While Segment is a powerful and relevant DMP and/or CDP solution, it is not the most appropriate for all business models.
The reason? Prices climb pretty quickly, especially for B2C players; the lack of an independent database and the rigidity of the data model limits your ability to strengthen your business intelligence.
Why are alternatives on the rise? The emergence of the modern data stack, through the crucial “single source of truth” role that your cloud data warehouse now plays, is an excellent opportunity to evolve towards a leaner, more flexible infrastructure, thanks to an independent database, and significantly less expensive for your customers’ data management.
Do you hesitate to choose Segment? Are you looking for alternatives? We have prepared a nice resource for you with a review of the alternatives to the main Segment modules: Connections, Personas, and Protocols.

Access our comparison of the best alternatives to Segment
To directly access the comparison of the best alternatives to Segment, we invite you to click on the button above.
📕 Summary
What is Segment?
From a web-tracking tool to a market-leading CDP
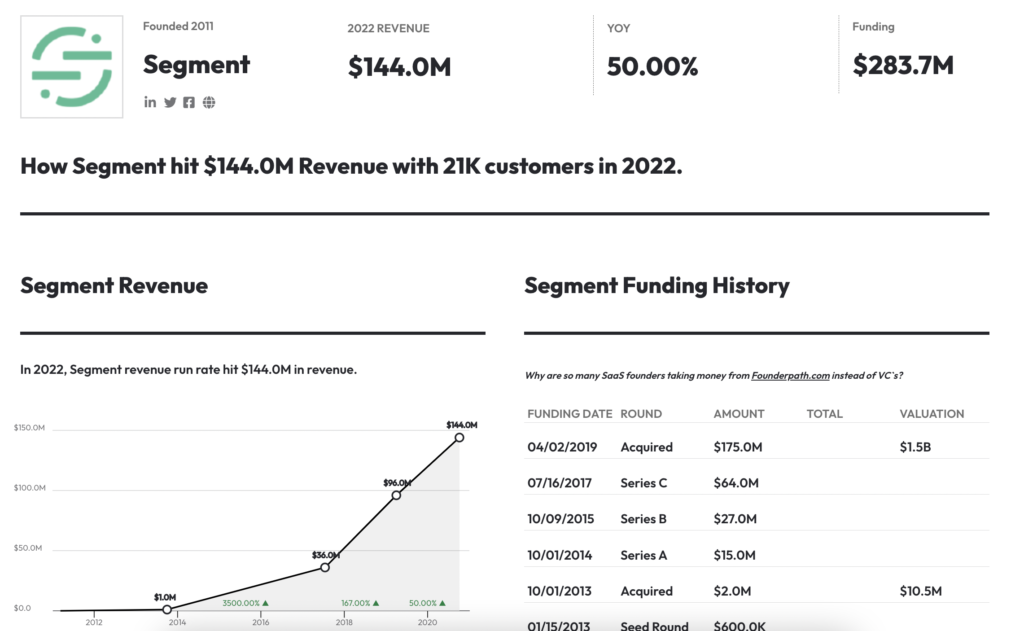
Founded in 2011, Segment was initially a web tracking tool in SaaS mode, allowing companies to track all the events that occur on the website, link them to a user ID, and store all weblogs in a data warehouse. With mid-market positioning (SME-ETI) and B2B, Segment was one of the first tools to democratize the extraction and storage of weblogs for BI purposes and customer experience personalization.
Slowly, Segment has broadened its functional spectrum. The platform has developed its integration capabilities with the company’s other data sources and tools. From a web-tracking tool, Segment has become a platform for managing CRM, marketing, sales, customer service data… In short, Segment has become a Customer Data Platform capable of connecting, unifying, and activating all customer data (essentially first-party) of the company.
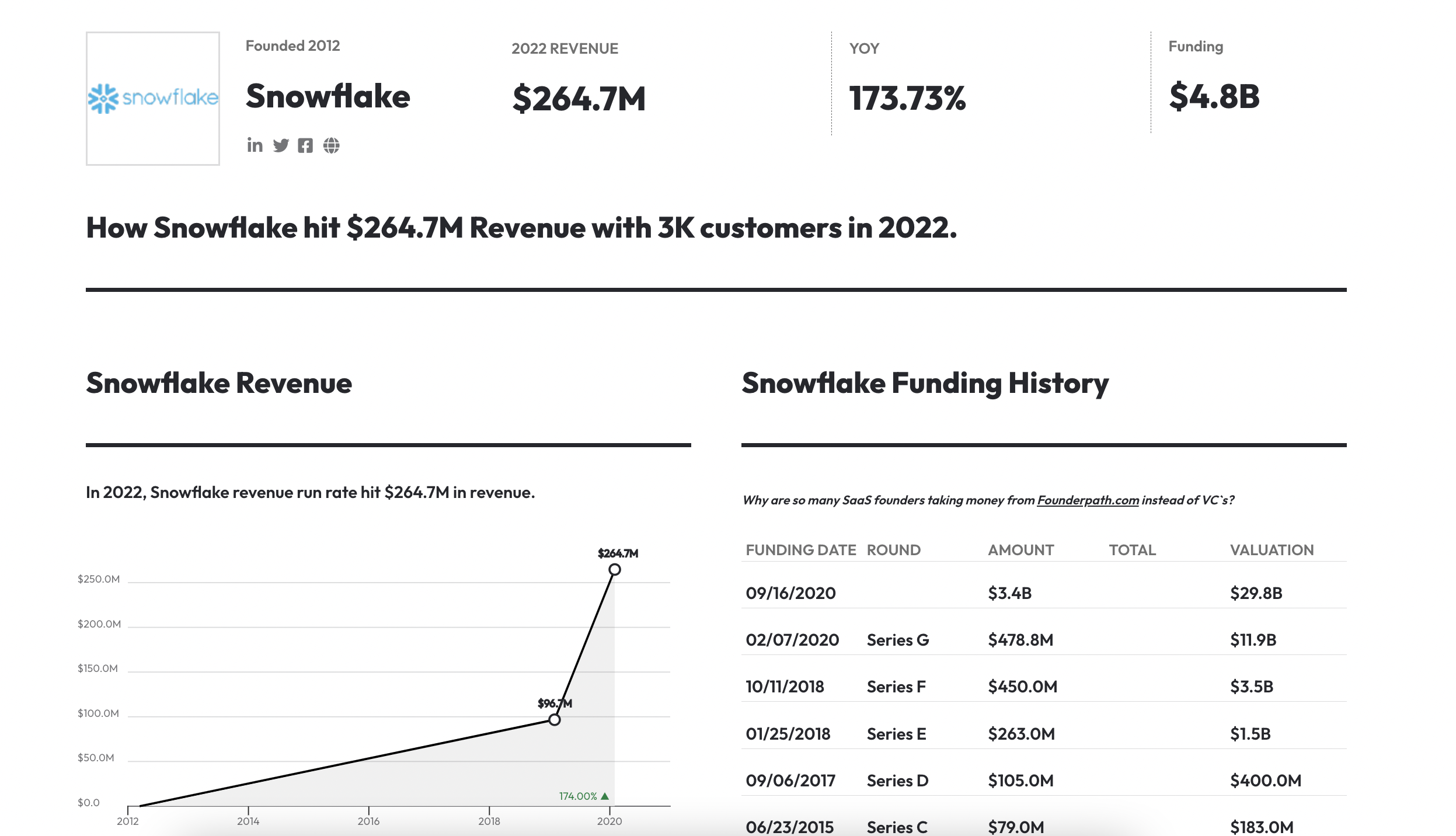
Let’s go even further: Segment is one of the leading players in the CDP market. In 2020, Segment generated $144 million in revenue and was acquired by Twilio for a whopping $3.2 billion. The start-up has become a giant and has more than 20,000 clients, including IBM, GAP, Atlassian, and Time magazine.
