Les solutions ETL (ou ELT) permettent d’extraire les données de différentes applications pour les verser dans un data warehouse. Comme vous l’avez deviné, le reverse ETL va dans l’autre sens. Il permet d’extraire les données du data warehouse pour alimenter toutes sortes d’applications : CRM, outils publicitaires, service client, etc.
Le potentiel est colossal. Cela permet d’avoir une seule source de vérité pour la plupart des applicatifs métiers. Fini les problèmes récurrents pour réconcilier les données de l’outil A avec l’outil B, ou pour gérer des flux entre applicatifs de tous les côtés.
Si le potentiel est aussi important, pourquoi ce type de solution émerge maintenant ? Historiquement le data warehouse est le socle de la BI uniquement. Il sert à construire des reportings, de grosses requêtes ponctuelles qui ne sont pas critiques. Si on demandait à un DSI des années 2000, ce serait une aberration d’alimenter un CRM, une application critique qui consomme des données chaudes, à partir d’un data warehouse.
La nouvelle génération de Data Warehouse cloud (Snowflake, Google BigQuery, AWS Redshift, ..), et l’écosystème qui va autour, change les règles du jeu. Beaucoup plus puissant, facile à maintenir, adapté pour tout type de requêtes, le data warehouse cloud moderne peut devenir un véritable référentiel opérationnel. Et les reverse ETL, c’est le chainon manquant pour assurer le dernier kilomètre.
Dans ce guide complet, nous allons vous expliquer tout ce qu’il faut savoir sur cette nouvelle composante de la stack data moderne.
📕 Sommaire
Qu’est-ce qu’un reverse ETL ? [Définition]
Généalogie du reverse ETL : au commencement était l’ETL
Le reverse ETL désigne une nouvelle famille de logiciels jouant déjà un rôle clé dans la stack data moderne. Alors, qu’est-ce que c’est ? De quoi parle-t-on ?Cela n’aura échappé à personne, dans « reverse ETL », il y a ETL. Pour comprendre ce qu’est un reverse ETL, il faut d’abord avoir une bonne compréhension de ce qu’est un ETL. Car le reverse ETL procède de l’ETL comme nous le verrons dans un instant.
Le « bon vieil ETL »…oui, car les outils ETL sont tout sauf des technologies nouvelles. Le concept d’ETL a émergé dans les années 1970.
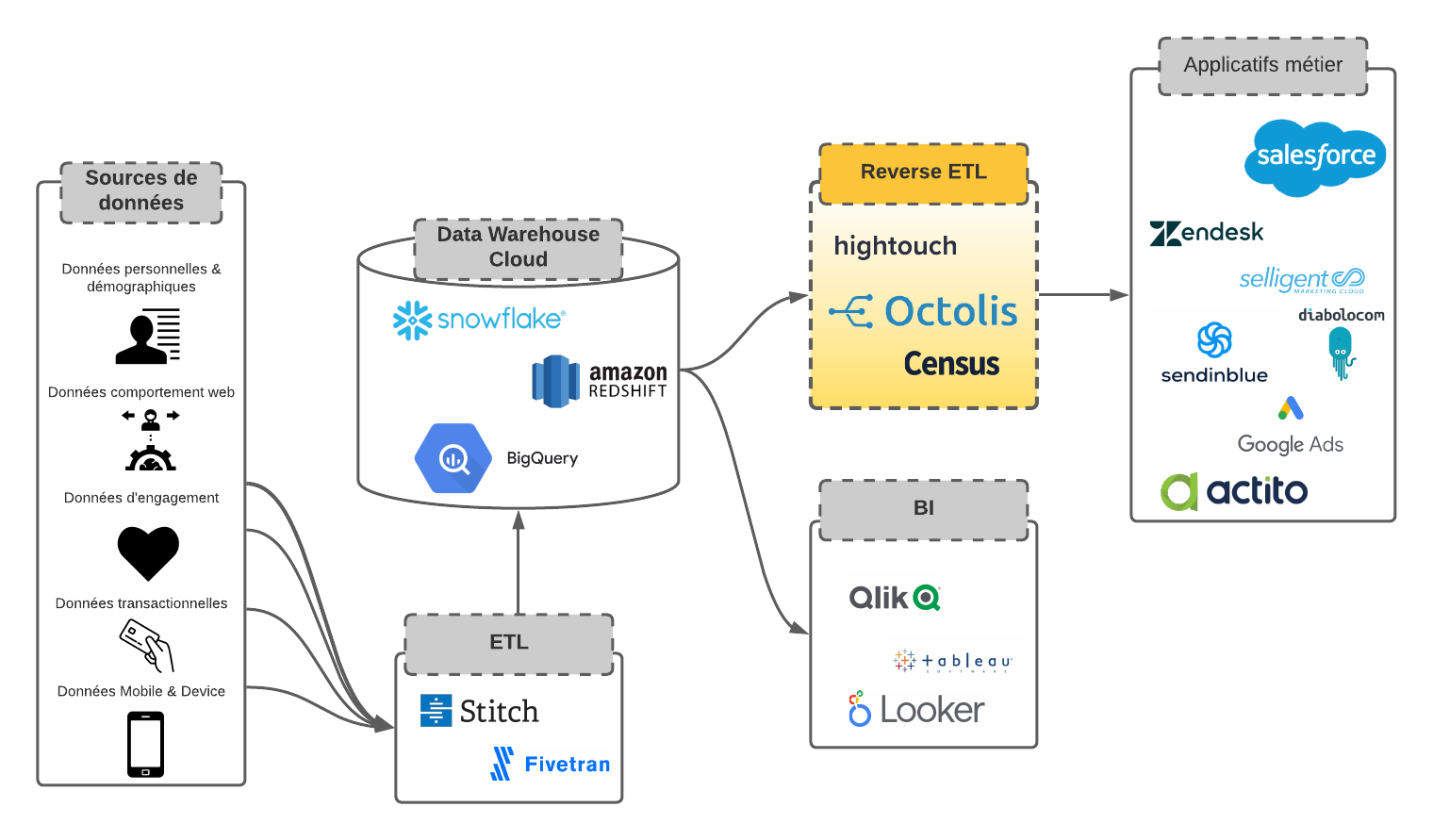
