Toutes les startups ont conscience que leur croissance doit s’appuyer sur une fonction Data / Analytics solide. De la conviction à la mise en œuvre, il y a un gouffre 🙂
Beaucoup de jeunes entreprises ont tendance à vouloir brûler les étapes, des décisions qui peuvent avoir des répercussions négatives sur leur développement, des héritages dont il est ensuite difficile de se débarrasser.
Il ne s’agit pas de savoir quelles sont les métriques à suivre (il y a beaucoup de bons articles à ce sujet), mais de savoir comment amener votre entreprise à les produire. Il s’avère que la question de la mise en œuvre – comment construire une entreprise qui produit des données exploitables – est en réalité beaucoup plus difficile à résoudre.
Dans cet article, largement inspiré de cet excellent post de Tristan Handy, foundateur de dbt, nous apportons des réponses concrètes afin de construire la fonction data / analytics à chaque étape de développement de votre organisation.
Que faut-il absolument mesurer à ce stade ? Théoriquement, vous pourriez mesurer des tonnes de choses, mais vous êtes si proche du cœur de votre activité que vous parvenez à prendre les bonnes décisions à l’instinct.
Les seules métriques qui comptent à ce stade, sont liées à votre produit. Pourquoi ? Car ces métriques vont vous permettre d’itérer plus rapidement pour identifier les axes d’amélioration, faire les bons ajustements qui vous permettront de vous rapprocher du Product / Market Fit. Toutes les métriques qui ne concernent pas directement votre produit sont secondaires !
Ce qu’il faut faire
Installer Google Analytics sur votre site internet via Google Tag Manager. Les données ne seront pas parfaites, mais ne perdez pas de temps dans des paramétrages compliqués, ce n’est pas la priorité.
Si vous créez un business e-commerce, vous devez vérifier que les données liées à votre site de vente en ligne remontent bien dans Google Analytics. GA est un bon outil pour tracker une activité e-commerce et le parcours de vos clients de la visite à l’achat, donc prenez le temps de vérifier que tout fonctionne bien.
Si vous éditez un logiciel ou une application, vous devez absolument tracker les événements. Peu importent les outils que vous utilisez, que ce soit Segment ou Mixpanel. À ce stade, nous vous conseillons d’utiliser les paramétrages par défaut proposés par votre outil. Cette approche n’est pas très scalable, mais pour le moment ça fera le job.
Si votre business model est basé sur la soubscription avec des revenus récurrents, utilisez un outil comme Baremetrics pour suivre les métriques d’abonnement.
Construire un reporting financier en utilisant un outil comme Quickbooks.
Pour votre prévisionnel, utiliser Google sheets.
Si vous n’avez pas de compétences techniques, vous aurez sûrement besoin d’un petit accompagnement pour Google Analytics et la mise en place du tracking des événements. Cela ne doit pas prendre plus de deux heures, mais il faut que ce soit bien fait.
Ce qu’il ne faut pas faire
C’est simple : vous devez uniquement vous concentrer sur les points listés plus haut et ne pas chercher à mesurer autre chose pour le moment. Ne laissez personne vous convaincre d’investir dans un Data Warehouse ou dans un outil de BI. Ne faites pas appel à des consultants. Restez focus sur l’essentiel.
Si vous vous lancez tout de suite dans des projets analytics compliqués, vous vous engagez dans un chantier que vous ne pourrez pas mettre en pause, car les données, l’activité et les objectifs de l’entreprise vont constamment évoluer. Attendez avant de construire un dispositif analytics plus élaboré.
Beaucoup de questions qui resteront sans réponse, et c’est très bien comme ça (pour l’instant).
#2 – Phase d’amorçage [10 – 20 employés]
Votre équipe commence à s’étoffer et ces nouveaux collaborateurs ont besoin de données pour faire leur travail. Tous ne sont pas experts en données, mais vous devez vous assurer que les basiques soient réalisés dans les règles de l’art.
