Le mix acquisition – fidélisation varie d’un secteur à l’autre. Globalement, on investit plus en fidélisation (vs l’acquisition) dans les secteurs à rétention forte. Nous pouvons prendre comme exemple le secteur des cosmétiques, où l’on peut noter une fréquence d’achat élevée et ainsi plus d’investissement sur la partie rétention, afin de continuellement stimuler cette fréquence d’achat et d’optimiser la lifetime value. Pour d’autres secteurs au contraire, comme ceux du luxe, le panier moyen est bien plus élevé, et les achats logiquement plus espacés. Les entreprises concernées ont donc tout intérêt à orienter leur budget vers l’acquisition de nouveaux clients, plutôt que vers la fidélisation.
Un modèle gratuit pour définir et monitorer votre budget marketing ecommerce
Cette ressource peut vous aider à définir et piloter le budget de votre équipe marketing. Elle vous permet de définir un budget prévisionnel détaillé sur la base d’hypothèses personnalisées et de piloter ensuite votre budget en comparant le budget prévisionnel au budget constaté/réel.
Pour le prévisionnel, un onglet « hypothèses » va vous permettre de définir un budget annuel que vous souhaitez allouer à la plupart de vos postes de dépense. Vous pouvez également définir des zones de répartition de ces dépenses, en créant des onglets « zones » ou « filiales ».
En ce qui concerne votre budget réel, l’onglet « »Budget constaté » vous permet de saisir chaque mois les montants réellement dépensés, et d’ainsi comparer votre budget prévisionnel avec les sommes vraiment dépensées.
Enfin, pour vous permettre d’ajuster votre prévisionnel en cours d’année, en fonction des évolutions stratégiques et opérationnelles de votre structure, nous calculons une colonne « Réel annualisé » sur la base des premiers mois de dépenses réelles. Il s’agit du budget que vous devrez prévoir si les dépenses réelles des prochains mois suivent les résultats des premiers mois.
L’intérêt de cet outil est qu’il va vous permettre de pouvoir observer et de prendre du recul sur vos dépenses, sur des périodes de temps longues (au fil de mois), de manière claire et visuelle. De cette vision globale, vous serez alors à-même de tirer une analyse vous permettant d’améliorer vos prévisions et votre exécution concernant vos dépenses marketing, via la comparaison entre vos prévisions et les dépenses effectivement réalisées.
De plus, l’ajustement automatiquement calculé par notre outil, à travers le « réel annualisé » vous permet de gagner un temps précieux et d’anticiper au mieux vos futures dépenses afin de vous concentrer sur la mise en application et les modifications concrètes à apporter au sein de votre entreprise pour atteindre vos objectifs (initiaux ou revus).
En plus de cet outil gratuit que nous vous mettons à disposition, il est également essentiel que vous puissiez vous pencher sur la découverte et la prise en main des principaux canaux de marketing en ecommerce.
Règle d’or 1 – Connaître les principaux canaux marketing en ecommerce
L’art de construire un budget marketing ecommerce consiste en partie à définir le bon mix-canal, c’est-à-dire à bien répartir vos efforts sur les différents canaux à votre disposition. Cela, évidemment, suppose d’avoir une bonne overview des canaux existants et utilisés en ecommerce.
Voici une liste (non exhaustive) des principaux canaux et media marketing en ecommerce :
Le trafic organique et payant. Le SEO (Search Engine Optimization) consiste à améliorer les résultats de recherche organiques de votre site web en optimisant les méta-titres, les descriptions, les balises H1, etc. Le SEM (Search Engine Marketing), quant à lui, consiste à acheter des annonces publicitaires pour que votre site apparaisse en première page des résultats de recherche pour des termes spécifiques.
Les réseaux sociaux. Les réseaux sociaux tels que Facebook, Instagram, Twitter, etc. permettent aux marques de promouvoir leurs produits auprès d’un public ciblé, en utilisant des annonces publicitaires ciblées et en créant du contenu engageant.
L’e-mail marketing. Il s’agit d’un moyen efficace pour communiquer avec vos clients existants et les inciter à effectuer des achats. Les marques peuvent utiliser des e-mails pour partager des offres exclusives, des promotions et des nouveaux produits avec leur liste de diffusion.
Le marketing d’affiliation. C’est un partenariat entre une marque et un site web ou un blogueur, qui promeut les produits de la marque en échange d’une commission su vos ventes.
L’inbound marketing. Il s’agit de créer et de partager du contenu informatif et intéressant sur le site web, les réseaux sociaux et les blogs, pour attirer les visiteurs et les inciter à acheter vos produits.
La vidéo. L’idée est de promouvoir vos produits via des vidéos sur les réseaux sociaux, les plateformes de partage de vidéos, les sites web et les blogs. Les vidéos peuvent être utilisées pour montrer vos produits en utilisation, pour donner des conseils d’utilisation, etc.
Les influenceurs. L’objectif est d’utiliser des personnalités populaires ou des experts dans un domaine pour promouvoir vos produits auprès de leur public. Les influenceurs ont généralement une grande communauté de followers sur les réseaux sociaux.
Le retargeting. Le but est le suivant : cibler les visiteurs qui ont déjà visité votre site web avec des annonces publicitaires, pour les inciter à revenir et à effectuer un achat. Il utilise les données de navigation des utilisateurs pour afficher des bannières publicitaires personnalisées sur les sites web visités par ces utilisateurs.
Le choix des canaux est bien évidemment dépendant des objectifs marketing de votre entreprise. Avant de commencer à répartir votre budget, il est important de définir des objectifs précis. Que voulez-vous accomplir avec votre budget marketing? Voulez-vous augmenter les ventes, améliorer la notoriété de votre marque ou fidéliser vos clients existants? Une fois que vous avez défini vos objectifs, vous pouvez commencer à planifier comment les atteindre.
Gartner a mené une étude intéressante qui permet de connaître l’allocation classique du budget marketing sur les différents canaux online :
Source : Gartner.
La distribution du budget sur les canaux offline :
Source : Gartner (idem).
Règle d’or 2 – Connaître les performances moyennes en ecommerce
Il existe un grand nombre d’études et de statistiques au sujet des performances moyennes en ecommerce. Nous vous recommandons notamment cet article qui est une sorte d’état de l’art sur le sujet. Toutes les dimensions sont passées en revue : acquisition, engagement on site, conversion, marges, rétention…
Connaître les performances moyennes va vous aider à prendre du recul sur vos propres performances et à détecter les zones d’amélioration. Par exemple, si vous avez un taux de conversion de 0,5% alors que le taux moyen dans votre secteur d’activité est de 2%, il y a sans doute des choses à faire pour améliorer vos performances.
Règle d’or 3 – Analyser les stratégies marketing de vos concurrents
Il est très intéressant de prendre le temps d’analyser ce que font vos concurrents, par exemple les ecommerçants situés dans le même secteur d’activité ou dans des secteurs proches, ou avec qui vous partagez des points de communs.
Il existe beaucoup d’outils qui peuvent vous permettre d’espionner la stratégie de vos concurrents. Voici une liste non exhaustive de ceux qu’il pourrait être particulièrement intéressant d’utiliser :
Les outils pour analyser le trafic web et la stratégie SEO de vos concurrents
Le traffic web est probablement l’un des premiers aspects que vous allez chercher à analyser, car il est une source d’information très utile pour votre société (à visée comparative) mais de surcroit car ce ne sont pas des données faciles à obtenir.
Semrush, un exemple d’outil pour analyser le trafic web (et la stratégie SEO) de vos concurrents.
La notion de traffic Web regroupe en effet de nombreux aspects différents, comme le nombre de visites par mois, mais également le nombre de visiteurs uniques par mois (le nombre de personnes différentes qui visitent le site), le profil de ces dits visiteurs et leur temps passé sur le site, ou encore les sources du traffic (proviennent-ils d’un moteur de recherche ou d’une publicité par exemple) etc.
Pour ce qui est de la stratégie SEO, son objectif est, rappelons-le, de générer plus de trafic en provenance des moteurs de recherche (en particulier de Google). L’idée avec cet axe d’analyse n’est donc pas de recueillir le volume et la nature du trafic web de la concurrence, mais plutôt de comprendre son mode d’obtention précis. Encore une fois, le but est d’obtenir une analyse comparative, entre vos propres stratégies et celles de sociétés évoluant dans le même milieu que vous, afin de trouver de potentielles nouvelles sources d’inspiration.
Pour ce faire, vous pouvez notamment axer votre recherche sur les aspects suivants de vos concurrents : les mots-clés sur lesquels ils se positionnent ainsi que leur backlinks. En effet, si vos concurrents se positionnent mieux que vous sur un mot-clé stratégique, il peut être intéressant de comprendre pourquoi.
De même, il est nécessaire de rester informé des nouveaux sites redirigeant vers ceux de vos concurrents, et d’ensuite approfondir le sujet afin de découvrir de quelle manière ils ont pu procéder pour en obtenir de nouveaux. Toute cette analyse vous permettra de développer au mieux votre propre SEO, en vous inspirant et en identifiant de potentielles nouvelles méthodes d’accroissement du traffic que vous pourrez à votre tour mettre en place.
La stratégie de publicité digitale de vos concurrents
En plus de votre stratégie SEO, il peut être intéressant pour vous d’analyser la stratégie publicitaire de vos concurrents, toujours dans un objectif d’amélioration personnelle.
Adbeat, un exemple d’outil pour espionner la stratégie publicitaire de vos concurrents.
Il pourra alors être intéressant pour vous de rechercher des informations comme le lieu de publicité de vos concurrents (quelles plateformes notamment), ou encore quel type d’annonce publicitaire ou de landing page affiche un meilleur taux de conversion que les autres.
La stratégie de vos concurrents sur les réseaux sociaux
Comme pour la stratégie publicitaire, une stratégie de réseaux sociaux est aujourd’hui nécessaire à toute entreprise voulant améliorer sa popularité. Il est donc nécessaire que vous puissiez être en mesure d’analyser la stratégie social media de vos concurrents, afin de rendre la vôtre meilleure une fois de plus.
Cela peut notamment passer par le fait d’identifier les réseaux sociaux sur lesquels vos concurrents sont présents, mais également d’analyser leurs publications (type, régularité, popularité), leur type d’abonnés et leur engagement etc.
La stratégie de contenus (blog / site web) de vos concurrents
Toujours en vue d’atteindre le même objectif, il est également primordial d’analyser la stratégie de contenus de vos concurrents, afin de rester au fait des tendances du marché et de qui fonctionne ou non (et, une fois de plus, de glaner de potentielles nouvelles idées). Il vous est alors possible d’effectuer cette recherche manuellement, en vous rendant directement sur les sites web et blogs de vos concurrents. Mais il vous sera également possible d’utiliser un agrégateur de contenus, afin d’être en mesure de pouvoir suivre de manière centralisée les publications des sites de l’ensemble de vos concurrents.
Une fois encore, vous pourrez vous intéresser à de multiples facteurs : le type de contenu (infographies, vidéos, guides pratiques, etc.), leur fréquence de publication, le trafic qu’elles génèrent (le nombre de vues), leur repartages sur les réseaux sociaux etc.
La couverture média de vos concurrents
Enfin, il est également intéressant de pouvoir suivre la couverture média de vos concurrents, et ainsi d’être informé à chaque fois qu’un site ou un blog mentionne leur nom. Cela peut vous permettre de rester au fait des évolutions du marché (lancement de nouveaux produits, une communication particulière, un nouveau design etc.).
L’outil Google Alert est certainement le plus simple à utiliser pour ce faire, en vous permettant d’être informé chaque fois que le nom d’une marque (le votre ou celui d’un concurrent) sera cité dans un contenu publié sur internet, avec la possible activation de notifications en temps réel.
Règle d’or 4 – Analyser et optimiser votre stratégie marketing en continu
Pour finir, il est primordial de garder en tête que l’analyse de votre stratégie marketing doit s’effectuer de manière continue, et non ponctuellement, afin de pouvoir en tirer le plus de bénéfices.
Dans cette approche continue, il convient néanmoins de ne pas vous perdre et de rester concentré sur les canaux les plus efficaces une fois les différents canaux analysés. Il est bien évidemment judicieux que vous puissiez allouer une plus grande partie de votre budget à un canal vous permettant d’atteindre les objectifs au cœur de votre stratégie.
Nous vous conseillons également d’utiliser des outils de suivi afin d’accroître vos résultats. Comme toujours, il est nécessaire que vous conserviez une prise de recul ainsi qu’un regard extérieur sur le déroulement de vos activités, pour être en capacité d’intervenir et de modifier votre process à tout moment. Des outils de suivi tels que Google Analytics pourront alors grandement vous aider dans le suivi des visiteurs de votre site web, en mesurant notamment le taux de conversion et en évaluant l’efficacité de vos efforts marketing.
Enfin, vous devrez penser à ajuster votre budget en fonction des résultats que vous observerez. Ainsi, les canaux se révélant moins efficaces que prévu verront alors leurs dépenses baisser, alors que celles-ci pourront augmenter pour les canaux montrant des résultats plus positifs.
Télécharger notre modèle gratuit de budget marketing prévisionnel
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Pour les éditeurs de marketing automation, 2022 a été marquée par des acquisitions, recrutements d’exécutifs et décisions stratégiques en tout genre. Par exemple, l’acquisition de la plateforme Goodfazer par Splio, le rachat d’Actito par le groupe QTNM ou encore l’annonce d’Insider d’être une unicorn après avoir levé 121 millions.
Voici donc un baromètre de l’année 2022 qui résume les éléments marquants pour les éditeurs de marketing automation.
Concernant notre méthodologie, nous avons regroupé les éditeurs par catégorie, à savoir Ecosystème, intermédiaires et légers. Les solutions écosystèmes correspondant aux solutions lourdes fournissant une série d’outils à un prix élevé, les solutions intermédiaires faisant la même chose dans une moindre mesure et les solutions légères pour les entreprises fournissant des outils à utilités précises à petit coût.
En 2022, a acquéri Napkin. Nouveau CFO et vice-président. Shopify investit 100 millions
Les news
Sendinblue
Sendinblue est une entreprise de logiciels de marketing basée en France, fondée en 2007 par Armand Thiberge, son actuel CEO. Au cours des derniers mois, l’entreprise a été très active sur le marché des acquisitions, avec cinq achats réalisés en 2021 et 2022, pour un montant estimé à 47 millions d’euros. Cela inclut Metrilo, Chatra, PusOwl, Metfox et Yodel.io. Ces acquisitions ont renforcé la plateforme de Sendinblue en matière de données client, de chat en direct, de notifications push et d’analyse.
En 2020, l’entreprise a également effectué une levée de fonds de 140 millions d’euros pour accompagner sa croissance. Pour soutenir cette croissance, Sendinblue a également nommé de nouveaux profils stratégiques tels que Olivier Legrand en tant que Chief Operating Officer, Laure Rudelle Arnaud en tant que Chief People & Impact Officer et Yvan Saule en tant que Chief Technology Officer. En novembre 2022, Sendinblue a également lancé deux nouvelles fonctionnalités: Sendinblue Meetings pour l’hébergement et le partage de liens vidéo automatisés et Payment Processing pour l’automatisation des factures via Stripe et la personnalisation des annulations.
Activecampaign
ActiveCampaign est une entreprise de logiciel de marketing et de gestion de la relation client fondée il y a quelques années. Elle est devenue l’un des plus importants fournisseurs de CRM et de ventes et marketing automatisés avec plus de 180 000 clients dans le monde. Son siège se trouve aux États-Unis et elle opère dans plusieurs pays.
En mai 2022, ActiveCampaign a acquis ActiveCampaign postmark, une entreprise de courrier électronique transactionnel. En janvier 2020, ActiveCampaign a levé 100 millions de dollars et en avril 2021, une autre levée de fonds de 240 millions a été annoncée.
Jason VandeBoom est le CEO et fondateur d’ActiveCampaign. Pour poursuivre sur la lancée de l’entreprise, Sameer Kazi a été nommé président et Kelly O’Connell a été élevée au poste de vice-président senior de la stratégie produit.
En avril 2022, ActiveCampaign a annoncé une intégration étendue pour Slack, permettant aux utilisateurs de gérer leur campagne marketing directement depuis l’application de messagerie Slack. Cette intégration permettra d’accroître l’efficacité et la productivité des équipes en automatisant certaines tâches de marketing et en facilitant la communication entre les différents services de l’entreprise.
Mailchimp
Mailchimp est une entreprise de marketing par courriel fondée en 2021. Elle est devenue l’un des principaux fournisseurs de solutions de marketing automatisé avec une présence internationale. Elle a réalisé plusieurs acquisitions avec les dernières en date étant Chatitive en janvier 2021, et Bigteam en juin 2020.
Ben Chestnut est le CEO de Mailchimp depuis 2001. Sous sa gérance, l’entreprise a connu une croissance stable et a continué à étendre ses fonctionnalités. En Septembre 2022, Mailchimp a lancé sa nouvelle campagne de marque créative, « Guess less, sell more », qui utilise des visuels et des actifs ludiques et légèrement étranges pour montrer qu’il est facile pour les PME de « supprimer les conjectures » de leur stratégie marketing.
En 2022, Mailchimp a amélioré ses fonctionnalités pour les entreprises de commerce électronique, avec l’ajout de 5 nouveaux déclencheurs de commerce électronique, de sondages clients, et de modèles de parcours pour récupérer des clients perdus. Cette mise à jour vise à aider les entreprises à maximiser leur chiffre d’affaires en automatisant les campagnes de marketing.
GetResponse
GetResponse est une entreprise de marketing automation fondée en 1999. Pour ses actualités, en Décembre 2022, GetResponse a réalisé une acquisition en achetant Recostream une entreprise spécialisée dans les outils de tracking des campagnes de marketing. Simon Grabowski est le fondateur et CEO de GetResponse.
Egalement en 2022, GetResponse est devenue une société par actions, ce qui permet à l’entreprise de continuer à croître et de financer des développements futurs. Cette transformation en société anonyme élargit les possibilités d’investissement et permet à GetResponse de mettre en place un plan d’options d’achat d’actions pour les employés. Les actionnaires actuels de l’entreprise conservent leurs actions et peuvent continuer à soutenir l’entreprise. Ce changement de statut permet à l’entreprise de poursuivre sur sa lancée, en se concentrant sur le développement de nouvelles fonctionnalités et en renforçant sa position sur le marché.
Campaign Monitor
Campaign Monitor est une entreprise de marketing automation fondée il y a quelques années. Elle est devenue l’un des principaux fournisseurs de solutions de marketing automatisé avec une présence internationale. En janvier 2019, Campaign Monitor a réalisé une acquisition en achetant Liveclicker et Sailthru, sa cinquième et sixième acquisition respectivement. En avril 2014, elle a levé 250 millions d’euros à travers une série A. Wellford Dillard en est le CEO depuis 2017.
En Avril 2022, Monitor Campaign a redesigné sa plateforme pour accueillir les SMS en plus des emails. Cela permet aux utilisateurs de bénéficier d’une plateforme de marketing de bout en bout pour les campagnes de marketing multi-canal. En avril 2021, Monitor Campaign a annoncé une intégration pour Salesforce, les clients de Campaign Monitor peuvent désormais accéder à toutes leurs données Salesforce, créer des tableaux de bord et déclencher facilement des e-mails transactionnels en quelques minutes et sans jamais quitter la plateforme. Cette mise à jour vise à simplifier les processus de marketing et les données pour les entreprises utilisant les deux plateformes.
Klaviyo
Klaviyo est une entreprise de marketing automation qui a été fondée en 2012. Elle a réussi à lever près de 800 millions de dollars à travers 7 séries de financement, la dernière se terminant en mai 2021 pour 320 millions de dollars. Shopify, une entreprise d’e-commerce, a également investi 100 millions de dollars dans Klaviyo en août 2022.
En novembre 2022, Klaviyo a annoncé son acquisition de Napkin, une entreprise spécialisée dans l’analyse des données pour les entreprises e-commerce. Cette acquisition permettra à Klaviyo de renforcer ses capacités d’analyse de données pour améliorer les campagnes de marketing de ses clients. Andrew Bialecki est le CEO de Klaviyo depuis 2012. En 2022, Amanda Whalen a rejoint l’entreprise en tant que CFO et Kim Peretti en tant que Vice-président Senior de Global Customer Success and Support.
Panorama des solutions type intermédiaire :
Les solutions qui apportent une utilité semi-limitée avec plusieurs outils et un coût moyen (entre 20K€ et 50K€ annuel).
Nom
Nb employés Déc. 2022
Croissance sur 2 ans (en %)
Nouvelles récentes
Les news
Splio
Fondée en octobre 2016, l’entreprise Splio est un acteur majeur dans le domaine du digital marketing et du data management. Elle opère dans plusieurs pays et a réussi à se tailler une place de choix dans ce marché hautement compétitif.
Récemment, Splio et D-Aim ont annoncé leur fusion, donnant naissance au nouveau groupe Splio + D-aim. Cette acquisition s’inscrit dans la stratégie de croissance de l’entreprise qui a déjà réalisé des rachats pertinents tels que celui de la start-up spécialisée dans les Mobile Wallets, Gowento, en novembre 2018, et de la plateforme de parrainage client Goodfazer en mars 2022. Ces acquisitions ont permis à l’entreprise de renforcer sa position sur le marché et de proposer des solutions de plus en plus innovantes à ses clients.
Depuis 2014, l’entreprise est dirigée par Mireille Messine, qui a su mettre en place une vision stratégique ambitieuse et une équipe de direction solide. En mars 2019, Splio a nommé Antoine Parizot au poste de Directeur général France et en août 2018, Charles Wells au poste de Chief Marketing Officer. Ces nominations ont permis à l’entreprise de poursuivre sa croissance et de proposer des produits toujours plus performants à ses clients.
Actito (CM group)
Fondée en 2008 sous le nom de Citobi, Actito est une entreprise belge spécialisée dans la technologie de marketing automation. Elle opère dans plusieurs pays et a réussi à se tailler une place de choix dans ce marché hautement compétitif. Aussi en 2018, Citobi a acheté MediQuality, une entreprise de solutions de gestion de la qualité de la communication, pour renforcer ses capacités dans le domaine de la communication multicanale. Cependant, en septembre 2018, Citobi a revendu MediQuality pour se concentrer sur son projet Actito et investir dans la technologie de marketing automation.
En juin 2019, Actito a fait l’acquisition de SmartFocus, une entreprise britannique de marketing automation, pour renforcer son offre de produits et de services. Cette acquisition a permis à Actito de proposer une plateforme de marketing automation encore plus complète et innovante à ses clients. Les cofondateurs, Benoît De Nayer et Kenya Rose, ont su mettre en place une vision stratégique ambitieuse et une équipe de direction solide pour faire de Actito une entreprise leader dans son domaine. D’ailleurs en 2022, Actito rejoint le groupe QTNM, ce qui a permis à l’entreprise de se développer encore plus rapidement.
Emarsys
Emarsys est une entreprise de marketing automation fondée en 2000 et basée en Autriche. Elle est reconnue pour sa plateforme de marketing automatisé innovante et performante.
En 2015 et 2016, Emarsys a levé 55,3 millions d’euros de capital pour financer sa croissance. Cet investissement a permis à l’entreprise de poursuivre son développement et d’innover en proposant des fonctionnalités toujours plus performantes sur sa plateforme.
En novembre 2020, SAP Newsbyte a racheté Emarsys pour renforcer sa capacité à fournir une solution globale de marketing automation. Cette acquisition a permis à Emarsys de bénéficier de l’expérience et des ressources de SAP pour accélérer son développement. Un moi plutôt, Emarsys avait également fait l’acquisition de Loyalsys, une entreprise de marketing relationnel, pour améliorer ses capacités de fidélisation de la clientèle.
En octobre 2021, Emarsys a annoncé la nomination de Joanna Milliken en tant que nouvelle CEO. Elle remplace à cette fonction le CEO sortant qui était en place depuis de nombreuses années et qui a permis à Emarsys de devenir un acteur incontournable de la marketing automation. Sous la direction de Joanna Milliken, Emarsys poursuit son expansion et innove pour améliorer les performances de ses produits et réduire ses limitations.
Braze
Braze est une entreprise de marketing automation fondée en 2011 et basée à New York. Elle est reconnue pour sa plateforme de marketing automatisé complète et innovante qui permet aux entreprises de connecter, segmenter et personnaliser les communications avec leurs clients à travers différents canaux.
En novembre 2021, Braze a été introduit en bourse et valorisé à 520 millions de dollars, ce qui lui a permis de renforcer sa position sur le marché. Ce succès est en partie du à Bill Magnuson, le CEO, qui a su mettre en place une vision stratégique ambitieuse et une équipe de direction solide.
En juin 2022, Braze a nommé Astha Malik au poste de Chief Marketing Officer, elle a permis à l’entreprise de poursuivre sa croissance et de proposer des produits toujours plus performants à ses clients. Braze a également renforcé ses partenariats avec d’autres leaders du secteur, tels que Snowflake et WhatsApp, afin de proposer des solutions encore plus puissantes et complètes à ses clients.
Les revenus du troisième trimestre ont augmenté de 45,6% par rapport à l’année précédente pour atteindre 93,1 millions de dollars, ce qui indique une croissance solide de l’entreprise. En novembre 2022, Braze a annoncé l’ajout de nouvelles fonctionnalités comme l’amélioration des outils d’analyse et de rapport, de gestion de l’audience et de création de campagnes pour continuer à offrir des solutions de qualité à ses clients.
NP6
NP6 est une entreprise de marketing automation fondée en France et qui opère dans de nombreux pays à travers le monde.
En janvier 2021, ChapsVision a acquis NP6 pour renforcer sa capacité à fournir des solutions de marketing automation innovantes et performantes à ses clients. Cette acquisition a permis à NP6 de bénéficier de l’expérience et des ressources de ChapsVision pour accélérer son développement. En Juillet 2016, NP6 avait fait l’acquisition de Ezakus, une entreprise de marketing relationnel, pour améliorer ses capacités de fidélisation de la clientèle.
A propos de son staffing, depuis 2019, NP6 est dirigé par Olivier Dellenbach qui a su mettre en place une vision stratégique ambitieuse pour NP6. NP6 continue d’innover en proposant des fonctionnalités toujours plus performantes sur sa plateforme pour répondre aux besoins de ses clients. L’acquisition récente par ChapsVision lui a permis de consolider sa position sur le marché.
Hubspot
Créée en 2006 par Brian Halligan et Dharmesh Shah, Hubspot est une entreprise de logiciel de marketing, de vente et de service basée aux États-Unis. Depuis sa création, Hubspot a connu une croissance rapide et est une entreprise en plein essor. Au cours des dernières années, Hubspot a multiplié les acquisitions, notamment en février 2021 avec l’acquisition de The Hustle, une entreprise spécialisée dans l’envoi de newsletters. Cette acquisition vient renforcer la capacité de Hubspot à connecter les entreprises à leurs clients.
En septembre 2021, Yamini Rangan a été nommée CEO de Hubspot. Elle a apporté une grande expérience en matière de stratégie et de développement commercial. En novembre 2022, Alyssa Harvey Dawson a été nommée Directeur juridique de Hubspot. Cette année a vu également le lancement de Operations hub, un outil qui permet aux entreprises de unifier leurs données clients dans une plateforme CRM connectée et d’automatiser une variété de tâches chronophages. Hubspot continue de se développer et de renforcer sa position de leader dans l’industrie.
Dialoginsight
Dialoginsight est une entreprise de taille moyenne qui a été fondée en 1999. Elle opère dans plusieurs pays, en mettant l’accent sur les solutions de gestion de données et de marketing numérique. Pascale Guay en est le CEO depuis sa création.
Dialoginsight a récemment lancé une nouvelle fonctionnalité appelée Bibliothèque d’assets, qui simplifie la gestion des contenus tels que les bannières d’information et les offres promotionnelles. Cette fonctionnalité aide les équipes à travailler plus efficacement tout en économisant du temps et de l’argent.
Acoustic
Acoustic est une entreprise de taille moyenne fondée en 2019. Détenue à l’origine par IBM, elle est maintenant une entité privée à part entière backée par Centerbridge Partners, mais continue d’utiliser l’interface de programmation d’applications d’IBM pour ses solutions. Elle opère dans plusieurs pays, en mettant l’accent sur les solutions de marketing numérique et de gestion de données.
En Octobre 2022, Acoustic a reçu un nouveau financement de Francisco Partners pour poursuivre son développement. En trois ans l’entreprise a maintenant atteints 600 employés et a étendu sa présence internationale. En janvier 2023, Mark Cattini a été nommé CEO.
Acoustic a adopté le cloud pour le marketing et a déplacé 90% de sa charge de travail vers AWS. En juin 2022, Acoustic a annoncé la sortie de Multichannel Composer, une solution permettant aux marques de combler le fossé de l’expérience numérique en permettant aux équipes marketing de toute taille d’orchestrer facilement des campagnes hyperpersonnalisées pour engager les consommateurs sur le moment.
Iterable
Iterable est une entreprise de marketing automation fondée en 2013 qui opère dans plusieurs pays. Elle a réussi à lever 342 millions de dollars de financement au total, son dernier tour s’est fini en juin 2021.
Malgré une situation financière stable, l’entreprise a été touchée par une crise interne. En avril 2021, Justin Zhu, le CEO et co-fondateur de Iterable, a été évincé de sa position pour avoir pris du LSD sur son lieu de travail. Depuis, Andrez Boni est le nouveau CEO de l’entreprise.
Iterable a profité de cette année 2022 pour se développer sur des marchés étrangers en commençant son expansion en Australie et Nouvelle Zélande. L’entreprise a également amélioré sa plateforme marketing en ajoutant plusieurs intelligences artificielles pour optimiser l’efficacité des promotions.
Customer.io
Customer.io est une entreprise de marketing automation. Elle a réussi à lever un peu plus de 5 millions de dollars à travers 7 séries de financement, le dernier datant de mars 2022.
Dernièrement, l’entreprise a annoncé son acquisition de Parcel en août 2022. Ce rachat permettra à Customer.io de renforcer sa plateforme en offrant des services de messagerie ciblée et automatisée sur les différents canaux d’échange avec ses clients. Customer.io a également annoncé l’ajout d’un nouveau canal de messagerie : les messages intégrés aux applications mobiles et Web. Ce nouveau canal de communication permet aux entreprises d’interagir avec leurs utilisateurs là où ils sont le plus actifs, renforçant ainsi les campagnes de marketing.
Panorama des solutions type écosystème :
Les solutions qui apportent une solution lourde avec une série d’outils et un coût élevé (plus de 50K€ annuel).
Nom
Nb employés Déc. 2022
Croissance sur 2 ans (en %)
Nouvelles récentes
Les news
Selligent
Selligent est une entreprise belge de marketing automation qui a été fondée en 2001 avec une levée de fond de près de 5 million. Elle propose une plateforme de marketing automatisé qui permet aux entreprises de connecter, segmenter et personnaliser les communications avec leurs clients à travers différents canaux. Elle opère dans de nombreux pays dans le monde.
En novembre 2020, Selligent a été acquise par CM Group, un groupe américain de services de marketing et de technologies, pour renforcer sa capacité à fournir des solutions de marketing automation innovantes et performantes à ses clients. Selligent fait depuis partie de l’offre Marigold, qui réunit sous une même marque l’ensemble des solutions martech et d’emailing cross-canal, technologies et services de l’entreprise.
De plus, depuis février 2020, Karthik Kripapuri est le CEO de Selligent. Il a mis en place une vision stratégique ambitieuse pour poursuivre son développement et sa croissance. En novembre 2021, Selligent a lancé Selligent Data Studio Pro, une solution qui permet de consolider les données au sein de la plateforme Selligent Marketing Cloud, créer une vue unique que l’utilisateur peut analyser, automatiser le partage de tableaux de bord et fournir aux spécialistes du marketing un outil de reporting transparent pour suivre les clients.
Salesforce Marketing Cloud
Salesforce Marketing Cloud, fondée en 1999, est aujourd’hui l’une des plus grandes entreprises de marketing cloud au monde, opérant dans divers pays. Le bilan financier de l’entreprise est impressionnant, avec des acquisitions majeures telles que Slack pour 28 milliards de dollars en décembre 2020 et Tableau pour 15 milliards en juin 2019.
Il y a eu quelques changements de direction récemment chez Salesforce Marketing Cloud, notamment Bret Taylor quittant son poste de Co-CEO un an seulement après avoir été promu pour partager le poste avec Marc Benioff, co-fondateur de Salesforce. Les CEOs de Slack et de Tableau ont également quitté l’entreprise. En Décembre 2022, Salesforce a annoncé l’expansion de l’écosystème de commerce AppExchange pour aider les détaillants à réduire les coûts, augmenter l’efficacité et favoriser la réussite des clients sur Commerce Cloud.
Enfin, également en décembre 2022 Salesforce a annoncé l’ajout de 250 applications de partenaires commerciaux à AppExchange pour aider à réduire les coûts, augmenter l’efficacité et favoriser la réussite des clients sur Commerce Cloud, et a également annoncé Genie, le premier CRM en temps réel.
Adobe campaign
Adobe Campaign, fondée en 1992, est une entreprise leader dans les solutions de marketing digital, présente dans le monde entier. Elle est une filiale d’Adobe Systems Incorporated.
En termes de performance financière, Adobe Systems Incorporated a annoncé un chiffre d’affaires record pour son quatrième trimestre de 2020, atteignant 2,99 milliards de dollars, en augmentation de 20 % par rapport à l’année précédente. Aucune acquisition ou rachat n’ont été annoncées récemment pour Adobe Campaign spécifiquement.
En termes de stratégie, Adobe Campaign a annoncé récemment son intention de renforcer sa présence en Asie en ouvrant un nouveau bureau à Tokyo, pour mieux servir les clients locaux et explorer de nouvelles opportunités commerciales. De plus, l’entreprise a annoncé la sortie de nouvelles fonctionnalités pour son produit, incluant des outils d’automatisation de marketing pour faciliter la gestion des campagnes et une intégration renforcée avec d’autres solutions Adobe.
Il n’y a pas de nouvelles récentes concernant le CEO d’Adobe Campaign, Shantanu Narayen.
Insider
Insider, fondée en 2020, est une entreprise en forte croissance avec une présence internationale. En 2021, l’entreprise a réussi à lever 32 millions de dollars, et en février 2022, elle a réussi à lever 121 millions de dollars supplémentaires.
Handle Cilliger, le PDG de Insider, a été classé parmi les trois premiers PDG en dehors des États-Unis et a mené l’entreprise à une entrée remarquable dans le cercle très fermé des licornes en Mars 2022. L’entreprise s’est également classée en première position dans les rapports G2 Winter ’23 dans six catégories, notamment les plateformes de données client, le marketing mobile et la personnalisation.
Au cours du quatrième trimestre de 2022, Insider a également révélé de nouvelles fonctionnalités telles que: nouvelle AMP pour e-mails, les intégrations TikTok et Shopify, les alertes de prix cross-canal et les alertes de retour en stock.
On assiste depuis quelques années à l’émergence de plateformes et d’outils (souvent no code) facilitant l’exploitation des données sur toute la chaîne de traitement : collecte, consolidation, unification, préparation, transformation, enrichissement, activation, BI…
Les ELT cloud remplacent progressivement les ETL lourds du passé, les data warehouses cloud prennent le relais des vieux Data Warehouses « on premise » (type Informatica), les « Reverse ETL » permettent de mettre les données du DWH à disposition des équipes métier. Etc. Et tout ça, c’est grâce à un écosystème de startups data particulièrement florissant et innovant dont Octolis, à son échelle, fait partie.
Nous avons voulu vous présenter dans cet article les startups data qui nous inspirent le plus. Plusieurs experts du domaine se sont prêtés au même jeu que nous. Vous découvrirez leurs tops startups data en deuxième partie d’article.
Un Top 12 très personnel des startups data qui nous inspirent
Castor, le data catalog inspiré des géants de la Tech
Castor est un outil collaboratif et automatisé de catalogage des données. Ciblant des cas d’utilisation tels que la rationalisation des projets de conformité des données et la migration vers le cloud, Castor se connecte aux entrepôts de données du cloud (Snowflake, BigQuery, Redshift, MySQL…) et aux outils de business intelligence (Looker, Tableau, PowerBI, Metabase…) pour créer et mettre à jour automatiquement la documentation à laquelle les employés peuvent se référer lorsqu’ils ont des questions relatives aux données.
Solution plug & play prenant la forme d’un moteur de recherche, Castor fournit une source unique de référencement et de documentation des données, pour les rendre claires et accessibles à tous dans l’entreprise.
Metaplane, le Datadog qui met vos tableaux de bord au propre
Metaplane est une plateforme d’observabilité des données utilisée par les équipes data dans les entreprises à forte croissance pour gagner du temps d’ingénierie et gagner en fiabilité des données. L’objectif principal est de détecter les anomalies des tableaux de bords pour résoudre le problème avant que cela n’impacte le travail des autres équipes dans
l’entreprise.
En surveillant de près les métadonnées, la plateforme identifie les signaux anormaux (grâce à l’historique, les volumes, les distributions…), depuis les warehouses jusqu’aux tableaux de bord de BI, et peut ainsi alerter dès qu’un tableau bord s’avère être défaillant.
Cube, le middleware pour préparer et exploiter vos données
Cube est une couche sémantique, c’est-à-dire un intergiciel entre la source de données et l’application de données, qui permet aux ingénieurs et développeurs de rendre leurs données cohérentes, sécurisées, performantes et accessibles dans toutes les applications.
Orientée API, la couche sémantique de Cube permet la modélisation des données (en créant une source de données unique et centralisée) et un contrôle d’accès aux données. Cube offre un système de mise en cache à deux niveaux (un cache en mémoire et des pré-agrégations configurables) permettant à chaque application en aval de recevoir rapidement les informations les plus récentes. Enfin, les API SQL, REST et GraphQL de Cube permettent de créer des interfaces personnalisées pour visualiser les données et tableaux de bord de BI.
Portable, pour connecter facilement toutes vos sources de données à votre Data Warehouse
Portable est une plateforme ELT (Extract Transform Load) permettant d’obtenir l’ensemble des données de toutes les applications business, et ce sans aucun code. Portable offre des pipelines de données simples et prêts à l’emploi que l’on peut configurer en quelques minutes.
En se connectant à plus de 300 sources de données, Portable permet de centraliser les données sources provenant de différentes applications métier dans l’entrepôt de données cloud (Snowflake, BigQuery, Redshift, PostgreSQL…) à des fins d’analyse, d’automatisation ou de développement de produits.
Les solutions développées sont des solutions d’e-commerce (pour optimiser les opérations et créer des expériences d’achat innovantes), de marketing (pour développer des audiences et expériences clients de grande qualité, analyser des campagnes), d’analyse des ressources humaines (embauche et rétention des meilleurs collaborateurs grâce à des données centralisées) et de promotion du produit.
Hasura, le GraphQL pour créer vos APIs 10x plus vite
Hasura implémente un moteur de métadonnées pour simplifier et accélérer le développement d’applications sans serveur, en rendant les données instantanément accessibles via des API GraphQL. Hasura fournit des API web prêtes à l’emploi permettant des opérations flexibles et sécurisées sur les données, particulièrement utiles pour les entreprises où toutes les nouvelles capacités (applications ou API) doivent se connecter aux données en ligne existantes et où il ne s’agit pas seulement de créer des applications entièrement nouvelles.
Les produits développés sont des API GraphQL et REST instantanées sur toutes les données nouvelles et existantes pour alimenter des applications et des API modernes (Hasura Community Edition, Hasura Cloud, Hasura Enterprise Edition).
Neon, la solution pour créer une BDD Postgres serverless
Neon est un produit PostgreSQL sans serveur et open source permettant de créer un service de base de données en cloud pour les développeurs. Il devient facile de créer des branches pour chaque déploiement de code dans sa pipeline CI/CD de sa base de données PostgreSQL, et ce, à un coût très faible grâce à la technique de « copy-on-write » de Neon. Neon propose également un système de stockage illimité (écrit en rust) spécialement conçu pour le cloud.
Les entreprises SaaS utilisent Neon pour maximiser la vitesse d’ingénierie et minimiser les coûts. L’architecture sans serveur minimise le coût de la maintenance pour les clients inactifs notamment.
Firebolt est un entrepôt de données sous forme de cloud pour les créateurs d’expériences analytiques de nouvelle génération, combinant les avantages et la facilité d’utilisation d’une architecture moderne avec des performances ultra rapides, en moins d’une seconde. En construisant une architecture basée sur SQL, Firebolt utilise de nouvelles techniques de compression qui peuvent connecter les lacs de données et réduire les besoins en capacité du cloud, ce qui se traduit par une réduction des coûts et de meilleures performances.
Firebolt propose des API, SDK et IDE web. Firebolt utilise ANSI-SQL et dispose d’un IDE SQL.
Lightdash, l’alternative open source de Looker conçue pour les analystes
Lightdash est une alternative BI open source à Looker, conçue pour les analystes sur la base des outils de données qu’ils utilisent déjà. Lightdash réunit l’interface visuelle avec l’interface de modélisation et de transformation des données, créant ainsi une source unique pour les analyses de données.
Dans Lightdash, tout se fait en code (les champs dans Lightdash sont définis dans le projet dbt), ce qui permet une meilleure gestion de son outil de BI. Développer ce dernier devient plus rapide que jamais : en utilisant le CLI de Lightdash avec un éditeur de texte, il est possible de tester, prévisualiser et enregistrer ses modifications dans Lightdash. En quelques clics, on peut facilement créer des graphiques à partir des données ajoutées à son projet Lightdash.
Superbase, pour créer des bases de données cloud sur-mesure
Pionnier en Windows databases, Superbase propose un produit de développement multiplateforme et des outils qui permettent aux entrepreneurs de créer leurs propres solutions à leurs problèmes de gestion de données.
Les produits disponibles sont la “Superbase: Next Generation”, qui s’installe facilement au système existant grâce à des options d’API, “Superbase Database Engine”, moteur de base de données puissant et rapide qui peut être exécuté à la fois sur Linux et Windows, et enfin “Superbase Classic”, outil RAD.
June, pour analyser en profondeur les produits B2B
June est un outil d’analyse pour le SaaS B2B qui se veut simple à configurer et facile à comprendre, en connectant facilement les sources de données pour obtenir un rapport des données d’utilisation des produits.
Pour vous aider à démarrer, June propose une bibliothèque de modèles de rapports prêts à l’emploi, permettant de suivre la rétention des utilisateurs, les utilisateurs actifs, le taux d’acquisition, d’engagement… June génère automatiquement des graphiques, classe la base d’utilisateurs en cohortes et calcule les indicateurs importants. Pour les plus aguerris, il est possible de créer des requêtes SQL personnalisées et de construire un modèle basé sur ces requêtes.
Trevor est une solution de Business Intelligence plug-and-play qui donne un accès simple et sûr à la base de données. L’interface « point & click » de Trevor offre la puissance de SQL, sans la courbe d’apprentissage. En effet, Trevor donne la possibilité aux collaborateurs d’une équipe qui ne sont pas ingénieurs ou analystes d’établir leurs propres rapports, même s’ils ne connaissent pas le langage SQL. Les membres de l’équipe partagent leurs résultats en temps réel, collaborent sur des requêtes et analysent les résultats pour comprendre les données.
Le plus de Trevor : l’installation est sécurisée et se fait en quelques minutes seulement. Trevor se connecte directement à la base de données, sans prendre de copie des données. Trevor permet aussi de créer facilement et partager des tableaux de bord intuitifs à l’ensemble de son équipe. Enfin, Trevor permet de créer des flux de travail puissants, en envoyant des données en quelques clics seulement vers Google Sheets, Slack, une messagerie électronique ou des milliers d’autres applications.
Octolis, la stack data des équipes marketing modernes
Octolis est une Customer Data Platform 2.0, largement no code, permettant d’unifier et de préparer l’ensemble des données online et offline. Fonctionnant en surcouche d’une base de données (DWH) indépendante, Octolis gère toutes les étapes de data prep et permet aux équipes métier d’avoir des données propres et exploitables dans leurs outils (CRM, Marketing Automtion, Ads, ERP, Service Client…). Octolis est le moyen le plus rapide de préparer vos données pour l’activation et la BI.
Date de création : 2021
Levées de fonds : Non
Site web : vous êtes dessus 🙂
Top 300+ startups data à suivre
Découvrez à présent notre sélection de benchmarks favoris proposés par d’autres acteurs, bien souvent des médias, des fonds d’investissement…qui, comme vous et nous, sont passionnés par l’univers des start-ups data.
Top 121 des startups data & analytics à suivre selon Seedtable
Alors que le secteur technologique des données et de l’analyse est en plein essor, Seedtable propose une sélection de startups data & analytics à suivre en 2022, d’au moins 10 salariés et en pleine croissance.
Cette liste présente la carte d’identité ultra synthétique de chaque start-up :
Top 100 des startups Data & BI européennes et israéliennes selon Accel
Partner chez Accel, Philippe Botteri a travaillé dans la tech pendant plus de 15 ans, dont près de 10 ans dans la Silicon Valley.
Constatant une perte de dynamisme dans le secteur du SaaS ces dernières années, Philippe Botteri commence son analyse en exposant les tendances similaires observées aux Etats-Unis et en Europe, l’impact de la dynamique des marchés publics sur le marché du financement privé, avant de conclure sur les 100 premières entreprises sélectionnées pour l’Accel Euroscape 2022.
Top 35 des startups unicornes Big Data selon Failory
Failory est un blog destiné aux fondateurs de startups et aux entrepreneurs, créé par Nico Cerdeira, étudiant argentin qui publie sur ce site interviews, articles et newsletters chaque semaine, avec plus de 25 000 entrepreneurs abonnés.
Son Top 35 regroupe les start-ups licornes du Big Data, classées de la valorisation la plus élevée à la plus faible, avec des informations détaillées et illustrées pour chacune.
Jennifer Li, Sarah Wang et Jamie Sullivan, partners chez a16z, proposent un article complet et détaillé d’un listing de 50 startups les plus intéressantes à suivre.
Alors que le marché de la data connaît la croissance la plus rapide avec une valeur estimée à plus de 70 milliards de dollars en 2021, la big data continue d’être l’un des moteurs d’innovation les plus dynamiques, pour les grandes entreprises comme pour les jeunes pousses.
À la croisée de l’informatique, de l’analytics et de l’intelligence artificielle, les startups phares du monde de la data présentées par les auteurs sont évaluées à plus de 100 milliards de dollars, et 20 ont atteint le statut de licorne d’ici 2021.
Top 20 des startups data analytics selon Exploding Topics
Josh Howarth, co-fondateur et CTO d’Exploding Topics, met en lumière la forte croissance de l’industrie de l’analyse des données, nourrie par l’arrivée de nouvelles entreprises sur le marché ces dernières années. Il passe en revue 20 des meilleures startups d’analyse à suivre en 2023 selon lui.
Pour chaque start-up, Josh Howarth présente la courbe de croissance, un bullet point de présentation de la structure et quelques lignes sur les solutions qu’elles proposent.
La performance de votre dispositif CRM réside dans votre capacité à l’organiser, le faire vivre et à le piloter.
Facile à dire, plus difficile à faire. Si toutes les PME ou presque utilisent aujourd’hui un CRM, rares sont celles qui parviennent à les exploiter pleinement.
Pour vous permettre de passer rapidement un cap sur le sujet, nous avons interrogé des experts du sujet :
A la clé ? Des conseils pratiques et des retours d’expérience en format texte synthétique ainsi que l’intégralité de leurs réponses en vidéo dans cet article.
1 – Pouvez-vous vous présenter en quelques mots ?
Grégoire Mialet
Je suis Grégoire Mialet, CEO de C-Ways. Notre objectif est de faire prendre conscience à nos clients de la valeur de la data et de tout ce que ça peut leur apporter aujourd’hui avec les nouveaux dispositifs : marketing automation, activation en temps réel, omnicanalité…
Des concepts sur lesquels ils butent quand ils passent à l’opérationnel. Bien que sensibles à l’expérience client, ils s’interrogent sur les outils à mettre en place pour connecter ou centraliser l’ensemble de leurs données clients.
Nous leur apportons des éléments de réponse stratégiques avant de les mettre en relation avec des éditeurs de solutions adaptés à leurs besoins.
Marion Duchatelet
Je suis consultante en e-mailing chez Basender.
J’accompagne nos clients dans le choix de leurs outils de routage, lorsqu’ils souhaitent se tourner vers un nouvel outil.
J’effectue également des audits de leur stratégie et par la même occasion je dresse leur feuille de route pour les trois à six douze prochains mois. Il peut s’agir d’analyses statistiques, des contenus email, des questions relatives à la personnalisation ou la segmentation.
Enfin, notre accompagnement prend la forme de séances de coaching pour m’assurer que les points qu’on a soulevés lors de l’audit soient bien appliqués tout au long de l’année.
Frédéric Miteve
Je pilote le pôle marketing CRM d’Acemis, un cabinet de conseil dont le cœur de métier est l’expérience client. Nous avons 20 ans d’existence et réalisons un chiffre d’affaires de 9 millions avec 35 collaborateurs. Notre cabinet accompagne des projets marketing B2B et B2C sur les outils de centre de contact, de marketing automation et de force de vente.
Clémentin Leduc
Je suis Marketing Scientist chez Almavia. Mon job consiste à aider nos clients à déployer des solutions marketing pertinentes pour aider nos clients à optimiser le « customer journey » de leurs propres clients.
Almavia propose un accompagnement global autour de l’expérience client – notamment à travers le déploiement de solutions CRM marketing – auprès de clients nationaux et internationaux.
2 – Quels sont les dispositifs de gouvernance que vous recommanderiez à une entreprise de taille moyenne ?
Grégoire Mialet
Dans ce type d’entreprise, le sujet est très isolé. L’équipe CRM de 2-3 personnes peine à faire comprendre les enjeux auprès de la direction générale.
« Le premier enjeu est lié à l’acculturation de la donnée clients et la connaissance clients »
Le premier niveau c’est de comprendre les données dont on a besoin pour traiter cette connaissance clients et pour générer l’activation. A ce stade, interagir sur le parcours transactionnel avec des logiques d’abandons de paniers, de cross-selling, d’up-selling suffit amplement.
En matière de gouvernance des données, je recommande d’aller sur des solutions cloud pour faciliter l’intégration des données et des solutions de type CDP pour réunir les données essentielles : retour de satisfaction client, plaintes auprès du service client, parcours digital et offline.
Marion Duchatelet
En général dans les organisations de cette taille, l’équipe CRM est une équipe marketing au sens plus large.
L’idéal est de pouvoir s’appuyer sur 2 documents partagés au sein de cette équipe :
Un planning d’envoi à six mois avec les éléments clés associés à chaque campagne : anglage, date, cible, tests…
Un document de suivi de la performance de ces campagnes : délivrabilité, taux d’ouverture, cliqueurs,..
Il y a plusieurs indicateurs que je vais surveiller en particulier. Par exemple, le nombre de cliqueurs, le nombre de désabonnements et le taux d’insatisfaction : pour savoir s’il est en-dessous de 10%. Et s’il est possible de l’avoir, je vais regarder le nombre de transactions.
Pour mener à bien ce projet, je conseille aux équipes CRM de prendre une heure par semaine pour compléter ces indicateurs dans leur outil de routage. Puis une fois par trimestre, de prendre du recul pour étudier l’évolution des indicateurs clés. Ensuite, il faut creuser par cibles pour déterminer le comportement de chaque profil : prospects, clients actifs, anciens clients, par produit, par pays etc.
Enfin, on présente cela au board : les instantes dirigeantes et l’équipe data/DSI, ou ceux qui sont en charge du modèle de données afin d’aligner toutes les parties prenantes en matière de vision, d’objectifs, de priorités, d’actions CRM, de statistiques. Il faut que l’ensemble des acteurs soit en phase. Puis de manière cyclique, on revalide chaque trimestre où on fait évoluer la stratégie.
Frédéric Miteve
Il est important de décloisonner les différents métiers en CRM (marketing, ventes, service) et d’associer les profils techniques des intégrateurs de données pour avoir une vue consolidée des clients et un parcours client sans couture. Pour cela, il est conseillé de créer des plateaux qui regroupent toutes les équipes et tous les profils nécessaires pour mettre en œuvre le projet, en impliquant au maximum tous les profils qui pourraient être concernés. Il est aussi important d’avoir un comité de pilotage avec les bonnes personnes impliquées pour faciliter la communication entre les métiers et les parties techniques.
Clémentin Leduc
Je recommande pour une petite équipe CRM dans une PME d’avoir un plan précis de déploiement pour dimensionner la gouvernance et améliorer l’implication des différentes équipes. Il est important de mettre en place un cadre précis pour les projets avec des actions bien définies et des rendez-vous réguliers pour analyser les problèmes et trouver des solutions. Il est également important de mettre en place des comités de pilotage et de projet réguliers et rapides, mais sans tomber dans la surconsommation de réunions. La fréquence idéale pour un comité de pilotage ou de projet est d’un par semaine pendant les six premiers mois.
3 – Comment mesurer l’impact d’un dispositif CRM ?
Grégoire Mialet
Aujourd’hui je pense que c’est très compliqué de mesurer efficacement une campagne car bien souvent, le coût de mesure est plus important que le coût de la campagne elle-même.
Notamment à travers l’email dont on sait que c’est un canal fragile du fait de la sollicitation excessive des consommateurs. Aujourd’hui, le taux d’ouverture est un indicateur mais il ne fait pas le succès d’une campagne.
Il faut surtout mettre l’accent sur des campagnes omnicanales, automatisées et scénarisées car l’impact d’un email peut parfois influer sur un acte d’achat en boutique. Il y a deux choses sur lesquelles s’attarder :
Les indicateurs de santé et d’engagement sur le long terme de sa base de données clients : fréquence d’achat, taux de rétention/attrition, l’évolution de leur panier etc.
Utiliser les populations blanches : populations figées sur une longue temporalité (6 mois) au cours de laquelle elle ne va rien recevoir. C’est un échantillon témoin qui comparé à l’échantillon test, permettra d’évaluer l’efficacité du plan CRM et éventuellement l’améliorer.
Marion Duchatelet
Je recommande de prendre les mêmes taux pour les scénarios (que pour les campagnes) mais en isolant les performances de chaque email. Parfois dans un scénario il y a trois e-mails. Si j’ai un taux d’insatisfaction qui est énorme sur le deuxième e-mail, peut-être que je devrais l’enlever ou parler autrement.
Il faut également mesurer les emails d’un point de vue temporel pour déterminer à quel moment les gens se désabonnent par exemple. Si l’insatisfaction est beaucoup plus grande dans le troisième email, est-il pertinent de le faire partir plus tôt ?
Il est nécessaire de se poser ce type de questions tous les trimestres, d’émettre des hypothèses afin de lister des points d’amélioration.
En substance, je conseille de se pencher sur le nombre de cliqueurs, le taux d’insatisfaction et le taux de conversion (si l’objectif principal est la conversion). Certaines marques relaient simplement le positionnement marketing et les valeurs de l’entreprise pour ne pas pousser à la surconsommation. D’autres marques ne veulent pas pousser à fond la conversion pour éviter d’entrer dans une logique de surconsommation.
Frédéric Miteve
Il est critique de mesurer l’impact du dispositif CRM en utilisant des indicateurs de bout en bout, c’est-à-dire en croisant les données des campagnes marketing avec les données issues des autres outils métiers pour analyser l’impact réel sur les ventes ou sur la fidélité des clients. Il faut aussi savoir prendre en compte la question de l’attribution des ventes, qui peut être complexe, en mettant en place un modèle d’attribution avancé pour éviter de dévaloriser certains canaux de communication.
Clémentin Leduc
Un cycle d’implémentation CRM se déroule en 3 phases / années :
Année 1 : Construction, faire en sorte que les outils fonctionnent, focus engagement.
Année 2 : Stabiliser la solution, mise en place des parcours clients.
Année 3 : Aller chercher l’incrémental, focus conversion.
Je recommande de bien établir les objectifs en début de projet afin de déterminer les impacts du dispositif CRM. Pour mesurer l’impact, nous utilisons plusieurs méthodes telles que la comparaison des résultats avant et après la mise en place du CRM, la mesure des retombées des campagnes marketing et l’utilisation d’outils de veille pour relier les retombées d’une campagne au chiffre d’affaires généré.
4 – Comment rapprocher la connaissance clients des actions CRM ?
Grégoire Mialet
La convergence est indispensable notamment pour prioriser les actions que l’on souhaite déployer. Au départ, on ne peut pas intervenir sur tous les sujets : marketing automation, campagnes classiques, campagnes de réactivation etc. C’est à ce moment-là que la connaissance clients intervient.
Par rapport aux comportements des clients, il faut se demander ce qui est prioritaire en termes d’impact business : améliorer la rétention, favoriser un deuxième achat, prioriser le cross-selling etc.
Le plus important c’est que cette connaissance clients soit diffusée au-delà de l’équipe CRM
Notamment à la direction générale qui va investir sur des sujets à forte valeur ajoutée. Cela nécessite une bonne interaction entre l’équipe CRM, l’équipe marketing et l’équipe data/SI.
Marion Duchatelet
C’est un vaste sujet. Quand on pose la question aux annonceurs, ce qu’ils aimeraient savoir sur leurs clients, c’est leurs centres d’intérêt. D’autant plus quand le catalogue produit est riche. Plusieurs approches sont possibles :
Catégoriser les liens : Associer les liens à des centres d’intérêts ou des catégories de produit en retail. On utilise ensuite ces centres d’intérêt pour segmenter notre base ou pour personnaliser nos emails.
Le scoring : En associant la catégorisation de liens à l’historique d’achat et à des questionnaires déclaratifs placés à des endroits stratégiques.
Le marketing téléphonique : Appeler 10-20 clients qui sont vraiment engagés envers la marque permettrait d’en savoir plus sur leur rapport à la marque.
Frédéric Miteve
Il est important de rapprocher la connaissance clients des actions CRM en utilisant un programme relationnel qui regroupe un ensemble de projets et d’acteurs. Cela permet de collecter des informations sur les clients à travers différents canaux et de les partager entre les équipes pour améliorer les actions marketing.
Il est essentiel d’avoir une structure qui permet de regrouper toutes ces informations pour une vision globale de la connaissance clients. Cependant, il peut être difficile de motiver les différentes équipes à contribuer à cette connaissance client, surtout dans les entreprises de petite taille qui n’ont pas de personne dédiée à cette tâche.
Clémentin Leduc
Pour rapprocher la connaissance clients des actions CRM, il est critique de définir les objectifs en début de projet et d’utiliser des études pour analyser le comportement des clients. Il est important de segmenter les clients en utilisant les données disponibles, ensuite on peut utiliser des outils pour pousser les analyses et améliorer les activations marketing. Il faut aussi rassembler toutes les divisions d’une entreprise pour avoir une vision consolidée des actions et des retombées. Enfin, il faut réconcilier les équipes de data pour utiliser les outils de veille disponibles.
5 – Comment penser un dispositif CRM dans un contexte international ?
Grégoire Mialet
Il n’y a pas de recette miracle. Il faut prendre en compte le niveau de maturité des pays sur le sujet. Certains pays ont des contraintes opérationnelles que l’on à tendance à oublier : gestion des réseaux, onboarding des équipes, notoriété de la marque etc. Ils ne peuvent pas être experts de tout.
Je recommande une gouvernance bien réfléchie, fruit d’une concertation entre tous les pays. Personnellement, je recommande un canva d’activation automatisé et centralisé qui doit être commun à tous les pays. Que j’aille en France ou en Italie, mon rapport à la marque doit être le même. Il doit y avoir un socle commun basé sur le cycle de vie client (soit toutes les interactions à forte valeur ajoutée que l’on va pouvoir automatiser). Dans tous les cas il faut un seul outil qui puisse nourrir les équipes pays et il faut également le temps de former les équipes pays à la maîtrise de cet outil.
Marion Duchatelet
Selon moi, ce qui marche assez bien, c’est l’autonomie des filiales dans tout ce qui est campagnes hebdomadaire et mensuelle. L’idéal c’est d’avoir un outil avec le même templating e-mail afin d’avoir une même cohérence graphique et idéalement une charte éditoriale partagée auprès de chaque équipe en prenant en ligne de compte les spécificités culturelles, la façon de traduire etc. Cela suppose de mettre à disposition un outil dans lequel le template est géré par le siège mais partagé aux locaux.
Puis chaque mois, je partagerais les bonnes pratiques par pays afin de confronter les idées et transposer celles qu’on peut reproduire d’un pays à un autre. Pour ce qui est des scénarios, c’est automatisé au sein d’un seul outil en général. C’est mieux que ce soit pris en main par le siège. Mais par contre la traduction des messages doit être vérifiée par l’équipe locale. L’essentiel c’est qu’il existe des réunions pour aligner tous les parties, être cohérent au niveau de la charte graphique des stats par pays etc…
Frédéric Miteve
Dans les projets internationaux, nous nous appuyons sur des cores modèles qui peuvent être intégraux ou partiels selon le degré de centralisation de l’organisation. Pour la connaissance client, cela dépend des comptes globaux ou locaux. Il est important de séparer les pays en groupes avec des fonctionnements différents pour s’adapter aux spécificités de chaque marché.
Clémentin Leduc
Pour une entreprise internationale, il est important d’avoir un socle commun pour le dispositif CRM qui convient à toutes les entités. Cela permet de garantir une continuité de service et facilite les évolutions au gré des besoins du groupe.
Cependant, il est également important de prendre en compte les différences culturelles, de comportement et de taille entre les différentes entités et de les intégrer dans une couche supplémentaire pour chacun des contextes. Il faut aussi considérer les demandes de développement pour un grand nombre de pays en même temps, pour éviter un déploiement et des évolutions complexes.
6 – Un petit mot en conclusion?
Marion Duchatelet
J’ai mis en place avec Jonathan Lauriaux un podcast cet été. Il s’intitule Sobriété marketing possible…?. Parce qu’on constate que si on veut être utile au monde de demain, il faut peut-être arrêter de pousser à la surconsommation notamment à travers l’emailing. Ce qu’on voit chez nos clients, c’est qu’ils ont du mal à relâcher la pression marketing et à savoir quoi mettre dans leurs e-mails.
En tant qu’individus, ils sont convaincus par la démarche. Mais au niveau business, ce n’est pas la feuille de route qu’ils ont choisie. On essaie de bousculer cette vision-là, d’énoncer des questions et d’apporter des réponses, parfois à nos propres interrogations. Pour ce faire, on interview des entreprises à impact qui ont déjà passé ce cap-là. Pour finir, je vais poser une question à vos lecteurs : Est-ce qu’on a vraiment besoin de scoring, de personnalisation ou d’IA dans une stratégie CRM/emailing ?
Frédéric Miteve
Chez Acemis, nous avons un ADN orienté client. Nous encourageons nos clients à se mettre à la place des clients finaux pour comprendre leurs besoins réels. Cependant, il est facile d’oublier cet objectif en se concentrant sur les projets techniques et organisationnels.
Pour cette raison, nous avons développé une offre autour de la « voix du client », pour prendre en compte les signaux faibles et forts des clients. Dans les projets marketing, nous insistons sur l’importance de s’organiser dès le début pour évaluer l’impact sur les clients et savoir si les campagnes et les contenus ont été utiles pour eux.
Zoom sur le coût d’un dispositif Data Analytics pour une PME
Le coût d’un dispositif Data Analytics, pour une PME, s’échellonne entre 10 000 et 100 000 euros par an. Le niveau d’investissement va dépendre de la taille de l’entreprise, du nombre d’employés et de vos besoins. Selon nous, les entreprises devraient réserver environ 2 à 6 % de leur budget total à l’analyse des données.
La bonne nouvelle, c’est que la Data Analytics n’est plus l’apanage des grandes entreprises. Les petites et moyennes génèrent des quantités considérables de données et peuvent clairement tirer profit d’une analyse des données pour prendre de meilleures décisions.
Nous allons voir dans cet article combien une PME qui souhaite faire de la Data Analytics doit être prête à investir pour atteindre ses objectifs.
Le budget consacré à la Data Analytics doit représenter 2 à 6 % de vos dépenses
En moyenne, les entreprises consacrent entre 2 et 6% de leurs dépenses totales à l’analyse des données, ce qui inclut le coût des outils, des salaires et des prestataires. La Data Analytics, domaine qui connaît une croissance considérable depuis quelques années, permet de convertir des données brutes (et non exploitées) en informations et en enseignements utiles à la prise de décision.
Le volume de données à disposition a également augmenté en raison de l’influence de l’Internet des objets (IoT) et des appareils connectés. Les données ont augmenté en volume tout en gagnant un nouveau niveau de diversité et de richesse. Pour qu’une entreprise soit performante, le réseau de données disponible doit être optimisé.
L’analyse de données offre la possibilité de prendre des décisions commerciales mieux informées et d’affiner les produits ou services proposés pour offrir à leurs clients une meilleure expérience. D’après une étude réalisée par SAS, 72 % des entreprises affirment que l’analyse des données a joué un rôle essentiel dans leur capacité d’innovation.
La différence de performance entre les grandes entreprises et les PME est due à l’analyse des données en tant que facteur de compétitivité. Cela souligne donc la nécessité de la Data Analytics quelle que soit la taille de votre entreprise.
Une entreprise qui a un chiffre d’affaires d’environ 2 millions d’euros doit investir près de 100 000 euros par an. D’ordinaire, cela semble être une somme importante à dépenser sur le revenu disponible, mais la plupart des entreprises de cet ordre disposent à peine des outils d’analyse de données nécessaires. Notons que cette estimation globale prend en compte le temps qui serait consacré à l’analyse des données et aux rapports par toutes les équipes.
Combien votre entreprise investit-elle aujourd’hui dans la Data Analytics ?
Si vous souhaitez vraiment maximiser la valeur de l’actif que représentent vos données clients, vous devez être prêt à investir un montant conséquent dans la Data Analytics.
Plusieurs options peuvent être envisagées pour mettre sur pied un dispositif de Data Analytics – et tout cela dépend de votre entreprise, de ses caractéristiques et de vos choix. Il y a essentiellement 3 postes de coût :
Le coût humain (salaires).
Le coût des outils.
Le coût des services/prestas.
Nous vous aidons à estimer le coût de votre dispositif Data Analytics dans ce modèle gratuit que nous vous invitons à utiliser :
Les personnes sont également cruciales lors de l’analyse des données, car l’objectif final est d’influencer la volonté de vos clients. Il est donc essentiel de se pencher sur la manière dont vous dénichez et tirez profit de ces talents.
Ainsi, le coût humain exige que vous identifiiez en amont ceux qui peuvent contribuer à intégrer les activités axées sur les données au sein de l’organisation. Ces personnes ont déjà des compétences analytiques dans votre entreprise, et vous pouvez les renforcer afin de réduire le coût de l’embauche de prestataires. Aussi, il convient de mettre en place une formation continue avec des outils accessibles et modernes.
Si vous êtes une PME, vous pouvez utiliser cette méthode pour réduire les coûts humains à long terme. Toutefois, vous devrez peut-être faire appel à des experts pour lancer le processus et former vos employés.
Les services
L’investissement de votre entreprise dans l’analyse des données doit être relativisé s’il s’agit d’un service acquis. Il existe des agences et d’autres entreprises qui se chargent de l’analyse des données pour d’autres sociétés, ce qui vous aiderait à déterminer le coût pour votre PME.
Par exemple, vous pourriez passer un contrat avec une agence de gestion de la relation client (CRM) pour mettre en place des flux de travail de marketing automatisés. Dans ce cas, l’agence passerait suffisamment de temps à réconcilier certaines sources de données clients. Elle contribuerait à développer un certain niveau de connaissance du client pour faciliter l’analyse ou la segmentation RFM, puis passerait aux flux d’e-mails.
Tout comme le coût humain, ce niveau de flux de travail aurait un coût distinct et jouerait un rôle essentiel dans l’investissement que votre entreprise consacre à l’analyse des données.
Des outils de reporting spécifiques aux PME existent pour faire de la Data Analytics. Pour en choisir un, il faut commencer par certains outils de reporting populaires comme Google Data Studio. Ce dispositif est basé sur les données de Gsheet et Google Analytics, qui se sont avérés efficaces pour analyser les données de l’entreprise.
Les entreprises trouvent toujours utiles les vrais outils de BI et achètent Metabase ou PowerBI, ce qui mène à l’étape suivante. L’étape suivante consiste à mettre en place une infrastructure de données de base avec un entrepôt de données.
Il existe Google BigQuery et des logiciels ETL comme Airbyte ou Fivetran. Pour ces outils, il existe des licences, qui varient d’un acteur à un autre, ce qui affecte le montant que votre entreprise devra dépenser.
Le coût de l’externalisation de la Data Analytics VS recruter en interne un Data Engineer/Analyst/Scientist
En fonction du type de service qu’ils proposent, les data engineers coûtent plus ou moins chers. Pour de nombreuses entreprises, une équipe interne de data scientists semble être la seule option. Disposer d’une équipe d’analystes de données est idéal pour les grandes entreprises.
Pour les petites et moyennes entreprises, ce n’est pas une solution disponible. La plupart de ces entreprises se tournent vers l’externalisation pour commencer leur parcours d’analyse de données.
Voici une ventilation du coût d’une équipe interne de science des données par rapport au prix de l’externalisation des services de données :
Les agences/cabinets Data Analytics
Le recours à des sociétés data analytics est connu pour être fiable en raison de plusieurs facteurs. Les consultants sont connus pour leur expérience dans divers secteurs. Il est donc plus facile pour eux de fournir des résultats plus rapidement.
Un avantage de cette méthode est le niveau d’engagement qu’elle requiert par rapport à l’embauche d’un employé à temps plein. Cependant, il est essentiel de noter que ces sociétés de conseil traditionnelles coûtent environ 50 à 100 euros de l’heure. Dans certains cas, les coûts sont encore plus élevés, car le travail s’étend sur des semaines ou des mois.
Un exemple de cabinet de conseil Data Analytics : Cartelis.
Ainsi, l’engagement d’une société de conseil nécessiterait au moins 2 000 à 4 000 euros pour une semaine de travail. Même s’il s’agit de la première option d’analyse des données pour votre entreprise, elle n’est pas forcément la plus rentable. Ce n’est pas forcément une solution durable car elle dépend de facteurs externes.
Les freelances spécialisés en Data Analytics
Les freelances peuvent remplir la même fonction que les cabinets de conseil, mais à un prix inférieur en raison de la main-d’œuvre nécessaire. Il peut s’agir d’un seul freelance ayant suffisamment d’expérience pour vous aider à analyser les données de votre entreprise.
Dans la plupart des cas, le coût de l’analyse dépend toujours de la portée du projet.
Le projet sera à court terme, comme dans les cabinets de conseil traditionnels, ce qui signifie un engagement minimal. L’engagement de freelances serait estimé à 1000 $ par semaine, ce qui est considérablement abordable. Les freelances externalisés peuvent également différer dans leur qualité, c’est pourquoi le recrutement est essentiel.
Un exemple de plateforme pour recruter un freelance IT : Freelance Informatique.
Cependant, il est impossible de déterminer le retour sur investissement (ROI) et la valeur ajoutée pour l’entreprise. Les barrières linguistiques et culturelles peuvent être un problème avec l’externalisation des freelances, car la plupart se trouvent dans des pays comme la Chine et l’Inde.
Cela peut entraîner des frictions entre votre entreprise et le fournisseur de services d’analyse de données. Bien que l’externalisation des freelances puisse contribuer à réduire les dépenses, vous devez tenir compte des différences.
Monter une équipe Data Analytics en interne
Avec un consultant interne, il y a quelqu’un qui fait partie de l’entreprise depuis un certain temps. Cela permet de confier les analyses de l’entreprise à quelqu’un qui est considéré comme une personne extérieure. La seule nécessité pour que cela fonctionne est de former l’employé pour qu’il comprenne le contexte de votre entreprise et de votre secteur.
Par rapport au travail avec des consultants, cela réduit le niveau de friction avec les tâches déléguées.
Trouver le bon analyste peut être une question de temps, ce qui entrave la qualité du service fourni.
Le processus d’embauche peut également être fastidieux et nécessiter un engagement pour s’assurer de trouver la personne idéale.
On peut également craindre que les analystes à plein temps deviennent superflus pendant la saison morte. Le coût minimal du maintien en poste d’un spécialiste interne est d’environ 60 000 $ par rapport à ce que coûtent les autres analystes de données.
Certains diront même que le processus d’embauche et d’intégration d’un nouvel employé est dû à cela. Bien qu’il s’agisse d’une option fiable, elle coûterait néanmoins beaucoup plus cher à l’entreprise.
Conclusion
Les données sont essentielles au développement de votre entreprise car elles permettent d’établir des modèles de comportement. Le comportement des clients, leurs besoins et les données acquises tout au long de la gestion d’une entreprise sont autant de bénéfices de l’analyse de données. Elles améliorent la capacité d’innovation d’une entreprise et fournissent une base pour des décisions plus axées sur les données.
La Data Analytics peut être externalisée à un prestataire de services, à un freelance, ou bien gérée en interne par vos équipes. Chacune de ces options a ses avantages et ses inconvénients. Certaines sont plus coûteuses que d’autres, et leur coût varie en fonction du budget alloué à l’analyse des données.
Toutefois, si nous devions donner une fourchette, il est conseillé aux entreprises de réserver environ 2 à 6 % de leur budget total à l’analyse des données.
Les outils d’exploitation des données tels qu’Octolis peuvent réduire considérablement le coût global de l’analyse des données. Octolis dispose d’une base de données marketing intelligente qui vous permettra d’intégrer vos sources de données et vos outils de CRM ou d’automatisation du marketing.
LinkedIn regorge d’influenceurs et de créateurs de contenu data dont l’activité est à suivre. C’est devenu la meilleure source d’information pour suivre l’actualité de domaines pointus et en pleine transformation comme le marketing digital. Afin de savoir quelles sont les tendances récentes ou accéder aux informations les plus pertinentes, il est souvent nécessaire de suivre certaines personnalités sur le réseau.
Ainsi, que ce soit pour rester à la page, être compétitif ou encore connaître ce qui se fait de mieux dans l’univers data, nous vous proposons notre sélection personnalisée des top influenceurs data & marketing à suivre !
Notre sélection personnelle des 20 influenceurs data & marketing à suivre
Après 7 ans passés en tant que directeur conseil sur des projets data / relation client, Yassine Hamou Tahra a co-fondé la CDP Octolis qui permet aux entreprises de mieux exploiter leurs données clients.
Nicolas est un entrepreneur, avec plus de 10 ans d'expérience dans le digital, la data et le conseil. Il se consacre actuellement à aider les entreprises à déployer leur data stack.
Ethan est le CEO de Portable, une startup américaine qui développe un outil no-code pour permettre aux entreprises de gérer leurs données utilisateurs.
Kelly est un vétéran du monde de la tech US. Actuellement Head of Partner Sales Engineering chez Fivetran, il écrit principalement sur des sujets martech.
Chad est Head of Data, Product Manager, Data Contracts Advocate chez Convoy. Il écrit sur la gestion des données et des contrats et gère une newsletter.
Top 163 des influenceurs data selon Mehdi Ouazza (Data creators club)
Mehdi Ouazza est un data engineer qui gère un blog appelé data creators club. Il vous propose un top des influenceurs data qui se veut le plus exhaustif possible. L’objectif est donc de réunir tous les créateurs de contenus liés de près ou de loin à la data. Les influenceurs de ce top sont aussi bien des data scientist, des designers ou des développeurs, impossible de ne pas trouver quelqu’un d’intéressant dans ce top.
Top 60 des influenceurs data selon Chanin Nantasenamat
Chanin Nantasenamat est un professeur de data et un créateur de contenu sur Medium. Il propose une liste de la crème de la crème des influenceurs data en termes d’expertise et de pédagogie du contenu. On apprécie l’effort de sélection des influenceurs et la qualité des contenus proposé.
Top 25 des influenceurs Data Scientist selon Data Science Salon
Data Science Salon est une organisation qui rassemble des passionnés de science des données et organise des conférences sur des thèmes variés. Ils proposent un top des intervenants et influenceurs passés par leurs conférences.
Ce top est plutôt orienté leaders d’opinion, avec des pontes et des grands cadres de grandes entreprises comme Amazon, Google ou Gartner.
Top 21 des influenceurs Big Data – Data Science – Analytics selon Rivery
Rivery est une solution de gestion de workflows et de pipelines ETL. Experts dans leurs domaines, ils proposent un top des influenceurs avec un focus Big Data.
Ce top se démarque par la diversité des profils proposé, sa taille et la description claire et précises des profils proposés.
The Data Dreamer est un média US reconnu qui couvre toutes les actualités liées à la data. Ils proposent dans ce top les 9 meilleurs influenceurs data à suivre pour être au courant de ce qui se fait de mieux dans le domaine. Moins orienté technique, ce top satisfera toutes les personnes qui cherchent des leaders d’opinions sur la data, ses utilisations et les conséquences pour la société.
Ikigai est un outil SaaS de Business Intelligence qui utilise l’IA pour proposer tous les scénarios opérationnels possibles et proposer des insights à l’utilisateur. Forts de leur expertise data, ils proposent leur top des influenceurs data que ce soit en analytics, en data science ou en BI. Idéal pour débuter, ce top désigne les voix les plus importantes dans des domain divers comme la Data Science, le Data Engineering ou la Data Governance.
Top 10 des influenceurs Big Data selon AI Magazine
AI Magazine est comme son nom l’indique un media qui touche à tout ce qui est lié à l’IA. Ils proposent ici leur top des influenceurs Big Data en fonction de l’expertise et l’expérience de la personnalité. Concis, ce top propose des profils pointus qui conviendront aux personnes plus expérimentées en IA et Big Data.
DataCentre est un magazine couvrant les actualités data. Ils proposent un top des influenceurs data sur la base de l’audience et de la diversité du contenu proposé. Dans la même veine que le précédent, ce top là est assez court mais propose cette fois une liste efficace des plus grands leaders d’opinions dans l’industrie, que ce soit en IA, en Big Data ou tout ce qui est lié au monde de la data en général.
Data Mania est un blog reconnu avec des articles sur le product management, la data et le growth marketing. Pour changer de LinkedIn, Data Mania propose une sélection d’influenceurs data marketing à suivre sur Twitter.
Plutôt orienté Lifestyle, le top conviendra parfaitement à tous ceux qui travaillent dans la data, avec à la fois des leaders technologiques et des leaders d’opinions, majoritairement américains.
Quelques conseils pratiques pour construire votre veille
Une fois que vous avez fait votre choix et suivi les influenceurs data de votre choix, vous pouvez organiser votre veille Linkedin. N’hésitez pas à explorer le contenu que vous propose le réseau, comme les suggestions de personnes liées aux influenceurs ou leur activité avec des posts d’autres créateurs de contenus.
Veillez ensuite à sélectionner les bons hashtags ! En effet, Linkedin vous permet certes de suivre des personnes et des entreprises, mais aussi des hashtags, ce qui s’avère pratique lorsque l’on s’intéresse à un sujet précis. Choisissez donc des hashtags pertinents, comme #martech, #bigdata ou encore #CRM en fonction de vos centres d’intérêts.
Pour compléter votre veille, vous pouvez aussi intégrer des groupes Linkedin en fonction des sujets auxquels vous vous intéressez. En exploitant l’aspect social du réseau vous pourrez avoir facilement et rapidement accès à des contenus pertinents que vous n’auriez pas vu seul.
Vous pouvez enfin utiliser les fonctionnalités avancées de LinkedIn pour optimiser votre veille, comme le marque-page et les requêtes booléennes. Il existe aussi des outils de veille comme Linkalyze ou Netvibes pour approfondir vos recherches d’informations grâce à des alertes sur des posts spécifiques par exemple.
Si les sujets data vous intéressent, nous avons quelques articles qui devraient vous intéresser :
La rétention client est une dimension de plus en plus importante en marketing client, surtout dans le contexte d’explosion des coûts d’acquisition et de recentrage des stratégies marketing sur la valorisation de l’actif client.
Pour améliorer la rétention client, il faut d’abord se donner les moyens de la mesurer. Nous allons nous attarder sur le taux de rétention client, le définir et expliquer comment le calculer au travers 2 méthodes (une méthode basique et une méthode plus avancée). Nous vous donnerons ensuite 8 pistes pour améliorer votre rétention client, en particulier dans l’univers Retail / Ecommerce.
Si la rétention client est une dimension importante, ce n’est pas l’unique KPI à suivre pour mesurer la performance client. En fin d’article, nous vous proposons les autres indicateurs à intégrer dans votre dispositif de pilotage.
Taux de rétention client ? Définition & enjeux
Définition du taux de rétention client
Le taux de rétention client est un indicateur clé de performance utilisé en marketing pour désigner la proportion de clients qui ont déjà souscrit à vos services et continuent à le faire sur une période donnée. Autrement dit, c’est votre capacité à fidéliser vos clients, à les « retenir ». Par exemple, si votre entreprise compte 10 clients au début de l’année, et en perd 2, votre taux de rétention est de 80% : vous avez retenu 80% de vos clients. Cela, c’est la méthode basique. Nous verrons dans un instant comment mesurer la rétention de manière plus fine.
Pourquoi la rétention client est votre principal KPI client
On estime qu’une augmentation de 5% de la fidélisation de vos clients peut accroître la rentabilité d’une entreprise de 25 à 95 %. Il y a plusieurs études sur le sujet, toutes convergent sur ces ordres de grandeur. L’amélioration de la rétention client est la clé pour augmenter le chiffre d’affaires d’une entreprise. Elle permet à la fois de développer les revenus en capitalisant sur votre plus précieux actif (vos clients existants) et de conjurer le syndrome du panier percé souvent associé aux stratégies marketing focalisées sur l’acquisition.
2 questions préalables avant de calculer le taux de rétention client
Avant de calculer votre taux de rétention e-commerce, vous devez vous poser 2 questions essentielles.
#1 – Qu’est-ce qu’un client fidélisé ?
On considère qu’un client est fidélisé à partir du moment où il reste actif sur une période donnée. Ce qu’il vous reste à déterminer, c’est ce que vous entendez par « actif ».
Est-ce que c’est un client qui a acheté au cours des 12 derniers mois ? Qui a atteint un certain montant de revenus ? Qui s’engage dans vos campagnes d’emailing ? Qui vous fait des retours réguliers sur vos produits ?
En définitive, vous devez définir un seuil à partir duquel vous pouvez considérer le client comme actif. Maintenant, il s’agit de savoir les segmenter…
#2 – Comment segmenter vos clients ?
Pour segmenter vos clients, il vous faut lier les données d’achat de chaque canal. Pour ce faire, la Customer Data Platform (CDP) sera votre meilleure amie pour vous donner plus de visibilité. Si le sujet vous intéresse, n’hésitez pas à jeter un œil à notre guide complet sur les Customer Data Platforms.
Une fois que vous disposez d’un ensemble complet de données, vous pouvez segmenter vos clients. Parmi les approches les plus populaires, on compte la segmentation par :
Canal marketing (réseaux sociaux, publicité en ligne, email marketing…) : il s’agit de la meilleure façon de mesurer votre retour sur investissement marketing.
Catégorie de produits : cette segmentation vous permet de voir quels produits sont les plus efficaces pour fidéliser les clients et vous donne la possibilité de contrôler les différents cycles de vie des produits.
Donnée démographique : l’âge, le sexe et les zones géographiques peuvent révéler quels types de groupes de clients votre marque attire.
Analyse RFM : cette segmentation permet une analyse plus complète du comportement client, basée sur la récence et fréquence des achats d’un client, ainsi que le montant (somme du chiffre d’affaires des achats cumulés sur une période donnée). Pour aller plus loin, découvrez notre guide complet sur la segmentation RFM.
A vous de déterminer celle(s) qui vous corresponde(nt) le plus !
2 méthodes pour calculer votre taux de rétention client
On peut mesurer le taux de fidélisation de la clientèle de 2 manières principales.
#1 – Calculer le taux de rétention client au niveau global (méthode basique)
Cette première méthode permet de donner une vue générale sur la manière dont votre marque conserve ses clients sur une période donnée.
Pour calculer cet indicateur, on utilise 3 variables :
Début des clients – Nombre de clients au début d’une période donnée.
Clients finaux – Nombre de clients à la fin d’une période donnée.
Nouveaux clients – Nombre de clients acquis au cours de la période.
On procède ensuite au calcul : (Clients finaux – Clients nouveaux) / Début des clients.
Prenons un exemple. Imaginons que vous avez commencé l’année avec 100 clients, que 80 d’entre eux ont passé commande et que vous avez gagné 10 clients de plus au cours de l’année. On considère donc que vous avez à la fin de l’année 80 + 10 = 90 clients actifs.
Votre taux de rétention client sera donc de : (90 – 10) / 100 = 80%.
Autrement dit, 80 % de votre base de clients existants ont continué à être clients au cours de la période déterminée. L’idée est de reporter ces taux de fidélisation dans le temps, comme dans le graphique ci-dessous.
Dernier point important : le choix de la période. La durée que vous choisirez pour étudier votre taux de rétention dépend du cycle de vie de votre produit. Ainsi, un concessionnaire automobile devra choisir une période bien plus longue (puisque la fréquence d’achats d’une voiture pour un même client est faible) qu’une marque de denrées alimentaires par exemple.
#2 – La méthode des cohortes
Plus facilement exploitable que la première, la méthode des cohortes permet de suivre le comportement des clients dans le temps, en fonction du moment où ils sont devenus clients.
Analyse de la rétention par cohorte trimestrielle.
En réalité, votre entreprise n’est pas statique. Chaque jour, un changement s’opère. L’analyse des cohortes vous permet de voir si ces changements ont eu un impact positif sur la fidélisation.
Cette méthode vous donne une idée précise de là où il faut vous améliorer. L’intégration de segments de cohortes dans votre analyse de fidélisation vous permet de mieux comprendre où votre boutique en ligne réussit et où elle échoue. De là, vous pourrez identifier des stratégies de fidélisation des clients efficaces à appliquer à d’autres catégories et lignes de produits.
8 stratégies pour augmenter le taux de rétention client en Ecommerce
Voici 8 stratégies que vous pourrez facilement mettre en œuvre pour améliorer la fidélisation de vos clients et stimuler la rentabilité de votre entreprise e-commerce.
#1 – Misez sur l’email marketing
La méthode d’email marketing peut prendre différentes formes : vous pouvez par exemple envoyer des emails de bienvenue à vos clients après leur premier achat, configurer des emails d’abandon de panier, de reconquête ou encore d’anniversaire pour motiver le client à acheter auprès de votre marque.
Une autre bonne façon de tirer parti de l’email marketing est de l’utiliser pour envoyer du contenu utile et pertinent à vos utilisateurs, comme des newsletters par exemple. Aujourd’hui encore, l’emailing reste le principal canal pour engager vos clients et les inciter à acheter plus.
#2 – Utilisez les réseaux sociaux
Les réseaux sociaux sont un excellent moyen de maintenir l’intérêt de vos clients et de vous rapprocher d’eux. Vous pouvez profiter d’un mail de remerciement lors du premier achat d’un client pour l’inviter à vous suivre sur les réseaux. Auquel cas, assurez-vous de proposer du contenu attrayant et riche en valeur ajoutée !
Une fois que vos clients vous suivent, vous pouvez les entretenir de différentes manières :
Partagez du contenu pertinent.
Partagez des liens et images vers vos produits les plus populaires.
Partagez des remises et des offres exclusives avec vos abonnés.
Organisez des concours lors d’occasions spéciales.
Interagissez avec vos clients via les commentaires de vos publications.
#3 – Offrez une expérience client personnalisée
La personnalisation de l’expérience client est aujourd’hui cruciale pour les fidéliser. Si vous n’y parvenez pas, ils se tourneront probablement vers vos concurrents.
Il existe plusieurs façons d’offrir une expérience d’achat personnalisée à vos clients :
Proposez des recommandations personnalisées lorsqu’ils visitent la page d’accueil de votre site Web ou sur d’autres pages de produits.
Utilisez un outil de gestion de la relation client (CRM) pour segmenter votre base de clients en fonction de leurs intérêts et de leur profil. Vous pouvez cibler chacune de ces listes avec des messages et des e-mails personnalisés.
Identifiez les clients qui n’ont pas effectué d’achat chez vous depuis longtemps. Envoyez des e-mails personnalisés pour vous assurer qu’ils redeviennent actifs.
#4 – Adoptez des procédures opérationnelles standard pour améliorer la satisfaction des clients
Le processus d’exécution des commandes de commerce électronique est complexe et de nombreux acteurs clés y participent. Un faux pas (retard dans la livraison, produits erronés ou endommagés, remboursement trop tardif) dans le processus peut entraîner une mauvaise expérience client, réduisant ainsi votre taux de fidélisation.
Pour résoudre ces problèmes potentiels, vous pouvez mettre en place des procédures opérationnelles standard (POS), qui vous aideront à vous assurer que les produits sont soumis à des contrôles de qualité rigoureux et que les bons produits sont livrés aux clients.
#5 – Créez du contenu de valeur pour susciter l’intérêt des clients
Le contenu peut être un moyen efficace d’engager vos clients et de les inciter à préférer votre marque à celle de vos concurrents. Bien que le contenu promotionnel puisse être bénéfique, il doit toujours être associé à du contenu informatif pour attirer les clients.
Vous pouvez ainsi rédiger des articles pertinents pour votre marque et en faire la promotion sur les réseaux sociaux et emails.
Créez du contenu premium utile et proposez-le comme aimant à prospects sur votre site Web. Ainsi, les utilisateurs s’inscriront sur votre liste de diffusion en échange du contenu que vous proposez.
#6 – Proposez un programme de fidélisation des clients
Les programmes de fidélisation ? Les clients en sont friands, à partir du moment où ils sont suffisamment attrayants. Diversifiez vos offres avec des remises exclusives, livraisons gratuites, services d’abonnement ou encore des cadeaux.
Vous pouvez de même utiliser la gamification en proposant un système de points ou organisant un concours exclusif qui vous permettra non seulement de gagner la fidélité de vos clients, mais aussi d’attirer des nouveaux clients !
#7 – Exploitez le contenu des utilisateurs
Le contenu généré par l’utilisateur est un excellent moyen de booster l’engagement de vos clients et de les fidéliser durablement.
Imaginez un hashtag d’un mot clé qui résonne avec votre marque. Demandez ensuite à vos followers sur les médias sociaux et aux visiteurs de votre site web de poster du contenu (commentaires, photos…) avec cet hashtag.
GoPro a créé par exemple une excellente stratégie de contenu généré par les utilisateurs en lançant le défi #GoProSnow. On trouve sur ses pages de réseaux sociaux de nombreuses photos et comptes plus de 17 millions d’adeptes.
#8 – Présentez l’histoire et les valeurs de votre marque
En dehors de tous les autres facteurs, créer un lien émotionnel avec vos clients peut être très utile. En rendant le parcours de l’acheteur plus émotionnel, vous pouvez offrir des expériences mémorables à vos clients et ainsi les inciter à rester fidèles à votre marque.
Vous pouvez par exemple créer ce lien émotionnel en parlant de l’histoire de votre marque, comment elle a vu le jour, quels combats elle a dû mener.
Vous pouvez également parler de vos valeurs. Si vous êtes engagé dans un projet ou convaincu en tant que marque, veillez à le faire savoir à vos clients. Si vos valeurs correspondent aux leurs, vous aurez un avantage certain sur vos concurrents !
Les indicateurs complémentaires du taux de rétention client
Le taux de rétention client vous permet donc de savoir quelle proportion de vos clients vous est restée fidèle. Néanmoins, rien n’est ni tout noir ni tout blanc : le taux de rétention reste grossier car chaque client est différent. Vous aurez beau constater que certains vous sont fidèles et d’autres non, vous n’en connaîtrez pas forcément la raison.
C’est pourquoi il est intéressant de compléter le taux de rétention par d’autres indicateurs comme :
Le taux d’attrition, soit l’inverse du taux de rétention. Ainsi si votre taux de rétention est de 90%, votre taux d’attrition sera de 10%. Cet indicateur complémentaire pose néanmoins les mêmes questions que le premier : à partir de quand considérer un client comme définitivement perdu ?
La diminution du chiffre d’affaires, soit le chiffre d’affaires récurrent que vous avez perdu sur une période donnée. Il permet de mesurer l’impact du départ de certains clients sur vos recettes.
L’indicateur de fidélité (NPS) qui permet d’étudier quels clients sont satisfaits de vos produits et quels sont ceux qui demandent une attention plus particulière. Un simple sondage vous permettra de le savoir.
Le taux d’achat répétés, soit le pourcentage de clients qui font à nouveau confiance à votre entreprise après leur premier achat. Il convient parfaitement aux entreprises qui ne vendent pas de contrats fixes.
La Lifetime Value (LTV) de vos clients, qui mesure les bénéfices engendrés en moyenne par un client tout au long de son cycle de vie. Il existe plusieurs méthodes pour la calculer mais la plupart cherchent à définir le coût d’acquisition et de fidélisation de la clientèle.
La relance téléphonique des clients inactifs – Enjeux & Méthodologie
Si la relance des clients inactifs est devenue une priorité pour beaucoup d’entreprises, sa mise en œuvre est souvent chaotique et déceptive. Les stratégies basées à 100% sur de la relance email échouent la plupart du temps. La clé de succès réside dans l’art de combiner intelligemment les différents canaux disponibles, en prenant en compte le potentiel de réactivation des clients et en intégrant dans ces canaux le bon vieux téléphone, qui reste le canal le plus puissant pour relancer des clients inactifs.
Un constat : Réactiver les clients inactifs par email est difficile
Ce qui est certain, c’est qu’il est difficile de réactiver des clients inactifs par email. D’abord parce que les taux de réponse par mail sont, en général, faibles. Ensuite, parce que la définition du client inactif veut qu’il soit moins réactif que la moyenne.
Maintenant, il est nécessaire de savoir dissocier les types de clients inactifs auxquels vous faites face. Certains sont faciles à réactiver, d’autres sont de vrais « dormeurs ». Les différencier est essentiel car l’effort que vous êtes prêt à investir doit être proportionnel à la valeur que vous pouvez en générer, et donc à la lifetime value de chacun. Vous n’accorderez pas la même quantité d’efforts à un client inactif qui représente un chiffre d’affaires faible, qu’à un ancien client à forte valeur et / ou qui correspond parfaitement à votre cible de clients.
Un exemple d’email de relance de clients inactifs, avec incentive.
Par exemple, si vous considérez qu’une réactivation efficace peut vous permettre de relancer 10% de vos clients inactifs, vous pouvez envisager d’investir maximum 10% du revenu que ces clients pourront générer une fois réactivés pour rentabiliser votre démarche. Disons 5% pour se laisser de la marge, ce qui permet une création de valeur considérable…
Quand est-ce qu’un client peut être qualifié d’inactif ?
En général, un client est considéré comme inactif quand sa date de dernier achat remonte à plus d’un an. Mais si l’on regarde d’un peu plus près, cette durée n’est qu’indicative puisqu’elle peut varier en fonction de votre secteur d’activité. Dans l’automobile ou le luxe par exemple, ce sera une bien plus longue plage de temps que dans le retail classique. Plus concrètement, on estime qu’un client devient inactif lorsque l’investissement commercial ne génère plus de ROI. Mais avant d’en arriver là, il reste fortement conseillé de suivre de près vos acheteurs récurrents qui seraient susceptibles de ne plus l’être !
L’art d’intégrer le téléphone dans vos mécaniques de relance des clients inactifs
Le téléphone devrait être une partie intégrante de vos mécaniques de relance des clients inactifs car il reste un des leviers de réactivation les plus efficaces. Malgré le développement de la digitalisation et des réseaux sociaux, le téléphone reste le canal de communication privilégié des Français. On estime que 57% des consommateurs utilisent en priorité ce canal. En plus d’être un moyen de communication très utilisé par les consommateurs, il permet une relance entièrement personnalisée, qui est ressentie et appréciée par le client.
Néanmoins, les autres canaux de réactivation comme les mails, SMS et ads retargeting ne sont pas à délaisser. Ils peuvent – et doivent – être combinés pour maximiser les chances de réussite de la campagne de relance.
Comme précisé plus haut, votre enjeu est de déterminer le niveau d’effort et de pression que vous souhaitez accorder en fonction de chaque segment clients. Imaginons par exemple que vous déterminez 3 types de clients inactifs : les passifs de niveau 1, 2 et 3 ; les passifs de niveau 1 étant des clients n’ayant fait aucune commande en 3 mois, et les inactifs de niveau 3 ceux n’ayant montré aucune réaction depuis très longtemps (les « gros dormeurs »).
Les clients inactifs de niveau 1 sont les plus faciles à réactiver : l’envoi d’un email de réactivation suffira dans un premier temps.
Les passifs de niveau 2 montrent plus de réserve : combinez l’envoi d’un email et d’un SMS pour maximiser vos chances de réactivation.
Enfin, les clients dormants de niveau 3, soit des clients que certaines entreprises considèrent comme perdus, demandent plus d’investissement : programmez l’envoi d’un email ainsi que d’une campagne d’ads retargeting pour attirer leur attention.
Vous pouvez suivre ce schéma standard pour tout type de clients. Pour les clients plus importants, n’hésitez pas à adopter cette même logique en décuplant le nombre de SMS, d’Ads ou encore d’appels téléphoniques.
Pour résumer, il faut savoir à la fois sérier l’utilisation des canaux (qui se combinent et se complètent) et adapter le mix-canal à la valeur du client inactif. Il ne reste plus qu’à l’appliquer !
3 raisons de la sous-utilisation du téléphone pour de la relance
Bien que le téléphone soit le meilleur levier pour réactiver ses clients, il reste sous-utilisé et ce, pour 3 raisons principales.
#1 – La motivation du service client… Tout un programme !
Qui dit appel téléphonique dit discussion à voix haute. Or, les appels sortants de relance téléphonique représentent un effort supplémentaire pour le service client. L’email semble tellement plus simple et met à l’aise. C’est pourquoi, il est difficile de motiver son service client puisqu’il voit plus facilement les contraintes liées à une relance téléphonique que ses fruits.
#2 – Il n’y a pas toujours d’équipe commerciale dans des boîtes B2C
Pour faire de la relance téléphonique, il faut des collaborateurs dédiés au service client. Ce qui n’est pas toujours le cas, surtout dans les petites / moyennes entreprises B2C.
En B2B, la culture du téléphone est bien plus présente, et ce pour 2 raisons. D’abord parce que le client moyen a bien plus de valeur (puisque les achats sont en général plus gros). Ensuite parce que le cycle commercial nécessite plus de traitements, plus de dévouement (communication one-to-one).
#3 – Certaines entreprises n’ont pas l’architecture adéquate
Certaines entreprises n’ont pas de base de données centralisée, souvent à cause de leur petite taille. Néanmoins, une fois une certaine quantité de clients dépassée, les données clients se dispersent et aucun outil ne permet de les faire circuler intelligemment jusqu’au service client. Comment relancer un client inactif par téléphone si on ne réussit pas à les identifier, si on ne peut pas scorer ses clients ? Et, à supposer que l’on réussisse à identifier les inactifs, comment notifier au service client les consommateurs à réactiver si aucun outil ne permet de faire remonter automatiquement toute l’information dans l’outil utilisé par ce service ?
C’est justement ces problèmes de tuyauterie qu’un outil comme Octolis permet de résoudre en remettant les données au cœur de votre plan de croissance !
4 étapes pour mettre en place une réactivation des clients inactifs par téléphone en B2C
Il est tout à fait possible de mettre rapidement en place la réactivation par téléphone en B2C. Ce n’est pas un projet lourd, donc vous n’avez aucune excuse !
Étape #1 – Définir les segments des gros clients passifs
Comme expliqué plus haut, l’utilisation du téléphone représente un effort supplémentaire pour le service client, c’est pourquoi il faut le réserver pour les clients réellement passifs.
Pour ce faire, il vous faut les identifier. Comment ? En mettant en place une segmentation client qui prend en compte le montant et la récence des achats (date de dernier achat) de chacun d’entre eux.
La segmentation RFM = l’une des meilleures approches pour identifier et segmenter les clients inactifs.
Cette segmentation, elle existe déjà : c’est la fameuse segmentation RFM. C’est une analyse qui repose sur 3 critères :
La Récence.
La Fréquence (des achats sur une période de référence donnée).
Le Montant (somme du chiffre d’affaires des achats cumulés sur cette période).
Si vous êtes intrigués par cette segmentation mais que vous ne savez pas complètement comment la mettre en place, n’hésitez pas à jeter un coup d’œil à notre guide complet sur la segmentation RFM !
Les gros inactifs que vous ne voulez pas perdre sont ceux qui n’ont pas commandé depuis longtemps (R = 1) mais dont le score M est élevé (4, 5, 6). Il s’agit de bien les cerner.
Étape #2 – Choisir un prestataire (call center ou logiciel service client)
Deux options s’offrent à vous.
Option #1 – Vous souhaitez externaliser les relances téléphoniques
Dans ce cas, vous devez choisir un partenaire call center. Pour en trouver un, nous vous conseillons Call of Success, la marketplace des call centers. Ce partenaire a pour but d’aider les entreprises à répondre à la pénurie de profils de commerciaux et conseillers clients en externalisant les ventes et le service client auprès des meilleurs centres de contacts. Cette plateforme digitale a démontré à plusieurs reprises ses compétences puisqu’elle permet de recruter 3 à 5 fois plus vite des talents que le recrutement interne !
Option #2 – Vous internalisez la gestion des appels de relance
Si vous avez un service client ou des collaborateurs capables de prendre en charge les appels, alors il vous faut un logiciel de gestion du service client. Ce logiciel permettra à vos collaborateurs de visualiser les clients à réactiver et d’avoir des fiches 360, recensant l’ensemble des infos clés sur chaque client.
L’internalisation coûte plus cher globalement, le coût du travail étant plus élevé en France par rapport aux call centers off-shore. Mais cela peut faire sens si vous avez des LTV élevées. Il faut toujours raisonner en termes de ROI. Si la valeur moyenne d’un client est de 1 000 euros et que vous espérez réactiver 5 à 10% de ces clients, alors ça vaut le coup !
Étape #3 – Organiser la “tuyauterie”
Quelle que soit l’option choisie, l’enjeu c’est d’être d’abord en capacité de centraliser vos données clients pour ensuite les transmettre au logiciel de service client ou partenaire call centers.
Il vous faut d’abord centraliser vos données clients pour pouvoir identifier les clients inactifs sur la base de toutes les informations à votre disposition et ainsi segmenter / scorer vos clients. C’est ce qu’on appelle la « Data Preparation » ou « Data Prep ».
Il faut ensuite être capable de créer des scénarios d’orchestration / d’activation. Par exemple, si le score de réactivation dépasse X, cela doit déclencher un envoi de notification dans l’outil de service client.
Pour cela, Octolis est le partenaire idéal dans la valorisation de vos données. La plateforme est une solution plug and play qui permet de croiser, enrichir et synchroniser vos données dans tous vos outils marketing & sales. Elle vous permet ainsi d’ordonner, préparer et analyser rapidement vos données pour une meilleure utilisation dans vos outils marketing ou vos reportings. La plateforme est entièrement sécurisée et idéale pour garder le contrôle de vos données, et s’intègre à tout type d’outils (Salesforce, Google Sheet, Shopify…) !
Étape #4 – Mettre en place une phase de test
Vous êtes enfin prêt ? Vous pouvez désormais déployer un PoC (Proof of Concept) et tester vos scénarios de réactivation par téléphone. Testez quelques semaines / mois, puis mesurez l’impact de la réactivation téléphonique (mesuré en pourcentage de clients réactivés). Enfin, comparez les résultats avec les scénarios de relance par email pour voir si ça vaut vraiment le coup.
Et si ça fonctionne, on scale !
Webinar : Quels sont les fondamentaux de la Connaissance clients en E-Commerce / Retail ?
On a échangé avec beaucoup de marques ecommerce / retail ces derniers mois pour présenter Octolis. ll y a un sujet qui revenait souvent : la connaissance clients.
Le sujet est compliqué. On atteint vite les limites de Google Analytics et d’Excel, mais l’étape d’après est difficile.
Dans ce webinar, les experts CRM de l’Agence Dn’D et d’Octolis vont vous proposer des solutions simples afin de gagner rapidement en maturité sur le sujet :
Les outils de Marketing Automation sont largement sous-utilisés.
Beaucoup d’entreprises s’équipent d’outils très costauds et chers, comme Salesforce ou Adobe, pour finalement déployer 2 scénarios qu’ils pourraient faire avec SendinBlue pour quelques centaines d’euros.
Heureusement, c’est loin d’être une fatalité.
Dans ce webinar, les experts data / CRM de Cartelis et d’Octolis vont vous présenter un plan d’action clair pour tirer parti au maximum de votre solution de marketing automation :
Le baromètre DNVB que vous allez découvrir est le fruit d’un partenariat entre Octolis et l’agence Coudac, experte en ecommerce et growth marketing. Cette collaboration a été l’occasion de faire un état des lieux des principales tendances en cours : prééminence du combo Shopify <> Klaviyo, super-performance de certains secteurs des DNVB, difficultés rencontrées par les pure players, montée en puissance des « ONVB », turbulences sur les Social Ads, etc.
Bref, vous allez apprendre des tas de choses. Même nous, qui éditons une CDP taillée pour le Retail et l’Ecommerce, qui connaissons bien le marché, nous avons appris des choses :). Cet article de synthèse présente les principaux enseignements du baromètre et présente notre méthodo.
Les 6 principaux enseignements à retenir sur les DNVB en 2022
#1 La nouvelle norme = le couple Shopify + Klaviyo
Plus de la moitié (55,6%) des DNVB utilisent Shopify pour éditer et gérer leur site ecommerce. 41,3% utilisent Klaviyo pour gérer les scénarios de marketing automation.
Comment expliquer un tel succès ?
Une intégration parfaite
Le premier élément de réponse semble être le partenariat noué entre ces deux acteurs. A l’origine, Klaviyo a été conçu pour les utilisateurs Shopify. Ses scénarios ont été taillés pour le e-commerce. Shopify a investi pas moins de 100 millions d’euros dans le développement de Klaviyo.
Aujourd’hui, bien que Klaviyo revendique de nouvelles intégrations, notamment avec PrestaShop et Magento, son intégration la plus profonde demeure celle avec Shopify.
Ils permettent de passer rapidement un cap sur le Marketing Automation et le CRM
Klaviyo exploite la moindre donnée clients provenant de Shopify, si bien que le commerçant a la possibilité de créer des flux d’e-mails et de SMS avec des triggers basés sur des events Shopify et d’utiliser ces mêmes données pour des segmentations plus fines. A cela s’ajoutent des scores sur l’étagère très utiles en e-commerce (LTV, panier moyen, les conversions, la fréquence d’achat, les articles préférés…).
De plus, disposer de ces 2 outils marque la fin du marketing de masse (absence de segmentation) et permet de mettre rapidement en place les scénarios d’automation classiques (mail de bienvenue, anniversaire, etc… ) ou plus avancés (relance de panier abandonnés, relance d’inactifs, cross-selling…)
Notons également que le développement par Shopify d’une offre de système de caisse permettrait aux DNVB d’exploiter les données offline dans leurs actions marketing-ventes, ce qui est aujourd’hui une friction que nombre d’entre elles regrettent lorsqu’elles développent leur activité en point de vente.
Une proposition de valeur qui va dans le sens de l’histoire : une relation clients plus approfondie
Le business model des DNVB et des D2C (Direct-To-Consumer) se base sur l’absence d’intermédiaire. Cette spécificité leur permet de gérer en propre leurs données clients. De cette maîtrise de la donnée découle une exploitation minutieuse et exhaustive qui, couplée à un branding percutant, permet d’offrir une expérience client plus personnalisée et plus séduisante.
Les DNVB accordent également beaucoup d’importance à la valorisation des clients existants. D’autant plus dans un contexte où en acquérir de nouveaux coûte + cher. En effet, l’année 2022 a été marquée par une explosion des coûts d’acquisition qu’a d’ailleurs dénoncée le collectif « We Are Lucioles« . En cause :
Le RGPD protège désormais les internautes mais limite la précision de campagnes ce qui impacte leurs performances.
La multiplication des marques sur des segments limités augmente la pression sur le client web, plus versatile et de moins en moins engagé.
Les GAFAM exercent un monopole toujours plus offensif.
Les limites du couple Shopify – Klaviyo
A partir d’un certain niveau de développement (80 – 100 employés / + 10M de CA), les DNVB envisagent des solutions plus robustes que celles qui sont présentées dans notre baromètre. Des solutions comme Braze par exemple, sont capables de gérer simultanément le push, l’email et le sms.
Notons également que les solutions « tout-en-un » qui centralisent la gestion du front et du back-end, limitent la créativité et la capacité à aller encore plus loin sur l’UX et la connaissance clients.
#2 Les catégories Bien-être, Alimentation et Accessoires surperforment
En moyenne, les DNVB de (+30 employés) ont vu leur croissance exploser. Mais les catégories qui se distinguent sont :
Les Accessoires (25%)
L’Alimentation (39%)
Le Bien-être (27%)
Ce succès s’explique pour les raisons suivantes :
Une fréquence d’achat importante et un CAC plus bas
C’est directement à la nature des produits. On achète plus souvent des produits alimentaires ou des accessoires qu’une voiture ou un appartement. Par ailleurs, les produits appartenant à ces 3 catégories coûtent moins cher. Ce combo fréquence d’achat élevée + CAC bas créé un terreau parfait pour créer des mécaniques relationnelles puissantes.
Un « unit economic » favorable
Les produits de beauté, par exemple, ont une valeur élevée, un poids et des dimensions faibles. C’est idéal pour les acteurs de la vente à distance.
Un engagement émotionnel fort
Pour que les facteurs de choix aillent au-delà de la simple comparaison des prix il faut que le client éprouve un certain attachement à l’égard du produit ou plus largement de la marque. Les 3 catégories de DNVB qui surperforment ont en général un branding fort.
Une disponibilité de catégories adjacentes appropriée pour améliorer la taille du panier/la CLTV > Upsell / cross sell
Les DNVB spécialisées dans les accessoires, l’alimentaire et le bien-être ont en général un grand catalogue produits, avec des produits très souvent complémentaires et similaires, ce qui favorise la mise en place de mécaniques de cross-sell/upsell, et donc l’augmentation de la lifetime value.
Nous avons remarqué que la croissance moyenne des entreprises omnicanales (online + offline) résiste mieux que les pures players (100% Ecommerce).
En effet, les 10 premiers résultats de notre Flops – 30 sont à:
70% des pures players
30% des flagships (DNVB ayant déployé des points de vente)
Cela s’explique par :
La conjoncture globale
Les chiffres du premier trimestre 2021 étaient excellents à cause des restrictions sanitaires liées au Covid-19. Cette baisse est en fait un retour à la normale.
Les produits fabriqués en Chine n’arrivent plus jusqu’aux entrepôts européens, car les ports et les usines sont à l’arrêt à cause de la stratégie zéro Covid du président Xi Jinping.
L’inflation modifie le comportement des consommateurs, qui font plus attention à leur portefeuille. Cela pèse sur les résultats de l’e-commerce non alimentaire.
La hausse des prix de l’énergie, des salaires ou encore du coût des emballages pèse sur les marges des e-commerçants, dont la rentabilité diminue à vue d’œil.
La loi de la concurrence, qui frappe de plein fouet le business model des DNVB déjà très exploité
L’éclosion de nombreuses DNVB ces dernières années entraîne une concurrence impitoyable sur les marges et les coûts d’acquisition. Et cette concurrence a tendance à s’accentuer quand les DNVB ciblent les digital natives.
Une grosse dépendance à l’acquisition en ligne, qui est aujourd’hui beaucoup plus chère.
Nous vous en parlions précédemment, le coût d’acquisition en ligne a doublé.
Vers un nouveau type d’acteurs : les ONVB
Face à l’accroissement des coûts d’acquisition en ligne, le RGPD et la versatilité du client en ligne, il est devenu plus difficile pour une DNVB d’acquérir et de retenir un utilisateur en ligne. Dans ce contexte, certaines DNVB ont commencé à s’intéresser au point de vente physique pour acquérir de nouveaux clients à moindre coût. Ce sont les ONVB ou (Omnicanal Native Vertical Brand).
A l’image de la D2C LePantalon qui a commercialisait uniquement sur son site internet avant d’ouvrir des points de vente physiques pour offrir une expérience client plus immersive.
Vous avez besoin de structurer rapidement votre relation omnicanale ?
On vous propose un template à télécharger gratuitement pour accélérer rapidement sur le sujet.
#4 Une année difficile sur les Social Ads
Les faits marquants de l’année 2022
Au niveau des social ads, 2022 fut une année difficile pour de nombreux e-commerçants. Les marques se sont heurtées à plusieurs obstacles :
La mise à jour de l’iOS 14 qui a rendu plus difficile le tracking des clients en ligne (entre 30 et 35% des données ont été perdues depuis iOS14) et par extension la performance de leurs campagnes publicitaires dans un contexte d’augmentation de la concurrence et donc de hausse des coûts.
Facebook, l’un des principaux moteurs de nombreux e-commerçants a vu son nombre d’utilisateurs diminuer pour la première fois en depuis sa création en 2004. L’un des principaux facteurs de cette diminution historique est la montée en puissance de TikTok et Pinterest qui signent les plus grosses progressions en 2022. En conséquence, les marques utilisent d’autres leviers pour diversifier leur stratégie d’acquisition en plus de leur levier principal, Facebook. Elles investissent à 44% dans Facebook Ads, à 29% dans Pinterest Ads et à 19% dans TikTok.
Notons tout de même que certains commerçants (les 25% les plus performants) ont réussi à tirer leur épingle du jeu.
Coûts
2021
2022
Variation
CPM
4,48€
5,74€
+15%
CPC
0,65%
0,68%
+4,5%
CTR
0,77€
0,85€
+10%
L’augmentation du CPC induit un gros impact sur le volume de clics sortants. Pour contenir l’augmentation du CPC, une seule solution, améliorer la qualité de ses ads pour augmenter le CTR et donc limiter l’augmentation du CPC.
Nos conclusions
Qu’est-ce qui différencie les 25% e-commerçants qui ont les meilleures performances ?
Peu importe la taille du business, il y a deux facteurs sur lesquels ils sont meilleurs :
La croissance de trafic en moyenne +250% (pour les – de 500k€) à +67% (pour les + de 5M) de croissance de trafic par rapport à l’année précédente. Ces performances s’expliquent donc par l’augmentation massive des dépenses publicitaires.
Le taux de conversion 2,62% en moyenne, + de 80% supérieur à la médiane à 1,46% des sites. Ce qui signifie que leurs produits et offres convertissent beaucoup plus de clients à l’échelle.
Évidemment, la combinaison des deux est un total banger puisque si vous augmentez votre trafic, mais que votre taux de conversion reste le même, autant vous dire que vous générez de la croissance pure.
#5 Levées de fonds & profils des dirigeants
Les fonds les plus représentés dans notre baromètre 2022 sont les suivants :
Experienced Capital (6.5%). Ce fonds d’investissement est dédié aux marques premium D2C.
Founders Future (6.5%). Créé en 2018 par l’entrepreneur Marc Menasé, ce fonds finance principalement des startups de la tech et du digital.
The Family (4,3%). Fonds d’investissements en capital-risque qui a notamment investi dans CaptainTrain, Algolia ou PayFit.
Vous trouverez ci-dessous ces 3 fonds d’investissements et leurs investissements associées :
A noter que la majorité des levées de fonds de notre baromètre (21/30) concerne les DNVB dont le nombre d’employés est inférieur à 30 collaborateurs.
En ce qui concerne le profil des dirigeants, voici les chiffres clés que nous avons identifiés :
Plus de 3/4 d’entre eux sont des hommes.
Plus de la moitié des dirigeants sont issus d’une école de commerce.
L’âge moyen pour créer une DNVB est de 36 ans.
L’école de commerce la plus représentée est HEC Paris.
La méthodologie suivie pour construire notre Baromètre DNVB
#1 Identification des acteurs + 1er niveau d’enrichissement via LinkedIn Sales Navigator
Pour sélectionner les 380+ acteurs DNVB qui figurent sur notre baromètre 2022, nous avons dans un premier temps mené une recherche sur Sales Navigator.
#2 Calcul et estimation du taux de croissance par entreprise
Pour établir le taux de croissance des DNVB sur 1 et 2 ans, nous nous sommes basés sur deux approches :
Lorsque le nombre d’employés de la DNVB était égal ou supérieur à 30, LinkedIn Premium nous fournissait son taux de croissance sur 1 et 2 ans.
Voici un exemple avec Jimmy Fairly :
En revanche, lorsque ce nombre était inférieur à 30, LinkedIn Premium ne nous fournissait aucune information.
Pour pallier cela, nous avons calculé le taux de croissance des DNVB concernées en calculant leurs taux de croissance linéaire sur 1 et 2 ans avec comme constante 2 employées à la date de création.
Voici un exemple avec la DNVB Hypnia :
Date de création : 2016
Nombre d’employés en 2016 : 2 (notre hypothèse)
Année de l’étude : 2022
Nombre d’employés en juillet 2022 : 16
Selon la méthode de calcul linéaire, nous avons : 16 / 2 ^ ( 1 / 2022 – 2016 ) ) – 1 = 26%
Ainsi depuis 2016, le taux de croissance sur 1 an d’Hypnia est de 26% d’après notre méthode de calcul linéaire.
Pour le taux de croissance sur 2 ans, nous avons mis ce résultat au carré.
#3 Données enrichies par différents outils sur les dimensions clefs
Stack marketing
Pour rappel, la stack marketing est la somme des outils utilisée par l’équipe marketing pour mener à bien ses projets et mesure leur efficacité. Les types d’outils les plus utilisés sont :
le CRM ou Customer Relationship Management comme HubSpot ou Salesforce.
Le CMS ou Content Management System comme PrestaShop ou Shopify.
L’outil de Marketing Automation comme SendinBlue ou Klaviyo.
L’outil de Ticketing comme Zendesk ou Gorgias.
Pour parvenir à identifier le plus d’outils marketing possibles en un minimum d’efforts, nous avons utilisé Wappalyzer.
Funding
Pour identifier le montant des levées de fonds et le nom des fonds d’investissement qui leur sont associés, nous avons exploité les données d’un référent en la matière : Crunchbase
Dirigeants
Enfin, pour approfondir et enrichir notre étude, nous avons fait appel à SocieteInfo pour identifier le nom des dirigeants.
#4 Croisement et analyse des données
Une fois que toutes ces infos étaient en notre possession, nous avons travaillé d’arrache-pied pour aboutir à des insights clés. On espère que notre ressource vous plaira !
Télécharger notre Baromètre DNVB 2022
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Les outils de CRM et d’emailing ne permettent pas d’avoir un suivi satisfaisant de l’impact des actions mises en place par l’entreprise. C’est probablement le constat que vous avez fait si vous atterrissez sur cet article.
Plusieurs éléments expliquent pourquoi beaucoup d’entreprises échouent à mesurer efficacement les actions CRM. D’abord, les actions CRM sont pour beaucoup cross-canal. Ensuite, une action CRM (une campagne ou un scénario) peut avoir des effets indirects, ou distants. Tout cela pose des problématiques complexes d’attribution. Dans ces conditions, mesurer l’impact des actions CRM est un challenge que nous allons vous aider à relever.
Pour mesurer l’impact des actions CRM, il faut d’abord commencer par construire une vision d’ensemble de toutes les actions déployées et rattacher toutes ces actions (campagnes et scénarios) à des objectifs précis, des KPIs mesurables. D’où la nécessite de construire un plan relationnel. C’est la démarche que nous allons vous présenter. Nous verrons ensuite comment mesurer la performance de vos campagnes et de vos scénarios relationnels.
Les limites des outils d’emailing / CRM pour mesurer l’impact des actions
Les reportings proposés par les outils d’emailing et de CRM sont limités par deux principaux inconvénients :
Ils sont très centrés sur les campagnes et les canaux de conversation. De ce fait, ils n’offrent pas de vision d’ensemble du « parcours client », mais seulement une lecture partielle et étroite des actions.
Les KPIs proposés sont relatifs à l’engagement : taux d’ouverture, taux de clics, taux de réactivité… Cela permet seulement d’analyser le comportement des clients à la lecture de l’email, mais pas l’impact business global des campagnes, avec par exemple le CA généré sur le site e-commerce.
Ces deux limites sont particulièrement importantes. Lorsque l’on met en place une campagne d’emailing, il est nécessaire de pouvoir mesurer les performances business qui en résultent. Or les actions marketing et CRM affectent durablement et souvent indirectement les parcours des clients. Par exemple, une campagne emailing peut avoir un impact sur les ventes en magasin : un client lit votre email, clique sur un produit, consulte la page du produit puis décide d’aller en magasin acheter le produit.
Ainsi, il est nécessaire de disposer d’informations supplémentaires. Vos responsables CRM doivent pouvoir prendre plus de hauteur. Cela est rendu possible grâce aux programmes et au plan relationnel.
Prendre de la hauteur : les programmes et le plan relationnel
Pour mesurer l’impact des actions CRM/Marketing au niveau du parcours client, il faut organiser les actions dans des programmes relationnels.
Un programme est un ensemble d’actions de marketing relationnel au service d’un objectif mesurable par un KPI. La logique des programmes permet de sortir de l’approche mono canal proposée par les outils CRM/Emailing classiques en se fondant sur des objectifs auxquels on associe un ensemble d’actions permettant d’exploiter plusieurs canaux et points de contact. Il existe deux types d’actions :
Les scénarios relationnels, qui se déclenchent en fonction du comportement des clients (scénario de bienvenue, scénario post-achat…) ou d’un événement client (scénario d’anniversaire, scénario d’anniversaire d’un contrat…).
Les campagnes marketing, qui sont ponctuelles ou périodiques (liées aux événements du calendrier).
Voici une manière de se représenter les différents programmes et les scénarios associés :
Les programmes sont listés dans un document de cadrage et de suivi qui s’appelle le plan relationnel. Il permet d’avoir une vision d’ensemble de ses actions CRM/Marketing. C’est un document indispensable pour piloter ses actions de marketing relationnel de manière cohérente.
Comme nous l’avons précisé, les actions qu’il s’agit de mesurer sont scindées en deux catégories : les campagnes et les scénarios. Or, ces deux mesures diffèrent. Il est donc nécessaire de combiner deux approches pour évaluer l’impact de ces actions.
Suivre l’évolution des performances de mes campagnes à travers le temps
Les campagnes, qui sont des actions marketing ponctuelles, doivent faire l’objet d’une planification. Elles peuvent être menées au travers de plusieurs canaux (mail, site web, magasin…). En organisant les actions dans un plan relationnel, mesurer la performance d’une campagne ne consistera plus à analyser le taux d’ouverture ou le taux de clics mais à mesurer l’impact de cette action sur le KPI du programme auquel elle est rattachée.
Il est important de suivre l’évolution des performances de vos campagnes et de les comparer entre elles. L’analyse comparative de vos différentes campagnes est le meilleur moyen d’identifier les axes d’amélioration et de mettre en lumière les éléments les plus performants. Par exemple, l’effet de chaque campagne de Noël devrait être mis en perspective avec celles des années passées afin d’obtenir une compréhension précise de l’évolution de l’efficacité de cette action.
Mesurer l’impact des scénarios relationnels
Contrairement aux campagnes ponctuelles, les scénarios sont des éléments du bloc CRM plus complexes et dont l’impact est beaucoup plus difficile à mesurer. En effet, les scénarios, qui forment un ensemble d’actions se déclenchant en réponse au comportement d’un client, possèdent trois principales caractéristiques :
Un objectif qui doit être lié au but global du programme,
Un déclencheur qui est le point de départ de l’action,
Une séquence qui définit l’ensemble des messages et actions automatisés.
Pour obtenir une vision précise de l’effet des scénarios, nous vous proposons trois approches possibles.
L’approche classique, basée sur le suivi de KPIs
Cela consiste à suivre quelques KPIs bien choisis : le KPI du programme relationnel auquel il est rattaché ainsi que des KPIs secondaires qui ont un impact indirect sur le KPI principal. Idéalement, chaque scénario est associé à un indicateur précis qui doit être celui du programme relationnel si ce dernier est correctement structuré.
Nous pouvons prendre par exemple l’abandon panier, avec comme KPI principal le taux de clients avec des paniers abandonnés qui réalisent un achat après X jours. Un autre exemple plus complexe est le cross-sell un mois après l’achat, ou la part de clients qui réalisent un deuxième achat entre 30 et 45 jours après le premier.
Il faut ensuite réussir à établir un reporting précis et complet pour suivre ces fameux indicateurs.
L’analyse de cohortes
L’analyse de cohortes consiste à étudier les comportements de différents groupes de clients constitués en fonction de critères objectifs (clients ayant reçus le même email, disposant du même abonnement…). On peut alors comparer la performance d’un scénario au sein de différentes cohortes établies selon la date d’entrée du client. Cela peut consister par exemple à mettre en place en mars un nouveau scénario pour pousser le passage du 1er au 2ème achat grâce à une séquence de 5 emails sur 3 mois après le premier achat.
Pour mesurer l’impact du scénario, il faut regarder l’évolution du nombre d’achat moyen (ou du CA en base 100) par cohorte basée sur la date du premier achat. Pour les clients ayant acheté après mars, il faut que le nombre d’achats 2 et 3 mois après le premier achat soit plus important que pour ceux ayant réalisé un premier achat en janvier. Évidemment, le scénario n’est pas un facteur unique de différenciation. La cyclicité, les campagnes marketing et de nombreux autres éléments peuvent affecter les ventes, ce qui rend difficile d’évaluer la fiabilité des résultats.
L’A/B Testing
Cette méthode est la plus rigoureuse, mais aussi la plus difficile à mettre en place. Il faut scinder le groupe à tester en deux, puis appliquer le scénario sur le groupe A et comparer ensuite les résultats avec le groupe B qui sert de groupe de contrôle. Pour obtenir des résultats satisfaisant, il est nécessaire d’avoir un volume suffisamment important de clients dans chaque groupe.
20 indicateurs clés pour mesurer la performance CRM
Après avoir mis en place ces recommandations, il faut pouvoir suivre l’évolution de la performance de votre CRM. Nous vous proposons pour cela une liste de 20 KPIs que nous jugeons nécessaire d’avoir dans vos dashboards de suivi de performance.
Nom du KPI
Description
Calcul
Taux d’activation
Permet de mesurer la performance de l’activité de prospection.
Nombre de prospects devenus clients / Nombre de prospects
Taux de clients actifs
Les clients ayant acheté ou interagi récemment avec l’entreprise.
Nombre de clients actifs / Nombre de clients
Taux de churn
Le taux de clients actifs devenant inactifs sur une période.
Nombre de clients perdus / Nombre de clients
Solde net d’acquisition client
Comparaison de la variation du nombre de client actifs et inactifs.
Cela représente le nombre de sollicitations qu’un client va recevoir toutes plateformes confondues. Un nombre trop important peut mener à une pression commerciale trop forte.
Somme des sollicitations par canaux / Nombre de clients contactés
Taux de réactivité
Le taux de réactivité représente l’efficacité des messages, que l’on peut mesurer de manière agrégée ou par canal.
Nombre de réponses / Nombre de contacts
Taux de désabonnement
Cet indicateur permet de se rendre compte de la pertinence des campagnes marketing.
Nombre de clients qui se désabonnent / Nombre de clients contactés
Nombre de commandes par période et par client
Cette mesure donne la moyenne du nombre de commandes par client contactés.
Nombre de commandes sur la période / Nombre de clients contactés
CA par période et par actif
Permet d’évaluer l’efficacité commerciale du CRM.
CA de la période par actif / Nombre de clients sollicités
CA des clients sollicités vs non sollicités
Cette mesure est extrêmement importante en ce qu’elle permet de mettre en perspective l’efficacité des actions CRM.
1 : CA lié aux clients sollicités / Nombre de clients sollicités 2 : CA lié aux clients non sollicités / Nombre de clients non sollicités Comparer 1 et 2
ROI global
Cet indicateur est aussi classique qu’essentiel pour se rendre compte de l’utilité du CRM.
Revenus liés au CRM – Dépenses liées au CRM
CAC (customer acquisition cost)
Mesure moyenne du coût d’acquisition client, à mettre en perspective avec le revenu moyen généré par client.
Dépenses totales de CRM / Nombres de clients conquis
CLV (customer lifetime value)
Cela représente la valeur moyenne d’un client au court de son cycle de vie. Il est particulièrement intéressant de mettre cette valeur en perspective du CAC.
Panier moyen par client x nombre moyen de paniers par client
Longueur des étapes du processus CRM
Mesure du temps passé à chaque étape du processus CRM (du premier contact à l’achat par exemple), en ayant pour objectif de réduire cette durée.
Mesure et comparaison des durées par étapes
Durée du cycle de vente
Le temps moyen qu’il faut à un client pour finaliser une vente. Le point de départ peut différer en fonction des analyses (arrivée sur le site, emailing…).
Temps en minutes/heure entre une action prédéfinie et la validation de la vente
Temps moyen de résolution des problèmes clients
Ce KPI est utilisé pour comprendre les étapes dans lesquelles les opérateurs individuels rencontrent le plus de difficultés. Il peut également rendre compte de la rapidité et de l'efficacité de la réponse au client.
Nombre d’heures ou de jours pour résoudre une demande d’un client
NPS (net promoter score)
Cette métrique représente, sur une échelle de 1 à 10, la probabilité que les clients recommandent l’entreprise.
Un sondage proposé aux clients, généralement après une action sur le site.
Taux de complétude
Mesure le taux de remplissage de la base de données par indicateur, ce qui donne un éclairage sur la connaissance des clients.
Nombre de lignes vides pour une colonne / Nombre de lignes
Dépenses des nouveaux clients
Cette mesure vise à montrer la valeur des « nouveaux clients ». La durée pendant laquelle un client est considéré comme « nouveau » doit être déterminée en fonction du type d’activité.
Panier moyen des nouveaux clients x nombre moyen de panier
Taux de revalorisation des ventes (upsell)
Le taux d'upsell est le nombre de clients qui améliorent leur achat, en choisissant une version plus chère d'un produit ou d'un service. La gestion de la relation client peut contribuer à augmenter le taux de vente en fournissant des informations utiles pour prédire quelles pistes sont les plus susceptibles de se transformer en direction "premium".
Nombre de clients revalorisant leur panier suite à une interaction CRM / Nombre de clients validant un panier
Mesurer l’impact de vos actions CRM est un processus complexe et exigeant qui requiert de nombreuses ressources. Disposer d’un accompagnement de qualité et de softwares performants représente un avantage certain, que nous vous aidons à établir dans notre comparatif des meilleurs prestataires CRM.
Il est nécessaire de suivre l’évolution de l’efficacité de ses actions en continue et de regrouper les résultats au sein de dashboards clairs et pertinents. C’est uniquement en travaillant sans cesse à l’amélioration de la performance de votre CRM que vous parviendrez à en faire un avantage concurrentiel capable de fidéliser vos clients et d’augmenter leur lifetime value, et de booster ainsi votre activité.
20+ méthodes pour collecter plus de données clients en magasin
Bien connaître ses clients est aujourd’hui crucial pour générer des revenus. Les données sont l’ingrédient indispensable pour solliciter vos clients de manière ciblée, personnalisée, intelligente et performante.
Le contexte actuel (fin des cookies tiers, RGPD…) appelle à un recentrage sur les données « first party », celles que vous collectez par vous-même auprès de votre clientèle. Disons-le clairement, si vous embasez moins de 20% de vos clients, vous passez à côté de beaucoup d’opportunités de développer votre activité.
Dans cet article, nous allons vous présenter plus de 20 techniques pour collecter des données auprès de vos clients et augmenter votre connaissance client.
Si vous embasez moins de 20% de vos clients, vous êtes clairement en retard, et vous perdrez un gros potentiel. Un client embasé génère bien plus qu’un client avec lequel vous êtes incapable de communiquer.
Pour embaser plus de clients et collecter plus de données sur eux, vous devez mettre en place une stratégie et des tactiques. Cela passe par la formalisation d’un plan de collecte.
Un plan de collecte c’est quoi ?
Un plan de collecte c’est l’ensemble des moyens utilisés par l’entreprise pour récupérer des informations de ses clients. Celui-ci est important car il permet une bonne compréhension des attentes de vos clients quant à votre marque, vos produits et le lien qu’ils veulent entretenir avec vous. Il est indispensable pour préparer le plan marketing client, qui structure le dialogue client.
Démarche pour construire un plan de collecte
Un plan de collecte est constitué de 3 étapes clés :
Vous devez d’abord définir vos objectifs : si vous voulez collecter des données, c’est pour mettre en place des actions de marketing-ventes. Vous devez d’abord avoir une vision claire de ce que vous voulez faire. On ne collecte pas des données pour le plaisir de collecter. D’ailleurs, c’est contraire au principe de minimisation des données mis en avant par le RGPD. Généralement, les entreprises cherchent à améliorer leur fidélisation & service client, mais aussi mesurer le succès d’un nouveau produit ou service, ou encore augmenter leurs ventes par l’utilisation.
Ensuite, il vous faut définir les données cibles, c’est-à-dire les données qui vous permettront de mettre en place vos actions. Vous listez l’ensemble des données dont vous allez avoir besoin. Cela peut aller du nom et prénom de vos clients (données dites « classiques »), en passant la date d’anniversaire de vos clients (données de « personnalisation »), à leurs pointures de chaussures (données « spécifiques »).
Finalement, vous pourrez concevoir un processus de collecte, c’est-à-dire imaginer les leviers/techniques/méthodes qui vont vous permettre de collecter ces idées grâce aux points de contact que vous entretenez avec vos clients. Notre article va vous présenter justement quelques idées sur ce sujet.
En résumé, dans le plan de collecte, on part du “pourquoi” (objectifs), on définit ensuite le “quoi” (les données cibles) puis le comment/quand (les mécaniques).
20+ méthodes pour collecter plus de données clients (notamment en magasin)
1 – Créer une newsletter
La newsletter reste aujourd’hui le moyen privilégié pour récupérer les données de vos clients. Le point positif, c’est que le message que vous souhaitez transmettre peut être plus long que ceux sur lesquels la concentration de vos clients est minime. Vous pouvez à la fois informer le client sur les nouveaux produits, les promotions du mois et les ventes flash.
Newsletter proposée par « Tout frais chez vous ».
La fréquence d’envoi des mails peut être réglée selon vos envies. Généralement il est déconseillé de programmer plus de 2 emails par mois car ceux-ci contribueront juste à inonder la boîte mail de vos clients !
2 – Introduire le parcours clients en amont pour inciter à l’inscription
Le parcours client, c’est tout ce dont le client doit s’attendre lorsqu’il entre en contact avec une marque : avantages cadeau, promotion, contact avec les professionnels… L’enjeu est de donner envie au client au moment où il s’inscrit. Il s’agit de détailler les avantages qui découleront de son expérience relationnelle avec la marque.
En gros, plus le client aura d’informations sur les avantages apportés, plus il sera enclin à faire partie de la base de données de l’entreprise !
3 – Faire un partenariat avec une entreprise concurrente
L’objectif ici est double. D’abord, si vous partagez des clients en commun, vous pourrez prendre connaissance d’informations clientèle dont vous n’aviez pas encore accès. De plus, si vous exploitez bien cette nouvelle base de données, vous aurez l’opportunité de « récupérer » une partie du public de vos entreprises concurrentes.
4 – Mettre en place un programme fidélité
Le programme de fidélité est la solution qui s’adapte le mieux aux besoins de votre clientèle. En échange de leurs informations personnelles, vous pouvez leur proposer toute une gamme d’avantages. Ces avantages sont désignés en fonction de leurs attentes et habitudes de consommation.
Nous vous détaillons un peu plus bas nos conseils pour établir un programme qui correspond à votre entreprise 👇
5 – Organiser un Jeu Concours
Qui n’a jamais rêvé de gagner un jeu concours ?
C’est généralement la méthode la moins contraignante pour vos clients (qui seront ravis de gagner un lot sans rien avoir à payer) et la plus utile pour vous.
6 – Exploiter le pouvoir des réseaux sociaux
Si vous n’avez pas encore de compte Instagram ou Facebook de votre marque, il ne faut plus attendre. Les réseaux sociaux constituent le moyen le plus à la mode pour avoir accès à des données clients. Plus vos posts seront marrants, plus ils inviteront aux commentaires (avec des phrases à compléter par exemple ou des amis à identifier), et plus vous étendrez votre base de données clients parmi vos followers.
Si vos clients repartagent vos posts, créent du contenu en utilisant vos hashtags ou vos identifiants, c’est encore mieux. Ils pourront atteindre leur cercle d’amis et recueillir des informations plus personnelles que celles dont vous avez accès.
7 – Proposer un jeu concours sur des bornes en magasin
Vous pouvez préparer avec soin un message qui s’affiche automatiquement lorsque les clients s’approchent de la borne de commande. Le message doit être percutant et l’inscription au Jeu Concours doit se faire rapidement. Vos clients ne doivent pas avoir l’impression de perdre trop de temps (surtout dans les restaurants, s’ils sont affamés !). A la suite de leur inscription, un message peut s’afficher du type : « Augmentez vos chances de gagner en laissant aussi votre numéro de téléphone ». Vous aurez ainsi l’embarras du choix quant au moyen de communication avec vos clients.
Pour plus de conseils quant à la manière de collecter des données via des jeux concours, enquêtes ou quiz, vous pouvez consulter Qualifio Engage, spécialiste dans ce domaine.
8 – Proposer des codes promo sur une borne après paiement
A l’inverse, vous pouvez programmer un message avec un code promo pour une prochaine commande, une fois le paiement effectué. Pour l’activer, vos clients n’ont qu’à laisser leurs coordonnées et ils recevront ce code par mail. Le point positif : ça incite vos clients à revenir passer commande dans un laps de temps très court. Le point négatif : si c’est la période de rush dans votre enseigne, il vaut mieux éviter pour ne pas trop faire attendre les autres qui font la queue !
9 – Générer des codes promo sur les tickets commande borne
Utilisez vos tickets de caisse comme des moyens directs de communication avec vos clients. La plupart font un effort pour le conserver, et vous pouvez ainsi faire passer un message qui a de grandes chances d’être lu. Vos tickets de caisse peuvent par exemple être accompagnés d’un code de promotion à activer depuis un compte client sur internet. Ils vous laissent un mail pour les contacter, et vous leur donnez un code promo en échange. Tout le monde est gagnant.
10 – Accompagner chaque ticket de caisse d’un code promo
Il en va de même pour les tickets de caisse récupérés après avoir passé une commande en caisse.
11 – Placer des tablettes fixes dans les files d’attente
Les files d’attente sont les moments où vos clients feraient n’importe quoi pour passer le temps. C’est l’endroit idéal pour installer des tablettes tactiles avec un message pour s’inscrire à un Jeu Concours par exemple. Vous pouvez proposer aux clients de laisser leur numéro de tel, leur mail et adresse ; le plus de coordonnées ils laissent, le plus ils auront de chance de remporter le jeu.
12 – Utiliser tous les supports disponibles : set de table, cabine d’essayage, etc.
L’objectif est d’utiliser toutes les ressources à votre disposition. Les endroits les plus visibles dans votre magasin, ou qui attirent les regards de vos clients dans des moments d’attente, sont à privilégier. Un set de table ou un mur dans une cabine d’essayage sont des endroits stratégiques pour afficher une devinette invitant vos clients à envoyer une réponse par SMS.
13 – Diffuser des messages audio dans vos magasins
Une bonne playlist dans un magasin ou un restaurant contribue grandement à l’atmosphère sympathique qu’il en dégage. Vous pouvez sans aucun problème placer un message de pub entre chaque chanson avec une devinette destinée à vos clients. Proposez à vos clients d’envoyer leur réponse par SMS afin de participer à un tirage au sort pour gagner des cadeaux. Veuillez à programmer votre message sonore un peu plus fort que le niveau de bruit des musiques et le tour est joué !
14 – Proposer un packaging et des goodies attrayants
En ce moment c’est la mode des goodies et des tote bags en particulier. On en voit partout. Vous pouvez surfer sur la tendance en proposant à vos clients des tote bags gratuits avec l’enseigne du magasin imprimé en échange de la création d’un compte client. Vos vendeurs peuvent proposer cet échange en caisse, après le paiement effectué. Succès assuré.
15 – Transformer vos flyers en point de collecte de données clients
C’est toujours bon de renouveler les méthodes qui fonctionnent. La distribution de flyers permet aux clients de conserver avec lui toutes les informations que vous souhaitez lui faire parvenir. Vous pouvez par exemple y imprimer une devinette marrante. Les clients doivent envoyer la bonne réponse par SMS et pourront être tirés au sort pour gagner un lot de cadeaux choisi par vos soins.
Le petit + : la distribution de flyers est d’autant plus intéressante pour les services drive, lorsque les clients n’entrent pas dans votre magasin. Ils repartent quand même avec un petit souvenir.
16 – Collecter des données clients via le Wifi public
Simple et efficace, le réseau wifi constitue un moyen privilégié pour récupérer les données de vos clients. Quand vos clients voudront se connecter au réseau internet de vos magasins, ils seront redirigés vers une page internet. Ils devront ensuite créer un profil avec leurs coordonnées pour accéder gratuitement au réseau internet. N’oubliez pas de garantir la qualité et le débit de votre service internet pour que vos clients le privilégient à l’option de données mobiles.
Le point positif : Vous pouvez également customiser des messages push pour inciter vos clients à se créer un compte client.
17 – Installer des panneaux d’affichage avec code promo
Vous pouvez décorer votre magasin de panneaux d’affichage au design attrayant et aux couleurs vives. Une fois que le client s’approche, il pourra apercevoir un QR code. Il sera alors redirigé vers un code promo à activer depuis un compte client.
18 – Collecter des données clients via vos vendeurs en magasin
Aucune méthode qu’on vous propose ne surpassera une bonne conversation. Les vendeurs de votre magasin sont les plus aptes à recueillir les données personnelles de vos clients ; leur date d’anniversaire, leur code postal, le nombre de leurs animaux de compagnie… Former vos vendeurs est alors primordial pour qu’ils puissent devenir des liens de confiance entre votre enseigne et vos clients.
19 – Créer un “espace club”
Votre clientèle sera plus apte à laisser ses coordonnées si on lui propose un statut exclusif, celui de membre d’un « espace club ». Vos clients doivent sentir qu’ils sont chouchoutés, et qu’ils ont accès à plus d’avantages que les autres. Votre entreprise peut par exemple garantir aux membres un accès aux préventes, à des codes promo, à des goodies gratuits…
20 – Encourager les réservations par téléphone
Cette méthode est particulièrement utilisée par les restaurateurs pour les réservations. Cependant, vous pouvez aussi la présenter comme un service après-vente. Si les clients sont mécontents ou veulent faire remonter des critiques, ils peuvent appeler l’entreprise. Cela vous permettra d’identifier le client par son numéro de téléphone et de proposer une compensation lors de sa prochaine visite par exemple ; pas mal pour le fidéliser !
21 – Diffuser des questionnaires de satisfaction
Un questionnaire de satisfaction c’est comme conduire une étude de marché. Elle doit être mise en avant comme un outil qui permettra à votre marque de mieux répondre à vos clients. Ceux-ci se sentiront alors concernés. Ils s’exprimeront volontiers et laisseront leurs coordonnées pour être au courant de l’avancée de l’enquête.
Notre conseil : les enquêtes de satisfaction peuvent être proposées sous forme de message pop-up en borne de commande par exemple !
22 – Proposer d’envoyer les tickets de caisse par SMS / email
Ce moyen est à la fois avantageux pour vos clients et écolo. Vous pouvez présenter l’option de cette manière : ce sera simple de retrouver le ticket de caisse s’ils doivent retourner le produit. Et en échange, vous aurez accès au mail de vos clients : pratique pour envoyer des newsletter !
Une autre approche pour collecter plus de données clients en magasin : mettre en place un programme de fidélité
Un programme de fidélité… c’est quoi au juste ?
Le fonctionnement d’un programme de fidélité, c’est très simple. Il doit récompenser vos clients qui achètent régulièrement vos produits ou font souvent appel à vos services. Ceux-ci reçoivent alors des avantages (cadeaux, code promo, accès au catalogue avant le reste des clients) pour les remercier de leur fidélisation. En résumé, fidéliser un client revient à augmenter la durée de temps qu’ils passeront aux côtés de votre marque et ainsi à augmenter le revenu moyen généré par chaque client.
Vu différemment, mettre la priorité sur la fidélisation de vos clients, c’est réduire vos coûts marketing et publicitaires. Fidéliser un client est « moins cher » qu’en attirer un nouveau et l’investissement est meilleur puisque celui-ci reviendra. Un client avec qui vous entretenez une bonne relation, se chargera d’en parler autour de lui et vous ramènera d’autres clients. D’ailleurs, le bouche-à-oreille est souvent la meilleure des publicités.
Vous pouvez promouvoir votre programme de fidélité au sein de vos magasins. En tant que client, je vais voir un panneau m’invitant à bénéficier d’avantages financiers ou matériels ou alors c’est un vendeur qui m’en parlera, ou bien j’entendrais un message radio…
Quel impact attendre d’un programme de fidéliser sur l’embasement client ?
De ce qu’on voit sur le marché, on peut réussir à “embaser” de 5 à 50% des clients passant en magasin. Ce taux dépend évidemment du niveau de remise / avantage inclus dans le programme de fidélité. Et aussi beaucoup du niveau d’intensité du push marketing du programme. Cela peut passer via la signalétique en magasin, ou par des vendeurs (qui doivent être incentivés et formés au préalable).
A ce sujet, une enquête du groupe Nielsen montre que 92% des consommateurs se fient plus facilement aux recommandations de leur entourage qu’aux messages publicitaires.
3 conseils pour construire un programme de fidélité
Réduisez au maximum les frictions pour s’inscrire au programme de fidélité. Évitez un grand nombre d’étapes. En résumé, le plus simple = le mieux.
Facilitez l’inscription au programme de fidélité depuis un téléphone (via SMS ou via une app). Vos clients pourront alors s’inscrire directement dans le magasin.
Vous pouvez mettre en place un système de parrainage notamment quand la fréquence d’achat de vos clients est faible ; par exemple, lorsque vous vendez des produits de longue durée de type cosmétique.
Nous espérons que vous serez inspirés par ces méthodes d’embasement client. Au sein de vos magasins ou en ligne, vous avez maintenant un grand choix de méthodes pour récupérer des données clients.
Augmenter la rétention client grâce à l’analyse de cohortes
Peu de marketers maîtrisent l’analyse des cohortes alors qu’il s’agit sans doute de la méthode la plus puissante pour comprendre la rétention client et identifier les axes d’amélioration. Intégrer une analyse de cohortes dans un reporting de la rétention client vous permettra de franchir un gros cap.
L’objectif de cet article est de vous initier à l’analyse des cohortes appliquée au marketing et à la connaissance client. Nous allons vous présenter 3 méthodes pour faire de l’analyse de cohortes + 4 cas d’usage concrets pour vous donner un aperçu de la puissance de cet outil.
L’importance de l’analyses des cohortes en marketing
Analyse des cohortes : Définition
L’analyse de cohortes est une méthode consistant à suivre dans le temps et à comparer des groupes d’individus homogènes appelés « cohortes ».
La méthode est utilisée par exemple dans la recherche médicale pour analyser et comparer les effets de long-terme d’un traitement.
Mais elle est utilisée dans bien d’autres domaines, dont le marketing. C’est le sujet de cet article 🙂
Intérêt de la méthode en marketing
En marketing, l’analyse des cohortes permet de suivre dans le temps le comportement de groupes homogènes d’utilisateurs ou de clients. Elle est très intéressante pour analyser la rétention client et la lifetime value.
L’analyse de cohortes vous permet en effet de suivre l’évolution dans le temps d’un paramètre appelé « métrique » (taux de rétention, panier moyen, LTV etc.) pour un groupe de personnes établi de manière fixe (classiquement, tous les utilisateurs ayant réalisés leur premier achat un jour donné).
Cela vous permet donc de faire un focus sur ces « métriques » clés pour développer des revenus durables, sans être dupés dans l’analyse par une croissance du revenu total, provenant le plus souvent de l’acquisition de nouveaux clients, qui peut cacher des problèmes majeurs dans votre stratégie de rétention clients et d’accroissement de la LTV.
Un des cas d’usage de l’analyse de cohortes en marketing : la mesure de la rétention client.
Comme dit le dicton, « ce que vous ne pouvez mesurer, vous ne pouvez l’optimiser ». Avec l’analyse de cohortes, vous allez donc désormais pouvoir :
Etudier la périodicité des achats et identifier les moments opportuns pour relancer vos acheteurs.
Identifier les fonctionnalités, les pages ou les modifications apportées qui améliorent la fidélisation de vos clients, mesurée par votre taux de rétention (c’est-à-dire sur 100 clients, le nombre qu’ils vous restent après une période donnée).
Construire un plan d’action pour améliorer l’engagement clients en fonction des fonctionnalités/produits les plus plébiscitées par vos utilisateurs.
Mettre en place un marketing efficace et bien ciblé qui ne suscitera pas l’acrimonie de vos utilisateurs.
Vous allez ainsi, par exemple, pouvoir identifier les meilleurs moments pour relancer vos acheteurs récurrents ou déployer efficacement des offres promotionnelles à vos clients existants en comparant les taux de rétention à la suite d’offres réalisées à des moments différents.
Mais concrètement, comment ça marche ?
3 méthodes pour mettre en place une analyse des cohortes sur sa base clients
Comment ça marche concrètement ? Il s’agit dans un premier temps d’identifier le type de cohortes que vous souhaitez étudier : cohorte constituée par date d’acquisition ou cohorte de visiteur ayant eu un même comportement à une date donnée.
Ensuite, vous devez clarifier l’hypothèse que vous souhaitez tester (ex: la deuxième relance par mail augmente-t-elle les actes d’achats ou le panier moyen ?), ainsi que l’indicateur pertinent (ex: le panier total ou le nombre d’achats au cours d’une période donnée).
ProfitWell propose un template Spreadsheet pour faire de l’analyse de cohortes. Vous pouvez le télécharger gratuitement ici. Voici à quoi il ressemble :
Ce Spreadsheet vous permet de visualiser l’évolution du revenu au cours du temps, en fonction de cohortes construites sur la date d’inscription.
Il vous suffit d’y renseigner dans l’onglet « transactions » les données que vous avez collectées et que vous souhaitez analyser, relatives par exemple aux transactions, ou aux désabonnements d’une newsletter. Le rapport d’analyse des cohortes sera automatiquement produit dans l’onglet dédié.
La prise en main de l’outil est très rapide, mais les possibilités analytiques sont limitées. Les formules n’étant pas cachées cela pourra vous permettre également de construire votre propre outil d’analyse sur tableur qui permettra de répondre aux besoins spécifiques de votre projet d’analyse, notamment en termes de construction des cohortes.
#2 L’analyse de cohortes avec Google Analytics
Le second outil à votre disposition pour mener une analyse de cohorte est Google Analytics, déjà célèbre parmi les marketers, et qui propose désormais un outil d’analyse de cohortes, en version bêta, également facile à prendre en main.
Cet outil vous permet notamment d’appliquer directement des analyses en cohorte aux données recueillies par Google Analytics, relatives à votre site e-commerce.
L’outil d’analyse de cohorte se situe dans l’onglet « Audience » et nécessite que vous choisissiez l’indicateur qui vous parait pertinent (à renseigner dans le champ « métrique ») et la « taille de la cohorte », c’est-à-dire la période de temps élémentaire sur laquelle vous souhaitez travailler (jours, semaine ou mois).
L’essentiel est de choisir une taille de cohorte pertinente par rapport à l’hypothèse que vous souhaitez tester : optez pour un jour pour identifier des effets directs d’une relance client ou d’un changement apporté au site, optez plutôt pour le mois si vous souhaitez visualiser votre rétention client de long-terme.
Pour optimiser votre analyse de cohorte vous pouvez également ajouter d’autres segments à l’analyse (en haut de la page). Par exemple, vous pouvez identifier d’où viennent la plupart de vos utilisateurs en ajoutant des segments site web/mobile et ainsi identifier plus finement les éventuelles déperditions de clients potentiels.
Enfin, choisissez plutôt une « métrique » directement liée à votre capacité à susciter des actes d’achat plutôt que des « vanity metrics » (métriques vaniteuses) telles que les métriques de trafic. Ces dernières non seulement ne se traduisent pas forcément en chiffre d’affaires mais peuvent vous amener à prendre des mauvaises décisions comme l’explique Patrick Han dans son article dédié à l’optimisation de votre analyse de cohortes sur Google Analytics.
Cette méthode se confronte aux mêmes limites que la précédente avec des possibilités analytiques limitées. Google Analytics, ne permet notamment pour l’instant qu’un seul « type de cohorte » (champ en haut de la page) : la date d’acquisition, qui correspond à la première interaction de l’utilisateur avec votre ressource.
#3 L’analyse de cohortes avec Octolis
Octolis propose un outil vous permettant de réaliser des analyses de cohortes plus sophistiquées que Google Sheets ou Google Analytics. Vous pouvez notamment y suivre des cohortes clients avec pour métrique le nombre d’achats ou le chiffre d’affaires cumulé.
Les principaux atouts de cet outil sont :
L’accès rapide à des données nettoyées et en temps réel.
La réconciliation des données online & offline, ce qui permet de consolider le chiffre d’affaire par client réalisé en ligne et en magasin. Cela étoffe l’analyse de cohorte en prenant en compte les effets d’attraction en magasin de votre stratégie e-commerce, et inversement.
La possibilité d’exploiter les données issues de ces analyses en temps réel dans les outils métiers pour déclencher automatiquement la bonne séquence email personnalisée ou de mieux recibler vos Ads vers de potentiels clients.
L’outil est également très ergonomique et facile à prendre en main, comme le montre la capture d’écran ci-dessus.
Comment exploiter une analyse des cohortes en Retail – Zoom sur 4 cas d’usage
Une fois l’analyse de cohorte réalisée, comment concrètement en tirer le plus utilement parti ? On vous donne quelques idées et exemples d’implémentation des conclusions d’une analyse de cohorte.
Premier cas d’usage – Comprendre le timing des achats
L’analyse des cohortes vous permet de comprendre quand vos clients reviennent naturellement et quelle est l’évolution dans le temps du contenu de leur panier.
Le premier usage de l’analyse de cohortes est donc de vous aider à optimiser le timing de vos campagnes post-achat afin d’accroître le taux de retour sur votre site au moment le plus opportun et de mettre en avant les produits les plus susceptibles de les attirer.
Vous pouvez y ajouter des catalyseurs de conversion tels que la livraison gratuite ou des offres promotionnelles.
Deuxième cas d’usage – Ajuster le budget d’acquisition (et le CAC)
L’analyse de cohortes grâce à des outils tels qu’Octolis vous permet d’optimiser votre retour sur investissement marketing en ciblant les bons types de prospects, les bons canaux d’acquisitions et les moments opportuns pour déployer vos campagnes d’Ads.
Vous pouvez ainsi concentrer vos budgets marketing en suivant les stratégies gagnantes identifiées et d’augmenter les acquisitions à budget marketing constant. Cela vous permet également d’investir davantage, en étant plus assuré d’un bon retour sur investissement de votre campagne publicitaire.
Cet enjeu est majeur dans la mesure où les coûts d’acquisition ont eu tendance à croître ces dernières années de l’ordre de 70 % dans les industries B2B et d’un peu plus de 60 % pour les marques B2C par rapport à il y a quatre ans, selon les chiffres compilés par ProfitWell.
Evolution du coût d’acquisition ces dernières années
Troisième cas d’usage – Optimiser vos campagnes de remises
Une autre utilisation intéressante de l’analyse de cohorte est de vous permettre d’optimiser votre stratégie de remise.
Pour ce faire, créez d’abord deux segmentations de cohortes comportementales, l’une qui a acheté avec une remise et l’autre qui a acheté sans remise. Ensuite, comparez le comportement de ces cohortes au cours des 90 jours suivants (ou tout autre délai pertinent pour votre entreprise).
Vous pouvez commencer à voir si les remises permettent de fidéliser les clients ou si elles ne font que perdre des revenus sans accroître le taux de conversion ou le panier moyen.
Quatrième cas d’usage – Améliorer vos campagnes
Il est difficile d’estimer en amont l’efficacité d’une campagne de bienvenue ou d’une campagne post-achat, et les éléments qu’il est préférable de mettre en avant.
L’analyse de cohortes vous permet de mettre en concurrence différentes campagnes, en comparant le taux de conversion à plusieurs horizons de ces dernières et d’ainsi identifier les éléments qui en font le succès en termes de graphisme, produits mis en avant etc.
Vous pouvez rapidement établir un graphique des performances des différents segments sur les périodes de 30 et 60 jours suivantes et, en fin de compte, comprendre quelle série d’email de bienvenue/relance réussit le mieux à transformer les nouveaux visiteurs en clients réguliers.
Comment mettre en place du cross-selling en Retail/Ecommerce ?
Comment mettre en place des scénarios de cross-selling depuis son outil de Marketing Automation ? Épineuse question. Les outils de Marketing Automation vous permettent de mettre en place et de déployer plusieurs cas d’usages classiques.
Mais si vous souhaitez aller un peu plus loin, la tâche peut vite s’avérer complexe. Surtout quand on est une PME…Dans cet article, nous allons vous donner les clés pour franchir cette étape.
A quel moment faut-il envisager le cross-selling ?
La montée en régime du cross-selling moderne
Le cross-selling est devenu plus visible, et surtout plus intelligent à l’ère du digital. On pense naturellement aux recommandations produits d’Amazon (qui étaient responsables de 35% des ventes dès 2006…) ou aux bornes du McDonald’s qui nous poussent à ajouter une petite glace à la fin.
La plupart des retailers ont mis en place des recommandations produits sur le site web, voire par email également. On estime généralement que cela permet d’augmenter le panier moyen de 5 à 20%. La fourchette est large car l’impact du cross-sell est rarement mesuré correctement.
Pour augmenter le panier moyen, les moteurs de recommandations privilégient :
Des produits complémentaires au produit initial
Des produits populaires (les produits les plus prisés par les clients passés)
Des produits pouvant générer un achat d’impulsion (juste avant la validation du panier)
En revanche, si ce sont les meilleures recommandations à court terme, ce ne sont pas forcément celles qui augmentent la valeur de vie à long terme. A long terme, ce ne sont pas les clients qui ont acheté un sac avec leur ordinateur qui seront les meilleurs clients, ce sont plutôt ceux qui ont auront acheté un ordinateur, un livre et une place de spectacle.
Différencier cross-selling et diversification produits
La diversification produits est une stratégie de cross-selling de long terme. L’objectif est d’augmenter le nombre de catégories différentes dans lequel un client a acheté au moins un produit. On peut aussi le formaliser différemment, l’objectif est d’augmenter la part de clients qui ont acheté au moins un produit dans plus de N catégories.
Cette deuxième formulation est souvent plus pertinente car il n’y a pas d’intérêt à pousser un client à tester toutes les catégories, l’enjeu c’est plutôt d’atteindre un niveau minimum de diversification chez davantage de clients.
Quand on analyse des bases clients de retailers, on se rend compte que les clients « multi-catégories » représentent très souvent une grosse partie des clients dépensant le plus ET des clients les plus fidèles. Ce sont des clients qui ont développé une véritable relation de confiance avec la marque. On parle ici d’une corrélation et non d’une relation de cause à effet, c’est un cercle vertueux qu’il faut alimenter.
Les clients satisfaits par leurs premiers achats, dans une ou deux catégories, seront plus enclins à découvrir une nouvelle catégorie de produits. Et si ce nouvel achat s’avère satisfaisant, ils achèteront désormais plus facilement dans d’autres catégories de produits, et ainsi de suite.
Attention toutefois à ne pas généraliser trop vite. Les opérations de cross-selling, ou de diversification produit, sont toujours rentables globalement, mais pas forcément pour tous les clients. Si vous poussez une nouvelle catégorie de produits à un client mécontent, cela pourrait s’avérer négatif. Voici une belle étude qui illustre les limites du cross-selling pour certains profils clients.
Quand faut-il investir sur la diversification produit ?
C’est une démarche qui fait davantage sens quand :
Vous avez plus de 40% de vos clients ayant réalisé plus de 2 achats qui ont acheté dans plus de 2 catégories de produit différentes.
Les clients multi-catégories ont une LTV au moins 30% supérieure aux autres. Vous pouvez comparer les clients de plus 2 ans ayant acheté dans 4+ catégories différentes par rapport à ceux ayant acheté dans 1 ou 2 catégories différentes.
Vous pouvez vous permettre d’attendre un an pour mesurer les fruits du travail.
Comment mettre en place du cross-selling ?
Prérequis pour mettre en place une stratégie de cross-selling :
Sources de données
Liste des clients
Achats réalisés
Produits achetés
Matrice de complémentarité entre catégories
Outils
Marketing Automation
Outil de transformation de données (comme Octolis ;-))
#1 Construire une matrice de cross-selling pour identifier les opportunités
Pour définir quelle(s) catégorie(s) de produits il faut recommander, la première étape c’est d’observer les corrélations historiques. Les clients ayant acheté dans la catégorie A ont-ils davantage acheté de produits dans la catégorie B, C ou D ?
Pour cela, on vous invite fortement à commencer par formaliser une matrice de cross-sell par catégories. Pour que les chiffres soient plus signifiants, on exclue généralement les clients ayant réalisé un seul achat.
Voici à quoi cela peut ressembler :
Dans l’exemple, on voit qu’il y a 54 230 clients ayant acheté au moins un produit de la catégorie A, et parmi eux, 22,7% ont également acheté un produit de la catégorie D. On ne sait pas si c’est avant ou après, mais on observe une corrélation.
#2 Construire une deuxième matrice avec les catégories recommandées
L’objectif est de construire le tableau qui permet de définir pour chaque client, quelles sont les catégories de produits à recommander en fonction des catégories de produits dans lesquelles il a déjà acheté.
La première matrice doit nous servir de base pour ce travail. Si on observe que 30% des clients ayant acheté dans la catégorie A ont aussi acheté un produit de la catégorie C, alors qu’ils sont 5% à avoir acheté dans la catégorie D, on a envie de recommander la catégorie C aux clients ayant acheté dans la catégorie A.
A nuancer néanmoins, car la connaissance de votre métier peut vous amener à faire des corrélations de produits qui ne sont pas encore observables dans l’historique d’achat. Les raisons peuvent être diverses :
Il peut s’agir d’une nouvelle catégorie de produit, donc peu d’historiques de données
Il peut s’agir d’une catégorie de produits très transversale plus facile à pusher,
Il peut s’agir d’une catégorie de produits avec une forte marge, etc.
Il y a plusieurs manières de construire cette matrice. Au départ, on recommande souvent que cela reste simple, tout en donnant un peu de souplesse aux responsables produits souhaitant faire évoluer les recommandations. Cela peut prendre la forme d’une note de 0 à 10 qui évalue la sensibilité d’un client d’une catégorie pour les autres catégories.
Voici à quoi peut ressembler la matrice de recommandation de catégories.
#3 Ajouter des champs calculés par client pour avoir le nombre et la liste des catégories
Une fois ce travail réalisé au niveau des catégories, on peut commencer à travailler par individu. On commence généralement par calculer pour chaque individu :
Le nombre de catégories de produits dans lequel il a acheté au moins un produit. Ce sera le KPI à améliorer qui sera suivi dans le temps.
La liste des catégories dans lesquelles un produit a déjà été acheté.
#4 Ajouter un champ calculé avec les catégories recommandées
On arrive à l’étape la plus complexe, il s’agit de créer un champ calculé avec les catégories à recommander en priorité. La démarche est relativement simple, on part de la liste des catégories dans lesquelles un produit a été acheté, et pour chacune de ces catégories, on regarde dans la matrice de complémentarité quelles sont catégories à suggérer.
Généralement, on prend les 2 catégories les plus corrélées à condition qu’elle dépasse au moins X% de corrélation dans la première matrice. On aboutit à la fin à une liste de catégories complémentaires aux catégories initiales.
Pour faire ce travail correctement, il faut aussi intégrer une logique de poids, afin d’être en mesure de prioriser la liste des catégories obtenue à la fin. Si un client a acheté 10 produits de la catégorie A, et un seul de la catégorie B, il est préférable de lui recommander des catégories de produits complémentaires de la catégorie A plutôt que de la catégorie B.
#5 Inviter les clients à découvrir les catégories complémentaires
Le plus simple est d’utiliser le canal email, mais il est tout fait possible de pusher les catégories complémentaires sur le site web ou dans vos publicités. Pour cela, il faut envoyer les champs calculés définis dans les étapes précédentes dans votre outil de Marketing Automation, et créer un scénario pour faire découvrir les catégories complémentaires.
Ce type de scénario est souvent restreint aux clients ayant déjà acheté plusieurs fois, dans plus de 2 catégories différentes. Il peut être déclenché X jours après le Nème achat (N > 1), à condition que le nombre de catégories dans lequel le client a déjà acheté soit supérieur à 2.
Dans une même séquence, on peut décider de pousser une ou plusieurs catégories, tout dépend du type de produits / services. Plus les produits sont chers, et supposent d’être bien présentés, plus on privilégie de présenter une seule catégorie de produits par message. L’email peut introduire la catégorie avec un zoom sur les 3 produits populaires de cette catégorie, et un code promo restreint sur la catégorie si cela fait sens.
Déployer en temps réel le cross-selling tout en gardant la main sur vos données
Auparavant, le déploiement de ce type de cas d’usage nécessitait l’appui de l’équipe technique, qui a une bande passante déjà bien remplie, ou l’allocation d’un budget spécifique pour faire appel à une agence. On était proche du lobbying interne.
L’étape d’après consistait à suivre le projet. Mais les échanges étaient souvent chronophages, laborieux et asynchrones. Autant vous dire que tout changement de stratégie pouvait nécessiter plusieurs semaines voire plusieurs mois de concertation avant d’être finalement adopter ou rejeter.
Aujourd’hui, il existe des CDP comme Octolis qui vont vous aider à :
Connecter vos sources de données afin d’avoir une vue unifiée
Créer une audience avec vos contacts, vos achats et vos produits et le GSheet matrice catégories
Exécuter rapidement en no-code (ou via requêtes SQL si un jour vous disposez d’une compétence data dans votre équipe) vos champs calculés « simples » :
Nombre de catégories où un achat a été réalisé
Liste des catégories où un achat a été réalisé
Ajouter le champ calculé avancé « Recommandation catégories »
Déployer vos cas d’usage en temps réel dans vos outils de Marketing Automation (Klaviyo, MailChimp, Braze…). Tout en vous laissant un niveau de contrôle et de transparence total.
Octolis s’appuie sur la logique de poids – évoquée précédemment – mais également sur d’autres données (en option) comme les pages visitées pour affiner et personnaliser la pertinence de la recommandation produits. CDP accessible pour les PME, Octolis permet aux équipes marketing de gagner en autonomie en en contrôle sur leurs données.
Choix Prestataire Data – Top 100 des agences et cabinets de conseil
Les prestataires data (cabinets de conseil, SSII, agences) sont de plus en plus nombreux. Leurs périmètres d’action sont larges et tous ne sont pas experts dans les mêmes domaines.
On peut faire appel à une agence data pour beaucoup de sujets différents : Data Management, BI, Web Analytics, ou encore Data Science.
Des terminologies plus ou moins claires qui laissent planer le doute quant aux compétences qui leur sont associées. Choisir le bon prestataire, dont l’expertise correspond à vos besoins est difficile dans un écosystème si hétérogène.
Nos clients font souvent appel à ces prestataires lorsqu’ils structurent leur dispositif data. On croise beaucoup d’acteurs différents et on a eu envie de vous faciliter la vie.
Résultat : Un top 100 (rien que ça!) des prestataires data au niveau français, classés par domaines d’expertise.
Choisir un prestataire pour un projet de Data Management
Le rôle d’un prestataire en Data Management
La notion de Data Management fait référence à l’ensemble des processus liés à l’intégration, au stockage, à l’organisation et à la maintenance des données que crée ou collecte une entreprise.
L’objectif d’une stratégie de Data Management est de standardiser, dédupliquer et désiloter des données issues de sources différentes et donc de formats très variés. Ces données saines et exploitables sont ensuite mises à la disposition des outils d’activation et d’analytics pour améliorer la performance opérationnelle et la prise de décision ‘data-driven’.
Plus concrètement, le rôle d’un prestataire spécialisé en Data Management consiste à cartographier les flux de données en fonction des objectifs métiers, et à aider à faire les bons choix en termes de dispositif data. Ce prestataire intervient en amont de l’activation : sur l’ingestion et la transformation des données.
Meet Your People c’est une équipe de consultants CRM indépendants basée à Paris.Notre mission ?Vous conseiller et vous accompagner dans la mise en œuvre d’une stratégie CRM éthique, responsable et performante. Donnons du sens à vos actions !
A la frontière de la Tech et de la Data, UnNest accompagne les équipes marketing in-house ou en agence pour utiliser au mieux leur donnée "First party".Nous mettons en place pour nos clients une équipe data externalisée, capable de délivrer des projets et des applications data en un temps record pour les marques, les "scale up" et les agences de marketing digital.
Analytics, Data Consulting, Digital Analytics, Data Marketing, Cloud Data Warehouse, RGPD, Data Engineering, Data Analysis, Tracking, Google Big Query, Fivetran, Google Cloud Platform, ETL, Martech
Notre culture business alliée à notre forte expertise technique nous permet d’accompagner avec succès les organisations dans l’organisation, le paramétrage et l’exploitation des outils de webanalyse.
Real Consulting Data is a digital and data science company dedicated to healthcare. It helps stakeholders accelerate their decision-making through a structured data ecosystem.
Business Intelligence, Real world evidence data, Market Research, Open Data, analytics, Real life data, Big data, Smart data, Health data, Data science, Datamining, Consulting, Market Access
CustUp est un conseil opérationnel en Relation Clients.Nous structurons et mettons en œuvre le Marketing Clients et les schémas de dialogue des entreprises.Pour ce faire, nous utilisons le CRM, le Marketing Automation et les Centres de Contacts.
Réinventer les processus métiers, optimiser les systèmes d’information ou rendre les nouvelles technologies de l’information et de la communication accessibles et efficaces pour toutes les entreprises.
Business Intelligence, Big Data, Master Data Management, Expertise TALEND, BI
Combining business consultancy, digital design thinking, marketing, technology and data to rapidly solve complex business problems for CEOs, their executives and investors.
Digital strategy, Digital transformation, Innovation, Data, UX, CRM, Branding, Digital marketing, Digital IT, Change management, Digital coaching, E-commerce, Due diligences
ADDINN est un cabinet de conseil et d'ingénierie en systèmes d'informations, spécialisé dans les secteurs de la Banque, de l'Assurance et de la Grande Distribution.
Pilotage / Gouvernance des projets, Transformation SI, Big Data, DevOps, Assistance Technique, Cartographie des processus, Digital & Software Factory
From strategy to roll-out, from ideas to reality. Keley helps start-ups to grow and big companies to become start-ups again. We offer an integrated approach that combines Strategy, Data, Consulting, Technology and Design, with smart profils.
eFrontech, société de conseil et intégrateur spécialisé, accompagne la mise en œuvre de solutions digitales au service de la relation client et de l’intelligence des données.
DataValue Consulting est un cabinet de conseil IT qui accompagne les entreprises des secteurs privé et public dans la valorisation de leur data.Le cabinet spécialiste s'appuie sur une double compétence de ses consultants en management et en technologie.
Conseil, Stratégie IT, Big Data, Data Management, Pilotage de la performance, Business Intelligence, EPM, Saas, Management, Technologie, AMOA, Expertise technologique, Data Marketing, Data, Données, Gouvernance de la Data, Consulting, Stratégie, Digital, Finance, Datavisualisation, Data Management, Data Intégration
Notre mission consiste à accompagner nos clients dans leur transformation, depuis la définition de la stratégie des systèmes d’informations jusqu’aux étapes de mise en œuvre opérationnelle et d’accompagnement du changement.
Transformation Agile, Transformation DATA, Architecture SI, Architecture d'Entreprise, Pilotage des Transformations, Performance Economique IT , Internal Digital Experience, Sourcing & Vendor Management, Monétique, Paiements, Architectures Innovantes, Gouvernance & Transformation du Run, Risques, Réglementaire & Conformité
To better serve its clients, the firm is organized around 3 Business Units:• The Consulting Business unit, The Solutions Business unit, .• The Expertise Business Unit.
Assistance à la maîtrise d'ouvrage, Organisation / Business process management, Conduite du changement, Data Cleansing, Choix de solutions, Risk Management, Digital Transformation, Design Thinking, BI, Nearshoring, Fintech, Credit Management System, Microfinance solutions, Stratégie RH
Apgar Consulting is a leading data advisory company, recognized by Analysts, that supports its customers in their journey to build a foundation for trusted data.
MDM, Data Governance, DQM, Data Migration, Information Strategy, Metadata Management, API, iPaaS, Master Data Management, Data Integration, Data Integration, Meta Data Management, Data Preparation, UX Design, Data visualization, TIBCO, EBX, Data Virtualization, Semarchy, Boomi, Data Catalog, Data Platform, Data Fabric, Data Architecture, Data Advisory
Kea & Partners est le premier cabinet européen de conseil en stratégie "Entreprise à Mission", au sens de la loi Pacte, également membre de la communauté B Corp. Depuis 2001, nous œuvrons aux côtés des directions générales à un capitalisme à visage humain.
Creator of value in the era of Data and DigitalKeyrus helps enterprises take advantage of the Data and Digital paradigm to enhance their performance, assist them with their transformation and generate new levers for growth and competitiveness.