ETL, si on déplie l’acronyme, signifie Extract – Transform – Load. Avant de désigner une famille d’outils, l’ETL désigne un processus – un processus que les outils du même nom permettent d’accomplir. L’ETL est le processus qui consiste à Extraire les données issues des différentes sources de données de l’organisation, à les Transformer et enfin à les Charger (Load) dans un Data Warehouse, c’est-à-dire un entrepôt de données. Les outils ETL servent à construire le pipeline de données entre les sources de données et la base dans laquelle les données sont centralisées et unifiées.
Les sources de données peuvent être : des événements issus des applicatifs, des données issues de vos outils SaaS, de vos bases de données diverses et variées, et même de votre data lake…Les outils ETL développent des connecteurs avec les principales sources de données pour faciliter la construction du pipeline de données.

Les ETL du passé étaient des solutions lourdes, On-Premise, fonctionnant avec des Data Warehouses eux-mêmes lourds installés sur les serveurs de l’entreprise. Depuis l’avènement des Data Warehouses Cloud (en 2012, avec Amazon Redshift), une nouvelle catégorie de logiciels ETL est apparue : les ETL Cloud. La cloudification des Data Warehouses, inaugurée par Amazon, a entraîné une cloudification des outils ETL. Fivetran et Stitch Data sont deux exemples emblématiques d’outils ETL Cloud.
Les ETL servent non seulement à charger les données des sources dans la destination que constitue le DWH, mais sont aussi utilisés pour transformer la donnée avant son intégration dans la base. Ce n’est donc pas simplement une tuyau, mais aussi un laboratoire.
Nous pouvons maintenant comprendre en quoi consiste le reverse ETL.
Un reverse ETL est une solution pour synchroniser les données du DWH avec vos applicatifs métiers
En clair, l’outil ETL permet de faire monter les données de vos différentes sources dans le DWH afin de centraliser et d’unifier les données de l’entreprise. Ces données sont ensuite utilisées pour faire de l’analyse data, de la BI.
Le reverse ETL a une fonction inverse de celle de l’ETL. Le reverse ETL est la solution technologique qui permet de faire redescendre les données centralisées du DWH dans les applicatifs métiers. Le reverse ETL apporte enfin la solution à un problème lancinant pour les entreprises. En effet, les entreprises parviennent assez bien et assez facilement à centraliser les données dans le Data Warehouse. Cette facilité, c’est aux ETL Cloud qu’on la doit. Mais ces données, une fois dans le DWH, sont difficiles à faire sortir de la base et à exploiter dans les outils métiers. En clair, elles sont utilisées pour faire de la BI, mais rarement exploitées pour alimenter les applicatifs métiers en l’absence de solutions simples de synchronisation.