Ce qu’il faut faire
Vous avez probablement recruté un marketer, assurez-vous qu’il maîtrise GA. Tous les liens utilisés dans vos campagnes marketing doivent être trackés par des balises UTM. Votre responsable marketing doit faire en sorte que les sous-domaines ne soient pas trackés deux fois. Il existe des tonnes de ressources pour apprendre à utiliser Google Analytics, il est très facile de se former rapidement.
Si vous avez un ou deux commerciaux, installer un CRM est très vite nécessaire. 2 options ici :
Utiliser un CRM léger comme Pipedrive. Si vous choisissez cette option, nous vous invitons à découvrir les 10 meilleurs CRM pour TPE/PME. Vous devriez y trouver votre bonheur.
Construire un CRM maison en utilisant un template Notion. C’est l’option que nous vous recommandons. Pourquoi ? Parce que migrer d’un CRM léger à un CRM plus costaud est chronophage et complexe. En attendant d’être plus structuré sur la partie « Sales », Notion est une excellente alternative aux CRM légers « sur l’étagère ».
Vous avez probablement recruté quelques CSM pour gérer la relation avec premiers clients. Les reportings proposés par les plateformes d’help desk sont souvent assez pauvres. Adaptez-les en ajoutant les bons KPIs, ceux qui font sens pour votre activité.
Mesurer la satisfaction de vos premiers clients. C’est absolument clé pour améliorer votre produit et assurer sa croissance. Mesurez le Net Promoter Score (NPS) et/ou le Customer Satisfaction Score (CSat) en utilisant un outil comme Delighted, Qualtrics, Hotjar, voire Typeform.
Ce qu’il ne faut pas faire
Il est encore trop tôt pour investir dans un Data Warehouse ou pour faire de l’analytics via SQL. Vous n’avez pas encore les équipes suffisantes et cela vous consommera trop de bande passante. Vous en êtes encore à un stade où vous devez passer le plus clair de votre temps à agir, à faire, plutôt qu’à analyser.
Contentez-vous pour le moment des reportings préconstruits proposés par les outils SaaS. Dernière chose, n’embauchez pas de data analyst à plein temps, votre argent sera mieux investi ailleurs.
#3 – Early Stage [20 – 50 employés]
C’est là que les choses commencent à devenir intéressantes. Vous avez levé des fonds en série A et dépassé les 20 collaborateurs. De nouvelles options commencent à s’ouvrir à vous. Vous pouvez commencer à structurer une infrastructure data et à vous équiper de solutions plus avancées, plus flexibles, plus scalables.
Il s’agit de la phase la plus critique : prometteuse si vous faites les choses bien, compromettante pour l’avenir de votre entreprise si vous gérez mal le changement de vitesse.
Ce qu’il faut faire
Mettre en place une infrastructure data. Vous allez être amené à choisir entre 2 approches :
L’approche Best of Breed qui consiste à construire soi-même sa stack data en choisissant les outils qui correspondent le mieux. Cela signifie, concrètement, investir dans :
Un Data Warehouse, comme Snowflake ou Redshift. Le DWH sert de base de données principale. Il centralise, consolide et unifie toutes les données de votre startup.
L’approche packagée / data operations hub, qui consiste à choisir un outil tout-en-un (comme Octolis!), fonctionnant en surcouche de votre data warehouse et permettant de déployer facilement vos cas d’usage métiers.
Architecture type de la Stack Data Moderne
Un dispositif data « moderne » consiste à placer le data warehouse (DWH) au centre de votre infrastructure data. En amont, le data warehouse est alimenté par les différentes sources de données via des pipelines ETL ; en aval ces données sont redistribuées sous forme d’agrégats à vos outils métiers via un Reverse ETL. Votre outil de BI se connecte à la même source unique de vérité : votre DWH.
