Construire son propre dispositif data est un projet ambitieux et complexe nécessitant de nombreuses ressources. Pourtant de multiples entreprises, souvent poussées par les data engineers, font le choix de développer leur propre outil. Cette décision peut s’avérer néfaste pour l’entreprise si elle n’est pas motivée par les bonnes raisons.
Mettre en place un dispositif data nécessite d’assembler de nombreux composants cloud et/ou open source, souvent plus d’une douzaine : Kubernetes, KubeFlow, AWS ECR, Elasticsearch, Airflow, Kafka, AWS Cloudwatch, AWS IAM, DBT et Redshift. Ces éléments sont ensuite liés entre eux à travers une brique de code, avec Terraform par exemple. Ce type d’architecture est d’autant plus complexe qu’il se doit d’offrir à chaque équipe, et donc à chaque compte, un accès sécurisé à l’outil.
A l’inverse, lorsque l’on utilise une solution déjà existante, il est seulement nécessaire de configurer ses accès AWS et d’utiliser un outil tel que Terraform. Il ne reste qu’à connecter les bases de données aux outils d’analyses, par exemple Azure Data Lake et Azure Data Factory. Aucun outil ne permet d’éliminer totalement ces étapes, mais la mise en place générale du dispositif est grandement simplifiée et accélérée.
Dans cet article inspiré de l’excellent Niels Claeys, on évoque dans le détail les raisons qui poussent les organisations à se tourner vers la construction d’un dispositif data ‘best of breed’ ainsi que les obstacles qui se dressent devant cette construction.
La passion de vos data engineers est un frein
La majorité des data engineers considèrent la construction d’un dispositif data comme un véritable challenge, un projet leur permettant de développer et d’éprouver leurs compétences. C’est même probablement dans l’ADN d’un ingénieur de vouloir construire ses propres outils.
Par conséquent, la plupart d’entre eux risquent de ne pas être totalement neutres lorsqu’ils considèrent les avantages et les inconvénients d’un tel projet. Leurs objectifs ne sont alors pas parfaitement alignés avec ceux de l’entreprise, ce qu’il est nécessaire de prendre en compte.
Voici les raisons pour lesquels les data engineers risquent de manquer d’objectivité :
Les data engineers ❤️ les nouveaux outils
Dans l’écosystème data, les technologies évoluent rapidement et la popularité des outils varie constamment. La maîtrise d’un nouveau software populaire est souvent valorisée sur un CV. De ce fait, de nombreux programmeurs vont chercher à utiliser les nouveaux outils en vogue pour en avoir une bonne compréhension au minimum.
Il est important pour une entreprise de permettre à ses développeurs de continuer à apprendre de nouvelles technologies, mais employer de nouveaux outils lors du développement d’une plateforme data complexe n’est certainement pas le cadre le plus optimal pour permettre cet apprentissage.
De plus, la découverte et la prise en main d’un nouvel outil représentent un défi souvent ludique pour un développeur. Mais l’excitation que peut éprouver le data engineer lors de la première utilisation d’une nouvelle technologie ne dure qu’un temps, et l’envie de travailler avec l’outil peut décroître à mesure que celui-ci devient familier et l’apprentissage plus sporadique.
De ce fait, construire une plateforme data représente pour un ingénieur l’opportunité d’acquérir de nouvelles compétences tout en travaillant sur un projet stimulant. Les développeurs préfèrent donc naturellement développer eux-mêmes leur dispositif data et soutiennent ce choix sans que cela soit nécessairement favorable pour l’entreprise.
Les data engineers ❤️ toujours leur propre code
Il est fréquent d’entendre des développeurs critiquer la qualité du code d’un produit ou la solution en elle-même. Nombreux sont ceux préférant leur code et leur solution à ce qui existe sur le marché, se targuant – à tort ou à raison – d’être capable de développer des outils de meilleure qualité.
