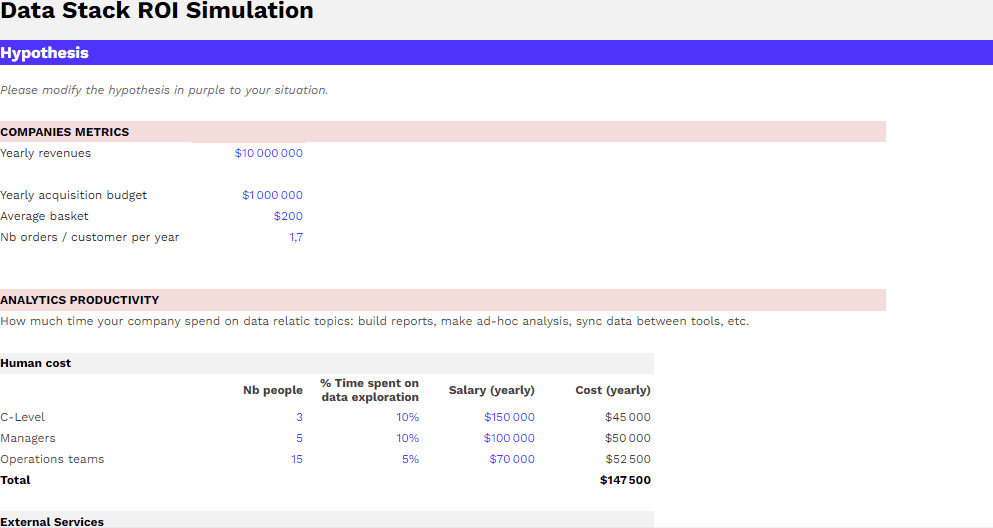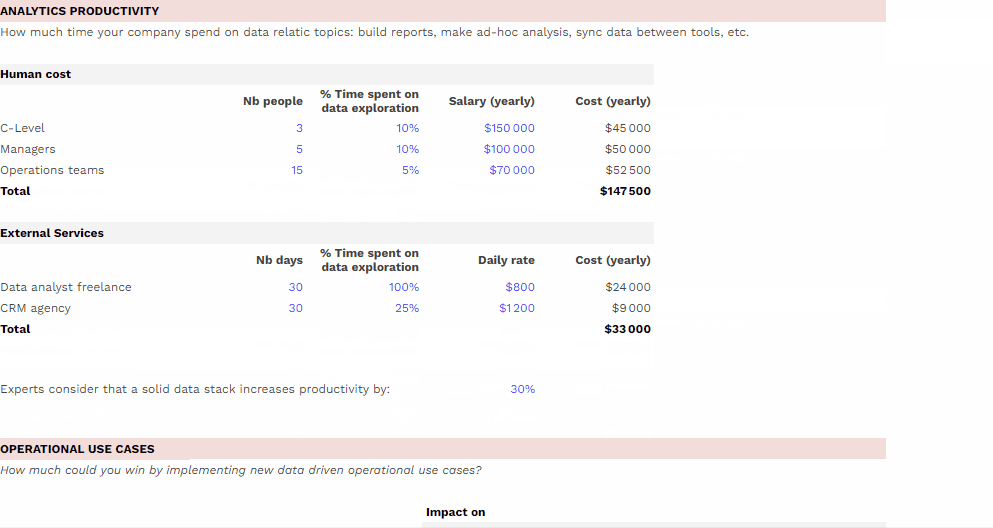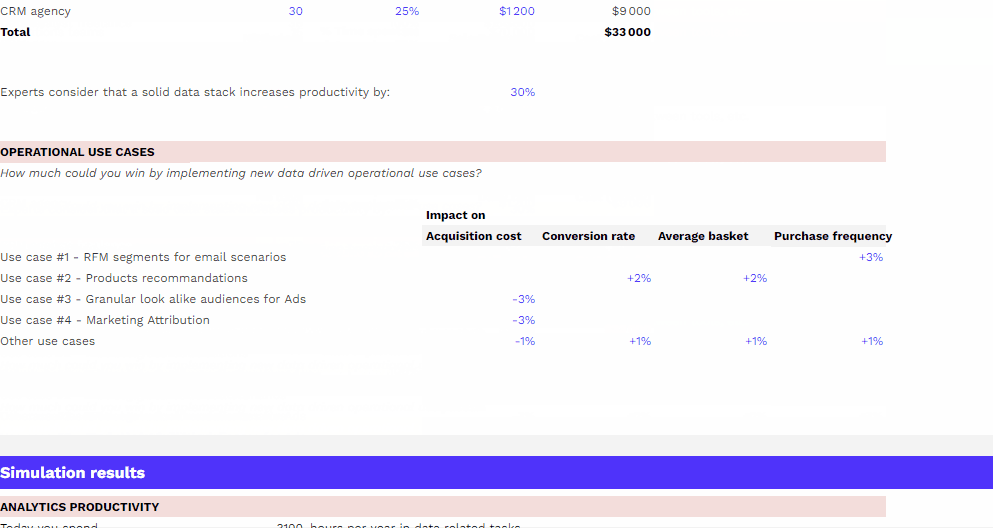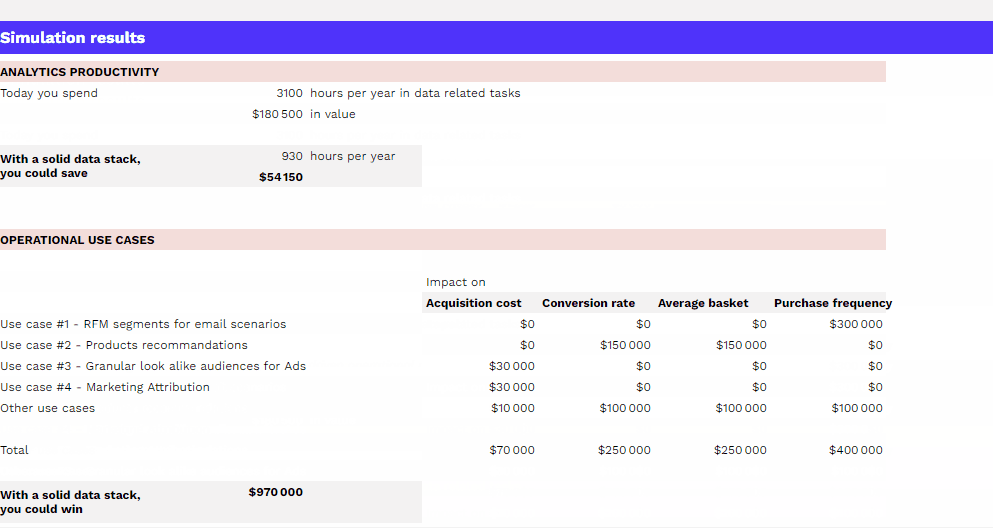
Le coût d’un projet Data Warehouse peut varier de 1 à 100, alors forcément impossible de donner une réponse toute faite. Nous allons vous partager les infos clés à connaître pour comprendre ce qui impacte le coût d’un Data Warehouse : les différents postes de coûts à anticiper, la différence importante à faire entre coût de stockage et coût de computing, batch et streaming de données…
En fin d’article, on a voulu vous présenter le prix des principales solutions data warehouse cloud du marché : BigQuery, Snowflake, Azure, Redshift (mais, spoiler alert, n’oubliez jamais que le coût d’un Data Warehouse ne se réduit jamais au seul coût de la licence…)
| Poste de coût | Présentation & Estimation |
|---|---|
| Coûts de stockage | 20 à 25 dollars par téraoctet par mois pour le cloud. Pour un stockage en local, la mise de départ débute à 3 500 $ et les coûts mensuels peuvent dépasser les 1 000 $ par mois. |
| Licence d'exploitation | Le coût des licences est calculé en fonction de la taille de la base de données, de votre utilisation (computing) et des services consommés (intégrations, cleansing...). Le coût peut varier de quelques milliers d'euros par an à plusieurs dizaines (voire centaines) de milliers d'euros par an. |
| Coût en ressource humaines | La construction d'un data warehouse peut impliquer des coûts significatifs en termes de ressources humaines. Ces coûts peuvent varier en fonction de la taille et de la complexité du projet, ainsi que du niveau d'expertise technique nécessaire. |
| Coût des outils connexes | Ce sont les coûts des outils supplémentaires nécessaires pour gérer et optimiser et utiliser vos données : ETL, outil de reporting, outil de Data Ops... |
📕 Guide complet sur le coût d’un Data Warehouse:
L’essentiel à retenir sur le coût d’un Data Warehouse
La création et la gestion d’un data warehouse peuvent être coûteuses pour une entreprise. Ces coûts peuvent varier considérablement en fonction de plusieurs facteurs clés.