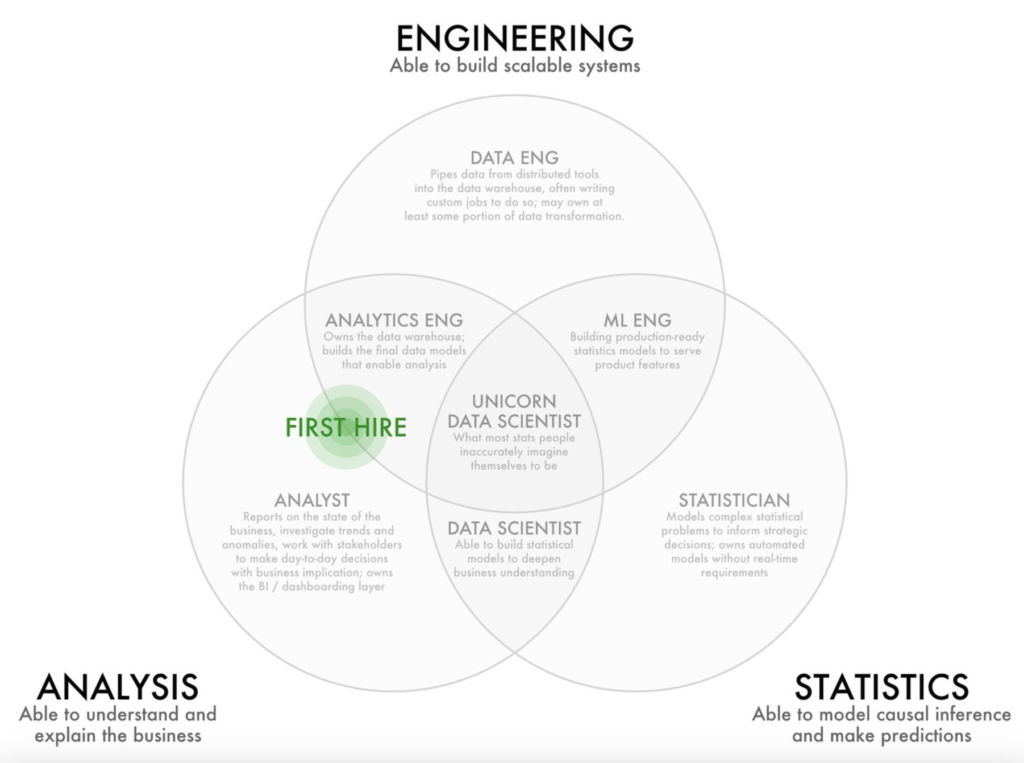
Embaucher 1 data analyst. Par la suite, vous aurez besoin de constituer une équipe Data/Analytics avec des data engineers, des data analysts, des data scientists…Mais pour le moment, vous avez seulement les moyens d’embaucher un data analyst à temps plein. Alors, ne faites pas d’erreur, prenez le temps qu’il faut pour trouver la bonne personne. Il faut que la personne que vous recrutez soit capable de vous délivrer de la valeur dès sa prise de poste. Ce sera aussi cette personne qui gérera les futurs recrutements pour constituer votre équipe data. Elle en constituera la colonne vertébrale. Choisissez une personne capable de retrousser ses manches et de mettre les mains dans le cambouis, mais privilégiez surtout quelqu’un qui sait faire parler les données et qui pense « business ».
Les 3 pôles de compétences des métiers de la data. Pour un premier recrutement, il faut cibler un profil à l’aise avec la technique (capable de gérer des pipelines de données, par exemple) mais aussi et surtout ayant de bonnes compétences d’analyse et une compréhension des enjeux business.
Envisager de faire appel à un consultant. Une fois que vous aurez recruté votre data analyst, soyez conscient que cette personne n’aura pas l’expertise nécessaire pour maniupler / gérer toutes les composantes de votre stack data. Or, commettre des erreurs à cette étape de développement peut se révéler très coûteux par la suite. Il est important de bien poser des fondations saines, c’est là-dessus qu’un accompagnement peut avoir du sens.
Ce qu’il ne faut pas faire
Il n’est pas encore temps d’embaucher un data scientist, même si le machine learning est au cœur de votre produit. À ce stade, vous avez besoin d’un profil généraliste qui aura la responsabilité de constituer l’équipe data/tech de votre start-up.