L’objectif ici n’est pas de comparer la qualité des codes ou le niveau des développeurs, mais de réfléchir aux intérêts de l’entreprise sur le long terme. Même en acceptant le postulat que vos développeurs seraient plus compétents que ceux ayant développé la solution déjà existante, choisir de construire son propre dispositif peut être contre-productif pour plusieurs raisons :
-
La durée de développement :
Développer une plateforme data complète, utile et capable de rivaliser avec les solutions du marché est un projet de grande envergure risquant de s’étaler sur plusieurs années et de monopoliser des ressources sur le long terme. Il faut plus longtemps encore pour en mesurer les bénéfices.
-
La maintenance de la plateforme :
Créer sa propre solution implique aussi de s’assurer de la maintenance du code sur le long terme. Cela impose d’avoir une excellente documentation et un code legacy de grande qualité ainsi que d’avoir toujours un développeur capable de mettre à jour le software.
-
La persistance des développeurs :
Les data engineers à l’origine de la plateforme sont susceptibles de changer de projet/équipe/entreprise au court de la vie du dispositif data. La transmission du projet s’en trouve alors complexifiée. De plus, les nouveaux développeurs risquent de vouloir à leur tour adapter le code et l’architecture du projet.
Ainsi, faire le choix de développer son propre outil représente le risque d’avoir une plateforme instable et difficile à maintenir. De plus, les développeurs comparent plus généralement la qualité intrinsèque du code, mais négligent la capacité de l’entreprise à maintenir l’outil et à le faire évoluer pour répondre à de nouveaux besoins.
Faire le choix d’une solution existante, c’est réduire le temps de développement et accroître la stabilité de ses outils.
Les data engineers ❤️ la liberté
Construire son propre outil, c’est aussi choisir les technologies mises à contribution dans le projet. Mais la diversité des IDE, des langages, des frameworks et des softwares rend ce choix complexe. En outre, les préférences individuelles des développeurs sont multiples et peuvent très souvent donner lieu à d’intenses débats. Ainsi la stack data de la plateforme risque d’être pensé en fonction des habitudes du data engineer plutôt que sur des critères objectifs de maintenance et scalabilité au sein de l’entreprise.
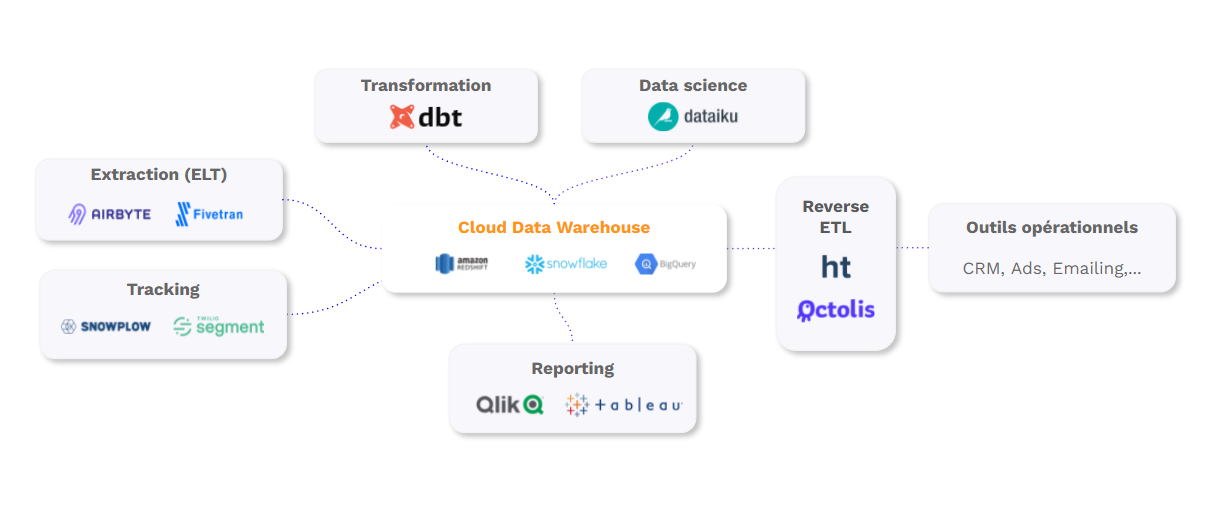
Exemple d’architecture data moderne
Plus encore, le fait de développer la solution offre une grande liberté quant à l’architecture de la plateforme. C’est parce que les développeurs savent qu’ils pourront coder avec les langages de leur choix et assembler les différentes briques à leur manière qu’ils préfèrent construire eux-mêmes le dispositif data.