Management & Transformation, Data Intelligence, Digital Experience
Business & Decision is an international Information Services Company, specializing, since its creation, in operating and analyzing Data.
Data, Digital, CRM, Digital Transformation, Data Science, Data Visualisation, Gouvernance des données, Intelligence artificielle, Protection des données, Green AI, Data Mesh, Customer experience, Data Intelligence, Data Architecture, Customer Management, Data Cloud, RGPD
Gfi became Inetum, Poisitive digital flow. Present in 26 countries, Inetum is a leading provider of value-added IT services and software. Inetum occupies a differentiating strategic position between global firms and niche entities.
Consulting, Applications Services, Infrastructure Services, Software, smart cities, IoT, Blockchain, DevOps, artificial intelligence, Industry 4.0, Digital Transformation, Outsourcing, Cloud, Innovation, Application Management, Cybersecurity, data management, digital banking, digital retail
4706
Quelles sont les différentes composantes de la stack data moderne ?
Vous souhaitez en savoir plus sur les outils et les briques de la stack data moderne ? Nous avons rédigé un article complet sur le sujet qui vous permettra d’y voir plus clair. Découvrez notre introduction à la stack data moderne.
Choisir un prestataire pour un projet BI
Le rôle d’un prestataire BI
L’objectif de la « BI » ou Business Intelligence est de transformer des données brutes en leviers d’actions pour l’entreprise afin d’orienter les prises de décisions.
Un prestataire en BI va donc s’attacher à rendre les données plus accessibles et lisibles à travers des dashboards ou reporting.
Un bon prestataire en Business Intelligence est très souvent un profil hybride, doté d’une double casquette :
Technique – Challenge la fiabilité des données, propose de les auditer si besoin, capable de traiter les données si besoin. Solide connaissance des principaux outils (Tableau, Power BI, Qlik) et vision ‘fonctionnelle’ pour vous proposer la meilleure approche.
Métier – En mesure de se mettre à votre place pour parfaitement saisir vos enjeux et vos objectifs quotidiens. Étudie vos fonctionnements et process à travers des interviews poussés avec les utilisateurs de la solution en question.
MFG Labs is a data consultancy and implementation company that supports companies in improving their decision-making, automating their processes and creating new services through data science, design and cutting-edge technologies.
Data analysis, Interaction design, Strategic consulting, Data science, Infrastructure, Development, Data engineering, Web analytics, Digital media, machine learning, deep learning, artificial intelligence, Operational research, big data, software development, Cloud, UX design, Decision-making tool, Statistics, applied mathematics, AI, reinforcement learning, optimisation, Data Strategy, logistics, media, decision making
Smartpoint est un acteur indépendant du conseil et des services en technologies de l'information, spécialisé en e-business, Customer Relationship Management et Business Intelligence.
Data, IA, Machine Learning, Deep Learning, Data Management, Cloud data platforms, Data insights, Devops, Data Quality Management, Business Intelligence, Smart Data, Data lake, Datawarehouse, Analytics, développement, Data Pipeline, Big Data, Data visualisation, Azure, AWS, GCP, Microstrategy, Qlik, Talend, Microsoft, Power BI, Tableau, Thoughtspot, MongoDB, Tibco, .NET, Angluar, Teradata, SGBD, IBM, Oracle
MLMCONSEIL est une société de conseil et de développement en ingénierie informatique, qui a pour but d'apporter une réponse fiable et innovante aux attentes des entreprises en tenant compte de leurs besoins et enjeux stratégiques.
Business Intelligence, ERP & CRM, Sécurité & Réseaux, Les Métiers AMOA & AMOE, Big Data, BI, ESN, SI, Intégration de système , Data Science
Founded in 2014, Actinvision strives to give you the means to analyze and generate value from your data, helping your organization adopt a data driven culture.
Business Intelligence, Data Integration, Data Visualization, BI Applications, Tableau Software, Analytics, Data Prep, Alteryx, Data Science, Self Service BI, dataiku, Datawarehouse, Snowflake, Power BI, Matillion, Talend, Informatica
Solutionec – Solution Excellence Center – is a Paris-based business intelligence and analytics consulting firm that delivers ambitious and innovative solutions for the leading players in the healthcare and life sciences industry worldwide.
Business Intelligence, Data Science, Analytics, Market Access, Forecasting, Sales Force Effectiveness, Performance Reporting, Market Assessments, Artificial Intelligence, Project Management, Marketing & CRM Analytics, Key Opinion Leader Analytics, Competitive Intelligence, Social Media Monitoring and Analysis, Data Managment
NeoSys est un cabinet de conseil spécialisé dans la transformation digitale des entreprises.
Gestion de projet, Conseil en systemes d'information, Developpement informatique, Externalisation / Offshoring, BI & Data, Business Solutions, ERP, CRM, CMS, DevOps, Business Productivity
Chez RS2i, nous avons à cœur de réaliser votre transformation digitale, et ce, grâce à notre expertise acquise de longue date.📝 ➟ 💻Depuis 30 ans, RS2i est reconnu comme le spécialiste de l’ingénierie informatique et intégrateur de solutions logicielles.
Transformation digitale, BPM, ECM, Big Data, BI, ERP, Case Management, Gestion de projets, Business consulting, Systèmes d'information, Ingénierie, Smart automation, OPCO, GED, IA, RPA, Data Virtualization, DATA
Elevate, agence conseil spécialiste en Data Marketing, Data & Tech et Consumer & Market Insights. Nous intervenons à la croisée du conseil et de la mise en oeuvre opérationnelle sur des projets Digital & Data en délivrant un accompagnement bout-en-bout.
Marketing, Webanalytics, Digital Analytics, Conversion, Adtech, Martech, Datalake, DMP, CRM, Digital Consulting, Data Consulting, Marketing Automation, Tracking, AB Test, Dashboard, Attribution, Analytics, Big Data, Data, Data Visualization, Data Science, CRO, MVT, Data Analysis, Personalization, Data Engineering, Social Listening, Customer Voice
Mydral est une Data Company. Notre mission est d’utiliser l’Analytics comme levier de transformation de l’entreprise. Nous démocratisons les outils de Data Prep et de Data Viz en les rendant accessibles à tous.
Business Intelligence, Business Discovery, Data Discovery, Projets BI Agile et Big Data, Formation et création de centres de compétences BI, Big data, BI Agile, Preuve de concept, Tableau Software, Centre de formation Tableau Software et Alteryx, Intelligence Artificielle, IA, Analytics, DataPrep, DataViz, DataScience
"Offrir la meilleure expérience analytique à nos clients".POLARYS est spécialisé dans le conseil, la conception et la mise en œuvre de projets décisionnels, Créée en 2004 par Eric Guigné, la société compte aujourd’hui plus de 160 collaborateurs qui conjuguent expérience métier et maîtrise des technologies.
Business Intelligence, Big Data, TMA, EPM, Conseil & Intégration, Pilotage de la performance, Reporting, Budgeting, Analyse, Pilotage de la masse salariale, Contrôle de gestion social, Gestion des rémunérations variables, Schéma directeur SI, AMOA, data science, datavizualisation, BI
KYU Associés, cabinet de conseil en Management vous accompagne sur vos enjeux de croissance, d’efficacité et de maitrise des risques.Créé en 2002, KYU compte aujourd’hui plus d’une cinquantaine de consultants à Paris, Londres et Cologne au service de grands groupes français et internationaux.
Offre et Expérience Client, Opérations, Risk Management, Customer Relationship, Change Management, Achats, Supply Chain, Lean Management, Etudes prospectives, Développement Produits, Assurance, Consulting, Systèmes d'information, Cyber, Business Continuity, Développement Produit, RSE, SAV, BI, Achats, Emploi, Formation, Compétences, Développement Durable
100% Data // Analysez mieux, Décidez plus vite. DecideOm vous donne les moyens de transformer vos données en indicateurs pertinents, pour faciliter le pilotage de votre activité et optimiser vos performances.
Augusta Reeves was founded in 1998 as an IT services company with three areas of expertise: 1. Integration of SAP solutions- Back-office solutions ECC 6.0 (all modules) 2. The integration of Electronic Document Management (EDM) solutions 3. The integration of SOA architectures and new associated technologies.
SAP, ERP, ECC, CRM, Hybris, SCP (SAP Cloud Platform), SAC (SAP Analytics Cloud), Cloud, Innovation, Transformation Digitale, Conseil Système d'Information, S/4 Hana, S/4 Hana Cloud, C/4 Hana, SAP Business ByDesign, Ingénierie & Services, Construction, Wholesale, BI Décisionnel, BTP, FIORI
Cabinet de conseil - Transformation des Métiers- Performance des organisations- Valorisation des données
Conseil en management, organisation, RH, Conseil en management des SI, Conseil opérationnel SI - AMOA, Management de projets, Conduite du changement, Business Intelligence / Big Data, Digitalisation, digital
Chez Cyllene, on couvre le spectre complet de votre besoin en termes de :📣 Conseils🧬 Définition d’architectures☁️ Hébergement & Services managés🔐 Cybersécurité & Formations♟ Déploiement de technologies applicatives et web🎲 Data Intelligence & Data Analytics.
Hébergement, Infogérance, Infrastructure, Cloud, Amazon Web Services, Microsoft Azure, Hybridation, Gestion globale de la sécurité, Audit, Réseaux, Délégation technique, Services Collaboratifs, Poste de travail, Développement d'applications, Marketing digital, Développement de sites internet
Founded in 2007, AVISIA has become over the years a leading player in Data, Digital & Technologies.Through a passionate team, we are specialized in Consulting, Integration and the realization of Data Centric projects.
Business Intelligence, Performance Analytique, Big Data, Conseil & AMOA, Data Science, Digital, Data Engineering, Décisionnel, Web Analytics, Google Cloud Platform, Dataiku, SAS, Google Analytics
Micropole partneres its customers in the creation of high value-added projects by helping them in their transformation at organizational, functional and technical levels.
consulting, engineering, training, e-commerce, relation client, business intelligence, transformation digitale, pilotage de la performance, gouvernance des données, master data management, connaissance client, élaboration budgétaire, big data, Digital Experience, Data intelligence
1269
Les meilleurs outils de BI
Quelles sont les différences entre un outil de data viz et un outil de BI ? Quels sont les meilleurs outils ? Comment les comparer ? On répond à toutes ces questions comparatif des meilleurs outils de Data Viz.
Choisir un prestataire pour un projet Web Analytics
Le rôle d’un prestataire Web Analytics
L’analyse Web est le processus de collecte, de traitement et d’analyse des données d’un site Web.
Les compétences que vous devez attendre de votre agence d’Analytics sont les suivantes :
Analyse de l’activité de vos utilisateurs sur votre site web via des outils de tracking (Google Analytics, Matomo, Jitsu).
Définition des KPIs à analyser, des objectifs à atteindre et d’un plan de taggage, qui permettront de visualiser l’activité en ligne.
Cartographie du parcours utilisateur et optimisation de l’UX / UI.
Identifier les canaux et les actions pour générer plus de trafic : Social Ads, Search Ads, SEO.
Optimiser la conversion on-site via des outils comme Optin Monster et de l’AB Test.
Cela nécessite bien sûr d’être très proche des équipes métiers et d’avoir une très bonne compréhension des enjeux business.
Du conseil à la mise en œuvre opérationnelle, nous permettons aux entreprises de toute taille disposant d’un business en ligne de booster leur croissance en collectant et transformant leurs données marketing (analytics, média, CRM, back-office, etc) en actions concrètes et intelligentes.
Expert du conseil et de l’accompagnement en stratégies marketing clients omni canal, notre mission a pour objectif d’accélérer vos performance business grâce à une meilleure Expérience client.
TrackAd develops technologies to improve the performance of digital advertising campaigns.They address the challenges of recruiting new customers, monitoring ROI, analyzing contribution and automating data collection.
"We are a full service digital agency!" à la française...For 11 years NewQuest has been providing web and digital services to clients all over the world.
E-marketing, Web Analytics, E-commerce, Internet solutions, IoT, Connected Objets, Web Development, Webdesign, UX Design, Video, Event, Digital Strategy, PrestaShop, MailChimp, WordPress, Motion Design
En 2008, Thierry Decroix et Sandra Retailleau décident de créer Data Filiation qui deviendra très vite Digitalkeys, agence experte en business digital. 2 serial entrepreneurs, passionnés du web qui ont déjà compris à l’époque le tournant du digital.
Business digital, e-commerce, SEO, SEM, AFFILIATION, E MAILING, PRM CRM, collecte de leads, Native Ads, sea, Référencement naturel, Liens sponsorisés, Programmatique, Web Analytics, Web Influence, Social Ads, Formation, Webmarketing, Retargeting, stratégie de contenu, Google Adwords, Formation, RTB, Google Partner Premier, TV, Content Marketing
Fondée en 2003 par des professionnels du Marketing et du Data, Waisso est une agence digitale spécialisée dans l’optimisation du marketing client en alliant technologie, data et contenu pour une approche plus innovante.
MARKETING CRM, MARKETING CLOUD, ADOBE PARTNER, SPRINKLR, GIGYA, DIGITAL MARKETING, CROSS CHANNEL, ACQUISITION, FIDELISATION, ORACLE, CAMPAIGN MANAGEMENT, CONSULTING, ANALYTICS, SEGMENTATION, CONTENU DIGITAL, BIG DATA, SOCIAL MEDIA, BUSINESS INTELLIGENCE, MOBILE MARKETING, ACQUISITION
1ère Position is a team of passionate experts living the Internet culture since 1999.
SEM (Search Engine Marketing), SEO (Search Engine optimization), smo, SEA (Search Engine Advertising), webmarketing, web marketing, Référencement naturel, social marketing, Google Adwords, Google Analytics, Facebook Ads, Twitter Ads, Linkedin Ads
ESV (previously eSearchvision) is a Digital Marketing Agency specialising in Search Marketing, Social Media, Data Analytics, Branding / Creative and Strategy Consulting Services. We are international specialists with over 12 languages spoken.
Search Marketing, Display Advertising, Mobile Advertising, Social Media Advertising, PPC, Performance Marketing, Marketing, International Campaign Management, Consultation, Services, Landing Page Optimization, RTB, Performance Display, Remarketing, Attribution Modeling
PIXALIONE est une Agence Search Marketing (SEO, SEA, SMA) & Web Analytics propriétaire d’une suite logicielle unique au monde issue de partenariats avec des écoles et universités comme le CNRS, ENPC, Centrale Paris, l'Universitat Politècnica de València.
SEO, SEA, Stratégie, Data Analytics, Refonte (SEO), RP Digitale, Content, Search Engine Analysis, Internet Marketing, Competitive Analysis, Keyword Analytics, Brand Monitoring, Content Analysis, Keyword Research, Backlinks Analysis, Netlinking, Référencement Naturel, Référencement Payant, Acquisition, Trafic, socialmedia, socialads, sma, social
Agence conseil en marketing digital organisée autour de trois métiers : • Conseil et réalisation de stratégies internet • eMarketing • Développements techniques spécifiques (back office, intégration systèmes d'information, reporting)
Marketing digital, Développement web, e-Commerce, SEO, SEA, SEM, Social ads, Gestion de projet, Identité graphique, UX Design, UX Design, Content marketing, Stratégie de marque, Planning stratégique, Webmarketing, Acquisition d'audience, Social media, CRM, E-réputation, Analytics
Créé en 2004, RESONEO est un cabinet de conseil en stratégie et en marketing pour le e-business qui réunit aujourd’hui 60 consultants spécialisés sur Internet et les nouvelles technologies.
SEO, SEM, Google Analytics, AMOA, eMarketing, Stratégie online, E-réputation, Stratégie de contenu, Data, SEA, Display, Social Ads, SMO, Formation
Depuis toujours, notre agence utilise au sein de sa structure ainsi que pour les projets clients des solutions Open Source et possède une très forte expérience dans ce domaine.
THELIA, Symfony, e-commerce, php, intelligence artificielle, AI, react.js, e-commerce b2b, data-visualisation, OCR, moteur de recommandation, prédiction, aide à la décision, big data, extranet, intranet, logiciels métiers, sirh, erp, crm
Some would think of us as one of the numerous management and IT consulting firm supporting their customers in their transformation projects. It’s true but good news, there is much more behind!
EPM / CPM cadrage, choix d'outil, implémentation, ERP, DATA & Analytics, DATA VISUALISATION, TAGETIK, ANAPLAN, SAP, SAPHANA, HANA, EPM
UNAMI, agence digitale, accompagne et réalise les ambitions web de plus d’une trentaine de grands comptes et de pure players dans des univers marketing B2C et B2B. Unami compte parmi ses clients SFR, LinkedIn, L'Express, Prisma Média, les Vins d’Alsace, dinh van, Mondadori, Numergy, Sodexo.
Stratégie digitale, UX, UI, Prototypage, Méthode agile, Tests utilisateurs, AB Testing, Analytics, Tableau de bord, Tracking, SEO, ContentSquare, Kameleoon, ABTasty, Google Analytics, AT internet, Hotjar, Google Data Studio
Agence SEO / SEA / Content Marketing / Social Ads / Data Analytics / Inbound Marketing / Recherche et Développement.
SEO, SEA, Display, Comparateurs / Marketplaces, Adexchange RTB, Web Content, Linking, Data Analytics, Stratégies digitales, Social Media (agence OnlySo), Facebook Ads, Inbound Marketing, Google Ads
Adone is now the 1st European management consulting firm in the Luxury and Retail industries and executes strategic and operational missions for Business and IT departments on projects involving: e-Commerce, Data, Customer Experience, Digital in Store, PIM-DAM, PLM, Supply Chain or else Green Transition.
Assistance à maîtrise d'ouvrage (AMOA), Gestion de projet, Conseil en système d'information, Digital, Luxe, Parfums et Cosmétiques, Mode, Horlogerie et Joaillerie, Tourisme, Hôtellerie, Digital in Store, PIM, DAM, CRM, Supply Chain, e-commerce, Data, Analytics, Clienteling, OMS, PMO, Consultant
fifty-five aide les marques à exploiter de façon optimale les données et la technologie pour développer des stratégies marketing plus pertinentes !
Web Analytics
456
Choisir un prestataire pour un projet Data Science
Le rôle d’un prestataire en Data Science
La Data Science consiste à traiter de larges volumes de données afin de dégager des tendances invisibles dont vont découler des informations qui serviront ensuite la prise de décision.
Un prestataire en Data Science va mettre en place des algorithmes complexes de machine learning afin de construire des modèles prédictifs et d’anticiper tel ou tel comportement client par exemple.
Les compétences principales d’un bon cabinet de conseil en Data Science :
Machine Learning & modeling – Les modèles mathématiques vous permettent d’effectuer des calculs et des prédictions rapides sur la base de ce que vous savez déjà des données. La modélisation fait également partie de l’apprentissage automatique et consiste à identifier l’algorithme le plus approprié pour résoudre un problème donné et à former ces modèles.
Statistiques – Les statistiques sont au cœur de la Data Science. Une solide maîtrise des statistiques peut vous aider à extraire plus d’intelligence et à obtenir des résultats plus significatifs.
Programmation – Un certain niveau de programmation est nécessaire pour mener à bien un projet de science des données. Les langages de programmation les plus courants sont Python et R.
Management de base données – Un data scientist compétent doit comprendre comment fonctionnent les bases de données, comment les gérer et comment en extraire des données.
Prevision.io develops a full automated Machine Learning Plateform that increase productivity in datascience projects , reduce time to market to delivers accurate predictive models and put them in production, and delivers a full palet of explainability to understand the decisions of the models.
Machine Learning, Predictive Analytics, Data Science, B2B, SaaS, Predictive Modeling, Artificial Intelligence, Enterprise Software, Big Data, Cloud Computing, Analytics
Our Mission : Discover new growth drivers and ensure their sustainability by helping companies harness the potential of their data.Our Approach : Combine a deep understanding of business specificities with Data Science and Software cutting-edge toolbox mastery.
Strategy, Data Science, Consulting, Software Craftsmanship, Big Data, Artificial Intelligence, Pricing, Predictive Maintenance, Marketing Tech
C-Ways is a consulting company specialised in data sciences. Thanks to innovative methods of data capture and modelling, C-Ways helps administrations and leading companies in the sectors of mobility, fashion, luxury goods, financial services, sport, consumer goods, etc. to make informed decisions.
market research, predictive marketing, data modeling, data science, client surveys, prospective, web analytics, automotive, retail, luxury, big data, data driven marketing, modeling, creative data
Fondée en 2007, BIAL-X est cabinet d'experts en performance Data.Ces dernières années marquent une véritable révolution du digital. Objets connectés, réseaux sociaux, smartphones … créent un fort volume de données.
Big Data, Business Intelligente, Data Science, Data Visualisation, Intelligence Artificielle, Transformation Digitale, Machine Learning, Deep Learning
The company was founded in 2010 by Abdelkrim Talhaoui, who earned a Master's in Mathematics from Telecom ParisTech and an MBA from ESSEC, and Mahmoud Zakaria, who holds a Master's in Mathematical Engineering and a Doctorate in Mathematics and Information Technology from Telecom ParisTech.
Data Science, Machine learning, Data Mining, Data Visualization, Deep Learning, Big Data, Intelligence Artificielle, Consulting, Formation
ALEIA is the AI platform (AI as a service) that proposes an open, secure, and industrialized solution to accelerate your Artificial Intelligence projects.
Data Science, Machine Learning, Artificial Intelligence, Automated Machine Learning, Augmented Analytics, Machine Learning Operations (MLOps), Applied AI, Enterprise AI, Datalake, End-to-End Data Science Platform, Data protection, Cyber, Energy, Logistic, Mobility
A la manière d’un véritable état-major dédié à nos clients, les équipes de Data-Major sont chargées de conseiller, synthétiser l’information, d’aider à la décision, d’organiser, de planifier, de délivrer, de piloter, de suivre, de contrôler et d’en tirer les enseignements.
Pilotage, Expertise, Développement, Data Intelligence, Data Management, Data Science, Qualité, Résultat, Business Intelligence, Architecture, Management, Consulting, Direction de projet, Gestion de projet, Créativité, Engagement, Humain Responsable, Data Exchange, DataViz, Roadmap, Flux, Data Hub, Pilotage, ESB, ETL, MDM, Master Data Management, Data Catalog, Transparence, API, Agile, AMOA, Optimisation des Processus, IA, Cloud, Architecture, Data Quality, Qualité des données, Data Analytics, Data Integration
Since 2003 Probayes the AI expert powering your performance.Referents on the whole value chain, we collaborate with all sectors.We are multi-specialists, ready to serve you and your strategic challenges.We shape with you your customized solution.
Artificial intelligence, chatbots, logistique, recherche opérationnelle, Gestion énergie, Optimisation, Réseaux Bayesiens, Réseaux de neurones, Vision, Traitement automatique du langage, Machine Learning, NLP, Data Science, Deep Learning, Fusion de capteurs, Ontologies, Séries temporelles, Classification non supervisée, Réapprentissage automatique, Traitement du signal, Analyse statistique, Industrie, Véhicule autonome, Automobile, Défense, Logistique, Distribution, Santé, Énergie, Banque, Assurance, classification supervisée, computer vision
Société pionnière dans l’Intelligence Artificielle appliquée à l’amélioration de la performance des organisations notamment dans le domaine de la Santé, la Banque et l'Assurance.
Big Data, Smart Data, Data Science, Analytics, Business Intelligence, Prédiction, Data Mining, Data visualisation, Smart Applications , Conduite du changement, Machine learning, Intelligence Artificielle, ROI, Indicateur de performance, Transformation numérique, Conseil stratégique opérationnel, Santé, Deep learning, Data Strategy, AI Application, Quinten Academy, AI strategy, NLP, Medtech, Device, IOT, RWE, Clinical Studies, Conventional Studies, HRTech, Insurtech
Beelix est une société de conseil en Transformation Digitale et Big Data animée par une approche qui lui est propre : le "Bee Yourself, Bee Your Best".
Crée en 2002, Equancy est un cabinet de conseil au croisement de la stratégie digitale et de la data. Sa mission : adresser les enjeux de croissance et de performance des entreprises, en exploitant les nouvelles technologies, l’Intelligence Artificielle et la donnée sous toutes ses formes.
Strategy, Data Science, Data Technology, Media Performance, Marketing Performance
Artefact est une agence digitale constituée d’experts du marketing et d’ingénieurs. Elle accompagne ses clients dans la mise en place d’expérience clients modernes grâce aux nouvelles technologies.
Data Science
1240
Choisir un prestataire pour un projet Big Data
Le rôle d’un prestataire Big Data
Comme son nom l’indique, le Big Data désigne simplement des ensembles de données extrêmement volumineux. Cette taille, associée à la complexité et à la nature évolutive de ces ensembles de données, leur a permis de dépasser les capacités des outils traditionnels de gestion des données.
Les caractéristiques des « Big Data » :
Volume – Les Big Data sont énormes, dépassant de loin les capacités des méthodes normales de stockage et de traitement des données.
Variété – Les grands ensembles de données ne se limitent pas à un seul type de données, mais se composent de plusieurs types de données. Les Big Data se composent de différents types de données, des bases de données tabulaires aux images et aux données audio, quelle que soit la structure des données.
Vélocité – La vitesse à laquelle les données sont générées. Dans le Big Data, de nouvelles données sont constamment générées et ajoutées aux ensembles de données fréquemment. Ce phénomène est très répandu lorsqu’il s’agit de données qui évoluent en permanence, comme les réseaux sociaux, les appareils IoT et les services de surveillance.
Fiabilité – Il y aura inévitablement certaines incohérences dans les ensembles de données en raison de l’énormité et de la complexité du big data.
Valeur – L’utilité des actifs du Big Data. La valeur du résultat de l’analyse des Big Data peut être subjective et est évaluée en fonction des objectifs commerciaux.
Votre prestataire doit donc être en mesure de gérer ce type de données. Mais vous l’avez compris, ces besoins sont limités à un petit nombre de grands groupes.
Parmi les outils à maîtriser on pense bien sûr à tous les data warehouse modernes AWS, Azure, GCP et Snowflake pour le stockage. Databriks ou Apache Hadhoop pour le processing.
Décilia est une société de conseil spécialisée dans la data intelligence. Forte de son expertise, elle accompagne depuis 2008 les acteurs du CAC 40 et les Grands Comptes à fort potentiel dans la réalisation de leurs projets data driven.
Business Intelligence, Big Data, Microsoft SQL Server, SAP Business Objects, Data Science, Azure, Machine Learning, Dataviz
DATALYO est un cabinet de conseil spécialiste de la donnée, basé à Lyon, Clermont-Ferrand et en Haute-Savoie.Indépendants et innovants, nous croyons en l'importance de comprendre et maîtriser les données pour créer de la valeur.
Big Data, Data, Business Intelligence, Dataviz, Machine Learning, Data Science
Cabinet de conseil en informatique spécialisé en Big Data et Intelligence Artificielle. Kaisens Data vous accompagne dans vos projets de transformation numérique avec une offre de service sur mesure. Venez découvrir notre expertise !
Big Data, Business Intelligence, Intelligence Artificielle, Data Science, Machine Learning, Deep Learning, NLP, Text Mining
Face au raz-de-marée du Big Data et de l’IA, deux possibilités pour les entreprises : subir ou saisir cette vague et profiter de son immense potentiel d’innovation.WeWyse vous aide à appréhender, à adopter et à transformer en business ces puissants leviers technologiques.
Big Data, Data Science, Data Strategy, Data Driven, Intelligence Artificielle, Machine Learning, Data, Deep Learning, BI, Data Visualization, Data Engineering
Tired of delayed deliveries, tripled budgets, unused data applications, and unhappy business users ?With Eulidia, embark on a smooth and exciting journey to turn data into business performance and increased competitivity.We accompany you from defining value-added business cases and objectives to the full realization of your data projects.
Business Intelligence, Datavisualization, Data Management, Big Data, Business Analytics, Data Science, Cloud, Conseil en management, UX BI, AWS, Datawarehousing, Machine Learning, Recherche Opérationnelle, Data Driven
Cenova est un cabinet de conseil en forte croissance dont la vocation est d’accompagner ses clients dans leur mutation vers de nouveaux modèles B2C, en particulier sur des enjeux d’omnicanalité, de mobilité, de numérisation et de personnalisation.
Marketing, Sales, Retail, Customer Experience, Transformation, SmartData, CRM, SCM, Innovation, Technology, Big Data, Digital Platform, omnicanal, Machine learning, mode, Mode, Luxe, Data Intelligence, Intelligence Artificielle
Ysance - Your Data in ActionTwo professions, one goal. With both of its professions, Ysance pursues a common goal: to reveal the value of your customer data and to put them into action.
Big Data, Data Integration, Data Architecture, Data Science, Dataviz & Analytics, Digital Marketing, Customer Journey, AI, Artificial Intelligence, Retail, Cloud
Pionnier du delivery agile depuis 2014, VAGANET met à disposition de ses clients des expertises techniques et fonctionnelles spécialisées dans la transformation et l’actualisation du patrimoine digital.
Prestations et services informatique, Développement Informatique, IOT, Big Data, DevOps, Nouvelles technologies, innovation, ITSM, Microsoft Dynamics 365, INFOR EAM, Power BI, Azure Cloud, AWS, CI/CD, IBM Maximo, SAP Business One, UX/UI
Créé fin 2014, Openvalue est un cabinet de conseil et d’intégration spécialisé en Data & Intelligence Artificielle : Machine Learning, NLP, Deep Learning, Computer Vision.
Internet des Objets, Big Data, Objets connectés, Innovations digitales, Dataviz, M2M, Machine to Machine, Machine Learning, Internet of Things, IoT, Business Intelligence, Cassandra, Cloud computing, NoSQL, Hadoop, MapReduce, ElasticSearch, Data Visualisation, Natural Language Processing, Computer vision, Deep Learning, Spark, Cloudera, Microsoft Azure, Intelligence Artificielle, Deep Learning, Spark, UX Design, Développement web
[LE DIGITAL PAR EXPERIENCE]Ntico, entreprise de services numérique est une communauté de talents, présentes à Lille et à Orléans, partageant des valeurs essentielles pour un accompagnement total et personnalisé de ses clients.
Informatique, Java/J2EE, Chefferie de projet, Direction de projet, Décisionnel, Web, Retail, IT, Cloud, DevOps, Data, Agilité, SupplayChain, BI, Flux, Ordonnancement, Lille
Le groupe Artemys se pose, depuis plus de trente ans, en acteur indépendant présent sur le marché des infrastructures, Cloud & DevOps, des End User Services, du BI et Big Data, de la sécurité et des réseaux, de l’Open Source et de l’accompagnement MOE et MOA.
Infrastructure, Stockage, Infogérance, Business intelligence, Expertise base de données, Centre de services, Assistance Technique, Migration serveurs, Active Directory, Microsoft Exchange, Virtualisation, Cloud, Architecture, End User Services, BI , Big Data, Mobilité, DevOps, OpenSource
Cellenza est un cabinet de Conseil IT, expert des technologies Microsoft.Nous accompagnons nos clients dans leurs projets stratégiques de transformation et d’innovation au service de leur business.
Use the full potential of your data and your IS to overcome your challenges in terms of availability, performance and security.Take control of your personal challenges around the Cloud, IoT, Big Data and DevOps automation with the support of Digora, a well-known expert in data management.
Infrastructure logicielle, bases de données, Gestion des données, haute disponibilité, Oracle, Cloud, Big Data, IoT, Conseil IT, consulting, database, sécurité informatique
Founded in 2001, ADVANCED Schema is a Consulting and Outsourcing Services company. Operating in Europe and North America, for 15 years the group has provided its clients with expertise in Data Warehousing, Business Intelligence and CRM.
Business Intelligence, Datawarehousing, Big Data, Customer Relationship Management, Digital, CRM, Developpement, Intelligence artificielle
Velvet Consulting is the leading consulting firm in assisting organizations in their customer orientation. Since 2004, thanks to our 250 Marketing enthusiasts people, we accelerate business performance by building a fullest and effective customer experience.
Stratégie Client, Performance, Innovation, Change, Datamining, Business Intelligence, Digital, CRM - Customer Relationship Management, EMA - Entreprise Marketing Automation, Big Data, Mobilité, Omnicanal, Big Data
Talan is a technology innovation and transformation consultancy. For more than 15 years, Talan has advised companies and administrations, supported them and implemented their transformation and innovation projects in France and abroad.
Conseil, AMOA SI, MOE, Support, Architecture SI, Transformation Agile, Digital, Consulting, IT Consulting, CRM, BIG DATA, IoT, Blockchain, IA, innovation, Data, big data
CGI accompagne ses clients dans la définition de leur stratégie d’intégration de l’IA ainsi que dans la mise en œuvre des projets d’automatisation, de machine learning, de RPA ou d’assistants virtuels.
La contraction de “méta” et “universe” donne “métaverse”. Mais qu’est ce que donne la contraction de “physique” et “digital” ? “Physital” , “Phygital ? Et c’est quoi au juste le “phygital” ? Un mélange entre le “e-commerce et les magasins” comme bon nombre de personnes le pensent ? Pour vous parler de ce terme nébuleux, galvaudé et à la mode, nous avons interviewé l’expert français du phygital commerce : Maxence Dislaire.
Maxence Dislaire
Le « Chevalier du Phygital Commerce »
Maxence Dislaire est un pionnier. En 2010 il a le nez creux. Convaincu que le Retail tel qu’on le connaît n’existera plus d’ici quelques années, il décide de partir en croisade en montant sa boîte : Improveeze. Celui qui se définit comme le “Chevalier du Commerce Phygital” mène depuis une campagne de sensibilisation à l’égard des retailers et pure players.
Son combat ? Aider les acteurs du retail qui connaissent une perte de vitesse ou qui veulent ouvrir des points de vente physiques. Comment ? En les aidant à se réinventer au travers d’un concept : le phygital commerce.
Peux-tu te présenter en quelques mots ?
Je viens du monde du digital, et je suis ingénieur de formation. Depuis près de 15 ans, je cherche la bonne manière de vendre avec des écrans interactifs. J’analyse les magasins sous l’angle du digital en magasin, pour aider tous les commerçants physiques à ne plus dépendre de leurs mètres carrés. J’aide les commerçants à ne plus être enfermés dans cette prison de mètres carrés et ne plus dépendre de leurs stocks pour être capable de vendre sans aucune limite. Grâce à des outils digitaux. Il y a énormément de bruits, de tests, d’échecs sur ce sujet en retail. Et à force d’avoir analysé des centaines de magasins en France et partout en Europe, j’ai fini par découvrir la recette des choses qui marchent et celle qui ne marchent pas. Il est même parfois possible d’expliquer pourquoi cela ne marche pas. Mais cette recette-là n’existe dans aucun livre aujourd’hui. Il n’y a pas de livre sur le “Phygital Commerce”. C’est peut-être pour cela que certaines personnes ne savent pas que le phygital commerce existe. Au risque de se dire “Je vais installer des bornes en magasin et avec mon site e-commerce, ça fera l’affaire”.
Qu’est ce qui t’a amené à t’intéresser au sujet du phygital commerce ?
Il y a 15 ans, ma bande de potes et moi avons décidé d’offrir à notre ami d’enfance, une guitare électrique pour son anniversaire. C’est moi qui suis chargé d’acheter son cadeau. Deux solutions s’offrent à moi. La première, c’est Internet. Sauf que comme je ne suis absolument pas musicien, je ne peux pas chercher d’ampli, ou de guitares sur Internet. Je ne saurais même pas quel mot-clé mettre. Et même si j’achetais quelque chose, je suis un peu près certain que ce serait décevant pour mon ami. Donc je décide d’aller voir un spécialiste dans un très grand magasin du Nord de la France qui fait 3000 m2. Je rentre dans le magasin et je vois sur ma droite des centaines de guitares accrochées sur le mur. Mais au bout de 20 minutes de visite guidée, je reviens bredouille à l’accueil. L’ampli, la guitare et l’étui à guitare que je recherchais étaient introuvables. Comme je suis néophyte et que je ne connais pas les magasins de musique, je demande naturellement au vendeur de m’indiquer d’autres points de vente dans la région. Je le vois très gêné. Puis il regarde autour de lui et me dit “Suivez-moi”. Il retourne sa caisse, sort son clavier, sa souris et commence à chercher sur Internet des guitares sur les sites de ses concurrents…Pendant 45 min.
Donc c’est à la suite d’une mauvaise expérience que tu t’es intéressé au sujet ?
Exactement ! A l’époque, je n’avais pas passé un bon moment avec ce vendeur lorsqu’il était sur Internet parce qu’au final, il faisait tout et moi rien, j’étais très passif. Je n’avais pas apprécié ce cérémonial de vente. Cette expérience-là m’a beaucoup fait réfléchir car en en apparence on pourrait se dire que le vendeur a commis une faute professionnelle. Mais ce jour-là, je me suis dit que le problème n’était pas le vendeur mais plutôt le modèle économique du magasin qui était obsolète.
Ce jour-là, j’ai également compris que les magasins étaient en train de “crever la gueule ouverte”. Le magasin est contraint par des mètres carrés et des stocks. Comment rivaliser avec une entreprise qui a un énorme catalogue et qui le promeut sur Internet ?
Peux-tu nous définir plus précisément la notion de “Phygital” ?
Le phygital c’est tout ce qui est digital dans les lieux accueillant du public. Ça inclue :
les magasins
les salles de sport
les gares
les aéroports
les distributeurs automatiques de billets
les écrans de publicité dans la rue
les plans interatifs….
Le phygital commerce c’est le phygital qui est lié au commerce. Comme le commerçant ne peut pas avoir des stocks infinis dans des mètres carrés qui sont finis, il va utiliser le digital pour vendre. Par conséquent, le phygital commerce répond à une problématique de vente, d’espaces, de mètres carrés. Et ces outils digitaux-là (tablette, mobile, borne…) sont ceux du commerçant.
L’idée du phygital commerce c’est de procurer la meilleure expérience de vente possible. Or en utilisant le téléphone des clients on ne peut pas tenir cette promesse. Si on laisse le client interagir avec son propre téléphone, on devient dépendant de son réseau mobile, de l’état de sa batterie ou de son téléphone. C’est pourquoi la meilleure expérience client en matière de cérémonial de vente, c’est lorsque le commerçant gère lui-même les outils digitaux.
En substance, le phygital commerce c’est le matériel dont dispose le commerçant qui n’appartient par extension pas aux clients. A l’inverse, dans le e-commerce, c’est le client qui maîtrise son matériel : ordinateur, tablette, téléphone. Le consommateur est chez lui. Voilà pourquoi je préfère utiliser une définition de sens plus qu’une définition issue du marketing. Un entrepreneur qui a besoin d’exécuter un plan business clair, précis, de briefer ses équipes, de les missionner, a besoin d’avoir une définition de sens pour appliquer sa stratégie.
On confond souvent omnicanal et phygital, peux-tu nous éclairer à ce sujet ?
Effectivement, le phygital commerce n’est pas à confondre avec l’omnicanal, une erreur qui est souvent faite. Quand vous recherchez le mot “phygital” sur Google, vous tombez souvent sur des articles où vous voyez le mobile du client en point de vente.
C’est très confus car il n’y a pas de règles sur le sujet. D’ailleurs, les trois principaux usages du téléphone mobile en magasin sont :
prendre des photos
téléphoner
rechercher sur Google
C’est rarement pour acheter en magasin. Si vous souhaitez avoir la meilleure stratégie omnicanale possible, vous avez besoin d’être :
le meilleur sur la partie physique. Et pour être le meilleur sur la partie physique, il faut que vous ayez du digital dans vos points de vente. Donc vous devez être le meilleur sur la partie phygitale.
Vous avez des pure players comme ProjetXParis qui ont ouvert des magasins sans aucun matériel digital. Mais ils s’inscrivent dans une stratégie omnicanale : ils ont un site web, des magasins…Mais à l’intérieur du magasin, il n’y a pas d’outils digitaux qui permettent de faire du phygital commerce. Si vous voulez atteindre le stade ultime de l’omnicanal, vous avez besoin de passer au commerce alternatif et phygital.
Quelles sont les raisons pour lesquelles peu d’enseignes ont encore vraiment accéléré sur le sujet ?
Le phygital commerce est un métier qui n’existe pas vraiment en tant que tel. Si vous cherchez des écoles de commerce spécialisées en phygital commerce vous n’en trouverez sans doute aucune. Pourtant, il y a des écoles de commerce spécialisées en digital, en e-commerce etc… Certains considèrent que c’est une extension ou une variante du digital. En échangeant avec beaucoup de personnes, j’ai parfois entendu “c’est un peu près du e-commerce sauf que c’est en point de vente” , “nous on va mettre notre site e-commerce en magasin”. C’est généralement très artisanal parce qu’il n’y a pas de recette. Il n’y a pas de livre qui nous dit que le phygital commerce c’est telle ou telle chose, comment il faut faire pour le mettre en œuvre et pourquoi il faut le faire de cette façon-là. Il existe des livres sur le e-commerce qui listent la recette. Par exemple, si un commerçant n’optimise pas son site web pour les moteurs de recherches son site web n’ira pas bien loin. Il en va de même pour le référencement naturel. Ce sont des ingrédients de la recette. Le phygital commerce c’est une autre recette qui n’est pas accessible facilement, il a fallu que je l’invente, que je l’analyse moi-même ces 15 dernières années et au-delà de cela, quand on ne sait même pas que la recette existe, on essaye de la déduire. C’est l’intuition qui va parler, le bon sens. Mais parfois le bon sens peut vous amener à faire des choses catastrophiques.
Je vais vous donner un exemple. Il y a quelques semaines, je suis allé voir un pure player qui a ouvert un point de vente physique. Il a probablement dû se dire “Je vais prendre mon site e-commerce et le mettre en magasin”. Pourquoi ? Parce qu’au moment de payer, il propose de payer via PayPal :
PayPal dans le e-commerce c’est plutôt une bonne pratique. C’est connu et apprécié des consommateurs. Pourtant une bonne pratique dans le monde de l’e-commerce devient une très mauvaise pratique dans le monde réel. Pire que tout, ce n’est pas légal.
A quel moment / A partir de quelle taille une enseigne doit-elle l’envisager ?
Ce que je constate depuis 15 ans, c’est que toutes les tailles d’entreprises sont passées au phygital commerce :
Des entreprises qui avaient déjà des points de vente physiques.
Des pure players qui voulaient en ouvrir.
Des petits commerçants qui voulaient développer leur activité.
Parce que les entreprises qui y ont recours ont un énorme caillou dans leurs chaussures. Elles ne peuvent pas écouler leurs produits car elles n’ont pas suffisamment de places en magasin. Au-delà du handicap évident, elles se mettent en défaut concurrentiel par rapport à des concurrents en ligne. En réalité, il n’y a pas de taille idéale. Tout simplement parce que c’est très vite rentable.
Prenons un exemple. Un magasin de jouets qui a 120 mètres carrés et un trampoline aura des difficultés à le vendre. Avec une borne, vous ne prenez pas de risque sur votre trésorerie, vous n’avez pas de loyer correspondant au trampoline qui prend énormément de place dans votre magasin, vous n’avez pas non plus à payer la manutention et le temps de mettre ce trampoline en zone d’exposition (décartonner, enlever les palettes, le mettre en magasin, l’étiqueter…). Cela prend un temps fou. Le commerçant qui arrive à vendre un trampoline à 600 euros depuis une borne, je peux vous dire que ces 600 euros-là valent beaucoup plus que ceux du trampoline immobilisé en magasin. Aujourd’hui le modèle traditionnel du commerce tel qu’on le connaît aujourd’hui, c’est-à-dire piloter par les stocks et les mètres carrés est mort. Il n’a plus aucun avenir. Pourtant c’est encore 99% du paysage.
Peux-tu nous présenter quelques exemples d’enseignes qui auraient dû prendre le virage du phygital commerce ?
Si je veux rester dans mon domaine d’expertise, je vais vous parler de PicWicToys. C’est la même histoire que Camaïeu sur le fond du modèle économique. Mais elle est plus facile à faire comprendre. PicWicToys a un peu moins de 100 magasins. Je suis allé dans l’un d’entre eux pour analyser ce qui s’y faisait. Au rayon plein air, j’ai vu ça :
Imaginez un instant le nombre de jeux de plein air que vous pouvez trouver chez Amazon.
D’un point de vue concurrentiel, ça n’a plus aucun avenir. Ceci n’a aucun sens face à l’offre des autres entreprises qui ont un positionnement à gamme large. Ce que j’appelle le “cancer du retail”, dont de nombreuses entreprises ont été victimes et seront victimes dans les années à venir, c’est le modèle économique “des 4 murs”.
Peux-tu nous présenter quelques exemples de phygitalisation réussies ?
Il y a 3 mois je suis arrivé à une conclusion très étonnante. J’ai cru pendant 15 ans que le marché du digital en point de vente serait pris et dominé par les retailers historiques : ceux qui ont de grandes chaînes de magasins et depuis que je travaille avec des pure players, j’ai remarqué qu’ils étaient beaucoup plus performants à tous les niveaux : en terme de chiffre d’affaires, d’agilité, de performance, de puissance de modèle économique, des compétences des équipes… Maintenant, je pense que ce sont les pure players qui vont dominer le retail de demain. Leur positionnement fait d’eux des entreprises très sensibles aux problématiques liées aux stocks, la trésorerie ou à la manutention. Les pure players veulent être hyper spécialisés dans un domaine précis et pour se faire ils doivent, proposer le catalogue de produits la plus large possible sur le segment en question. Ce positionnement se fait également ressentir en magasin. Les vendeurs ont la capacité de conseiller les clients sur plus de produits que leur magasin peut en compter. Là ou les vendeurs des retailers historiques étaient habitués à uniquement vendre ce qu’ils avaient sous leurs yeux ou en stocks.
Basket4Ballers
Basket4Ballerz était pure player PrestaShop depuis 13 ans. Puis ils ont finalement décidé d’ouvrir un magasin puis un deuxième à Paris. Lorsqu’un pure player ouvre un magasin, c’est un énorme challenge. Le pure player qui se lance à un plusieurs centaines de milliers de références en catalogue. C’est ce qui fait sa force. La raison d’être des pure players c’est de se différencier des magasins physiques en référençant toute l’offre possible sur un segment donné. Pour devenir parfois le référent en la matière. C’est ce qu’a fait Amazon. C’est ce que fait ManoMano. C’est ce que fait Motoblouz sur le segment de la Moto et c’est ce que fait Basket4Ballerz sur le segment du Basketball.
Les produits de la NBA, très prisés sur leur site internet, représentent 30% de leur chiffre d’affaires. Bien loin des 100 000 mètres carrés qu’il faudrait pour accueillir tous les produits du catalogue. Comment faire pour générer du chiffre d’affaires en point de vente physique sachant qu’un tiers de ses produits NBA sont vendus en ligne ? Une technique issue du phygital commerce existe. C’est le phygital commerce proactif. Elle consiste à utiliser une borne interactive avec un système de boutons et de mindmap qui entourent l’écran. L’objectif est de représenter le fait qu’il y a plus d’offres que ce qui est visible de prime abord sur un écran ordinaire. Car avec le syndrome du paresseux, les clients ne vont que rarement sur les écrans maintenant. En revanche, avec ce petit “coup de pouce”(nudge), il y a 2000 fois plus d’interactions écran que sur un écran ordinaire. C’est ce qu’on appelle une technique d’acquisition de trafic phygitale. L’acquisition de trafic phygitale n’a rien à voir avec l’acquisition de trafic en ligne. En ligne, il y a Google, en point de vente phygital il y a ce “coup de pouce”(nudge) par exemple.
Motoblouz
Motoblouz suit la même trajectoire que Basket4Ballerz. C’est un pure player à l’origine qui a décidé de commercialiser ses produits en points de vente physiques. Ils ont près de 300 000 produits en catalogue. Leur entrepôt fait 60 000 mètres carrés. Mais leur magasin en fait seulement 200 !
C’est pourquoi ils ont installé des bornes interactives aux quatre coins du magasin. Résultat, 1,5 million d’euros de chiffre d’affaires dont 80% sont faits sur les bornes interactives. La marge nette de ce 1,2 million d’euros n’aurait pas été la même si elle avait été réalisée grâce à des stocks en magasin (loyers, trésorerie, manutention…).
En conclusion, que proposes-tu avec Improveeze aux enseignes retail qui veulent avancer sur le sujet ?
Improveeze est une agence d’accompagnement global pour les pure players et retailers qui veulent ouvrir des points de vente physiques. Nous sommes en train de nous hyperspécialiser dans l’accompagnement des pure players, des DNVB qui veulent passer le cap du point de vente physique avec la bonne méthode. Et la bonne méthode c’est de refléter la puissance de son offre et la puissance de son storytelling. Nous les aidons à bâtir et déployer une stratégie opérationnelle dans le retail : nous couvrons l’emplacement, l’agencement, les outils, les méthodes, l’animation des vendeurs, la gouvernance d’entreprise, la stratégie de contenu.
Nous fournissons également la solution logicielle et matérielle qui est dédiée au cérémonial de vente en magasin (POS, bornes interactives, mobiles vendeurs, écrans interactifs etc…). Enfin nous fournissons également des prestations liées aux matériels : installation, maintenance, hotline… Et en parallèle, nous avons Phygital Academy, qui est un centre de formation, de coaching et de conseil en stratégie retail phygitalisée. Nous aidons les entreprises à appréhender le phygital commerce et à le mettre en œuvre.
Suivez Maxence Dislaire sur LinkedIn et venez assister au store Tour phygital qu’il anime en ligne en visio tous les premiers jeudi de chaque mois, entre 12 et 13h30 !
Construire une roadmap data est un jeu d’équilibre où l’on cherche à la fois à répondre aux besoins business immédiats mais aussi à poser des bases stables pour l’architecture du système de données. Il y a cependant deux écueils majeurs lorsque l’on établit sa roadmap :
Se concentrer principalement sur les enjeux à court terme.La prise de décisions fondées sur des exigences à court terme risque très probablement d’apporter des incohérences à long terme, qui vont peu à peu se transformer en dette technique.
Se projeter trop loin et se déconnecter de l’activité métier.Réfléchir à une construction optimale de l’infrastructure data sans prendre en compte les besoins actuels des équipes métiers va pénaliser l’ensemble de l’entreprise. En effet, les autres acteurs ne pourront pas tirer partir du dispositif data avant un certain temps, ce qui rend impossible le développement d’une activité « data centric ».
Il est donc nécessaire de naviguer entre ces deux extrêmes pour développer une roadmap data équilibrée qui porte ses fruits à court terme, tout en offrant une architecture stable sur le long terme. Pour cela, nous avons établi un framework vous permettant de trouver cet équilibre précieux et de construire une roadmap data adaptée à vos besoins.
Construire votre roadmap data : le guide étape par étape
Pour clarifier le processus de construction d’une roadmap data, nous avons choisi de prendre l’exemple d’une équipe data fictive de 10 personnes pour laquelle on construit une roadmap sur 12 mois. Les besoins de cette équipe sont ceux que l’on observe le plus fréquemment. Le développement de cette feuille de route se fait en 5 étapes :
#1 – Recenser les besoins métiers
La première étape de la construction d’une roadmap data consiste évidemment à recenser les besoins métiers. Cela passe d’abord par des entretiens avec les principaux responsables des sujets nécessitant une intervention de l’équipe data. Le lead de l’équipe data se doit ainsi de rencontrer les responsables métiers des équipes support, sales, marketing…
Lors de ces réunions, l’accent doit être mis sur les exigences à 12 mois qu’il faut réussir à identifier et à prioriser. Cela permet de déterminer les « besoins data » qui incombent à votre équipe et d’estimer le nombre de projets sur lesquels il est nécessaire d’intervenir.
Une bonne pratique est de collecter les retours de ces échanges dans un tableur où l’on décrit les objectifs des projets, les principaux KPIs qui y sont liés, les leviers d’actions… Ainsi, il est plus facile de se rendre compte de la charge de travail requise par chaque business unit et de regrouper les projets similaires.
#2 – Filtrer les besoins
Après avoir collecté l’ensemble des requêtes, il est nécessaire d’appliquer un ensemble de filtres sur celles-ci afin de pouvoir les prioriser. Yann-Erlé le Roux propose ainsi un système de « tamis » permettant in fine d’attribuer à chaque tâche un degré de priorité.
Le tamis est constitué de 4 filtres :
Alignement avec le plan stratégique de l’entreprise
Valeur Business
Degré de difficulté de mise en œuvre
Capacité à s’intégrer dans l’architecture data de l’organisation
Pour chaque intervention, on associe un score de 1 à 3 à chaque filtre. Il s’agit ensuite de sommer l’ensemble pour obtenir une note allant de 4 à 12. En opérant ainsi, il est possible de classer directement les projets par un tri décroissant. On obtient alors directement un premier ordre de priorité sur les tâches.
#3 – Définition des priorités
Une fois la liste triée par ordre décroissant des notes, on peut ajouter une valeur de priorité qui permet d’affiner ce classement. 5 degrés de priorité suffisent à classer l’ensemble des projets :
P0 : Cas d’usage priorisé par le COMEX dans le cadre d’un plan global de transformation ou d’un virage stratégique.
P1 : Cas d’usage « Must », le projet est essentiel dans l’entreprise et permet d’améliorer significativement l’efficacité d’une équipe.
P2 : Cas d’usage « Should », le projet est pertinent et son impact dans les équipes est non négligeable.
P3 : Cas d’usage « Nice to have/Bonus », l’idée est intéressante mais l’impact est difficile à évaluer ou trop faible pour justifier de mobiliser d’importantes ressources
P4 : Projet abandonné
En établissant ainsi un classement en 5 niveaux, on obtient une version « 1.0 » de la roadmap data et surtout un premier éclairage quant à la charge de travail.
#4 – Estimation de la charge de travail
Après avoir déterminé l’ordre de priorité des UC, il faut définir pour chacun une estimation de la charge de travail en jours travaillés. Une bonne façon de procéder est d’établir un classement en « taille de tee-shirt » :
XS : 10 JH
S : 20 JH
M : 40 JH
L : 60 JH
XL : 100 JH
XXL : 150 JH
Il suffit alors de sommer les jours travaillés pour obtenir la charge totale, tout en tenant compte de la charge de travail maximale. Dans notre cas par exemple, la limite est de 2060 JH (10 ETP x 206 jours travaillés).
#5 – Attribution des sujets
Maintenant que les sujets sont ordonnés par ordre de priorité et que la charge de travail a été définie, il faut les attribuer aux équipes correspondantes. On les réparti généralement ainsi :
Equipe data seule,
Avec la DSI sans code projet,
Avec la DSI avec code projet,
Les parties prenantes : contributeurs, owner industrialisation, owner R&D…
Pour clarifier la portée du projet auprès des équipes, il est nécessaire de déterminer le degré de maturité du projet :
Exploration,
POC,
Industrialisation,
Run
Il faut ensuite segmenter entre les différents métiers concernés :
Data analyst,
Data scientist,
Data engineer,
Scrum master…
Lorsque toutes ces étapes ont été réalisées, il est enfin possible de choisir le timing pour les projets, que l’on organise en trimestre généralement, mais dont le maillage peut être adapté aux besoins. Il s’agit ensuite d’adapter ces use cases à la méthodologie de gestion de projet que vous utilisez : en Agile, on regroupe les use cases en groupes appelés EPIC qui sont associés à des grands thèmes (par exemple : projets transverses, stratégie entreprise, efficacité du développement, efficacité des opérations, connaissance clients).
En complément de cet article et pour approfondir certains points, nous vous invitons à découvrir notre guide complet pour structurer la fonction data en startups. On y détaille les besoins (stratégiques, technos, humains) en fonction du stade de développement de l’entreprise.
Construire votre roadmap data : s’adapter aux besoins de votre organisation
Le rôle de l’équipe data
Si les besoins de chaque entreprise différent en termes de données, quelques règles générales peuvent être adoptées pour s’assurer de développer une roadmap data s’inscrivant dans la stratégie générale de la firme. Essentiellement, cela se résume à se demander pourquoi l’équipe data existe au sein de votre société. Quelles sont les problématiques centrales ? Quels problèmes devez-vous résoudre ? Quelles solutions pouvez-vous apporter ?
Ces questions permettent de classifier l’ensemble des sujets en trois catégories :
Rôle
Le problème
La solution
L'objectif
Analyse
La direction a besoin de données pour orienter et guider la prise de décision
Construire des dashboards et développer une histoire autour des données pour faciliter la compréhension des données stratégiques
Apporter un éclairage et de nouvelles informations
Automatisation
De nombreuses tâches répétitives et chronophages doivent être réalisées à la main
Développer des processus automatiques permettant d'accélérer significativement le traitement de ces tâches
Economiser des ressources, du temps et de l'argent
Développement de produit
Il y a une opportunité de générer un revenu en créant un produit data
Transformer des données brutes en une solution technique profitable
Créer une source de revenu supplémentaire
Adopter cette grille de lecture lors de la construction de votre roadmap permet de gagner en pertinence. Ainsi, vous pouvez prendre du recul sur chaque sujet que vous devez intégrer à votre roadmap. De cette façon, vous vous assurez que votre feuille de route conduise au développement et renforcement du rôle central de votre équipe au sein de l’entreprise.
Les éléments à considérer en amont
Lorsque l’on se pose la question de la place de l’équipe data au sein de l’entreprise pour construire une roadmap pertinente, il faut aussi considérer un certain nombre de motivations en amont et d’influences extérieurs qui affectent fortement la construction de cette feuille de route. Les équipes de Teradata proposent une structure en trois parties pour bien différencier ces éléments.
Les drivers sont à l’origine des besoins data et justifient la mise en place d’une roadmap. Ils permettent également un mécanisme crucial de cadrage. Chaque projet déployé, chaque problème de qualité des données traité et chaque politique de gouvernance des données établie doivent avoir un lien clair avec l’activité de l’entreprise.
Business Initiatives and Use Cases. S’il peut être utile et pertinent de proposer de nouvelles initiatives, il est encore plus crucial d’identifier les activités commerciales déjà planifiées et financées de l’entreprise nécessitant l’intervention de l’équipe data. Ce faisant, la roadmap data prend une place centrale dans la stratégie d’entreprise. Elle intervient à tous les niveaux pour proposer des leviers d’actions novateurs dont les effets sont rapidement observables.
Corporate Objectives. Il faut ici rechercher les objectifs définis par la direction qui s’appliquent de façon transversale dans l’entreprise. Cela peut être par exemple une migration généralisée vers le cloud ou une nouvelle approche managériale. L’équipe data a alors la possibilité d’intervenir sur des sujets de large envergure.
Business Use Case Prioritization. Une fois ces éléments pris en compte, il faut organiser ces tâches par ordre d’importance. Vous pouvez alors vous référer au point #3 de l’établissement de la roadmap data.
Une fois les drivers pris en compte, il faut s’intéresser aux nombreux éléments qui viennent influencer la roadmap et la capacité à développer et à mettre en place de nouveaux projets.
Information Prioritization. Les données que requièrent les différentes équipes se recoupent très régulièrement (données clients et produits pour les sales ou le marketing, données de production pour la direction financière et les opérations…). Ainsi, lorsque l’on prévoit de créer de nouvelles sources d’informations, il est particulièrement utile de recenser tous les use cases possibles et de comptabiliser les utilisateurs finaux. Cela permet d’évaluer l’impact final du projet, auquel s’ajoutent souvent des externalités positives.
Current State Architecture. Ici, l’équipe acquiert une compréhension de l’état actuel de la technologie, des données et d’autres facteurs qui affectent l’architecture data. Le degré de précision de cette analyse se fait en fonction des besoins spécifiques. Une description détaillée n’est utile que lorsque les projets data doivent être intégrer dans un écosystème complexe.
Capability Assessment. La réussite de ses projets dépend du travail commun de personnes aux compétences techniques et non techniques, telles que la gouvernance des données, les capacités analytiques, les processus organisationnels… L’idée est de ne planifier que ce qui est nécessaire quand c’est nécessaire, tout en améliorant continuellement les capacités générales de votre équipe. Cela permet de bénéficier d’une plus grande flexibilité, tout en conservant un cap précis.
Enfin, lorsque vous avez une compréhension suffisante de ces sujets, vous pouvez prendre certaines décisions et évaluer l’impact de celles-ci.
Implementation Alternatives. Lorsque l’on réfléchi à l’implémentation des nouvelles technologies et des nouveaux projets dans le SI, un certain nombre d’alternatives à l’infrastructure actuelle apparaissent. Il faut alors choisir entre l’architecture déjà en place ou l’utilisation de nouvelles solutions. Nous avons déjà abordé ce sujet dans un article sur la construction de son propre dispositif data.
Future State Architecture.L’équipe doit avoir une vision précise de l’état futur de l’architecture de data. Cette vision doit clairement indiquer comment les initiatives et les cas d’usage seront intégrés dans l’écosystème, et doit prévoir l’évolution de l’architecture pour répondre aux besoins de la manière la plus rentable et efficace possible.
Data and Analytics Roadmap. La feuille de route finale reprend tous ces éléments pour définir précisément les projets et nommer des responsables qui devront respecter un agenda clairement établi. Construire cette roadmap doit se faire de manière structurée, et c’est pourquoi nous vous conseillons vivement d’utiliser le framework présenté ci-dessus.
Construire une roadmap data est loin d’être un exercice trivial, et le succès des projets entrepris par l’équipe data dépend très fortement de la qualité de cette feuille de route. Pour cette raison nous vous conseillons fortement d’appliquer le cadre que nous vous avons proposé pour procéder par étapes. Ainsi vous vous assurez d’avoir :
Une vision claire et précise des projets à entreprendre,
Une estimation fiable de la charge de travail,
Une classification des tâches par ordre de priorité et d’importance,
Un calendrier précis de votre année permettant de suivre attentivement l’avancée des projets
Ces trois avantages sont décisifs pour la réussite de votre équipe et pour le développement de la data dans votre organisation. Répéter ce processus est la garantie d’avoir une équipe fiable année après année, capable de tenir ses engagements et de fournir des leviers d’actions efficaces qui s’intègrent parfaitement dans un écosystème que vous pouvez alors faire évoluer.
Ainsi, le développement de votre roadmap data doit être une de vos préoccupations majeurs. Plus encore, il est absolument nécessaire de revenir régulièrement sur cette roadmap pour pouvoir l’adapter, la corriger ou la préciser afin d’avoir toujours une vision claire des projets à venir et d’être capable de guider au mieux votre équipe.
Il faut investir du temps et de l’amour dans le recrutement de son responsable CRM. Pour 3 raisons :
Un excellent profil peut avoir 10 fois plus d’impact qu’un profil moyen.
Le métier de responsable CRM est complexe, à la croisée de plusieurs compétences. Pas évident d’évaluer les compétences d’un candidat, surtout si vous n’êtes pas familier du monde du CRM.
Ce n’est pas en utilisant le process de recrutement classique (passif) que vous réussirez à recruter la perle rare (tensions sur le marché oblige).
Pour vous aider à structurer la démarche de recrutement de votre responsable CRM, nous vous proposons une ressource 100% gratuite. Il s’agit d’un test de recrutement que nous utilisons chez Octolis pour débusquer les meilleurs talents. Mais avant, on vous rappelle les missions d’un bon responsable CRM et les compétences qu’il faut évaluer en priorité.
Fiche de poste standard du responsable CRM dans une PME
Prenons pour hypothèse que vous êtes une PME et que le responsable CRM que vous allez recruter sera tout seul dans l’équipe CRM, assisté éventuellement par un alternant. Pour vous aider à construire la fiche de poste, nous allons présenter les principales missions du responsable CRM.
Une précision avant de commencer : on parle parfois de « chef de projet CRM », de « CRM manager », de « responsable marketing client », de « responsable relation client ». L’imagination est sans limites, mais dites-vous bien que tous ces intitulés sont équivalents à « responsable CRM ». On parle du même métier, même s’il peut y avoir quelques nuances (qui sont souvent subjectives).
Les missions d’un responsable CRM
Le responsable CRM est la personne chargée de définir et de mettre en œuvre le plan d’animation de la relation prospects et clients. Formulé autrement, le responsable CRM est la personne qui définit, déploie et mesure la performance des actions de marketing relationnel. Il anime le dialogue avec les prospects et les clients. Vous avez la big picture, passons maintenant au détail.
La construction du plan relationnel
Le plan relationnel est l’ensemble des actions de marketing relationnel que l’entreprise va déployer sur les points de contacts des parcours prospects et clients. Dans une PME dont l’équipe CRM est composée d’un seul responsable CRM, c’est ce dernier qui pilote la construction du plan relationnel. Pour réaliser cette mission, le responsable CRM va devoir suivre plusieurs étapes :
1 – Définir les objectifs CRM de l’entreprise. La définition des objectifs CRM dépend des objectifs stratégiques de l’entreprise. C’est donc en collaboration avec l’équipe dirigeante, et éventuellement avec les autres services (équipe commerciale…), que le responsable CRM doit réaliser cette première étape. Voici quelques exemples d’objectifs :
Améliorer le suivi de la performance commerciale.
Mieux fidéliser les clients existants.
Améliorer les process d’acquisition de nouveaux clients.
Augmenter le taux de conversion des leads.
Augmenter le panier moyen (développer l’upsell – le cross sell).
Optimiser la satisfaction client.
Réactiver les clients inactifs.
Etc.
2 – Cartographier les parcours prospects et clients. Ce travail consiste à construire une représentation claire des étapes, points de contact et canaux qui constituent vos parcours prospects et clients. La représentation des parcours clients, c’est la carte à partir de laquelle le responsable CRM va construire son plan d’actions.
Exemple de cartographie des parcours clients réalisés par nos amis de chez Cartelis, un cabinet de conseil en CRM.
3 – Définir les programmes, campagnes et scénarios relationnels. Sur la base des objectifs CRM de l’entreprise et des parcours clients, le responsable CRM va construire les actions de marketing relationnel qui permettront d’atteindre les objectifs. Ses actions se déclinent en campagnes marketing (opérations ponctuelles) et éventuellement en scénarios automatisés (déclenchement automatique d’actions ou envoi automatique de messages en fonction du comportement client). La mise en place de scénarios suppose plus de maturité et implique d’avoir un outil de « marketing automation » à disposition.
Les programmes sont des ensembles cohérents d’actions (campagnes et scénarios) répondant à un des objectifs CRM. Par exemple, le programme « Satisfaction Client » ou le programme « Activation ».
Définition des programmes relationnels. Source : Cartelis.
Le plan relationnel prend la forme d’un document listant l’ensemble des programmes et décrivant le fonctionnement des scénarios s’il y en a.
Déployer les actions de marketing relationnel (campagnes et scénarios)
Le responsable CRM a aussi pour mission de déployer les différentes actions définies dans le plan relationnel. C’est lui qui va mettre en place les campagnes marketing (notamment les campagnes emailing) et déployer les scénarios automatisés. Ce travail inclut essentiellement la création des contenus (emails, posts, etc.) et le paramétrage des campagnes & scénarios dans les outils marketing.
Mesurer les résultats des actions
Dans une petite ou moyenne organisation ayant un dispositif data peu élaboré, la mesure des résultats s’effectue le plus souvent à l’aide des modules de reporting intégrés dans les outils marketing.
N’importe quel outil marketing donne accès à des rapports de performance qui permettent de suivre, généralement en temps réel, l’évolution des différents indicateurs de performance (KPIs) et l’impact des actions déployées. Un outil d’emailing par exemple offre un tableau de bord pour suivre la performance des campagnes via les indicateurs classiques que sont les taux de délivrabilité, d’ouverture et de clics.
Un responsable CRM plus chevronné pourra utiliser un Google Sheets ou, mieux, un petit outil de Business Intelligence (comme Metabase) pour créer des reportings omnicanaux, c’est-à-dire des reportings permettant de suivre la performance de l’ensemble des actions menées sur les différents canaux et avec les différents outils marketing.
Metabase, un outil de reporting no code pour créer des reportings sur mesure.
Exploiter les données prospects et clients
Aujourd’hui, les données clients sont l’aliment du CRM et du marketing relationnel. Plus vous aurez de données clients, plus vous serez capable de les centraliser, de les unifier, de les mettre à la disposition des différents outils, plus vous pourrez faire de choses. C’est aussi simple que ça.
Aujourd’hui, un responsable CRM doit savoir jongler avec les données clients, c’est-à-dire être capable de :
Nettoyer les données clients de la base prospects et clients pour la maintenir propre.
Imaginer de nouvelles mécaniques de collecte de données clients, pour aller chercher des données que l’entreprise n’a pas mais dont le responsable CRM aurait besoin pour mieux personnaliser et cibler ses actions.
Piloter la performance CRM de manière data-driven, en s’appuyant sur des données, sur des chiffres consolidés.
Développer une meilleure connaissance client par l’analyse des reportings pour dégager des enseignements et des tendances générales sur le comportement et les préférences des clients.
Le responsable CRM n’a pas besoin d’avoir des compétences d’ingénieur data pour mener à bien ces missions autour des données. Les outils marketing modernes proposent des interface no code pour manipuler les données clients sans compétences techniques avancées.
Piloter les projets digitaux autour des données clients
Une meilleure exploitation des données clients suppose une modernisation des outils et technologies utilisées. Dans une PME dont l’équipe CRM se réduit à un seul responsable CRM, c’est ce dernier qui va devoir gérer les projets digitaux visant à mieux collecter et utiliser les données : changement de logiciel CRM, mise en place d’une Customer Data Platform, mise en conformité RGPD, etc. Un responsable CRM est souvent amené à endosser le rôle de chef de projet CRM.
Salaire et profil classique
Comme partout, le salaire d’un responsable CRM dépend beaucoup du nombre d’années d’expérience. Le salaire d’un CRM manager est compris entre 40 et 70k€. 3 commentaires :
Forcément, plus vous proposez une rémunération intéressante plus vous aurez de chances d’attirer les meilleurs profils.
La chance n’est pas le destin. Pour nuancer le premier commentaire, précisons que vous pouvez très bien recruter un très bon responsable CRM junior à 40k et un responsable CRM de la vieille école, peu technophile, à 70k.
Dans des métiers aussi mouvants que ceux du CRM, l’ancienneté a moins de poids dans l’évaluation des candidats.
Les responsables CRM sont en général issus d’écoles de commerce (bac +4/+5) ou de BTS marketing (bac +2). On voit aussi de plus en plus de responsables CRM venant d’écoles spécialisées en marketing digital.
A quoi ressemble un ou une bon(ne) responsable CRM ?
On s’est maintenant fait une bonne idée du périmètre d’intervention d’un responsable CRM évoluant dans une entreprise de type PME. Il est l’orchestrateur du dialogue avec les prospects et les clients, dialogue qu’il met en place grâce à des outils marketing et à l’exploitation des données.
Les missions, naturellement, appellent des compétences. C’est ce dont nous allons parler maintenant.
Nous insisterons moins sur les compétences techniques, dont la plupart peuvent se déduire assez facilement du listing des missions que l’on vient de présenter, que sur les soft skills qui, selon nous, sont les plus différenciantes.
Un très bon responsable CRM se caractérise moins par ses compétences techniques que par son état d’esprit et ses capacités intellectuelles générales. Mieux vaut, par exemple, recruter un responsable CRM junior hyper motivé pour apprendre de nouvelles choses et prêt à remettre en questions ses habitudes qu’un profil senior rigide dans sa manière de travailler.
Alors, à quoi reconnaît un ou une bon(ne) responsable marketing ?
La capacité d’analyse
Le responsable CRM doit posséder de solides compétences analytiques. Vous me direz, analyser quoi ? On a déjà en partie répondu à cette question. Il y a deux objets d’analyse principaux :
La base de données clients. L’analyse de la base permet de développer la connaissance client, mais aussi la connaissance produits (quels sont les produits les plus achetés ?). Voir à ce sujet notre article : « Connaissance clients – Exemple de reporting clients sur Excel« .
Les actions déployées (campagnes, scénarios). Le responsable CRM doit savoir mesurer la performance des campagnes et scénarios déployés pour faire vivre le dialogue prospects/clients.
Le responsable CRM doit absolument avoir des compétences analytiques pour pouvoir tirer des enseignements qui serviront à améliorer la performance des actions futures.
Précisons que l’on parle ici plus de compétences « intellectuelles » que de compétences techniques dures. Un responsable CRM n’a pas besoin de connaître le langage SQL pour être un bon analyste.
Source : Elios.
La capacité à apprendre vite
Le développement ininterrompu de nouveaux canaux, la part toujours croissante du digital et des réseaux sociaux dans les parcours, le rôle de plus en plus central des données clients, l’évolution des bonnes pratiques (ce qui fonctionnait hier ne fonctionne plus toujours aujourd’hui), les évolutions de fond dans le comportement des consommateurs, l’arrivée sur le marché d’outils marketing de plus en plus puissants – tous ces facteurs font évoluer en permanence les métiers du CRM et du marketing.
Un(e) bon(ne) responsable CRM doit avoir la capacité à apprendre vite et ne doit pas avoir d’aversion au changement. Le bon responsable CRM, c’est celui qui s’enthousiasme des nouvelles perspectives qu’offre le déploiement d’un nouvel outil d’emailing, c’est celui qui suit régulièrement des blogs sur le CRM pour muscler ses compétences et se tenir informé des nouvelles tendances.
Il y en fait ici deux compétences qui entrent en jeu :
Une compétence intellectuelle : la capacité à apprendre vite.
Une compétence attitudinale : la volonté d’apprendre toujours plus.
La rigueur
Le responsable CRM doit gérer une multitude d’actions, une multitude de canaux, une multitude de données, une multitude d’outils, a plusieurs interlocuteurs…Pour faire face à la multiplicité, une grande rigueur s’impose. Elle se manifeste dans toutes les dimensions de l’activité d’un CRM manager :
La formalisation du plan relationnel.
La construction du plan d’actions et le fait de s’y tenir.
Le maintien au propre de la base de données.
La documentation de tous les traitements de données et des actions marketing déployées.
La mise en place des conventions internes pour être certain que tous les collaborateurs parlent de la même chose et utilisent les mêmes mots.
La gestion d’un projet de A à Z.
La création des campagnes (respect des deadlines).
La capacité à animer des projets
Le responsable CRM est amené à gérer et animer des projets. Nous avons vu tout à l’heure qu’il avait vocation à piloter les projets digitaux autour des données clients ou de la sélection des logiciels. Dans une PME dont l’équipe marketing se réduit à un responsable marketing, c’est ce dernier qui est sera généralement désigne comme chef de projet CRM, chef de projet CDP, chef de projet digital…
Cette casquette de chef de projet suppose des compétences particulières : des capacités d’organisation, de pilotage, de leadership, de communication, de suivi et contrôle de budget – bref toutes les compétences attendues d’un chef de projet.
Les compétences bonus
Voici certaines compétences bonus qui peuvent faire la différence :
La capacité à bien écrire. Dans une petite PME, c’est souvent le responsable CRM qui est chargé de rédiger le contenu des emailings, des posts sur les réseaux sociaux, parfois même des articles de blog…Il est toujours possible, à condition d’avoir un minimum de budget, d’externaliser tout ou partie du travail rédactionnel à un freelance ou une agence, mais il est évident que recruter un responsable CRM qui sait (bien) écrire est un plus !
La créativité en communication. Certains responsables CRM sont plus créatifs que d’autres. Dans un monde où il y a de plus en plus d’émetteurs, où les consommateurs croulent sous les messages et les offres, la capacité à communiquer de manière créative, différente, originale, décalée est de plus en plus recherchée.
Le côté bricoleur. Les outils marketing et CRM modernes permettent à des profils purement métier d’effectuer beaucoup de choses qui étaient autrefois réservées aux techniciens. On parle d’outils « self-service » ou « no code » pour désigner ces outils nouvelle génération qui rendent autonomes les équipes métier. Mais il y a toujours certaines opérations qui nécessitent un esprit un peu plus bricoleur, par exemple : être capable de mettre en place un flux de données, ou bien faire un SQL. Un bon responsable CRM a cet état d’esprit et, en tout cas, la volonté d’apprendre à faire ce genre de choses (sans devenir un expert).
Un exemple d’outils no code ? Octolis, qui permet d’unifier les données clients et de créer des segments/audiences facilement synchronisables dans les outils marketing/CRM.
Ce qu’un responsable CRM n’a pas besoin de savoir faire
Un responsable CRM doit pouvoir toucher à tout. Il doit être surtout excité par l’idée d’apprendre de nouvelles choses et d’ajouter de nouvelles skills à son CV. Malgré tout, un responsable CRM n’a pas besoin de :
Savoir coder en HTML. Il est toujours bon de connaître les bases du HTML (qui s’acquièrent assez vite), mais un CRM manager n’a pas vocation à créer des templates de mails from scratch en HTML. Premièrement parce que ce n’est pas son rôle, deuxièmement parce que les outils marketing no code permettent d’éditer des contenus web ou des emails ultra-personnalisés sans avoir à écrire une ligne de code. La connaissance du HTML, et plus généralement du code, n’est plus une compétence nécessaire pour créer des contenus sur-mesure.
Faire du design. Le responsable CRM n’est pas un designer. Il mobilise volontiers les ressources du design pour créer des communications percutantes, mais ce n’est pas lui qui les crée. Soit il fait appel à des prestataires (agences de design, freelances), soit il utilise les modèles de design proposés par ses outils CRM – marketing ou des petits outils comme Canvas.
Être un expert de la solution CRM. Le responsable CRM n’a pas besoin de connaître le détail de toutes les fonctionnalités proposées par le logiciel. C’est parfois impossible et toujours inutile. Le responsable CRM doit maîtriser les fonctionnalités qui répondent aux cas d’usage du logiciel, qui eux-mêmes découlent des besoins métiers et des objectifs CRM.
Comment évaluer vos candidats responsables CRM
Nous avons préparé un template pour vous aider dans la phase de recrutement de votre responsable CRM. Il s’agit d’un test de recrutement d’une durée d’un peu moins de 2 heures où l’on demande aux candidats de répondre à des questions / cas pratiques / exercices. Nous avons beaucoup utilisé ce test de recrutement dans notre propre expérience et, croyez-nous, cela permet de faire assez bien le tri.
Voici quelques exemples de questions :
C’est quoi les différences entre un outil de marketing automation à 100€ / mois, et un autre à 2000€ / mois ?
A quel moment penses-tu qu’on a besoin de mettre en place une CDP en amont de la solution CRM / marketing automation ?
Que faire si ma délivrabilité sur Gmail devient d’un coup très mauvaise ?
Pourrais-tu écrire un email de quelques lignes pour réactiver nos clients passifs ?
Le canal email génère peu de conversions selon Google Analytics. Un consultant m’a dit que c’était un problème d’attribution, mais je n’ai rien compris à son explication. Pourrais-tu m’en dire plus ?
Les questions sont classées en catégories : culture CRM, animation des campagnes, analyse clients, pilotage projets. Nous avons inclus aussi un test bonus technique qui consiste à construire un petit dispositif CRM.
Nous vous proposons d’intégrer ce questionnaire/test de recrutement dans votre entretien. Deux approches sont possibles :
L’approche automatique. Chez Octolis, pour certains postes, on réalise des tests à distance. Une fois le premier call de qualification passé, on invite le candidat à télécharger le questionnaire depuis une URL qu’on lui envoie par email. Il s’agit de l’URL d’un formulaire (personnellement, on utilise Tally, qu’on recommande, mais vous pouvez utiliser l’outil de votre choix). A la suite de son inscription, le candidat reçoit l’URL de la page Notion que nous vous avons présenté rapidement à l’instant (gif). Une fois le questionnaire test réalisé, le candidat doit envoyer la réponse à travers un autre formulaire pour que l’on puisse intégrer les dates de commencement et de fin de test dans une table. Le temps passé sur le test de recrutement est un indicateur important, évidemment.
L’approche traditionnelle. Vous n’êtes pas obligé d’utiliser tel quel le modèle de questionnaire que nous vous proposons. Vous pouvez très bien piocher quelques questions et les soumettre aux candidats en utilisant la procédure de votre choix.
Le métier exige des compétences assez diverses à la fois d’ordre commercial, marketing, technique et statistique et les profils bien formés et expérimentés sont donc assez sollicités.
Télécharger notre template de questionnaire dédié au recrutement d’un responsable CRM
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Au départ, on se contente souvent des statistiques disponibles dans son CRM ou son outil d’emailing. Mais cela devient très vite insuffisant pour analyser ses clients…Hélas, force est de constater que beaucoup d’ecommerçants et retailers en restent à cette étape. Résultat : ils ne savent pas qui sont leurs meilleurs clients, qui sont les clients inactifs, pourquoi un client devient inactif, pourquoi un client revient, etc.
Ces informations sont clés ! L’impact de la connaissance client sur la performance d’une entreprise n’est pas à démontrer. Toutes les études convergent. McKinsey, pour n’en citer qu’une, a montré que les entreprises qui avaient une très bonne connaissance client affichaient un ROI supérieur à 115% à celui des autres entreprises, et en moyenne des profits plus élevés de 93% (source).
Pour vous aider à augmenter et structurer votre connaissance client, nous avons construit un modèle GSheet de reporting client. Vous pouvez le télécharger gratuitement. Le lien est en fin d’article.
Dans cet article, nous allons résumer les principales données à intégrer dans un reporting client et vous donner quelques clés méthodologiques pour construire votre dispositif de pilotage client.
Que doit contenir un reporting sur votre base clients ?
Tableau résumé
Voici un tableau synthétique des principales questions auxquelles doit répondre un reporting de la base clients.
Catégories
Questions clés
Qui sont mes clients ?
Quel est l’âge / genre / langue de mes clients ?
Quel est le canal d’inscription ? (boutique, newsletter ecommerce, programme de fidélité, ...)
Où habitent-ils ? (pays, code postal)
Dans quelle mesure ma base clients est-elle exploitable ?
Quel est le taux de complétion des colonnes Email, Téléphone, Adresse postale, .. ?
Quelle est la part de contacts optin email / SMS ?
Quelle est la part de contacts qui ont ouvert au moins un email au cours des 90, 180, 365 derniers jours ?
Quel est le comportement d’achats de mes clients ?
Quelle est la répartition de mes clients selon le nombre d’achats réalisés ?
Quel est le panier moyen, fréquence d’achat, CA cumulé total ?
Quel est la LTV de mes clients selon la catégorie du premier produit acheté ?
Quel est le niveau de rétention de mes clients ?
Quelle est l’évolution du taux de passage au 2ème achat ?
Comment la catégorie du premier achat détermine la fréquence d’achat ?
Quelle est l’évolution du nombre d’achats / CA cumulé par cohortes du premier achat
Quel est le ratio LTV / CAC ?
Autres
Analyse du coût d’acquisition par canal / par catégorie de produit du premier achat ?
Étude du ratio LTV / CAC selon différents critères
Évolution du NPS
Analyse RFM
...
Détaillons maintenant chacune des catégories.
Qui sont mes clients ?
C’est le premier niveau de connaissance client. A minima, une base clients doit donner des informations sur l’identité de vos clients, leur profil. Voici les questions fondamentales à se poser :
Quel est l’âge de mes clients ? Quel est le genre de mes clients ? Où habitent-ils (ville, pays) ? L’âge, le genre et l’adresse sont les 3 données « socio-démographiques »de base.
Quelle est la langue de mes clients ? Une donnée importante à avoir pour gérer de manière adéquate les interactions clients, entre autres.
D’où viennent les contacts ou clients ? Il est intéressant d’avoir une répartition par canal, par magasin, par campagne marketing…
Dans quelle mesure pouvez-vous leur parler facilement ? C’est une question de plus en plus sensible depuis l’entrée en vigueur du RGPD. Cela renvoie à la gestion des consentements. Quel est le taux d’optin email ou SMS par exemple ?
On peut aller plus loin en intégrant dans le reporting des données relatives au niveau CSP, à la présence sur les réseaux sociaux, à l’appétence par thématiques ou catégories de produits, aux préférences par canal, à la sensibilité à la pression marketing…
Dans quelle mesure ma base clients est-elle exploitable ?
Un reporting de la base clients ne s’intéresse pas qu’aux clients, il s’intéresse à la base en tant que tel et à son potentiel d’activation/d’exploitation. Pour être pleinement exploitable, une base clients doit être saine. Il est intéressant d’intégrer dans un reporting quelques informations sur la qualité de la base, relatives notamment :
Au taux de complétion des colonnes principales : email, téléphone, adresse postale…
A la part des contacts option email / sms.
Au niveau d’engagement de la base. Par exemple, la part des contacts ayant ouvert au moins 1 email au cours des X derniers jours.
Quel est le comportement d’achats de mes clients ?
La connaissance client consiste à savoir qui sont vos clients, mais aussi ce qu’ils font, la manière dont ils se comportent. Les données sociodémographiques doivent être associées à des données comportementales. Le comportement client qui intéresse le plus une entreprise est bien sûr le comportement d’achat.
Dans notre exemple de reporting client, que vous pouvez télécharger gratuitement, nous avons intégré des informations comme :
La répartition des clients par nombre de commandes. Ce point est essentiel. Êtes-vous capable de faire en sorte qu’un primo acheteur achète une deuxième fois, une troisième fois, etc. Cela nous conduit à la question de la rétention dont nous reparlerons dans un instant.
Le profil client Ecommerce vs Boutique. Dans le modèle de reporting client que nous proposons, nous affinons l’analyse en prenant en considération l’âge, le sexe et la localisation du client (Paris vs France entière).
Voici d’autres données relatives au comportement d’achat des clients qui peuvent avoir leur place dans un reporting de la base clients : le panier moyen, la fréquence d’achat, le chiffre d’affaires cumulé…
S’intéresser au comportement d’achat du client, c’est s’intéresser en fait à 2 choses : aux clients et aux produits. Un reporting du comportement d’achat des clients peut donc très utilement être enrichi d’un reporting centré produits. Dans notre notre modèle téléchargeable, nous proposons un reporting centré sur la connaissance produits qui permet de synthétiser les informations business clés relatives à votre catalogue :
Le nombre de produits avec plus de X ventes.
Le nombre de produits avec plus de Y ventes.
La part du Top 10 des produits dans le pourcentage des ventes annuelles.
Le Top 10 des produits qui ont généré le plus de CA sur les 12 derniers mois.
Le Top 10 des produits qui ont généré la meilleure marge brute sur les 12 derniers mois.
La performance par catégorie de produits.
Il y a d’autres questions plus avancées qui méritent d’être posées. Par exemple :
Quelle est la corrélation entre les produits ou entre les catégories de produits ? L’idée est de savoir quels produits ou catégories de produits le client d’un produit X ou d’une catégorie Y est le plus susceptible d’acheter en deuxième achat.
Le sujet du comportement d’achat nous mène tout naturellement au sujet de la rétention client. Ce n’est pas à vous qu’on apprendra qu’il est moins coûteux de retenir un client que d’en acquérir un nouveau et que la rétention est le secret des entreprises à succès. Si vous n’êtes pas tout à fait convaincu et que vous continuez de consacrer l’essentiel de votre budget sur des campagnes d’acquisition, voici 3 statistiques éloquentes au sujet de la rétention client (source : 99firms) :
La probabilité de vendre à un client existant est de 60 / 70%.
82% des entreprises que la rétention client coûte moins cher que l’acquisition.
Une augmentation de 5% de la rétention client génère une augmentation des profits de l’ordre de 25% à 95%.
Quelles sont les informations relatives à la rétention que l’on peut intégrer dans un reporting client ? Il y a beaucoup de réponses possibles? Voici les dimensions d’analyse que nous avons choisi d’intégrer dans notre modèle de reporting client :
L’évolution de la fréquence d’achat en fonction du nombre d’achats. C’est une donnée intéressante pour, notamment, bien calibrer les scénarios d’upsell/cross-sell et, plus généralement, les programmes relationnels. Nous proposons de comparer les comportements boutique et ecommerce.
Le passage du 1er au 2ème achat. Ce passage du 1er au 2ème achat est presqu’aussi important que le passage du statut de prospect (ou de simple visiteur) à celui de client primo acheteur. Nous vous suggérons de calculer le taux de passage des clients ayant réalisé 1 achat à ceux ayant réalisé 2 achats ou plus.
Il est possible d’aller un cran plus loin en affichant des dimensions comme la liste des principaux produits d’appel et la liste des produits participant le plus au repeat business. Ce sont là encore des données très instructives pour améliorer vos scénarios relationnels.
Votre reporting client peut également intégrer quelques indicateurs classiques comme le taux de rétention client, le taux de churn, le taux d’achats répétés, le Net Promoter Score (NPS), le taux de clients membres du programme de fidélité, la customer lifetime value…
L’analyse par cohortes est elle aussi très utile pour analyser la rétention et l’impact de vos actions sur celle-ci. Une analyse de ce genre n’a pas forcément sa place dans un reporting client, mais permet d’aller plus loin dans la compréhension du comportement de vos clients.
L’analyse par cohortes consiste à suivre l’évolution du comportement de différentes cohortes de clients de mois en mois. Cet exemple montre que 29% des clients dont le premier achat remonte à janvier 2021 ont acheté le mois suivant, c’est-à-dire en février 2021. Par contre, 37% clients dont le premier achat a été réalisé en février 2021 ont acheté en mars 2021. Pourquoi ? Un effet de saisonnalité ? Le fruit d’efforts marketing particuliers réalisés en février et en mars ? L’analyse par cohortes est idéale pour détecter et comprendre l’impact des actions marketing.
L’analyse par cohortes que vous pouvez voir est une capture d’écran d’Octolis, et plus précisément du modèle de reporting Ecommerce / Retail que nous proposons à tous nos clients. Ce modèle de reporting par défaut, personnalisable, adaptable, transformable intègre de nombreuses analyses (plus ou moins avancées) pour mesurer la rétention client. Voici quelques exemples :
Ou encore :
Pour finir, un petit mot de la lifetime value, un indicateur très intéressant qui permet de savoir la valeur moyenne qu’un client génère tout au long de sa vie de client. Cette valeur peut s’exprimer en chiffre d’affaires ou en revenus. Il est notamment très intéressant de la comparer au coût d’acquisition client (CAC), en calculant un ratio LTV / CAC. Ce ratio peut évoluer en fonction de la période de l’année, comme dans l’exemple ci-dessous. Le ratio LTV / CAC peut être utilisé pour bien doser ses efforts d’acquisition.
Comment s’y prendre pour construire un reporting clients solide ?
#0 Quelques rappels sur la fonction d’un reporting client
Pour commencer, rappelons ce qu’est un reporting et sa fonction. Il existe 2 outils de connaissance clients :
Les reportings, qui servent à donner un aperçu global d’une situation à intervalles réguliers. Il intègre un certain nombre de métriques affichées de manière visuelle : courbes, camemberts, tableaux…
L’exploration, qui désigne la capacité à produire des analyses ad hoc pour répondre à des questions spécifiques et ponctuelles dont les réponses n’ont pas vocation à s’intégrer dans un reporting. Par exemple : « Combien de nouveaux clients inscrits à Noël ont acheté un produit depuis ? ». Les questions sont posées par le métier, les réponses sont données par l’équipe data.
Nous nous concentrons dans cet article sur le reporting. Un reporting doit :
Etre construit en vue d’un certain type d’utilisateurs. Le reporting client du dirigeant ne sera pas le même reporting client que ceux utilisés par les équipes opérationnelles.
Être facile à lire visuellement, ce qui suppose un travail de discrimination, de sélection des KPIs et des dimensions à afficher. Toutes les analyses clients n’ont pas vocation à alimenter des reportings (cf. les analyses ad hoc).
#1 – Définir les objectifs et le mode d’utilisation du reporting
Dans les grandes organisations, le dispositif de pilotage de la connaissance client s’articule autour de différents (niveaux de) reportings, chaque reporting répondant à un ensemble de questions liées et s’adressant à un type précis d’utilisateurs : responsable acquisition, responsable CRM, dirigeant…Dans une organisation avec peu de moyens, nous recommandons de limiter le nombre de reportings.
La première étape pour construire un reporting de la connaissance client est de définir les objectifs du reporting. Pourquoi souhaitez-vous créer un reporting ? Dans le cas d’un reporting connaissance client, il s’agit de déterminer quelles sont les informations relatives à la base clients vous aimeriez voir afficher sur le reporting. La réponse à cette question dépend bien entendu des cas d’usage du reporting que vous vous apprêtez à mettre en place.
Cette prise de hauteur est importante. L’erreur la plus courante consiste à se précipiter sur la sélection des KPIs et des dimensions. C’est le plus sûr moyen de construire un reporting illisible (car trop chargé) et/ou inexploitable.
Vous devez également définir la manière dont le reporting sera partagé aux utilisateurs. Le reporting peut être intégré directement dans les outils des utilisateurs (sous forme de tableau de bord) ou partagé périodiquement au format Excel par exemple.
#2 – Définir les KPIs et les dimensions d’analyse
Un reporting est composé de différents indicateurs jugés importants et utiles pour répondre aux questions que l’on se pose. Ce sont les fameux KPIS, Key Performance Indicators. La sélection des KPIs est l’aboutissement de l’étape précédente.
En réfléchissant aux objectifs du reporting, vous avez réussi à définir les questions auxquelles le reporting devait apporter des réponses. De ces objectifs et de ces questions, vous déduisez des indicateurs.
Prenons un exemple schématique. Vous voulez créer un reporting client pour que l’équipe marketing puisse analyser la rétention client. L’une des questions auxquelles le reporting doit répondre est : « Quel est le taux de clients membres du programme de fidélité ? ». Le KPI sera : Taux de clients encartés.
Un petit conseil : pour ne pas surcharger le reporting, il est important de ne retenir que les KPIs les plus significatifs. Il faut éviter de dépasser les 30 – 40 KPIs, même si cela dépend évidemment des reportings…
#3 – Définir le cadre technique : extraction, préparation et visualisation des données
Une fois que vous avez défini les dimensions d’analyse et les KPIs que vous souhaitez intégrer dans le reporting, il faut réfléchir à l’alimentation en données. Comment allez-vous récupérer les données dont vous avez besoin ? Il y a plusieurs manières techniques d’alimenter un reporting. Voici une petite synthèse :
L’approche la plus simple consiste à utiliser les fonctionnalités de reporting des outils marketing, mais c’est une approche très vite limitante. Vous serez très contraints par les limites fonctionnelles des outils. Une approche plus pertinente consiste à connecter votre base clients (elle-même connectée à vos sources de données) à un outil de data prep comme Octolis et à un BI léger comme Data Studio ou Metabase.
À l’étape précédente, vous allez sans doute vous apercevoir que certains KPIs sont très complexes à calculer, que les efforts pour obtenir les réponses à certaines de vos questions seraient disproportionnés. Vous allez sans doute devoir faire des compromis. Réfléchir sur le cadre technique très tôt dans le projet permet d’avoir rapidement une compréhension du champ des possibles et d’orienter le projet dans la direction de ce qui est techniquement réalisable.
#5 – Intégrer et préparer les données
Vous savez à présent quelles sont les KPIs que le reporting client affichera. Vous pouvez construire ces KPIs car vous disposez des données nécessaires. La prochaine étape est rapide à énoncer, plus longue à mettre en place. Il s’agit d’intégrer et de préparer les données qui viendront alimenter le reporting client.
Vous avez pour cela besoin d’une base client et d’un outil de data management (CDP, Data Ops…). Cet outil vous servira à construire une table clients contenant toutes les informations nécessaires pour alimenter le reporting : âge, revenus totaux, revenus sur les 365 derniers jours, nombre de commandes, panier moyen, etc.
L’exemple de reporting connaissance client que nous vous offrons en téléchargement peut être alimenté par les tables « contacts », « produits », « commandes » construites et enrichies dans Octolis :
Contrairement à ce que l’on pourrait penser, peu d’entreprises du Retail et du Ecommerce disposent d’une vision complète de leurs clients. Pourquoi ? Parce qu’il manque souvent d’un outil permettant de consolider les données clients. Elles sont éparpillées dans différents outils : la plateforme ecommerce, l’ERP, le POS, le support client, les réseaux sociaux…Une solution de préparation des données comme Octolis a justement pour vocation de remédier à ce problème. Une fois unifiées, préparées et enrichies, les données peuvent être synchronisées avec votre outil de reporting, mais aussi avec les outils opérationnels de l’entreprise : service client, CRM, Marketing Automation, plateformes publicitaires…
#6 – Construire le reporting
Une fois les données consolidées, préparées, enrichies, traitées (scorings, agrégats), il faut réfléchir à la manière dont elles vont s’organiser dans le reporting. La conception de la maquette peut se faire via un outil de wireframing. L’organisation et le format d’affichage des différents éléments du reporting dépendent de l’outil dans lequel le reporting est construit : les outils métier, Excel, un outil de reporting léger (Metabase) ou plus avancé (Tableau, Looker…).
#7 – Recette & Dispositif de suivi
Un reporting n’est jamais parfait du premier coup. Prenez le temps d’examiner la manière dont est utilisé le reporting par les utilisateurs cibles, documentez les bugs éventuels, les suggestions des utilisateurs. Posez-vous les bonnes questions concernant l’alimentation en données, le choix des KPIs, le design du reporting…Qu’est-ce qui peut être amélioré (à tous les niveaux : alimentation en données, choix des KPIs, design du reporting, modes d’utilisation) ?
Télécharger notre liste des analyses clients incontournables
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Définir le salaire de votre prochain data analyst est loin d’être aisé. Pour cela, vous devez d’abord établir une fourchette salariale en fonction d’un ensemble de facteurs qui vous sont propres :
Le niveau développement de la fonction analytique au sein de votre organisation. En effet, plus votre équipe data est structurée, plus il est facile pour un nouveau membre de s’y intégrer – d’un point de vue opérationnel comme technique. Cela affecte nécessairement le niveau d’expérience que vous devez exiger du candidat, et donc directement le salaire que vous pouvez proposer.
L’industrie dans laquelle vous évoluez, ainsi que la spécialisation que vous attendez. Ces critères déterminent votre nombre de candidat potentiel, une industrie spécialisée étant naturellement plus restrictive qu’un marché très ouvert. Aussi les analystes spécialisés sont très prisés et bénéficient d’un effet d’enchères de la part des entreprises qui les démarchent.
Votre besoin réel en termes d’analytics. Parfois l’intervention d’un free-lance peut s’avérer être une solution moins coûteuse, mais tout aussi efficace.
Une fois ces critères établis, il est possible de se comparer au marché et de déterminer une fourchette salariale suffisamment compétitive pour attirer les talents dont vous avez besoin. Nous vous proposons donc des chiffres précis à partir de ces observations afin de vous aider à fixer un intervalle en fonction de vos besoins.
Pourquoi vous en entendez tant parler aujourd’hui ?
La data analyse a pris une place centrale dans les entreprises au cours de la dernière décennie, et le data analyst est devenu incontournable pour toute entreprise en phase de croissance.
C’est lui qui assure le traitement des données afin de livrer des conclusions visant à améliorer l’activité de l’organisation. Il peut intervenir à tous les niveaux pour étudier les processus, le marché ou les ventes. Il doit aussi interagir avec tous les métiers, des équipes financières aux équipes marketing et commerciales.
Les missions des data analysts sont variées :
Collecte de données,
Création de dashboard pour faciliter la transmission des conclusions des analyses
Reporting auprès des équipes métiers ou de la direction
…
Il est toutefois important de noter une distinction entre deux rôles essentiels : le data analyst et le data scientist. Le second s’applique principalement à l’élaboration de modèles prédictifs et d’algorithmes d’intelligence artificielle en utilisant pour cela un large panel d’outils techniques et mathématiques. Le data scientist a donc un profil plus scientifique et une expertise plus importante dans le domaine de la data, ce qui justifie que sa rémunération soit généralement plus élevée.
Les data scientists et les data analysts se sont imposés dans les entreprises au point de devenir des pierres angulaires des organisations les plus performantes. Leurs apports sont essentiels pour toute entreprise souhaitant rester compétitive, et leur rémunération fait, par conséquent, l’objet de nombreuses considérations.
Quelles sont les compétences d’un bon Data Analyst ?
Sens business, SQL, Python, Data viz et capacité à faire le lien entre les équipes data et métier. Le Data Analyst est un mouton à 5 pattes dont la polyvalence est très préieuse pour les organisatisons. Découvrez notre guide complet sur le sujet.
Salaire d’un data analyst, quelles différences en fonction du profil ?
RollThePay établit le salaire moyen d’un data analyst en France à 43 370 € par an avec une fourchette allant de 26 520 € à 68 172 €.
À cette large fourchette s’ajoutent les bonus et l’intéressement, qui sont aussi dispersés.
La dispersion des salaires des data analystes est donc importante, mais elle s’explique par des variations de l’expérience, des compétences et du type de contrat de l’employé.
Salaire d’un data Analyst en fonction de l’expérience
Le premier facteur de différenciation de salaire pour un data analyst est l’expérience. L’expérience d’un data analyst se traduit par une meilleure compréhension des besoins des équipes et la production d’analyses plus pertinentes. Il est donc naturel que ce soit une qualité récompensée par un salaire plus intéressant.
La croissance de la rémunération au cours de la carrière d’un data analyst n’est pas linéaire. Après quelques années d’expérience – environ 5 ans – on peut observer une marche qui peut être interprétée comme un point pivot dans la progression de l’analyste.
Cette importante augmentation (+20 à +25%) s’explique par l’apport certain qu’offre l’expérience au terme des premières années de carrière. En effet, la data analyse étant à la fois un métier technique et analytique, ce n’est que lorsque l’employé est capable de créer de véritables synergies entre ces deux facettes, et entre les différents acteurs avec lesquels il travaille, qu’il maximise la valeur ajoutée de l’analyse de données. À partir de ce moment, votre data analyst sera capable de proposer des leviers d’actions efficaces à partir d’observations factuelles.
Transformer les données brutes de la sorte implique d’avoir une certaine expérience de terrain. Après quelques années de pratique, l’analyste acquiert une intuition plus précise permettant à la fois de saisir rapidement les besoins métiers et de savoir de façon presque instinctive ce que les données peuvent offrir comme éléments de réponse.
En plus de ces critères et de ces points de référence, vous devez vous interroger sur le rôle que vous souhaitez donner à votre futur data analyst. Si vous souhaitez mettre sur pied une équipe data, à l’initiative de votre future recrue, cette dernière doit être capable de faire preuve de leadership, d’un profond sens business et d’une grande maîtrise de l’ensemble de l’écosystème technologique. Ces compétences rares doivent naturellement être valorisées dans la rémunération pour attirer les meilleurs talents.
Comment construire votre équipe data ?
Définir les besoins de votre organisation, quelle approche pour intégrer votre équipe data et comment constituer votre équipe data. On vous partage toutes les clés pour contruire une équipe data solide dans cet article.
Les principales compétences impactant le salaire d’un data analyst
L’exposition à des outils technologiques de pointes pour les data analysts explique les fortes disparités des salaires. En effet, si certains se contentent d’effectuer des analyses simples avec des outils facilement accessibles, d’autres choisissent de recourir à des softwares plus complexes et offrent ainsi des conclusions plus poussées et pertinentes. Dans le second cas, le data analyst, conscient de sa maîtrise technique, exige bien souvent une rémunération supérieure.
Les outils techniques qu’utilisent les data scientists sont particulièrement variés, du langage de programmation (R ou python généralement) aux outils de Business Intelligence (Power BI, Tableau) en passant par la gestion de base de données. Cependant tous ces outils n’offrent pas les mêmes avantages de rémunération. Lorsque les compétences techniques recherchées sont rares sur le marché, on observe une véritable inflation des salaires.
Plus encore, la maîtrise d’outils technologiques de pointes affecte fortement la rémunération des data analysts. O’Reilly a ainsi pu déterminer dans un sondage que les data analysts maîtrisant Hadoop, Spark ou Python étaient deux fois plus à avoir obtenu une importante augmentation au cours des trois dernières années. Ainsi on peut observer de fortes disparités selon les softwares utilisés.
Énumérer les compétences essentielles pour un data analyst est une tâche assez longue compte tenu de la diversité des outils et des compétences requises. De plus, la seule maîtrise de certains softwares recherchés par les entreprises ne suffit pas à être un data analyst hors pair. La data analyse est un métier complet et vaste, et un bon analyste doit savoir utiliser des techniques lui permettant de faire face à des défis aussi variés.
Compétences d’un data analyst
Nous avons donc regroupé dans un article les compétences essentielles pour un data analyst, ainsi que celles lui permettant de se démarquer. La lecture de cet article vous permet de découvrir en détail ce qu’un data analyst doit être capable de maîtriser afin de pouvoir prétendre à un salaire supérieur à la moyenne.
Il existe aussi d’importantes disparités en fonction de la zone géographique et les secteurs d’activité, avec en tête la finance et le service aux entreprises.
Salaire d’un data Analyst Freelance
Une alternative à l’embauche d’un data analyst est le free-lance. Ce choix peut-être pertinent pour répondre à des besoins plus spécifiques ou ponctuels. La question de la rémunération se pose néanmoins. La plateforme codeur permet de trouver des free-lances et présente publiquement la grille tarifaire des data analysts selon leur expérience. En septembre, le tarif journalier s’élevait à 310€, soit 44€/heure, et le coût moyen des projets était de 4 100€.
Profil du data analyst
Tarif Journalier Moyen
Data analyst débutant
140
Data analyst junior
280
Data analyst confirmé
350
Data analyst senior
560
Cette solution permet donc de bénéficier ponctuellement de l’expertise d’analystes compétents tout en limitant le coût de développement du projet.
Salaire d’un data analyst, quelles différences en fonction de l’industrie ?
Si la data analyse représente un enjeu considérable dans toutes les industries, cet or digital prend une place encore plus stratégique dans certains secteurs. De manière générale, l’importance accordée à la data, et donc la rémunération octroyée aux analystes, dépend du volume de données et de l’avantage que procure la maîtrise de celles-ci.
Ainsi, dans un secteur comme la finance, où le volume d’informations croît sans cesse, la gestion des données est devenue la clé de domination du marché. Il serait impensable aujourd’hui de voir prospérer une banque d’investissement qui ne disposerait pas d’un pôle data de pointe. Le secteur bancaire dispose de sources innombrables pour alimenter les datalakes, des données de marchés obtenues en temps réels aux informations liées aux clients. Ces données ont autant d’usages que de sources : ciblage marketing, détection d’investissement potentiel, prédiction de l’orientation des marchés…
Un deuxième secteur où l’utilisation de la data analyse est devenue centrale est celui de la santé. Là encore les sources et usages de la data sont multiples : analyses d’épidémies, aide au diagnostic, suivi de traitements… Une utilisation efficace de ces données permet d’avoir une meilleure compréhension des maladies et de proposer des traitements plus efficaces.
La data analyse est donc essentielle pour ces deux secteurs, qui ont en commun une abondance de sources d’information. Les entreprises maîtrisant ces données disposent d’un avantage concurrentiel certain. Cela provoque naturellement une inflation des salaires dans ces milieux où il faut absolument embaucher les meilleurs talents.
Plus encore, il est possible de se spécialiser au sein des industries afin de développer une véritable expertise pour certains outils. Ainsi un data analyst se spécialisant en finance, dans l’étude des marchés ou dans le domaine de la santé peut accéder à une rémunération supérieure à la moyenne. Cela s’explique principalement par des responsabilités plus importantes ou des tâches plus complexes.
Salaire d’un data analyst en France : comparaison avec l’étranger
Salaire moyen d’un data analyst junior en Europe
Selon Glassdoor, en 2021, voici la répartition des premiers salaires en euros en fonction des pays :
Pays
Salaire junior moyen
Italie
29 200
Espagne
30 000
France
40 000
Royaume-Uni
43 600
Pays-Bas
51 500
Allemagne
52 000
Suisse
90 000
Il existe une grande volatilité des salaires entre les pays, mais aussi au sein des pays. Certains sont sujets à une plus grande variance dans la fourchette salariale, comme le révèle l’étude d’O’Reily :
Toutefois, ces résultats sont à mettre en perspective avec le PIB de chaque pays. On peut observer une corrélation très nette entre PIB/habitant et salaire du data analyst. Cela se traduit par une rémunération similaire pour les data analysts en comparaison du niveau de vie du pays.
Salaire moyen d’un data analyst aux Etats-Unis
C’est aux États-Unis que l’on trouve le plus d’offres aux salaires élevés. Il peut être compliqué d’y estimer le salaire d’un data analyst compte tenu de la largeur de la fourchette salariale. La rémunération dépend principalement de deux facteurs : la ville et l’entreprise. Voici la rémunération moyenne selon la ville d’après une étude de Etudes tech:
Seattle : 150 000$ par an ;
San Francisco : 135 000$ par an ;
Los Angeles : 135 000$ par an ;
New York : 100 000$ par an ;
Phoenix : 96 000$ par an ;
Washington : 87 000$ par an ;
Le salaire du data analyst dépend aussi fortement de l’entreprise dans laquelle celui-ci travaille. Les salaires dans les réputées GAFAM sont généralement les plus élevés (jusqu’à 140 000$ chez Meta). Les cabinets de conseils ou les grandes entreprises américaines telles que Target offrent aussi de très importantes rémunérations.
Ainsi, le salaire d’un data analyst varie grandement en fonction de l’entreprise, de l’industrie et de l’expérience. Il faut donc prendre en compte chacun de ces critères pour estimer la juste rémunération d’un candidat ou pour se fixer un objectif de revenu.
La data analyse est un métier varié qui permet d’évoluer rapidement en progressant sur des thématiques techniques et business, et pour lequel de nombreuses formations existent, quel que soit le niveau !
Comment recruter votre premier Data Analyst ?
Vous avez identifié la fourchette salariale que vous souhaitez attribuer à votre futur Data Analyst ? Découvrez désormais comment recruter la personne qui correspondra le mieux aux besoins de votre organisation grâce à cet article.
Avoir la volonté de mettre la data au cœur d’une stratégie commerciale et produit est une chose, être en mesure de construire une équipe data solide, capable de diffuser efficacement ses analyses dans les différentes strates de l’entreprise, en est une autre.
La construction d’une équipe data est une étape complexe pour une organisation. Cela implique la mobilisation de compétences diverses, un recrutement avisé, ainsi qu’une connaissance précise des besoins et des objectifs à atteindre.
Dans cet article nous abordons les étapes clés de cette construction : définition des besoins en fonction des objectifs et de la maturité data, choix du modèle d’intégration avec les autres équipes et bien sûr les profils à privilégier.
Toutes les entreprises ne sont pas égales face à leurs données, certaines ont saisi l’importance de cette matière dans leur croissance, d’autres ont accumulé plus de retard et sont aujourd’hui incapables de les exploiter.
En amont de la constitution d’une équipe data, il est important pour une entreprise d’évaluer son degré de maturité, pour ainsi mieux définir les étapes à suivre vers le Graal et l’organisation “data driven”.
Quelle est la maturité data de votre entreprise ?
La maturité data peut se définir par l’ensemble des moyens, connaissances et actions visant à améliorer la performance globale de l’entreprise grâce aux données.
Tout d’abord, est définie comme donnée toute information utilisée par l’entreprise pour automatiser ou numériser des processus. Les données sont issues de sources diverses (CRM, équipements, capteurs) et leur volume est amené à augmenter dans les années à venir.
Les 5 piliers de la maturité data
Dans son enquête menée en Novembre 2021 auprès de 179 entreprises en Ile-de-France, l’Observatoire de la Maturité Data a établi un rapport qui met en exergue plusieurs points clés.
Pour évaluer la maturité data d’une organisation, l’observatoire a défini 5 piliers pour situer la maturité des entreprises sur le sujet.
Le Potentiel data : Désigne la richesse et diversité des données disponibles au sein de l’entreprise afin de déterminer le potentiel de valorisation.
La stratégie data : Qui vise à évaluer la capacité de l’entreprise à générer de la valeur grâce à son patrimoine
L’organisation et la gouvernance : Permettent d’évaluer l’organisation et les règles permettant d’optimiser l’efficacité de la gestion des données dans l’entreprise (Ethique des données, RGPD, Cybersécurité)
Les compétences : Moyens humains et compétences internes mobilisés pour la valorisation des données dans l’entreprise.
La culture data : Reflète tous les aspects liés à la sensibilité des acteurs de l’entreprise vis-à-vis de l’usage des données et la connaissance des enjeux.
La maturité d’une organisation est évaluée au niveau de la quantité de données qu’elle possède, mais également à travers sa stratégie, sa gouvernance, sa capacité à instaurer une culture data et à susciter l’adhésion des collaborateurs pour la valoriser.
Les 7 profils de maturité data
Sur la base de ces piliers, nous ressortons 7 niveaux de maturité qui ont été déterminés pour permettre à une organisation de se situer.
Aujourd’hui, les entreprises prennent conscience de leur retard et mettent en place les outils de pilotage et via les outils de reportings. Cependant, à peine 7% des entreprises interrogées sont suffisamment matures pour passer l’étape du pilotage prédictif impliquant des compétences en Data Science.
Le schéma ci-dessous nous montre la répartition des entreprises sur l’échelle de maturité.
Le patrimoine data, aussi appelé Capital Data (ou capital données) désigne l’ensemble des informations que possède une organisation.
La naissance de solutions basées sur le Machine Learning et Deep Learning a transformé tous les actifs d’une entreprise en source de données potentielle et exploitable. Il est donc important d’avoir une lecture structurée du capital d’informations, et de bien définir les typologies et sources de données (notamment en distinguant les données structurées des non-structurées).
Le croisement des données permet de faire ressortir des informations qui peuvent être précieuses. Pour ceci, il est important de les classer selon certaines caractéristiques:
Avoir une vision de clair de ce patrimoine est incontournable pour définir son niveau de maturité.
Objectifs à atteindre grâce aux données
Les cas d’usage potentiels sont très nombreux, et au regard de ces possibilités, l’identification de ces cas est une étape clé. Il est donc primordial de prioriser les objectifs à atteindre.
À travers le graphique ci-dessus, on dégage 4 types d’objectifs :
Métiers ou Business : Acquérir, fidéliser, améliorer l’expérience client.
Prise de décision : Pilotage, anticiper.
Productivité : Performance opérationnelle, réduction des coûts.
Rupture : Transformer les modèles économiques
La nature des objectifs que vous allez poursuivre via la construction de votre équipe data va impacter le choix des différents profils qui la constitueront.
En amont de la constitution de l’équipe data, une bonne démarche consiste à identifier, au sein de l’organisation, les personnes dont les postes sont en lien avec l’exploitation des données. Il ne s’agit peut-être pas uniquement des personnes ayant le terme « données » dans leur titre, mais de tout employé qui n’a pas peur de l’analyse des données ou qui possède déjà des compétences en SQL, comme les Business Ops par exemple.
Si vous ne prenez pas le temps de localiser soigneusement les personnes qui travaillent déjà sur les données, vous risquez de vous retrouver avec une structure d’équipe de données mal structurée, peu susceptible de répondre aux besoins de votre entreprise.
Aussi, avant de choisir le modèle d’intégration de votre équipe data, gardez en tête que cette structure doit être le plus évolutive possible.
Modèles d’intégration centralisé
Le modèle centralisé place l’équipe Data au centre des activités des autres fonctions. C’est une structure qui se présente sous forme de plateforme de données centralisée, où l’équipe chargée des données a accès à la data et fournit des services à l’ensemble des autres fonctions dans le cadre de leurs projets.
Dans le modèle centralisé, l’équipe data est dirigée par le responsable des données, et elle entretient une relation similaire à celle d’un consultant avec son client.
L’équipe chargée des données peut appuyer les autres équipes tout en travaillant sur son propre agenda et le responsable des données dispose d’une vue panoramique de la stratégie de l’entreprise, et peut affecter les personnes chargées des données aux projets les plus adaptés à leurs compétences.
Aussi, ce modèle offre plus de possibilités pour développer les talents et les compétences du fait de la grande variété de projets et du travail en équipe qui favorise les acquisitions de compétences. Cependant, il implique pour le responsable des données de veiller à ne pas déconnecter l’équipe data des autres unités opérationnelles car les data analysts, scientists et engineers ne sont pas immergés dans les activités quotidiennes.
Ce modèle est particulièrement adapté aux entreprises en pleine croissance car sa flexibilité lui permet de s’adapter aux besoins changeants de celles-ci.
Modèle Décentralisé
Contrairement au modèle centralisé, qui place l’équipe data au centre des activités, le modèle décentralisé préconise le recrutement des profils nécessaires pour chaque unité opérationnelle, mais qui garde tout de même la plateforme data centralisée. L’équipe constituée répond directement au responsable de l’unité et les profils data recrutés sont impliqués dans les problématiques spécifiques à leur entité d’appartenance, avec peu d’interactions avec les autres équipes data.
L’avantage de ce modèle est que chaque unité peut appliquer la méthodologie agile car les membres étant en lien direct avec le responsable, l’équipe data est plus réactive et est dédiée à des fonctions spécifiques. Par ailleurs, les données étant disponibles directement au sein des équipes de l’unité, cela permet à l’équipe data d’accéder directement aux ressources dont elles ont besoin.
Modèle Fédéré / Centre d’excellence
Enfin, il y a le modèle fédéré, qui est plus adapté aux entreprises à la maturité data avérée. Dans ce modèle, les profils chargés d’effectuer les tâches relatives aux données sont intégrés dans les unités commerciales. Mais sont pilotées par un groupe centralisé (centre d’excellence) qui assure le soutien et la formation. Bien que les Data Analysts et data scientists soient déployés dans les différents départements, il y a toujours un responsable de données pour superviser le projet en cours. Cela assure la priorisation des projets et la qualité des services.
Le modèle fédéré convient aux grandes entreprises disposant d’une feuille de route claire et qui sont « data driven ». Cependant, il implique une équipe data plus importante car il y a des profils dans le centre d’excellence ainsi que dans les unités.
#3 Constitution de l’équipe Data
Les métiers incontournables d’une équipe Data
Pour avoir une bonne compréhension des trois principaux profils en Data Science, envisageons ceux-ci dans le déroulement d’un projet type en data.
Un projet data se décline par 4 étapes principales:
La collecte de données : extraire et réunir les données pertinentes au projet
L’exploration : Comprendre la donnée qui a été collectée
L’exploitation : Valoriser les données à disposition dans un but prédictif. Cette étape recourt au Machine Learning et Deep Learning
La Mise en production (phase d’industrialisation): Mise en production des modèles et ainsi faire passer le projet à grande échelle.
Le Data Analyst
Missions
Le Data Analyst explore les données dans le but d’avoir une visibilité sur le passé, et d’analyser les tendances et les corrélations pour aider à la prise de décision. Ses missions s’articulent autour des tâches qui ont trait à l’extraction, l’analyse, et la présentation des données.
L’extraction des données depuis une base grâce à SQL
Analyse des données (en Python ou R)
Création de dashboards avec les outils de Business Intelligence (Tableau, Power BI)
Optimisation des processus grâce au Machine Learning
Intervention dans le projet data
Bien que le périmètre d’intervention du Data Analyst puisse varier en fonction de la structure dans laquelle il évolue, on le trouvera très souvent dans la phase d’exploration, car le gros de son travail sera de comprendre la data à disposition et de lui donner du sens. Le Data Analyst consacre donc une grande partie de son temps à explorer les données, les analyser et les présenter au management.
Pour avoir une vision plus exhaustive sur les compétences d’un Data Analyst, vous pouvez vous référer à notre article dédié au sujet.
Le Data Scientist / Machine Learning Engineer
Le Data Scientist est la « star » dans l’univers de la Data. Son profil est très prisé et il joue un rôle central dans l’ensemble du pipeline d’un projet data. Selon le type de structure dans laquelle il évolue, son rôle peut se concentrer sur la création des modèles de prédiction (Machine Learning).
Par la nature transverse de son métier, les missions du Data Scientist sont très variées, mais le plus souvent, on retrouve les tâches suivantes:
Développement des algorithmes de Machine Learning pour optimiser un processus ou automatiser une tâche.
Présentation des résultats d’analyse
Recueil des données pour alimenter la database ou pour construire un algorithme.
Exploration et Nettoyage des données pour les rendre utilisables.
Intervention dans le projet data
Dans une organisation de plus petite taille, et notamment dans une startup, le data scientist occupe un rôle de couteau suisse, ses taches s’étendent de l’exploration des données à la mise en production. Dans une structure plus importante et au sein d’une équipe avec divers profils, son rôle est plus spécifique et il est fréquent que le Data Scientist soit assigné aux seules missions de construction des modèles de Machine Learning.
Il est à souligner que l’arrivée à maturité d’un grand nombre d’entreprises en matière d’intelligence artificielle a favorisé la mutation du profil de data scientist. En effet, les entreprises matures sont passées du stade du POC (Proof of Concept) à la phase d’industrialisation et doivent par conséquent couvrir tout le cycle de vie d’un modèle de Machine Learning, de sa conception à son monitoring en passant par le déploiement. Par conséquent, le rôle du Data Scientist est voué à se transformer et inclure l’étape de la mise en production, ce qui le rapproche du Data Engineer.
Le Data Engineer
Mission et compétences
Le Data Engineer travaille dans divers contextes pour construire des systèmes servant à collecter, gérer et transformer les données « brutes » (raw data) en informations exploitables que le Data Analyst et Data Scientist peut exploiter. L’objectif est d’accroître l’accessibilité aux données afin qu’une organisation puisse reposer dessus pour évaluer et optimiser ses performances. Ses principales missions sont :
L’industrialisation / monitoring des algorithmes de Machine Learning développés par les data scientists
La centralisation et standardisation des données récoltées dans un Data Lake
La conception et implémentation du pipeline ETL.
Monitoring des flux de données.
A retenir dans cet ensemble de missions, le processus ETL constitue le coeur du métier du Data Engineer. En effet, l’Extraction, la Transformation et le chargement (Load) des données sont les principales étapes qui permettent à une organisation de devenir « data driven ».
Les compétences du Data Engineer sont surtout techniques, elles comprennent la maîtrise des langages de programmation, la connaissance d’une ou plusieurs plateformes Cloud, ainsi que les outils de standardisation d’environnement.
Dans le cadre d’un projet data classique, le Data Engineer intervient principalement en amont lors de l’implémentation du processus ETL.
Son rôle comprend aussi la phase finale d’un projet data, à savoir la mise en production. Dans cette phase, il est chargé d’industrialiser le modèle et d’assurer sa scalabilité.
Postes plus spécifiques : Machine Learning Scientist, Data Architect, Cloud Data Engineer.
Bien que le Data Analyst, Scientist et Engineer soient les trois profils les plus connus et les plus recherchés, les besoins des entreprises mettent en lumière des profils parfois moins classiques, mais qui répondent aux lacunes de compétences pour la réalisation d’un projet.
Ainsi, lorsqu’une entreprise dispose de profils techniques comme le Data Engineer et le Data Scientist, mais qu’elle a besoin d’un profil scientifique plus pointu dans un domaine précis (Computer vision, time series), ou pour améliorer ses algorithmes de Machine Learning, elle peut recruter un Machine Learning Scientist, dont le rôle premier sera d’effectuer les travaux de recherche sur les algorithmes avant leur mise en production.
Le Cloud Data Engineer est un autre exemple de profil à considérer lorsqu’une entreprise repose sa stratégie data sur le Cloud Computing.
Le processus de recrutement
Multiplicité des entretiens et variation selon les profils.
Les entreprises font passer quatre à cinq entretiens dans la plupart des cas. Les recrutements comprennent en général plusieurs tests, des questions théoriques pour vérifier les connaissances indispensables chez le candidat. Des tests techniques, et des entretiens opérationnels avec les pairs. Ainsi, la multiplicité des entretiens peut rendre le processus plus ou moins long. Celui-ci peut durer quelques jours à plusieurs semaines.
La structure de l’entreprise détermine ensuite la forme des entretiens. Lorsqu’il s’agit de cabinets de conseils, il est coutume de faire passer un entretien « conseil » pour évaluer la capacité de consultant du candidat. Mais dans une startup, le processus contient un premier entretien RH, suivi d’un ou deux tests techniques, et un test « fit » pour valider la compatibilité du candidat avec la culture de l’entreprise.
Tests techniques
Cette phase vise à tester les compétences en programmation et la maîtrise des outils exigés pour le profil recherché. Afin de contrôler cela, une première vérification via le CV est nécessaire, pour voir si le candidat a déjà mis en pratique les éléments qu’il a mentionnés.
Des questions techniques simples peuvent être posées durant l’entretien pour vérifier le niveau attendu, et un exercice de programmation permet d’évaluer l’expérience et le savoir faire. Aussi, il est courant de tester les connaissances du candidat en Machine Learning (exemple : Différence entre Machine Learning Supervisé, et Non Supervisé)
Suivant le profil souhaité, le recruteur peut tester le candidat sur la maîtrise d’une technologie inhérente au poste (SQL ou Tableau pour le Data Analyst par exemple, ou la programmation en Scala pour le Data Engineer).
L’importance des soft skills
En dépit de leurs aspects très techniques, les postes en Data accordent une grande importance pour le savoir-être des candidats et leur capacité à communiquer avec des interlocuteurs non spécialistes. Ainsi, un Data Scientist par exemple, doit être capable d’expliquer les outils qu’il a développés et les méthodes mises en œuvre en sachant adapter son discours à une audience qui n’a pas le bagage technique.
Parmi les soft skills, notons quelques-unes des compétences incontournables :
Curiosité intellectuelle : Chercher à en savoir davantage que ce que les résultats montrent en surface.
Connaissance métier : Il est important que le profil recruté connaisse les métiers et le domaine d’activité dans lequel il opère.
Communication efficace : Comme mentionné ci-dessus, un profil spécialisé est amené à communiquer avec un interlocuteur qui n’a pas le bagage technique, une communication « vulgarisée » permet de fluidifier les échanges et le déroulement des projets, et d’obtenir des résultats plus facilement.
Enjeux RH: Formation continue et Turnover
Recruter et intégrer l’équipe data au sein d’une organisation est une étape clé, mais la nature évolutive du domaine, et les aspirations personnelles et professionnelles des candidats obligent les entreprises à considérer la veille technologique et la montée en compétences comme des enjeux clés pour leur compétitivité.
Formation Continue et Upskilling
Compte tenu du caractère innovant de la Data Science, les plans de formation classiques se révèlent peu efficaces. En effet, un Data scientist est régulièrement amené à lire les papiers scientifiques et autres documentations pour rester au fait des dernières découvertes, de nouveaux algorithmes, ou de nouvelles pratiques.
Par conséquent, les formations courtes et régulières s’avèrent plus adaptées pour suivre le rythme des changements.
Dans le cas d’un pur player, il n’est pas rare que l’organisation ait en son sein un département R&D pour rester à la pointe. Quantmetry, un cabinet de conseil spécialisé en data et pure player en IA, dédie près de 20% de la masse salariale à la R&D et ce, pour permettre à ses collaborateurs de prendre part à des projets en partenariat avec le monde académique.
Aussi, la démarche de formation peut se faire à l’initiative de l’employé. Il est nécessaire pour un bon profil de mettre en place une activité de veille sur les technologies. Notamment à travers les blogs d’entreprises actrices dans le Big Data, ou des publications dans les revues universitaires.
Un autre moyen pour se former à travers la pratique consiste à participer aux compétitions en Data Science. Cette approche permet de participer à des événements et de s’améliorer au contact des autres par le partage de connaissances.
La démarche de formation peut se faire à l’initiative du management en proposant des formations courtes à intervalles réguliers. Mais c’est une approche qui peut être coûteuse et chronophage car elle rogne sur l’emploi du temps du salarié. Cependant, il est nécessaire que le Data Analyst / Scientist / Engineer soit proactif et se forme régulièrement seul.
Turnover
La Data Science a connu une évolution fulgurante durant les dernières années, le volume de données a explosé et les besoins des entreprises avec.
Ce faisant, les métiers de la data sont en tension et les entreprises peinent à recruter les profils nécessaires.
Par conséquent, les candidats se retrouvent en position de force et ont plus de facilités pour orienter leur carrière professionnelle et leurs prétentions salariales.
Ainsi, cet état de fait implique pour les entreprises de gérer la rotation des effectifs, et tenter de maintenir un taux de turnover au minimum.
Ainsi, 365 Data Science, un organisme de formation en ligne spécialisé dans le domaine, a dressé dans cet article le portrait robot du Data Scientist en 2021 (Notre constat est extensible au profil de Data Analyst et Data Engineer).
Les résultats les plus intéressants de l’enquête révèlent que le Data Scientist « type » est employé depuis environ un an, avec une moyenne de 6 ans d’expérience préalable dans le domaine. Aussi, les professionnels interrogés ont changé d’entreprise deux fois ou plus depuis 2017.
Les raisons de ce turnover sont multiples, mais nous pouvons avancer quelques hypothèses pour l’expliquer.
Le manque d’engagement des employés est l’une des principales causes de la rotation du personnel. Lorsqu’un employé ne ressent pas l’impact de son rôle, estime que son salaire est insatisfaisant, ou est affecté par son environnement de travail, il est plus simple dans un marché en tension d’avoir de meilleures opportunités.
Un décalage entre les attentes du profil recruté et les missions quotidiennes: Si le recruteur ne définit pas correctement les rôles dans la description du poste, cela peut induire en erreur le candidat et ce dernier se verra octroyer des tâches qui sont en décalage avec ses compétences.
Opportunités: L’évolution constante du domaine et l’apparition de nouveaux défis incitent les professionnels à suivre le rythme et à rechercher de nouvelles opportunités. Sans possibilité de développement professionnel, les profils en Data Science n’auront aucune difficulté à changer d’employeur jusqu’à trouver l’entreprise qui correspond à leurs besoins.
La rétention des profils est donc primordiale, et les entreprises doivent accompagner leurs offres avec des avantages pour fidéliser les employés:
Équilibre vie privée / vie professionnelle.
Télétravail : Comme le montre une étude menée par Microsoft, 70% des employés souhaitent un environnement de travail plus flexible.
Opportunités : formations pour acquérir une compétence spécifique, implication des employés dans la définition des objectifs de développement professionnel dans l’entreprise, possibilité de promotion. Autant de mesures qu’une entreprise peut prendre afin qu’un profil recruté soit impliqué et motivé pour contribuer à sa croissance.
Recruter son premier data analyst est un défi de taille aux conséquences importantes pour l’entreprise. C’est lui qui va poser les fondations de votre équipe data sur deux aspects à la fois :
D’un point de vue humain : développement de l’équipe
D’un point de vue technique : choix des technologies et de l’architecture pour construire un système data stable, viable et pertinent.
Un véritable challenge en somme, mais qui peut être résolu si l’on possède les bonnes clefs de compréhension.
Nous avons donc développé pour vous un guide complet en s’appuyant sur les sources les plus pertinentes et notre expérience afin de vous aider à définir les compétences dont votre premier data analyst doit disposer et de vous accompagner dans le processus de recrutement et d’intégration de votre futur collaborateur !
Identifiez de qui vous avez besoin
Quand recruter un data analyst ?
Trouver LA bonne personne dans une entreprise grandissante signifie d’abord trouver la personne qui s’inscrit le mieux dans votre lancée. Il faut employer l’individu dont les compétences et l’expérience sont la clef pour accélérer votre croissance. Ces critères sont évidemment variables en fonction du stade de développement de votre entreprise.
Tristan Hardy a établi une classification des besoins en data analyse pour une entreprise selon sa taille. Il rappelle ainsi que la majorité des start-up recrutent leur premier data analyst alors qu’elles sont encore en « early stage ».
Le moment idéal pour recruter son premier data analyst est lorsque l’entreprise a dépassé ses tout premiers stades et qu’elle compte entre 20 et 50 employés. À ce niveau, les données dont elle dispose émanent principalement des applications utilisées pour votre activité (un dashboard Stripe ou Facebook…). Si la plupart des entreprises à ce stade de développement disposent des principaux outils analytiques (Google analytics, Mixpanel…), très peu ont une infrastructure data complète avec un data warehouse et des outils BI.
C’est donc une problématique qui intervient rapidement dans le développement de la structure et qu’il est nécessaire d’anticiper.
Qu’attendre de son premier data analyst ?
Définir clairement les tâches dont votre premier data analyst doit s’acquitter est essentiel pour exploiter efficacement vos données et apporter une véritable plus-value aux équipes métiers. Puisque c’est cet analyst qui va poser les fondations de votre infrastructure data, il doit être capable de :
Avoir une approche transverse et communiquer avec toutes les équipes.
Cela est primordial afin de comprendre précisément les besoins des équipes et de transmettre clairement les résultats des analyses. De plus, il est nécessaire d’être capable de s’adresser à toutes les équipes pour ancrer la data analyse dans la culture de l’entreprise et les processus métiers.
Construire des modèles de données optimaux.
La structure que met en place le premier data analyst sera utilisée pendant plusieurs années. Il faut donc qu’elle soit résiliente et parfaitement adaptée aux besoins commerciaux. Pour cela, le premier data analyst doit être compétent dans l’usage de Git et de SQL et doit aussi savoir construire des tables de données. Un candidat incapable de se servir de Git manque très certainement d’expérience avec les autres outils plus complexes, il est donc essentiel de tester ces compétences lors du recrutement. Une infrastructure data mal conçue peut avoir des répercussions sur plusieurs années et des coûts de restructuration particulièrement importants.
Il faut ainsi choisir quelqu’un pouvant endosser les rôles d’analyst et d’analytics engineer, c’est-à-dire quelqu’un capable de mettre en place une infrastructure propice à l’usage de la data et de réaliser des analyses pertinentes.
Andrew Bartholomew positionne ainsi ce qui doit être le premier analyst dans l’écosystème data :
La question de la séniorité se pose aussi lors du recrutement. Deux aspects doivent être pris en compte :
L’expérience :
Le candidat est-il capable de construire une infrastructure complexe répondant aux besoins de l’entreprise avec les contraintes qui lui sont imposées ? Nous considérons qu’il faut avoir pour cela au moins 4 ans d’expérience. Il est peu probable qu’un candidat ayant moins d’expérience puisse mener le développement d’un tel projet efficacement et prendre les décisions les plus optimales pour l’entreprise.
Le management :
Bien que le sujet ici soit le premier data analyst, il faut aussi considérer l’évolution de votre équipe data. Le candidat est-il capable de manager une équipe de 5 personnes, de trouver les talents nécessaires à son équipe et de les recruter ?
Le processus de recrutement d’un data analyst décrypté
#1 La structure de l’offre d’emploi
Pour convaincre les meilleurs candidats de postuler, il est crucial d’avoir une offre d’emploi structurée afin que les lecteurs comprennent la teneur du rôle. Trop d’offres n’apportent pas assez de précisions ou de détails, ce qui rebute les candidats qui craignent d’arriver dans une entreprise où la place de l’équipe data n’a pas été véritablement définie.
Nous avons trouvé une structure en 5 parties, particulièrement efficace pour ce type d’offre :
Présentation générale et contexte :
Dans cette première partie, il faut présenter l’entreprise au candidat ainsi que vous attentez pour ce rôle. Vous pouvez préciser le degré de spécificité de l’emploi (est-ce que cela porte sur un domaine en particulier), et la structure actuelle de votre équipe. Il faut aussi expliquer les besoins que vous avez dans votre équipe.
Exigences :
Cette partie permet de présenter vos attentes techniques au candidat. Vous devez y lister les technologies qu’il est essentiel de maîtriser, et celles qui sont « un plus » – attention à bien séparer ces deux catégories.
La difficulté de cet exercice est de trouver le bon degré de précision. Une liste trop abstraite conduirait des candidats trop peu expérimentés à postuler, quand une liste trop précise risquerait de vous priver de bons éléments. Il faut donc déterminer si, pour une technologie donnée, vous souhaitez avoir un candidat maîtrisant l’outil exact ou ayant de l’expérience avec ce type de software. Par exemple, si vous utilisez Airflow, voulez-vous d’un candidat sachant maîtriser cette plateforme, ou d’une personne expérimentée avec les outils d’orchestration des données ?
Nous recommandons de lister entre 5 et 10 technologies pour être précis et concis.
Responsabilités :
Cette partie est probablement la plus importante pour le candidat. C’est là qu’il détermine si le rôle l’intéresse. Il faut donc être spécifique et surtout pertinent pour que celui-ci puisse se projeter et désirer obtenir l’emploi. Mettez en avant les missions intéressantes qui seront confiées à l’employé.
Processus de recrutement :
Un candidat séduit par les points précédents va naturellement se demander comment postuler et se préparer aux entretiens. Il faut donc dédier une partie entière de l’offre à la présentation du processus de recrutement.
Les candidats sont bien plus susceptibles de postuler s’ils connaissent la teneur du processus de recrutement. Cela permet donc d’avoir plus de candidats, qui sont eux-mêmes mieux préparés. C’est donc le meilleur moyen pour vous, in fine, de sélectionner le candidat le plus apte.
Vos premiers mois :
Cette partie permet de se différencier de la majorité des offres d’emploi. En présentant aux candidats la teneur de leurs premiers mois, vous les aider à la fois à se projeter et en même temps à se rassurer.
Plus encore, en définissant les principaux points qui vont occuper les premiers mois de la personne recrutée, vous prouvez aux candidats que l’emploi que vous proposez est intéressant et nécessaire pour votre activité.
Emilie Schario propose plusieurs exemples d’offres d’emploi suivant cette structure.
#2 Partager la meilleure offre d’emploi n’est pas suffisant
Les data analysts font partie des emplois les plus difficiles à recruter. Même en ayant une offre d’emploi de très bonne qualité, il n’est pas certain que vous trouviez la personne adaptée à vos besoins.
Nous vous proposons donc un ensemble de conseils supplémentaires afin de vous aider dans cette tâche.
Se rapprocher de la communauté data
La meilleure façon de rencontrer l’individu capable de répondre à vos besoins est de chercher directement au sein de la communauté data et dans les groupes de data analysts. Il existe de nombreuses communautés en ligne, dont le degré d’engagement varie. LinkedIn est l’une des ressources les plus efficaces pour cela, avec de nombreux groupes d’échanges au sein desquels les membres partagent leurs projets. Vous avez ainsi directement aux profils des individus et à leurs portfolios.
D’autres plateformes permettent de découvrir des individus très engagés dans cette communauté, à l’instar de Quora ou de StackOverflow.
Enfin, il existe des rencontres et des évènements en physique durant lesquels sont présentés les outils les plus en vogue, l’évolution des techniques et des plateformes data… Y assister permet de mieux comprendre cet écosystème, de savoir que chercher et peut-être de rencontrer votre futur data analyst.
Juger les projets, pas seulement les CV
L’Analytics requiert de nombreuses compétences techniques qu’il est très difficile d’évaluer sur un CV. Chaque candidat s’évalue de sa propre manière, et le niveau mis en avant sur le CV ne reflète pas nécessairement la réalité. Pour cette raison, il est souvent plus pertinent de juger un candidat sur ses projets, ou du moins d’y prêter une grande attention.
Les développeurs incluent très généralement leur portfolio dans leurs candidatures. Vous pouvez aussi le demander dans les éléments du dossier. Ces portfolios permettent de se rendre compte du niveau réel de l’individu, d’avoir une idée de son expérience et même de mieux connaître le candidat.
Plus encore, vous pouvez proposer un jeu de données en libre accès en ligne, sur Kaggle par exemple. Cela permet aux candidats de montrer leur expertise sur des données réelles et similaires à celles qu’ils pourraient exploiter chez vous. Vous pouvez même organiser des compétitions à partir de ces data sets afin de détecter des data analysts possédants les compétences recherchées.
#3 Faire passer un entretien à un data analyst
Un entretien pour un data analyst doit permettre d’évaluer ses compétences techniques, comportementales et relationnelles. Chacune de ces 3 facettes de l’individu est extrêmement importante pour un métier transverse.
> Compétences Techniques
Exemples de questions
Intérêt de la question
Qu'attendre comme réponse ?
Quels outils d'analyse statistique et logiciels de base de données avez-vous déjà utilisés ?
Quels sont vos préférés et pourquoi ?
Évaluer l’expérience de l’individu
Capacité d’adaptation
SQL, le langage dominant dans ce secteur
Des outils de BI
Volonté d’apprendre de la part du candidat
Comment vous y prendriez vous pour mesurer la performance commerciale de notre entreprise, et quelles sont les informations les plus importantes à prendre en compte ?
Évaluer la capacité du candidat à comprendre les besoins de l’entreprise
Des éléments prouvant que le candidat s’est intéressé à l’entreprise
Une approche business qui puisse s’appliquer dans l’entreprise
Quelles sont les meilleures pratiques en matière de nettoyage des données ?
Quelles sont les étapes à suivre ?
Estimer le niveau technique du candidat
Des exemples de pratiques tels que « classer les données par attributs »
Des exemples de la propre expérience du candidat
> Compétences Comportementales
Exemples de questions
Intérêt de la question
Qu'attendre comme réponse ?
Parlez-moi d'un moment où vous pensez avoir fait preuve d'une bonne intuition en data.
Détecter la capacité du candidat à rapidement analyser un graphique ou un ensemble de données
Un exemple précis en détaillant ce qui a mis « la puce à l’oreille » du candidat, son analyse et sa manière de résoudre le problème
Décrivez votre projet data le plus complexe, du début à la fin.
Quels ont été les principaux challenges et comment les avez-vous relevés ?
Avoir des précisions sur le niveau du candidat et sur son expérience
Le candidat doit prouver qu’il peut résoudre des problèmes complexes tout en prenant en compte les autres parties prenantes
Parlez-moi d'une occasion où vous avez mis en place une expérimentation. Comment avez-vous mesuré le succès ?
Estimer la capacité du data analyste à mettre en place des outils utiles à l’entreprise
Exemple précis et clair, type A/B testing
Des mesures et des KPIs pertinents
> Compétences Relationnelles
Exemples de questions
Intérêt de la question
Qu'attendre comme réponse ?
À votre avis, quelles sont les trois meilleures qualités que partagent les bons data analyst ?
Les softs skills sont essentiels pour un data analyst
Conscience qu’un data analyste a un rôle relationnel
Comment expliqueriez-vous vos résultats et vos processus à un public qui ne connait pas le rôle d'un data analyst ?
Estimer la capacité d’un candidat à s’adresser à des audiences variées
Capacité à vulgariser la data analyse
Conscience de l’importance de clarifier les conclusions d’une analyse
Qu'est-ce qui vous a attiré vers l'analyse des données ?
Comprendre les motivations du candidat
Un intérêt prononcé pour la data analyse
Une ouverture sur d’autre champ de la data, tel que l’AI
Comment tirer le meilleur parti de votre premier analyst de données ?
Embaucher la bonne personne n’est que la première étape du processus. Une fois qu’elle a rejoint votre équipe, vous voulez vous assurer que la personne pour qui vous avez passé tant de temps (et d’argent !) à recruter sera en mesure d’être efficace le plus rapidement possible.
Une bonne façon de gérer cette situation est de fixer des objectifs à 30/60/90 jour que vous passerez en revue chaque semaine lors des entretiens individuels.
Dans cette vidéo, un employé de dbt explique ce qu’il a particulièrement apprécié le fait d’avoir un plan à 3 mois dans l’offre d’emploi. Plus encore, cela lui a facilité son intégration dans l’équipe data et lui a permis de suivre son évolution au cours des premiers mois.
Les attentes à 1 mois
Le premier mois est décisif pour l’intégration d’un individu dans une entreprise. Dans le cas d’un data analyst, dont les fonctions imposent qu’il soit en contact avec toutes les équipes, ce premier mois doit lui permettre de bien saisir les enjeux de chaque équipe et de proposer en réponse à cela des premiers KPIs ainsi qu’une roadmap pour les mois à venir. Les principales tâches consistent en :
Récupérer les données des outils data pour les regrouper dans un Data Warehouse,
Sélectionner les principaux outils de reporting (une tâche souvent plus complexe qu’il n’y paraît),
Présenter les premiers indicateurs et les premiers reportings (à ce niveau, les conclusions des analyses sont encore sommaires),
Rencontrer tous les principaux interlocuteurs
Les attentes à 2 mois
Le deuxième mois constitue une transition entre le premier où le data analyst découvre les données et les outils, et le troisième au cours duquel il finalise ses premiers modèles.
Les attentes lors de ce deuxième mois doivent donc porter sur la transition entre ces deux étapes :
Mise en place d’un dashboard regroupant les principaux KPIs
Développement d’un premier modèle. À ce stade, il faut surtout s’assurer que le data analyst ait bien saisi les enjeux sur lesquels porte son modèle.
Les attentes à 3 mois
C’est au cours du troisième mois que l’on peut attendre du data analyst d’avoir fini son premier modèle de données. Il doit alors être capable de répondre simplement à des questions de la part des équipes métiers sans avoir à effectuer de requêtes particulièrement complexes.
Toutefois, cette limite de trois mois est grandement dépendante de la taille de l’entreprise et du volume de données dont vous disposez.
Ainsi, le recrutement de votre premier data analyst est aussi crucial que complexe. Afin d’embaucher le talent capable d’utiliser de façon optimale vos données, il est nécessaire de :
Publier une offre claire et structurée
Se rapprocher des groupes de data analysts
Mettre en place un processus de recrutement visant à évaluer les compétences techniques, comportementales et relationnelles du candidat
Préparer son intégration afin de suivre sa progression au cours des premiers mois.
CRM vs CDP : les limites à utiliser un CRM comme base clients principale
La solution CRM a longtemps été utilisée comme base clients principale par les entreprises. Le logiciel CRM, qu’il s’agisse d’un CRM commercial comme Salesforce, d’un CRM Marketing (Automation) comme Splio ou Adobe Campaign, servait à la fois de base clients et d’outil de gestion de la relation clients.
Puis est apparue une nouvelle famille de logiciels : les Customer Data Platforms (ou CDP), conçues pour jouer ce rôle de référentiel client en lieu et place du CRM. Les logiciels CRM ont des limites structurelles en matière de gestion de base de données. Les CRM gèrent mal les données comportementales, le temps réel ou encore la réconciliation multi-sources (indispensable pour pouvoir disposer de données unifiées). Ce sont ces limites qui expliquent très largement le succès des CDP.
Avec la multiplication des outils, des sources de données, la place croissante des données comportementales, de plus en plus d’entreprises font le choix de gérer leur base clients indépendamment de leur logiciel CRM principal. Ce nouveau paradigme consistant à découpler la base clients et les outils d’activation est rendu possible par la dernière génération de CDP.
Lorsque l’on cherche à construire ou améliorer son écosystème CRM, il faut se poser cette question essentielle : quel système ou quel outil doit jouer le rôle de base clients principale ? Certaines entreprises continuent de penser que le CRM peut jouer ce rôle. D’autres au contraire choisissent de s’équiper d’une CDP. Beaucoup, enfin, sont un peu perdues et ne savent plus trop quoi en penser. C’est notamment pour ces entreprises que nous avons écrit cet article.
Dans cette publication, nous allons commencer par vous aider à mieux comprendre les différences entre CRM et CDP. Nous prendrons ensuite le temps de présenter les exigences requises pour qu’une base clients puisse jouer le rôle de référentiel client. Cela nous conduira à aborder les différentes raisons pour lesquelles nous pensons que le logiciel CRM n’est plus adapté pour jouer ce rôle.
Comprendre les différences entre CRM et CDP
Avant toute chose, il faut rappeler que CDP et CRM ne sont pas des solutions concurrentes, mais complémentaires. Une entreprise qui est équipée d’une CDP dispose la plupart du temps d’un CRM.
Pour commencer, voici un tableau synthèse des principales différences entre CRM et CDP :
CRM
CDP
Rôle
Gérer la relation clients : les interactions commerciales (gestion des leads), marketing (campagnes et scénarios) et servicielles (support client))
Gérer la base de données clients : réconciliation des données autour d’un ID client, hub data pour les autres systèmes
Utillisateurs
Profils métiers
Profils martech ou data
Ingestion de données
Batch ou manuel
Temps réel ou presque
Réconciliation / déduplication
Basée généralement sur l'email
Réconciliation déterministe ou probabiliste basée sur plusieurs clés
Transformation de données
Basique ou inexistante
Avancée : normalisation, enrichissement, segmentation, scoring, création d'audiences...
Définition du CRM – Customer Relationship Management
Un logiciel CRM sert à centraliser la gestion des interactions clients. Il existe quatre familles de CRM :
Les CRM commerciaux, utilisés par la force de vente, conçus pour gérer le suivi des opportunités commerciales, piloter l’activité commerciale. C’est la famille CRM la plus ancienne.
Les CRM Marketing, utilisés par l’équipe marketing, conçus pour gérer la segmentation client, les campagnes et scénarios marketing.
Les CRM orientés service client, destinés aux centres de contacts et servant à gérer les interactions sur les canaux du service client : tickets, téléphone, livechat…
Les solutions CRM tout-en-un qui permettent de gérer aussi bien les interactions commerciales, marketing et servicielles.
Le CRM est donc un outil avant d’être une base de données. Sauf que, nous le rappelions en introduction, le CRM joue de fait depuis longtemps le rôle de base de données. Il stocke :
Les données froides, essentiellement des données de profil et des informations de contact : nom, prénom, genre, date de naissance, téléphone, adresse postale.
L’historique conversationnel : les échanges par mail, sur les réseaux sociaux, les notes de rendez-vous, etc.
Les éditeurs ont tous développé des connecteurs pour que le CRM accueille d’autres types de données, par exemple les données transactionnelles et, avec beaucoup moins de succès, les données comportementales/de navigation web. Cela a contribué à accentuer cette évolution du CRM qui, d’outil d’activation et de gestion des interactions, s’est progressivement transformé en référentiel clients principal.
Rappel définition CDP – Customer Data Platform
Une Customer Data Platform est une technologie qui sert à unifier les données clients, à les préparer en fonction des cas d’usage de l’entreprise et, enfin, à les redistribuer aux autres systèmes de l’entreprise (outils d’activation et outils de reporting). C’est fondamentalement un outil de Data Management.
Une CDP sert à opérer 4 activités principales :
Connecter. Elle se connecte à l’ensemble des sources de données clients de l’entreprise, avec des flux de données qui peuvent être construits via des connecteurs natifs, des APIs, des webhooks, des chargements de fichiers plats, etc.
Structurer. Les données sont organisées dans un modèle de données personnalisé en fonction des besoins de l’entreprise. Elles sont dédupliquées sur la base d’une ou de plusieurs clés de rapprochement. La déduplication permet de consolider les données, de les réconcilier et de les unifier autour de profils clients persistants.
Préparer. Les données, une fois unifiées, sont utilisées pour construire des audiences, des segments, des scores et d’autres champs calculés.
Synchroniser. Les segments, les audiences, les scores sont ensuite redistribuées aux outils d’activation (CRM, Service Client, Marketing Automation, outils publicitaires…).
Le CDP Institute a identifié 5 critères pour qu’une solution puisse être qualifiée de Customer Data Platform :
Ingérer des données en provenance de n’importe quelle source.
Capturer tout le détail des données ingérées.
Stocker les données ingérées de manière persistante.
Créer des profils clients unifiés.
Partager les données avec les systèmes qui en ont besoin.
Zoom sur les principales différences
Résumons ici les principales différences entre CRM et CDP :
La finalité. Le CRM sert à gérer la relation client, la CDP à gérer les données clients. CRM et CDP servent tous deux, bien que de manière différente, à améliorer la performance client.
Les utilisateurs. Les CRM sont utilisés par les équipes opérationnelles impliquées dans la gestion du dialogue clients : les commerciaux, le marketing, le service client essentiellement. Les CDP ont vocation à être utilisées par des profils marketing plutôt technophiles et les équipes data. CRM et CDP sont conçus pour être utilisés de manière autonome par les équipes métier (sans l’équipe IT).
Les données. Un CRM gère très bien les données froides et les historiques relationnels (conversationnels, contractuels, transactionnels) mais mal les données chaudes. A l’inverse, une CDP gère tous types de données, y compris les données comportementales (web tracking…). CRM et CDP se concentrent essentiellement sur les données first-party, suivant en cela le sens de l’histoire (fin des cookies tiers).
Le mode d’ingestion des données. Les CDP gèrent le temps réel ou le quasi-temps réel, que ce soit en entrée (connexion aux sources) ou en sortie (distribution aux outils de destinations). Les données du CRM sont soit ingérées en batch, soit enregistrées manuellement par les utilisateurs. Cela s’explique par le fait que les cas d’usage du CRM ne nécessitent pas l’ingestion en temps réel.
Que faut-il pour gérer correctement votre base clients principale ?
La formulation des différences entre CRM et CDP donne déjà des pistes de réponse à la question que nous nous sommes proposé de traiter dans cet article : quel outil ou système doit jouer le rôle de base de données principale. Poursuivons notre investigation. Nous allons à présent définir les principales caractéristiques que doit avoir une base clients pour pouvoir jouer le rôle de BDD principale ou de « Référentiel Client Unique ».
La base clients principale doit être exhaustive
La base de données doit centraliser l’ensemble des données clients qui ont un intérêt connu ou potentiel pour l’entreprise. Une entreprise peut stocker différents types de données :
Les données de profil.
Les informations de contact.
L’historique des interactions, qu’elles soient conversationnelles ou transactionnelles.
Les données de préférence.
Les données comportementales : navigation web, utilisation des produits (comportement dans le logiciel, dans l’appli…)…
Les données d’engagement, par exemple le comportement email (ouvertures, clics, etc.).
Etc.
Il existe plusieurs manières de catégoriser les différents types de données clients. Peu importe ici. L’essentiel à retenir est qu’une base clients, pour pouvoir être exhaustive et jouer son rôle de base maître, doit être en capacité de gérer tous types de données : les données chaudes aussi bien que les données chaudes, les données tierces aussi bien que les données personnelles, les données online aussi bien que les données offline, les logs web aussi bien que les numéros de téléphone.
La base clients principale doit être unifiée
La base clients principale a vocation à agréger l’ensemble des données clients collectées via les différentes sources de données de l’entreprise. Cette agrégation produit nécessairement des doublons, qui peuvent avoir 2 origines :
Un client peut être identifié différemment dans deux outils différents. Par exemple, un client peut être identifié par son email dans l’outil de Marketing Automation, par un numéro client sur l’espace en ligne et par un téléphone dans le logiciel du service client. Résultat : si vous n’utilisez pas de clé(s) de rapprochement, vous ne pourrez pas savoir que c’est le même client qui se cache derrière les trois identifiants. Vous aurez trois doublons, trois identités non réconciliées.
Un même outil peut stocker un même client à deux endroits différents. Exemple : si vous utilisez un CRM qui utilise l’email comme identifiant unique et qu’un client utilise deux emails, vous aurez deux fiches contacts, deux identités.
Dans les deux cas, le problème est fondamentalement le même : il n’y a pas, comme on dit dans le jargon, de résolution d’identité.
Il faut absolument être capable d’unifier les données qui rejoignent la base clients principale. Comment ? Via le paramétrage de règles plus ou moins complexes de déduplication, permettant de faire matcher les données entre elles, de procéder aux fusions d’enregistrements.
La base clients principale doit être propre
Une base de données propre est une base qui remplit 4 conditions. Il faut que les données qu’elle stocke soient :
Soumises à un modèle de données cohérent et adapté. Le modèle de données définit la manière dont les données viennent s’organiser dans les tables qui composent la base de données.
Normalisées. La normalisation renvoie à la manière dont sont enregistrées et affichées les données. Pour l’objet « genre » par exemple, on peut utiliser les formats « F » et « M », ou bien « Femme » et « Homme »…Il faut que pour chaque objet soit défini un seul et unique format. C’est ce que l’on appelle la « normalisation » des données.
Nettoyées. Le nettoyage désigne l’ensemble des opérations consistant à vérifier l’exactitude des données et à supprimer/mettre à jour les données inexactes.
Régulièrement mises à jour. Le nettoyage des données, qui est une opération ponctuelle et périodique, doit être complété par la mise en place de flux de données automatisés permettant de mettre à jour régulièrement les données, voire en temps réel pour ce qui est des données comportementales.
Une base de données clients, pour jouer le rôle de base principale, doit donc proposer :
Un ou plusieurs modèles de données suffisamment souples pour répondre aux besoins de l’entreprise et aux caractéristiques de ses données.
Des fonctionnalités de normalisation des données.
Des fonctionnalités de gestion de la qualité des données et d’enrichissement.
Une gestion du temps réel ou quasi-temps réel pour être en capacité de mettre à jour en continu et sans délais les données comportementales/chaudes.
La base clients principale doit servir de hub avec les autres systèmes
La base clients principale doit pouvoir facilement alimenter les autres systèmes de l’entreprise, qu’il s’agisse des outils opérationnels / d’activation (CRM ventes, CRM marketing / marketing automation, CRM service client, DSP / plateformes publicitaires…) ou des outils d’analyse (BI, reporting, data science…).
Elle doit facilement pouvoir se « câbler » aux outils de destination, que ce soit via des connecteurs natifs, une solide API, des webhooks ou des exports manuels.
Les limites structurelles de la plupart des solutions CRM / marketing pour jouer le rôle de base clients
La plupart des logiciels CRM / Marketing ne sont pas conçues pour jouer le rôle de base clients principale, pour la bonne raison qu’il s’agit de logiciels de gestion de la relation clients, et non d’outils de structuration des données clients.
Modèle de données rigide
Le modèle de données proposé par les solutions CRM est plus ou moins rigide, souvent plus que moins. Pour rappel :
Les CRM légers (les gestionnaires de campagnes ou les petits CRM Sales, par exemple) sont monotables. L’ensemble des données est organisé dans une seule et unique table.
Les outils intermédiaires sont multitables mais « figés ». Le modèle de données s’organise sur plusieurs tables (clients, produits, commandes…), mais il est difficile d’ajouter de nouvelles tables ou de modifier la relation entre les tables.
Les outils avancés comme Salesforce sont à la fois multitables et souples.
La conséquence, c’est qu’il est difficile de faire évoluer le modèle de données d’un CRM, sauf à disposer d’un CRM très avancé (et en général très coûteux) comme Salesforce. Première limite.
Pas de réconciliation multisources
Dans la plupart des CRM, c’est l’email qui sert de clé. Cela signifie que si le même individu s’inscrit avec deux emails différents, cela créera deux lignes dans le CRM, même si l’individu s’est inscrit avec le même téléphone, le même nom x prénom, le même code postal…
La conséquence est que cela génère des doublons dans la table Contacts, comme nous l’avons vu tout à l’heure, mais aussi et surtout des difficultés pour associer le contact avec tous ses points de contact. Si par exemple un individu écrit au service client avec un autre email que celui avec lequel il s’est inscrit, et si je ne peux pas réconcilier les contacts et les tickets du service client en utilisant plusieurs clés, alors il ne sera pas possible d’associer l’individu au ticket client.
Il faudrait pour cela que le CRM permette de gérer des règles de déduplication multisources. C’est avec ce type de règles que l’on pourra dire à l’outil : « Si deux contacts ont un email différent mais la même adresse postale + le même nom/prénom, alors les deux contacts doivent être dédupliqués et fusionnés ».
Pas ou peu de normalisation & nettoyage des données
Dans un outil CRM, les possibilités de nettoyage de données sont très limitées :
Normalisation. Il n’est pas possible d’utiliser des règles de type « Find & replace » qui permettent, par exemple, de remplacer tous les « FR » en « France », ou tous les « Mlle » en « F ».
Nettoyage des champs importants. Les CRM n’intègrent pas, sauf rares exceptions, de service permettant de vérifier l’existence des adresses emails, de faire de la RNVP pour les adresses postales…
Par conséquent, la normalisation et le nettoyage des données doivent être réalisés en amont du CRM, à l’aide de scripts personnalisés complexes à maintenir.
Pas de champs calculés & scoring
Un outil CRM, c’est comme Excel mais sans les formules de calcul…Dans la plupart des solutions CRM il n’est pas possible d’ajouter des champs calculés. Certains outils CRM proposent des champs calculés par défaut (panier moyen CA, cumulé, etc.) qui sont impossibles à modifier.
Or la capacité à créer des champs calculés est essentielle, notamment pour déployer des scénarios de marketing automation. Par exemple, pour pouvoir exclure les clients qui ont récemment exprimé une insatisfaction, il nous faut un champ « statut du dernier ticket client » ou bien « nombre de tickets clients sur les X derniers jours ». La création de ce type de champs calculés (scoring ou autre) est très difficile, et souvent impossible dans un CRM.
Pas d’accès direct à la base de données pour faire des reportings
Une base clients principale sert à activer les clients, à « agir », mais aussi à analyser les données, à faire du reporting. Faire du reporting sur une base de données CRM n’est pas simple, car les rapports à disposition dans l’outil sont très vite limités.
Prenons l’exemple des scénarios automatisés. Pour pouvoir mesurer leur impact, il faut utiliser l’analyse de cohortes. Si l’on souhaite, par exemple, déployer un nouveau scénario d’upsell qui consiste à envoyer une séquence de messages 1 mois après le premier achat, nous aurons besoin de regarder par cohorte mensuelle de nouveaux acheteurs si le nombre d’achats après 2 mois a augmenté.
Comment faire cela dans un logiciel CRM ? Vous n’avez qu’une seule solution : exporter les données dans une base de données / un datawarehouse, et ensuite brancher votre outil de reporting sur la base en question. Il n’est pas possible de brancher l’outil de reporting directement sur le logiciel CRM, il faut passer par l’intermédiaire de la base de données…
Le sens de l’histoire, c’est le découplage entre la base clients et l’activation des données clients
Du logiciel CRM à l’écosystème CRM
Le CRM désigne aujourd’hui la gestion de l’ensemble des interactions et des activations avec les clients identifiés. Dans la plupart des entreprises, le CRM n’est plus opéré par un seul logiciel, comme par le passé, mais par un ensemble d’outils, une combinatoire de solutions :
Un gestionnaire de campagnes.
Un outil de marketing automation (ou CRM Marketing)
Un outil de gestion de l’activité commerciale et des pipelines de ventes (ou CRM Sales)
Un outil de helpdesk/ticketing (ou CRM Service Client).
Des plateformes publicitaires pour retargeter les clients connus avec des Ads.
Le CRM est devenu un environnement, un écosystème de logiciels. C’est l’une des raisons pour lesquelles il n’est plus vraiment possible d’utiliser le CRM comme référentiel clients : une entreprise utilise des outils CRM, mais a besoin d’une base clients principale.
Les bénéfices à gérer une base clients séparément
Si vous avez lu tout ce qui précède, vous commencez sans doute à prendre conscience des bénéfices qu’il y a à gérer une base clients séparément.
Avoir une base clients séparée permet de :
Connecter l’ensemble des sources de données clients de l’entreprise, en toute liberté, sans limitations et de manière simple (via des connecteurs, des APIs…). Les capacités de connexion sont en effet freinées quand la base clients est construite dans un outil qui appartient à un écosystème constitué (Salesforce par exemple) : l’éditeur cherchera bien souvent à ce que vous utilisiez les autres outils de sa suite.
Créer une vision client unique exhaustive, associant données chaudes et données froides. Ce bénéfice découle du précédent.
Préparer les données au même endroit. Vous gérez de manière centralisée les segments clients, les audiences, les scores, les règles de déduplication…Vous n’avez plus besoin de faire ce travail dans chaque outil de votre écosystème CRM.
Ne pas enfermer les données dans un modèle de données rigide. Vous créez un modèle de données souple, sur-mesure, adapté à vos cas d’usage présents et futurs.
Synchroniser facilement les données préparées dans les différents systèmes qui en ont besoin, et ce en temps réel quand c’est nécessaire.
Pouvoir utiliser la base clients pour alimenter les outils d’activation mais aussi les outils de reporting, et ce directement, sans devoir passer par un système intermédiaire.
Rester maître de ses données clients. Les problématiques autour du contrôle des données deviennent cruciales pour beaucoup d’entreprises. Construire une base de données indépendante permet de garder un contrôle total sur ses données. Si le sujet vous intéresse, nous vous invitons à lire notre guide complet sur le sujet : Pourquoi est-il important de garder le contrôle des données des clients ?
Petite présentation de l’approche proposée par Octolis
Nous avons été consultants Data / CRM pendant de longues années. Nous avons été très souvent été confrontés aux limites du CRM au fil de nos missions. Certains de nos clients disposaient d’un Référentiel Client unique sur mesure, du coup très flexible, mais chaque changement suppose une intervention technique. D’autres clients s’équipaient de solutions CDP de première génération, on dispose d’une belle interface pour manipuler les données, mais la contrepartie, c’est qu’on n’a pas le contrôle des données, et moins de flexibilité sur le modèle de données.
Il nous paraissait évident qu’il fallait réconcilier les deux approches. Une base de données sur mesure, contrôlée / hébergée par les clients matures, avec une interface logicielle par dessus.
C’est d’ailleurs le sens de l’histoire. La démocratisation des datawarehouses encourage cette approche hybride. Les CDP ouvrent la voie, mais on commencent à voir d’autres types de logiciels SaaS qui utilisent le datawarehouse des clients comme socle.
Certains de nos clients disposent déjà d’une base clients principale : dans ce cas, nous « branchons » Octolis sur cette base. Si vous n’avez pas encore de base principale, Octolis la crée pour vous.
Nous avons tenu à créer une interface logicielle self service, accessible aux profils métiers, utilisable à l fois par les profils marketing (en « no code ») et les équipes data en SQL. CDP nouvelle génération, Octolis vous permet de gérer les 4 fonctions que nous avons présentées plus haut : Connexion, Préparation, Structuration, Synchronisation.
Voici un très rapide aperçu de la solution. Vous êtes tout d’abord invité à connecter les différentes sources de données. Parmi ces sources de données, bien sûr, figure la base clients indépendante.
C’est sur le menu « Audiences » que vous préparez et structurez les données : règles de déduplication, normalisation, construction d’audiences et de segments, création de champs calculés (indicateurs, scorings…).
Vous pouvez synchroniser à tout moment dans vos outils et dans votre base principale les données préparées et transformées dans Octolis.
Pourquoi Octolis ?
Pour en savoir plus sur Octolis, l’origine de notre solution, nos convictions et la vision qui nous anime, nous vous invitons à découvrir l’article que nous avions publié à son lancement : Pourquoi nous lançons Octolis ?
Relancer les clients inactifs : définition, méthode & bonnes pratiques
Une base de contacts contient entre 20% et 50% de clients inactifs. Au lieu d’investir dans des campagnes d’acquisition pas toujours rentables, imaginez que vous réussissiez à relancer une bonne partie de ces clients inactifs ?
Réactiver ses clients inactifs permet d’augmenter le reach des campagnes de l’ordre de 10% à 20%. C’est les résultats que nous observions dans notre ancienne vie de consultants data & CRM.
Le potentiel est donc énorme. Pour pleinement le réaliser, vous devez dans un premier temps être capable d’identifier vos clients dormants puis utiliser les bons leviers et les bonnes approches pour réussir à renouer le dialogue.
Relancer les clients inactifs ou passifs : un enjeu business majeur
Pourquoi les clients inactifs sont souvent laissés de côté par les marques ?
Peu de marques font l’effort de réactiver leurs clients inactifs. C’est contre-intuitif quand on connaît les enjeux et le potentiel des mécaniques de réactivation.
Il y a plusieurs raisons à ce manque d’intérêt :
Les entreprises ont toujours cette fâcheuse tendance à préférer l’acquisition à la rétention, la conquête à la fidélisation. Plutôt qu’améliorer la qualité de sa base de contacts, on cherche à l’augmenter, à la faire grossir.
Certaines marques se font à l’idée que les consommateurs sont devenus volatils, plus difficiles à retenir, et qu’il vaut mieux investir dans de l’acquisition que perdre du temps dans de la rétention ou de la réactivation. Cette raison rejoint la précédente.
Pour des raisons de délivrabilité, les entreprises ont tendance à focaliser leurs efforts sur les clients actifs. Les clients inactifs, qui ne réagissent plus aux sollicitations, sont retirés des segments exploités dans les campagnes. Cela part d’une bonne intention (la préservation de la réputation de l’adresse IP), mais cela conduit à négliger les clients inactifs. On finit par ne plus penser à eux, par ne plus les adresser, par les oublier. Plutôt que de chercher de nouvelles approches pour solliciter les inactifs et reconquérir leur cœur, on relègue les clients dormants aux oubliettes.
Disons-le clairement : ce sont trois mauvaises raisons de laisser de côté les clients inactifs. Et voici pourquoi.
Un non-ouvreur ou inactif n’est pas un client perdu
Un client qui n’ouvre plus vos messages n’est pas forcément un client perdu.
Le fait qu’un client n’ouvre plus vos messages et soit inactif peut signifier que le contenu de vos messages ne l’intéresse pas, que vos offres ne sont pas pertinentes, que vous n’utilisez pas le bon canal pour le solliciter, que la fréquence des messages est inadaptée, qu’il estime que vous ne le chouchoutez pas assez…L’inactivité, le plus souvent, révèle un problème de communication plus qu’un désintérêt pour votre offre et vos produits.
Une fois que l’on a compris ça, chercher à réactiver les clients inactifs devient une évidence.
Cap sur les programmes de fidélisation !
20% des clients représentent 80% de votre chiffre d’affaires. Ce principe de Pareto se vérifie presque toujours. Il est donc nécessaire de chouchouter vos meilleurs clients en mettant en place un programme de fidélisation. Découvrez notre sélection des meilleurs exemples de programmes de fidélisation.
Un préalable : définir et segmenter les clients inactifs
Définir la notion de client inactif
Chaque entreprise a sa définition de ce qu’est un client inactif. Vous devez trouver la vôtre pour pouvoir ensuite identifier qui sont vos clients inactifs. C’est le point de départ.
Nous n’allons pas vous donner la définition de ce qu’est un client inactif mais vous donner les clés pour construire votre définition.
Au bout de combien de temps devient-on un client inactif ?
Un client inactif (ou dit aussi « client passif » ou « client dormant », peu importe le terme utilisé) est un client qui n’ouvre plus vos messages. Votre définition d’un client inactif doit indiquer à partir de combien de temps d’inactivité un client entre dans le segment « clients inactifs ». Vous pouvez aussi raisonner par campagnes. Il y a donc 2 approches possibles :
Un client inactif est un client qui n’ouvre plus les messages depuis X jours.
Un client inactif est un client qui n’ouvre plus les messages depuis X campagnes.
Dans la pratique, les entreprises utilisent plutôt le nombre de jours.
Le vrai enjeu consiste à définir le « X ». Il dépend en fait de votre activité et de la fréquence d’envoi de vos messages. Si vous envoyez une newsletter mensuelle, le nombre de jours pour qu’un client soit considéré comme inactif sera plus élevé que si vous envoyez une newsletter hebdomadaire.
En général, X = 1 mois ou 2 mois. Mais dans certains cas, X peut être égal à 1 an.
De quelle inactivité parle-t-on ?
Depuis le début, on considère l’inactivité comme une absence d’ouverture des emails envoyés à votre base clients. C’est l’approche basique. Mais il est tout à fait possible de prendre en compte les autres canaux, par exemple la publicité, le SMS, les magasins, le ecommerce. Un client qui n’ouvre plus vos messages depuis 2 mois mais qui a acheté un produit sur votre site il y a 2 jours est-il un client inactif ? Non, bien sûr.
D’où la question : de quelle inactivité parle-t-on ? Plus vous intégrez de choses dans votre définition de l’inactivité, plus votre définition de ce qu’est un client inactif sera juste et précise.
Mais disons que se concentrer sur l’ouverture des emails est plus simple pour commencer.
Créer un segment « clients inactifs »
Votre base de contacts contient certainement des adresses qui n’existent plus. Scoop : une adresse mail qui n’existe plus n’est pas un client inactif.
Vous devez nettoyer votre base de données. Comment ? En faisant des tests de délivrabilité :
Les hard bounces doivent être supprimés. Ce sont des adresses emails qui n’existent plus.
