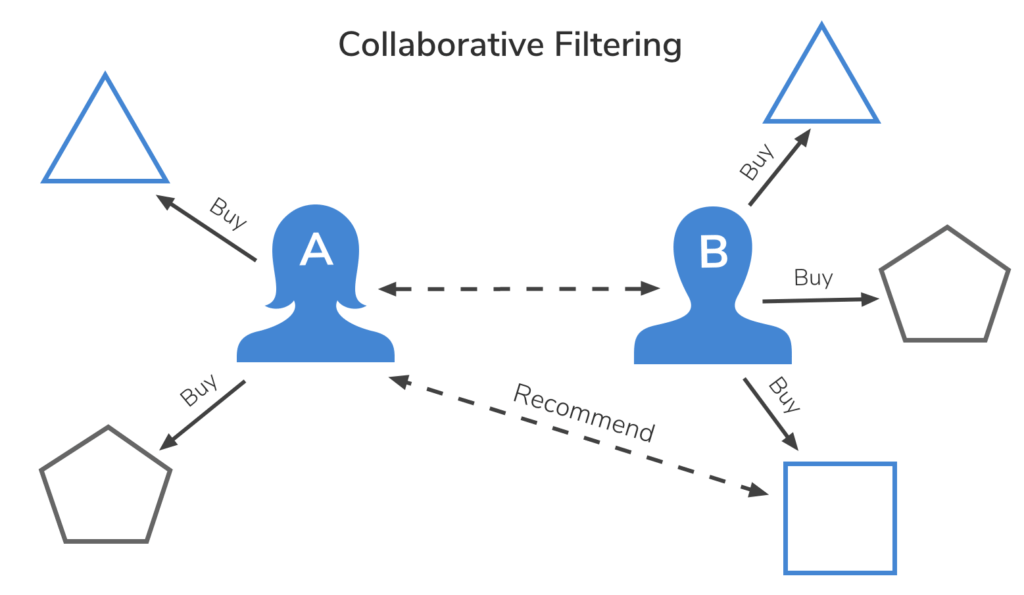
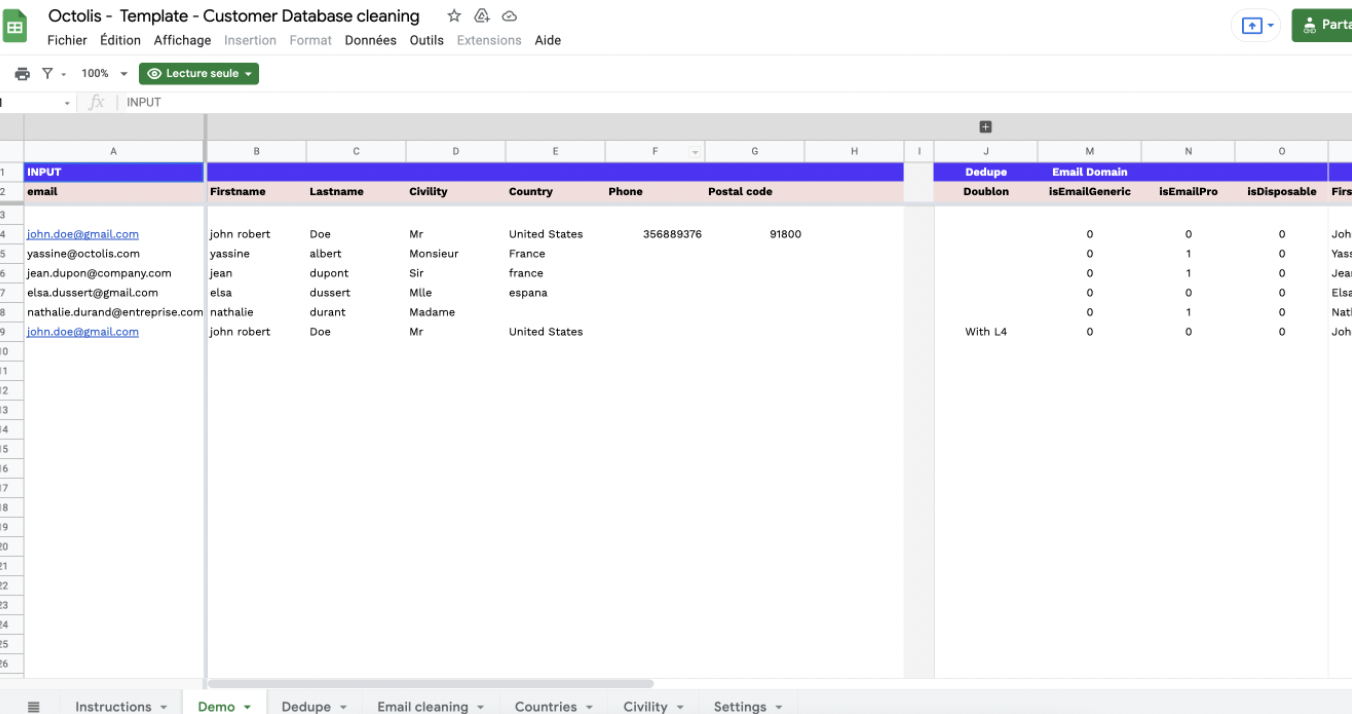
Toute entreprise souhaitant devenir plus mature en matière d’exploitation des données clients rencontre tôt ou tard le sujet épineux de la déduplication des données.
L’unification et la déduplication des données clients sont la condition nécessaire pour pleinement exploiter vos données clients, que ce soit pour l’activation omnicanale de vos parcours clients ou pour le reporting/BI.