Discovering the functional scope of Segment
Segment essentially allows for (1) connecting the different sources of customer data of the company, (2) building a unique customer vision and audience, and, finally, (3) monitoring the quality and integrity of data. These are the three main modules offered by the platform: Connections, Personas & Protocols.
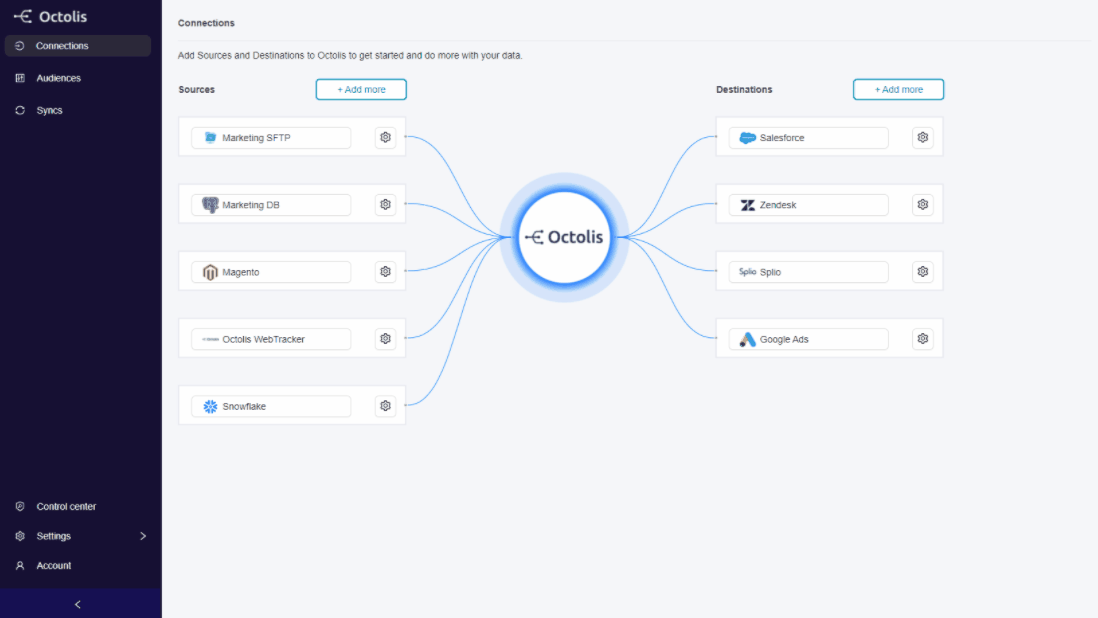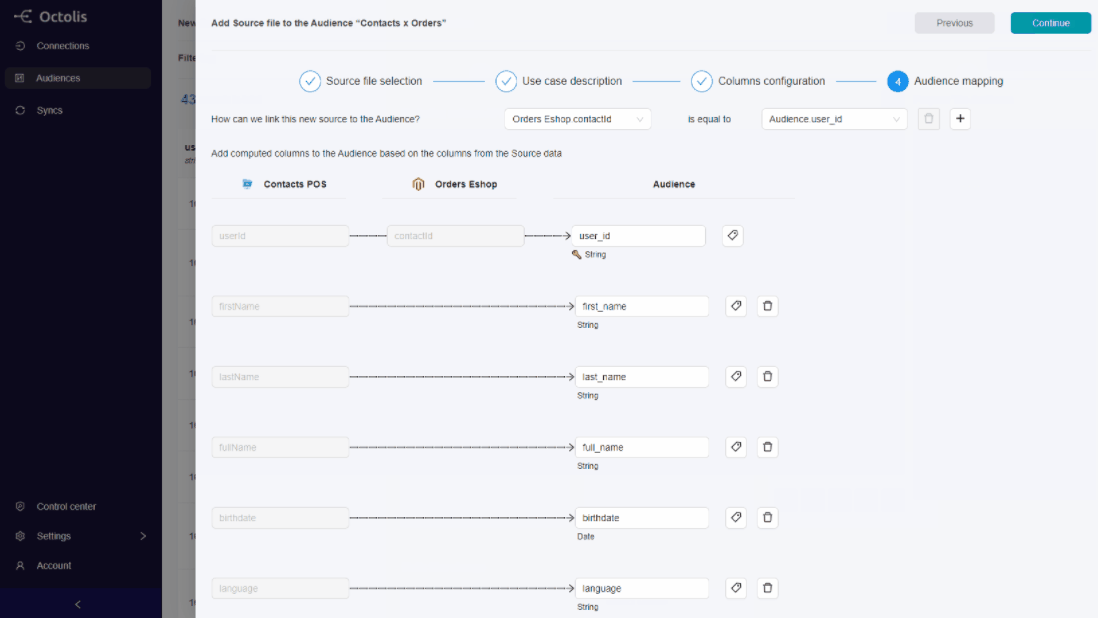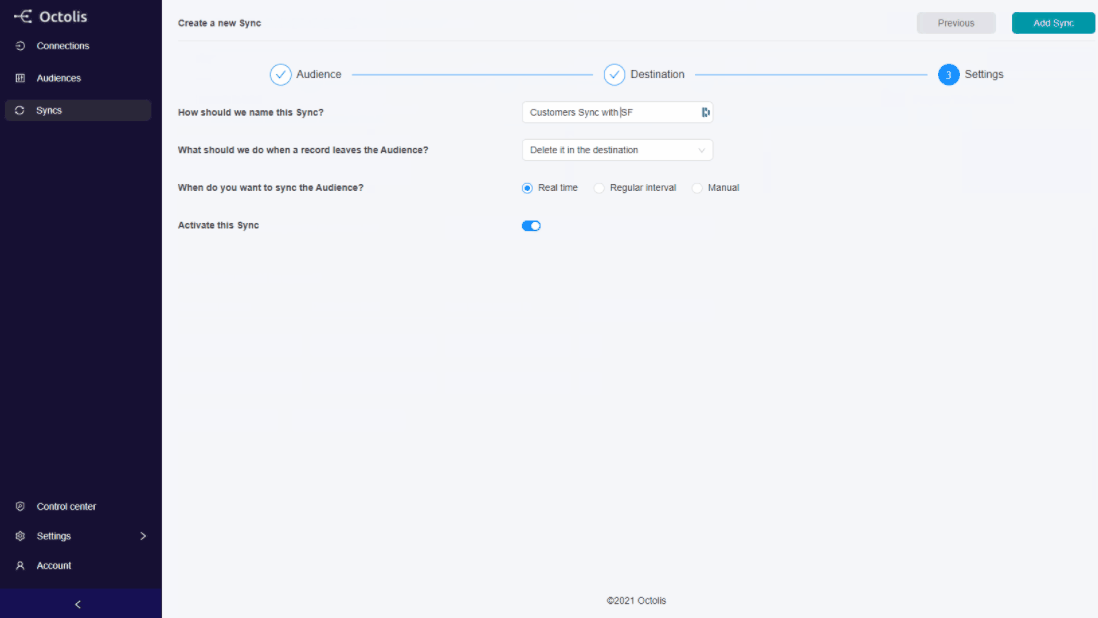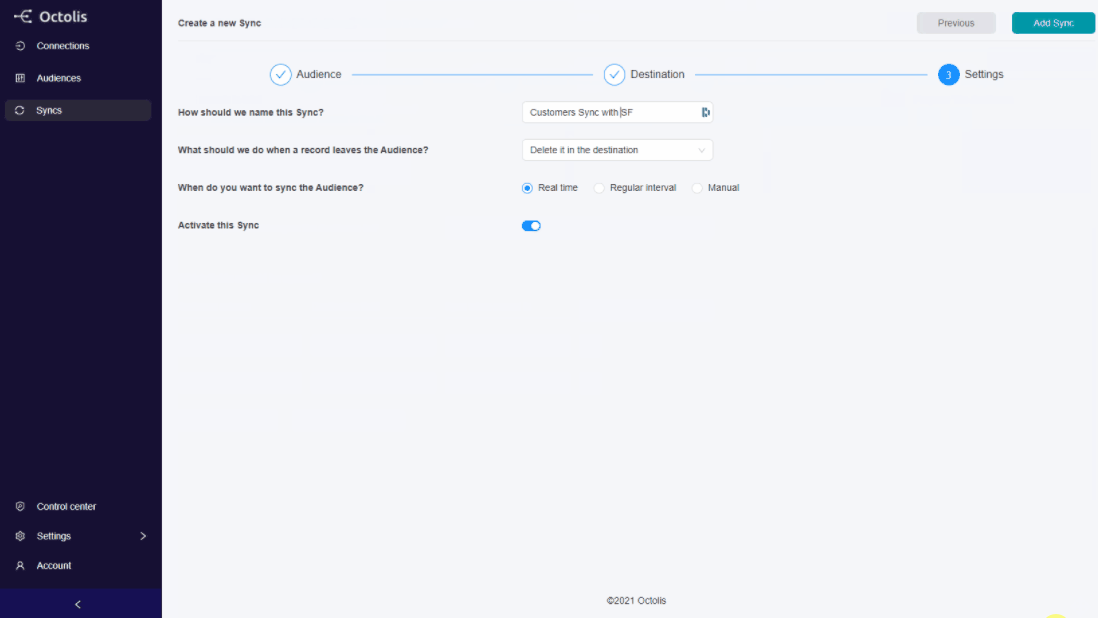
#1 Connecting data [Connections]
“Connecting” a data source to a Customer Data Platform such as Segment involves generating events related to the behavior of visitors of the website or web application. Segment turns web behaviors into events and events into actionable data.