Les soft bounces doivent être mis en quarantaine. Ce sont des adresses qui ne reçoivent plus vos messages pour des raisons temporaires : une boîte de réception pleine, par exemple.
Vous pouvez à partir de là construire votre segment des clients inactifs. Il est constitué :
Des clients qui répondent à la définition que vous avez construite d’un « client inactif » (cf. supra).
Des adresses emails qui ne sont ni des hard bounces, ni des soft bounces.
Construire le segment « clients inactifs » avec la méthode RFM
Il est possible d’utiliser la segmentation RFM (Récence, Fréquence, Montant) pour construire le segment des clients inactifs. De manière plus générale, cette méthode RFM vous permettra de segmenter vos clients en fonction de leur comportement d’achat. Elle est très utilisée dans le Retail. Découvrez notre guide complet pour construire une segmentation RFM.
2 leviers pour relancer les clients inactifs
Un client inactif n’est pas un client perdu, c’est un client avec lequel vous devez procéder autrement pour faire naître ou renaître son intérêt pour vos produits et vos offres. Nous allons vous présenter deux approches complémentaires pour réveiller des clients dormants. La première consiste à créer des campagnes ou des scénarios de réactivation emails, la deuxième consiste à réactiver vos clients avec des Ads.
Réactiver vos inactifs avec des campagnes ou scénarios emails
Votre client ne réagit plus à vos emails ? Ce n’est peut-être pas le canal qui est le problème, mais votre manière de solliciter le client. La première approche, classique mais à l’efficacité éprouvée, consiste à réactiver les clients inactifs par des campagnes emails. Ici, place à la créativité marketing !
Voici plusieurs techniques possibles :
Envoyer un questionnaire de satisfaction. Trop de promotionnel tue le promotionnel et créé des clients inactifs. Certains clients inactifs ont peut-être besoin d’amour, de relationnel, d’empathie, d’attention. Envoyer un questionnaire de satisfaction suffit parfois à renouer le fil du dialogue. Les réponses de vos clients vous permettront d’ailleurs d’identifier les axes d’amélioration de vos produits et de vos communications.
Proposer une offre spéciale (code promo, coupon…). Disons-le clairement, cette technique est l’une de celles qui fonctionnent le mieux, mais elle a un coût pour l’entreprise. Nous vous conseillons de réserver cette approche aux clients vraiment très inactifs, qui ont besoin d’un sérieux incentive pour revenir vers vous.
Envoyer une invitation à une vente privée. Les ventes privées sont très appréciées des clients. Tous les clients aiment se sentir privilégiés, VIP.
Proposer au client de gérer ses préférences. Une pression marketing trop forte peut être cause d’inactivité. Donner la possibilité au client de régler la fréquence de messages et les thématiques peut être un moyen de les réactiver.
Quelle que soit l’approche que vous choisirez, n’oubliez pas les bonnes pratiques de l’emailing.Vous les connaissez certainement déjà :
Travaillez avec amour et intelligence votre objet. C’est la partie la plus importante de l’email. C’est lui qui incitera vos clients inactifs à ouvrir ou non votre message.
Exploitez la connaissance client. Personnalisez vos emails avec le prénom et/ou nom de vos clients. Ciblez les offres proposées en fonction de l’historique d’achat de vos clients, de leurs centres d’intérêt. Plus vos messages seront personnalisés et ciblés, plus vous aurez de chance d’atteindre le coeur de vos clients inactifs.
Envoyez les campagnes au bon moment. Un conseil : n’attendez pas 3 ans avant de mettre en place des campagnes de réactivation. Plus vous serez réactifs, plus vous aurez de chances de réveiller vos clients dormants.
Faites des tests. Il n’y a pas de recette magique en email marketing. Testez différentes approches pour reconquérir vos clients inactifs et généralisez celles qui fonctionnent le mieux.
Voici un conseil pour aller un peu plus loin : dans votre outil de Marketing Automation, mettez en place un scénario de réactivation, avec une séquence progressive de messages. Voici à quoi cela pourrait ressembler :
Envoi d’un premier email de reprise de contact, dont l’objet pourrait être « [Prénom], vous nous avez manqué ». Dans cet email, vous pouvez rappeler ce que vous faites, mettre en avant la valeur de votre service, formuler votre proposition de valeur ou bien présenter vos nouvelles collections. Rendez-vous intéressant sans utiliser un ton trop « commercial ».
Si le premier email n’a pas été ouvert : envoi à J+5 d’un deuxième email comportant un questionnaire de satisfaction.
Si le deuxième email n’a pas été ouvert : envoi à J+10 d’un troisième email avec un code promo à utiliser sur le site internet.
Si le troisième email n’est pas ouvert, envoi à J+15 d’un quatrième email…l’email de la dernière chance. On peut imaginer un objet surprenant pour tenter, une dernière fois, de susciter l’intérêt du client. Par exemple : « Désinscrivez-vous », ou « Il est temps de se dire adieu (ou pas…).
Un exemple d’email de relance de clients inactifs.
Relancer les clients inactifs via les Ads
La deuxième approche consiste à réactiver vos clients inactifs en utilisant des annonces publicitaires. C’est une approche beaucoup moins utilisée et pourtant son potentiel est grand. C’est surtout adapté si vous avez un grand nombre de clients inactifs. Pourquoi ? Prenons un exemple, pour bien comprendre :
Vous avez construit votre segment des clients inactifs. Il regroupe tous les clients qui n’ont pas réagi à vos sollicitations depuis 3 mois. Il représente 10 000 contacts.
Vous construisez une campagne de retargeting ciblant ce segment. Supposons que 15% des clients exposés aux annonces se rendent sur le site. Soit 1 500 clients.
Parmi ces 15% de clients inactifs qui se rendent sur le site, tous ne vont pas acheter. Supposons que 10% d’entre eux effectuent un achat. Soit 150 clients.
La relance des 10 000 clients inactifs vous a permis de générer 150 paniers achetés, ce qui est assez peu.
Changeons d’échelle. Imaginez que votre base contient 100 000 clients inactifs. Si l’on garde les mêmes hypothèses, la relance de vos clients via des Ads vous permettra de générer 1 500 paniers achetés, ce qui est beaucoup plus intéressant.
Il faut donc avoir une base de contacts/un segment de clients inactifs suffisamment grand pour que la relance via des Ads soit pertinente. Si vous êtes dans cette situation, vous pouvez mettre en place cette technique en deux étapes :
Etape #1 : Exporter le segment vers Google/Facebook Ads. Une fois que vous avez construit votre segment « clients inactifs » dans votre outil d’emailing, vous pouvez l’exporter dans votre compte Google Ads ou Facebook Ads. Il est important que le segment soit régulièrement mis à jour dans Google Ads/Facebook Ads. L’utilisation d’une plateforme comme Octolis vous permet de gérer de manière centralisée tous vos segments clients et de mettre en place des flux de synchronisation en temps réel dans vos outils de destination, en l’occurrence Google Ads et/ou Facebook Ads.
Etape #2 : Créer une campagne Google/Facebook Ads. Vous devez ensuite créer votre ou vos campagne(s) de relance des inactifs. Ce travail de créa sera plus rapide si vous avez déjà des templates de campagnes, bien entendu. Présentation des nouveaux produits, remise, offre exceptionnelle : quel que soit le contenu des annonces, vous devez garder en tête l’objectif : convaincre les clients de se rendre sur le site et d’acheter.
Nous avons mis l’accent sur les deux principaux canaux pour relancer les clients inactifs : l’email et le retargeting. Si vos clients ont une grande lifetime value, il est possible d’utiliser le SMS et le téléphone.
Nous espérons vraiment vous avoir convaincus de l’importance de réactiver les clients inactifs. Si vous suivez les bonnes pratiques, si vous segmentez intelligemment les inactifs, si vous imaginez des campagnes originales, si vous allez plus loin en créant des scénarios marketing, croyez-nous : vous réussirez à réactiver beaucoup de vos clients. Le ROI des campagnes de réactivation dépasse presque toujours le ROI des campagnes d’acquisition. Qu’attendez-vous pour vous lancer ? 🙂
Le CRM est un sujet complexe qui requiert des compétences variées. Difficiles de les avoir toutes en interne, du coup, cela fait vivre beaucoup de prestataires. On peut faire appel à un prestataire pour beaucoup de sujets différents : parcours clients, aide au choix de solutions CRM (marketing, commercial ou service client), paramétrage des logiciels, conception des messages, etc. Les spécialités se recoupent et sont difficiles à lire quand on n’est pas expert du métier.
Nos clients installent souvent Octolis lors d’une phase de restucturation de leur écosystème CRM. Du coup, on croise beaucoup de professionnels différents. Des cabinets de conseil CRM, des ESN / intégrateurs techniques, des agences en conception d’emails, des freelances data, etc.
A force de croiser des prestas, on s’est dit que ce serait sympa de consolider les noms quelque part. Résultat, un fichier assez complet de 70+ professionnels CRM dans un GSheet téléchargeable.
On a essayé de les classifier, et d’en sélectionner quelques uns pour chaque catégorie dans l’article ci-dessous. Je parle d’essayer, car c’est difficile de mettre dans une seule catégorie des boites de services qui font tout, avec des profils à la fois consultants strat, développeur, chef de projet CRM.
Meet Your People c’est une équipe de consultants CRM indépendants basée à Paris.
Notre mission ? Vous conseiller et vous accompagner dans la mise en œuvre d’une stratégie CRM éthique, responsable et performante. Donnons du sens à vos actions !
Badsender est une agence spécialisée en eCRM et en email marketing.
Conseil - Stratégie eCRM et emailing, choix outils de gestion de campagne ou audit délivrabilité
Déploiement - Qu’il s’agisse de migrer vos données et vos campagnes vers votre nouvelle plateforme emailing ou de déployer votre nouvelle stratégie eCRM
Production - L’intégration HTML d’emails, la rédaction de contenus et la conception de designs d’emails
Cabinet de conseil Data Marketing & CRM.
Nous accompagnons nos clients, qu'il s'agisse de grands groupes ou de PME, dans leur projet de transformation digitale avec une approche centrée autour des données clients. Notre équipe de consultants de haut niveau met en place des dispositifs d'analyse et d'exploitation des données à très forte valeur ajoutée : modélisation du parcours client, scoring comportemental, benchmark DMP / CRM, déploiement de scénarios relationnels, etc.
Architecture CRM, Parcours clients, Plan relationnel, Marketing Automation, RCU / CDP, Analytics, Données clients, RGPD, Data gouvernance, Data Marketing, OKR, Attribution
Expert du conseil et de l’accompagnement en stratégies marketing clients omni canal, notre mission a pour objectif d’accélérer vos performance business grâce à une meilleure Expérience client.
Pour cela, nous diagnostiquons les parcours clients, construisons vos personas, définissons vos futurs Parcours cibles, élaborons la stratégie data et formulons vos scénarios de marketing automation …
CustUp est un conseil opérationnel en Relation Clients.
Nous structurons et mettons en œuvre le Marketing Clients et les schémas de dialogue des entreprises.
Pour ce faire, nous utilisons le CRM, le Marketing Automation et les Centres de Contacts. Nous organisons la collecte et l’exploitation des Données Clients : le carburant de la Relation Clients à distance.
CRM, Centre de contacts, Abonnement, Marketing client, Relation client, Parcours Client, GDPR, RGPD, DMP, Données Client, Service Client, Automated marketing, Formation Relation Client
Fondée en 2010, L’Agence Relatia, l'agence de marketing relationnel digital SoLoMo, en particulier pour les enjeux Drive2Store ou Store2Digital. Notre spécialité : acquisition ou fidélisation de vos clients via l'exploitation des dernières innovations en terme de services connectés.
E-CRM, Emailing, E-Marketing, M-CRM, Mobile Marketing, Advertising, email responsive, Agence digitale, digital Marketing, Agence E-CRM, drive to store, geolocalisation, datamining
Créé en 2003, Colorado Groupe accompagne ses clients pour imaginer et mettre en œuvre une expérience client fluide, efficace et innovante.
Colorado Groupe s’appuie sur la complémentarité de ses 2 activités : 1. Le conseil en marketing et innovation sur l’Expérience Client 2. ’analyse des attentes clients et le développement du Customer Insight avec sa solution SaaS innovante ConsumerLive
Conseil en relation client, Pilotage et management de l'expérience client, Solution de Customer Feedback Management et Solutions d'écoute et d'analyse de la Voix du Client
Créés pour l'ère numérique de deuxième génération, nous sommes une équipe d'entrepreneurs de la transformation numérique. Nous combinons le conseil aux entreprises, la réflexion sur le design numérique, le marketing, la technologie et les données pour résoudre rapidement des problèmes commerciaux complexes pour les PDG, leurs cadres et les investisseurs. Nous constituons des taskforces d'entrepreneurs pour mener des opérations numériques stratégiques avec des investisseurs et des entreprises.
Digital strategy, Digital transformation, Innovation, Data, UX, CRM, Branding, Digital marketing, Digital IT, Change management, Digital coaching, E-commerce, Due diligences
Fondée en 2003 par des professionnels du Marketing et du Data, Waisso est une agence digitale spécialisée dans l’optimisation du marketing client en alliant technologie, data et contenu pour une approche plus innovante.
Nous avons construit une entreprise où des hommes et des femmes, relevant de différentes expertises (ingénieurs, data scientists, consultant marketing, etc.) travaillent ensembles pour répondre aux nouvelles exigences d’un marketing bouleversé par le digital.
Marketing Crm, Marketing Cloud, Adobe Partner, Sprinklr, Gigya, Digital Marketing, Cross Channel, Acquisition, Fidelisation, Oracle, Campaign Management, Consulting, Analytics, Segmentation, Contenu Digital, Big Data, Social Media, Business Intelligence, Mobile Marketing, Acquisition
VERTONE est un cabinet de conseil en stratégie et management. Il se distingue par ses missions d’orientations stratégiques autour des métiers du marketing, du développement commercial, de l'expérience client et de la fidélisation, avec une approche centrée sur le client final.
Strategy and management consulting, Marketing strategy, Customer relationship management, Digital strategy, Customer value development, Product and offer strategy, Stratégie marketing, Conseil en stratégie et management, Management de la relation client, Stratégie digitale, Développement de la valeur client, Innovation d'offres et de services, Fidélisation client
KPC est un acteur de référence dans le pilotage de la performance et de l’expérience client. Grâce à la convergence de nos savoir-faire, nous proposons des solutions pour construire l’entreprise intelligente et digitale de demain.
La gestion intelligente des données est au coeur de notre ADN, et de notre culture d’entreprise. Nos partenariats stratégiques et nos équipes pluri-disciplinaires permettent à KPC d’offrir à ses clients la vision, l’expérience et le savoir-faire nécessaires pour développer, personnaliser, intégrer et déployer les solutions les plus performantes.
Data Intelligence & Analytics, Customer Experience & Digital, ERP, Data Science, Big Data, Marketing Automation, Transformation Numerique, Crm, Adobe Campaign, Ia, Salesforce,, Selligent Et Anaplan
Velvet Consulting est le cabinet leader de l'accompagnement des entreprises dans leur orientation client. Depuis 2004, grâce à 200 passionnés de Marketing, nous accélérons la performance des sociétés en construisant une expérience client riche, innovante et efficace grâce à notre approche globale et la complémentarité de nos pôles d’expertises.
Depuis juillet 2020, nous avons rejoint le groupe WPP et le réseau Wunderman Thompson.
Stratégie Client, Performance, Innovation, Change, Datamining, Business Intelligence, Digital, CRM, Marketing Automation, Big Data, Mobilité, Omnicanal, Big Data
Niji est une société de conseil, de design et de mise en œuvre technologique, au service de la transformation numérique des entreprises. Niji accompagne depuis 2001 un très grand nombre d'acteursdans l’accélération et la réussite de leur mutation digitale, au service de leur stratégie, de leur distribution multicanale et de leur fonctionnement interne.
Conseil en stratégie numérique, Ingénierie et conseil technologique, Design de service, Réalisation logicielle
979
Sélection d’ESN & conseil IT
> Pour définir l’architecture technique CRM et intégrer les outils CRM à l’écosystème existant
Artefact is an award-winning responsible strategy and design firm. We help your organization face the future with confidence and craft the products and experiences that bring your vision to life. Our touchstone is responsible design – creating lasting value for people, business, and society.
Named one of Fast Company's Most Innovative Companies, we partner with organizations like Dell, Hyundai, Eli Lilly, Seattle Children's Hospital, the Bill and Melinda Gates Foundation, and more.
user experience design, interaction design, product design, digital innovation, software design, industrial design, creative
VERTONE est un cabinet de conseil en stratégie et management. Il se distingue par ses missions d’orientations stratégiques autour des métiers du marketing, du développement commercial, de l'expérience client et de la fidélisation, avec une approche centrée sur le client final.
Strategy and management consulting, Marketing strategy, Customer relationship management, Digital strategy, Customer value development, Product and offer strategy, Stratégie marketing, Conseil en stratégie et management, Management de la relation client, Stratégie digitale, Développement de la valeur client, Innovation d'offres et de services, Fidélisation client
Grâce à notre équipe de plus de 200 consultants, spécialistes et experts, nous sommes un accélérateur de performance intervenant du cadrage à la réalisation. Connecteur entre le marketing et l'IT, pragmatique et indépendant, nous œuvrons pour le transfert de compétences à nos équipes clientes.
conversion, optimisation, webanalytics, formation, adtech, martech, datalake, datascience, digital marketing, digital consulting, data consulting, DMP, Marketing Automation, data engineering, CRO, Consulting, Marketing, Technologie
Colombus Consulting est une société de conseil en management spécialisée dans le changement d'entreprise et la gestion de projets complexes. Il intervient sur les secteurs des services financiers, des marchés financiers, de l'énergie et des services publics. Basés en France et en Suisse, nos +170 consultants interviennent au niveau opérationnel et exécutif.
C’est pour accompagner les grands acteurs du Luxe dans leur transformation digitale et les aider à créer des expériences clients remarquables, qu'Adone Conseil a été créé en 2007.
Adone réalise des missions stratégiques et opérationnelles sur des projets e-Commerce, Data, Customer Experience, Digital in Store, PIM-DAM, PLM, Supply Chain ou encore Green Transition.
Assistance à maîtrise d'ouvrage (AMOA), Gestion de projet, Conseil en système d'information, Digital, Luxe, Parfums et Cosmétiques, Mode, Horlogerie et Joaillerie, Tourisme, Hôtellerie, Digital in Store, PIM, DAM, CRM, Supply Chain, e-commerce, Data, Analytics, Clienteling, OMS, PMO, Consultant
Depuis plus de 50 ans, nous avons bâti notre réputation en reflétant les besoins des marques de la meilleure façon possible. Nous comprenons les avantages de tout offrir sous un même toit. C'est pourquoi les architectes, les designers et les entreprises de divers secteurs d'activité choisissent AGI pour tous leurs besoins en matière de signalisation, d'image de marque et de maintenance.
Architectural Imaging, Architectural Signage, National Programs, Image Maintenance, Facility Design Services, Interior Signage and Wayfinding, ATM Housing, Kiosks, and Toppers, Digital Signage, Exterior Signage, Innovative Solutions, Sign Maintenance, Electrical Service, EVCE Installation & Service, Interior & Exterior Lighting
Niji est une société de conseil, de design et de mise en œuvre technologique, au service de la transformation numérique des entreprises. Niji accompagne depuis 2001 un très grand nombre d'acteursdans l’accélération et la réussite de leur mutation digitale, au service de leur stratégie, de leur distribution multicanale et de leur fonctionnement interne.
Conseil en stratégie numérique, Ingénierie et conseil technologique, Design de service, Réalisation logicielle
Accenture est une entreprise internationale de conseil en management, technologies et externalisation. Combinant son expérience et ses capacités de recherche et d’innovation développées et mises en œuvre auprès des plus grandes organisations du monde sur l’ensemble des métiers et secteurs d’activité, Accenture aide ses clients - entreprises et administrations - à renforcer leur performance.
Management Consulting, Systems Integration and Technology, Business Process Outsourcing et Application and Infrastructure Outsourcing
Acteur international du conseil et des technologies, Keyrus a pour mission de donner du sens aux données, en révélant toute leur portée, notamment sous un angle humain.
S'appuyant sur l'expérience cumulée de plus de 3 000 collaborateurs et présent dans 22 pays sur 4 continents, Keyrus est l'un des principaux experts internationaux en matière de données, de conseil et de technologie.
Management & Transformation, Data Intelligence, Digital Experience
Talan est un cabinet de conseil en innovation et transformation par la technologie.
Depuis plus de 15 ans, Talan conseille les entreprises et les administrations, les accompagne et met en œuvre leurs projets de transformation et d’innovation en France et à l’international.
Conseil, AMOA SI, MOE, Support, Architecture SI, Transformation Agile, Digital, Consulting, IT Consulting, CRM, BIG DATA, IoT, Blockchain, IA, innovation, Data, big data
À la confluence du conseil en management et du conseil numérique, Wavestone accompagne les entreprises et organisations de premier plan dans la réalisation de leur transformation la plus critique sur la base d'une conviction unique et centrale : il ne peut y avoir de transformation réussie sans une culture partagée d'enthousiasme pour le changement.
Strategy & Management Consulting, Innovation Management & Funding, Marketing, Sales & Customer Experience, Digital & IT Strategy, Digital & Emerging Technologies, IT & Data Architecture
BearingPoint est un cabinet de conseil indépendant avec des racines européennes et une portée mondiale.Nous transformons les entreprises. Nous aidons nos clients à atteindre leurs objectifs en appliquant notre profonde expertise sectorielle et fonctionnelle pour comprendre et répondre à leurs besoins spécifiques.Nos consultants sont passionnés et très engagés, avec un état d'esprit pragmatique mais innovant.
Business Consulting, Technology Consulting, Management Consulting, Digital & Strategy, Advanced Analytics, Digital Platforms, RegTech, Software Development et Agile Advisor
Des idées sur lesquelles vous pouvez agirFondée en 1976, CGI est l'une des plus grandes entreprises de services-conseils en TI et en affaires au monde. Dans 21 secteurs d'activité et sur 400 sites dans le monde, nous fournissons des services-conseils en TI et en affaires complets, évolutifs et durables qui sont informés à l'échelle mondiale et fournis à l'échelle locale.
Business consulting, Systems integration, Intellectual property, Managed IT, Business process services, Digital transformation, Emerging technology
57529
Conseil opérationnel & Agences CRM
> Pour piloter la mise en place d’un nouvel outil, paramétrer des campagnes / scénarios, créer des messages, etc.
Studio de création graphique et agence digitale au service des entreprises depuis 2006, Alter Création concentre son énergie afin de mettre en lumière tous vos projets de communication, de la création de votre identité visuelle à la réalisation de votre site web, de vos éditions sur tous supports à vos campagnes e-mailings.
Agence de marketing digital à ParisComexplorer est une agence qui propose, grâce à une méthodologie unique, d’aider les entreprises à accroitre leur vente, leur trafic web, à qualifier leur leads, à transformer et fidéliser leur clientèle. Inspiré du modèle startup, l’agence propose une nouvelle approche du marketing, plus pragmatique et plus pertinente : le lean marketing.
Badsender est une agence spécialisée en eCRM et en email marketing.
Conseil - Stratégie eCRM et emailing, choix outils de gestion de campagne ou audit délivrabilité
Déploiement - Qu’il s’agisse de migrer vos données et vos campagnes vers votre nouvelle plateforme emailing ou de déployer votre nouvelle stratégie eCRM
Production - L’intégration HTML d’emails, la rédaction de contenus et la conception de designs d’emails
Majelice est une agence digitale experte en email marketing.Nous accompagnons nos clients dans leur transformation digitale par le biais de mise en œuvre d’opérations de e-marketing (email & SMS).Nous répondons avec le même soin et la même expertise à tous les besoins de nos clients, qu’il s’agisse de la mise en place d’une simple newsletter, d’un scénario de fidélisation ou d’une mécanique complexe de recrutement multicanal.
email marketing, emailing, sms marketing, creation graphique, emails personnalisés, campagnes scénarisées, real time email marketing, routage, délivrabilité, responsive design, intégration html, analyse et recommandations, animation de bases de données, newsletters, marketing automation
FYSANE est une agence de Marketing Automation dont le siège est basé à Paris. Elle intègre les compétences nécessaires pour mener à bien la transformation digitale de votre entreprise.Notre mission est de vous accompagner dans la réalisation de vos projets, de la conception à la mise en œuvre tout en garantissant un suivi.Notre partenariat avec Adobe nous permet de mettre à disposition des consultants ayant une expertise dans la solution de l’écosystème Marketing Automation Adobe Campaign Classic ou Standard.
Cabinet de conseil Data Marketing & CRM.
Nous accompagnons nos clients, qu'il s'agisse de grands groupes ou de PME, dans leur projet de transformation digitale avec une approche centrée autour des données clients. Notre équipe de consultants de haut niveau met en place des dispositifs d'analyse et d'exploitation des données à très forte valeur ajoutée : modélisation du parcours client, scoring comportemental, benchmark DMP / CRM, déploiement de scénarios relationnels, etc.
Architecture CRM, Parcours clients, Plan relationnel, Marketing Automation, RCU / CDP, Analytics, Données clients, RGPD, Data gouvernance, Data Marketing, OKR, Attribution
Inbound Value est une agence de communication digitale spécialisée dans l’Inbound Marketing. Notre agence travaille principalement avec des clients en B2B notamment dans le secteur des « SaaS » (Software As A Service). Nous permettons à des entreprises BtoB de saisir les opportunités que leur offre internet, en leur apportant plus de trafic qualifié ainsi que des leads de qualité qui sont susceptibles de devenir des clients.
Inbound Marketing, SEO, Social Media, Marketing Digital, Hubspot, Strategie digitale, Content Marketing, Growth Hacking, E-Mail Marketing, Lead Generation, Trafic Generation, B2B, SaaS, Marketing Automation
CustUp est un conseil opérationnel en Relation Clients.
Nous structurons et mettons en œuvre le Marketing Clients et les schémas de dialogue des entreprises.
Pour ce faire, nous utilisons le CRM, le Marketing Automation et les Centres de Contacts. Nous organisons la collecte et l’exploitation des Données Clients : le carburant de la Relation Clients à distance.
CRM, Centre de contacts, Abonnement, Marketing client, Relation client, Parcours Client, GDPR, RGPD, DMP, Données Client, Service Client, Automated marketing, Formation Relation Client
Markentive fournit des talents, des processus et des technologies pour faire de votre transformation un succès. Que votre projet soit de trouver l'inspiration, de construire un écosystème digital (CRM, Site Web, Marketing), de mener des campagnes ou simplement de développer vos compétences, nos experts peuvent vous aider. Markentive vous invite à prendre le chemin de la croissance (pour de bon).
Agence conseil en marketing client du groupe Loyalty Company.Kiss The Bride marie nativement la précision des data et la force des émotions pour donner naissance à des expériences clients originales, engageantes et profitables. 3 directions d’Agences : Lille / Paris / LyonHub d’expertises pluridisciplinaires : Consulting & Projects management - Data & Engineering - Création, Content & Social - Digital - Plateformes technologiques - Opérations marketing140 collaborateurs - 25 M€ de CA - 21 récompenses professionnelles - +100 clients
communication, digital, marketing, marketing client, relation client, stratégies de fid et d'engagement, animation de réseaux, performance commerciale, data, expérience client
Fondée en 2003 par des professionnels du Marketing et du Data, Waisso est une agence digitale spécialisée dans l’optimisation du marketing client en alliant technologie, data et contenu pour une approche plus innovante.
Nous avons construit une entreprise où des hommes et des femmes, relevant de différentes expertises (ingénieurs, data scientists, consultant marketing, etc.) travaillent ensembles pour répondre aux nouvelles exigences d’un marketing bouleversé par le digital.
Marketing Crm, Marketing Cloud, Adobe Partner, Sprinklr, Gigya, Digital Marketing, Cross Channel, Acquisition, Fidelisation, Oracle, Campaign Management, Consulting, Analytics, Segmentation, Contenu Digital, Big Data, Social Media, Business Intelligence, Mobile Marketing, Acquisition
Située à Paris, Montpellier, Lille & Nantes, Dn'D est une agence conseil en création d’expériences digitales et E-Commerce.
Elle conseille et accompagne les entreprises du B2B et du B2C (luxe, retail, industrie, grande consommation, etc) dans leur stratégie online depuis 2004.
E-Commerce Agency, Consulting, Web Design, Web Development, Web Marketing, Magento, Akeneo PIM, Oro CRM, Mirakl MarketPlace, PWA, Vue Storefront, Adobe, CRM, Marketing Automation et OroCommerce
Nous sommes une agence CX Digitale. Les conversations et interactions composent notre terrain de jeu. Nous concevons, réalisons et animons de nouvelles expériences qui alimentent les conversations entre les marques & les clients.
Nous optimisons vos canaux digitaux avec une approche customer centric en identifiant les opportunités et en implémentant de nouvelles solutions.
Chatbot, Digital CRM, Digital Marketing, Social Media Management, Social Media Intelligence, Social Ads, Brand Community, Social Influence Marketing, eCRM, Interaction design, Visual IVR, Digital Care, Customer Support, Artificial Intelligence, Automation, Selfcare
Velvet Consulting est le cabinet leader de l'accompagnement des entreprises dans leur orientation client. Depuis 2004, grâce à 200 passionnés de Marketing, nous accélérons la performance des sociétés en construisant une expérience client riche, innovante et efficace grâce à notre approche globale et la complémentarité de nos pôles d’expertises.
Depuis juillet 2020, nous avons rejoint le groupe WPP et le réseau Wunderman Thompson.
Stratégie Client, Performance, Innovation, Change, Datamining, Business Intelligence, Digital, CRM, Marketing Automation, Big Data, Mobilité, Omnicanal, Big Data
232
Cabinets de conseil data
> Pour analyser votre base clients, et exploiter vos données au maximum
Présent dans 26 pays, Inetum est un leader incontournable des services informatiques à valeur ajoutée et des logiciels. Inetum occupe un positionnement stratégique différenciant entre les opérateurs de taille mondiale et les acteurs de niche. Avec près de 27 000 collaborateurs, le Groupe atteindra ainsi les 2,3 milliards d’euros de chiffre d’affaires sur 2019 (pro forma).
A la frontière de la Tech et de la Data, UnNest accompagne les équipes marketing in-house ou en agence pour utiliser au mieux leur donnée "First party"
Nous mettons en place pour nos clients une équipe data externalisée, capable de délivrer des projets et des applications data en un temps record pour les marques, les "scale up" et les agences de marketing digital.
Analytics, Data Consulting, Digital Analytics, Data Marketing, Cloud Data Warehouse, RGPD, Data Engineering, Data Analysis, Tracking, Google Big Query, Fivetran, Google Cloud Platform, ETL et Martech
MFG Labs est une société de conseil et réalisation experte en data et en intelligence artificielle. Nous aidons les entreprises à améliorer leurs prises de décisions, à optimiser leurs processus et à créer de nouveaux services grâce à l'application de data science, de digital analytics, de design et des technologies les plus avancées.
Data analysis, Data science, Infrastructure, Development, Data engineering, Web analytics, Digital media, machine learning, big data, software development
C-Ways est une société de conseil spécialisée en data sciences. Grâce à des méthodes innovantes de captation et de modélisation de données, C-Ways accompagne dans leurs décisions les administrations et les entreprises leaders des secteurs de la mobilité, de la mode, du luxe, des services financiers, du sport, de la grande consommation…
market research, predictive marketing, data modeling, data science, client surveys, big data, data driven marketing, modeling et creative data
Artefact is an award-winning responsible strategy and design firm. We help your organization face the future with confidence and craft the products and experiences that bring your vision to life. Our touchstone is responsible design – creating lasting value for people, business, and society.
Named one of Fast Company's Most Innovative Companies, we partner with organizations like Dell, Hyundai, Eli Lilly, Seattle Children's Hospital, the Bill and Melinda Gates Foundation, and more.
user experience design, interaction design, product design, digital innovation, software design, industrial design, creative
The ELEVATE Group is a collection of 3 hyper-focused businesses each with a different center of gravity. All under one global roof. The result: A Group that's much stronger than the sum of its parts.
We bring clarity to our customers toughest revenue generations through Data Integrity, Demand Generation, and Business Insights.
Data Integrity, Demand Generation, Data Analytics, Lead Generation, CRM Management, Marketing Automation Management, BI Dashboard Development, Marketing Strategy, Contact Identification
Rhapsodies Conseil, s’investit auprès de chacun de ses clients pour concevoir des réponses sur mesure combinant compétences métiers, expertises techniques et pratiques agiles. Nos solutions novatrices sont bâties en collaboration étroite avec nos clients dans une démarche de co-construction garantissant une réponse alignée à leurs besoins.
Transformation Agile, Transformation DATA, Architecture SI, Architecture d'Entreprise, Pilotage des Transformations, Performance Economique IT , Internal Digital Experience
DataValue Consulting est un cabinet de conseil IT qui accompagne les entreprises des secteurs privé et public dans la valorisation de leur data.
Le cabinet spécialiste s'appuie sur une double compétence de ses consultants en management et en technologie. Nous aidons nos clients depuis la formalisation de leur stratégie jusqu’à la mise en œuvre de leurs projets data.
Conseil, Stratégie IT, Big Data, Data Management, Pilotage de la performance, Business Intelligence, Gouvernance de la Data, Datavisualisation, Data Management, Data Intégration
Grâce à notre équipe de plus de 200 consultants, spécialistes et experts, nous sommes un accélérateur de performance intervenant du cadrage à la réalisation. Connecteur entre le marketing et l'IT, pragmatique et indépendant, nous œuvrons pour le transfert de compétences à nos équipes clientes.
conversion, optimisation, webanalytics, formation, adtech, martech, datalake, datascience, digital marketing, digital consulting, data consulting, DMP, Marketing Automation, data engineering, CRO, Consulting, Marketing, Technologie
KPC est un acteur de référence dans le pilotage de la performance et de l’expérience client. Grâce à la convergence de nos savoir-faire, nous proposons des solutions pour construire l’entreprise intelligente et digitale de demain.
La gestion intelligente des données est au coeur de notre ADN, et de notre culture d’entreprise. Nos partenariats stratégiques et nos équipes pluri-disciplinaires permettent à KPC d’offrir à ses clients la vision, l’expérience et le savoir-faire nécessaires pour développer, personnaliser, intégrer et déployer les solutions les plus performantes.
Data Intelligence & Analytics, Customer Experience & Digital, ERP, Data Science, Big Data, Marketing Automation, Transformation Numerique, Crm, Adobe Campaign, Ia, Salesforce,, Selligent Et Anaplan
Acteur international du conseil et des technologies, Keyrus a pour mission de donner du sens aux données, en révélant toute leur portée, notamment sous un angle humain.
S'appuyant sur l'expérience cumulée de plus de 3 000 collaborateurs et présent dans 22 pays sur 4 continents, Keyrus est l'un des principaux experts internationaux en matière de données, de conseil et de technologie.
Management & Transformation, Data Intelligence, Digital Experience
Talan est un cabinet de conseil en innovation et transformation par la technologie.
Depuis plus de 15 ans, Talan conseille les entreprises et les administrations, les accompagne et met en œuvre leurs projets de transformation et d’innovation en France et à l’international.
Conseil, AMOA SI, MOE, Support, Architecture SI, Transformation Agile, Digital, Consulting, IT Consulting, CRM, BIG DATA, IoT, Blockchain, IA, innovation, Data, big data
Business & Decision est un groupe international des services du numérique, spécialisé, depuis sa création, dans l’exploitation et l’analyse de données.
Data Intelligence, Big Data, Data Gouvernance, véritables socles de l’intelligence artificielle et de l’expérience digitale, sont les domaines d’expertise et de spécialisation du groupe.
Business & Decision, filiale d’Orange Business Services, emploie 2 400 talents dans 10 pays dans le monde et dans 14 villes en France.
Data, Digital, CRM, Digital Transformation, Data Science, Data Visualisation, Gouvernance des données, Intelligence artificielle, Protection des données, Green AI, Data Mesh
2921
Intégrateurs data / CRM
> Pour mettre en place les flux de données, et paramétrer les outils CRM
Cezium est votre partenaire de confiance sur tous les sujets relatifs au marketing digital:- spécialiste des solutions de marketing automation (notamment Salesforce Marketing Cloud)- conseil avisé sur les sujets DMP (POC ou stratégie d'industrialisation)- partenaire innovant (ISV sur la plate-forme Salesforce avec des applications dédiées à Marketing Cloud) - coaching et formation.
Ateja founded in 2012. Intégrateur des solutions CRM Sage. Sage CRM Standard. Développement de projets ETL Talend Open Studio. Déploiement de portail intranet Microsoft Sharepoint.
Emploi 5 personnes.
www.ateja.fr
Basé à Euratechnologies - technopole NTIC
Depuis 2004, Synaltic est un véritable spécialiste en Data Management, et propose une nouvelle perspective sur les systèmes d’information de plus en plus « Data Driven ».
Grâce à ses choix de partenaires dès leur plus jeune âge et l'appui de ses 30 collaborateurs certifiés, Synaltic accompagne ses clients dans toutes les étapes de la valorisation de leurs données. Il s’agit d’un véritable artisan de la donnée avec des valeurs indissociables telles que le partage, la curiosité, la polyvalence, l'innovation et la durabilité.
Expertise, Projet, Formation, Support, R&D, Data Preparation, Dataviz, Développement, Data Lake, Data Integration, Méthodologie Projet, Conseil, Open Source, Open Data, Data Management, Business Intelligence
AI&DATA est la plus ancienne société de Data Marketing en France. Créés en 1972 (nous fêtons nos 50 ans en 2022 !), nous avons déjà réalisé plus de 2 000 projets data, principalement pour les Grands Comptes, tous secteurs confondus.
Nous travaillons principalement pour des grands comptes dans tous les secteurs d’activité : Leclerc Voyages, Compagnie Marco Polo, Bioderma, Botanic, EDF, Puy du Fou, MAIF, Harmonie Mutuelle, Société Générale, etc... Au total, nous gérons pour ces marques près de 250 millions de clients et 50 milliards de transactions par an.
Datamining, CRM services, Data Quality, Marketing strategy, Datascience, Datamarketing, Textmining, Machine Learning, Consulting, Data Training
Synolia est une société de conseil et de services spécialisée dans la mise en place de dispositifs sur-mesure plaçant le client au cœur de l’entreprise.
Rapidement Synolia tisse des liens étroits avec des éditeurs innovants et s’entoure des meilleurs talents, tous partageant les mêmes valeurs d’innovation, d’excellence et de proximité.
Fondé en 2007, AVISIA est devenu au fil des années un acteur de référence en Data, Digital & Technologies.
A travers une équipe de passionnés, nous sommes spécialisés dans le Conseil, l’Intégration et la réalisation de projets « Data Centric ».
Business Intelligence, Performance Analytique, Big Data, Conseil & AMOA, Data Science, Digital, Data Engineering, Décisionnel, Web Analytics, Google Cloud Platform, Dataiku, SAS, Google Analytics
Chez Cyllene, on couvre le spectre complet de votre besoin en termes de :
1. Conseils
2. Définition d’architectures
3. Hébergement & Services managés
4. Cybersécurité & Formations
5. Déploiement de technologies applicatives et web
6. Data Intelligence & Data Analytics
RCU, CDP, Architecture data, Hébergement, Maintenance, Infogérance, Base de données, Data analytics
218
Télécharger notre Top 70+ prestataires CRM français
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Il n’est pas facile de mesurer le ROI d’un dispositif data ou l’impact d’une fonction data. Pour un dirigeant soucieux de bien doser ses investissements, c’est un challenge.
Il y a au moins 2 raisons qui expliquent cette difficulté :
La fonction data est relativement nouvelle. Il n’y a pas encore de framework faisant autorité permettant de mesurer son impact. D’ailleurs, le rôle et la place dans l’organisation de la fonction data ne sont pas toujours bien clairs. Certaines équipes data reportent au CTO, d’autres aux CFO, d’autres au CMO…
La fonction data a un impact indirect sur les KPIs business de l’entreprise. Il s’agit d’une fonction support qui n’est pas directement génératrice de revenus comme peuvent l’être les fonctions Marketing ou Sales.
Votre équipe data a entre 0 à 5 personnes ? Son rôle principal est la fiabilisation des données, c’est-à-dire la gestion de la qualité des données. C’est sur cela que vous allez pouvoir la juger et mesurer son ROI.
Votre équipe data a entre 5 à 10 personnes ? Son rôle principal est l’opérationnalisation des données, c’est-à-dire la mise à disposition des données directement dans les outils des équipes métier.
Votre équipe data a plus de 10 personnes ? Son rôle est l’amélioration de la productivité des équipes.
Source : Castordoc.
De ces rôles ou objectifs découlent des indicateurs que nous allons vous détailler. Nous avons aussi conçu pour vous une ressource GSheets 100% home-made qui devrait vous être utile. Pour produire ce guide, nous avons choisi de nous inspirer du beau travail réalisé par nos amis anglophones de chez Castordoc.
ROI d’une petite équipe data : Fournir des données fiables
Une petite équipe data (entre 0 et 5 personnes) doit se concentrer sur un objectif principal : fournir des données propres et fiables aux équipes business et aux décisionnaires. C’est donc la qualité des données qui va servir d’étalon pour mesurer le ROI de l’équipe et de l’infrastructure data.
Il existe 5 critères pour évaluer la qualité d’une donnée : l’exactitude, l’exhaustivité, la cohérence, la fiabilité et l’utilisabilité. Chacun de ces critères peut se décliner en KPIs et être utilisé pour évaluer le ROI de l’équipe data.
L’exactitude
L’exactitude des données définit le niveau de correspondance entre vos données et la réalité. C’est le critère de base. Si le nombre de commandes enregistré dans le data warehouse est différent de celui rapporté par les commerciaux, il y a un problème, vos données sont inexactes Le KPI consiste à évaluer la proportion de données exactes parmi l’ensemble de vos données.
Une autre approche consiste à calculer le taux d’exactitude pour chaque data set et à le rendre accessible aux utilisateurs sous la forme d’un pourcentage affiché dans leurs outils. On peut ensuite définir une règle de gouvernance : « si moins de X% d’exactitude, ne pas utiliser ce champ ».
La complétude
Le taux de complétude désigne le pourcentage de champs complétés pour un attribut donné. Par exemple, si vous avez l’adresse postale de 80% de vos contacts, 80% est le taux de complétude de l’attribut « adresse ». On peut aussi calculer le champ de complétude d’une base de données, en prenant en compte l’ensemble des colonnes. Le taux de complétude se mesure de la manière suivante :
Là encore, le taux de complétude peut être affiché dans les outils des utilisateurs métier et des règles peuvent être définies pour déterminer à partir de quel taux de complétude un champ peut être utilisé (pour créer un segment par exemple).
La cohérence
La cohérence désigne l’absence de conflit entre vos données. Si vous avez 2 outils qui stockent les adresses postales et que ces 2 outils affichent des valeurs différentes, il y a un conflit et donc un problème de cohérence. Soit dit en passant, l’unification des données dans une base centrale résout ce problème. Mais on peut aussi parler de conflit dans un même outil si, par exemple, votre revenu mensuel n’est pas cohérent avec votre chiffre d’affaires et vos coûts. Il y a donc 2 types de conflits. La cohérence est plus complexe à calculer que les autres métriques. Elle se calcule à deux niveaux : entre deux colonnes, entre deux tables.
La fiabilité
Une donnée est fiable si elle fait l’objet de confiance de la part des personnes qui l’utilisent. Pour qu’une donnée soit fiable, elle doit disposer d’un niveau de garantie suffisant quant à sa qualité. Si l’équipe marketing décide de ne pas utiliser telles données parce qu’elle estime qu’elles ne reflètent pas la réalité, il y a un problème de fiabilité. La fiabilité est un critère subjectif dépendant des critères objectifs présentés plus haut : exactitude, complétude et cohérence. Il y a plusieurs manières de mesurer la fiabilité des données.
L’utilisabilité
La question est simple : est-ce vos données sont utilisées par le métier ? Pour être utilisées, elles doivent être utilisables. Pour être utilisables, les données doivent être facilement accessibles et facilement interprétables.
Un ensemble de données répondant aux 4 critères vus précédemment peut très bien être inutilisable si les données sont difficiles à trouver et à comprendre…L’utilisabilité est le critère ultime de qualité des données. On peut améliorer l’utilisabilité des données en ajoutant des métadonnées, en documentant les données. D’où la métrique que nous vous proposons.
Deux autres métriques sont possibles : le nombre de requêtes d’utilisateurs demandant à ce que la donnée soit présentée autrement, le nombre d’utilisateurs cibles utilisant effectivement les systèmes qui leur sont destinés.
ROI d’une équipe data de taille intermédiaire : Faciliter l’exploitation opérationnelle des données
Une équipe data de taille intermédiaire (entre 5 et 10 personnes) n’a plus pour seul objectif de fiabiliser les données pour aider l’entreprise à prendre des décisions data-driven. Elle doit aussi rendre ces données exploitables au quotidien par les équipes métiers, par les opérationnels. L’exploitation opérationnelle de la donnée est son enjeu.
Impact sur les performances opérationnelles
Créer des reportings avec des données fiables, c’est bien, mais les données n’ont pas seulement vocation à alimenter des tableaux de bord. Le niveau supérieur consiste à pousser les données directement dans les outils utilisés par le métier pour que les équipes puissent utiliser les données au jour le jour, dans leurs process quotidiens. Les données sont « opérationnalisées ».
C’est, par exemple, mettre en place un flux permettant que le NPS remonte automatiquement dans la fiche client du CRM, avec mise à jour en temps réel quand il s’agit de données chaudes. Et plus largement, cela consiste à faire en sorte que les segments, les scores et autres agrégats calculés dans l’outil de data management soient automatiquement synchronisés dans les applicatifs métier, au bon endroit.
C’est ce que l’on appelle « l’operational analytics », qui est facilitée par l’adoption d’outils gérant les flux de données de la base centrale vers les différents applicatifs (ce qu’on appelle les Reverse ETL).
Nous avons produit un article invité sur le site du Journal du Net au sujet de cette approche « operational analytics » . Si vous voulez aller plus loin, nous vous en recommandons chaudement la lecture.
A un niveau plus avancé donc, mesurer le ROI d’une équipe data ou d’une stack data va consister à mesurer l’augmentation des performances des équipes métiers grâce aux données mises à disposition dans leurs outils. Grâce aux données rendues opérationnelles :
Les marketers utilisent des segments plus fins qui leur permettent de concevoir des campagnes mieux ciblées
Les commerciaux priorisent mieux les leads dans leur pipeline
Le support priorisent mieux les tickets
Nous avons conçu un framework qui va vous aider à mesurer le ROI de l’operational analytics sur la partie qui nous intéresse : le marketing. Le fonctionnement de ce framework est simple :
Vous renseignez le coût de votre dispositif data : le coût homme et le coût logiciels.
Vous estimez ensuite ce que vous pourriez gagner grâce à votre stack data. Pour cela, vous devez définir vos différents cas d’usage et, pour chaque cas d’usage, faire une estimation de son impact sur la réduction des coûts d’acquisition et/ou sur la performance (conversion, panier moyen, fréquence d’achat).
Les pourcentages sont calculés en valeurs monétaires sur la base des métriques que vous avez renseignées dans le template.
Une fois tout cela fait, vous n’avez plus qu’à utiliser la formule [(gains – coûts) / coûts] pour calculer le ROI de votre dispositif data.
Impact sur l’Analytics
Une bonne infrastucture data, une bonne stack data permet aussi de booster le ROI de l’équipe data. Il y a plusieurs métriques ou dimensions à prendre en compte pour mesurer cet impact :
L’équipe data est moins sollicitée pour fournir des analyses ad hoc. L’operational analytics permet aux équipes métier de gagner en autonomie dans la production d’analyses adhoc du fait de la mise à disposition des données directement dans les applicatifs et de l’utilisation d’outils self-service business user-friendly. Pour mesurer cet impact, vous pouvez utiliser la métrique suivante :
L’équipe data a plus facilement et rapidement accès aux données. Un manque de documentation, l’absence de data cataloging ou une mauvaise gouvernance des données peuvent compliquer l’accès aux données. Il faut parfois plusieurs jours pour qu’un data scientist accède aux données dont il a besoin pour construire ses modèles. Avec une bon dispositif data, les professionnels de la donnée perdent moins de temps à accéder aux données et consacrent plus de temps à les analyser, les exploiter.
L’équipe data répond plus rapidement aux demandes du métier. La mise en place d’une stack data moderne ou, en tout cas, d’une infrastructure data cohérente permet de traiter plus rapidement les demandes des équipes métier. Comment calculer cet impact ? Par exemple en mesurant la satisfaction des équipes métier vis-à-vis de l’équipe data ou en calculant un temps moyen de réponses (plus difficile à mesurer…).
ROI d’une équipe data importante : Améliorer la productivité
Une équipe data bien structurée, comportant au moins 10 personnes, peut se proposer des objectifs encore plus ambitieux : améliorer la productivité de l’organisation. Comment ? De 3 manières : en optimisant la stack data, en réduisant le temps passé par les équipes métier sur les sujets data, en améliorant la productivité des équipes analytics et métier.
Optimisation de la stack data
Dans une stack data moderne, l’architecture Data et IT est simplifiée. Finies les infrastructures lourdes basées sur des solutions anciennes On-Premise, finie la multiplication inutile des outils, fini le temps perdu à maintenir des pipelines de données complexes ou des bases de données qui tombent régulièrement en panne.
L’un des ROI d’une équipe data mature réside dans sa capacité à mettre en place une stack data moderne adaptée aux objectifs/besoins de l’entreprise et à optimiser le coût général de l’infrastructure data, du management de la data.
Comme nous l’expliquions dans notre article De la stack data moderne à l’expérience data moderne, « la stack data moderne rend simple, rapide, souple et abordable ce qui était autrefois compliqué, long, rigide et coûteux ». L’automatisation des process, des flux, l’effondrement des coûts de stockage, tout cela fait gagner du temps et de l’argent.
Comprendre la stack data moderne
Un Data Engineer qui aurait été cryogénisé en 2010 et que l’on réveillerait aujourd’hui ne comprendrait pas grand-chose à la stack data moderne. Il n’a fallu que quelques années pour que tout change dans la manière de collecter, extraire, acheminer, stocker, préparer, transformer, redistribuer et activer les données. On vous explique tout dans notre guide introductif à la Stack Data Moderne.
Réduction du temps passé par les équipes métier sur les sujets data
L’objectif d’une équipe data mature est, par les moyens qu’elle met à disposition, par l’infrastructure qu’elle construit, de limiter le temps passé par les équipes métier à travailler sur des sujets data, que ce soit construire des reportings, effectuer des analyses adhoc ou synchroniser les données entre les outils, etc.
Notre framework vous permet de calculer le coût total lié au temps passé par les équipes métier sur les sujets data. Vous pouvez vous en servir pour estimer ce que cela vous coûte aujourd’hui et ce que cela vous coûterait si vous optimisiez l’organisation des équipes et votre dispositif data.
Productivité des équipes data
Une organisation et une infrastructure data solides permettent d’augmenter la productivité de l’équipe data. Une équipe data mature comprend deux types de profils bien distincts :
Les ingénieurs data, chargés de gérer l’infrastructure, les pipelines, la disponibilité des données.
Les analystes, au sens large, ce qui inclut les data analysts et les data scientists.
Dans une équipe data structurée, chacun de ces deux types profils génère un ROI différent pour l’entreprise :
Le ROI principal délivré par les « ingénieurs data » = la disponibilité des données pour les analystes. Les ingénieurs data ont rarement un impact direct sur les KPIs business d’une entreprise. En revanche, on peut mesurer leur impact sur la productivité des équipes analytics. La disponibilité (et la fraîcheur) des données est un bon indicateur pour évoluer l’efficience d’une stack data. Quels KPIs utiliser ? Par exemple, le nombre de fois qu’un dataset est délivré dans les temps aux équipes analytics, ou bien la fréquence de rafraîchissement des datasets (jour, heure, temps réel). Une autre solution consiste à mesurer le downtine, c’est-à-dire le temps perdu à résoudre les incidents. Voici comment le mesurer :
Si vous avez 10 incidents data par mois et que chacun prend en moyenne 4 heures pour être détecté et 3 heures pour être résolus, votre downtime mensuel est de 70 heures.
Le ROI principal délivré par les « analystes data » = la réduction du volume de sollicitations provenant des équipes métier. On pourrait dire, en caricaturant un peu, que les ingénieurs data travaillent à améliorer la productivité des analystes data et que les analystes data travaillent à améliorer la productivité des équipes métier. Si les équipes métier (marketing, sales, service client, finance…) passent leur temps à interroger les analystes pour obtenir des réponses à leurs questions, c’est que les données ne sont pas suffisamment opérationalisées. Cela impacte leur productivité mais aussi celles des analystes data, qui ont moins de temps à consacrer à leur cœur de métier : la production d’analyses (data analysts) et la production de modèles (data scientists). Le ROI des analystes de la data peut se mesurer au volume de sollicitations en provenance des équipes métier.
En résumé :
Le ROI des ingénieurs data se mesure à l’impact qu’ils ont sur la productivité des analystes data.
Le ROI des analystes data se mesure à l’impact qu’ils ont sur la productivité des équipes métier.
Plus que jamais, à ce stade de maturité de l’équipe data, ce n’est pas les outputs (la qualité des données, par exemple) qui permettent d’évaluer le ROI de l’infrastructure data, mais les impacts (sur le business).
Conclusion
Résumons-nous. Notre conviction est que c’est la taille, le degré de maturité de l’organisation et le niveau de structuration de l’équipe data qui déterminent les objectifs et les indicateurs de mesure de ROI de la fonction data. Le rôle et le niveau d’ambition d’une équipe data ne peuvent pas être le même suivant qu’elle comporte 2 ou 30 personnes…
Si votre entreprise a une fonction data récente avec des ressources limitées (0 – 5 personnes), c’est sa capacité à fournir des données fiables au métier qui servira de boussole pour évaluer le ROI.
Si votre entreprise dispose d’une fonction data plus étoffée et plus mature (5 – 10 personnes), c’est la capacité à « opérationnaliser » les données qui servira d’indicateur.
Si votre entreprise a une fonction data structurée, comportant au moins 10 personnes avec des rôles bien définis, répartis entre les ingénieurs data et les analystes data, le ROI se mesurera à partir de l’impact sur la productivité de l’entreprise.
Une fois que l’on a compris l’objectif principal de la fonction data de son entreprise, les métriques sont relativement faciles à déduire. Nous vous en avons donné quelques-unes, vous pourrez sans doute en imaginer d’autres. Nous espérons aussi que la ressource que nous avons produite vous sera utile. Nous comptons sur vous pour en faire un bon usage 🙂
Téléchargement de notre template ROI Data Stack.
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Dans la course vers une relation client toujours plus personnalisée et omnicanale, les programmes de fidélisation qui visent à récompenser les clients réguliers et à instaurer avec eux une relation durable jouent un rôle de plus en plus important.
Ces programmes répondent à un constat simple, 15 à 20% de clients qui représentent 50 à 80% de votre chiffre d’affaires : il est donc nécessaire de valoriser le plus possible vos meilleurs clients.
Les programmes de fidélités modernes, auxquels les clients sont plus sensibles, dépassent le simple avantage économique. Plus encore, l’éternelle « carte de fidélité » n’est plus un élément indispensable d’un programme. Il vaut mieux désormais se recentrer sur la relation avec le client pour proposer une expérience unique qui vous permettra de vous distinguer de la concurrence.
Nous avons donc sélectionné les exemples les plus réussis dont vous pouvez vous inspirer pour vos programmes de fidélités.
#1 Appartenance à un club avec le Nike+ Run Club
Le Nike+ Run club permet à tous les utilisateurs de l’application Nike, débutant ou confirmé, d’appartenir à un « club » et d’être accompagné dans la pratique de leur sport. Le mot d’ordre dans la description de l’application par Nike : « nous sommes là pour vous », est représentatif de cette volonté.
Les utilisateurs font ainsi partie d’une très large communauté organisée autour de la marque de sport. On peut y enregistrer ses chaussures, suivre le détail de ses performances et partager chacune de ses courses.
L’une des forces de cette application est sa gratuité : même un utilisateur qui n’est pas encore client chez Nike peut s’inscrire et faire partie de cette communauté. Une fois membre, l’utilisateur est plus susceptible de devenir client ou de le rester.
L’autre atout de cette application est le coaching personnalisé – là encore accessible gratuitement. Chaque utilisateur est donc accompagné dans la pratique de son sport par un « coach » virtuel de Nike, une voix qui guide l’utilisateur lors de ses courses. Nike prend ainsi une place importante dans la pratique du sport par l’utilisateur, qui associe alors la marque à sa progression.
#2 Les programmes à points, le club Oh My Cream
Le programme à point est un système simple grâce auquel le client va gagner un certain nombre de points par euro dépensé, en échange desquels il peut bénéficier d’avantages exclusifs et de réductions.
Ce système permet d’inciter directement le client à accroître la taille de son panier, ce dernier étant récompensé en fonction de la valeur de ses achats. De plus, le fonctionnement simple et clair de ce type de programme facilite l’adhésion des utilisateurs qui ont facilement accès à la grille de récompenses.
Un exemple de programme à points est le club Oh My Cream, de la marque de soin skincare. Ce club repose sur 3 niveaux – Argent, Or et Platine – qui offrent des réductions, mais donnent également accès à des ventes privées et même à des initiations exclusives et des journées privilèges.
Ainsi, pour chaque euro dépensé, le client gagne un point. Parvenu à 220 points, le client entre dans le programme au niveau Argent et reçoit un bon de réduction de 10% utilisable sur la commande de son choix. Ce système continue jusqu’à ce que le client atteigne les 1300 points – le niveau Platine – lorsque sa fidélité est récompensée par des invitations exclusives à des évènements privés, et où chacune de ses commandes est agrémentée d’une surprise.
Le club Oh My Cream est donc un exemple intéressant de programme à points. Facilement compréhensible et transparent, les clients y adhérent rapidement. Plus encore, ce système ne repose pas seulement sur une offre économique, mais propose aussi des expériences uniques aux clients les plus fidèles.
#3 Le parrainage avec Mon Petit Placement
Les programmes de parrainage récompensent une autre facette de la fidélité du client : les recommandations. Leur objectif premier est d’accroître la base de clients en se reposant sur les utilisateurs existants. Cela présente plusieurs avantages :
Réduction du coût d’acquisition client :
En laissant les utilisateurs promouvoir eux-mêmes la plateforme, l’entreprise réalise des économies significatives. Pour que cela soit effectivement rentable, il est nécessaire de calculer l’avantage qu’en retirent les parrains pour que l’offre soit incitative et en même temps intéressante économiquement pour l’entreprise.
Sélection des clients potentiels :
Les utilisateurs qui recommandent la plateforme le font à des individus très susceptibles d’être intéressé par le service. C’est donc un moyen indirect mais précis de sélectionner les clients potentiels.
Récompense pour l’attachement à l’entreprise :
Ce système de récompense dépasse les simples récompenses liées aux achats et encourage les clients à recommander le service, créant de fait un plus grand attachement à la marque.
Le programme de fidélité de Mon Petit Placement est un exemple de système de parrainage efficace. Chaque parrain bénéficie de 15% de réduction à vie par filleul sur ses frais de gestion, et chaque filleul reçoit à son tour cette réduction de 15% lors de la création de son compte. Plus encore ces réductions sont cumulables ! C’est donc un système simple dont les utilisateurs bénéficient directement et qui récompense de façon importante les individus qui recommandent Mon Petit Placement.
#4 Mettre en avant les valeurs partagées : Body Shop
Tous les programmes de fidélités ne sont pas construits seulement autour d’avantages économiques. The body shop par exemple a centré son offre de fidélité autour de ses valeurs d’entreprise, notamment la lutte contre les violences sexuelles.
Le programme de fidélité The Body Shop offre la possibilité de convertir ses points de récompenses en dons. Ainsi, les récompenses ne bénéficient pas directement au client mais sont transmises à une association de son choix.
En opérant ainsi, l’entreprise se rapproche de ses clients à travers une lutte commune pour des valeurs partagées. Ce système reposant sur la charité permet donc de créer une relation plus profonde avec le client qui développe alors un attachement plus important pour la marque. Les clients sont généralement sensibles à ce type de programme qui permet de dépasser la simple relation commerciale et de mettre en avant des valeurs importantes pour l’entreprise.
#5 Le programme de fidélité par palier : Philosophy
La marque de produits cosmétiques Philosophy a choisi un type de programme de fidélité semblable à celui à points, mais en y incluant un système supplémentaire de paliers. Comme pour le système à points, le client dispose d’une certaine cagnotte liée à son activité lui permettant d’accéder à des avantages exclusifs. Cependant, le programme de Philosophy présente deux différences notables :
Le multiplicateur de points :
Les clients sont répartis en 3 niveaux en fonction du nombre de points dont ils disposent. A chaque niveau est associé un multiplicateur de points. Ainsi, un client au premier niveau gagne des points à chaque achat selon une grille, au deuxième niveau le nombre de points gagnés est multiplié par 1,25 et au troisième niveau par 1,5. Les avantages du multiplicateur sont même renforcés pendant le mois de l’anniversaire du client.
Ce système récompense ainsi les clients à la hauteur de leur fidélité. Plus encore la marque les incite directement à passer à l’échelon supérieur en leur envoyant mensuellement un « compteur de gratitude » et surtout en proposant une gamme d’articles sélectionnés pour le client à partir de ses commandes passées.
Gain de points supplémentaires :
Philosophy ne récompense pas seulement les achats mais aussi l’activité de ses clients sur les réseaux sociaux. Des points supplémentaires peuvent être gagnés en échanges d’actions en ligne, comme le fait de suivre la marque sur les réseaux ou d’écrire un avis. De plus, la marque a intégré le parrainage dans son système à points.
Philosophy a donc mis en place un programme de fidélité très complet, qui récompense les différentes facettes de la fidélité du client à la hauteur de son attachement à la marque.
#6 Le programme de fidélité payant avec Barnes & Noble
Ce type de programme de fidélité se distingue sensiblement de ceux évoqués précédemment, car le client doit ici payer pour en faire partie. Si cette stratégie peut sembler contre intuitive au premier abord, elle peut cependant s’avérer très efficace pour inciter le client à finaliser sa commande et ainsi augmenter la LTV des membres du programme.
En effet, en rendant payant l’accès à des avantages exclusifs, l’entreprise est en mesure de proposer un service plus complet et plus attrayant. Ces avantages permettent de réduire le taux d’abandon de panier – de plus de 75% – en réduisant drastiquement le nombre de barrières à l’achat. Ces barrières à l’achat, telles que les frais et délais de livraison, peuvent ainsi être supprimées avec des offres de livraison gratuite et/ou prioritaire, des coupons de réductions …
Barnes and Noble propose un tel type de programme de fidélité : pour 25€ par an, le client a accès à un service de livraison gratuit, à des ventes exclusives et à de nombreuses réductions.
Il est cependant primordial de porter une attention particulière à la valeur que l’offre représente pour un client lorsque l’on met en place ce type de programme. Les économies potentiellement réalisées grâce à ce type d’offre doivent être suffisamment supérieures au coût de l’abonnement pour convaincre le client d’y souscrire.
#7 Autre type de programme de fidélité : les abonnements
Les abonnements peuvent être considérés comme une forme de programme de fidélité qui donne un accès exclusif à un service uniquement réservé aux clients abonnés.
Ce type d’offre présente un avantage particulier par rapport aux autres programmes : en engageant les clients sur une certaine durée, une entreprise va mécaniquement augmenter la LTV de sa clientèle. Généralement, le coût mensuel d’un abonnement est inversement proportionnel à la durée de l’engagement. Ainsi l’entreprise fidélise ses clients sur la durée et les incite à rester sur le long terme.
Le petit ballon, une marque permettant de découvrir chaque mois des bouteilles de vin livrées à domicile, fidélise sa clientèle au travers d’abonnements. Il n’est pas possible d’avoir accès à ce service pour une durée inférieure à 3 mois, ce qui garantit à l’entreprise un minimum de 3 achats par clients abonnés.
Le système d’abonnement suppose néanmoins que le client est disposé à payer de manière régulière pour avoir accès aux produits de l’entreprise. C’est donc un programme de fidélité particulièrement efficace, mais dont la mise en place dépend évidemment du type de service que propose la marque.
En conclusion : cherchez la simplicité
Il existe de nombreuses variantes des programmes de fidélités, chacune ayant ses spécificités, qui permettent d’attirer les clients auprès de la marque et d’accroître leur Lifetime Value.
Cependant, la condition nécessaire à la réussite de tous ces programmes reste l’engagement des clients. Un membre d’un programme de fidélité doit y souscrire et en faire usage pour que la mise en place d’un tel système soit source de valeur pour l’entreprise.
Notre recommandation principale, quel que soit le type de programme, est donc : la simplicité. Il est nécessaire de mettre en place un système simple et facile à comprendre pour que le client y adhère et en fasse usage régulièrement.
De l’application Nike à l’offre d’abonnement Le petit ballon, tous les exemples que nous avons sélectionnés proposent une offre que l’on comprend instantanément – coach running, livraison gratuite, ventes privées… – et dont on saisit directement la valeur. Le client peut ainsi facilement se projeter et est alors plus susceptible de devenir membre du programme.
ROPO : Comment mesurer son impact et en tirer parti ?
Vous avez un site e-commerce. Certains visiteurs s’y rendent pour faire leurs recherches mais finalisent leur parcours d’achat en magasin. Il y a donc une part du CA des magasins qui est attribuable en droit au digital. Comment la mesurer ? C’est l’enjeu du ROPO, un enjeu d’attribution très simple à comprendre, plus difficile à traiter.
Les enjeux liés au ROPO sont plus actuels que jamais. Les points de contact dans le Retail se sont multipliés. On parle maintenant de commerce omnicanal, de « commerce unifié ». Les barrières entre le digital et le offline sont enjambées sans scrupule par les consommateurs.
Contrairement à ce qu’on prédisait il y a 10 ou 20 ans, le e-commerce n’a pas dépassé le commerce physique, qui reste loin devant. Le vrai chantier de travail consiste par conséquent à améliorer la coordination du online et du offline pour générer plus de ventes en ligne et en magasin.
Le ROPO est un comportement client qu’il faut intégrer dans les modèles d’analyse de la performance.
Notre volonté dans cet article est double :
Vous aider à mesurer le ROPO, c’est-à-dire la part des ventes offline attribuable à vos efforts digitaux (site web, email…).
Vous montrer comment on peut utiliser le ROPO pour améliorer le chiffre d’affaires global de l’entreprise.
Ajoutons que le ROPO est un enjeu marketing ET organisationnel. On ne peut pas faire l’impasse sur ce deuxième aspect. Bon nombre des problèmes business auxquels peut faire face une entreprise trouvent leur origine dans des problèmes d’organisation.
En l’occurrence, beaucoup de retailers se sont développés en deux pôles séparés : un pôle magasins et un pôle e-commerce. Force est de constater que les objectifs des responsables de magasins ne sont que très rarement harmonisés avec les objectifs des responsables e-commerce. Cela crée des problèmes en interne en termes d’attribution des ventes, si ce n’est des conflits.
La mesure et la prise en compte du ROPO ont aussi pour finalité de casser cette logique pour que les deux dimensions – online & offline – ne soient plus concurrentes mais complémentaires, et que toutes les fonctions business de l’entreprise aillent dans la même direction.
Le ROPO : un enjeu marketing encore et toujours d’actualité pour les retailers
Research Online Purchase Offline [ROPO] – Définition
ROPO est l’acronyme de Research Online, Purchase Offline. Le ROPO décrit la part du chiffre d’affaires réalisé en magasin qui revient aux efforts investis online.
Il n’y a pas un commerçant qui ne doute de l’influence du online sur le offline. Combien de parcours d’achat commencent sur le web pour s’achever en magasin ?
« Je cherche un produit sur un site internet en utilisant mon ordinateur ou mon mobile, je le trouve, je cherche le magasin le plus proche de chez moi, je vérifie qu’il a ce produit en magasin, si oui je m’y déplace pour l’acheter ».
Le offline peut aussi influencer les ventes online, même si c’est moins le sujet de notre article :
« Je me balade dans la rue par une belle journée estivale, j’entre dans un magasin, je découvre mon futur frigidaire dans les rayons, mais je préfère commander sur le site web pour bénéficier de la livraison ».
Voici deux exemples typiques de la manière dont le online et le offline peuvent s’intégrer dans un même parcours d’achat. Nous aurions aussi pu parler du click & collect, bien sûr. On utilise le web pour acheter, mais aussi pour trouver un magasin ou vérifier que le magasin a le produit recherché.
La part des ventes en magasin attribuable au digital porte le nom d' »effet ROPO ».
Source : Google.
En 2008, Google France publiait les résultats d’une enquête mettant en avant l’effet ROPO. Dans le schéma ci-dessous, extrait de cette étude, on peut voir que beaucoup de recherches en ligne aboutissent sur un achat en magasin. L’inverse existe aussi, mais dans une proportion beaucoup plus faible. Ces chiffres sont périmés mais ont pour mérite de montrer que le ROPO n’est pas une réalité nouvelle.
Source : Google. Il s’agit des résultats d’une enquête menée en 2008. Beaucoup de choses ont changé depuis. La part de recherches réalisée en ligne est bien supérieure à 39% aujourd’hui, mais on voit déjà, en 2008, qu’une partie des recherches en ligne aboutit à des achats en magasin. C’est la définition même de l’effet ROPO.
On pourrait multiplier les statistiques démontrant l’impact du comportement ROPO. Il y a par exemple une étude de DigitasLBi Global Survey menée en 2014 qui nous apprend que 88% des consommateurs font des recherches en ligne avant d’acheter en magasin (Source). On a aussi trouvé une étude du très sérieux organisme Statista qui mesure l’impact du ROPO pour chaque famille de produits. L’étude est plus récente (2021) mais ne concerne que le marché polonais…Si ça vous intéresse, vous pouvez aller y jeter un œil.
Il est finalement assez difficile de trouver des chiffres, des études. La faiblesse de la littérature statistique illustre la difficulté qu’il y a à mesurer l’effet ROPO. Mais nous allons vous donner des techniques pour y arriver 🙂
Pourquoi cette tendance est toujours d’actualité ?
L’effet ROPO a été mis en évidence il y a 15 ans mais il est plus d’actualité que jamais. Pourquoi ? Parce que, plus que jamais :
Les consommateurs lisent des avis clients en ligne avant de se déplacer en magasin pour acheter. Les avis clients sont utilisés pour se faire une idée sur un produit, un service, une marque, un magasin…Une étude du cabinet McKinsey de 2021 a montré que le volume d’avis clients déposés en ligne avait bondi de 87% entre 2019 et 2020. La lecture des avis est devenue un incontournable en phase de recherche.
Les consommateurs utilisent internet pour trouver leur magasin. Une étude Bright Local de 2017 montre que 97% des consommateurs utilisent le web pour trouver un magasin proche de chez eux. On utilise le web non seulement pour découvrir des produits et les notes attribuées par les clients à ces produits, mais aussi pour trouver des magasins où se déplacer.
Les consommateurs utilisent le web pendant leur expérience en magasin. Beaucoup de consommateurs sortent leur smartphone quand ils sont en magasin que ce soit pour comparer les prix, télécharger leur coupon, vérifier s’il existe des promotions sur le site, scanner des QR codes, chercher des produits.
La conclusion qui s’impose est simple : la plupart des achats en magasin sont l’aboutissement d’un parcours d’achat qui a commencé sur le web.
Pourquoi les magasins physiques sont-ils encore si importants ?
On a un moment cru que l’ecommerce prendrait la place du commerce physique, que les boutiques en ligne finiraient par remplacer les magasins physiques. Force est de constater que cette prédiction ne s’est pas accomplie.
Le commerce en ligne (produits et services) a encore connu une belle progression en France en 2021, s’établissant à 129 milliards d’euros. Mais il faut remettre les choses en perspective et rappeler que cela ne représente que 14,1% du commerce de détail (Source : Fevad). Près de 5 achats sur 6 sont donc réalisés en magasin.
Source des données : Fevad. Graphique produit par Comarketing News. Malgré la progression importante et continue du ecommerce, la vente en ligne ne représentait que 14,1% du commerce de détail en 2021 en France.
Comment expliquer la place toujours largement prédominante des magasins dans le commerce de détail ?
Il y a deux raisons principales selon nous :
Les clients aiment essayer les produits avant de les acheter. Et ça, ce n’est pas possible sur une boutique en ligne…On recherche en ligne, mais on préfère se déplacer en magasin pour toucher, essayer, regarder, sentir avant d’acheter.
Les clients ont une aversion pour la livraison. Sur internet, la livraison est le principal frein à l’achat. Les délais de livraison, les coûts de livraison, la complexité des procédures de retour font partie des principales raisons des abandons de panier.
Comment mesurer l’impact du digital sur les ventes physiques ?
Passons maintenant de la théorie à la pratique. Il existe trois approches pour mesurer l’impact du digital sur les ventes en magasin.
#1 Créer un multiplicateur ROPO basé sur les données Google Analytics
Cette technique permet de mesurer la contribution indirecte de votre site ecommerce sur vos ventes en magasin en utilisant Google Analytics.
Précisons d’entrée de jeu que le calcul du ROPO repose nécessairement sur un modèle d’attribution probabiliste, et non déterministe (sauf dans le cas du click & collect).
Des signaux ROPO aux hypothèses
La démarche consiste d’abord à :
Identifier les signaux du comportement ROPO. Le store locator est l’exemple de signal par excellence d’un comportement ROPO. Vous pouvez légitimement faire l’hypothèse qu’un visiteur de votre site qui recherche sur votre site web le magasin le plus proche de chez lui a l’intention de se déplacer en magasin pour acheter.
Construire des hypothèses crédibles, basées sur l’expérience de l’équipe marketing, sur les résultats des campagnes marketing passées. Il y aura forcément une dose d’intuition dans ces hypothèses, il est impossible de faire autrement. Pour chaque signal identifié, vous devez faire 3 hypothèses :
Le pourcentage de signaux qui se transforme en visite en magasin. Si l’on reprend notre exemple, il est possible d’estimer le pourcentage d’utilisateurs du store locator qui sont vraiment en recherche active d’un magasin en analysant de manière avancée les parcours web dans Google Analytics.
Le pourcentage de visites en magasin qui se transforment en achat (taux de conversion en magasin).
Le panier moyen des visiteurs de magasins provenant du site web. Vous pouvez vous baser sur le panier moyen qui apparaît dans vos reportings.
Des hypothèses au calcul de l’effet ROPO
Ces hypothèses vont vous permettre de calculer le revenu offline attribuable à votre site ecommerce. Si vous avez 10 000 visiteurs par mois qui utilisent le store locator, que vous faites les hypothèses que 20% se déplaceront effectivement en boutique, que 40% d’entre eux achèteront pour un panier moyen de 50 euros, vous pouvez estimer que le chiffre d’affaires généré grâce au store locator de votre site web est de :
10 000 x 0,20 x 0,40 x 50 = 40 000 €
Vous devez faire le même calcul pour tous les signaux digitaux que vous avez identifié.
Il faut aussi, bien entendu, intégrer les achats click & collect.
De l’effet ROPO au calcul du coefficient multiplication ROPO
Une fois que vous avez une estimation du chiffre d’affaires magasin généré grâce au ecommerce, vous pouvez définir un coefficient multiplicateur ROPO. Il se calcule en divisant le chiffre d’affaires online par le chiffre d’affaires généré en magasin grâce au site. Si votre ecommerce génère 100 000 euros de CA par mois et que le CA généré offline grâce au site est estimé à 50 000 euros, votre coefficient est de 2.
Ce coefficient multiplicateur vous permet de gagner du temps dans le calcul du ROPO. Vous avez fait 200 000 euros de CA ecommerce ce mois-ci ? Alors, le CA ROPO est de 100 000 euros. Vous n’avez plus qu’à intégrer ce coefficient dans le compte de résultats pour mesurer la contribution réelle du digital au chiffre d’affaires global de l’entreprise.
#2 Evaluer la contribution de l’email sur le CA des magasins
La première technique permet de mesurer la part du site ecommerce dans le CA en magasin. La deuxième technique que nous allons vous présenter va vous permettre cette fois de mesurer la contribution de l’email, de vos campagnes et scénarios d’emailing.
Là encore, il s’agit de construire un modèle d’attribution basé sur des hypothèses. La technique consiste à attribuer X% des ventes offline au canal email en fonction des ouvertures et clics dans vos emailings. Il est important de prendre en compte la dimension temporelle, c’est-à-dire le temps qui s’écoule entre l’ouverture ou le client et la vente offline.
Voici la démarche à suivre :
Vous définissez les campagnes emailings qui entrent dans le périmètre de votre calcul, à savoir : les campagnes emailings qui selon vous ont un impact sur les ventes physiques. Vous pouvez intégrer toutes les campagnes de nature promotionnelle.
Vous définissez une règle d’attribution : si 100 clients cliquent dans un email et qu’ils achètent en magasin dans les XX jours suivant l’ouverture, alors vous attribuez YY% des ventes au canal email. Il y a donc 2 choix à faire, et même 3 :
Le choix de l’événement email : l’ouverture ou le clic. Le clic témoigne d’un niveau d’engagement plus élevé que la simple ouverture. Nous avons pour cette raison tendance à conseiller à nos clients d’utiliser le clic.
Le choix de la plage de temps : 30 jours, 45 jours, 60 jours…Le choix doit être cohérent avec le cycle d’achat moyen et les habitudes d’achat dans votre secteur d’activité.
Le pourcentage d’attribution au canal email en cas de conversion magasin.
Ce modèle d’attribution n’est possible que si et seulement si vous identifiez les clients qui achètent en magasin, au moyen du programme de fidélité ou autre.
#3 Evaluer la contribution du site web sur le CA des magasins
Cette troisième approche est une alternative à la première approche basée sur le coefficient multiplicateur ROPO. Elle est identique à la deuxième approche dans son fonctionnement.
La technique utilisée pour mesurer la contribution du canal email aux ventes offline peut en effet aussi être utilisée pour mesurer la contribution du site ecommerce. Si un internaute visite le site ecommerce et qu’il achète en magasin dans les XX jours suivant, la vente est attribuée au ecommerce. On peut ajouter plus de granularité dans l’analyse en déclinant :
Selon le canal d’acquisition du visiteur ecommerce : SEO, AdWords…
Selon le nombre de pages visitées : on peut par exemple décider d’attribuer 20% d’une vente physique au site ecommerce si le visiteur a visité 2 pages, 40% s’il a visité 10 pages, etc.
Selon la nature des pages visitées, leur degré d’intention. Si le visiteur visite la page produit du produit X et qu’il achète ce produit X en magasin 10 jours après, l’attribution est plus évidente que si ce visiteur avait visité la page d’un produit appartenant à une autre famille (ou, pire, une page institutionnelle).
Il existe beaucoup de possibilités pour complexifier le modèle, mais une chose est sûre : il n’est praticable que sur les visiteurs identifiés du site web et en magasin.
Comment transformer l’effet ROPO en opportunités business ?
L’analyse du ROPO ne sert pas simplement à améliorer l’attribution des ventes entre le digital et le offline. Le ROPO peut aussi être utilisé comme levier pour améliorer la stratégie marketing et générer plus de revenus. Voici quelques pistes d’actions.
Utiliser le ROPO pour adapter la stratégie marketing et augmenter les ventes (online et offline)
L’analyse de l’effet ROPO permet d’adapter sa stratégie marketing afin d’augmenter la conversion en magasin et sur le site. Dans un de ses articles de blog, Matthieu Tranvan, expert marketing, propose une démarche intéressante. Elle consiste à construire une segmentation client basée sur le ROPO.
Le graphique ci-dessous, tiré d’un cas client de Matthieu Tranvan, présente les différences de taux de conversion en fonction de deux variables :
La présence ou non d’un magasin dans la région du visiteur web.
L’utilisation ou non du store locator.
Les résultats ne sont pas surprenants : un visiteur qui utilise le store locator et qui découvre qu’il existe un magasin près de chez lui convertira beaucoup moins sur le site ecommerce. Il se sert du site ecommerce pour trouver son magasin et se déplace dans le magasin proche de chez lui pour effectuer son achat.
On peut dégager 3 personas à partir de cette analyse :
Persona 1 : une personne vivant en zone urbaine, plutôt jeune, qui utilise le site pour trouver un magasin proche de chez lui. Il préfère acheter en magasin.
Persona 2 : une personne qui vit également en zone urbaine mais qui préfère acheter en ligne plutôt que de se déplacer en magasin. Elle n’utilise pas le store locator. On peut imaginer une personne urbaine mais plus âgée ou une personne avec des enfants à charge – en tout cas il s’agit d’une personne moins encline à marcher ou à prendre sa voiture pour effectuer un achat.
Persona 3 : une personne qui est en dehors de la zone de chalandise d’un magasin, qui habite probablement en zone rurale ou périphérique. Cette personne utilise le site internet pour faire ses achats, par nécessité plus que par choix.
Voici un exemple de segmentation que l’on peut créer à partir d’une analyse du ROPO. Cette segmentation peut ensuite être utilisée pour affiner sa stratégie marketing et ses offres promotionnelles : remise en magasin, livraison offerte, livraison en 1 jour…
Le ROPO comme levier pour augmenter la conversion web
Pour finir nous allons vous présenter trois techniques consistant à augmenter la conversion web grâce au ROPO.
#1 Améliorer votre scénario de relance de panier abandonné
La première consiste à intégrer les achats en magasin dans votre scénario de relance de panier abandonné. Imaginez une personne qui visite votre site web, qui ajoute un produit à son panier et l’abandonne avant de finaliser la commande. Que faites-vous ? Vous lui envoyez un message de relance. C’est comme ça que fonctionne tout bon scénario de relance de panier abandonné.
Sauf qu’il est possible que ce client décide d’acheter le produit en magasin. Combien de paniers abandonnés sur le web se transforment en paniers achetés en magasin ? Plus que vous ne le croyez !
Notre conseil : intégrez les données transactionnelles magasins dans votre scénario de relation de panier abandonné. Cela vous permettra de ne pas envoyer l’email de relance aux clients qui ont finalement acheté en magasin, mais de leur envoyer à la place un email post-transactionnel. Cela suppose d’étendre un petit peu le délai avant l’envoi du message de relance…
#2 Inciter à l’achat les visiteurs du site web pendant leur recherche sur votre site
S’il y a un effet ROPO, cela veut bien que vos clients commencent leur parcours d’achat sur votre site ecommerce. Il existe des leviers pour augmenter le taux de conversion ecommerce, pour inciter les visiteurs à convertir plus rapidement pendant leur phase de recherche. Comment ? En levant les freins à l’achat en ligne.
C’est-à-dire ? Par exemple, en mettant en avant le fait que la livraison est gratuite si c’est le cas, que les retours sont gratuits, si c’est le cas, en améliorant la visibilité des produits qui correspondent aux préférences, habitudes, comportements navigationnels des visiteurs, etc. Vous pouvez aussi inciter les visiteurs à conclure leur achat sur le web en leur proposant des remises, un cadeau au-delà de X euros achetés, etc.
Cet article n’a pas pour vocation de vous détailler les différentes stratégies possibles pour augmenter le taux de conversion d’un site ecommerce, mais sachez que si vous avez un effet ROPO, c’est d’abord parce que votre site ecommerce est un point de contact clé de votre business. Un point de contact qui peut être optimisé.
#3 Mesurer l’effet ROPO des campagnes Facebook Ads
Facebook propose une fonctionnalité qui permet de mesurer l’impact des publicités sur les achats en boutique. Vous pouvez tracer les achats en magasin qui ont eu lieu suite à une exposition à une annonce Facebook.
Pour utiliser cette fonctionnalité, vous devez charger vos données clients (email, téléphone, nom et prénom, adresse, date de naissance) dans votre compte Facebook. Cela vous permet ensuite d’identifier les achats magasin réalisés suite à l’exposition à une publicité. Vous pouvez régler la durée : 24 heures, 7 jours, 28 jours…
Nous arrivons à la conclusion de cet article.
Résumons les 2 enjeux du ROPO :
Réussir à le mesurer pour rendre à César ce qui est à César, en identifiant la part des ventes offline que l’on doit attribuer au digital (site ecommerce, emailings…).
Exploiter l’analyse de l’effet ROPO pour booster aussi bien les ventes ecommerce que les ventes en magasin.
Nous avons abordé ces deux sous-sujets, sans avoir la prétention de les épuiser. Mais nous espérons que cet article a répondu aux principales questions que vous vous posiez sur le ROPO.
Vous l’aurez compris, la mesure et l’utilisation du ROPO supposent une bonne intégration des données, uneréconciliation des données online et offline.
C’est là qu’une Customer Data Platform légère comme Octolis peut intervenir.
En tant qu’éditeur, mais aussi dans notre ancienne vie de consultants, nous avons eu l’occasion d’accompagner des entreprises confrontées à des enjeux d’attribution dont celui du ROPO.
Si vous êtes en prise avec ces problématiques, qui sont aussi de beaux challenges à relever, nous pouvons en discuter ensemble. N’hésitez pas à nous contacter si vous voulez savoir comment une solution comme Octolis peut vous aider à intégrer l’effet ROPO dans votre stratégie marketing. On vous répondra rapidement, promis.
Pourquoi ma société est-elle passée d’Excel à Power BI ?
Pour lire, analyser et interpréter les data, la première solution d’une entreprise est souvent l’utilisation de tableurs tels qu’Excel ou Google Sheets. Les fonctions de création de visuels de ces outils permettent de rapidement faire parler nos données. Mais ces tableurs ont leurs limites, et beaucoup d’entreprises ont fait le choix de passer à des outils de data visualisation tels que Power BI (développé par Microsoft, Power BI est actuellement le leader sur le marché des outils de data visualisation).
Nous avons recueilli le témoignage de Rémi et Pierre, ils ont tous les 2 fait le choix de passer d’Excel à Power BI au sein de leur entreprise, mais avec des profils assez différents :
Rémi est Sales Manager, et ex Data Manager à BMS International (Vendeur Amazon dans le top 100 des vendeurs Amazon européens). A BMS International, ils utilisent la data tous les jours pour suivre la rentabilité de nos produits, fournisseurs, transporteurs, équipes…
Pierre est PDG de la société AXAL, leader de la livraison spécialisée, le déménagement et le transport d’œuvres d’Art dans le grand Est. Afin de rester concurrentiel, AXAL a besoin de franchir un cap dans l’exploitation de la grande quantité de données qu’ils ont en leur possession.
Jean-Pascal Lack
Data Viz & Power BI Expert
Ingénieur centralien et expert Power BI avec plus de 7 années d’expérience, Jean-Pascal a accompagné de nombreuses entreprises (des grands groupes comme Sanofi, LVMH à des PME) à mettre en place des tableaux de bords Power BI pour différents usages métiers.
D’où vous est venue l’idée de passer à Power BI ?
🗣️ Rémi
Notre start-up étant assez jeune, nous utilisions uniquement des fichiers Google Sheets pour faire du reporting. Cependant, au fur et à mesure que nous grandissions, le nombre de data a exploité a grandi exponentiellement, et nous nous sommes vite retrouvés face aux limites de Google Sheets : une taille de fichier limité à 4 millions de cellules, et un fichier qui devient déjà lent dès le franchissement du seuil d’1 million de cellules.
On ne pouvait donc pas conserver la data au niveau le plus fin (détail des ventes au jour), nous étions alors obligés d’agréger les data à la semaine voire au mois : cela avait un double désavantage, nous perdions non seulement en finesse des data et donc d’analyse, mais l’agrégation des data était aussi un travail long et manuel.
Par ailleurs, dès que l’on voulait analyser la data selon un nouvel axe (par marque, année de lancement, zone de production, performance des produits), il fallait recréer un outil pour transformer et agréger la data selon l’axe voulu.
Nous avons donc fait le choix de nous tourner vers un outil de data visualisation, dont contrairement à Excel ou Google Sheets, la fonctionnalité première est l’analyse et la visualisation des données.
🗣️ Pierre
Dans notre société nous avons 3 ERP différents pour chacun de nos services. Il en résulte que la data ainsi que les quelques tableaux de bord étaient éparpillés.
Nous avons donc fait le choix de passer à un outil de data visualisation pour améliorer ces 2 points d’une part automatiser l’extraction de la data, d’autre part faciliter et centraliser l’accès à nos tableaux de bord.
Suite à un audit sur notre stratégie digitale ainsi qu’une recommandation de notre partenaire KPMG, nous avons creusé la piste de l’outil de data visualisation Power BI.
Nous nous sommes alors aperçus des points ci-dessous qui nous ont confortés sur le choix de Power BI :
Power BI est intégré à la suite Microsoft 365 (que l’on utilise déjà chez nous)
Il est possible de consulter nos rapports Power BI directement via le web (sans avoir à installer un logiciel)
Power BI est largement utilisé dans le monde de l’entreprise et est leader sur son marché
💡 L’avis de Jean-Pascal Lack, expert Power BI
Avec la grande quantité de données éparpillées dans les différents outils qu’utilise une entreprise, il devient très difficile d’analyser précisément la data, soit juste avec un simple tableur, soit via les indicateurs standards mis à disposition par l’outil.
Pour permettre à son entreprise de faire les meilleurs choix, en s’appuyant sur des KPI explicites, adéquats et précis, l’utilisation d’un outil de data visualisation devient vite nécessaire. Ils sont une multitude à avoir émergé ces dernières années, dont le leader actuel est Microsoft Power BI.
Que vous apporte Power BI de plus comparé à Excel ?
🗣️ Rémi
La migration vers Power BI nous a permis de revoir nos différentes règles métiers ainsi que les transformations depuis nos sources de données. Alors qu’avant nous avions des règles de métiers différentes en fonction des outils/ services, désormais nous avons homogénéisé nos règles et centralisé au même endroit toutes nos sources de données. Cela nous a permis d’améliorer grandement notre confiance en nos données.
« Désormais nous avons homogénéisé nos règles et centralisé au même endroit toutes nos sources de données. Cela nous a permis d’améliorer grandement notre confiance en nos données »
Par ailleurs, une fois le modèle de données créé sous Power BI, une autre grande force de Power BI est sa capacité de filtrer facilement et rapidement la donnée selon plusieurs axes de son choix. Nous avons pu gagner en profondeur de l’analyse et identifier des patterns qui ne nous étaient pas facilement accessibles auparavant.
🗣️ Pierre
Excel est très flexible, mais malheureusement Excel ne permet pas de facilement d’extraire de la donnée. Cette étape d’extraction de la donnée de nos différents outils était donc très chronophage et les collaborateurs n’avaient pas le temps de produire (et donc consulter !) les indicateurs internes. Par faute de temps, ils produisaient et consultaient les indicateurs seulement lorsque cela leur était directement demandé.
Grâce au module d’extraction et de transformation de données de Power BI, le temps de production de nos rapports a été divisé par 4 au moins ! Désormais les collaborateurs produisent et consultent quotidiennement les différents indicateurs et cela change complètement notre manière de piloter nos activités. Nous allons même extraire des informations avec Power BI dans des fichiers PDF, ce qui nous semblait à l’époque inimaginable car trop manuel.
« Grâce au module d’extraction et de transformation de données de Power BI, le temps de production de nos rapports a été divisé par 4 au moins ! »
Par ailleurs, la mise en forme est plus poussée avec Power BI, ce qui permet de faire des tableaux de bord très clairs. En témoigne l’adoption très rapide de Power BI par les différents services, chacun a désormais son tableau de bord.
💡 L’avis de Jean-Pascal Lack, expert Power BI
Power BI est bien plus performant que Excel dans bien des domaines, mais si je devais donner mon top 3, cela serait :
Automatisation et extraction des données.Power BI peut se connecter à une multitude de sources de données (fichier Excel, CSV, PDF, TXT, site web, base de données, outils en ligne tels qu’Asana, Zendesk, Google Analytics mais aussi à un dossier contenant des centaines de fichiers Excel ayant un format similaire) via son ETL (Power Query).
Par ailleurs Power BI dispose d’une interface de mise à jour automatique des données d’un tableau de bord ce qui permet de s’assurer que les utilisateurs consultent toujours un tableau de bord à jour.
Accepte un gros volume de données. Power BI peut se connecter à plusieurs sources de données, créer plusieurs tables de données, les nettoyer, les transformer, les relier entre elles, et ceci sur plusieurs dizaines de millions de lignes de données. Pour le lecteur d’un tableau de bord sous Power BI, l’affichage des visuels sera quasiment instantané, il ne remarquera même pas que derrière un simple visuel se cachent en réalité des millions de lignes d’informations. Cela est littéralement impossible sur un tableur tel qu’Excel.
Interface de création de visuel très user-friendly. Pas besoin d’être un expert en UX pour faire des rapports clairs via Power BI ! L’interface se base principalement sur un système de drag & drop ce qui la rend très intuitive. Par ailleurs, Power BI propose une grande sélection de visuels, même des cartes géographiques, qui sont paramétrables et personnalisables en quelques clics sans taper une ligne de code.
L’interface de Tableau
Quelles sont vos limites actuelles avec Power BI ?
🗣️ Rémi
Au début, nous nous attendions à migrer tous nos rapports et outils Excel sous Power BI. Cependant, il est important de noter qu’un utilisateur ne peut pas rentrer de la data dans Power BI, car Power BI se limite à être un outil spécialisé dans la data visualisation.
Nous avons alors compris que l’on ne remplacera pas tous nos fichiers Excel par des rapports Power BI, mais plutôt que Power BI est complémentaire à Excel, puisque c’est l’outil qui permet de visualiser des données rentrées sous Excel.
« on ne remplacera pas tous nos fichiers Excel par des rapports Power BI, mais plutôt que Power BI est complémentaire à Excel, puisque c’est l’outil qui permet de visualiser des données rentrées sous Excel. »
🗣️ Pierre
L’interface de Power BI est relativement facile à prendre en main, ce qui nous permet après une petite formation de créer assez facilement nous-même des rapports assez simples. Par contre, si l’on veut créer des KPI sur mesure, ou faire des tableaux de bords plus poussés, nous avons besoin d’un expert Power BI, c’est là que nous avons fait appel à un consultant externe.
💡 L’avis de Jean-Pascal Lack, expert Power BI :
Grâce à son interface intuitive, un utilisateur novice ayant eu une formation peut rapidement créer son propre tableau de bord. En revanche, dès que l’on veut créer un tableau de bord se basant sur plusieurs tables de données ou créer des indicateurs spécifiques, il faudra faire appel à un utilisateur expérimenté sur Power BI, afin de garantir d’avoir à la fois un rapport performant, mais aussi des KPI justes.
Par ailleurs, il ne faut pas avoir à choisir entre Excel ou Power BI, ce sont avant tout deux logiciels complémentaires. Excel est un tableur, il permet de très facilement de saisir de la donnée, alors que Power BI est un outil qui permet entre autres de justement de mieux visualiser la donnée qui est présente dans ses fichiers Excel.
A-t-il été difficile pour votre société de vous former sur Power BI ou de trouver des personnes avec ces compétences ?
🗣️ Rémi
Nous avons pris plus d’un an pour trouver la bonne personne ! Etant donné que nous n’avions aucune personne avec un profil IT, nous cherchions plus qu’un simple développeur Power BI, mais un analyste qui pouvait avoir une vraie compréhension des enjeux du business, et qui pouvait tout prendre en charge, de la rédaction du cahier des charges, au développement et déploiement de la solution au sein de l’entreprise.
Par ailleurs, du fait de la spécificité de notre activité, nos besoins en reporting évoluent quasiment tous les trimestres. C’est pourquoi nous avons fait le choix de recruter en CDI un expert data avec plusieurs années d’expérience.
🗣️ Pierre
Nous n’avions pas la compétence en interne et nous n’avions pas besoin d’une personne à temps plein sur Power BI, suite à des recommandations nous nous sommes donc tournés vers la plateforme de freelance Malt.
Depuis 6 mois désormais, un freelance expert Power BI nous accompagne à hauteur de 3 heures par semaine sur la mise en place et le déploiement de tableaux de bord Power BI.
Lors de la sélection de notre freelance, nous avons mis l’accent sur l’aspect pédagogique du freelance. En effet, nous voulions devenir au maximum autonomes sur la création, la maintenance et l’évolution de nos tableaux de bord. Nous avons désormais plusieurs personnes chez nous qui peuvent créer par eux-mêmes leurs propres tableaux de bord via Power BI !
« Lors de la sélection de notre freelance, nous avons mis l’accent sur l’aspect pédagogique du freelance. En effet, nous voulions devenir au maximum autonomes sur la création, la maintenance et l’évolution de nos tableaux de bord. »
💡 L’avis de Jean-Pascal Lack, expert Power BI :
Si vous voulez déployer Power BI au sein de votre entreprise, le recrutement d’un expert Power BI est recommandé pour vous assurer que les bons choix sont faits dès le début.
En fonction de votre profil et de votre besoin, vous pourrez alors vous tourner vers une des 3 solutions suivantes : recruter en interne, recruter un freelance, ou passer par une ESN.
Le choix de l’ESN est souvent le plus sécurisé (où l’ESN aura la charge de répondre précisément à votre besoin, et disposera d’une expertise approfondie sur tous les sujets de la data), mais la plus chère.
Le recrutement d’un freelance expérimenté (via une des multiples plateformes qui existent) est une solution qui présente l’avantage d’être très rapide et flexible, tout en combinant un bon rapport qualité/prix.
Enfin le recrutement en interne vous assurera un meilleur transfert de connaissances au sein de votre entreprise. C’est l’option la moins chère mais aussi la moins flexible.
De la stack data moderne à l’expérience data moderne
La stack data moderne a un sens différent suivant la personne à qui vous vous adressez.
Pour les ingénieurs analytics, c’est un bouleversement technologique majeur. Pour les fondateurs de startups, c’est une révolution dans la manière de travailler. Pour les investisseurs, ce sont des dizaines de milliards de dollars levés et un marché florissant. Pour Gartner, la stack data moderne est à la base d’une stratégie data & analytics totalement nouvelle.
Etc. Etc.
Pour nous, la stack data moderne rend simple, rapide, souple et abordable ce qui était autrefois compliqué, long, rigide et coûteux.
Il fallait autrefois dépenser des dizaines de milliers d’euros pour maintenir une base de données qui tombait régulièrement en panne, embaucher un ingénieur à temps plein pour intégrer les données Salesforce au data warehouse, payer toute une équipe de développeurs pour permettre aux analystes d’utiliser SQL dans un navigateur.
Aujourd’hui, tout cela ne vous prend que 30 minutes. C’est un game changer incroyable.
Les organisations n’ont pas encore pleinement pris conscience de la révolution apportée par la stack data moderne. C’est notre conviction et c’est aussi celle partagée par Benn Stancil, chief analytics officer et fondateur de Mode, dans une très belle tribune publiée sur son blog « The Modern Data Experience« . Nous nous en sommes très largement inspirés pour rédiger l’article que vous vous apprêtez à découvrir.
Nous le rejoignons complètement sur la nécessité de penser la stack data moderne comme une expérience. La finalité n’est pas de construire une nouvelle architecture data/tech, c’est de transformer l’expérience des utilisateurs (business, data et tech). A trop penser techno, on finit par en oublier l’essentiel et faire échouer les projets.
La stack data moderne peine à rendre la data plus accessible aux utilisateurs business
Nous avons vu que chacun s’accordait à penser que la stack data moderne était quelque chose de formidable, même si c’est pour des raisons différentes. Mais interrogez les utilisateurs business, vous n’aurez pas le même son de cloche. Pour eux, la stack data moderne n’a rien de fantastique.
Pour la plupart des gens en fait (je parle des gens agréables, sociaux, du genre à pouvoir passer une soirée sans se disputer sur le formatage SQL), la stack data moderne est une expérience, et souvent…un ensemble d’expériences désagréables :
Essayer de comprendre pourquoi la croissance ralentit la veille du conseil d’administration
Essayer de mettre tout le monde d’accord sur les revenus trimestriels quand les différents outils & dashboards disent tous des choses différentes.
Partager à un client les métriques d’usage de son produit et entendre ce client vous expliquer que sa liste d’utilisateurs actifs inclut des individus qui ont arrêté d’utiliser le produit depuis plus de 6 mois.
Recevoir un message Slack du CEO qui vous dit que son rapport d’activité quotidien est encore cassé.
Etc.
Pour reprendre l’analogie d’Erik Bernhardsson, fondateur de Modal Lab, si la stack data moderne est un restaurant, toutes les frustrations que l’on vient de décrire sont celles que l’on a lorsque l’on mange un plat sans saveur. Le chef a investi dans l’amélioration des cuisines, mais les clients (les utilisateurs business, mais aussi les analystes data) sont ici pour déguster de bons plats servis par un personnel attentionné dans un cadre agréable.
Tant que vous n’arrivez pas à ce résultat, votre technologie, votre « stack data moderne », si révolutionnaire qu’elle soit, est quelque chose de théorique.
Définition et analyse de la Stack Data Moderne
Vous n’êtes pas certain de comprendre ce que recouvre ce terme ? Dans ce cas, nous vous invitons chaudement à lire notre article introductif à la stack data moderne. Vous y découvrirez ce qui a conduit à cette nouvelle organisation des outils au service d’un meilleur usage de la data et les principales briques constituant la stack data moderne.
La stack data moderne se résume trop souvent à une multiplication des outils
Les utilisateurs business n’arrivent pas à utiliser les données comme il faudrait. Ils sont insatisfaits, frustrés. La première réaction quand quelque chose ne fonctionne pas consiste à multiplier les outils. On crée des cartographies de tous les outils et systèmes à disposition et on essaie de trouver l’endroit où on pourrait venir en caler un nouveau.
Même si chaque outil pris individuellement permet de réaliser les tâches pour lesquelles il est fait de manière plus efficace, fractionner l’écosystème en utilisant des briques de plus en plus petites ne permet pas de résoudre les vrais challenges.
Représentation d’une stack data moderne. Source : a16z.
Comme l’explique bien Erik Bernhardsson, l’hyperspécialisation nous rend excellents pour couper des oignons et cuire les tartes aux pommes, mais c’est une mauvaise façon de gérer un restaurant.
Non, la stack data moderne ne consiste pas à empiler le plus d’outils possibles. Elle ne doit pas être le prétexte à une prolifération des technos. Prendre cette voie, c’est le plus sûr moyen de créer une stack data qui ne remplit pas sa promesse : aider les utilisateurs à travailler mieux grâce aux données.
Benchmark complet des outils de la Stack Data Moderne
Même si la stack data moderne ne se réduit pas à une combinaison de nouveaux outils (et c’est tout le propos de l’article que vous lisez), on ne peut pas faire l’impasse sur les technologies. On vous a préparé un benchmark complet des outils de la stack data moderne. Type d’outil, origine, modèle économique, réputation sur le marché… chaque solution est présentée dans le détail, dans un beau GSheet facile à exploiter et téléchargeable gratuitement. Bonnes découvertes !
La stack data moderne peine à devenir une culture d’entreprise
Lorsque nous réfléchissons aux limites de la stack data moderne telle qu’elle est imaginée et vécue dans bon nombre d’entreprises, c’est le terme de « culture » qui nous vient, cette culture vaguement définie comme une combinaison des compétences que nous avons (ou pas), des structures organisationnelles de nos équipes et à partir de termes flous comme « culture des données », « culture data-driven ».
Ces éléments sont importants, mais il faut bien être conscient qu’une culture data ne s’inculque pas en offrant à ses équipes des manuels ou en organisant des séminaires.
Si les gens ne sont pas enthousiasmés par l’avenir que leur promettent les promoteurs de la stack data moderne, si les gens sont rebutés par le travail à accomplir pour devenir « data-driven », nous ne pouvons pas nous contenter de les inviter à rejoindre le bateau. Il faut réussir à gagner leur enthousiasme. Il faut les convaincre.
Pour cette raison, la stack data moderne comprise comme projet techno n’est pas suffisante. Ce n’est pas de cette manière que vous créerez de l’adhésion. Les entreprises doivent aller plus loin que la stack data moderne et chercher à concevoir une expérience data moderne. Je vous présenterai dans un instant quelques principes directeurs pour construire ce chemin.
Quelques exemples inspirants de stack data efficientes
On dit parfois que les équipes data devraient toujours penser ce qu’elles créaient comme un produit et leurs collègues comme des clients. Si on admet cette idée, quel devrait être ce produit ? A quoi devrait ressembler le chemin qui nous mène d’une question, qui nous fait passer par des technologies, des outils, des collaborations, des échanges pour aboutir à une réponse ? Comment construit-on une stack data moderne conçue comme un produit au service des utilisateurs cibles ?
On n’arrive que rarement à répondre de manière satisfaisante à ces questions.
Ce n’est pas une fatalité. Certaines entreprises ont réussi à trouver des réponses pertinentes.
Airbnb, Uber et Netflix ont construit des stack data intégrées, avec des outils analytics, des outils de reporting, un catalogue de métriques, des catalogues de données et des plateformes ML. Contrairement aux éditeurs des logiciels qu’ils utilisent, les outils qui composent ces stacks data sont au service d’un objectif plus grand qu’eux-mêmes. Les outils sont au service de l’entreprise, et non l’inverse.
Les résultats sont impressionnants :
Chez Uber par exemple, les salariés peuvent rechercher une métrique, la visualiser à travers différentes dimensions et passer directement d’une exploration no-code à l’écriture de requêtes, tout cela pendant qu’une IA veille à éviter les redondances.
Airbnb a construit un dispositif similaire : un data catalog et un référentiel de métriques sont connectés à un outil d’exploration des données et un IDE SQL.
Netflix a créé un workflow pour créer, partager, déployer, planifier et explorer des notebooks qui gèrent tout, des dashboards à la production de modèles.
La stack data de Netflix, une machine de guerre au service de l’efficience opérationnelle.
Les questions les plus importantes à se poser
Il ne fait aucun doute que ces outils ne sont pas parfaits. Mais ils offrent une fenêtre sur les questions les plus importantes qu’il faut se poser :
A quoi ça sert d’utiliser une stack data moderne ?
Qu’est-ce qu’une stack data m’apporte de plus concrètement ?
Quelle est la meilleure façon pour les gens de répondre à une série de questions, de faire confiance aux réponses et de décider ce qu’il faut faire ensuite ?
En quoi pouvons-nous aider les gens qui se préoccupent d’avoir une stack data moderne qui marche, sans se soucier d’où passe la frontière entre un produit et un service ?
Qu’est-ce que nous pouvons construire aux gens qui sont dans le restaurant pour qu’ils profitent de leur dîner et n’aient pas à penser à qui prépare les oignons et comment les cuisiniers cuisinent ?
La stack data moderne est décentralisée et cela a un coût
Quelle que soit la définition de la stack data moderne que vous utilisez, presque tout le monde, nous compris, s’accorde à dire qu’elle doit être décentralisée.
Je ne cherche pas ici à vous vendre une approche plus qu’une autre. Mon objectif n’est pas d’entamer une discussion sur les fondements philosophiques de la stack data moderne. Doit-elle être cloud-first, plutôt modulaire ou monolithique, version control ou peer review ? Ce n’est pas le sujet.
Mon point, c’est que la décentralisation qui sous-tend l’approche stack data moderne a un coût. Pourquoi ? Parce que l’architecture se reflète sur l’expérience de ses utilisateurs. Les lignes de faille qui séparent les produits de la stack deviennent des lignes de faille entre les différentes expériences d’utilisation. Il est là le challenge.
Si la stack data moderne est parfois décevante, c’est que loin d’aider les utilisateurs, elle conduit à une fragmentation de l’expérience. La fragmentation des outils aboutit à une fragmentation de l’expérience. C’est ce contre quoi il faut chercher à aller.
Pour trouver la solution, posons-nous cette question : comment une multitude d’entités souveraines et souvent concurrentes peuvent-elles s’unir pour construire quelque chose de cohérent ?
Un petit détour par l’évolution du commerce international
L’histoire du commerce international peut nous aider à trouver la solution. Avant la Première Guerre mondiale, la plupart des accords commerciaux internationaux (traités sur les tarifs et les restrictions) étaient des accords bilatéraux, entre deux pays. Au fur et à mesure que les pays européens se sont industrialisés, un réseau d’accords bilatéraux a vu le jour, centré sur les principaux partenaires commerciaux et souvent piloté par eux : dans le cas européen, la Grande-Bretagne et la France.
En 1947, après deux guerres mondiales, la crise de 29 et la mode pour le protectionnisme, 23 des principaux partenaires commerciaux du monde ont signé l’Accord général sur les tarifs douaniers : le GATT. En raison du poids des membres fondateurs, l’accord n’a cessé d’attirer à lui de nouveaux signataires dans la deuxième moitié du XXème siècle. Le GATT a finalement été remplacé en 1995 par l’Organisation mondiale du commerce, l’OMC. Aujourd’hui, l’OMC a 164 membres qui représentent 98% du commerce international.
Bien que de nombreux pays négocient encore des accords commerciaux bilatéraux ou régionaux, le commerce mondial est principalement régi par les traités mondiaux de l’OMC plutôt que par un réseau complexe de milliers d’accords bilatéraux.
La stack data moderne doit accomplir la même évolution que celle du commerce international
Encore aujourd’hui, la stack data, ce sont des centaines d’Etats membres en orbite autour de grosses plateformes comme Snowflake, Fivetran, dbt et quelques autres. Les relations entre les éditeurs sont gérées par des intégrations bilatérales qui permettent de combler les fossés entre les outils. Les intégrations bilatérales sont à la stack data ce que les accords bilatéraux sont au commerce international.
Dans des écosystèmes aussi complexes que ceux du commerce international ou des technologies data, les intégrations bilatérales montrent rapidement leurs limites. L’approche n’est pas scalable. On aboutit à un patchwork désordonné d’accords ou d’intégrations qui ne peut que se désagréger (et qui se désagrége) avec le temps. Le GATT et l’OMC en sont la preuve.
Toutes les solutions de Data Management proposent des connecteurs, et Octolis n’y déroge pas, évidemment. Mais construire une stack data moderne ne se réduit pas à faire des ponts entre chacune de vos solutions. Octolis propose un outil tout-en-un qui vous permet de rationaliser vos intégrations et de centraliser la préparation des données.
Construits à partir des plus grandes économies du monde, ces accords ont créé une vision commune et des principes directeurs de la politique commerciale qui, même s’ls ne sont pas toujours juridiquement contraignants, ont contribué à faire pencher le monde dans une direction commune.
La stack data moderne doit accomplir la même évolution. Nous allons essayer de synthétiser les principes directeurs qui doivent la gouverner.
Différentes approches pour construire une Stack Data Moderne
La stack data, c’est l’ensemble des outils gravitant autour du data warehouse qui va vous permettre de valoriser vos données et de pleinement les exploiter dans vos applicatifs métier. Sachez qu’il existe plusieurs manières de construire une stack data moderne, plusieurs approches possibles : l’approche best of breed, l’approche agence, l’approche tout-en-un. Pour en savoir plus, découvrez notre article sur le sujet.
Principes directeurs pour une expérience data moderne
La stack data moderne fournit une roadmap SI. Pour que la stack data moderne se traduise pour les utilisateurs par une expérience data moderne, quelques principes directeurs doivent être suivis. Voici ceux auxquels je crois.
#1 Les utilisateurs business doivent pouvoir faire leur métier sans devoir se transformer en data analyst
On a beaucoup parlé de démocratisation des données. C’est une expression à la mode et les objectifs sont louables : permettre à chaque utilisateur de manipuler les données en autonomie et ainsi libérer les équipes data des tâches ingrates qui leur sont traditionnellement confiées pour qu’elles puissent se concentrer sur des projets à forte valeur ajoutée.
La démocratisation des données a eu tendance à devenir une prescription : « Devenez tous analystes grâce aux outils no code ! ». Ce projet a largement échoué comme on peut le constater aujourd’hui avec le recul que l’on a.
L’expérience de la stack data moderne que nous appelons de nos vœux ne consiste pas à mettre les données dans les mains des utilisateurs pour leur laisser le soin de les analyser. Ce que nous voulons, c’est intégrer les données dans les systèmes opérationnels où elles se trouvent déjà pour libérer la productivité de leurs utilisateurs. Les données doivent aider les gens à mieux faire leur travail, plutôt que de leur ajouter un nouveau travail à faire.
#2 La data science et la BI doivent fusionner
On a pris l’habitude de penser que les analystes data devaient travailler dans des outils techniques avancés et que tous les autres collaborateurs devaient utiliser des outils de BI user-friendly. C’est faux. Les outils de BI drag & drop peuvent être très utiles pour les data scientists chevronnés et tout le monde peut devenir un consommateur d’analyses avancées.
Les data scientists ont aussi vocation à utiliser des outils de Data Viz (ici, PowerBI).
Dans une expérience data moderne, les utilisateurs doivent pouvoir passer sans problème de la visualisation d’un KPI provenant d’un catalogue de données sous contrôle à l’exploration de ce KPI à l’aide de groupements et de filtres, puis à son incorporation dans des analyses techniques approfondies. On doit pouvoir visualiser sur la même interface hommes machines des KPIs intégrés à des tableaux de bord et explorer les données qui alimentent ces KPIs pour approfondir le niveau d’analyse.
Les personnes qui consomment des données ne devraient jamais avoir à sortir d’un outil pour approfondir leurs analyses. Si la stack data moderne nous parle d’intégration des données dans une architecture tech, l’expérience data moderne nous parle d’intégration des expériences.
#3 Les utilisateurs doivent avoir confiance dans les données qu’ils ont sous les yeux
« Est-ce que ces données sont fiables ? » est l’une des questions les plus frustrantes et l’une des plus courantes que les gens posent à propos des données. Aujourd’hui, la réponse à cette question dépend essentiellement de signaux implicites :
Qui a construit ces résultats ?
Est-ce que ça a été modifié récemment ?
Est-ce que ça paraît crédible ?
Ces questions nous conduisent à des recherches interminables. On utilise plusieurs outils pour confirmer les résultats. On perd du temps. Voire pire : on n’utilise pas les données, faute de confiance.
Pour que les utilisateurs aient confiance dans les données qu’ils visualisent et qu’ils manipulent, il faut que chaque set de données indique de lui-même si les processus amont qui l’ont constitué sont corrects ou non, à jour ou non, en un mot : fiables.
Dans une expérience data moderne, on passe du temps à débattre sur les actions à prendre à cause d’un chiffre lu sur un tableau de bord plutôt qu’à vérifier si ce chiffre est juste ou non.
#4 Ne pas oublier ce que l’on a appris
Les informations que nous présentent les outils de BI sont éphémères. Elles disparaissent au fil des mises à jour des données et des mises à jour du design des reportings. Les données récentes chassent les données anciennes. Les analyses ad hoc sont notées à la va-vite et sans méthode. Les conversations se perdent dans les flux Slack.
Dans une expérience data moderne, ce que les données nous apprennent fait l’objet d’un enregistrement, d’une historisation. On ne perd rien des analyses que l’on a faites. On garde la mémoire des enseignements. C’est le plus sûr moyen d’avancer et de ne pas refaire les erreurs du passé.
#5 Les métriques doivent être gérées à un niveau global
En général, les métriques sont pilotées à un niveau local dans les outils de BI. Chaque équipe gère à son niveau ses KPIs, leur mode de calcul, les ratios de synthèse, l’évolution du dispositif de pilotage. Dans une stack data décentralisée et modulaire, on aboutit rapidement à un patchwork de calculs dupliqués et souvent contradictoires.
Une expérience data moderne suppose de la coordination. La gestion et l’évolution des métriques doivent être centralisées. Si les règles de calcul d’un KPI change, ce changement doit être diffusé partout : dans les tableaux de bord de BI, dans les notebooks Python, dans les pipelines ML opérationnels.
#6 Il ne faut pas communiquer uniquement par tableaux
A force de vous plonger dans les données, vous ne finissez par ne plus voir que des structures relationnelles : des tables, des lignes, des colonnes, des jointures. Et pour cause, la plupart des outils data présentent les données sous cette forme. Et c’est sous cette forme que les data analysts se confrontent aux donnés.
Mais pour tous les autres utilisateurs, les données se présentent de manière plus protéiforme, sous forme de métriques dans une série temporelle, de représentations abstraites dans des domaines métiers complexes, de comptes rendus écrits…Les utilisateurs doivent pouvoir interroger et explorer les données de différentes manières, pas uniquement dans des tables et des colonnes.
#7 Il faut construire un pont entre le passé et le futur
Il est tentant de concevoir la stack data moderne comme une discontinuité, le saut d’un passé que l’on veut oublier vers un avenir radieux. Construire une stack data moderne, pour beaucoup, c’est faire table rase du passé. C’est une conception fausse. Ce n’est pas une rupture, c’est une transition. Une transition qui ne mettra pas un terme à tous les problèmes et tous les freins que peut rencontrer un utilisateur de données. Dites-vous bien que vous continuerez à utiliser Excel ! Dans une expérience data moderne, il faut savoir négocier avec cette réalité et admettre qu’une partie du passé se conserve.
#8 L’expérience data moderne est création continue d’imprévisibles nouveautés
Les analyses ne sont pas prévisibles. Ce n’est pas un processus linéaire qui peut être anticipé. On sait d’où l’on part : une question. On ne sait pas où l’on va. Une question en appelle de nouvelles. De la même manière, une infrastructure data est un système évolutif qui se transforme à mesure que les enjeux business et que les sources de données changent.
Les analyses construites à partir de l’infrastructure data évoluent et font évoluer le système qui leur sert de base. L’expérience data moderne répond à la logique des systèmes émergents. Elle démarre petite, grandit, grossit, conquiert de nouveaux territoires. Les expériences et les systèmes rigides ont toujours un coût à la fin.
#9 L’expérience data moderne casse les murs
Les stacks data ont pour habitude de créer des murs et les différents utilisateurs collaborent entre eux en se jetant des choses par-dessus les murs érigés : les ingénieurs data jettent des pipelines aux analysts, les développeurs BI jettent des rapports aux utilisateurs métiers, les analystes jettent des résultats à qui veut bien les recevoir. Le caractère modulaire des stacks data modernes est une tentation à créer encore plus de murs.
De la même manière que dbt a cassé un mur, une expérience data moderne doit briser les autres en encourageant la collaboration et le partage entre les équipes business, data et tech.
Il y aurait beaucoup de choses à dire sur chacun de ces sujets. Ce sont des sujets dont il faut parler, ce sont des conversations qu’il faut avoir. Si l’on ne pense pas l’expérience data moderne qui doit accompagner la stack data moderne, on peut réussir à construire une belle architecture d’outils, mais la promesse à laquelle on croyait (la révolution technologique, la transformation du fonctionnement de l’entreprise) ne se réalisera pas.
Pourquoi construire un dispositif data par vous-même n’est pas une bonne idée ?
Construire son propre dispositif data est un projet ambitieux et complexe nécessitant de nombreuses ressources. Pourtant de multiples entreprises, souvent poussées par les data engineers, font le choix de développer leur propre outil. Cette décision peut s’avérer néfaste pour l’entreprise si elle n’est pas motivée par les bonnes raisons.
Mettre en place un dispositif data nécessite d’assembler de nombreux composants cloud et/ou open source, souvent plus d’une douzaine : Kubernetes, KubeFlow, AWS ECR, Elasticsearch, Airflow, Kafka, AWS Cloudwatch, AWS IAM, DBT et Redshift. Ces éléments sont ensuite liés entre eux à travers une brique de code, avec Terraform par exemple. Ce type d’architecture est d’autant plus complexe qu’il se doit d’offrir à chaque équipe, et donc à chaque compte, un accès sécurisé à l’outil.
A l’inverse, lorsque l’on utilise une solution déjà existante, il est seulement nécessaire de configurer ses accès AWS et d’utiliser un outil tel que Terraform. Il ne reste qu’à connecter les bases de données aux outils d’analyses, par exemple Azure Data Lake et Azure Data Factory. Aucun outil ne permet d’éliminer totalement ces étapes, mais la mise en place générale du dispositif est grandement simplifiée et accélérée.
Dans cet article inspiré de l’excellent Niels Claeys, on évoque dans le détail les raisons qui poussent les organisations à se tourner vers la construction d’un dispositif data ‘best of breed’ ainsi que les obstacles qui se dressent devant cette construction.
La passion de vos data engineers est un frein
La majorité des data engineers considèrent la construction d’un dispositif data comme un véritable challenge, un projet leur permettant de développer et d’éprouver leurs compétences. C’est même probablement dans l’ADN d’un ingénieur de vouloir construire ses propres outils.
Par conséquent, la plupart d’entre eux risquent de ne pas être totalement neutres lorsqu’ils considèrent les avantages et les inconvénients d’un tel projet. Leurs objectifs ne sont alors pas parfaitement alignés avec ceux de l’entreprise, ce qu’il est nécessaire de prendre en compte.
Voici les raisons pour lesquels les data engineers risquent de manquer d’objectivité :
Les data engineers ❤️ les nouveaux outils
Dans l’écosystème data, les technologies évoluent rapidement et la popularité des outils varie constamment. La maîtrise d’un nouveau software populaire est souvent valorisée sur un CV. De ce fait, de nombreux programmeurs vont chercher à utiliser les nouveaux outils en vogue pour en avoir une bonne compréhension au minimum.
Il est important pour une entreprise de permettre à ses développeurs de continuer à apprendre de nouvelles technologies, mais employer de nouveaux outils lors du développement d’une plateforme data complexe n’est certainement pas le cadre le plus optimal pour permettre cet apprentissage.
De plus, la découverte et la prise en main d’un nouvel outil représentent un défi souvent ludique pour un développeur. Mais l’excitation que peut éprouver le data engineer lors de la première utilisation d’une nouvelle technologie ne dure qu’un temps, et l’envie de travailler avec l’outil peut décroître à mesure que celui-ci devient familier et l’apprentissage plus sporadique.
De ce fait, construire une plateforme data représente pour un ingénieur l’opportunité d’acquérir de nouvelles compétences tout en travaillant sur un projet stimulant. Les développeurs préfèrent donc naturellement développer eux-mêmes leur dispositif data et soutiennent ce choix sans que cela soit nécessairement favorable pour l’entreprise.
Les data engineers ❤️ toujours leur propre code
Il est fréquent d’entendre des développeurs critiquer la qualité du code d’un produit ou la solution en elle-même. Nombreux sont ceux préférant leur code et leur solution à ce qui existe sur le marché, se targuant – à tort ou à raison – d’être capable de développer des outils de meilleure qualité.
L’objectif ici n’est pas de comparer la qualité des codes ou le niveau des développeurs, mais de réfléchir aux intérêts de l’entreprise sur le long terme. Même en acceptant le postulat que vos développeurs seraient plus compétents que ceux ayant développé la solution déjà existante, choisir de construire son propre dispositif peut être contre-productif pour plusieurs raisons :
La durée de développement :
Développer une plateforme data complète, utile et capable de rivaliser avec les solutions du marché est un projet de grande envergure risquant de s’étaler sur plusieurs années et de monopoliser des ressources sur le long terme. Il faut plus longtemps encore pour en mesurer les bénéfices.
La maintenance de la plateforme :
Créer sa propre solution implique aussi de s’assurer de la maintenance du code sur le long terme. Cela impose d’avoir une excellente documentation et un code legacy de grande qualité ainsi que d’avoir toujours un développeur capable de mettre à jour le software.
La persistance des développeurs :
Les data engineers à l’origine de la plateforme sont susceptibles de changer de projet/équipe/entreprise au court de la vie du dispositif data. La transmission du projet s’en trouve alors complexifiée. De plus, les nouveaux développeurs risquent de vouloir à leur tour adapter le code et l’architecture du projet.
Ainsi, faire le choix de développer son propre outil représente le risque d’avoir une plateforme instable et difficile à maintenir. De plus, les développeurs comparent plus généralement la qualité intrinsèque du code, mais négligent la capacité de l’entreprise à maintenir l’outil et à le faire évoluer pour répondre à de nouveaux besoins.
Faire le choix d’une solution existante, c’est réduire le temps de développement et accroître la stabilité de ses outils.
Les data engineers ❤️ la liberté
Construire son propre outil, c’est aussi choisir les technologies mises à contribution dans le projet. Mais la diversité des IDE, des langages, des frameworks et des softwares rend ce choix complexe. En outre, les préférences individuelles des développeurs sont multiples et peuvent très souvent donner lieu à d’intenses débats. Ainsi la stack data de la plateforme risque d’être pensé en fonction des habitudes du data engineer plutôt que sur des critères objectifs de maintenance et scalabilité au sein de l’entreprise.
Exemple d’architecture data moderne
Comprendre la stack data moderne
Un Data Engineer qui aurait été cryogénisé en 2010 et que l’on réveillerait aujourd’hui ne comprendrait pas grand-chose à la stack data moderne. Il n’a fallu que quelques années pour que tout change dans la manière de collecter, extraire, acheminer, stocker, préparer, transformer, redistribuer et activer les données. On vous explique tout dans notre guide introductif à la Stack Data Moderne.
Plus encore, le fait de développer la solution offre une grande liberté quant à l’architecture de la plateforme. C’est parce que les développeurs savent qu’ils pourront coder avec les langages de leur choix et assembler les différentes briques à leur manière qu’ils préfèrent construire eux-mêmes le dispositif data.
Mais cette liberté pour le développeur peut rapidement se transformer en contraintes pour l’entreprise. En effet, le choix du data engineer va dépendre de plusieurs critères susmentionnés, tels que la popularité de l’outil, la possibilité d’utiliser son propre code… A l’inverse, l’entreprise doit considérer avant tout l’intégration du dispositif data dans son SI, la possibilité de le faire évoluer et de le maintenir à jour.
En résumé, l’entreprise est soumise à des contraintes quand le développeur cherche à être libre dans son travail. Cette opposition peut conduire à un choix contre-productif de la part du data engineer.
Les obstacles liés à la construction d’une plateforme data
Les considérations des data engineers ne sont pas les seules raisons pour lesquels construire son propre dispositif data n’est pas une bonne idée. D’autres problématiques s’ajoutent à ces considérations :
Les coûts d’exploitation sont supérieurs aux coûts de construction
Construire une ébauche de dispositif data est l’affaire de quelques jours pour un data engineer expérimenté. C’est probablement pour cette raison que le temps de développement est très souvent grandement sous-estimé. En effet, s’il est relativement facile de mettre en place un premier MVP, il est autrement plus complexe de coder une plateforme complète, stable et facile à maintenir.
Coûts d’une plateforme data au cours de son cycle de vie complet (Source)
Une fois la première version live déployée, il est nécessaire de s’assurer qu’une équipe soit responsable de :
Maintenir le code à jour :
Mettre à jour les dépendances, corriger les vulnérabilités et les failles de sécurités…
Gérer les bugs :
Au cours de son cycle de vie, la plateforme va subir de nombreux bugs qu’il faut fixer rapidement pour assurer la disponibilité du dispositif. Il est donc nécessaire d’avoir en permanence un développeur ayant une connaissance précise du code et capable d’intervenir rapidement.
Faire évoluer le dispositif :
Pour transformer le MVP en dispositif complet, il est nécessaire de prendre en compte les retours des utilisateurs et d’y ajouter les fonctionnalités manquantes. Il est aussi important de s’assurer que l’usage de la data par les équipes métiers n’est pas redondant et de proposer des solutions le cas échéant.
Ainsi, les coûts d’exploitation de la plateforme risquent d’être nettement supérieurs aux coûts de construction. Ces coûts d’exploitation sont généralement sous-estimés et le coût total du projet sera probablement bien supérieur aux estimations. De plus, si l’investissement initial pour construire la plateforme peut sembler légitime face à l’acquisition d’un software, il est cependant plus difficile de justifier les coûts d’exploitation par rapport à un abonnement à une solution existante (surtout si celle-ci est plus complète).
Au cours du cycle de vie du dispositif, il est probable que l’entreprise ne perçoive pas un retour sur investissement suffisant pour justifier les dépenses d’exploitation. Le projet est alors véritablement vain.
Votre plateforme data ne sera pas pensée comme un produit
Lorsque le dispositif data n’est pas une finalité, mais un moyen de répondre à des problématiques rencontrées par les employés, le résultat est souvent fragmentaire et présente de nombreuses limites.
Une plateforme peu fonctionnelle
Dans une entreprise où la plateforme data n’est pas le produit final, mais seulement un support pour les équipes métiers, il est très probable que l’outil ne soit pensé qu’en réponse à des cas d’usages précis. Le dispositif final risque alors de ressembler plus à un assemblage disparate de fonctionnalités qu’à un produit complet.
Dans ce cas, il est assez rare de travailler à améliorer les performances globales de l’application ou de proposer des fonctionnalités plus globales visant à faciliter l’expérience de l’utilisateur final. L’accent est mis sur les cas d’usages restant, au détriment de la cohérence globale du dispositif et de sa fonctionnalité.
Une solution peu efficace pour améliorer la productivité
Proposer une plateforme pour répondre à des cas d’usages spécifiques permettra aux équipes métiers de réaliser certaines tâches plus facilement, mais n’est pas suffisant pour accroître sensiblement leur productivité. De plus, les ressources étant limitées lors du développement d’une application en interne, il est probable que les solutions visant à réellement augmenter la productivité soient reléguées au second plan, l’accent étant mis sur la capacité à répondre aux besoins spécifiques à l’origine de la plateforme.
En effet, proposer un service permettant d’augmenter la productivité requiert le développement d’outils encore plus complexe venant s’ajouter au dispositif en construction. Il est peu probable qu’une entreprise dont l’activité n’est pas directement en lien avec la construction d’un tel software dispose des ressources suffisantes pour s’emparer d’un projet de grande envergure et le mener convenablement à son terme.
Conclusion
Construire un dispositif data entier est un projet souvent plus complexe et coûteux que prévu. Pour cette raison, il est nécessaire de définir très clairement ses besoins et de s’assurer que le ROI du projet soit particulièrement important avant d’entamer la construction d’un dispositif data.
Mesurer le ROI de son dispositif data
Pour vous aider à mesurer le ROI de votre dispositif data, nous mettons à votre disposition un template téléchargeable gratuitement à adapter à votre organisation dont l’utilisation est détaillé dans l’article associé..
Dans la majorité des cas, il sera possible de trouver une solution existante répondant à ces besoins et de constater que la mise en place d’une telle solution offre un retour sur investissement plus important. Nous conseillons donc de s’orienter vers de telles solutions qui permettront des économies de temps, d’argent et de ressources.
Data viz : Les meilleurs outils de visualisation des données
Adopter un outil de data visualisation oui mais lequel ? Quels sont les types d’outils à ma disposition ? Existe-t-il des outils gratuits pour initier cette démarche avant d’aller plus loin ? En quoi un outil de « data viz » est-il différent d’un outil de business intelligence ? Sur quels critères choisir mon outil de data viz ?
Voici les questions auxquelles nous avons tâché de répondre dans cet article, bonne lecture 🙂
Quels sont les différents types d’outils de visualisation de données ?
Comprendre la différence entre data visualisation et Business Intelligence
Face à la complexité du traitement de la donnée, les entreprises ont de plus en plus recours à des outils permettant de transformer cette ressource en leviers d’actions utilisables par les différentes équipes à des fins stratégiques.
Il existe pour cela deux catégories principales d’outils : les outils de data visualisation et les outils de business intelligence (BI).
On définit la visualisation de données comme étant le processus permettant de transformer d’importants volumes de données dans un contexte visuel. La visualisation des données consiste à générer des éléments visuels à partir des données. Il peut s’agir de tableaux, de graphiques, de diagrammes, d’images, de modèles, de films, etc.
Exemple de dashboard animé réalisé avec Tableau Public
Les outils et applications de Business Intelligence quant à eux sont utilisés pour analyser les données des opérations commerciales et transformer les données brutes en informations significatives, utiles et exploitables.
La première étape de toute forme de Business Intelligence consiste à collecter des données brutes ou des données historiques. Ensuite, les outils de Business Intelligence aident à la visualisation, à la création de rapports et aux fonctions d’analyse qui sont utilisées pour interpréter de grands volumes de données à partir des données brutes.
Exemple de dashboard de BI réalisé avec Power BI
Caractéristiques
Data visualisation
Business Intelligence
Objectif
Faciliter la compréhension des conclusions d’une analyse de données
Transformer des données brutes en leviers d’actions pour l’entreprise afin d’orienter les prises de décisions
Définition
Représentation graphique des élément clefs de l’analyse de données
Ensemble des pratiques de collecte, d’analyse et de présentation de données visant à orienter la prise de décisions
Expertise requise
La manipulation de ces outils est plus facile que pour les softwares d’analyse statistique traditionnels
Ce processus nécessite une variété de compétences, de la collecte de données à la prise de décisions
Type d'usage
Présentation de l’information en temps réel ou après le traitement des données
Prise de décision en direct ou après analyse
Types de données
Tables de données structurées
Jeux de données reliés entre eux concernant l'activité de l'entreprise
Focus
Créer des rapports graphiques clairs
Donner des indications business et éclairer la prise de décisions
Utilisé pour
Représenter de façon la plus intuitive les indicateurs clefs de l’activité
Définir et calculer les principaux indicateurs clefs
Caractéristiques principales
Représentation intuitive de l’information
Lecture facile et rapide de l’information permettant de mieux la mémoriser
Permet d’interagir avec la donnée
Permet d’analyser l’activité de l’entreprise et de suivre les principaux indicateurs (KPI)
Aide les dirigeants et les managers à prendre des décisions éclairées par l’analyse des performances passées
Ces deux types d’outils sont donc essentiels dans un contexte où l’usage efficace de la data est clef pour faire face à la concurrence. Les outils de BI permettent de prendre des décisions étayées par l’analyse des performances passées quand les outils de data visualisation visent à représenter clairement ces analyses.
Outils de data visualisation gratuits et open source
Il existe une multitude d’outils de visualisation de données, de qualité parfois inégale, dont certains sont open source – le code est accessible publiquement – et d’autres gratuits. Le choix du type d’application a une importance certaine sur la capacité de l’entreprise à traiter les données de façon pertinente et efficace.
Open source
Un software est dit open source lorsque son code source est accessible publiquement, souvent sur des plateformes dédiées telles que Git Hub. Ainsi chaque développeur peut lire, copier et éditer le code de l’application et s’en servir librement pour un usage personnel ou professionnel.
L’accès au code lorsque l’on utilise une application open source est un atout indéniable qui offre la possibilité de personnaliser le software pour le rendre parfaitement adéquat aux besoins de l’entreprise, sans avoir besoin de développer intégralement un outil en interne. Une application open source permet donc de bénéficier d’un gain de temps et d’une réduction des coûts de développement sans souffrir pour autant d’un manque de flexibilité.
Gratuit
On trouve des applications d’une complexité très variable parmi le vaste catalogue des outils de data visualisation, dont les plus complets requièrent du temps et des efforts avant d’être complètement maîtrisés. Il existe cependant des outils gratuits, plus légers et plus accessibles qui nécessitent un temps de prise en main bien moindre.
La facilité d’usage de ces applications allant de pair avec la facilité d’implémentation au sein des équipes rend le recours à ces outils particulièrement intéressant pour des personnes peu formées au code et ayant besoin de mettre en place une solution rapidement.
Top 50 des dashboards Ecommerce sur Google Data Studio
Vous souhaitez mettre en place des dashboards de data viz pour suivre de plus près les performances de votre activité e-commerce ? Découvrez et testez les meilleurs dashboards Data Studio que nous avons sélectionnés pour vous.
Qu’attendre d’un outil de visualisation de données ?
Caractéristiques principales
Les outils de visualisation de données sont essentiels dans le traitement de la data, mais pour que leur usage soit pertinent il est nécessaire qu’ils répondent à certaines caractéristiques afin de faciliter la compréhension qu’auront les utilisateurs de l’ensemble des données.
Caractéristiques
Attentes
Intégrabilité
La possibilité d’intégrer les représentations graphiques des données dans les applications déjà implémentées afin d’en faciliter l’accès.
Possibilités d'action
Les représentations graphiques doivent être porteuses de sens et offrir des conclusions qui pourront être mises en place au sein de l’activité.
Performance
L’usage régulier d’un outil de data visualisation dépend de la vitesse à laquelle il va fournir des conclusions à l’utilisateur, qui risque de s’en détourner si le temps d’attente est trop important.
L’usage des GPU par certaines applications permet de réduire les temps de calculs et de latence, et offre ainsi une meilleur expérience pour l’utilisateur.
Infrastructure dynamique
Le recours à des services cloud dédiés pour la gestion du big data permet faciliter la gestion de jeux de données volumineux et de réduire le cout de développement et d’implémentation pour les outils de data visualisation.
Exploration interactive
L’outil doit permettre aux utilisateurs d’interagir facilement avec leurs jeux de données (par le biais de filtres ou de groupement par exemple) afin qu’ils puissent rapidement valider ou vérifier leurs hypothèses.
Collaboration
La possibilité pour plusieurs utilisateurs de travailler simultanément sur une même analyse, évitant ainsi le recours à l’envoi de fichiers statiques et permettant un gain de temps non négligeable.
Support pour le streaming de data
Un support pour le streaming de data permet d’utiliser des sources de données variées apportant un volume de données plus important, tels que les réseaux sociaux, les applications mobiles ou l’internet des objets (IoT).
Intégration d’intelligence artificielle
L’utilisation d’intelligence artificielle permet de simplifier, d’accélérer et d’approfondir les analyses, allant même jusqu’à fournir des prédictions. Il faut cependant s’assurer que cela n’affecte pas négativement les performances.
Management des métadonnées intégré
Une bonne gestion des métadonnées permettra aux utilisateurs métiers d’avoir une compréhension claire des données qu’ils manipulent et ainsi de préciser leur analyses.
Accès simplifié en libre-service
La possibilité de créer rapidement un modèle pour tester des hypothèses sans avoir besoin de recourir à un développeur.
Principaux critères de différenciation
Lorsque l’on compare différents outils de data visualisation, il faut accorder une attention particulière à certaines caractéristiques qui vont véritablement différencier les outils entre eux.
Capacité à s’adapter au besoin business :
Lors du choix d’un outil il est nécessaire de s’interroger d’abord sur la façon dont la data visualisation pourra répondre aux besoins de l’entreprise afin de s’assurer que le software soit capable de faire face à tous les cas d’usage.
Une bonne application permettra d’ajouter des extensions ou de créer des graphiques customisés qui s’adapteront parfaitement aux besoins.
Facilité d’apprentissage :
En fonction des profils (tech, métiers…) concernés par l’usage de l’application, il faudra prêter une attention particulière à la facilité de prise en main de l’outil.
Certains outils ne requièrent pas d’expérience particulière, d’autres seront plus complexes mais proches d’outils existants tel qu’Excel, et d’autres enfin nécessiteront le recours au code.
Captation et stockage des données :
Certains outils permettent de se connecter facilement à un grand nombre de bases de données assurant ainsi une implémentation facile dans le SI. Il faut aussi considérer la capacité de l’outil à transformer ces données pour proposer une analyse pertinente.
Analyse et interprétation :
En fonction du software, les filtres, les groupements et les autres moyens d’analyses de données seront plus ou moins puissants et nombreux. Cela aura un effet direct sur la qualité du traitement des données et son interprétation.
Prix :
Le prix est naturellement un élément différenciant majeur réparti sur une fourchette particulièrement large allant de la gratuité totale à des abonnements de plus de 100€ par mois et par utilisateur. Il est toutefois pertinent de s’intéresser aux packages que proposent les outils les plus chers, dont les versions basiques seront parfois suffisantes.
Communauté d’utilisateurs :
Les problématiques auxquelles la documentation de l’outil n’apporte pas de réponse sont récurrentes. La possibilité de se tourner vers d’autres utilisateurs plus expérimentés est alors un atout considérable. Ainsi, certains outils comme Power Bi ou Tableau bénéficient d’une importante communauté active sur divers forums tels que Stackoverflow ou les forums dédiés des applications où il sera possible de trouver de l’aide et bien souvent une solution.
A titre d’indication, on trouve plus de 30 500 résultats sur stackoverflow en cherchant le mot-clef « powerbi » concernant des sujets aussi variés que l’utilisation d’une API Rest sur Power BI desktop ou l’intégration d’image dans un reporting Power BI.
Meilleurs outils de data visualisation
En considérant les points précédents, nous avons sélectionné les meilleurs outils de data visualisation : ceux que nous préférons et que nos clients utilisent le plus.
FusionCharts is another JavaScript-based option for creating web and mobile dashboards. It includes over 150 chart types and 1,000 map types. It can integrate with popular JS frameworks (including React, jQuery, React, Ember, and Angular) as well as with server-side programming languages (including PHP, Java, Django, and Ruby on Rails).
Grafana is open-source visualization software that lets users create dynamic dashboards and other visualizations. It supports mixed data sources, annotations, and customizable alert functions, and it can be extended via hundreds of available plugins. That makes it one of the most powerful visualization tools available.
Sigmajs is a single-purpose visualization tool for creating network graphs. It’s highly customizable but does require some basic JavaScript knowledge in order to use. Graphs created are embeddable, interactive, and responsive.
Polymaps is a dedicated JavaScript library for mapping. The outputs are dynamic, responsive maps in a variety of styles, from image overlays to symbol maps to density maps. It uses SVG to create the images, so designers can use CSS to customize the visuals of their maps.
Chart.js is a simple but flexible JavaScript charting library. It’s open source, provides a good variety of chart types (eight total), and allows for animation and interaction.
Free
Meilleurs outils BI
Nous avons sélectionné les meilleurs outils de data visualisation : ceux que nous préférons et que nos clients utilisent le plus.
Microsoft Power BI is one of the leading business intelligence solutions on the market. It allows you to connect any data source to produce reporting and data visualisation. Power BI also offers advanced data preparation capabilities.
This is a much older product than Power BI because it had launched way back in 1993, even before the world was exposed to data-driven decision makings. This product also aims at providing data insights from large data sets.
Metabase is a business intelligence tool that is an open-source and easy method to generate dashboards and charts. It also solves ad-hoc queries without implying SQL and views the elaborated data as rows in the database. The user can configure it in five minutes and give him a separate platform to answer the queries.
Looker is a BI tool that helps you analyze and share real-time analytics. It also combines all the data and provides an overview.
On plan
Meilleurs outils de data visualisation gratuits et en open source
Les considérations économiques poussent souvent à choisir un outil gratuit. Ce choix sensé au premier abord peut avoir des conséquences négatives s’il n’est pas bien réfléchi. En effet, implémenter un outil inadapté affectera directement la qualité des analyses et imposera de changer d’outil peu de temps après. Nous conseillons donc de s’orienter vers notre sélection d’applications.
Redash is a cloud-based and open-source data visualization and analytics tool. It runs on an SQL server and sports an online SQL editor. The tool has both hosted and open-source/self-hosted versions.
Also known simply as D3, D3.js is an open-source JavaScript library used for visualizing and analyzing data. The acronym ‘D3’ stands for ‘data-driven documents’. Thus, with a strong emphasis on the web standards of HTML, SVG, and CSS, D3 focuses on efficient data-based manipulation of documents.
RapidMiner is a suite of software programs on the cloud. The entire suite is used for shoring up a sequential data analytics environment. In-depth data visualization is only a part of the suite.
Built on D3.js, RAWGraphs makes data sourcing and visualization extremely easy. Here are other features and functionalities of this tool that merits it a place among the best open-source data visualization tools of today.
KNIME is one of the best open-source data visualization software out there right now.
The interface is considerably easy to master. It also presents its data output in a way that anyone with basic knowledge of charts and graphs can understand.
Tableau Prep est la solution de data preparation proposée par Tableau, l’un des principaux concurrents de Power BI. Beaucoup plus abordable que Power BI, le module Tableau Prep vous permet de consolider, dédupliquer et nettoyer les données que vous utiliserez pour faire vos analyses dans Tableau.
Infogram is a fully-featured drag-and-drop visualization tool that allows even non-designers to create effective visualizations of data for marketing reports, infographics, social media posts, maps, dashboards, and more.
Datawrapper was created specifically for adding charts and maps to news stories. The charts and maps created are interactive and made for embedding on news websites. Their data sources are limited, though, with the primary method being copying and pasting data into the tool.
Flourish Public enables immersive storytelling rather than more traditional ways of visualizing as tables, diagrams, and dashboards. Unlike Tableau Public, Flourish does not require a desktop edition.
Free
Construire une segmentation RFM – Le Guide complet
Si vous n’avez toujours pas mis en place de segmentation RFM aujourd’hui, vous n’avez pas raté votre vie mais par contre vous passez à côté d’une belle opportunité de développer votre activité. Ce message s’adresse tout particulièrement aux Retailers 🙂
La segmentation RFM consiste à segmenter vos clients en fonction de leur comportement d’achat, avec pour finalité de construire une stratégie marketing plus ciblée, plus intelligente, plus ROIste, plus en phase avec les besoins, attentes et propensions de vos clients. A la clé, une meilleure rétention client, une optimisation de la lifetime value et des campagnes d’acquisition plus efficaces.
Si vous pensez comme nous qu’il est plus logique d’inviter vos meilleurs clients à rejoindre votre programme de fidélité plutôt que de leur envoyer des promotions tous les mois, alors vous comprendrez rapidement la logique du modèle RFM. Une logique simple, facile et efficace.
Dans ce guide complet, on vous explique ce qu’est la segmentation RFM, les résultats que ça permet d’atteindre et surtout comment construire une segmentation RFM étape par étape (avec un cas pratique).
La segmentation RFM est un type de segmentation qui permet d’analyser le comportement d’achat de vos clients et de les segmenter à partir de trois variables : Récence (R), Fréquence (F) et Montant (M).
La segmentation RFM est simple à mettre en place dans la mesure où elles se basent sur des données que vous avez forcément dans votre système d’information, à savoir les données transactionnelles, l’historique d’achat de vos clients stocké dans votre système de caisse et/ou votre solution ecommerce.
Le RFM est une technique de segmentation ancienne. Elle était utilisée dans les années 1960 par les entreprises de VAD pour réduire la taille des catalogues papiers : par exemple, pour n’envoyer que les produits les plus chers aux meilleurs clients :). Depuis les années 1960, les cas d’usage se sont multipliés.
La segmentation RFM reste l’une des techniques les plus intéressantes pour segmenter les clients dans le Retail et l’Ecommerce.
Son utilisation est pourtant loin d’être généralisée et c’est vraiment dommage. Si nous réussissons à convaincre des retailers et des ecommerçants de se lancer dans la segmentation RFM, alors cet article aura atteint son but.
10 exemples et méthodes de segmentation client
La segmentation client peut prendre des formes différentes (dont la segmentation RFM) mais consiste toujours à diviser les clients en groupes homogènes appelés « segments ». Si les cas d’usage de la segmentation sont multiples, le principal consiste à mettre en place des actions spécifiques pour chaque segment. La segmentation rend possible un marketing ciblé. Pour élargir vos horizons, nous vous invitons à découvrir 10 exemples et méthodes de segmentation client.
Récence, Fréquence, Montant
La segmentation RFM se construit à partir de 3 métriques : Récence, Fréquence, Montant.
La récence désigne le temps écoulé depuis le dernier achat. Elle est exprimée en nombre de jours. Une récence de 8 par exemple signifie que le dernier achat remonte à 8 jours. On dira que la récence a une valeur de 8.
Pourquoi utiliser cette variable ? La logique est simple : plus un client a acheté récemment, plus il y a de chances qu’il achète de nouveau chez vous. A l’inverse, un client qui n’achète plus depuis longtemps a peu de chances de repasser commande. Toutes les variables utilisées dans le modèle RFM visent à mesurer le niveau d’engagement client.
Il est important de prendre en compte le contexte de votre activité pour analyser correctement cette variable. Les cycles d’achat sont différents d’un secteur à l’autre. L’exemple souvent cité est celui du secteur automobile, où les périodes interachats sont beaucoup plus longues que dans le secteur du prêt-à-porter par exemple.
F pour Fréquence
La fréquence est la variable qui indique le nombre de commandes passées sur une période donnée. Elle permet d’identifier les clients les plus engagés et les plus loyaux.
Si vous choisissez de prendre l’année comme période de référence et que votre client a acheté 9 fois au cours de l’année écoulée, la fréquence est égale à 9.
Là encore, l’interprétation de cette variable doit prendre en compte les caractéristiques de votre secteur d’activité. Le choix de la période de référence doit aussi s’appuyer sur votre contexte business. On choisit généralement l’année, le trimestre ou le mois.
M pour Montant
Le montant désigne le montant des commandes passées par le client au cours de la période de référence. Il s’exprime en euros.
Cette variable permet notamment de distinguer les clients dépensiers des dénicheurs de bonnes affaires. Un client qui a passé 10 commandes de 10 euros n’a pas le même profil d’acheteur qu’un client qui a passé une commande 100 euros, mais si au final le chiffre d’affaires généré est le même.
Top 50 des dashboards ecommerce Google Data Studio
Data Studio est un outil facile d’utilisation et gratuit pour construire des reportings et des tableaux de bord à partir de vos données. Nous avons sélectionné pour vous les 50 meilleurs modèles de dashboards ecommerce pour piloter votre performance dans tous ses aspects. A lire ne serait-ce que pour évaluer la richesse de cet outil de « DataViz ».
L’importance du RFM dans le Retail
Se concentrer sur les clients qui ont le plus de valeur
Si on applique le principe de Pareto au modèle RFM, alors 80% de vos revenus proviennent de 20% de vos clients – vos meilleurs clients. Cette proportion se vérifie très souvent !
Vous avez intérêt à focaliser vos efforts sur vos meilleurs clients. Cela vous permettra :
D’augmenter le revenu par client de vos meilleurs clients.
De mieux maîtriser vos coûts marketing.
La segmentation RFM permet d’identifier de manière simple qui sont vos meilleurs clients.
Vos meilleurs clients sont ceux qui achètent le plus fréquemment, qui génèrent le plus de chiffre d’affaires et qui ont acheté récemment. Autrement dit, ce sont les clients qui ont les meilleurs scores R, F et M. Nosu reviendrons en détail tout à l’heure sur la signification des scores, mais avoir un très bon score R, c’est tout simplement faire partie des clients qui ont acheté le plus récemment. Idem pour F et M.
Maximiser la rétention
Acquérir des clients coûte plus cher que de fidéliser ses clients actuels. On a déjà dû vous le répéter 100 fois, mais c’est vrai !
Ce n’est pas pour rien que les entreprises multiplient leurs efforts pour améliorer la rétention des clients, que cela passe par la mise en place d’un programme de fidélité ou la construction d’un dialogue clients plus riche et plus ciblé.
Le modèle RFM peut vous aider à :
Identifier qui sont vos meilleurs clients.
Analyser les indicateurs clés de performance pour chaque segment RFM afin de savoir où en est votre entreprise par rapport à vos objectifs de rétention.
Faire une analyse qualitative de vos meilleurs clients pour identifier les actions les plus efficaces pour améliorer leur fidélité.
Créer un marketing différencié pour chaque segment RFM : meilleurs clients, clients occasionnels, clients à potentiel, clients à risque d’attrition, etc.
Améliorer vos campagnes d’acquisition en ciblant des audiences partageant les mêmes caractéristiques que vos meilleurs clients.
Bref, le modèle RFM est très pertinent pour construire un marketing relationnel ciblé dans le Retail. Et, croyez-nous, c’est la meilleure manière de retenir et fidéliser vos clients.
Segmenter sa base client à partir d’un score RFM
Le modèle RFM permet de segmenter sa base clients en créant des segments de clients construits sur la base des trois variables R, F et M.
Les meilleurs clients. Ils ont les meilleurs scores en R, en F et en M. Leur dernier achat est très récent, ils achètent souvent et pour de gros montants. Ils ont certainement souscrit votre programme de fidélité si vous en avez un 🙂
Les dépensiers. Ce sont les clients qui ont un excellent score M, sans être au top sur les deux autres variables R et F. Ils achètent pour de gros montants, mais moins fréquemment que les meilleurs clients.
Les clients fidèles. Ce sont les clients qui ont un excellent score F. Ils ont une très bonne fréquence d’achat, mais ont un panier moyen moins élevé que celui des dépensiers.
Les clients à risque. Ce sont d’anciens bons clients qui ont aujourd’hui un mauvais score R et un score F. Ils n’ont pas acheté depuis longtemps.
…/…
Voilà 4 exemples de segments que vous pouvez construire sur la base de l’analyse des scores RFM. Dans la pratique, les entreprises utilisent une dizaine de segments RFM, parfois une quinzaine.
Voici à titre d’exemples les segments RFM utilisés par Octolis. Les chiffres désignent les scores. Les Champions, par exemple, ont un score Récence et un score Fréquence*Montant de 5 ou 6 (sur une échelle de 6).
Comme vous pouvez le constater, nous avons fusionné Fréquence et Montant, ce qui est classique dans nos univers métier.
Mettre en place une segmentation RFM pas à pas
Nous allons maintenant vous expliquer étape par étape comment construire un modèle RFM et la segmentation qui va avec.
Les prérequis pour construire un modèle RFM
Pour construire un modèle RFM, vous devez être capable d’identifier vos clients. C’est la base. Vous ne pouvez savoir qu’un client est un de vos meilleurs clients si vous ne connaissez pas d’abord l’identité de ce client. Logique.
Vous avez donc besoin d’identifiants clients. Cela peut être un customer ID, une adresse email, un nom + prénom, un téléphone…Peu importe, il faut une information, une donnée qui vous permette d’identifier vos clients.
Ensuite, vous avez besoin des données transactionnelles sur vos clients. Plus précisément, vous devez connaître pour chaque client :
La date de dernier achat. Cette donnée vous permettra de construire le score Récence.
Le nombre de transactions réalisé sur la période de référence (le mois, le trimestre ou l’année). Cette information vous permettra de construire le score Fréquence.
Le montant dépensé sur la période, qui vous permettra de construire le score M. Il s’agit du montant total des achats par client sur la période de référence.
Toutes ces informations sont accessibles dans votre système de caisse et/ou dans votre solution ecommerce. Vous avez donc en principe tout à disposition. C’est l’une des forces de la segmentation RFM.
Construire le tableau des valeurs RFM
Avec ces informations, vous allez pouvoir construire un tableau de ce type :
Id Client
Récence (jour)
Fréquence (nombre)
Montant (total)
1
4
6
540
2
6
11
940
3
46
1
35
4
23
3
65
5
15
4
179
6
32
2
56
7
7
3
140
8
50
1
950
9
34
15
2630
10
10
5
191
11
3
8
845
12
1
10
1510
13
27
3
54
14
18
2
40
15
5
1
25
Ce tableau contient les valeurs R, F et M pour chaque client.
Rappelons que la récence est exprimée en nombre de jours depuis le dernier achat, la fréquence en nombre de commandes réalisées sur la période, et le montant en devise, ici l’euro.
Des valeurs RFM aux scores R, F et M
Une valeur, c’est une donnée brute. Un score, c’est une évaluation : c’est bien ou c’est pas bien. Est-ce que 500 euros de montant (la valeur) est bien ou pas ? Si c’est bien, le score sera élevé.
A partir des valeurs RFM extraites de votre système d’information, vous allez pouvoir construire un score pour chacune des trois variables :
Un score R
Un score F
Un score M
Le score est souvent calculé sur une échelle de 1 et 5. 1 désigne le score le plus bas, 5 le score le plus haut. Par exemple, un client qui n’a pas acheté sur la période a un score F de 1 et un score M de 1.
Les scores sont généralement calculés de manière relative. Si vous utilisez l’échelle classique de 1 à 5, le score de 5 est attribué aux 20% des clients qui ont la meilleure valeur R. Le score 1 est attribué aux 20% des clients qui ont la moins bonne valeur R.
Mais vous pouvez ajouter plus de granularité en adoptant une échelle plus large, de 1 à 6, de 1 à 7, voire de 1 à 10. Si vous choisissez de répartir les scores sur une échelle de 1 à 10, vous attribuerez un score de 10 aux 10% meilleurs clients.
Mais dans l’exemple qui suit, pour que ce soit plus simple à comprendre, nous avons choisi d’utiliser une échelle de 1 à 5.
Vous pouvez donc calculer chaque score séparément. Par exemple, voici un exemple de tableau pour le calcul du score R :
ID Client
Récence
Rang
Score R
12
1
1
5
11
3
2
5
1
4
3
5
15
5
5
4
2
6
5
4
7
7
6
4
10
10
7
3
5
15
8
3
14
18
9
3
4
23
10
2
13
27
11
2
6
32
12
2
9
32
13
1
3
46
14
1
8
50
15
1
On utilise ici un scoring relatif. Il y a 15 clients et une échelle de 1 à 5. Donc 3 clients par score. Les clients sont classés par score décroissant. Dans cet exemple, les meilleurs clients (score de 5) sont les clients 12, 11 et 1.
Vous pouvez faire la même démarche pour calculer les scores F et M.
ID Client
Fréquence
Score F
9
15
5
2
11
5
12
10
5
11
8
4
1
6
4
10
5
4
5
4
3
13
3
3
7
3
3
4
3
2
14
2
2
6
2
2
15
1
1
8
1
1
3
1
1
ID Client
Montant
Score M
9
2630
5
12
1510
5
8
950
5
2
940
4
11
845
4
1
540
4
10
191
3
5
179
3
7
140
3
4
65
2
6
56
2
13
54
2
14
40
1
3
35
1
15
25
1
Des scores R, F et M au score RFM
Vous pouvez ensuite combiner les différents scores R, F et M pour obtenir un score RFM. Ce n’est pas forcément ce que nous recommandons, car l’intérêt des scores R, F et M est surtout de construire des segments (spoiler alert, on vous en parle plus bas).
Si vous voulez construire un score RFM global, vous pouvez le faire en additionnant les scores R, F et M et en divisant le tout par 3. Voici à quoi ressemble un tableau présentant les scores RFM :
ID Client
Cellules RFM
Score RFM
1
5,4,4
4.3
2
4,5,4
4.3
3
1,1,1
1.0
4
2,2,2
2.0
5
3,3,3
3.0
6
2,2,2
2.0
7
4,3,3
3.3
8
1,1,5
2.3
9
1,5,5
3.7
10
3,4,3
3.3
11
5,4,4
4.3
12
5,5,5
5.0
13
2,3,2
2.3
14
3,2,1
2.0
15
4,1,1
2.0
Le client 1 a un score R de 5, un score F de 4 et un score M de 4. Il a donc un score de (5 + 4 + 4) / 3 = 4.3.
Dans cet exemple, nous attribuons un poids égal à chaque variable, mais vous pouvez utiliser un système de pondération. Cela fait sens dans certains cas, comme nous le verrons tout à l’heure.
Mettez en place des recommandations de produits
La recommandation de produits est l’un des moyens les plus simples pour augmenter le panier moyen et, au-delà, le chiffre d’affaires dans le ecommerce. Dites-vous bien que 35% des ventes d’Amazon sont générées grâce à des recommandations proposées sur la plateforme et par email. Découvrez notre guide complet sur la recommandation de produits ecommerce : Méthode & Outils.
Des scores aux segments RFM
Si vous utilisez une échelle de scoring de 1 à 5, vous avez théoriquement 5 x 5 x 5 combinaisons possibles, soit 125 combinaisons. Vous pouvez donc créer 125 segments clients. Si vous utilisez une échelle de scoring de 1 à 6, de 1 à 7, les combinaisons se multiplient.
Mais ça n’a pas de sens d’utiliser autant de segments.
La bonne pratique consiste à limiter le nombre de segments à 20 maximum.
Dans ce cas, vous pouvez par exemple créer un segment « Champions » réunissant les clients ayant :
Une méthode plus simple pour calculer les scores RFM
La méthode que nous venons de vous présenter a le mérite de vous présenter la logique du modèle RFM. Vous partez de vos données, vous les transformez en valeurs R, F, M, ces valeurs sont ensuite transformées en scores R, F et M, puis en segments RFM.
Mais plutôt que de construire manuellement vos scores RFM sur Excel, vous pouvez utiliser un outil qui vous fait les calculs automatiquement. Cela vous fera économiser du temps, supprimera le risque d’erreurs humaines et vous permettra de vous concentrer sur l’essentiel : la conception des actions marketing (campagnes et scénarios) sur chaque segment RFM.
Notre solution Octolis vous permet de créer des segments RFM automatiquement.
Vous n’avez que deux choses à faire si vous choisissez d’automatiser le modèle RFM.
La première chose consiste à définir les segments. Chez Octolis, nous utilisons 11 segments. Nous utilisons des scores compris sur une échelle de 1 à 6. Le segment « Champions » regroupe les clients ayant un score R de 5 ou 6 et un score F*M de 5 ou 6.
Mais après, à vous de faire votre sauce en choisissant des segments signifiants. Une quinzaine tout au plus, pas la peine de monter une usine à gaz.
Une fois que vous avez défini les segments et leurs caractéristiques, vous pouvez les configurer dans Octolis de manière intuitive. Aucune compétence technique n’est requise. L’interface est marketing user-friendly.
Pour alimenter les données qui nourrissent le modèle RFM (les ID clients et les données transactionnelles), il vous suffit de connecter vos sources de données à Octolis. Nous proposons des connecteurs avec des systèmes de caisse et des solutions ecommerce pour créer le pipeline en quelques clics, sinon il y a les APIs qui ne sont pas beaucoup plus compliquées à utiliser.
Exploiter votre segmentation RFM
Remettre votre score RFM dans votre contexte business
Dans l’exemple que nous venons de vous présenter, nous attribuons un poids égal à chacune des 3 variables R, F et M.
Or, ces variables n’ont pas forcément la même importance suivant votre business. Si vous voulez construire un score RFM global, il peut être intéressant de pondérer les scores.
Par exemple :
Dans un business qui commercialise des produits ayant une longue durée de vie, la valeur M est souvent (très) élevée alors que les valeurs R et F sont faibles. C’est typiquement le cas dans les secteurs de l’automobile, de l’immobilier ou encore dans l’électroménager. On n’achète pas un frigo tous les quatre matins, et encore moins un bien immobilier. Dans ce contexte business, il est pertinent de donner plus de poids aux variables R et M qu’à la variable F.
Dans les secteurs du prêt-à-porter et des cosmétiques, un client qui achète des produits tous les mois aura un score R et F plus élevé que le score M. Dans ce cas, il faut donner plus de poids aux scores R et F qu’aux scores M.
Ce sont deux exemples qui montrent qu’il est souvent judicieux d’utiliser un système de pondération pour calculer les scores RFM.
Le guide du Scoring Client
Le scoring client permet de prioriser vos budgets marketing pour les clients les plus susceptibles d’acheter, et de mieux segmenter votre fichier client pour obtenir de meilleures performances dans vos campagnes. Découvrez notre guide complet sur le Scoring Client : Définition, exemples et méthode en 5 étapes.
Intégrer la dimension historique (passage d’un segment à l’autre entre les périodes N et N-1)
Un client peut passer d’un segment A à un segment B. C’est même la règle ! La segmentation RFM est dynamique. Pour aller plus loin, il est intéressant d’intégrer dans votre analyse des segments à l’instant t les segments de la période précédente. Le passage d’un segment à l’autre entre la période N-1 et la période N peut être l’occasion de mettre en place des scénarios marketing spécifiques.
De cette manière, vous ne vous contentez pas de cibler les actions marketing sur vos segments RFM, vous ciblez des actions spécifiques sur les clients ayant changé de segment. Vous ajoutez à la dimension structuraliste de la segmentation à l’intant t une dimension historique.
Visualiser votre RFM plus simplement
Nous vous conseillons d’utiliser une matrice RFM pour mieux visualiser vos segments RFM et leur poids respectif dans votre base clients.
Voici celle proposée par Octolis :
La taille des rectangles est proportionnelle à la taille des segments. En passant la souris sur les rectangles, vous pouvez voir en un coup d’œil le poids respectif de chaque segment RFM.
Aller plus loin
Le modèle RFM est puissant, mais a malgré tout quelques limites :
L’erreur humaine…Si vous optez pour l’approche manuelle (Excel), vous ne pouvez pas écarter le risque d’erreur humaine…D’où l’intérêt d’utiliser un outil pour automatiser les calculs à partir de vos données transactionnelles.
Juste 3 variables. La segmentation RFM n’utilise que 3 variables, 3 variables liées au comportement d’achat de vos clients. C’est passé à côté de beaucoup d’autres variables de segmentation intéressantes. Il est aujourd’hui possible de construire des modèles prédictifs intégrant plus de variables, et donc plus puissants.
La sur-sollicitation des meilleurs clients. Beaucoup d’entreprises utilisent la segmentation RFM pour bombarder leurs meilleurs clients de communications et délaisser les autres clients. Il y a un usage du modèle RFM qui peut s’avérer contre-productif…et dans lequel tombent pas mal d’entreprises.
Des hypothèses critiquables. Un client peut très bien ne pas acheter pendant 3 mois et se mettre tout à coup à devenir un acheteur compulsif. Les hypothèses qui servent de base au modèle RFM ne se vérifient pas toujours. Par exemple : « Un client qui a acheté récemment a plus de chances d’acheter à nouveau » : eh bien, c’est souvent vrai, mais pas toujours et pas pour tous les clients.
Une segmentation pas assez granulaire. Beaucoup de Retailers construisent une segmentation RFM sur l’ensemble de leurs produits alors que le comportement client est souvent différent d’une gamme de produits à l’autre. On se retrouve donc à comparer des choux et des carottes et surtout à mettre en place des communications (notamment, des recommandations de produits) qui sont peu pertinentes pour les clients. Avec, au final, un impact négatif sur la rétention et la fréquence d’achat.
Mais, sur ce dernier point, sachez qu’il existe des solutions pour calculer un score RFM par produit ou par gamme de produits. Octolis en fait partie. Notre solution vous permet de calculer en temps réel un RFM par produit. Surtout, une solution comme Octolis vous permet de faire remonter automatiquement les segments RFM dans vos outils d’activation : Marketing Automation, Facebook & Google Ads…
Voilà, nous espérons que ce guide d’introduction à la segmentation RFM vous aura apporté les éclairages que vous attendiez. Pour une entreprise du Retail qui veut se lancer dans la segmentation client, le modèle RFM reste la référence. Vous avez des doutes ou des questionnements sur le bon modèle de segmentation à mettre en place dans votre entreprise ? Eh bien, n’hésitez pas à nous contacter. On se fera un plaisir d’échanger avec vous !
Comment construire votre stack data moderne ? Comparaison des approches possibles
Le meilleur investissement que vous puissiez faire si vous voulez mieux exploiter vos données, c’est construire une stack data moderne.
La stack data, c’est l’ensemble des outils gravitant autour du data warehouse qui va vous permettre de valoriser vos données et de pleinement les exploiter dans vos applicatifs métier.
Il existe essentiellement 3 approches pour construire une stack data moderne :
L’approche best of breed : vous construisez chaque brique de la stack data en choisissant les meilleurs outils de leur catégorie.
L’approche agence : vous confiez la construction de la stack data à un prestataire.
L’approche tout-en-un : vous connectez à votre data warehouse un outil de Data Ops capable de gérer l’ensemble des traitements nécessaires à la valorisation des données.
Nous nous focalisons dans cet article sur les stack data modernes. Ces stack data, construites à partir d’outils cloud et d’outils self service (no ou low code) sont moins lourdes, moins chères, moins IT-dependantes que les stack data du passé. Elles deviennent la norme, surtout dans les entreprises les plus matures.
Pour comprendre la fonction clé d’une stack data aujourd’hui, il faut partir de ce constat évident : les données, en particulier les données clients au sens large, sont l’un des actifs les plus précieux des entreprises. Sauf que ces données sont généralement sous-utilisées et ne délivrent pas toute la valeur qu’elle détienne.
Pour être pleinement valorisées, les données doivent être correctement connectées, consolidées, nettoyées, préparées, transformées, enrichies et activées dans les outils de destination : CRM, marketing Automation, analytics/BI…
La stack data désigne l’assemblage cohérent d’outils qui sert à réaliser toutes ces opérations, de la connexion des données à leur activation en passant par leur préparation et enrichissement.
La stack data est une imbrication d’outils au service d’une meilleure exploitation des données par l’entreprise.
A quoi reconnaît-on une organisation data-driven ? Au fait qu’elle dispose d’une stack data moderne ! Avoir une stack data est une condition nécessaire, bien que pas suffisante, pour devenir data-driven.
La stack data facilite la circulation des données dans l’organisation et leur exploitation par les différents utilisateurs finaux.
Les stack data qualifiées de « modernes » ont 2 caractéristiques essentielles qui les distinguent des anciennes stack data. Elles se basent sur :
Des solutions cloud, et en particulier un data warehouse cloud servant de pivot, de « hub des données ».
Des outils low ou no-code (on parle aussi d’outils self-service) qui permettent de démocratiser l’accès et la manipulation des données.
Les composantes d’une Stack Data Moderne
La stack data moderne est un ensemble d’outils gravitant autour d’un data warehouse construit sur une plateforme cloud. Une stack data moderne contient 5 briques clés, 5 composantes fondamentales qu’on peut désigner par des verbes :
Collecter. Une entreprise possède une dizaine, une vingtaine, une trentaine de sources de données. C’est grâce à elles que l’organisation collecte les données sur les différents canaux et aux différentes étapes des parcours clients.
Connecter (ou « charger », ou « stocker »). Les sources de données sont connectées à un data warehouse (DWH) cloud qui sert de réceptacle principale des données.
Transformer. Les données sont préparées, consolidées, nettoyées, transformées au moyen d’outils spécifiques. Si la transformation des données précède leur chargement dans le DWH, on parle d’outils ETL (Extract-Transform-Load). Dans le cas contraire, de plus en plus fréquent, on parle d’outils ELT (Extract-Load-Transform).
Analyser. Les données stockées dans le DWH sont utilisées pour produire des analyses, des reportings, des data visualisations via des outils de Business Intelligence (BI).
Activer. Les données du DWH ne servent pas seulement à créer des reportings, elles servent aussi à alimenter les outils d’activation (CRM, marketing automation…), via une solution « Reverse ETL ».
Chacune de ces composantes de la stack data moderne désigne une étape du cycle de vie des données et fait appel à un ou plusieurs outils.
Nous allons vous décrire plus précisément chacune de ces composantes, en vous épargnant la première qui nous amènerait à vous détailler les différentes sources de données utilisées par les entreprises. On va éviter la liste à la Prévert.
Connecter – Charger – Stocker : la place pivot du Data Warehouse
Le data warehouse sert de réceptacle des données. Il met en connexion l’ensemble des sources de données de l’entreprise et permet ainsi de stocker l’ensemble des données de l’organisation dans un même endroit. Comme nous le disions plus haut, le DWH joue le rôle de pivot de la stack data moderne. C’est autour de lui que gravitent toutes les autres composantes. C’est l’émergence de cette nouvelle génération de data warehouse basés dans le cloud qui a permis le développement de la stack data moderne.
Le data warehouse a la capacité de stocker tous types de données. Lorsqu’il permet même de stocker des données non structurées, « en vrac », on parle de « data lake ». D’ailleurs, dans certaines organisations, le data warehouse cloud est construit en aval d’un data lake qui accueille de manière indifférenciée toutes les données générées par les sources.
Comment intégrer les données dans le data warehouse ?
Il existe plusieurs réponses à cette question. Nous vous proposons un panorama des différentes familles d’outils permettant de connecter vos sources de données à votre data warehouse. Découvrez notre panorama des outils d’intégration des données.
Un data warehouse cloud est une solution scalable et puissante. La réduction des coûts de stockage et l’augmentation de la puissance de calcul (qui permet d’exécuter des requêtes SQL sur de gros volumes de données en quelques secondes) sont les deux évolutions majeures sur le marché des data warehouses – évolutions permises grâce au cloud.
