Qu’est-ce que la stack data moderne ?
La stack data moderne a un sens différent suivant la personne à qui vous vous adressez.
Pour les ingénieurs analytics, c’est un bouleversement technologique majeur. Pour les fondateurs de startups, c’est une révolution dans la manière de travailler. Pour les investisseurs, ce sont des dizaines de milliards de dollars levés et un marché florissant. Pour Gartner, la stack data moderne est à la base d’une stratégie data & analytics totalement nouvelle.
Etc. Etc.
Pour nous, la stack data moderne rend simple, rapide, souple et abordable ce qui était autrefois compliqué, long, rigide et coûteux.
Il fallait autrefois dépenser des dizaines de milliers d’euros pour maintenir une base de données qui tombait régulièrement en panne, embaucher un ingénieur à temps plein pour intégrer les données Salesforce au data warehouse, payer toute une équipe de développeurs pour permettre aux analystes d’utiliser SQL dans un navigateur.
Aujourd’hui, tout cela ne vous prend que 30 minutes. C’est un game changer incroyable.
Les organisations n’ont pas encore pleinement pris conscience de la révolution apportée par la stack data moderne. C’est notre conviction et c’est aussi celle partagée par Benn Stancil, chief analytics officer et fondateur de Mode, dans une très belle tribune publiée sur son blog « The Modern Data Experience« . Nous nous en sommes très largement inspirés pour rédiger l’article que vous vous apprêtez à découvrir.
Nous le rejoignons complètement sur la nécessité de penser la stack data moderne comme une expérience. La finalité n’est pas de construire une nouvelle architecture data/tech, c’est de transformer l’expérience des utilisateurs (business, data et tech). A trop penser techno, on finit par en oublier l’essentiel et faire échouer les projets.
📕 Sommaire
Les limites de la stack data moderne
La stack data moderne peine à rendre la data plus accessible aux utilisateurs business
Nous avons vu que chacun s’accordait à penser que la stack data moderne était quelque chose de formidable, même si c’est pour des raisons différentes. Mais interrogez les utilisateurs business, vous n’aurez pas le même son de cloche. Pour eux, la stack data moderne n’a rien de fantastique.
Pour la plupart des gens en fait (je parle des gens agréables, sociaux, du genre à pouvoir passer une soirée sans se disputer sur le formatage SQL), la stack data moderne est une expérience, et souvent…un ensemble d’expériences désagréables :
Pour reprendre l’analogie d’Erik Bernhardsson, fondateur de Modal Lab, si la stack data moderne est un restaurant, toutes les frustrations que l’on vient de décrire sont celles que l’on a lorsque l’on mange un plat sans saveur. Le chef a investi dans l’amélioration des cuisines, mais les clients (les utilisateurs business, mais aussi les analystes data) sont ici pour déguster de bons plats servis par un personnel attentionné dans un cadre agréable.
Tant que vous n’arrivez pas à ce résultat, votre technologie, votre « stack data moderne », si révolutionnaire qu’elle soit, est quelque chose de théorique.
La stack data moderne se résume trop souvent à une multiplication des outils
Les utilisateurs business n’arrivent pas à utiliser les données comme il faudrait. Ils sont insatisfaits, frustrés. La première réaction quand quelque chose ne fonctionne pas consiste à multiplier les outils. On crée des cartographies de tous les outils et systèmes à disposition et on essaie de trouver l’endroit où on pourrait venir en caler un nouveau.
Même si chaque outil pris individuellement permet de réaliser les tâches pour lesquelles il est fait de manière plus efficace, fractionner l’écosystème en utilisant des briques de plus en plus petites ne permet pas de résoudre les vrais challenges.
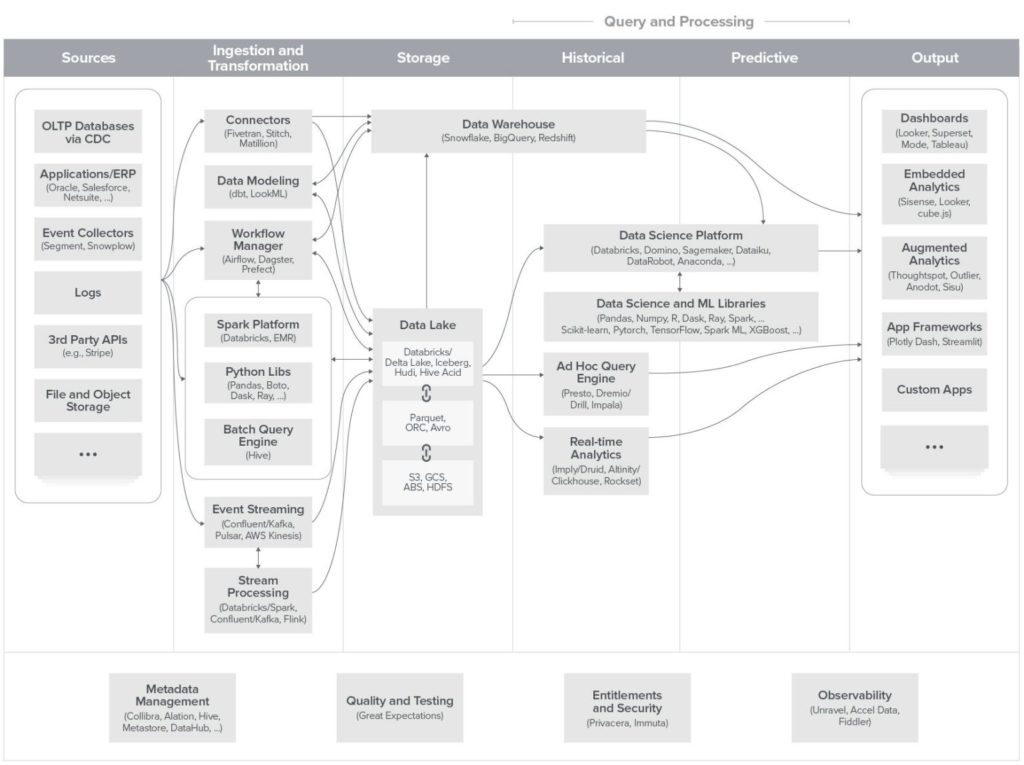
Comme l’explique bien Erik Bernhardsson, l’hyperspécialisation nous rend excellents pour couper des oignons et cuire les tartes aux pommes, mais c’est une mauvaise façon de gérer un restaurant.