📕 Sommaire
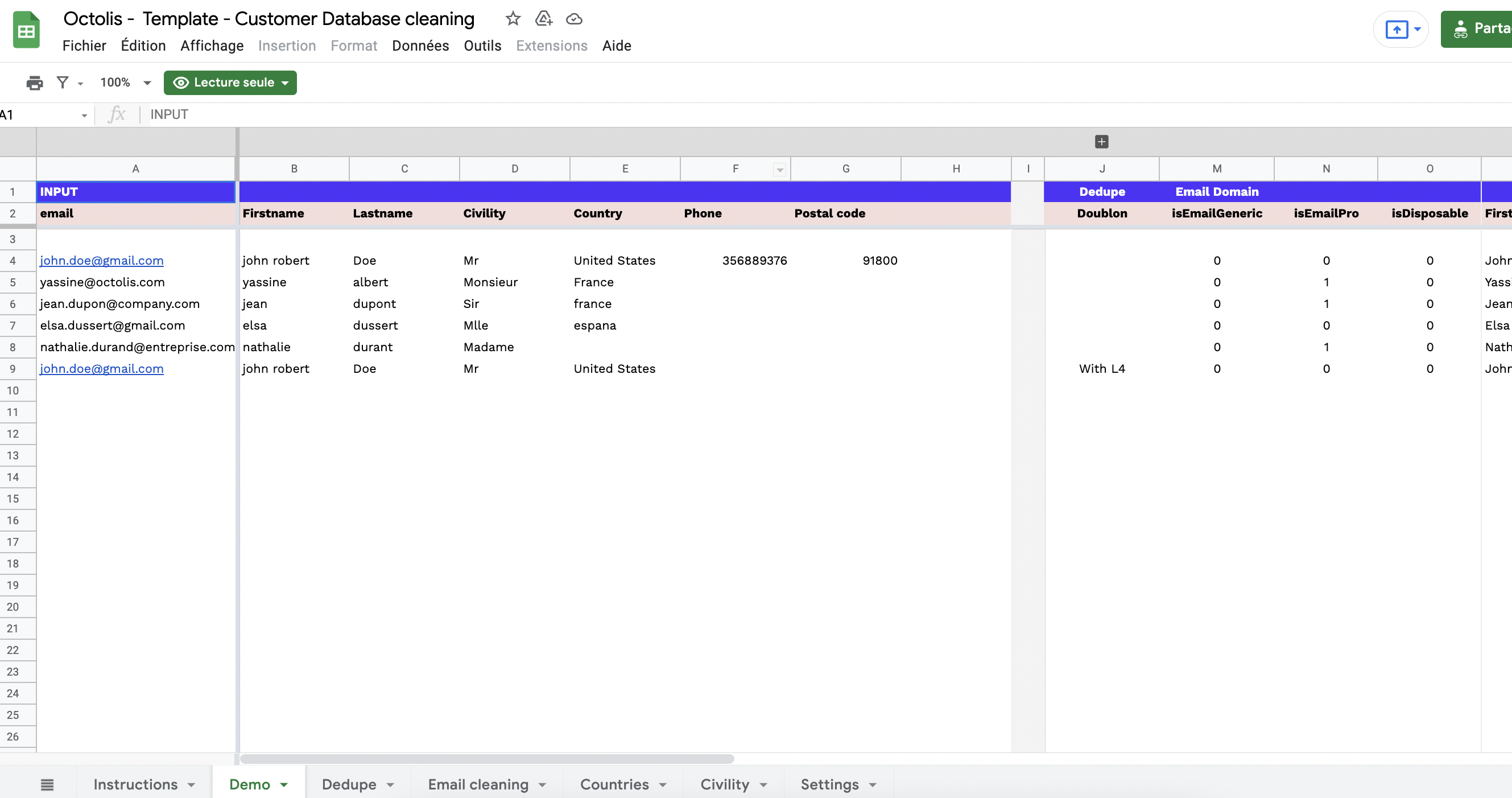
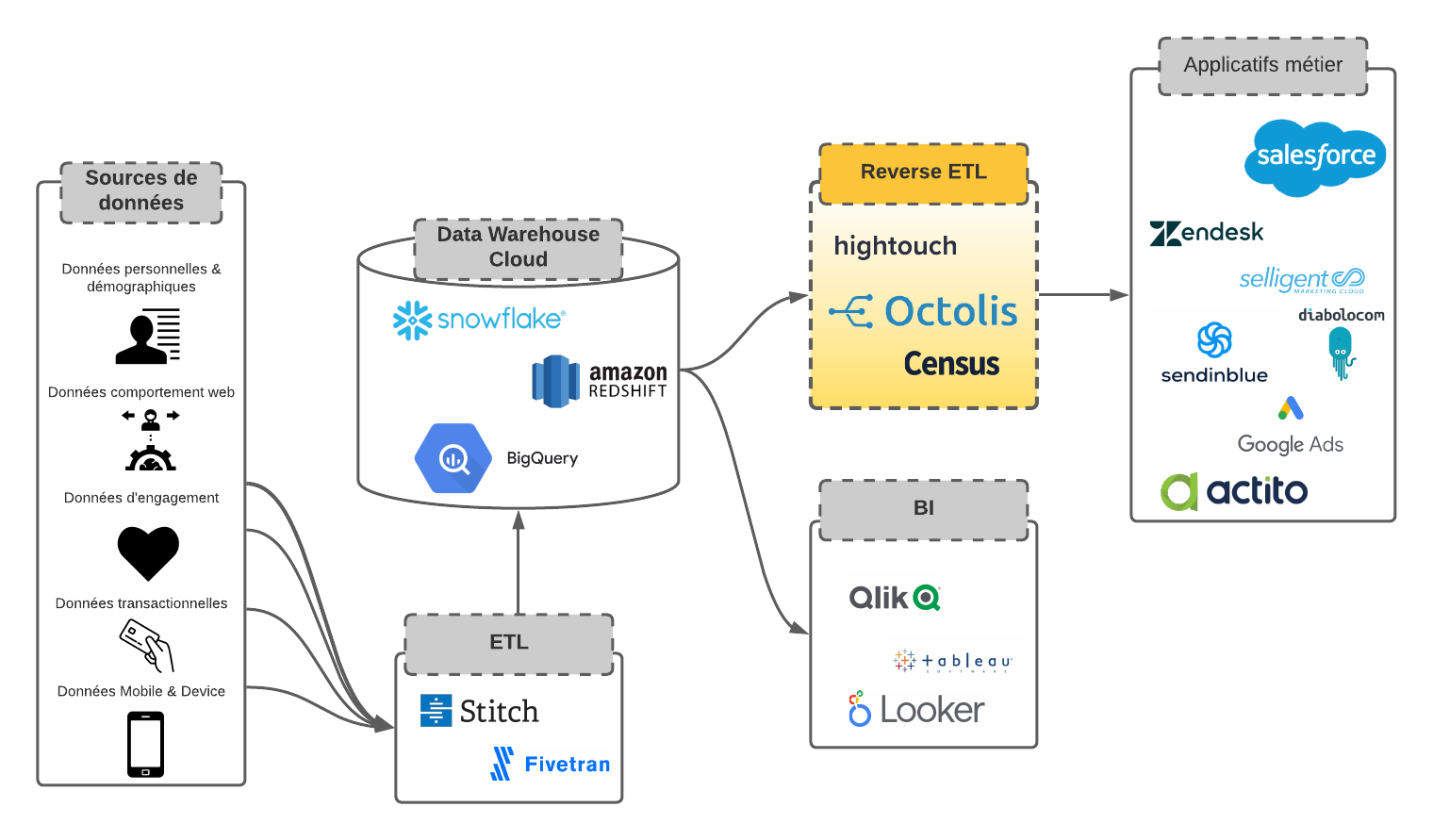
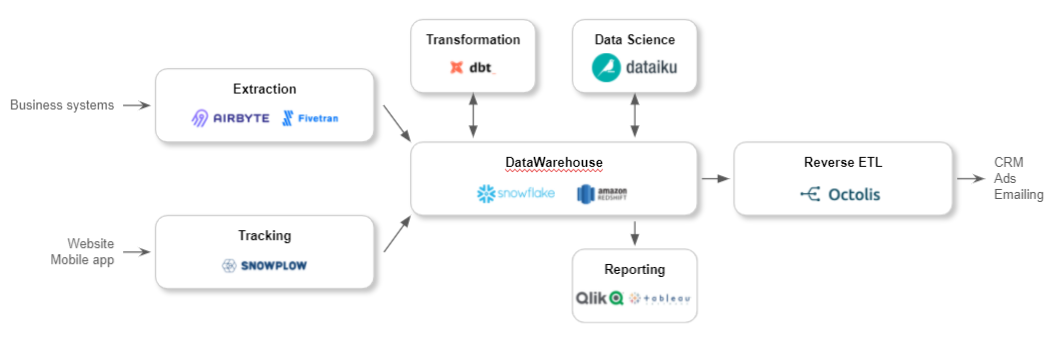
Pour faire simple, la déduplication des données est une problématique qui se pose dès lors que vous souhaitez unifier les données en provenance de différentes sources dans une plateforme unique (de type Customer Data Platform, par exemple).