Les solutions DWH les plus connues du marché restent celles proposées par les GAFAM :
Voici 2 autres caractéristiques des data warehouses cloud, pour achever de brosser le tableau de cette technologie incontournable :
Les DWH sont serverless. Vous n’avez pas à gérer les serveurs. Ils sont fournis et maintenus par l’éditeur.
Les DWH sont facturés à l’usage. Vous payez ce que vous utilisez, que ce soit en termes d’espace de stockage ou de puissance de calcul. Certaines solutions, comme Snowflake, facturent distinctement le stockage et le computing, ce qui augmente encore la souplesse tarifaire.
Une introduction à la Stack Data Moderne
Un Data Engineer qui aurait été cryogénisé en 2010 et que l’on réveillerait par malice aujourd’hui ne comprendrait plus grand-chose à la Stack Data Moderne. Heureusement pour lui, il pourrait rapidement se mettre à jour en découvrant notre guide introductif à la Stack Data Moderne. Un article qui complète bien celui que vous êtes en train de lire.
Ingérer : la gestion des pipelines de données via une solution ELT/ETL
La deuxième composante de la Stack Data regroupe l’ensemble des outils qui permettent de faire circuler les données entre les différents systèmes. Et plus précisément : entre les sources de données et le data warehouse.
Une solution ELT ou ETL sert à brancher les sources de données (outils marketing, réseaux sociaux, logs, APIs…) au data warehouse.
Il y a essentiellement deux manières d’intégrer les données :
ETL. La première consiste à transformer les données avant de les charger dans le data warehouse. Si bien que les données arrivent bien préparées dans l’entrepôt de données en fonction des règles de modélisation de votre DWH. C’est l’option traditionnelle que l’on appelle ETL : Extract – Transform – Load, qui était utilisée dans les stack data anciennes. On transforme (T) avant de charger (L).
EL(T). La deuxième approche, plus moderne et plus souple, consiste à utiliser un outil qui va charger les données dans le data warehouse sans les transformer. Dans ce cas, les transformations des données sont réalisées en aval, soit par le même outil, soit par un autre outil, soit en utilisant les fonctions proposées nativement par l’éditeur du data warehouse. On parle alors d’EL(T).
Dans la famille des outils EL(T), on trouve notamment Stitch ou Fivetran. 2 références. Ces solutions ont développé des connecteurs avec des solutions leaders (Facebook, Salesforce, Google Analytics…) qui vous permettent de connecter vos sources de données à votre entrepôt de données en quelques secondes, via une interface no-code.
Outil EL(T), Stitch Data propose des dizaines et des dizaines de connecteurs natifs pour connecter vos sources de données à votre data warehouse en quelques clics.
Le modèle économique de ces solutions est basé sur le volume de données ingéré, exprimé en nombre d’événements ou en lignes. A noter qu’il existe aussi des outils EL(T) open source, donc gratuits, mais dont la prise en main requiert des compétences IT. Je pense notamment à Airbyte, ou bien au framework Singer, qui propose une belle bibliothèque de scripts écrits en Python pour connecter vos sources au data warehouse. Pour la petite histoire, Stitch utilise le code de Singer pour créer ses connecteurs en 3 clics.
En optant pour un outil ELT payant comme Stitch ou Fivetran, ce que vous payez, c’est l’interface user-friendly et les connecteurs natifs, pas la technologie sous-jacente qui s’appuie généralement sur des frameworks open source. Après, il y a clairement un ROI à utiliser un outil payant, surtout si vous êtes une jeune entreprise et que vous n’avez pas les compétences internes pour utiliser un framework open source. Les connecteurs facilitent quand même vraiment la vie !
Transformer : le nettoyage et la consolidation des données
Avec des outils ETL ou ELT (sans parenthèses sur le « T »), la transformation des données est réalisée par le même outil que celui utilisé pour charger les données dans le data warehouse. Vous avez un même outil qui s’occupe du « L » et du « T ». Un exemple de logiciel ELT ? Weld, par exemple.
Mais la tendance générale consiste à utiliser des outils différents pour ces deux opérations.
Dans une stack data moderne, on a généralement :
Un outil EL qui sert à créer les pipelines de données, à charger les données provenant de vos différentes sources dans le data warehouse.
Transformer des données consiste à appliquer aux données chargées dans le DWH un certain nombre de règles et de fonctions adaptées à vos cas d’usage et au design du Data Warehouse. Les opérations de transformation classiques incluent, notamment, le renommage de colonnes, la jonction de plusieurs tables, l’agrégation de données…
Un exemple d’outil ? dbt. Cette solution permet aux data analysts et aux data engineers de transformer les données du DWH beaucoup plus facilement qu’auparavant, via l’édition de codes de transformation SQL. dbt fait partie de ces outils dont on parle beaucoup en ce moment, et à juste titre tant la solution est à la fois simple et puissante. C’est grâce à ce genre d’outils qu’un data analyst peut gérer la transformation des données lui-même, sans avoir besoin de l’appui d’un data engineer ou d’un développeur Python. Précisons que dbt est open source, même s’ils proposent aussi une version payante.
dbt est l’outil de référence pour transformer les données stockées dans le Data Warehouse, via des scripts SQL.
Databricks, qui a signé un partenariat avec Google Cloud (mais fonctionne aussi sur Azure et AWS).
Passons à l’étape suivante. A quoi servent les données transformées du data warehouse ? A faire deux choses : de l’analyse et de l’activation. Commençons par l’analyse.
Analyser : la solution de DataViz / BI
Les données organisées du data warehouse sont d’abord utilisées pour alimenter un outil de Business Intelligence (BI) qui sert à construire des reportings, des tableaux de bord, des data visualisations, des modèles prédictifs.
L’analyse des données permet de piloter les performances de l’entreprise, d’identifier des tendances, des évolutions, de mieux cerner les parcours clients, de mieux comprendre le comportement des clients, d’identifier la part de chaque canal dans la performance (via des modèles d’attribution) et de manière plus générale d’éclairer les prises de décision.
L’analyse des données s’effectue depuis un outil de Business Intelligence (comme Tableau, Looker, PowerBI ou QlikView), dont l’utilisateur principal est le data analyst. Ces outils permettent de créer des reportings avancés à partir de toutes les données du Data Warehouse auxquelles ils sont connectés via des connecteurs ou des APIs.
Ces outils coûtent relativement cher, sauf Google Data Studio, qui est 100% gratuit. Data Studio est une solution assez puissante, que nous avons beaucoup utilisée dans notre passé de consultants, et qui a l’avantage (par définition) de bien s’intégrer à l’écosystème de Google Cloud. On recommande aussi Metabase, qui est un outil de BI open source.
Un exemple de reporting Data Studio.
Les reportings sont synchronisés avec toutes les sources que vous voulez (votre data warehouse, Google Ads, les réseaux sociaux, des spreadsheets, etc.) et donc mis à jour en temps réel. Les outils de BI ont fait de gros efforts pour proposer des interfaces très simples d’utilisation. Ils proposent des templates de reporting souvent très bien pensés et qui permettent de gagner beaucoup de temps.
Les outils de BI sont aussi appelés « outils de DataViz » ou « outils de Data Visualization » dans le sens où ils permettent de présenter les données de manière visuelle, sous forme de graphiques, de tableaux, de courbes, de charts…
Dashboards ecommerce Google Data Studio
Google Data Studio est une solution de BI gratuite et proposant de nombreux templates personnalisables de bonne qualité. Pour vous en rendre compte par vous-même, nous vous invitons à découvrir notre sélection des 50 meilleurs dashboards ecommerce de Google Data Studio.
Activer : le Reverse ETL pour redistribuer les données à vos outils
Il y a encore quelques années, les données stockées dans le data warehouse n’étaient utilisées que pour faire du reporting et de l’analyse. Le data warehouse servait de socle de la BI. C’était sa seule fonction. Les temps ont changé et l’une des caractéristiques de la stack data moderne est l’avènement de ce qu’on appelle les Reverse ETL.
Un Reverse ETL, comme l’indique son nom, fait l’inverse d’un outil ETL. Un outil ETL charge les données en provenance de vos sources de données dans le data warehouse. Un Reverse ETL est une solution qui sert à extraire les données stockées dans le data warehouse pour les mettre à disposition des outils d’activation / business : CRM, marketing automation, help desk, comptabilité…
Un Reverse ETL permet de mettre les données du data warehouse au service des équipes métiers : marketing, ventes, service client, digital, finance…Il synchronise les données agrégées du DWH dans les applicatifs utilisés au quotidien par le métier.
Avec un Reverse ETL, par exemple, vous pouvez intégrer les données Stripe et Zendesk (préalablement chargées dans le data warehouse) dans votre CRM Hubspot.
Si on avait parlé des Reverse ETL à un DSI des années 2000, il nous aurait ri au nez. Qu’un data warehouse serve à alimenter un CRM (via notre Reverse ETL) était une idée absurde. Le data warehouse était le réceptable des données froides, le CRM et les outils d’activation en général le réceptacle des données chaudes. Mais avec l’avènement de la nouvelle génération de data warehouse cloud, les règles du jeu changent : le data warehouse peut devenir un référentiel opérationnel. Et ça change tout !
A la découverte des Reverse ETL
Le Reverse ETL est le chaînon manquant qui empêchait jusqu’au début années 2020 de synchroniser les données du data warehouse dans les applicatifs métier. Pour en savoir plus sur cette technologie incontournable de la stack data moderne, nous vous invitons à découvrir notre guide introductif sur les Reverse ETL.
Si vous vous allez plus loin, nous vous conseillons de jeter un œil à cette liste de ressources consacrée à la stack data moderne.
3 approches pour construire votre Stack Data
Voici les 3 options qui s’offrent à vous pour construire votre stack data moderne. Pour construire notre tableau, nous avons pris pour hypothèse une entreprise ayant un effectif d’une cinquantaine de personnes.
Best of breed
Outsourcée
Tout-en-un
Ce dont vous avez besoin
Au moins 1 ingénieur analytics
Un budget significatif
Un petit budget
Un Data/Business analyst (ou un profil Business Ops)
Combien ça coûte ?
Environ 500€ par mois pour les outils et quelques mois de votre ingénieur analytics
Installation initiale : 10 - 30k€
Exploitation : 2 - 5k€ par mois
Environ 1 000€ par mois pour les outils
Quelques jours de votre Business Analyst
Stack Techno
Un outil comme Fivetran + dbt + BigQuery + Metabase
Choisie par l'agence
Un outil comme BigQuery + Octolis + Metabase
Option #1 – Construire en interne une Stack Data best of breed
La première option consiste à construire votre stack data moderne vous-même en allant chercher le « meilleur » outil de chaque catégorie. Voici les grandes étapes à suivre si vous optez pour cette option :
Définir vos objectifs et l’organisation cible. Pour quelles raisons souhaitez-vous déployer une stack data moderne ? Vous devez partir des objectifs de votre organisation et ensuite les décliner en cas d’usage data. Ce travail incontournable d’expression du besoin vous aidera à prendre les bonnes décisions tout au long de votre projet.
Choisir les outils de votre stack data. Nous avons passé en revue les principales composantes d’une stack data moderne. Pour chaque composante, il existe plusieurs outils possibles. A vous de choisir ceux qui répondent le mieux à vos objectifs, vos besoins, vos contraintes, votre budget. Ne souscrivez pas un seul abonnement à un logiciel avant d’avoir une vision cible des principaux outils qui constitueront votre stack data. Le choix le plus structurant est celui du data warehouse. Choisissez ensuite votre ETL/ELT, votre outil de data transformation, votre Reverse ETL, votre outil de BI. Vous devez choisir des outils qui se connectent bien entre eux. Le critère de la connectivité est l’un des principaux à prendre en compte. Typiquement, des outils comme Fivetran ou Stitch se valent à peu près, ils font la même chose, la différence réside surtout au niveau des capacités d’intégration, des connecteurs disponibles.
Mettre en place les pipelines de données et configurer le data warehouse. L’étape suivante consiste à construire les flux de données entre vos sources de données et votre data warehouse, via votre outil EL(T)/ETL. Vous devez aussi construire le modèle de données de votre data warehouse, c’est-à-dire définir la manière dont les données vont s’organiser dans les tables de votre DWH. C’est sans doute l’étape la plus technique, celle qui nécessite de vraies compétences IT (maîtrise de SQL en particulier).
Construire vos premiers reportings. C’est une étape techniquement facile. Les outils de BI proposent des interfaces user-friendly et permettent de connecter les sources de données de manière relativement simple. La difficulté est de construire des reportings intelligents, pertinents, utiles, bien pensés. Si vous n’avez pas besoin de compétences IT pour construire vos premiers rapports, vous devrez en revanche vous entourer de professionnels de la data : en particulier d’un ou de plusieurs data analysts.
Définir les process internes. L’avantage d’une stack data moderne, c’est qu’elle est utilisable par presque tout le monde. Mais cela fait naître un risque au niveau de l’intégrité de vos données. Il est donc essentiel de définir des process internes, des règles en matière de traitement des données, de gestion des accès et des droits, de définir des procédures, des rôles, d’établir une documentation, etc. Bref, vous devez poser les bases d’une bonne et saine Gouvernance des Données. Où l’on voit que construire une stack data moderne est un projet autant organisationnel que technique…
Définir une roadmap. Nous vous recommandons d’adopter une approche progressive dans le déploiement de votre stack data. C’est un projet suffisamment complexe et chronophage en soi…donc ne cherchez pas à tout transformer d’un coup. Nous pensons en particulier ici aux cas d’usage de la stack data. Ils ont vocation à augmenter avec le temps, à s’enrichir, à s’affiner. Mais ne cherchez pas à les déployer tous en même temps. Commencez par les cas d’usage prioritaires. Nous vous conseillons aussi de mettre en place une bonne direction de projet, avec des instances de pilotage.
Benchmark des outils de la Stack Data Moderne
Vous êtes intéressé(e) par cette option ? Nous vous invitons à découvrir notre benchmark complet des outils de la stack data moderne. Pour chaque famille d’outils (ETL, data warehouse, data prep…), nous vous proposons les meilleures solutions du marché.
Option #2 – Déléguer la mise en place de votre Stack Data à une agence
La deuxième option, plus coûteuse, consiste à déléguer la construction de votre Stack Data à une agence. Voici les étapes à suivre si c’est l’option que vous choisissez :
Définir vos besoins. Vous devez construire un cahier des charges solide dans lequel vous formalisez vos objectifs, décrivez votre situation actuelle (notamment l’état de votre écosystème Data/Tech), vos cas d’usage cibles en matière de données. Vous devez être le plus exhaustif et précis possible. Le cahier des charges va vous forcer à bien formaliser l’expression de votre besoin et à la partager à votre agence partenaire. C’est le document qui servira de point de repère tout au long du projet.
Choisir l’agence. Il existe des dizaines et des dizaines d’agences data sur le marché. Vous devez choisir celle la plus en phase avec votre besoin, vos attentes, vos contraintes…Nous vous conseillons de tester au moins 3 ou 4 agences. Interrogez-les sur votre projet, vous pourrez les évaluer en fonction de la manière dont elles répondent à vos questions et comprennent votre cahier des charges. Pensez aussi à scruter les références clients des agences ciblées. Nous vous conseillons même de demander aux agences cibles des exemples de cas clients proches du vôtre. Allez même plus loin : demandez à l’agence de vous communiquer les coordonnées d’1 ou 2 clients pour les contacter et leur demander un retour d’expérience.
Suivre de près le projet. Il est important de mettre en place des instances de pilotage (points hebdos, CoPil) afin de suivre de près l’avancement du projet, éviter les dérives, contrôler le respect du planning et du budget. La qualité de la communication entre votre entreprise et l’agence est clé si vous voulez obtenir des livrables et des résultats à la hauteur de vos espérances.
Option #3 – Construire en interne une Stack Data via une solution tout-en-un
Nous avons défini la stack data moderne comme une imbrication d’outils. Pour être plus précis, il faudrait parler d’une imbrication de fonctions, dans la mesure où il existe des outils tout-en-un couvrant plusieurs composantes de la stack data.
Un outil comme Octolis par exemple gère à la fois l’ingestion des données, leur modélisation et leur « opérationnalisation », c’est-à-dire la redistribution des données du DWH aux outils de destination. Octolis joue donc à la fois le rôle d’outil EL(T), d’outil de data prep et de Reverse ETL. Nous sommes ce que l’on appelle un outil de « DataOps ».
La troisième option que nous présentons consiste donc à construire votre Stack Data Moderne à partir de deux solutions clés :
Un data warehouse cloud.
Un outil tout-en-un de « DataOps ».
Panorama des fonctionnalités d’un outil de Data Ops comme Octolis.
Cette option a plusieurs avantages :
Elle est plus rapide à déployer.
Elle est plus simple à déployer et à prendre en main. Pas besoin d’avoir une grosse équipe data, vous n’avez besoin que d’un data analyst ou d’un analytics engineer pour construire les rapports (et vous aider à paramétrer le DWH).
Elle est moins coûteuse. Un outil de Data Ops coûte moins cher comparé à l’addition des coûts d’un EL(T), d’un outil de data prep et d’un Reverse ETL.
Résultat : le ROI est plus rapide.
Enfin, c’est une solution souple et scalable.
C’est l’option que nous recommandions souvent dans notre vie de consultants et c’est pourquoi nous avons développé Octolis. Cette option est particulièrement recommandée pour les entreprises de mid-market (PME) qui n’ont ni les grosses équipes data nécessaires pour construire une stack data best of breed ni le budget pour confier le travail à une agence.
Si vous choisissez cette option, voici schématiquement les étapes à suivre :
Définir les besoins. Dans cette option comme dans les autres, il faut commencer par formaliser les objectifs, les besoins métiers et les cas d’usage de la stack data. C’est la base de tout projet data !
Choisir un data warehouse et une solution Data Ops. Dans cette option d’organisation, les deux outils clés sont le data warehouse, réceptacle des données, et l’outil de Data Ops qui va servir à réaliser la plupart des opérations sur les données que nous avons décrites dans la première section de l’article.
Installer la stack data à partir de la solution de Data Ops. C’est dans la solution de Data Ops que vous allez connecter vos sources à votre data warehouse, préparer les données (nettoyage des données, consolidation, enrichissement, agrégation) et synchroniser les données agrégées dans les outils de destination.
Construire les premiers rapports, en utilisant un outil de BI comme Metabase ou Data Studio. Vous allez avoir besoin de quelques jours de travail de votre data analyst pour produire les rapports clés. Ne construisez pas une usine à gaz, concentrez-vous sur les quelques rapports prioritaires pour le suivi de votre activité.
Définir la roadmap et les process internes. Même commentaire que pour l’option 1. Définissez une roadmap de déploiement et d’évolution de votre stack data et mettez en place une gouvernance des données pour préserver l’intégrité de la stacj, des données, et encadrer l’utilisation des outils.
Le choix de la méthode de construction de votre stack data doit être en adéquation avec la taille de votre entreprise, vos cas d’usage cibles, vos contraintes (IT, budgétaires) et les caractéristiques de l’organisation (taille de l’équipe data).
Les trois options que nous vous avons présentées ont chacune leur intérêt. Nous sommes convaincus que la troisième est celle qui convient le mieux aux entreprises mid-market : les startups dans leur première phase de croissance et les PME ayant une maturité data intermédiaire et une équipe data réduite à 1 ou 2 personnes.
Quelles compétences pour être un bon Data Analyst ?
Pour recruter un Data Analyst, il est essentiel d’avoir une compréhension très claire de son rôle dans l’entreprise et des compétences requises, qui sont comme nous le verrons un subtil mélange de hard et de soft skills.
Votre première étape, en tant que recruteur, va consister à rédiger une fiche de poste décrivant le rôle de la personne dans l’entreprise, les résultats attendus et les compétences exigées. Pour réaliser cette étape, nous vous conseillons de découvrir cet excellent modèle basé sur le fameux livre « Who: The A Method for Hiring ».
Dans notre article, nous avons fait le choix de la simplicité. Après avoir rappelé ce qu’était un Data Analyst, son rôle, ses tâches, nous passerons en revue les principales compétences attendues.
source : beamjobs.
Précisons d’emblée que les compétences recherchées varient en fonction des caractéristiques et de la taille de l’organisation. Pour prendre un exemple très simple, si vous n’avez pas de data engineer, vous devrez recruter un data analyst capable de jouer le rôle de data engineer, de gérer les pipelines de données. On parle parfois d' »analytics engineer » pour définir ces profils polyvalents.
La graphique proposée ci-dessus met en avant les compétences techniques recherchées par les recruteurs. On retrouve les grands classiques : la maîtrise du SQL (la base), des outils de BI, d’Excel, des langages de programmation Python ou R…Mais la qualité d’un data analyst se mesure de plus en plus à ses soft skills comme nous allons le voir. Bonne lecture !
Une équipe data réunit des profils dont les compétences se répartissent autour de 3 grands pôles :
L’ingénierie data, c’est-à-dire l’organisation des pipelines des données, la capacité à organiser les flux entre les sources de données, le data warehouse et les outils. Le Data Engineer est le métier de la data qui incarne le mieux ce pôle.
La data analysis, qui consiste à analyser les données pour en tirer des enseignements utiles pour le business et les prises de décision stratégiques. Le Data Analyst est le métier de la data qui incarne le mieux ce pôle et celui sur lequel on va concentrer dans cet article.
La modélisation, qui consiste à construire des modèles d’analyse avancés, notamment des modèles statistiques et prédictifs. Ce sont les mathématiciens et les statisticiens de haut niveau qui incarnent le mieux ce pôle.
Ces trois pôles dessinent un ensemble de rôles. Nous avons parlé des Data Engineers, des Data Analysts, des statisticiens. Mais il existe aussi des profils à l’intersection de plusieurs pôles, comme le montre très bien le schéma. Le Data Analyst est à l’intersection du pôle Analysis et du pôle Statistics. Les analytics engineers sont en quelque sorte des data analysts ayant une forte appétence pour la gestion des flux et transformations de données (ETL).
Surtout, ces différents rôles peuvent être endossés par 1 ou n personnes suivant la taille de l’organisation et les enjeux autour de la data. Typiquement, dans les petites organisations, le Data Analyst et le Data Engineer sont généralement la même personne. À l’inverse, dans les grandes organisations, un même rôle peut être partagé entre plusieurs personnes.
Avant d’entrer dans le détail des compétences nécessaires à un Data Analyst, rappelons les différences entre un Data Analyst, un Data Engineer, un Data Scientist et un Analytics Engineer.
Data Engineer, le gestionnaire des pipelines de données
Le data engineer est le rôle qui consiste à mettre en place les pipelines de données. Il gère la manière dont les données sont stockées dans le système d’information, chargées dans l’entrepôt de données et redistribuées dans les différents outils de l’entreprise. Il est responsable de l’infrastructure data de l’entreprise. C’est un technicien.
En résumé, le data engineer est celui qui gère les process ETL : Extraction – Transformation – Load. Il utilise pour cela des outils spécialisés comme Stitch ou Fivetran. Il assure la maintenance et les évolutions du data warehouse cloud de l’entreprise : Snowflake, BigQuery, Redshift, Azure…
Pour prendre des exemples parlants, c’est votre data engineer qui garantit que votre instance dbt est bien sur la dernière version, qui gère les permissions dans Snowflake, qui gère et édite les workflows Airflow.
Panorama des outils d’intégration des données
En 2020 une organisation utilise en moyenne 110 applications Saas, contre seulement 8 en 2015. Ces outils augmentent la performance opérationnelle mais créent des silos qui freinent le déploiement des cas d’usage de la donnée. Découvrez notre tour d’horizon des outils pour intégrer toutes les données de votre entreprise : iPaaS, ETL, ELT, CDP, Reverse ETL.
Data Analyst, celui qui transforme les données en enseignements business
Le Data Analyst a pour rôle de dégager des enseignements à partir de l’analyse des données de l’entreprise. Il est chargé de faire « parler les données », via des outils de Business Intelligence et des méthodes d’analyse. Il construit des tableaux de bord et des data visualizations à l’aide d’outils comme Power BI, Tableau ou Looker.
Le Data Analyst est sans doute le rôle le plus important dans une équipe data, car c’est lui qui fait le pont entre le reste de l’équipe data et les équipes métier. Il analyse les données pour répondre aux questions posées par les décideurs et le métier.
Il a un pied dans les données et un pied dans le business.
Mais nous aurons l’occasion dans quelques instants de revenir en détail sur ce rôle clé 🙂
Data scientist, le constructeur de modèles d’analyse avancés (machine learning, IA…)
Le data scientist créé des modèles d’analyse, des algorithmes de machine learning pour prédire ou automatiser les actions data-dépendantes. Il se base sur les principes de la data science pour répondre à des questions complexes auxquelles l’analyse classique ne permet pas de répondre.
Les tâches et responsabilités d’un Data Analyst
Recentrons-nous sur le métier de Data Analyst. Le rôle d’un Data Analyst est d’interpréter les données pour répondre à des problématiques spécifiques.
Voici une liste des principales tâches qu’un Data Analyst est amené à réaliser au cours de ses journées :
Rassembler les données. Les data analysts sont souvent amenés à collecter les données eux-mêmes, quelles que soient les formes que cela prend : mettre en place des sondages, tracker les caractéristiques des visiteurs du site internet ou acheter des sets de données auprès de fournisseurs spécialisés.
Nettoyer les données. Les données brutes peuvent contenir des informations dupliquées, des erreurs ou des valeurs aberrantes. Nettoyer les données consiste à maintenir la qualité des données. De la qualité des données dépend la validité des analyses !
Modélisation des données. La modélisation des données consiste à organiser les données en vue des analyses. Elle permet au data analyst de choisir le type de données qu’il souhaite stocker/collecter et d’établir les relations entre les catégories de données. Une bonne maîtrise de la structure des bases de données relationnelles est requise !
Interprétation des données. Interpréter les données consiste essentiellement à découvrir des patterns ou des tendances grâce à l’analyse des données.
Présenter les résultats. Le data analyst communique les résultats de ses analyses aux décideurs et au métier. Comment ? En utilisant l’art de la data visualization, en construisant des graphiques, des tableaux, des rapports pour présenter les informations dans un format compréhensible par les personnes intéressées.
Les tâches d’un data analyst varient d’une entreprise à l’autre. Le travail d’un data analyst ne sera pas le même dans une petite organisation et dans une grande organisation. Dans les entreprises qui ont de grosses équipes data, le data analyst utilise beaucoup moins ses compétences en modélisation de données (ce travail est confié aux analytics engineers) mais est beaucoup plus focus sur la compréhension du business et la collaboration entre l’équipe data & les équipes métier.
C’est la compétence technique numéro 1. C’est le principal outil utilisé par les data analysts pour mettre à jour, organiser et explorer les données stockées dans des bases relationnelles. SQL est un langage de base de données très puissant sur lequel les data analysts peuvent facilement passer plusieurs heures par jour. Vous trouverez la mention de « SQL » dans toutes les fiches de poste de Data Analyst.
Dans tous les process de recrutement, on demande au candidat de rédiger des requêtes SQL. C’est vraiment la base. Le succès de SQL, qui est un langage remontant aux années 1970 (!), s’explique par le succès persistant des bases de données relationnelles.
Voici quelques exemples de la manière dont un data analyst utilise le SQL :
Joindre, agréger et filtrer les données d’une table de données
Extraire des rapports CSV pour les parties prenantes (données brutes)
Créer des rapports plus complets à partir de données issues de Tableau, Looker…
Créer des connexions de données statiques ou live pour alimenter les reportings ou les tableaux de bord
Tableurs
Reconnaissons qu’il est parfois plus facile de gérer, visualiser et manipuler vos données dans une feuille de calcul après les avoir requêtées avec SQL. Utiliser des tableurs n’est sans doute pas la compétence la plus intéressante, mais c’est probablement l’une de celles qu’un data analyst utilise le plus souvent au quotidien.
Microsoft Excel et Google Sheets sont les deux principales solutions du marché. Excel propose des fonctionnalités plus avancées mais Google Sheets a l’avantage d’être plus adapté au travail collaboratif.
Voici quelques exemples de la manière dont un data analyst utilise les tableurs Excel ou Google Sheets :
Visualiser rapidement des données
Partager rapidement des données
Mettre en lumière certaines données pour faire des comparaisons
Classer des données
Grouper des données (en utilisant des tableaux croisés dynamiques)
Faire des analyses rapides à la volée (en mode « dirty »)
Utiliser la pléthore de fonctions que les tableurs proposent (ce sont des outils bien plus puissants qu’on le pense généralement !)
Imaginer et utiliser des formules de calcul maison
Utiliser la mise en forme conditionnelle
Présenter des enseignements aux parties prenantes de l’entreprise (un Excel peut très bien être utilisé pour créer des tableaux de bord et des reportings)
Langages de programmation (R et Python)
SQL permet d’extraire les données dont on a besoin à partir de l’entrepôt de données. Les langages de programmation R et Python, quant à eux, permettent de faire des analyses (beaucoup) plus avancées que ce qu’il est possible de faire avec un tableur Excel.
Les langages de programmation les plus utilisés par les data analysts sont R et Python. Ce ne sont pas les seuls. On utilise aussi (mais beaucoup moins) SAS et Java. Maîtriser un ou plusieurs langages de programmation est un gros avantage quand on est data analyst.
Voici quelques exemples de la manière dont un data analyst utilise les langages de programmation R ou Python :
Calculer la significativité statistique d’un phénomène
Utiliser des bibliothèques pour réaliser des tâches plus facilement et/ou plus efficacement :
Bibliothèques Python : Pandas pour la préparation et la manipulation des données, Matplotlib pour la data visualization, Scikit-learn pour l’analyse régressive et les arbres de décision.
Bibliothèques R : Dplyr pour la préparation et la manipulation des données, Ggplot2 pour la data visualization.
Réaliser des expérimentations et tester des hypothèses
Utiliser des techniques statistiques classiques comme ANOVA (Analyse de la Variance)
A/B tester des produits
Analyser les valeurs aberrantes
Analyser la qualité des données
Faire de la régression
Il y a des tonnes de fonctions qui utilisent des méthodologies statistiques et peuvent être mises en œuvre grâce aux langages de programmation. Tous les data analysts ne maîtrisent pas ces langages, mais c’est un avantage compétitif certain. Il est de plus en plus conseillé, quand on est data analyst ou qu’on aspire à le devenir, de maîtriser au moins un de ces langages informatiques.
Les data analysts doivent être capables de partager de manière claire, simple et concise les résultats de leurs analyses. La data visualization permet de communiquer des informations et des enseignements basés sur la data à des personnes qui ne sont pas data analysts.
Elle consiste, comme son nom l’indique, à utiliser des moyens visuels : graphiques, courbes, bâtonnets, etc. pour illustrer des enseignements. La Data Visualization est une des compétences incontournables du data analyst. Tableau, Power BI, Jupyter Notebook et Excel sont parmi les outils les plus populaires pour créer des data visualizations.
Voici quelques exemples de la manière dont un data analyst utilise la data visualization :
Articuler des données complexes dans un format (visuel) facile à comprendre
Partager des données ou des résultats aux autres parties prenantes de manière simple
Comparer des données entre elles
Explorer les données. Point important : la data visualization peut aussi être utilisée pour découvrir des enseignements impossibles à déduire de suites de chiffres.
Visualiser beaucoup de données et d’informations dans un même endroit, sans avoir à scroller ou à sauter d’un écran à l’autre.
Data preparation
On estime que près de 80% du temps de travail des professionnels de la data consiste à nettoyer et préparer les données. C’est colossal. Mais ce travail est indispensable car avant d’analyser les données il faut les réunir, les consolider, les nettoyer et parfois les transformer. De mauvaises données aboutissent à de fausses analyses.
Ce n’est clairement pas la partie la plus intéressante du métier de data analyst. C’est d’ailleurs dommage que la data prep continue de consommer autant de bande passante quand on sait qu’il existe des solutions (dont Octolis) permettant d’automatiser toutes les étapes de préparation des données.
Octolis, une solution Data Ops permettant de gérer l’ensemble des étapes de préparation des données sur une même interface.
Voici quelques exemples de la manière dont un data analyst utilise la data preparation :
Choisir les données à intégrer dans le périmètre de l’analyse.
Identifier les sources dans lesquelles sont captées et/ou stockées ces données.
Récupérer des données pour les intégrer dans un environnement d’analyse (tableur, outil de BI…)
Normaliser les données
Nettoyer les données, en retraitant les données erronées ou aberrantes qui peuvent affecter l’analyse
Outils de Data Preparation
Les équipes data passent le plus clair de leur temps à préparer les données. C’est une aberration quand on sait qu’il existe des outils de dataprep qui permettent de faire d’énormes gains de productivité. Découvrez notre panorama des outils de data preparation.
Les soft skills que doit maîtriser un Data Analyst
La pensée critique
Cette compétence n’est pas propre au métier de data analyst, tout le monde est d’accord. Mais c’est important de la mentionner ici car c’est le genre de compétences qui permet de distinguer les bons data analysts des moins bons.
Qu’est-ce que la pensée critique appliquée à la data analysis ? C’est, par exemple, la capacité à savoir quelles données collecter et comment les processer pour obtenir les réponses aux questions qu’on cherche. Connecter des données ne nécessite pas de pensée critique. Mais savoir quelles données connecter, c’est une autre affaire et c’est sur cette capacité, souvent fondée sur l’intuition, qu’on reconnaît un bon data scientist. La pensée critique, c’est aussi ce qui permet au data analyst :
D’imaginer les modèles d’analyse les plus adaptés pour répondre à tel ou tel type de questions
D’identifier des patterns derrière et au-delà des données qu’il a sous les yeux
L’écriture et la communication
Le data scientist interprète les données pour aider les décideurs à prendre des décisions et les équipes métier à travailler plus efficacement. Contrairement au data engineer, le data analyst est en contact direct avec les autres parties prenantes de l’entreprise. Il doit savoir se faire comprendre d’elles. Le data analyst doit savoir s’exprimer face à des personnes qui n’ont pas forcément de compétences en analyse data.
Les compétences relationnelles font partie des soft skills du data analyst. Il doit savoir s’exprimer, parler, expliquer, mais aussi écouter (en phase de kick off, le data analyst écoute plus qu’il ne parle). Il doit savoir vulgariser, parler de manière simple et accessible de sujets techniques parfois très ardus.
Un data analyst est amené à rédiger des rapports et des recommandations. Il doit donc aussi savoir écrire. Il doit être bilingue et maîtriser aussi bien la langue des chiffres que celles des mots.
Les capacités communicationnelles sont une compétence fondamentale : vous pouvez être le meilleur analyste du monde, si vous ne savez pas expliquer les résultats de vos analyses et convaincre vos collègues de l’intérêt de vos analyses, vous ne faites pas le job jusqu’au bout.
La résolution de problèmes
Un data analyst est une personne qui trouve des réponses à des questions posées par les équipes métier. Il doit avoir une bonne compréhension des questions posées et des problèmes sous-jacents à résoudre. Il doit être capable de reformuler les questions dans le langage de la data et de l’analyse.
Son rôle est aussi de découvrir des patterns, des tendances et des relations entre données permettant d’amener à des découvertes utiles. La résolution de problèmes est une compétence indissociable de la pensée critique. Il faut être innovant et créatif pour devenir un bon data scientist.
La compréhension du business
Le data scientist ne travaille pas dans les nuages, même s’il utilise certainement beaucoup d’outils cloud. Il travaille au sein d’une entreprise qui évolue dans un secteur spécifique, avec une activité particulière, des parcours clients singuliers.
Le data analyst est partie prenante de son entreprise. Son travail, ses analyses sont au service des finalités business : améliorer la productivité, mieux cibler les clients, réduire les coûts, réduire le churn, augmenter la performance commerciale, etc.
Une bonne compréhension de l’activité et du contexte métier de l’entreprise est absolument indispensable. Un data analyst qui travaille pour une boutique en ligne, par exemple, doit avoir une parfaite compréhension du ecommerce et de ses enjeux. Un data analyst qui travaille pour une entreprise de vente de quincaillerie aux professionnels doit comprendre ce marché et son fonctionnement.
Nous avons fait le tour des principales compétences techniques et « soft » requises pour exercer le métier de Data Analyst. En tant que recruteur, ce sont toutes les compétences que vous devez évaluer. En fonction de votre entreprise et de votre besoin, certaines compétences seront plus critiques que d’autres. Quoi qu’il en soit, prenez le temps de faire le bon choix. Le recrutement d’un data analyst est une étape importante dans la vie d’une entreprise.
Top 50 des dashboards Ecommerce sur Google Data Studio
Google Data Studio est un outil formidable. L’outil est très facile d’utilisation, le plus compliqué comme souvent, c’est de savoir ce qu’on veut. Il est possible de faire des dashboards dans tous les sens, et beaucoup de boites se retrouvent avec plusieurs dashboards qui se recoupent plus ou moins, et qui sont souvent incomplets et pas vraiment mis à jour.
Avant de vous lancer dans la création d’un dashboard, je vous conseille clairement de prendre le temps de définir vos besoins précisément, et trouver les bonnes inspirations.
Vous trouverez ci-dessous notre top 50 des dashboard e-commerce.
La plupart sont gratuits et vous pourrez facilement copier celui qui sera le plus proche de votre besoin.
Ce dashboard présente la situation de l’entreprise de manière assez globale, en mettant en évidence les chiffres clés et les informations les plus importantes. Ce type de dashboard est principalement utilisé par les cadres supérieurs et les fondateurs pour avoir une vision des résultats de l’entreprise sans avoir trop de détails. Cela leur permet de prendre les décisions adéquates et d’avoir les principaux KPIs mis en évidence.
Ce type de dashboard est assez similaire au précédent, sauf qu’il est beaucoup plus détaillé. Bien que les fondateurs et les cadres supérieurs soient également la cible, ces dashboards offrent souvent une meilleure compréhension. En effet, il va permettre une analyse plus détaillée et ainsi creuser les mêmes KPIs mais de manière plus précise.
Le dashboard d’acquisition permet de bien observer « l’apport » de vos nouveaux clients à votre entreprise, et c’est une donnée clé pour votre réussite. Ce type de dashboard est destiné pour les managers d’acquisition et les managers de trafic.
Principaux KPI = CAC (Customer Acquisition Cost), LTV (Life Time Value), Churn Rate, New client rate, Conversion rate…
Segmentation par canal
La segmentation par canal est une étape clé dans la compréhension et l’analyse des données. Si votre stratégie est de vous concentrer sur certains points alors ce type de dashboard peut vous être très intéressant par exemple pour mettre en avant la gestion des produits, les indicateurs clés de performance. La segmentation par canal offre une explication approfondie de la préférence des produits, de la tendance de croissance de l’industrie, des principaux moteurs du marché en utilisant les diagrammes de données notamment. Ces dashboards sont beaucoup utilisés par les Channel Manager.
Principaux KPI = Average Income per Client, Conversion rate, Demographics KPI (age, country…) , Engagement, Traffic…
Analyse de funnel
Grâce aux dashboards d’analyse de funnels, vous pouvez déterminer où les utilisateurs entrent et sortent du processus de conversion/vente. Vous pouvez ensuite déterminer et éliminer les ralentissements et blockages dans ce processus pour booster les ventes du site Web. Ce type de dashboard est régulièrement utilisé par les data analyst.
Principaux KPI = Performance over time, Clics and Impressions, Customer Lifetime Value, Sales Funnel Flow…
Performance de Google Ads
Ces dashboards de performance de vos campagnes Google Ads mettent en avant des informations vitales pour vos campagnes en cours et les suivantes. Un dashboard Google Ads vous aidera à garder le contrôle de vos campagnes Google Ads en trouvant les bons mots-clés pour le bon public. Ces informations seront très utiles pour les marketer et ceux qui sont à l’origine de cette campagne.
Principaux KPI = Clics, Impressions, CPC, Conversion, CPA, Top Campaigns…
Retention
Un dashboard de rétention (fidélisation) de la clientèle permet de suivre les principaux indicateurs centrés sur le client, tels que le taux de fidélisation, le taux de désabonnement, la croissance du MRR et le nombre de clients fidèles. De cette façon, une entreprise génère des informations détaillées sur ses opportunités de croissance. Les responsables de la rétention CRM auront une grande utilité à utiliser ce genre dashboard;
Principaux KPI = Taux de retention et de désabonnement, Le Net Promoter Score (NPS) , Taux de rachat, Panier moyen
Performance des produits
Les dashboards qui concernent la performance des produits fournissent des informations sur les performances des campagnes et des produits afin que votre équipe puisse procéder aux ajustements nécessaires pour atteindre les objectifs de vente. Cet outil est utilisé par les responsables chefs de produits
Principaux KPI = CLTV, Taux de rétention, Satisfaction client, Sessions par utilisations
SEO
Le dashboard SEO affiche tous les éléments-clés de votre campagne SEO dans une interface en temps réel. Cela inclut généralement des mesures telles que le suivi du classement des mots-clés, le trafic organique, les conversions Web et les backlinks créés. Les dashboards SEO améliorent les performances des recherches organiques de vos clients et vous fournissent toutes les données dont vous avez besoin pour rendre compte de vos progrès.
Avec ce type de dashboard, vous pouvez obtenir rapidement un aperçu des performances de vitesse de votre site Web en quelques clics seulement. Vous pouvez également trouver les tendances et approfondir les différents systèmes d’exploitation et navigateurs pour obtenir les meilleurs/pires sites.
Principaux KPI = Vitesse de la page, SEO, Traffic, Taux de rebond, Durée moyenne de la session,
Approche méthodologique
1. Définir vos dashboards
La plupart des gens vont être satisfaits d’un dashboard qui offre une vue d’ensemble de leur activité, mais choisir le bon dashboard est très important. Pour que votre entreprise d’Ecommerce cartonne, il est de votre devoir de savoir et de comprendre comment votre entreprise fonctionne vraiment, ce qui fonctionne bien, ce qui ne fonctionne pas et quelles pourraient être les meilleures décisions à prendre. Il existe une multitude de dashboards sur le web et vous pouvez vous sentir perdu et ne pas vraiment savoir lequel est le meilleur pour votre cas d’utilisation. Faisons aussi simple que possible pour vous, le dashboard d’Ecommerce dont vous aurez besoin dépend de vos objectifs et de ce que vous voulez voir, comprendre et réaliser avec vos données.
Quel que soit le dashboard dont vous avez besoin, il existe deux points de départ importants pour toute entreprise e-commerce :
Premièrement, les sources de trafic, il est capital pour vous de connaître les performances de votre entreprise. Si vous surveillez vos sources de trafic, vous serez en mesure de voir clairement quels canaux rapportent le plus de visites, de taux de conversion et donc de revenus à votre entreprise. En vous adaptant à ces données, vous pourrez envisager une stratégie pour cibler et augmenter le trafic vers ces sources.
Ensuite, votre revenu, oui c’est évident et bien sûr il doit être inclus dans votre dashboard même si certains dashboards spécifiques ne se concentreront pas sur le revenu mais sur la pertinence de vos campagnes (Google Ads, Emailing …). Vous pouvez utiliser le revenu pour donner une vue d’ensemble de votre activité mais aussi pour le décomposer par produits, canaux, etc…
2. Dresser la liste de toutes les sources de données dont vous avez besoin
Data Studio peut se brancher nativement à tous les outils Google : Search Console, Google Analytics, Google Ads, etc. Vous pouvez également brancher des GSheet, ou encore mieux connecter Data Studio à BigQuery, le Data Warehouse de Google dans lequel vous pouvez faire descendre des données d’autres outils.
Avant de construire vos dashboards, il faut lister toutes les sources de données dont vous aurez besoin. Idéalement, il faut faire ce travail en partant de chaque rapport / graphique dans votre dashboard idéal. Vous listez les rapports dans un Gsheet, et pour chacun, vous notez les sources de données qui seront nécessaires.
3. Choisissez vos outils
Les outils de dashboard
Dans le domaine du Ecommerce, on retrouve le plus souvent :
Google Data Studio : Google Data Studio va vous fournir tout ce dont vous avez besoin pour transformer les analyses de données de vos clients en informations compréhensibles.Les rapports sont faciles à lire et à partager, et peuvent être personnalisés pour chaque client. Vous pouvez également choisir comment afficher les données (sous forme diagramme à barres, graphique, graphique linéaire, etc.).
Metabase : Metabase est un outil de BI open source. Il vous permet de poser des questions sur vos données et d’afficher les réponses dans des formats adaptés, qu’il s’agisse d’un graphique à barres ou d’un dashboard détaillé.
Qlikview : QlikView est une solution classique d’analyse predictive, en clair QlikView vous permet de développer et de fournir rapidement des dashboards interactifs. L’utilisation de QlikView est nettement plus compliqué que Google Data Studio mais vous permet aussi certaines analyses plus détaillées.
Besoin d’un Data Warehouse ?
Au début, vous pouvez connecter votre outil de dashboard directement aux sources de données. Lorsque le nombre de sources de données augmente et que la nécessité de « joindre » des dashboards apparaît, il est judicieux d’envisager un Data Warehouse (comme Google BigQuery ou une simple base de données Postgres) dans lequel vous consoliderez toutes les sources de données. Quels sont les signaux d’alarme quand on a besoin d’un Data Warehouse?
Si vous devez analyser vos données et qu’elles proviennent de plusieurs sources
Si vous devez séparer vos données analytiques de vos données transactionnelles.
Si vous voulez augmenter les performances de vos analyses les plus fréquentes.
Pipelines de données, comment collecter les données ?
Google Data Studio peut se connecter directement à tous les outils Google, cependant vous pouvez avoir besoin d’autres sources de données (backend Ecommerce, service client, ..).
Dans ce cas vous pouvez envisager des outils comme Supermetrics, Funnel, Octolis pour les utilisateurs du marketing, le processus est simple, la solution choisie permet d’extraire les données de vos sources (quelle qu’elles soient), les transforme pour pouvoir mieux les exploiter puis les connecte à une DWH.
Une autre alternative, si vous avez des compétences en ingénierie serait Fivetran et Airbyte. Fondamentalement, Fivetran permet de recueillir efficacement les processus buisness et les données des clients à partir de leurs sources, de sites Web et de serveurs associés. Les données recueillies sont ensuite transférées à d’autres outils à des fins d’analyse, de marketing et de stockage de données.
20 modèles de dashboard de performance globale
The Ecommerce Speed Dashboard
Le modèle de ce dashboard est conçu pour les entreprises d’Ecommerce qui ont mis en place un suivi d’Ecommerce amélioré sur Google Analytics.
Ce rapport est fait pour vous si vous recherchez des informations détaillées organisées d’une meilleure manière que les données de Google Analytics.
Le dashboard montre le revenu annuel, les achats et le revenu par achat.
En outre, le modèle montre des informations sur la vue du produit, vous serez en mesure de filtrer les données en fonction du profil, de la date, de la source et du pays.
L’objectif est de déterminer le montant de vos revenus, le taux de conversion et les produits les plus performants.
Source : Google Analytics
Prix : Gratuit
The Aro Digital eCommerce Dashboard
Le dashboard Ecommerce d’Aro est un modèle global contenant de nombreux détails sur les transactions de commerce électronique.
Il dispose d’une très bonne sélection de KPI, ce qui vous permet de segmenter toutes vos données dans un endroit unique, qu’il s’agisse de données démographiques ou de canaux.
Le modèle comprend 4 pages qui présentent la plupart des éléments clés du marketing de recherche.
Source : Shopify, Snapchat, Instagram, Pinterest, Facebook, GA
Prix : Gratuit
Hubspot Marketing Performance template
Source : Hubspot
Prix : Gratuit
Website Master Template
Sources : Google Analytics, Google Ads, Google Search Console
Prix : Gratuit
4 modèles de dashboard de segmentation par canal
Mobile ecommerce dashboard
Source : Google Analytics
Prix : Gratuit
E-commerce performance report
Source : Google Analytics
Prix : Gratuit
Website summary
Source : Google Analytics
Prix : Gratuit
Attribution report
Source : Google Analytics
Prix : Gratuit
4 modèles de dashboard d’acquisition
The Merchandise Store Website Performance Report
Source : Google Analytics
Prix : Gratuit
Engagement, Loyalty, and Traffic Growth Dashboard
Source : Google Analytics
Prix : Gratuit
Social Media Dashboard Import
Source : Google Analytics
Prix : Gratuit
Website performance report for the merchandise store
Source : Google Analytics
Prix : Gratuit
4 modèles de dashboard d’analyse de funnel
The Facebook Campaign Template
Ce dashboard contient des informations très pertinentes sur l’Ecommerce, la première page nous permet de voir quelques détails sur les revenus et les achats, et la dernière page vous avez accès à un dashboard d’aperçu des funnels avec quelques détails sur les campagnes à faible funnels.
Il est difficile de trouver de bons modèles Facebook, la plupart d’entre eux sont orientés-Ecommerce, et celui-ci donne un véritable aperçu de la campagne Facebook, pas trop spécifique mais plutôt détaillé.
Ce modèle fournit des données sur les impressions, les clics et les achats, mais aussi sur les objectifs de la campagne, le montant dépensé, les revenus, le ROAS et les résultats.
Pour vous donner un aperçu du dashboard, il y a 6 pages : aperçu, répartition de l’audience, répartition de la créativité, aperçu du funnel et enfin niveau de la campagne.
Source : Google Analytics
Prix : Gratuit
GA4 Ecommerce Conversion Funnel Template
Source : Google Analytics
Prix : 59€
E-mail Dashboard
Source : Google Analytics
Prix : Gratuit
The Enhanced Ecommerce Funnel Template
Source : Google Analytics
Prix : Gratuit
4 modèles de dashboard de performance des campagnes Google Ads
Adwords Performance Snapshot
Source : Google Analytics, Google Ads
Prix : Gratuit
Ultimate Google Ads report
Source : Google Ads
Prix : Gratuit
Adwords Data Studio Template Report
Source : Google Analytics, Google Ads
Prix : Gratuit
Adsens monthly Overview
Source : Google Ads
Prix : Gratuit
8 modèles de dashboard de retention
Google Merchandise Store Report
Source : Google Analytics
Prix : Gratuit
The Sales and Shopping Behavior Dashboard
Source : Google Analytics
Prix : Gratuit
Google Analytics 4 Data Studio Template
Source : Google Analytics
Prix : 69€
Periodic Revenue Template
Source : Google Analytics
Prix : 49€
Ultimate Google Ads Dashboard
Source : Google Analytics
Prix : Gratuit
The perfect Google Analytics Dashboard
Source : Google Analytics
Prix : Gratuit
All in one Ecommerce Dashboard
Source : Google Analytics
Prix : Gratuit
Ecommerce Performance Report
Source : Google Analytics
Prix : Gratuit
3 modèles de dashboard de performance des produits
The Enhanced eCommerce Dashboard
Source : Google Analytics
Prix : 100€
All-in-one Search Console Template
Source : Google Analytics
Prix : Gratuit
Google Merchandise Store Ecommerce Report
Dans ce dashboard, vous pouvez trouver toutes les dimensions et métriques concernant les produits ajoutés aux paniers, les ventes, les sessions, le taux de « ajouté panier « . Pour aller droit au but, vous pouvez filtrer vos données par catégorie d’appareil, type d’utilisateur et pays…
En conclusion, ce dashboard vous offre une vue globale des tendances et des informations assez pointues.
Source : Google Analytics
Prix : Gratuit
2 modèles de dashboard SEO
SEO Dashboard
Source : Google Analytics
Prix : Gratuit
Search Console Explorer Studio v1.3
Source : GA4
Prix : Gratuit
1 modèle de dashboard de performance de la vitesse du site
Performance de la vitesse du site
Source : GA4
Prix : Gratuit
Téléchargement de notre benchmark complet des dashboard Ecommerce data studio.
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Toutes les startups ont conscience que leur croissance doit s’appuyer sur une fonction Data / Analytics solide. De la conviction à la mise en œuvre, il y a un gouffre 🙂
Beaucoup de jeunes entreprises ont tendance à vouloir brûler les étapes, des décisions qui peuvent avoir des répercussions négatives sur leur développement, des héritages dont il est ensuite difficile de se débarrasser.
Il ne s’agit pas de savoir quelles sont les métriques à suivre (il y a beaucoup de bons articles à ce sujet), mais de savoir comment amener votre entreprise à les produire. Il s’avère que la question de la mise en œuvre – comment construire une entreprise qui produit des données exploitables – est en réalité beaucoup plus difficile à résoudre.
Dans cet article, largement inspiré de cet excellent post de Tristan Handy, foundateur de dbt, nous apportons des réponses concrètes afin de construire la fonction data / analytics à chaque étape de développement de votre organisation.
Que faut-il absolument mesurer à ce stade ? Théoriquement, vous pourriez mesurer des tonnes de choses, mais vous êtes si proche du cœur de votre activité que vous parvenez à prendre les bonnes décisions à l’instinct.
Les seules métriques qui comptent à ce stade, sont liées à votre produit. Pourquoi ? Car ces métriques vont vous permettre d’itérer plus rapidement pour identifier les axes d’amélioration, faire les bons ajustements qui vous permettront de vous rapprocher du Product / Market Fit. Toutes les métriques qui ne concernent pas directement votre produit sont secondaires !
Ce qu’il faut faire
Installer Google Analytics sur votre site internet via Google Tag Manager. Les données ne seront pas parfaites, mais ne perdez pas de temps dans des paramétrages compliqués, ce n’est pas la priorité.
Si vous créez un business e-commerce, vous devez vérifier que les données liées à votre site de vente en ligne remontent bien dans Google Analytics. GA est un bon outil pour tracker une activité e-commerce et le parcours de vos clients de la visite à l’achat, donc prenez le temps de vérifier que tout fonctionne bien.
Si vous éditez un logiciel ou une application, vous devez absolument tracker les événements. Peu importent les outils que vous utilisez, que ce soit Segment ou Mixpanel. À ce stade, nous vous conseillons d’utiliser les paramétrages par défaut proposés par votre outil. Cette approche n’est pas très scalable, mais pour le moment ça fera le job.
Si votre business model est basé sur la soubscription avec des revenus récurrents, utilisez un outil comme Baremetrics pour suivre les métriques d’abonnement.
Construire un reporting financier en utilisant un outil comme Quickbooks.
Pour votre prévisionnel, utiliser Google sheets.
Si vous n’avez pas de compétences techniques, vous aurez sûrement besoin d’un petit accompagnement pour Google Analytics et la mise en place du tracking des événements. Cela ne doit pas prendre plus de deux heures, mais il faut que ce soit bien fait.
Ce qu’il ne faut pas faire
C’est simple : vous devez uniquement vous concentrer sur les points listés plus haut et ne pas chercher à mesurer autre chose pour le moment. Ne laissez personne vous convaincre d’investir dans un Data Warehouse ou dans un outil de BI. Ne faites pas appel à des consultants. Restez focus sur l’essentiel.
Si vous vous lancez tout de suite dans des projets analytics compliqués, vous vous engagez dans un chantier que vous ne pourrez pas mettre en pause, car les données, l’activité et les objectifs de l’entreprise vont constamment évoluer. Attendez avant de construire un dispositif analytics plus élaboré.
Beaucoup de questions qui resteront sans réponse, et c’est très bien comme ça (pour l’instant).
#2 – Phase d’amorçage [10 – 20 employés]
Votre équipe commence à s’étoffer et ces nouveaux collaborateurs ont besoin de données pour faire leur travail. Tous ne sont pas experts en données, mais vous devez vous assurer que les basiques soient réalisés dans les règles de l’art.
Ce qu’il faut faire
Vous avez probablement recruté un marketer, assurez-vous qu’il maîtrise GA. Tous les liens utilisés dans vos campagnes marketing doivent être trackés par des balises UTM. Votre responsable marketing doit faire en sorte que les sous-domaines ne soient pas trackés deux fois. Il existe des tonnes de ressources pour apprendre à utiliser Google Analytics, il est très facile de se former rapidement.
Si vous avez un ou deux commerciaux, installer un CRM est très vite nécessaire. 2 options ici :
Utiliser un CRM léger comme Pipedrive. Si vous choisissez cette option, nous vous invitons à découvrir les 10 meilleurs CRM pour TPE/PME. Vous devriez y trouver votre bonheur.
Construire un CRM maison en utilisant un template Notion. C’est l’option que nous vous recommandons. Pourquoi ? Parce que migrer d’un CRM léger à un CRM plus costaud est chronophage et complexe. En attendant d’être plus structuré sur la partie « Sales », Notion est une excellente alternative aux CRM légers « sur l’étagère ».
Vous avez probablement recruté quelques CSM pour gérer la relation avec premiers clients. Les reportings proposés par les plateformes d’help desk sont souvent assez pauvres. Adaptez-les en ajoutant les bons KPIs, ceux qui font sens pour votre activité.
Mesurer la satisfaction de vos premiers clients. C’est absolument clé pour améliorer votre produit et assurer sa croissance. Mesurez le Net Promoter Score (NPS) et/ou le Customer Satisfaction Score (CSat) en utilisant un outil comme Delighted, Qualtrics, Hotjar, voire Typeform.
Ce qu’il ne faut pas faire
Il est encore trop tôt pour investir dans un Data Warehouse ou pour faire de l’analytics via SQL. Vous n’avez pas encore les équipes suffisantes et cela vous consommera trop de bande passante. Vous en êtes encore à un stade où vous devez passer le plus clair de votre temps à agir, à faire, plutôt qu’à analyser.
Contentez-vous pour le moment des reportings préconstruits proposés par les outils SaaS. Dernière chose, n’embauchez pas de data analyst à plein temps, votre argent sera mieux investi ailleurs.
#3 – Early Stage [20 – 50 employés]
C’est là que les choses commencent à devenir intéressantes. Vous avez levé des fonds en série A et dépassé les 20 collaborateurs. De nouvelles options commencent à s’ouvrir à vous. Vous pouvez commencer à structurer une infrastructure data et à vous équiper de solutions plus avancées, plus flexibles, plus scalables.
Il s’agit de la phase la plus critique : prometteuse si vous faites les choses bien, compromettante pour l’avenir de votre entreprise si vous gérez mal le changement de vitesse.
Ce qu’il faut faire
Mettre en place une infrastructure data. Vous allez être amené à choisir entre 2 approches :
L’approche Best of Breed qui consiste à construire soi-même sa stack data en choisissant les outils qui correspondent le mieux. Cela signifie, concrètement, investir dans :
Un Data Warehouse, comme Snowflake ou Redshift. Le DWH sert de base de données principale. Il centralise, consolide et unifie toutes les données de votre startup.
L’approche packagée / data operations hub, qui consiste à choisir un outil tout-en-un (comme Octolis!), fonctionnant en surcouche de votre data warehouse et permettant de déployer facilement vos cas d’usage métiers.
Architecture type de la Stack Data Moderne
Un dispositif data « moderne » consiste à placer le data warehouse (DWH) au centre de votre infrastructure data. En amont, le data warehouse est alimenté par les différentes sources de données via des pipelines ETL ; en aval ces données sont redistribuées sous forme d’agrégats à vos outils métiers via un Reverse ETL. Votre outil de BI se connecte à la même source unique de vérité : votre DWH.
Embaucher 1 data analyst. Par la suite, vous aurez besoin de constituer une équipe Data/Analytics avec des data engineers, des data analysts, des data scientists…Mais pour le moment, vous avez seulement les moyens d’embaucher un data analyst à temps plein. Alors, ne faites pas d’erreur, prenez le temps qu’il faut pour trouver la bonne personne. Il faut que la personne que vous recrutez soit capable de vous délivrer de la valeur dès sa prise de poste. Ce sera aussi cette personne qui gérera les futurs recrutements pour constituer votre équipe data. Elle en constituera la colonne vertébrale. Choisissez une personne capable de retrousser ses manches et de mettre les mains dans le cambouis, mais privilégiez surtout quelqu’un qui sait faire parler les données et qui pense « business ».
Les 3 pôles de compétences des métiers de la data. Pour un premier recrutement, il faut cibler un profil à l’aise avec la technique (capable de gérer des pipelines de données, par exemple) mais aussi et surtout ayant de bonnes compétences d’analyse et une compréhension des enjeux business.
Envisager de faire appel à un consultant. Une fois que vous aurez recruté votre data analyst, soyez conscient que cette personne n’aura pas l’expertise nécessaire pour maniupler / gérer toutes les composantes de votre stack data. Or, commettre des erreurs à cette étape de développement peut se révéler très coûteux par la suite. Il est important de bien poser des fondations saines, c’est là-dessus qu’un accompagnement peut avoir du sens.
Ce qu’il ne faut pas faire
Il n’est pas encore temps d’embaucher un data scientist, même si le machine learning est au cœur de votre produit. À ce stade, vous avez besoin d’un profil généraliste qui aura la responsabilité de constituer l’équipe data/tech de votre start-up.
Ne construisez vos propres pipelines ETL. C’est une perte énorme de temps. Optez pour un logiciel sur l’étagère comme Stitch ou Fivetran, c’est simple et efficace.
Pour votre Data Warehouse, ne cherchez pas à faire des économies en construisant une base de données en Postgres. Ce n’est pas beaucoup moins cher que d’opter pour une solution cloud sur l’étagère, mais vous perdrez en revanche un temps fou quand vous devrez migrer votre BDD – et vous devrez le faire à un moment ou à un autre car Postgres est beaucoup moins scalable qu’une solution Data Warehouse Cloud.
#4 – Phase intermédiaire [50-100 employés]
Cette étape est potentiellement la plus complexe à gérer. Vous avez encore une équipe et des ressources (relativement) limitées, mais vos équipes business ont de plus en plus besoin de métriques solides.
Ce qu’il faut faire
Mettre en place des process solides pour gérer les modèles de données et sécuriser la transformation des données. Les modèles de données, c’est-à-dire la manière d’organiser les données dans votre base de données, sont dictés par les besoins métiers et les finalités business. Tous les utilisateurs des données doivent pouvoir faire évoluer les modèles de données. Ils doivent aussi pouvoir transformer les données. Mais, par sécurité et pour éviter tout problème, assurez-vous qu’un système de contrôle de version est utilisé et mettez en place un environnement de transformation transparent. Il existe des outils spécialement conçus pour ça, notamment dbt.
Migrer votre web analytics et votre event tracking sur une solution comme Snowplow Analytics ou Jitsu. Ces outils permettent de faire la même chose que les outils payants, mais ont l’avantage d’être open source. Pourquoi faire ce changement ? Pour être en capacité de collecter des données plus granulaires et pour éviter de payer des licences exorbitantes (plusieurs centaines de K€ par mois…) à Segment, Heap ou Mixpanel.
Quelle solution de web analytics choisir ?
Les solutions de web analytics sur l’étagère sont très abordables, voire gratuites, dès lors que vous avez de petits volumes de données. Mais les tarifs augmentent très rapidement avec la croissance du volume de données géré (calculé en nombre d’utilisateurs ou en nombre d’event trackés).
Nous avons produit une ressource Notion sur les alternatives à Segment dans laquelle on présente (notamment) les principales solutions de web analytics open source du marché.
Faire grandir votre équipe data intelligemment. Le cœur de votre équipe data doit être constitué d’analystes ayant une sensibilité business forte – c’est-à-dire des personnes expertes en SQL, qui maîtrisent parfaitement l’outil de BI mais qui passent aussi beaucoup de temps à faire le pont entre les équipes data « pures » (les data engineers) et les équipes métier/business. Dans une startup, la donnée est au service du business. La capacité de dialogue entre votre équipe data et les équipes métier reposent en partie sur votre capacité à recruter le ou les bons « business analysts ». C’est aussi à ce stade de développement de votre startup que vous allez pouvoir (enfin) recruter un data scientist.
Commencer à construire des modèles prédictifs. Vous pouvez commencer à utiliser des modèles prédictifs simples. Par exemple, si vous êtes un éditeur de logiciel SaaS, vous avez intérêt à déployer un modèle de prédiction du churn. Si vous êtes un e-commerçant, vous pouvez commencer à travailler sur un modèle de prévision de la demande. A ce stade, vos modèles prédictifs ne seront pas forcément très sophistiqués, mais ce sera déjà une énorme avancée par rapport aux tableurs google sheet bricolés par le département Finance 🙂
Consacrer du temps et de l’énergie à l’attribution.. C’est un sujet qui mériterait tout un article, mais disons simplement ici que c’est un chantier clé que vous ne pouvez pas confier à un tiers. Pour mesurer finement la contribution des différents canaux marketing, vous devez mettre en place des modèles d’attribution. Vous pouvez commencer par utiliser les modèles standards (ceux proposés par les outils analytics) avant de vous lancer dans la construction d’un modèle sur-mesure.
Ce qu’il ne faut pas faire
Arrivé à cette phase de développement de votre startup, le risque est de s’emballer et d’investir dans une grosse infrastructure data. Ne faites pas cette erreur ! Non seulement ce serait se lancer dans un projet inutilement coûteux, mais aussi qui dit infrastructure lourde dit perte d’agilité. Voici quelques conseils pour que votre startup reste agile :
Exploiter toute la puissance de votre Data Warehouse. N’hésitez pas à booster votre abonnement, à augmenter les ressources de calcul activées, à augmenter l’espace de stockage. Vous pouvez vous le permettre et ça ne vous coûtera pas très cher.
Utiliser des Jupyter Notebooks pour les travaux de Data Science. Si vos données sont déjà pré-agrégées dans votre entrepôt de données, vous n’aurez pas encore besoin de le faire sur Spark ou un cluster Hadoop.
Trouver des solutions low-cost pour créer des pipelines ETL sur les sources données sans connecteurs. Utilisez un ETL open source, par exemple Singer.
#5 – Phase de croissance [150 – 500 employés]
Ici, tout l’enjeu est de mettre en place des process analytics scalables. Vous devez trouver un équilibre entre obtenir des réponses dont vous avez besoin aujourd’hui et mettre en œuvre des process analytiques qui s’adapteront à la croissance de votre équipe.
Prenons deux cas de figure pour rendre les choses plus parlantes. Si votre entreprise compte 150 employés, votre équipe analytics représente certainement entre 3 et 6 personnes à temps plein. Mais si l’entreprise a 500 employés, l’équipe analytics peut facilement dépasser les 30 personnes. Et, croyez-nous, ça change tout.
Quand il y 3, 4, 5 ou 6 analystes, il n’y a pas besoin de process très formalisés : les personnes sont en contact quotidien, travaillent peut-être dans le même bureau, elles s’échangent des informations (ou des morceaux de code :)) de manière informelle. Et ça fonctionne très bien comme ça. Mais dès que l’équipe atteint les 10 personnes, il faut organiser le travail en commun et les échanges d’informations grâce à des process plus formels.
Ce franchissement de seuil appelle des changements dans les manières de travailler. Si vous ne réussissez pas à gérer correctement ce changement, vous verrez que vous deviendrez de moins en moins efficace à mesure que votre équipe grandira. « Plus » deviendra égal à « moins »: votre équipe sera plus nombreuse mais réussira moins bien à « faire parler les données ». Elle deviendra moins efficace. Voici ce qu’il faut faire pour éviter cette situation.
Ce qu’il faut faire
Faire du data testing. Vous avez maintenant des flux de données qui alimentent votre Data Warehouse et qui proviennent d’une dizaine de sources a minima. Vous allez devoir mettre en place des process pour vous assurer que les données qui entrent dans l’entrepôt continuent d’être conformes aux règles que vous avez fixées : unicité des données, absence de champs nuls, etc. Si vous n’avez pas de process qui contrôlent la manière dont les données sont chargées dans le Data Warehouse, c’est la qualité des données qui est en péril, et in fine la qualité des analyses produites à partir d’elles. dbt propose une fonctionnalité intéressante pour tester vos données et vérifier qu’elles sont organisées comme vous le souhaitez.
Utiliser les requêtes pull et faites des code reviews. Les codes analytics sont un actif précieux, au même titre que le code de votre site internet ou de votre application. Pour maintenir la qualité de vos codes analytics, vous devez prendre au sérieux le contrôle des versions. Familiarisez tous les membres de votre équipe avec git, formez-les à l’utilisation des branches…Tous les codes qui sont déployés en production doivent être fusionnés via une requête pull qui intègre une révision de la part d’un membre de l’équipe.
Documenter tout ce que vous faites. L’environnement data de votre entreprise est devenu complexe. Le seul moyen pour gérer efficacement tout cet actif et faciliter l’exploitation des données par tous consiste à investir du temps et de l’argent dans la documentation. Si vous ne le faites pas, vos data analystes passeront plus de temps à chercher où sont les données et comment les utiliser qu’à faire un travail d’analyse.
Ce qu’il ne faut pas faire
Votre startup collecte maintenant des volumes importants de données. Pour cette raison, faire des analyses est devenu plus difficile. Cela nécessite d’avoir à disposition une équipe composée de talents, de gens motivés, prêts à se former pour acquérir de nouvelles compétences.
Le code reviews, qui consiste à vérifier la bonne santé d’un code informatique et à identifier les éventuels bugs, est une activité qui consomme du temps et de l’énergie. Les data analystes n’ont pas forcément l’habitude de faire des code reviews. La documentation des données et des traitements est aussi quelque chose de pénible en soi. Certains membres de l’équipe montreront peut-être des réticences, mais la complexication des données, de l’infrastructure, de l’organisation impose des adaptations et la mise en place de process plus rigoureux.
Il faut réussir à le faire comprendre à votre équipe et ne pas transiger sur ce point ! In fine, ces process rendront le travail d’analyse plus simple, plus rapide et plus fiable. C’est leur implémentation qui est une étape un peu pénible à passer.
Conclusion
La fonction Data / Analytics de votre startup va se construire progressivement. Elle doit se construire progressivement. Mettre la charrue avant les bœufs est le plus sûr moyen de foncer dans le mur. Si vous suivez les étapes dans l’ordre, sans précipitation, vous ferez de l’exploitation de vos données un avantage compétitif important.
D’après statistica, en 2020 une organisation utilise en moyenne 110 applications Saas, contre “seulement” 8 en 2015. Si le recours de plus en plus fréquent à ces outils a considérablement augmenté les performances opérationnelle des organisations, elle s’est en revanche accompagnée de la création de “silos de données” qui freinent la mise en place de cas d’usage nécessitant le recours à plusieurs outils.
Pour répondre à ce nouvel enjeu, de nouveaux outils d’intégration de données se développent : les iPaaS, les CDP, les ELT mais également les Reverse ETL. Quel est le positionnement de chacun de ces outils, comment les comparer et surtout comment faire le bon choix, on vous dit out dans cet article !
On appelle intégration des données le processus de centralisation de l’information entre bases de données (internes ou externes). Il peut s’agir des datawarehouses, ainsi que des outils et systèmes tiers qui génèrent et stockent de la donnée. L’objectif est d’avoir une vue unique de données provenant de plusieurs sources. Les outils d’intégration utilisent tous la même technologie sous-jacente : les API.
Prenons l’exemple d’une application mobile utilisant les outils suivants pour gérer son activité :
Facebook et Google Ads afin d’acquérir de nouveaux utilisateurs
Google Analytics pour suivre le trafic sur son site web et sur l’application mobile
Une base de données MySQL pour stocker les informations générales
Marketo pour l’envoi d’emails marketing et la gestion des prospects
Zendesk pour le support client
Netsuite pour la comptabilité et le suivi financier
Chacune de ces applications contient un silo d’informations sur les opérations de l’entreprise. Pour obtenir une vue à 360 degrés de son activité, ces données doivent être regroupées en un seul endroit. C’est ce processus que l’on appelle communément « intégration des données ».
Les bénéfices d’un processus d’intégration de données solide
Tout d’abord, l’intégration des données permet d’améliorer la collaboration et l’unification des systèmes au sein d’une société. En effet, les employés de différents départements ont de plus en plus besoin d’accéder aux données de l’entreprise, qu’elles concernent les clients ou les produits. Une source unique et sécurisée de données facilite l’entraide entre équipes et booste l’efficacité de l’entreprise.
De plus, un processus d’intégration solide permet de faire gagner du temps aux équipes IT chargées de développement. Les employés n’ont alors plus besoin d’établir des connexions eux-mêmes évitent également de refaire tous les rapports manuellement, les données peuvent être mises à jour en temps réel.
Enfin, l’intégration assure des données de plus grande qualité. Au fur et à mesure que les données sont intégrées dans le système centralisé, les problèmes de qualité sont identifiés. Les améliorations nécessaires sont mises en œuvre plus rapidement que lorsque les données viennent de plusieurs sources. Les données sont donc plus fiables.
Quels outils pour intégrer vos données ?
Des solutions ont été créées pour résoudre le problème d’intégration des logiciels et des applications fonctionnant de manière isolée les unes des autres, ne disposant pas d’un flux de communication automatique. Il existe différents types d’intégration que l’on peut regrouper sous des familles d’outils :
iPaaS (Integration Platform as a Service) : les données circulent directement entre les applications Cloud, avec peu ou pas d’intégration dans l’iPaaS comme Zapier ou Integromat.
CDP (Customer Data Platform) : les données circulent entre les applications Cloud via une plateforme hub centrale qui permet des transformations modérées de la data.
ETL (Extract, Transform and Load) : les données sont transférées des applications Cloud vers un datawarehouse, en passant par une couche de transformation robuste intégrée à l’outil.
ELT (Extract, Load, and Transform) : les données passent des applications Cloud à un datawarehouse directement, et la transformation des données a lieu dans le datawarehouse via SQL. La principale différence ici est qu’avec l’ETL, la transformation a lieu avant le chargement des données dans l’entrepôt, alors qu’avec l’ELT, la transformation a lieu après.
Reverse ETL : les données passent d’un datawarehouse à des applications Cloud, à l’inverse du processus ETL, on peut ici citer Octolis en France ou encore Census aux US.
Comme le montre le schéma ci-dessous, le recours à ses différentes solutions a suivi l’évolution de l’organisation du SI clients. Cette organisation s’est structurée d’abord principalement autour du couple CRM marketing- iPaas, puis au travers des CDP et enfin aujourd’hui la stack data moderne bascule un nouveau couple : Datawarehouse Cloud & Reverse ETL!
L’évolution des outils d’intégration de données depuis 2010
Les iPaas comme Zapier / Integromat
Les iPaas (Integration Platform as a Service) sont des plateformes technologiques qui relient les différents systèmes utilisés par une entreprise, permettant l’intégration et le partage des données entre eux, offrant ainsi une vision unique. L’iPaas fonctionne comme un tuyau d’un outil A vers un outil B. L’inconvénient majeur réside donc dans la difficulté d’intégrer plusieurs sources.
Une plateforme iPaas « en tant que service » fournit un cadre et un environnement dans le Cloud.
L’un des avantages principaux des iPaaS est le fait qu’ils offrent une interface visuelle pour construire des intégrations, permettant aux équipes commerciales de prendre le contrôle de leurs besoins d’automatisation des flux de travail. Grâce aux ‘iPaaS, des concepts de codage sont transformés en une interface utilisateur facile à manipuler, même pour les profils non techniques.
Parmi les solutions iPaas les plus populaires aujourd’hui, nous retrouvons Tray et Workato, plutôt ciblées pour les grandes entreprises, et Zapier, Integromat et Automate.io, plutôt destinées aux PME.
Avantages
Simplicité d’utilisation de l’interface
Nombre de connecteurs disponibles
Inconvénients
Prix élevé : Bloquant pour de gros volumes de données
Difficulté à croiser les données de plusieurs sources
Les CDP comme Segment ou Tealium
Les Customer Data Platform collectent et rassemblent les données provenant de différentes sources et les envoient vers différentes destinations.
Côté métier, la CDP permet aux équipes marketing de créer des segments basés sur le comportement et les caractéristiques des utilisateurs, et de synchroniser ces segments avec des outils tiers pour offrir des expériences personnalisées. Le tout sans dépendre des équipes techniques d’ingénierie de données.
Sur le marché, on retrouve des CDP horizontales telles que Segment, mParticle, Lytics et Tealium, ainsi qu’à des CDP verticales telles que Amperity (retail et hôtellerie) et Zaius (ecommerce), qui s’attachent à répondre aux besoins de secteurs spécifiques.
Avantages
Personnalisation forte
Manipulation des données facile par les équipes métiers
Inconvénients
Déplacements de données selon modèle prédéfini
Fournisseurs de logiciels pas toujours compatibles
Les outils ETL / ELT comme Talend ou Fivetran
Dans la famille d’outils ETL, les données sont d’abord extraites des bases de données et sources tierces (principalement des outils SaaS pour les ventes, le marketing et le support), puis transformées pour répondre aux besoins des analystes, et enfin, chargées dans un datawarehouse.
La transformation des données est particulièrement gourmande en ressources et en temps, ce qui a un impact significatif sur le délai entre l’extraction et le chargement des données.
Cependant, grâce aux progrès des technologies de l’écosystème data, l’ETL est en train d’être remplacé par l’ELT, plus rapide et plus flexible. On peut dire que l’ELT est l’approche moderne de l’ETL, qui est en grande partie alimentée par les datawarehouses Cloud tels que Redshift, Snowflake et BigQuery. Devenus extrêmement rapides et fiables, ces solutions permettent d’effectuer la transformation au sein même du datawarehouse.
Pour les segments des ELT et ETL, les principaux outils du marché sont Talend, Airbyte et Fivetran.
Avantages
Souplesse
Fonctionnement en « batch » ou « unitaire »
Inconvénients
Connecteurs sortants généralement limités aux base de données
Utilisation réservée à des profils assez techniques
Les outils d’activation de données ou reverse ETL comme Octolis
L’outil de Reverse ETL s’est construit en partant du constat que les équipes IT n’arrivent pas à répondre efficacement aux demandes d’extraction de données des départements sales, marketing ou encore service client. Le manque d’intégration des données limite énormément l’utilisation des outils métiers de la stack marketing.
Tandis que l’ETL que nous avons vu précédemment fait « monter » les données sources dans le datawarehouse, le Reverse ETL fait « redescendre » ces données dans les applications métiers. Le Reverse ETL synchronise les données du datawarehouse dans les outils d’activation, tel que le montre le schéma :
Source : La stack data moderne, Octolis
Un outil de Reverse ETL comme Octolis, l’outil français de référence prend en charge :
L’extraction de données d’un datawarehouse à un rythme régulier
Le chargement de ces données dans les outils de vente, de marketing et d’analyse
Le déclenchement d’une API arbitraire chaque fois que les données changent
Les équipes IT gèrent déjà le datawarehouse comme la source principale de données clients, qu’ils gardent propre et cohérente à des fins d’analyse. Le transfert de ces données vers les applications Cloud, à partir de la même source, est donc une évidence. Les équipes IT peuvent enfin gérer un pipeline de données unique pour que les équipes métiers puissent analyser et agir sur les données.
Les équipes de vente, de marketing et d’analyse vont maintenant pouvoir être en mesure d’analyser et d’agir sur des données qui étaient jusque-là compliquées à avoir.
Points forts des outils Reverse ETL
Croisement de plusieurs sources
Fonctionnement en « batch » ou « unitaire »
Simplicité d’usage pour des profils marketing ou data analysts
Les Reverse ETL constituent une nouvelle famille de logiciels d’intégration de données souple et qui a vocation à devenir une pièce fondamentale de la stack data moderne.
Recommandation de produits ecommerce : Méthode & Outils
La recommandation de produits est l’un des moyens les plus simples pour augmenter le panier moyen et, au-delà, le chiffre d’affaires de votre ecommerce. Dites-vous bien que 35% des ventes d’Amazon sont générées grâce à des recommandations proposées sur la plateforme et par email.
On sait en plus que les clients aiment les recommandations de produits. On estime que 56% des clients sont plus susceptibles de revenir sur le site s’il offre des recommandations de produits.
On est donc dans un modèle gagnant-gagnant.
Et pourtant, il y a encore beaucoup d’ecommerçants qui n’ont pas sauté le pas.
C’est dommage, car les technos sont là. Il existe aujourd’hui de très bons logiciels bon marché proposant des moteurs de recommandations avancés. Contrairement à ce qu’on pense souvent, la recommandation de produits n’est pas quelque chose de très complexe. Pas d’usine à gaz, on peut commencer par des choses simples et rapides à déployer.
C’est ce constat qui nous a donné l’idée de vous concocter un article complet sur le sujet.
La recommandation de produits : un puissant levier de performance ecommerce pas assez exploité
La recommandation de produits ecommerce, c’est quoi ?
Comme on dit souvent, une image vaut mieux que mille mots. Voici une capture d’écran du site de prêt à porter Asos, plus précisément : d’une page produit. Sous la description du produit, Asos propose des recommandations de produits similaires :
La recommandation de produits en ecommerce, c’est tout simple, c’est ça. Tout le monde, en tant que consommateur, a déjà été confronté à ce type de recommandations.
Il existe plusieurs manières de faire de la recommandation de produits en ecommerce.
On distingue en effet les approches suivant :
Ce sur quoi on se base pour sélectionner les produits recommandés :
Les contenus consultés par le client : « Vous avez consulté ce produit ? Alors ce produit pourrait vous intéresser ! ».
Les autres produits consultés par les clients ayant consulté le produit que je consulte : « Les clients qui ont consulté ce produit ont aussi consulté ces produits ». Nous présenterons ces deux approches dans la prochaine partie.
Mais il est possible aussi de recommander les produits les plus achetés, des produits souvent achetés ensemble (produits complémentaires), les produits tendances, les produits les plus consultés, etc.
Le moment et le canal où on propose les recommandations : pendant le parcours de découverte sur le site ecommerce, pendant le check out ou bien après la visite sur le site (email marketing). On y reviendra, mais retenez ceci : on peut recommander des produits à toutes les étapes des parcours clients.
Amazon est sans aucun doute le maître de la recommandation de produits. Nous l’avons dit, c’est cette approche, cette technique qui, entre autres, a permis au géant américain de devenir ce qu’il est. Ne vous étonnez pas si on utilise souvent des exemples d’Amazon pour illustrer notre article. Signalons d’ailleurs, en passant, que la recommandation de produits n’est pas une problématique limitée au ecommerce. Pensez à Netflix par exemple et à ses recommandations de films ou séries.
Ne pas faire de recommandations de produits quand on est ecommerçant, c’est se priver d’un énorme levier du business.
Comprendre et mettre en place un Scoring Client
Le scoring client permet de prioriser vos budgets marketing pour les clients les plus susceptibles d’acheter, et de mieux segmenter votre fichier client pour obtenir de meilleures performances dans vos campagnes. Découvrez notre guide complet sur le Scoring Client : définition, exemple et méthode en 5 étapes.
Comment fonctionne un moteur de recommandations produits ?
Vous avez un site ecommerce. Vous voulez faire de la recommandation de produits. Comment s’y prendre ? Il y a l’approche « à la mano » qui consiste à prendre chaque produit de votre catalogue et à définir les produits qui peuvent être recommandés pour ce produit :
Produit A : produits à recommander = Produits B, D, H, Y.
Produit B : produits à recommander = Produits A, H, M, V.
Produit C : produit à recommander = Produits Z.
Etc.
C’est une méthode très fastidieuse, surtout si vous avez un gros catalogue. L’alternative consiste à mettre en place ce qu’on appelle un « moteur de recommandations ». C’est un outil, plus précisément un algorithme, qui permet d’automatiser les recommandations en fonction des données qui l’alimentent et des règles que vous configurez en phase de paramétrage.
Il existe 3 approches pour construire un moteur de recommandations.
Approche #1 – Une méthode de filtrage selon les contenus (pages vues, rubriques consultées, etc.)
Le moteur recommande des produits basés sur l’historique de navigation et sur l’historique d’achat. On parle parfois de « recommandation objet » ou de modèle « content based ». L’idée sous-jacente à cette approche, c’est que si vous aimez un produit (vous avez consulté la page du produit, vous l’avez ajouté à votre panier, voire vous l’avez déjà acheté), alors vous devriez aimer les produits similaires ou complémentaires.
Sur le site web, bien entendu, vous ne pouvez baser les recommandations sur l’historique d’achat que si le client est identifié. Mais cette méthode de filtrage des produits recommandés peut fonctionner sur les visiteurs anonymes grâce aux cookies de navigation. Voici un exemple des recommandations proposées par Amazon sur sa page d’accueil aux visiteurs anonymes :
Approche #2 – Le filtrage collaboratif
Dans ce cas, l’algorithme du moteur de recommandations utilise les données des autres visiteurs ou clients du site. On parle parfois de « recommandation sociale » ou « user based ». Si vous visitez la page du produit A, le moteur va pouvoir vous recommander :
Soit des produits que les autres visiteurs de la page produit A ont aussi visité.
Soit des produits que les clients qui ont acheté le produit A ont aussi visité ou acheté.
C’est une présentation schématique bien sûr, mais l’idée à retenir est que cette approche consiste à baser les recommandations sur le comportement de navigation et/ou d’achat des autres visiteurs ou clients.
Voici un autre exemple tiré d’Amazon et qui illustre cette approche :
Approche #3 – La méthode hybride
Comme son nom l’indique, cette approche consiste à mixer les deux précédentes. Le moteur sélectionne les produits recommandés en fonction des données relatives aux autres utilisateurs ET en fonction d’attributs spécifiques au visiteur. Dans un autre univers, c’est l’approche mise en place par Spotify pour sa playlist « Découvertes de la semaine », qui propose des musiques en fonction des morceaux que vous avez écoutés mais aussi en fonction des utilisateurs ayant écouté les mêmes morceaux que vous.
L’approche hybride est celle qui permet de proposer les recommandations les plus pertinentes, mais c’est aussi la plus complexe à mettre en œuvre.
Les bénéfices de la recommandation de produits en ecommerce
Mettre en place un moteur de recommandations de produits sur votre site vous coûtera de l’argent. C’est un investissement. Pour quel retour ? Parlons justement du retour sur investissement de la recommandation de produits. Ils sont multiples.
#1 Augmenter l’engagement client
Nous l’avons rappelé en introduction, les clients aiment qu’on leur recommande des produits. De manière plus générale, ils aiment vivre une expérience client « personnalisées ». En marketing, la personnalisation est toujours payante. Etre en capacité de proposer des produits personnalisés, pertinents, contribue à enrichir l’engagement des clients.
Si Netflix a séduit des millions d’utilisateurs, c’est grâce à son algorithme de recommandations. Pas besoin de chercher des heures dans le catalogue de films et de séries : on vous propose sur un plateau les contenus vidéos qui sont susceptibles de vous intéresser.
#2 Booster les performances de votre newsletter
Les recommandations de produits, cela se passe sur le site ecommerce comme on l’a vu, mais aussi dans les emailings, dans la newsletter. Nous en reparlerons tout à l’heure.
Proposer des produits personnalisés est le must pour une newsletter ecommerce. Cela vous aidera à générer :
Plus d’inscriptions à la newsletter, si vous précisez dans le formulaire de capture que votre newsletter propose des produits personnalisés. « Inscrivez-vous à notre newsletter pour découvrir des produits que vous aimez ! ».
Plus de conversions sur votre site ecommerce. En intégrant des recommandations de produit dans votre newsletter, vous générez plus de ventes sur votre boutique en ligne, vous faites de l’emailing un puissant canal de vente.
Mesurer et améliorer la lifetime value
Il y a un énorme paradoxe autour de la lifetime value : c’est sans aucun doute l’indicateur business le plus important, notamment en ecommerce…et pourtant seulement une minorité d’entreprises l’utilisent. Découvrez notre guide complet sur la lifetime value, ce que c’est, comment l’utiliser, comment l’améliorer.
#3 Réduire les abandons de panier
Les abandons de panier sont la bête noire des ecommerçants. Réduire les abandons de panier devrait être un objectif prioritaire pour les acteurs du ecommerce. Les recommandations de produit sont une technique pour l’atteindre.
Il existe plusieurs tactiques possibles. Par exemple, vous pouvez utiliser une exit popin présentant des produits personnalisés pour inciter les visiteurs à rester sur le site et à acheter.
Les exit popins sont très efficaces pour limiter les rebonds. Vous pouvez aussi les utiliser pour offrir des réductions, offrir la livraison, etc. Bref, il existe plein de solutions pour empêcher qu’un visiteur qui a ajouté un produit dans son panier ne parte pas sans avoir finalisé sa commande.
#4 Gagner du temps
Suggérer des produits, faire du cross-selling ou de l’upselling de manière manuelle est quelque chose de très chronophage. Et, en faisant comme ça, pas sûr que vous tombiez toujours juste et que vous recommandiez des produits pertinents. Mettre en place un moteur de recommandations permet de soulager à la fois les équipes marketing et les équipes commerciales.
Tout ce que vous avez à faire, c’est paramétrer le moteur de recommandations, l’alimenter avec les bonnes données, mettre en place les règles, etc. Une fois que c’est fait, le moteur « tourne » tout seul et propose à votre place des recommandations à vos visiteurs et ou clients.
Donc, non, il ne faut pas prendre peur, il ne faut pas se dire « un moteur de recommandations, c’est du machine learning, c’est de l’IA, c’est hyper-complexe à créer ». En réalité, ce n’est pas un projet si complexe que ça, car il existe des outils qui permettent de déployer avec facilité des moteurs de recommandations personnalisées. Nous en présenterons quelques-uns tout à l’heure.
2 chiffres à retenir :
Près d’un tiers des revenus ecommerce sont générés grâce aux recommandations de produits. Cela représente 12% des achats totaux.
Le taux de conversion des visiteurs qui cliquent sur une recommandation de produits est 5,5 fois plus élevé que celui des autres clients.
Mettre en place la recommandation de produits ecommerce tout au long des parcours clients
Vous pouvez recommander des produits à vos clients tout au long de leur parcours, c’est-à-dire :
Pendant la phase de recherche/découverte des produits sur le site.
Pendant la réalisation de la commande (le check out).
Après une visite sur le site ecommerce (emailing et remarketing).
#1 La recommandation de produits en phase de découverte sur le site
Voici la situation : un internaute visite un site ecommerce, le parcourt, recherche et découvre des produits. Vous pouvez lui recommander des produits complémentaires ou similaires pendant ce parcours, l’objectif étant de l’inciter à ajouter plus de produits à son panier et/ou de l’aider à trouver le bon produit pour lui, lui faire gagner du temps.
Ces recommandations peuvent être poussées sur les pages produits. Voir l’exemple d’Asos donné en début d’article, mais aussi et surtout (à tout seigneur tout honneur) l’exemple d’Amazon qui est historiquement le premier acteur du ecommerce à avoir massivement utilisé cette technique.
Voici un autre exemple (Mango) :
Sur beaucoup de sites ecommerce, vous trouverez des recommandations sur les pages produits. C’est devenu une pratique standard. Encore une fois, la nature des recommandations peut varier. Cela peut être :
Les produits similaires
Les produits achetés par les autres clients du produit sur la page duquel vous êtes
Les best-sellers
Les produits tendances
Les produits les mieux notés
Etc.
Mais vous pouvez aussi « pousser » vos recommandations sur d’autres pages : sur la page d’accueil (voir l’exemple d’Amazon cité plus haut), sur les pages catégories, voire sur les pages d’erreurs 404. Pourquoi pas ?
Il est possible aussi de proposer des recommandations de produits dans des bannières ou dans des popups : voir l’exemple d’exit popin présenté plus haut.
#2 La recommandation de produits pendant le check out
Votre visiteur a ajouté des produits à son panier et s’apprête à finaliser sa commande. C’est le moment de lui proposer d’autres produits pour l’inciter à ajouter plus de produits dans son panier. C’est ce que fait très bien…Amazon…encore lui ! J’ajoute un MacBook à mon panier, Amazon me propose d’ajouter des produits complémentaires avant de passer la commande.
Les recommandations de produits qui fonctionnent le mieux pendant le check out sont :
Les produits complémentaires ou les accessoires. Par exemple : proposer un logiciel antivirus ou une sacoche à un visiteur qui s’apprête à finaliser la commande d’un ordinateur. Cela suppose d’être en capacité de bien établir les relations entre vos produits dans votre Product Information System (logiciel PIM). C’est techniquement plus complexe que de proposer des produits similaires.
Les produits fréquemment achetés ensemble. Ici, vous pouvez utiliser le filtrage collaboratif.
#3 La recommandation de produits post-visite sur le site ecommerce
A partir de maintenant, on quitte le site ecommerce. Il n’y a pas que sur votre boutique en ligne que vous pouvez proposer des recommandations de produits. Vous pouvez aussi le faire :
Dans des campagnes ou scénarios email.
Avec du remarketing.
Les campagnes et les scénarios email
Vous ne pouvez pas solliciter les visiteurs anonymes de votre site ecommerce par email. Par définition. Vous n’avez pas leur adresse email. La sollicitation par email n’est possible que sur les clients ayant déjà acheté ou sur les visiteurs inscrits à votre newsletter.
L’email est un excellent canal pour envoyer des recommandations de produits. Il y a plusieurs approches possibles :
La newsletter promotionnelle, dont nous avons déjà parlé plus haut. Vous pouvez personnaliser les recommandations en fonction des informations que vous avez sur vos contacts : données socio-démographiques (âge, genre), historique d’achat, préférences exprimées…Mais vous pouvez aussi utiliser la newsletter pour recommander vos meilleurs produits, vos nouveaux produits, vos produits en promotion, etc.
L’email de relance de panier abandonné. Là, on s’inscrit dans un scénario et non dans une campagne. La mécanique consiste à envoyer un email automatique de relance de panier abandonné aux clients identifiés n’ayant pas finalisé leur achat. L’email de relance rappelle le contenu du panier, incite à le finaliser, mais peut aussi proposer des produits similaires ou des alternatives. Bref, des recommandations de produits.
Les emails transactionnels de type confirmation de commande ou confirmation d’expédition sont aussi de bons moments pour pousser des recommandations de produits et inciter vos clients à acheter à nouveau.
Le remarketing
Un client visite en général plusieurs sites ecommerce et consulte entre 8 et 19 produits avant de prendre sa décision d’achat. Le remarketing est une technique bien connue qui consiste à afficher des bannières de publicité présentant vos offres et vos recommandations sur d’autres sites que le vôtre. Je visite le site A. Je quitte le site A et je me rends sur le site B. Sur le site B, pendant ma navigation, je vois s’afficher une bannière me présentant des produits du site A (ceux que j’ai consultés ou des produits similaires). Tout le monde fait quotidiennement ou presque cette expérience. Le site B peut d’ailleurs être (et est souvent) un réseau social : Facebook par exemple.
Quel outil choisir pour mettre en place la recommandation de produits ?
Il existe essentiellement deux familles d’outils permettant de configurer un moteur de recommandations et de recommander des produits à vos clients, que ce soit sur le site web ou dans vos campagnes/scénarios marketing :
Les solutions spécialisées, comme par exemple Adoric, Kibo, Nosto ou Barilliance. Il existe quelques acteurs français, comme Nuukik ou Target2Sell. Les tarifs varient entre 50 et 300 euros par mois.
Les grands éditeurs CRM qui, pour certains, intègrent un module dédié à la recommandation de produits.
Le point commun à tous ces outils ? Ils proposent un moteur de recommandations basé sur un algorithme dans lequel vous venez configurer des règles. Le carburant du moteur, ce sont les données clients. C’est pour cette raison que cela ne sert à rien de déployer un moteur de recommandations si vous n’avez pas au préalable des données consolidées et unifiées. C’est ici qu’intervient une solution comme Octolis, qui va vous permettre de connecter l’ensemble des données et de les unifier. Vous pourrez ensuite venir les synchroniser facilement dans votre solution de recommandations.
Une fois qu’on a dit cela (et cela me semblait important de le faire), voici quelques conseils pour choisir votre outil de recommandations :
Choisissez un logiciel qui convient à votre univers métier. Certains moteurs de recommandation sont adaptés pour toutes les industries, mais d’autres sont plus adaptés pour certains types de produits et services.
Choisissez un logiciel qui propose un connecteur avec la plateforme ecommerce que vous utilisez. Si le logiciel propose un connecteur, l’intégration sera beaucoup plus simple !
Si vous êtes utilisateur d’une solution CRM qui propose un module dédié à la recommandation de produits, vous pouvez regarder ce qu’il vaut, sans pour autant vous interdire de regarder ce que proposent les pure players.
Sélectionnez les 2 ou 3 solutions répondant le mieux à votre cahier des charges et testez-les. Les pure players proposent parfois des versions gratuites. Les autres peuvent être testés sous forme de démo.
Conclusion
Si vous cherchez des leviers pour générer plus de revenus ecommerce, nous vous conseillons clairement de mettre en place un système de recommandation de produits. Il existe des solutions relativement abordables qui permettent de le faire de manière simple. J’espère vous avoir convaincu !
Je vous conseille de recommander des produits à toutes les étapes des parcours clients, et pas uniquement sur le site internet. L’email reste un canal majeur pour faire de la recommandation de produits.
Enfin, consolidez vos données, nettoyez-les, vous en aurez besoin pour faire tourner votre moteur de recommandations 🙂
Les meilleurs outils de Data Preparation – Famille d’outils, fonctionnalités & exemples
Les équipes data passent le plus clair de leur temps à préparer les données. J’ai vu passer une étude qui montre que les Data Scientists consacrent en moyenne 80% de leur temps à préparer / nettoyer les données. C’est une aberration quand on sait qu’il existe des outils de dataprep qui permettent de faire d’énormes gains de productivité.
Il y a plusieurs manières de faire de la dataprep, du SQL custom aux outils no code en passant par les outils spécialisés et les outils de BI intégrant des fonctionnalités de dataprep.
Il n’est pas facile de faire son choix.
Avant de choisir une solution, il est important de prendre le temps de comprendre le marché, le positionnement des différentes solutions, les différences en matière de périmètre fonctionnel, etc.
Panorama des différents types d’outils de Data Preparation
Voici un panorama des différentes familles d’outils qui peuvent aider dans la préparation des données.
Catégorie
Description
Exemples de solutions
ETL
Les solutions ETL ont toutes des fonctionnalités de data prep (le T de ETL signifie "Transform").
Talend, Xplenty, Skyvia
SQL / Python
Les langages de bases de données comme SQL ou Python permettent de faire de la data prep, modulo de bonnes compétences techniques.
DBT, Pandas, AWS Glue
Outils de dataprep spécialisés
Solutions spécialisées dans la vérification et le nettoyage d'un type particulier de données : les adresses emails, les adresses postales, les données CRM...
Emailable (emails), Egon (adresses postales), Cloudingo (données Salesforce)...
Dataprep intégrée dans des outils de BI
Certains outils de BI intègrent des fonctionnalités/modules de data prep.
PowerBI, Tableau Prep, ToucanToco...
Dataprep intégrée dans des outils DataOps
Les outils de DataOps sont nombreux à intégrer des fonctionnalités de data prep : nettoyage, normalisation, déduplication, enrichissement...
Octolis, Y42, Keboola, Weld...
Dataprep intégrée dans des outils de Data Science
La préparation des données peut être réalisée dans les outils de Data Science.
Dataiku, Alteryx, Rapidminer...
Les fonctionnalités proposées par les outils de dataprep
Pour choisir le bon outil, il faut avoir une bonne compréhension des fonctionnalités proposées par les outils de dataprep. Il y a 4 fonctionnalités clés des outils de data preparation.
#1 Accès aux données et exploration à partir de n’importe quel set de données
L’accès aux données désigne la capacité de votre outil de dataprep à accéder à l’ensemble des sources de données que constitue votre système d’information. Quelles sont les sources que vous pouvez connecter à l’outil de dataprep ? Quels sont les formats de données gérés ? Quid de l’API ? Quid des connecteurs proposés par l’éditeur ? Ce sont autant de questions à vous poser lors de votre analyse des outils du marché.
Il faut que vous choisissiez un outil dans lequel vous pouvez intégrer facilement les données en provenance de vos différentes sources, sans limitations et indépendamment de l’endroit où sont stockées ces données. Vous avez des fichiers Excel, des fichiers CSV, des documents Word, un entrepôt de données SQL, des applications cloud, des systèmes opérationnels (CRM, marketing automation, ERP) ? Assurez-vous de pouvoir les importer dans l’outil de dataprep.
L’étape suivante consiste à explorer les données collectées pour mieux comprendre ce qu’elles contiennent et ce qu’il va falloir faire pour préparer les données en vue des cas d’usage cibles. Les données sont « profilées » : identification des patterns, de la distribution des données, des relations entre les variables et les attributs, des anomalies, des valeurs aberrantes ou manquantes, etc. L’outil de data prep doit permettre un travail exploratoire sur chaque data set.
#2 Nettoyage des données
Les outils de dataprep proposent ensuite des fonctionnalités pour nettoyer les données (data cleansing). Le nettoyage des données est indispensable pour disposer de data sets fiables, valides et exploitables.
Le nettoyage des données regroupe un certain nombre d’opérations : la suppression des valeurs aberrantes, la vérification de l’orthographe, la correction des erreurs de saisie, la standardisation des cases, l’identification et le marquage des cellules vides, la normalisation des formats (les dates, par exemple), l’élimination des données manquantes, la suppression ou la fusion des données dupliquées, le masquage des informations sensibles ou confidentielles…
Un template à télécharger pour cleaner vos données clients
Nous avons conçu un guide complet sur le nettoyage d’une base clients, les traitements à opérer et les différentes méthodes de nettoyage. Cerise sur le gâteau, on vous offre un template Excel pour nettoyer facilement un petit fichier clients 🙂
#3 Enrichissement des données
L’enrichissement des données est la troisième fonctionnalité clé des outils de dataprep. Enrichir les données consiste à améliorer le taux de complétude de la base de données (les cellules vides) et/ou à ajouter de nouveaux champs. L’enrichissement des données permet ensuite de mieux segmenter et personnaliser les campagnes/scénarios marketing ou les actions commerciales. Si l’enrichissement des données est si important, c’est que la personnalisation et le ciblage sont des clés de performance en marketing-ventes. Plus vous avez d’informations sur vos clients ou contacts, mieux c’est !
L’enrichissement de données peut s’effectuer de deux manières complémentaires :
A partir de sources de données internes.
A partir de sources de données externes : fournisseurs de données spécialisés, bases de données publiques, LinkedIn…
L’enrichissement des données améliore la valeur et le potentiel d’activation de vos données.
#4 Export des données
Les données, une fois préparées, doivent être exportées dans les outils de destinatation : outils d’activation, outils d’analyse, entrepôt de données, CDP…Les capacités d’export des données sont un facteur discriminant dans le choix d’un outil de data preparation.
Gardez le contrôle de vos données clients
Le contrôle des données devient un enjeu clé pour les entreprises. Découvrez pourquoi vous ne devez pas stocker vos données dans vos logiciels (CRM, Marketing Automation, ERP…), mais dans une base de données indépendante. On vous explique tout dans notre guide complet sur le contrôle des données.
Les principaux critères différenciants
Voici quelques critères à prendre en compte dans le choix de votre outil de dataprep :
Le niveau de technicité requis. Il existe des outils no code qui permettent de procéder aux opérations de dataprep sans savoir programmer. A l’inverse, certains outils sont destinés aux utilisateurs maîtrisant parfaitement le code (le langage SQL notamment). Entre les deux, on trouve toute une série d’outils nécessitant quelques connaissances en code. Ce sont outils « low code », dont l’utilisation nécessite une bonne collaboration entre les équipes IT et métier.
La vitesse de traitement. On distingue classiquement les outils qui redistribuent les données préparées en temps réel (real time) et ceux qui redistribuent les données préparées toutes les X minutes/heures (batch processing). Dans certains secteurs, le temps réel est un réel besoin. Dans beaucoup d’autres, le batch processing est suffisant.
Le nombre de recettes packagées. Une recette est un ensemble de traitements séquencés réalisés sur un set de données. Les outils de dataprep proposent des recettes packagées qui permettent de gagner du temps.
Le prix. Certains outils de dataprep « self service » proposent des offres gratuites qui, si vos cas d’usage sont basiques, peuvent faire l’affaire. Les outils de dataprep les plus évolués peuvent coûter jusqu’à 100 000 euros par an.
Les meilleurs outils de data preparation
Les outils de dataprep self service, testables rapidement
Les outils de dataprep self service sont des solutions légères, faciles à prendre en main et conçues pour les équipes métier/business. Il n’y a pas besoin d’être technophile pour les utiliser. Ces outils ont aussi l’avantage de proposer des tarifs très abordables. Nous en recommandons 3 : Tye, Paxada et InfogixData360.
Nom
Description
Pricing
Les outils de dataprep pour les grandes entreprises
Les grandes entreprises ont souvent des besoins avancés en dataprep, étant donné la quantité de données à gérer, leur diversité et la complexité des écosystèmes data. Certaines solutions de dataprep sont conçues pour les grandes entreprises. Elles proposent des fonctionnalités de dataprep avancées et ont souvent un périmètre fonctionnel qui déborde la préparation des données. Ce sont, sans surprise, des solutions très coûteuses.
Nom
Description
Pricing
Les outils de dataprep spécialisés sur un sujet spécifique
Si vos besoins de dataprep se limitent à vouloir nettoyer et normaliser des adresses emails, il n’est pas sûr que vous ayez (tout de suite) besoin d’investir dans une solution de dataprep avancée. Il existe sur le marché de bonnes solutions spécialisées dans la préparation de données spécifiques : les adresses emails, les adresses postales, les données Salesforce.
Nom
Description
Pricing
Les outils de dataprep intégrés dans un outil de Business Intelligence (BI)
Les solutions de Business Intelligence leaders du marché proposent toutes des fonctions de dataprep. C’est le cas, notamment, de Power BI, de Tableau ou de Dataiku. Si vous envisagez d’investir dans un outil de BI, vous pourrez l’utiliser pour préparer vos données.
Nom
Description
Pricing
Les outils de Data Ops
Les outils de Data Ops sont des solutions sur l’étagère tout-en-un pour gérer les données de l’entreprise au service du business. Un outil de Data Ops permet, depuis une interface simple, de connecter l’ensemble des sources de données, de transformer les données et de les redistribuer sous forme d’agrégats aux outils d’activation et aux outils de BI. La transformation inclut le nettoyage des données, leur normalisation, leur consolidation, leur enrichissement et la création d’agrégats/d’audience à des fins d’activation ou d’analyse. Les outils de Data Ops s’intègrent dans une architecture IT de type stack data moderne.
Nom
Description
Pricing
Marketing cross-canal – Définition, Exemples et Méthodologie
Il est de plus en plus difficile de suivre le parcours du client. Cela s’explique par le fait que les consommateurs engagent les marques sur différents canaux, passant souvent par plusieurs points de contact numériques avant d’être prêts à acheter. C’est pourquoi le concept de marketing cross canal a fait son apparition.
L’omnicanal permet aux entreprises de s’adapter à l’innovation technologique, tout en améliorant l’expérience utilisateur. Cross canal, omnicanal, commerce unifié : les termes ne manquent pas pour désigner l’expérience client ultime à laquelle aspirent toutes les marques !
Dans cet article, on aborde le sujet du marketing cross canal à travers des exemples et les enjeux data que soulève la mise en place de cette relation client uniforme, sur tous les canaux.
Marketing cross canal : une approche aujourd’hui incontournable
La mort du marketing multi canal
Tout d’abord, pour bien comprendre la différence entre multicanal et omnicanal, commençons par une définition. Le marketing multicanal consiste à utiliser séparément plusieurs canaux uniques pour communiquer avec les clients et les engager. Cependant, les différents canaux fonctionnent indépendamment et n’offrent donc pas une expérience unifiée de l’expérience utilisateur.
L’une des principales raisons pour lesquelles le marketing multicanal ne fonctionne plus est que les comportements d’achat des consommateurs ont fondamentalement changé ces dernières années. Aujourd’hui, vous pouvez accéder aux produits d’une marque via Facebook, Instagram, leur site de e-commerce, leur newsletter, les comparateurs de prix… etc. Les internautes peuvent passer par sept points de contact (ou plus !) avant de réaliser leur premier achat.
Assurer la cohérence multicanale de votre marketing devient alors un véritable défi, puisque vous devez modifier vos messages marketing pour chaque canal. En effet, les utilisateurs doivent avoir la même première impression de votre marque qu’ils voient une publicité sur Facebook ou qu’ils se connectent sur votre site.
Selon une étude d’Accenture, 91 % des consommateurs sont plus susceptibles de faire des achats auprès de marques qui leur fournissent des recommandations pertinentes. Pour cela, une stratégie omnicanale est un facteur clef de réussite. Alors que l’approche multicanale traite chaque source de donnée séparément, l’omnicanal place l’utilisateur au centre de son modèle, pour lui proposer une expérience personnalisée.
Et l’avènement du marketing cross canal
Le marketing omnicanal, quant à lui, utilise plusieurs canaux connectés entre eux pour atteindre et convertir les clients. Il permet une transition plus simple et plus transparente d’un canal à l’autre. Les différents canaux enregistrent des informations sur le client et les communiquent entre eux, de manière à créer un parcours client unique et unifié.
Lorsque vous faites du marketing cross-canal, vos messages et votre image de marque sont cohérents sur plusieurs canaux. Ces canaux fonctionnent ensemble, ce qui permet d’engager efficacement les clients lorsqu’ils passent d’un canal à un autre et d’un appareil à un autre dans leur parcours d’achat.
Une bonne stratégie de marketing cross-canal apporte de nombreux avantages. Parmi eux :
Exploiter les données clients pour créer des expériences pertinentes et personnalisées. Grâce aux rapports et aux analyses, vous pouvez voir quels sont les canaux préférés des clients, quel contenu les a poussés à la conversion et quels sont les éventuels points de blocage
Renforcer la cohérence de la marque sur l’ensemble des canaux et des campagnes de marketing, ce qui permet de cultiver une relation de confiance avec les clients
Gagner du temps pour vous concentrer sur la stratégie marketing, car vous n’avez plus besoin de créer des messages individuellement pour chaque canal
Optimiser le retour sur investissement (ROI) de votre marketing. En concentrant vos efforts de marketing sur l’ensemble des canaux, vous pourrez cartographier clairement les points de contact afin de déterminer comment une personne est devenue un prospect et comment ce prospect est devenu un client. À partir de là, vous pourrez contextualiser et personnaliser le message et l’offre pour vos clients cibles.
Pour résumer, une approche marketing omnicanale va stimuler la croissance de votre entreprise, en s’adaptant aux attentes de vos utilisateurs. En effet, les clients attendent une expérience transparente et cohérente entre les canaux. S’ils visitent votre page Facebook par exemple, ils s’attendront à retrouver votre style sur votre site web ou même dans vos newsletters.
Exemples de cas d’usages cross canal
Le marketing omnicanal peut s’utiliser pour attirer et convertir les visiteurs, augmenter les taux de fidélisation, favoriser les recommandations ou encore réactiver les clients qui n’ont pas acheté depuis longtemps.
Voici quatre exemples de cas d’utilisation pour vous aider à comprendre concrètement l’application du marketing cross-canal.
Activer de nouveaux internautes
Imaginons une marque de vêtements. Une cliente visite votre boutique physique, ne se décide pas sur une robe en particulier et repart donc sans rien acheter.
Et bien, pour convertir cette cliente grâce au crosscanal, vous pouvez lui demander si elle souhaite recevoir des notifications push sur les nouveaux arrivages via son mobile. Vous pouvez également lui proposer une réduction en échange de son adresse mail, pour l’intégrer à votre base de données client et la solliciter pour des campagnes ultérieures.
Lutter contre l’abandon de panier
Vous avez un site de e-commerce et certains internautes placent des produits dans le panier sans jamais passer à l’achat ? Pour remédier à ce problème, vous pouvez créer un flux de panier abandonné.
L’omnicanal vous permet alors de lancer des campagnes de retargeting sur les réseaux sociaux ou encore d’afficher des pop-ups sur le site web. Vous pouvez également envoyer des emails ou des SMS pour rappeler aux internautes ce qu’ils ont laissé dans leur panier. En travaillant le wording de votre message et en affichant la photo de l’un des articles du panier abandonné, vous pourrez convertir de nombreuses transactions qui étaient jusque-là sur pause !
Up-selling et cross-selling
Ces deux techniques de vente sont des stratégies possibles pour vendre aux clients existants. L’objectif est d’augmenter la valeur moyenne des commandes, en vendant un meilleur produit de la même gamme (up-selling) ou en offrant des extras et accessoires (cross-selling).
L’up-selling et le cross-selling peuvent être implémentés par le biais de l’email marketing, en diffusant des publicités sur Facebook, par SMS ou bien directement sur le site web en les affichant sur les pages de détail des produits. Ce cas d’usage du cross-canal s’applique à tous les secteurs d’activité.
Réactivation de clients inactifs
Vous avez des clients qui ont acheté une fois ou deux sur votre site, mais que vous n’avez pas revus depuis ? Si oui, vous pouvez utiliser des campagnes de marketing cross-canal pour les inciter à revenir ! Dans l’illustration ci-dessous, on prend l’exemple d’une marque de vêtements.
Vous pouvez leur envoyer une réduction par email, leur présenter des ventes flash par notifications push sur le web ou encore lancer des publicités Facebook de retargeting. Les options sont multiples pour réactiver ces clients inactifs !
Comment mettre en place une stratégie marketing cross canal ?
Une stratégie de marketing cross-canal réussie vous aidera à vous connecter aux internautes, au bon endroit et au bon moment, pour les transformer en clients acheteurs. Investir dans le marketing omnicanal peut donc vous aider à faire grandir rapidement votre entreprise. Cependant, cela peut aussi s’accompagner de certains défis que vous devez garder à l’esprit.
Les challenges du marketing cross canal
Premièrement, vous ne pouvez fournir des messages et des recommandations personnalisés que si vous disposez d’une vue complète à 360 degrés de chaque client. Pour ce faire, vous devez collecter des informations à partir de plusieurs sources disparates (par exemple : messagerie, réseaux sociaux, boutique en ligne, sites physiques, applications mobiles… etc). Puis, vous devrez les transformer en insights actionnables, au sein d’une base de données unifiant ces différentes sources.
Deuxièmement, le marketing omnicanal nécessite de bons outils. En général, une marque a besoin de six à dix outils différents pour offrir des expériences personnalisées. Le problème est qu’à mesure que ces piles technologiques se développent, la complexité, le coût et l’inefficacité des campagnes augmentent également. Vous devez donc définir vos objectifs, votre budget et votre stratégie dès le départ, afin de déterminer les outils qui pourraient correspondre à votre besoin.
L’exécution d’un marketing omnicanal implique plusieurs divisions du marketing, mais également des équipes data, aux profils plus techniques. Pour une mise en œuvre efficace sur tous les canaux, elle nécessite les bonnes technologies. Dans la suite de l’article, nous vous aidons à choisir l’outil adapté.
Choisir le bon outil
Offrir une expérience client personnalisée passe avant tout par une bonne connaissance du parcours d’achat des différents profils utilisateurs. Une CDP va vous permettre de mesurer les interactions avec vos clients et prospects, sur tous vos canaux, en mettant à disposition une base de données unifiée. La CDP est donc l’alliée du cross-canal !
Pour constituer votre CDP, vous avez plusieurs options :
CDP dites « sur l’étagère »
Il existe de nombreuses raisons d’utiliser des CDP prêtes à l’emploi. Elles sont notamment plébiscitées pour leur rapidité de déploiement sur le marché ou leur facilité d’installation. Ainsi, si vous disposez de peu de temps ou de peu de ressources techniques, une CDP sur étagère peut faire l’affaire.
En revanche, ces CDP prêtes à l’emploi proposent des modèles préconçus qui peuvent être limitants si votre projet dépasse le scope de l’outil. De manière générale, les CDP sur étagère offrent moins de profondeur sur des fonctionnalités comme la résolution d’identité ou les intégrations. Si vous avez besoin d’un outil flexible avec un niveau avancé de personnalisation, ce type de CDP n’est pas le plus adapté.
Il existe alors des alternatives qui pourraient s’avérer plus pertinentes pour les besoins particuliers de votre entreprise.
CDP sur mesure
Face au manque de flexibilité des CDP sur étagère, certaines entreprises font le choix du sur mesure, et construisent une plateforme adaptée à leurs besoins. Premier avantage, cette solution permet de se focaliser sur les cas d’usages marketing que vous avez définis comme stratégiques. Elle permet aussi d’en développer des nouveaux à mesure que vous construisez la CDP.
D’autre part, une CDP sur mesure vous permet de reprendre le contrôle de vos données. En effet, elles seront alors hébergées sur vos serveurs et non plus chez un éditeur tiers comme c’est le cas des CDP sur étagère.
Bien sûr, cette option a également ses inconvénients. Pour commencer, elles exigent des compétences en ingénierie et data. Peu d’organisations disposent de moyens suffisants pour mobiliser une équipe sur un tel projet, pouvant d’étendre jusqu’à 4 mois. La construction d’une CDP in-house est ainsi réservée aux grandes structures, qui sont plus matures sur l’exploitation de leurs données client.
Utiliser votre datawarehouse comme un hub opérationnel
L’objectif d’une CDP est de créer une base de données centralisée, unifiant plusieurs sources de votre organisation où se trouvent des données client. Mais en réalité, le datawarehouse s’inscrit déjà comme la source unique de vérité de vos données. Qu’il soit cloud ou moderne, un datawarehouse est un référentiel de données qui regroupe différentes sources disparates.
La dernière option pour construire votre CDP est donc d’utiliser directement votre datawarehouse ! En effet, en se plaçant comme le référentiel opérationnel de votre dispositif data, il vous permet de répondre aux cas d’usages traditionnels d’une CDP. Parmi eux, on retrouve d’une part la vision client unifiée. Elle permet d’analyser le comportement de vos utilisateurs sur tous les canaux en temps réel. D’autre part, il y a l’intégration de vos segmentations et modèles de scoring dans vos outils métiers.
Mais, pour que vos données remontent de votre datawarehouse vers vos outils métiers opérationnels, il vous faudra des connecteurs. Encore une fois, à moins de disposer d’une grande équipe d’ingénieurs data disponibles, il est difficile de créer et maintenir ce type de connecteurs sur mesure. La solution se présente donc comme une CDP 2.0. Elle répond à ce besoin précis tout en se basant sur votre datawarehouse existant.
Les avantages à utiliser votre data warehouse comme CDP
Ce nouveau type de CDP comme Octolis utilisant le datawarehouse comme un hub opérationnel présente de nombreux avantages :
Données centralisées dans un seul répertoire. Contrairement aux CDP sur étagère et sur mesure, vos données client ne sont pas séparées de la source du datawarehouse, ce qui permet de réduire le coût et le temps de déploiement.
Traitements des données. Le procédé est simplifié puisque vous ne transformez vos données qu’une seule fois. Elles sont ensuite stockées pour être utilisées par la suite dans vos outils métiers.
Contrôle des données. Vos données sont hébergées sur vos serveurs, vous en êtes maîtres.
La segmentation client, c’est un outil très puissant, mais la réalité, c’est que peu de marketers l’utilisent correctement.
Il ne suffit pas de jouer avec quelques filtres dans Mailchimp ou Salesforce. La segmentation client, c’est un exercice complexe qui requiert de prendre du recul sur les objectifs marketing, les axes pertinents de personnalisation, la méthodologie de suivi des résultats, etc.
Avant toute chose, il faut comprendre l’état de l’art du sujet. A moins de travailler dans une grande entreprise, ou une scaleup très mature, la première étape, c’est déjà de connaitre les bonnes pratiques du sujet et de les adapter à votre métier.
On vous a préparé un article complet sur la segmentation client, avec notamment 9 exemples de segmentation clients classiques pour vous inspirer.
De plus, nous avons compilé ces segmentations ainsi que leurs segments les plus importants dans un Gsheet. Retrouvez cette ressource à la fin de l’article.
Qu’est-ce qui fait un bon segment client?
Une bonne segmentation doit inclure ces 6 caractéristiques :
Pertinent : il n’est généralement pas rentable de cibler de petits segments – un segment doit donc être suffisamment important pour être potentiellement rentable.
Mesurable : sachez identifier les clients de chaque segment, garder le contrôle des données clients et mesurer leurs caractéristiques comme les données démographiques ou le comportement du consommateur.
Accessible : cela semble évident, mais votre entreprise doit être en mesure d’atteindre ces segments via différents canaux de communication et de distribution. Par exemple, si elle vise les jeunes, votre entreprise doit avoir des comptes Twitter et Tumblr et savoir comment les utiliser pour faire la promotion de vos produits ou services.
Stable : pour maximiser les retombées de vos campagnes, chaque segment doit être suffisamment stable pendant une longue période. Par exemple, le niveau de vie est souvent utilisé comme moyen de segmentation mais celui-ci est dynamique et en constante évolution. Il n’est donc pas forcément judicieux de segmenter sur la base de cette variable au niveau mondial.
Différenciable : les personnes (ou les organisations, dans le marketing B2B) d’un segment doivent avoir des besoins similaires et clairement différents des besoins des personnes des autres segments.
Actionnable : être en mesure de fournir des produits ou des services à vos segments. Une compagnie d’assurance américaine s’est ainsi rendu compte, après avoir consacré beaucoup de temps et d’argent à l’identification d’un segment, qu’elle ne pouvait trouver aucun client pour son produit d’assurance dans celui-ci, et qu’elle n’était pas non plus capable de concevoir une stratégie pour les cibler.
Les dimensions classiques de la segmentation client
Géographique
Démographique (B2C)
Démographique (B2B)
Psychographique
Comportemental
Continent
Age
Secteur
Classe sociale
Usage
Pays
Sexe
Nombre d'employés
Niveau de vie
Loyauté
Etat
Revenus annuel
Maturité de l'entreprise
Valeurs
Intérêt
Région
CSP
Situation financière
Personnalité
Passion
Département
Etat matrimonial
Détention/ actionnariat
Convictions
Sensibilité
Taille d'agglomération
Niveau d'étude
Valorisation/ capitalisation boursière
Présence digitale et sur les réseaux sociaux
Habitude de consommation
Ville
Profession
Business model
Centres d'intérêts
Mode de paiement
Quartier
Culture
Secteur servi
Connaissance
Climat
Religion
Technologie utilisée
Nature de la demande
Langue
Format du produit ou packaging
Fréquence d'achat
La segmentation client se divise en 4 principales catégories :
Segmentation géographique: elle regroupe les clients en fonction de leur localisation. Par exemple, l’endroit où ils vivent, travaillent ou partent en vacances.
Segmentation Démographique: elle regroupe les clients en utilisant des caractéristiques comme l’âge, le sexe, le revenu ou le secteur d’activité.
Segmentation Psychographique: elle regroupe les clients en fonction de leurs caractéristiques psychologiques, comme leurs intérêts, opinions ou statut social.
Segmentation Comportementale: elle regroupe les clients en fonction de leur comportement d’achat ou de l’étape du parcours client. Par exemple, les clients qui dépensent beaucoup, ceux qui achètent au rabais ou ceux qui risquent de changer d’avis.
9 exemples actionnables de segmentation client
1. Petits, moyens, et gros
La segmentation PMG s’appuie sur la loi de Pareto qui stipule que 20 % de vos clients génèrent 80 % de votre chiffre d’affaires. Il faut donc axer ses efforts en priorité sur cette minorité de clients.
Cette segmentation découpe les clients en trois segments :
Les gros clients : qui représentent une part minime des clients, mais un pourcentage élevé du chiffre d’affaires. Généralement défini par le top 5% des clients en terme de Chiffre d’Affaires cumulé.
Les clients moyens : qui sont peu nombreux et représentent une part significative de chiffre d’affaires. Généralement défini par le top 20% des clients en terme de Chiffre d’Affaires cumulé.
Les petits clients : la masse qui ne représente qu’une part modérée voire faible de votre chiffre d’affaires.
Une fois ces trois populations déterminées, il faut identifier leurs points communs et comprendre leurs attentes pour y répondre de manière spécifique. Votre stratégie marketing (message, rythme des communications, offres promotionnelles, etc.) ne sera pas la même selon si vous vous adressez aux petits ou aux gros clients.
Au contraire, plus les clients représentent une part importante de votre chiffre d’affaires, plus vous allez personnaliser votre communication pour leur proposer une expérience client exceptionnelle grâce à des logiciels de marketing automation.
2. La promophilie
La promophilie désigne cette catégorie d’acheteurs sensibles aux promotions. La recherche de la bonne affaire est leur première motivation. Ce sont les fameux “coupon lover”.
Il s’agit d’un critère de segmentation comportementale. Ils passent énormément de temps à surfer sur le web pour dénicher le produit le moins cher. Si vous souhaitez prioriser ce type de consommateurs, vous avez tout intérêt à mettre en place des programmes de fidélité.
Opérationnellement, l’objectif est de définir des segments en fonction de la réactivité à des campagnes de promotion. Par exemple, ceux qui ont acheté votre produit avec un coupon dans les X derniers jours.
3. Les étapes dans le parcours client
Phase de vie du client
Segment
Définition
Conversion
Les clients potentiels
Contacts qui n’ont pas encore réalisé d’achat mais qui ont montré de l’intérêt pour une de vos campagnes d’acquisition.
Croissance
Les primo-acheteurs
Les clients qui n’ont acheté qu’une seule fois et qu’il s’agit de transformer en acheteurs récurrents.
Fidélisation
Les clients répétitifs
Les clients ayant réalisé au moins deux achats séparés dans le temps.
Rétention
Les clients fidèles
Les clients qui ont acheté plusieurs fois dans une période de temps courte.
Re-conquête
Les clients répétitifs à risque
Les clients qui ont acheté plusieurs fois mais n’ont plus rien acheté depuis longtemps.
Attrition
Les clients répétitifs inactifs
Les clients fidèles que vous avez perdus.
Vous pouvez ainsi créer 6 segments de clients différents :
Les clients potentiels (les prospects): il s’agit de contacts qui n’ont pas encore réalisé d’achat mais qui ont montré de l’intérêt pour une de vos campagnes d’acquisition. Il faut les amener à une première conversion avec des campagnes de retargeting, des coupons pour jouer sur le FOMO afin d’accélérer la conversion, du contenu éducatif pour aider à convaincre, etc.
Les primo-acheteurs (les nouveaux « vrais « clients) : ce sont les clients qui n’ont acheté qu’une seule fois et qu’il s’agit de transformer en acheteurs récurrents. Il faut leur rappeler votre existence via des recommandations produits, du contenu éducatif ou une demande d’avis sur le premier produit acheté.
Les clients qui ont acheté au moins deux fois (les clients répétitifs) : ce sont les acheteurs ayant réalisé au moins deux achats séparés dans le temps. Il faut nourrir un dialogue avec eux pour ne pas les perdre et qu’ils deviennent vos ambassadeurs. Encouragez-les à réaliser de nouveaux achats avec des offres sur les nouveaux produits, un formulaire de renouvellement de commande ou encore des coupons exclusifs.
Les clients fidèles (vos meilleurs clients) : ce sont les clients qui ont acheté plusieurs fois dans une période de temps courte. Ce sont vos ambassadeurs qui ont démontré leur attachement à votre marque et à ses produits. Pour maintenir leur loyauté, impliquez-les dans votre démarche d’innovation produit en leur donnant accès en avant-première à vos nouvelles offres ou en leur envoyant des demandes d’avis client.
Les clients répétitifs à risque : ce sont les clients qui ont acheté plusieurs fois mais n’ont plus rien acheté depuis longtemps. Récupérez-les en leur envoyant des messages positifs concernant vos produits, en leur adressant un coupon avec durée d’utilisation limitée dans le temps ou encore un questionnaire avec incentive.
Les clients répétitifs inactifs : ce sont les clients fidèles que vous avez perdus. Il faut réactiver la relation et renouer le dialogue en envoyant de grosses promotions produits ou un questionnaire de type : « Comment puis-je vous aider ? ».
Le Net Promoter Score (NPS) est l’indicateur de la satisfaction et de la fidélité client. Il mesure ainsi la probabilité que vos clients recommandent votre marque, vos produits ou vos services. Selon la note donnée par le client, ce dernier est classé dans une des 3 catégories suivantes :
Promoteurs (note de 9 ou 10)
Passifs (7 ou 8)
Détracteurs (0 à 6)
Si la segmentation NPS induit une homogénéité entre chaque segment de clients, ce n’est pas toujours le cas. Tous les détracteurs ne se valent pas. Un détracteur à 0 ne va pas forcément ruiner votre réputation mais il sera peut-être plus enclin à se plaindre de votre entreprise que celui qui vous a donné une note de 6.
Cela vaut également pour vos promoteurs et vos passifs. Vos promoteurs ne font pas tous de la promotion et certains passifs ne le sont peut-être pas tant que ça. Une étude a ainsi révélé que les clients qui attribuent une note de 8, 9 ou 10 étaient tous similaires en termes de probabilité de recommandation.
Concentrez-vous donc sur les passifs qui vous donnent une note de 8 pour stimuler les recommandations des clients. En revanche, il y a une différence significative entre une note de 7 et de 8, ou entre 6 et 7 en termes de probabilité de recommandation.
Vous pouvez développer différentes stratégies pour les détracteurs qui vous ont donné une note de 6 afin de les convertir en promoteurs. Prêtez attention à la satisfaction de vos passifs pour leur donner le coup de pouce nécessaire pour les convertir en promoteurs. Utilisez le NPS pour stimuler les recommandations des clients.
5. Les segments RFM (Récence, Fréquence, Valeur)
La segmentation RFM est l’un des outils les plus populaires de scoring client en fonction de leurs achats précédents. Elle est particulièrement utilisée par les spécialistes du marketing direct qui peuvent non seulement scorer chaque client, mais aussi prédire les comportements de chaque segment vis-à-vis des futures campagnes marketing.
A partir de l’analyse RFM, on peut en tirer 6 segments :
Segment client
RFM
Description
Action marketing
Le noyau dur - Vos meilleurs clients
111
Des clients très engagés qui ont acheté vos produits récemment, le plus souvent, et qui ont généré le plus de revenus.
Concentrez-vous sur les programmes de fidélisation et le lancement de nouveaux produits. Ces clients ont prouvé qu'ils étaient disposés à payer plus, alors ne proposez pas de réductions pour générer des ventes supplémentaires. Concentrez-vous plutôt sur des actions à forte valeur ajoutée en recommandant des produits en fonction de leurs achats précédents.
Les loyaux - Vos clients les plus fidèles
X1X
Les clients qui achètent le plus souvent dans votre magasin.
Les programmes de fidélisation sont efficaces pour ces visiteurs réguliers. Les programmes d'engagement et les évaluations sont également des stratégies courantes. Enfin, pensez à récompenser ces clients par une livraison gratuite ou d'autres avantages de ce type.
Les baleines - Vos clients les plus payants
XX1
Les clients qui ont généré le plus de revenus pour votre magasin.
Ces clients ont démontré une forte volonté de payer. Envisagez des offres premium, des niveaux d'abonnement, des produits de luxe ou des ventes croisées ou incitatives à valeur ajoutée pour augmenter la valeur ajoutée totale. Ne perdez pas votre marge avec des remises.
Les prometteurs - Clients fidèles
X13, X14
Des clients qui reviennent souvent, mais qui ne dépensent pas beaucoup.
Vous avez déjà réussi à créer la fidélité. Concentrez-vous sur l'augmentation de la monétisation par le biais de recommandations de produits basées sur les achats passés et d'incitations liées à des seuils de dépenses (fixés en fonction de la valeur ajoutée moyenne de votre magasin).
Les recrues - Vos clients les plus récents
14X
Les nouveaux acheteurs qui visitent votre site pour la première fois.
La plupart des clients ne deviennent jamais fidèles. Avoir des stratégies claires pour les nouveaux acheteurs, telles que des mails de bienvenue, portera ses fruits.
Les infidèles - Autrefois fidèle mais aujourd'hui disparu
44X
D'excellents anciens clients qui n'ont pas acheté depuis longtemps.
Les clients partent pour diverses raisons. En fonction de votre situation, proposez des offres de prix, le lancement de nouveaux produits ou d'autres stratégies de fidélisation.
6. L’(in)activité client
A minima, la plupart des entreprises classent les clients en deux catégories : les clients actifs et les clients inactifs. Ces catégories indiquent la date à laquelle un client a effectué son dernier achat ou s’est engagé avec vous pour la dernière fois. Pour les produits hors-luxe, les clients actifs sont ceux qui ont acheté au cours des 12 derniers mois (et inversement pour les clients inactifs).
Pour segmenter la base client selon le niveau d’activité ou d’engagement, on utilise parfois un scoring Récence Fréquence Engagement, comme un RFM à la différence que les transactions sont remplacés par toutes formes de points de contacts (pages visitées, ouverture email, clic email, ..) auxquels on associe un nombre de points, exemple : +1 ouverture email, +3 visite site web, +5 clic email, etc.
7. La fréquence d’achat
Les clients actifs constituent votre base de clients fidèles et les ambassadeurs de votre marque. Ils sont plus susceptibles de partager vos posts, d’encourager les autres à acheter vos produits et de laisser des commentaires.
Ciblez ces clients fidèles en leur faisant bénéficier de codes de réduction exclusifs ou d’un programme de fidélité pour assurer votre croissance organique et multiplier votre portée organique en ligne.
Les programmes de fidélisation constituent un excellent moyen d’améliorer la fréquence d’achat, puisqu’ils détournent de façon efficace les clients de la concurrence en focalisant leur attention sur vos offres. En distribuant aux clients des points de fidélité, vous les motivez à augmenter la fréquence d’achat
8. La valeur client
Cela peut conduire à, ou être basé en partie sur un programme de segmentation de la RFV.
La valeur d’un client est strictement déterminée par ses dépenses cumulées. Une échelle LTV (Life Time Value) peut être utilisée pour déterminer l’éligibilité aux offres, aux récompenses de fidélité, aux promotions et autres campagnes spéciales.
Construire un scoring client en donnant une valeur élevée ou faible à chaque segment peut permettre de comprendre comment les clients de grande valeur vous trouvent de manière générale, et donc comment vous pouvez orienter votre stratégies d’acquisition.
9. Les sources d’acquisition
Dans leur parcours d’acheteur, vos clients potentiels sont susceptibles d’interagir avec votre entreprise par de multiples canaux d’acquisition, notamment lorsque vous développez une relation client omnicanale.
Analyser ces résultats vous permet d’être stratégique et d’investir là où c’est rentable. De plus, la source d’acquisition à l’origine peut être très structurante pour expliquer les comportements clients par la suite.
On peut même aller jusqu’à segmenter par cohorte d’acquisition pour observer à plus moyen terme les comportements induits par certaines campagnes.
Les clients recommandés sont 4 fois plus susceptibles de guider d’autres personnes vers votre marque. Segmenter votre public selon qu’il a été recommandé ou non est une approche efficace pour améliorer vos ventes par recommandation.
Ciblez vos clients actuels qui ont rejoint votre programme de recommandation et développez des campagnes qui transformeront ces clients en super fans.
La segmentation est une base solide, mais elle n’offre pas tout ce dont vous avez besoin pour développer des offres personnalisées et établir des relations solides avec vos clients actuels.
Là encore, il s’agit d’une excellente base de travail pour les données clients mais la segmentation offre une vision très générale du client. Personnaliser vos offres de fidélisation ou vos messages permet, en plus, de cibler et d’adapter les messages et les offres aux différents clients en fonction de leurs désirs, motivations et besoins uniques.
C’est pourquoi on parle souvent de la segmentation comme de l’étape 1. De la personnalisation (en 1-10 segments) et de la micro segmentation (10-30 segments) comme de l’étape 2.
Pour parvenir à une véritable personnalisation, les équipes marketing doivent exploiter l’intelligence artificielle (IA) et les algorithmes de machine learning (ML). Ces technologies avancées permettent de capturer et d’analyser en permanence chaque interaction d’un client avec votre marque. Grâce à cette analyse, les entreprises peuvent individualiser les offres et les messages destinés à des clients spécifiques, et ce à grande échelle.
Par exemple, Starbucks, qui compte plus de 30 000 magasins et près de 19 millions de membres actifs de leur programme de récompense, vise à devenir la marque la plus personnalisée au monde. L’entreprise utilise actuellement une IA pour apprendre en permanence les préférences et les désirs de ses clients en fonction des achats et des interactions.
Les capacités d’IA et du machine learning ont permis à Starbucks de créer des offres de fidélité individualisées à grande échelle. Les résultats ont été phénoménaux : 10 fois la vitesse d’exécution des opérations marketing et trois fois le marketing personnalisé et la stimulation des ventes.
La segmentation seule est donc loin de fournir la valeur d’une véritable personnalisation et de fournir des informations avec le même niveau de sophistication ou de détail. Elle ne peut pas non plus délivrer des messages ciblés et personnalisés à un énorme volume de clients uniques.
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Difficile d’évaluer à quel point vous perdez du temps et des opportunités à cause d’un fichier clients incomplet, pas fiable, pas normalisé, mais c’est beaucoup. Je cherchais des chiffres sur le net pour illustrer mon point, et ils sont tellement gros qu’ils me paraissent peu crédibles (12% Cost of Poor Data to Overall Revenue »). En tout cas, les enjeux de qualité de données, c’est au minimum 20% de productivité perdue pour toutes les personnes qui travaillent avec des données clients sur des outils CRM, emailing, service client..
C’est important d’évaluer le coût d’une mauvaise qualité des données clients, car cela déterminera le budget à investir sur le sujet. Il y a un coût humain dans la perte de productivité, mais il y a aussi des pertes business, encore plus difficiles à évaluer mais bien réelles. Quelques exemples de mon expérience perso: le programme de fidélité attribue des cadeaux à des profils clients présents en double, et on se retrouve avec 20% de cadeaux envoyés au même foyer en double, le responsable CRM fait des campagnes sur « Country » = « Spain », et on se rend compte qu’on perd 30% des contacts dont le champ « Country » contient plutôt « Espana » ou « es », le sales, etc.
Vous devez investir au moins 20% de votre budget CRM dans la préparation des données clients. Vos équipes et vos clients vous en remercieront.
Le sujet est complexe. Il y a beaucoup de problèmes à adresser pour avoir une belle base de données clients.
Dans cet article, on va faire un tour des principaux types de traitements à réaliser (dédoublonnage, nettoyage email, format téléphone, RNVP, etc.), en présentant les différentes solutions envisageables.
Pour aider nos lecteurs qui n’ont pas le budget pour envisager les solutions qui seront présentées, et qui souhaitent juste bricoler un peu mieux qu’avant, on a un petit cadeau. Un template Gsheet qui contient quelques formules bien utiles pour nettoyer basiquement un fichier clients.
Les traitements pour nettoyer votre base de données clients
Qu’est-ce qu’une base client de mauvaise qualité ?
Doublons, données erronées, incomplètes, non normées sont autant d’indices d’une base de données de mauvaise qualité.
Doublons
Il y a un doublon lorsqu’un contact se trouve en double dans une même base de données. L’existence de doublons dans un fichier ou dans une base de données peut avoir 2 origines :
Les utilisateurs (= l’entreprise). Les erreurs humaines existent, en particulier au moment de la saisie des données. Il arrive qu’un ou plusieurs utilisateurs enregistrent plusieurs fois le même contact dans la base avec une syntaxe ou une orthographe différente.
Les contacts. Par exemple, un contact peut très bien s’inscrire deux fois à la même newsletter en donnant deux adresses emails différentes. Comme l’email est généralement l’ID utilisé par le logiciel emailing, cela génère un doublon…même si les autres informations données (nom, prénom) sont les mêmes dans les deux cas.
Les champs sont rarement tous complétés, tout simplement parce qu’on n’a jamais toutes les informations sur tous les contacts. Le « taux de complétude » est rarement à 100%. La plupart du temps, ce n’est pas gênant, mais des fois, ca peut être très problématique. Les équipes commerciales ne veut pas travailler sur un fichier aussi incomplet, les équipes marketing ne veulent pas personnaliser un message avec une variable dispible à 70%, etc.
Beaucoup de bases de données clients ressemblent à un gruyère composé de plein de trous qui correspondent aux champs vides. Cela a évidemment une incidence sur la qualité de la base de données et son potentiel d’activation (comment voulez-vous envoyer un email aux plus de 50 ans si vous connaissez l’âge de seulement 5% de vos contacts ?).
Données non normées
M. ou Mr. ? 75 ou Paris ? Bien souvent, peu importe le format que l’on choisit, l’essentiel est de choisir un seul format par type de données. C’est l’art de ce que l’on appelle la « normalisation ». Le manque ou l’absence de normalisation des données pose un gros problème de lisibilité et d’activation de la base (des données non normées se traduisent par des variables inexploitables).
Données obsolètes
Les données n’expriment pas une vérité éternelle. Elles vivent comme vivent vos contacts. Une donnée correcte à l’instant t peut donc devenir obsolète à l’instant t+1. On peut prendre l’exemple des adresses postales, des numéros de téléphone, des professions, etc. En fait, la plupart des données (presque toutes) sont sujettes à l’obsolescence.
Nous avons passé en revue les principaux éléments qui portent atteinte à la qualité d’une base de données client. Nous allons voir maintenant les traitements à réaliser pour optimiser la qualité des données, les corriger, les nettoyer dans votre BDD.
Les princpaux traitements à appliquer pour nettoyer votre base clients
Voici une liste des principaux traitements pour maintenir et/ou optimiser la qualité des données. Pour chaque traitement, nous proposons une description, des exemples et les solutions possibles.
Traitement
Description
Exemples
Solutions possibles
Dédoublonnnage
Identification & fusion des doublons de contact, sur la base d’une ou plusieurs clés.
Plusieurs fois la même adresse mail dans ma bdd clients.
- Ponctuel : prestation agence / Excel / ETL - Live : logiciel CDP, ou extension CRM.
Normalisation des données
Correction des valeurs de différentes colonnes pour respecter une nomenclature.
“Mlle” devient “Madame” ou “Espana” devient “ES”.
- Ponctuel : prestation agence / Excel / ETL - Live : logiciel CDP, ou extension CRM.
Nettoyage des emails
Supprimer les fausses adresses email de votre base pour éviter les bounces.
Supprimer ou fusionner “anti-spam@..”
Winpure, Data Ladde, TIBCO Clarity...
Format des numéros de téléphone
Normaliser les N° aux formats internationaux.
"06 XX ..” devient “+33 6...”.
- Ponctuel : prestation agence / Excel / ETL - Live : logiciel CDP, ou extension CRM, exemple XXX sur Salesforce
RNVP des adresses postales
Le traitement RNVP permet de limiter le nombre de PND lors d'une campagne de marketing direct postal ou lors de la livraison de colis et permet également de bénéficier des tarifs d'affranchissement spécifiques.
“mme dupont julie appt 213 2e étage...” devient : ”Madame Julie Dupont Appartement 213, Etage 2”.
Outils spécifiques (DQE Adresse, Cap Address, 76310) ou agence (Capency...).
Code pays
Normaliser les pays de naissance et résidence de vos contacts selon les normes ISO.
Espagne : - ES - ESP - Spanish - es.
- Ponctuel : prestation agence / Excel / ETL - Live : logiciel CDP, ou extension CRM.
Déduplication
Identifier les données qui apparaissent dans plusieurs fichiers du système d’information et les fusionner dans une seule base.
Un ID unique pour mon CRM et mon outil de Marketing Automation.
Mise en place d'un Référentiel Client Unique + accompagnement par un cabinet de conseil.
Découvrez notre guide sur les Customer Data Platforms
Les solutions CDP permettent de préparer, scorer et synchroniser votre base clients. Cela peut faire sens d’étudier le sujet si vous avez des enjeux importants sur votre base clients (et un peu de budget..). Je vous invite à parcourir notre guide sur les CDP pour en apprendre un peu plus sur le sujet.
L’approche Do it yourself sur Excel
Nous avons réalisé un modèle Excel qui vous permet d’appliquer des règles de nettoyage sur un fichier de contacts.
L’onglet « Démo » réalise plusieurs actions en même temps, et génère un ensemble de colonnes en « output » avec le résultat post nettoyage. Pour ceux qui cherchent surtout un peu d’inspiration pour enrichir ce qu’ils font déjà, on a mis chaque traitement réalisé dans un onglet dédié.
Onglet Déduplication
Cet onglet permet de gérer les déduplications. Le bloc de gauche renvoie aux données contenues dans votre fichier. Dans notre exemple, nous avons 4 adresses différentes pour seulement deux individus : John & Matilda. La colonne « Qualification » permet d’identifier les doublons. La troisième colonne fait ressortir 1 compte unique avec l’information associée.
Deux points de vigilance à avoir quand on procède à un dédoublonnage :
L’information liée au doublon supprimée est perdue.
Il y a un risque de fusionner des contacts distincts. Il faut en être conscient.
Onglet Nettoyage des emails
Cet onglet sert à qualifier l’adresse email, et plus précisément à identifier si l’adresse est :
Générique. Pour rappel, une adresse email générique est une adresse qui est rattachée à un service ou à une fonction plus qu’à un individu. C’est le cas par exemple des adresses contact@, admin@, info@, etc. C’est la partie locale de l’adresse email (avant l’arobase) qui permet d’identifier ce type d’emails.
Professionnelle. C’est cette fois-ci l’adresse du serveur (la partie de l’email après l’arobase) qui permet de détecter le caractère professionnel ou non de l’adresse : prénom.nom@mon-entreprise.com.
Jetables. Il s’agit des adresses emails temporaires, qui s’autodétruisent automatiquement après un certain temps. Ce sont des adresses créées par des contacts qui veulent s’abonner à un service sans avoir à utiliser leur adresse personnelle ou professionnelle (pour des raisons de privacy ou de sécurité). Il existe plusieurs services comme Temp Mail qui permettent de générer facilement des adresses temporaires.
Onglet Pays
Nous avons vu plus haut les problèmes liés à l’absence de normalisation des données. Ce problème touche en particulier les informations de pays : en fonction des langues et des conventions liées aux outils que vous utilisez, le format des informations de pays ne seront pas les mêmes.
Dans cet onglet, vous gérez les différents formats utilisés par vos outils pour le pays. Par exemple, pour l’Espagne : Espagne, España, Espana, Spain, Spagna…Dans l’output (votre fichier nettoyé), cette diversité sera ramenée à l’unité d’un même format : ES. Tout l’enjeu est de bien indiquer toutes les formes possibles que peut prendre l’enregistrement du pays dans vos outils. Vous trouverez dans l’onglet « Settings » toutes les appellations potentielles pour chaque pays. Vous pouvez enrichir ce listing.
Civilité
Cet onglet fonctionne de la même manière que le précédent. Il permet de normaliser les civilités, c’est-à-dire de ramener toute la diversité des appellations possibles au duo M & F. Dès qu’une occurrence de « Monsieur », « Mister », « M. », « Mr. », « Senor », apparaîtra dans votre fichier, elle sera identifiée comme « M ». Là encore, vous pouvez enrichir les formats que nous proposons dans l’onglet « Settings ».
Vous pouvez aussi procéder au nettoyage des données en utilisant des outils. Vous avez trois grandes options :
1. Les modules de « cleansing » proposés par votre outil CRM (surtout vrai pour Salesforce..),
2. Un outil CDP / Data management (comme Octolis 😇),
3. Oter pour une ou plusieurs solutions spécialisées.
Les outils de data management comme Octolis
Certains outils d’activation (CRM, Marketing Automation, etc.) proposent des fonctionnalités natives de Data Management. Ce n’est pas étonnant quand on sait l’impact de la qualité des données sur la performance des campagnes et scénarios marketing. Les suites marketing ont pris leurs devants.
La limite de cette approche renvoie au problème plus général de la fragmentation des stack data et marketing. L’entreprise dispose de 15 outils dont peut-être un tiers propose des fonctionnalités de management de la qualité des données. Mais le nettoyage et la normalisation, dans cette architecture éclatée, s’effectuent dans chaque outil séparément.
Chaque outil a ses formats et ses règles de normalisation. Dit autrement : les données sont normalisées POUR le logiciel CRM, POUR le logiciel de Marketing Automation, etc. Il n’y a pas normalisation au niveau global du SI Client.
Une solution comme Octolis permet de résoudre ce défi. Octolis est une plateforme de data management qui fonctionne « au-dessus » de la base client. La solution Octolis permet de réconcilier, unifier, dédupliquer toutes les données stockées dans la base de données indépendante de l’entreprise et facilite la normalisation et le nettoyage. L’utilisation d’un outil de ce genre suppose bien entendu d’avoir une base de données pivot. Mais, dans les faits, la plupart des entreprises ont une base de ce type, qu’elle s’appelle data warehouse ou data lake.
Cette approche consistant à utiliser une base de données indépendante de tous les applicatifs et autres outils de l’entreprise, connectée à une solution comme Octolis, c’est ce que l’on appelle la Stack Data Moderne.
Précisons qu’Octolis permet de couvrir la plupart les besoins classiques de normalisation et de nettoyage. Certains cas d’usage avancés ne sont pas possibles, par exemple le traitement RNVP.
L’importance de la qualité des données est telle que certains outils ont été développés spécialement pour gérer cet aspect. Ce sont des solutions dites « Best of Breed » qui se concentrent sur une brique fonctionnelle et une seule : la Data Quality.
On trouve par exemple les outils de nettoyage d’emails. Par exemple : Bouncer, Zerobounce, MailnJoy ou encore Hunter. Ces outils proposent des connecteurs et une API permettant d’intégrer à peu tous vos logiciels ayant des fichiers d’adresses. Ces outils ne s’arrêtent pas à la validation des emails mais proposent des fonctionnalités avancées, comme Zerobounce qui donne accès à un score d’activité pour chaque adresse email.
D’autres permettent de savoir si vous êtes blacklistés par certains fournisseurs d’accès internet. La tarification de ces outils est basée sur le nombre d’emails vérifiés. Comptez entre 20 et 60 euros pour 10 000 emails et entre 200 et 400 euros pour 100 000 emails.
Solutions spécialisées : RNVP
La RNVP est l’action qui consiste à Restructurer, Normaliser et Valider (confronter les adresses avec le référentiel national) les adresses pPstales…
Le traitement RNVP permet de :
Limiter le nombre de plis non distribuables (PND, ou bounces) lors d’une campagne de marketing postal ou d’une livraison de colis.
Eviter qu’un représentant de votre entreprise (un commercial de terrain par exemple) se déplace chez un prospect ou un client en ayant la mauvaise adresse…
Bénéficier de tarifs d’affranchissement spécifiques. Les adresses RNVP donnent droit à une réduction des coûts d’affranchissement.
Ajoutons que le traitement RNVP est important pour deux raisons :
Les gens déménagent et les entreprises aussi.
Il y a plus de 200 000 changements de dénomination de voies par an sur le territoire français. On vous apprend peut-être quelque chose 🙂.
76310 et Cap Adresse sont deux bons outils de RNVP. Leur tarification est basée sur la taille de la base de données.
Nettoyer une base de données clients : Télécharger notre modèle Excel gratuit
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Il y a un énorme paradoxe autour de la lifetime value : c’est sans aucun doute l’indicateur business le plus important, notamment en ecommerce…et pourtant seulement une minorité d’entreprises l’utilisent. Selon une étude anglaise, seulement 34% des marketers affirment savoir vraiment ce que signifie la lifetime value. Quand on connaît tout ce qu’on peut faire grâce à cet indicateur, c’est à tomber les bras à terre. Et on ne parle pas seulement de mesure, de reporting, mais aussi et surtout de potentiel d’activation.
Si vous souhaitez développer vos revenus, il n’y a pas vraiment d’hésitation à avoir : vous devez calculer et utiliser la lifetime value.
Découvrons ensemble ce qu’est la lifetime value et surtout comment l’exploiter intelligemment pour maximiser votre actif client.
La lifetime value est un indicateur business qui consiste à estimer la somme des revenus générés par un client sur toute sa durée de vie.
La lifetime value est une estimation de la somme des revenus que génère un client tout au long de sa durée de vie.
C’est l’indicateur qui vous permet de savoir combien vous rapporte un client tout au long de sa relation avec votre entreprise, depuis son premier achat jusqu’au moment où il met fin à sa relation et n’achète plus.
Si un client vous génère en moyenne 50 euros de revenus par mois et qu’il reste client 3 ans, sa lifetime value sera de 50 x 12 x 3 = 1 800 euros. La lifetime value est une valeur monétaire, elle s’exprime en euro, par exemple.
On parle aussi, mais plus rarement, de « valeur client à vie », de « customer lifetime value ». L’acronyme LTV (ou CLTV) est quant à lui très répandu.
Quelques précisions s’imposent :
La lifetime value est la somme du revenu moyen (c’est-à-dire la marge) généré par un client tout au long de sa vie. MAIS, parfois, souvent même, on utilise le chiffre d’affaires à la place du revenu.
La lifetime value est une estimation. Par définition, il n’est pas possible de déterminer la lifetime value de M.Dupont avant qu’il ait mis fin à sa relation avec votre entreprise. Mais il est possible d’estimer sa lifetime value en fonction de son profil, des données à disposition de votre SI, de la lifetime value du segment client auquel il appartient, etc.
La lifetime value peut se calculer à plusieurs niveaux : au niveau global (tous vos clients), au niveau d’un segment client, voire au niveau de chaque client.
La Lifetime Value est un indicateur clé dans les secteurs d’activité pour lesquels la maîtrise des coûts d’acquisition est un enjeu clé. Cela concerne notamment :
Les business models d’abonnement, par exemple les business SaaS.
Le Retail et le Ecommerce.
Zoom sur 4 cas d’usage de la Lifetime Value
Voici quelques cas usages typiques de la LTV. La liste est loin d’être exhaustive.
Cas d’usage #1 – Déterminer le coût d’acquisition client (CAC) cible
Le fait d’être en capacité d’estimer combien tel client va vous rapporter au total vous permet d’évaluer les investissements marketing et commerciaux maximum pour acquérir ce client. L’idée sous-jacente, c’est qu’il est bien sûr absurde de dépenser plus pour acquérir un client que les revenus que ce client apportera à l’entreprise.
Si vous savez que le client vous rapportera en moyenne 10 000 euros, vous pouvez certainement justifier un investissement de 3 000 euros pour le convertir. Les efforts marketing et commerciaux doivent toujours être proportionnés au revenu qu’on espère générer.
Dans la même optique, vous pouvez utiliser la LTV pour identifier le point mort, c’est-à-dire le moment où le seuil de rentabilité est atteint, où les revenus générés dépassent les coûts investis.
Le ratio LTV / CAC est très important.
Si le ratio est inférieur à 1, l’activité n’est pas viable, et si le ratio est supérieur à 3, c’est un très bon signe à condition que ce soit stable. Source : Ecommerce Finance Model Valuation
Cas d’usage #2 Cibler en priorité les clients les plus profitables
Nous supposons que vous avez déjà construit une segmentation client. Si c’est le cas, alors la LTV est l’un des indicateurs les plus pertinents pour évaluer la valeur de chaque segment. Nous vous encourageons vivement à calculer la LTV de vos différents segments. Vous identifierez de cette manière vos meilleurs segments. Vous pourrez ensuite imaginer des actions spécifiques pour ces clients VIP, en pensant bien à les chouchouter !
Ici comme tout à l’heure, l’indicateur de Lifetime Value apparaît comme un excellent outil pour optimiser les efforts et les investissements marketing.
La Lifetime Value permet d’évaluer qui sont vos meilleurs clients !
Cas d’usage #3 – Détecter vos points faibles et vos axes d’amélioration
Tout le travail nécessaire pour calculer la Lifetime value va vous aider à identifier des points faibles ou en tout cas des axes d’amélioration de votre entreprise. L’utilisation de la Lifetime Value induit une manière de réfléchir résolument « customer centric » qui ne peut que vous éclairer sur beaucoup de choses ! Rien que pour cette raison et dans une démarche d’amélioration continue, calculer la Lifetime Value de ses clients, de ses segments, vaut la peine.
Cas d’usage #4 – Planifier votre budget publicitaire annuel
Cela rejoint ce que nous disions plus haut. Si vous connaissez votre LTV, vous pouvez plus facilement et plus précisément déterminer le budget à investir en acquisition, en campagnes publicitaires, etc.
Une introduction au calcul de la LTV
Maintenant que vous connaissez la définition de la Lifetime Value et que vous connaissez ses usages possibles, intéressons-nous à son calcul.
Une seule formule de calcul de la LTV ?
Non, il existe plusieurs formules pour calculer la Lifetime Value pour deux raisons :
Nous avons vu dans la première partie que la variable utilisée pour construire cet indicateur pouvait être la marge ou le chiffre d’affaires. Cela induit des formules de calcul différentes.
La formule de calcul dépend aussi du business model de l’activité. Cela nécessite quelques explications…
La formule de calcul de la LTV, en un sens, c’est toujours :
[Ce que me rapporte un client par mois] X [Durée de vie du client].
Mais le calcul du premier membre de la formule ([Ce que me rapporte le client par mois]) est directement lié au business model de l’activité. Dans une activité Ecommerce, ce que me rapporte un client se calcule par la formule Panier Moyen X Fréquence d’achat. Dans un business model d’abonnement, le calcul est plus simple : c’est le prix de l’abonnement.
Calcul de la LTV : marge ou chiffre d’affaires ?
Calculer la Lifetime Value en utilisant le chiffre d’affaires est beaucoup plus simple. Le calcul de la LTV à partir de la marge est plus complexe, mais permet seul d’avoir une vision de la performance financière.
La formule de calcul de la LTV en Ecommerce
En Ecommerce, la formule de la Lifetime Value est la suivante :
Chaque élément de cette formule est lui-même un indicateur ayant une formule de calcul.
Panier Moyen
C’est le chiffre d’affaires divisé par le nombre de commandes. Une entreprise qui génère un CA de 1 000 000 € et qui a 30 000 commandes a un panier moyen de : 1 000 000 / 30 000 = 33 €.
Fréquence d’achat
La fréquence d’achat se calcule en divisant le nombre total de commandes par le nombre de clients (uniques). Si vous avez 1 000 commandes par an et 50 clients, la fréquence d’achat est de 1 000 / 50 = 20.
Marge brute
La marge brute, c’est le chiffre d’affaires moins les coûts d’achat, le tout divisé par le chiffre d’affaires puis multiplié par 100 pour obtenir un pourcentage.
Par exemple, si vous achetez un produit 50 euros et que vous le revendez 100 euros :
Le taux de churn, ou taux d’attrition, calcule la perte de clients sur une période donnée. Il se calcule de la manière suivante :
Taux de churn = (Nombre de clients perdus à la fin de la période – Nombre de clients au début de la période) / nombre de clients au début de la période.
Là encore, on multiplie par 100 le résultat pour obtenir un pourcentage.
Prenons un exemple. Vous souhaitez calculer le taux d’attrition entre le 1er janvier et le 1er février. Vous aviez 110 clients au 1er janvier et vous avez 80 au premier février. Votre taux d’attrition est égal à : (80 – 110) / 110 = – 0,27.
Conseils pratiques pour améliorer la Lifetime Value en Ecommerce
L’amélioration de la lifetime value devrait être l’un des objectifs prioritaires de toute entreprise ecommerce. Justement, comment y parvenir ? Pour répondre à cette question, il faut reprendre chacun des termes de l’équation. L’amélioration de la lifetime value passe par l’amélioration d’une ou de plusieurs des variables qui constituent la formule de calcul que nous avons développé tout à l’heure. C’est-à-dire :
Augmenter le panier moyen et/ou
Augmenter la fréquence d’achat et/ou
Augmenter la marge brute et/ou
Diminuer le churn.
Nous allons vous donner quelques conseils pour améliorer chacune de ces variables. Sans prétendre, évidemment, à l’exhaustivité. Ce sont quelques pistes à explorer…
Améliorer le panier moyen
Augmenter le panier moyen consiste à faire en sorte que vos clients réalisent des commandes plus élevées. Comment ? En les incitant à ajouter plus de produits dans leur panier. Comment ? En leur proposant, pendant le parcours d’achat, des produits complémentaires. C’est ce que l’on appelle le cross-selling. Une autre option consiste à proposer à des clients des produits de gamme supérieure. On parle alors d’up-selling, très utilisé dans les univers de service mais aussi dans le retail.
Voici quelques pistes à explorer :
Proposer des produits personnalisés sur le site, faire des recommandations de produits basées sur les préférences des clients. Cela suppose, bien entendu, que le visiteur qui parcourt le site soit un visiteur connu.
Envoyer des campagnes emails personnalisées proposant des recommandations de produits basées sur l’historique d’achat et/ou d’autres informations sur vos clients (préférences d’achat, informations socio-démographiques…).
Mettre en avant des produits complémentaires ou similaires pendant le parcours d’achat, en fonction des produits ajoutés au panier.
Créer des packs de produits.
Offrir la livraison au-delà d’un certain montant d’achat.
Créer un programme de fidélité pour inciter les clients à acheter plus pour gagner des points/récompenses.
Améliorer la fréquence d’achat
Vous avez peut-être des clients qui achètent beaucoup, qui ont un gros panier moyen, mais qui achètent peu souvent…ou moins souvent que vous le voudriez. Il existe différentes techniques pour inciter les clients à acheter plus souvent et ainsi augmenter leur fréquence d’achat. Mais elles se réduisent pour l’essentiel à une chose : créer des campagnes et scénarios emails ou mobile (et même du marketing direct postal si vous utilisez ce canal). On pense aux campagnes promotionnelles ou aux scénarios de relance de panier abandonné (la relance de panier abandonné est un excellent moyen d’augmenter la lifetime value !).
Nous entrons ici dans les arcanes du marketing relationnel, dans le plan relationnel…C’est en communiquant de manière régulière et pertinente avec vos clients, en entretenant avec eux une relation clients en dehors des moments d’achat que vous parviendrez à les rendre plus fidèles et plus acheteurs. Le sujet est vaste. Sur ce vaste sujet, nous vous invitons à découvrir le guide complet sur le plan marketing relationnel publié par nos amis de chez Cartelis.
Améliorer la marge brute
Pour augmenter la marge brute, vous avez deux leviers :
Augmenter les prix.
Réduire les coûts d’achat des produits.
Voici deux pistes pour augmenter la marge brute :
Utiliser un gestionnaire de stocks pour être en capacité de bien estimer vos besoins de réapprovisionnement, limiter les stocks au nécessaire tout en évitant le risque de rupture de stock (fatal dans le secteur du ecommerce, où les clients veulent avoir tout tout de suite).
Commercialiser des produits à forte marge. C’est simple et logique ! Le taux de marge varie énormément d’un produit à l’autre. Vous devez identifier et commercialiser des produits à fort taux de marge, tout en restant dans votre univers. Vous pouvez aussi mettre en avant dans vos communications les produits ayant le plus fort taux de marge (cf. les recommandations de produits dont nous parlions plus haut).
Réduire le taux de churn
Le taux de churn est une métrique très complexe. Il y a beaucoup de raisons, de facteurs qui peuvent conduire un client à cesser d’acheter chez vous. Il n’y a pas de secrets pour réduire le churn : vous devez augmenter la rétention client, la fidélité client. Cela passe par :
La mise en place d’un plan relationnel béton,
Une compréhension sans cesse renouvelée des besoins de votre cible, afin d’ajuster vos offres en permanence dans le sens des attentes clients,
L’amélioration de l’expérience client à toutes les étapes des parcours clients : amélioration du site web, optimisation du service client, amélioration des services proposés ou offerts au client…
Calculer la Lifetime Value grâce à une Customer Data Platform
Le calcul et le suivi de la lifetime value suppose de disposer de données agrégées, consolidées, unifiées. La formule de calcul présentée plus haut met bien en évidence cette nécessité : vous devez connaître le panier moyen, la fréquence d’achat, la marge brute, les statuts des clients, les préférences clients, etc. Mais cette connaissance ne suffit pas, encore faut-il qu’elle soit unifiée, réunie dans un même système. C’est pour cette raison que notre dernier conseil sera le suivant : investissez dans une solution d’unification des données clients, transactionnelles, financières…
On ne peut pas raisonnablement mettre en place une stratégie basée sur la lifetime value sans avoir un Référentiel Client Unique. Les Customer Data Platforms représentent la solution moderne pour consolider et unifier les données clients (au sens large du terme, incluant les données transactionnelles…).
C’est à partir d’une solution de ce type que vous pourrez efficacement (et facilement) calculer la lifetime value et l’utiliser pour segmenter, personnaliser votre marketing relationnel. Pourquoi « facilement » ? Parce qu’avec une CDP, vous avez toutes les variables de la formule de la lifetime value dans un même endroit. Les lifetime values peuvent être calculées automatiquement dans la CDP une fois que vous avez connecté toutes les données nécessaires.
En clair : avec une CDP, vous pouvez connecter toutes vos données, calculer la lifetime value de tous vos clients et envoyer les segments/agrégats calculés à vos outils d’activation pour mieux communiquer avec vos clients…et augmenter leur lifetime value.
Octolis propose une solution CDP moderne pour exploiter vraiment votre base clients.
Nous avons publié un guide complet sur les Customer Data Platforms si vous souhaitez en apprendre davantage.
Conclusion
Dans le ecommerce, les opportunités de maximiser les revenus sont nombreuses. Les actifs clients sont généralement sous-exploités. La lifetime value est l’une des meilleures boussoles pour développer les revenus d’une activité ecommerce tout en restant résolument customer-centric. Nous avons vu ce qu’elle était, comment la calculer, pourquoi l’utiliser et comment l’améliorer. Maintenant…à vous de jouer !
Scoring client : Définition, exemples et méthode en 5 étapes
Le scoring client permet de prioriser vos budgets marketing pour les clients les plus susceptibles d’acheter, et de mieux segmenter votre fichier client pour obtenir de meilleures performances dans vos campagnes.
Par exemple, pour identifier vos promoteurs les plus convaincus et en faire vos champions.
Dans cet article, on vous présente 3 exemples très concrets de modèles de scoring client, et on vous propose un guide en 5 étapes pour construire un scoring client qui soit efficace et exploitable rapidement.
Scoring client: une définition
Définition
Le scoring client consiste à attribuer un score à chacun des clients d’une organisation. Ce score peut avoir un objectif analytique – par exemple pour estimer la valeur d’un client (LTV – VVC en français pour valeur vie client) – ou opérationnel pour délimiter des segments clients et décider des actions marketing à mener.
Les entreprises utilisent ces méthodes d’analyse de la valeur pour définir quels clients sont sources de bénéfices importants. Le but : utiliser les informations collectées pour communiquer efficacement avec ces segments les plus précieux. Le modèle RFM (Recency, Frequency, Monetary) est l’une des méthodes les plus couramment utilisées.
Le principal avantage de la méthode RFM est qu’elle donne des informations détaillées sur ces clients en utilisant trois critères seulement. Cela réduit la complexité du modèle d’analyse de la valeur client sans pour autant compromettre sa précision.
Le scoring client n’est pas strictement limité aux clients actifs. Les clients inactifs peuvent être l’un des segments les plus importants des fiches d’évaluation clients.
Scoring client VS Lead scoring
Critère
Scoring client
Lead scoring
Objectif
Rétention, upsell, maximisation de la LTV des clients existants
Acquisition de nouveaux clients
Fonctionnement
Analyse d’un stock (généralement important) de données passées
Mise à jour continuelle d’un score en flux à chaque action d’un prospect
Équipe concernée
Marketing
Commerciale
Démarche
Définition de segments mutuellement exclusifs
Gradation de prospects sur une échelle plus ou moins linéaire
Le lead scoring cherche à estimer l’espérance de gain sur un prospect avec deux types de variables:
Un score d’intention: La probabilité de conversion d’un prospect (lead) en client.
Un score de potentiel: La valeur estimée (expected LTV) du prospect s’il devient client.
C’est plutôt utilisé en B2B et l’objectif est d’aider les équipes commerciales à maximiser leur espérance de gains en priorisant les leads au plus gros potentiel et à la plus forte intention d’achat.
Le scoring client a plutôt pour objectif de segmenter une base de clients existants (un stock) en segments mutuellement exclusifs. L’enjeu est moins de prioriser les segments à travailler que de définir des actions marketing adaptées pour maximiser la valeur client au sein de chaque segment.
Un exemple très simple: imaginez que vous proposez un coupon de 10% exactement au même moment à tous vos clients:
Certains étaient déjà en cours d’achat, et vous aurez perdu 10% de chiffre.
D’autres étaient sur le point d’acheter à la concurrence, et vous les aurez réactivés.
D’autres enfin ont acheté hier, et ne répondront pas à l’offre.
Le scoring client permet de ne viser que le bon segment (le 2ème dans notre exemple ) et d’envisager d’autres actions pour les autres segments – par exemple proposer un upsell aux premiers, et demander aux derniers leur avis sur leur achat.
Scoring client et loi de Paretto
Le modèle RFM est lié à la célèbre loi de Pareto qui stipule que 80 % des effets sont le produit de 20 % des causes. Appliquée au marketing, cela signifie que 80 % de vos ventes proviennent de 20% de vos clients (les meilleurs).
Le modèle RFM: un standard pour le scoring clients
Les méthodes traditionnelles de segmentation utilisées par les sociétés d’études de marché avant l’arrivée de l’analyse de données, utilisent des variables telles que les facteurs démographiques et psychographiques pour regrouper leurs clients.
Les chercheurs utilisent toujours des échantillons pour prédire le comportement global d’une population, ce qui empêche la définition de segments précis.
Ces études sont réalisées manuellement, dépendent de chercheurs qualifiés et sont sujettes à l’erreur humaine. Un échantillon peut donc être incorrect pour de nombreuses raisons : un nombre insuffisant de consommateurs, un mauvais ratio entre les différentes populations, des facteurs psychographiques variables, etc.
La segmentation RFM est l’un des outils les plus populaires pour évaluer les clients en fonction de leurs achats précédents. Il est particulièrement utilisé par les spécialistes du marketing direct.
Avec cette analyse RFM, ils peuvent non seulement scorer chaque client (ce qui est d’une utilité considérable dans son application ensuite), mais aussi prédire les comportements de chaque segment vis-à-vis des futures campagnes marketing.
Les campagnes peuvent être planifiées avec plus de précision et deviennent donc plus rentables.
Combien de temps s’est écoulé depuis le dernier achat ? Plus le temps est court, plus la valeur du client est élevée.
La première étape devrait consister à diviser l’ensemble de la base de clients en 3, 4 ou 5 segments égaux.
La valeur maximale est attribuée aux 20, 25 ou 33% des clients qui ont effectué des achats il y a le moins longtemps. La valeur minimale est attribuée aux clients dont le dernier achat a eu lieu il y a le plus longtemps.
Fréquence
Combien de fois le client a-t-il fait des achats dans le magasin ? Plus sa récurrence d’achat est forte, plus sa valeur est élevée.
Sur une base divisée en 5 segments pour la date du dernier achat, on divise à nouveau les clients en 5 groupes égaux en fonction du nombre d’achats qu’ils ont effectués depuis le début de la relation avec votre marque.
Monetary (Valeur)
Combien le client a-t-il payé dans le magasin ? Bien entendu, plus la dépense est élevée, plus la valeur du client est élevée.
Il est maintenant temps de passer à la dernière partie de l’analyse – déterminer combien le client a dépensé au total pour vos produits. Tout comme dans la segmentation précédente, il est recommandé dans ce cas d’utiliser une échelle de 1 à 3, 4 ou 5.
Limites du modèle RFM
La principale limite du RFM est qu’il ne permet pas d’évaluer le potentiel d’un nouveau client car l’ancienneté des clients n’est pas prise en compte. Un client devenu client hier aura mécaniquement beaucoup moins de valeur que les clients les plus anciens dans ce modèle.
Il est possible de regrouper les clients en fonction des 3 facteurs énoncés ci-dessus. Par exemple, regrouper tous les clients dont l’ancienneté est inférieure à 60 jours dans un même bac. De même, les clients dont l’ancienneté est supérieure à 60 jours et inférieure à 120 jours dans un autre seau. Nous appliquerons également le même concept pour la Fréquence et la Valeur.
Vidhya ont défini eux-mêmes des fourchettes pour chaque score basées sur la nature de l’activité. Les fourchettes pour la fréquence et les valeurs monétaires seront aussi définies de cette manière.
Cette méthode de notation dépend de chaque entreprise, car c’est elle qui décide de la fourchette qu’elle considère comme pertinente pour la récurrence, la fréquence et les valeurs monétaires Attention cependant, les fourchettes ne sont pas des fractiles/ quantiles.
Le gros avantage est qu’il est très simple de la mettre en place. Mais le calcul d’une telle fourchette pour les scores RFM présente aussi des limites:
Au fur et à mesure que l’entreprise se développe, les fourchettes de scores peuvent nécessiter des ajustements fréquents.
Si vous avez une activité à paiement récurrent, mais avec des conditions de paiement différentes – mensuelles, annuelles, etc. – les calculs sont erronés.
Ils ont acheté récemment, achètent souvent et dépensent le plus !
Récompensez-les. Ils peuvent être les premiers à adopter les nouveaux produits. Ils feront la promotion de votre marque.
Clients fidèles
2-5
3-5
Dépensent souvent de l'argent chez vous. Réagissent aux promotions.
Vendez des produits plus chers. Demandez-leur des avis. Engagez-les.