Mais cette liberté pour le développeur peut rapidement se transformer en contraintes pour l’entreprise. En effet, le choix du data engineer va dépendre de plusieurs critères susmentionnés, tels que la popularité de l’outil, la possibilité d’utiliser son propre code… A l’inverse, l’entreprise doit considérer avant tout l’intégration du dispositif data dans son SI, la possibilité de le faire évoluer et de le maintenir à jour.
En résumé, l’entreprise est soumise à des contraintes quand le développeur cherche à être libre dans son travail. Cette opposition peut conduire à un choix contre-productif de la part du data engineer.
Les obstacles liés à la construction d’une plateforme data
Les considérations des data engineers ne sont pas les seules raisons pour lesquels construire son propre dispositif data n’est pas une bonne idée. D’autres problématiques s’ajoutent à ces considérations :
Les coûts d’exploitation sont supérieurs aux coûts de construction
Construire une ébauche de dispositif data est l’affaire de quelques jours pour un data engineer expérimenté. C’est probablement pour cette raison que le temps de développement est très souvent grandement sous-estimé. En effet, s’il est relativement facile de mettre en place un premier MVP, il est autrement plus complexe de coder une plateforme complète, stable et facile à maintenir.

Coûts d’une plateforme data au cours de son cycle de vie complet (Source)
Une fois la première version live déployée, il est nécessaire de s’assurer qu’une équipe soit responsable de :
-
Maintenir le code à jour :
Mettre à jour les dépendances, corriger les vulnérabilités et les failles de sécurités…
-
Gérer les bugs :
Au cours de son cycle de vie, la plateforme va subir de nombreux bugs qu’il faut fixer rapidement pour assurer la disponibilité du dispositif. Il est donc nécessaire d’avoir en permanence un développeur ayant une connaissance précise du code et capable d’intervenir rapidement.
-
Faire évoluer le dispositif :
Pour transformer le MVP en dispositif complet, il est nécessaire de prendre en compte les retours des utilisateurs et d’y ajouter les fonctionnalités manquantes. Il est aussi important de s’assurer que l’usage de la data par les équipes métiers n’est pas redondant et de proposer des solutions le cas échéant.
Ainsi, les coûts d’exploitation de la plateforme risquent d’être nettement supérieurs aux coûts de construction. Ces coûts d’exploitation sont généralement sous-estimés et le coût total du projet sera probablement bien supérieur aux estimations. De plus, si l’investissement initial pour construire la plateforme peut sembler légitime face à l’acquisition d’un software, il est cependant plus difficile de justifier les coûts d’exploitation par rapport à un abonnement à une solution existante (surtout si celle-ci est plus complète).
Au cours du cycle de vie du dispositif, il est probable que l’entreprise ne perçoive pas un retour sur investissement suffisant pour justifier les dépenses d’exploitation. Le projet est alors véritablement vain.
Votre plateforme data ne sera pas pensée comme un produit
Lorsque le dispositif data n’est pas une finalité, mais un moyen de répondre à des problématiques rencontrées par les employés, le résultat est souvent fragmentaire et présente de nombreuses limites.
-
Une plateforme peu fonctionnelle
Dans une entreprise où la plateforme data n’est pas le produit final, mais seulement un support pour les équipes métiers, il est très probable que l’outil ne soit pensé qu’en réponse à des cas d’usages précis. Le dispositif final risque alors de ressembler plus à un assemblage disparate de fonctionnalités qu’à un produit complet.
Dans ce cas, il est assez rare de travailler à améliorer les performances globales de l’application ou de proposer des fonctionnalités plus globales visant à faciliter l’expérience de l’utilisateur final. L’accent est mis sur les cas d’usages restant, au détriment de la cohérence globale du dispositif et de sa fonctionnalité.
-
Une solution peu efficace pour améliorer la productivité
Proposer une plateforme pour répondre à des cas d’usages spécifiques permettra aux équipes métiers de réaliser certaines tâches plus facilement, mais n’est pas suffisant pour accroître sensiblement leur productivité. De plus, les ressources étant limitées lors du développement d’une application en interne, il est probable que les solutions visant à réellement augmenter la productivité soient reléguées au second plan, l’accent étant mis sur la capacité à répondre aux besoins spécifiques à l’origine de la plateforme.