En résumé, la création et la gestion d’un data warehouse peuvent être coûteuses pour une entreprise. Ces coûts dépendent de la taille du data warehouse, du choix du matériel et des logiciels, des coûts de main-d’œuvre, de la gestion des données et de l’évolutivité. Les entreprises doivent prendre en compte ces facteurs clés pour anticiper les coûts et déterminer la meilleure stratégie pour la mise en place et la gestion de leur data warehouse.
Estimer le coût du déploiement de votre Data Warehouse
Le coût de la licence
Une composante importante du coût total est la licence d’exploitation. La plupart des fournisseurs proposent une licence annuelle ou pluriannuelle, dont le coût dépend des besoins spécifiques de l’entreprise. Le prix varie en fonction de la taille du data warehouse, du nombre d’utilisateurs, des fonctionnalités nécessaires, la durée de la licence, de la région d’hébergement…
Pour un data warehouse de taille moyenne, le coût d’une licence annuelle s’élève généralement à quelques milliers d’euros. Les frais de maintenance peuvent être inclus dans le coût de la licence, ou facturés séparément. Il est important de noter que le coût des licences peut également varier en fonction du fournisseur.

Il est donc nécessaire de comparer les offres et de choisir un fournisseur qui répond aux besoins spécifiques de l’entreprise, tout en offrant des prix compétitifs et des fonctionnalités adaptées. Certains fournisseurs de plateformes cloud proposent même des programmes de tarification qui permettent de réaliser des économies en fonction de la quantité d’utilisation.
Le coût des outils connexes : ETL, BI…
En plus des coûts de licence et de la plateforme cloud, il faut considérer les coûts des outils supplémentaires nécessaires pour gérer et optimiser le data warehouse et utiliser vos données. Ces outils supplémentaires incluent des outils d’intégration de données pour charger et transformer les données, des outils de gestion des métadonnées, et des outils de BI pour permettre aux utilisateurs de requêter et d’analyser les données.
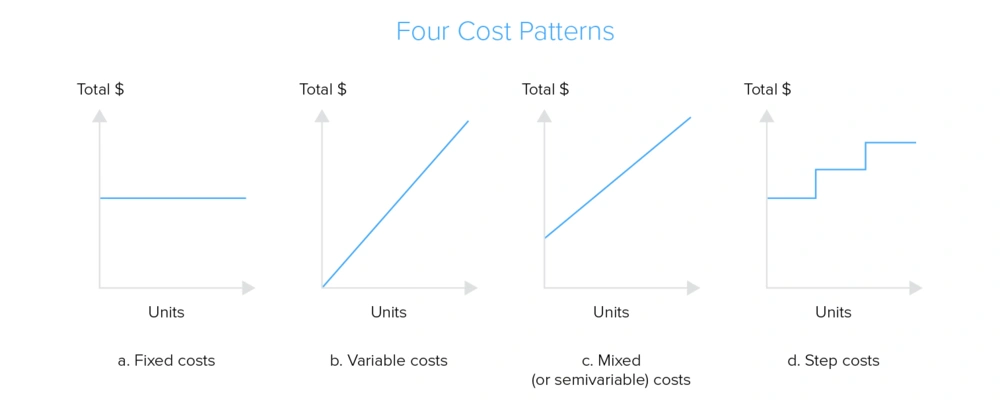
Le coût de ces outils supplémentaires peut varier là aussi en fonction du fournisseur et de la quantité de données traitées. Par exemple, les outils d’intégration de données peuvent coûter environ 20 000 par an. Les outils de gestion des métadonnées et d’analyse peuvent coûter entre 5 000 et 50 000 dollars par an en fonction de la complexité de l’environnement et du volume de données traitées. Il existe 4 types de facturations principaux que nous vous présentons ci-dessous.
Le coût des ressources humaines
La construction d’un data warehouse peut impliquer des coûts significatifs en termes de ressources humaines. Ces coûts peuvent varier en fonction de la taille et de la complexité du projet, ainsi que du niveau d’expertise technique nécessaire. Voici quelques-unes des ressources humaines qui peuvent être impliquées dans la construction d’un data warehouse :
- Chef de projet : les responsables de la gestion globale du projet. Il travaille avec les parties prenantes pour comprendre les exigences commerciales, développer un plan de projet et assurer la coordination de l’équipe de projet.