Clients fidèles en devenir
3-5
1-3
Clients récents, mais qui ont dépensé une somme conséquente et acheté plus d'une fois.
Proposez un programme d'adhésion/de fidélité, recommandez d'autres produits.
Clients récents
4-5
0-1
Ils ont acheté très récemment, mais pas régulièrement.
Aidez-les à s'intégrer, donnez-leur rapidement des récompenses, commencez à construire une relation.
Clients prometteurs
3-4
0-1
Ce sont des acheteurs récents, mais qui n'ont pas beaucoup dépensé.
Créez la notoriété de la marque, proposez des essais gratuits.
Clients ayant besoin d'attention
2-3
2-3
En moyenne assez récents, ils ont une fréquence d'achat et une valeur monétaire supérieure à la moyenne. Ils n'ont peut-être pas acheté très récemment cependant.
Faites des offres à durée limitée, Recommandez en fonction des achats passés. Réactivez-les.
Clients passifs
2-3
0-2
Inférieures à la moyenne en termes de nouveauté, de fréquence et d'argent. . Vous les perdrez si vous ne les réactivez pas.
Partagez des ressources précieuses, recommandez des produits populaires / des renouvellements à prix réduit, reconnectez-vous avec eux.
Clients en danger
0-2
2-5
Ils ont dépensé beaucoup et acheté souvent. Mais il y a longtemps. Il faut les faire revenir !
Envoyez des e-mails personnalisés pour renouer le contact, proposez des nouvelles choses, fournissez des ressources utiles.
Clients indispensables
0-1
4-5
Ils ont fait les plus gros achats, et souvent. Mais ne sont pas revenus depuis longtemps.
Récupérez-les avec un renouvellement de l'offre ou en leur proposant de nouveaux produits, ne les perdez pas au profit de la concurrence, parlez-leur.
Clients en hibernation
1-2
1-2
Le dernier achat commence à dater. Ce sont ceux qui dépensent peu et ont le nombre de commandes le plus faible.
Proposez d'autres produits pertinents et des remises spéciales. Recréez la valeur de la marque.
Clients perdus
0-2
0-2
Les scores de récence, de fréquence et d'argent sont les plus bas.
Ravivez l'intérêt avec une campagne de sensibilisation, ignorez-la sinon.
Les Quintiles fonctionnent avec n’importe quel secteur d’activité puisque les fourchettes sont choisies à partir des données elles-mêmes. Elles distribuent les clients de manière égale pour qu’il n’y ait pas de croisements.
R, F et M ont ici des scores de 1 à 5, il y a donc un total de 5x5x5 = 125 combinaisons de valeur RFM. Les trois dimensions de R, F et M peuvent être représentées sur un graphique en 3D. Si vous cherchez à savoir combien de clients vous avez pour chaque valeur RFM, vous devrez alors examiner 125 points de données.
Dans cette approche, il faut tracer la fréquence + le score monétaire sur l’axe Y (plage de 0 à 5) et l’ancienneté (plage de 0 à 5) sur l’axe X. Cela réduit les combinaisons possibles de 125 à 50.
Il est logique de combiner F et M en une seule combinaison, car les deux sont liés au volume d’achat du client. R sur l’autre axe nous donne un aperçu rapide des niveaux de réengagement avec le client.
Attention, cette fois les scores sont inversés: 4 est la valeur minimale, et 1 la valeur maximale.
Segment client
RFM
Description
Action marketing
Le noyau dur - Vos meilleurs clients
111
Des clients très engagés qui ont acheté vos produits récemment, le plus souvent, et qui ont généré le plus de revenus.
Concentrez-vous sur les programmes de fidélisation et le lancement de nouveaux produits. Ces clients ont prouvé qu'ils étaient disposés à payer plus, alors ne proposez pas de réductions pour générer des ventes supplémentaires. Concentrez-vous plutôt sur des actions à forte valeur ajoutée en recommandant des produits en fonction de leurs achats précédents.
Les loyaux - Vos clients les plus fidèles
X1X
Les clients qui achètent le plus souvent dans votre magasin.
Les programmes de fidélisation sont efficaces pour ces visiteurs réguliers. Les programmes d'engagement et les évaluations sont également des stratégies courantes. Enfin, pensez à récompenser ces clients par une livraison gratuite ou d'autres avantages de ce type.
Les baleines - Vos clients les plus payants
XX1
Les clients qui ont généré le plus de revenus pour votre magasin.
Ces clients ont démontré une forte volonté de payer. Envisagez des offres premium, des niveaux d'abonnement, des produits de luxe ou des ventes croisées ou incitatives à valeur ajoutée pour augmenter la valeur ajoutée totale. Ne perdez pas votre marge avec des remises.
Les prometteurs - Clients fidèles
X13, X14
Des clients qui reviennent souvent, mais qui ne dépensent pas beaucoup.
Vous avez déjà réussi à créer la fidélité. Concentrez-vous sur l'augmentation de la monétisation par le biais de recommandations de produits basées sur les achats passés et d'incitations liées à des seuils de dépenses (fixés en fonction de la valeur ajoutée moyenne de votre magasin).
Les recrues - Vos clients les plus récents
14X
Les nouveaux acheteurs qui visitent votre site pour la première fois.
La plupart des clients ne deviennent jamais fidèles. Avoir des stratégies claires pour les nouveaux acheteurs, telles que des mails de bienvenue, portera ses fruits.
Les infidèles - Autrefois fidèle mais aujourd'hui disparu
44X
D'excellents anciens clients qui n'ont pas acheté depuis longtemps.
Les clients partent pour diverses raisons. En fonction de votre situation, proposez des offres de prix, le lancement de nouveaux produits ou d'autres stratégies de fidélisation.
Comment construire un modèle de scoring client adapté à votre activité
1. Collecter et rassembler les données clients
Le modèle RFM implique l’analyse de l’historique client des transactions. Pour cela, il est important de toujours garder le contrôle des données clients. La première étape consiste à extraire les données RFM de chaque client par ordre croissant.
Il faut également choisir un référentiel de temps sur lequel on va analyser les transactions – par exemple, les 12 ou 24 derniers mois.
Pour limiter l’impact de l’acquisition de nouveaux clients sur les données (par exemple dans un contexte de forte croissance), on peut décider d’étudier une cohorte d’acquisition. Vous devez donc étudier toutes les données transactionnelles des 3 derniers mois par exemple, mais uniquement pour les clients acquis il y a plus d’un an.
2. Définir les paliers RFM
Les entreprises doivent créer des filtres personnalisés afin de segmenter efficacement les clients. Pour mieux comprendre, vous devez créer des exemples de filtres comme dans l’exemple ci-dessous. Attention toutefois car il s’agit d’un aspect important qui variera en fonction de la nature de votre activité.
3. Attribuer un score à chaque client
Vous pouvez maintenant attribuer à chaque client une note basée sur le tableau ci-dessus. Ce faisant, vous convertissez les valeurs absolues des transactions en blocs de transactions similaires, sur la base du RFM. Maintenant, vous n’avez plus besoin des valeurs absolues mentionnées entre parenthèses, et vous utilisez simplement le score pour la segmentation et l’analyse. Après avoir attribué des scores, vous pouvez créer des groupes de clients similaires, qui ont des scores identiques ou similaires dans les trois critères.
4. Nommer les segments
Les étiquettes utilisées seront basées sur les différentes caractéristiques des trois notes que les clients ont reçues. Comme on a utilisé 5 segments de notation, et qu’il y a 3 critères, il y a une possibilité de 5*5*5 = 125 segments uniques.
Vous pouvez décider du nombre de segments que vous souhaitez avoir. Avoir beaucoup de segments permet d’être plus précis dans l’automatisation des actions marketing, mais représente aussi un coût opérationnel énorme. C’est un jeu du juste milieu. En général, on travaille avec environ 5 à 10 segments.
5. Opérationnaliser la segmentation dans vos actions marketing
Une fois que les entreprises ont segmenté et étiqueté chaque client, elles peuvent personnaliser tous leurs messages. Les clients à risque peuvent être ciblés par des offres, de remises ou des gratuités, tandis que les clients fidèles peuvent bénéficier d’un niveau de service supérieur afin de les valoriser davantage.
Pour construire une relation client omnicanale, les clients récents peuvent recevoir des informations sur d’autres produits susceptibles de les intéresser, tandis que les meilleurs clients peuvent bénéficier d’un accès plus large aux produits et être utilisés comme une source d’information, avant de le lancer auprès d’autres clients. Tout cela peut être fait simultanément bien entendu.
Une fois l’analyse RFM terminée, plusieurs actions peuvent être mises en place :
Prioriser vos budgets marketing : une stratégie média différenciée sous différents formats et supports, pour des durées variables, peut être créée pour cibler différents segments en fonction de leurs caractéristiques. Vous pouvez ainsi choisir d’inclure ou exclure certains segments de votre cible.
Personnaliser vos messages: conséquence directe de la segmentation, vous pouvez maintenant personnaliser davantage les messages que vous envoyez à vos clients. Les emails personnalisés sont un moyen puissant pour augmenter votre taux de réponse de vos prospects.
Identifier et engager vos champions: lors du lancement d’un nouveau produit, le client champion peut être engagé pour créer du bouche-à-oreille. Cette promotion améliore la perception du produit par les autres clients et pousse à l’achat.
Zoom sur les limites de Segment et les meilleures alternatives
Si Segment est de toute évidence une solution DMP et/ou CDP puissante et pertinente, elle n’est pas la plus appropriée à tous les business models.
La raison ? Les prix grimpent assez vite, surtout pour les acteurs du B2C, l’absence de base de données indépendante et la rigidité du modèle de données limitent votre capacité à renforcer votre business intelligence.
Pourquoi les alternatives solides ont-elles le vent en poupe ? L’émergence de la stack data moderne, à travers le rôle crucial de « source unique de vérité » que joue désormais votre data warehouse cloud, est en fait une excellente occasion d’évoluer vers une infrastructure plus légère, plus flexible grâce à une base de données indépendante, et surtout moins coûteuse pour la gestion des données de vos clients.
Vous hésitez à choisir Segment ? Vous cherchez des alternatives ? Nous avons préparé pour vous une belle ressource avec un passage en revue des alternatives aux principaux modules de Segment : Connections, Personas et Protocols.
D’un outil de webtracking à une CDP leader du marché
Fondé en 2011, Segment était à l’origine un outil de tracking web en mode SaaS permettant aux entreprises de tracker tous les événements qui se produisent sur le site web, de les rattacher à un ID utilisateur et de stocker tous les logs web dans un entrepôt de données. Avec un positionnement mid-market (PME-ETI) et B2B, Segment a été l’un des premiers outils à démocratiser l’extraction et le stockage des logs web à des fins de BI et de personnalisation de l’expérience client.
Petit à petit, Segment a élargi son spectre fonctionnel. La plateforme a développé ses capacités d’intégration avec les autres sources de données et outils de l’entreprise. D’un outil de webtracking, Segment est devenu une plateforme permettant de gérer les données CRM, marketing, commerciales, les données du service client…Bref, Segment est devenu une Customer Data Platform, capable de connecter, unifier et activer toutes les données clients (essentiellement first-party) de l’entreprise.
Allons même plus loin : Segment est l’un des principaux acteurs sur du marché CDP. En 2020, Segment a généré un revenu de 144 millions de dollars et a été racheté par Twilio pour la coquette somme de 3,2 milliards de dollars. La start-up est devenue un géant et compte plus de 20 000 clients, dont IBM, GAP, Atlassian ou encore le Time magazine.
À la découverte du périmètre fonctionnel de Segment
Segment permet essentiellement de (1) connecter les différentes sources de données clients de l’entreprise, de (2) construire une vision client unique et des audiences et, enfin, de (3) monitorer la qualité et l’intégrité des données. Ce sont les trois principaux modules proposés par la plateforme : Connections, Personas & Protocols.
#1 La connexion des données [Connections]
« Connecter » une source de données à une Customer Data Platform comme Segment consiste à générer des événements (events) liés au comportement des visiteurs du site web ou de l’application web. Segment transforme des comportements web en événements et les événements en données activables.
Pour mettre en place les connexions, Segment propose une bibliothèque d’APIs mais aussi, et c’est ce qui fait sa force, une vaste bibliothèque de connecteurs natifs.
Segment propose une vaste bibliothèque de connecteurs natifs (300+).
Outre l’impressionnante bibliothèque de sources et de destinations disponibles, Segment gère très bien :
La transformation des events. Certains types de données doivent être transformés avant d’être injectés dans d’autres outils de destination. Le module « Functions » permet de traiter des transformations d’événements de base avant de les envoyer à des applications externes avec « seulement dix lignes de JavaScript ». Segment propose également une fonction de transformation et d’enrichissement des données sans code qui n’est disponible que dans le cadre de son offre Business.
La synchronisation des données dans le data warehouse. Segment prend en charge les principales solutions de datawarehouse : Redshift, BigQuery, Postgres, Snowflake ou IBM DB2. Cependant, la fréquence de synchronisation est limitée à 1 ou 2 par jour avec les plans Free et Team. Elle peut être beaucoup plus courte, mais vous devrez passer au plan Business, qui est beaucoup plus coûteux.
La connexion aux sources de données est l’étape la plus technique dans Segment. Elle requiert l’implication de l’équipe Tech/Data.
#2 La vision client 360 et la construction de segments [Personas]
Une fois connectées, les données peuvent être unifiées autour d’un ID client unique. Segment offre un module (appelé « Personas ») qui permet de visualiser toutes les données rattachées à tel ou tel client et d’accéder à la fameuse « vision client unique » ou « vue client 360 ». Les données clients peuvent ensuite être utilisées pour construire des segments, c’est-à-dire des listes de contacts partageant des critères définis (socio-démographiques, comportementaux…). Les segments d’audience sont ensuite activables dans les outils de destination : MarTech et AdTech notamment.
Le module « Personas » de Segment est user-friendly, utilisable par les équipes métier en toute autonomie. Précisons que « Personas » n’est accessible que dans le plan « Business ».
Bon à savoir
Comme pour la grande majorité des fonctionnalités avancées de Segment, Personas n’est disponible que dans l’offre Business.
#3 La gestion de la Data Quality [Protocols]
Le troisième module clé de la plateforme Segment est appelé « Protocols » et sert à monitorer la qualité et l’intégrité des données. Précisons qu’il existe de nombreuses solutions technologiques « Best of Breed » offrant des fonctionnalités de Data Quality avancées. Par exemple, Metaplane ou Telm.ai. Octolis, les fonctions de Data Quality sont natives, ce qui signifie concrètement que vous n’avez pas besoin d’investir un budget supplémentaire dans une solution ou un module tiers pour gérer la qualité de vos données.
Découvrez les alternatives à Segment
Vous connaissez maintenant les 3 principaux modules de Segment. Pour chacun de ces modules, nous vous proposons les meilleures alternatives.
Nous avons présenté Segment, son histoire, ses fonctionnalités. Incontestablement, Segment est un bon outil. Il serait absurde de remettre en cause cette évidence, mais Segment a plusieurs limites. C’est sur ces limites que nous aimerions attirer votre attention dans cette deuxième partie.
Il y a deux principales limites : des prix qui augmentent rapidement et un manque de contrôle des données.
Limite #1 – Les prix de Segment augmentent rapidement
Segment propose une tarification basée sur le nombre de visiteurs traqués par mois (MTU : monthly tracked users) sur les différentes sources (site web, application mobile…). Ce modèle tarifaire convient aux entreprises qui génèrent de gros revenus par utilisateur et ont des utilisateurs très actifs (plus de 250 événements par mois). Au-delà de 250 événements par mois et par utilisateur en moyenne, vous devez passer sur le plan « Business » de Segment avec des prix personnalisés (sur devis).
Si vous envisagez d’utiliser Segment comme Customer Data Platform, vous arriverez rapidement à un budget de 100 000 dollars par an, surtout si vous êtes une entreprise B2C. En B2C, le nombre d’événements, de segments et de propriétés est toujours plus élevé qu’en B2B.
Segment n’a pas su adapter son offre pour s’adapter aux besoins et aux contraintes des entreprises souhaitant utiliser la plateforme pour déployer des cas d’usage CDP.
Les 3 formules proposées par Segment
Prenons deux exemples :
Vous avez un site web qui totalise 100 000 visiteurs uniques avec trois pages vues par mois en moyenne par visiteur. L’abonnement mensuel, pour 100 000 visiteurs traqués, est à environ $1000 par mois.
Imaginons que le site dédié à votre CRM génère environ 8000 MTUs pour une moyenne de 200 événements par MTU. Dans ce cas, Segment vous coûtera environ $120 par mois car vous restez sous la limite des 10 000 MTU du plan Team.
Limite #2 – Segment ne vous donne pas un contrôle complet sur vos données
L’ensemble des logs est stocké sur les serveurs de Segment. Vous avez la possibilité d’envoyer tous les logs sur votre datawarehouse si vous en avez un, mais vous devrez payer un supplément. Il y a ici à notre avis un des principaux inconvénients d’une solution comme Segment.
A cause ou grâce au durcissement du droit en matière de protection des données personnelles (RGPD notamment), le sens de l’histoire veut que les données first party soient stockées par l’entreprise dans son entrepôt de données, et non dans les différents logiciels et services SaaS. C’est le meilleur moyen de garder un contrôle entier sur ses données.
Le fait que les logs soient stockés dans Segment pose d’ailleurs un autre problème : vous êtes contraints de vous plier à un modèle de données qui n’est pas forcément adapté à votre entreprise. Segment propose un modèle de données limité à deux objets : les utilisateurs et les comptes et, dans la plupart des cas, un utilisateur ne peut appartenir qu’à un seul compte.
Dans quels cas Segment peut rester un bon choix ?
Malgré les limites que nous venons de rappeler, Segment peut rester un choix pertinent dans certains cas précis. Pour schématiser, on peut dire que les entreprises qui réunissent les critères suivants peuvent trouver un intérêt à choisir cette plateforme :
Vous êtes une entreprise B2B, avec peu d’utilisateurs/clients.
Vous avez une petite équipe IT/Data.
Le volume d’événements est faible ou moyen.
L’argent n’est pas un problème pour votre entreprise.
Vous souhaitez déployer des cas d’usage standards.
À partir d’un certain niveau de maturité et de développement de vos cas d’usage, vous aurez des besoins plus avancés en termes de tracking, d’agrégats. Cela signifie que vous devrez activer le module « Personas » que nous vous avons présenté plus haut. Sachez que ce module additionnel est facturé en plus…et coûte très cher. À ce moment-là, vous serez confrontés à une alternative : rester sur Segment et être prêt à payer 100k€ par an…ou changer d’architecture et opter pour la mise en place d’une stack data moderne.
La Stack Data Moderne offre de plus en plus d’alternatives à Segment
Répétons encore une fois que Segment est indubitablement un très bon outil. Le problème n’est pas là. En revanche, nous pensons qu’il appartient à une famille d’outils (les CDP sur l’étagère) qui est déjà dépassée.
Les limites des CDP sur l’étagère
Les Customer Data Platforms sur l’étagère ont connu leur heure de gloire à la fin des années 2010. On assiste depuis quelque temps à l’émergence de nouvelles approches pour collecter, unifier et transformer les données clients. Nous vous présenterons dans un instant l’approche moderne, mais avant voici les principales limites des Customer Data Platforms sur l’étagère dont Segment fait partie :
#1 Les CDP ne sont plus la source unique de vérité
De plus en plus, c’est le sens de l’histoire comme nous l’avons vu, les données sont stockées et unifiées dans des datawarehouse cloud comme BigQuery, Snowflake ou Redshift. Les données centralisées dans le datawarehouse (DWH) sont utilisées pour faire du reporting et de la BI. Le DWH centralise TOUTES les données, contrairement aux Customer Data Platforms qui ne contiennent que les données générées via les sources connectées : essentiellement des données clients au sens large.
#2 Les CDP ont tendance à générer des silos de données
Il y a deux raisons principales. Premièrement, les CDP sont conçues By Design pour les équipes marketing. Les éditeurs mettent clairement en avant cette caractéristique….sauf que ça n’a pas que du bon. Pourquoi ? Parce que ça conduit les équipes marketing d’une part et les équipes data d’autre part à travailler chacune dans leur coin sur des outils différents. On se retrouve avec deux sources de vérité :
La Customer Data Platform pour l’équipe marketing.
Le datawarehouse ou le data lake pour l’équipe IT.
Une CDP autonomise l’équipe marketing vis-à-vis de l’IT mais favorise le cloisonnement des deux fonctions, et in fine leur désalignement.
Nous sommes au contraire convaincus que les équipes marketing et IT/Data doivent travailler main dans la main.
#3 Les CDP standards ont des capacités limitées de préparation & transformation des données
Les Customer Data Platforms conventionnelles ont des fonctionnalités limitées en termes de transformation des données. Ce problème fait d’ailleurs écho à la problématique des modèles de données. Les transformations de données ne sont possibles que dans le cadre des modèles de données imposés.
Le manque de flexibilité des modèles de données offerts (ou imposés…) par les CDP conduit à organiser les données d’une manière qui ne fait pas toujours sens d’un point de vue business.
#4 Le manque de contrôle des données
Nous avons déjà mis en relief ce problème. Le fait de stocker toutes les données dans votre CDP pose des problèmes de privacy et de sécurité. Il devient de plus en plus incontournable de stocker les données en dehors des logiciels, dans une base autonome gérée par l’entreprise elle-même. Ce qui nous amène au point suivant.
Le contrôle des données, pourquoi faire ?
Le contrôle des données n’est pas un « nice to have », c’est un must have. Découvrez pourquoi il est capital de garder le contrôle de ses données.
La montée en puissance des Data Warehouses Cloud
En une décennie, beaucoup de choses ont changé dans la manière de collecter, d’extraire, de faire circuler, de stocker, de préparer, de transformer, de redistribuer et d’activer les données. L’évolution la plus importante est à trouver dans la place centrale que jouent désormais les datawarehouse cloud modernes. Le DWH devient le pivot du système d’information, le centre de l’architecture IT autour duquel gravitent tous les autres outils.
Amazon a joué un rôle décisif dans cette révolution, avec le lancement de Redshift en 2012. C’est l’effondrement des coûts de stockage et l’augmentation exponentielle de la puissance de calcul des machines qui a changé la donne. Cela a entraîné une démocratisation des datawarehouses. Aujourd’hui, une petite entreprise avec des besoins limités peut utiliser Redshift pour quelques centaines d’euros par mois. Pour information, la licence annuelle d’un datawarehouse classique, « On-Premise », atteint facilement les 100k€…
Schéma type d’une stack data modern, avec le cloud data warehouse comme pivot.
Les datawarehouse clouds sont devenus le nouveau standard pour la plupart des organisations. Ils sont utilisés pour stocker toutes les données, notamment les données clients mais pas que. Toutes les données de l’entreprise peuvent y être centralisées et organisées.
Comprendre le rôle des Reverse ETL
Les solutions de datawarehouse cloud ont connu un essor important depuis 2012. Les Gafam se sont presque tous engagés sur ce marché : Google a développé BigQuery, Microsoft a lancé Azure, etc. On a aussi vu l’émergence de purs players comme Snowflake par exemple qui connaît une croissance ébouriffante.
Source : Get Latka.
Mais il manquait une brique fonctionnelle permettant de synchroniser les données du datawarehouse dans les logiciels d’activation, pour ne pas que le datawarehouse ne serve qu’à faire du reporting. Une nouvelle famille d’outils est apparue à la fin toute fin des années 2010 pour remplir cette fonction : les Reverse ETL.
Un Reverse ETL synchronise les données du DWH dans les outils opérationnels : Ads, CRM, support, Marketing Automation…Il fait donc l’inverse d’un ETL qui, lui, sert à faire remonter les données dans le datawarehouse. D’où le nom « Reverse ETL ». Avec un Reverse ETL :
Vous gardez le contrôle de vos données, car celles-ci restent dans votre data warehouse : le Reverse ETL est un outil de synchronisation. Vos données ne quittent jamais le DWH.
Vous pouvez créer des modèles de données personnalisés, loin d’être limités aux deux objets proposés par Segment (utilisateurs et comptes).
Les data warehouses modernes et les Reverse ETL dessinent une nouvelle architecture : la stack data moderne. Avec ces deux technologies associées, votre data warehouse devient votre CDP. Cette architecture rend possible la mise en place de l’approche « Operational Analytics » qui, en un mot, consiste à mettre les données au service des opérations business et non plus uniquement au service de l’analytics.
A la découverte de la Stack Data Moderne
La stack data moderne est l’architecture consistant à faire du data warehouse la source unique de vérité du SI et à utiliser un Reverse ETL pour activer les données du DWH dans les logiciels opérationnels. Découvrez notre guide complet sur la Stack Data Moderne.
Accéder à notre comparatif des meilleures alternatives à Segment
Pour accéder à la ressource, il vous suffit de cliquer sur le bouton ci-dessous
Une fois dans notre espace dédiée, vous découvrirez d'autres ressources structurantes, les plus complètes nécessitent une inscription rapide mais sont toutes gratuites !
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Êtes-vous vraiment certain d’avoir le contrôle sur vos données clients ? Si vous lisez ces lignes, c’est peut-être qu’un doute vous assaille. Et vous avez raison de douter, car il y a des chances que vous n’ayez pas la maîtrise de vos données.
Si vos données clients sont stockées dans vos logiciels (CRM, CDP, Marketing Automation), vous n’avez pas un accès complet aux données et vous n’êtes pas libre de gérer les règles de sécurité et de confidentialité de manière aussi fine qu’il le faudrait. Vous êtes prisonnier des modèles de données proposés (imposés…) par les éditeurs. Vous êtes enfermé dans leur écosystème. Rassurez-vous, si vous êtes dans ce cas vous n’êtes pas le seul. La plupart des organisations acceptent de stocker leurs données dans leurs applicatifs Saas.
Il est temps que les choses changent et que vous repreniez le contrôle de vos données clients.
Commençons par préciser de quoi on parle. Qu’est-ce que ça veut dire concrètement avoir le contrôle de ses données ? Il y a 3 dimensions clés associées au contrôle des données. Avoir le contrôle sur ses données, c’est :
Avoir un accès complet à ses données.
Pouvoir gérer la sécurité des données (droits & permissions).
Gestion de la confidentialité des données.
Revenons en détail sur chacun de ces points, en nous appuyant sur des exemples d’outils : Google Analytics, Snowflake et Amazon S3.
Critères
Google Analytics
Snowflake
AWS S3
Data center 'in-house'
Accessibilité des données
🔒
🔒🔒
🔒🔒🔒
🔒🔒🔒
Sécurité des données
🔒
🔒🔒
🔒🔒
🔒🔒🔒
Contrôle de la confidentialité
🔒
🔒🔒
🔒🔒
🔒🔒🔒
#1 Accessibilité des données (Niveau d’ouverture des données)
Première dimension de contrôle des données : l’accessibilité, le niveau d’accès à vos données. Il varie suivant les outils et systèmes utilisés. Si l’on prend les exemples de Google Analytics, de Snowflake et de AWS 3, il y a un point commun : dans les trois cas, les données sont hébergées dans le cloud, mais le niveau d’accessibilité des données n’est pas du tout identique.
Les données stockées dans Google Analytics ne sont accessibles qu’au travers des tableaux de bord et rapports auxquels Google vous donne accès. Il n’y a pas moyen d’accéder aux données sous-jacentes qui sont utilisées pour construire les dashboards. Vous ne pouvez pas faire de requête SQL sur la base de données Google Analytics. Donc, clairement, le niveau d’accès aux données sur Google Analytics est très faible. Vous n’avez pas le contrôle de vos données !
Dans une infrastructure cloud comme Snowflake, vous pouvez interagir avec vos données via des requêtes SQL complexes, en bénéficiant de toute la puissance de calcul offerte par un DWH Cloud moderne. Par contre, vous ne pouvez pas exécuter de Spark jobs.
Ce serait possible techniquement, mais très coûteux à faire dans la pratique. C’est en revanche faisable avec Amazon S3 qui, de ce fait, est la solution qui offre le meilleur niveau d’accès aux données. Non seulement, vous pouvez connecter S3 à vos outils de BI et exécuter des requêtes SQL, mais vous pouvez extraire les données et les charger dans Spark ou vos autres applications.
La question de l’accès aux données englobe aussi celle de la portabilité des données, c’est-à-dire de la capacité d’extraire les données de l’outil où elles sont stockées pour les héberger ailleurs, dans une autre base, un autre outil. En matière de portabilité, c’est Amazon S3 qui remporte la palme. Vous pouvez facilement basculer vos données d’Amazon S3 vers Google Cloud par exemple. À l’inverse, les données de Google Analytics ne peuvent être extraites vers d’autres systèmes dans leur état brut.
#2 Sécurité des données (gestion et contrôle des accès & permissions)
La deuxième dimension du contrôle des données, c’est la sécurité. Le niveau de sécurité des données se mesure à la capacité que vous avez de gérer les accès à vos données. Si vous gérez tout, alors le niveau de sécurité des données est au top. Si vous choisissez une solution cloud, qu’il s’agisse de Google Analytics et d’une infrastructure cloud comme Amazon S3, vous n’avez pas de contrôle complet sur la sécurité des données. Vous êtes limité par les fonctionnalités de gestion d’accès & de droits proposées par la solution.
Sur Google Analytics, vous pouvez gérer les accès basés sur l’utilisateur, mais vous ne pouvez pas mettre en place un contrôle d’accès basé sur les attributs, contrairement à ce qui est possible avec Amazon S3. Si vous stockez vos données sur vos propres machines, vous pouvez créer des mécaniques de gestion des droits et des permissions 100% sur-mesure. Le niveau de contrôle sur la sécurité des données sera toujours inférieur avec une solution SaaS/Cloud qu’avec une solution auto-hébergée. Plus les données que vous stockez sont sensibles, plus il est important de bien s’informer sur les politiques appliquées par les éditeurs cloud…
Les besoins en matière de gestion de la sécurité ne sont pas les mêmes d’une entreprise à l’autre. Une entreprise qui a une petite base clients et qui collecte peu de données sur ses clients aura typiquement moins de gêne à héberger ses données dans une infrastructure cloud comme Snowflake ou Amazon S3 qu’une grande banque qui stocke de gros volumes de données très sensibles.
#3 Gestion de la confidentialité
La gestion de la confidentialité est la troisième dimension du contrôle des données.
La sécurité des données, dont nous avons parlé plus haut, c’est la question de savoir qui a accès à vos données. La confidentialité des données, c’est la question de l’usage des données et celle de savoir si l’usage que vous voulez faire des données est légal et consenti par l’utilisateur.
Reprenons nos 3 exemples pour illustrer cette dimension : Google Analytics, Snowflake et Amazon S3. Dans ces trois entreprises, il y a des collaborateurs qui ont accès à vos données brutes. Par contre, ce qu’ils peuvent faire ou font avec vos données varie :
Google Analytics. Il y a forcément des salariés de Google qui ont accès aux rapports que vous avez configurés dans Analytics. Il est très probable que Google utilise « vos » données Google Analytics pour créer un profil utilisateur et à des fins marketing. Même si l’on ne sait pas très bien ce que Google fait de vos données visiteurs/clients, il n’y a aucun doute sur le fait qu’il les utilise.
Snowflake et AWS3. Il y a des chances que des salariés au sein de ces entreprises aient un accès plus ou moins limité à vos données brutes, mais leurs capacités d’analyse sont plus limitées. Il faudrait qu’ils soient capables de faire du reverse engineering pour utiliser vos données. Ils n’ont pas la capacité de relier les données clients entre elles et de créer un profil utilisateur comme peut le faire Google. Par ailleurs, signalons que, dans S3, vous avez la possibilité de crypter vos données.
En matière de confidentialité, c’est à des solutions d’infrastructure cloud comme Snowflake ou AWS 3 que va le point, clairement.
Absence de contrôle des données = risque
Le couplage données <> applicatifs, un héritage des éditeurs de CRM/CDP
Les données clients sont exploitées par les solutions CRM, les logiciels de Marketing Automation et autres Customer Data Platforms. Elles en constituent le carburant. Ce qui caractérise ces logiciels, c’est le couplage données <> applicatifs. En clair, vos données sont stockées dans les applicatifs, dans vos logiciels. Il n’y a pas de séparation de la couche de données et de la couche logicielle.
C’est le mode de fonctionnement traditionnel des éditeurs de CRM et de CDP. Les données sont collectées, stockées et activées par et dans le logiciel. Le CRM, ou la CDP, est à la fois base de données (avec accès restreint aux données) et outil d’activation. Le développement du modèle SaaS dans l’univers du CRM n’a pas changé grand-chose à cette situation : le couplage reste la règle. Traditionnel ou SaaS, même combat. Même chose pour les Customer Data Platforms dont on parle tant depuis quelques années.
Pourquoi stocker les données clients dans les logiciels (CRM, CDP…) est problématique ?
Le fait que les données clients soient stockées dans les applicatifs pose problème pour plusieurs raisons. Ce caractère problématique, pour des raisons évidentes, est rarement évoqué par les éditeurs, pas plus que par les intégrateurs et autres ESN qui profitent de la prison dont ce couplage est synonyme.
Le « Guantanamo numérique », évoqué par Louis Naugès, où les ESN jouent le rôle de gardiens des DSI emprisonnés.
Les données clients sont votre actif le plus précieux. Or, les éditeurs CRM, CDP, Marketing Automation ne vous donnent qu’un accès restreint à ces données. Vous êtes prisonnier des modèles de données imposés par le logiciel, vous ne vous pouvez pas accéder à vos données dans leur état brut et les organiser dans le modèle de données de votre choix. Vous êtes limité par les choix d’infrastructure faits par l’éditeur de la solution.
Les conséquences sur le plan métier sont plus graves qu’elles ne le semblent. Le manque de flexibilité des modèles de données proposées par ces éditeurs réduit la capacité de vos équipes marketing à adapter les scores et les règles de traitement aux spécificités de votre activité. Des campagnes moins ciblées ou une personnalisation moins importante, peut être fatal dans la course à la relation client ultime et omnicanal que mènent les marques aujourd’hui.
L’autre conséquence directe de ce manque de flexibilité réside dans le manque de progression et de maturité de vos équipes dans l’exploitation des données clients. Vos équipes métiers ne vont pas apprendre à imaginer des cas d’usage en dehors du cadre proposé par votre CRM ou CDP et vous passerez à côté d’opportunités au sein de votre parcours client.
Découvrir des cas d’usages métiers
Pour vous aider à imaginer ce que vous seriez en mesure de faire si vous aviez un total contrôle sur vos données, nous avons constitué une librairie de cas d’usages concrets, n’hésitez pas à la consulter.
D’autre part, l’accès à votre base de données clients, organisée et stockée dans votre CRM/CDP, est payant. Vous devez payer pour visualiser et utiliser vos données ! Vous devez payer des droits d’accès. Comme chacun sait, le modèle économique des solutions classiques d’activation des données clients (CRM, Marketing Automation, ERP, CDP) est la tarification au nombre d’utilisateur. Même un utilisateur qui n’a besoin d’accéder à la base de données de manière très ponctuelle devra s’acquitter d’un abonnement.
En fait, vous êtes enfermé dans un écosystème donné qui vous coupe de l’extérieur. Cet écosystème, c’est celui construit par l’éditeur. Il peut être vaste : pensons aux CRM qui proposent des dizaines de modules différents. Mais ça n’en reste pas moins un cadre rigide.
L’exemple de BlackBerry
Pour illustrer, prenons l’exemple de BlackBerry. On doit cet exemple à David Bessis, qui le décrit dans un bel article Medium consacré à la montée en puissance des technologies data ouvertes. Grosso modo, BlackBerry étaient les rois du monde de 2001 à 2008. Et puis est arrivé l’iPhone, en 2007. Et puis un peu plus tard encore, Android. Et patatra, BlackBerry s’est effondré.
Entre 2008 et 2012, la part de marché de BlackBerry a été divisée par 20. Il y a plusieurs raisons à cela, mais la principale est la suivante : BlackBerry a été construit comme une boîte noire. Personne ne pouvait créer d’applications BlackBerry, c’était BlackBerry qui avait la main sur l’écriture du code…contrairement à iOS et Android qui se sont tout de suite positionnés comme des plateformes ouvertes.
À l’instar de BlackBerry, les éditeurs CRM / CDP sont des plateformes fermées qui freinent le développement et l’enrichissement de vos cas d’usage data. Pensez-y, comme vous seriez plus libres si vous pouviez disposer de vos données dans une base indépendante de votre CRM/CDP pour pouvoir l’exploiter dans d’autres outils, pour d’autres finalités !
Une solution, même s’il s’agit d’une suite de logiciels, ne peut pas tout faire. S’enfermer dans l’écosystème d’un éditeur, c’est forcément passer à côté de certains usages de la donnée clients.
Comment la stack data moderne permet de reprendre le contrôle de vos données ?
Nous avons montré qu’il y avait un problème : le couplage des données et des applicatifs qui les utilisent. La conséquence, c’est le manque de contrôle des données, de vos données clients. La solution, c’est ce dont nous allons parler maintenant : la Stack Data Moderne. Le terme est barbare, jargonneux, on vous l’accorde, mais la réalité qu’il désigne est simple. C’est une nouvelle manière d’organiser les données, une organisation tripartite :
Un Datawarehouse Cloud qui sert de socle data de l’entreprise. C’est la base de données principale de l’entreprise qui permet d’unifier les données structurées et semi-structurées.
Les outils métiers qui exploitent les données à des fins d’analyse mais aussi et surtout à des fins d’activation. En clair, les outils de BI de type Tableau ou PowerBI mais aussi et surtout les outils de type CRM, Marketing Automation, Google/Facebook Ads, Diabolocom…
Un ETL et/ou un Reverse ETL qui permet de faire circuler la donnée entre le Datawarehouse et les autres systèmes de l’entreprise : les logiciels.
Le Datawarehouse moderne comme socle opérationnel
Précisons que nous ne parlons pas ici des Datawarehouses de la nouvelle génération, en plein essor depuis le début des années 2010 : les Datawarehouses cloud. On pense à des noms comme BigQuery (Google), Snowflake, Redshift (Amazon) ou Azure (Microsoft)… Ces infrastructures cloud se sont démocratisées et sont désormais accessibles aux PME, aux startups…
Alors, de quoi parle-t-on ? Un Datawarehouse moderne est une base de données cloud qui sert à stocker toutes les données structurées ou semi-structurées de l’entreprise. Plus qu’un simple entrepôt, un Datawarehouse est une machine de guerre qui permet d’exécuter des requêtes SQL et de réaliser des opérations de jointure sur des volumes énormes de données…le tout beaucoup plus rapidement que les bases de données transactionnelles (OLTP).
Nous sommes convaincus aujourd’hui :
Que les données doivent être stockées dans une base de données distincte des logiciels.
Que le Datawarehouse cloud est de loin la solution la plus puissante et la plus économique pour faire office de base de données maîtresse.
Dans cette optique, le Datawarehouse a vocation à devenir la clé de voûte, la solution pivot du système d’information de l’entreprise moderne. Dans cet article sur la Stack Data Moderne, nous revenons plus en détail sur nos convictions vis-à-vis des infrastructures cloud de type Datawarehouse et les principaux avantages de ces solutions. Découvrez aussi notre article « Pourquoi vous devez utiliser votre Data Warehouse pour jouer le rôle de Customer Data Platform« .
ETL & Reverse ETL
On peut se représenter la Stack Data Moderne de cette manière :
L’ETL et le Reverse ETL sont les outils qui permettent de mieux faire circuler la donnée dans le système d’information et dans les outils, tout en en gardant le contrôle. Plus précisément :
L’ETL (Extract – Transform – Load) est la technologie qui se connecte aux sources de données, les transforme et les charge dans le Datawarehouse cloud. Deux exemples d’ETL ? Stitch Data & Fivetran.
Le Reverse ETL est une famille de solutions plus récente qui permet de redistribuer les données du Data Warehouse aux outils métiers (CRM, Marketing Automation, ecommerce…), sous forme de segments, d’agrégats, de scorings. Il est la pièce maîtresse qui permet de mettre les données du datawarehouse au service des équipes métiers. Un exemple de Reverse ETL ? Octolis !
C’est cette architecture data moderne, articulant Data Warehouse Cloud et ETL/Reverse ETL, qui assure le plus haut niveau de contrôle des données :
Les données sont stockées dans une base de données indépendante des logiciels. En clair, elles ne sont stockées ni dans vos applicatifs métiers, ni dans votre ETL, ni dans votre Reverse ETL, mais dans votre entrepôt de données.
Vous pouvez créer des modèles de données sur-mesure répondant à vos besoins et cas d’usage spécifiques.
Les performances de calcul de votre BDD sont bien meilleures que ce qu’offrent les éditeurs de CRM/CDP.
Vous contrôlez de manière centralisée et granulaire les accès et les permissions à la base de données (le DWH).
Conclusion
Les entreprises doivent prendre conscience des risques et des coûts qu’il y a à stocker les données clients dans des logiciels, aussi puissants soient-ils (CDP). Aujourd’hui, il est possible et souhaitable que vous repreniez le contrôle sur vos données clients. Nous avons vu que cela passait par une nouvelle organisation de vos données, ce qu’on appelle de manière un jargonneuse la « stack data moderne » : vos données clients sont hébergées et consolidées dans un Data Warehouse et redistribuées à vos logiciels via une solution de type « Reverse ETL » comme Octolis.
La souveraineté des données est une condition nécessaire (bien que non suffisante) pour déployer des cas d’usage des données innovants et ROIstes. En clair, reprendre le contrôle de vos données clients est la première étape pour devenir réellement data-driven.
Premier test utilisateur après des mois de développement
Nous sommes très heureux de lancer officiellement Octolis en ce mois de janvier 2022.
Pour ne pas connaître la même déconvenue que le concepteur de ce labyrinthe, nous avons développé Octolis en nous appuyant très tôt sur des feedbacks clients.
Cela fait quasiment un an que nous avons des clients qui utilisent la première version du produit, dont de belles marques comme KFC ou Le Coq Sportif. On est resté discrets, et on a énormément travaillé pendant des mois avec quelques clients pour améliorer notre produit, encore et encore.
Et maintenant, il est temps d’ouvrir les portes, Octolis est désormais accessible à toutes les entreprises qui le souhaitent !
Nous avons beaucoup à dire sur les raisons qui nous ont poussées à lancer Octolis. Si vous n’avez pas le temps de tout lire, voici ce que pouvez retenir en quelques mots :
Nous sommes convaincus que la montée en régime des datawarehouses cloud modernes va profondément changer les organisations. Quand toutes les données de l’entreprise sont stockées dans un entrepôt, je peux utiliser cet entrepôt pour alimenter toutes mes équipes, tous mes outils. Octolis, c’est en quelque sorte le logisticien de vos données.
Nous allons donner aux PME les moyens de devenir vraiment “data driven”. Pas pour créer des reportings à peine utilisés, pas pour faire un énième POC de machine learning qui ne sera jamais mis en production, mais pour améliorer les actions du quotidien.
Nous avons développé la solution de data management qu’on aurait aimé avoir dans nos précédentes expériences. Une solution suffisamment simple pour être utilisée par des marketers, et ouverte/souple pour les équipes tech/data.
Le problème classique du silotage des données
Clément et moi, nous sommes rencontrés chez Cartelis, où nous avons été consultants data pendant des années. On a eu la chance de travailler pour des entreprises avec des tailles et des niveaux de maturité digitale très variées, de belles start-up comme Openclassrooms, Blablacar ou Sendinblue, mais aussi des entreprises plus traditionnelles comme RATP, Burger King ou Randstad.
Dans quasiment toutes les entreprises pour lesquelles nous avons travaillé, il y avait de gros challenges autour de la réconciliation des données clients.
Le problème est assez simple en apparence. Toutes les équipes aimeraient disposer d’un maximum d’informations sur chaque client dans les outils qu’elles utilisent au quotidien. Les équipes commerciales veulent voir dans leur logiciel CRM si le client a utilisé le produit récemment pour le relancer au bon moment, les équipes marketing veulent mettre en place des messages automatisés après qu’un client se soit plaint auprès du service client ou qu’il ait visité une page spécifique du site internet, le service client veut prioriser les tickets clients en fonction de la taille et du risque de perdre un client, etc.
Les outils qui permettent d’interagir avec les prospects / clients sont de plus en plus puissants, mais ils sont sous-exploités car on a du mal à les alimenter avec toutes les données dont on a besoin. La raison principale, c’est qu’on a des données intéressantes partout. Les parcours clients sont complexes, les interactions entre l’entreprise et ses clients reposent sur de plus en plus de canaux et d’outils différents (application mobile, chat automatisé, marketing automation, retargeting publicitaire, service client, etc.), cela génère une quantité phénoménale de données potentiellement utilisables pour personnaliser la relation client.
Pour répondre à ce challenge, la plupart des entreprises commencent de manière pragmatique par mettre en place des tuyaux entre les outils. Pour chaque projet, on met en place de nouveaux tuyaux grâce à des outils simples en apparence comme Zapier ou Integromat. Évidemment, cela devient très vite un gros sac de nœuds, difficile à maintenir et à faire évoluer.
Ensuite vient le moment où on juge qu’il est temps de centraliser toutes les données clients au même endroit. On liste les nombreux avantages (connaissance client complète, accélération des projets, ..) pour justifier du ROI potentiel, on définit un budget cible, et on prend son souffle pour se lancer dans un gros projet “Référentiel Clients (Unique)” ou “Base clients 360” qui fait peur.
La grosse question, c’est de savoir quelle forme va prendre ce fameux référentiel clients complet. Les options envisagées la plupart du temps sont principalement :
Une solution déjà existante : CRM ou ERP
Une base de données sur mesure
Une solution logicielle dédiée à cet objectif, une “Customer Data Platform”
En réalité, la source de vérité unique existe déjà dans beaucoup d’entreprises, ça s’appelle un “datawarehouse”.
Historiquement le datawarehouse est une base de données qui sert de socle pour des analyses, et non pour des usages opérationnels. Les solutions utilisées comme datawarehouses étaient construites pour supporter de grosses requêtes ponctuelles, avec des données mises à jour une fois par jour au mieux. Désormais, les datawarehouses modernes peuvent supporter tout type de requêtes, en quasi-temps réel, à un prix beaucoup plus compétitif, sans effort de maintenance, et ça change tout.
La stack data moderne définit un nouveau paradigme
Le gros changement des dernières années, c’est la montée en régime d’une nouvelle génération de datawarehouse cloud (Snowflake, Google BigQuery, Firebolt, ..). L’introduction en bourse record de Snowflake en 2020, avec une valorisation qui continue d’augmenter, est le reflet financier de cette rupture majeure. Cela fait pourtant des années qu’Oracle, IBM ou Microsoft proposent des solutions de type “Data warehouses” (ou Data Lakes), qu’est ce qui a changé concrètement ?
La nouvelle génération de datawarehouses cloud dispose de 3 avantages majeurs :
Rapidité / puissance : on peut accéder à une puissance de calcul phénoménale par rapport aux standards de 2010 en quelques clics.
Prix : le découplage entre le stockage et le traitement des données a réduit significativement le coût de stockage. On paie à l’usage, en fonction des requêtes réalisées, mais stocker de gros volumes de données ne coûte quasiment plus rien.
Accessibilité : la mise en place et la maintenance sont beaucoup plus simples, il n’est plus nécessaire d’avoir un régiment d’ingénieurs réseau pour gérer un datawarehouse.
Voici un très bon article sur le sujet des datawarehouse écrit par nos amis de Castor si vous souhaitez en savoir plus.
Grâce à ces innovations, l’adoption des datawarehouses cloud explose, et c’est tout un nouvel écosystème qui est en train de se structurer autour.
Des outils “Extract Load (Transform)” comme Airbyte ou Fivetran pour alimenter le datawarehouse avec les données présentes dans tous les applicatifs internes.
Des outils comme DBT pour transformer les données directement dans le datawarehouse.
Des outils comme Dataiku pour faire des projets de data science directement dans votre datawarehouse.
Des outils de reporting comme Metabase ou Qlik
Et désormais des outils d’activation (ou reverse ETL dans la novlangue martech) comme Octolis pour enrichir les outils opérationnels à partir des données du datawarehouse.
Si le sujet de la stack data moderne vous intéresse, on a écrit un article plus complet sur le sujet.
Le datawarehouse moderne devient un socle pour l’analyse et l’opérationnel
Il est désormais possible d’utiliser le datawarehouse comme un référentiel opérationnel. On peut assez facilement construire l’équivalent d’une Customer Data Platform dans un datawarehouse, c’est ce que certains experts appellent l’approche Headless CDP.
C’est une tendance de plus en plus populaire dans les entreprises matures, qui aura un impact significatif sur l’ensemble de la chaîne de valeur du SaaS. Dans cet article, David Bessis, le fondateur de Tinyclues, insiste sur le fait que cette évolution va limiter la dépendance aux solutions logicielles complètes proposées par Adobe / Salesforce / Oracle. Cela peut expliquer pourquoi Salesforce a investi significativement dans Snowflake d’ailleurs…
Les avantages d’utiliser le datawarehouse comme socle des outils opérationnels sont nombreux.
Limiter le travail d’intégration / traitement de données, on importe les données à un seul endroit, on les transforme une seule fois, et elles servent partout ensuite.
Garder le contrôle des données, et faciliter le passage d’une solution logicielle à l’autre.
Aligner l’analyse et l’action, ce sont les mêmes données qui servent pour les reportings et pour alimenter les outils. Quand un analyste calcule une fréquence d’achat, cela peut aussi servir dans les outils CRM ou emailing.
Cela permet d’accélérer de nombreux projets qui étaient compliqués jusqu’à présent. On pense forcément aux cas d’usages classiques d’une “Customer Data Platform” :
vision 360 de chaque prospect / client avec toutes les interactions associées à chaque individu
segmentations / scorings avancés utilisables dans les outils marketing
utilisation des données “first party” dans les campagnes d’acquisition pour cibler des profils similaires à vos meilleurs clients, relancer les non-ouvreurs emails ou utiliser la LTV comme indicateur de succès des campagnes.
Mais on peut penser aussi à des cas d’usages moins centrés sur les données clients, comme par exemple :
enrichir un moteur de recommandations produit du stock produit disponible ou de la marge par produit.
créer des “events web” à partir des appels téléphoniques ou des achats offline pour avoir une vision complète des parcours clients dans les outils d’analytics web.
générer des alertes Slack quand une campagne Adword est mal paramétrée ou un lead mal complété sur Salesforce.
Jusqu’à présent, les entreprises qui utilisaient leur datawarehouse pour des usages opérationnels mettaient en place des connecteurs sur mesure pour envoyer les données du datawarehouse vers les outils métiers. Ces connecteurs peuvent être assez complexes à mettre en place car il faut gérer des problèmes de format de données, des flux en “batch” ou en temps réel, des quotas API, etc. Et puis il faut maintenir ces connecteurs une fois qu’ils sont mis en place.
Une nouvelle catégorie d’outils est en train d’émerger pour faciliter la synchronisation des données du datawarehouse aux outils métiers. Même si le terme ne fait pas encore consensus, c’est le concept de “Reverse ETL” qui est le plus souvent utilisée pour parler de cette nouvelle catégorie d’outils.
Octolis permet à toutes les PME de s’équiper pour exploiter leurs données dans leurs outils existants
La plupart des start-up matures ou des grandes entreprises disposant d’une belle équipe d’ingénieurs data ont déjà mis en place ce type d’architecture, mais on en est encore très loin dans la plupart des entreprises de taille moyenne.
Cela va s’accélérer à pleine vitesse dans les prochaines années. L’écosystème autour de la “stack data moderne” a beaucoup mûri, et les décideurs sont de plus en plus conscients que la maturité data est un axe prioritaire dans les prochaines années.
Le blocage est souvent humain, les compétences en ingénierie data sont rares et chères.
Octolis veut devenir la solution de référence pour les PME / ETI qui veulent passer un gros palier dans l’exploitation de leurs données sans disposer d’une équipe d’ingénieurs data.
On propose une solution clé en main qui permet de :
Centraliser les données de différents outils dans un datawarehouse
Croiser et préparer ses données facilement, pour avoir de belles tables de référence avec les clients, achats, produits, contrats, magasins, etc.
Synchroniser les données avec les outils opérationnels : CRM, Marketing Automation, Ads, Service client, Slack, etc.
Nous sommes convaincus chez Octolis qu’il est possible de donner de l’autonomie aux équipes marketing tout en laissant un certain niveau de contrôle aux équipes IT.
L’interface du logiciel Octolis est suffisamment simple pour qu’un marketer puisse croiser / préparer des données, et les envoyer où il en a besoin. Cette simplicité ne signifie pas qu’il s’agit d’une boîte noire. Les données sont hébergées dans la base de données ou le datawarehouse de chaque client, accessible par les équipes IT à tout moment, sur laquelle on branche un outil de reporting.
Avec Octolis, une PME peut disposer d’un socle solide pour monter ses reportings, et surtout pour accélérer tous ses projets marketing / sales.
Le potentiel est énorme, les cas d’usages sont innombrables, et nous nous levons très motivés tous les matins pour améliorer encore et encore le produit et aider nos clients à exploiter pleinement le potentiel de leurs données !
Comparatif de 40+ logiciels de marketing automation – Benchmark téléchargeable
Pour les non-initiés, l’écosystème des logiciels de marketing automation est difficilement lisible.
Et pour cause, il existe des dizaines de solutions que l’on peut assimiler à des outils marketing automation ! Pourtant, difficile voire impossible, de comparer une solution légère comme Sendinblue dont le prix s’élève à quelques dizaines d’euros par mois à une solution beaucoup plus complète comme Salesforce Marketing Cloud pour laquelle on parlera de dizaine de milliers d’euros.
Vous souhaitez déployer un logiciel de marketing automation mais vous peinez à identifier la solution adaptée à votre besoin ?
Pas de panique 🙂 On a comparé pour vous plus de 40 logiciels, qu’on a catégorisés en fonction de leur positionnement, de leur coût et de leur périmètre fonctionnel !
Pour comparer des choux avec des choux, il faut comprendre la différence entre choux et carottes
Avant de rentrer dans le vif du sujet, commençons par rappeler quelques bases importantes lorsqu’il s’agit de choisir votre outil « CRM Marketing » ou de marketing automation.
Différents types de logiciels de marketing automation
Nous l’avons évoqué au cours de l’introduction, de plus en plus de logiciels se revendiquent comme appartenant à cette nouvelle famille d’outils. Comme vous pouvez l’imaginer, il existe peu de points communs entre une solution à moins de 5k € par an comme Sendinblue et une solution comme Adobe Campaign, pour laquelle il faudra compter environ 10 fois plus !
Pour faciliter votre compréhension du marché, nous avons catégorisé les outils disponibles à travers 3 grandes familles. Ce classement est principalement basé sur le prix, mais ce dernier impacte directement la couverture fonctionnelle proposée et principalement en ce qui concerne la gestion de la base de données clients.
Les solutions « légères » : Souvent issues d’outils d’emailing, ces solutions se sont développées et proposent désormais des modules de marketing automation corrects. La gestion des données clients est basique et la plupart du temps limitée à une clé « email ».
Les solutions « intermédiaires » : Plus robustes, elles permettent une gestion de la base de données clients (sans grande flexibilité) sur laquelle reposent vos scénarios de marketing automation.
Les solutions « avancées » : On les appelle également « écosystèmes » tellement ces solutions se révèlent puissantes et souples en termes d’architecture et de BDD mulli-tables. Leur limite ? Le coût bien entendu, tant sur le set-up que sur la licence. Ces outils s’adressent définitivement à des organisations très matures.
Différents niveaux de profondeur pour chaque fonctionnalité
L’utilisation de termes très jargonneux sur les pages « produit » de ces différentes solutions ne facilite pas votre compréhension. En effet, si la majorité des logiciels proposent les briques fonctionnelles ci-dessous, leur profondeur est en réalité très variable.
On vous invite à lire l’article source réalisé par nos partenaires Cartelis, un cabinet de conseil data / CRM, pour avoir plus de détail sur les différents niveaux de profondeur de chaque fonctionnalité.
Pour les organisations matures dont les besoins sont avancés notamment en termes de référentiel client et de vision 360° des clients, votre choix ne se résume pas aux solutions « avancées » évoquées précédemment.
Il y a pas mal de limites structurelles à faire de votre solution de Marketing Automation votre base de données clients principale, notamment :
Modèle de données rigide
Pas de traitements de données : déduplication multi-clés, ajout de champs calculés, etc.
Pas d’accès direct à la base de données
Pas de traitements de données en temps réel
Dépendance forte à l’éditeur de la solution de Marketing Automation, etc.
Pour répondre à ces limites, de plus en plus d’entreprises font le choix de mettre en place une base de données clients en amont de leur solution de Marketing Automation. Il peut s’agir d’un Référentiel Client Unique (RCU) sur mesure, et/ou d’un logiciel de type Customer Data Platform (CDP) comme Octolis qui permet de gérer la base de données clients.
En simplifiant, vous pouvez considérer qu’il y a deux grandes approches.
Dans le cas de l’approche #1, on a tendance à prendre un logiciel Marketing Automation intermédiaire ou avancée, qui propose plus de souplesse dans la gestion des données. Dans le cas de l’approche #2, on peut choisir un outil de Marketing Automation plus léger sur la gestion des données.
Pour réfléchir à l’organisation de votre écosystème CRM (ou SI Clients dans la novlangue IT), la question de l’organisation des données clients doit la première. Il faut lister vos sources de données, les traitements nécessaires (réconciliation, traitements, champs calculés, etc.), et à partir de là, comparer les différentes options d’architecture envisageables. La grille de lecture ci-dessous peut faire peur, mais elle permet de prendre le sujet dans son ensemble. A noter que dans le schéma ci-dessous, la terminologie « eCRM » correspond à l’outil de marketing automation.
Grille de lecture des différentes architectures CRM envisageables
On y pense pas assez au départ, mais très souvent, une architecture associant un outil CDP et un outil de marketing automation léger permet de répondre à l’ensemble des exigences. On dispose ainsi de la flexibilité nécessaire pour gérer la base de données dans la CDP (surtout si le logiciel CDP est indépendant de la BDD comme c’est le cas chez Octolis), et d’un outil de marketing automation léger ou intermédiaire facilement utilisable par les équipes.
Les logiciels de marketing automation pour PME / ETI (B2C)
Intéressons nous maintenant aux solutions destinées aux entreprises dont le CA annuel se situe entre 5 et 10 millions d’€. Ces solutions qualifiées d’intermédiaires vous offrent la possibilité de manipuler (avec plus ou moins de précision) votre base de données clients sur laquelle reposent vos scénarios. Cette connexion avec la base de données vous permet d’associer vos contacts à des événements, ainsi que de croiser plusieurs sources de données.
En termes de positionnement, il faudra compter entre 20 et 50k € / an pour exploiter une solution de ce type. En fonction de vos besoins, il sera nécessaire de prévoir une phase d’intégration afin de déployer la solution à vos outils existants et de paramétrer les différentes sources de données.
Splio est un CRM marketing très orienté commerce de détail. Made in France, Splio est une solution particulièrement dynamique et innovante. De nouveaux modules sont régulièrement lancés (dernièrement : Splio Loyalty, qui permet de gérer des programmes de fidélité avancés). Splio est bon aussi bien sur la partie gestion de base de données que sur la partie activation des données (campagnes, automation).
Lancée en 2000 par une équipe belge, Actito est un logiciel CRM marketing qui s’adresse essentiellement aux PME et aux ETI (positionnement mid-market). Très complet, Actito présente les 4 fonctionnalités clés des CRM marketing : la base de données, la gestion de campagnes marketing, l’automation et le reporting. Avec une mention spéciale pour l’outil de Marketing Automation, à la fois assez simple à utiliser et ultra-complet. Globalement, l’interface d’Actito est l’une des plus ergonomiques du marché et les prix sont très compétitifs. Qui plus est, l’éditeur a noué un grand de nombre de partenariats qui permettent d’enrichir les fonctionnalités proposées.
Lancé au début des années 2000, Emarsys est un CRM marketing destiné principalement aux acteurs du e-commerce et du Retail en général (c’est la solution CRM utilisée par eBay notamment). La solution permet d’orchestrer des campagnes marketing en omnicanal et de créer des scenarios complexes de Marketing Automation basés sur le comportement des clients sur le site web. L’outil propose aussi un moteur de recommandation très puissant. Côté coût, Emarsys se situe dans la moyenne du marché.
Braze (anciennement Appboy) est une plateforme d'engagement tout au long du cycle de vie qui crée des liens solides entre les gens et leurs marques préférées. Braze donne aux marques les moyens d'humaniser leurs liens avec les clients grâce à la technologie, ce qui se traduit par une meilleure expérience et une meilleure rétention, une valeur vie client et un retour sur investissement accrus. Les équipes utilisent Braze pour offrir des expériences de messagerie hautement personnalisées qui couvrent tous les canaux, toutes les plateformes et tous les appareils.
NP6 conjugue Customer Data Platform et marketing automation omnicanal, conçue pour augmenter l'engagement et la fidélité client. Depuis une interface unique et intuitive, NP6 vous permet de centraliser toutes vos données online et offline, de segmenter finement vos audiences et de communiquer avec vos clients sur leurs canaux favoris : email, mobile, web, réseaux sociaux, print, ...
Le Blueshift SmartHub CDP offre aux spécialistes du marketing tous les outils nécessaires pour fournir des expériences pertinentes et connectées tout au long du parcours du client omnicanal. Cette plateforme unique, flexible et facile à utiliser, unifie les données clients de toute source, libère l'intelligence avec une IA personnalisable et active les données en temps réel avec une prise de décision automatisée. Les spécialistes du marketing peuvent désormais orchestrer une expérience client omnicanal connectée et la façonner activement en fonction de la compréhension et des comportements des clients en temps réel.
Un logiciel d'e-mail marketing et de marketing automation "tout-en-un". Proposez un e-mail marketing mobile et réactif extrêmement facile à utiliser, des modèles de newsletter, des campagnes SMS, un générateur de pages de renvoi, un outil d'enquête, des outils d'optimisation, des fonctionnalités de marketing automation, des formulaires de lead intelligents et un stimulateur de ventes e-commerce.
Act-On est une plateforme de marketing automation qui stimule l'innovation pour permettre aux marketeurs de donner le meilleur d'eux-mêmes. Act-On est un espace de travail intégré apte à répondre aux besoins de l'expérience client, de la reconnaissance à l'acquisition en passant par la rétention et la fidélisation. Grâce à Act-On, les marketeurs peuvent générer de meilleurs résultats commerciaux et maximiser la valeur vie client (CLV).
Autopilot convient aux start-up, aux PME et aux grandes entreprises. Il vous permet de créer des e-mails au format texte, télécharger des fichiers HTML personnalisés, sélectionner votre modèle de bibliothèque ou créer votre propre bibliothèque à l'aide de notre éditeur d'e-mails avancé, équipé de fonctionnalités glisser-déposer. Vous pouvez envoyer des e-mails ciblés concernant les comportements et les centres d'intérêt, les personnaliser à l'aide de texte dynamique, réaliser des tests A/B et ajouter des points de contact multicanaux, tels que les messages envoyés par le biais d'applications, les SMS et les publicités Facebook. Vous pouvez suivre la performance de vos e-mails grâce à des fonctions détaillées de reporting et l'optimiser en vous basant sur les résultats en temps réel.
Mapp Cloud est une solution intégrée de marketing cloud qui réalise à la fois l'acquisition d'audiences ciblées, l'orchestration et l'exécution de campagnes marketing cross-canal.
387
Les logiciels de marketing automation destinés aux grandes entreprises (B2C)
Commençons notre panorama des outils de marketing automation B2C par les solutions destinées aux ETI, dont le CA est supérieur à 10 millions d’€ annuel.
Singulièrement différentes des outils que nous avons présentés jusque-là, ces solutions « écosystèmes » sont principalement proposées par les mastodontes de la gestion de la relation client : Oracle, Salesforce et Adobe.
On note tout de même que des acteurs Européens comme Selligent (Belgique) proposent des alternatives solides et sont plus adaptés aux besoins des ETI qu’à ceux des grands groupes.
La fourchette de prix se situe ici entre 20 et 50k€ annuel pour les solutions comme Selligent, puis au-delà des 50k€ pour les outils proposés par les firmes américaines.
Adobe Campaign (anciennement Neolane) est la solution d’Adobe dédiée à la gestion des campagnes et scenarios marketing cross-canal. Elle fait partie de la suite Adobe Marketing Cloud. C’est le CRM marketing le plus utilisé dans les grands groupes. La solution est très complète, aussi bien en ce qui concerne les fonctionnalités de base de données que du Marketing Automation. Revers de la médaille, Adobe Campaign n’est pas le logiciel le plus simple à intégrer et à utiliser…
Solution marketing leader pour accroître l'engagement avec chaque consommateur. Utilisez sa gestion de données performante pour collecter, organiser et stocker en toute sécurité des first, second et third-party data ainsi que des données hors ligne afin de créer des profils de données consommateurs complets. Personnalisez chaque interaction tout au long du parcours avec votre marque à l'aide de l'IA intégrée. Impliquez ensuite chaque consommateur à grande échelle en utilisant les solutions e-mail, mobiles, publicitaires et sociales leaders du secteur.
Lancé en 1999, Selligent s’adresse aux grandes entreprises, notamment dans les secteurs du tourisme, de l’automobile, de l’édition et des services financiers. La solution excelle aussi bien sur le volet base de données que sur les fonctionnalités de gestion de campagnes et de reporting CRM. Selligent permet aussi de faire du Marketing Automation à un niveau avancé. C’est une valeur sure. L’interface a le mérite d’être très ergonomique et facile à prendre en main. Selligent s’enrichit régulièrement de nouvelles briques fonctionnelles, ce qui contribue à l’intérêt de la solution (rachat récent d’un moteur d’IA pour de la recommandation).
Magnews est la plateforme multicanale pour le Marketing Digital et Marketing Automation par e-mail, SMS, notifications push, web, marketing et réseaux sociaux, disponible en format SaaS en ligne et sur site (“on premise”).
Grâce à une seule plateforme, les équipes marketing peuvent gérer et orchestrer toutes les interactions avec les clients que ce soit par email, sms, les réseaux sociaux, l'affichage et le web.
Anciennement IBM Watson Campaign Automation, Acoustic permet d'offrir des expériences exceptionnelles aux clients tout au long du parcours de l'acheteur en tirant parti des données clients, en fournissant des informations analytiques et en automatisant les interactions inter-canaux pertinentes.
Zeta Global est une société de technologie marketing basée sur les données qui combine le troisième plus grand ensemble de données (2,4B+ identités) avec l'intelligence artificielle axée sur les résultats pour débloquer les intentions des consommateurs, personnaliser les expériences et favoriser l'acquisition, la fidélisation et la croissance des clients.
1251
Les logiciels de marketing automation pour TPE (B2C)
Terminons notre tour d’horizon des outils de marketing automation par les solutions destinées aux TPEs orientées B2C. Pour donner un ordre de grandeur quant à la maturité de votre entreprise, nous avons considéré comme TPE les entreprises dont le CA est inférieur à 2 millions d’€.
Ces solutions « légères » sont pour la plupart issues de solutions d’emailing à l’origine limitée à l’envoi de newsletters. Ces outils sont désormais plus complets mais les fonctionnalités de marketing automation proposés sont souvent limitées à la clé email.
En fonction de vos besoins, le coût annuel de ces solutions s’élève à :
Moins de 5k € pour des outils très légers comme Sendinblue.
Entre 5 et 20k€ pour des outils plus robustes comme ActiveCampaign.
Nom
Description
Nb employés
Les logiciels de marketing automation pour des acteurs B2B
Comme nous l’avons évoqué au cours de l’introduction, les solutions de marketing automation orientées B2B sont très souvent développées par des éditeurs de CRM commerciaux et proposent donc des fonctionnalités différentes de celles citées précédemment :
Faire le tri client / prospect
Rattacher un individu à une entreprise
Scorer les prospects (individuellement ou par entreprise)
Remonter les données depuis l’outil de marketing automation vers le CRM commercial
HubSpot CRM s'adresse aux petites et moyennes entreprises (10-200 employés) pour lesquelles les feuilles de calcul ne suffisent pas, mais qui n'ont pas besoin des fonctions avancées d'une CRM complexe pour grande entreprise.
Webmecanik est un outil d'automatisation marketing complet Français idéal pour les PME, ETI et agences web qui gèrent plusieurs comptes clients, que ce soit en B2B ou en B2C. Webmecanik Automation permet de mettre en place des campagnes marketing automatisées performantes. L'objectif étant de développer de manière pertinente une meilleure gestion de la relation client.
Intercom construit une suite de produits de messagerie pour les entreprises visant à accélérer leur croissance tout au long du cycle de vie du client. Il s'agit d'une plateforme de croissance complète pour le marketing, les ventes et le soutien. Les entreprises les plus prospères au monde, comme Atlassian, Shopify et New Relic utilisent Intercom afin de stimuler leur croissance par le biais de chats, de bots et de communications personnalisées avec les clients.
Le système Bridgemail de Makesbridge couvre toutes les fonctions essentielles de gestion des prospects, telles que le marketing par courrier électronique, le publipostage, le suivi des prospects, l'automatisation des ventes, les pages de renvoi, les réponses automatiques, le suivi des campagnes et l'analyse web.
SALESmanago Marketing Automation fournit des solutions de nouvelle génération qui redéfinissent la façon dont les outils de marketing traditionnels sont utilisés dans les entreprises d'e-commerce, B2C et B2B. Chaque jour, ils vont au-delà des attentes concernant les capacités d'e-mail marketing, le contenu dynamique de site web personnalisé, le marketing sur les médias sociaux, le marketing automation anonyme, la publicité en ligne. L'objectif principal est de créer un produit qui permet aux utilisateurs de mettre en œuvre tout type de processus de marketing qu'ils désirent.
Pionnier dans le domaine du marketing automatisé, Eloqua est lancé en 1999 et racheté par Oracle en 2013. Particulièrement axée sur le B2B, la solution fédère une grande communauté de 70 000 utilisateurs. Cet outil est particulièrement puissant pour vous permettre de suivre vos leads, grâce à un logiciel CRM intégré, pour améliorer vos techniques d’acquisition sur de multiples canaux et pour édifier votre lead scoring. Par ailleurs, il vient en aide aux entreprises concernant leur stratégie de lead nurturing pour diffuser des contenus à forte valeur ajoutée, selon les actions réalisées par les contacts, destinées à les transformer en clients. Pour vous aider dans votre plongeon dans le marketing automatisé, Oracle met à votre disposition de nombreuses ressources et des services de consulting. Ce qui n’est pas du luxe, car la plateforme est assez complexe et nécessite une formation au préalable.
Marketing automation, une plateforme intelligente sur le CRM. Pardot permet aux équipes de marketing et de vente de travailler ensemble pour rechercher et suivre des leads, conclure davantage d'affaires et maximiser le retour sur investissement. La gestion des leads de Pardot comprend l'intégration au CRM, l'e-mail marketing, le suivi des leads, le lead scoring et le reporting du retour sur investissement afin d'aider les équipes de marketing et vente à collaborer pour générer et qualifier les leads, raccourcir les cycles de vente et suivre le retour sur investissement du marketing.
47306
Téléchargement du benchmark complet de 40+ solutions de marketing automation
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
On parle beaucoup de Customer Data Platforms ou CDP en ce moment. Le terme « CDP » désigne d’ailleurs des choses différentes : des solutions « pure players », mais aussi des CRM et outils Marketing qui se sont emparés du terme de manière habile.
Il y a probablement une mode autour de l’expression « CDP », mais cette agitation de surface cache un vrai mouvement de fond. Plus que jamais, les entreprises ont besoin d’exploiter davantage les données clients pour améliorer la performance marketing et commerciale.
Les solutions CDP sur l’étagère ne sont pas les seules approches envisageables pour traiter ce besoin. Beaucoup d’entreprises choisissent de construire leur base de données clients sur-mesure.
Contrairement à ce qu’on peut penser, les grands gagnants de ce mouvement de fond ne seront pas forcément les éditeurs de logiciels CDP ou les solutions CRM, mais plutôt les grandes plateformes Cloud.
🚀 La montée en régime des Customer Data Platforms
Une Customer Data Platform est une solution sur l’étagère conçue pour organiser, unifier et transformer les données clients. Les promesses mises en avant par les éditeurs sont toujours les mêmes :
La CDP gère toutes les données, online et offline, y compris les données comportementales contrairement aux CRM classiques.
Elle peut se connecter à toutes les sources de données et outils d’activation, grâce à toute une panoplie de connecteurs qui fait la fierté des éditeurs de CDP.
Elle est simple d’utilisation et redonne par là-même le pouvoir aux équipes marketing et, plus généralement, aux utilisateurs métier.
On comprend alors l’engouement autour de cette technologie.
3 indices du succès des CDP
La CDP est indéniablement à la mode. Plusieurs indices en témoignent :
Le volume de recherches dans Google sur les expressions « CDP » et « Customer Data Platform ». Le graphique Google Trends est très clair.
Source : Google Trends
Le nombre croissant d’éditeurs de logiciels qui s’emparent de l’expression CDP. Vous vendez une solution marketing de gestion des données clients ? Appelez-la « CDP », c’est plus vendeur !
Tous les cabinets de conseil vous le diront, il y a de plus en plus de projets CDP.
Un simple effet de mode ?
Il y a certainement un effet de mode, mais comme nous le disions au début, cet effet de mode concerne l’expression « CDP ». Les drivers de cette tendance sont eux très solides. Si l’on parle tant de CDP, c’est d’abord parce que cette technologie répond à des problèmes qui ne font que s’accroître :
La pression du marché, des clients, à mettre en place une relation client ultra personnalisée sur tous les canaux. Les entreprises veulent toutes proposer une expérience client omnicanale. Et ça, ce n’est pas le bon vieux CRM qui permet de le faire.
La multiplication des sources de données et la dispersion croissante des données qui en découle.
La volonté des équipes marketing de gagner en autonomie pour exploiter les données dans leurs outils opérationnels : emailing, retargeting, chatbot, etc. Le marketing en a marre du Data Lake.
L’accessibilité des technologies IA / Data permettant d’exploiter les données comportementales.
Tous ces problèmes, tous ces besoins font directement écho aux promesses de la CDP que nous avons rappelées plus haut. Logique dans ces conditions que la CDP apparaisse comme la solution idéale et connaisse cet engouement.
📚 De nombreuses approches possibles pour construire sa CDP
Plusieurs approches sont possibles pour construire une CDP. La première consiste à acheter une CDP sur l’étagère. Dans ce cas, vous ferez votre choix sur un marché composé de deux types d’acteurs : les gros et les petits, les mastodontes du CRM et les pure players. L’autre option consiste à construire votre CDP sur-mesure : l’approche Build (vs l’approche Buy).
Les gros éditeurs CRM ont envahi le marché de la CDP
Les géants du CRM ont tous ou presque lancé leur offre CDP. C’est d’ailleurs un signe qui ne trompe pas. Salesforce, Microsoft, Adobe, SAP, tous ces mastodontes ont suivi le mouvement, surfant sur l’engouement pour l’expression CDP. Les « CDP » développées par ces acteurs ne sont pas conçues comme des plateformes ouvertes, mais plutôt comme des briques logicielles rattachées à l’écosystème CRM de l’éditeur. Salesforce CDP, par exemple, est une brique de Marketing Cloud.
L’offre de Salesforce résume toutes les promesses de la CDP :
L’unification des données autour d’un identifiant client unique pour obtenir la fameuse vision client unique.
La création de segments d’audience à partir des données unifiées afin de mettre en place des actions et campagnes ultra-ciblées.
L’activation des données dans les outils marketing et commerciaux.
La landing page de Salesforce CDP est un bréviaire des promesses de la CDP.
L’essor des pure players CDP depuis 2015
A côté de ces acteurs dominants gravite toute une galaxie de « pure players » mais aussi d’anciennes DMP ou d’anciens gestionnaires de tags qui se sont reconvertis en CDP.
Le marché de la CDP est constitué d’un grand nombre d’éditeurs. Le CDP Institute en recense 151 dans son rapport de juillet.
Le marché se divise en deux groupes d’acteurs :
Les gros acteurs matures, qui existaient avant 2013. A coup de levées de fonds retentissantes et de rachats, ces leaders se renforcent.
Les petites CDP créées après 2014 (date d’émergence de l’expression CDP). Bon nombre d’entre elles se sont faites racheter.
On assiste donc à un mouvement de concentration. Les gros rachètent les petits. La dynamique du marché est portée par les leaders.
Source : CDP Institute.
Build vs Buy
La distinction « gros » vs « petits » ne doit pas masquer la vraie distinction structurante : Buy Vs Build. Il y a deux manières de s’équiper d’une Customer Data Platform :
Acheter une solution du marché, une solution sur l’étagère > Buy
Construire une CDP sur-mesure conçue pour les besoins spécifiques de l’entreprise > Build.
L’engouement autour des CDP a eu tendance à éclipser la deuxième approche. On a fini par associer l’expression « CDP » aux solutions sur l’étagère. Les choses changent et les approches sur-mesure rencontrent un succès croissant. Nous verrons tout à l’heure pourquoi.
Comment choisir entre ces deux options technologiques ? Rappelons les forces et faiblesses de ces deux options sur les principaux critères de sélection :
Le coût. En ce qui concerne le coût de déploiement, c’est l’option CDP sur l’étagère qui est la plus intéressante. Et pour cause, construire une CDP sur-mesure demande plus de travail que d’acheter une licence et d’installer un logiciel pré-paramétré. Par contre, les coûts d’exploitation d’une CDP sur-mesure sont plus faibles. Les licences des CDP sur l’étagère se vendent très cher…
La customization. Construire une CDP permet de disposer d’une plateforme répondant parfaitement aux cas d’usage cibles de l’entreprise. A l’opposé, les CDP « prêtes à porter » imposent leurs modèles de données et ne permettent pas toujours de déployer tous les cas d’usage cibles.
La sécurité des données. Si vous optez pour l’option CDP sur l’étagère, vos données seront hébergées sur les serveurs de l’éditeur. Si vous choisissez de construire votre CDP, les données seront hébergées sur vos serveurs (en local) ou dans le cloud sur des serveurs que vous louez. Vous avez donc un meilleur contrôle sur vos données.
La complexité. Une Customer Data Platform est alimentée par un nombre important de sources de données. Chaque source de données a son langage, son modèle de données. Réussir à unifier ces données dans une base sur-mesure est un challenge. Comme toujours, Sur-mesure se déplace toujours avec sa sœur « Complexité ». Si vous visez la simplicité, choisir une CDP sur-mesure est très tentant…
Le temps de déploiement. Installer et configurer une CDP sur l’étagère est plus rapide que d’en créer une de toute pièce. Dans le premier cas, comptez un mois de déploiement, dans le deuxième cas entre 2 et 4 mois.
On le voit, chacune des deux options (Buy ou Build) a ses avantages et ses inconvénients. Dans une telle situation difficile de faire son choix…Mais doit-on vraiment faire un choix entre ces deux options ? Pourquoi ne pas réunir le meilleur des deux mondes ? Nous allons vous présenter une troisième approche, hybride et Data Warehouse first.
L’approche hybride, Data Warehouse first, a le vent en poupe
Le sens de l’histoire pointe de plus en plus vers cette approche. Cette approche hybride consiste à construire la CDP dans votre Data Warehouse Cloud. Cette approche permet de bénéficier de toutes les fonctionnalités que l’on est en droit d’attendre d’une CDP moderne : des tonnes d’intégrations possibles, la résolution d’identité indispensable pour construire un Référentiel Unique, etc. Tout en gardant le contrôle sur les données.
Cette approche mérite l’attention. Pourquoi ? Pour au moins 3 raisons. C’est l’approche :
La plus rentable. Vous n’avez pas à payer un éditeur de CDP pour qu’il héberge vos données sur ses serveurs. Les éditeurs de CDP font payer le stockage des données beaucoup plus cher qu’un éditeur de Data Warehouse Cloud. En utilisant le DWH, le stockage de vos données devient une commodité.
La plus sécurisée. Les données ne sont pas contrôlées par l’éditeur de CDP, mais par vous.
La plus flexible. La connectivité est un point fort des solutions de Data Warehouse Cloud. Chaque plateforme de DWH propose des centaines de connecteurs avec les principales sources de données et outils MarTech. Mais vous n’êtes pas limités par les connecteurs natifs proposés par les CDP. Les DWH proposent des solutions d’intégrations plus souples et plus larges.
🏆 Un changement de paradigme qui va bénéficier aux (gros) éditeurs de plateformes cloud plus qu’aux éditeurs SaaS
L’approche hybride entraîne un changement de paradigme. Sa principale caractéristique est la place centrale jouée par le Data Warehouse Cloud. Les acteurs proposant des solutions de DWH Cloud ont certainement de beaux jours devant eux. Le temps où le marché des MarTech était dominé par un oligopole composé de Salesforce, Oracle, SAP et Adobe est en passe d’être révolu. Et si les principaux acteurs MarTech devenaient BigQuery (Google), Redshift (Amazon), Azure (Microsoft) ou encore Snowflake ? Ce sont eux qui ont tout à gagner du développement des approches DWH-first, clairement.
Les CDP sur l’étagère sont des ETL avec une couche logicielle
Dans le passé (mais ce passé est encore le présent de beaucoup d’organisations), les entreprises utilisaient des applications dont chacune disposait de sa propre base de données. Que ces applications soient développées par le même éditeur ou par des éditeurs différents…Par exemple, si vous utilisez Salesforce Marketing Cloud (pour le marketing), Salesforce Commerce Cloud (pour le commerce) et Salesforce Service Cloud (pour le service client), vous avez trois systèmes indépendants avec chacun sa base de données. Vos données ne sont pas unifiées.
La dispersion des données qui en résulte a conduit à l’émergence des CDP. Ces CDP sur l’étagère, au fond, ne sont rien d’autre que des outils ETL conçus pour construire des pipelines de données et synchroniser les données entre les applications. Elles fonctionnent de la même manière (Extract – Transform – Load et partagent les mêmes défauts : les pipelines sont coûteux à mettre en place, coûteux à maintenir et exposent aux fuites.
Les solutions de datawarehouse cloud ont de gros avantages
Et puis se sont développées les plateformes cloud, les BigQuery, les Snowflake, proposant une approche radicalement différente. Ces technologies vous permettent de construire votre base de données unifiée dans le cloud et fonctionnent de la même manière qu’une CDP…sans pipelines.
Connecter une source de données à votre Data Warehouse BigQuery ne consiste en rien d’autre qu’à ajouter les bonnes permissions dans la clé API BigQuery de votre source de données. La connexion des données devient incroyablement plus simple :
Il n’y a pas de migration de données.
Le stockage n’est plus un problème, votre DWH peut mettre en musique un volume potentiellement infini de données…sans aucune maintenance requise.
Une plateforme cloud est un système ouvert qui permet facilement de greffer à votre infrastructure des outils tiers, contrairement aux CDP du marché qui enferment dans un environnement rigide.
La puissance de calcul proposée par les solutions DWH Cloud est bien supérieure à ce qu’offrent les solutions CDP du marché.
Dans un DWH Cloud, vous pouvez gérer de manière centralisée et granulaire les droits et les accès.
Les applications tierces peuvent accéder à de grandes quantités de données et les interroger autant qu’elles le souhaitent sans que cela n’ait d’impact sur leur fonctionnement et leur disponibilité.
La connexion des données n’engendre aucune fuite (et pour cause, il n’y a pas de tuyaux) et aucuns lags de synchronisation.
Le temps où l’empilement des outils entraînait l’empilement des données sera peut-être bientôt un mauvais souvenir. Construire votre CDP dans votre Data Warehouse vous permet de connecter facilement vos sources de données, d’unifier ces données et de les redistribuer ensuite aux applicatifs métier.
Cette approche permet réellement de construire une « plateforme » au sens rigoureux du terme, et non pas une suite de logiciels.
Conclusion
Une entreprise qui souhaite mieux exploiter ses données clients et qui cherche une solution technologique pour y parvenir doit clairement envisager l’alternative hybride que nous avons présentée. Non, la CDP sur l’étagère n’est pas la seule option. Non, il ne faut pas forcément choisir entre les approches Buy et le 100% Build. L’approche DWH first connaît un engouement croissant. A la plus grande joie des grandes plateformes cloud…La croissance à trois chiffres d’un acteur comme Snowflake est emblématique de cette évolution majeure. A suivre !
Construire une relation client omnicanale pas à pas – Guide & Template
On parle beaucoup de relation client omnicanale, vous l’aurez remarqué, mais reconnaissons que peu d’entreprises réussissent à la mettre en œuvre. En clair : vous avez n canaux d’interaction clients ; ces canaux doivent fonctionner ensemble ; chaque interaction client doit s’appuyer sur les interactions précédentes pour proposer une expérience client harmonisée. C’est tout le défi de la relation client omnicanale. Facile à dire, difficile à faire.
Si vous avez la sincère conviction que la relation client omnicanale est la clé (et vous avez raison) mais que vous ne savez pas comment vous y prendre ni par où commencer, alors ce guide est fait pour vous. Nous allons voir ce que recouvre vraiment ce terme de « relation client omnicanale » et vous expliquer comment exploiter efficacement notre ressource.
Vous ne rêvez pas, nous allons vous offrir une ressource préparée avec amour pour vous aider à structurer votre démarche et construire pas à pas une relation client omnicanale. Parce que le verbe « offrir » est parfois trompeur en marketing, précisons : gratuitement. Vous trouverez le lien pour accéder à la ressource en bas de l’article. Mais ne vous précipitez pas dessus, nous avons des choses à vous dire.
On pourrait aussi reformuler la question : qu’est-ce qu’un marketing omnicanal ? Depuis que le marketing est devenu relationnel, la relation client et le marketing entretiennent des relations intimes et se confondent souvent.
Une relation client omnicanale est une relation client qui combine les différents canaux pour créer une expérience client harmonisée sur les différents points de contact du parcours client.
Deux exemples de combinaisons de canaux emblématiques de l’approche omnicanale :
Envoyer une notification push promotionnelle lorsqu’un client est en magasin (Mobile + Magasin).
Envoyer un email promotionnel en fonction du comportement du client sur le site et de son historique d’achat online et offline (Email + Site web).
La relation client omnicanale met en musique les différents canaux et renforce l’efficacité de chaque interaction par cette imbrication. Plus facile à dire qu’à faire, clairement…C’est un challenge redoutable pour les entreprises car les canaux se sont beaucoup diversifiés. Pour ne citer que les principaux :
Canaux online : site web, site ecommerce, moteurs de recherche, application mobile, réseaux sociaux (Facebook, Instagram, Twitter, Tiktok, LinkedIn, YouTube…), email, messageries instantanées (WhatsApp, Messenger…), SMS…
Nous sommes donc placés devant toute une cartographie de canaux qui s’interpénètrent. C’est le versant « spatial » de la relation client omnicanale. La relation client omnicanale cartes sur table. Il y a aussi la dimension temporelle, qui est tout aussi importante et en fait inséparable de la dimension topographique.
A chaque point de contact, la relation client doit pouvoir s’appuyer sur l’ensemble de l’historique relationnel. C’est valable à tous les niveaux :
Le service client, lorsqu’il est en contact avec un client, doit pouvoir accéder (depuis ses outils) à tout l’historique relationnel pour traiter au mieux les demandes/réclamations (appels entrants) et proposer des offres adaptées (appels sortants).
Sur le site web, vous devez proposer des recommandations produits en phase avec les préférences produits de vos clients.
Etc.
La relation client omnicanale, par delà la relation client multicanal
On confond encore, parfois, omnicanal et multicanal. C’est pourtant l’ombre et la lumière. Une relation client est multicanal dès lors qu’elle s’opère par différents canaux : le site web, le téléphone, l’application mobile, l’email, le SMS, etc. Vous êtes une entreprise, vous avez deux canaux d’interaction (le magasin et le téléphone), vous êtes multicanal. Mais vous êtes loin d’être omnicanal.
La relation client omnicanale est une relation client orchestrée. Les canaux ne sont pas additionnés, ils sont connectés entre eux, en interaction – ils sont intégrés pour constituer une expérience client homogène. Concrètement :
Si vous envoyez un email promotionnel qui ne prend pas en compte les achats de votre client en boutique ou sur votre site ecommerce, vous êtes dans le multicanal. Vous interagissez sur différents canaux mais vos interactions ne prennent pas en compte celles qui précédent.
Si vous envoyez un email promotionnel avec des recommandations personnalisées basées sur les préférences d’achat du client, vous êtes dans une approche omnicanale. Chaque nouvelle interaction (votre email promotionnel) intègre les informations et les données générés par les interactions qui précédent (les achats off/online).
C’est un exemple parmi d’autres, mais assez emblématique.
En fait, seule la relation client omnicanale permet d’individualiser les interactions et peut prétendre au qualificatif de « customer-centric ».
En clair, il ne suffit pas de communiquer sur différents canaux, il faut que votre communication soit harmonisée sur tous les canaux. Aujourd’hui, toutes les entreprises sont multicanal, mais peu parviennent à proposer une relation client omnicanale. Certaines y parviennent avec succès. C’est le cas d’IKEA.
L’exemple d’IKEA
Prenons un exemple d’organisation étant parvenue avec succès à mettre en œuvre une relation client omnicanale : IKEA. Pourquoi les gens adorent Ikea ? Vous me direz : parce que c’est pas cher. Oui, sans doute. Mais pas uniquement. Les gens aiment aussi IKEA parce que la marque propose une expérience client omnicanale de haut niveau.
Le site web d’IKEA est vraiment bien conçu. Il permet de savoir si tel article ou tel article est disponible ou non dans tel magasin. Si le produit n’est pas disponible, vous pouvez demander à être informé par email de sa remise en disponibilité. Site web – magasin – email : tout fonctionne ensemble, en parfaite symbiose et harmonie, et permet de délivrer une expérience client satisfaisante.
Mais ce n’est pas tout. En magasin, vous pouvez récupérer gratuitement le dernier catalogue pour découvrir les nouveaux produits et de nouvelles inspirations. Le site web est personnalisé en fonction des recherches réalisées par l’internaute. Si vous avez ajouté une lampe à votre panier, vous trouverez des recommandations de lampes sur les pages du site. Inutile de préciser qu’IKEA propose également le click & collect, le must-have pour connecter le site web aux magasins.
Et le smartphone dans tout ça ? Vous voulez acheter sur votre smartphone ? Pas de problème, IKEA propose deux applications mobiles. La première, classique, qui a la même fonction que le site web, la deuxième (IKEA Space) qui vous permet de visualiser les produits Ikea dans votre logement.
Magasins, site web, boutique en ligne, catalogues, applications : les canaux online et offline dialoguent, se renvoient la balle, interagissent – bref, ils sont parfaitement intégrés. C’est cela, l’omnicanalité. IKEA propose un parcours client omnicanale sans friction. Tous les canaux se combinent harmonieusement pour délivrer une expérience client uniforme.
Comment mettre en place une relation client omnicanale ?
Finie la théorie, passons à la pratique. Maintenant que nous savons ce qu’est une relation client omnicanale, nous pouvons passer aux choses sérieuses. Nous avons conçu pour vous (avec beaucoup d’amour, il faut le dire) une ressource pour vous aider à structurer votre démarche et organiser votre relation client omnicanale. Elle est en téléchargement gratuit. Nous allons passer en revue les étapes de la démarche à mettre en place et vous expliquer comment utiliser efficacement notre ressource.
#1 Cartographier le parcours client omnicanal à travers vos points de contact online et offline
La première étape consiste à cartographier votre parcours client omnicanal. Pourquoi ? Parce qu’avant d’organiser une relation client omnicanale sur vos différents canaux et aux différentes étapes du parcours, vous devez disposer d’une représentation claire de ces canaux et de ces étapes qui constituent le parcours client. Pas de relation client omnicanale sans une bonne compréhension du parcours client omnicanal.
Nous vous proposons d’utiliser une représentation sous forme de matrice à deux dimensions : les canaux et les étapes. C’est simple et efficace.
Vous avez :
Les étapes du parcours qui sont disposées en colonnes : Je me renseigne, Je me crée un compte…Nous vous conseillons de formuler à la première personne du singulier, histoire de bien vous mettre à la place de vos clients.
Les lignes correspondent aux différents canaux : le site web, l’email marketing, le sms, le téléphone, etc.
L’intersection d’une étape et d’un canal correspond à un point de contact.
Cette méthode de cartographie du parcours client a fait ses preuves et permet d’aboutir à une représentation fidèle. Nous vous conseillons d’effectuer ce travail de cartographie de manière collaborative, par exemple sous la forme d’un atelier réunissant les différents métiers en relation avec les clients : le marketing, la force de vente, le service client, le digital…
Nous vous proposons un code couleur pour qualifier l’expérience de vos clients sur chacun des points de contact :
Jaune = Normal. Le point de contact fonctionne bien. Il est générateur de satisfaction. Le recenser est suffisant. Ce n’est pas là que doivent porter vos actions.
Orange = Friction. Le point de contact est mal géré. Il constitue une friction dans le parcours du client, un irritant qui peut dégrader l’expérience client. Générateur d’insatisfaction, il doit être optimisé.
Vert = Opportunité. Il s’agit des points de contact qui pourraient bénéficier de l’historique issu des autres canaux et être travaillés pour construire une relation client omnicanale. Ce sont sur ces points de contact (existants, mais plus souvent cibles) que vous devrez concentrer vos efforts. Par exemple : le client est sur le site web (= canal), il consulte une page produit (= étape), vous pourriez lui proposer un click & collect gratuit (= nouveau point de contact à déployer pour renforcer l’omnicanalité). Un exemple parmi d’autres. Nous vous proposons dans la ressource quelques idées d’opportunités.
Vous allez voir, cette méthode de cartographie est très stimulante. Non seulement elle permet de faire le point sur l’existant, d’aboutir à une représentation fidèle du parcours actuel, mais aiguise l’imagination et permet d’identifier des points de contact permettant de créer des passerelles entre les canaux. Elle est un support de créativité.
#2 Identifier vos cas d’usages
Le travail précédent sur le parcours client omnicanal nous a permis d’identifier :
Les zones de frictions à améliorer.
Mais aussi et surtout les opportunités de développer de nouveaux points de contact favorisant l’intégration des canaux.
Comment transformer en réalité ces opportunités détectées lors du mapping du parcours client ? En formalisant les cas d’usage. Formaliser signifie lister, organiser et qualifier. Nous vous proposons une grille simple et efficace pour qualifier vos cas d’usage :
Dans la partie gauche, vous êtes invité :
A lister et à organiser vos idées permettant de développer une approche omnicanale. C’est ce que nous appelons, dans notre jargon, les cas d’usage.
A organiser ces cas d’usage dans des catégories et en fonction d’objectifs.
La partie droite est dédiée à la qualification des cas d’usage en fonction :
De leur impact business.
De l’impact sur l’expérience vécue par le client.
De sa difficulté de mise en œuvre.
Cette qualification va vous permettre d’identifier les cas d’usage prioritaires, ceux à déployer en premier. Remarque : la priorisation des cas d’usage est forcément très liée à votre activité et à vos personas. Il faut bien prioriser les canaux auxquels vos clients sont les plus sensibles.
Ce travail est le prolongement de celui sur les parcours client. Les deux peuvent d’ailleurs être menés de front. Vous verrez, les idées de cas d’usage germeront dans votre esprit pendant le travail de cartographie du parcours.
#3 La définition des scénarios de marketing automation
L’étape précédente a permis d’organiser vos idées et vos objectifs pour renforcer le caractère omnicanal de votre relation client. Le plus difficile commence ! Il faut maintenant imaginer les actions à déployer pour atteindre ces objectifs. Ces actions prennent la forme de scénarios de marketing automation. Faut-il rappeler ce qu’est un scénario de marketing automation ?
Le scénario se distingue des campagnes marketing. Une campagne est une opération ponctuelle. Un scénario est une mécanique pérenne. Par exemple : envoyer un email de bienvenue après une inscription. Pour déployer une relation client omnicanale, le marketing automation est l’outil incontournable. On ne peut pas faire de relation client omnicanale sans automatisation des actions relationnelles.
Nous vous invitons donc à cartographier vos scénarios en utilisant le template accessible dans notre ressource :
En colonnes figurent les étapes de la relation clients : Bienvenue, Activation, Relationnel, Upsell. Certains scénarios sont destinés à tous vos contacts. Par exemple, le scénario de bienvenue, le scénario anniversaire. D’autres sont ciblés sur un groupe de contacts : Cible 1, Cible 2, etc. C’est ce que figurent les lignes de la matrice de cartographie que nous vous proposons.
Ce travail de cartographie vous permet de construire une vue synthétique des scénarios à déployer pour construire une relation client omnicanale. Vous organisez vos scénarios en répondant à trois questions :
Qui ? A qui s’adresse chacun de vos scénarios ? Quelle cible ?
Quand ? A quelle étape du parcours client se déclenchent vos scénarios ? Il s’agit ici de positionner vos scénarios sur les parcours / phases de vie client.
Où ? Quel canal envisagez-vous d’utiliser ? L’email ? Le SMS ?
La question du « Comment » reste en suspens. C’est la raison pour laquelle nous vous proposons un autre modèle de document vous permettant de spécifier la mécanique de chaque scénario. C’est l’onglet suivant de notre ressource :
Dans cet onglet, nous vous invitons à :
Organiser vos scénarios en programmes. Chaque programme répond à un objectif précis. Par exemple : Conversion, Activation, Upsell, Satisfaction Client. Pour bien comprendre l’imbrication des scénarios dans les programmes relationnels, nous vous invitons à découvrir l’excellent article de Cartelis sur le sujet : Plan marketing relationnel : Guide & Exemple.
Définir le fonctionnement de chaque scénario, c’est-à-dire :
Le déclencheur (trigger) du scénario, autrement dit le point d’entrée. Par exemple, le scénario « bienvenue » se déclenche lorsque le contact s’inscrit ou achète un produit. Le scénario « anniversaire » se déclenche à la date d’anniversaire du contact. Il existe deux types de triggers : un comportement client (inscription par exemple) ou un événement client (anniversaire par exemple).
Les séquences de messages. Par exemple, pour un scénario de relance de panier abandonné : envoi d’un premier email de relance à J+1, envoi d’un deuxième email avec code promo à J+5. Notre template présente un exemple de séquence pour vous montrer la démarche à suivre.
La cartographie des scénarios est le document de référence qui est utilisé pour le partage d’information en interne. Le document de spécification des scénarios est quant à lui destiné aux équipes opérationnelles chargées de déployer les scénarios dans les outils.
Nous attirons votre attention sur un point : il est difficile de maintenir l’ensemble des scénarios, surtout lorsque l’on se retrouve avec des dizaines de scénarios actifs. D’où l’importance de disposer de documents maîtres répertoriant et décrivant l’ensemble des scénarios C’est aussi à cela que servent les modèles que nous vous proposons.
#4 Spécifications des besoins d’intégration de données
Le carburant de vos scénarios de marketing automation, ce sont les données – et en particulier les données clients (mais aussi les données produits). Pour déployer les différents scénarios que vous avez imaginés à l’étape précédente, vous allez avoir besoin de collecter des données sur vos clients. Nous vous proposons un modèle de document pour avoir une vision globale des données cibles nécessaires à la mise en place de vos scénarios.
Dans la partie gauche, vous listez et décrivez l’ensemble des scénarios. Dans la partie droite, vous qualifiez :
Les variables nécessaires, c’est-à-dire les données requises : la liste des achats sur 12 mois, les motifs d’appel, la liste des produits complémentaires…
Les sources, c’est-à-dire les bases et outils où vous pouvez venir récupérer ces données.
Comme vous pouvez le constater, nous décrivons le dernier onglet de notre modèle GSheet. Autrement dit, nous sommes arrivés au bout de la présentation de la ressource et vous avons présenté les grandes étapes de la démarche à suivre pour structurer et déployer une relation client omnicanale. Maintenant, comme on dit, à vous de jouer ! N’hésitez pas à nous contacter si vous avez des questions.
Téléchargement du modèle GSheet pour cadrer vos projets de relation client omnicanale
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
La tendance est de transformer les données après les avoir chargées dans un entrepôt de données moderne tel que Google BigQuery, Snowflake, AWS Redshift ou Microsoft Synapse. Ainsi, l’ELT plutôt que l’ETL est de plus en plus utilisé pour référencer le traitement des données. L’acronyme se décompose de la façon suivante :
E pour Extraction des données depuis leur source.
T pour Transformer les données brutes en informations propres et utiles.
L pour Loading vers le data warehouse.
Le P de « Publier » vient désormais compléter le process ETL. Il s’agit du processus de publication des données post-transformation à l’endroit exact où elles seront ensuite consommées.
Dans cet article, nous reprenons la définition de process ELTP d’Analen et présentons le fonctionnement et les avantages d’une solution d’intégration de données reposant sur le process ELTP.
Après l’ELT, pourquoi passer au process ELTP ?
La nécessité de l’operational analytics dans les organisations data driven
L’operational analytics est le terme employé pour parler de l’approche analytics moderne. Cette approche utilise la donnée pour piloter les opérations business et driver les actions de vos équipes en temps réel. L’operational analytics va donc plus loin que l’approche traditionnelle, qui consiste simplement à analyser des données pour comprendre les opérations.
Dans cette approche traditionnelle, on s’intéresse aux données pour mieux comprendre son business, et aider à la prise de décision stratégique. Pour cela, on utilise des tableaux, et des outils de reporting à l’aide de solutions de BI et de Data Visualization. L’analytics traditionnel répond à des questions du type : « Est-ce que ce produit génère des revenus ? ». C’est une démarche d’analyse, basée sur du moyen/long terme.
En revanche, l’operational analytics est l’art de faire parvenir aux équipes métiers (sales, marketing, support, service client) les données dont elles ont besoin pour prendre leurs décisions. C’est une démarche court terme, qui se passe en temps réel. Il s’agit d’apporter la donnée là où il faut quand il le faut, c’est-à-dire quand les utilisateurs métiers en ont besoin. L’operational analytics donne des réponses à des questions telles que : « Quel client dois-je relancer en priorité ? ».
Le process ELT ne résout pas la problématique de l’actionnabilité
Plaçons-nous dans un scénario de scoring PQL (Product Qualified Lead). Supposons que votre entreprise commercialise un SaaS. Votre client potentiel entre en contact avec votre service par le biais d’une publicité en ligne. Les fonctionnalités de base sont gratuites, mais l’utilisateur doit saisir son adresse mail et certaines informations professionnelles.
Si vous utilisez des outils de marketing automation tels qu’Hubspot ou Pardot, vous pouvez connaître le canal par lequel est arrivé le prospect, ainsi que son adresse mail. En revanche, ces outils de marketing automation ne vous permettent pas d’obtenir les données liées à l’utilisation de votre logiciel. Pourquoi ? Tout simplement parce que ces données d’utilisation sont généralement stockées dans une base de données de production.
Vous avez peut-être franchi une étape supplémentaire en ayant mis au point un algorithme de Machine Learning pour calculer un score PQL, afin d’indiquer quels utilisateurs gratuits seraient susceptibles de se convertir en clients payants. Mais tant que les données restent dans le datawarehouse, elles ne seront pas utilisées directement par les applications marketing. Elles ne sont donc pas actionnables.
Un score PQL est une donnée à laquelle vous devez avoir accès dans vos outils de marketing automation car ce sont les outils que les équipes Sales et marketing utilisent au quotidien. En effet, ils sont souvent trop occupés pour passer du temps sur un outil de BI ou exécuter des requêtes afin de savoir quels prospects doivent être priorisés. C’est là qu’intervient le process ELTP.
Qu’est-ce qu’un process ELTP ?
« Publier » : Pousser la donnée en dehors du DWH
Nous l’avons évoqué, la publication d’indicateurs quantitatifs (également appelés metrics) vers les applications de sales, marketing ou service client est essentielle. Le ‘P’ d’un process ELTP prend en charge le problème du « dernier kilomètre » du traitement de données pour rendre les opérations commerciales plus agiles, efficaces et rapides.
Un autre exemple convaincant pour une entreprise de type SaaS est le Customer Success. Un bon Customer Success doit permettre de fidéliser vos clients. Cela passe notamment par le calcul d’un « Health Score » par client, qui permet d’identifier les clients les plus susceptibles de se désabonner de votre service, et donc minimiser le taux de churn.
Pour ces entreprises, la possibilité d’exploiter ce Health Score directement dans l’outil de gestion du service client, comme Zendesk, MailChimp ou Slack est très intéressant. Cela permettrait aux équipes de mettre des mesures en place pour éviter à ce client de se désabonner.
Exemple de résolution du problème du « dernier kilomètre » dans le traitement des données
Ces animations GIF ont été publiées sur Twitter par Anelen. Elles ont été créées automatiquement et à des intervalles de temps précis. Pour cela, les données ont été extraites des sources (géologiques et financières), transformées (y compris la partie destinée à produire l’animation GIF) et transmises à une application de réseaux sociaux (Twitter dans ce cas).
Cette première animation concerne un relevé de données à la fois géologique et géographique. Elle représente les occurrences de tremblements de terre durant les dernières 24h, par coordonnées GPS. Grâce au process d’ETLP, le post Twitter est actualisé automatiquement. Les données sont mises en forme, puis l’animation est produite et injectée dans le système de programmation de publications Twitter. Enfin, elle est publiée à l’heure préalablement définie par les équipes.
Dans cette seconde animation, ce sont des données publiques d’origine financière qui sont utilisées. Sur une période de 5 jours, on observe l’évolution d’un indicateur de performance boursière de 5 entreprises multinationales représentées par leur logo. Sans le process ELTP, il aurait fallu récupérer manuellement les données financières et les réinjecter dans la plateforme de gestion des réseaux sociaux.
Automatiser la publication des données
Ces dernières années, l’activité des ELT s’est développée. Il existe maintenant de nombreux services permettant de transférer automatiquement des données de diverses applications en ligne vers un datawarehouse. Cependant, peu de ressources et de services permettent d’automatiser la publication des données transformées, et encore moins sans compétences en développement.
Il existe notamment des solutions comme Singer.io proposant un processus ETL en Open Source pour les organisations. La communauté construit des extracteurs de données appelés « tap » et des chargeurs de données appelés « target ». Les spécifications de l’outil aident les Data Engineers à créer une combinaison source-destination pour chaque cas d’usage business.
Dans un cadre typique d’ELT, les applications cloud telles que Salesforce et Marketo sont les sources de données (taps), et les entrepôts de données sont les destinations (targets).
Le futur des process ELTP
L’avenir des process réside dans leur capacité à être exploités et mis en place directement par les profils métiers, sans avoir recours à l’IT. On assiste déjà à l’émergence de solutions no-code exploitables par des profils non techniques. On parle bien sûr d’Octolis !
En effet, nous accompagnons nos clients dans le développement de programmes permettant de faire communiquer des données du datawarehouse vers vos applications métiers. Octolis vous ainsi aide à résoudre le problème du « dernier kilomètre de données » afin de les rendre actionnables par vos équipes, au quotidien.
Reprenons l’exemple du service client. La satisfaction de vos clients est bien sûr un indicateur que vous suivez de très près et par conséquent vous cherchez des solutions pour réduire la frustration chez vos clients mécontents. Pour manifester leur mécontentement, ces derniers appellent le plus souvent votre service client.
Cibler ces contacts et leur proposer un geste commercial ou un simple message d’excuse par email est un excellent moyen de réduire leur frustration. Malheureusement, la remontée des données issues de votre service client vers votre outil de marketing automation est rarement réalisable sans compétences techniques. C’est désormais le cas 🙂
On vous laisse découvrir ce cas d’usage plus en détail en suivant ce lien.
Nous pensons que l’agilité opérationnelle passe par l’autonomie data des équipes. Nous aidons pour cela nos clients à faire croiser et redistribuer leurs données internes dans tous leurs outils métiers, afin de décupler leur potentiel.
Benchmark complet des outils de la stack data moderne
L’écosystème Data a beaucoup évolué ces dernières années. Des centaines d’outils ont émergé pour couvrir des besoins de plus en plus spécifiques. Même quand on réalise une veille très régulière, on découvre chaque semaine de nouveaux outils prometteurs.
On a pris le sujet à bras le corps, et on vous a préparé un benchmark complet des outils de la stack data moderne. Type d’outil, origine, modèle économique, réputation sur le marché… chaque solution est présentée dans le détail, sous d’un beau GSheet, facile à exploiter et téléchargeable gratuitement 🙂
Le GSheet est en téléchargement gratuit en bas de l’article, et pour ceux qui veulent avoir un aperçu rapide, on a extrait les principaux acteurs de chaque catégorie ci-dessous. N’hésitez pas à commenter l’article pour suggérer de nouveaux outils, on mettra à jour la ressource de temps en temps.
#1 ELT
Le processus ELT (Extract – Load – Transform) est une amélioration d’un processus existant depuis maintenant plus de 30 ans : l’ETL (Extract – Transform – Load). Avec les outils ELT, on charge (L) avant de transformer (T).
Les outils ELT chargent donc les données brutes directement dans le Data Warehouse cible, au lieu de les déplacer vers un serveur de traitement pour les transformer. Ici, le nettoyage, l’enrichissement et la transformation des données s’effectuent dans le Data Warehouse lui-même. Les données brutes y sont stockées indéfiniment, ce qui permet de multiples transformations et, in fine, les cas d’usage métiers.
La limite de ces outils réside dans leur complexité : ils impliquent la multiplication de Data Lake s dont la connexion aux solutions métiers est un vrai challenge et nécessite la création de connecteurs sur-mesure.
xPlenty est une solution ELT moderne. Une alternative à Fivetran.
30
#2 Web tracking « first party »
Les solutions de tracking « first party » & « third party » se réfèrent aux types de cookies sur lesquels ces solutions s’appuient.
Les cookies « first party » sont inscrits entre des pages qui partagent un eTLD+1 (effective top-level domain plus one part), par exemple en naviguant de blog.cartelis.com/article_1 à blog.cartelis.com/article_2.
Les cookies « third party » en revanche, sont inscrits entre des pages qui ne sont pas issues du même domaine. Ces cookies étant très utilisés pour le retargeting notamment, leur collecte est désormais limitée au consentement des utilisateurs par la directive « ePrivacy » en Europe. Cela entraîne des pertes de données importantes (30-40%), les solutions de tracking de ce type sont donc beaucoup moins précises.
Dans ce contexte, les plateformes de collecte de données « first party » utilisent des cookies définis côté serveur, ce qui leur permet d’être moins affectées par cette perte de données et donc de fournir des données plus précises tout en respectant la vie privée des utilisateurs.
Keen.io est une solution de web tracking first party très utilisé par des startups qui cherchent une alternative low cost à Segment pour historiser les logs web / mobile.
Jitsu est le petit dernier, une solution de tracking open source prometteuse avec plusieurs fonctionnalités très intéressantes.
5
#3 Data Warehouse cloud
Ces solutions sont distribuées en mode SaaS et ce sont donc les éditeurs (les outils ci-dessous) qui ont la charge de la maintenance. Contrairement aux architectures des Data Warehouses traditionnels, ici chaque solution dispose d’une architecture différente mais propose des avantages similaires (par rapport aux architectures traditionnelles) :
Coûts initiaux & permanents beaucoup plus faibles : Les différents composants requis pour les entrepôts de données traditionnels, sur site, entraînent des dépenses initiales coûteuses et ces solutions prennent la maintenance en charge.
Rapidité : Les solutions sur le cloud sont nettement plus rapides à déployer, en partie grâce à l’utilisation de l’ELT.
Flexibilité : Les Data Warehouse Cloud sont conçus pour tenir compte de la diversité des formats et des structures des données volumineuses.
Évolution : Les ressources élastiques du cloud sont idéales pour l’échelle requise par les grands ensembles de données.
Retrouvez ci-dessous les principaux outils de ce type du marché :
Firebolt est un cloud datawarehouse qui fournit aux entreprises tech des performances rapides pour une gestion de données à grande échelle.
117
#4 Data transform
La transformation des données est le processus qui consiste à modifier le format, la structure ou les valeurs des données. Les processus tels que l’intégration de données, la migration de données, l’entreposage de données et le traitement de données peuvent tous impliquer une transformation des données.
La transformation des données peut être :
Constructive (ajout, copie et réplication de données),
Destructive (suppression de champs et d’enregistrements),
Esthétique (normalisation des salutations ou des noms de rue)
Sstructurelle (renommage, déplacement et combinaison de colonnes dans une base de données).
Dans une stack data moderne, les solutions de transformation de données ci-dessous, n’interviennent qu’au moment de la requête (selon le modèle ELT).
Dataform est une solution de préparation / transformation de données très intégrée à l'écosystème Google Cloud.
2
#5 Orchestration de données
L’orchestration des données est le processus qui consiste à prendre des données en silo à partir de plusieurs emplacements de stockage de données, à les combiner et à les organiser, puis à les rendre disponibles pour les outils d’analyse de données. L’orchestration des données permet aux entreprises d’automatiser et de rationaliser la prise de décision basée sur les données.
Les solutions d’orchestration des données permettent d’alimenter de nombreux processus, notamment :
Le nettoyage, l’organisation et la publication de données dans un entrepôt de données,
Le calcul de mesures commerciales,
L’application de règles pour cibler et impliquer les utilisateurs par le biais de campagnes emails,
La maintenance de l’infrastructure de données
L’exécution d’une tâche TensorFlow pour entraîner un modèle de machine learning
Apache Airflow est la solution d'orchestration de flux de données de référence, pour créer, planifier et surveiller des flux en lignes de commande et via une interface.
Dagster, une bibliothèque open source pour la création de systèmes tels que les processus ETL et les pipelines ML.
#6 Data science
Les outils de Data science ont qui vise à remédier à ce problème :
Comme les entreprises ont commencé à collecter de grandes quantités de données provenant de nombreuses sources différentes, il est de plus en plus nécessaire de disposer d’un système unique pour les stocker.
Rendre les images, les sons et les autres données non structurées facilement accessibles pour entraîner des modèles de machine learning.
Les outils de Data science permettent donc d’extraire des informations exploitables à partir de données brutes afin d’identifier des tendances et des corrélations au sein de celles-ci.
Databricks est une plateforme complète en surcouche de votre datawarehouse avec des fonctionnalités Analytics et Data science avancées.
2395
#7 Data Catalog / Gouvernance
Un catalogue de données est un inventaire organisé des actifs de données qui permet aux analystes et aux autres utilisateurs de données de localiser, d’accéder et d’évaluer les données dans un emplacement centralisé pour des utilisations analytiques et commerciales.
Les catalogues de données s’appuient sur les métadonnées pour permettre d’effectuer rapidement des recherches dans l’ensemble de l’écosystème de données d’une organisation, de comprendre les données à leur disposition et de les rendre opérationnelles.
Amundsen est un moteur de recherche de données et de métadonnées open source qui permet d'indexer des ressources de donnée (tables, tableaux de bord, flux, etc...).
#8 Data activation
Les outils de data activation croisent et synchronisent vos données clients issues de multiples sources, online et offline, afin de les rendre actionnables dans vos outils métiers pour créer des segments d’audience sur-mesure et donc personnaliser au maximum l’expérience client.
On retrouve ici différentes sous-catégories d’outils :
Syncari est une plateforme complète pour croiser et synchroniser des données.
41
#9 Dataviz
Les outils de visualisation de données permettent de créer plus facilement des représentations visuelles de grands ensembles de données. Lorsqu’il s’agit d’ensembles de données comprenant des centaines de milliers ou des millions de points de données, l’automatisation du processus de création d’une visualisation, du moins en partie, facilite considérablement le travail du concepteur.
Ces visualisations de données peuvent ensuite être utilisées à des fins diverses : tableaux de bord, rapports annuels, documents de vente et de marketing, diapositives pour investisseurs, et pratiquement partout où les informations doivent être interprétées immédiatement.
Ces outils permettent de visualiser la data à travers des graphiques ou autres éléments visuels.
Mode est un outil complet d'analyse de données et de reporting pour les professionnels des données et les responsables commerciaux. Mode combine un éditeur SQL cloud, des manuels collaboratifs pour Python et R, des visuels interactifs ainsi que des rapports et tableaux de bord en direct qui peuvent être partagés.
161
Malgré nos efforts pour vous présenter dans le détail quelques dizaines de solutions qui représentent selon nous les catégories principales d’outils de la stack data moderne, difficile d’être exhaustif car il en existe en réalité des centaines.
Pour avoir une idée du dynamisme de l’offre sur ce marché florissant, on vous invite à jeter un coup d’œil à la cartographie du marché des outils Data réalisée par mattturck.com.
Téléchargement de notre benchmark complet des outils qui composent la stack data moderne
Pour accéder à la ressource, il vous suffit de vous inscrire en quelques clics.
Au clic sur le bouton ci-dessous, vous arriverez sur un formulaire d'inscription rapide. Une fois inscrit, il y a un onglet "Ressources" qui apparaîtra dans le menu du haut qui vous permettra d'accéder à l'ensemble des ressources en téléchargement gratuit.
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
Vos données de contacts sont dispersées dans vos différents outils / bases de données ? Vous voulez unifier vos données clients pour mieux les exploiter ? C’est le challenge de nombreuses entreprises, et il n’est pas simple.
Les outils CRM peuvent jouer partiellement ce rôle, mais ils ont de grosses limites structurelles : manque de souplesse dans le modèle de données, incapacité à réconcilier différentes tables, difficulté à rajouter des champs calculés, surtout sur des données comportementales (ex: essayez de calculer le nombre d’emails ouverts sur les X derniers jours..).
Les éditeurs de logiciels CRM ont lancé des offres « CDP » ou « Customer 360 » pour répondre à ces challenges, mais ce n’est pas la seule approche possible. En simplifiant, deux solutions s’offrent à vous :
Déployer une Customer Data Platform sur l’étagère.
Faire de votre Data Warehouse votre Customer Data Platform.
La première option ne permet pas de construire une stack data moderne et présente plusieurs inconvénients. Les technologies datawarehouse ont beaucoup changé, et désormais il est possible d’utiliser votre DataWarehouse comme une CDP.
L’émergence des Customer Data Platforms
La Customer Data Platform est une technologie à la mode. Comment expliquer ce succès ? Quelles sont les limites de ces solutions « sur l’étagère » ?
Pourquoi tant de bruit autour des Customer Data Platforms (CDP) ?
C’est bien connu, la donnée clients est devenue l’actif le plus précieux des entreprises. C’est elle qui permet de proposer des expériences clients personnalisées, d’optimiser le ciblage marketing, de construire des programmes relationnels efficaces…
Les entreprises n’ont jamais eu autant de données à disposition. Comme le dit joliment Angela Sun dans un article publié sur Hull.io : « Il y a désormais plus de bytes de données dans le monde que d’étoiles dans l’univers. »
Ce sont les étoiles qui sont devenues la limite de ce qu’il est possible de faire grâce aux données. Réjouissons-nous ! C’est la bonne nouvelle.
Mais la donnée clients n’a de valeur que si elle est organisée, unifiée et synchronisée. Et c’est là que l’on bute sur le problème majeur auquel sont confrontées la plupart des entreprises : la dispersion des données dans le système d’information. Aujourd’hui peu d’entreprises exploitent pleinement leurs données.
Les raisons de cette dispersion des données sont bien connues : multiplication des points de contact, des canaux, nouvelles technologies, essor des SaaS…Inutile d’y revenir, nous nous intéressons ici aux solutions.
Justement, la Customer Data Platform est apparue comme la solution à ce problème. Le succès des CDP est à la hauteur des enjeux. Depuis 2018, la CDP est dans toutes les bouches comme le montre ce graphique :
Mais, qu’est-ce qu’au juste une Customer Data Platform ?
Customer Data Platform : Définition & fonctionnement
Adobe, Salesforce, Oracle, SAP : tous ces acteurs proposent aujourd’hui des « Customer Data Platforms ». Le marché des CDP draine des investissements colossaux. Selon une étude, le chiffre d’affaires combiné des éditeurs de CDP s’élèvera à plus de 10 milliards de dollars en 2025, contre 2,4 milliards en 2020.
La Customer Data Platform est une technologie qui permet d’unifier toutes les sources de données clients online et offline de l’entreprise (essentiellement first-party) pour créer une source unique de vérité. Les données sont unifiées autour de profils clients consistants : individus en B2C, entreprises en B2B. Le coeur de la CDP, c’est la « résolution d’identité », chaque nouveau point de contact est attribuée à un individu unique pour avoir une vision 360° de chaque contact.
La Customer Data Platform répond directement au problème dont nous avons parlé tout à l’heure. Elle unifie les données dispersées. Elle met fin à l’éclatement des données dans le système d’information.
L’unification des données facilite la gestion des données, leur enrichissement, leur nettoyage mais aussi bien sûr leur activation par les différents outils MarTech de l’entreprise. Les données unifiées et nettoyées de la CDP sont redistribuées aux autres outils sous forme de segments, d’agrégats, de scorings…Bref, la CDP est un constructeur d’audiences. Et ce n’est pas tout, l’unification des données dans la CDP facilite aussi la gouvernance des données et aide les entreprises à gérer leurs données en conformité avec les règles de protection des données (GDPR et consorts). Pour mieux comprendre le périmètre fonctionnel d’une CDP, vous pouvez parcourir cet article réalisé par notre partenaire, le cabinet de conseil Cartelis.
L’utilisation d’une Customer Data Platform ne nécessite pas de compétences techniques avancées, raison pour laquelle la CDP est généralement gérée directement par l’équipe marketing. C’est l’une des forces des CDP et l’une des raisons de l’engouement pour ces technologies.
Segment et Treasure Data sont de beaux exemples de Customer Data Platforms. Mais il existe un bon nombre des acteurs français, comme Ysance ou Campdebase.
La Customer Data Platform unifie les données autour de profils clients consistants. Source : NP6.
Les promesses déçues de la Customer Data Platform
Pour plusieurs raisons, nous pensons que les promesses faites par les CDP sur l’étagère n’ont pas été tenues. Tout d’abord, et c’est ce qui saute le plus aux yeux, les Customer Data Platforms…ne sont pas des plateformes. Ce ne sont pas des plateformes ou des écosystèmes conçus comme des frameworks sur lesquels des applications tierces pourraient venir se greffer. Les CDP « sur l’étagère » proposées par les Salesforce et autres Adobe sont en réalité des suites de logiciels qui vous enferment dans un environnement rigide.
C’est d’ailleurs une ironie de l’histoire, si on se rappelle que le grand mot d’ordre de Salesforce à ses débuts était « The End of Software ».
Au-delà de ce problème de dépendance à l’éditeur, il existe d’autres limites importantes :
Votre Customer Data Platform n’est pas une source unique de vérité. Pourquoi ? Parce que la CDP n’est pas un hub, mais un nœud juste un peu plus gros que les autres dans le SI Client. Un logiciel de plus en somme…La preuve ? Si vous faites de la BI, vous n’allez pas extraire les données de votre CDP, mais de votre Data Warehouse. On se retrouve ainsi avec plusieurs « single source of truth », et cela pose rapidement des problèmes. Dans la CDP, la déduplication des contacts est réalisée différemment que dans le datawarehouse, du coup, on n’obtient pas le même nombre de contacts dans la CDP / CRM que dans les reportings branchés sur le datawarehouse. Plus gênant encore, les règles de calcul du chiffre d’affaires, avec la prise en compte des remboursements / promotions notamment, sont réalisés par des analystes directement dans le datawarehouse, du coup, le CA ne sera pas le même dans la CDP que dans vos reportings. Après quelques années, ces exemples se multiplient, et créent plein de difficultés au quotidien.
La CDP empêche une coordination efficace entre le Marketing et l’IT. La Customer Data Platform s’est construite sur une promesse tape à l’oeil : l’équipe marketing allait enfin reprendre le contrôle sur la gestion des données clients. Plus besoin de l’équipe IT, l’équipe marketing allait devenir autonome. Cette approche ne va pas dans le bon sens selon nous. La gestion d’une stack data moderne repose sur un dialogue efficace entre l’IT et le marketing, pas sur un court-circuitage de l’IT. Ce dialogue est nécessaire pour répondre aux et challenger les problèmes data complexes, pour construire des modèles de données adaptés aux besoins du marketing. Lorsque l’on met hors jeu l’équipe IT dans la gestion d’une technologie, ce n’est pas à l’équipe marketing que l’on redonne le pouvoir, c’est à l’éditeur.
La Customer Data Platform n’est pas une technologie flexible. Cela rejoint le point précédent. La CDP impose ses modèles de données ou en tous cas ne donne que peu de marges de manœuvre dans la personnalisation de ces modèles. Segment Personas, par exemple, ne propose que deux objets de base : les utilisateurs et les comptes. Vous ne pouvez unifier vos données qu’autour de l’un ou l’autre de ces objets. Qui plus est, il est impossible à un utilisateur d’appartenir à plusieurs comptes. Vous êtes forcés de faire entrer vos données dans un moule semi-rigide qui ne correspond pas forcément aux caractéristiques de votre métier.
La Customer Data Platform est une solution coûteuse. Les CDP coûtent cher. Et acheter une CDP, c’est aussi acheter la philosophie de son éditeur, sa politique en matière de données…et donc perdre un peu de contrôle sur la manière de collecter, de transformer et d’exploiter les données.
La Customer Data Platform n’est donc pas l’alpha et l’oméga. De plus en plus d’entreprise se tournent vers une autre approche pour unifier et activer les données clients : transformer le Data Warehouse en Customer Data Platform. L’essor des technologies de Data Warehouse Cloud modernes (Snowflake en particulier, mais aussi les incontournables BigQuery et Redshift) ont rendu cette approche possible et très compétitive.
Pourquoi vous devez construire votre Customer Data Platform dans votre Data Warehouse
Vous avez déjà votre CDP : c’est votre Data Warehouse
Lorsqu’on dit « Customer Data Platform », on pense tout de suite aux solutions sur l’étagère se définissant explicitement comme des « CDP ». Mais en fait, on peut tout à fait construire une « Customer Data Platform » sans utiliser de CDP sur l’étagère…Vous voyez où je veux en venir ? Oui, votre Data Warehouse peut jouer le rôle d’une Customer Data Platform.
Pourquoi acheter quelque chose que l’on a déjà (au moins en puissance) ?
Qu’est-ce qu’un Data Warehouse Cloud ?
Un Data Warehouse (DWH) est une base dans laquelle vous agrégez les données en provenance de vos différentes sources. Les données sont chargées dans le DWH par lots (en batch) via un outil ETL (Extract – Transform – Load) comme Talend (ou ELT comme Fivetran). Une fois chargées dans le DWH, les données sont organisées en tables de faits et en tables de dimensions. Utiliser un DWH consiste à joindre les différentes tables via des requêtes SQL.
La modélisation en étoile des données du Data Warehouse. Exemple avec un Data Mart de Ventes.
Les Data Warehouse sont traditionnellement utilisés pour faire du reporting et de la BI. Un DWH stocke notamment les données de commande (table 1), les données du catalogue produit (table 2), les événements utilisateurs (table 3). Il permet ainsi de répondre à des questions comme : « Combien de commandes avons-nous par mois pour chaque famille de produit ? » > La réponse est obtenue en joignant les tables 1, 2 et 3 via une requête SQL.
Le Reverse ETL, la brique pour transformer votre DWH en CDP
Mais les solutions Data Warehouse modernes, cloud, permettent d’aller beaucoup plus loin que la simple analyse de données. Couplé à un outil « Reverse ETL », un Data Warehouse est en mesure de devenir une Customer Data Platform. Un Reverse ETL, c’est une solution pour activer vos données internes. C’est la brique qui permet de synchroniser les données du Data Warehouse avec les applicatifs métiers et autres outils marketing (CRM, Marketing Automation, Service client, outils publicitaires, etc.).
Avec une solution comme Octolis, vous pouvez synchroniser n’importe quel agrégat / segment de données dans vos outils métiers. Soit en utilisant une interface visuelle, soit en utilisant SQL.
Le Reverse ETL vous permet par exemple de faire redescendre :
Les données relatives à la fréquence d’achat des clients dans la solution de Marketing Automation.
Le revenu généré par chaque contact / entreprise dans le CRM Commercial.
Les top clients, avec leur LTV, dans vos outils publicitaires type Google Ads / Facebook.
Les données relatives à l’utilisation des services dans Zendesk…
On pourrait lister des dizaines de cas d’usage, cf. bibliothèque de cas d’usages.Le principe est toujours le même : alimenter en continu les applicatifs métiers avec les données du DWH dont les équipes ont besoin. Le Reverse ETL permet de transformer votre Data Warehouse en une base clients opérationnelle.
Conclusion
Cette approche consistant à monter la Customer Data Platform dans le DWH (via un Reverse ETL) est à envisager très sérieusement. Pourquoi ? Parce qu’elle réunit les avantages principaux des CDP sur l’étagère, sans leurs inconvénients. Cette approche permet en effet de :
Concevoir une CDP répondant exactement à vos besoins. Avec des outils comme dbt et Octolis, vous pouvez faire travailler votre Data Warehouse exactement comme vous en avez besoin.
Créer une infrastructure data plus solide. Là où les CDP sur l’étagère ne gèrent que les données clients, le Data Warehouse peut accueillir toutes vos données. Cela facilite la valorisation et la gouvernance des données.
Gagner en flexibilité. Les outils nécessaires à la transformation de votre DWH en CDP sont peu onéreux…contrairement aux CDP sur l’étagère qui coûtent très cher. L’approche « DWH » vous permet de gérer votre stack data de manière flexible, sans avoir besoin à chaque fois de contacter le support de la CDP et de vous entendre dire : »Notre outil ne permet pas de faire ça… ».
Data catalog – Définition & comparatif des solutions
Un data catalog est un outil de gestion des métadonnées, conçu pour aider les entreprises à trouver facilement et à gérer la quantité de données stockées dans leurs différents systèmes. Les data catalog centralisent les métadonnées en un seul endroit, offrant une vue complète de chaque élément dans l’ensemble des bases de données.
Ainsi, le data catalog contribue à rendre les sources de données plus faciles à gérer pour les utilisateurs. Il est conçu pour aider les analystes ou autres professionnels à trouver rapidement les données dont ils ont besoin.
Quelles sont les fonctionnalités clés d’un data catalog ?
Fonctionnalités principales
Intégration
Pour mettre en œuvre une solution de data catalog efficace, vous devez être en mesure de la connecter à tous les systèmes de l’entreprise : applications, bases de données, fichiers et même API externes. Un bon data catalog doit donc permettre les intégrations automatisées de toutes ces sources.
Moteur de recherche
L’une des caractéristiques les plus importantes d’un catalogue de données est la fonctionnalité de recherche. Elle doit permettre de requêter sur l’ensemble des métadonnées renseignées, pour trouver les mots-clefs recherchés. Des options de filtre et de tri doivent être disponibles.
Data lineage
Le data lineage aide les utilisateurs à comprendre l’origine de chaque donnée, et les transformations qu’elle a subi dans le temps. Cela permet de visualiser comment différents éléments de données sont liés les uns aux autres, s’ils fusionnent ou se séparent. Le data lineage est essentiel pour répondre aux exigences réglementaires en matière de traçabilité des données (GDPR).
Fonctionnalités secondaires
Collaboration
L’aspect collaboratif d’un data catalog comprend des actions simples comme la possibilité d’évaluer un ensemble de données, de le commenter, de le partager avec des collègues, ou même de l’assigner à quelqu’un. Cela doit permettre d’optimiser la communication entre collaborateurs, dans l’objectif d’augmenter la connaissance au sein de l’équipe.
Registre des métadonnées internes
Dans un data catalog, il ne suffit pas de savoir quels champs se trouvent dans quels systèmes, il faut pouvoir les relier à des termes commerciaux afin d’expliquer aux utilisateurs finaux la signification de chaque donnée. Ainsi, le registre de métadonnées doit inclure, pour chaque élément du data catalog, une description business et métier précise. Celle-ci doit permettre aux différentes équipes utilisant les données de comprendre rapidement comment celles-ci ont été créées ou calculées.
Gestion des métadonnées et modèles
Les bons catalogues de données vous permettent d’ajouter librement des métadonnées supplémentaires, ou d’étiqueter vos termes avec des tags. Ils permettent également de gérer tout type de métadonnées, notamment des éléments tels que les rapports, les API ou les serveurs.
Les principaux outils de data catalog
Solutions de data catalog modernes
Alors que les actifs de données augmentaient de manière exponentielle et que de plus en plus de personnes utilisaient le catalogue de données, les entreprises ont réalisé que toutes ces données devaient être gérées en termes de signification, de qualité et de droits d’administration.
conçu pour apporter de la valeur aux utilisateurs finaux automatiquement quelques heures après le déploiement. Il guide ensuite les utilisateurs vers la documentation d’une manière collaborative et sans douleur.
Ils aident les responsables des données à maintenir la documentation des données, les traitements, le lignage, la cartographie des informations personnelles, la propriété, etc.
Dans ce contexte, les catalogues de données de deuxième génération proposent des fonctionnalités plus avancées.
Voici notre tableau comparatif des 5 meilleurs data catalog modernes :
Solutions de data catalog open source
Les outils de data catalog open source constituent actuellement une excellente option, car ils proposent toutes les fonctionnalités attendues, et sont performants. De plus, ils défient toute concurrence avec un accès gratuit à leur code.
Les data catalog open souce sont excellents pour le scaling, offrent de nombreuses options de personnalisation et peuvent être utilisés sur de gros volumes de données. De plus, vous pourrez facilement faire appel à des développeurs pour personnaliser davantage le logiciel, pour répondre à vos besoins les plus pointus.
Voici notre tableau comparatif des 5 meilleurs data catalog open source :
Solutions de data catalog Enterprise
Nous nous intéressons ici aux solutions de data catalog optimisées pour les grandes entreprises (plus de 1000 employés).
La taille de l’entreprise influence notamment au niveau du cadrage des besoins technologiques. Selon les cas, on peut être amené à travailler sur des fonctionnalités plus avancées, ou plus sécurisées.
Voici notre tableau comparatif des 5 meilleurs data catalog Enterprise :
Comparatif fonctionnel complet
Nos amis de Castor ont réalisé un comparatif vraiment complet d’une quarantaine de solution de data catalog du marché, avec une dizaine de critères fonctionnels précis.
On vous recommande clairement d’y jeter un coup d’oeil si vous cherchez une solution.
Les solutions ETL (ou ELT) permettent d’extraire les données de différentes applications pour les verser dans un data warehouse. Comme vous l’avez deviné, le reverse ETL va dans l’autre sens. Il permet d’extraire les données du data warehouse pour alimenter toutes sortes d’applications : CRM, outils publicitaires, service client, etc.
Le potentiel est colossal. Cela permet d’avoir une seule source de vérité pour la plupart des applicatifs métiers. Fini les problèmes récurrents pour réconcilier les données de l’outil A avec l’outil B, ou pour gérer des flux entre applicatifs de tous les côtés.
Si le potentiel est aussi important, pourquoi ce type de solution émerge maintenant ? Historiquement le data warehouse est le socle de la BI uniquement. Il sert à construire des reportings, de grosses requêtes ponctuelles qui ne sont pas critiques. Si on demandait à un DSI des années 2000, ce serait une aberration d’alimenter un CRM, une application critique qui consomme des données chaudes, à partir d’un data warehouse.
La nouvelle génération de Data Warehouse cloud (Snowflake, Google BigQuery, AWS Redshift, ..), et l’écosystème qui va autour, change les règles du jeu. Beaucoup plus puissant, facile à maintenir, adapté pour tout type de requêtes, le data warehouse cloud moderne peut devenir un véritable référentiel opérationnel. Et les reverse ETL, c’est le chainon manquant pour assurer le dernier kilomètre.
Dans ce guide complet, nous allons vous expliquer tout ce qu’il faut savoir sur cette nouvelle composante de la stack data moderne.
Généalogie du reverse ETL : au commencement était l’ETL
Le reverse ETL désigne une nouvelle famille de logiciels jouant déjà un rôle clé dans la stack data moderne. Alors, qu’est-ce que c’est ? De quoi parle-t-on ?Cela n’aura échappé à personne, dans « reverse ETL », il y a ETL. Pour comprendre ce qu’est un reverse ETL, il faut d’abord avoir une bonne compréhension de ce qu’est un ETL. Car le reverse ETL procède de l’ETL comme nous le verrons dans un instant.
Le « bon vieil ETL »…oui, car les outils ETL sont tout sauf des technologies nouvelles. Le concept d’ETL a émergé dans les années 1970.
ETL, si on déplie l’acronyme, signifie Extract – Transform – Load. Avant de désigner une famille d’outils, l’ETL désigne un processus – un processus que les outils du même nom permettent d’accomplir. L’ETL est le processus qui consiste à Extraire les données issues des différentes sources de données de l’organisation, à les Transformer et enfin à les Charger (Load) dans un Data Warehouse, c’est-à-dire un entrepôt de données. Les outils ETL servent à construire le pipeline de données entre les sources de données et la base dans laquelle les données sont centralisées et unifiées.
Les sources de données peuvent être : des événements issus des applicatifs, des données issues de vos outils SaaS, de vos bases de données diverses et variées, et même de votre data lake…Les outils ETL développent des connecteurs avec les principales sources de données pour faciliter la construction du pipeline de données.
Fivetran propose plus de 150 connecteurs avec des sources de données.
Les ETL du passé étaient des solutions lourdes, On-Premise, fonctionnant avec des Data Warehouses eux-mêmes lourds installés sur les serveurs de l’entreprise. Depuis l’avènement des Data Warehouses Cloud (en 2012, avec Amazon Redshift), une nouvelle catégorie de logiciels ETL est apparue : les ETL Cloud. La cloudification des Data Warehouses, inaugurée par Amazon, a entraîné une cloudification des outils ETL. Fivetran et Stitch Data sont deux exemples emblématiques d’outils ETL Cloud.
Les ETL servent non seulement à charger les données des sources dans la destination que constitue le DWH, mais sont aussi utilisés pour transformer la donnée avant son intégration dans la base. Ce n’est donc pas simplement une tuyau, mais aussi un laboratoire.
Nous pouvons maintenant comprendre en quoi consiste le reverse ETL.
Un reverse ETL est une solution pour synchroniser les données du DWH avec vos applicatifs métiers
En clair, l’outil ETL permet de faire monter les données de vos différentes sources dans le DWH afin de centraliser et d’unifier les données de l’entreprise. Ces données sont ensuite utilisées pour faire de l’analyse data, de la BI.
Le reverse ETL a une fonction inverse de celle de l’ETL. Le reverse ETL est la solution technologique qui permet de faire redescendre les données centralisées du DWH dans les applicatifs métiers. Le reverse ETL apporte enfin la solution à un problème lancinant pour les entreprises. En effet, les entreprises parviennent assez bien et assez facilement à centraliser les données dans le Data Warehouse. Cette facilité, c’est aux ETL Cloud qu’on la doit. Mais ces données, une fois dans le DWH, sont difficiles à faire sortir de la base et à exploiter dans les outils métiers. En clair, elles sont utilisées pour faire de la BI, mais rarement exploitées pour alimenter les applicatifs métiers en l’absence de solutions simples de synchronisation.
Le reverse ETL est une solution d’intégration des données souple pour synchroniser les données du DWH avec applicatifs utilisés par le marketing, les sales, l’équipe digital et le service client pour ne citer qu’eux. Les reverse ETL se caractérisent par leur souplesse et leur simplicité d’utilisation, tout comme leurs aînés les outils ETL Cloud. Via des connecteurs et modulo un travail de SQL, les données sont préparées, transformées, mappées puis synchronisées dans les applicatifs métier. Les reverse ETL permettent même de se passer des requêtes SQL et d’éditer les flux depuis une interface visuelle. Vous choisissez la colonne ou la table de la base de données que vous voulez utiliser et vous créez le mapping depuis l’inrerface visuelle pour spécifier où est-ce que vous souhaitez que les données apparaissent dans Salesforce, dans Zendesk, etc. Plus besoin de scripts. Plus besoin d’APIs.
Une fois le flux en place, les données sont synchronisées dans les applicatifs non pas en temps réel, mais suivant des batchs très courts de l’ordre de la minute. Les reverse ETL, comme Octolis, sont basés sur une approche que l’on appelle « tabular data streaming », vs l’approche « event streaming ». Ce que fait le reverse ETL, c’est copier et coller à intervalles très réguliers les tables du système source (le DWH) dans le système cible (l’applicatif métier).
Tout comme les outils ETL, les reverse ETL ne sont pas uniquement des tuyaux. Ils permettent de transformer les données du DWH, de les préparer, c’est-à-dire de nettoyer les données, de créer des segments, des audiences, des scorings, de construire un référentiel client unique.
Pourquoi les solutions reverse ETL ont le vent en poupe aujourd’hui ?
Maintenant que nous savons ce qu’est un Reverse ETL et comment ça fonctionne schématiquement, intéressons-nous un peu plus au « pourquoi ».
Pourquoi vouloir sortir les données du DWH ?
Il a fallu des années pour que les entreprises parviennent à centraliser et unifier leurs données dans une base maîtresse : le Data Warehouse Cloud. Et encore… beaucoup d’entreprises n’en sont pas encore là et ne disposent toujours pas de référentiel unique.
Mais pourquoi vouloir aller plus loin et faire sortir les données que l’on a soigneusement centralisées dans le Data Warehouse ?
D’abord, il faut bien se dire que les données restent quoi qu’il en soit dans le Data Warehouse. Le reverse ETL synchronise des set de données dans les applicatifs métiers, sans les déplacer au sens strict. Synchroniser ne veut pas dire migrer. Donc pas de panique, vos données restent au chaud dans le DWH.
Ce que fait le reverse ETL, c’est mettre ces données centralisées du DWH au service des applicatifs métiers. C’est bien connu, le médicament est à la fois remède et poison. On a utilisé jusqu’à présent le DWH comme remède au silotage des données…pour aboutir à une nouvelle forme de silotisation. Les données aujourd’hui, dans beaucoup d’entreprises, sont silotées dans le Data Warehouse. Sans un reverse ETL, les données stockées dans le DWH ne sont pas utilisées ou très peu par les applicatifs métiers. A quoi servent-elles ? A faire de la BI et du dashboarding comme nous l’avons dit plus haut. C’est dommage. Le DWH aboutit à la création de définitions et d’agrégats de données très intéressants pour le business, grâce à tout le travail réalisé avec SQL : la lifetime value, le marketing qualified lead, le product qualified lead, le score de chaleur, l’ARR, etc. Mais ces données signifiantes pour le business ne sont pas utilisées directement par les équipes business et les outils qu’elles utilisent.
Avec un reverse ETL, vous pouvez utiliser ces définitions, et les colonnes associées dans le DWH, pour créer de profils clients et des segments d’audience. Avec un reverse ETL, le Data Warehouse ne sert plus uniquement à alimenter la BI, il sert directement à alimenter les applicatifs métier.
Le reverse ETL était la pièce manque de la stack data, la pièce qui empêchait cette stack data d’être véritablement moderne.
Quels sont les cas d’usage d’un reverse ETL ?
Entrons un peu plus dans le concret et voyons quels sont les cas d’usage que rend possible un outil de type reverse ETL.
Il y a essentiellement trois familles de cas d’usage :
#1 L’Operational Analytics
Cette nouvelle expression désigne une nouvelle manière d’envisager l’analytics. Dans l’approche Operational Analytics, les données ne sont plus utilisées seulement pour créer des rapports et des analyses, mais sont distribuées intelligemment aux outils métiers. C’est l’art et la manière de rendre la donnée opérationnelle pour les équipes métiers en l’intégrant dans les outils qu’ils utilisent au quotidien. Si l’on y réfléchit, c’est l’approche qui permet vraiment de devenir data-driven, qui permet aux équipes de prendre en compte les données dans toutes leurs décisions et actions. Le tout en douceur, simplement, facilement, sans prise de tête, sans passer par la lecture de rapports de BI indigestes.
Comment déployer cette approche « Operational Analytics » ? Comment devenir data-driven ? Réponse : en utilisant un reverse ETL bien sûr ! Le reverse ETL permet de transformer les données en analyses (en segments, en agrégats) et les analyses en actions.
Imaginez un commercial qui veut connaître les comptes clés, ceux sur lesquels concentrer ses efforts ? Dans l’approche classique, à l’ancienne, on fait appel à un data analyst qui va utiliser du SQL pour repérer les leads à forte valeur dans le DWH et ensuite présenter le tout dans un beau tableau de BI…que personne ne lira et n’exploitera, bien entendu. On peut chercher à former les commerciaux à la lecture des tableaux de bord et des reportings. Mais dans la pratique, c’est toujours compliqué et c’est ce qui freine le devenir data-driven de beaucoup d’organisations. C’est cette difficulté à mettre les données et les analyses à la disposition des équipes métier qui empêche la pleine exploitation des données à disposition de l’entreprise.
Dans l’approche Operational Analytics, plus besoin de former les commerciaux à l’utilisation des rapports de BI, le data analyst intègre directement les données correspondantes du Data Warehouse dans un champ personnalisé Salesforce.
Un reverse ETL permet à un data analyst de déployer l’Operational Analytics aussi facilement que de créer un rapport.
#2 L’automatisation des flux de données
Un reverse ETL permet de mettre facilement et automatiquement au service des équipes métiers les données dont elles ont besoin à un instant t. En clair, non seulement il met à disposition des équipes métier les données dont ils ont besoin dans leurs outils, mais il facilite le travail des data analysts et autres data engineers.
Par exemple, si votre équipe commerciale demande à l’IT quels sont les clients à fort risque d’attrition, un reverse ETL constitue la solution qui permet de facilement donner la réponse…sans avoir à passer un temps fou à extraire les données du DWH. On pourrait aussi prendre les exemples :
D’un commercial qui veut pouvoir visualiser dans Salesforce les clients ayant une lifetime value supérieure à X€.
D’un conseiller de clientèle qui veut pouvoir visualiser dans Zendesk les comptes ayant opté pour le support premium.
D’un responsable produit qui veut accéder aux feedbacks Slack des utilisateurs ayant déployés telle fonctionnalité.
Du comptable qui veut synchroniser les attributs clients dans son logiciel de comptabilité.
Etc.
Le reverse ETL permet de gérer facilement et de manière automatisé ces requêtes métiers du quotidien qui faisaient autrefois l’enfer de l’équipe IT. Il répond en ce sens à un problème récurrent dans les organisations : la communication, ou plutôt la mauvaise communication entre l’IT et les équipes métiers. Plus besoin de concevoir des APIs à la pelle. L’harmonie entre l’IT et le métier est rétablie.
#3 Le reverse ETL, une solution à la multiplication des sources de données
Les sources de données se multiplient. L’un des enjeux de la stack data moderne est de gérer cette multiplication des sources de données. Le reverse ETL répond à cet enjeu. Il permet de tirer profit de cette formidable mine d’or de données à disposition pour créer une expérience client mémorable. Car, in fine, c’est bien la finalité. Ou plutôt les deux finalités :
Pour le client : Lui offrir une expérience plus riche, plus pertinente grâce à des actions plus personnalisées, plus ciblées au niveau du contenu, du canal de diffusion, du moment de réalisation. Générer plus de satisfaction client.
Pour l’entreprise : Augmenter la rétention client et développer le revenu par client.
Le reverse ETL permet de transformer la connaissance client qui est produite grâce au couple DWH – BI en expérience enrichie pour le client.
Deux alternatives aux logiciels reverse ETL : la Customer Data Platform & l’iPaaS
Il existe des alternatives aux logiciels reverse ETL et notre article ne serait pas complet si nous ne les mentionnions pas.
Reverse ETL vs CDP
Les Customer Data Platforms connaissent un essor important depuis le milieu des années 2010. Une CDP est une plateforme sur-l’étagère qui permet de construire un référentiel client unique en connectant toutes les sources de données de l’organisation. En ce sens, la CDP est une alternative au Data Warehouse. L’avantage par rapport au Data Warehouse, c’est que la CDP n’est pas qu’une base de données destinée à des usages de BI. La CDP propose des fonctionnalités avancées pour :
Préparer la donnée en vue des cas d’usage métiers : segmentation, création d’agrégats, de scores…
La redistribuer, via des connecteurs natifs ou sur-mesure, aux applicatifs métiers.
En clair, la CDP joue le même rôle que le couple DWH – reverse ETL. Il n’y a d’ailleurs pas nécessairement à choisir entre CDP et DWH. Une même entreprise peut en effet associer :
Un Data Warehouse qui servira à la BI.
Une Customer Data Platform qui permettra d’activer les données clients, de les mettre à la disposition des équipes métiers.
Comparée à la combinaison Data Warehouse – reverse ETL, la Customer Data Platform se caractérise par :
Une plus grande ridigité. La CDP impose ses modèles de données et impose des limites dans la création de modèles sur-mesure.
Les CDP sont des solutions très coûteuses, inaccessibles pour la plupart des TPE, et même des PME.
Les CDP ne favorisent pas la communication entre l’IT et les équipes métiers. La CDP est conçue pour les équipes métiers, et en particulier pour le marketing. L’objectif des éditeurs est de rendre les équipes métiers autonomes vis-à-vis de l’IT. Or, selon nous, l’enjeu est de fluidifier la communication entre l’IT et le métier, pas de la détruire. Pour déployer des cas d’usage data complexes, l’IT a son rôle à jouer.
C’est pour cette raison que nous préférons l’approche consistant à associer le Data Warehouse à un outil reverse ETL. Elle offre plus de souplesse. En deux mots, un reverse ETL permet de transformer votre Data Warehouse en Customer Data Platform.
Reverse ETL vs iPaaS
Un iPasS est une solution d’intégration en mode SaaS : Integration Platform as a Service. Integromat est sans doute la solution iPaaS la plus emblématique du marché aujourd’hui. Les iPaaS proposent en général des interfaces visuelles, faciles d’utilisation, qui permettent de connecter les applications et sources de données entre elles. Le fonctionnement est proche de celui du reverse ETL : Vous sélectionnez une source, vous sélectionnez un outil de destination et vous éditez le mapping pour définir l’endroit où les données issues de la source vont s’intégrer dans l’outil de destination (l’endroit et le « comment »). L’exemple ci-dessous montre la conception d’un mapping entre les emails et Google Spreadsheet :
Integromat – Intégration Email – GSheets.
Pas besoin d’APIs, pas besoin de scripts, et même pas besoin de SQL. Les solutions iPaaS sont pour cette raison prisées des personnes au profil non-technique. Un iPaaS permet de créer des flux de données 1:1 directement entre les sources et la destination, sans passer par le Data Warehouse. Pour cette raison, l’iPaaS peut être utilisé par les entreprises ayant des besoins limités en matière d’intégration data. Mais ce n’est pas l’option à privilégier par l’entreprise qui souhaite se doter d’une infrastructure IT organisée autour d’une base de données jouant le rôle de pivot.
Conclusion
Le reverse ETL est déjà utilisé par les entreprises les plus avancées en matière de data et a vocation à s’imposer dans les entreprises qui souhaitent mieux exploiter leurs données. C’est une solution qui permet de franchir un cap sérieux vers une meilleure valorisation des données stockées dans le Data Warehouse. Nous aurons l’occasion de revenir plus en détail sur les enjeux autour de cette brique data incontournable.
Un Data Engineer qui aurait été cryogénisé en 2010 et que l’on réveillerait par malice aujourd’hui ne comprendrait plus grand-chose à la stack data moderne. Dites-vous bien qu’il n’a fallu que quelques années pour que tout change dans la manière de collecter, extraire, acheminer, stocker, préparer, transformer, redistribuer et activer les données. Nous avons clairement changé de monde et les opportunités de générer du business grâce aux données n’ont jamais été aussi grandes.
A quoi ressemble la stack data moderne ? On peut commencer avec un premier schéma très macro.
Clairement, l’évolution la plus marquante est la place centralise prise peu à peu par le Data Warehouse Cloud, devenu système pivot de l’infrastructure IT. De là découlent toutes les autres transformations notables :
L’augmentation exponentielle de la puissance de calcul et l’effondrement des coûts de stockage.
Le remplacement des outils ETL classiques par les solutions EL(T) Cloud.
Le développement de solutions de BI Cloud « self service ».
L’émergence récente des Reverse ETL qui permettent de faire descendre les données du Data Warehouse Cloud dans les outils métiers, de mettre enfin la stack data au service de la stack marketing.
Entrons dans le cœur du sujet. Nous allons vous présenter les contours de la stack data moderne. Nous avons choisi deux angles :
L’angle historique : Qu’est-ce qui a amené à l’émergence de la stack data moderne ?
L’angle disons géographique/topographique. Nous allons passer en revue les différentes briques qui composent cette stack data moderne.
🌱 Les changements à l’origine de la stack data moderne
La stack data moderne définit l’ensemble des outils et bases de données utilisés pour gérer les données destinées à alimenter les applicatifs métiers. L’architecture de la stack data a connu de profondes transformations ces dernières années, marquées par :
La montée en régime des Data Warehouses Cloud (DWH) qui s’imposent progressivement comme la source maîtresse des données. Le DWH a clairement vocation à devenir le pivot de la stack data et nous aurons l’occasion d’en reparler longuement dans nos articles de blog. Vous qui croyez encore à la Customer Data Platform sur l’étagère, abandonnez toute espérance.
Le basculement de l’ETL (Extract-Transform-Load) vers l’EL(T) : Extract – Load – (Transform). « ETL » en tant que concept, process, autant qu’en terme d’outils (logiciels ETL). Dans une stack data moderne, les données sont chargées dans la base maîtresse avant d’être transformées, via des solutions EL(T) dans le cloud, plus légères que les traditionnels outils ETL.
L’utilisation croissante de solutions analytics self-service (comme Tableau) pour faire de la BI, produire les reportings et autres data visualizations.
La montée en régime des DataWarehouse Cloud (DWH)
Le Data Warehouse est une technologie vieille comme le monde, ou presque. En tous cas ce n’est pas un mot nouveau, loin de là. Et pourtant nous assistons à une transformation majeure dans le paysage du Data Warehousing depuis une petite dizaine d’années. Les solutions DWH traditionnelles cèdent progressivement la place à des solutions dans le cloud : les Data Warehouse Cloud. On peut dater précisément cette évolution : octobre 2012, date de mise sur le marché de la solution DWH Cloud d’Amazon : Redshift. Il y a clairement un avant et un après, même si Redshift perd aujourd’hui du terrain.
On peut dire que c’est Amazon, avec Redshift, qui a donné la principale impulsion ayant donné naissance à la stack data moderne. Toutes les autres solutions du marché qui ont suivi ont une dette envers le géant américain : Google BigQuery, Snowflake et quelques autres. Cette évolution a parti lié avec la différence entre les systèmes MPP (Massively parallel processing) ou OLAP comme Redshift et les systèmes OLTP classiques comme Postgres. Mais cette discussion mériterait à elle seule tout un article que nous produirons sans doute un jour. Pour faire court, disons que Redshift permet de traiter des requêtes SQL et de réaliser des jointures sur d’énormes volumes de données de 10 à 10 000 fois plus rapidement que les bases OLTP. Précisons quand même que Redshift n’est pas la première base MPP. Les premières sont apparues une décennie plus tôt, mais en revanche Redshift est bien :
La première solution de base de données MPP basée dans le Cloud.
La première solution de BDD MPP accessible financièrement à toutes les entreprises. Une TPE qui a des besoins limités peut utiliser Redshift pour quelques centaines d’euros par mois. Pour information ou pour rappel : avec les solutions classiques On-Premise, il faut compter pas loin de 100k€ de licence annuelle.
Depuis quelques années, on assiste à une montée en puissance de BigQuery et surtout de Snowflake. Ces deux solutions proposent désormais les meilleures offres du marché, tant au niveau du prix que de la puissance de calcul. Mention spéciale pour Snowflake qui propose un modèle de tarification très intéressant, puisque la facturation du stockage est indépendante de la facturation du computing.
Mais parce qu’il faut rendre à César ce qui lui appartient – César étant ici Redshift, rappelons ces quelques chiffres :
RedShift a été lancé en 2012. Il y a 10 ans.
BigQuery, la solution DWH Cloud de Google, n’a intégré le standard SQL qu’en 2016.
Snowflake n’est devenu mature qu’en 2017-2018.
Ce qui change avec les Data Warehouse Cloud
Résumons-nous. L’avènement de Redshift et des autres solutions Data Warehouse Cloud qui ont suivi ont permis de gagner sur plusieurs niveaux :
Rapidité. C’est ce que nous venons de voir. Un DWH Cloud permet de réduire significativement le temps de traitement des requêtes SQL. La lenteur des calculs était le principal frein à l’exploitation massive des données. Redshift a fait sauter de nombreuses barrières.
Connectivité. Le Cloud permet de connecter beaucoup plus facilement les sources de données au Data Warehouse. Plus généralement, un DWH Cloud gère beaucoup plus de formats & sources de données qu’un entrepôt de données traditionnel installé sur les serveurs de l’entreprise (On-Premise).
Accès utilisateurs. Dans un Data Warehouse classique, « lourd », installé sur les serveurs de l’entreprise, on limite volontairement le nombre d’utilisateurs pour limiter le nombre de requêtes et économiser les ressources serveurs. Cette option technologique classique a donc des répercussions au niveau de l’organisation :
DWH On-Premise : Géré par une équipe centrale. Accès restreints/indirects pour les utilisateurs finaux.
DWH Cloud : Accessibles et utilisables par tous les utilisateurs cibles. L’utilisation de serveurs virtuels permet de lancer des requêtes SQL simultanées sur une même BDD.
Flexibilité & Scalabilité. Les solutions Data Warehouse Cloud sont beaucoup moins onéreuses que les solutions On-Premise classiques (type Informatica ou Oracle). Elles sont aussi et surtout beaucoup plus flexibles, avec des modèles de tarification basés sur le volume de données stocké et/ou les ressources de computing consommées. En ce sens, l’avènement des Data Warehouses Cloud a permis de démocratiser l’accès à ce type de solutions. Alors que les DWH classiques étaient des solutions lourdes accessibles uniquement aux grandes entreprises, les DWH Cloud sont des solutions légères, flexibles accessibles à une TPE / startup.
Le passage des solutions ETL à EL(T)
Extract-Transform-Load : ETL. Extract-Load-(Transform) = EL(T). En déroulant ces acronymes, on comprend assez facilement la différence :
Lorsque l’on utilise un process ETL (et les outils ETL qui permettent d’opérer ce process), on transforme la donnée avant de la charger dans la base cible : le Data Warehouse.
Lorsque l’on utilise un process EL(T), on commence par charger toutes les données structurées ou semi-structurées dans la base maîtresse (DWH) avant d’envisager les transformations.
Quelles sont les enjeux sous-jacents d’une telle inversion ? C’est tout simple. Les transformations consistent à adapter le format des données à la base cible, mais aussi à nettoyer, dédupliquer et à réaliser un certain nombre de traitements sur les données issues des sources pour les adapter au design du Data Warehouse…et ne pas trop l’encombrer. L’enjeu est bien là. Transformer avant de Charger permet d’évacuer une partie des données et donc de ne pas trop surcharger la base maîtresse. C’est d’ailleurs pour cette raison que toutes les solutions classiques de Data Warehouse fonctionnaient avec des solutions ETL lourdes. Il fallait absolument faire du tri en amont du chargement dans le DWH dont les capacités de stockage étaient limitées.
Avec les Data Warehouse Cloud, le coût de stockage est devenu une commodité et la puissance de calcul a énormément augmenté. Résultat : Plus besoin de transformer avant de charger. La combinaison DWH On-Premise – ETL On-Premise cède le pas progressivement devant la combinaison moderne DWH Cloud – EL(T) Cloud. Le fait de charger les données dans le Data Warehouse avant toute transformations permet d’éviter de se poser les questions stratégiques et business au moment du process d’extraction et d’intégration des données dans le DWH. Le coût de gestion du pipeline est considérablement réduit, on peut se permettre de tout charger dans le DWH « sans se prendre la tête » – et ainsi on ne se prive pas des cas d’usage futurs de la donnée.
La tendance au self service Analytics
Nous avons parlé du Data Warehouse Cloud qui devient le pivot de la stack data moderne. En amont, nous avons les outils EL(T) qui font la connexion entre les multiples systèmes de données et l’entrepôt de données. Les données du Data Warehouse Cloud sont ensuite utilisées pour faire de la BI, de l’analyse de données, du dashboarding, du reporting.
L’avènement des DWH Cloud a contribué à « cloudifier » non seulement les solutions d’intégration (les ETL/ELT), mais aussi les solutions de BI. Nous avons aujourd’hui sur le marché des dizaines d’éditeurs de solutions de BI dans le cloud, abordables et conçues pour les utilisateurs métiers. Ce sont des solutions simples à utiliser et proposant des connecteurs natifs avec les principaux Data Warehouses Cloud du marché. Power BI, Looker ou Tableau sont solutions de BI Cloud de référence :
Une solution comme Tableau permet de connecter toutes les sources de données en quelques clics et de créer à partir d’elles des rapports sur-mesure, sur la base de modèles de données simplifiés. Une solution de BI permet un pilotage de la performance global basé sur des modèles d’attribution omnicanaux, contrairement aux modules de reporting proposés par les applicatifs métiers ou les solutions de web analytics (Google Analytics…). Un outil comme Looker, branché au Data Warehouse, désilote l’analyse de données. La BI est l’un des principaux cas d’usage d’un Data Warehouse. Avec l’avènement des DWH Cloud, il était naturel que se développe de solutions de BI SaaS. Et cela s’est fait.
Data Warehouse Cloud, EL(T), solutions analytics « self-service » : ces trois familles d’outils sont étroitement liées et constituent les pièces maîtresses d’une stack data moderne.
🔎 Zoom sur les briques de la stack data moderne
Nous allons maintenant passer en revue de manière plus détaillée les principales briques composant la stack data moderne, en partant du schéma présenté en introduction.
Schéma type d’une stack data moderne
Nous apprécions ce schéma de la stack data moderne proposé par a16z.
Les sources de données, c’est-à-dire l’ensemble des systèmes, bases et outils fournisseurs de données. Ces sources peuvent être internes ou externes (solutions d’enrichissement…). Le phénomène auquel nous assistons depuis des années, lié au développement du digital, c’est l’explosion non seulement des volumétries de données, mais aussi des sources de données – et donc des formats, des structures de données. Cette effervescence constitue à la fois un énorme potentiel et un sacré défi.
Les solutions d’ingestion et/ou de transformation des données. Nous retrouvons ici toutes les technologies concourant à réaliser le process Extract – Load et éventuellement Transform : EL(T). C’est-à-dire les solutions permettant l’acheminant (avec ou sans transformations) des données issues des sources dans la ou les bases maîtresses.
La base ou les bases maîtresse(s) de stockage des données. On trouve ici deux familles de solutions : les Data Warehouse Cloud et les Data Lake. Le DWH stocke des données structurées ou semi-structurées tandis que le Data Lake peut stocker vraiment n’importe quels types de données. En clair, le Data Lake est une baignoire dans laquelle on verse en vrac toutes les données sans aucunes transformations, sans aucuns traitements, dans leur état brut. Le Data Lake est utilisé pour des cas d’usages data très avancés de type Machine Learning. C’est l’outil des Data Scientists. Le Data Warehouse reste un « entrepôt » organisant les données de manière structurée, même si ses capacités à intégrer les données semi-structurées augmentent clairement. C’est le développement de ces capacités d’ailleurs qui rend le DWH de plus en plus pivot – contrairement au Data Lake « pur » qui joue de plus en plus un rôle secondaire. Nous y reviendrons.
Les outils de préparation et de traitement de la donnée. Nous avons vu que le Data Warehouse Cloud tendait à devenir l’outil de référence pour transformer les données, via SQL. Il existe quantités de solutions pouvant accompagner le DWH dans ce process de transformation des données en vue des usages BI ou business. Les outils de préparation et de transformation dessinent la famille de solutions data la plus large et hétéroclite.
Les outils de BI et les outils d’activation, qui sont les outils de destination des données du Data Warehouse Cloud. Le DWH est à la base utilisé pour la BI. Il l’est de plus en plus pour alimenter en quasi temps réel les applicatifs métiers. C’est ici qu’intervient les Reverse ETL comme Octolis. Nous vous présenterons dans quelques instants le rôle des Reverse ETL dans la stack data moderne.
Passons maintenant en revue chacune de ces briques de la stack data moderne.
Le Data Warehouse Cloud
Le DWH Cloud constitue la fondation de la stack data moderne, la solution pivot autour de laquelle gravite tous les autres outils. Il stocke les données structurées et semi-structurées de l’entreprise. Il n’est pas simplement une base de données, il est aussi un laboratoire de la donnée, une véritable machine. Il est un lieu de préparation et de transformation des données via un outil principal : le SQL, même si on utilise de plus en plus Python (mais c’est un autre sujet).
Le Data Warehouse Cloud est parfois construit en aval d’un Data Lake qui sert, comme nous l’avons vu, de fourre-tout, de baignoire de données stockées dans leur état brut. On peut très bien utiliser à la fois un Data Lake et un Data Warehouse Cloud. On n’a pas nécessairement besoin de faire le choix entre les deux technologies. A vrai dire, elles remplissent des rôles différents et peuvent se montrer complémentaires…même s’il y a fort à parier que le sens de l’histoire soit à la fusion des deux technologies. Signalons d’ailleurs que certains acteurs, comme Snowflake, proposent des solutions de Data Warehouse Cloud et de Data Lake intégrées. Ce serait d’ailleurs l’objet possible d’un article : Data Lake et Data Warehouse Cloud ont-ils vocation à fusionner ? Ce n’est pas l’objet de cet article, mais sachez que c’est un débat qui remue la tête de beaucoup d’experts !
Quoi qu’il en soit, c’est autour du Data Warehouse Cloud, connecté ou fusionné avec le Data Lake, que s’organise toute la stack data moderne.
Les solutions EL(T)
Comme nous l’avons vu dans la première section de l’article, les solutions EL(T) prennent l’ascendant sur les outils ETL classiques. Cette évolution traduit une transformation au niveau du process d’intégration des données, une évolution majeure dans la manière de construire le pipeline de données.
Une question que vous vous êtes peut-être posées : Pourquoi mettre « T » entre parenthèses ? Pour la simple et bonne raison que l’outil utilisé pour la construction du pipeline de données entre les systèmes sources et le Data Warehouse Cloud n’a plus besoin de transformer la donnée. Les solutions EL(T) Cloud (Fivetran, Stitch Data…) servent avant tout à organiser la tuyauterie. C’est leur rôle principal. Ce sont désormais les solutions de Data Warehouse Cloud et des outils tiers qui prennent en charge les phases de transformation.
Une solution DWH Cloud permet de transformer des tables de données avec quelques lignes de SQL. C’est d’ailleurs une évolution dont nous aurons à reparler : La plupart des opérations de Data Preparation et de Data Transformation peuvent aujourd’hui être réalisées dans le Data Warehouse Cloud lui-même en utilisant SQL. Les transformations sur les données sont donc de moins en moins traitées par les Data Engineers (en Java, Python et autre Scala) et de plus en plus prises en charge par les Data Analysts et équipes business utilisant le SQL. Ceci amène d’ailleurs un vrai : Quel rôle pour le Data Engineer demain ? Son rôle dans l’organisation et la maintenance de la stack data moderne n’est pas assuré. L’objectif de la stack data moderne est de redonner du pouvoir (sinon « le » pouvoir) aux utilisateurs finaux des données. Une stack data qui se modernise est une stack data de plus en plus au service des équipes métier et de la stack marketing qu’ils manient. La stack data moderne casse les barrières entre data et marketing, elle est la condition sine qua non d’un Data-Marketing efficient, la condition pour devenir « data-driven » véritablement.
Les solutions de préparation / transformation
Dans une stack data moderne, la préparation et la transformation des données s’effectuent :
Soit dans le Data Warehouse Cloud lui-même, comme nous l’avons vu.
Soit en aval du Data Warehouse Cloud, via des outils ETL.
Soit, cas le plus fréquent, par le DWH renforcé par des outils tiers.
La préparation ou transformation des données est l’art de rendre la donnée exploitable. Cette phase consiste à répondre à une question simple : Comment transformer des données brutes en set de données exploitables par le business ?
Un exemple de solution de préparation des données brutes : Dataform.
La transformation des données est un process multiforme qui implique des natures de traitements assez différentes : nettoyage des données, déduplications, paramétrage de règles sur-mesure de mise à jour des données, enrichissements des données, création d’agrégats, de segments dynamiques…Les outils de préparation et de transformation sont également utilisés pour maintenir la qualité des données (Data Quality). Parce que la « transformation » des données fait référence à des opérations de nature différente, on ne s’étonnera pas que la stack data moderne accueille plusieurs outils appartenant à cette grande famille multiforme.
Les solutions de data management (Gouvernance des données)
Le fait que le Data Warehouse Cloud soit accessibles et utilisables par un grand nombre d’utilisateurs est bien entendu une chose positive. Le problème potentiel, c’est le chaos que ces accès élargis peuvent occasionner en matière de Data Management. Pour ne pas tomber dans ce piège, l’entreprise doit absolument :
Intégrer un ou plusieurs outils de Data Management dans la stack data.
Documenter et mettre en place des règles de gouvernance des données.
Les enjeux autour de la Gouvernance des Données sont plus actuels que jamais. La première raison, c’est celle que nous venons de rappeler : l’ouverture en accès et en édition des solutions de la stack data. La deuxième raison, c’est l’explosion des volumétries de données qui impose la mise en place de règles stricts de gouvernance. La troisième raison est le renforcement des règles régissant l’utilisation des données à caractère personnel. Le fameux RGPD notamment…
La gouvernance des données est un sujet sensible et généralement traité de manière insatisfaisante par les organisations. Ce n’est pas le sujet le plus sexy, mais il faut clairement l’intégrer dans la feuille de route.
Les solutions reverse ETL
Terminons par une toute nouvelle famille de solutions data, beaucoup plus sexy pour le coup et promise à un bel avenir : les Reverse ETL. Nous publierons prochainement un article très complet sur le Reverse ETL, son rôle, sa place dans la stack data moderne. Résumons ici en quelques mots les enjeux et les fonctionnalités proposées par ces solutions d’un nouveau genre.
L’enjeu, il est en vérité très simple : Les données issues des sources de données diverses et variées de l’entreprise remontent de mieux en mieux dans le Data Warehouse Cloud, mais ces données ont encore beaucoup de mal à redescendre dans les outils d’activation : le CRM, le Marketing Automation, la solution de ticketing, l’ecommerce, etc.
Le Reverse ETL est la solution qui organise et facilite la redescente des données du DWH dans les outils utilisés par les équipes opérationnelles. Avec un Reverse ETL, les données du Data Warehouse Cloud ne sont plus seulement utilisées pour alimenter la solution de BI, elles sont mises au service des équipes métier, dans les outils qu’ils utilisent au quotidien.
C’est pour cela que l’on parle de « Reverse ETL ». Là où l’ETL (ou ELT) fait monter les données dans le DWH, le Reverse ETL fait l’inverse. Il fait redescendre les données depuis le DWH dans les outils. Le Reverse ETL est la solution qui permet de mettre en connexion la stack data et la stack marketing au sens large. Il est à l’interface des deux. Un exemple ? Avec un Reverse ETL, vous pouvez faire descendre les données d’activité web (stockées dans le DWH) dans le logiciel CRM pour aider les commerciaux à améliorer leur relation prospects/clients. Mais c’est un cas d’usage parmi tant d’autres…Les cas d’usage sont multiples et ont vocation à devenir de plus en plus nombreux dans les prochains mois et prochaines années. Census, HighTouch et bien entendu Octolis sont trois exemples de Reverse ETL.
🏁 Conclusion
Les infrastructures, les technologies, les pratiques et jusqu’aux métiers du Data marketing au sens le plus large ont évolué à une vitesse incroyable. Nous avons vu la place centrale que cette stack data moderne accorde au Data Warehouse Cloud. Tout pivote autour de ce point de gravité.
Certaines évolutions récentes, et nous pensons notamment à la mode des Customer Data Platforms sur l’étagère, faussent un peu la compréhension de ce qui se passe réellement. Il ne faut pas s’y tromper, c’est clairement du côté des Data Warehouses (qui n’ont plus rien à voir avec leurs ancêtres On-Premise) que pointe la flèche de l’avenir.
Vers le côté des DWH Cloud…et vers tout l’écosystème d’outils gravitant autour : EL(T), solutions de BI Cloud…et bien sûr Reverse ETL.