To set up connections, Segment offers a library of APIs but also, and this is its strength, a vast library of native connectors.
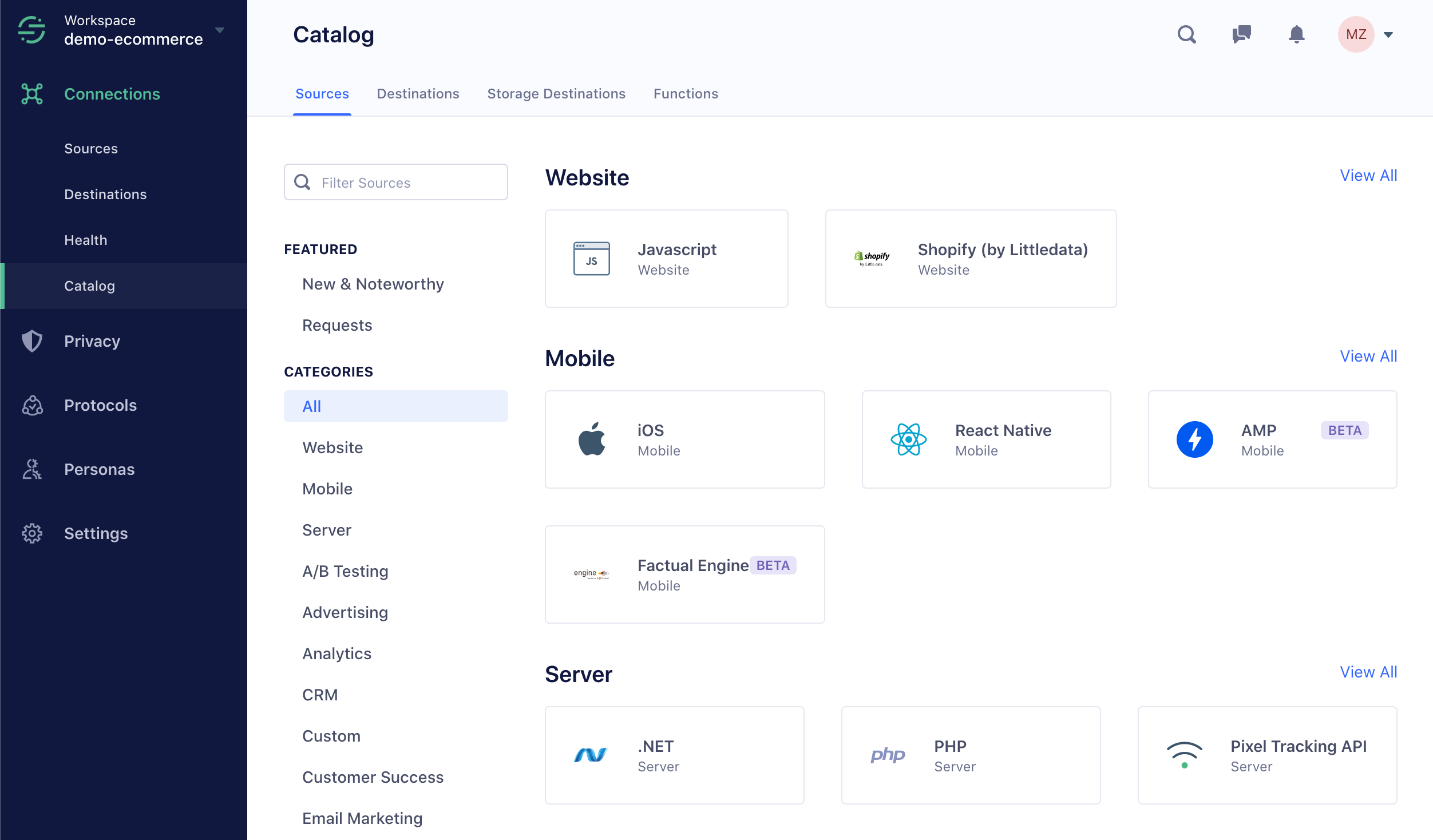
In addition to the impressive library of sources and destinations available, Segment handles very well:
Connecting to data sources is the most technical step in Segment. It requires the Tech/Data team’s involvement.