Non, la stack data moderne ne consiste pas à empiler le plus d’outils possibles. Elle ne doit pas être le prétexte à une prolifération des technos. Prendre cette voie, c’est le plus sûr moyen de créer une stack data qui ne remplit pas sa promesse : aider les utilisateurs à travailler mieux grâce aux données.
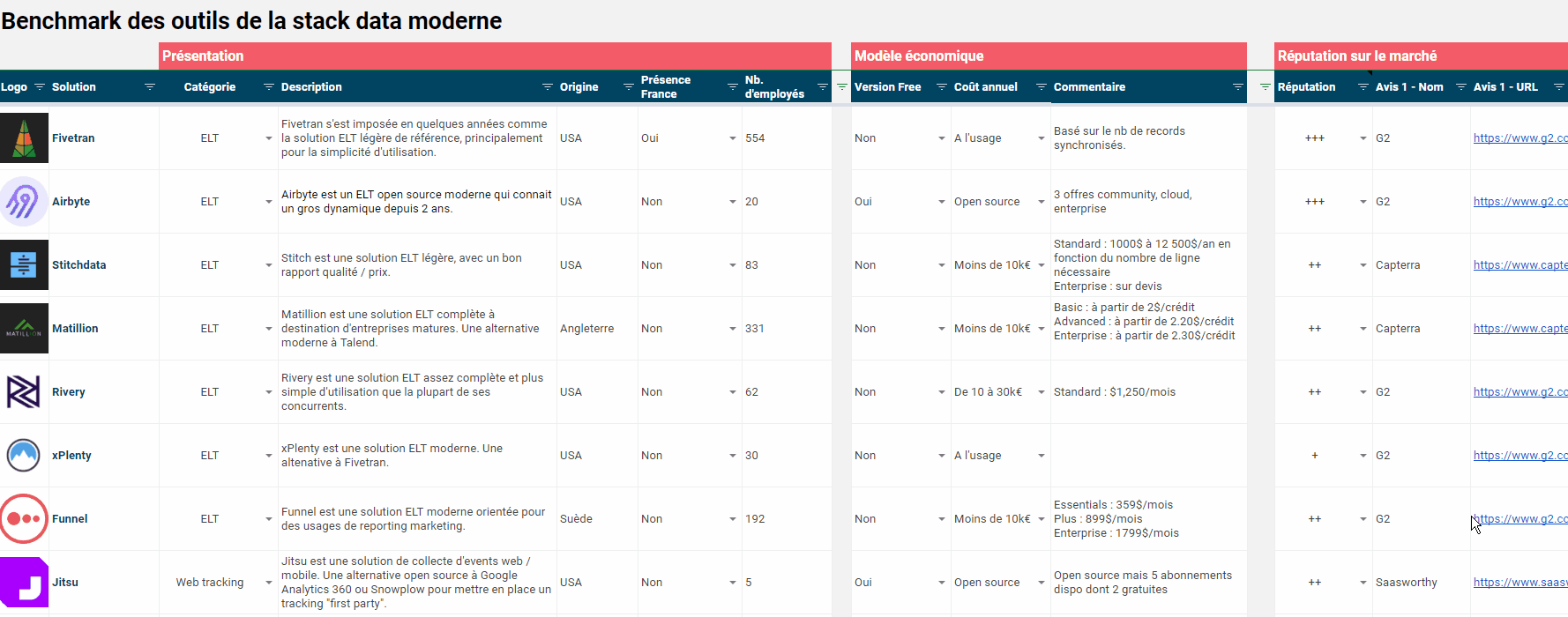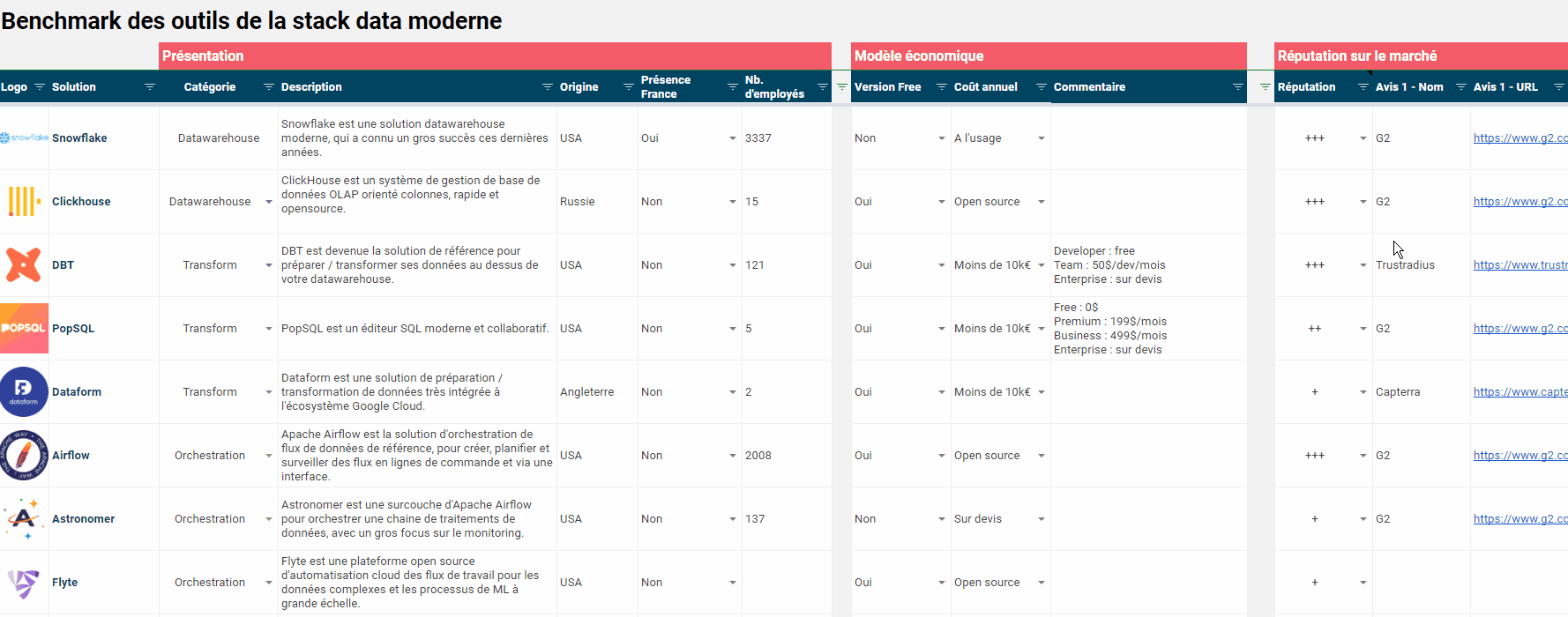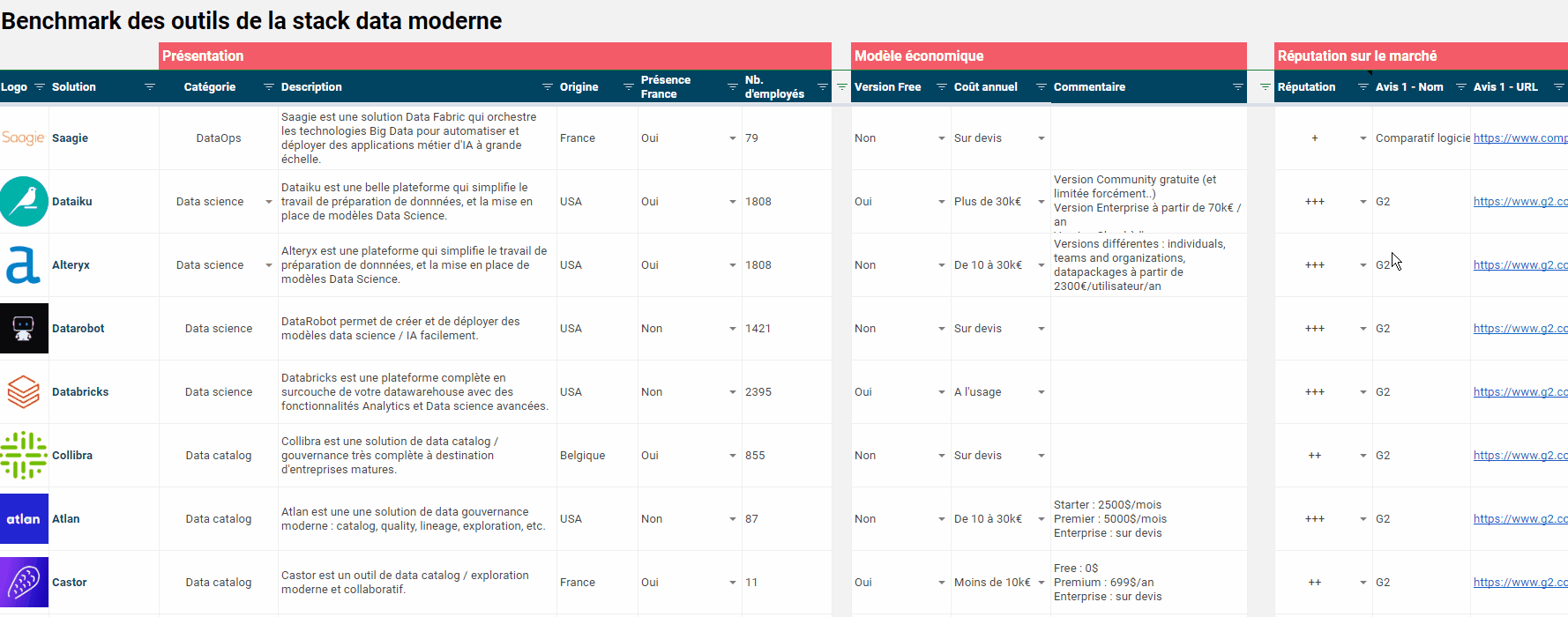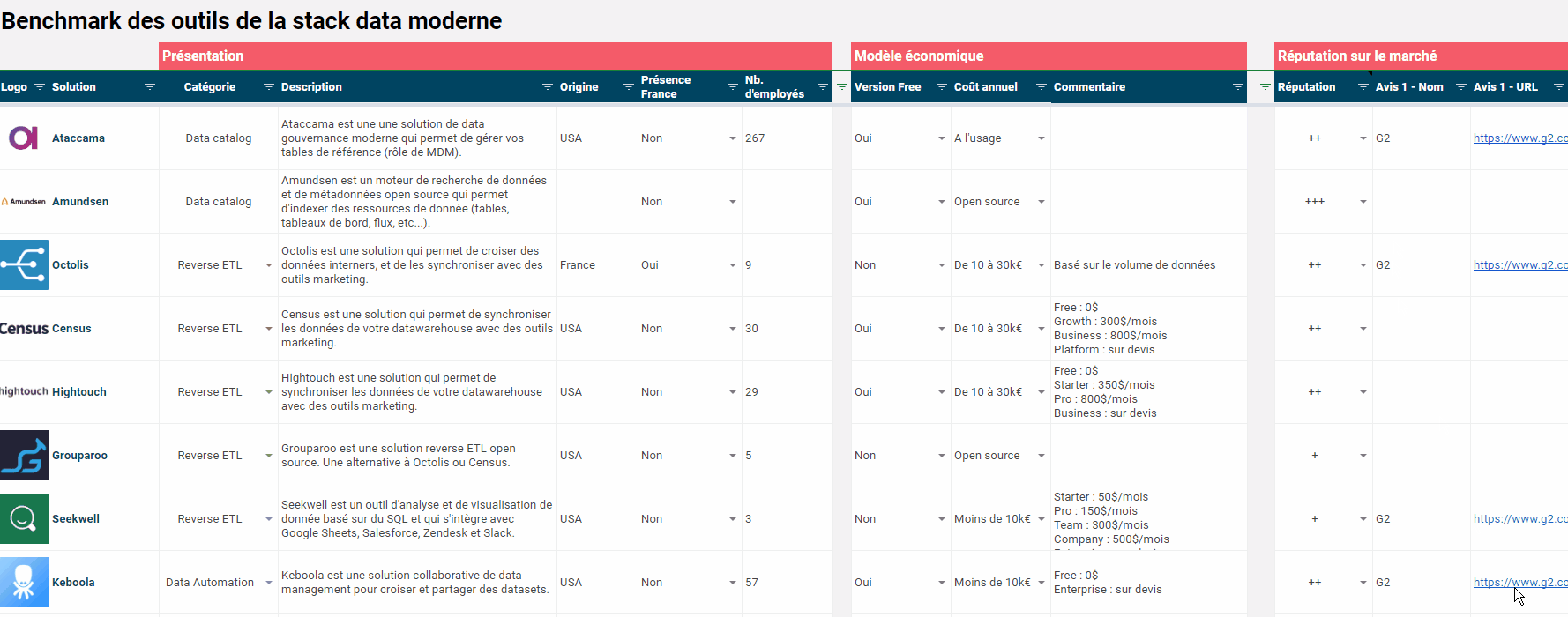
Benchmark complet des outils de la Stack Data Moderne
Même si la stack data moderne ne se réduit pas à une combinaison de nouveaux outils (et c’est tout le propos de l’article que vous lisez), on ne peut pas faire l’impasse sur les technologies. On vous a préparé un benchmark complet des outils de la stack data moderne. Type d’outil, origine, modèle économique, réputation sur le marché… chaque solution est présentée dans le détail, dans un beau GSheet facile à exploiter et téléchargeable gratuitement. Bonnes découvertes !
La stack data moderne peine à devenir une culture d’entreprise
Lorsque nous réfléchissons aux limites de la stack data moderne telle qu’elle est imaginée et vécue dans bon nombre d’entreprises, c’est le terme de « culture » qui nous vient, cette culture vaguement définie comme une combinaison des compétences que nous avons (ou pas), des structures organisationnelles de nos équipes et à partir de termes flous comme « culture des données », « culture data-driven ».
