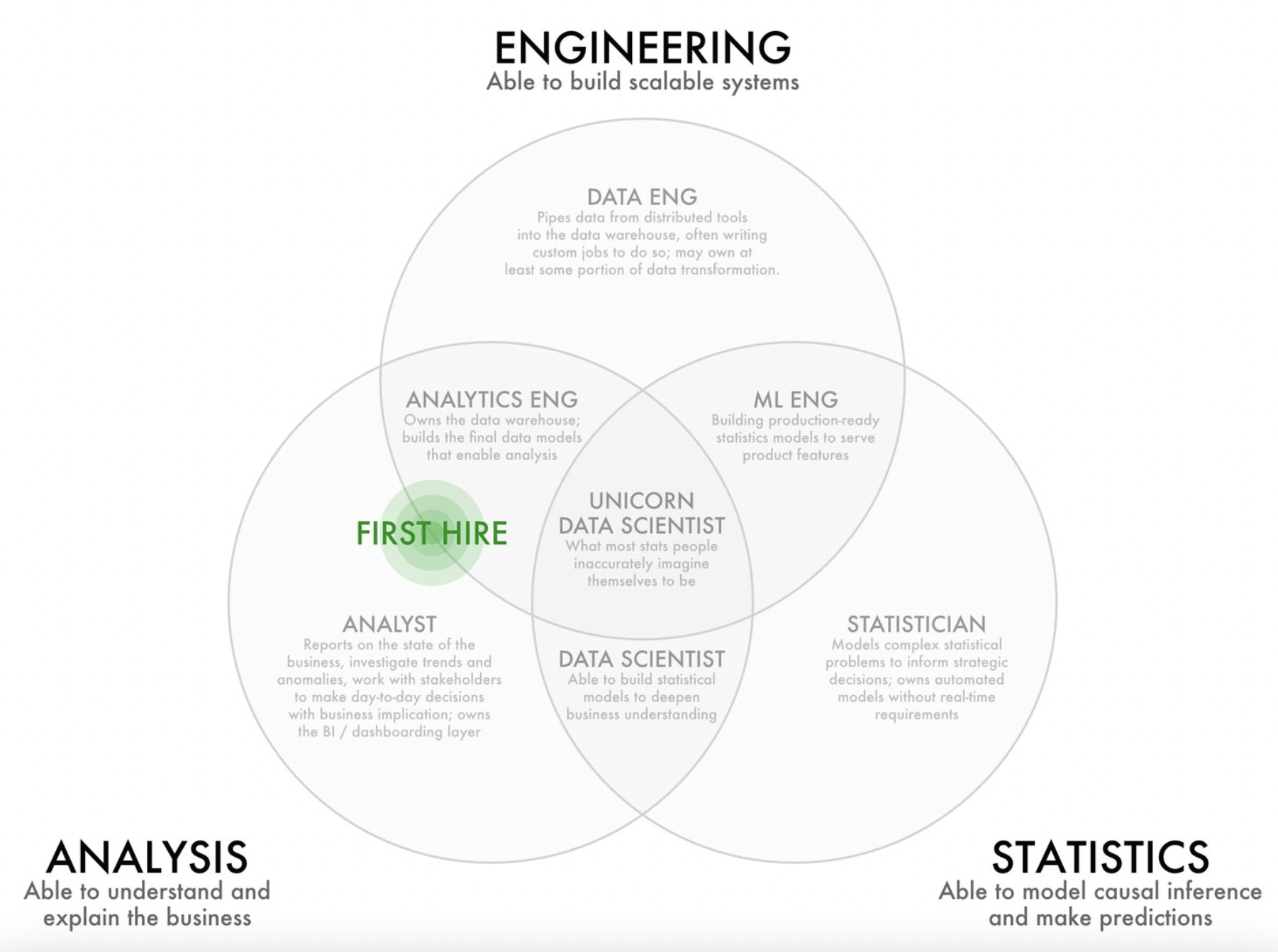
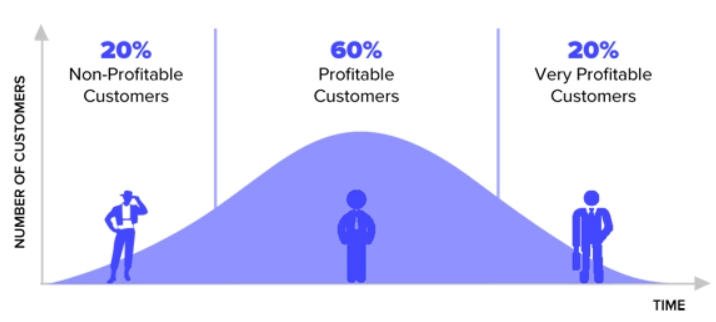
Small-mid-sized companies can expect to spend anywhere between $10,000 to $100,000 per year to do data analytics. The amount you will pay depends on the number of employees and your business needs. However, companies should set aside approximately 2-6% of their total budget for data analytics.