Le reverse ETL est une solution d’intégration des données souple pour synchroniser les données du DWH avec applicatifs utilisés par le marketing, les sales, l’équipe digital et le service client pour ne citer qu’eux. Les reverse ETL se caractérisent par leur souplesse et leur simplicité d’utilisation, tout comme leurs aînés les outils ETL Cloud. Via des connecteurs et modulo un travail de SQL, les données sont préparées, transformées, mappées puis synchronisées dans les applicatifs métier. Les reverse ETL permettent même de se passer des requêtes SQL et d’éditer les flux depuis une interface visuelle. Vous choisissez la colonne ou la table de la base de données que vous voulez utiliser et vous créez le mapping depuis l’inrerface visuelle pour spécifier où est-ce que vous souhaitez que les données apparaissent dans Salesforce, dans Zendesk, etc. Plus besoin de scripts. Plus besoin d’APIs.
Une fois le flux en place, les données sont synchronisées dans les applicatifs non pas en temps réel, mais suivant des batchs très courts de l’ordre de la minute. Les reverse ETL, comme Octolis, sont basés sur une approche que l’on appelle « tabular data streaming », vs l’approche « event streaming ». Ce que fait le reverse ETL, c’est copier et coller à intervalles très réguliers les tables du système source (le DWH) dans le système cible (l’applicatif métier).
Tout comme les outils ETL, les reverse ETL ne sont pas uniquement des tuyaux. Ils permettent de transformer les données du DWH, de les préparer, c’est-à-dire de nettoyer les données, de créer des segments, des audiences, des scorings, de construire un référentiel client unique.
Pourquoi les solutions reverse ETL ont le vent en poupe aujourd’hui ?
Maintenant que nous savons ce qu’est un Reverse ETL et comment ça fonctionne schématiquement, intéressons-nous un peu plus au « pourquoi ».
Pourquoi vouloir sortir les données du DWH ?
Il a fallu des années pour que les entreprises parviennent à centraliser et unifier leurs données dans une base maîtresse : le Data Warehouse Cloud. Et encore… beaucoup d’entreprises n’en sont pas encore là et ne disposent toujours pas de référentiel unique.
Mais pourquoi vouloir aller plus loin et faire sortir les données que l’on a soigneusement centralisées dans le Data Warehouse ?
D’abord, il faut bien se dire que les données restent quoi qu’il en soit dans le Data Warehouse. Le reverse ETL synchronise des set de données dans les applicatifs métiers, sans les déplacer au sens strict. Synchroniser ne veut pas dire migrer. Donc pas de panique, vos données restent au chaud dans le DWH.
Ce que fait le reverse ETL, c’est mettre ces données centralisées du DWH au service des applicatifs métiers. C’est bien connu, le médicament est à la fois remède et poison. On a utilisé jusqu’à présent le DWH comme remède au silotage des données…pour aboutir à une nouvelle forme de silotisation. Les données aujourd’hui, dans beaucoup d’entreprises, sont silotées dans le Data Warehouse. Sans un reverse ETL, les données stockées dans le DWH ne sont pas utilisées ou très peu par les applicatifs métiers. A quoi servent-elles ? A faire de la BI et du dashboarding comme nous l’avons dit plus haut. C’est dommage. Le DWH aboutit à la création de définitions et d’agrégats de données très intéressants pour le business, grâce à tout le travail réalisé avec SQL : la lifetime value, le marketing qualified lead, le product qualified lead, le score de chaleur, l’ARR, etc. Mais ces données signifiantes pour le business ne sont pas utilisées directement par les équipes business et les outils qu’elles utilisent.
Avec un reverse ETL, vous pouvez utiliser ces définitions, et les colonnes associées dans le DWH, pour créer de profils clients et des segments d’audience. Avec un reverse ETL, le Data Warehouse ne sert plus uniquement à alimenter la BI, il sert directement à alimenter les applicatifs métier.
Le reverse ETL était la pièce manque de la stack data, la pièce qui empêchait cette stack data d’être véritablement moderne.
Quels sont les cas d’usage d’un reverse ETL ?
Entrons un peu plus dans le concret et voyons quels sont les cas d’usage que rend possible un outil de type reverse ETL.