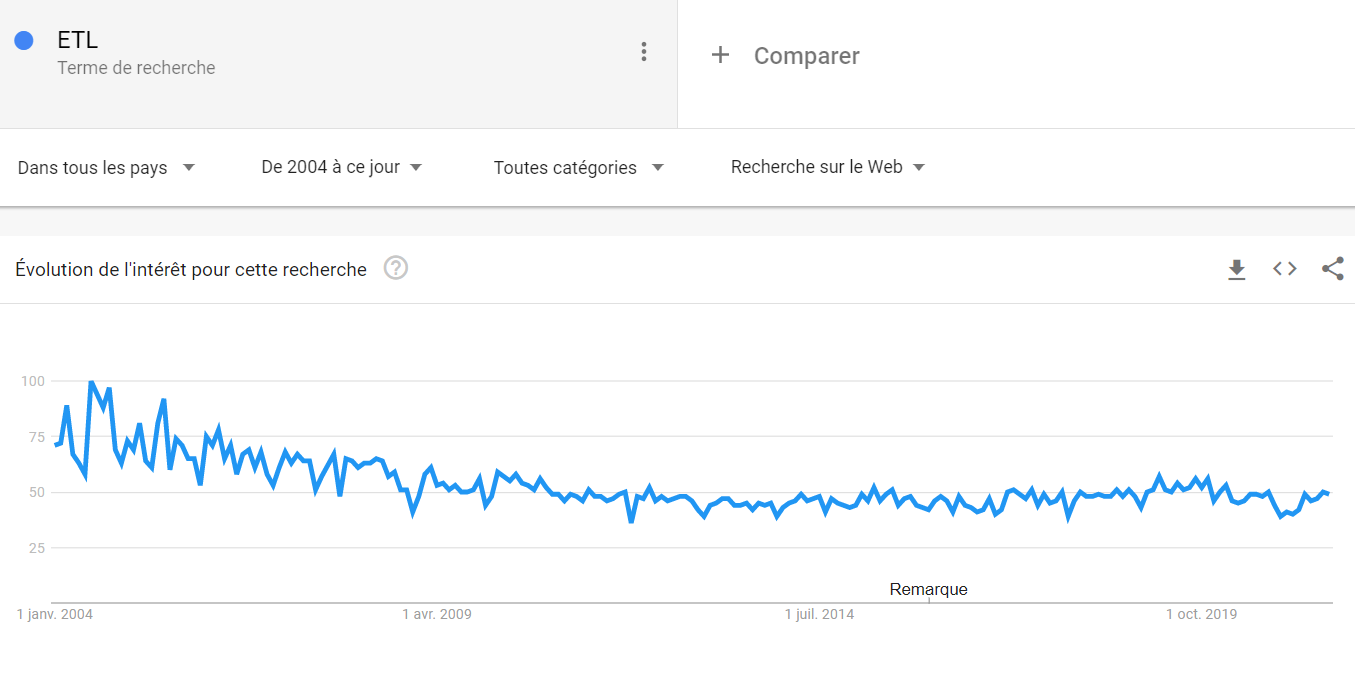
Le sujet est complexe, mais de plus en plus à l’ordre du jour dans les entreprises en raison de la multiplication des canaux, des points de contact et des outils qui engendre naturellement une dissémination des données et des duplications.
On va vous présenter dans ce guide les principaux enjeux autour de la déduplication des données et les principales méthodes de déduplication.
L’essentiel à retenir sur la déduplication des données clients
Pour commencer, qu’est-ce que la déduplication des données ?
Définition simple de la déduplication des données
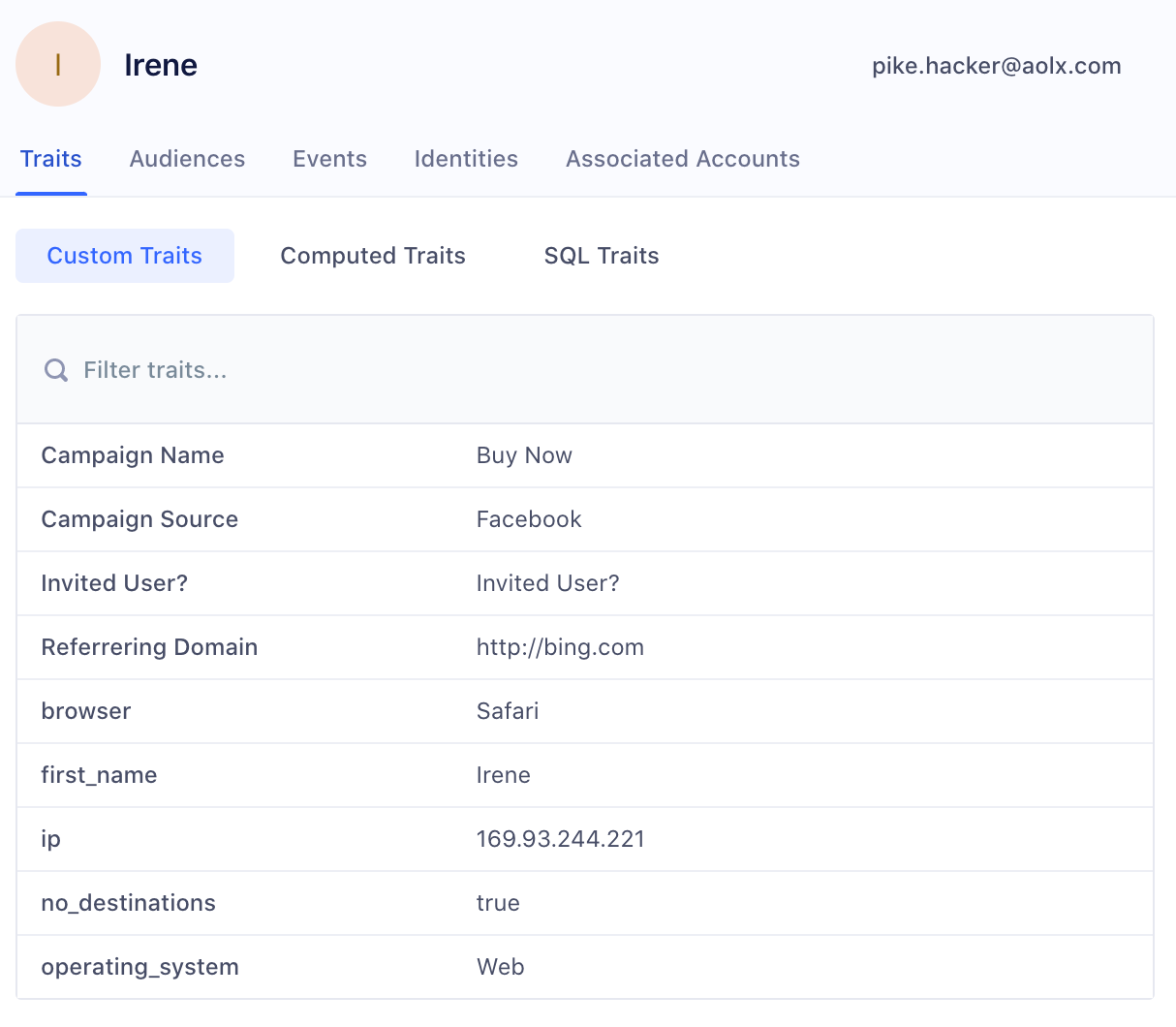
La déduplication des données clients est le processus de fusion des informations clients provenant de différentes sources pour créer une vue client 360 unifiée. Elle vise à résoudre les problèmes de doublons et d’incohérences causés par la dissémination des données dans plusieurs outils, l’utilisation d’identifiants clients différents, les erreurs humaines de saisie et les problèmes de synchronisation entre les systèmes.
L’objectif est d’agréger toutes les données au même endroit, dans une base de référence, pour obtenir une vision complète et précise du client, essentielle pour des décisions stratégiques et des actions marketing ciblées.
Déduplication vs Dédoublonnage des données
Le dédoublonnage et la déduplication des données sont deux concepts qu’il est important de bien distinguer :
En résumé, le dédoublonnage concerne la gestion des doublons au sein d’une même base de données, tandis que la déduplication des données clients concerne la consolidation des informations clients disséminées dans plusieurs outils ou bases de données différentes pour créer une vue globale et unifiée des clients.
L’enjeu derrière la déduplication des données : l’unification de données multi-sources
L’enjeu majeur derrière la déduplication des données réside dans la nécessité de faire face à la croissance exponentielle des outils et technologies utilisés par les entreprises, en particulier dans le domaine du marketing et de la relation client (MarTech). Avec la multiplication des canaux et des points de contact clients, les entreprises sont confrontées à un afflux massif de données clients provenant de sources diverses.
Au cœur de cette problématique se trouve l’unification des données clients, qui est devenue le principal défi depuis plusieurs années. L’objectif est de rassembler toutes ces données éparpillées dans une base de données centrale ou un référentiel client, pour créer une vue client 360 complète et cohérente. Cette vue unifiée permet aux entreprises de mieux comprendre leurs clients, d’identifier leurs besoins et leurs préférences, et d’offrir des expériences personnalisées et pertinentes.
La déduplication des données joue un rôle crucial dans ce processus d’unification. Elle consiste à identifier et à éliminer les doublons d’informations clients qui peuvent exister dans les différentes sources de données. En effet, lorsque les données clients proviennent de multiples canaux et outils, il y a souvent des risques de redondance et d’incohérence dans les enregistrements.