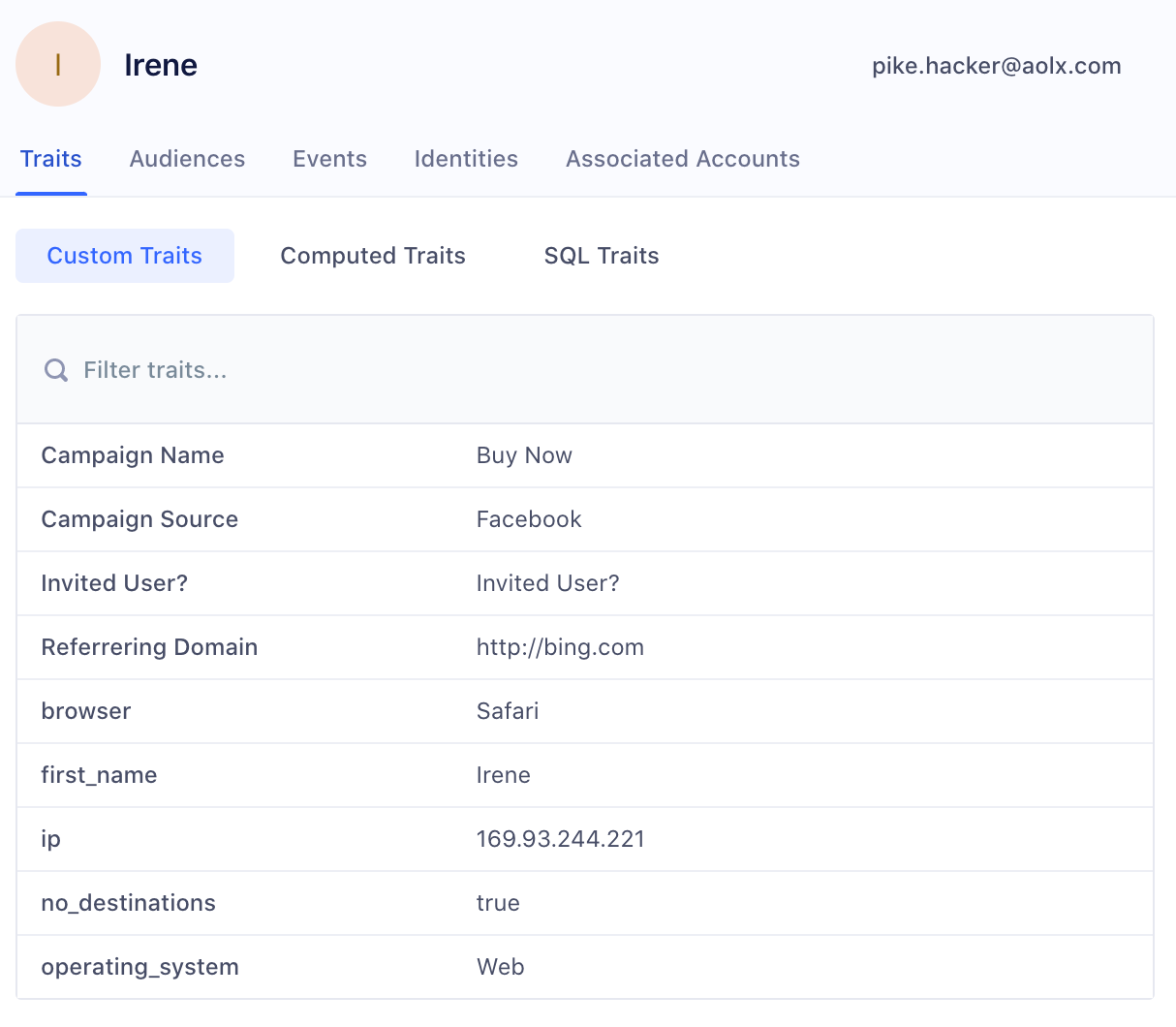
#2 The 360 Customer View and Building Segments [Personas]
Once connected, data can be unified around a single customer ID. Segment offers a module (called “Personas”) that allows you to view all the data related to a particular customer and to access the famous “single customer view” or “360 customer view”. Customer data can then be used to build segments, i.e., lists of contacts sharing defined criteria (socio-demographic, behavioral, etc.). The audience segments can then be activated in the destination tools: MarTech and AdTech.
Segment’s “Personas” module is user-friendly, and usable by business teams with complete autonomy. Note that “Personas” is only accessible in the “Business” plan.
#3 Data Quality Management [Protocols]
The third key module of the Segment platform is called “Protocols” and is used to monitor data quality and integrity. It should be specified that there are many “Best of Breed” technological solutions offering advanced Data Quality functionalities. For example, in Metaplane or Telm.ai., Octolis, Data Quality functions are native, which means that you do not need to further invest in a third-party solution or module to manage the quality of your data.
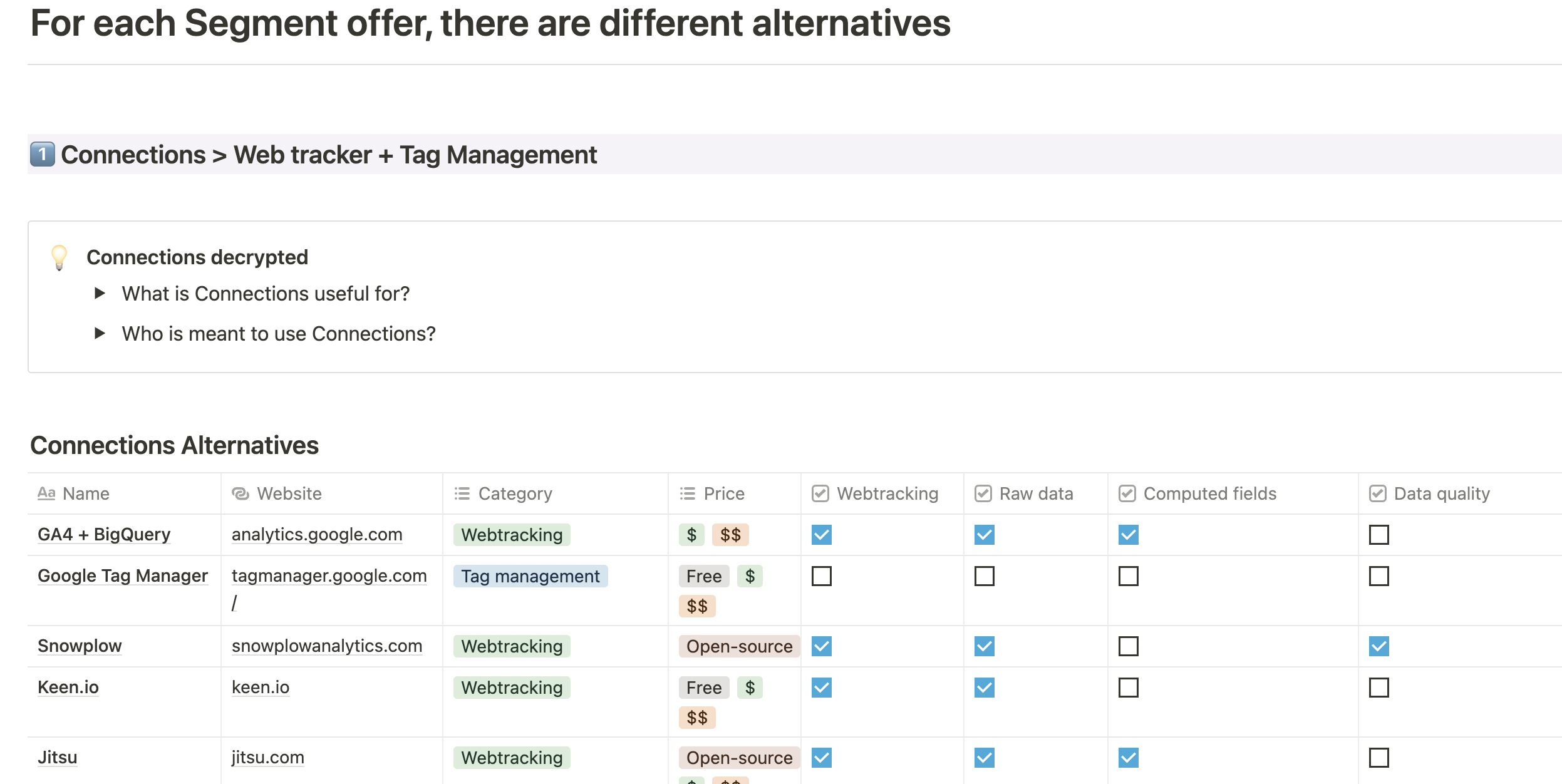
Discover the alternatives to Segment
You now know the three main modules of Segment. For each of these modules, we offer you the best alternatives.
The main disadvantages of Segment
We have presented Segment, its history, and its features. Unquestionably, Segment is a good tool. It would be absurd to call this evidence into question, but Segment has several limitations to which we would like to draw your attention in this second part.
There are two main limitations: rapidly rising prices and a lack of data control.
Limitation #1 – Segment’s prices are increasing rapidly
Segment offers pricing based on the number of visitors tracked per month (MTU: monthly tracked users) on the different sources (website, mobile application, etc.). This pricing model is suitable for companies that generate significant revenue per user and have very active users (over 250 events per month). Beyond 250 events per month and per user on average, you must switch to the “Business” Segment plan with personalized prices (on quote).
If you plan to use Segment as your Customer Data Platform, you will quickly reach a budget of $100,000 per year, especially if you are a B2C company. In B2C, the number of events, segments, and properties is always higher than in B2B.
Segment has not been able to adapt its offer to suit the needs and constraints of companies wishing to use the platform to deploy CDP use cases.