Data analytics is no longer a thing for only large enterprises. Today, small and mid-sized businesses also generate a sizeable amount of data. Business owners can gain helpful insight and make more informed decisions with data analytics.
This post provides everything you need to know about data analytics costs for small and mid-sized companies.
Read on to discover how much you’ll spend while optimizing your business.
The data analytics budget should represent 2-6% of your expenses
Most companies offer approximately 2-6% of their total expenses on data analytics, including tools, salaries, and services. It promises a considerable level of growth, and it has revealed that new tools are underway. These tools have been able to help convert raw and unprocessed data into insight.
Data has also grown due to the influence of the Internet of Things (IoT) and connected devices. It has increased in volume while gaining new diversity and richness. For a business to be successful, the available data network has to be optimized.
It offers the opportunity to make better-informed business decisions and refine products or services offered to provide their customers with a better experience.
Based on a study done by SAS, it has been revealed that 72% of organizations claimed that data analytics has been critical to their innovativeness.
The difference in the performance of more prominent corporations and SMEs has been traced back to analytics as a competitive landscape. Thus, this highlights the need for data analytics.
For example, if a company has a revenue of approximately 2M$, it would require almost 100K$ every year. Ordinarily, this seems like a large amount to spend out of the revenue available, but most companies with this range barely have the required data analytics tools. However, this global estimate takes into consideration the time that would be spent on the data analysis and reports by all the teams.
How much does your company invest in data analytics today?
Today’s cost of investing in data analytics depends on varying factors. These factors include:
- available tools,
- the severity of support,
- and analytics.
If you need to make data-driven decisions that are sufficient to provide long-term growth, then you must spend a considerable amount on data analytics.