Cependant, il est essentiel de noter que la déduplication n’est qu’une étape parmi d’autres dans le processus d’unification des données. L’unification va au-delà de la simple suppression des doublons, car elle implique également la normalisation, la consolidation et la synchronisation des informations clients provenant de diverses sources.
Ainsi, l’enjeu majeur derrière la déduplication des données réside dans la création d’une vue client complète, permettant aux entreprises de mieux exploiter leurs données, de mieux comprendre leurs clients, et ce afin de prendre des décisions stratégiques plus éclairées et d’offrir des expériences clients plus personnalisées et satisfaisantes.
Quelques cas d’usage concrets de la déduplication des données
La déduplication des données joue un rôle essentiel dans de nombreux cas d’usage concrets, permettant aux entreprises d’améliorer leurs opérations et d’optimiser leur relation client. Voici quelques exemples pratiques :
- Amélioration de la qualité des données clients : La déduplication aide à éliminer les doublons et les incohérences dans les informations clients, garantissant ainsi que chaque enregistrement est précis et à jour. Cela contribue à améliorer la qualité globale de vos données, ce qui est essentiel pour des prises de décision fiables et des actions marketing ciblées.
- Unification des profils clients : En consolidant les données clients provenant de diverses sources, la déduplication permet de créer une vue client 360 complète et cohérente. Cela permet aux équipes marketing et aux équipes de service client de disposer d’une image précise et unifiée de chaque client, favorisant ainsi une meilleure compréhension de leurs besoins et de leurs préférences.
- Optimisation de l’expérience client : Grâce à cette connaissance approfondie des clients, les entreprises peuvent offrir des expériences clients plus personnalisées et pertinentes. La déduplication des données permet de mieux cibler les clients avec des offres et des communications adaptées, améliorant ainsi la satisfaction et la fidélité des clients.
- Réduction des coûts opérationnels : En éliminant les doublons de données clients, les entreprises évitent les inefficiences et les redondances dans leurs opérations. Cela peut entraîner des économies de temps et de ressources, en simplifiant les processus et en améliorant l’efficacité générale de l’entreprise.
- Prise de décision éclairée : Une déduplication réussie permet d’obtenir des données fiables et cohérentes, ce qui est essentiel pour prendre des décisions stratégiques éclairées. Les dirigeants peuvent compter sur des informations précises pour établir des objectifs, identifier les opportunités de croissance et anticiper les tendances du marché.
- Conformité et sécurité des données : La déduplication contribue à garantir que les informations clients sont correctes et à jour, ce qui est crucial pour respecter les réglementations de protection des données telles que le RGPD. En évitant les doublons, les entreprises minimisent également les risques liés à la sécurité des données.
- Amélioration de l’efficacité des campagnes marketing : En éliminant les doublons, les entreprises peuvent mieux segmenter leur base de clients et cibler les audiences appropriées. Cela permet d’optimiser les campagnes marketing en évitant de solliciter plusieurs fois les mêmes clients, améliorant ainsi le retour sur investissement de votre dispositif data.
Les risques associés aux données dupliquées
Les données dupliquées peuvent entraîner de nombreux risques pour les entreprises, notamment :
La méthode pour dédupliquer vos données clients
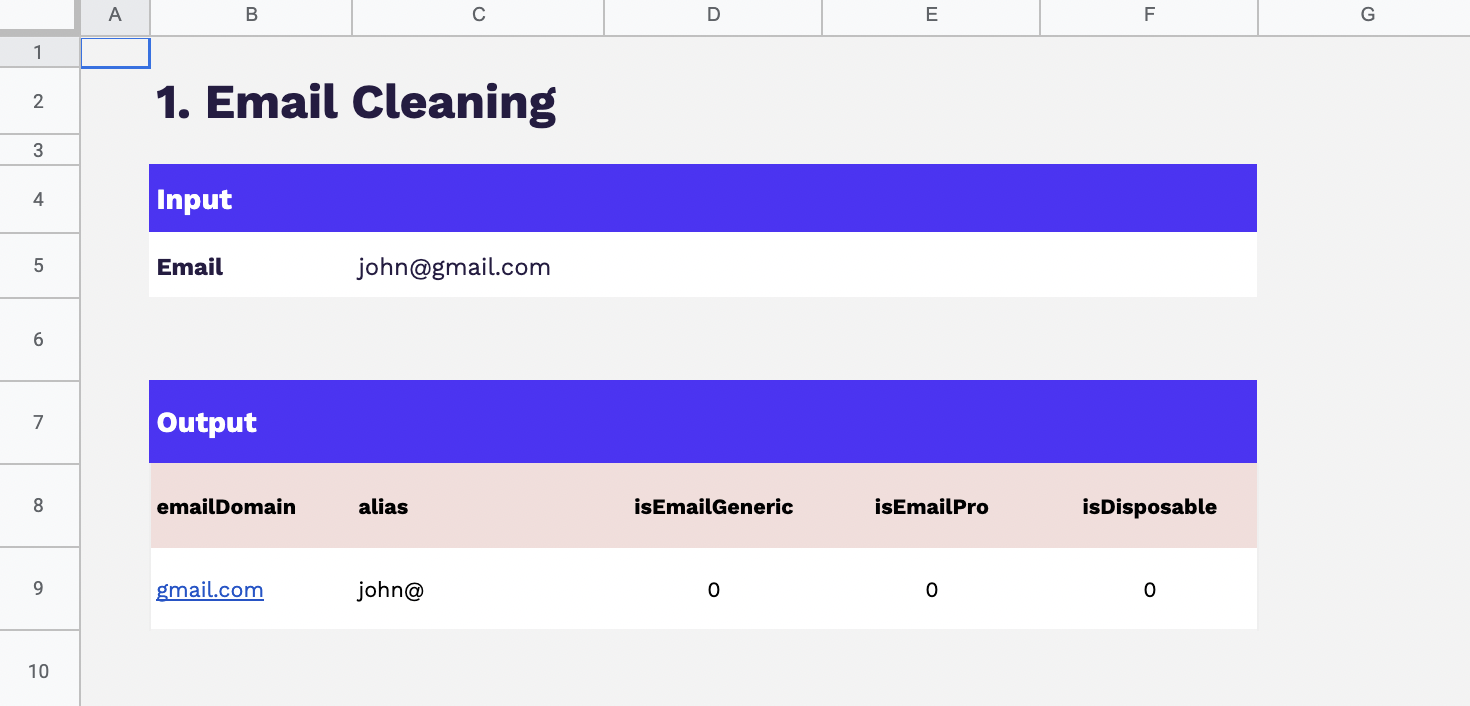
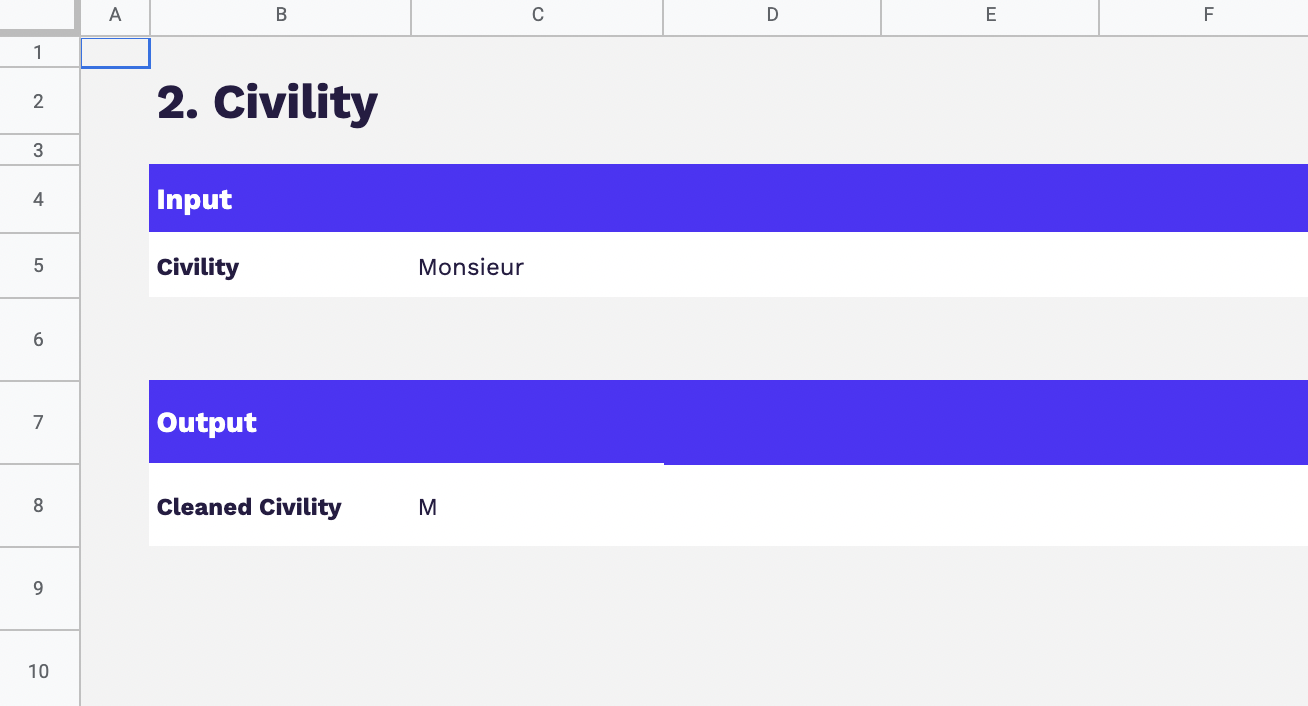
Les préalables à la déduplication des données : normalisation & nettoyage
Avant de se lancer dans le processus de déduplication des données, deux étapes essentielles sont à prendre en compte : la normalisation et le nettoyage des données.