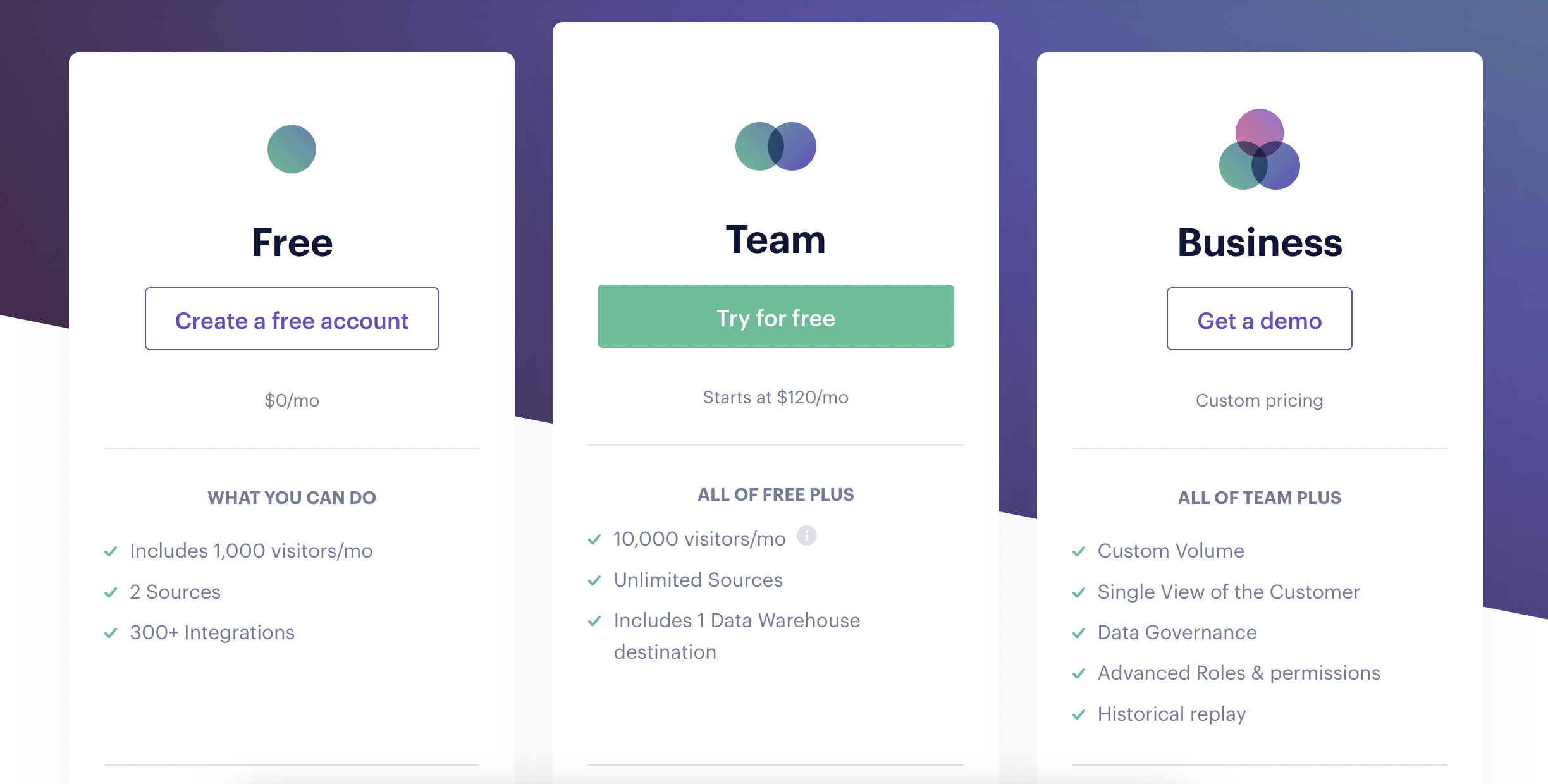
Let’s take two examples:
- You have a website that totals 100,000 unique visitors with three page views per month on average per visitor. The monthly subscription for 100,000 tracked visitors is around $1000 per month.
- Let’s imagine that the site dedicated to your CRM generates around 8000 MTUs for an average of 200 events per MTU. In this case, Segment will cost you around $120 per month because you stay under the Team plan’s 10,000 MTU limit.
Limitation #2 – Segment does not give you complete control over your data
All logs are stored on Segment’s servers. You can send all the logs to your data warehouse if you have one, but you must pay a supplement. In our opinion, this is one of the main disadvantages of a solution like Segment.
Because of or thanks to the tightening of the law on personal data protection (RGPD in particular), first-party data has to be stored by the company in its data warehouse and not in the various software and SaaS services. This is the best way to keep complete control over your data.
The fact that the logs are stored in Segment also poses another problem: you are forced to comply with a data model that is not necessarily adapted to your company. Segment offers a data model limited to two objects: users and accounts, and in most cases, a user can belong to only one account.
In which cases can Segment remain a good choice?
Segment can remain a relevant choice despite the limits we just recalled in some instances. To simplify, we can say companies that meet the following criteria may find interest in choosing this platform:
- You are a B2B company with few users/customers.
- You have a small IT/Data team.
- The volume of events is low or medium.
- Money is not a problem for your business.
- You want to deploy standard use cases.
From a certain level of maturity and development of your use cases, you will have more advanced needs in terms of tracking and aggregates. This means you will have to activate the “Personas” module that we presented to you above. Be aware that this additional module is charged extra… and is very expensive. At that point, you will be faced with an alternative: stay on Segment and be ready to pay 100k€ per year…or change architecture and opt for the implementation of a modern data stack.
Modern Data Stack offers more and more alternatives to Segment
Let’s repeat once again that Segment is undoubtedly a perfect tool; the problem is not there. Nonetheless, we believe it belongs to a family of tools (off-the-shelf CDPs) that is already outdated.
Off-the-shelf CDPs limits
Off-the-shelf Customer Data Platforms had their heyday in the late 2010s. For some time now, new approaches to collecting, unifying, and transforming customer data have emerged. We’ll walk you through the modern approach in a moment, but first, here are the main limitations of on-the-shelf Customer Data Platforms of which Segment is a part:
#1 CDPs are no longer the single source of truth
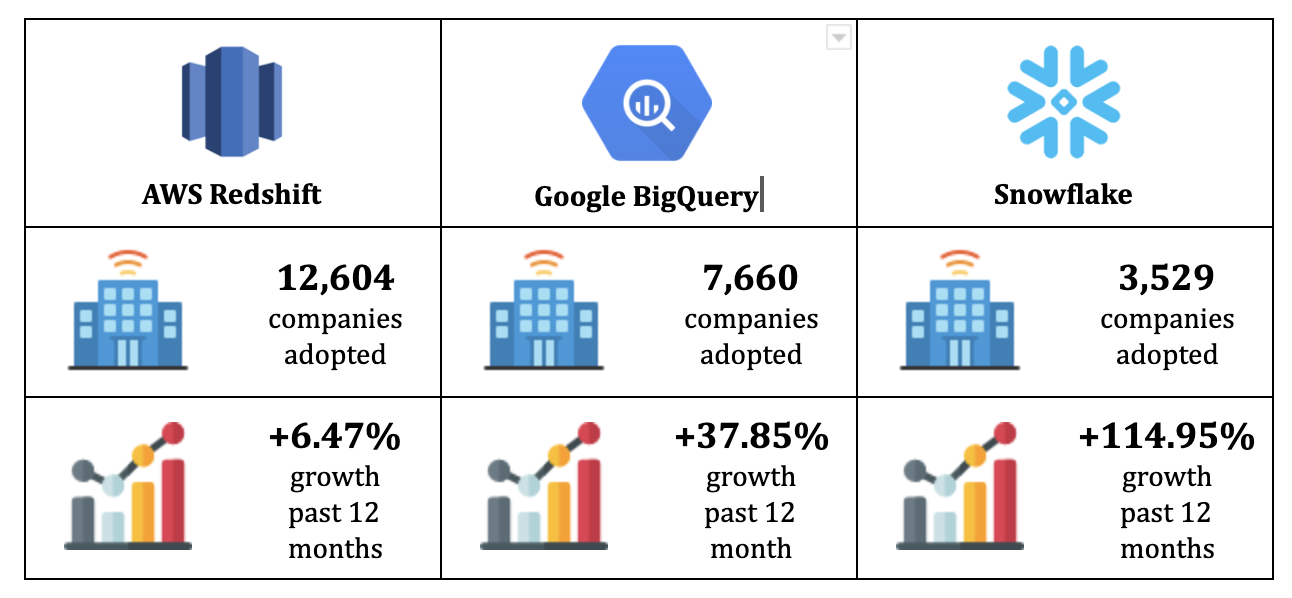
Increasingly, it’s the course of history as we have seen; data is stored and unified in cloud data warehouses like BigQuery, Snowflake, or Redshift. The data warehouse (DWH) centralizes ALL the data used for reporting and BI, unlike Customer Data Platforms which only contain data generated via connected sources: essentially customer data in the broad sense.