Ces éléments sont importants, mais il faut bien être conscient qu’une culture data ne s’inculque pas en offrant à ses équipes des manuels ou en organisant des séminaires.
Si les gens ne sont pas enthousiasmés par l’avenir que leur promettent les promoteurs de la stack data moderne, si les gens sont rebutés par le travail à accomplir pour devenir « data-driven », nous ne pouvons pas nous contenter de les inviter à rejoindre le bateau. Il faut réussir à gagner leur enthousiasme. Il faut les convaincre.
Pour cette raison, la stack data moderne comprise comme projet techno n’est pas suffisante. Ce n’est pas de cette manière que vous créerez de l’adhésion. Les entreprises doivent aller plus loin que la stack data moderne et chercher à concevoir une expérience data moderne. Je vous présenterai dans un instant quelques principes directeurs pour construire ce chemin.
Quelques exemples inspirants de stack data efficientes
On dit parfois que les équipes data devraient toujours penser ce qu’elles créaient comme un produit et leurs collègues comme des clients. Si on admet cette idée, quel devrait être ce produit ? A quoi devrait ressembler le chemin qui nous mène d’une question, qui nous fait passer par des technologies, des outils, des collaborations, des échanges pour aboutir à une réponse ? Comment construit-on une stack data moderne conçue comme un produit au service des utilisateurs cibles ?
On n’arrive que rarement à répondre de manière satisfaisante à ces questions.
Ce n’est pas une fatalité. Certaines entreprises ont réussi à trouver des réponses pertinentes.
Airbnb, Uber et Netflix ont construit des stack data intégrées, avec des outils analytics, des outils de reporting, un catalogue de métriques, des catalogues de données et des plateformes ML. Contrairement aux éditeurs des logiciels qu’ils utilisent, les outils qui composent ces stacks data sont au service d’un objectif plus grand qu’eux-mêmes. Les outils sont au service de l’entreprise, et non l’inverse.
Les résultats sont impressionnants :
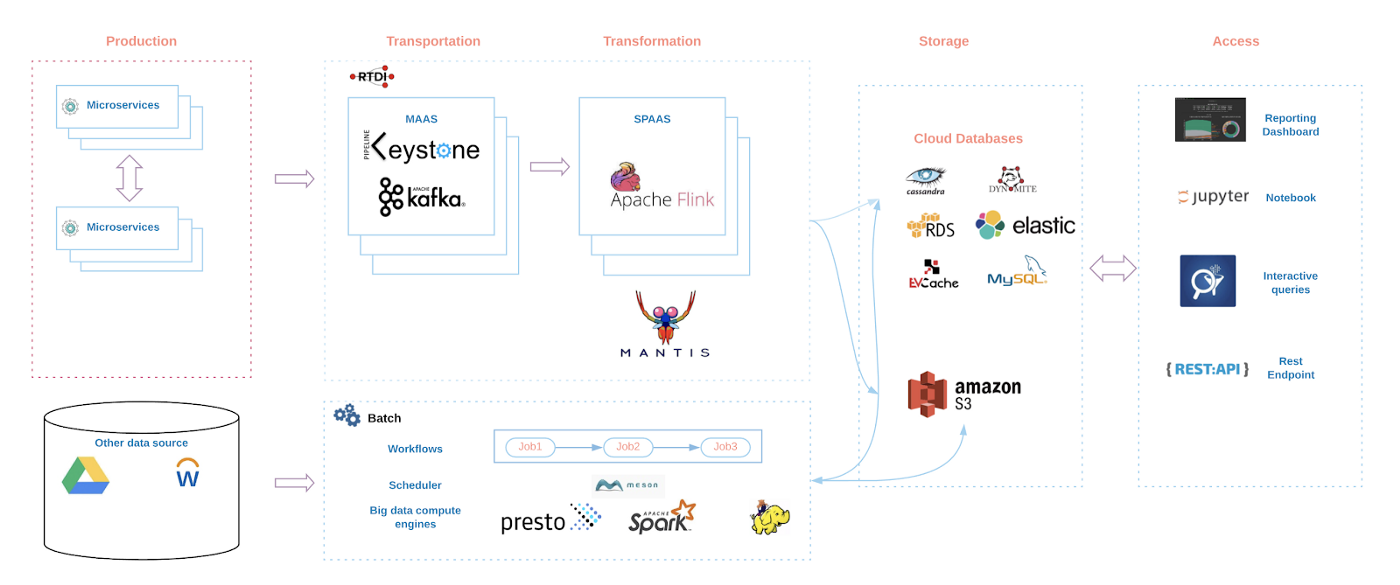
Les questions les plus importantes à se poser
Il ne fait aucun doute que ces outils ne sont pas parfaits. Mais ils offrent une fenêtre sur les questions les plus importantes qu’il faut se poser :
La stack data moderne est décentralisée et cela a un coût
Quelle que soit la définition de la stack data moderne que vous utilisez, presque tout le monde, nous compris, s’accorde à dire qu’elle doit être décentralisée.