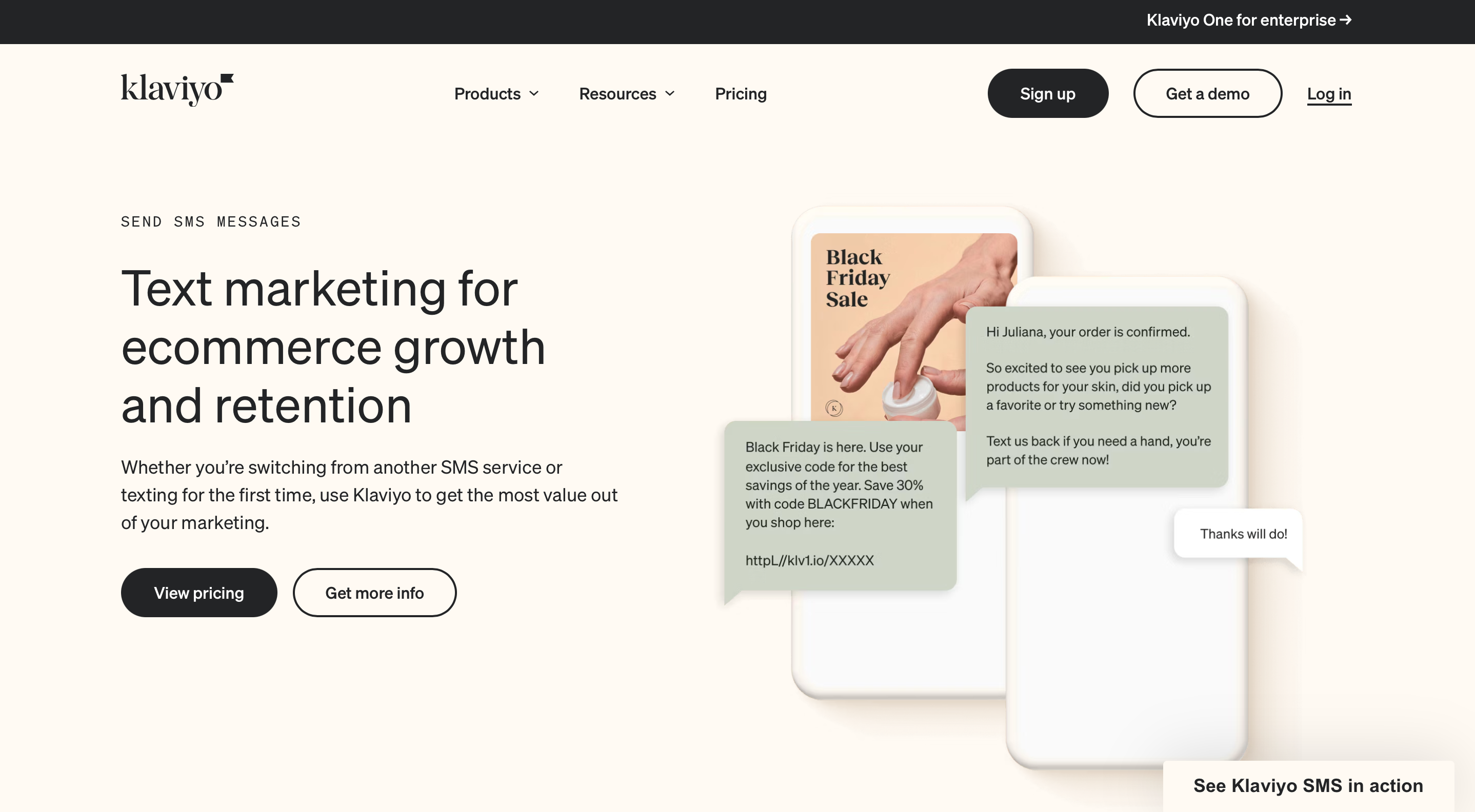

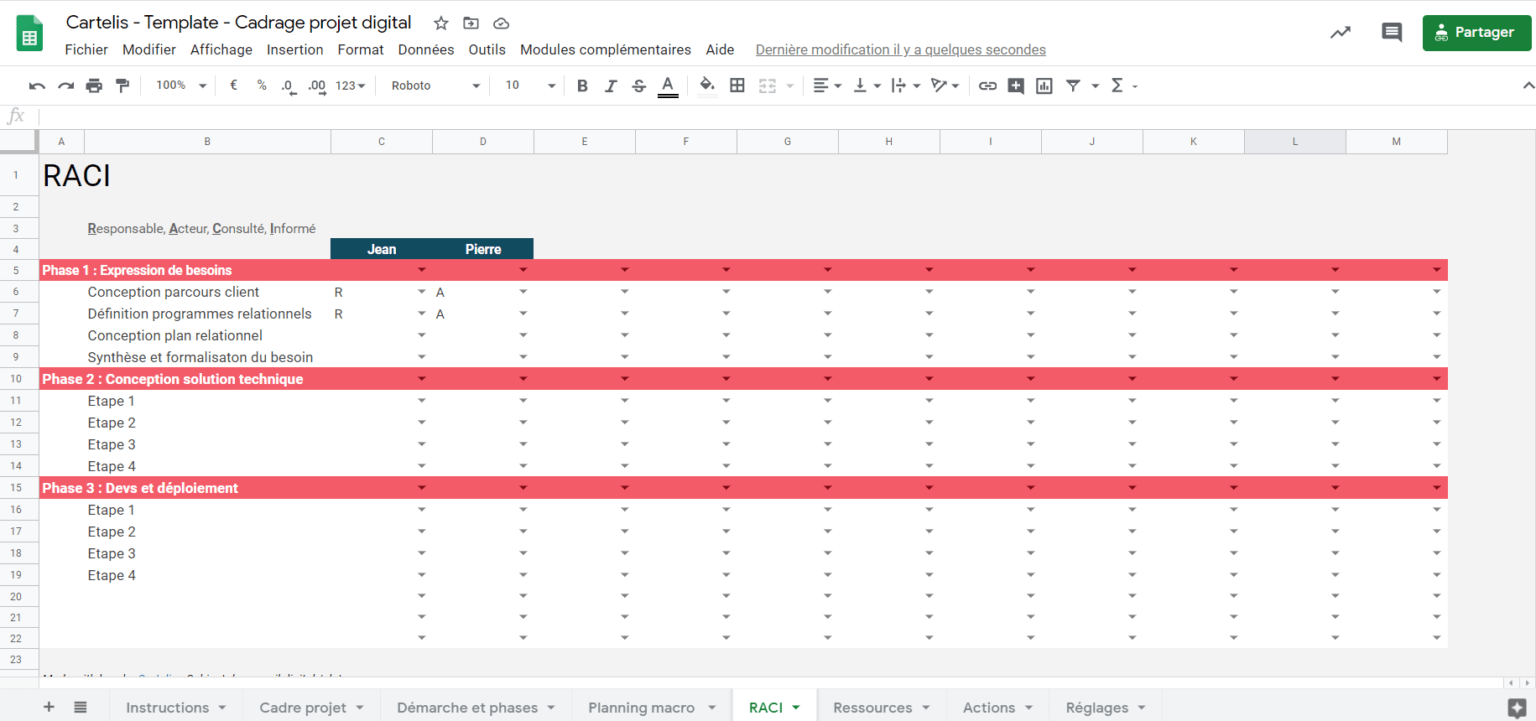
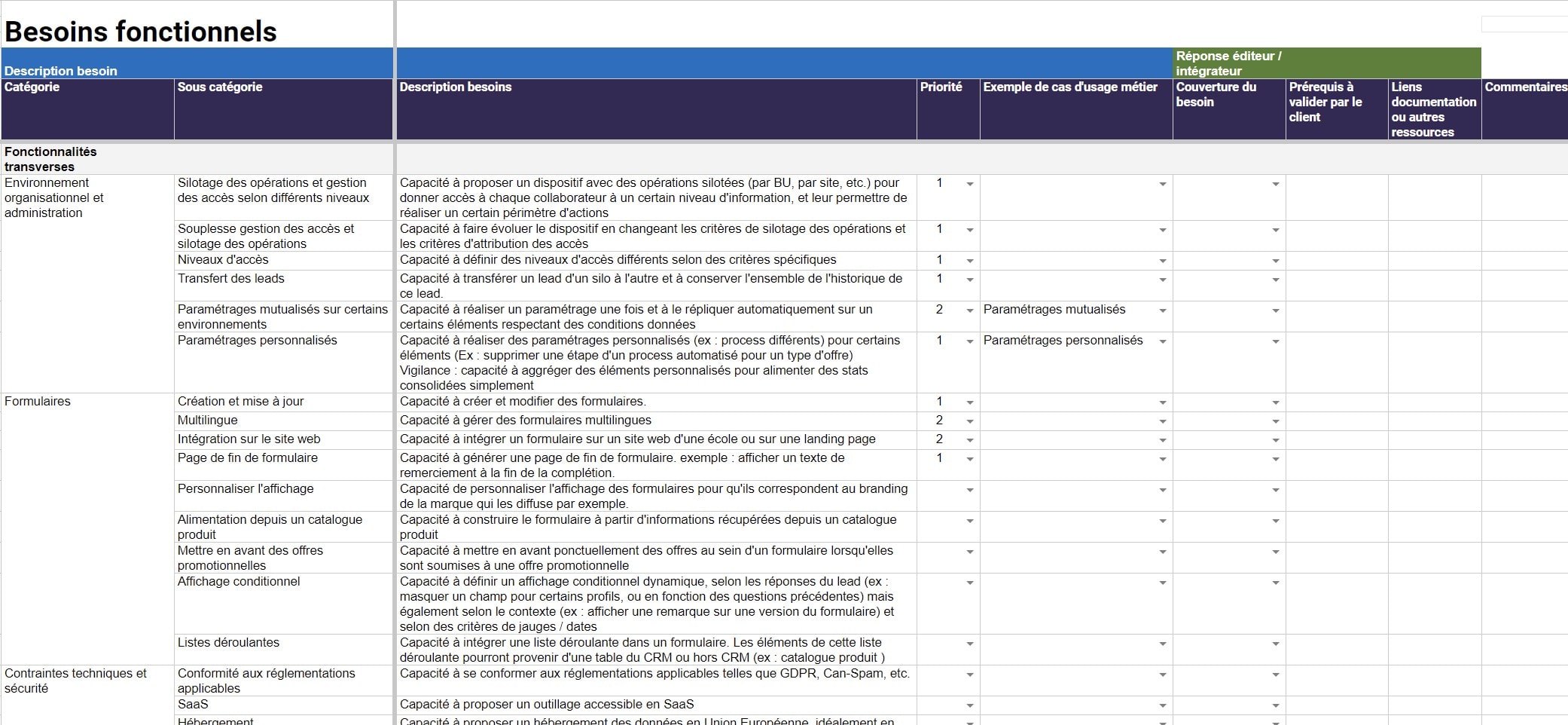
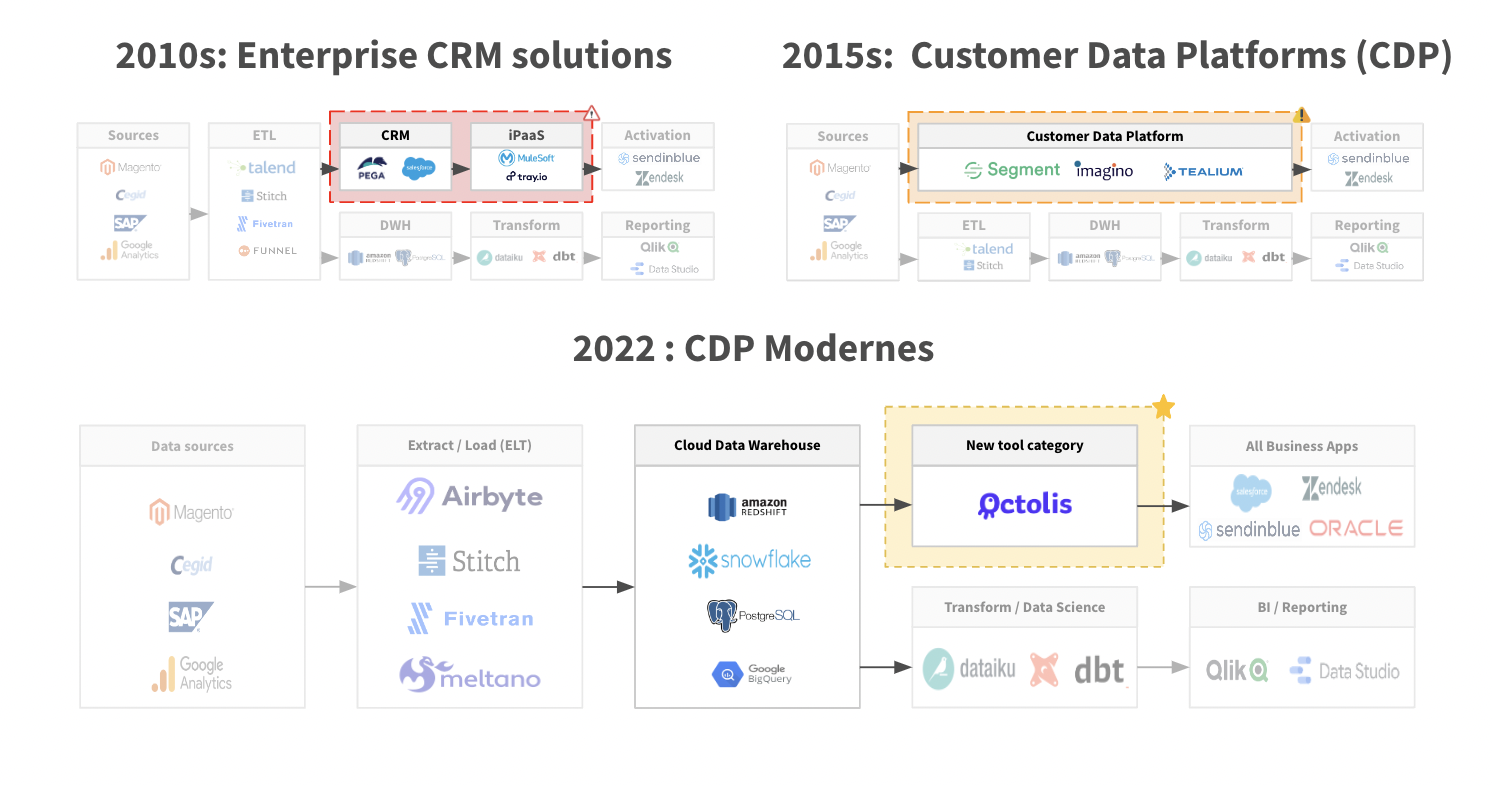

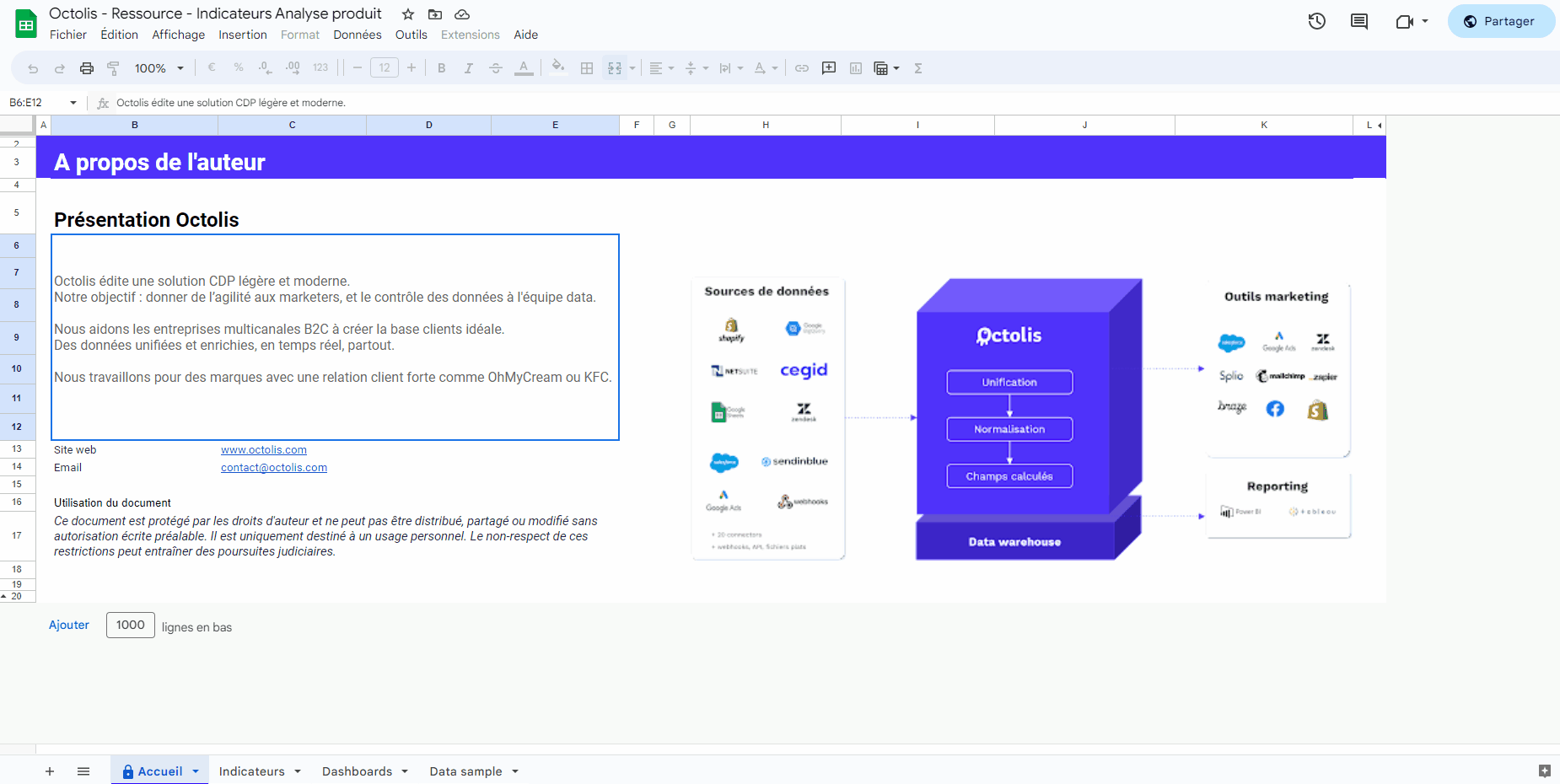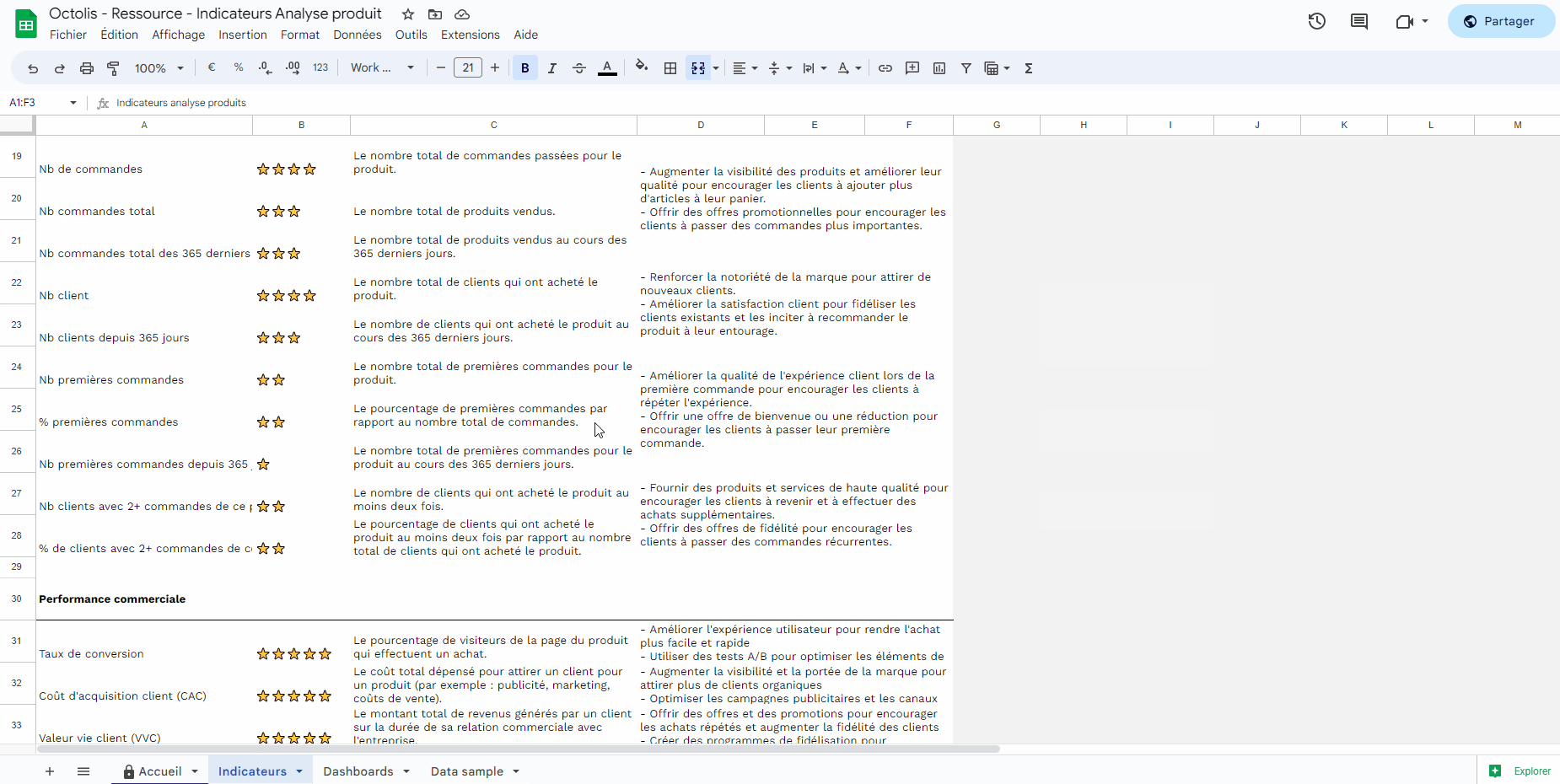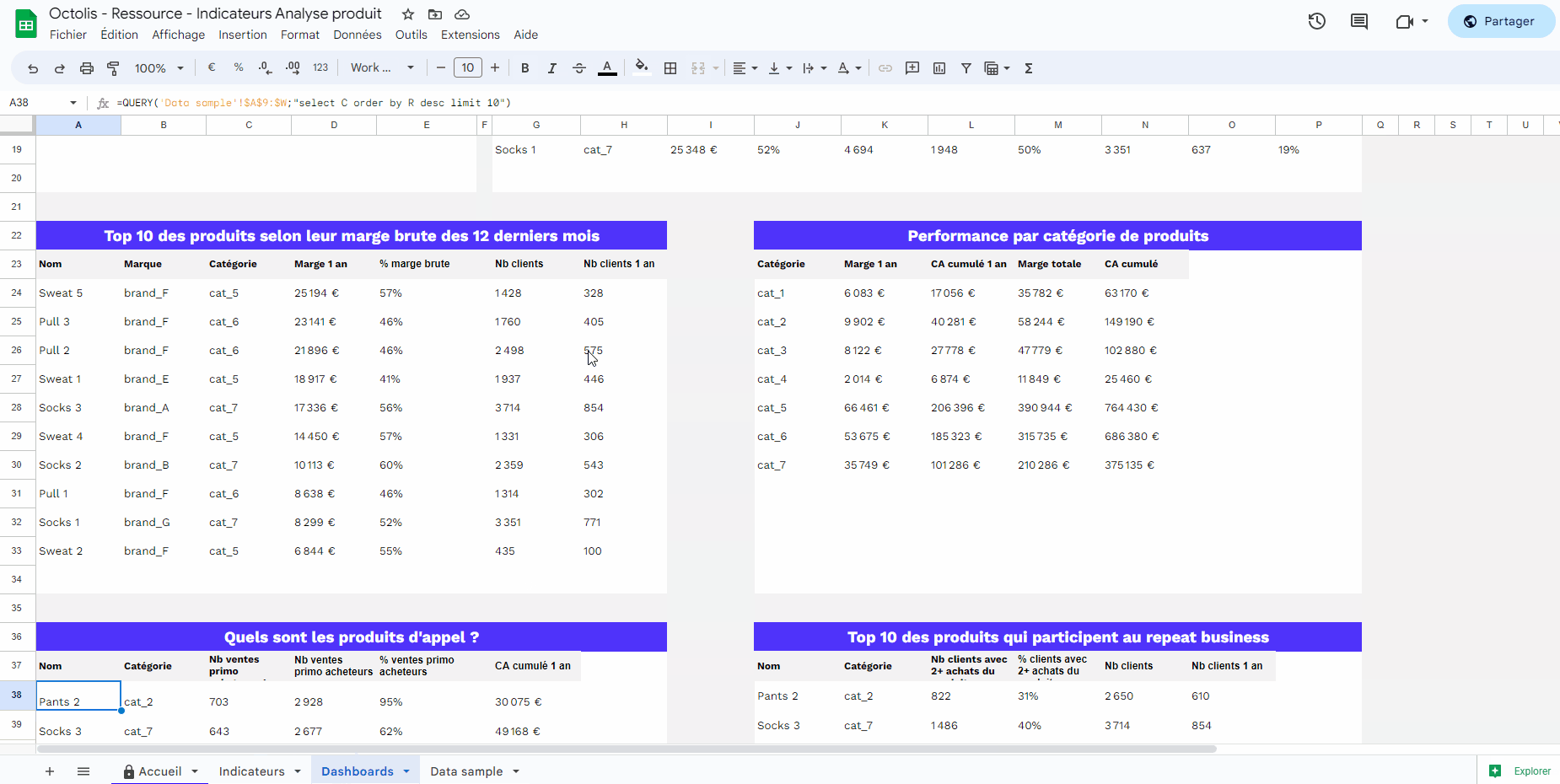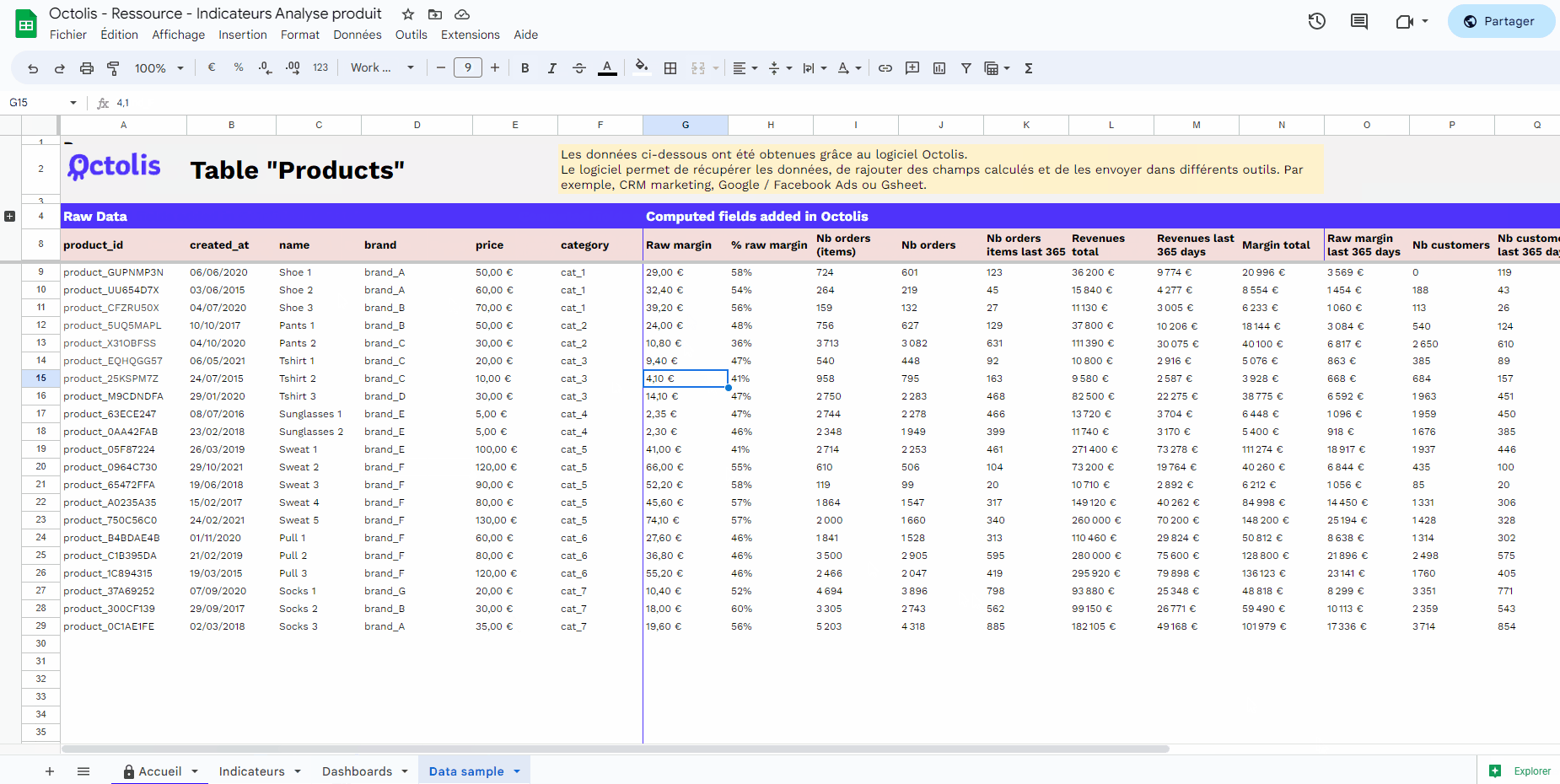




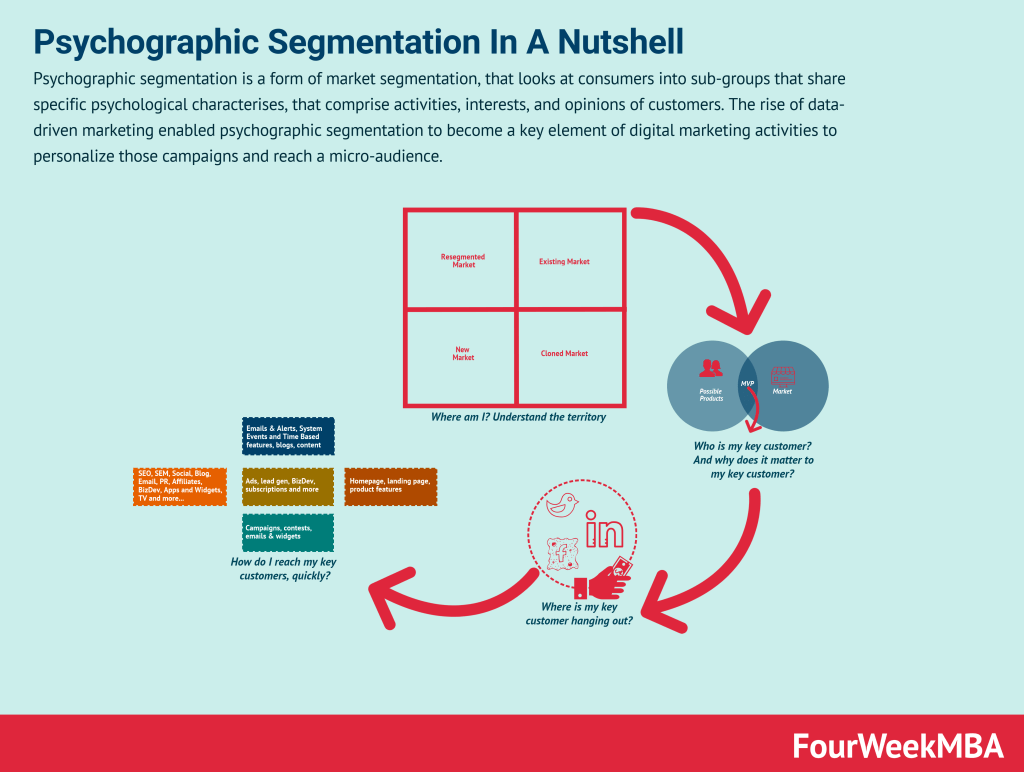
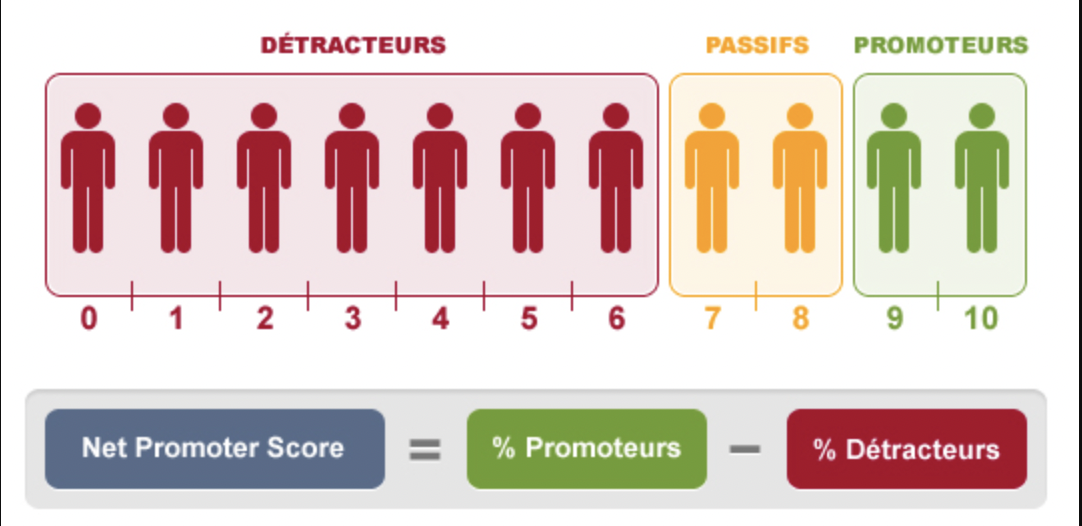


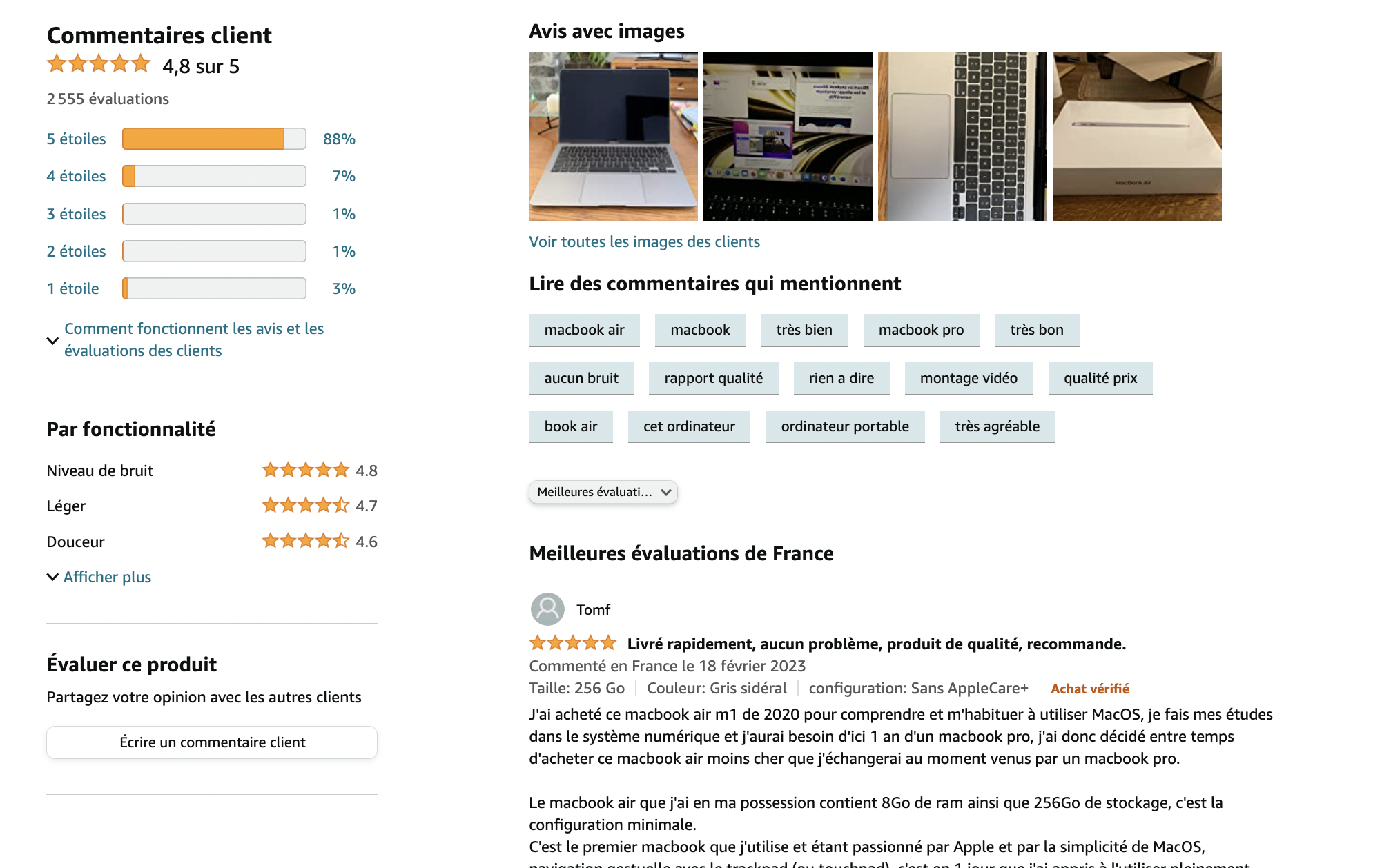

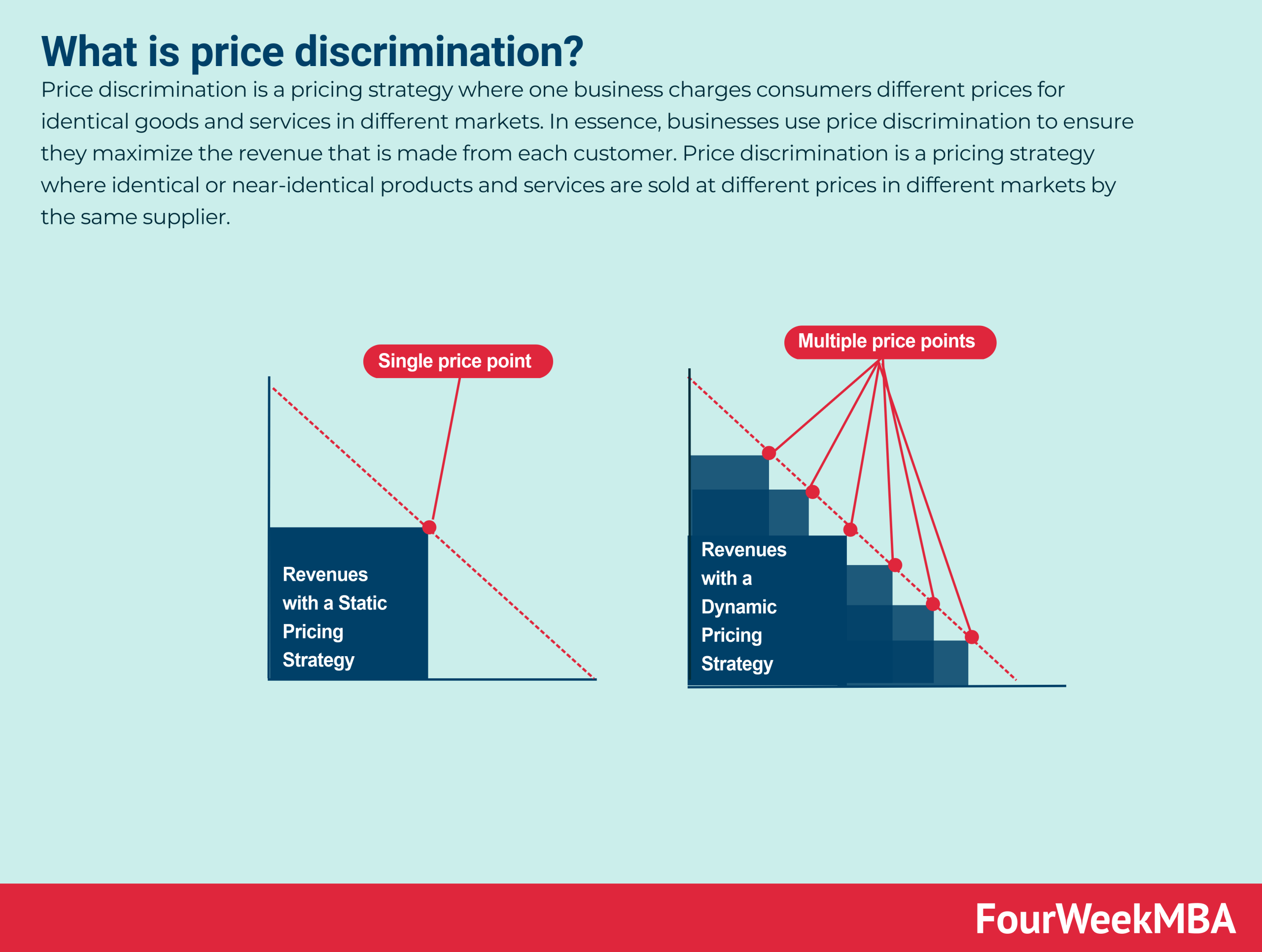

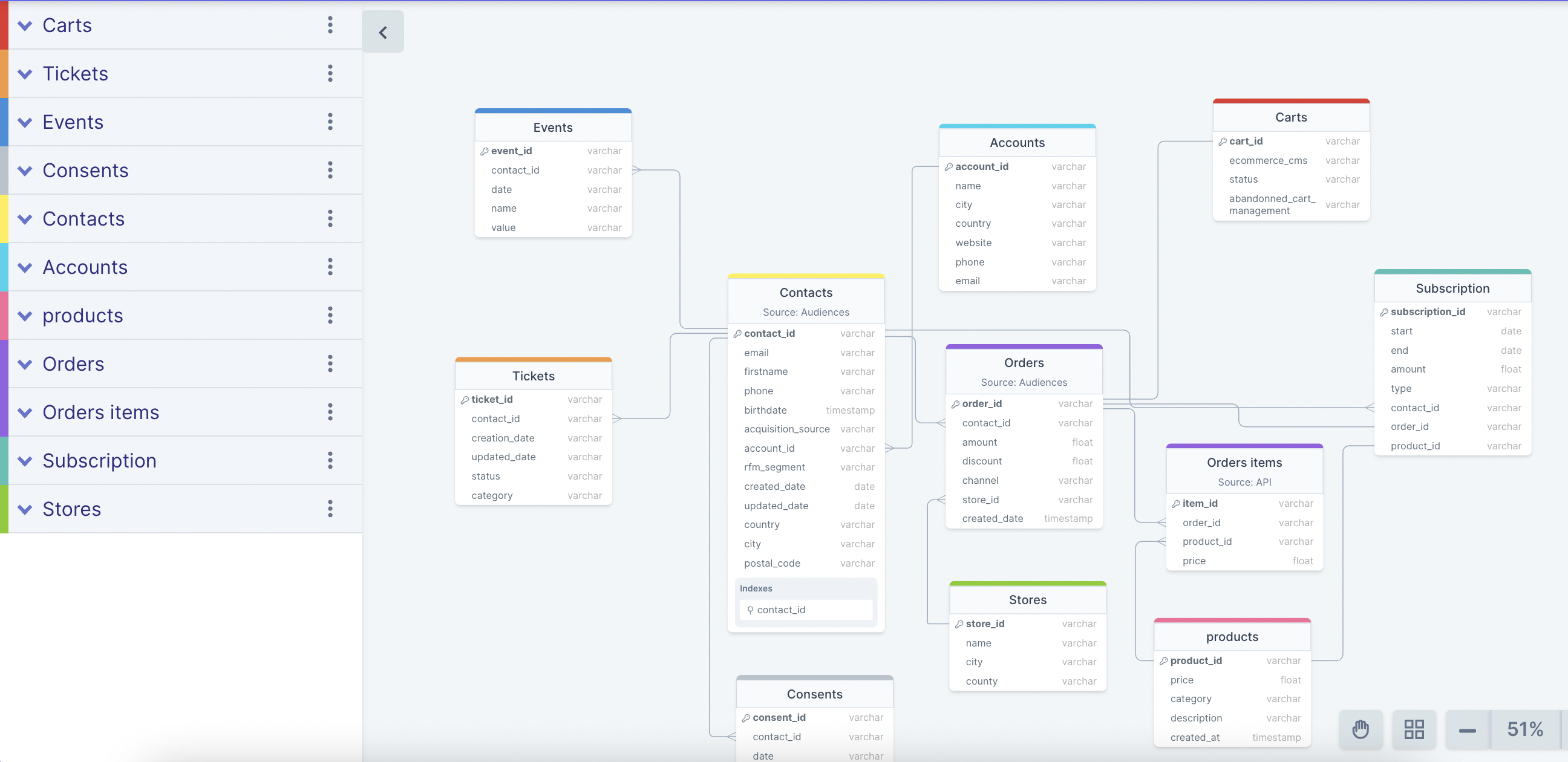




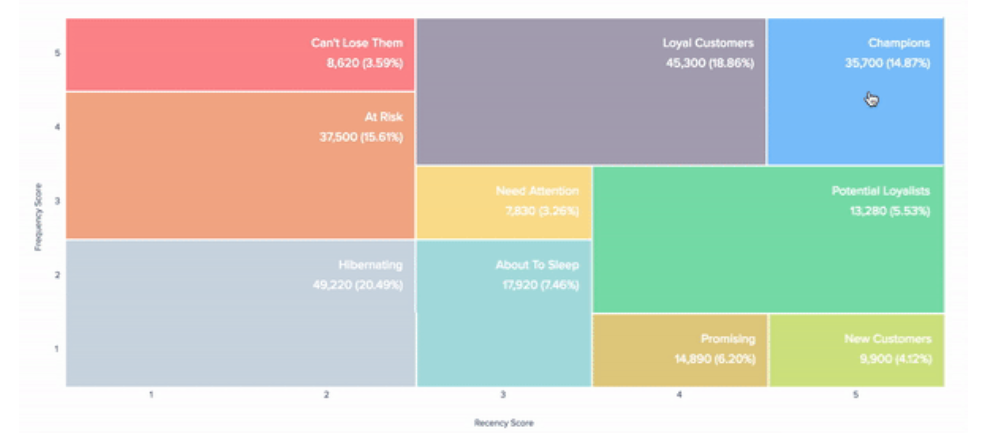

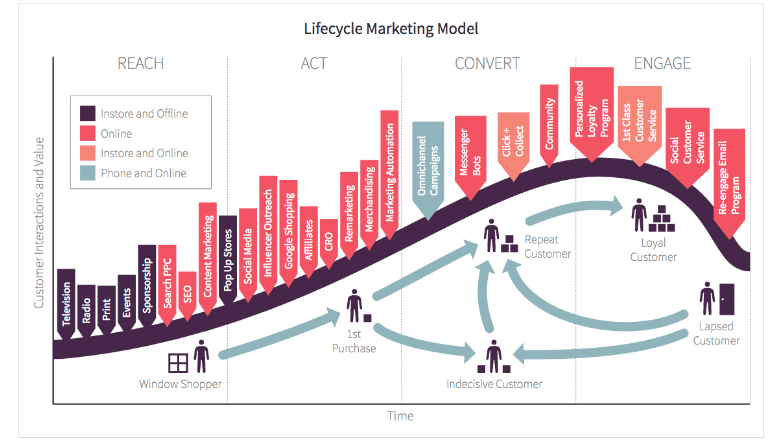
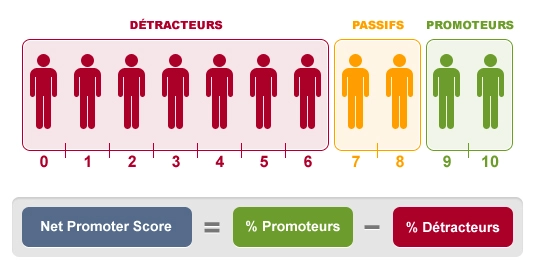
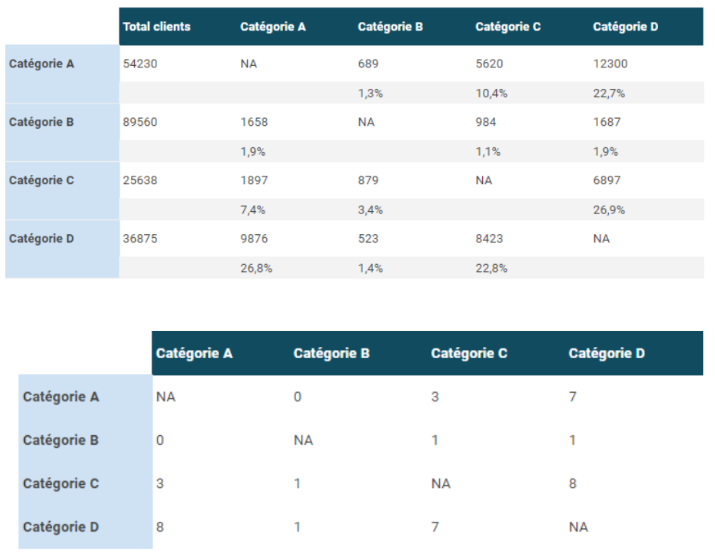
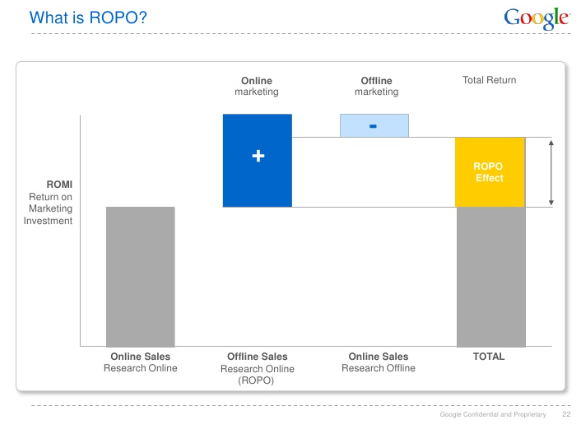

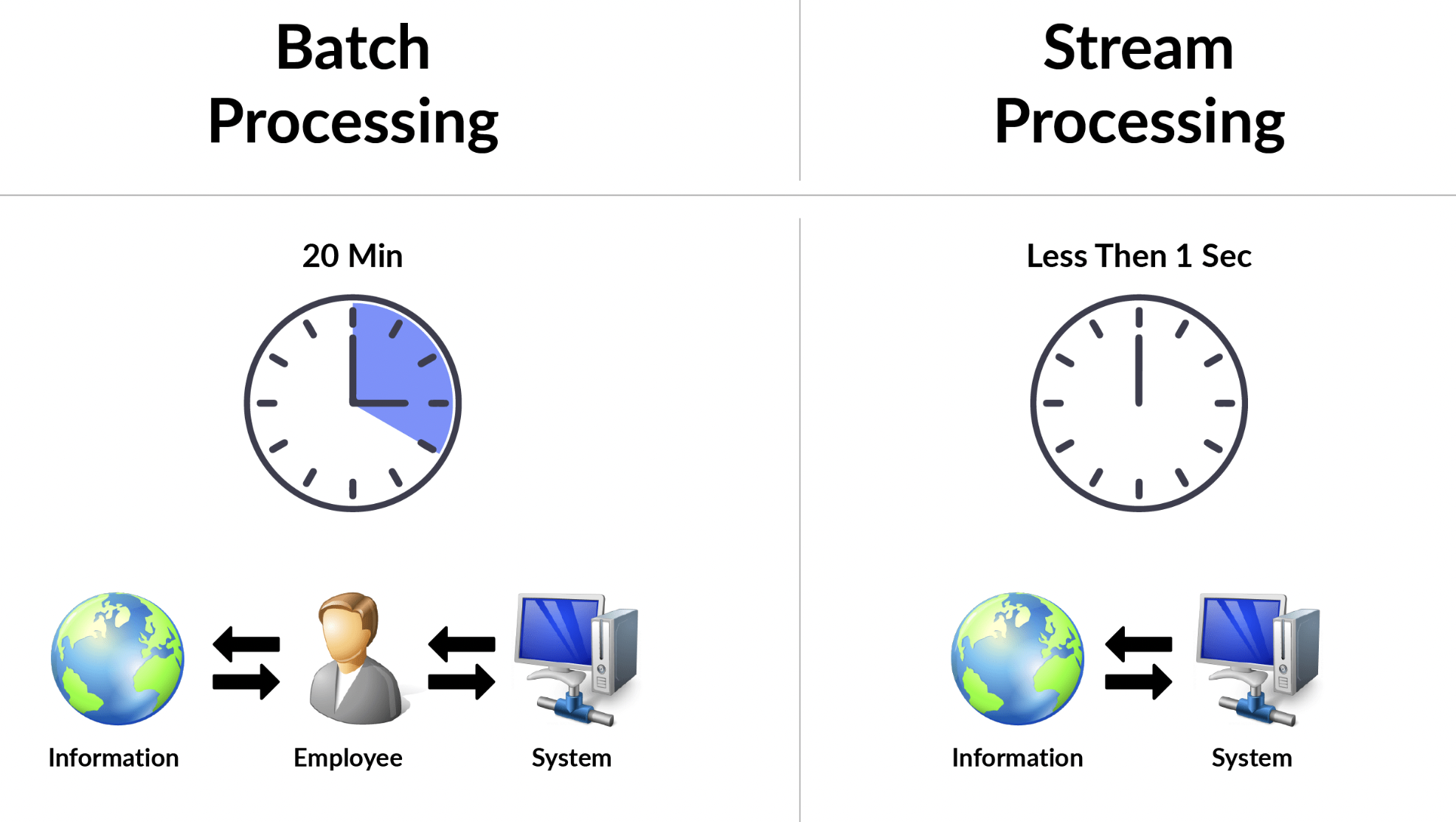
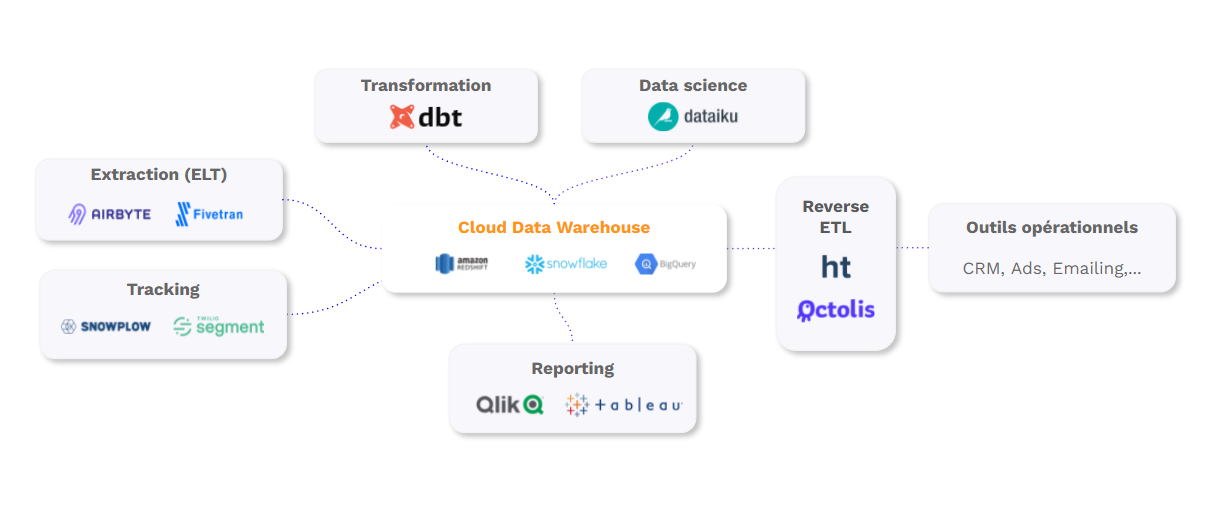
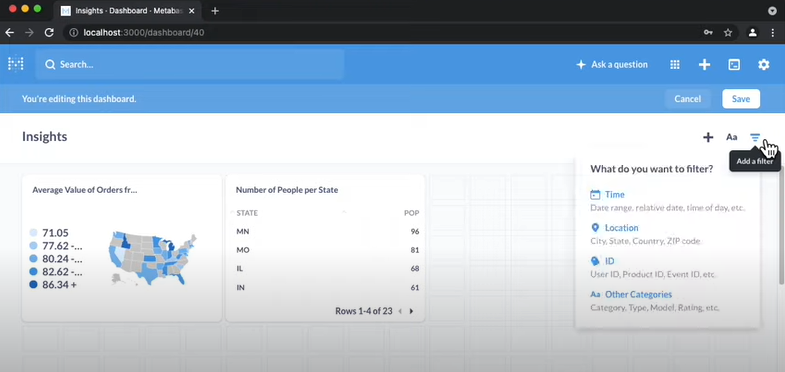

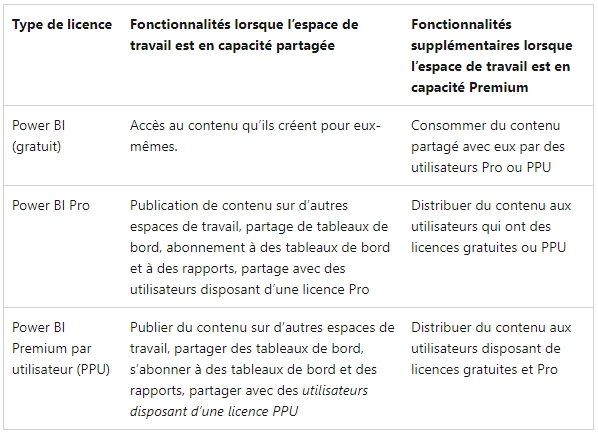
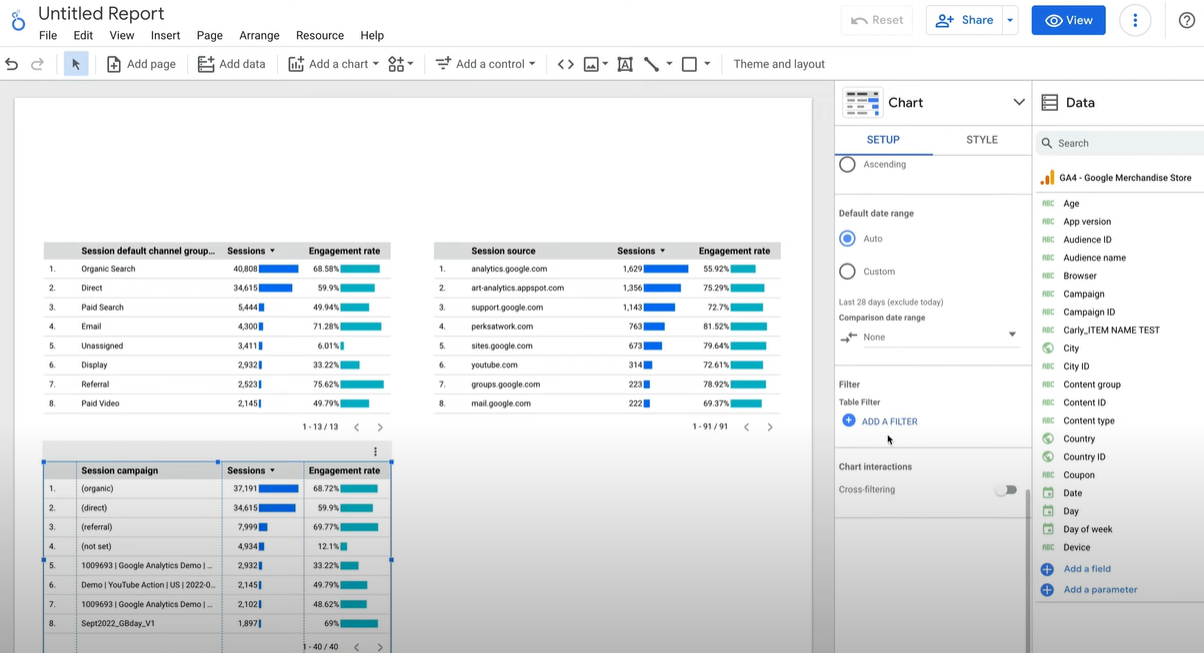

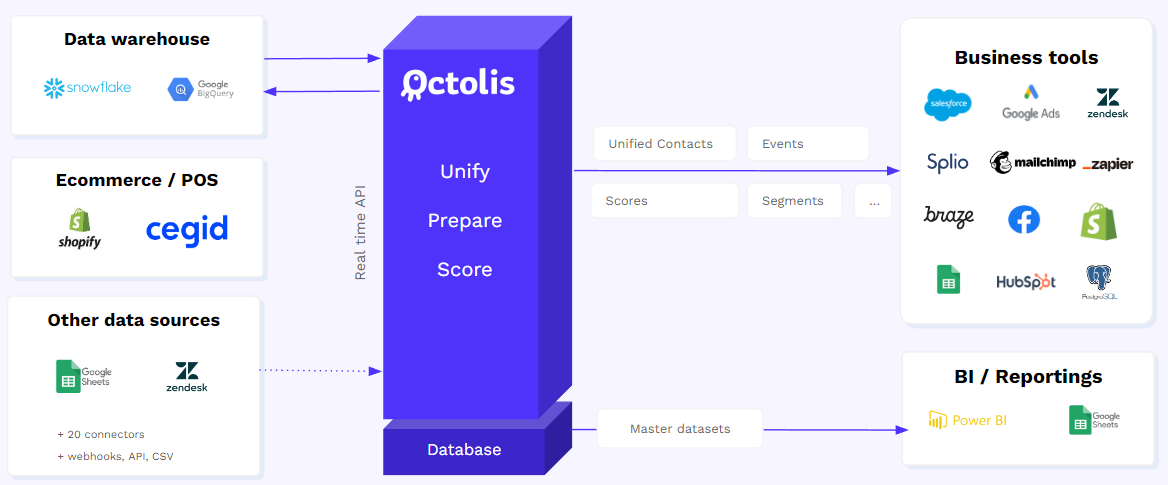


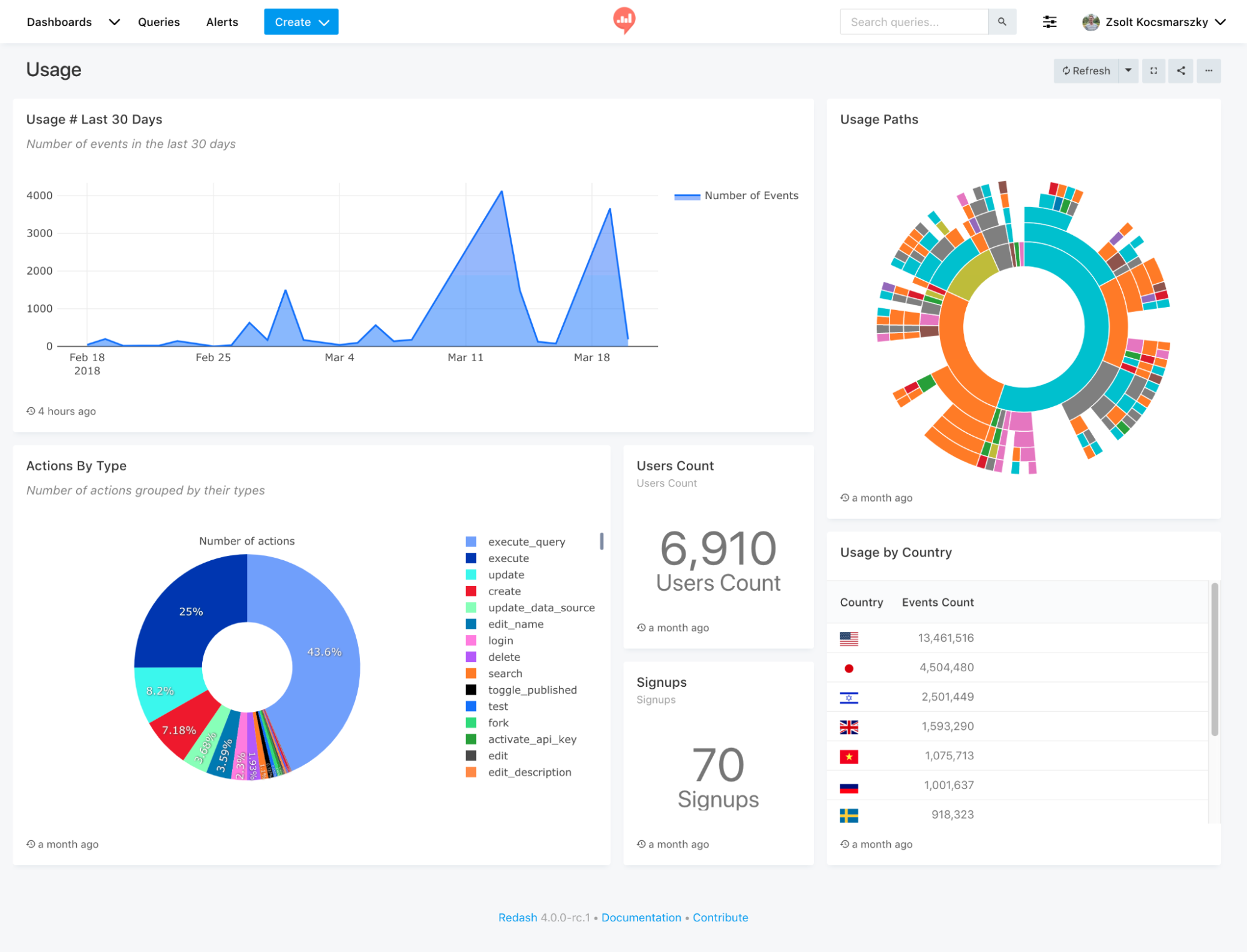

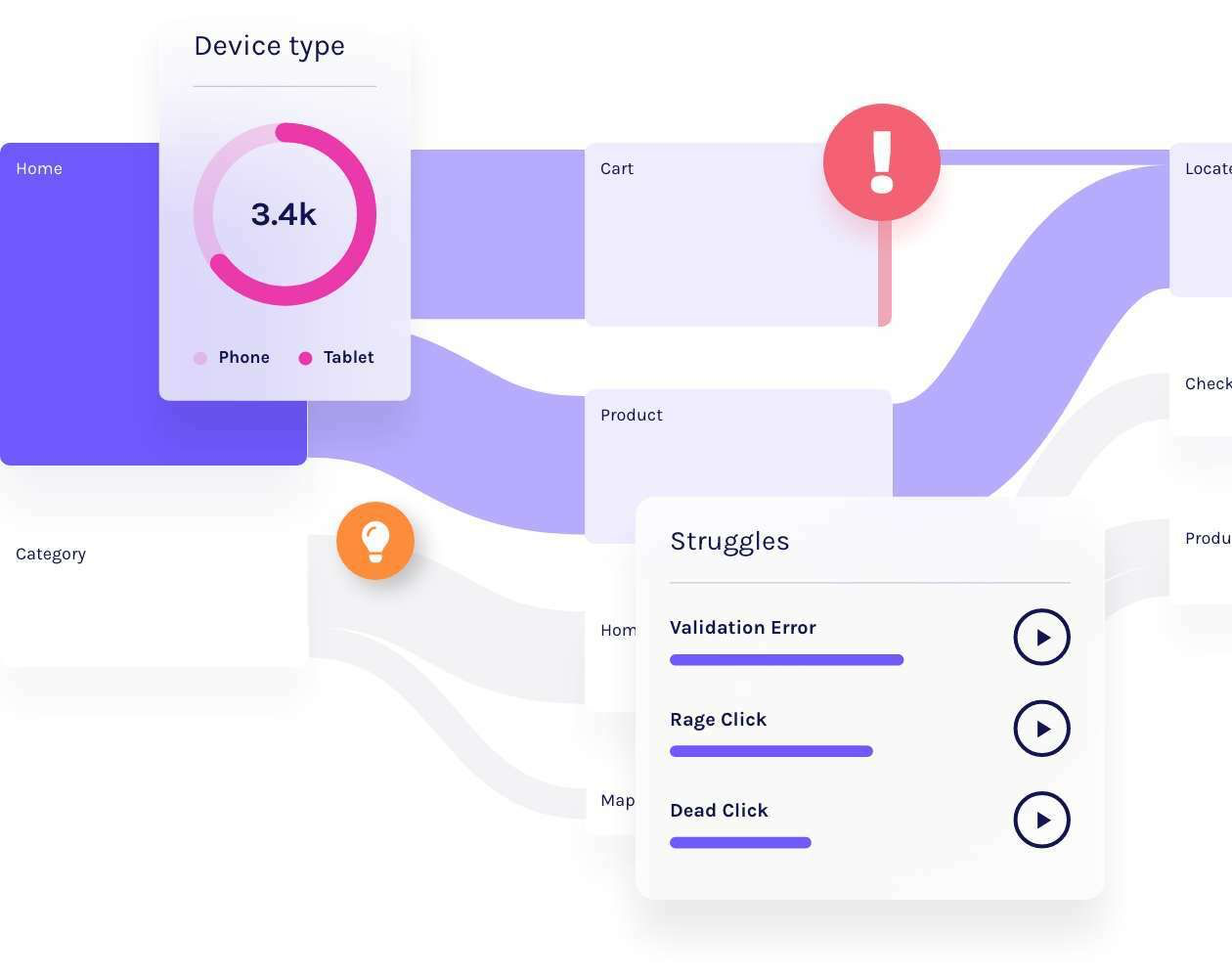

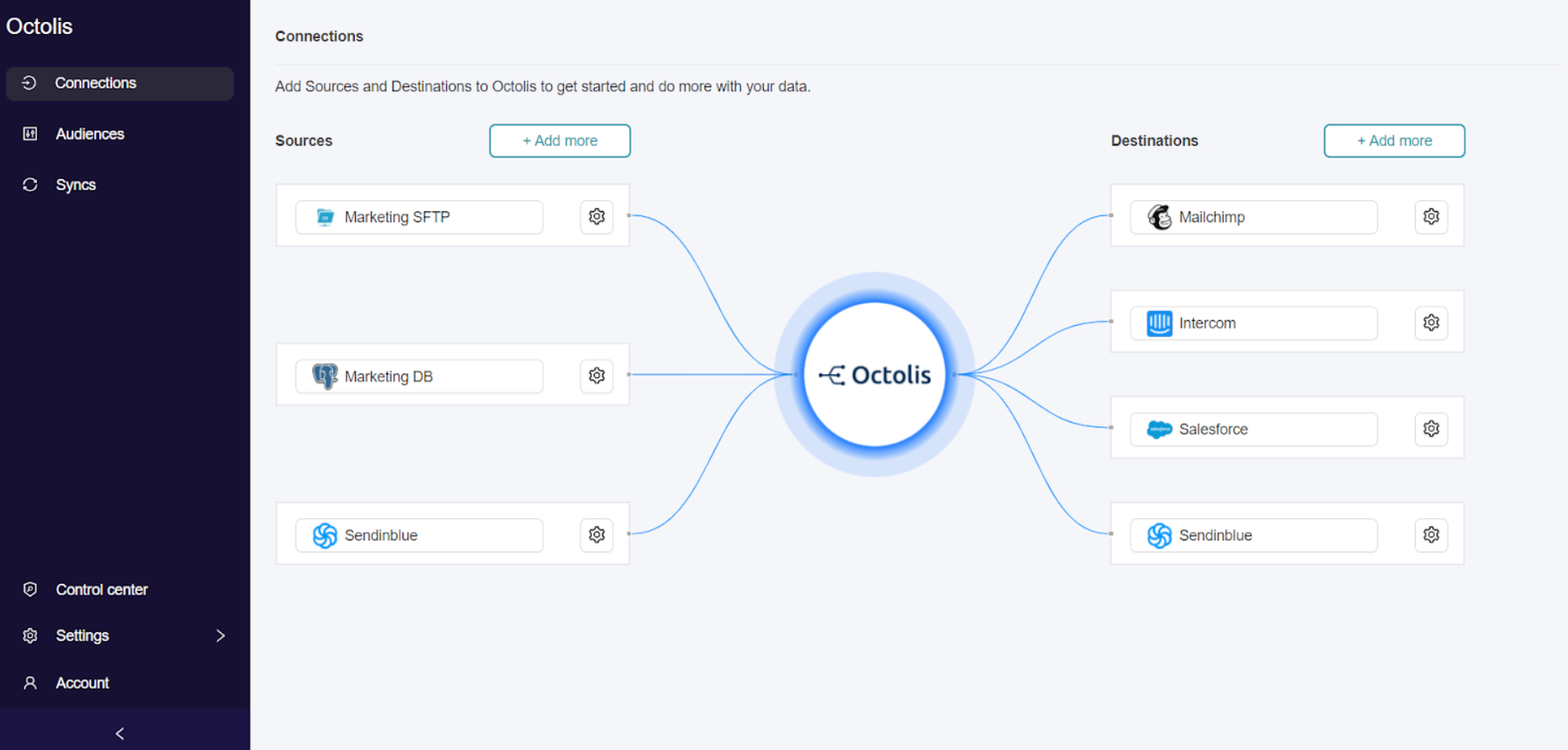
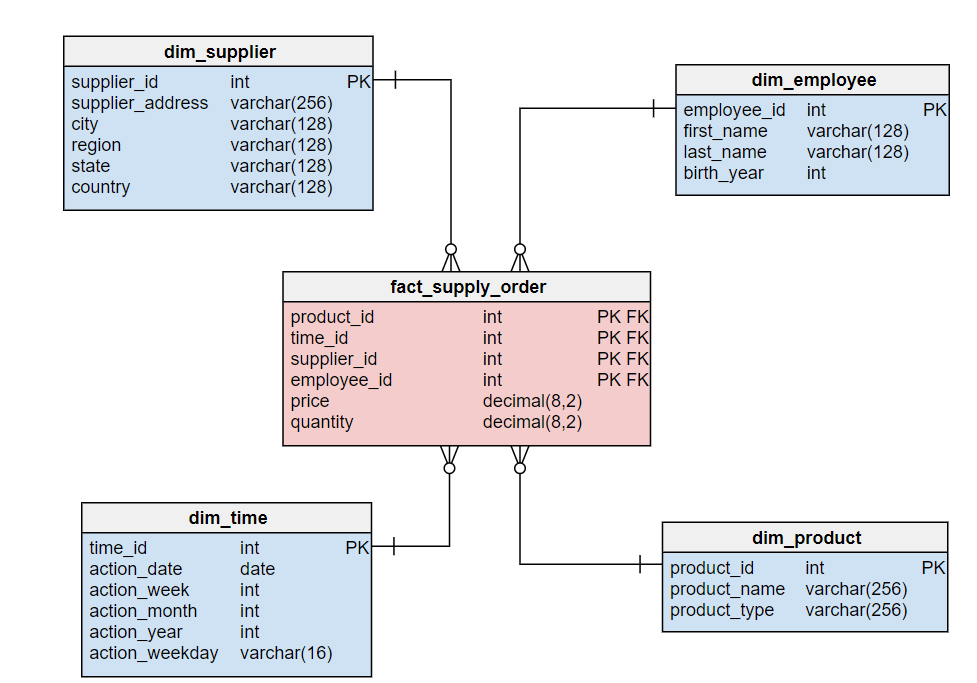



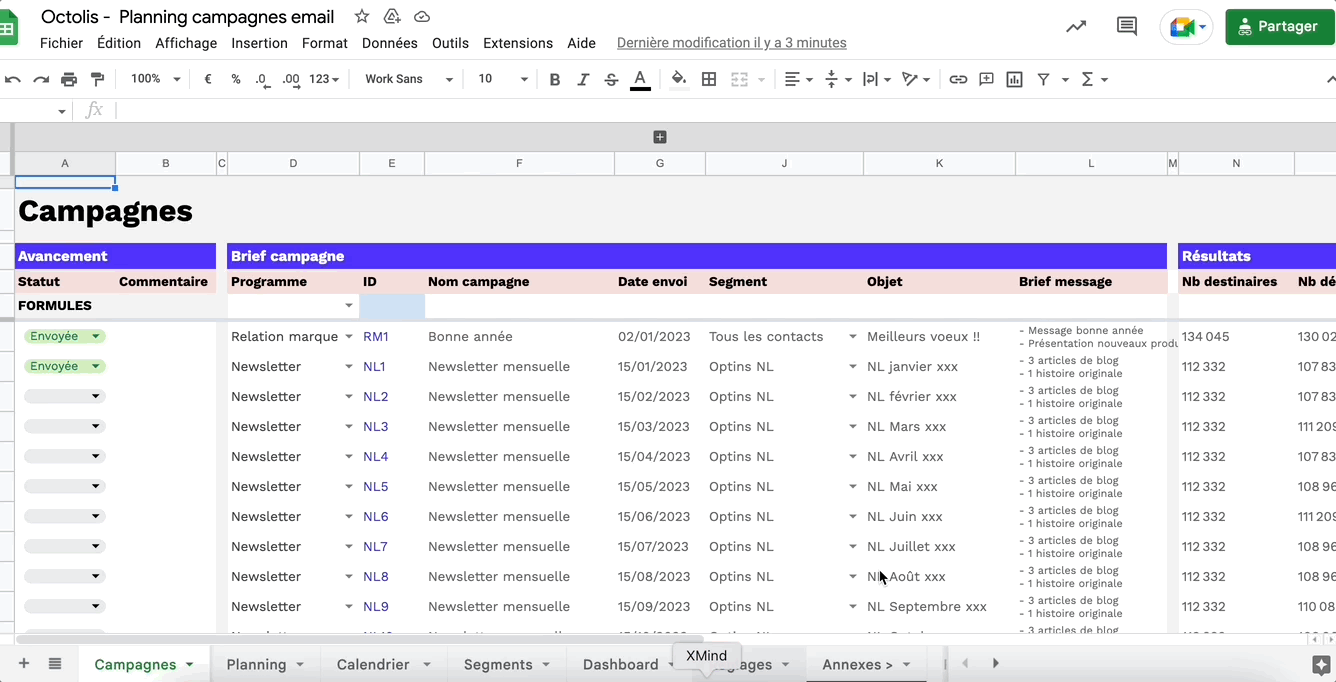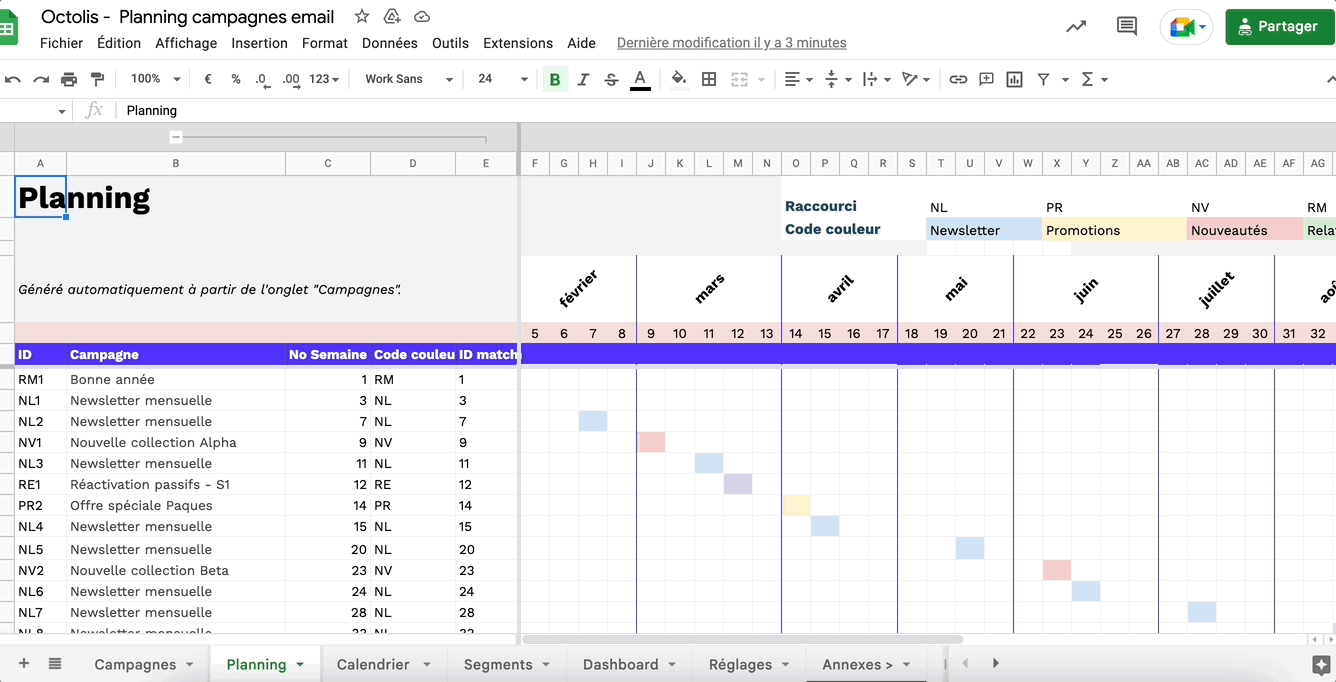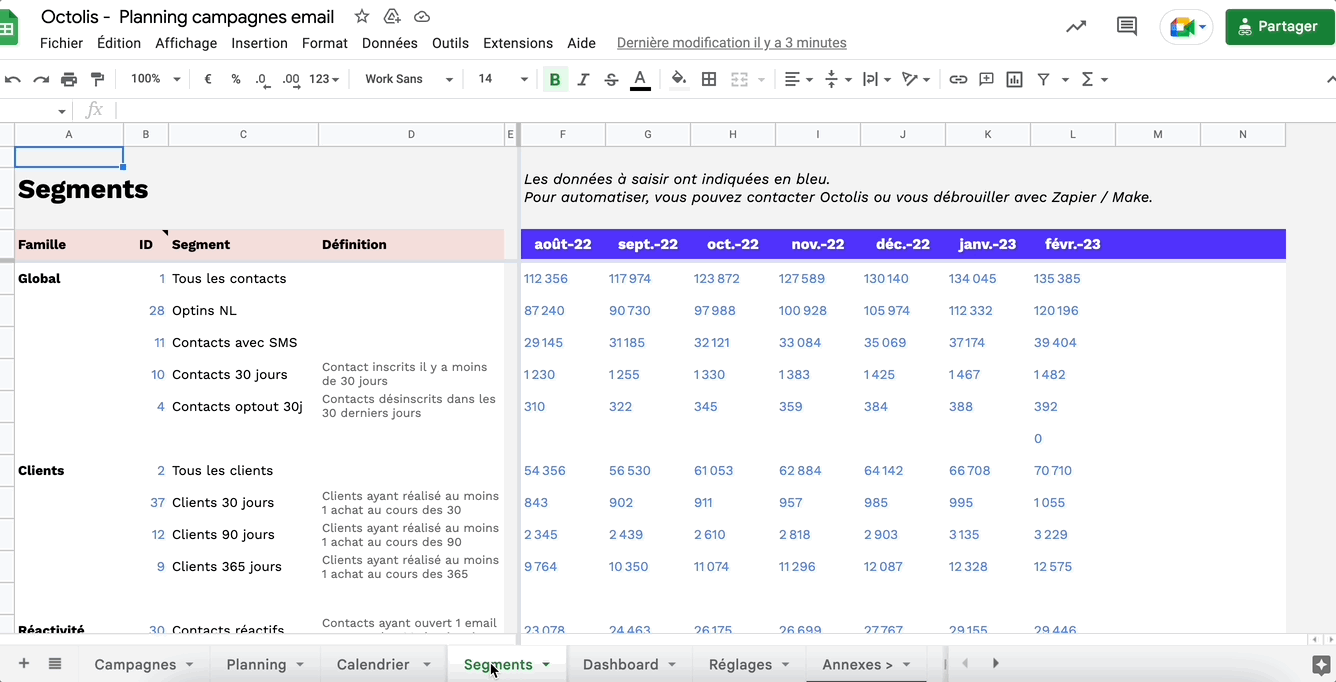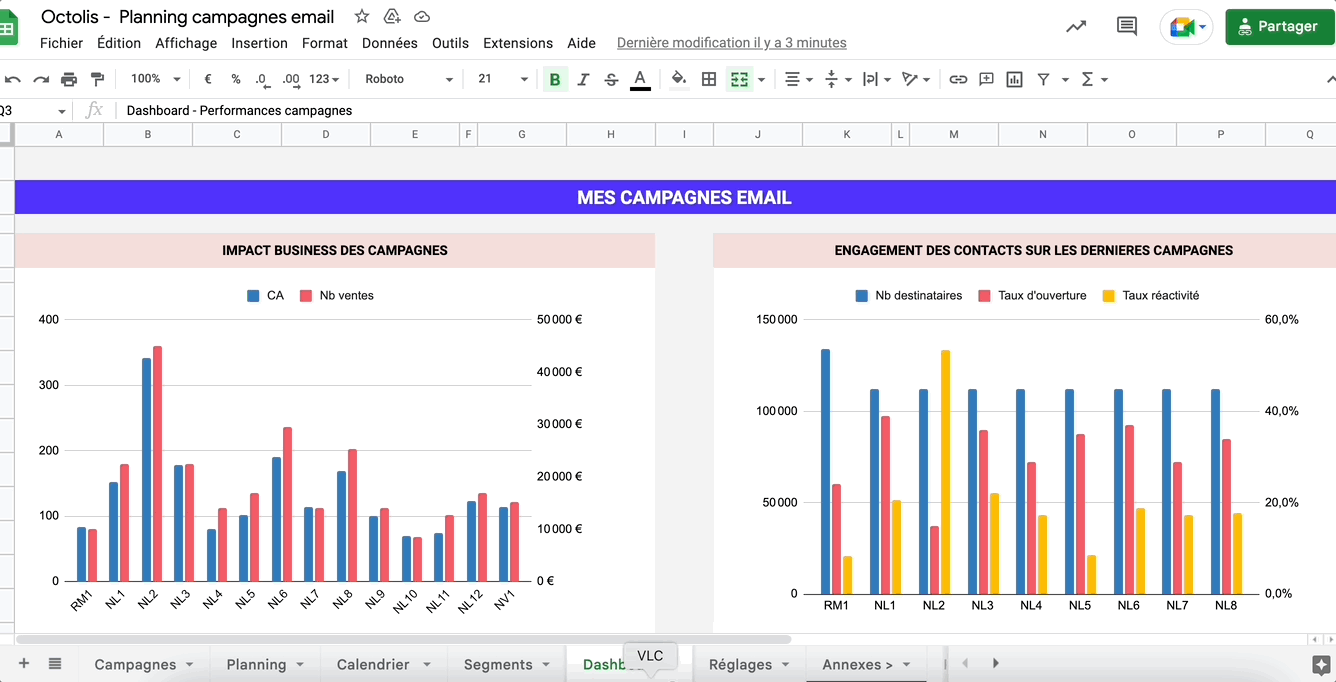
 Tout d’abord, il faut définir le mois à partir duquel commence le calendrier des campagnes.
Tout d’abord, il faut définir le mois à partir duquel commence le calendrier des campagnes.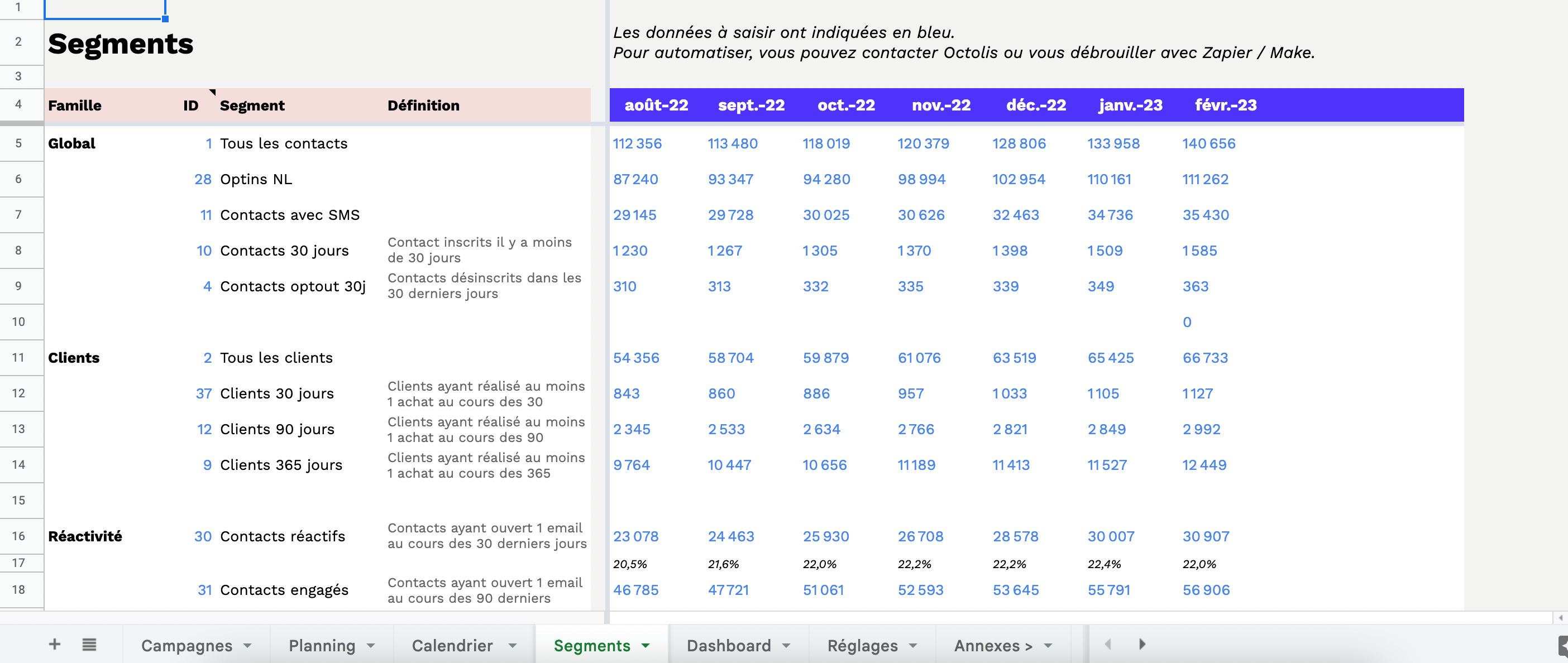
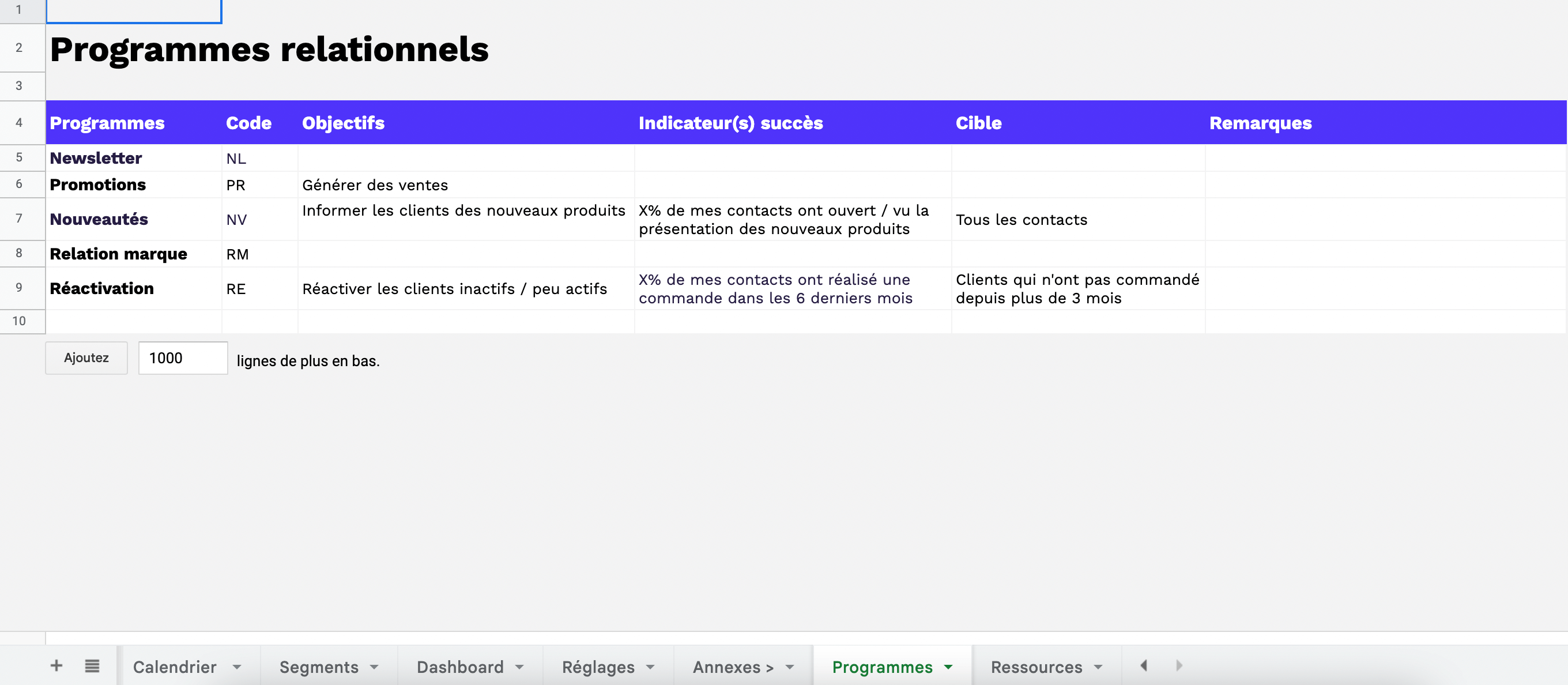
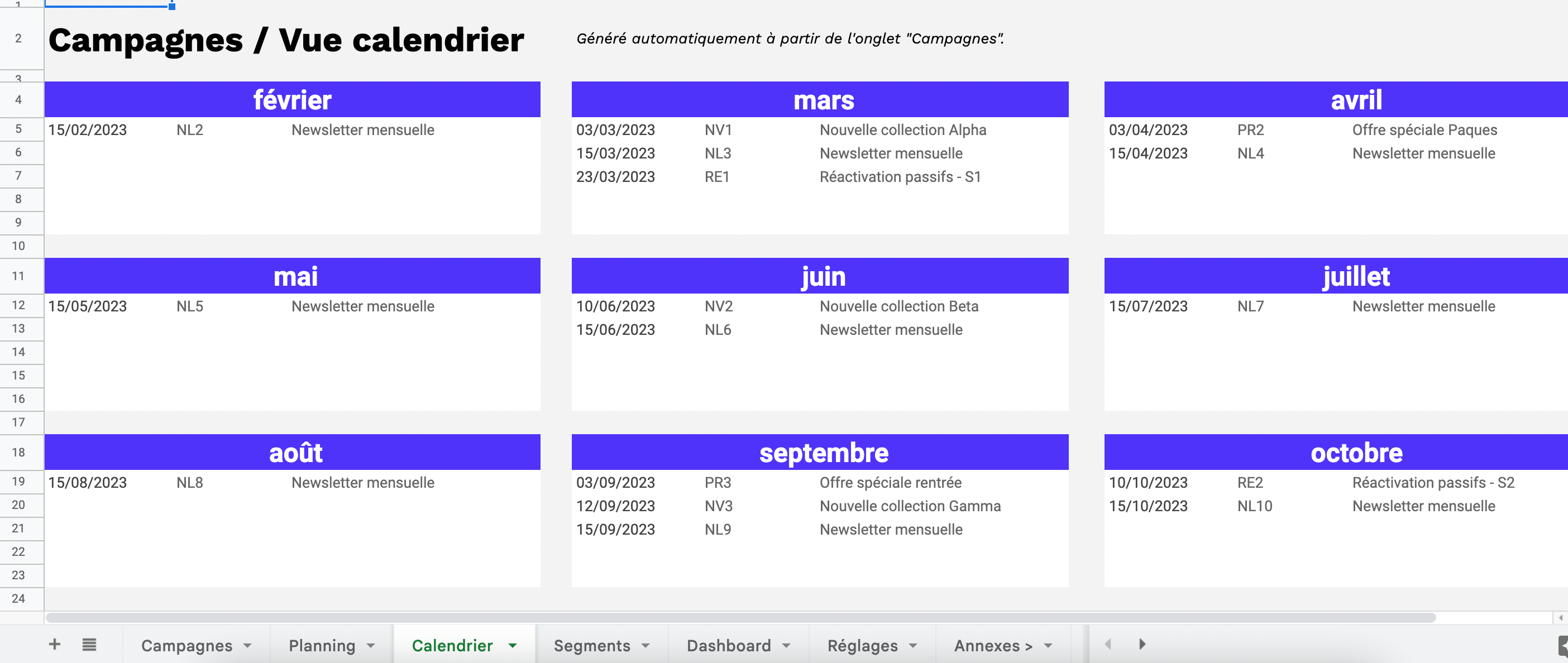
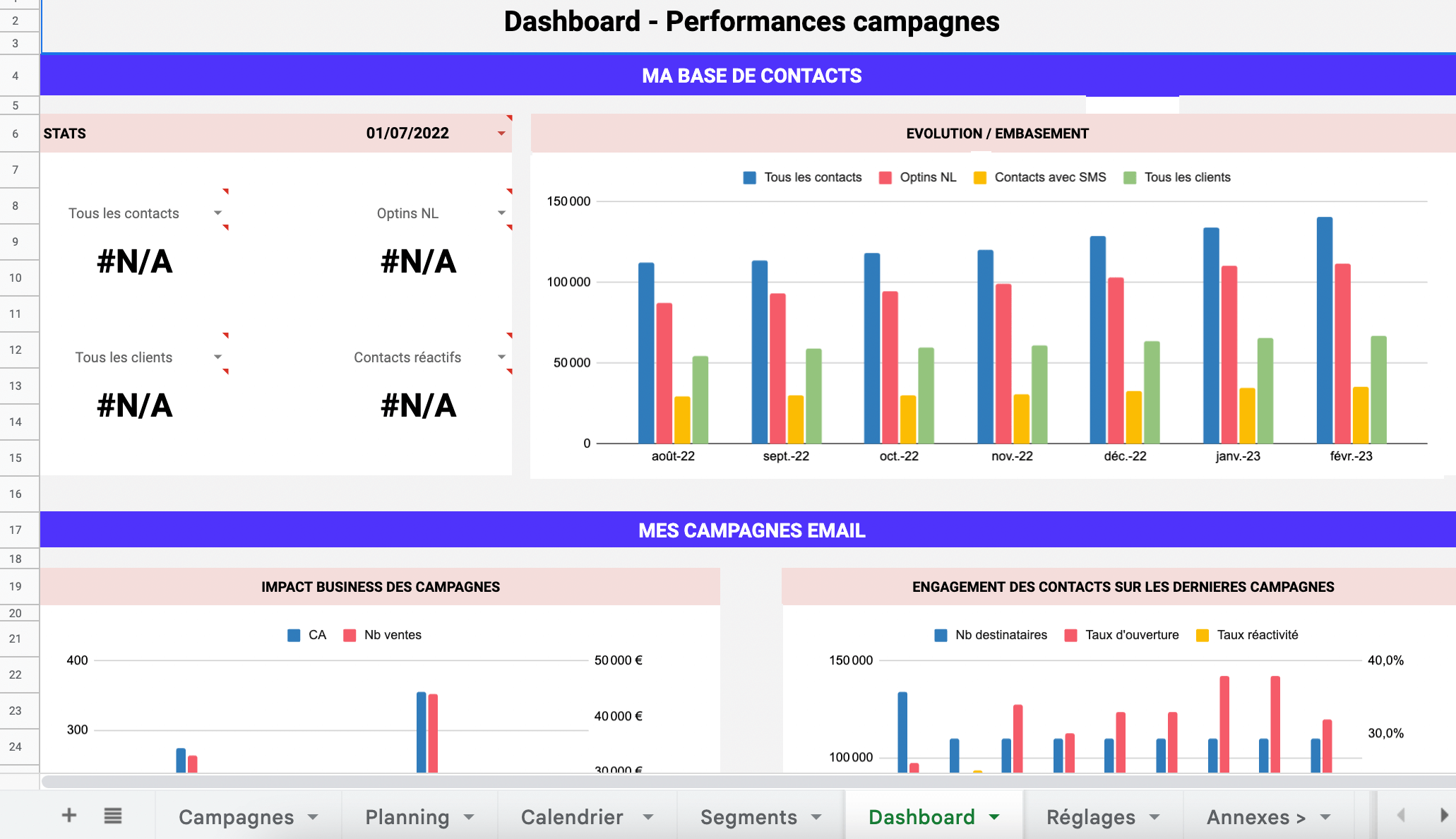
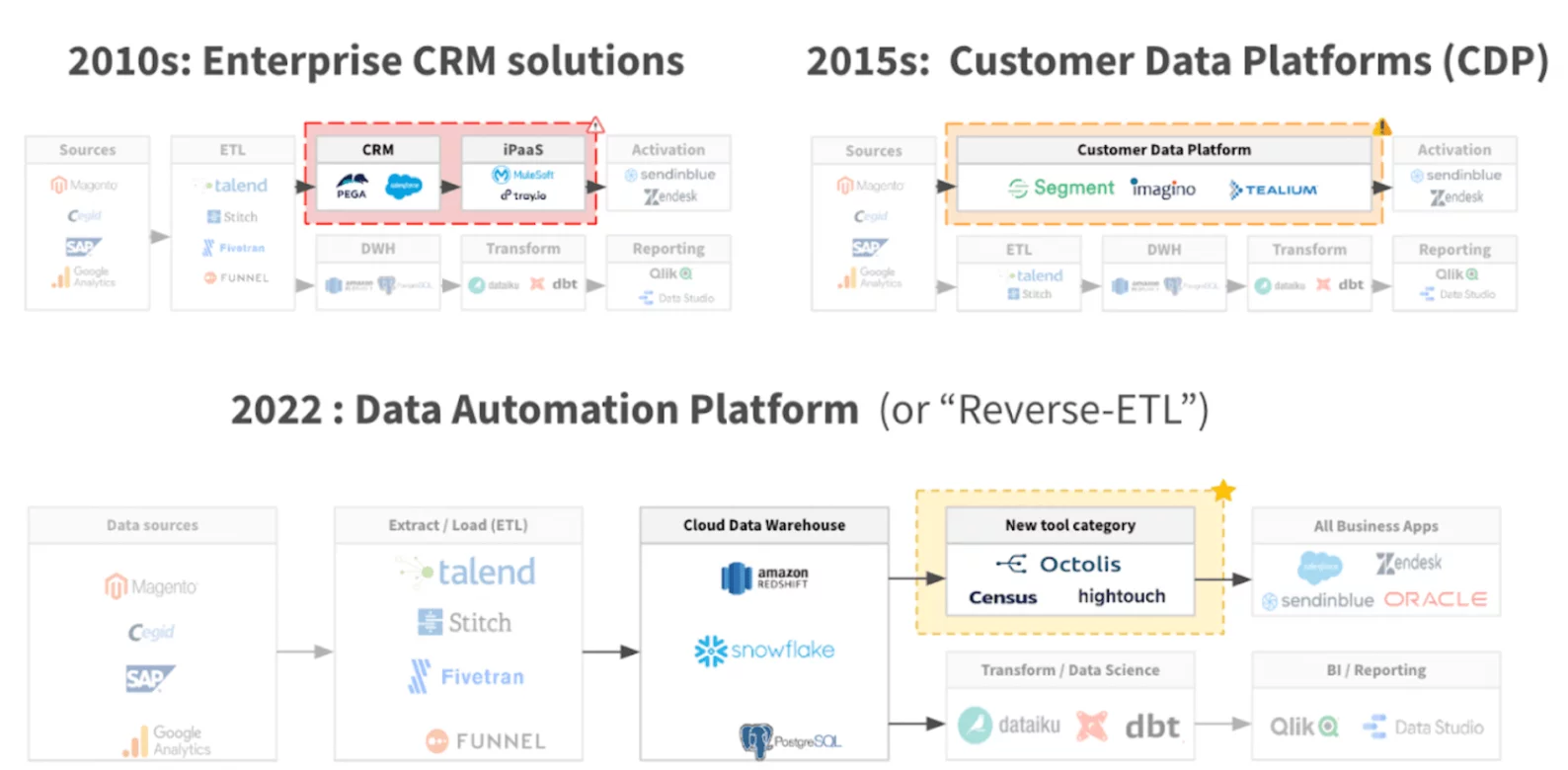
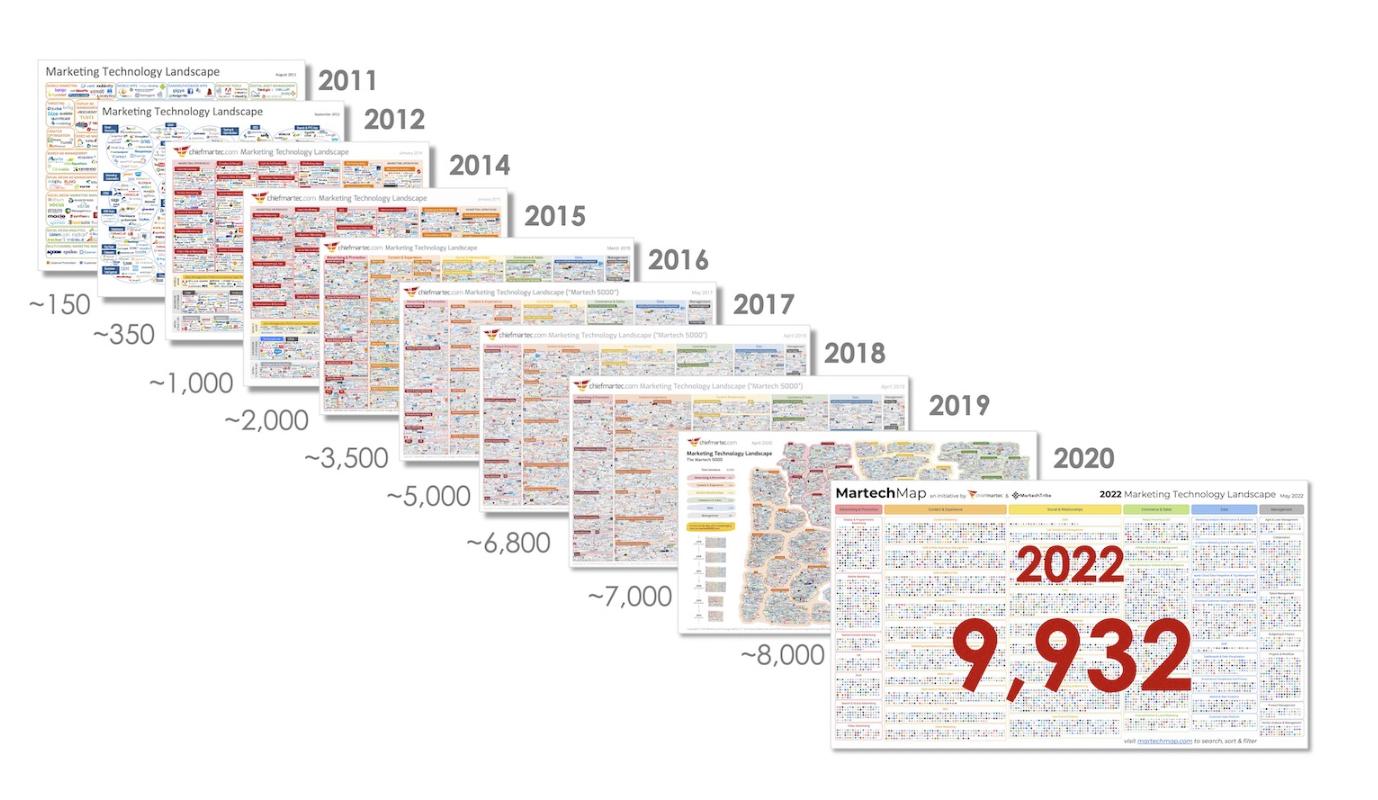