#2 CDPs tend to generate data silos
This happens for two main reasons. First, CDPs are built By Design for marketing teams. The publishers highlight this feature… except that it doesn’t offer only advantages. Why? Because it leads the marketing teams, on the one hand, and the data teams, on the other hand, to work each in their corner on different tools. We end up with two sources of truth:
- The Customer Data Platform for the marketing team.
- The data warehouse or data lake for the IT team.
A CDP empowers the marketing team from IT but promotes the compartmentalization of the two functions and their misalignment.
On the contrary, we are convinced that the marketing and IT/Data teams must work hand in hand.
#3 Standard CDPs have limited data preparation & transformation capabilities
Conventional Customer Data Platforms have limited data transformation capabilities. This problem echoes the data models’ issue. Data transformations are only possible within the framework of imposed data models.
The lack of data models’ flexibility offered (or imposed…) by the CDP leads to organizing the data in a way that does not always make sense from a business point of view.
#4 Lack of data control
We have already highlighted this problem. Storing all the data in your CDP poses privacy and security issues. It has become more and more essential to store data outside the software, in an autonomous database managed by the company itself. This brings us to the next point.
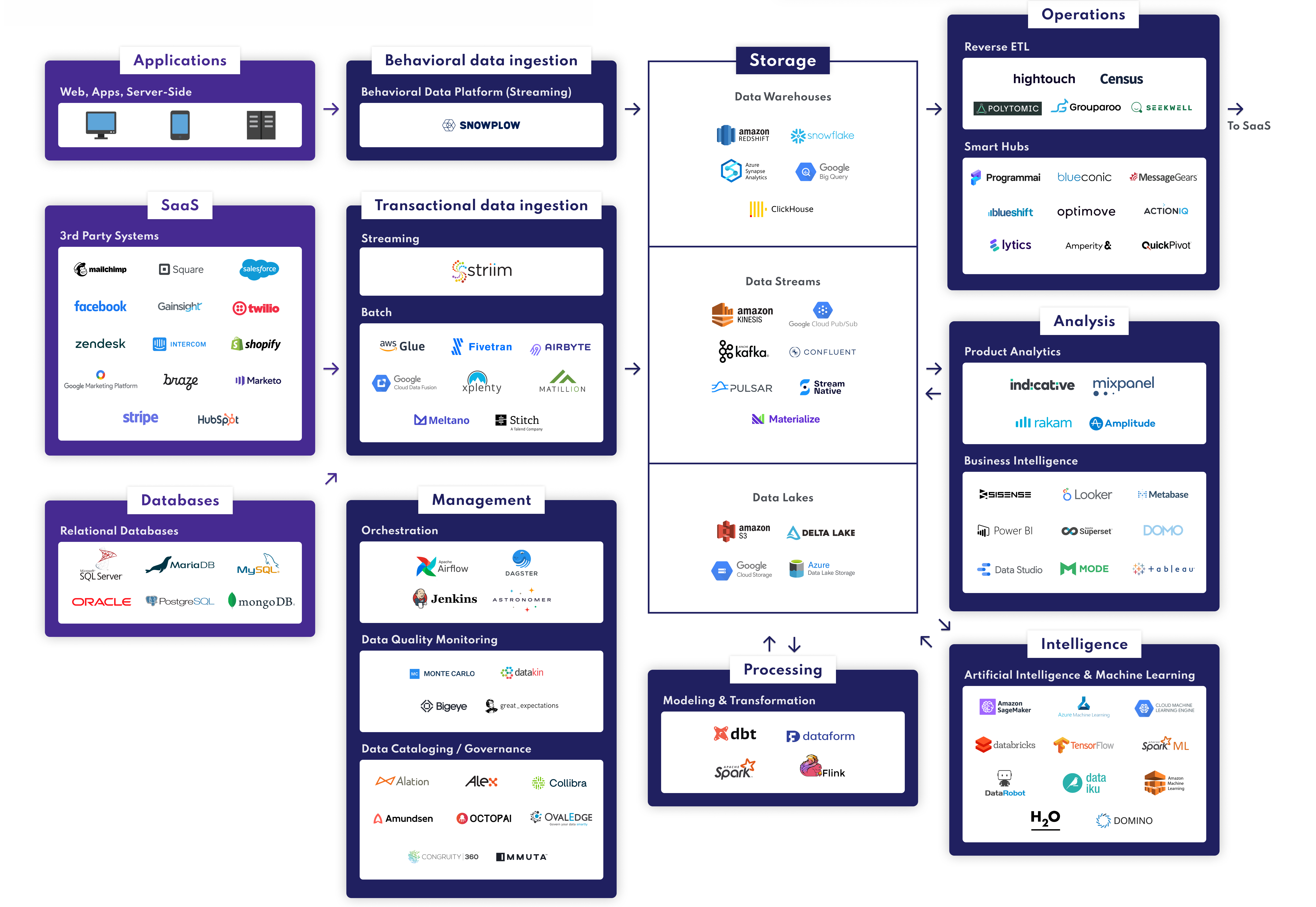
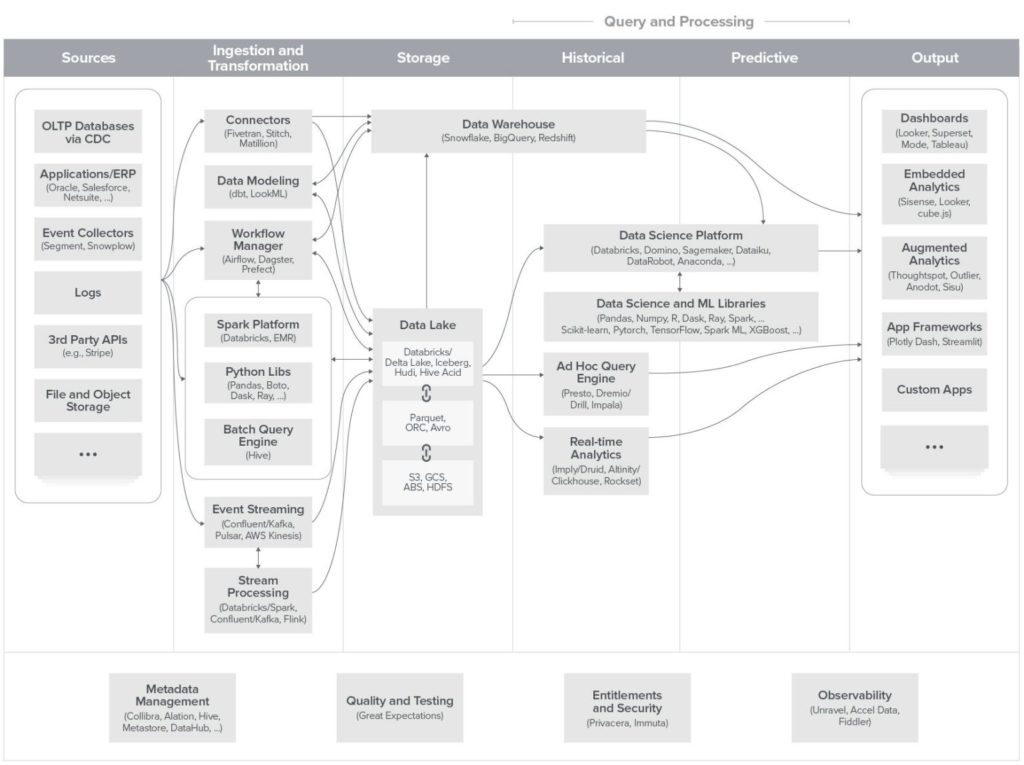
The Rise of Cloud Data Warehouses
A lot has changed in a decade in collecting, extracting, circulating, storing, preparing, transforming, redistributing, and activating data. The most significant development is that modern cloud data warehouses now play a central role. The DWH becomes the pivot of the information system, the center of the IT architecture around which all the other tools gravitate.