Je ne cherche pas ici à vous vendre une approche plus qu’une autre. Mon objectif n’est pas d’entamer une discussion sur les fondements philosophiques de la stack data moderne. Doit-elle être cloud-first, plutôt modulaire ou monolithique, version control ou peer review ? Ce n’est pas le sujet.
Mon point, c’est que la décentralisation qui sous-tend l’approche stack data moderne a un coût. Pourquoi ? Parce que l’architecture se reflète sur l’expérience de ses utilisateurs. Les lignes de faille qui séparent les produits de la stack deviennent des lignes de faille entre les différentes expériences d’utilisation. Il est là le challenge.
Si la stack data moderne est parfois décevante, c’est que loin d’aider les utilisateurs, elle conduit à une fragmentation de l’expérience. La fragmentation des outils aboutit à une fragmentation de l’expérience. C’est ce contre quoi il faut chercher à aller.
Pour trouver la solution, posons-nous cette question : comment une multitude d’entités souveraines et souvent concurrentes peuvent-elles s’unir pour construire quelque chose de cohérent ?
Un petit détour par l’évolution du commerce international
L’histoire du commerce international peut nous aider à trouver la solution. Avant la Première Guerre mondiale, la plupart des accords commerciaux internationaux (traités sur les tarifs et les restrictions) étaient des accords bilatéraux, entre deux pays. Au fur et à mesure que les pays européens se sont industrialisés, un réseau d’accords bilatéraux a vu le jour, centré sur les principaux partenaires commerciaux et souvent piloté par eux : dans le cas européen, la Grande-Bretagne et la France.
En 1947, après deux guerres mondiales, la crise de 29 et la mode pour le protectionnisme, 23 des principaux partenaires commerciaux du monde ont signé l’Accord général sur les tarifs douaniers : le GATT. En raison du poids des membres fondateurs, l’accord n’a cessé d’attirer à lui de nouveaux signataires dans la deuxième moitié du XXème siècle. Le GATT a finalement été remplacé en 1995 par l’Organisation mondiale du commerce, l’OMC. Aujourd’hui, l’OMC a 164 membres qui représentent 98% du commerce international.
Bien que de nombreux pays négocient encore des accords commerciaux bilatéraux ou régionaux, le commerce mondial est principalement régi par les traités mondiaux de l’OMC plutôt que par un réseau complexe de milliers d’accords bilatéraux.
La stack data moderne doit accomplir la même évolution que celle du commerce international
Encore aujourd’hui, la stack data, ce sont des centaines d’Etats membres en orbite autour de grosses plateformes comme Snowflake, Fivetran, dbt et quelques autres. Les relations entre les éditeurs sont gérées par des intégrations bilatérales qui permettent de combler les fossés entre les outils. Les intégrations bilatérales sont à la stack data ce que les accords bilatéraux sont au commerce international.
Dans des écosystèmes aussi complexes que ceux du commerce international ou des technologies data, les intégrations bilatérales montrent rapidement leurs limites. L’approche n’est pas scalable. On aboutit à un patchwork désordonné d’accords ou d’intégrations qui ne peut que se désagréger (et qui se désagrége) avec le temps. Le GATT et l’OMC en sont la preuve.

Construits à partir des plus grandes économies du monde, ces accords ont créé une vision commune et des principes directeurs de la politique commerciale qui, même s’ls ne sont pas toujours juridiquement contraignants, ont contribué à faire pencher le monde dans une direction commune.
La stack data moderne doit accomplir la même évolution. Nous allons essayer de synthétiser les principes directeurs qui doivent la gouverner.
Principes directeurs pour une expérience data moderne
La stack data moderne fournit une roadmap SI. Pour que la stack data moderne se traduise pour les utilisateurs par une expérience data moderne, quelques principes directeurs doivent être suivis. Voici ceux auxquels je crois.
#1 Les utilisateurs business doivent pouvoir faire leur métier sans devoir se transformer en data analyst
On a beaucoup parlé de démocratisation des données. C’est une expression à la mode et les objectifs sont louables : permettre à chaque utilisateur de manipuler les données en autonomie et ainsi libérer les équipes data des tâches ingrates qui leur sont traditionnellement confiées pour qu’elles puissent se concentrer sur des projets à forte valeur ajoutée.
La démocratisation des données a eu tendance à devenir une prescription : « Devenez tous analystes grâce aux outils no code ! ». Ce projet a largement échoué comme on peut le constater aujourd’hui avec le recul que l’on a.
L’expérience de la stack data moderne que nous appelons de nos vœux ne consiste pas à mettre les données dans les mains des utilisateurs pour leur laisser le soin de les analyser. Ce que nous voulons, c’est intégrer les données dans les systèmes opérationnels où elles se trouvent déjà pour libérer la productivité de leurs utilisateurs. Les données doivent aider les gens à mieux faire leur travail, plutôt que de leur ajouter un nouveau travail à faire.