- Architecte de données : les responsables de la conception du data warehouse, y compris la modélisation de données, la définition de la structure de stockage des données et la conception de l’architecture globale.
- Analyste de données : ils analyses des données pour identifier les tendances et les modèles. Ils peuvent être nécessaires pour aider à la conception des modèles de données, la rédaction des spécifications et la validation des données.
- Ingénieur en informatique : ils permettent la mise en œuvre de l’architecture technique du data warehouse. Ils peuvent être nécessaires pour travailler sur la mise en place de bases de données, la configuration de serveurs et la gestion des interfaces de programmation d’applications (API).
- Testeur : Les testeurs assurent la qualité du data warehouse. Ils travaillent avec l’équipe de développement pour tester les données et les fonctionnalités pour s’assurer qu’elles répondent aux exigences spécifiées.
- Formateur : Les formateurs sont responsables de la formation des utilisateurs sur l’utilisation du data warehouse. Le coût des formateurs dépend du niveau d’expertise requis et de la méthode de formation choisie. En outre, il est important de considérer les coûts de formation qui peuvent varier en fonction de la complexité du data warehouse et du nombre d’utilisateurs.
En fin de compte, le coût total des ressources humaines nécessaires pour construire un data warehouse dépendra des spécificités de chaque projet. Cependant, il est important de comprendre que la construction d’un data warehouse peut nécessiter une équipe de personnes qualifiées et spécialisées pour garantir un projet réussi qui répond aux besoins commerciaux.
Le coût de la maintenance du Data Warehouse
La maintenance d’un data warehouse est également un coût important à prendre en compte. Cela peut inclure des coûts pour le personnel de maintenance, des mises à jour logicielles, des réparations matérielles, etc.
En résumé, il est important de considérer l’ensemble des coûts liés à la mise en place et à la gestion d’un data warehouse, y compris les coûts de licence, les coûts de la plateforme cloud, les coûts des outils supplémentaires et les coûts de formation. En prenant en compte tous ces facteurs, les entreprises peuvent élaborer un budget réaliste pour leur projet de data warehouse et s’assurer que leur investissement est rentable.
Comprendre la facture de votre Data Warehouse
Le prix du stockage
La première composante de la facture de votre data warehouse est le prix du stockage. Ce coût du stockage dépendra de plusieurs facteurs, notamment la quantité de données stockées, la fréquence d’accès aux données, le type de stockage utilisé, etc. Le stockage peut être effectué en interne, en utilisant des disques durs, ou via un stockage en cloud, en utilisant des services de stockage tels que Amazon S3, Google Cloud Storage ou Microsoft Azure Blob Storage. Le site Light IT propose une analyse détaillée des différents providers clouds.
Si vous optez pour un stockage en cloud, les coûts seront souvent basés sur la quantité de données stockées et la fréquence d’accès aux données. Les fournisseurs de cloud peuvent également facturer des coûts supplémentaires pour les opérations de lecture et d’écriture, les transferts de données et les frais de gestion. En revanche, si vous optez pour un stockage en interne, vous devrez prendre en compte les coûts de l’achat de disques durs, de la maintenance, de l’espace physique nécessaire, etc.
Les frais de stockage peuvent varier en fonction de la quantité de données stockées et du type de stockage utilisé. Pour un stockage cloud, les coûts peuvent varier de 20 à 25 dollars par téraoctet par mois. Pour un stockage sur site, les coûts incluent d’abord la mise de départ, qui débute à 3 500 $. Les coûts mensuels peuvent varier, et inclus l’électricité, la maintenance… Ils peuvent dépasser les 1 000 $ par mois.
Le prix des ressources de calcul (compute)
La deuxième composante de la facture de votre data warehouse est le prix des ressources de calcul. En effet, le traitement des données nécessite souvent des ressources de calcul importantes pour effectuer des requêtes complexes et générer des rapports.
Le coût des ressources de calcul dépendra de plusieurs facteurs, notamment la quantité de données à traiter, la complexité des requêtes, la fréquence d’exécution des requêtes, etc. Les ressources de calcul peuvent être fournies par des serveurs internes ou des services de cloud computing tels que Amazon EC2, Google Compute Engine ou Microsoft Azure Virtual Machines.
