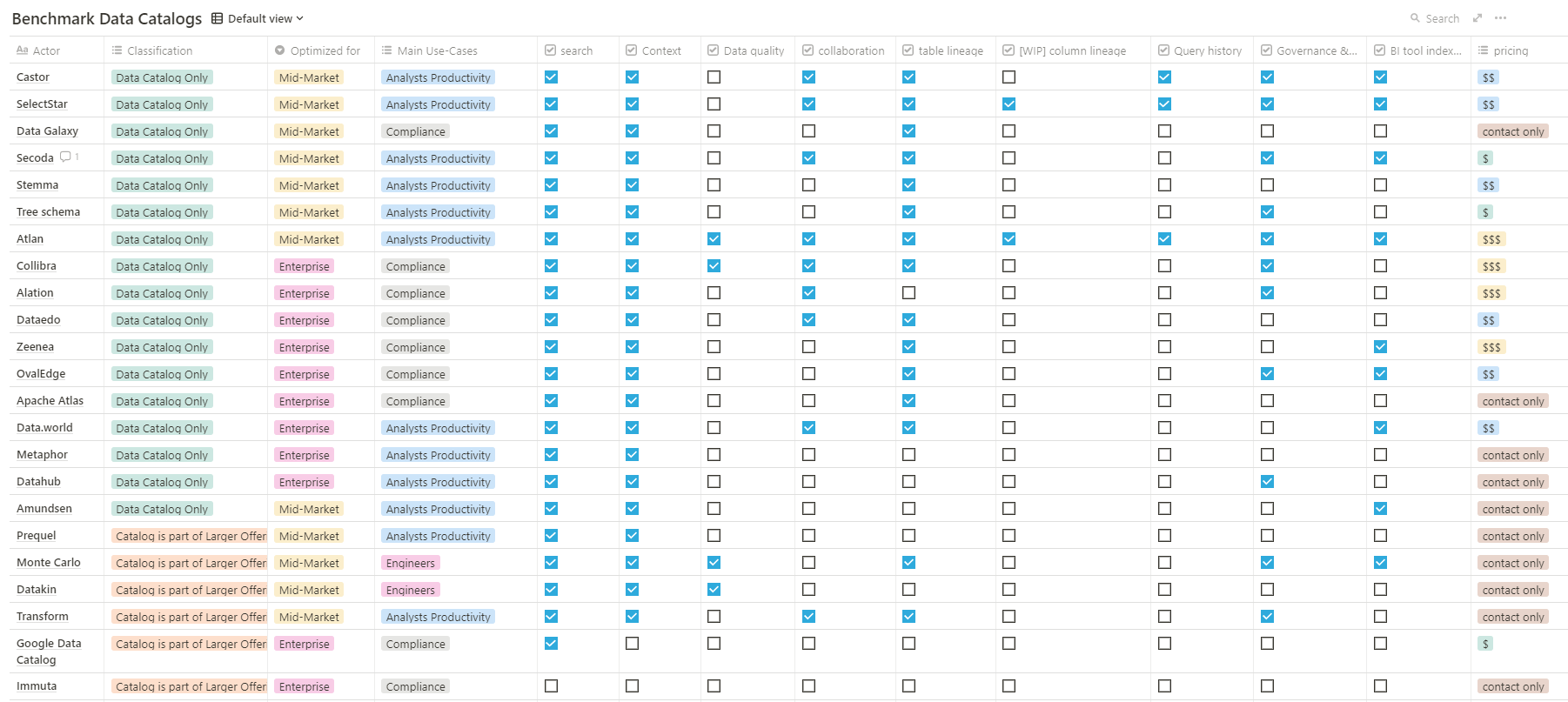
La tendance est de transformer les données après les avoir chargées dans un entrepôt de données moderne tel que Google BigQuery, Snowflake, AWS Redshift ou Microsoft Synapse. Ainsi, l’ELT plutôt que l’ETL est de plus en plus utilisé pour référencer le traitement des données. L’acronyme se décompose de la façon suivante :
- E pour Extraction des données depuis leur source.
- T pour Transformer les données brutes en informations propres et utiles.
- L pour Loading vers le data warehouse.
Le P de « Publier » vient désormais compléter le process ETL. Il s’agit du processus de publication des données post-transformation à l’endroit exact où elles seront ensuite consommées.