#2 La data science et la BI doivent fusionner
On a pris l’habitude de penser que les analystes data devaient travailler dans des outils techniques avancés et que tous les autres collaborateurs devaient utiliser des outils de BI user-friendly. C’est faux. Les outils de BI drag & drop peuvent être très utiles pour les data scientists chevronnés et tout le monde peut devenir un consommateur d’analyses avancées.
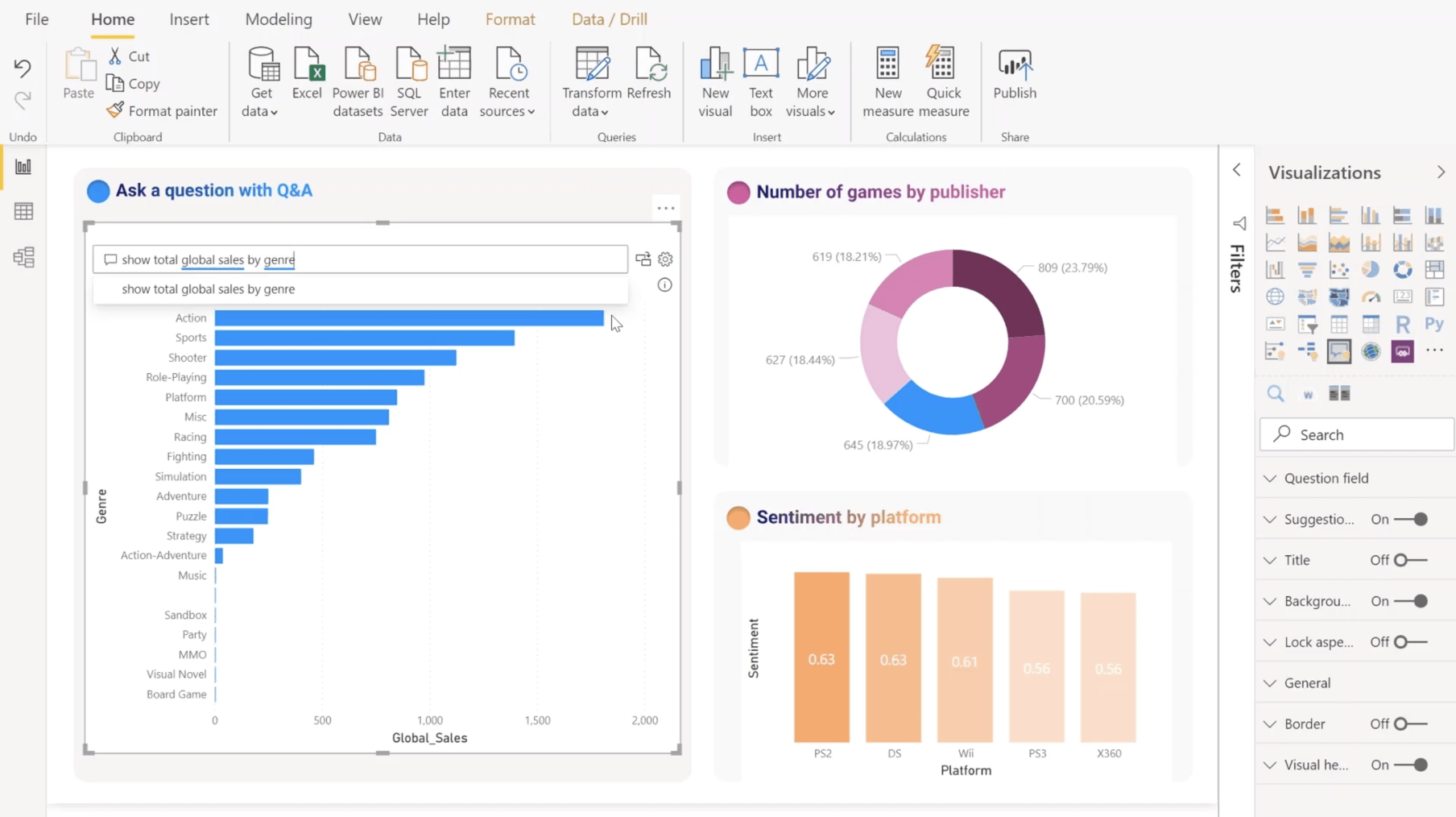
Dans une expérience data moderne, les utilisateurs doivent pouvoir passer sans problème de la visualisation d’un KPI provenant d’un catalogue de données sous contrôle à l’exploration de ce KPI à l’aide de groupements et de filtres, puis à son incorporation dans des analyses techniques approfondies. On doit pouvoir visualiser sur la même interface hommes machines des KPIs intégrés à des tableaux de bord et explorer les données qui alimentent ces KPIs pour approfondir le niveau d’analyse.
Les personnes qui consomment des données ne devraient jamais avoir à sortir d’un outil pour approfondir leurs analyses. Si la stack data moderne nous parle d’intégration des données dans une architecture tech, l’expérience data moderne nous parle d’intégration des expériences.