Amazon played a decisive role in this revolution with the launch of Redshift in 2012. The game was changed by the collapse of storage costs and the exponential increase in the computing power of machines. This has led to a democratization of data warehouses. Today, a small business with limited needs can use Redshift for a few hundred dollars a month. For information, the classic data warehouse annual license, “On-Premise”, easily reaches 100k€…
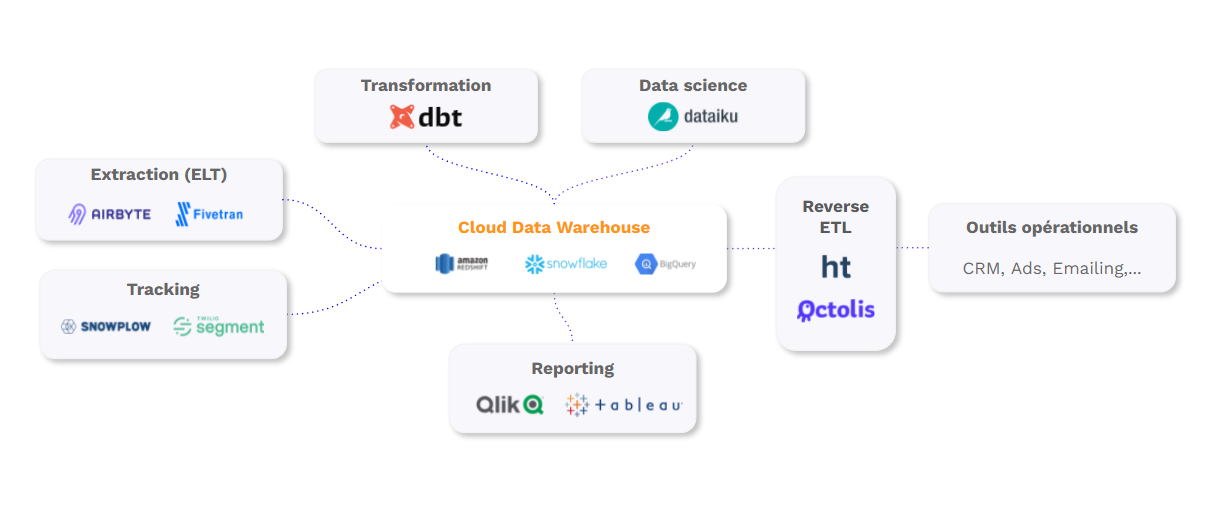
Cloud data warehouses have become the new standard for most organizations. They are used to store all data, including customer data, but not only. All company data can be centralized and organized there.
Understanding the role of Reverse ETL
Cloud data warehouse solutions have experienced significant growth since 2012. Gafams have almost all entered this market: Google has developed BigQuery, Microsoft has launched Azure, etc. We have also seen the emergence of pure players like Snowflake, which is experiencing spectacular growth.
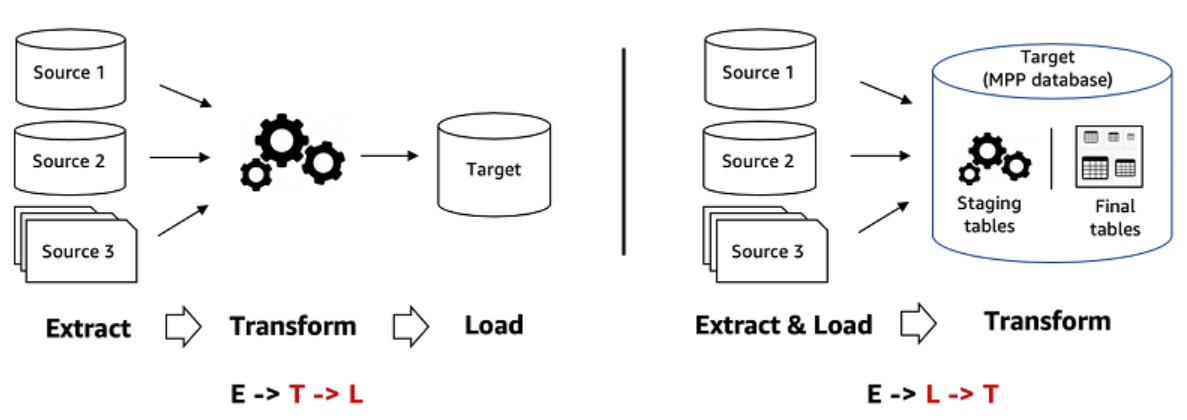
But there was a lack of a functional brick allowing warehouse data to be synchronized in the activation software so that it would not only be used for reporting. A new family of tools appeared at the end of the 2010s to fulfill this function: Reverse ETLs.
A Reverse ETL synchronizes the data from the DWH in the operational tools: Ads, CRM, support, Marketing Automation… Therefore, it does the opposite of an ETL which is used to send data back to the data warehouse. Hence the name “Reverse ETL”. With a Reverse ETL:
- You control your data because it remains in your data warehouse: the Reverse ETL is a synchronization tool. Your data never leaves the DWH.
- You can create custom data models, far from being limited to the two objects offered by Segment (users and accounts).
Modern data warehouses and Reverse ETLs draw a new architecture: the modern data stack. With these two technologies combined, your data warehouse becomes your CDP. This architecture makes it possible to implement the “Operational Analytics” approach which, in a nutshell, consists of putting data at the service of business operations and no longer solely at the service of analytics.
Discovering Modern Data Stack
Modern data stack is the architecture of making the data warehouse the sole source of truth for the IS and using a Reverse ETL to activate DWH data in operational software. Check out our complete guide to Modern Data Stack.
Access our comparison of the best alternatives to Segment
Pour accéder à la ressource, il vous suffit de cliquer sur le bouton ci-dessous
Une fois dans notre espace dédiée, vous découvrirez d'autres ressources structurantes, les plus complètes nécessitent une inscription rapide mais sont toutes gratuites !