Dans cet article, nous reprenons la définition de process ELTP d’Analen et présentons le fonctionnement et les avantages d’une solution d’intégration de données reposant sur le process ELTP.
Après l’ELT, pourquoi passer au process ELTP ?
La nécessité de l’operational analytics dans les organisations data driven
L’operational analytics est le terme employé pour parler de l’approche analytics moderne. Cette approche utilise la donnée pour piloter les opérations business et driver les actions de vos équipes en temps réel. L’operational analytics va donc plus loin que l’approche traditionnelle, qui consiste simplement à analyser des données pour comprendre les opérations.
Dans cette approche traditionnelle, on s’intéresse aux données pour mieux comprendre son business, et aider à la prise de décision stratégique. Pour cela, on utilise des tableaux, et des outils de reporting à l’aide de solutions de BI et de Data Visualization. L’analytics traditionnel répond à des questions du type : « Est-ce que ce produit génère des revenus ? ». C’est une démarche d’analyse, basée sur du moyen/long terme.
En revanche, l’operational analytics est l’art de faire parvenir aux équipes métiers (sales, marketing, support, service client) les données dont elles ont besoin pour prendre leurs décisions. C’est une démarche court terme, qui se passe en temps réel. Il s’agit d’apporter la donnée là où il faut quand il le faut, c’est-à-dire quand les utilisateurs métiers en ont besoin. L’operational analytics donne des réponses à des questions telles que : « Quel client dois-je relancer en priorité ? ».
Le process ELT ne résout pas la problématique de l’actionnabilité
Plaçons-nous dans un scénario de scoring PQL (Product Qualified Lead). Supposons que votre entreprise commercialise un SaaS. Votre client potentiel entre en contact avec votre service par le biais d’une publicité en ligne. Les fonctionnalités de base sont gratuites, mais l’utilisateur doit saisir son adresse mail et certaines informations professionnelles.
Si vous utilisez des outils de marketing automation tels qu’Hubspot ou Pardot, vous pouvez connaître le canal par lequel est arrivé le prospect, ainsi que son adresse mail. En revanche, ces outils de marketing automation ne vous permettent pas d’obtenir les données liées à l’utilisation de votre logiciel. Pourquoi ? Tout simplement parce que ces données d’utilisation sont généralement stockées dans une base de données de production.
Vous avez peut-être franchi une étape supplémentaire en ayant mis au point un algorithme de Machine Learning pour calculer un score PQL, afin d’indiquer quels utilisateurs gratuits seraient susceptibles de se convertir en clients payants. Mais tant que les données restent dans le datawarehouse, elles ne seront pas utilisées directement par les applications marketing. Elles ne sont donc pas actionnables.
Un score PQL est une donnée à laquelle vous devez avoir accès dans vos outils de marketing automation car ce sont les outils que les équipes Sales et marketing utilisent au quotidien. En effet, ils sont souvent trop occupés pour passer du temps sur un outil de BI ou exécuter des requêtes afin de savoir quels prospects doivent être priorisés. C’est là qu’intervient le process ELTP.
Qu’est-ce qu’un process ELTP ?
« Publier » : Pousser la donnée en dehors du DWH
Nous l’avons évoqué, la publication d’indicateurs quantitatifs (également appelés metrics) vers les applications de sales, marketing ou service client est essentielle. Le ‘P’ d’un process ELTP prend en charge le problème du « dernier kilomètre » du traitement de données pour rendre les opérations commerciales plus agiles, efficaces et rapides.
Un autre exemple convaincant pour une entreprise de type SaaS est le Customer Success. Un bon Customer Success doit permettre de fidéliser vos clients. Cela passe notamment par le calcul d’un « Health Score » par client, qui permet d’identifier les clients les plus susceptibles de se désabonner de votre service, et donc minimiser le taux de churn.
Pour ces entreprises, la possibilité d’exploiter ce Health Score directement dans l’outil de gestion du service client, comme Zendesk, MailChimp ou Slack est très intéressant. Cela permettrait aux équipes de mettre des mesures en place pour éviter à ce client de se désabonner.
Exemple de résolution du problème du « dernier kilomètre » dans le traitement des données
Ces animations GIF ont été publiées sur Twitter par Anelen. Elles ont été créées automatiquement et à des intervalles de temps précis. Pour cela, les données ont été extraites des sources (géologiques et financières), transformées (y compris la partie destinée à produire l’animation GIF) et transmises à une application de réseaux sociaux (Twitter dans ce cas).