#3 Les utilisateurs doivent avoir confiance dans les données qu’ils ont sous les yeux
« Est-ce que ces données sont fiables ? » est l’une des questions les plus frustrantes et l’une des plus courantes que les gens posent à propos des données. Aujourd’hui, la réponse à cette question dépend essentiellement de signaux implicites :
Ces questions nous conduisent à des recherches interminables. On utilise plusieurs outils pour confirmer les résultats. On perd du temps. Voire pire : on n’utilise pas les données, faute de confiance.
Pour que les utilisateurs aient confiance dans les données qu’ils visualisent et qu’ils manipulent, il faut que chaque set de données indique de lui-même si les processus amont qui l’ont constitué sont corrects ou non, à jour ou non, en un mot : fiables.
Dans une expérience data moderne, on passe du temps à débattre sur les actions à prendre à cause d’un chiffre lu sur un tableau de bord plutôt qu’à vérifier si ce chiffre est juste ou non.
#4 Ne pas oublier ce que l’on a appris
Les informations que nous présentent les outils de BI sont éphémères. Elles disparaissent au fil des mises à jour des données et des mises à jour du design des reportings. Les données récentes chassent les données anciennes. Les analyses ad hoc sont notées à la va-vite et sans méthode. Les conversations se perdent dans les flux Slack.
Dans une expérience data moderne, ce que les données nous apprennent fait l’objet d’un enregistrement, d’une historisation. On ne perd rien des analyses que l’on a faites. On garde la mémoire des enseignements. C’est le plus sûr moyen d’avancer et de ne pas refaire les erreurs du passé.
#5 Les métriques doivent être gérées à un niveau global
En général, les métriques sont pilotées à un niveau local dans les outils de BI. Chaque équipe gère à son niveau ses KPIs, leur mode de calcul, les ratios de synthèse, l’évolution du dispositif de pilotage. Dans une stack data décentralisée et modulaire, on aboutit rapidement à un patchwork de calculs dupliqués et souvent contradictoires.
Une expérience data moderne suppose de la coordination. La gestion et l’évolution des métriques doivent être centralisées. Si les règles de calcul d’un KPI change, ce changement doit être diffusé partout : dans les tableaux de bord de BI, dans les notebooks Python, dans les pipelines ML opérationnels.
#6 Il ne faut pas communiquer uniquement par tableaux
A force de vous plonger dans les données, vous ne finissez par ne plus voir que des structures relationnelles : des tables, des lignes, des colonnes, des jointures. Et pour cause, la plupart des outils data présentent les données sous cette forme. Et c’est sous cette forme que les data analysts se confrontent aux donnés.
Mais pour tous les autres utilisateurs, les données se présentent de manière plus protéiforme, sous forme de métriques dans une série temporelle, de représentations abstraites dans des domaines métiers complexes, de comptes rendus écrits…Les utilisateurs doivent pouvoir interroger et explorer les données de différentes manières, pas uniquement dans des tables et des colonnes.
#7 Il faut construire un pont entre le passé et le futur
Il est tentant de concevoir la stack data moderne comme une discontinuité, le saut d’un passé que l’on veut oublier vers un avenir radieux. Construire une stack data moderne, pour beaucoup, c’est faire table rase du passé. C’est une conception fausse. Ce n’est pas une rupture, c’est une transition. Une transition qui ne mettra pas un terme à tous les problèmes et tous les freins que peut rencontrer un utilisateur de données. Dites-vous bien que vous continuerez à utiliser Excel ! Dans une expérience data moderne, il faut savoir négocier avec cette réalité et admettre qu’une partie du passé se conserve.
#8 L’expérience data moderne est création continue d’imprévisibles nouveautés
Les analyses ne sont pas prévisibles. Ce n’est pas un processus linéaire qui peut être anticipé. On sait d’où l’on part : une question. On ne sait pas où l’on va. Une question en appelle de nouvelles. De la même manière, une infrastructure data est un système évolutif qui se transforme à mesure que les enjeux business et que les sources de données changent.
Les analyses construites à partir de l’infrastructure data évoluent et font évoluer le système qui leur sert de base. L’expérience data moderne répond à la logique des systèmes émergents. Elle démarre petite, grandit, grossit, conquiert de nouveaux territoires. Les expériences et les systèmes rigides ont toujours un coût à la fin.
#9 L’expérience data moderne casse les murs
Les stacks data ont pour habitude de créer des murs et les différents utilisateurs collaborent entre eux en se jetant des choses par-dessus les murs érigés : les ingénieurs data jettent des pipelines aux analysts, les développeurs BI jettent des rapports aux utilisateurs métiers, les analystes jettent des résultats à qui veut bien les recevoir. Le caractère modulaire des stacks data modernes est une tentation à créer encore plus de murs.
De la même manière que dbt a cassé un mur, une expérience data moderne doit briser les autres en encourageant la collaboration et le partage entre les équipes business, data et tech.
Il y aurait beaucoup de choses à dire sur chacun de ces sujets. Ce sont des sujets dont il faut parler, ce sont des conversations qu’il faut avoir. Si l’on ne pense pas l’expérience data moderne qui doit accompagner la stack data moderne, on peut réussir à construire une belle architecture d’outils, mais la promesse à laquelle on croyait (la révolution technologique, la transformation du fonctionnement de l’entreprise) ne se réalisera pas.