Il y a essentiellement trois familles de cas d’usage :
#1 L’Operational Analytics
Cette nouvelle expression désigne une nouvelle manière d’envisager l’analytics. Dans l’approche Operational Analytics, les données ne sont plus utilisées seulement pour créer des rapports et des analyses, mais sont distribuées intelligemment aux outils métiers. C’est l’art et la manière de rendre la donnée opérationnelle pour les équipes métiers en l’intégrant dans les outils qu’ils utilisent au quotidien. Si l’on y réfléchit, c’est l’approche qui permet vraiment de devenir data-driven, qui permet aux équipes de prendre en compte les données dans toutes leurs décisions et actions. Le tout en douceur, simplement, facilement, sans prise de tête, sans passer par la lecture de rapports de BI indigestes.
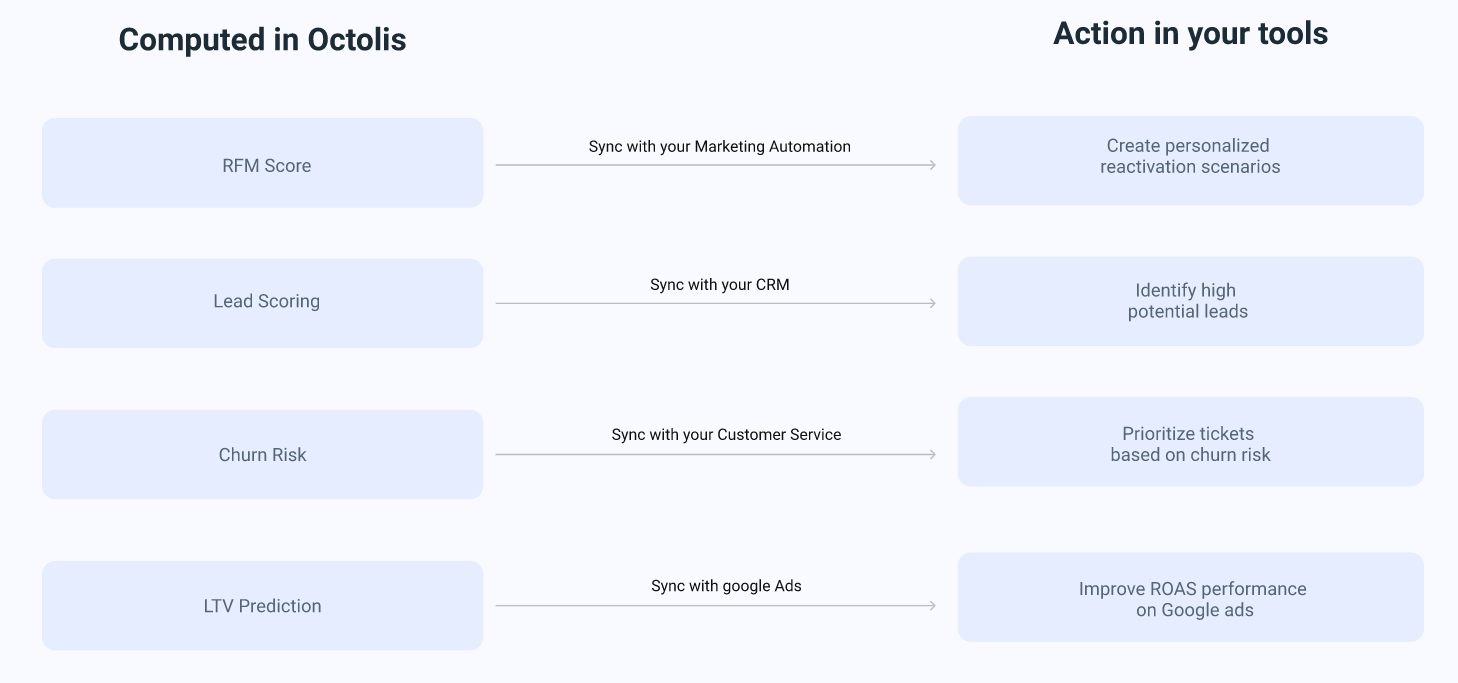
Comment déployer cette approche « Operational Analytics » ? Comment devenir data-driven ? Réponse : en utilisant un reverse ETL bien sûr ! Le reverse ETL permet de transformer les données en analyses (en segments, en agrégats) et les analyses en actions.
Imaginez un commercial qui veut connaître les comptes clés, ceux sur lesquels concentrer ses efforts ? Dans l’approche classique, à l’ancienne, on fait appel à un data analyst qui va utiliser du SQL pour repérer les leads à forte valeur dans le DWH et ensuite présenter le tout dans un beau tableau de BI…que personne ne lira et n’exploitera, bien entendu. On peut chercher à former les commerciaux à la lecture des tableaux de bord et des reportings. Mais dans la pratique, c’est toujours compliqué et c’est ce qui freine le devenir data-driven de beaucoup d’organisations. C’est cette difficulté à mettre les données et les analyses à la disposition des équipes métier qui empêche la pleine exploitation des données à disposition de l’entreprise.