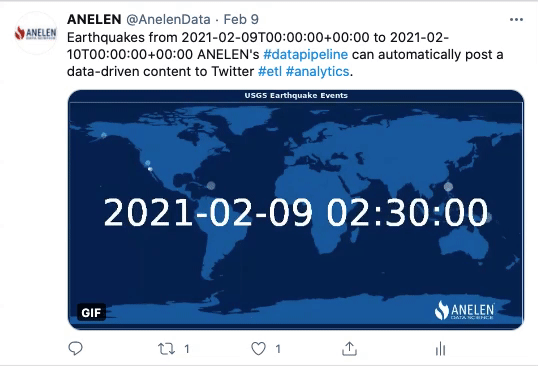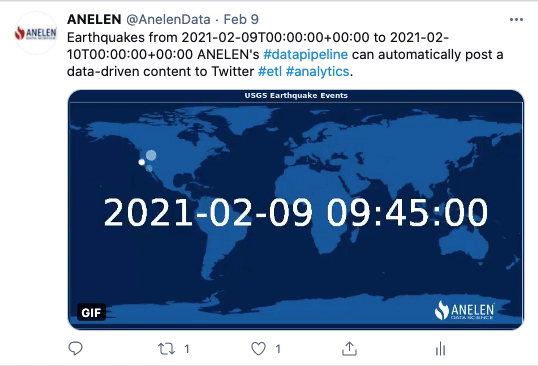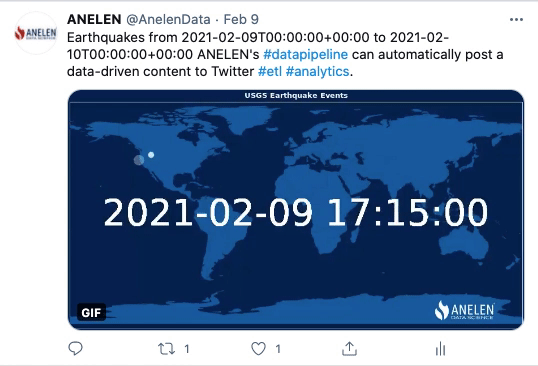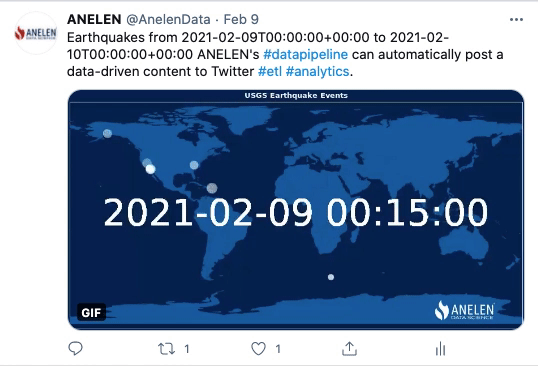
Cette première animation concerne un relevé de données à la fois géologique et géographique. Elle représente les occurrences de tremblements de terre durant les dernières 24h, par coordonnées GPS. Grâce au process d’ETLP, le post Twitter est actualisé automatiquement. Les données sont mises en forme, puis l’animation est produite et injectée dans le système de programmation de publications Twitter. Enfin, elle est publiée à l’heure préalablement définie par les équipes.