However, investing or the intention of engaging the data analysis capacities is not sufficient in itself.
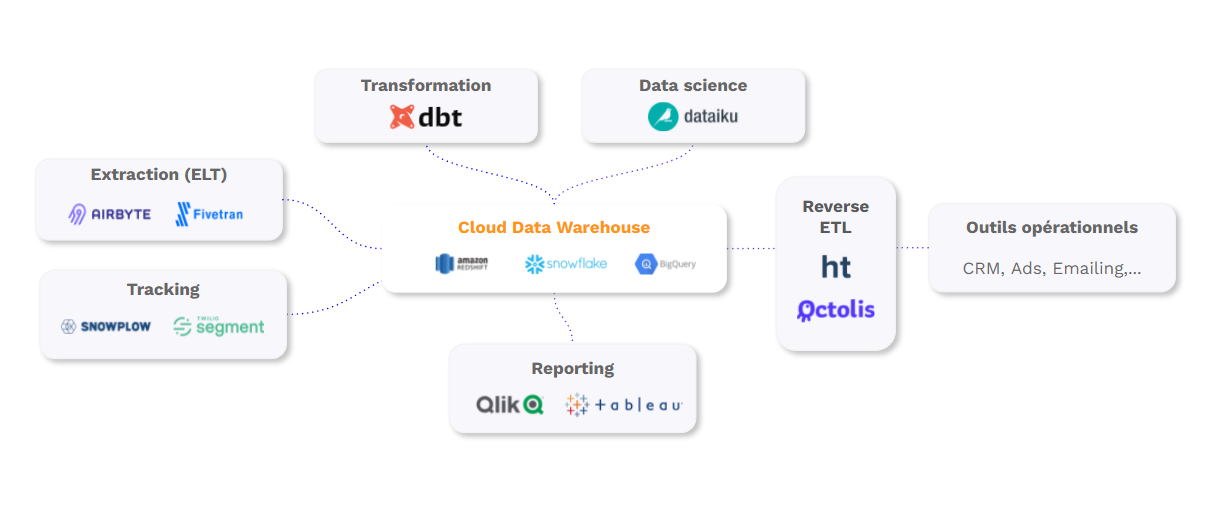
Various options are available for consideration when engaging in data analytics, and all of this depends on your company. Thus, the human cost, services, and tools have to complement each other, as represented in the table below:
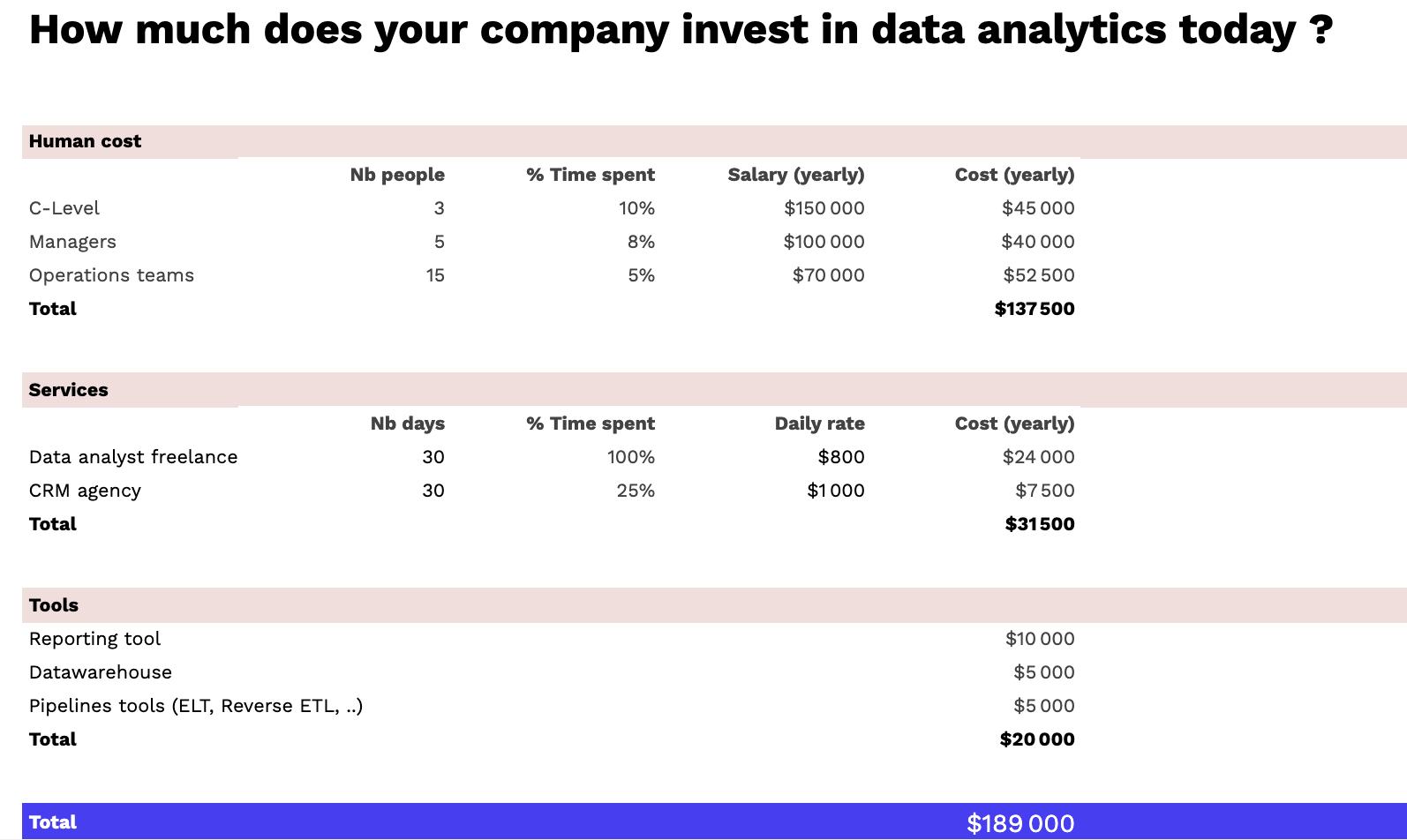
Human Cost
People are also crucial when conducting data analysis as the end goal is to influence the willingness of your customers. It is essential to look at how you source and enable the necessary talent.
Thus, the human cost demands that you identify those who can help integrate data-driven activities within the organization.
Those who do it already have analytical skills in your company, and you can build their skills to reduce the cost of hiring experts. It involves adopting user-friendly training with tools that can be accessible to those trusted with the duties.
Small or medium-sized companies can use this to reduce human costs in the long run. Yet, you may need to get experts to start the process and train your in-house employees.
Services
Your company’s investment in data analytics has to place into perspective if it is a service acquired. There are agencies and other companies that take up the task of data analysis for other companies, which would be important in determining the cost for your SME.
For instance, you could contract a Customer Relations Management (CRM) agency to build some automated marketing workflows. In this case, the agency would spend enough time reconciling some customer data sources. It would help develop a certain level of customer knowledge to aid the analysis or some RFM segmentation and then move on to email workflows.
Just as the human cost, this workflow level would cost separately and play a vital role in your company’s money on data analysis.
Tooling
Specific essential reporting tools are used in data analysis suitable for your SME. Selecting one should begin with some popular reporting tools like Google Data Studio. The device is based on Gheet data and Google analytics, which have proven efficient in analyzing company data.