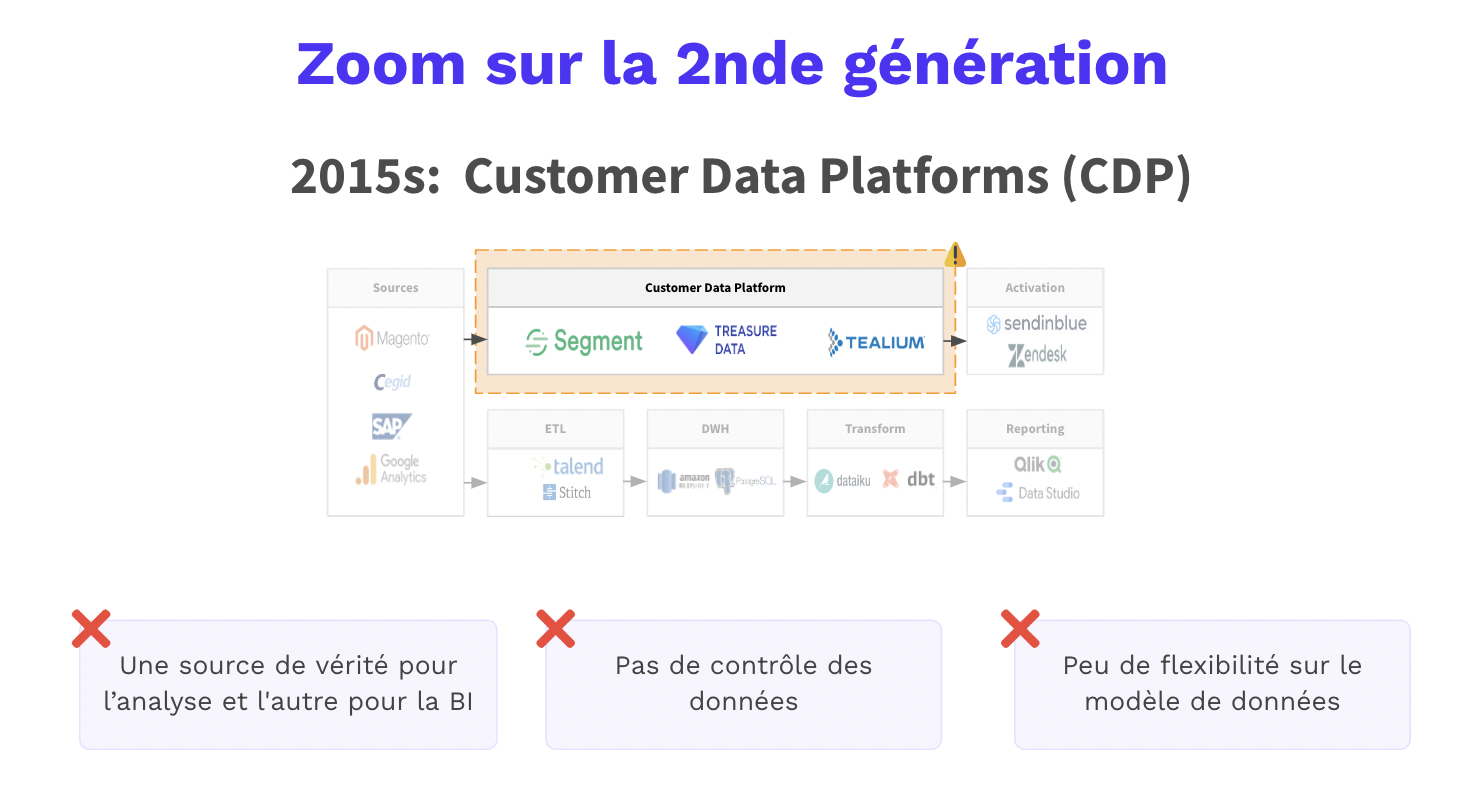
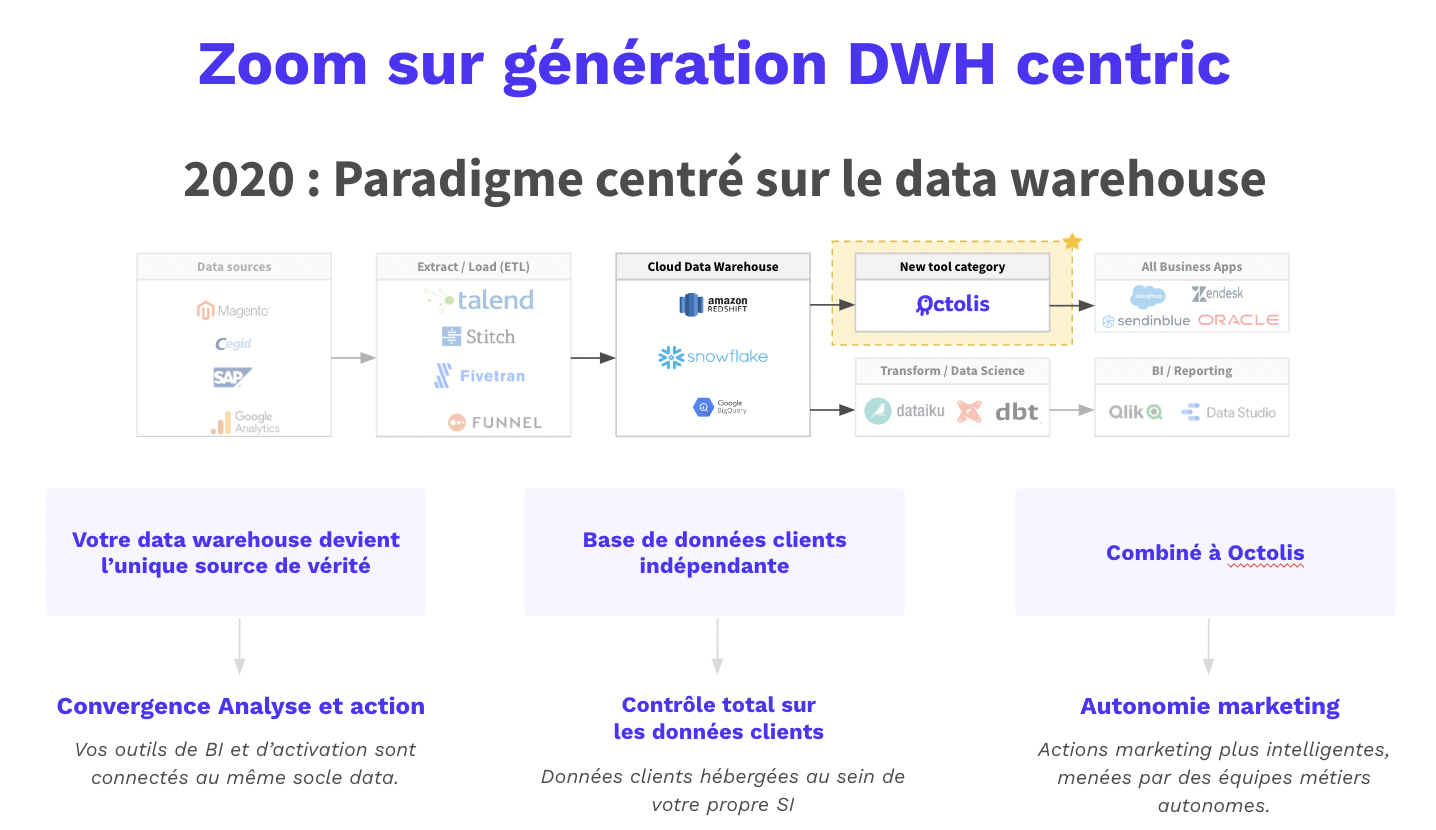
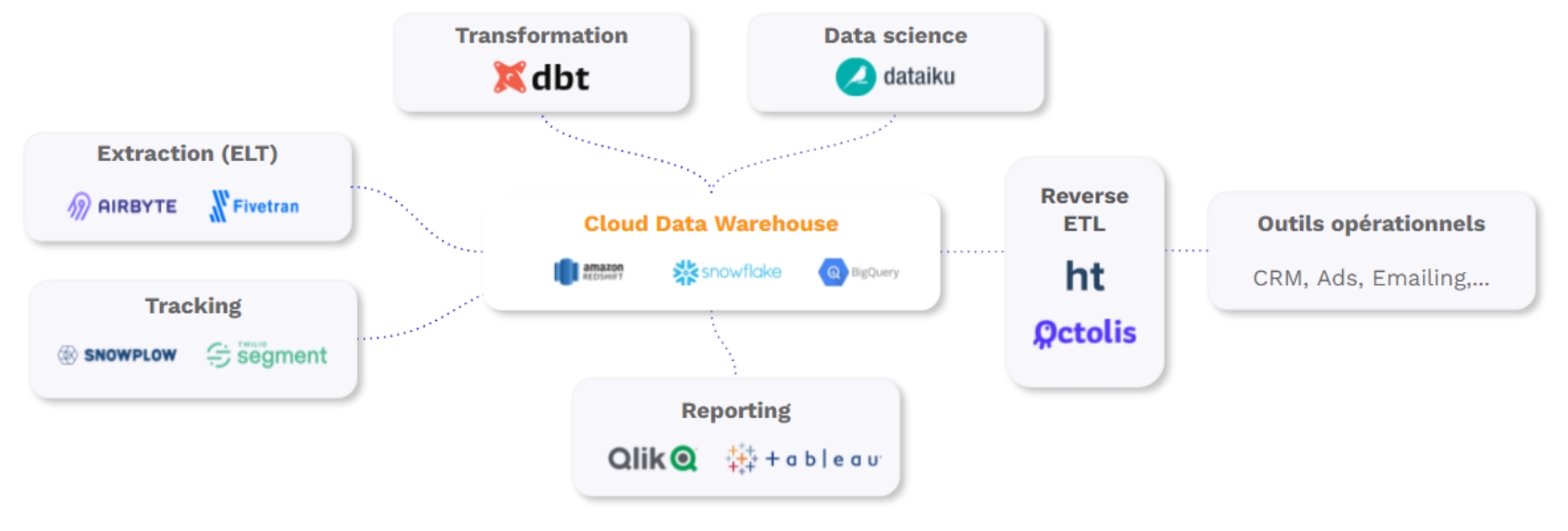
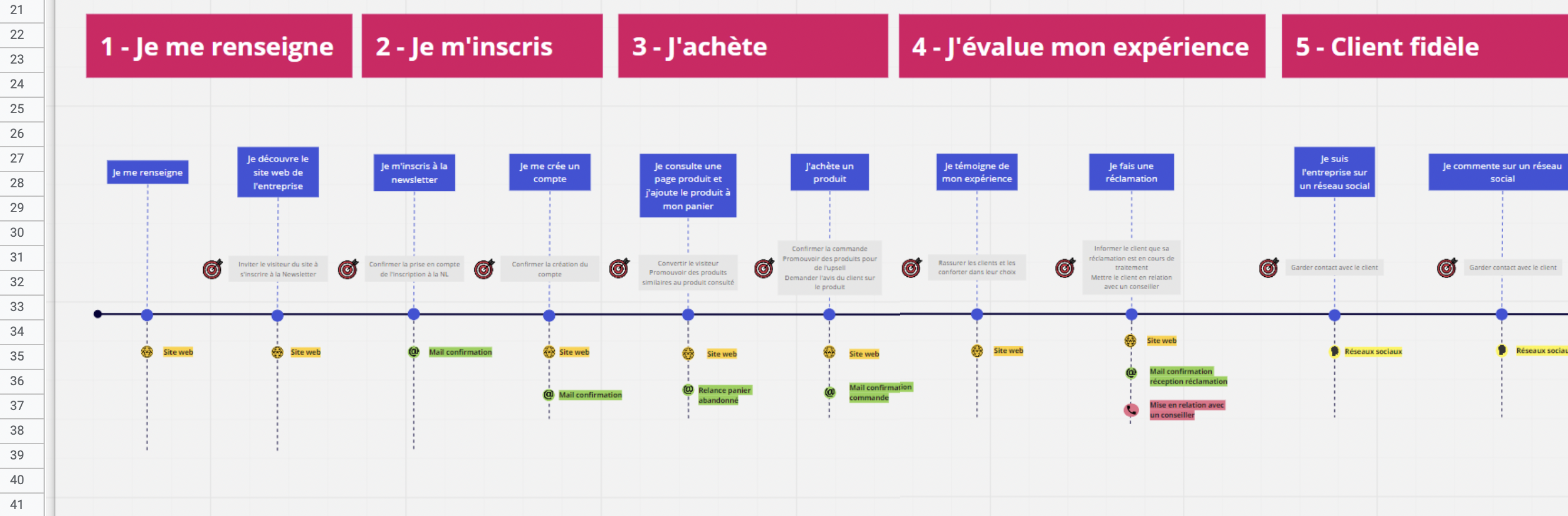
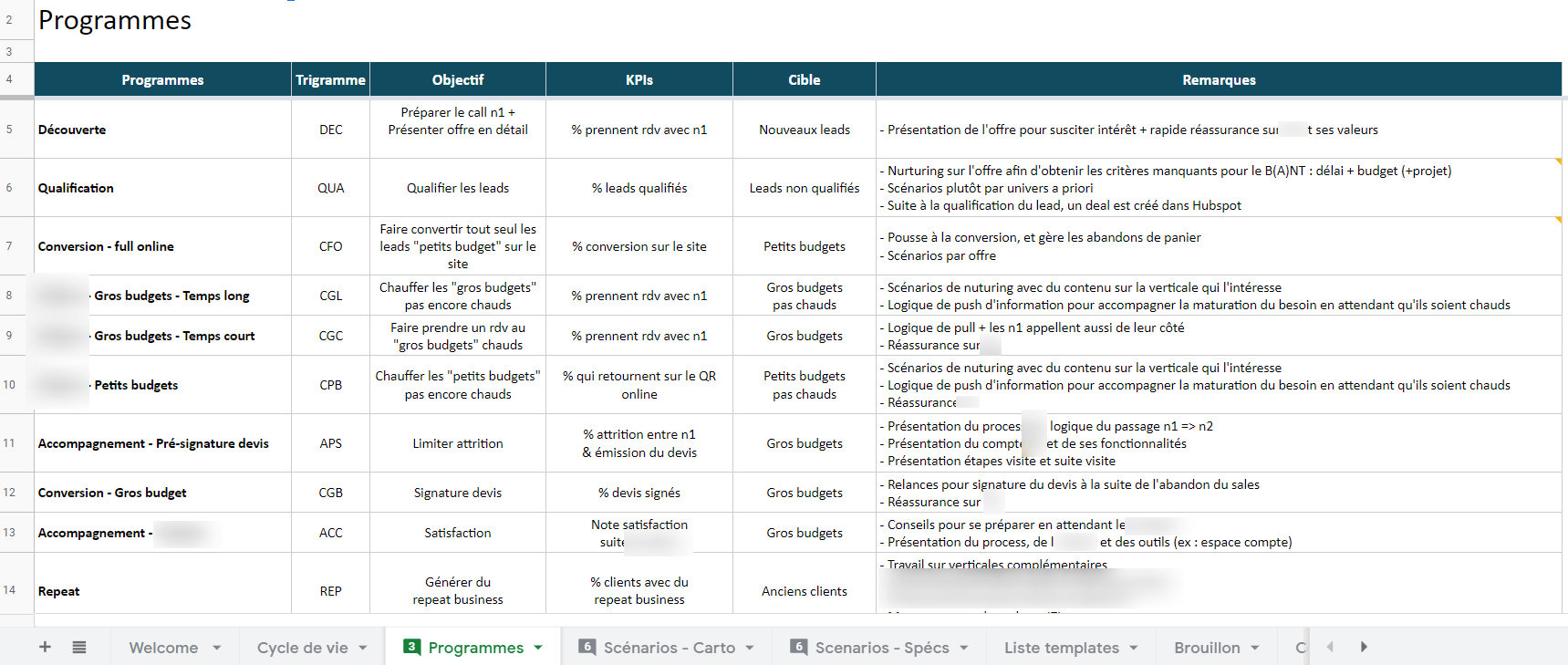
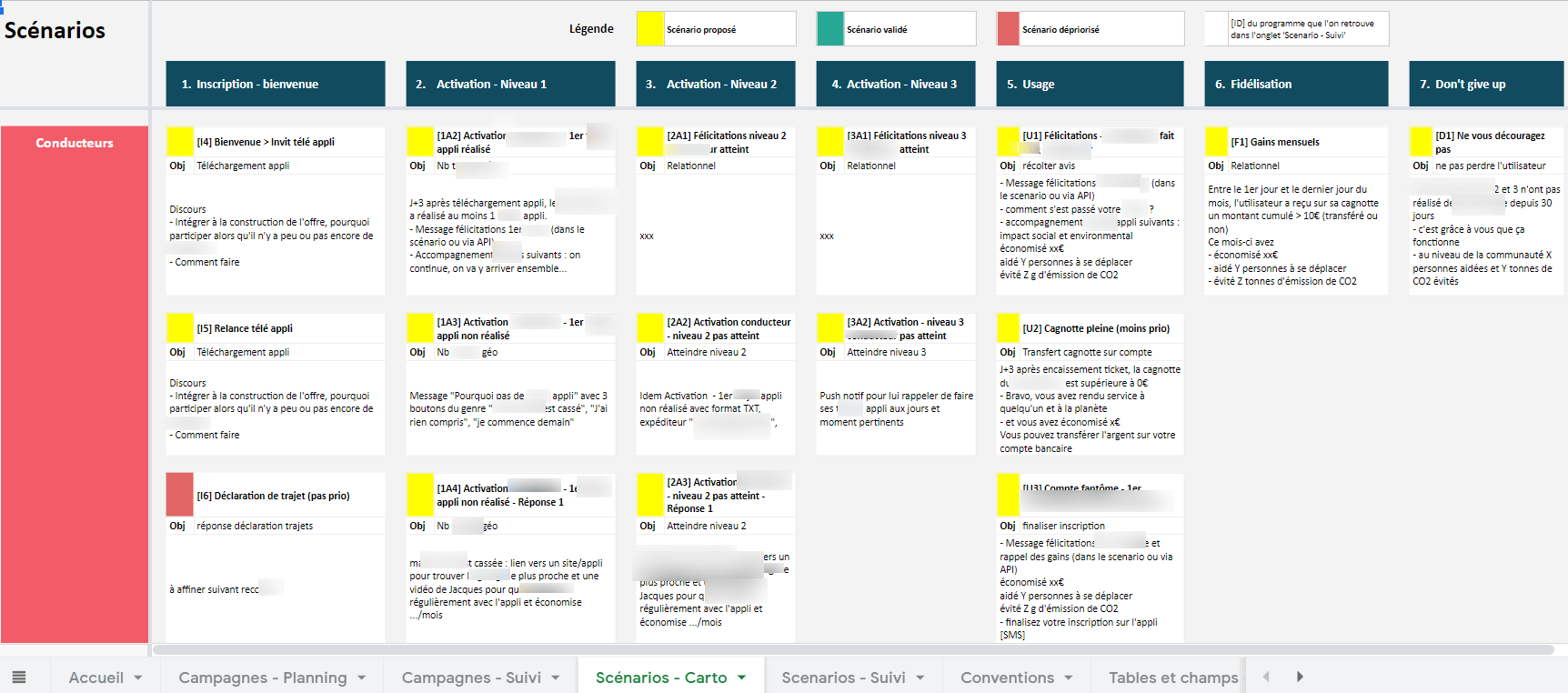
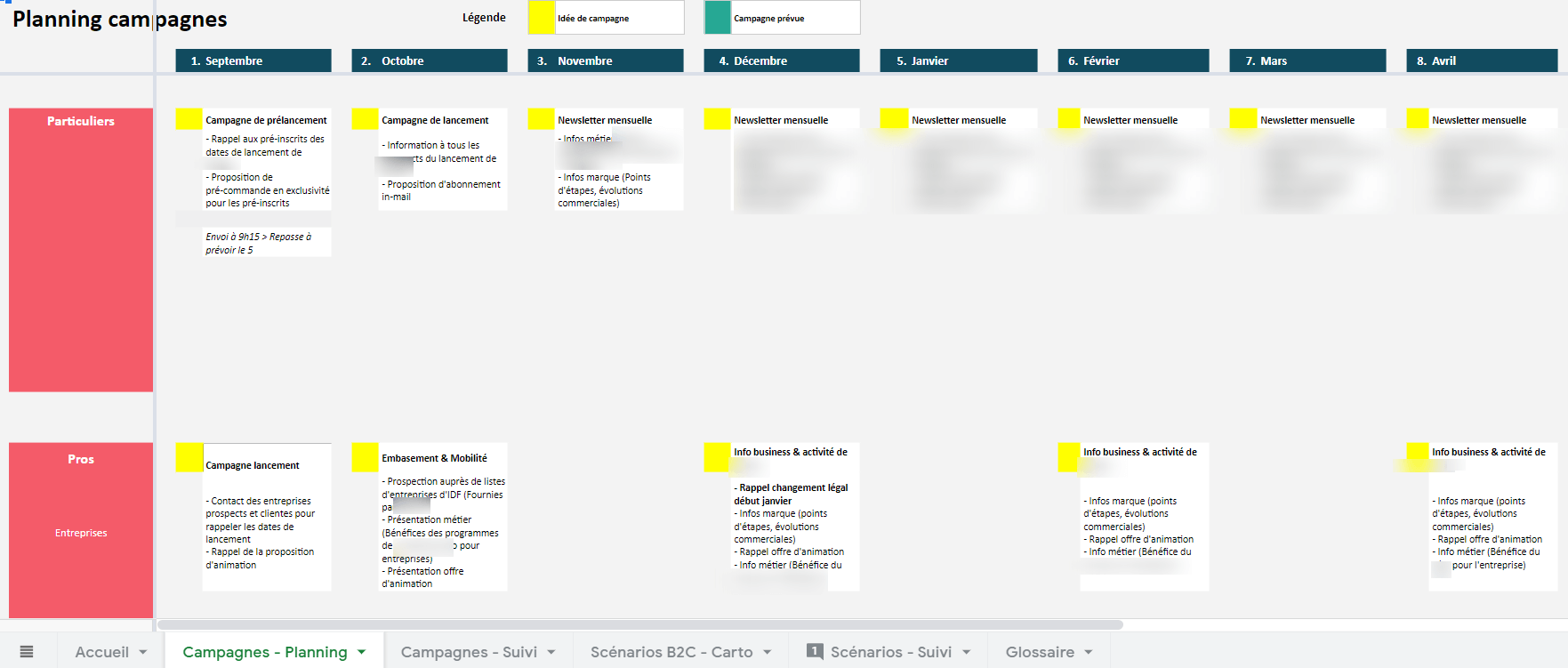
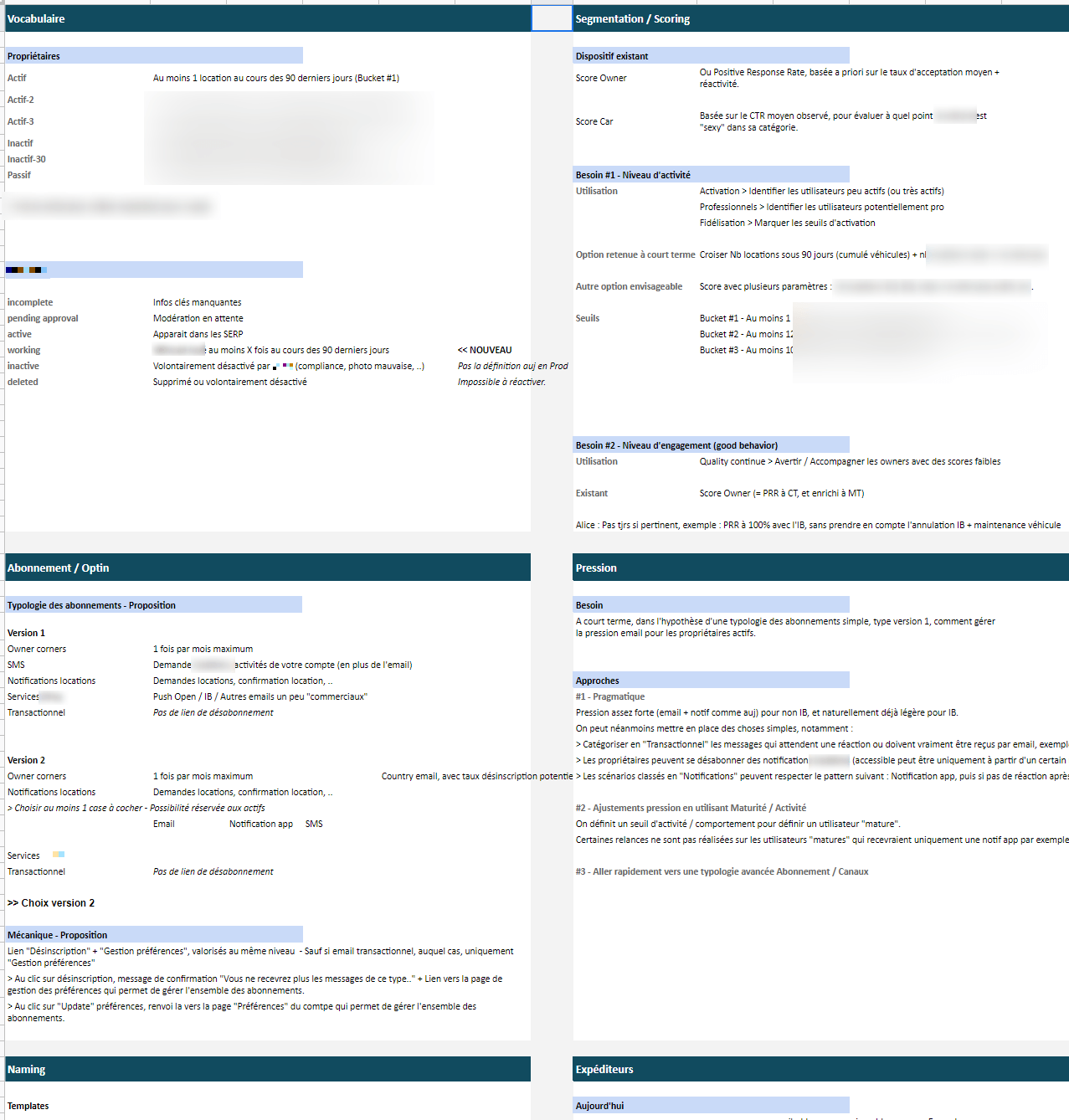

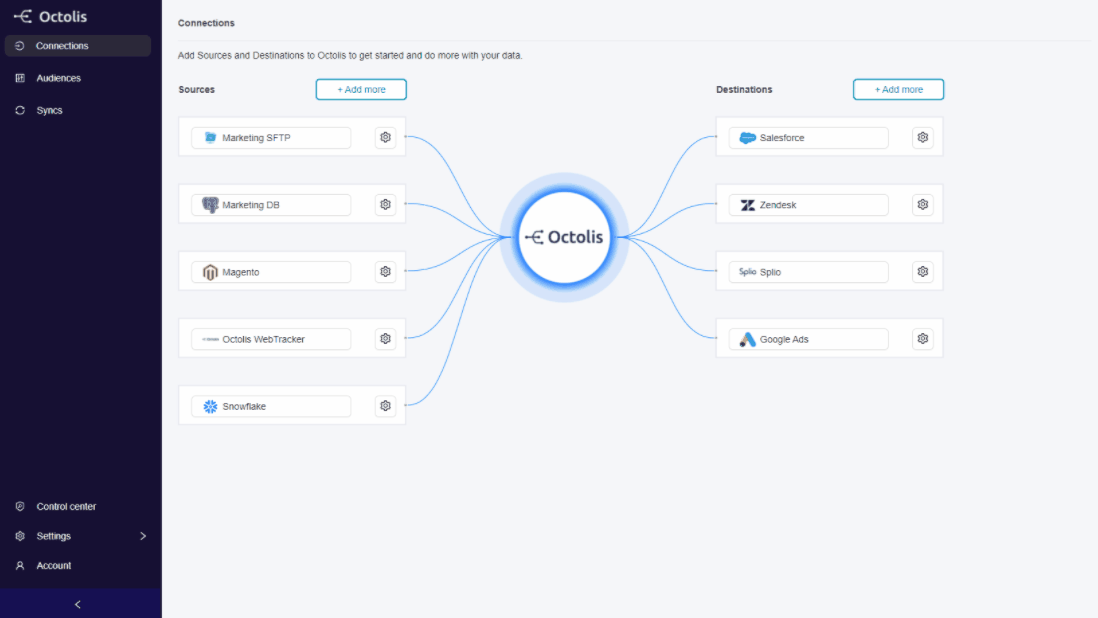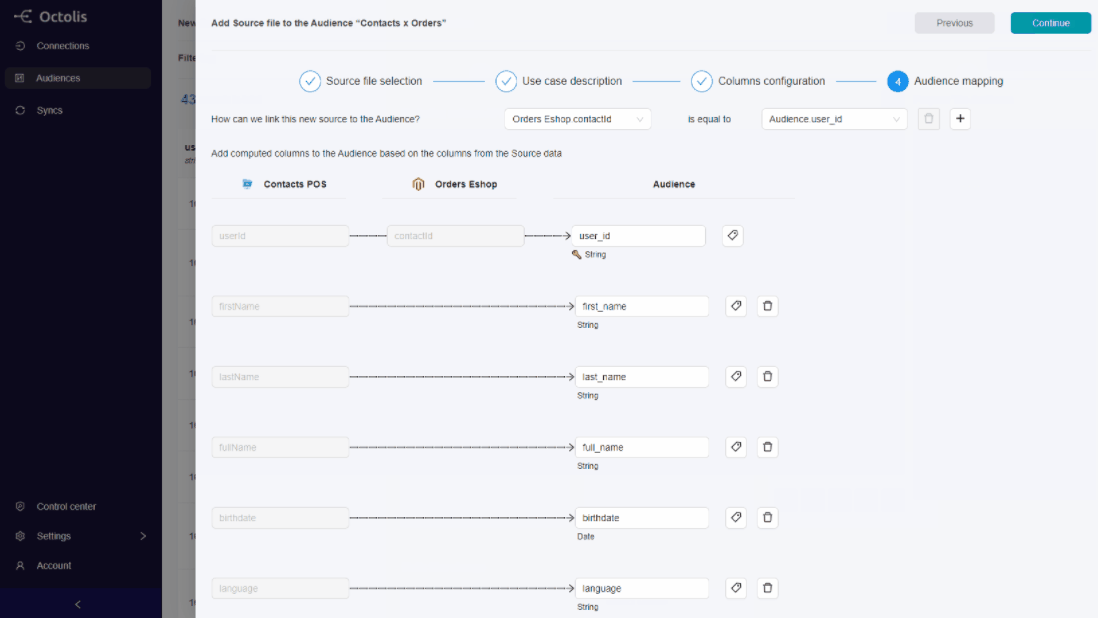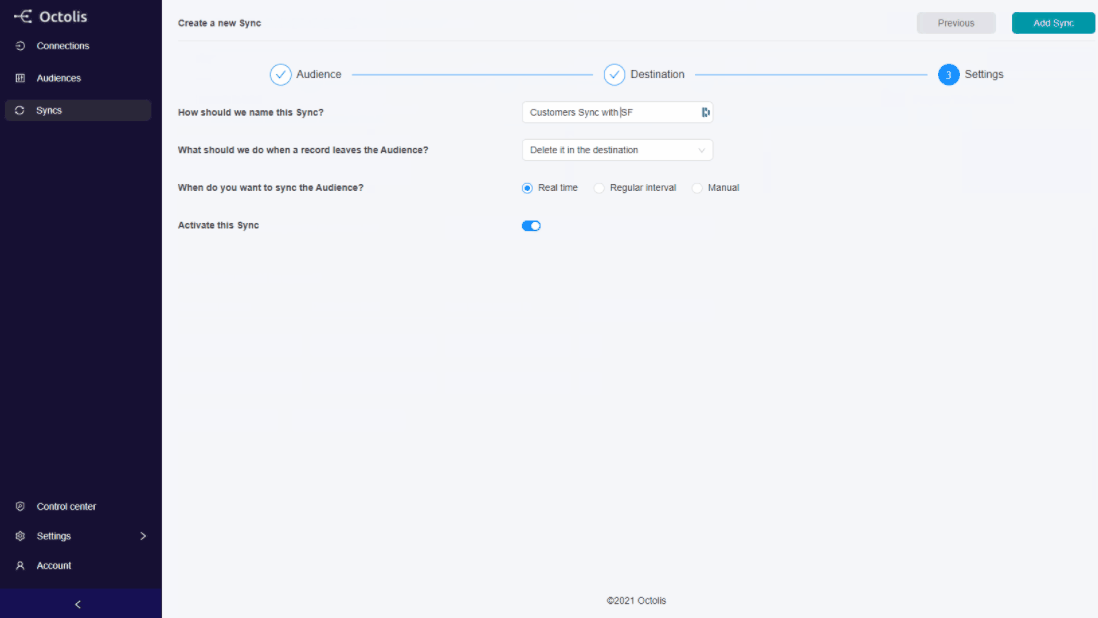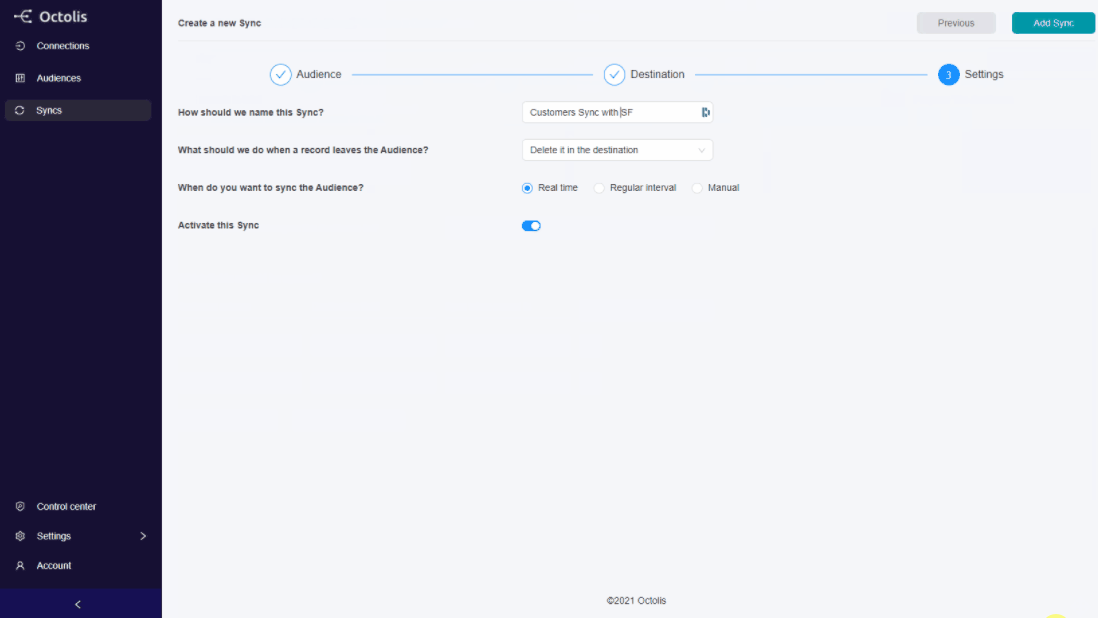

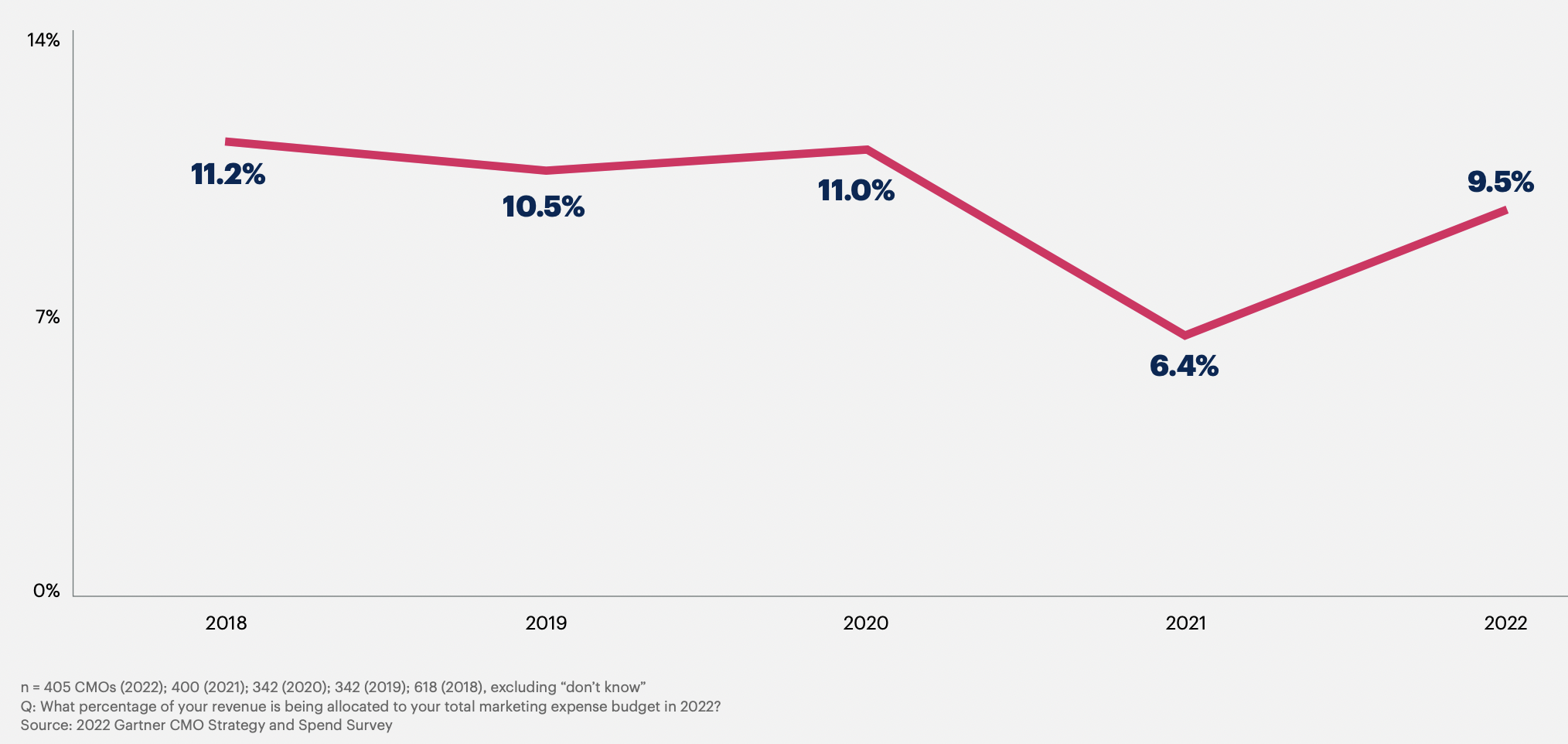
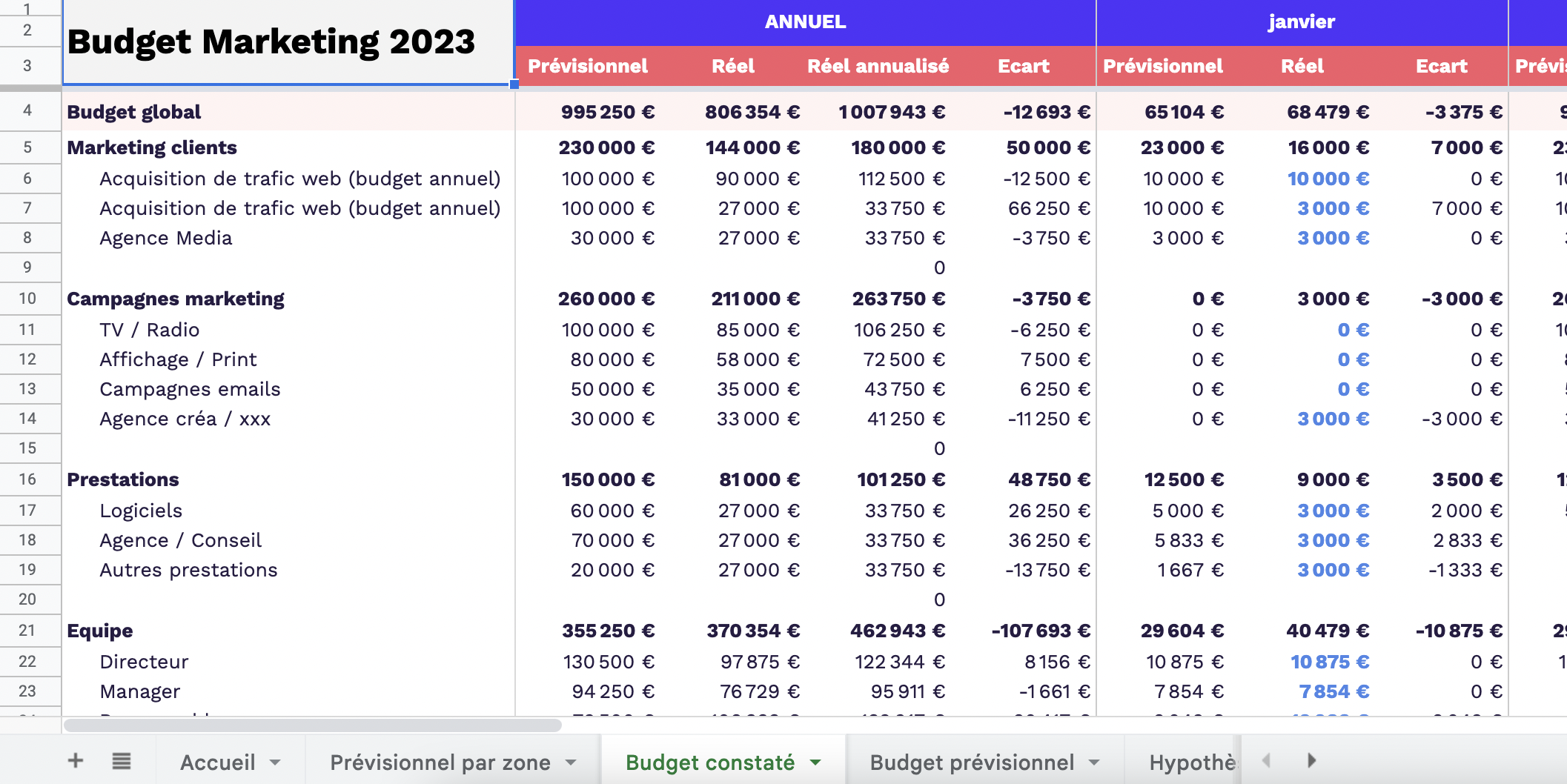
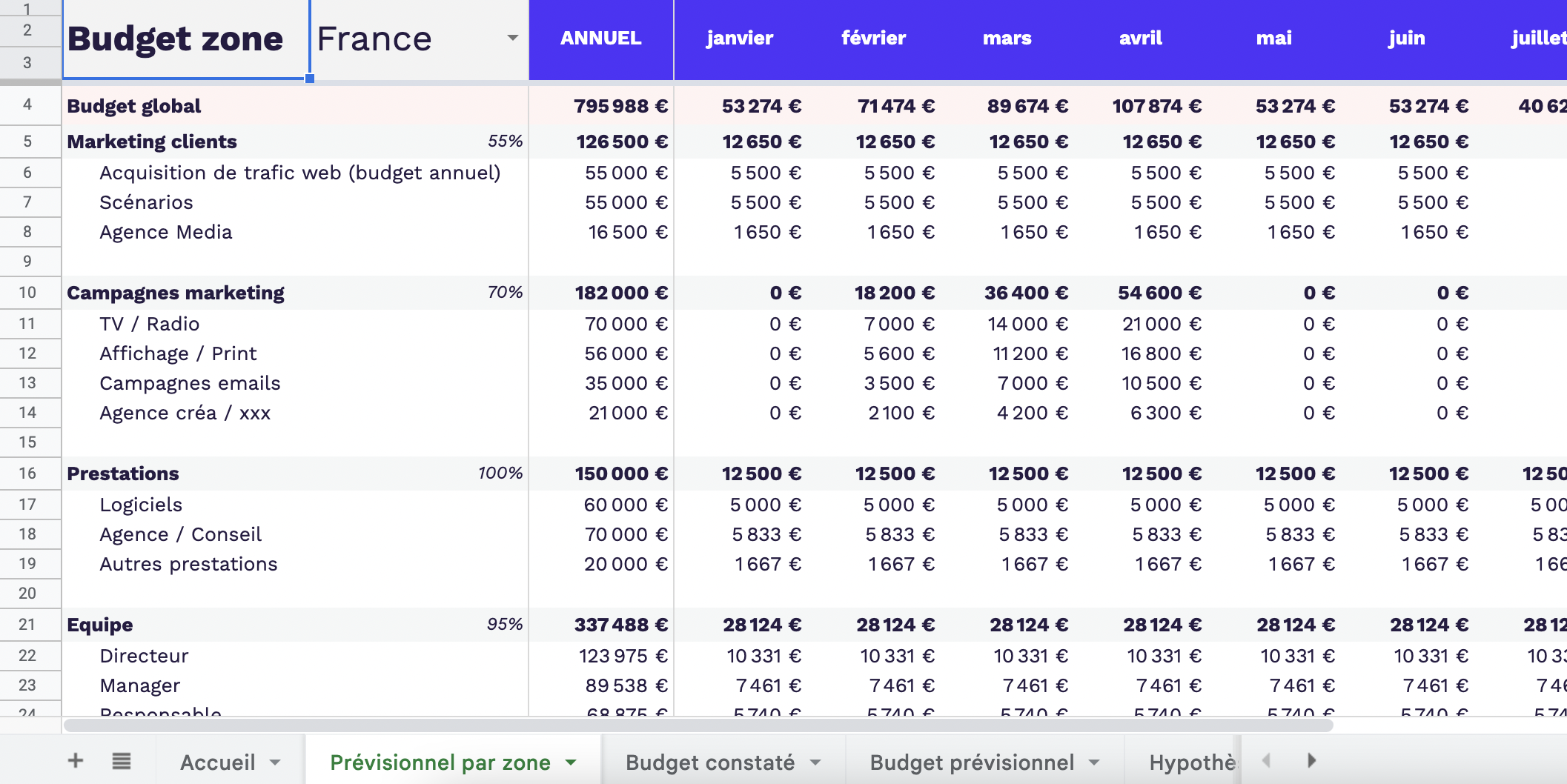
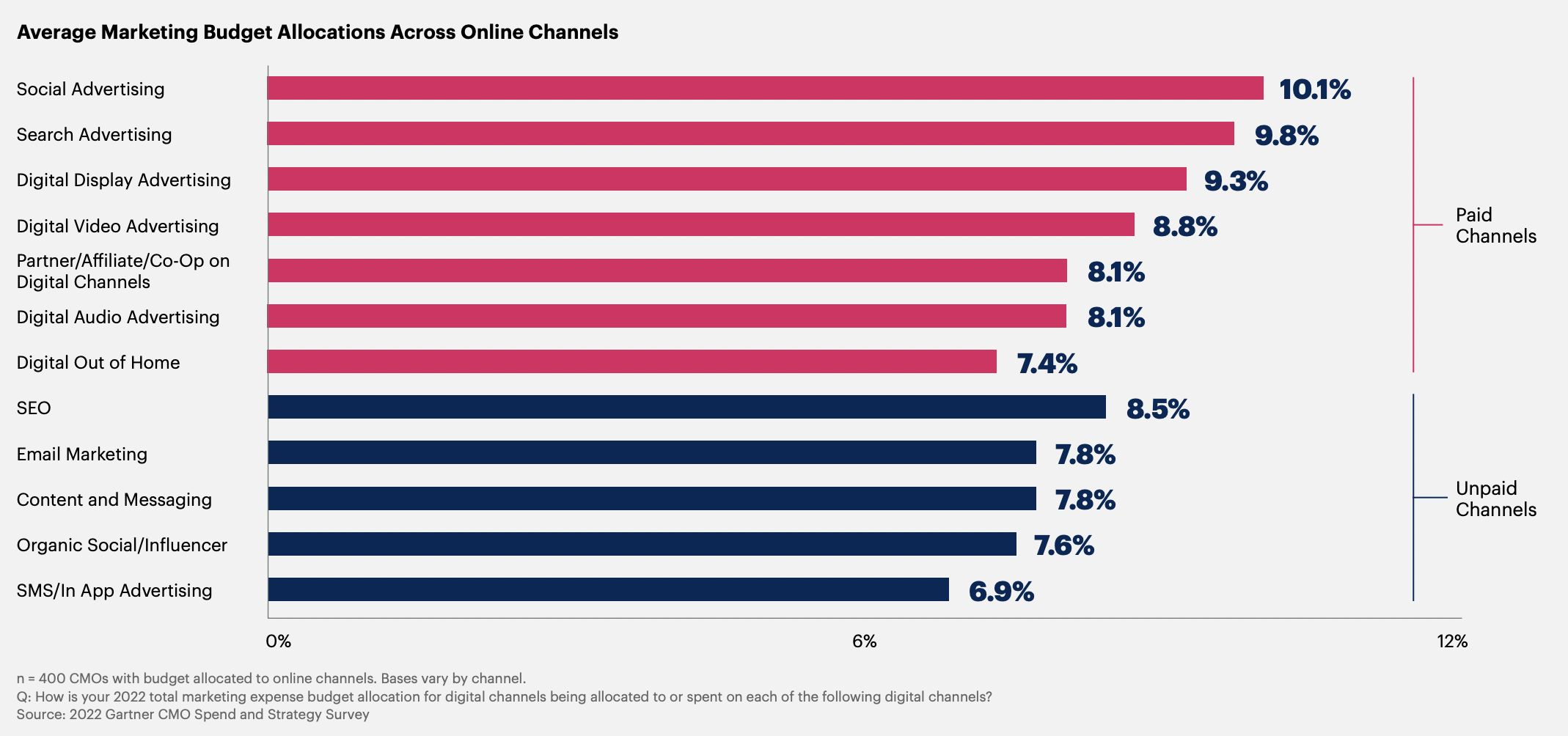
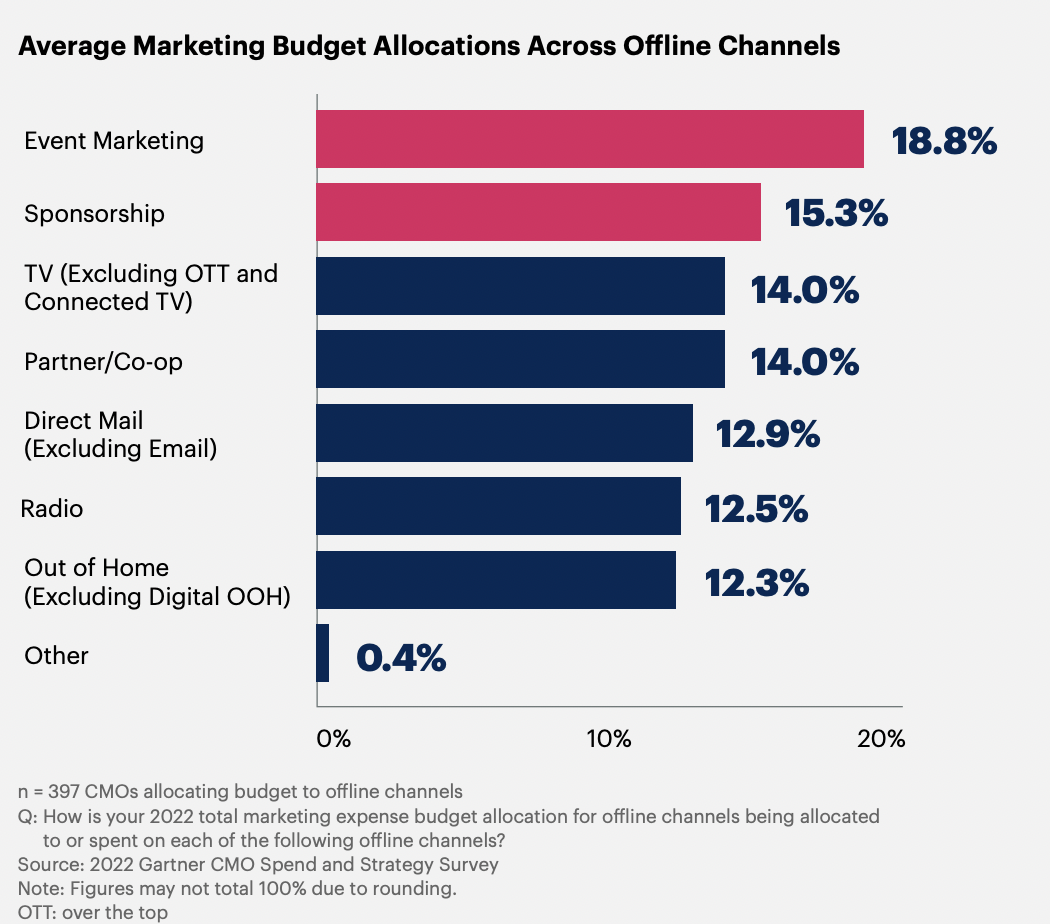
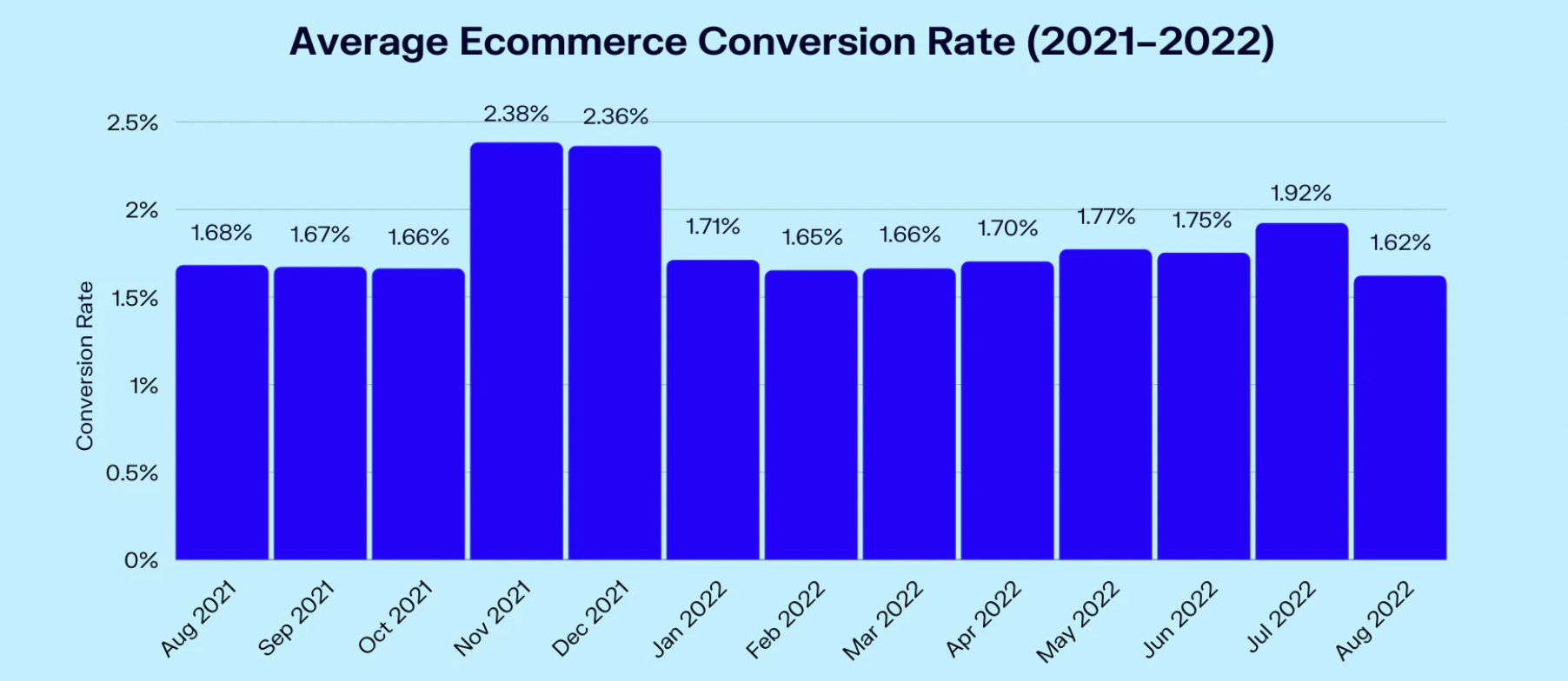
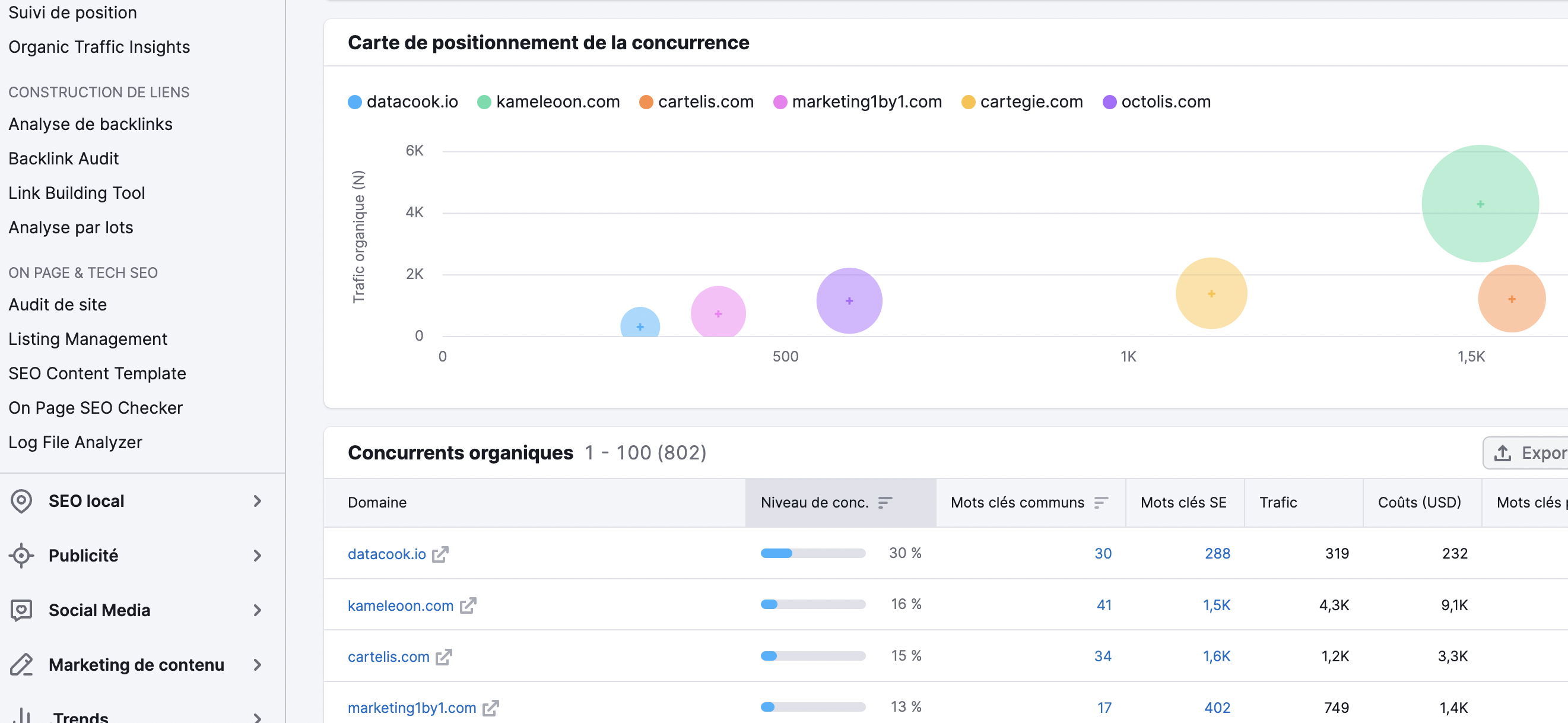
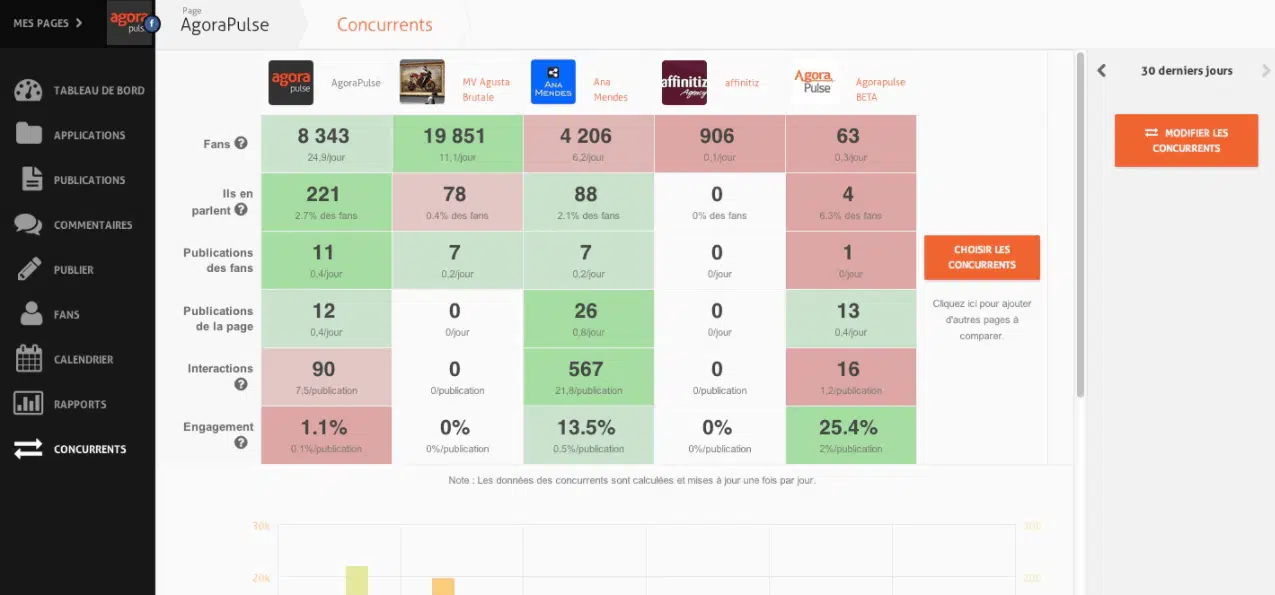
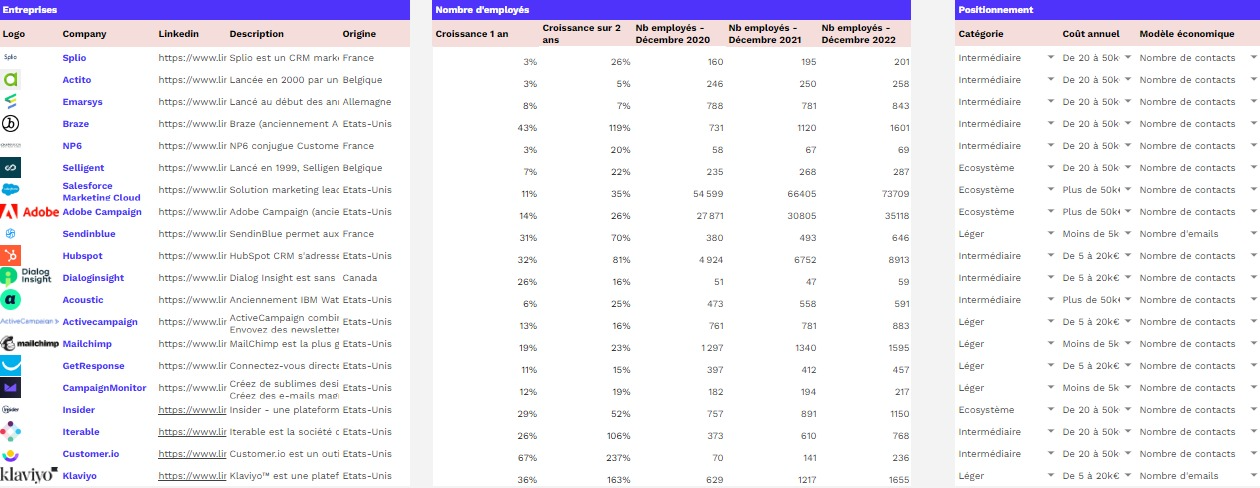
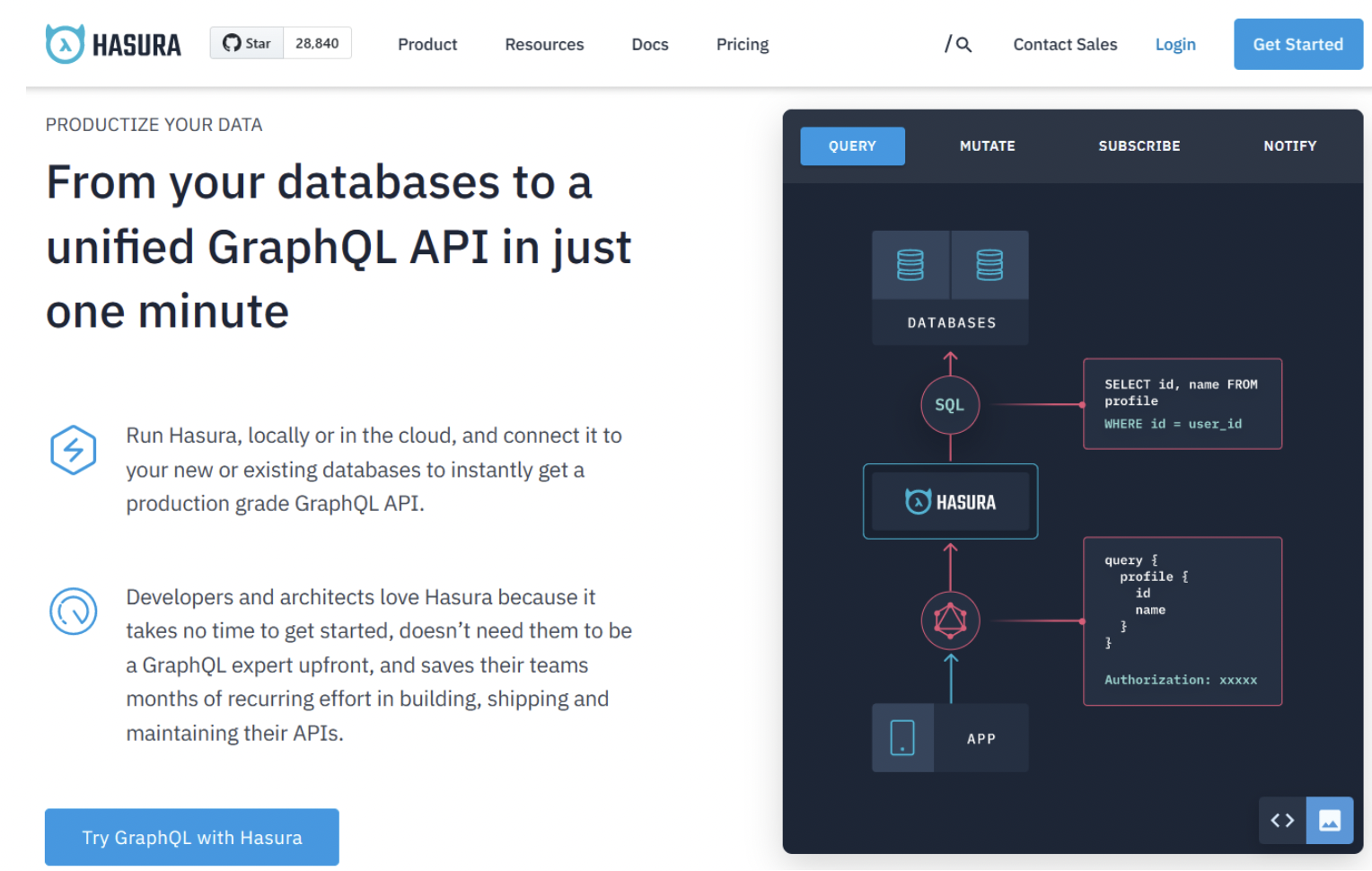
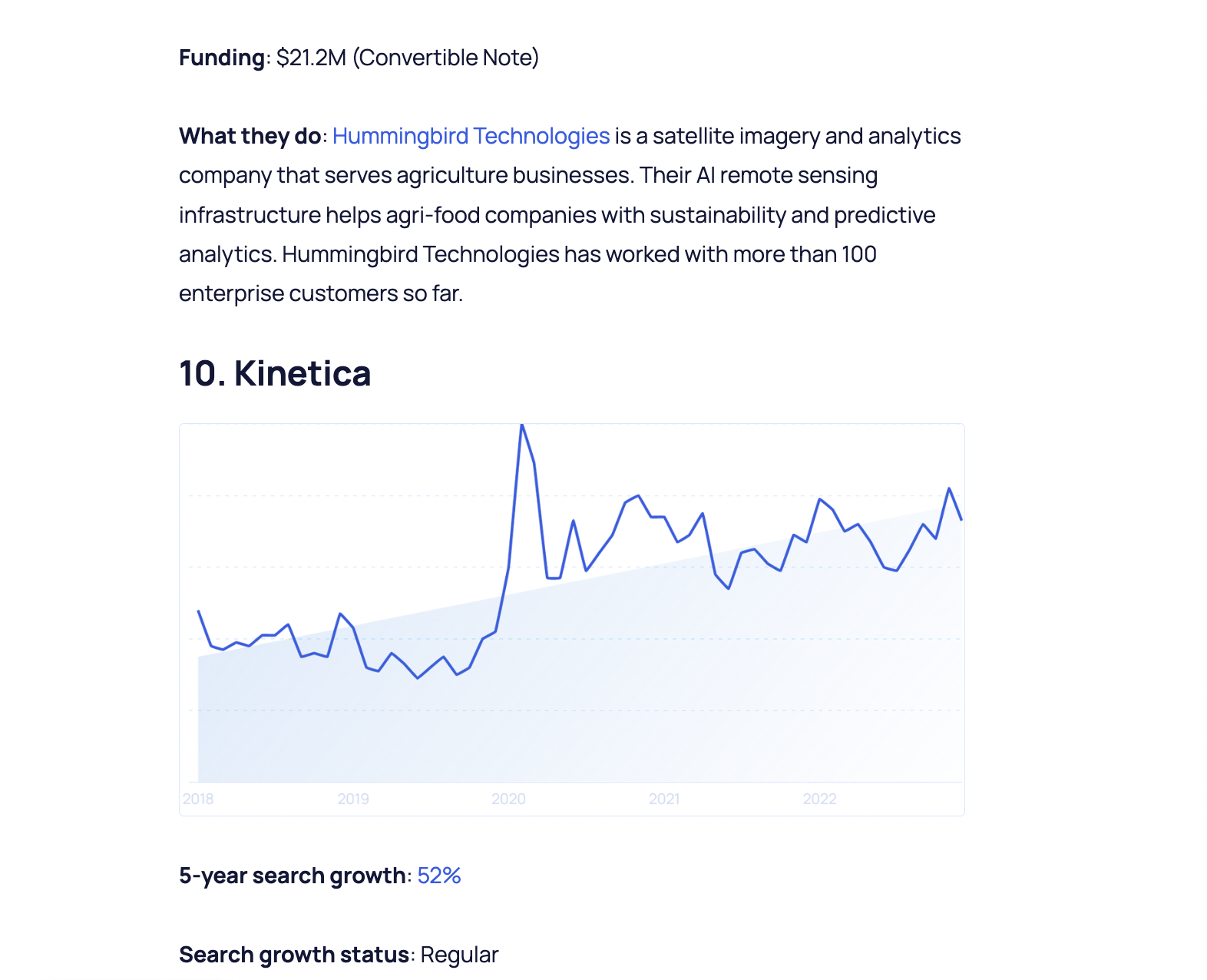


 Nicolas Chollet (Consultant Data UnNest)
Nicolas Chollet (Consultant Data UnNest)


 Benjamin Rogojan (Seatlle Data Guy)
Benjamin Rogojan (Seatlle Data Guy) Kelly Kohllefel (Fivetran)
Kelly Kohllefel (Fivetran) David Raab (CDP Institute)
David Raab (CDP Institute) Redha Moulla (AxIa)
Redha Moulla (AxIa) Chad Sanderson (Convoy)
Chad Sanderson (Convoy) Maxence de Villepion (Cargo)
Maxence de Villepion (Cargo) Christophe Blefari (Christophe Blefari)
Christophe Blefari (Christophe Blefari) Nicolas Jaimes (Minted)
Nicolas Jaimes (Minted) Arnold Haine (BVA)
Arnold Haine (BVA)

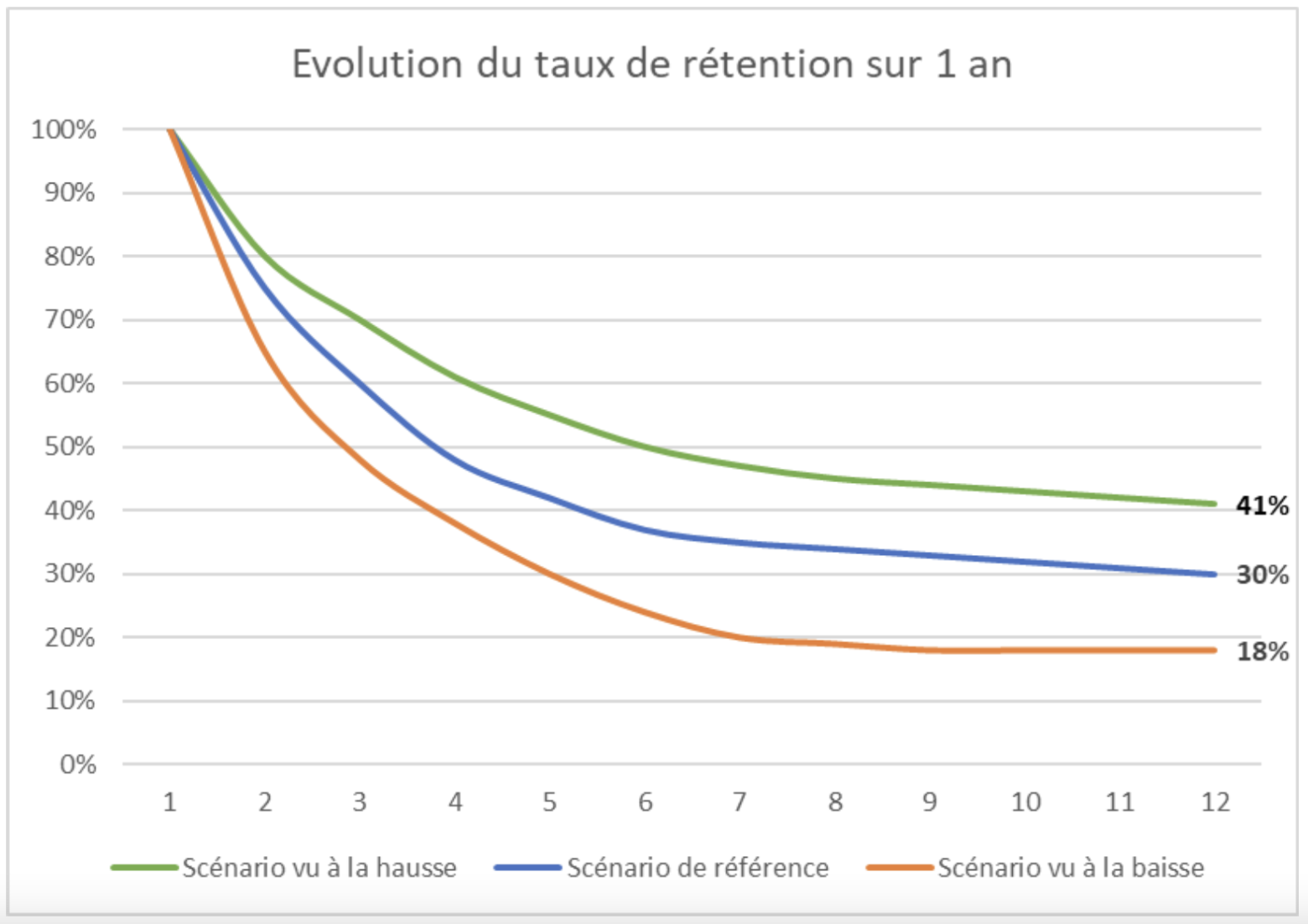



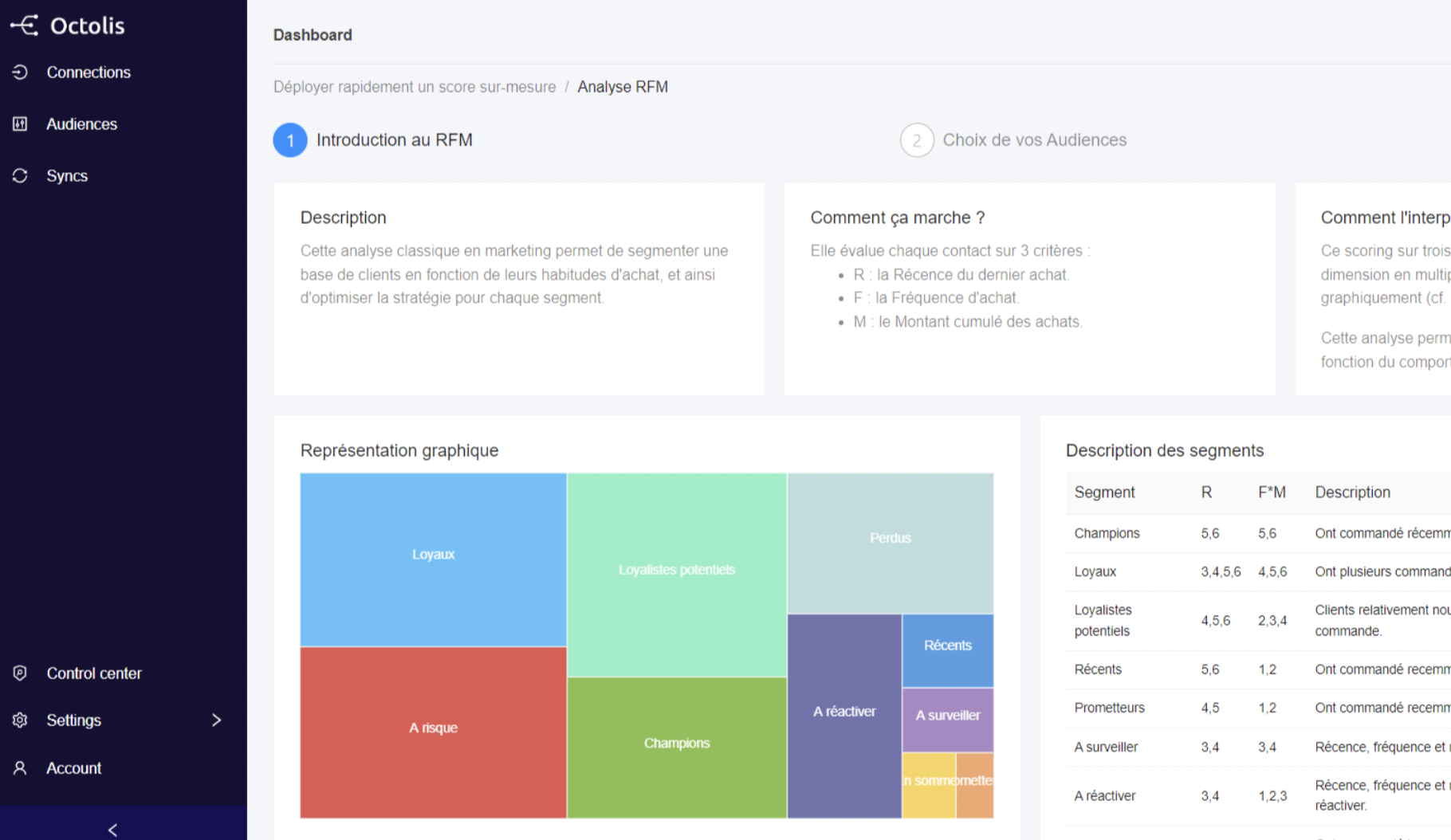
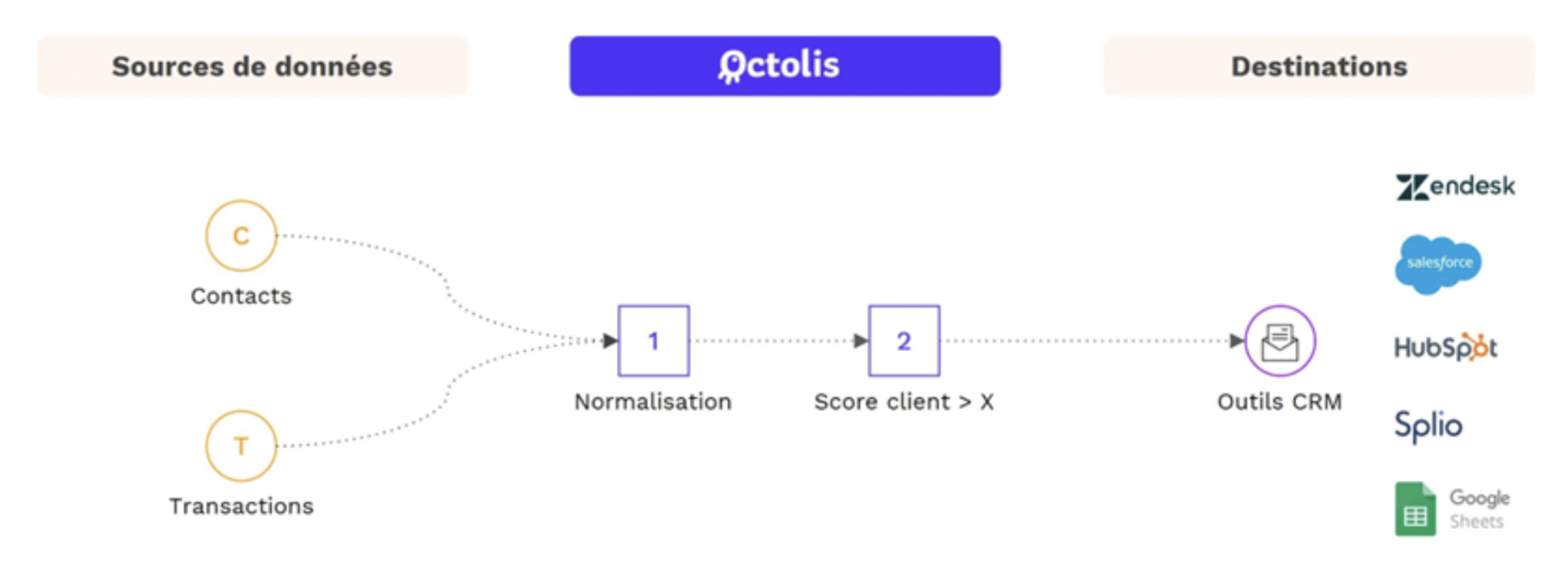
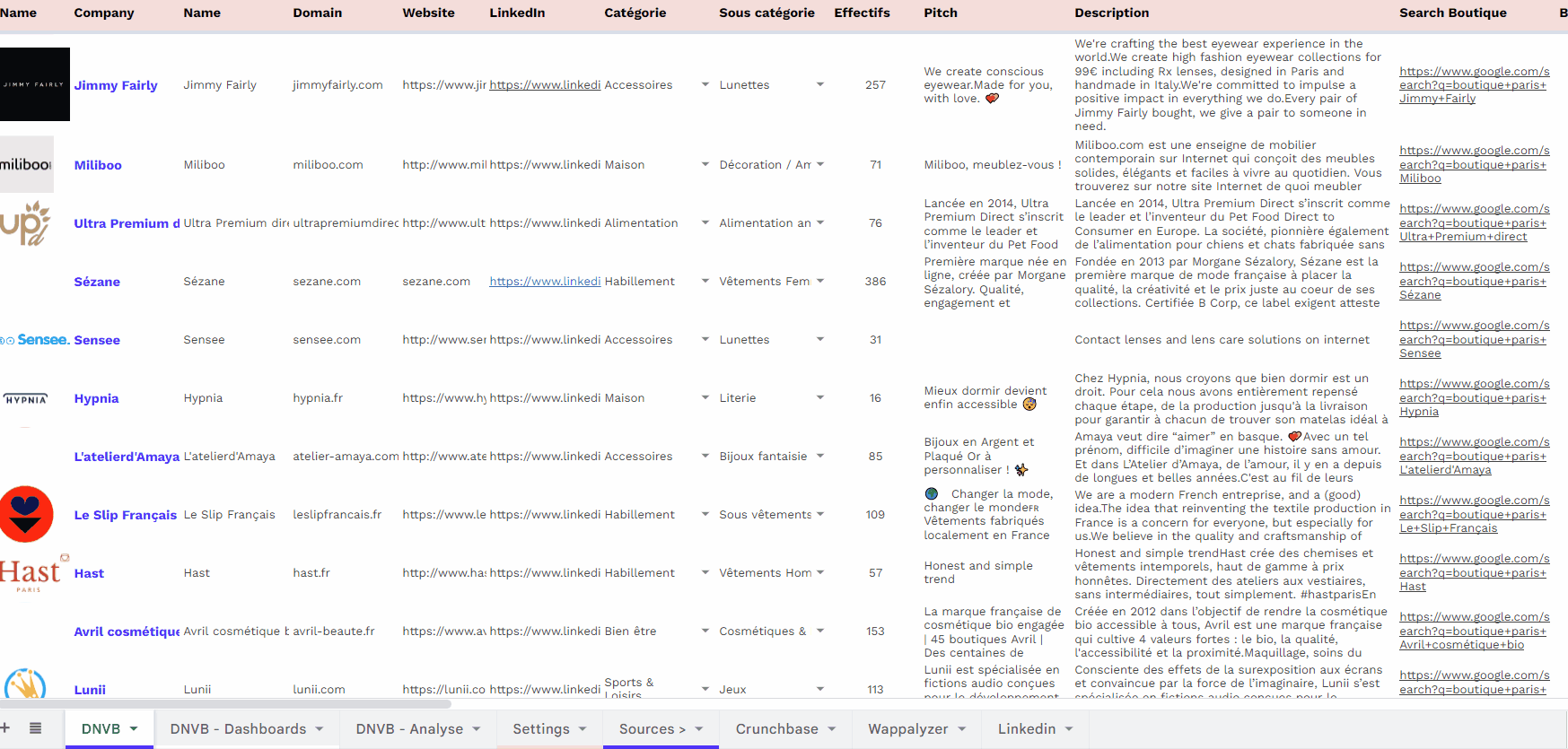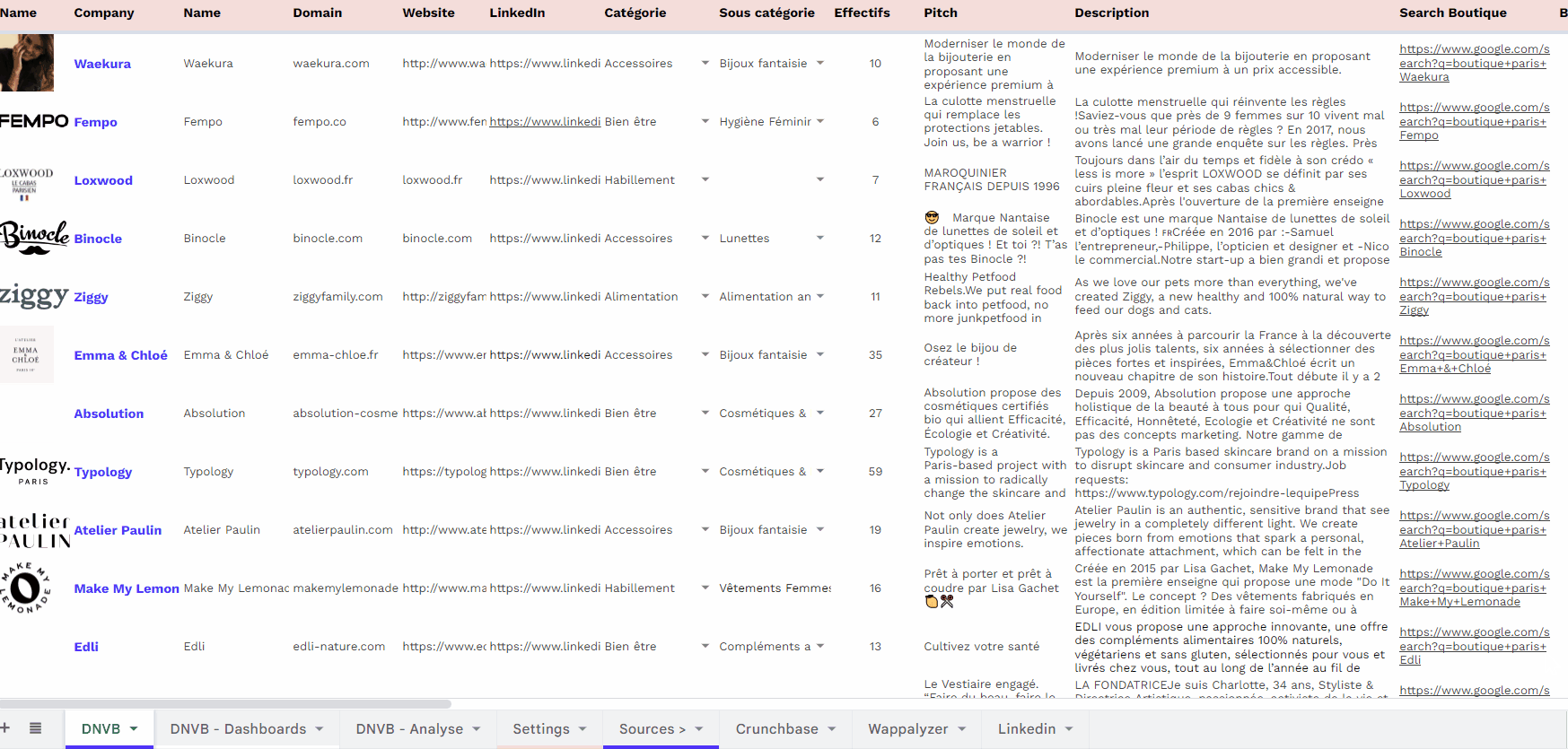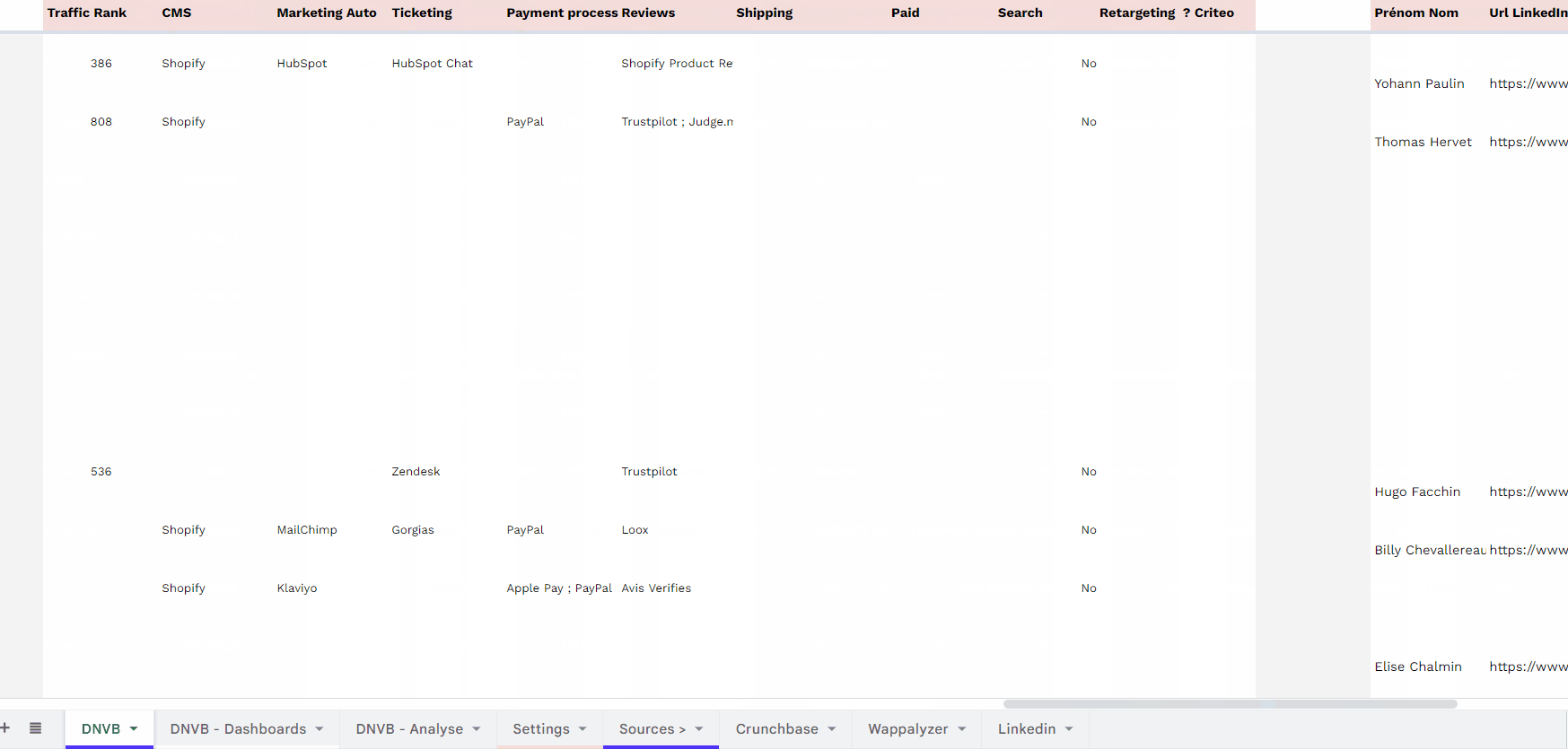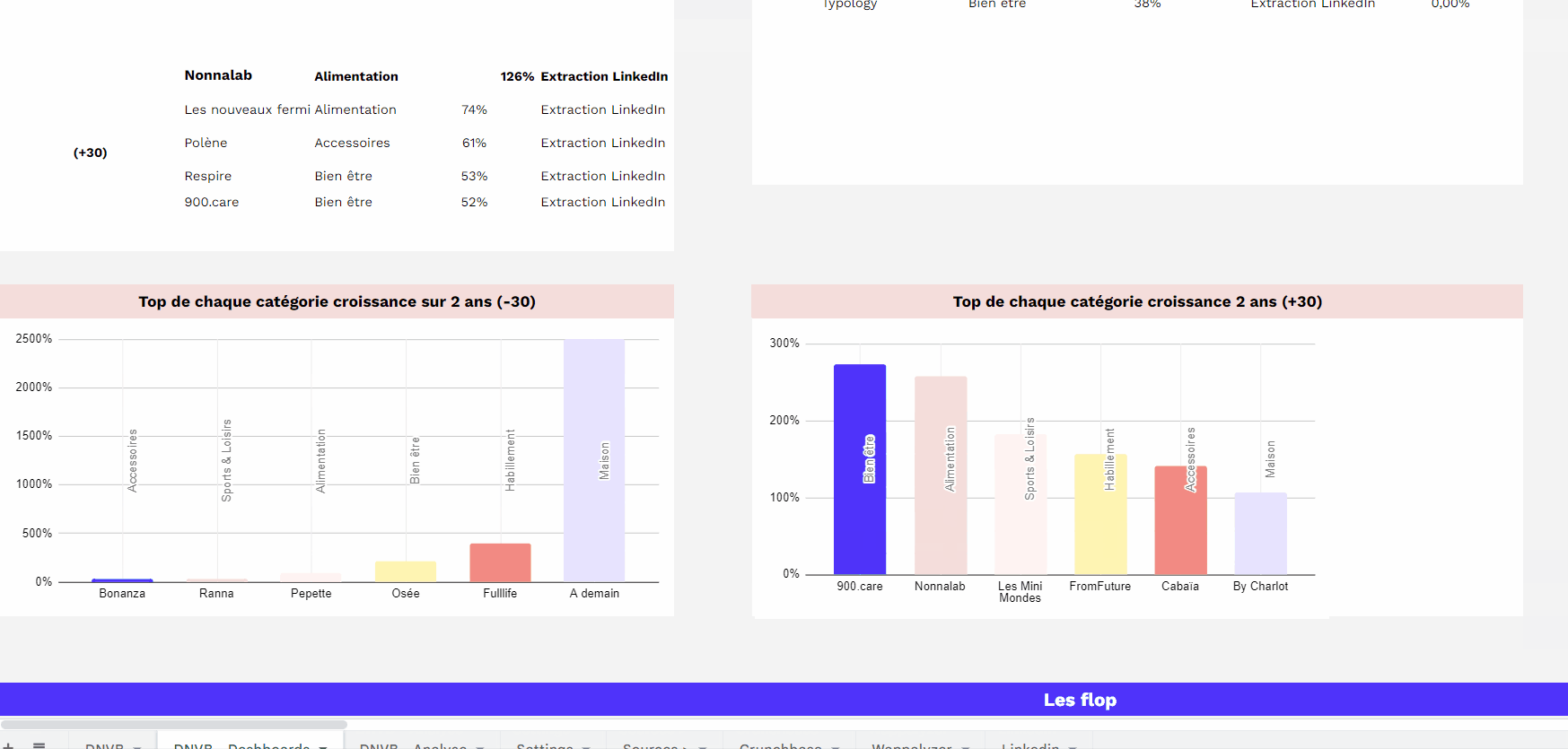
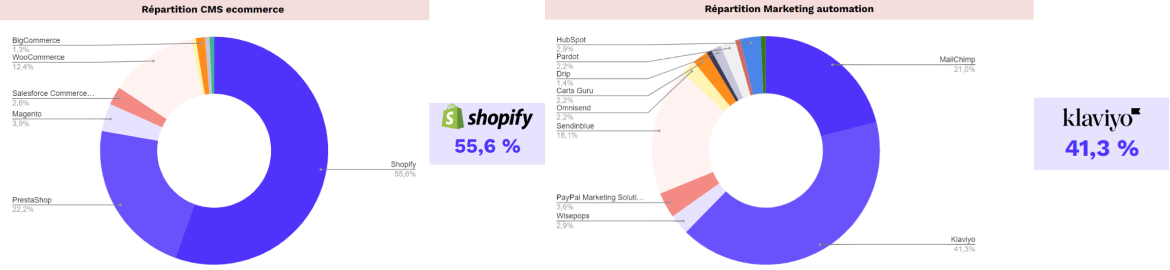
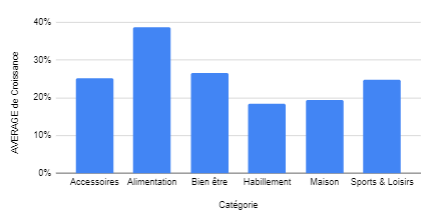

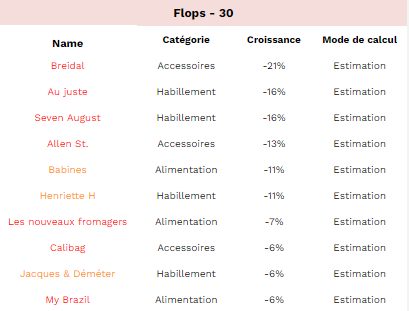
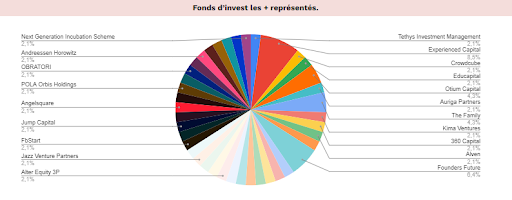

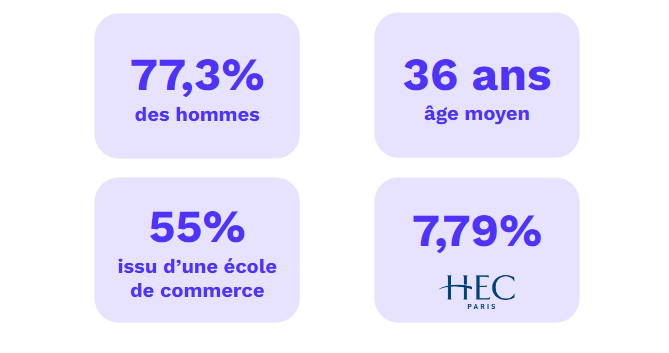
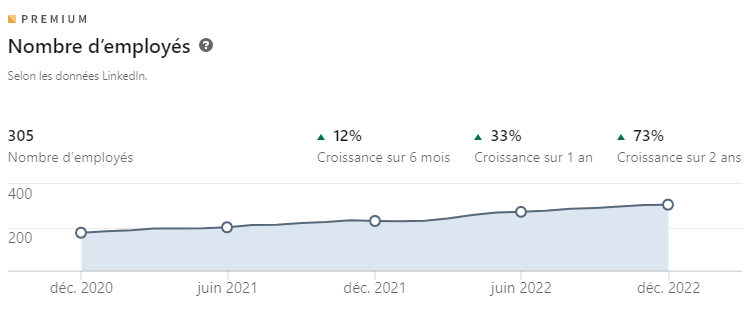
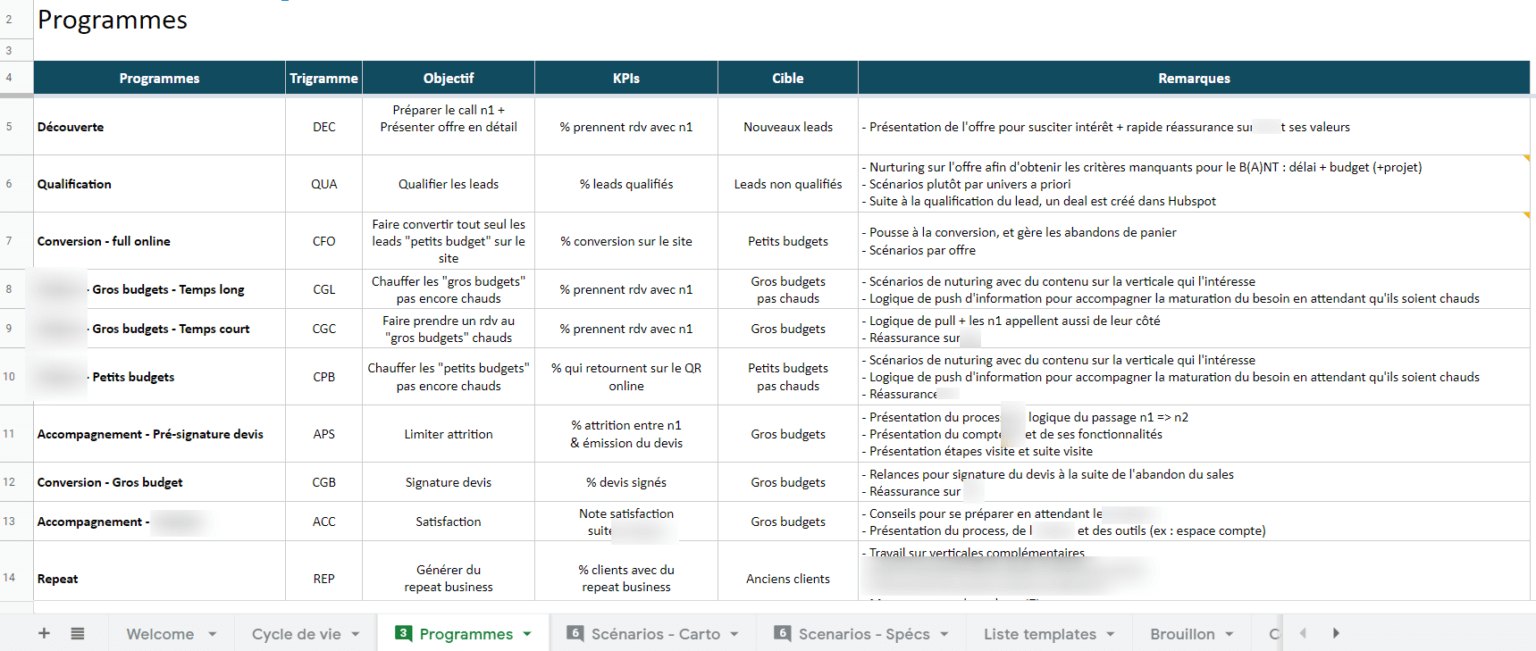






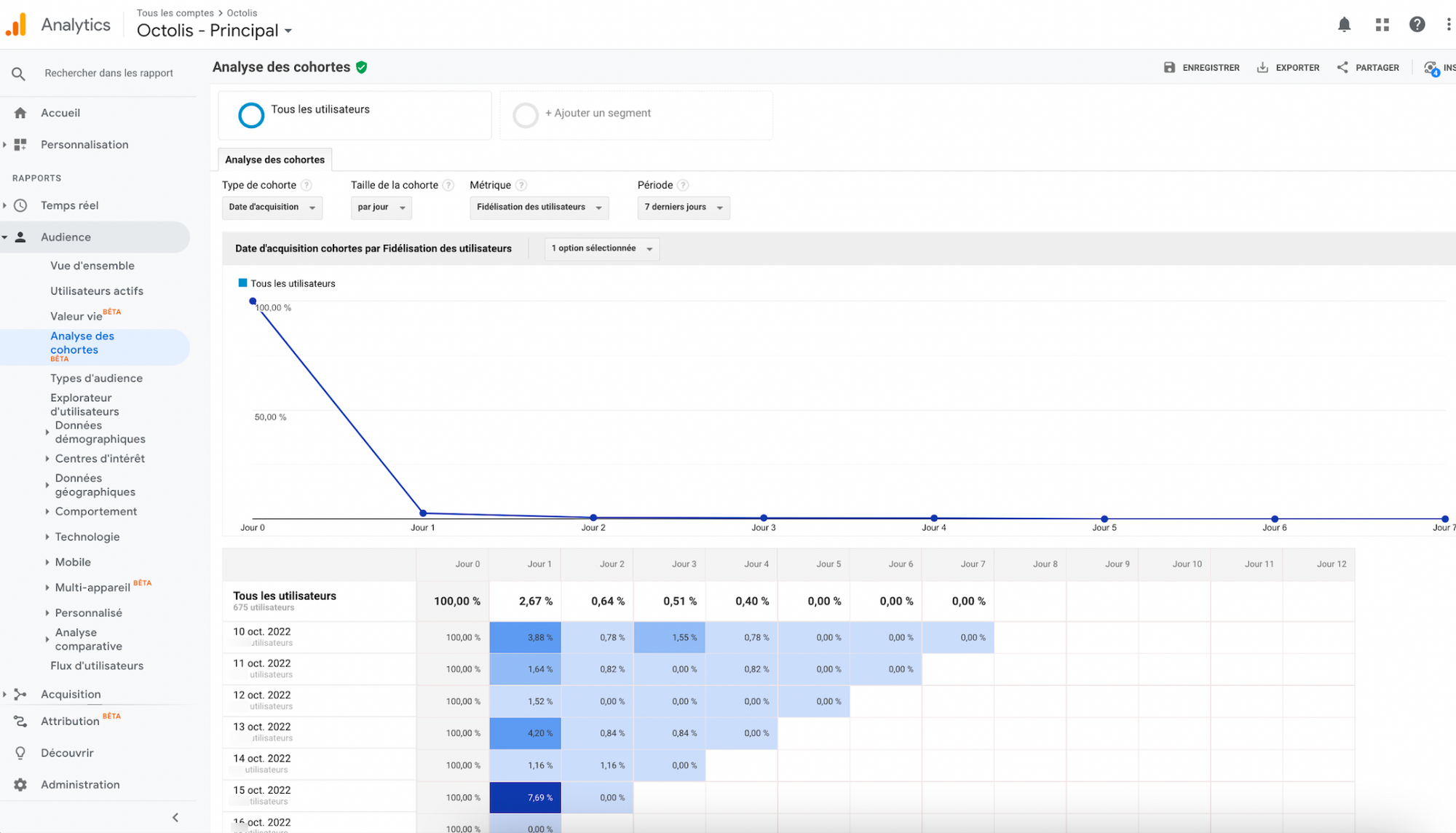


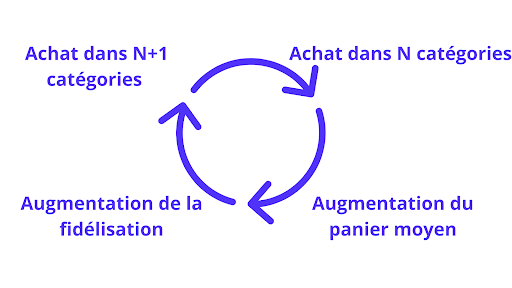
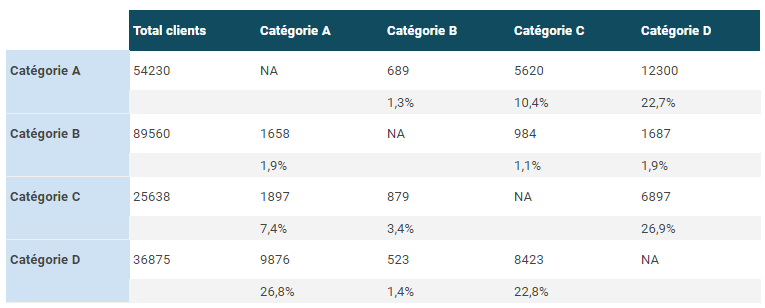
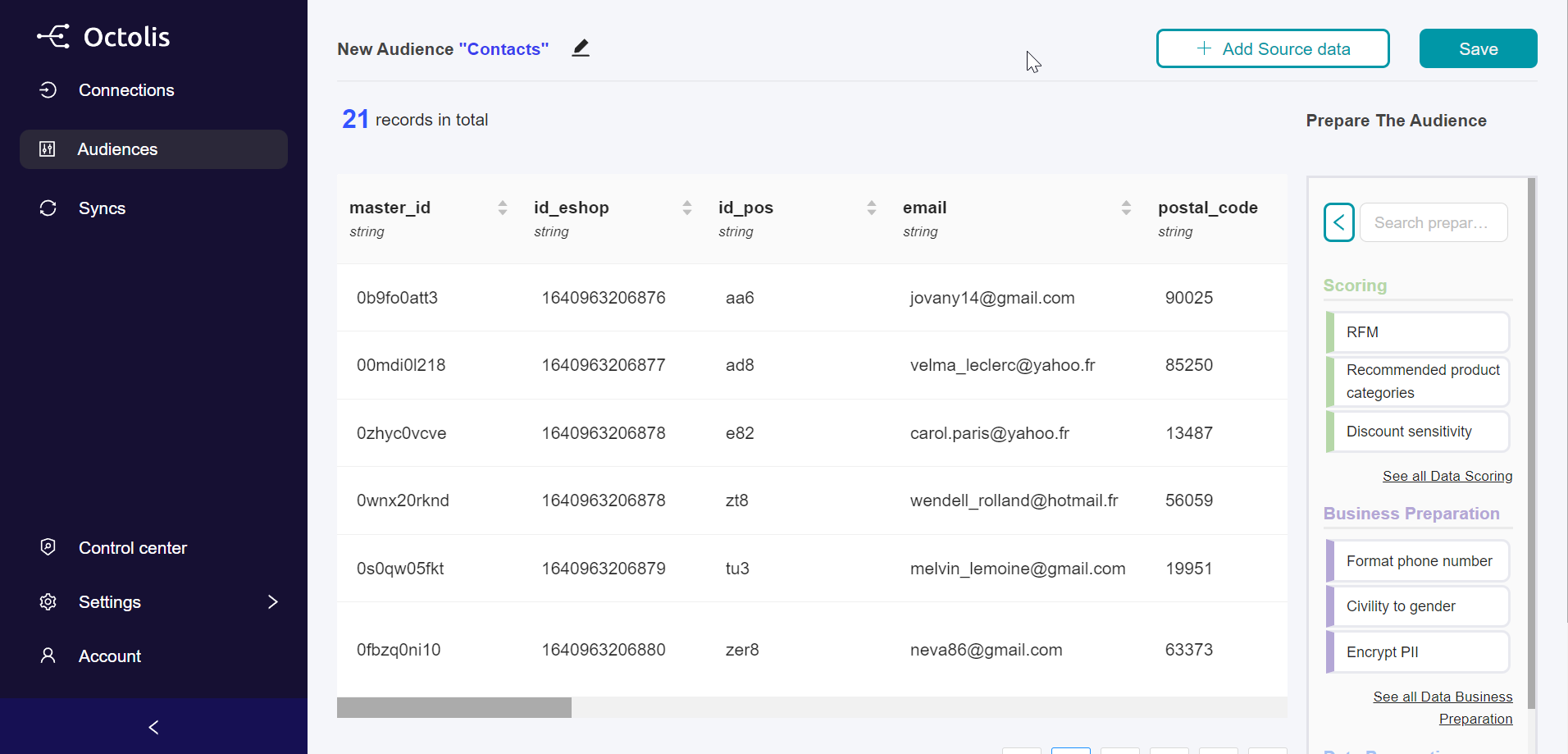









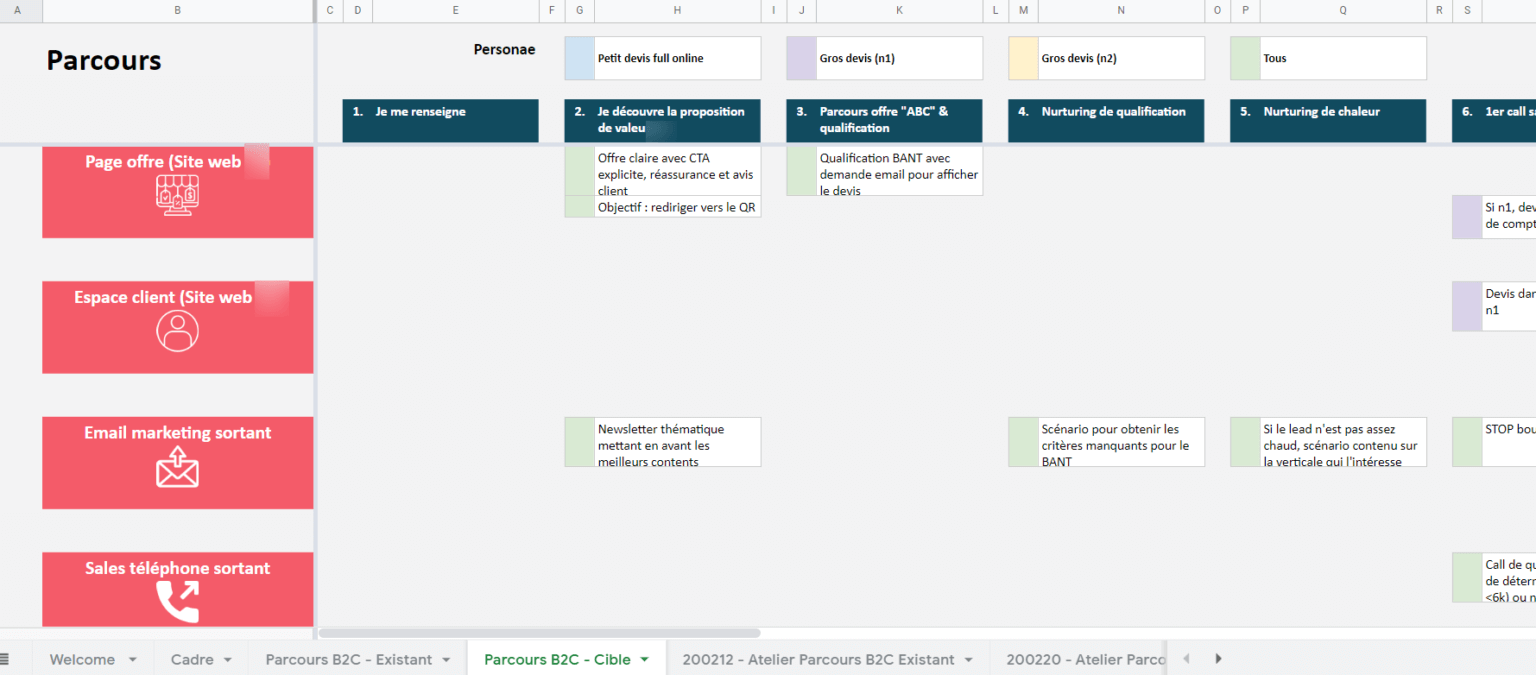
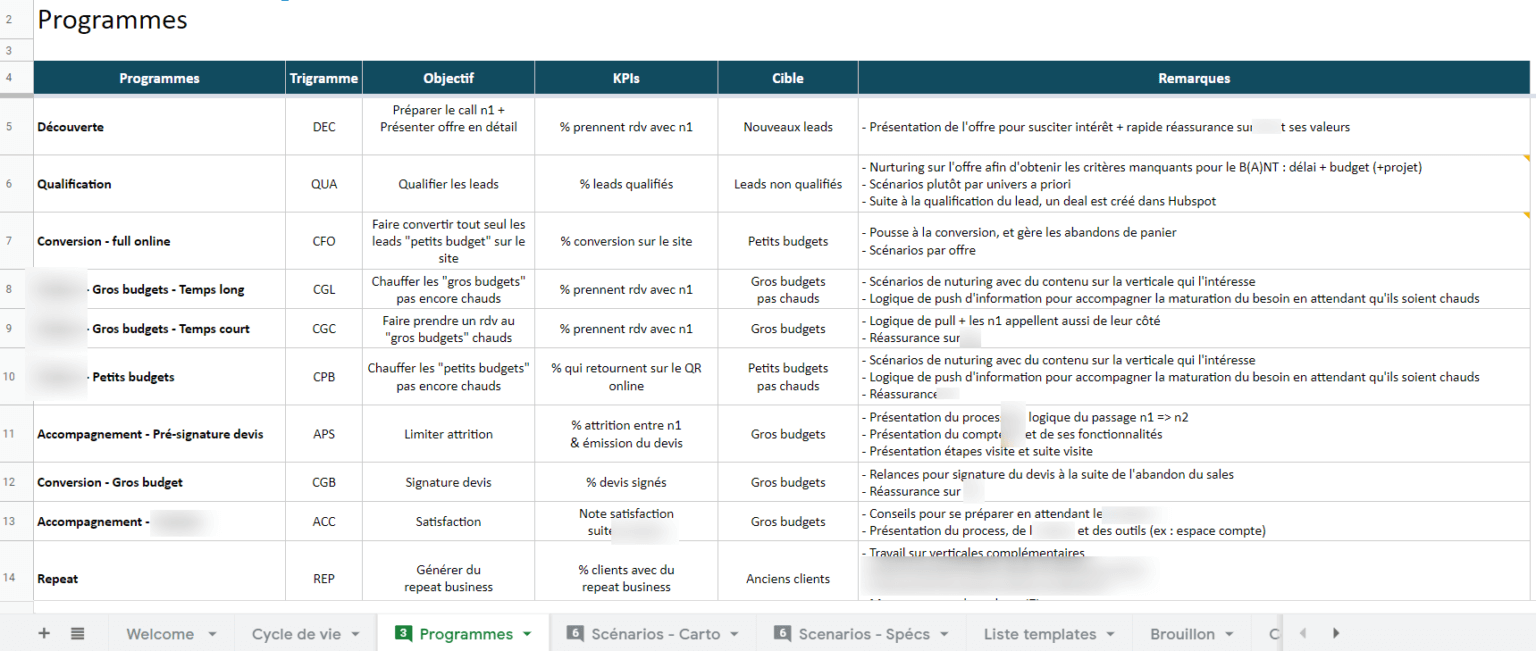
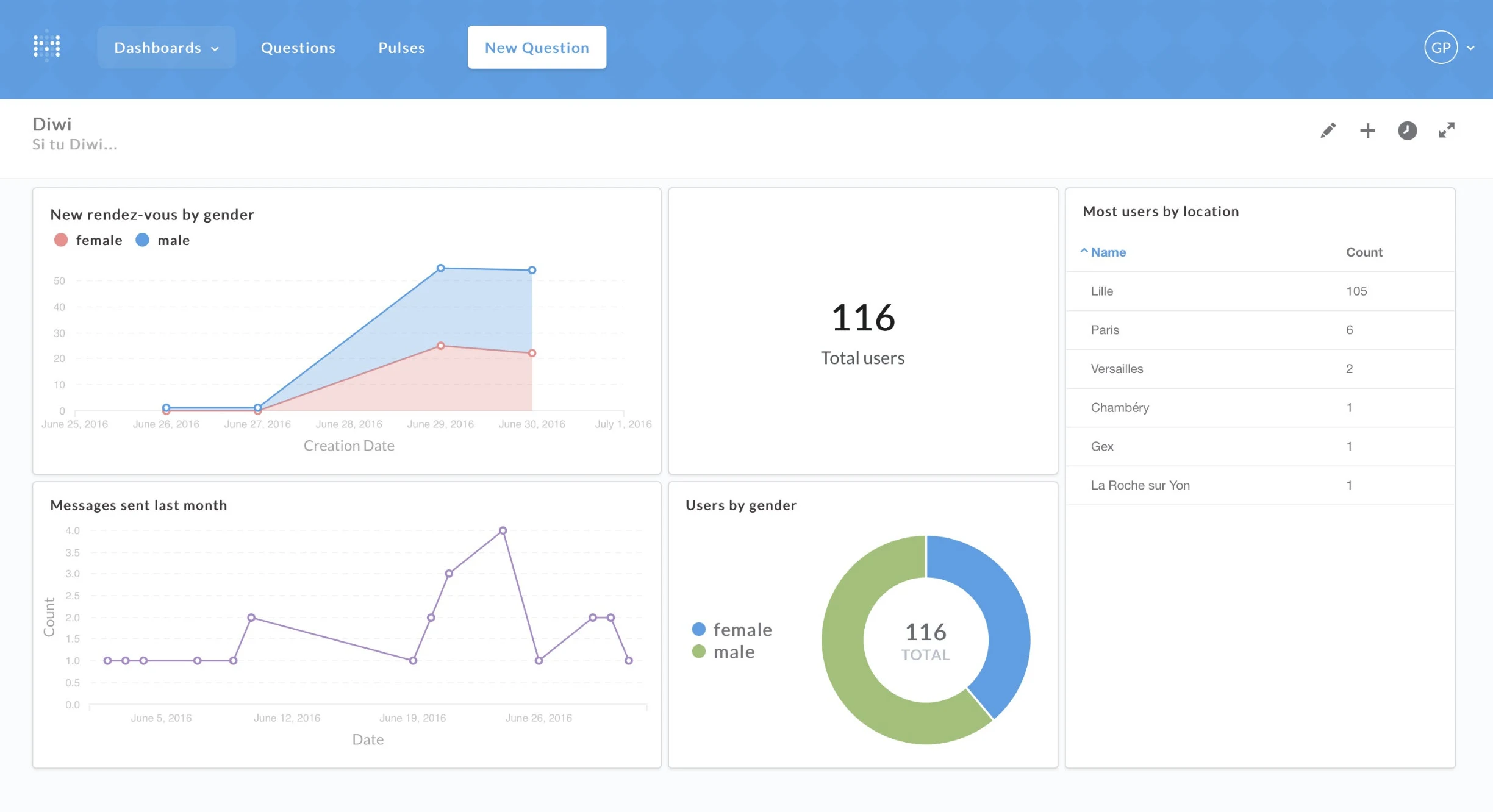
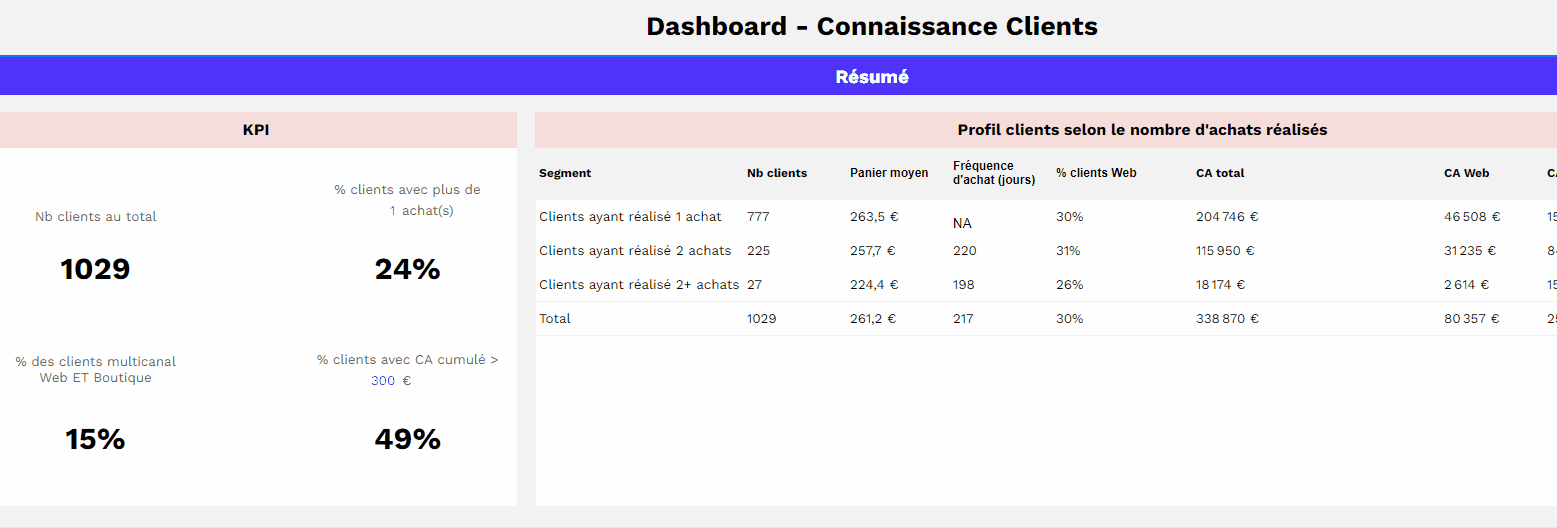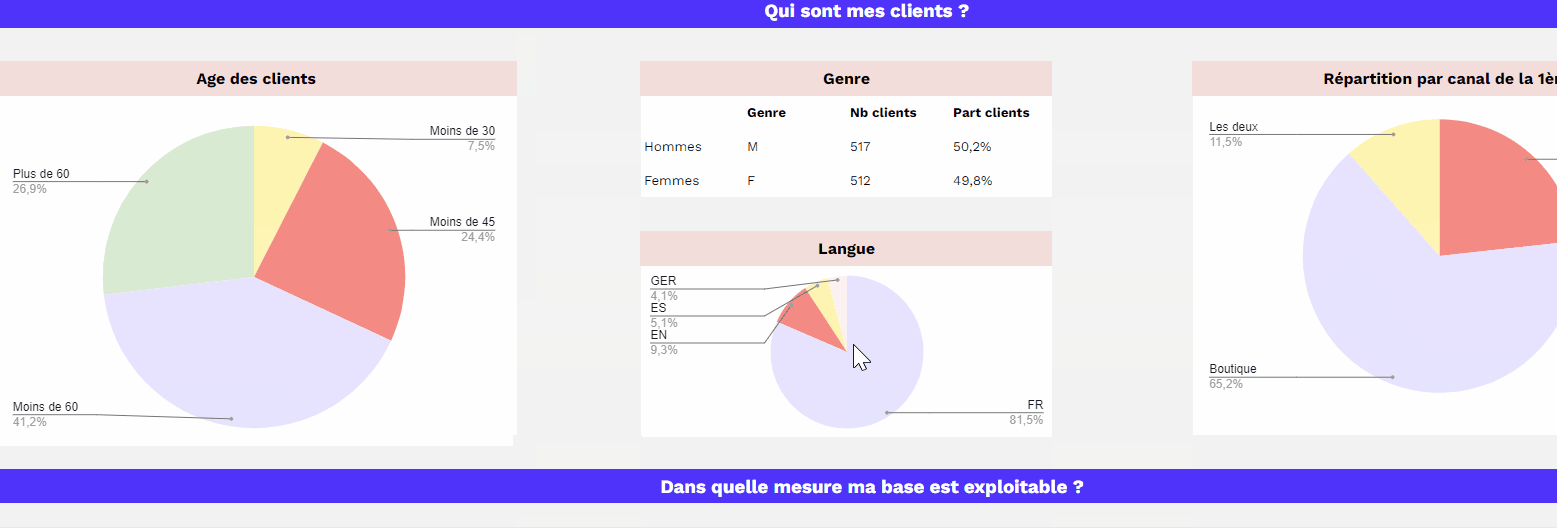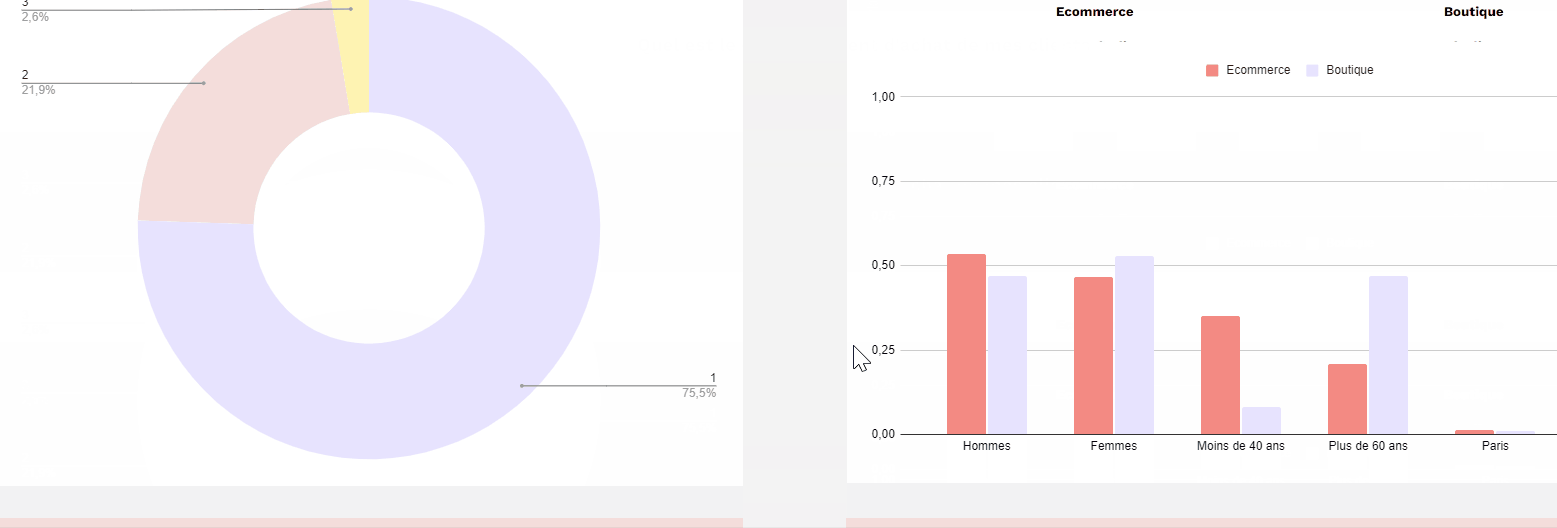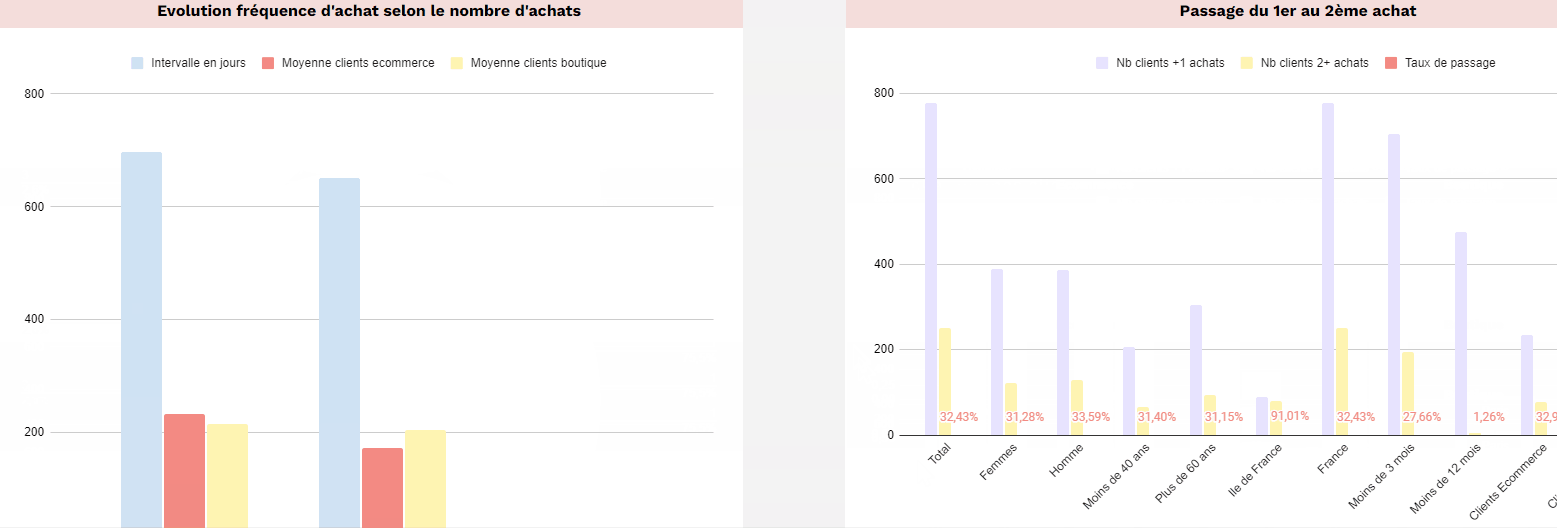
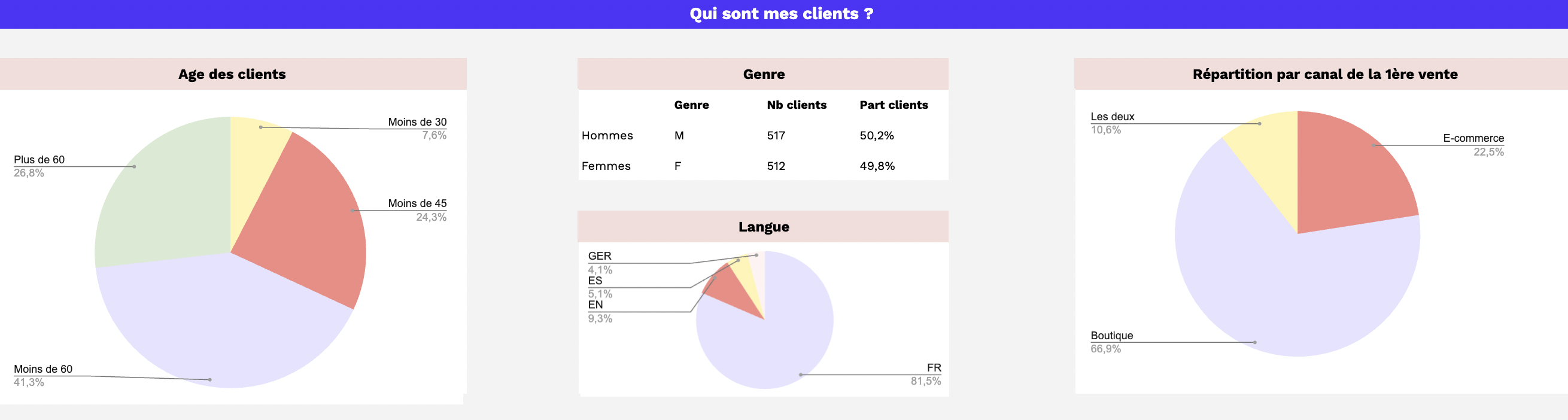
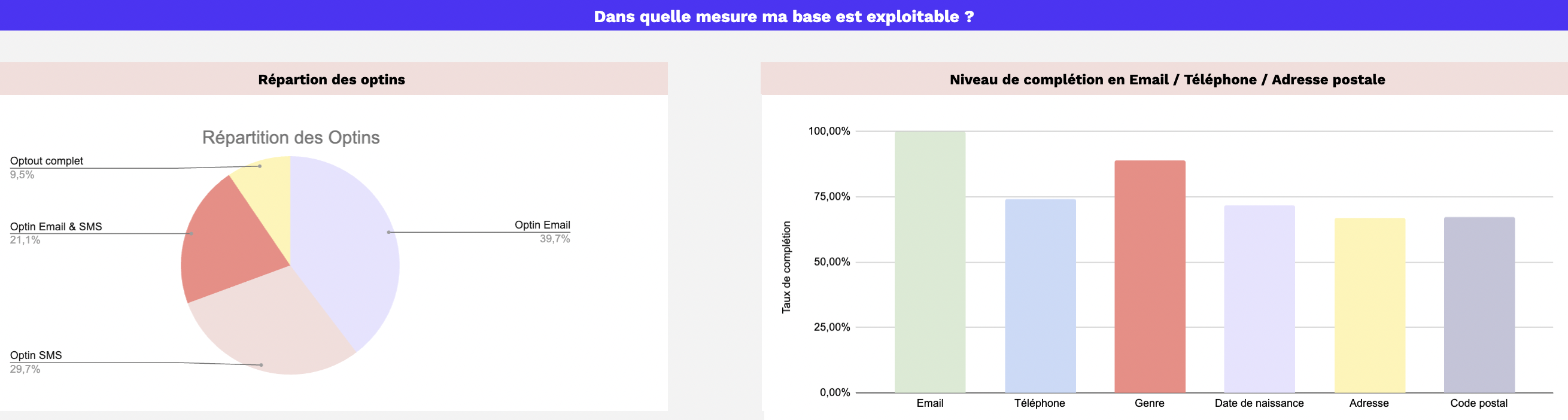
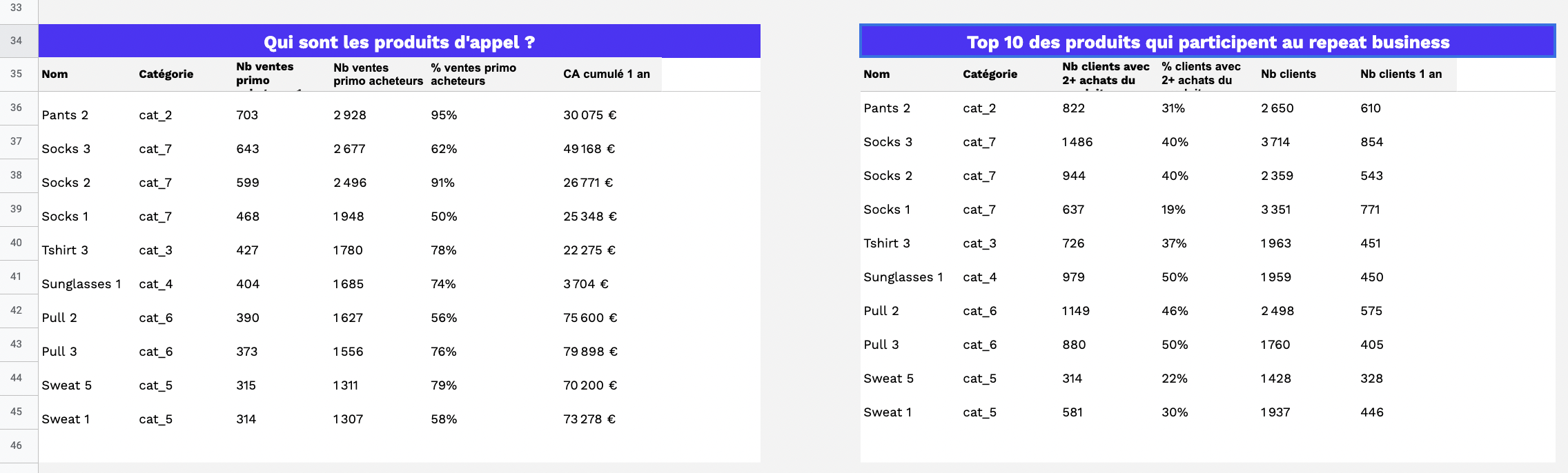