En effet, proposer un service permettant d’augmenter la productivité requiert le développement d’outils encore plus complexe venant s’ajouter au dispositif en construction. Il est peu probable qu’une entreprise dont l’activité n’est pas directement en lien avec la construction d’un tel software dispose des ressources suffisantes pour s’emparer d’un projet de grande envergure et le mener convenablement à son terme.
Conclusion
Construire un dispositif data entier est un projet souvent plus complexe et coûteux que prévu. Pour cette raison, il est nécessaire de définir très clairement ses besoins et de s’assurer que le ROI du projet soit particulièrement important avant d’entamer la construction d’un dispositif data.
Mesurer le ROI de son dispositif data
Pour vous aider à mesurer le ROI de votre dispositif data, nous mettons à votre disposition un template téléchargeable gratuitement à adapter à votre organisation dont l’utilisation est détaillé dans l’article associé..
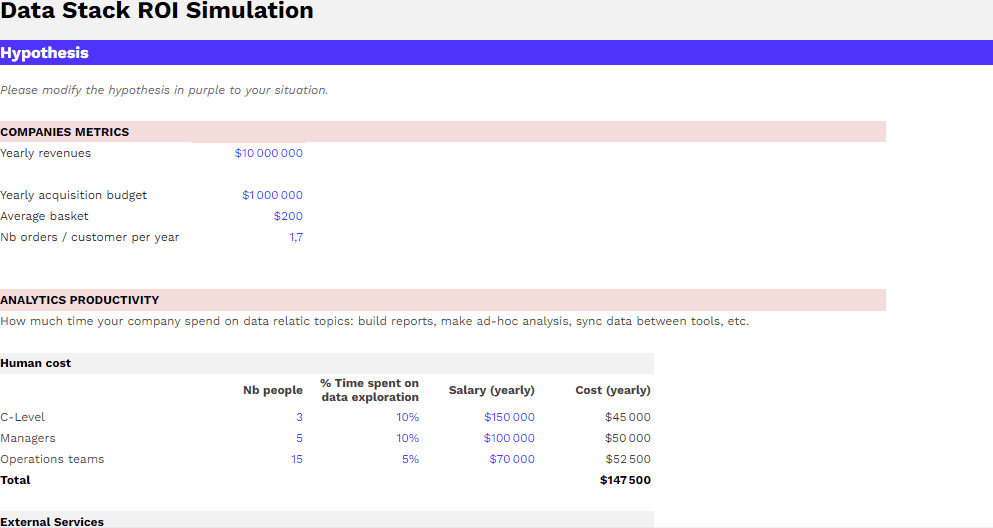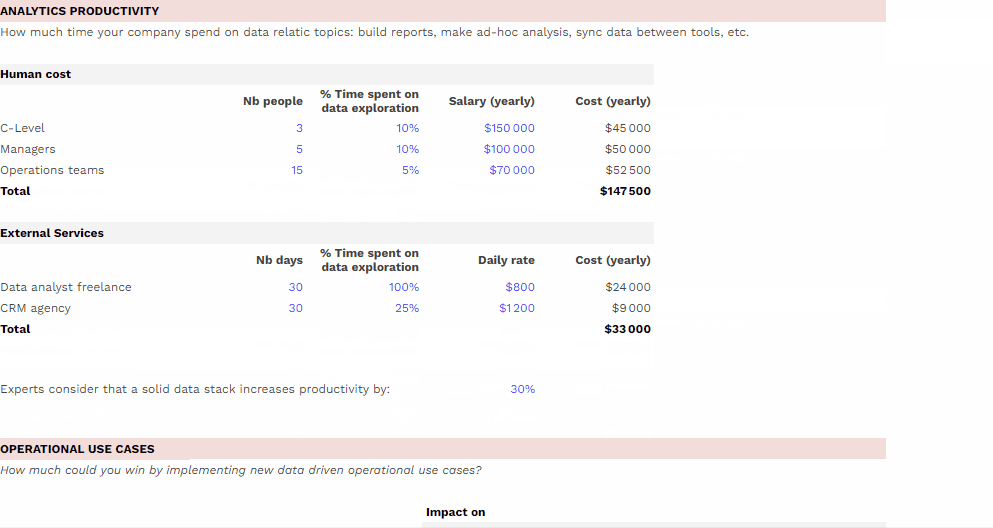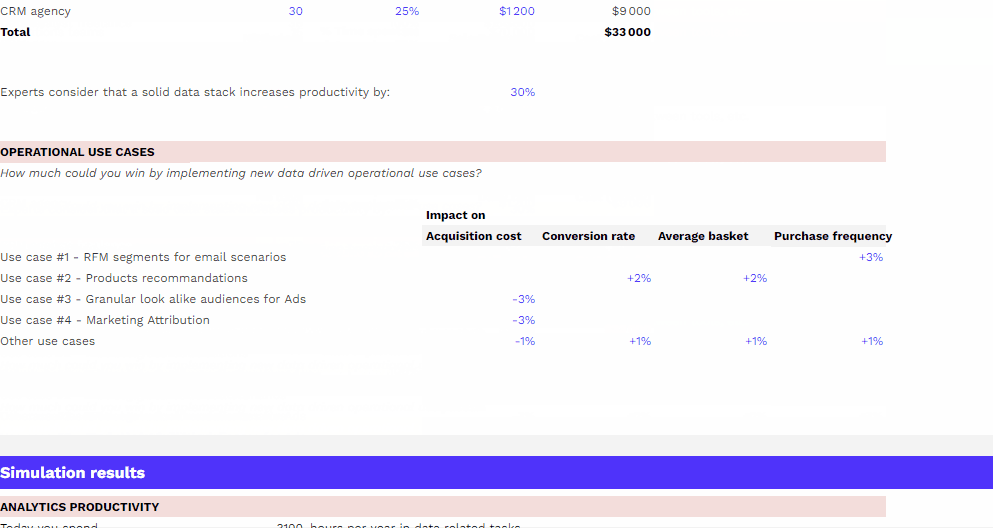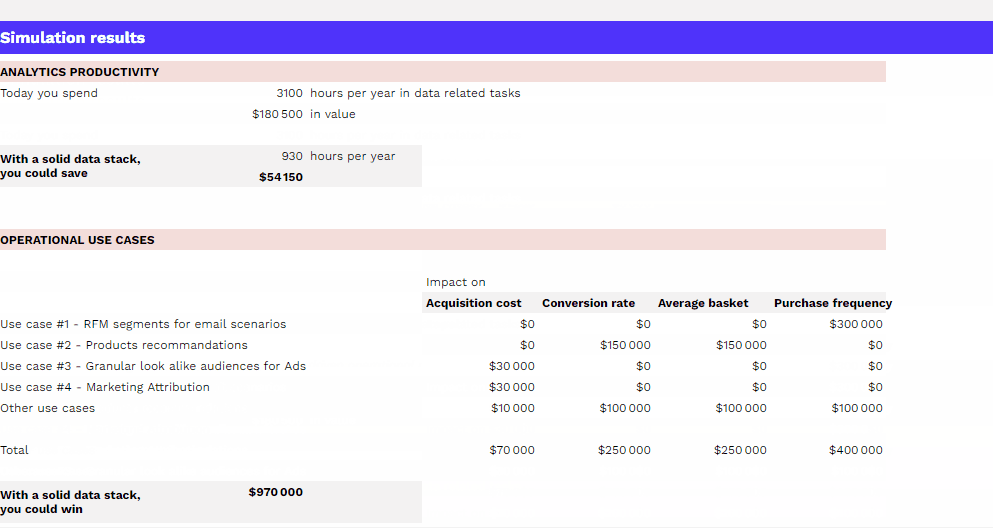
Dans la majorité des cas, il sera possible de trouver une solution existante répondant à ces besoins et de constater que la mise en place d’une telle solution offre un retour sur investissement plus important. Nous conseillons donc de s’orienter vers de telles solutions qui permettront des économies de temps, d’argent et de ressources.