Dans l’approche Operational Analytics, plus besoin de former les commerciaux à l’utilisation des rapports de BI, le data analyst intègre directement les données correspondantes du Data Warehouse dans un champ personnalisé Salesforce.
Un reverse ETL permet à un data analyst de déployer l’Operational Analytics aussi facilement que de créer un rapport.
#2 L’automatisation des flux de données
Un reverse ETL permet de mettre facilement et automatiquement au service des équipes métiers les données dont elles ont besoin à un instant t. En clair, non seulement il met à disposition des équipes métier les données dont ils ont besoin dans leurs outils, mais il facilite le travail des data analysts et autres data engineers.
Par exemple, si votre équipe commerciale demande à l’IT quels sont les clients à fort risque d’attrition, un reverse ETL constitue la solution qui permet de facilement donner la réponse…sans avoir à passer un temps fou à extraire les données du DWH. On pourrait aussi prendre les exemples :
Le reverse ETL permet de gérer facilement et de manière automatisé ces requêtes métiers du quotidien qui faisaient autrefois l’enfer de l’équipe IT. Il répond en ce sens à un problème récurrent dans les organisations : la communication, ou plutôt la mauvaise communication entre l’IT et les équipes métiers. Plus besoin de concevoir des APIs à la pelle. L’harmonie entre l’IT et le métier est rétablie.
#3 Le reverse ETL, une solution à la multiplication des sources de données
Les sources de données se multiplient. L’un des enjeux de la stack data moderne est de gérer cette multiplication des sources de données. Le reverse ETL répond à cet enjeu. Il permet de tirer profit de cette formidable mine d’or de données à disposition pour créer une expérience client mémorable. Car, in fine, c’est bien la finalité. Ou plutôt les deux finalités :
Le reverse ETL permet de transformer la connaissance client qui est produite grâce au couple DWH – BI en expérience enrichie pour le client.
Deux alternatives aux logiciels reverse ETL : la Customer Data Platform & l’iPaaS
Il existe des alternatives aux logiciels reverse ETL et notre article ne serait pas complet si nous ne les mentionnions pas.
Reverse ETL vs CDP
Les Customer Data Platforms connaissent un essor important depuis le milieu des années 2010. Une CDP est une plateforme sur-l’étagère qui permet de construire un référentiel client unique en connectant toutes les sources de données de l’organisation. En ce sens, la CDP est une alternative au Data Warehouse. L’avantage par rapport au Data Warehouse, c’est que la CDP n’est pas qu’une base de données destinée à des usages de BI. La CDP propose des fonctionnalités avancées pour :
En clair, la CDP joue le même rôle que le couple DWH – reverse ETL. Il n’y a d’ailleurs pas nécessairement à choisir entre CDP et DWH. Une même entreprise peut en effet associer :
Comparée à la combinaison Data Warehouse – reverse ETL, la Customer Data Platform se caractérise par :
C’est pour cette raison que nous préférons l’approche consistant à associer le Data Warehouse à un outil reverse ETL. Elle offre plus de souplesse. En deux mots, un reverse ETL permet de transformer votre Data Warehouse en Customer Data Platform.