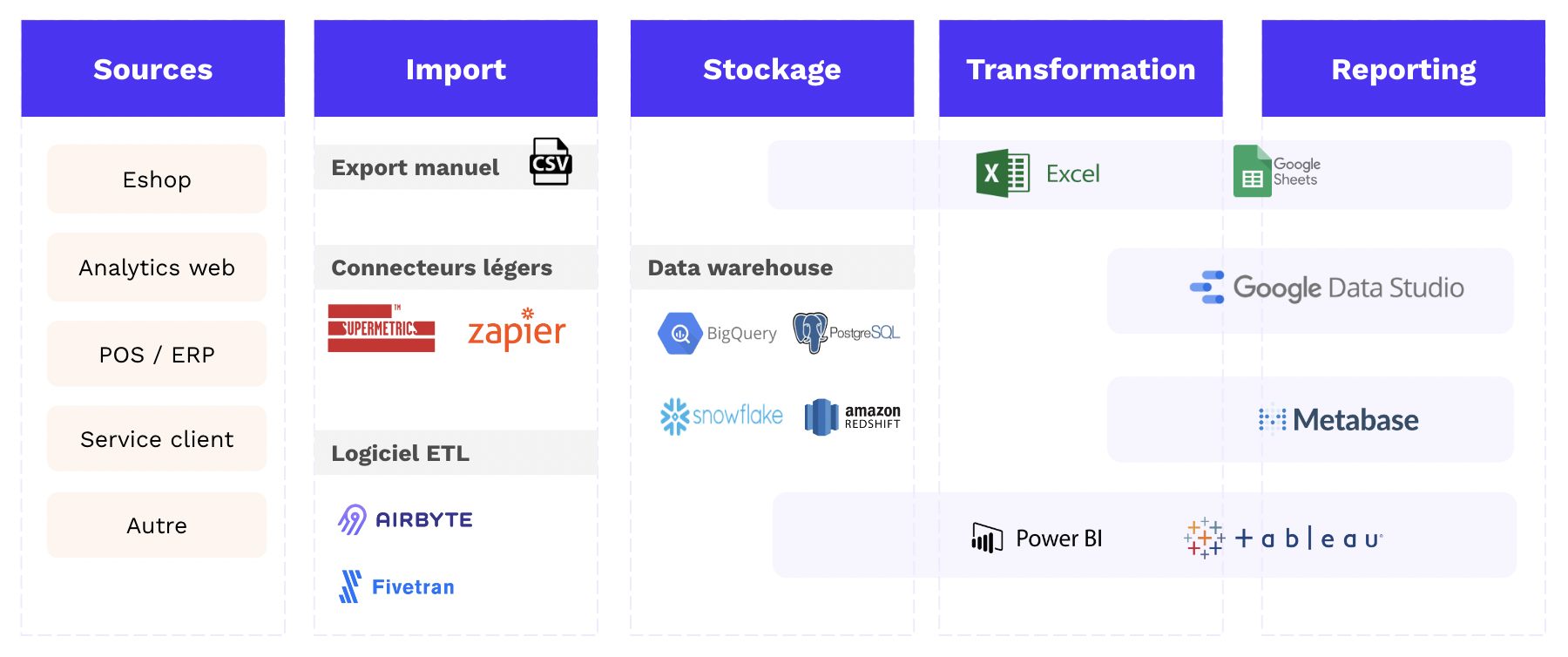
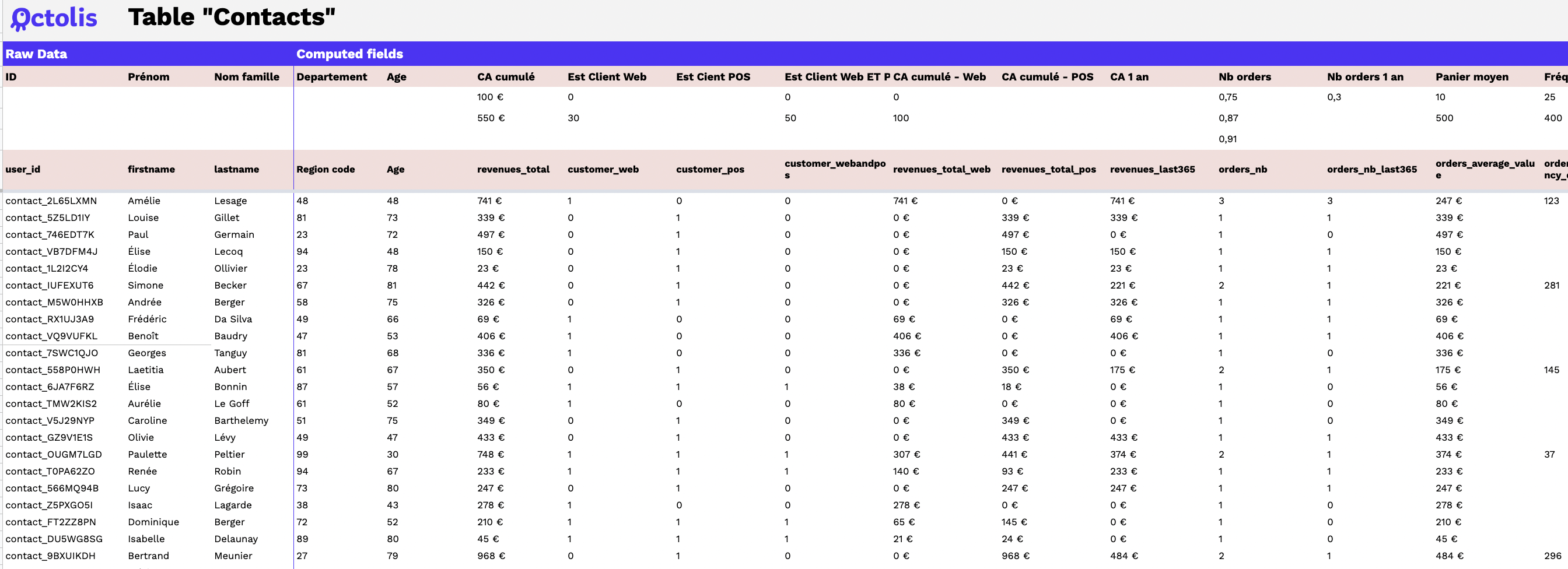
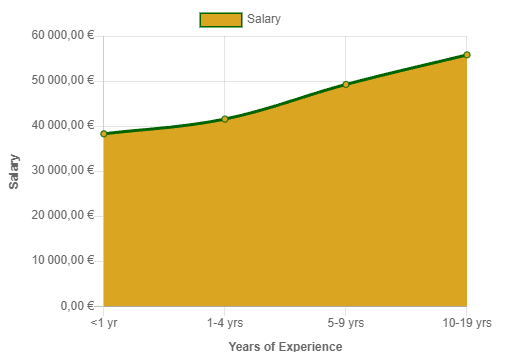
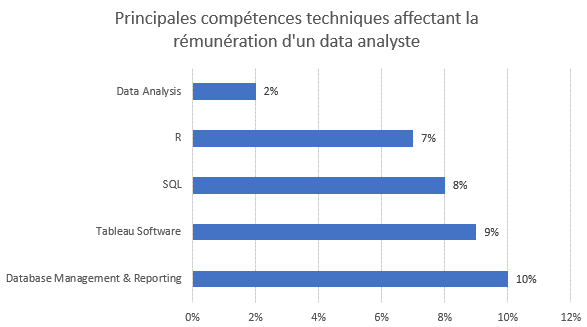
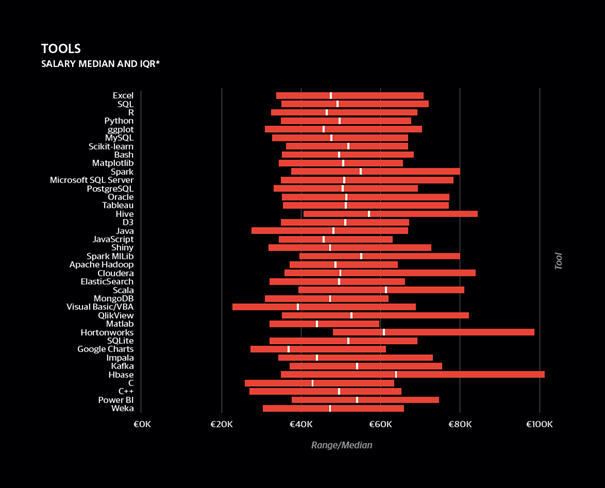
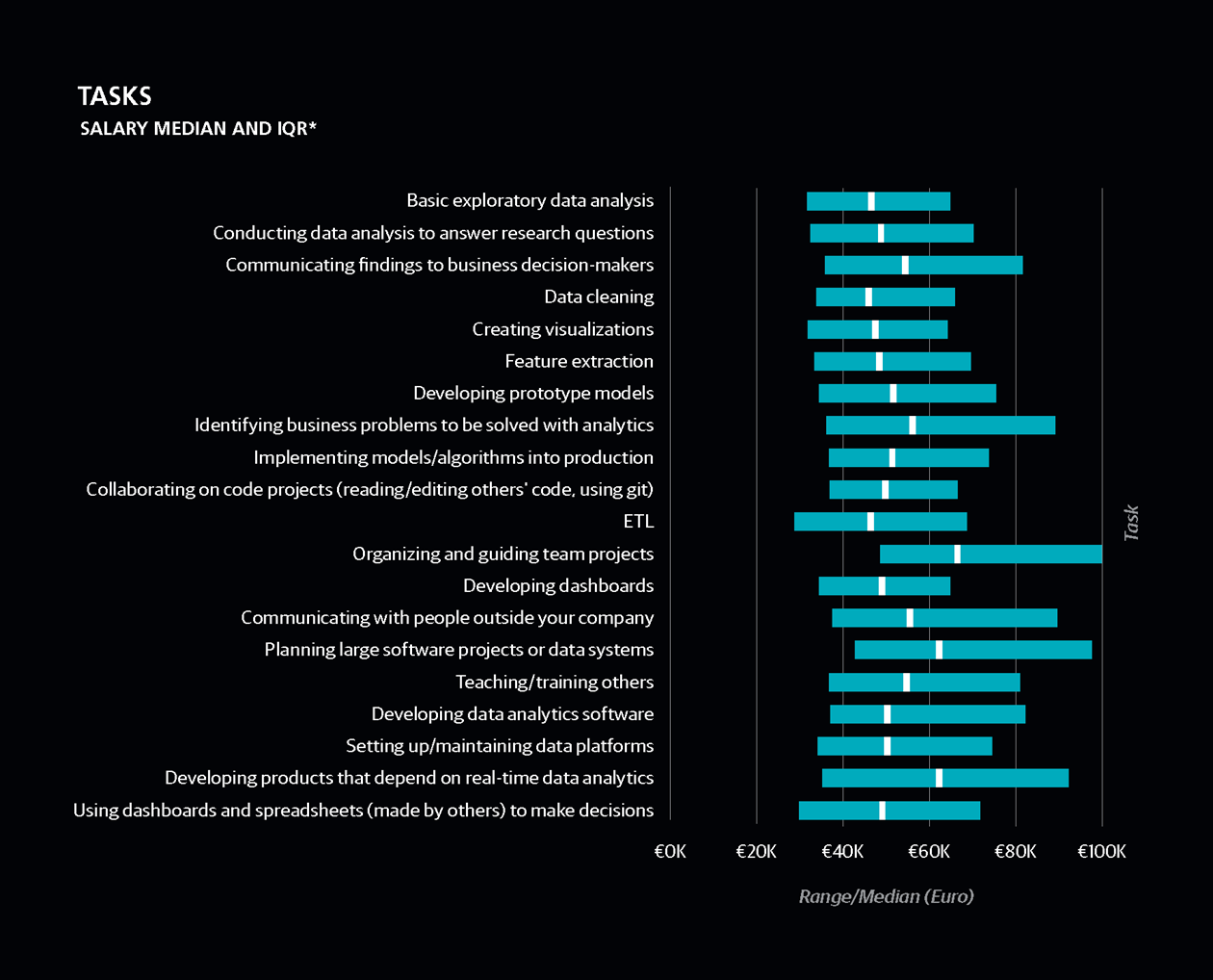
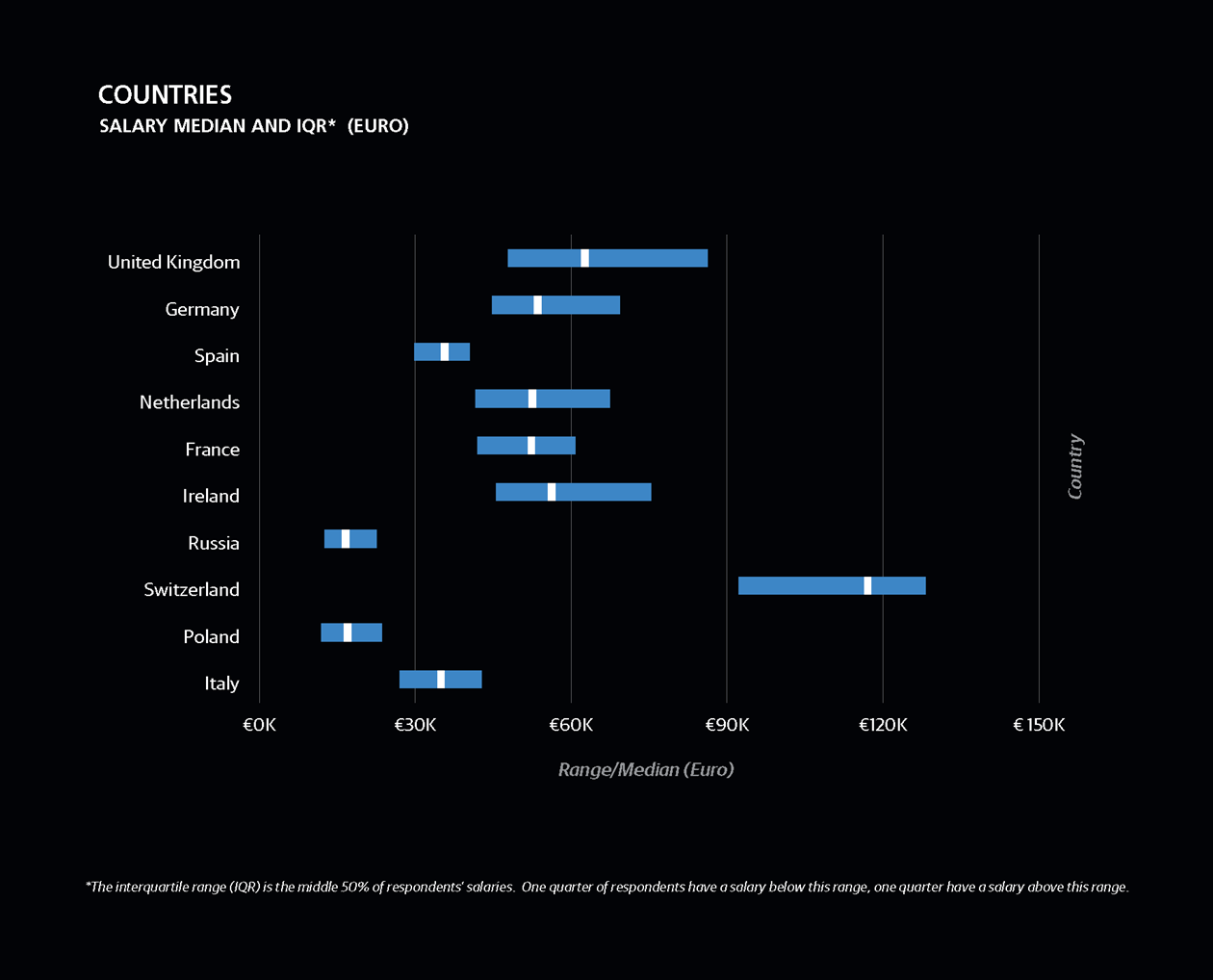
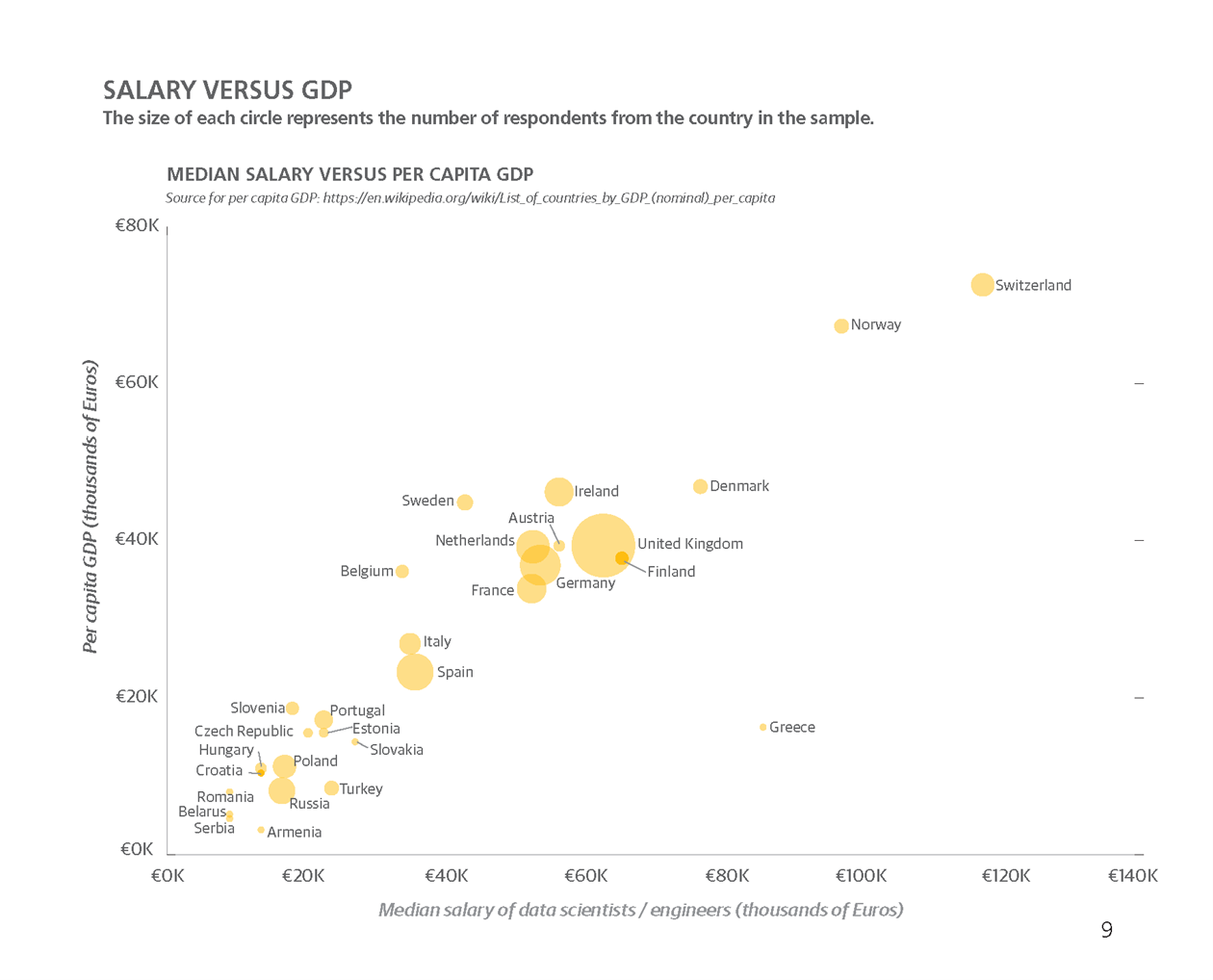
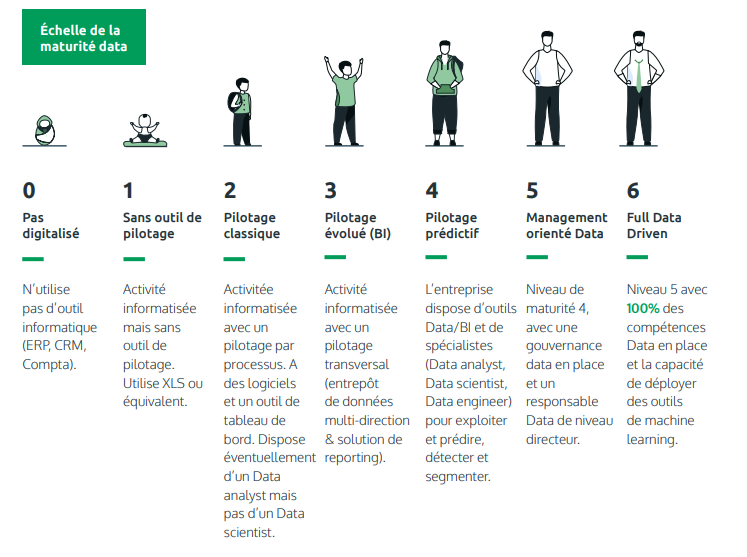

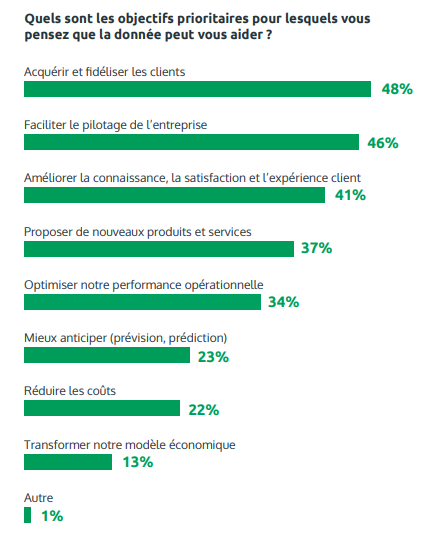
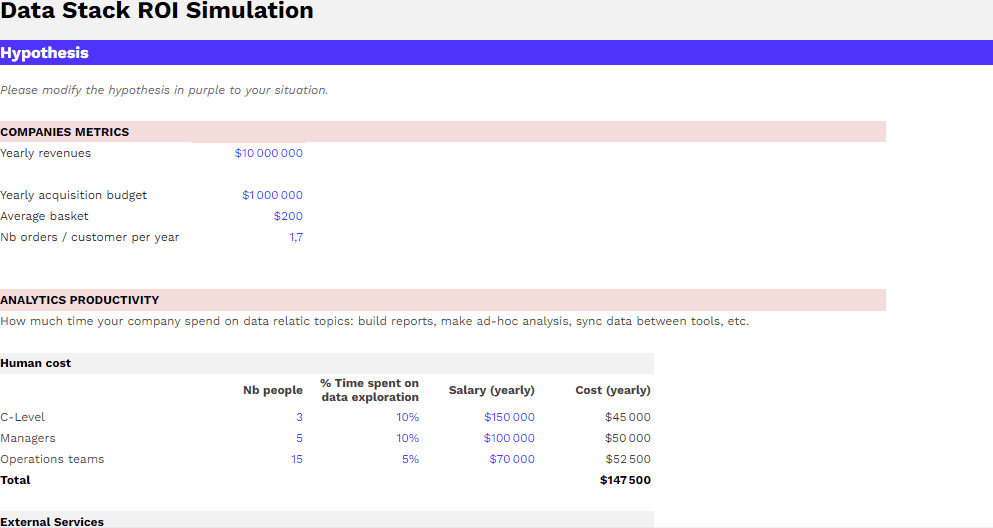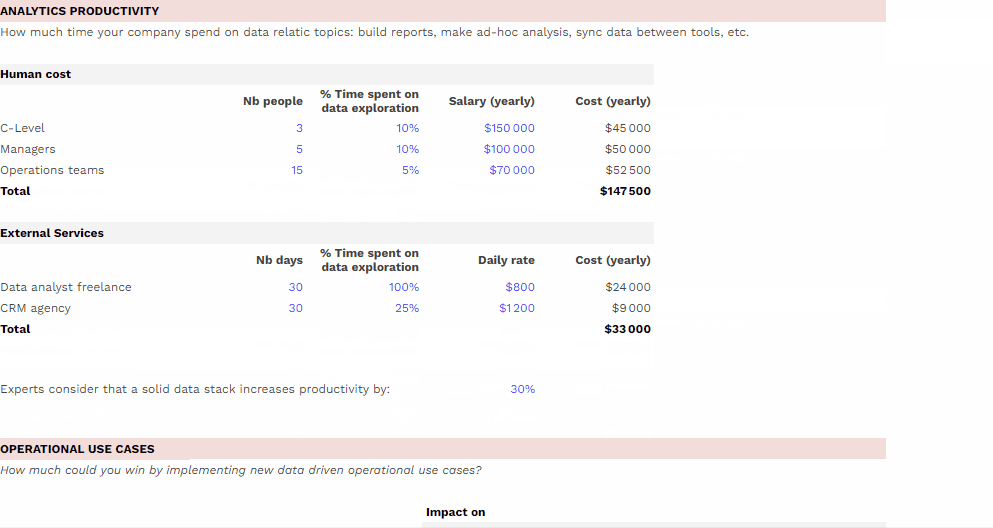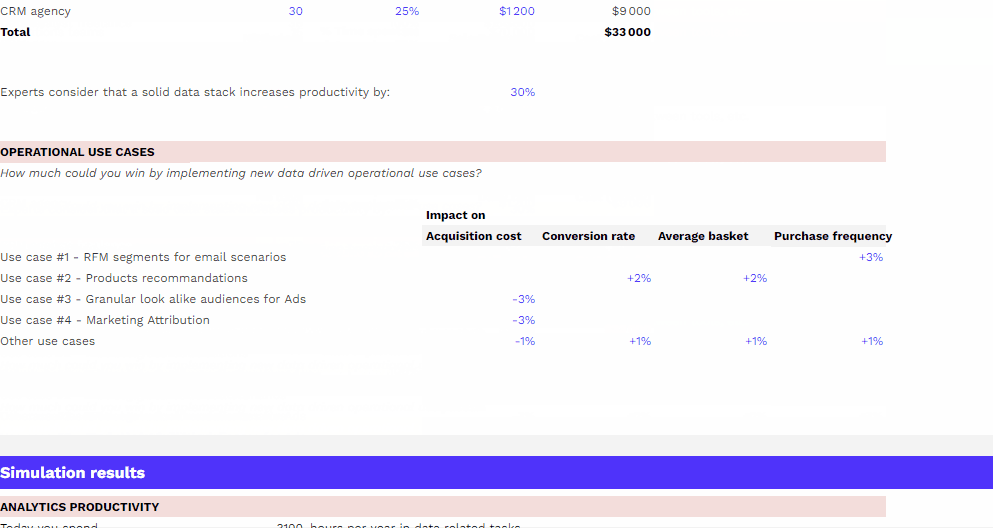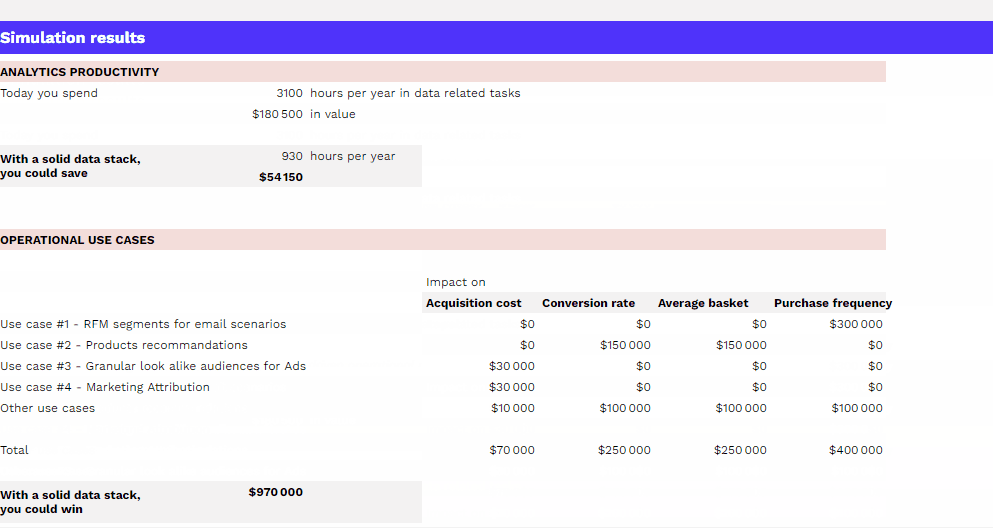

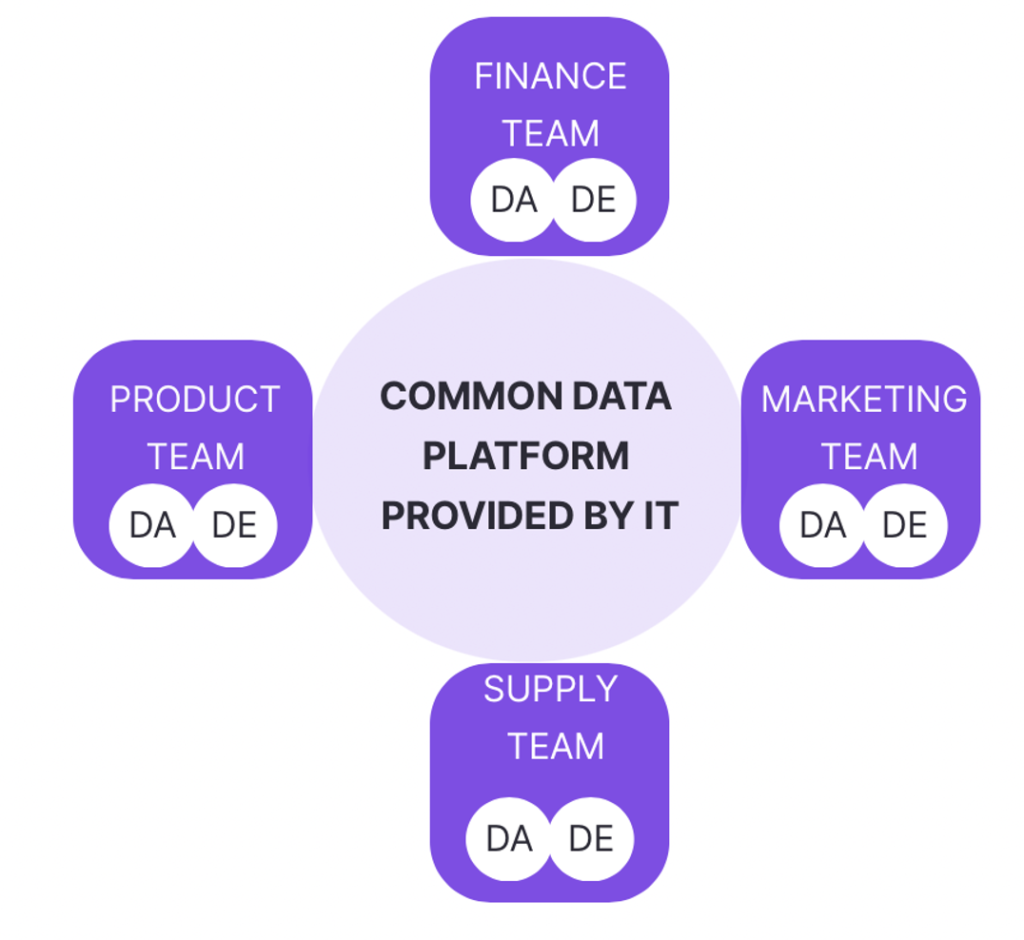



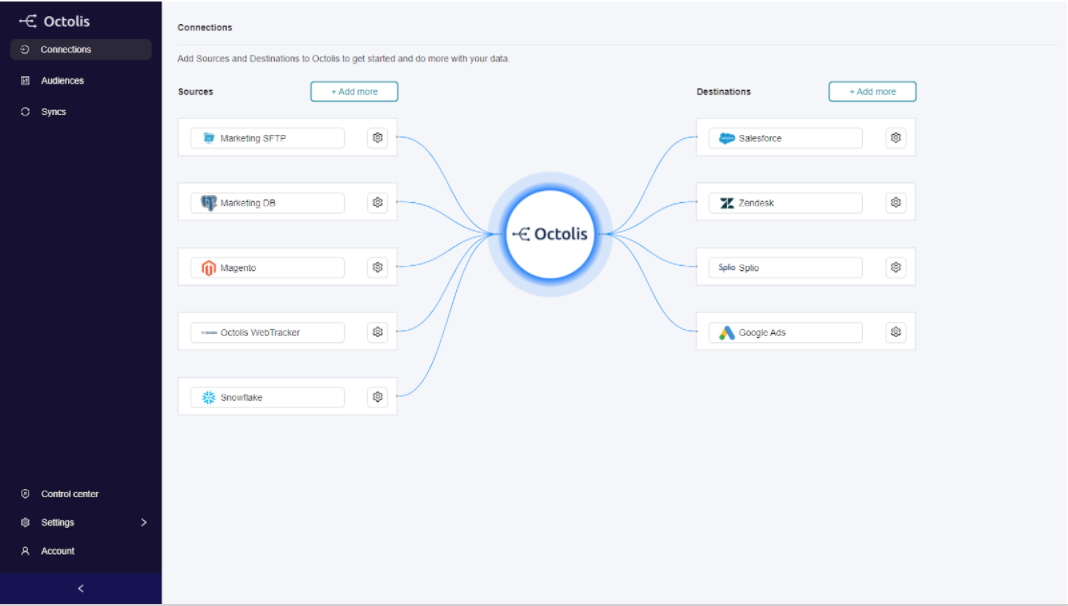
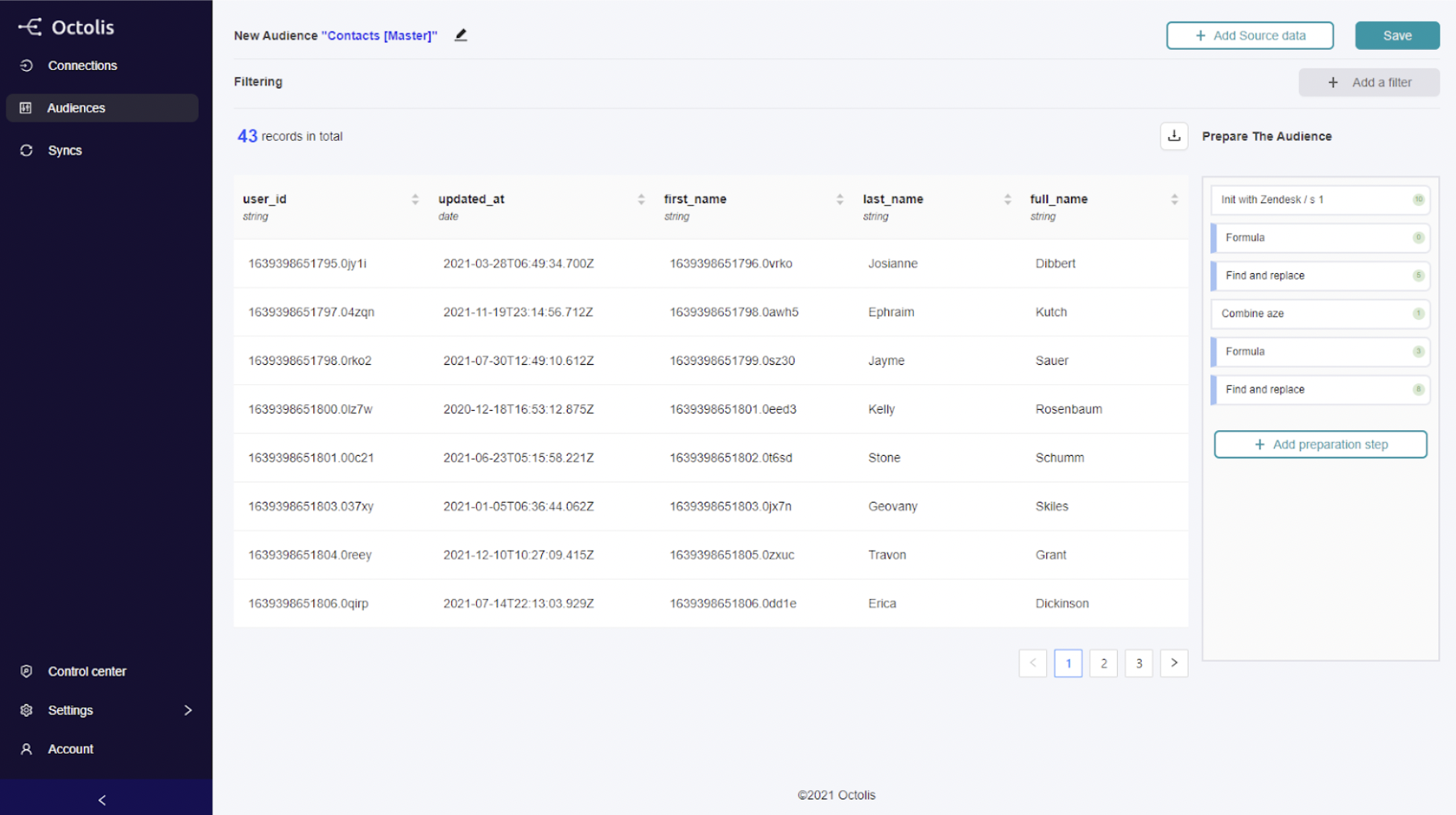
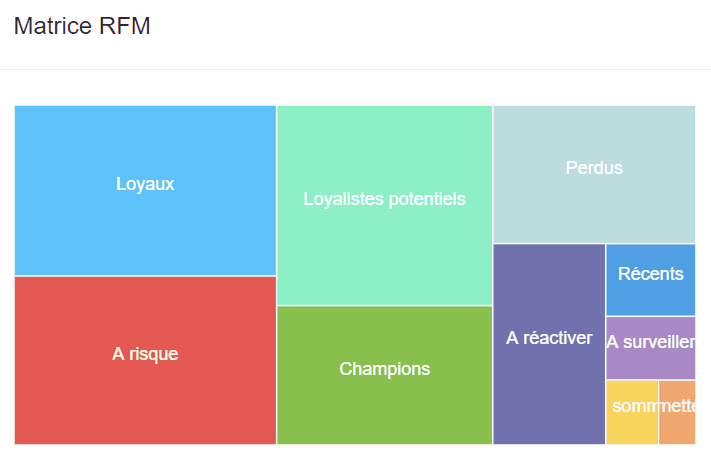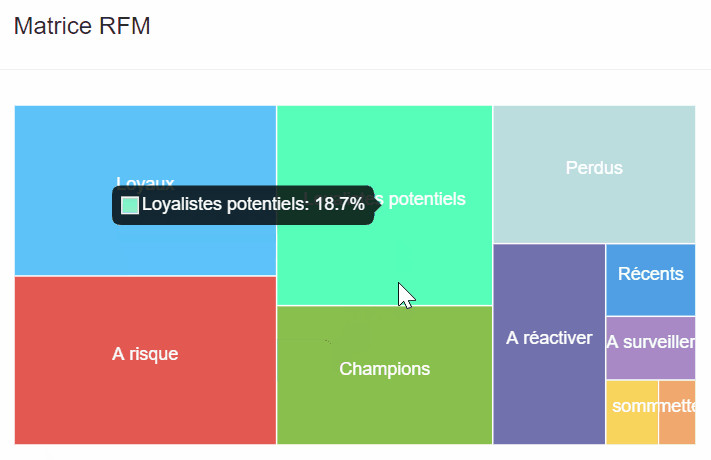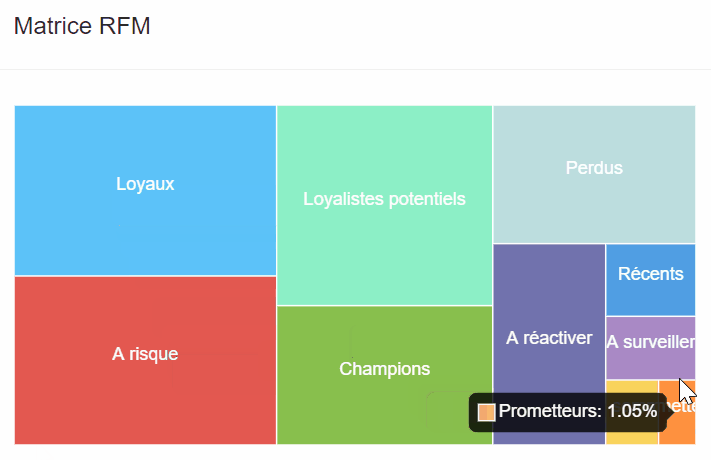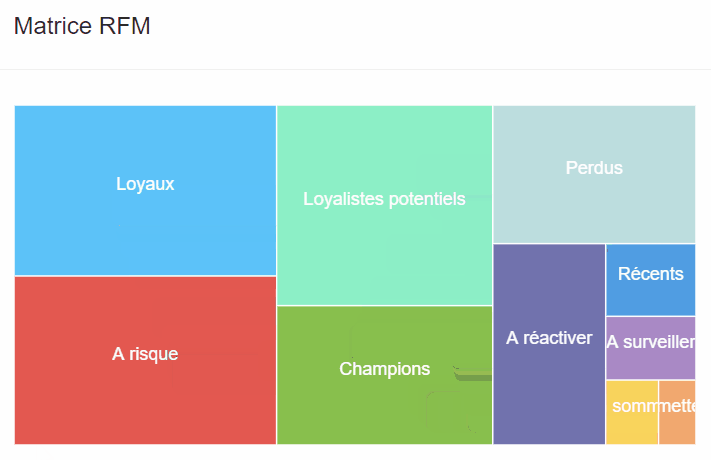






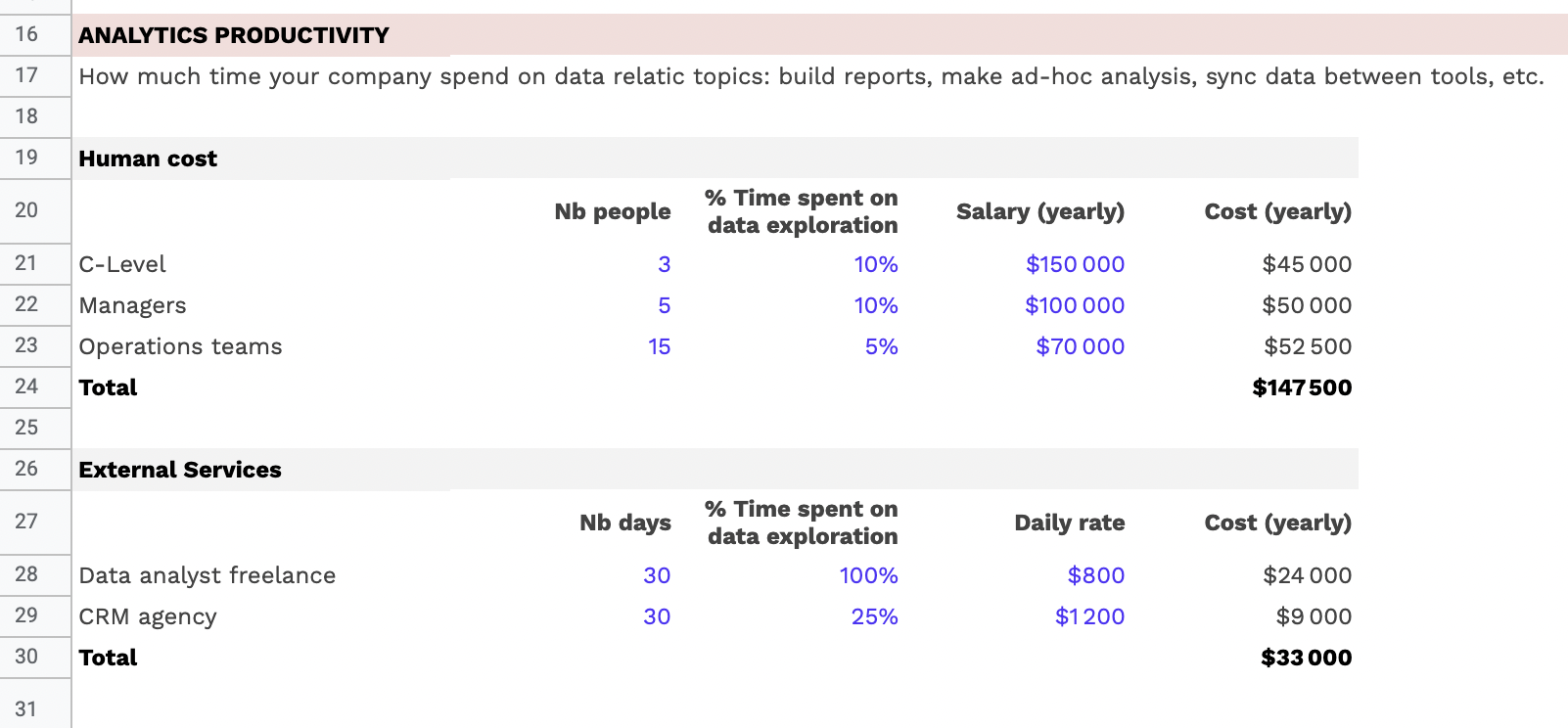

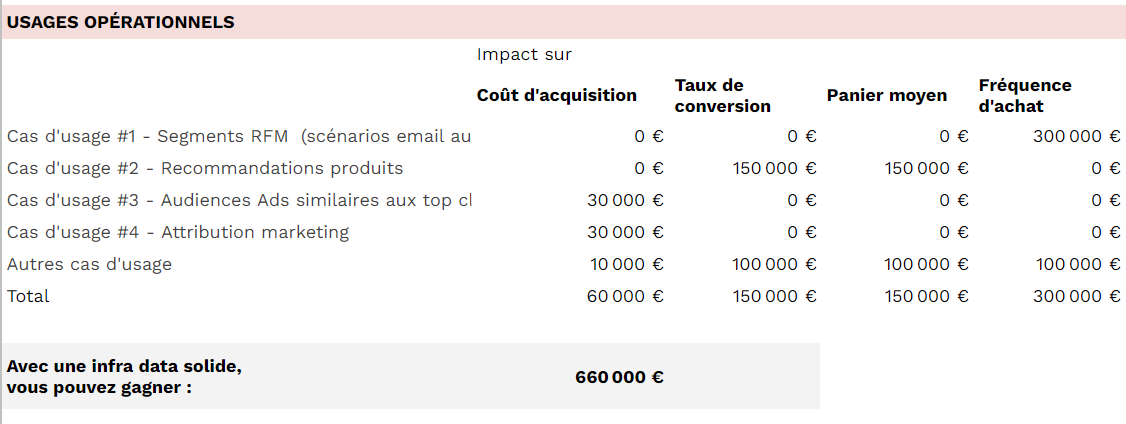


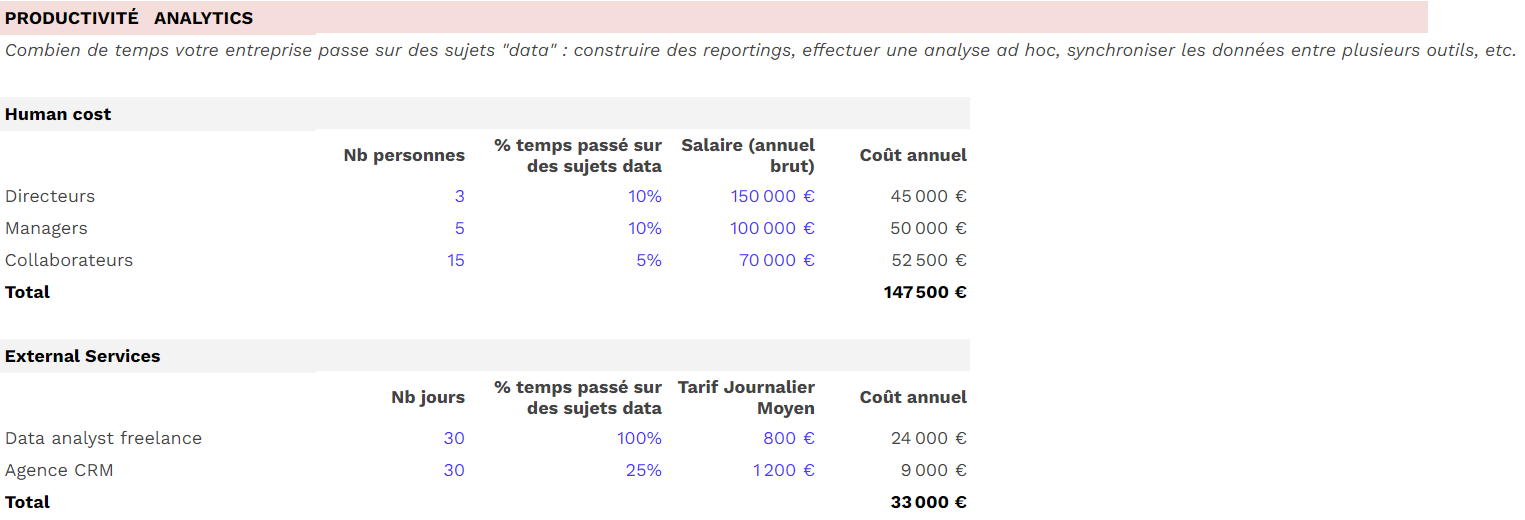





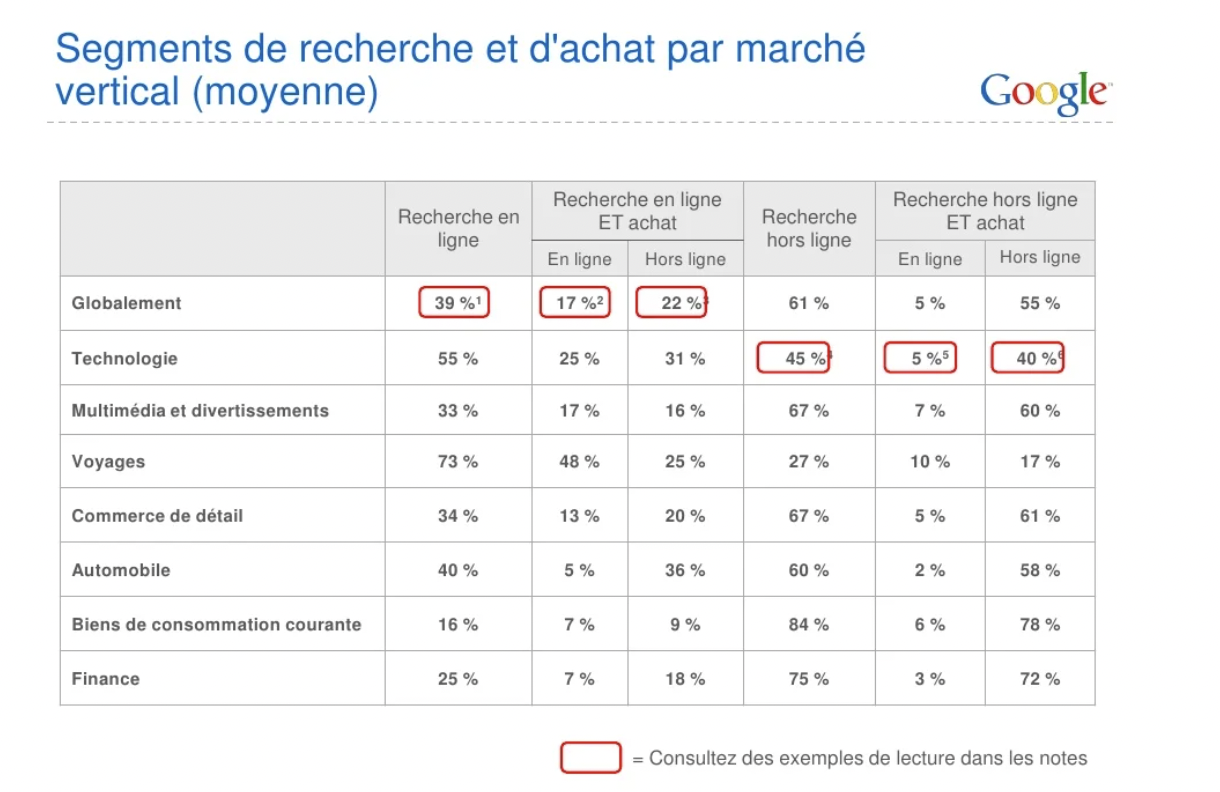
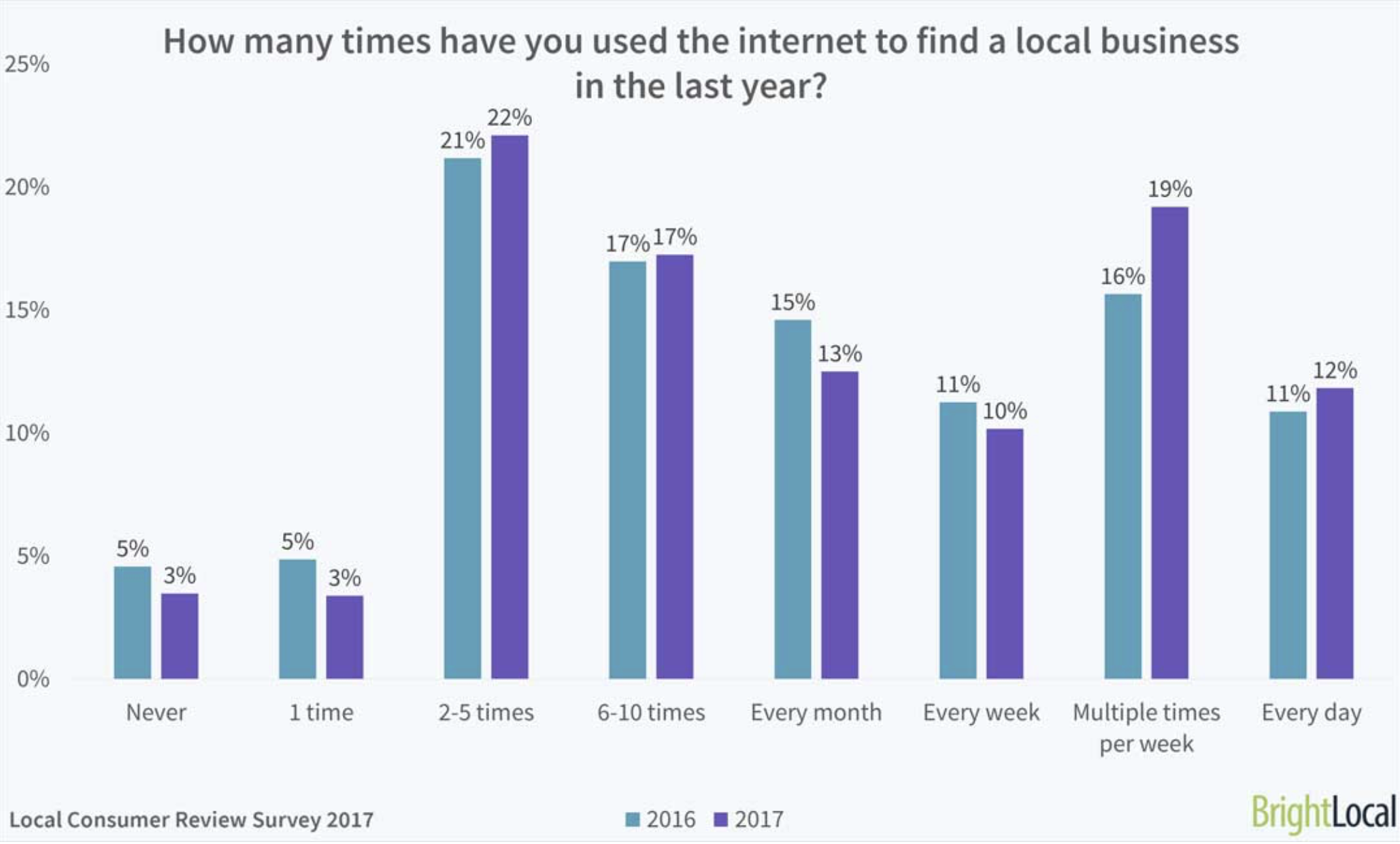
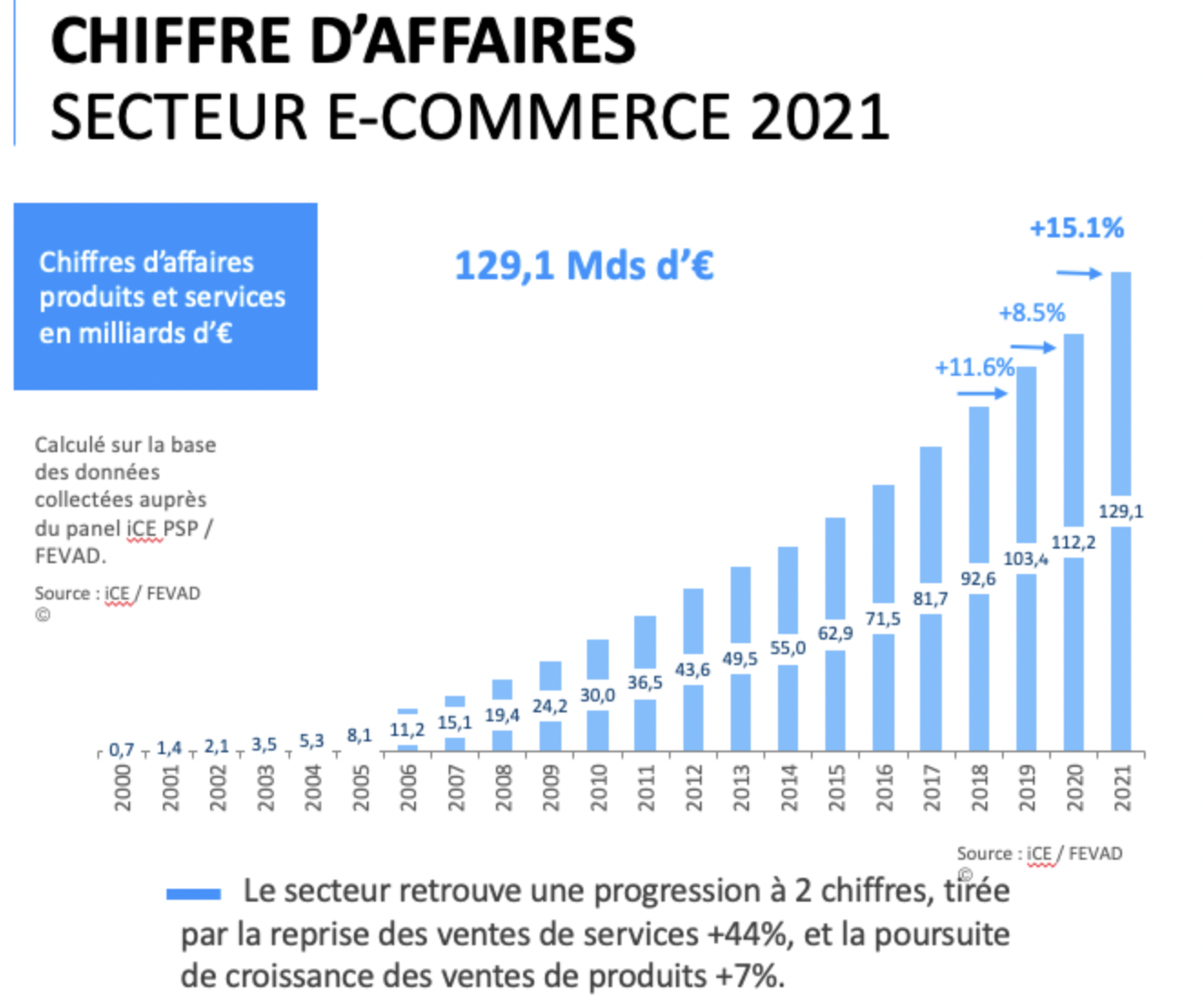



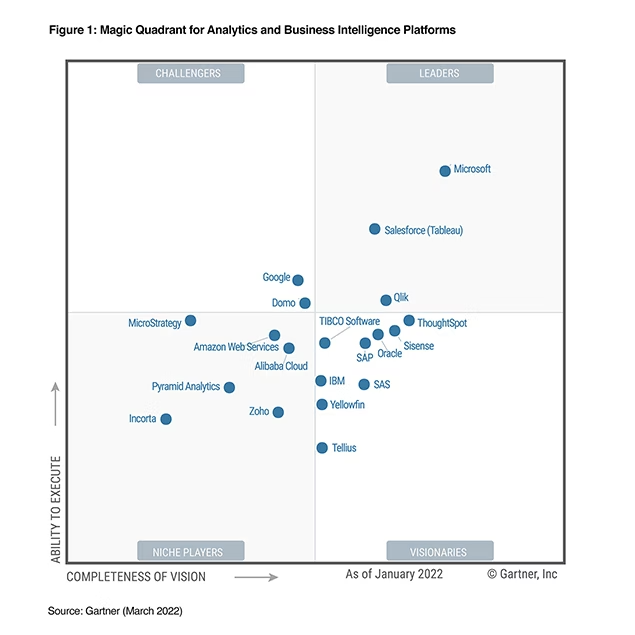
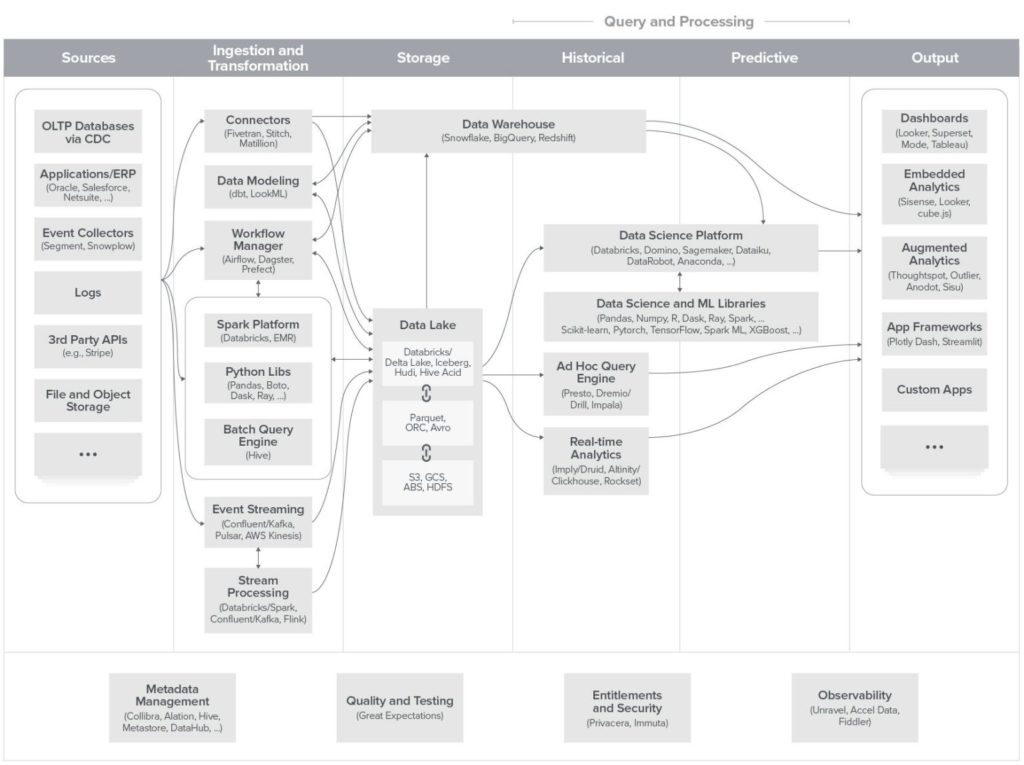
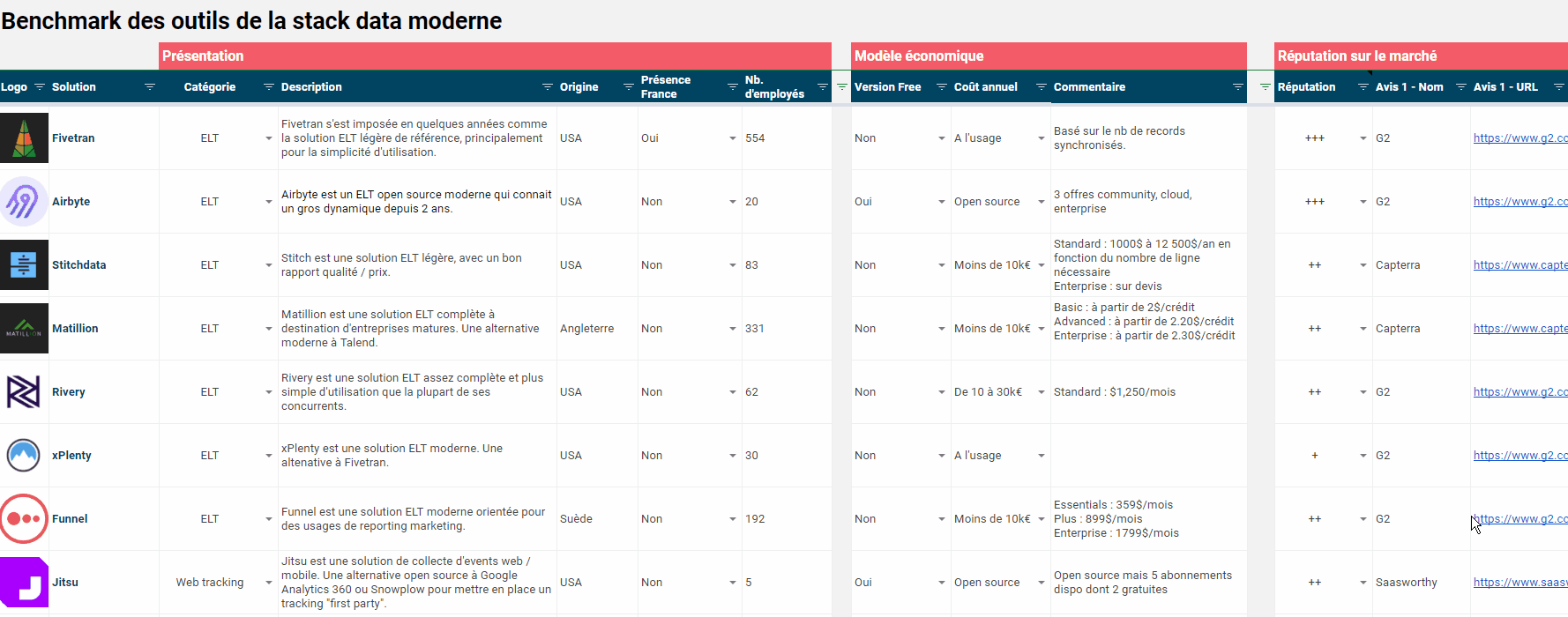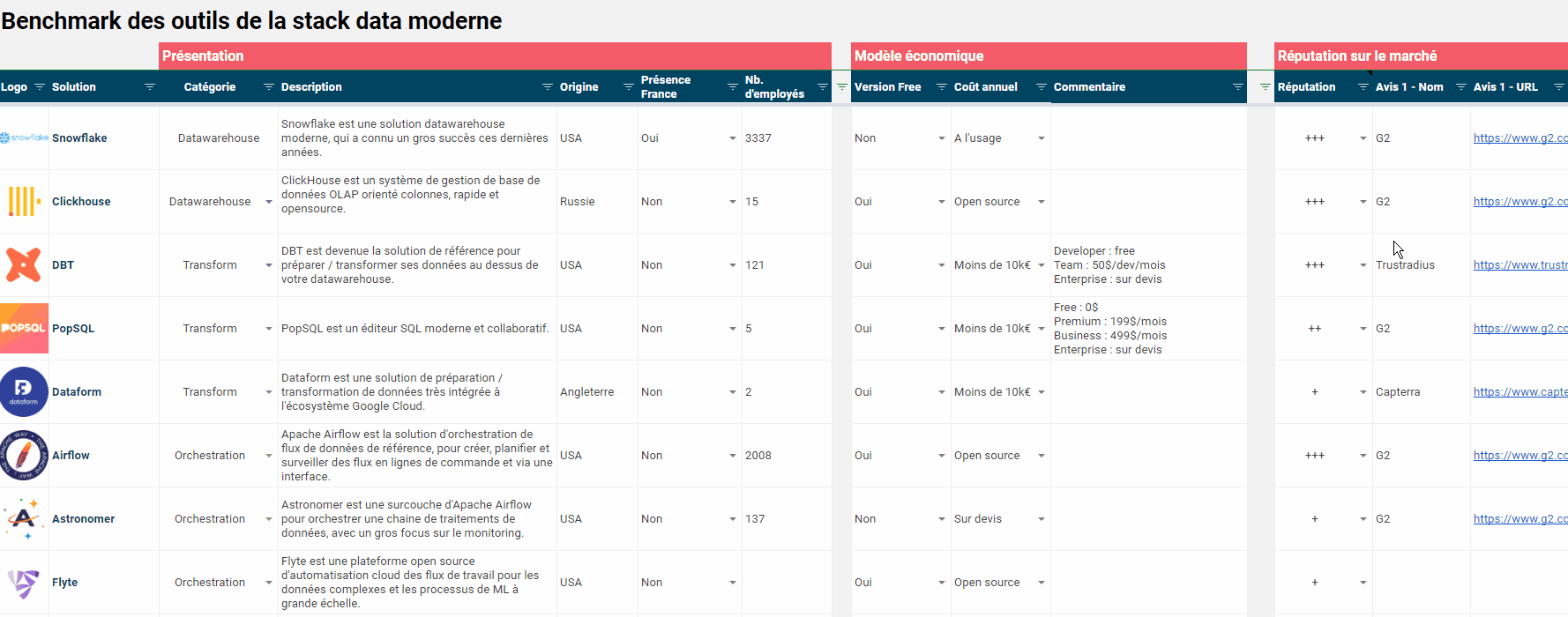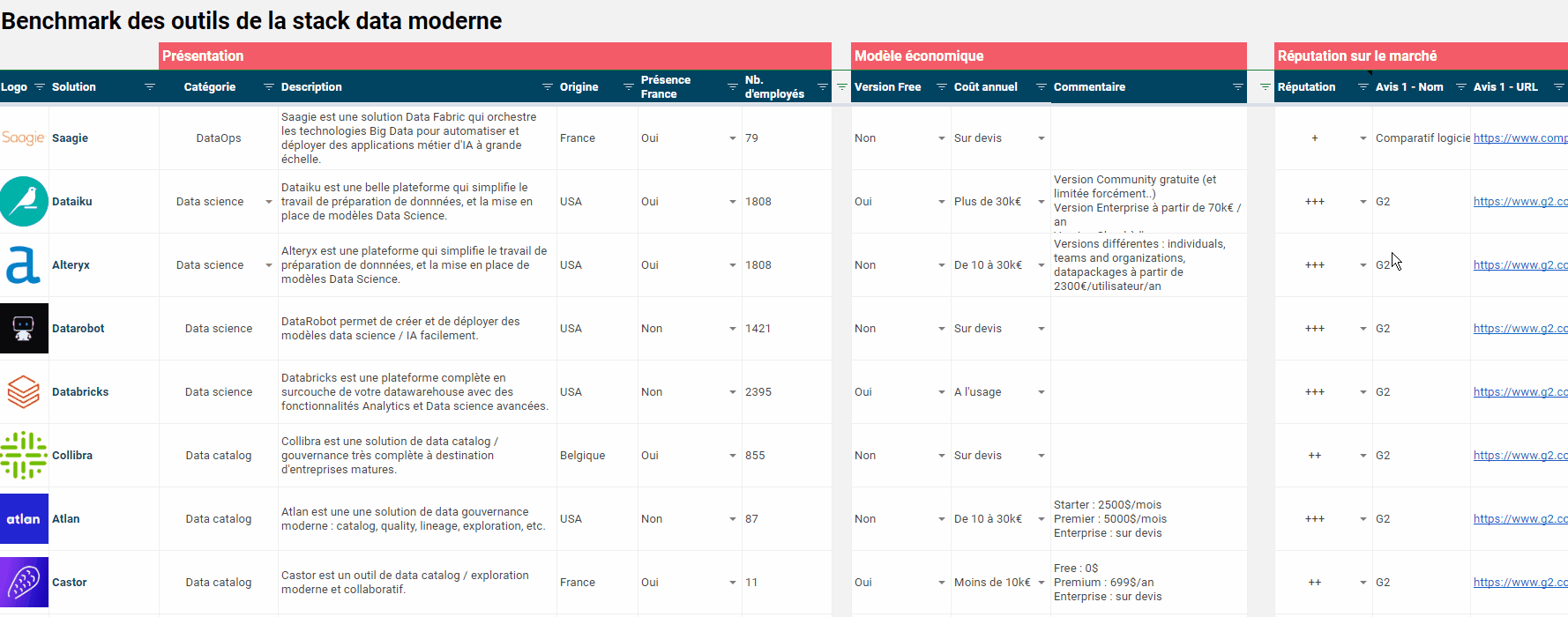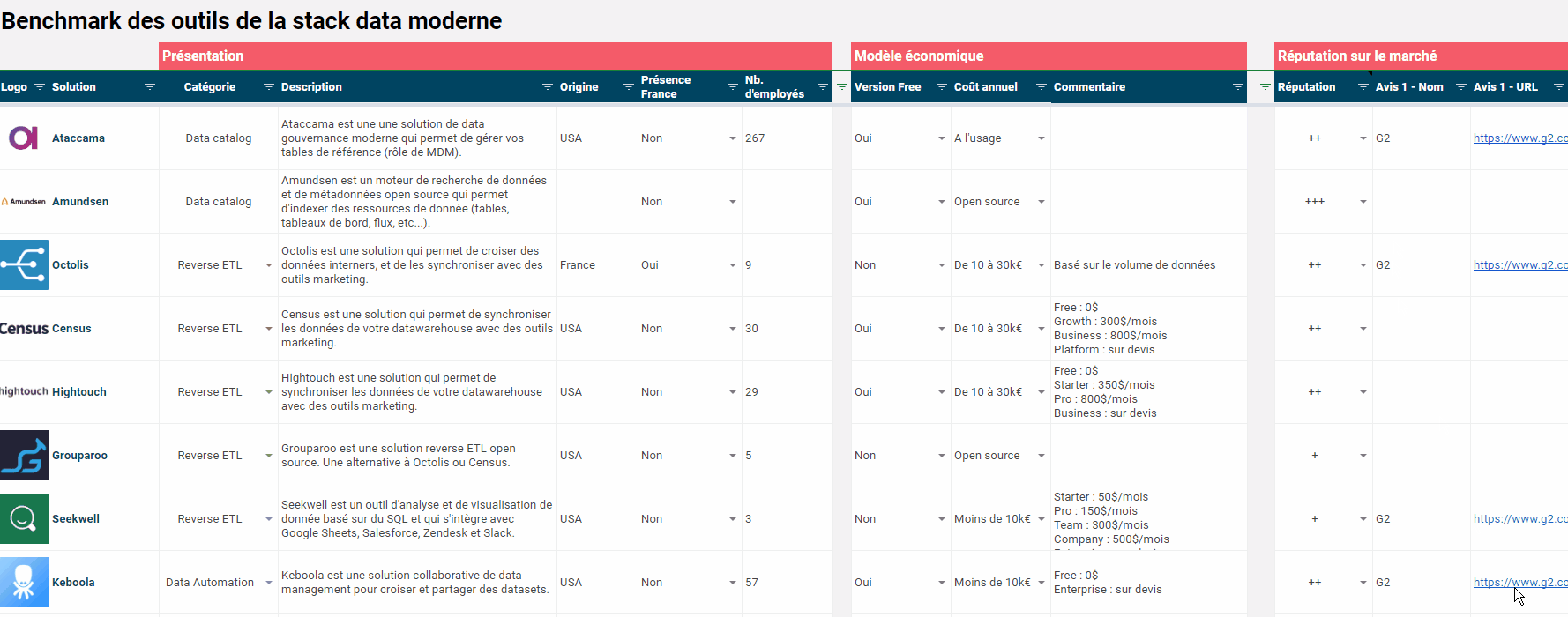
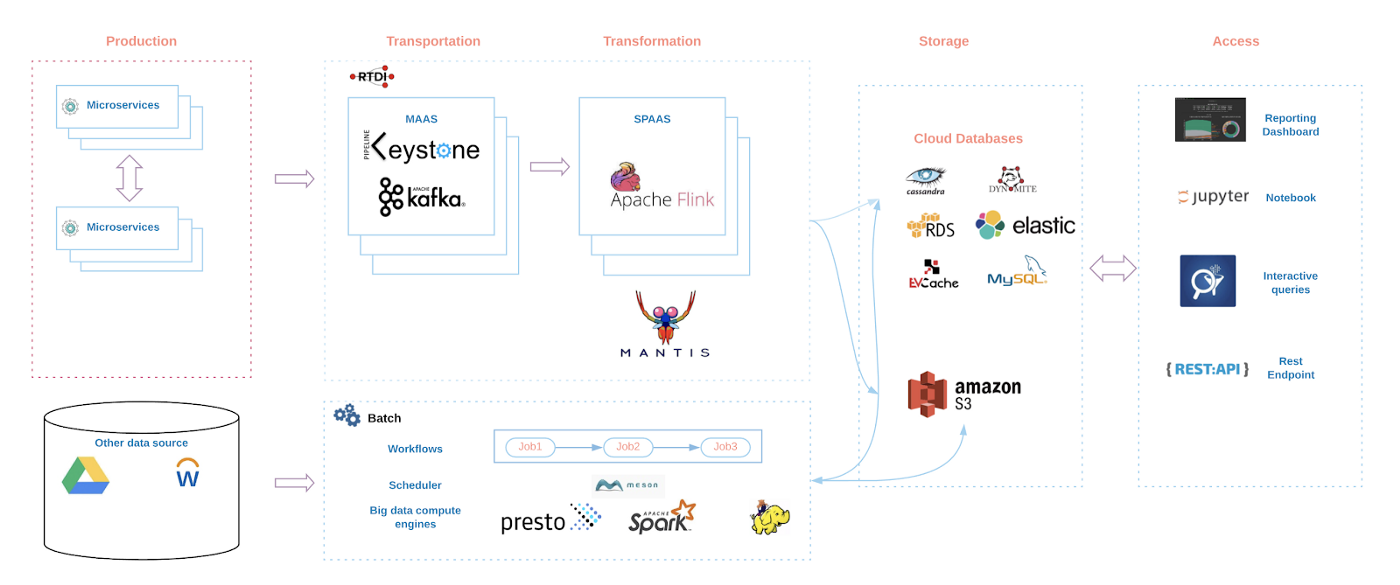

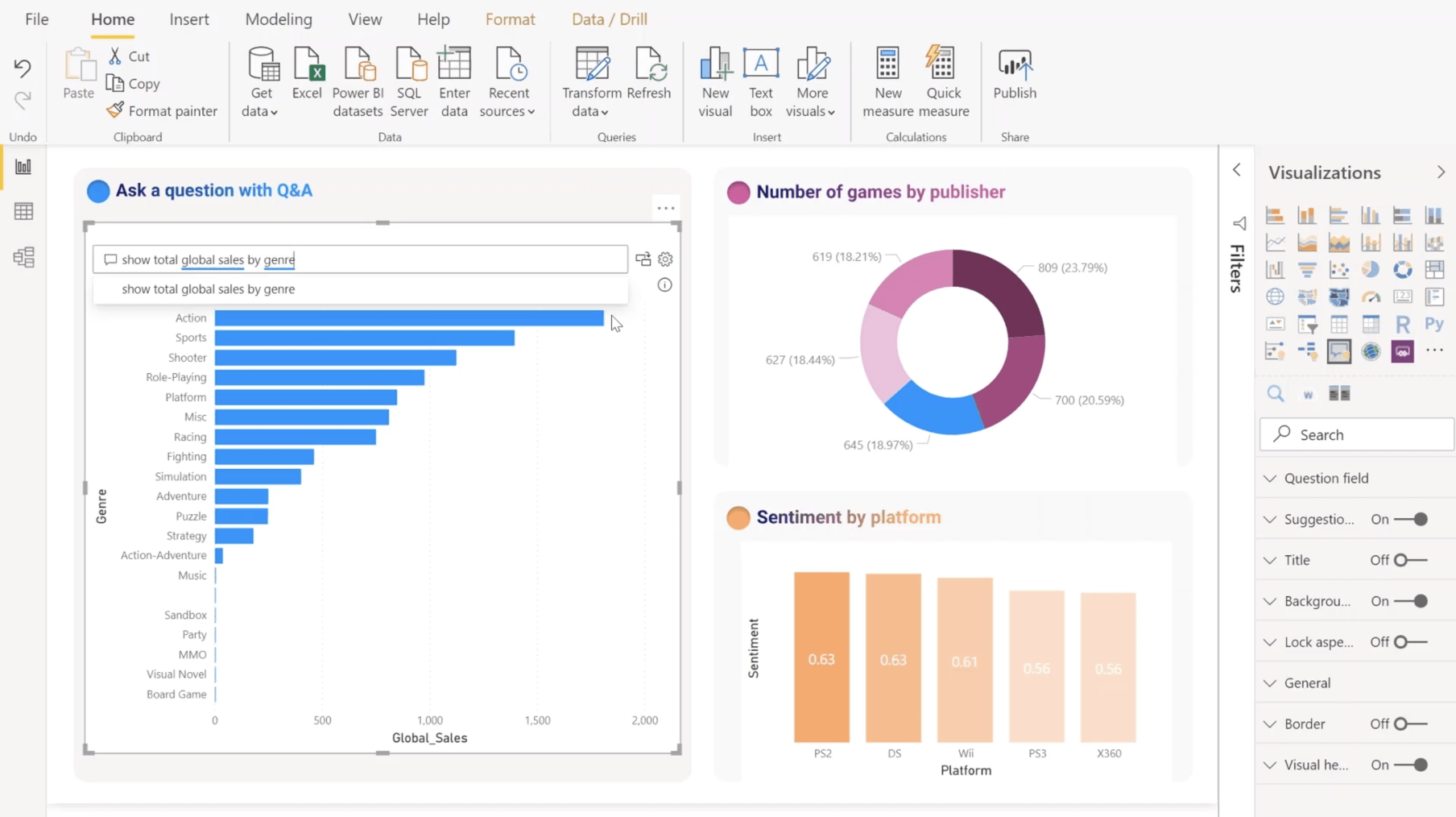



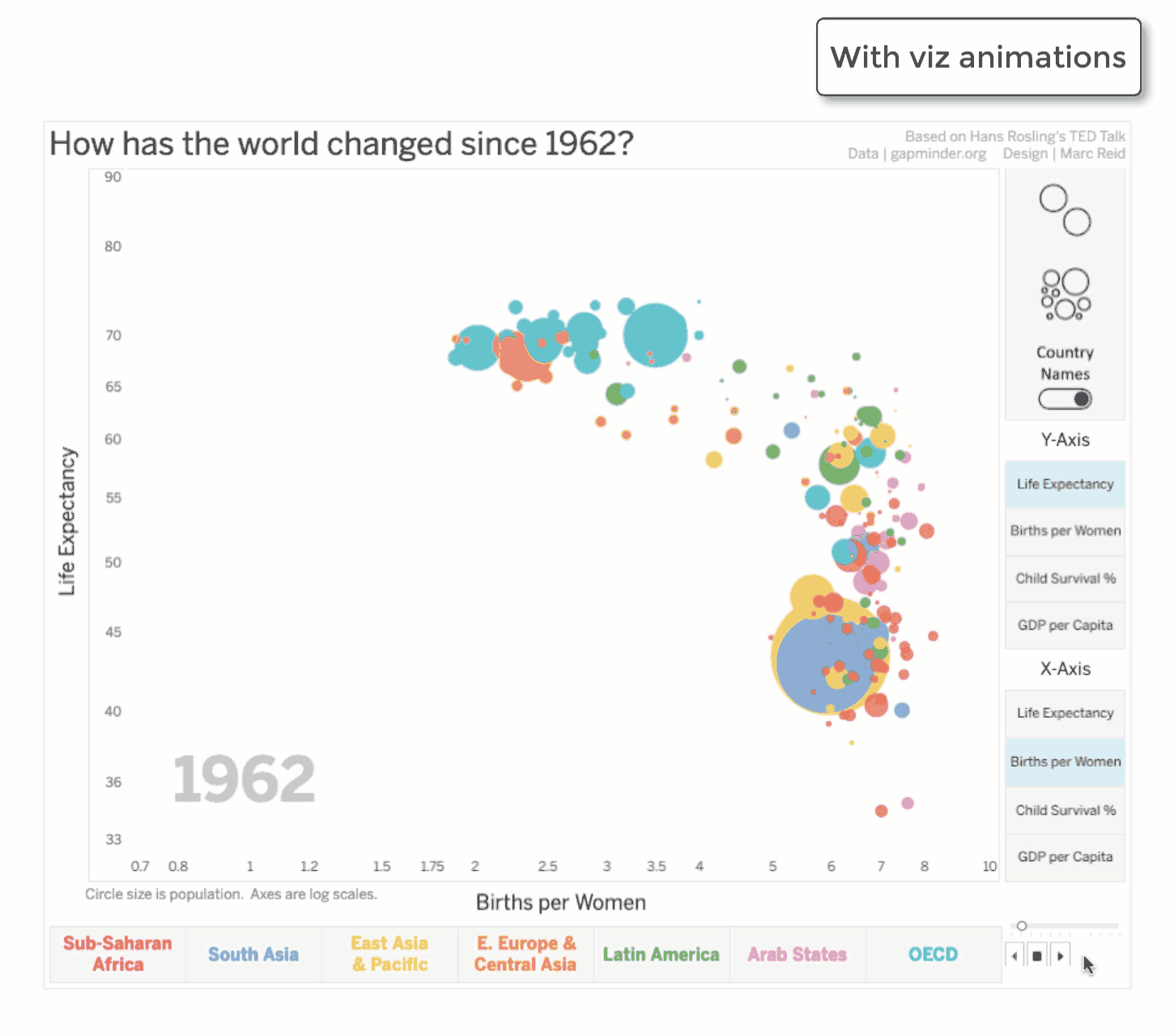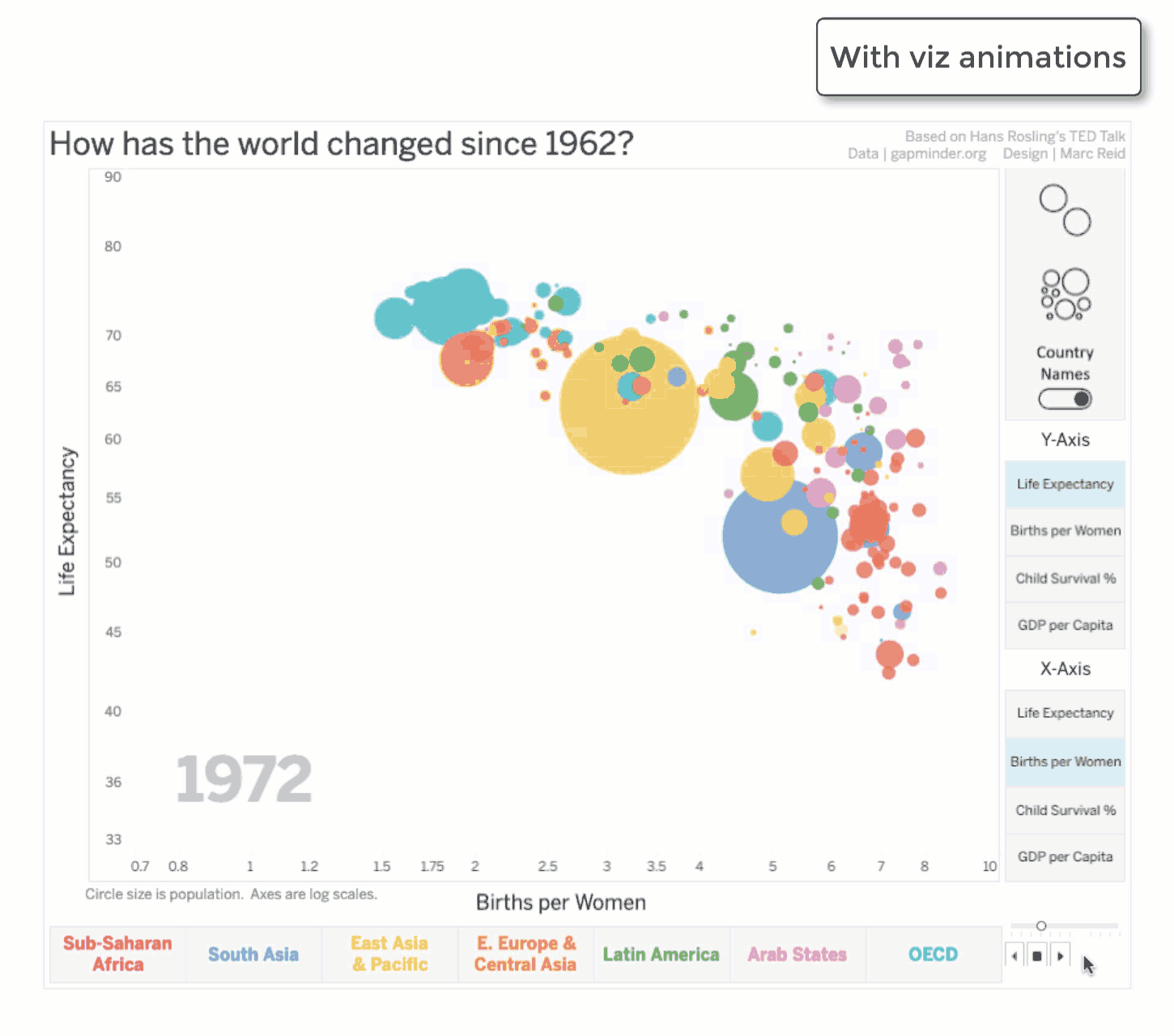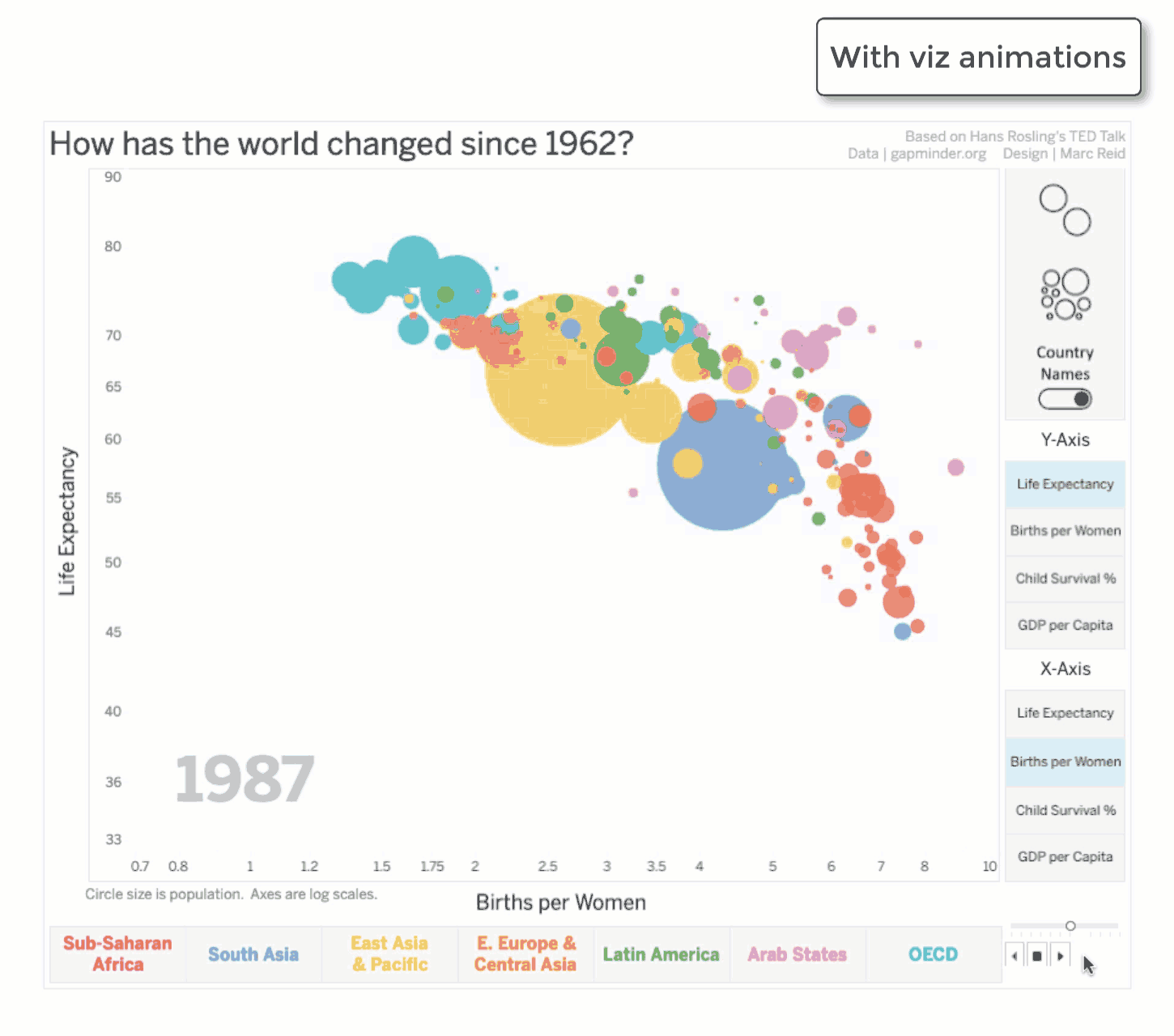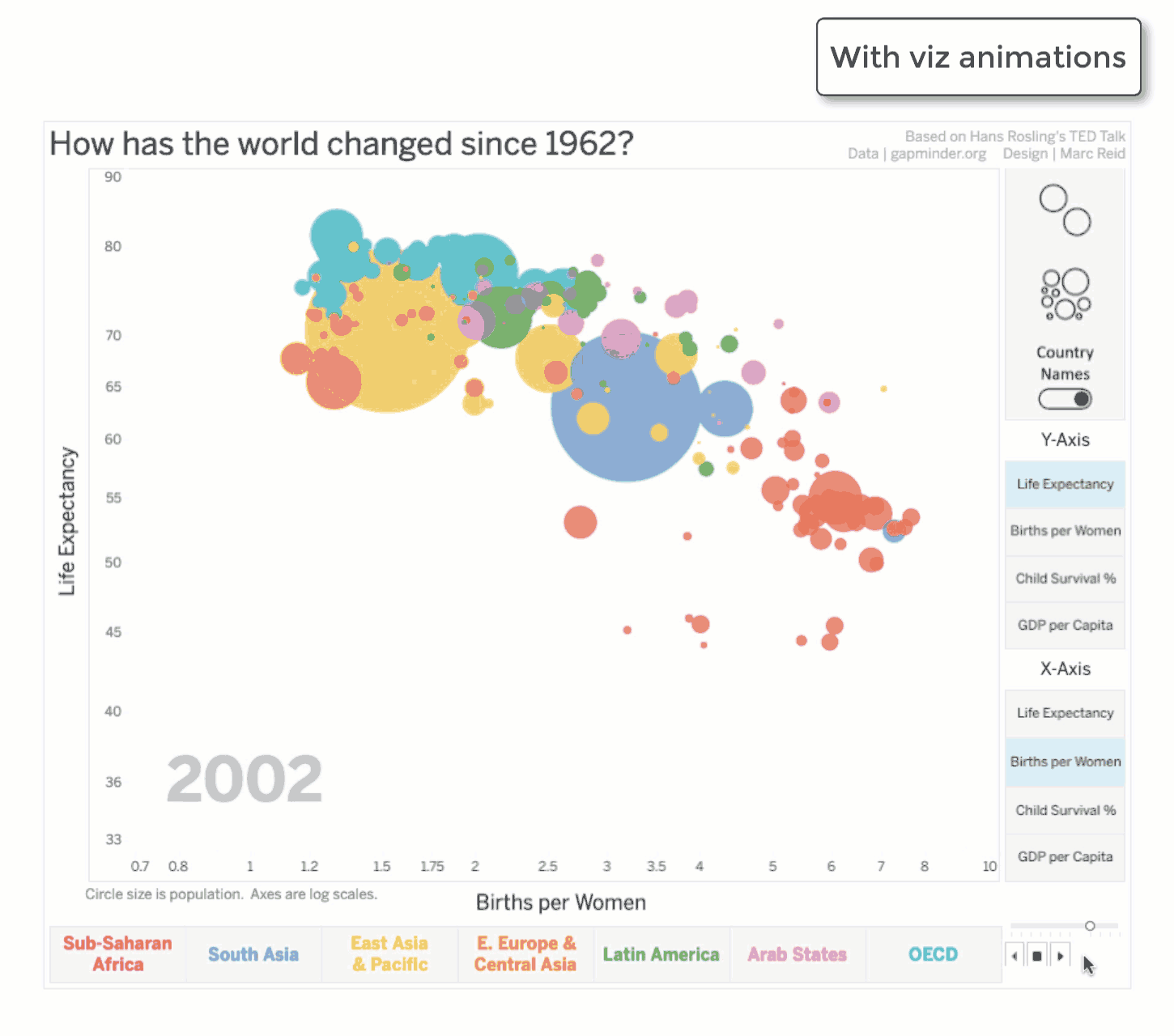



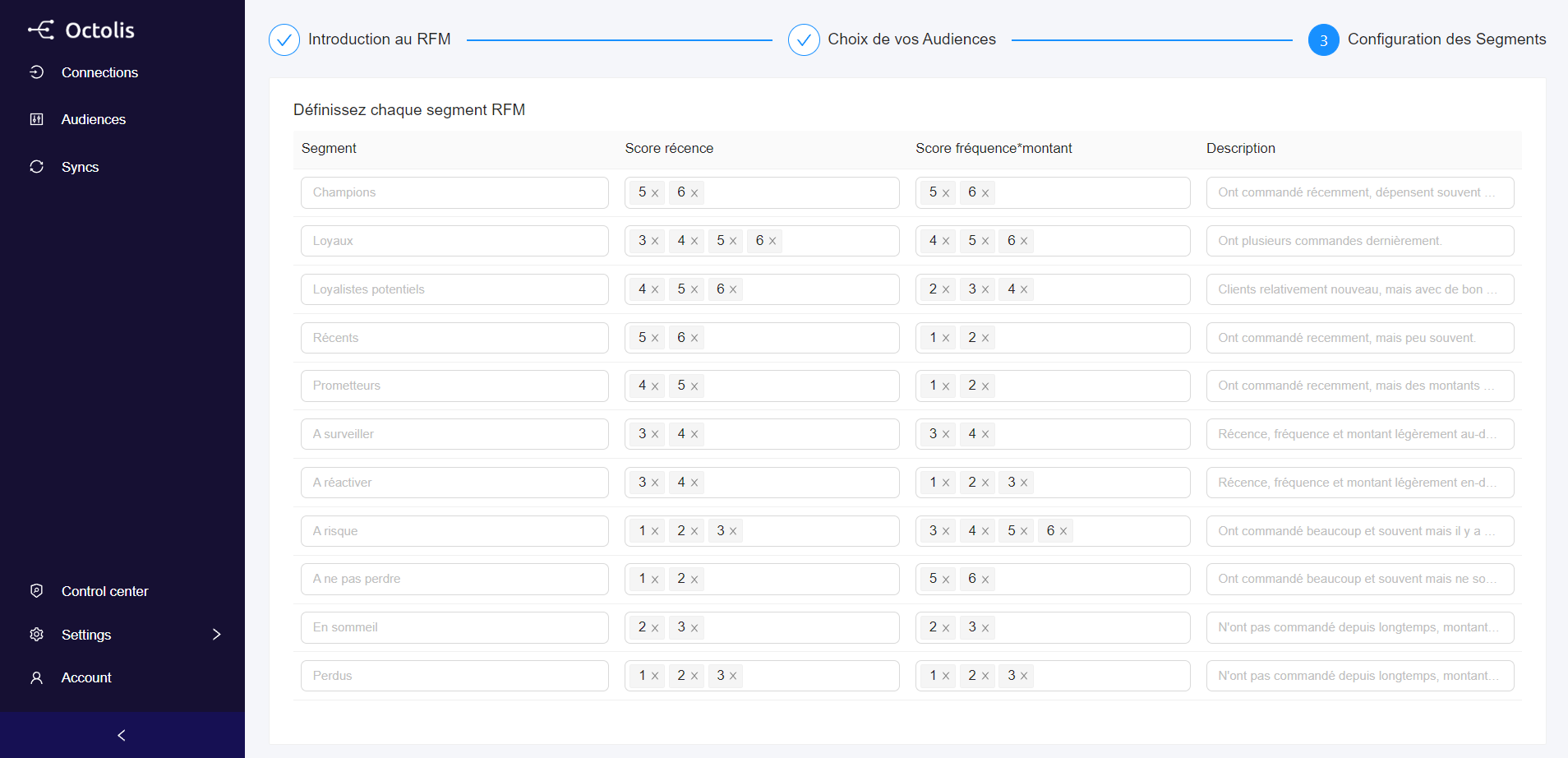


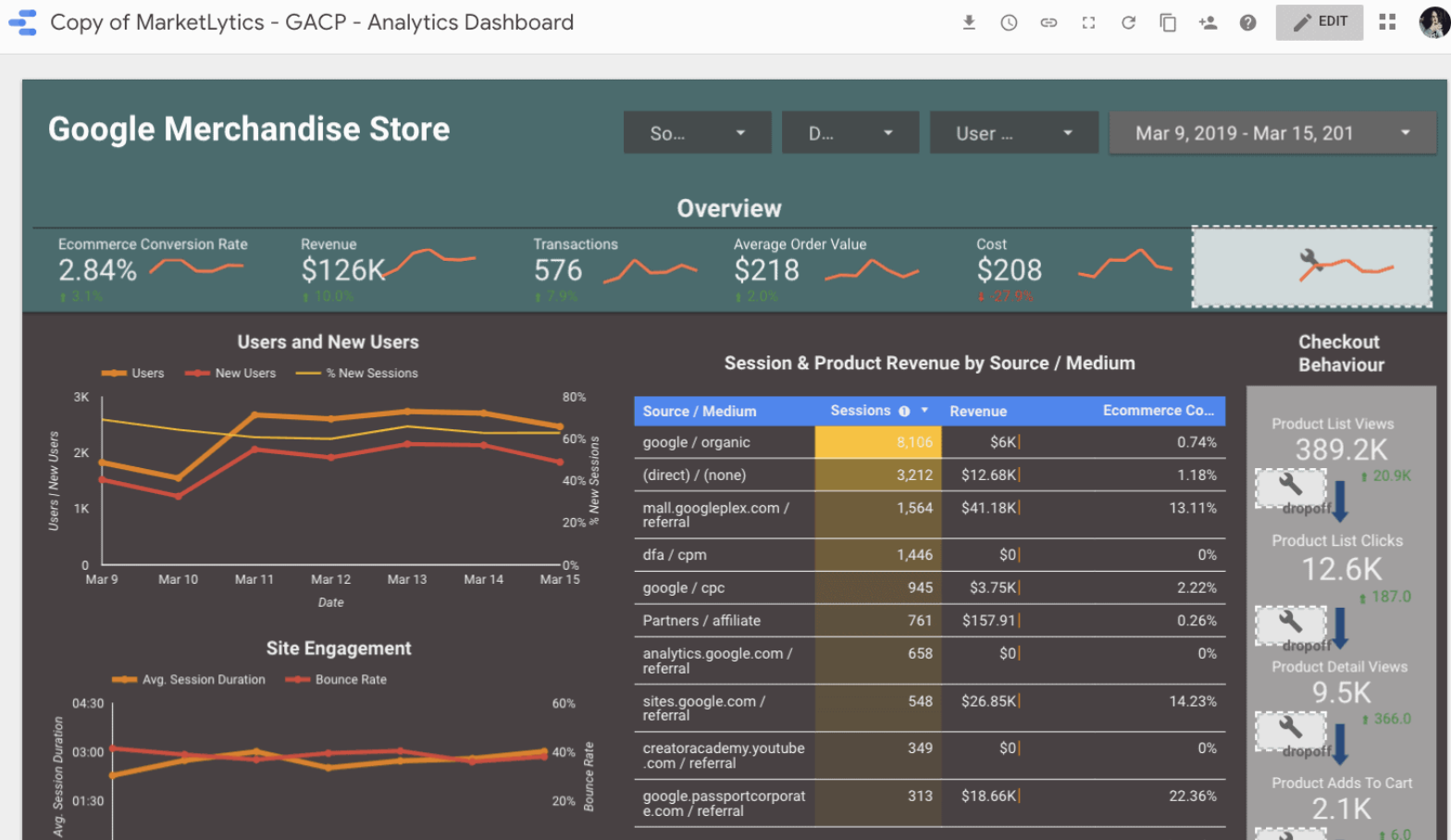


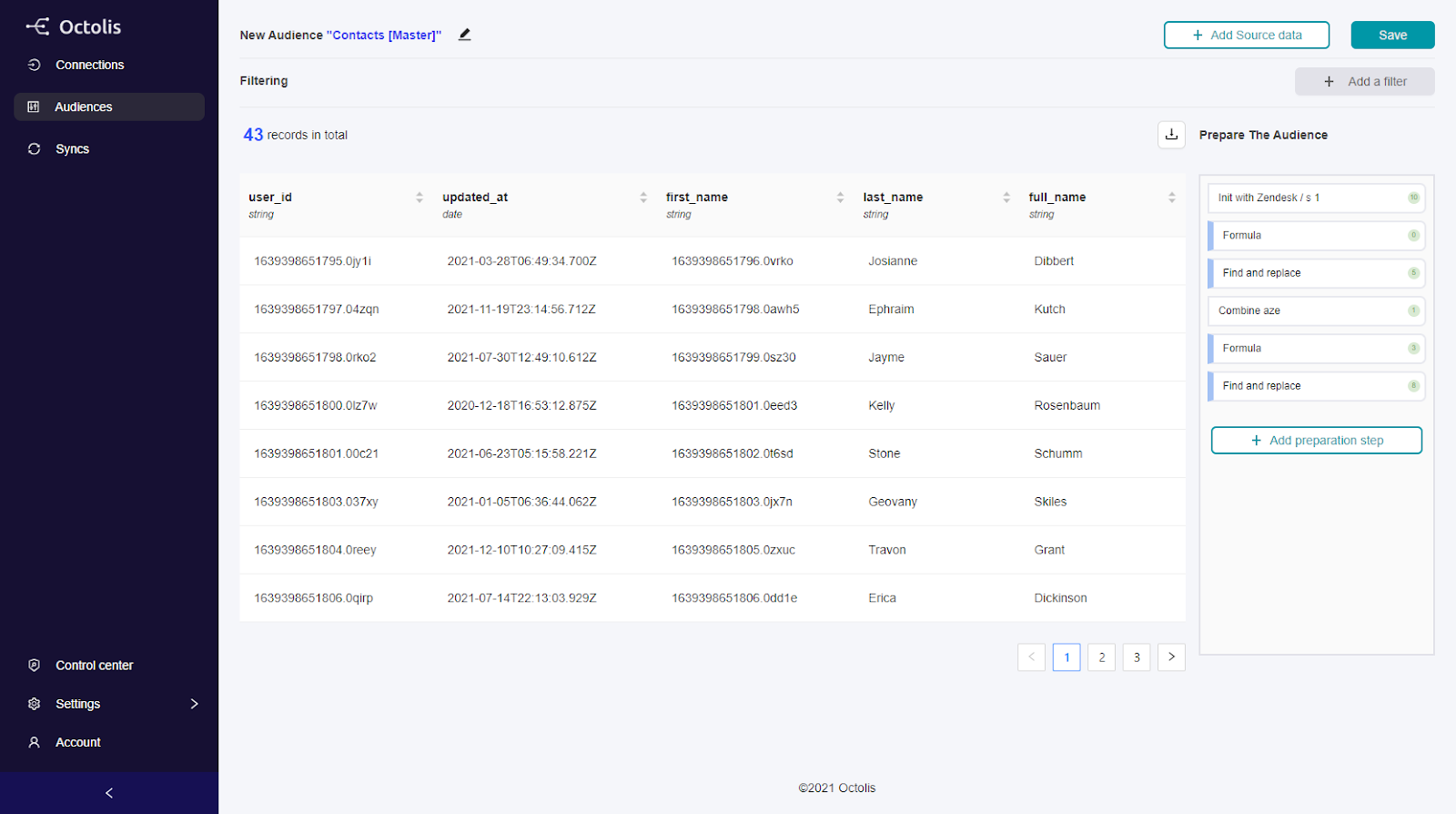

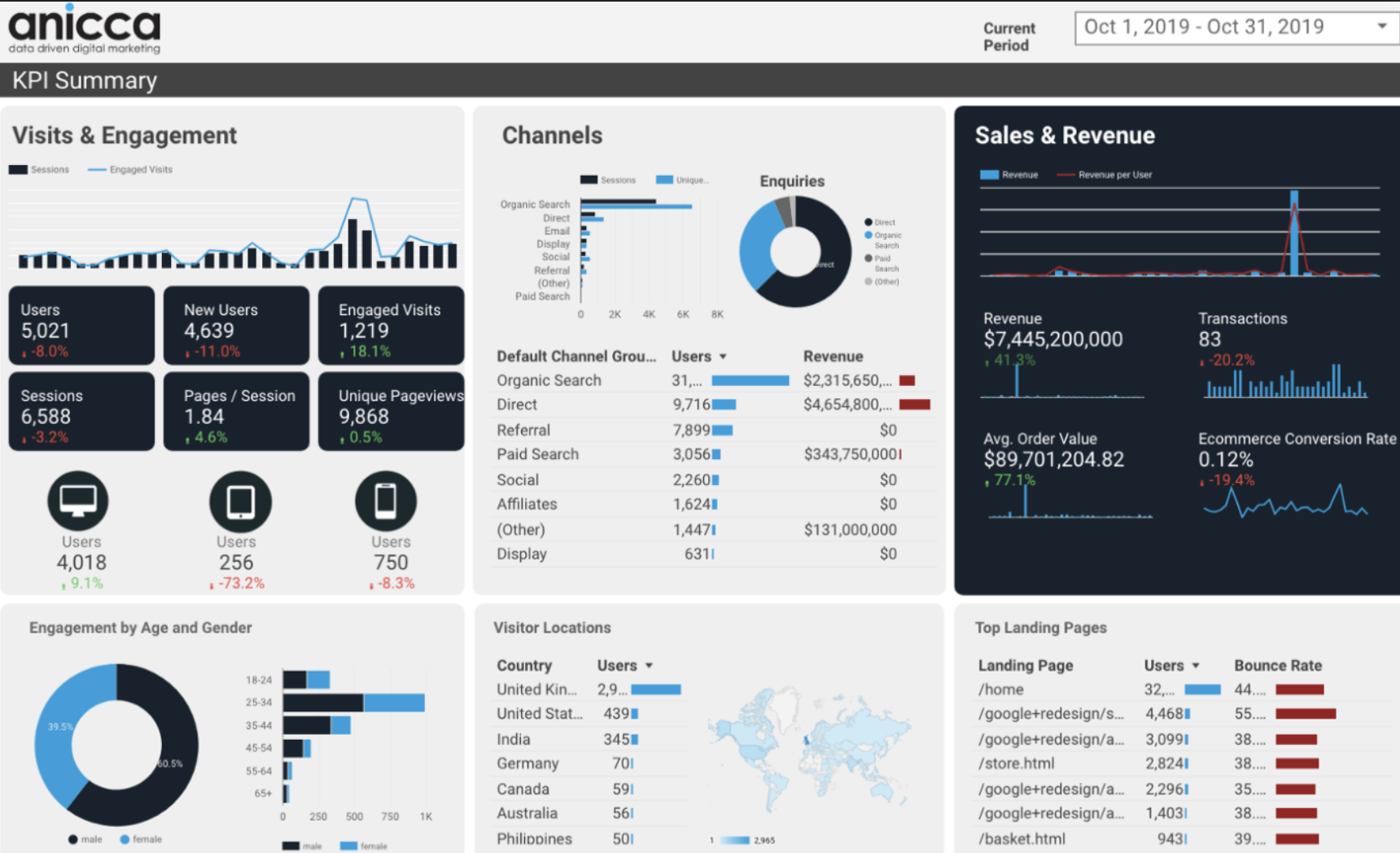
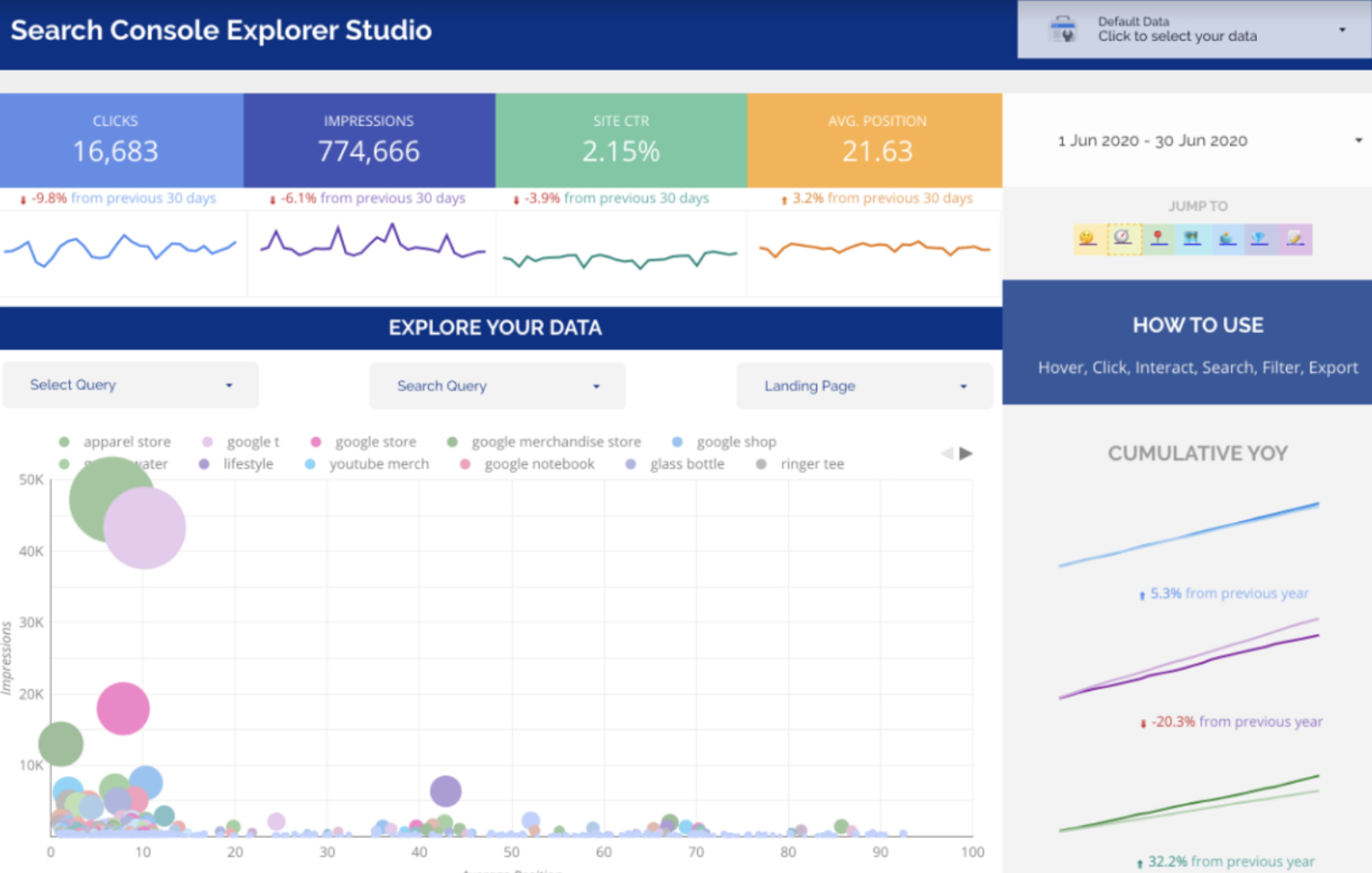
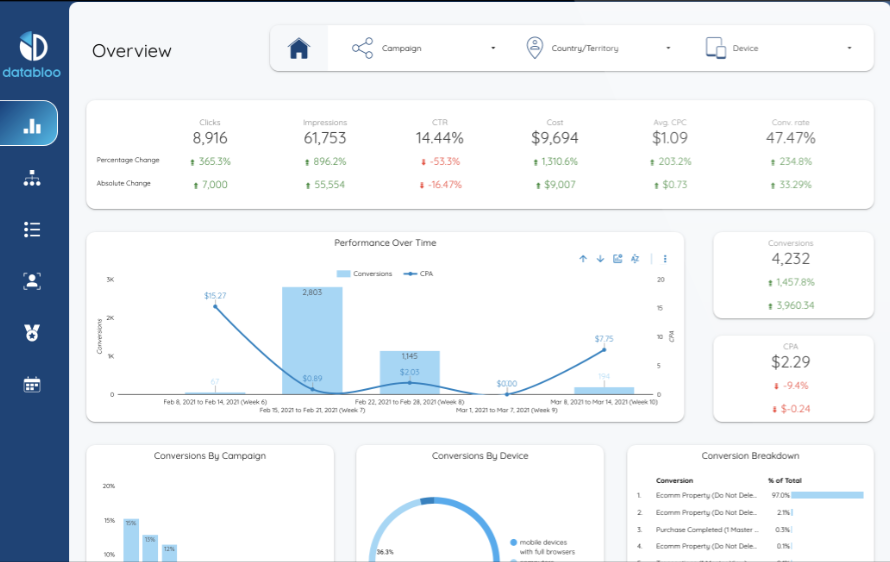
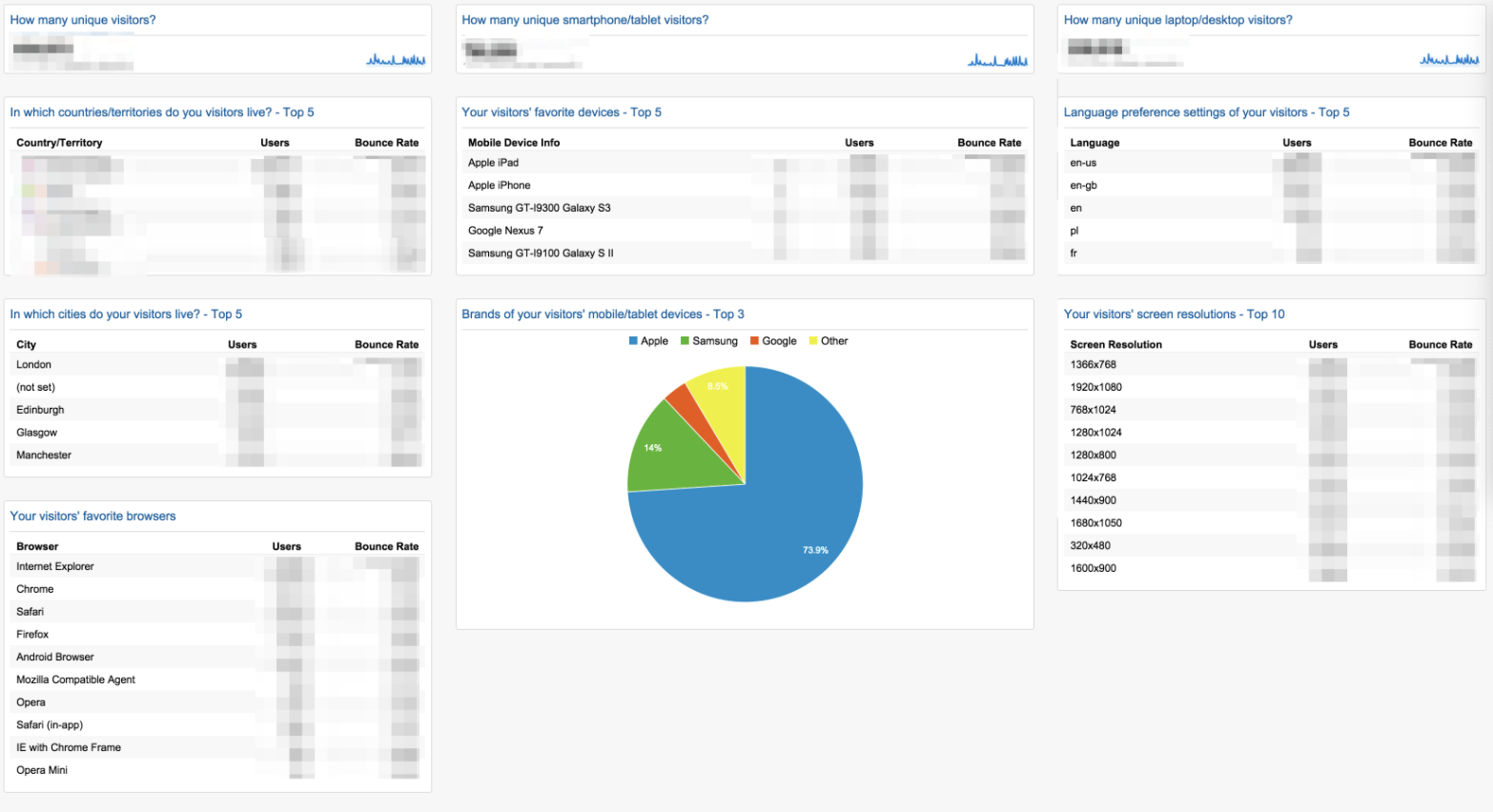
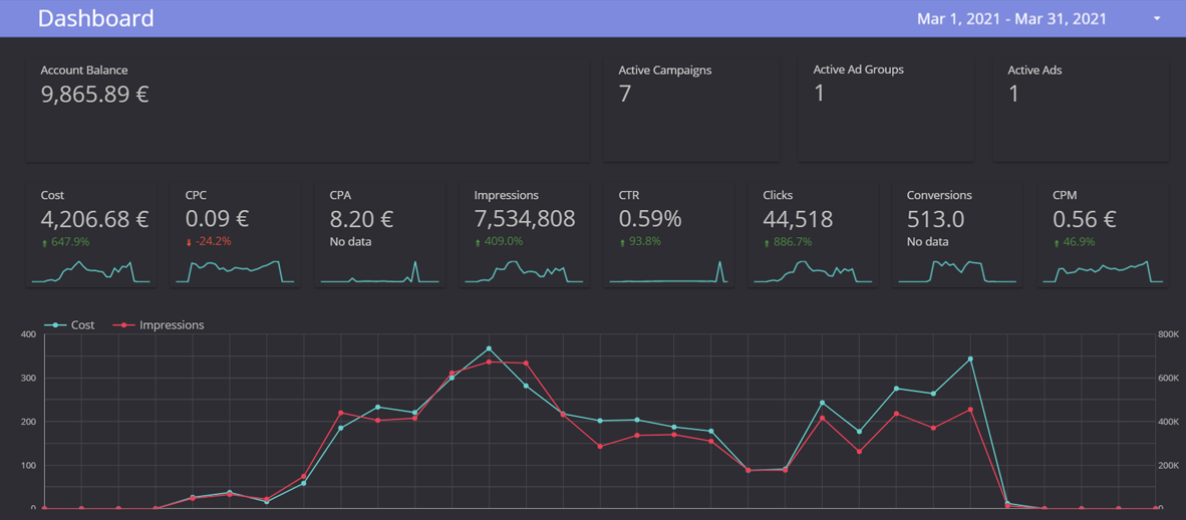
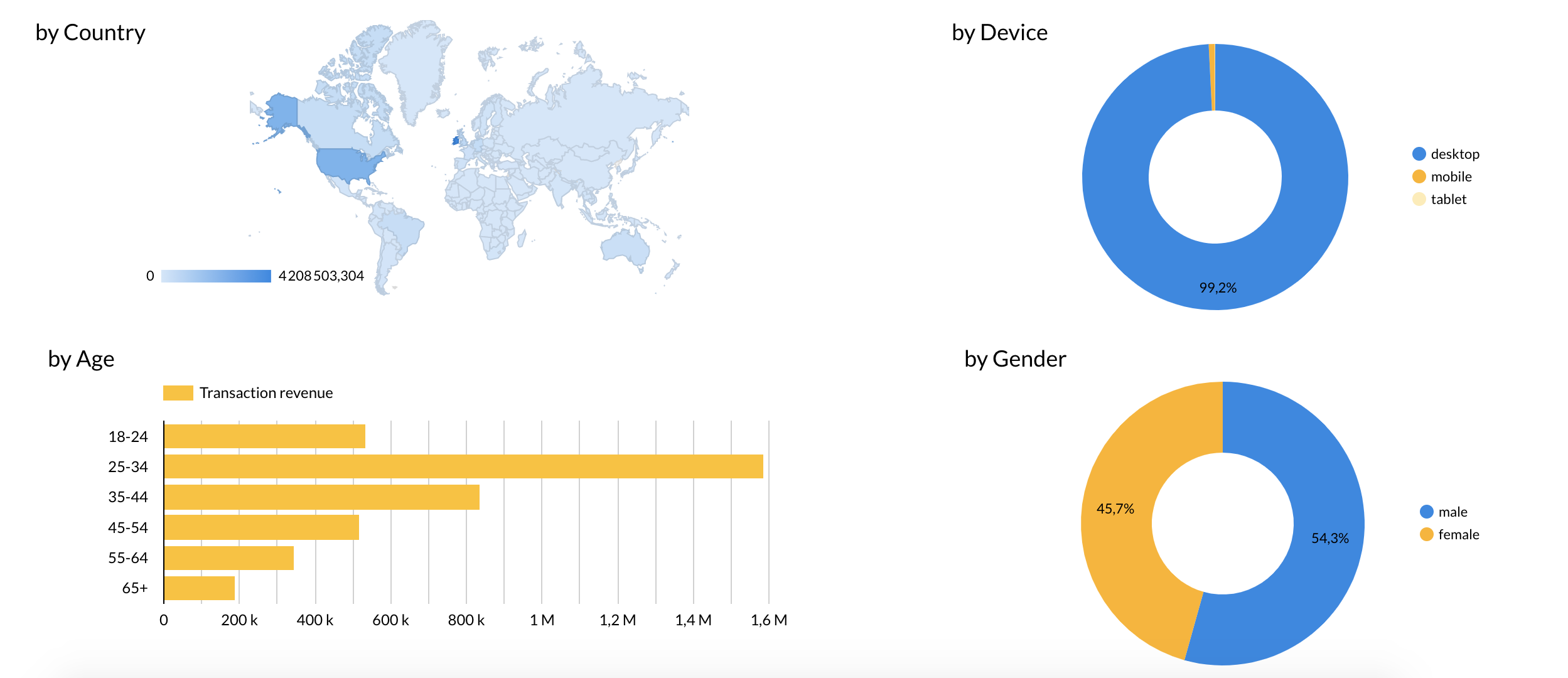
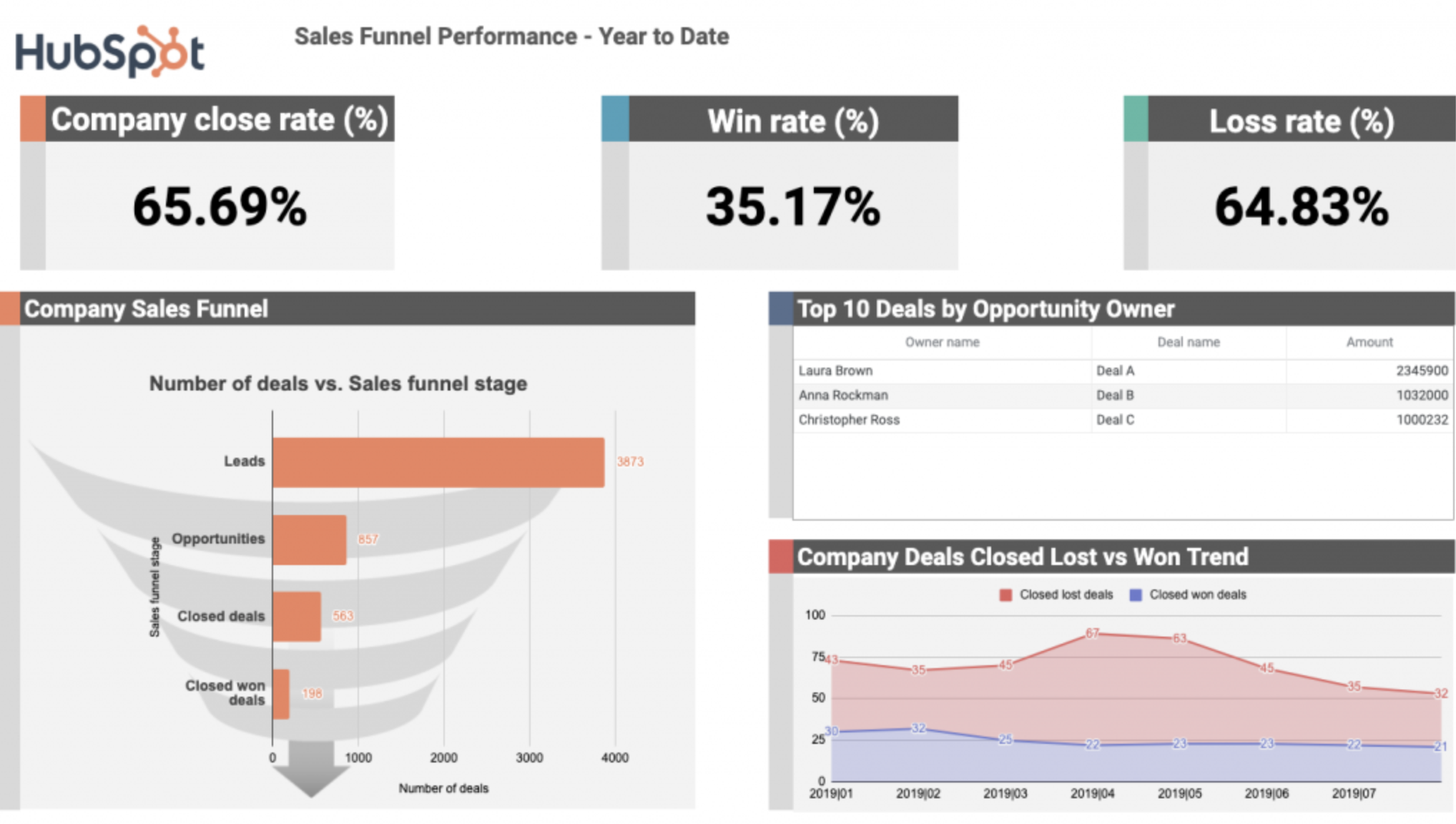
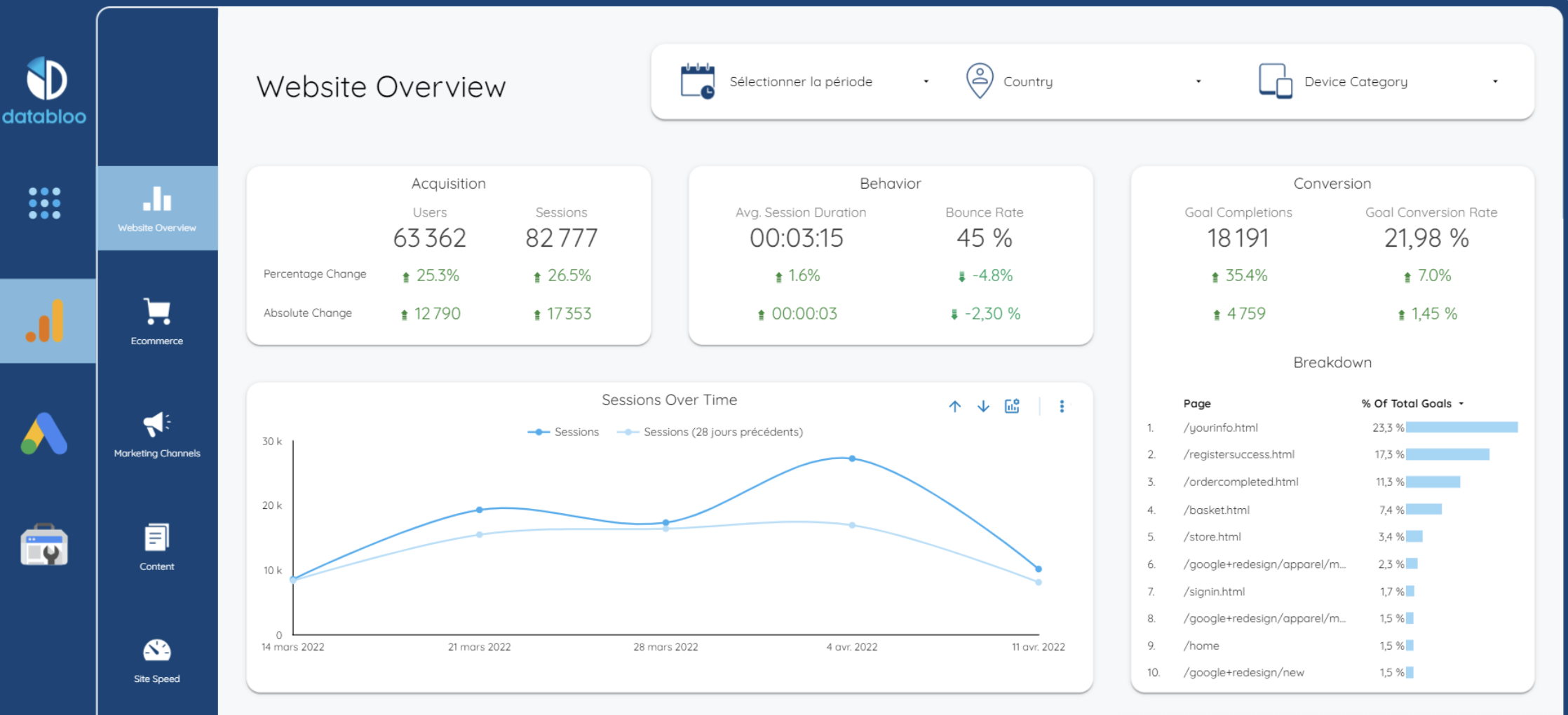
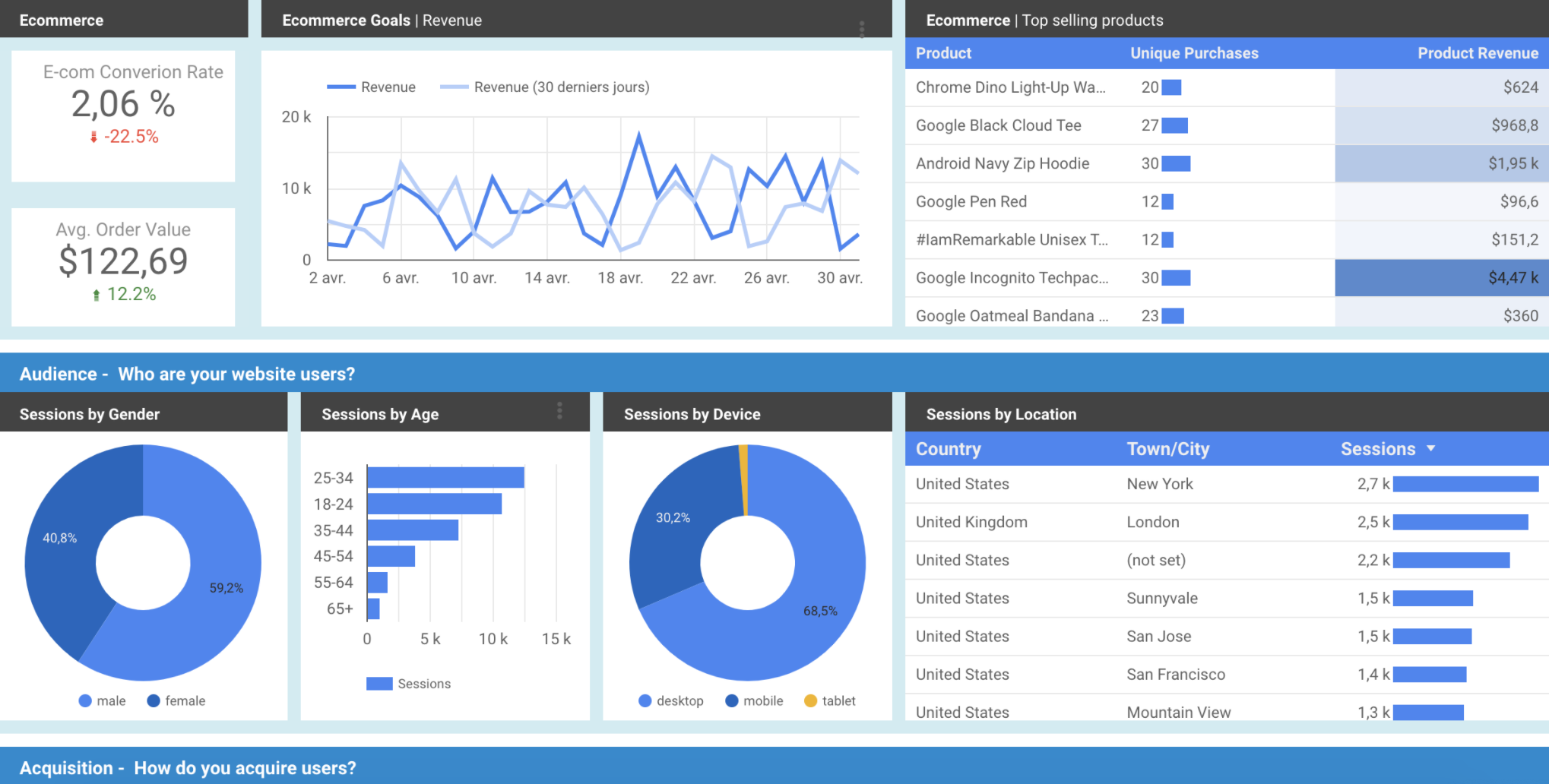
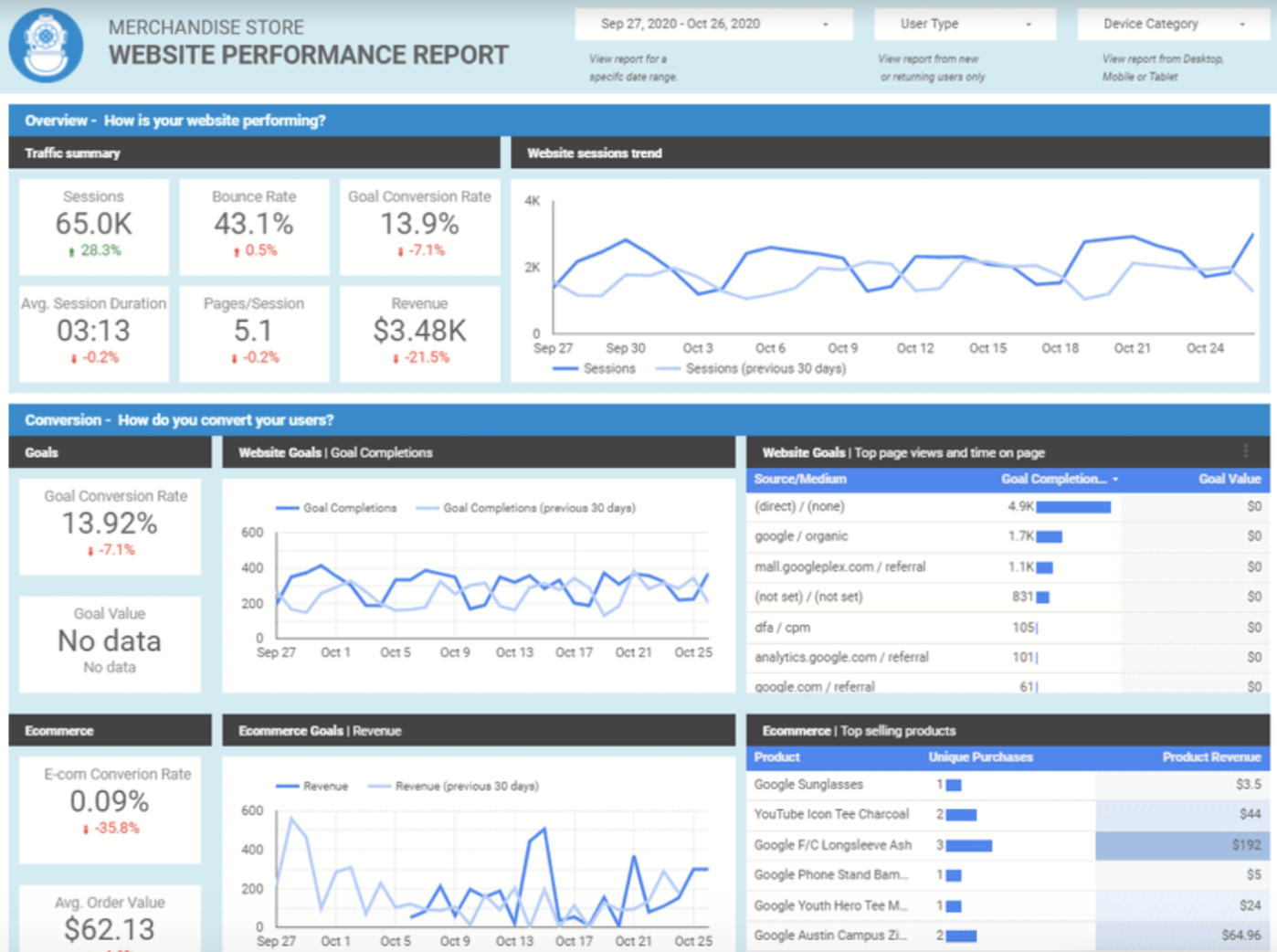
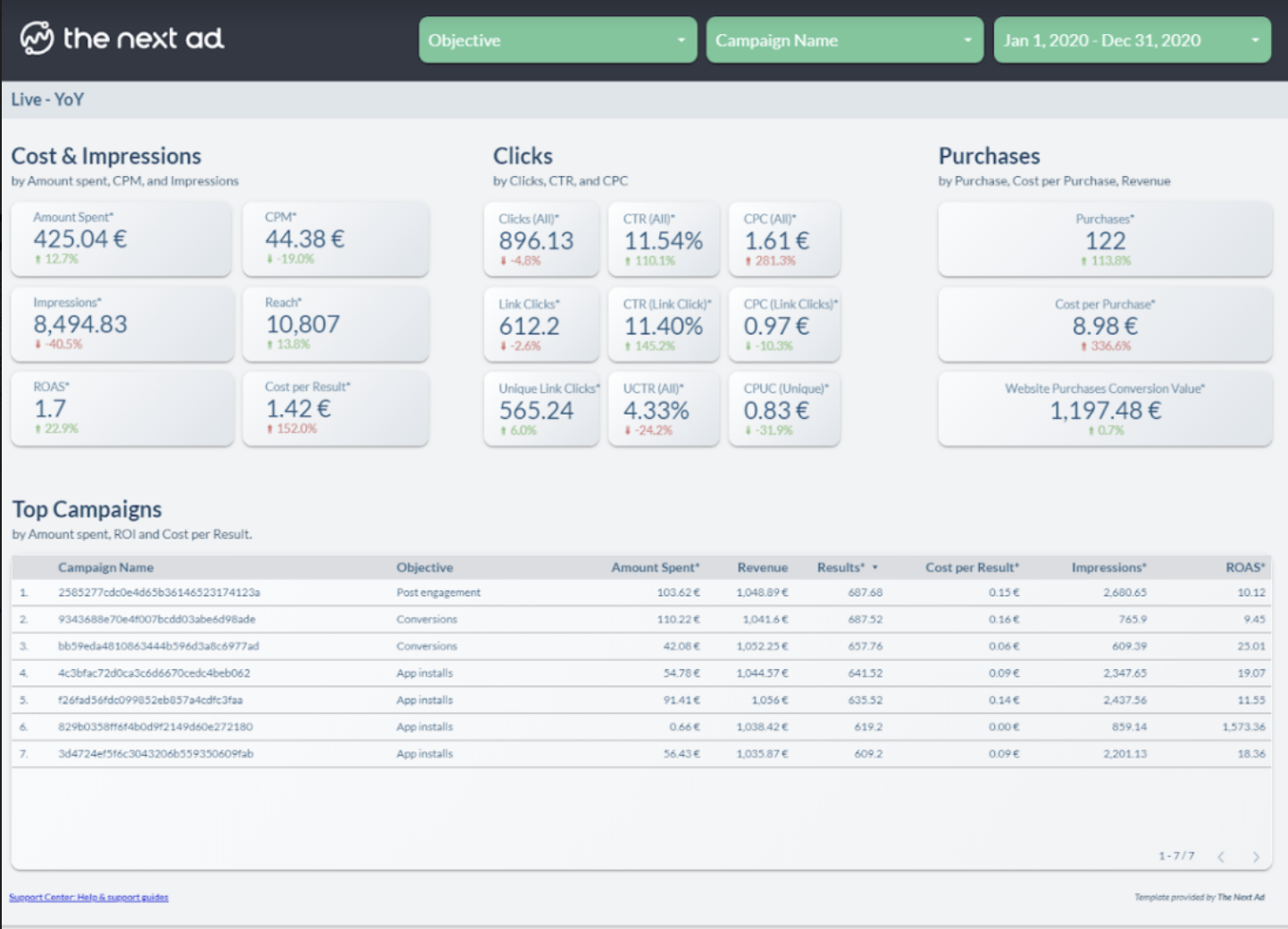
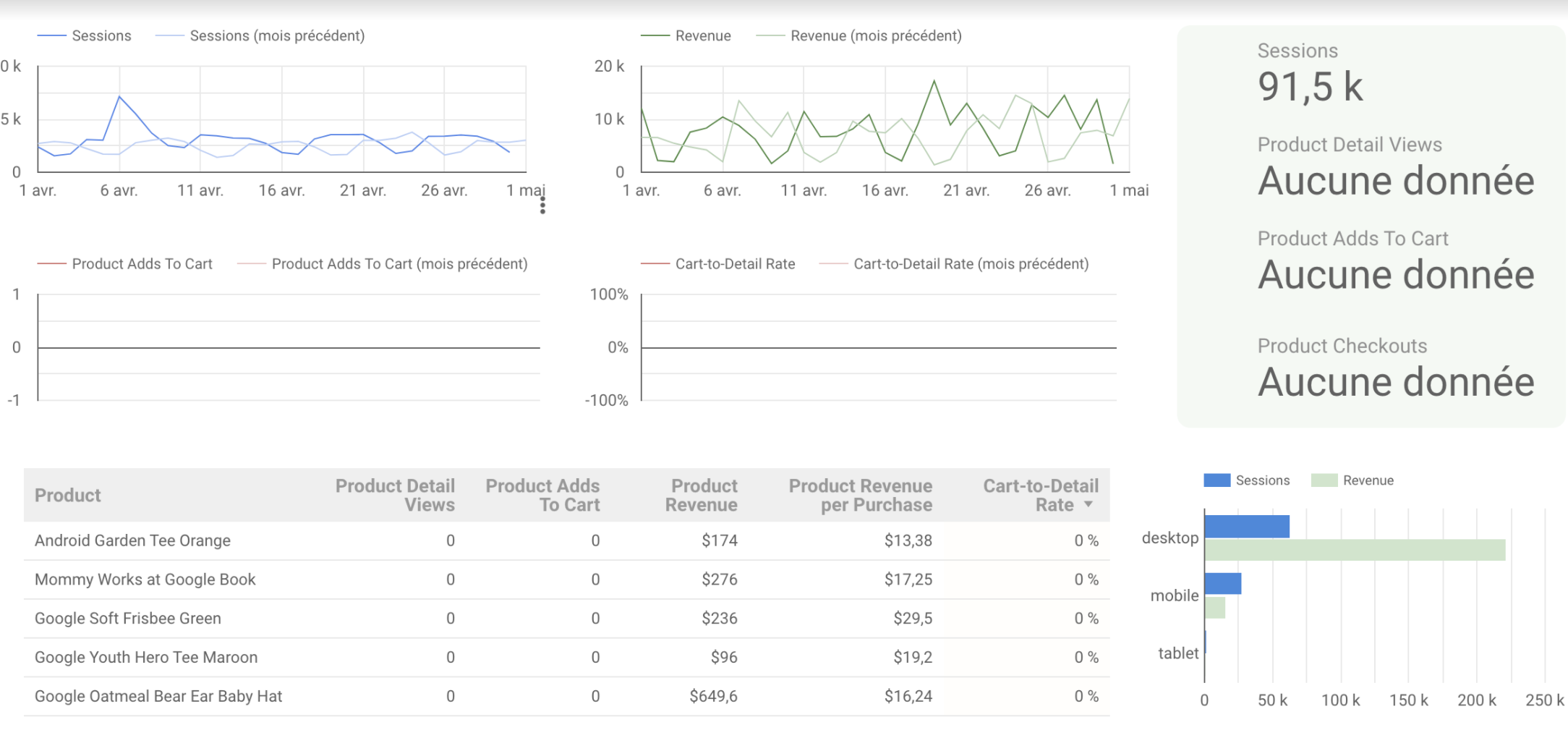
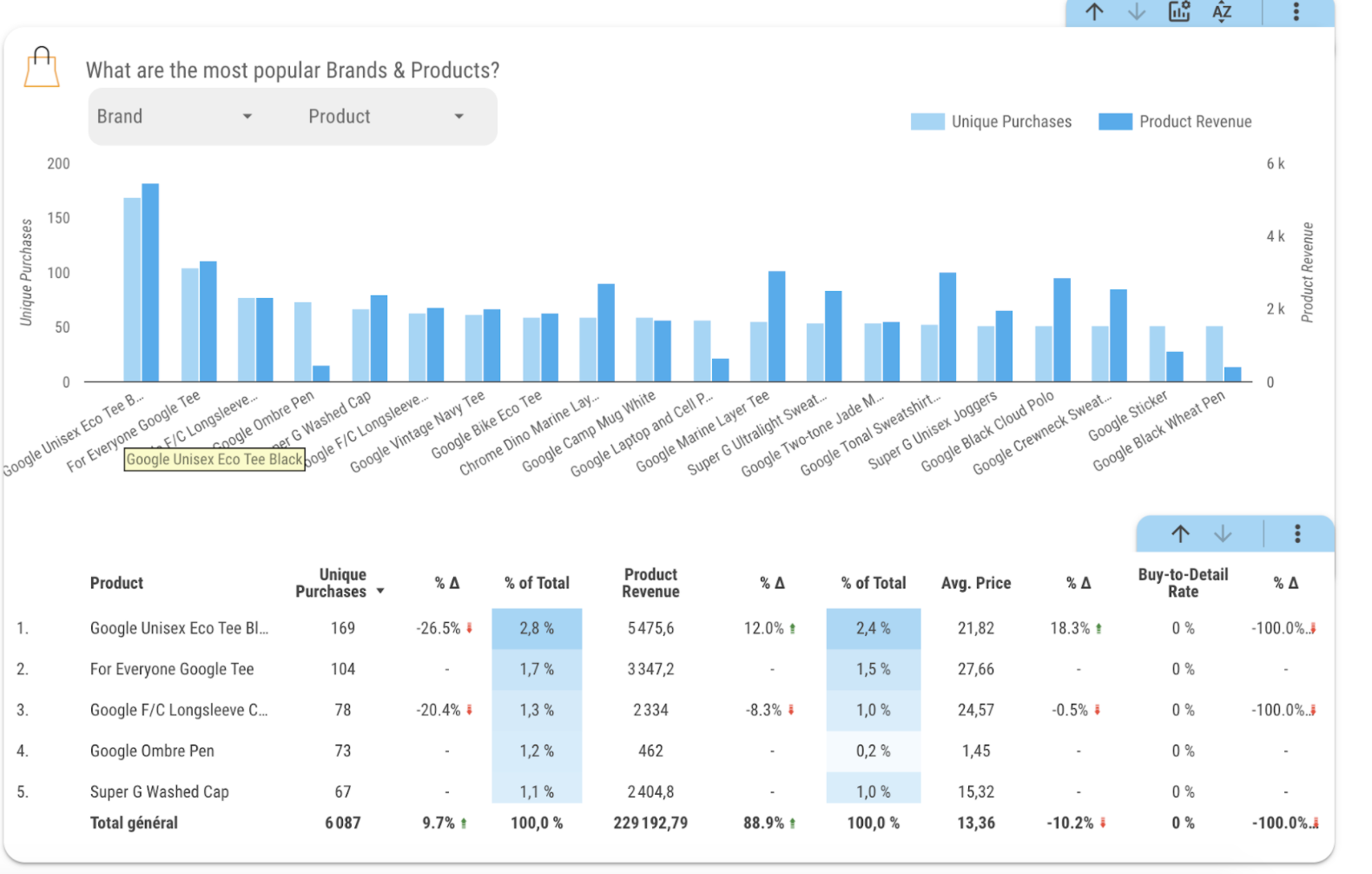

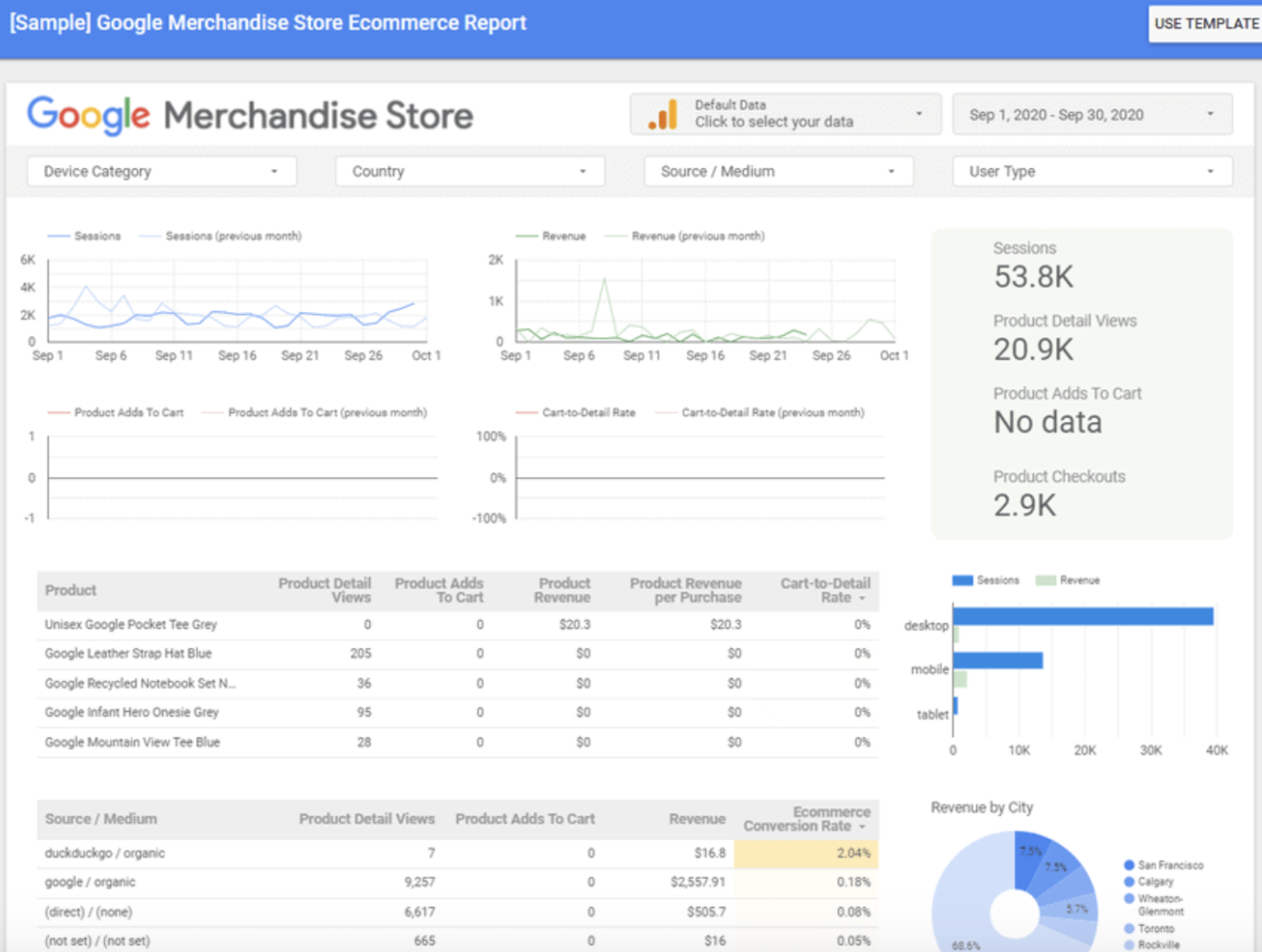



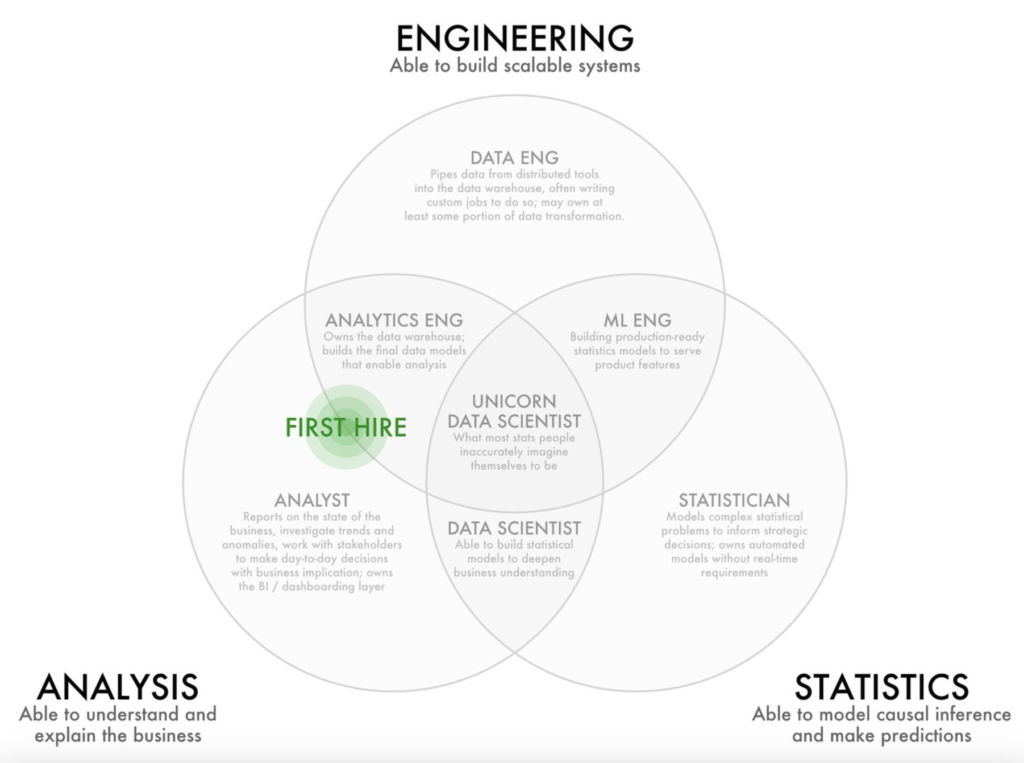
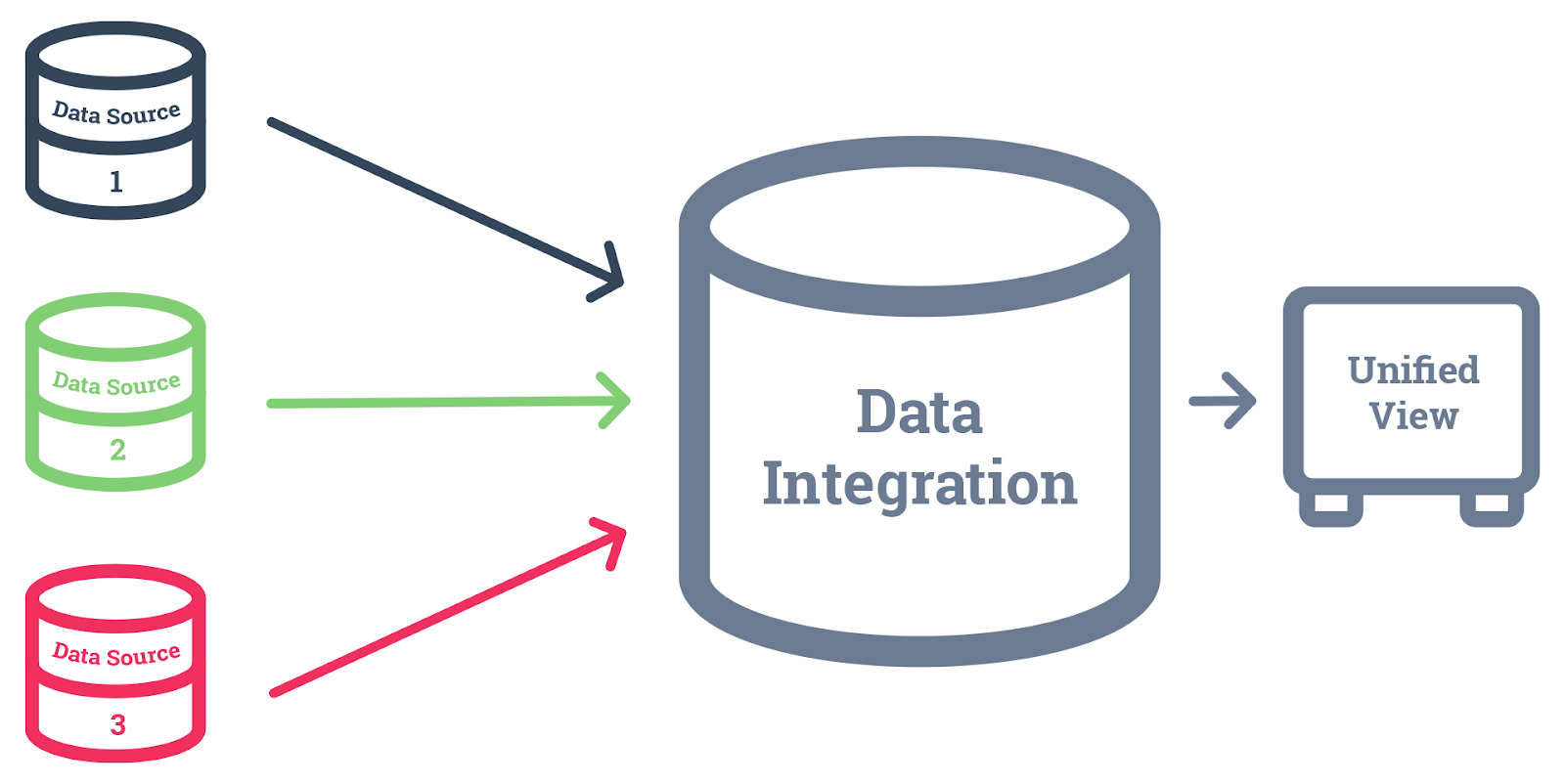 Prenons l’exemple d’une application mobile utilisant les outils suivants pour gérer son activité :
Prenons l’exemple d’une application mobile utilisant les outils suivants pour gérer son activité :