En résumé, la normalisation et le nettoyage des données sont des préalables indispensables avant de se lancer dans la déduplication. Ces étapes permettent de s’assurer que les données sont cohérentes, comparables et exemptes d’erreurs, créant ainsi un terrain propice à une déduplication réussie et efficace.
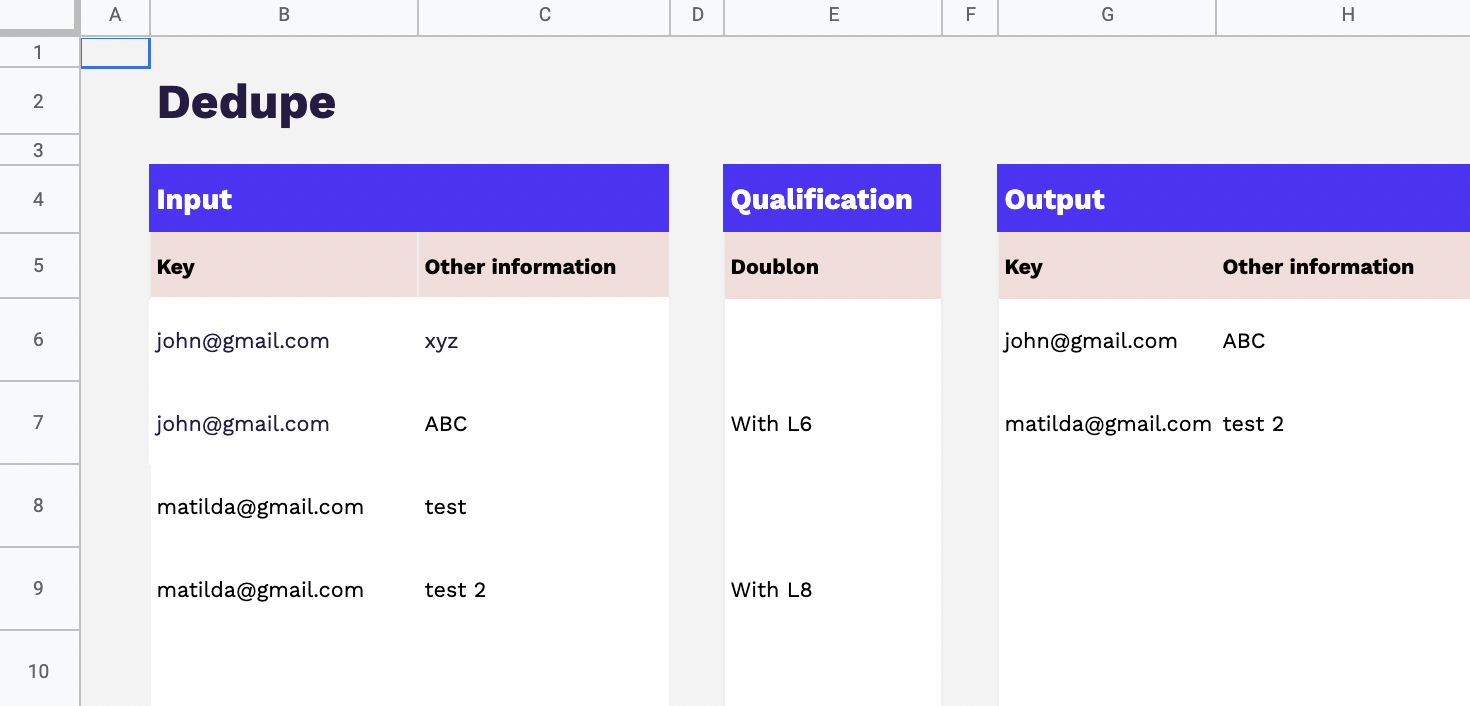
La création du graph d’identités (Identity Graphs)
Le graph d’identités est une table visuelle qui regroupe les identifiants utilisés sur les points de contact et par les outils de l’entreprise, offrant une vue globale des clients et des données associées à ces identifiants. Certains logiciels offrent des représentations visuelles pour faciliter la compréhension des interrelations complexes entre les différents points de contact.
Les éléments du graph d’identités comprennent :
Il permet de visualiser les types de données rattachés à chaque identifiant, tels que les données démographiques, les préférences, les historiques d’achats, etc. L’objectif est d’obtenir une vue complète et unifiée des clients pour améliorer les expériences personnalisées, la satisfaction client et les décisions stratégiques basées sur des données précises.