Reverse ETL vs iPaaS
Un iPasS est une solution d’intégration en mode SaaS : Integration Platform as a Service. Integromat est sans doute la solution iPaaS la plus emblématique du marché aujourd’hui. Les iPaaS proposent en général des interfaces visuelles, faciles d’utilisation, qui permettent de connecter les applications et sources de données entre elles. Le fonctionnement est proche de celui du reverse ETL : Vous sélectionnez une source, vous sélectionnez un outil de destination et vous éditez le mapping pour définir l’endroit où les données issues de la source vont s’intégrer dans l’outil de destination (l’endroit et le « comment »). L’exemple ci-dessous montre la conception d’un mapping entre les emails et Google Spreadsheet :
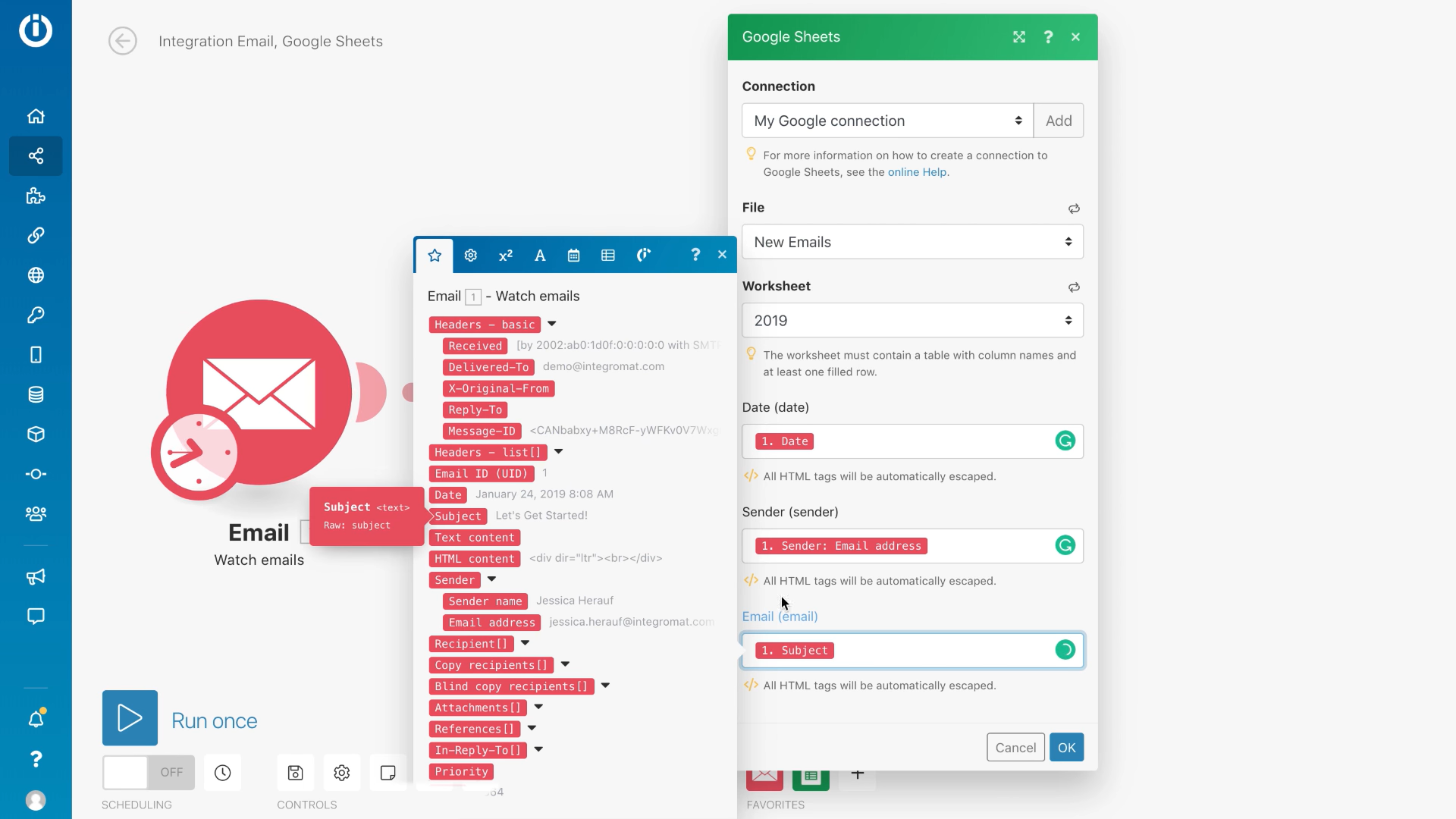
Pas besoin d’APIs, pas besoin de scripts, et même pas besoin de SQL. Les solutions iPaaS sont pour cette raison prisées des personnes au profil non-technique. Un iPaaS permet de créer des flux de données 1:1 directement entre les sources et la destination, sans passer par le Data Warehouse. Pour cette raison, l’iPaaS peut être utilisé par les entreprises ayant des besoins limités en matière d’intégration data. Mais ce n’est pas l’option à privilégier par l’entreprise qui souhaite se doter d’une infrastructure IT organisée autour d’une base de données jouant le rôle de pivot.
Conclusion
Le reverse ETL est déjà utilisé par les entreprises les plus avancées en matière de data et a vocation à s’imposer dans les entreprises qui souhaitent mieux exploiter leurs données. C’est une solution qui permet de franchir un cap sérieux vers une meilleure valorisation des données stockées dans le Data Warehouse. Nous aurons l’occasion de revenir plus en détail sur les enjeux autour de cette brique data incontournable.