Companies still find simple BI tools helpful and purchase the Metabase or PowerBI, which leads to the next stage. The next step is to implement a basic data infrastructure with a data warehouse.
There is Google BigQuery and ETL software like Airbyte or Fivetran. These tools have licenses, and these cost differently while influencing how much your company needs to spend.
The cost of outsourcing data services vs. in-house data analysts/engineers/scientists
Data engineers cost differently based on the type of service they are offering. For many companies, an in-house data science team seems like the only option. Having a team of data analysts is ideal for big companies.
For small and mid-sized businesses, it isn’t an available solution. Most of these companies turn to outsource to start their data analytics journey.
Here is a breakdown of how much an in-house data science team costs vs. the price of outsourcing data services:
Data Analytics consulting firms
Using data analytics firms is known to be reliable due to several factors. Consultants are known for their experience in various industries. However, this makes it easier for them to deliver results faster.
An advantage of this is the level of commitment it requires compared to when having to hire a full-time employee. However, it is essential to note that these traditional consulting firms would cost approximately $50-100 per hour. In some cases, the costs are even higher, as the job would span through weeks or months.
So, engaging a consulting firm would require at least $2000 – $4000 for a week’s work. Even though this may be the first option for data analytics for your company, it may not be the most cost-efficient. It may not be a sustainable alternative as it relies on external factors.
Outsourced data analytics freelancers
Freelancers can serve the same function as consulting firms but with a lower price due to the workforce needed. It could be a single freelancer with enough experience to help analyze your company’s data.
In most cases, it is still reliant on the project’s scope as it drives the cost of the analysis.
The project would be short-term, just as found in traditional consulting firms, which means minimal commitment. Engaging freelancers would be estimated at $1000 per week, which is considerably affordable. Outsourced freelancers can also differ in their quality, and research is critical.
However, the return on investment (ROI) and value-added to the business can not be determined. Language and cultural barriers can be a problem with outsourcing freelancers as most are in places like China and India.
This could constitute friction between your company and a data analytics service provider. Though outsourcing freelancers may help reduce spending, you must consider the differences.
In-house data analytics team
With an in-house consultant, there is someone who is always on call and has been a part of the company for a while. This provides an opportunity to have someone who is considered an outsider handling the company’s analytics. The only necessity for this to work is training the employee to understand your business and industry context.
Compared to working with consultants, this reduces the level of friction with delegated tasks.
Finding the right analyst can be time-sensitive, obstructing the quality of service provided.
The hiring process can also be tedious and require a commitment to ensure that you find the perfect fit.
There are equal concerns that full-time analysts may become redundant during the offseason. The minimal cost of keeping an in-house specialist is approximately $60,000 compared to what other data analysts cost.
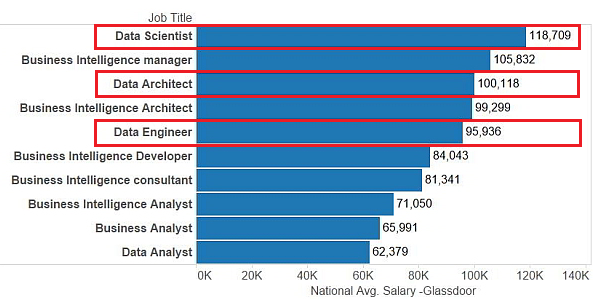
Some may even argue that the process of hiring and integrating a new employee is for this reason. Though this is a reliable option, it would still cost the company much more.
Wrapping up
Data is critical in scaling up your business as it helps establish behavior patterns. Customer behavior, needs, and data acquired throughout running a company all contribute to the data that is to be analyzed. It improves the innovativeness of a business and provides a basis for more data-driven decisions.
These data analytical processes can be done by either an outsourcing firm, a freelancer, or an in-house team for a small or medium-sized company. Each of these options has its advantages and disadvantages. Some are more expensive than others, so they cost differently based on the budget set aside for data analytics costs.
However, companies should set aside approximately 2-6% of their total budget for data analytics.
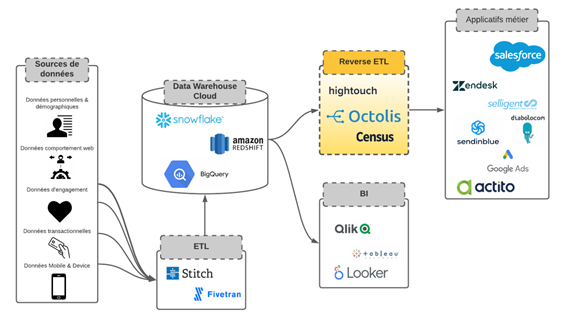
Data Operation tools such as Octolis can significantly lower the overall cost of data analysis. Octolis has an intelligent marketing database that would allow you to integrate your data sources and CRM tools or marketing automation.