Ne construisez vos propres pipelines ETL. C’est une perte énorme de temps. Optez pour un logiciel sur l’étagère comme Stitch ou Fivetran, c’est simple et efficace.
Pour votre Data Warehouse, ne cherchez pas à faire des économies en construisant une base de données en Postgres. Ce n’est pas beaucoup moins cher que d’opter pour une solution cloud sur l’étagère, mais vous perdrez en revanche un temps fou quand vous devrez migrer votre BDD – et vous devrez le faire à un moment ou à un autre car Postgres est beaucoup moins scalable qu’une solution Data Warehouse Cloud.
#4 – Phase intermédiaire [50-100 employés]
Cette étape est potentiellement la plus complexe à gérer. Vous avez encore une équipe et des ressources (relativement) limitées, mais vos équipes business ont de plus en plus besoin de métriques solides.
Ce qu’il faut faire
Mettre en place des process solides pour gérer les modèles de données et sécuriser la transformation des données. Les modèles de données, c’est-à-dire la manière d’organiser les données dans votre base de données, sont dictés par les besoins métiers et les finalités business. Tous les utilisateurs des données doivent pouvoir faire évoluer les modèles de données. Ils doivent aussi pouvoir transformer les données. Mais, par sécurité et pour éviter tout problème, assurez-vous qu’un système de contrôle de version est utilisé et mettez en place un environnement de transformation transparent. Il existe des outils spécialement conçus pour ça, notamment dbt.
Migrer votre web analytics et votre event tracking sur une solution comme Snowplow Analytics ou Jitsu. Ces outils permettent de faire la même chose que les outils payants, mais ont l’avantage d’être open source. Pourquoi faire ce changement ? Pour être en capacité de collecter des données plus granulaires et pour éviter de payer des licences exorbitantes (plusieurs centaines de K€ par mois…) à Segment, Heap ou Mixpanel.
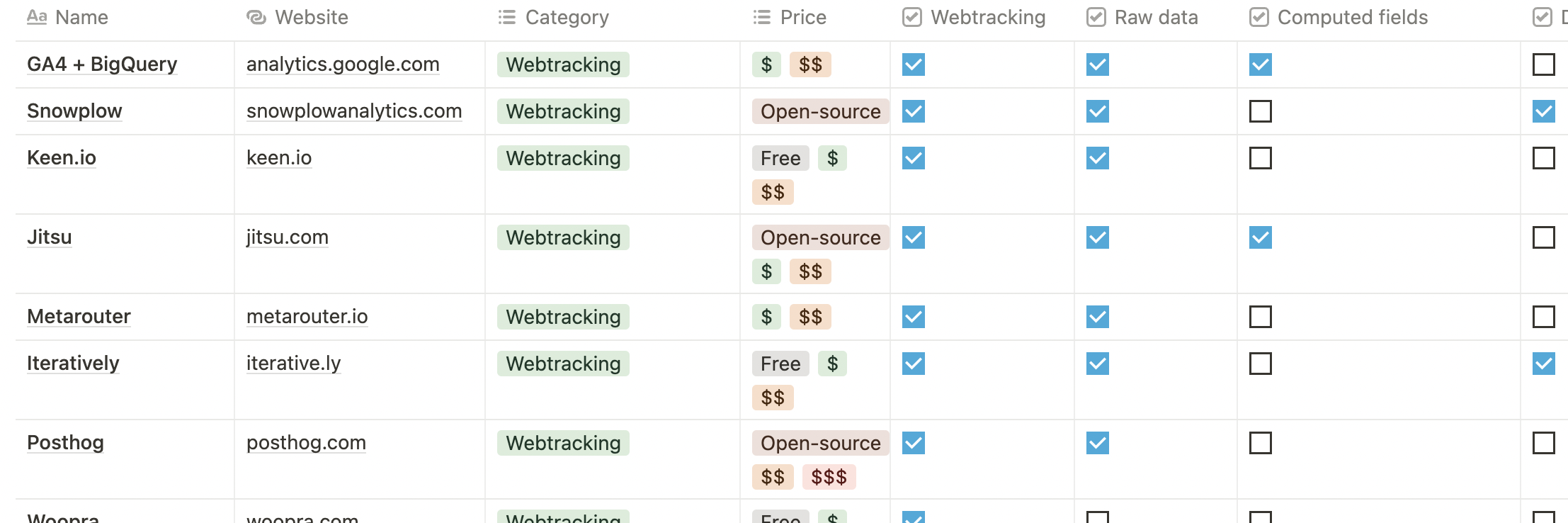
Quelle solution de web analytics choisir ?