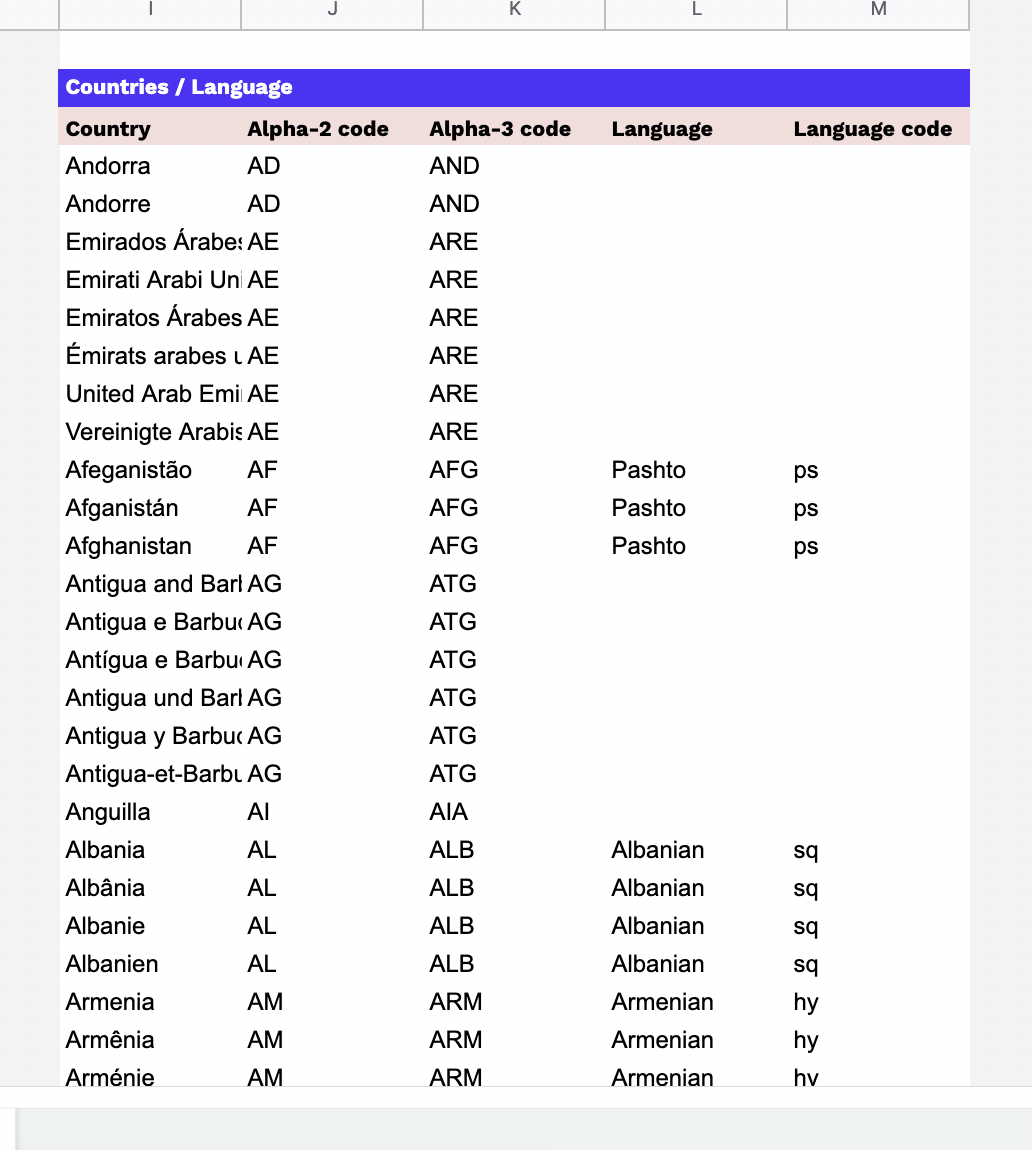
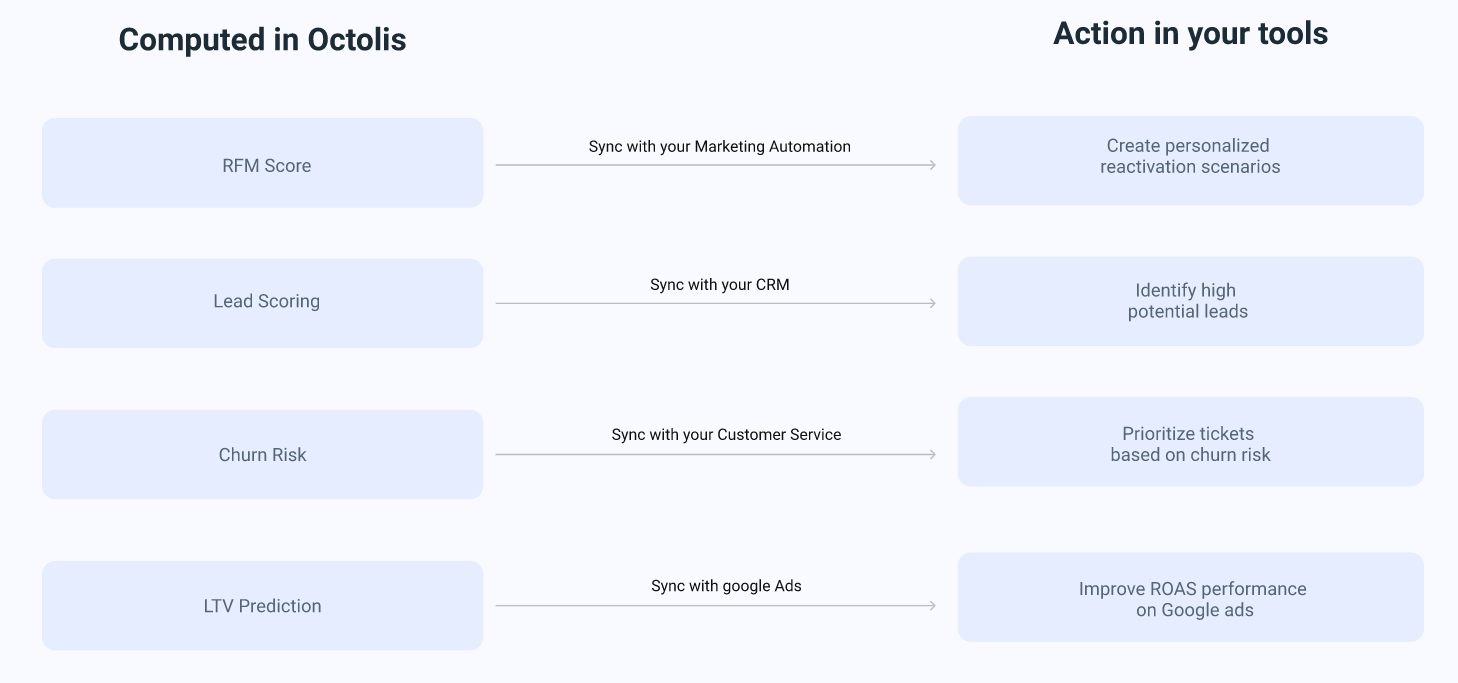
Le choix des clés de déduplication
Les clés de déduplication sont les identifiants sélectionnés pour unifier les enregistrements similaires et éliminer les doublons dans le graph d’identités. Il est recommandé d’utiliser des clés d’unification qui sont spécifiques, persistantes et uniques pour chaque client. Les clés d’unification servent à identifier de manière fiable et précise les clients, garantissant ainsi que les enregistrements pertinents sont regroupés ensemble.
En univers Retail / Ecommerce, deux clés fréquemment utilisées pour la déduplication sont :
Il est important de noter que différentes entreprises peuvent avoir des besoins spécifiques en matière de clés de déduplication en fonction de leurs données et de leur secteur d’activité. Par conséquent, il est possible d’utiliser des règles en cascade avec une priorisation pour la déduplication.
Les règles en cascade permettent de hiérarchiser l’utilisation des différentes clés de déduplication dans le processus de déduplication. Par exemple, on peut commencer par utiliser l’email comme clé principale, puis en cas d’absence d’email, utiliser la combinaison du nom, du prénom et de l’adresse comme clé de secours.
Matching déterministe Vs matching probabiliste
Le processus de déduplication des données peut être réalisé à l’aide de deux approches distinctes : le matching déterministe et le matching probabiliste. Ces approches peuvent être utilisées de manière complémentaire pour obtenir des résultats plus précis.
Ces deux approches peuvent être utilisées de manière complémentaire pour obtenir des résultats plus robustes. Par exemple, le matching déterministe peut être utilisé en priorité pour les enregistrements avec des clés d’identification claires et uniques, tandis que le matching probabiliste peut être utilisé pour détecter des correspondances potentielles lorsque les clés d’identification sont manquantes ou inexactes.
Dans le cadre de l’identity resolution, qui vise à créer une vue client unifiée, le choix entre le matching déterministe et le matching probabiliste dépend des besoins spécifiques de l’entreprise et de la qualité des données disponibles. Une combinaison judicieuse de ces deux approches peut permettre une déduplication précise et complète, conduisant à une meilleure compréhension des clients et à des actions marketing plus efficaces.