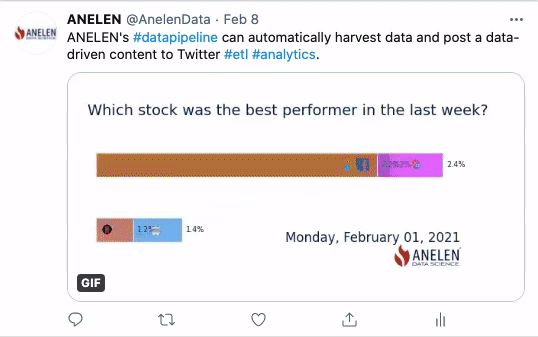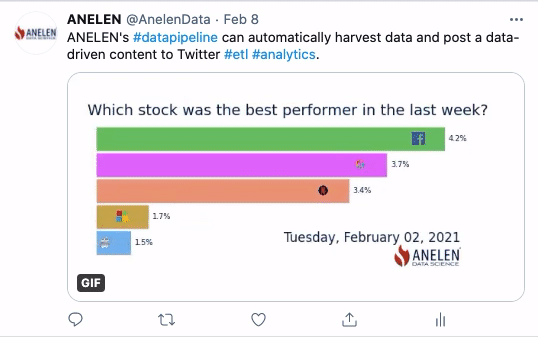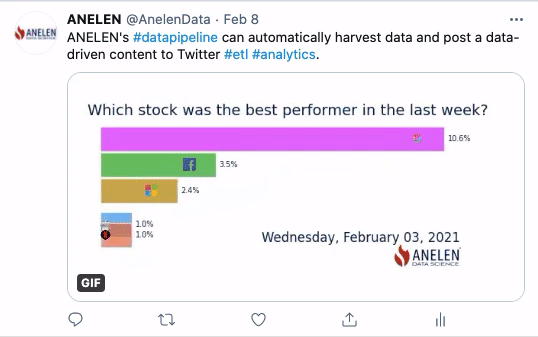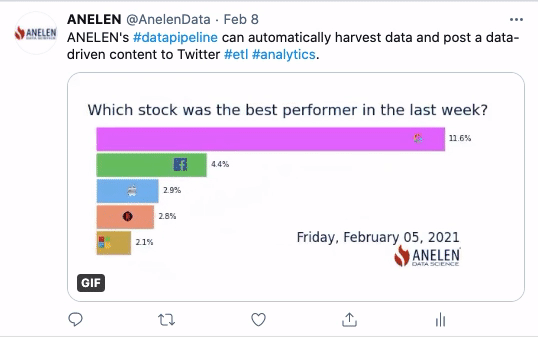
Dans cette seconde animation, ce sont des données publiques d’origine financière qui sont utilisées. Sur une période de 5 jours, on observe l’évolution d’un indicateur de performance boursière de 5 entreprises multinationales représentées par leur logo. Sans le process ELTP, il aurait fallu récupérer manuellement les données financières et les réinjecter dans la plateforme de gestion des réseaux sociaux.
Automatiser la publication des données
Ces dernières années, l’activité des ELT s’est développée. Il existe maintenant de nombreux services permettant de transférer automatiquement des données de diverses applications en ligne vers un datawarehouse. Cependant, peu de ressources et de services permettent d’automatiser la publication des données transformées, et encore moins sans compétences en développement.
Il existe notamment des solutions comme Singer.io proposant un processus ETL en Open Source pour les organisations. La communauté construit des extracteurs de données appelés « tap » et des chargeurs de données appelés « target ». Les spécifications de l’outil aident les Data Engineers à créer une combinaison source-destination pour chaque cas d’usage business.
Dans un cadre typique d’ELT, les applications cloud telles que Salesforce et Marketo sont les sources de données (taps), et les entrepôts de données sont les destinations (targets).
Le futur des process ELTP
L’avenir des process réside dans leur capacité à être exploités et mis en place directement par les profils métiers, sans avoir recours à l’IT. On assiste déjà à l’émergence de solutions no-code exploitables par des profils non techniques. On parle bien sûr d’Octolis !
En effet, nous accompagnons nos clients dans le développement de programmes permettant de faire communiquer des données du datawarehouse vers vos applications métiers. Octolis vous ainsi aide à résoudre le problème du « dernier kilomètre de données » afin de les rendre actionnables par vos équipes, au quotidien.
Reprenons l’exemple du service client. La satisfaction de vos clients est bien sûr un indicateur que vous suivez de très près et par conséquent vous cherchez des solutions pour réduire la frustration chez vos clients mécontents. Pour manifester leur mécontentement, ces derniers appellent le plus souvent votre service client.
Cibler ces contacts et leur proposer un geste commercial ou un simple message d’excuse par email est un excellent moyen de réduire leur frustration. Malheureusement, la remontée des données issues de votre service client vers votre outil de marketing automation est rarement réalisable sans compétences techniques. C’est désormais le cas 🙂
On vous laisse découvrir ce cas d’usage plus en détail en suivant ce lien.
Nous pensons que l’agilité opérationnelle passe par l’autonomie data des équipes. Nous aidons pour cela nos clients à faire croiser et redistribuer leurs données internes dans tous leurs outils métiers, afin de décupler leur potentiel.