Les solutions de web analytics sur l’étagère sont très abordables, voire gratuites, dès lors que vous avez de petits volumes de données. Mais les tarifs augmentent très rapidement avec la croissance du volume de données géré (calculé en nombre d’utilisateurs ou en nombre d’event trackés).
Nous avons produit une ressource Notion sur les alternatives à Segment dans laquelle on présente (notamment) les principales solutions de web analytics open source du marché.
Faire grandir votre équipe data intelligemment. Le cœur de votre équipe data doit être constitué d’analystes ayant une sensibilité business forte – c’est-à-dire des personnes expertes en SQL, qui maîtrisent parfaitement l’outil de BI mais qui passent aussi beaucoup de temps à faire le pont entre les équipes data « pures » (les data engineers) et les équipes métier/business. Dans une startup, la donnée est au service du business. La capacité de dialogue entre votre équipe data et les équipes métier reposent en partie sur votre capacité à recruter le ou les bons « business analysts ». C’est aussi à ce stade de développement de votre startup que vous allez pouvoir (enfin) recruter un data scientist.
Commencer à construire des modèles prédictifs. Vous pouvez commencer à utiliser des modèles prédictifs simples. Par exemple, si vous êtes un éditeur de logiciel SaaS, vous avez intérêt à déployer un modèle de prédiction du churn. Si vous êtes un e-commerçant, vous pouvez commencer à travailler sur un modèle de prévision de la demande. A ce stade, vos modèles prédictifs ne seront pas forcément très sophistiqués, mais ce sera déjà une énorme avancée par rapport aux tableurs google sheet bricolés par le département Finance 🙂
Consacrer du temps et de l’énergie à l’attribution.. C’est un sujet qui mériterait tout un article, mais disons simplement ici que c’est un chantier clé que vous ne pouvez pas confier à un tiers. Pour mesurer finement la contribution des différents canaux marketing, vous devez mettre en place des modèles d’attribution. Vous pouvez commencer par utiliser les modèles standards (ceux proposés par les outils analytics) avant de vous lancer dans la construction d’un modèle sur-mesure.
Ce qu’il ne faut pas faire
Arrivé à cette phase de développement de votre startup, le risque est de s’emballer et d’investir dans une grosse infrastructure data. Ne faites pas cette erreur ! Non seulement ce serait se lancer dans un projet inutilement coûteux, mais aussi qui dit infrastructure lourde dit perte d’agilité. Voici quelques conseils pour que votre startup reste agile :
Exploiter toute la puissance de votre Data Warehouse. N’hésitez pas à booster votre abonnement, à augmenter les ressources de calcul activées, à augmenter l’espace de stockage. Vous pouvez vous le permettre et ça ne vous coûtera pas très cher.
Utiliser des Jupyter Notebooks pour les travaux de Data Science. Si vos données sont déjà pré-agrégées dans votre entrepôt de données, vous n’aurez pas encore besoin de le faire sur Spark ou un cluster Hadoop.
Trouver des solutions low-cost pour créer des pipelines ETL sur les sources données sans connecteurs. Utilisez un ETL open source, par exemple Singer.
#5 – Phase de croissance [150 – 500 employés]
Ici, tout l’enjeu est de mettre en place des process analytics scalables. Vous devez trouver un équilibre entre obtenir des réponses dont vous avez besoin aujourd’hui et mettre en œuvre des process analytiques qui s’adapteront à la croissance de votre équipe.