Avec un peu de chance, vous aurez une bonne surprise, il y aura d'autres ressources qui vous seront utiles 😊
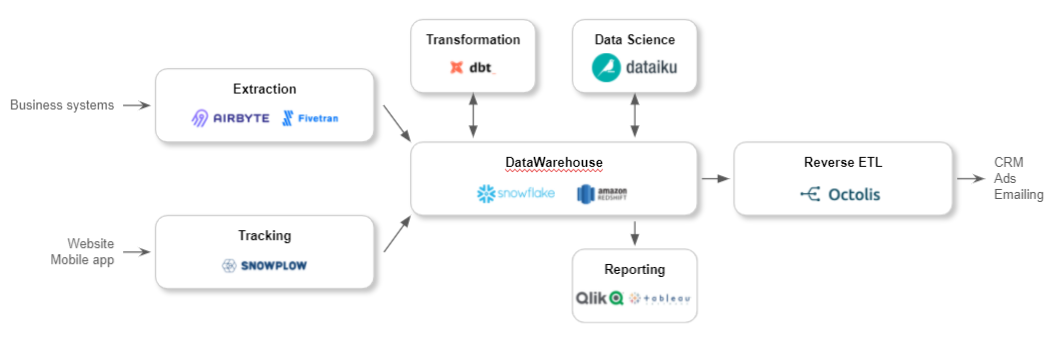

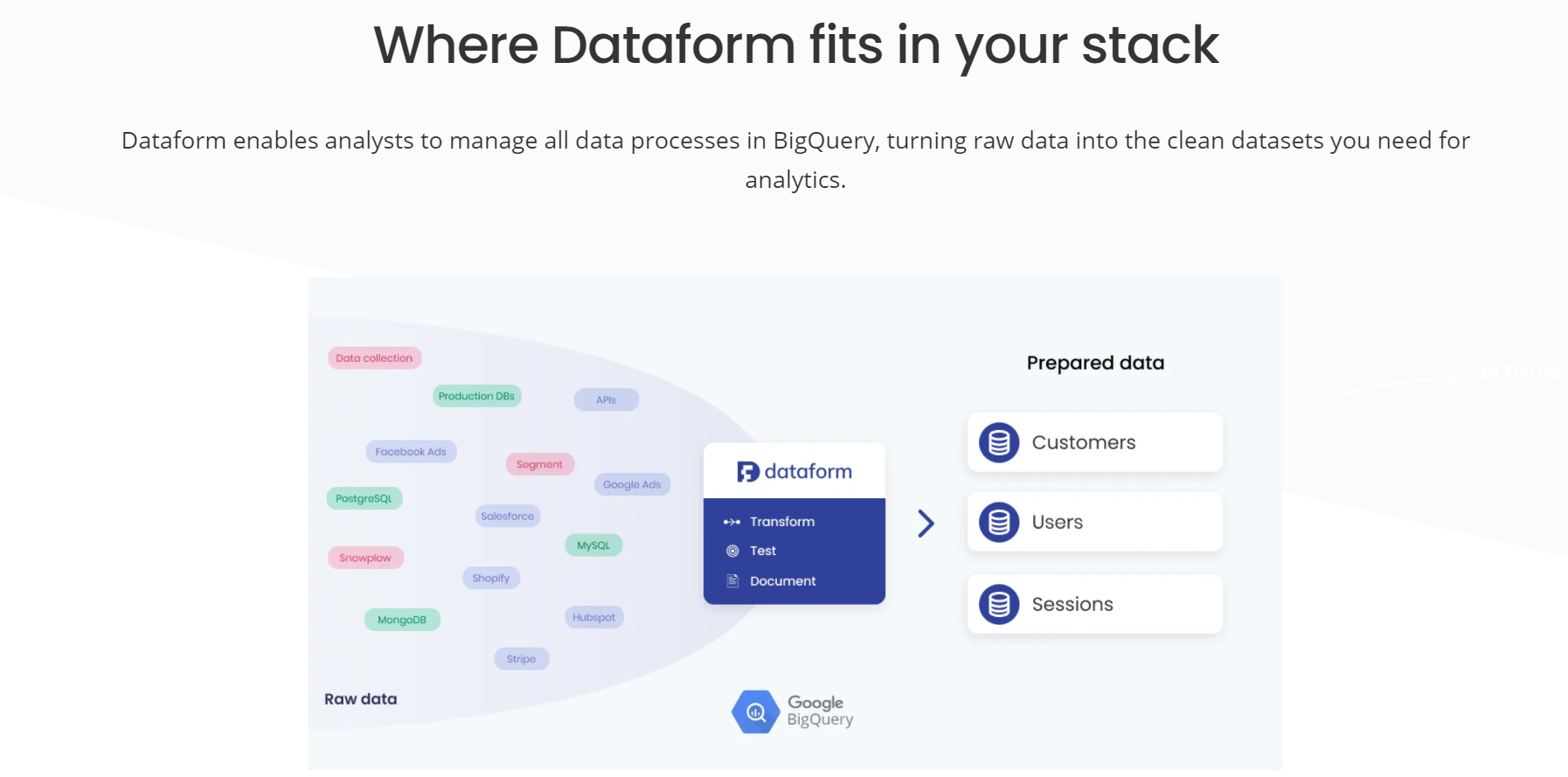

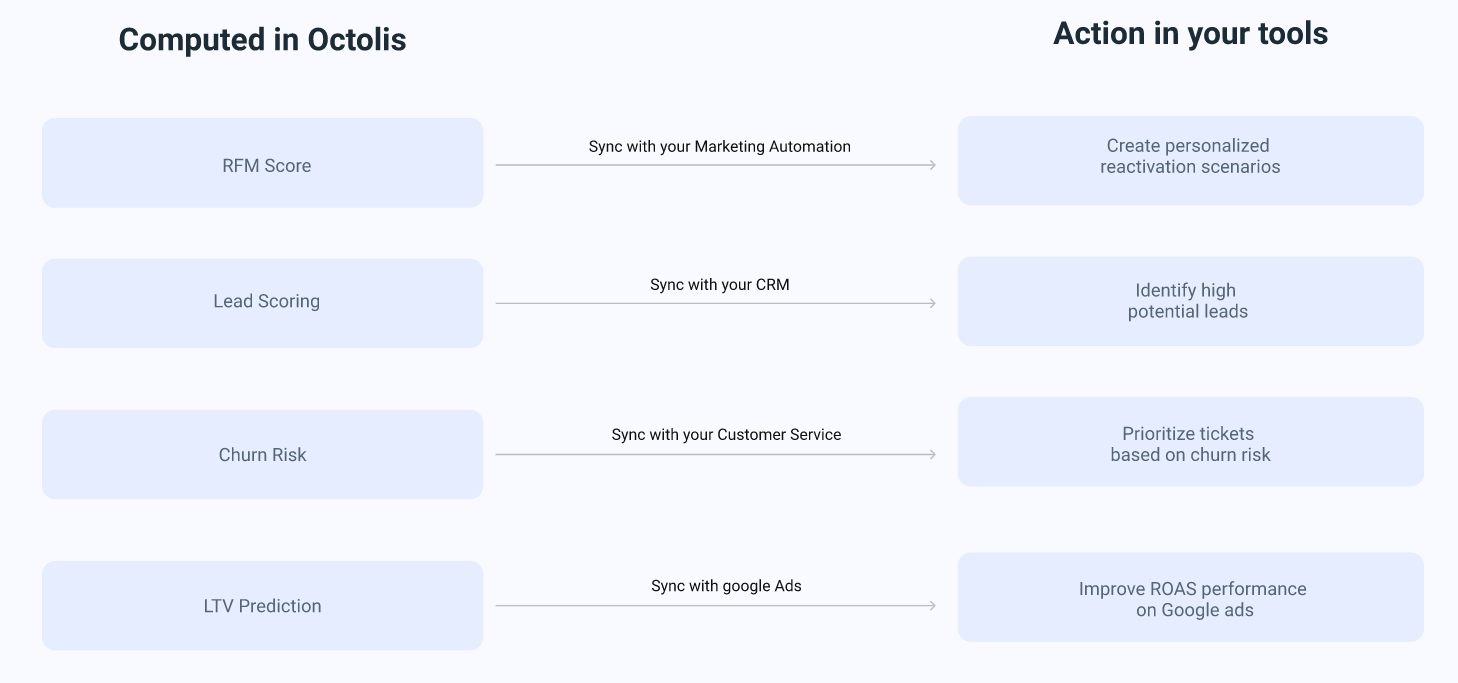
 Reverse ETL is a flexible data integration solution for synchronizing DWH data with applications used by marketing, sales, digital team, and customer service, to name a few.
Reverse ETL is a flexible data integration solution for synchronizing DWH data with applications used by marketing, sales, digital team, and customer service, to name a few.