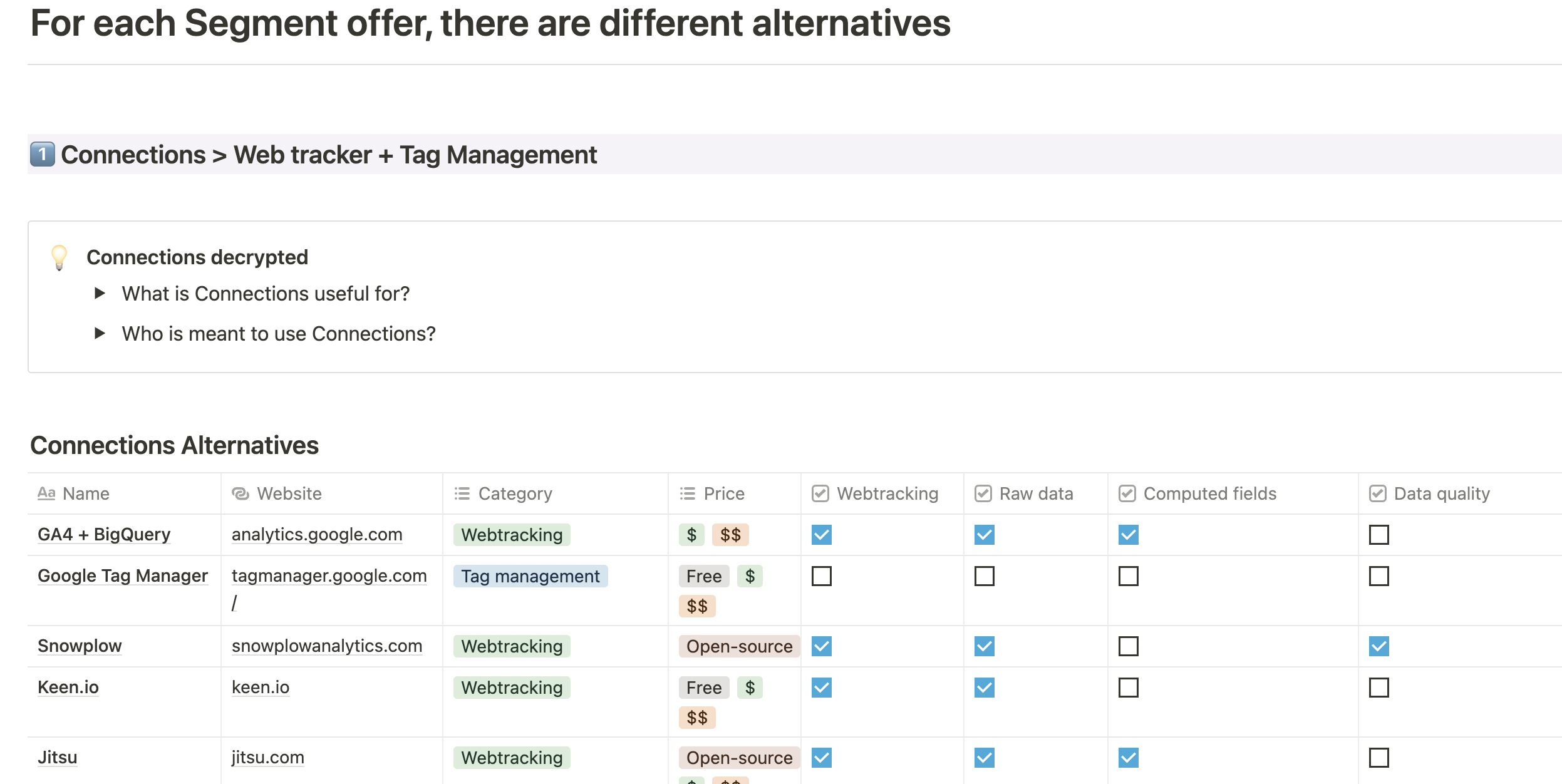
Les outils pour dédupliquer vos données clients
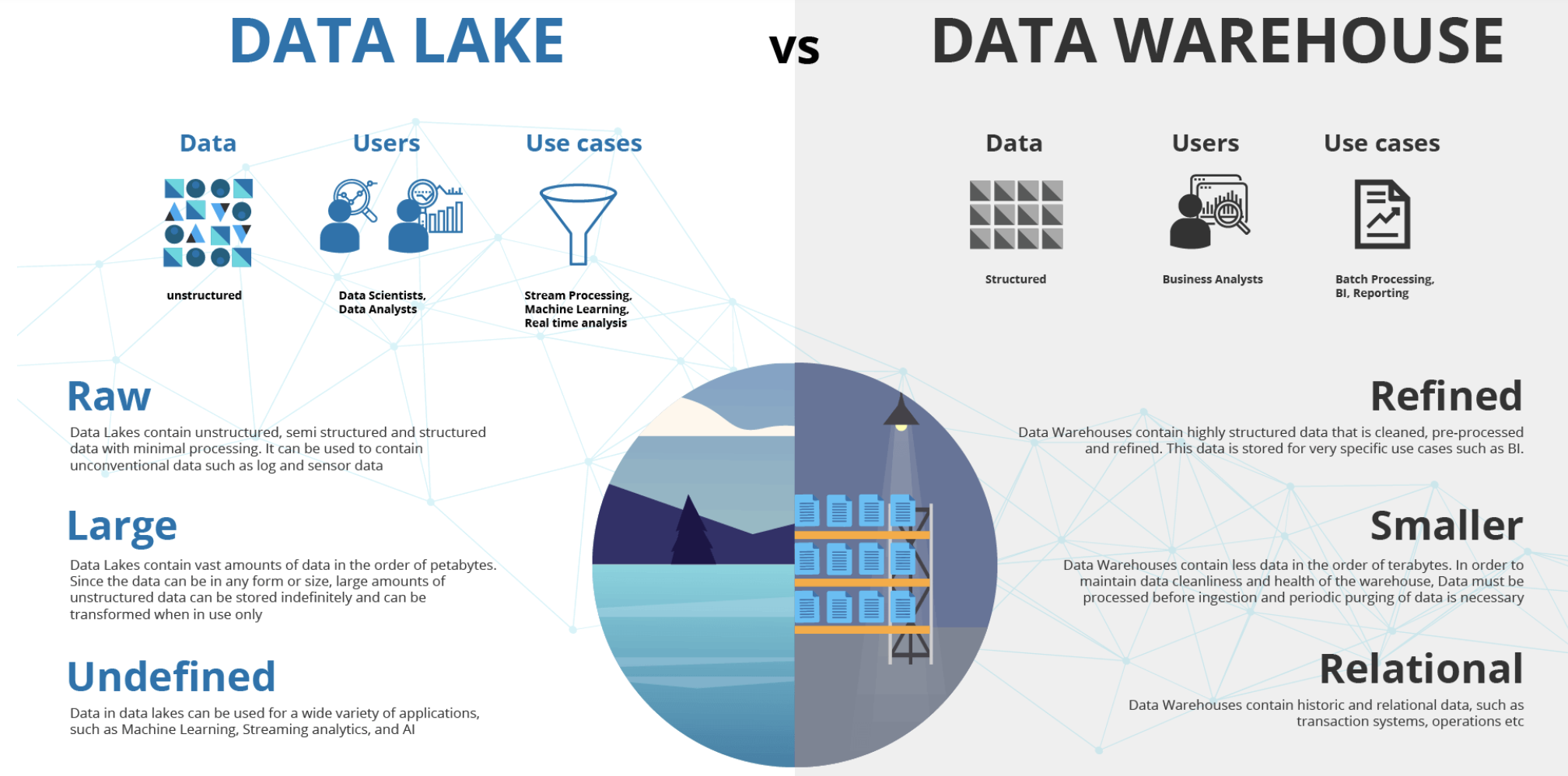
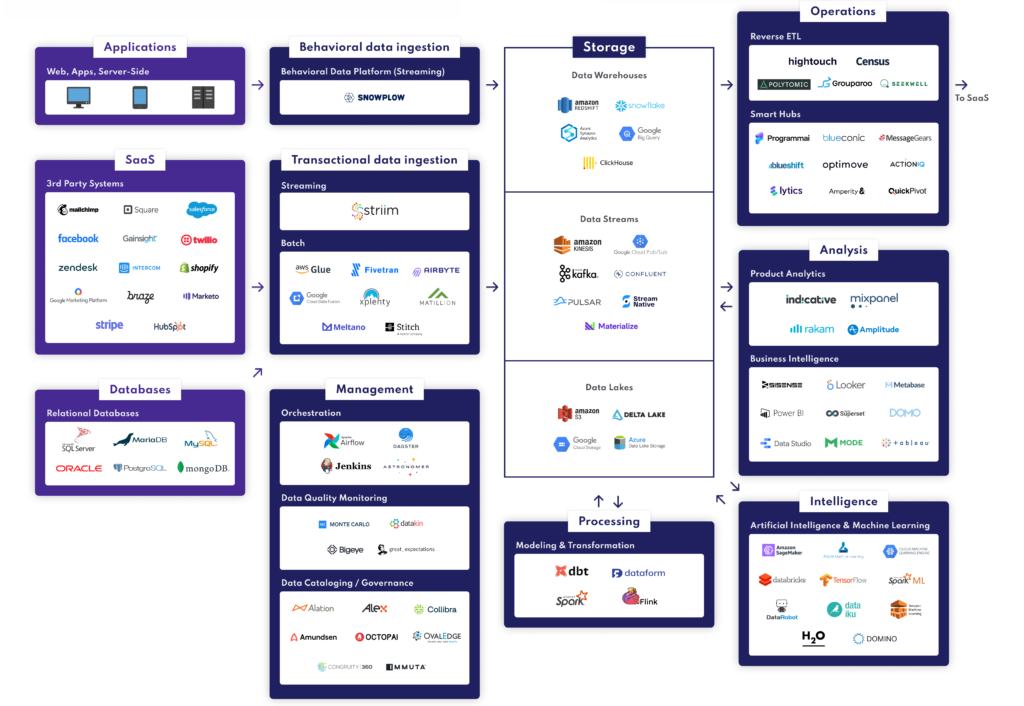
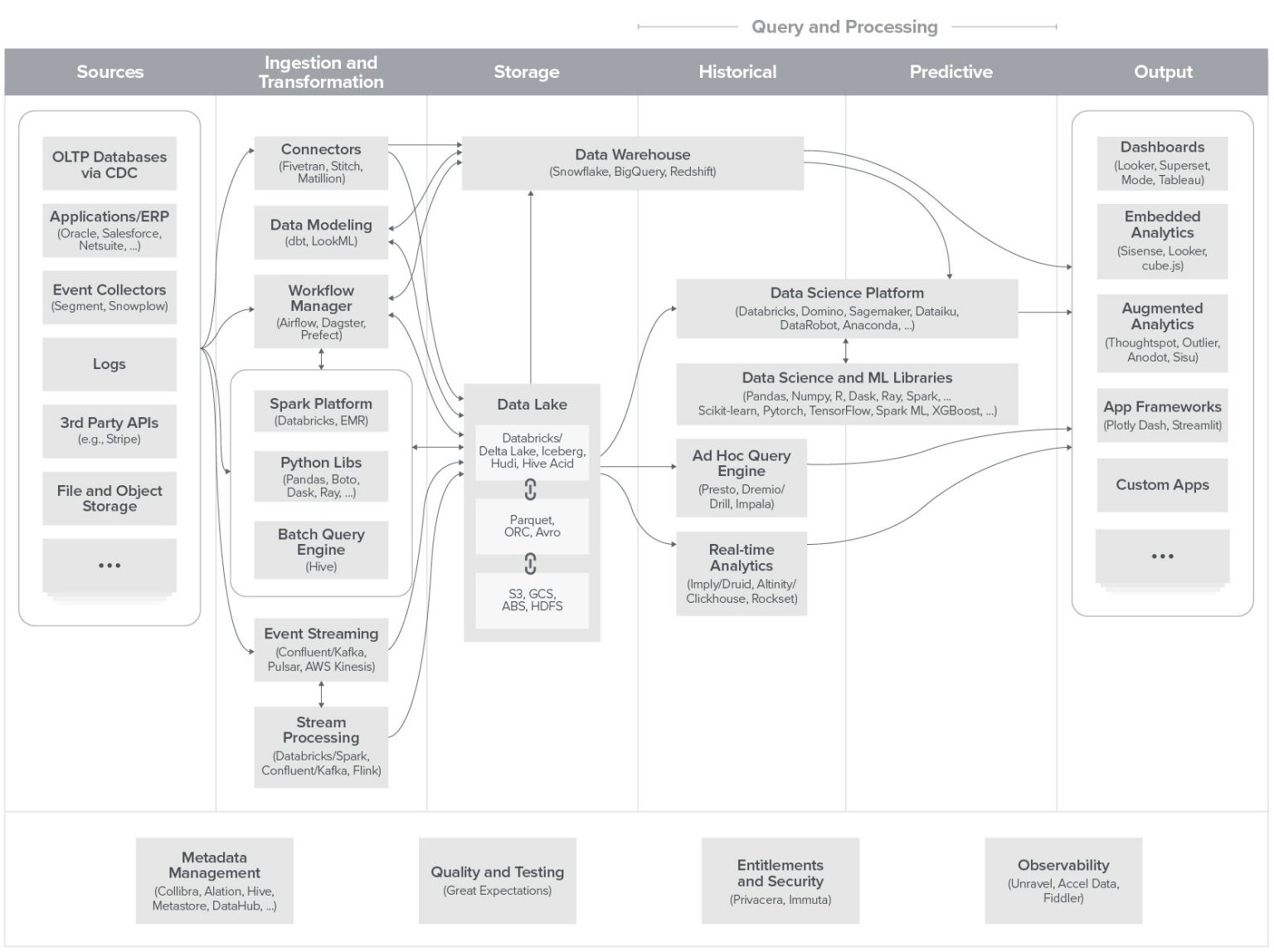
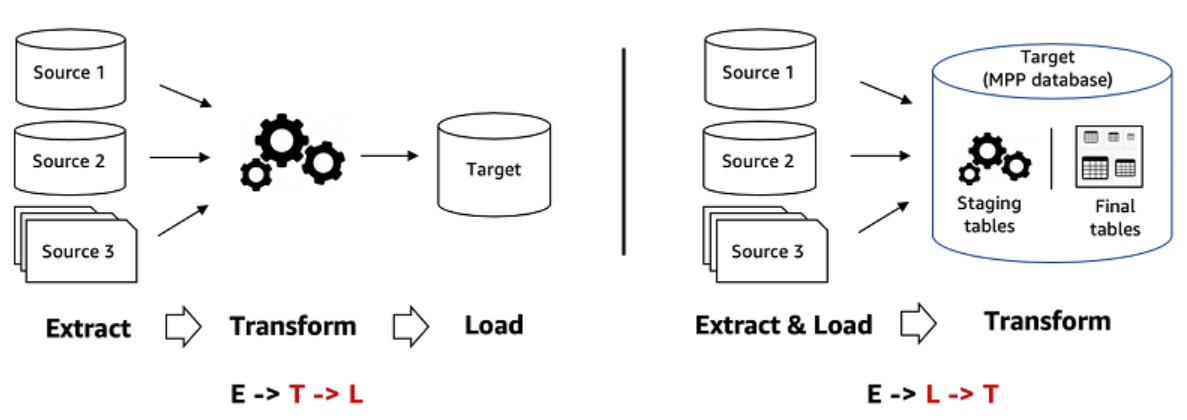
Pour dédupliquer les données clients, plusieurs solutions et types d’outils sont disponibles, chacun offrant des fonctionnalités spécifiques adaptées aux besoins des entreprises.
Chaque type d’outil a ses avantages et ses inconvénients, et le choix dépendra des besoins, de la taille et des ressources de l’entreprise. Les Data Warehouses avec SQL peuvent être une option solide pour les entreprises ayant déjà des infrastructures de données en place et des compétences en SQL. Les CDP sur l’étagère peuvent être une solution rapide et simple pour les entreprises cherchant une approche globale, tandis que les outils de préparation et de qualité des données spécialisés offrent une personnalisation plus poussée et une meilleure adaptabilité aux besoins spécifiques.
Conclusion
En résumé, la déduplication des données et l’identity resolution sont des processus cruciaux pour obtenir une vue client complète et exploiter efficacement les informations clients. Les entreprises doivent s’appuyer sur des outils adaptés, des clés d’unification appropriées et une approche équilibrée entre le matching déterministe et probabiliste pour assurer la fiabilité, la précision et la cohérence de leurs données clients.