Prenons deux cas de figure pour rendre les choses plus parlantes. Si votre entreprise compte 150 employés, votre équipe analytics représente certainement entre 3 et 6 personnes à temps plein. Mais si l’entreprise a 500 employés, l’équipe analytics peut facilement dépasser les 30 personnes. Et, croyez-nous, ça change tout.
Quand il y 3, 4, 5 ou 6 analystes, il n’y a pas besoin de process très formalisés : les personnes sont en contact quotidien, travaillent peut-être dans le même bureau, elles s’échangent des informations (ou des morceaux de code :)) de manière informelle. Et ça fonctionne très bien comme ça. Mais dès que l’équipe atteint les 10 personnes, il faut organiser le travail en commun et les échanges d’informations grâce à des process plus formels.
Ce franchissement de seuil appelle des changements dans les manières de travailler. Si vous ne réussissez pas à gérer correctement ce changement, vous verrez que vous deviendrez de moins en moins efficace à mesure que votre équipe grandira. « Plus » deviendra égal à « moins »: votre équipe sera plus nombreuse mais réussira moins bien à « faire parler les données ». Elle deviendra moins efficace. Voici ce qu’il faut faire pour éviter cette situation.
Ce qu’il faut faire
Faire du data testing. Vous avez maintenant des flux de données qui alimentent votre Data Warehouse et qui proviennent d’une dizaine de sources a minima. Vous allez devoir mettre en place des process pour vous assurer que les données qui entrent dans l’entrepôt continuent d’être conformes aux règles que vous avez fixées : unicité des données, absence de champs nuls, etc. Si vous n’avez pas de process qui contrôlent la manière dont les données sont chargées dans le Data Warehouse, c’est la qualité des données qui est en péril, et in fine la qualité des analyses produites à partir d’elles. dbt propose une fonctionnalité intéressante pour tester vos données et vérifier qu’elles sont organisées comme vous le souhaitez.
Utiliser les requêtes pull et faites des code reviews. Les codes analytics sont un actif précieux, au même titre que le code de votre site internet ou de votre application. Pour maintenir la qualité de vos codes analytics, vous devez prendre au sérieux le contrôle des versions. Familiarisez tous les membres de votre équipe avec git, formez-les à l’utilisation des branches…Tous les codes qui sont déployés en production doivent être fusionnés via une requête pull qui intègre une révision de la part d’un membre de l’équipe.
Documenter tout ce que vous faites. L’environnement data de votre entreprise est devenu complexe. Le seul moyen pour gérer efficacement tout cet actif et faciliter l’exploitation des données par tous consiste à investir du temps et de l’argent dans la documentation. Si vous ne le faites pas, vos data analystes passeront plus de temps à chercher où sont les données et comment les utiliser qu’à faire un travail d’analyse.
Ce qu’il ne faut pas faire
Votre startup collecte maintenant des volumes importants de données. Pour cette raison, faire des analyses est devenu plus difficile. Cela nécessite d’avoir à disposition une équipe composée de talents, de gens motivés, prêts à se former pour acquérir de nouvelles compétences.
Le code reviews, qui consiste à vérifier la bonne santé d’un code informatique et à identifier les éventuels bugs, est une activité qui consomme du temps et de l’énergie. Les data analystes n’ont pas forcément l’habitude de faire des code reviews. La documentation des données et des traitements est aussi quelque chose de pénible en soi. Certains membres de l’équipe montreront peut-être des réticences, mais la complexication des données, de l’infrastructure, de l’organisation impose des adaptations et la mise en place de process plus rigoureux.
Il faut réussir à le faire comprendre à votre équipe et ne pas transiger sur ce point ! In fine, ces process rendront le travail d’analyse plus simple, plus rapide et plus fiable. C’est leur implémentation qui est une étape un peu pénible à passer.
Conclusion
La fonction Data / Analytics de votre startup va se construire progressivement. Elle doit se construire progressivement. Mettre la charrue avant les bœufs est le plus sûr moyen de foncer dans le mur. Si vous suivez les étapes dans l’ordre, sans précipitation, vous ferez de l’exploitation de vos données un avantage compétitif important.