Si vous optez pour un service de cloud computing, les coûts seront souvent basés sur la quantité de ressources utilisées, la durée d’utilisation, la complexité des requêtes et les frais de gestion. Les fournisseurs de cloud peuvent également proposer des options de tarification à la demande ou réservées, qui peuvent permettre de réduire les coûts. En revanche, si vous optez pour des serveurs internes, vous devrez prendre en compte les coûts de l’achat de serveurs, de la maintenance, de l’espace physique nécessaire, etc.
En résumé, le coût des ressources de calcul est une composante importante de la facture de votre data warehouse. Il est important de comprendre les coûts associés à chaque option de traitement disponible et de déterminer celle qui convient le mieux aux besoins de votre entreprise.
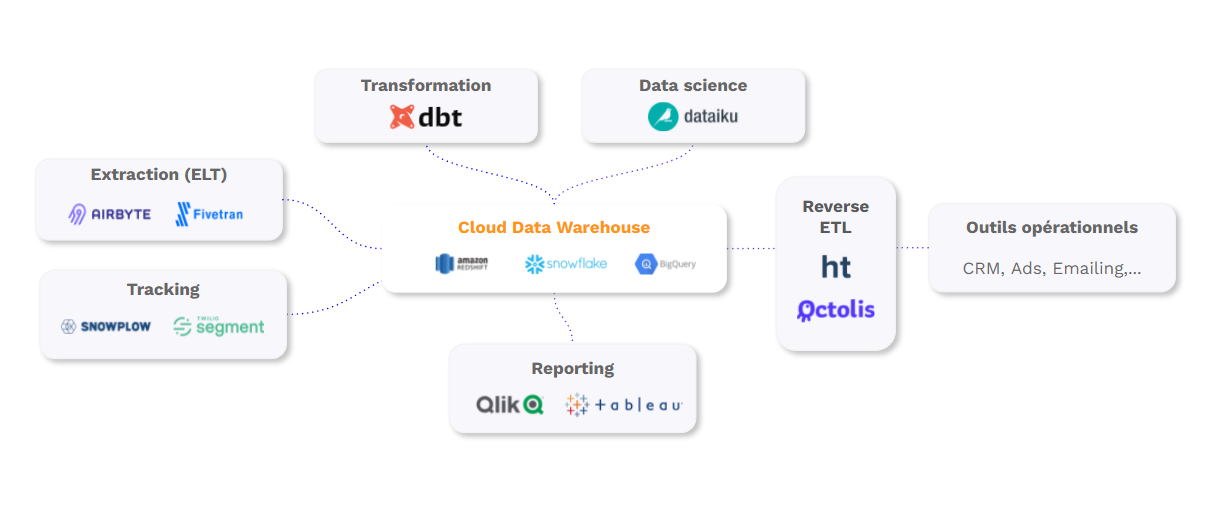
La tendance moderne : la décorrélation du stockage et du compute
La tendance moderne en matière de data warehouse est la décorrélation du stockage et du compute. Cette tendance permet de séparer la gestion du stockage des données de la gestion du traitement de ces données, deux tâches distinctes qui peuvent être effectuées de manière indépendante. La décorrélation de ces tâches permet de traiter les données sans avoir à les déplacer vers un emplacement centralisé, ce qui peut être bénéfique en termes de coûts et de performances.
Cette tendance se manifeste souvent par l’utilisation de services de cloud computing tels que Amazon Redshift, Google BigQuery ou Microsoft Azure Synapse Analytics. Ces services offrent une séparation du stockage et du traitement, ce qui permet d’optimiser les coûts en payant uniquement pour les ressources de traitement nécessaires. En effet, avec cette approche, le stockage des données peut être effectué dans un emplacement centralisé et économique, tandis que le traitement peut être effectué de manière distribuée et à la demande, en fonction des besoins de l’entreprise.
Batch VS Streaming
Le quatrième point à considérer est le choix entre le traitement par lot (batch) ou le traitement en continu (streaming) des données.
Le traitement par lot est le traitement de grands volumes de données en une seule fois, généralement sur une période donnée, comme une journée ou une semaine. Cette approche est souvent utilisée pour des tâches d’analyse historique ou de génération de rapports réguliers, qui n’ont pas besoin d’une réponse en temps réel. Le traitement par lot peut être moins coûteux que le traitement en continu, car il peut être effectué en dehors des heures de pointe et ne nécessite pas de ressources en continu.
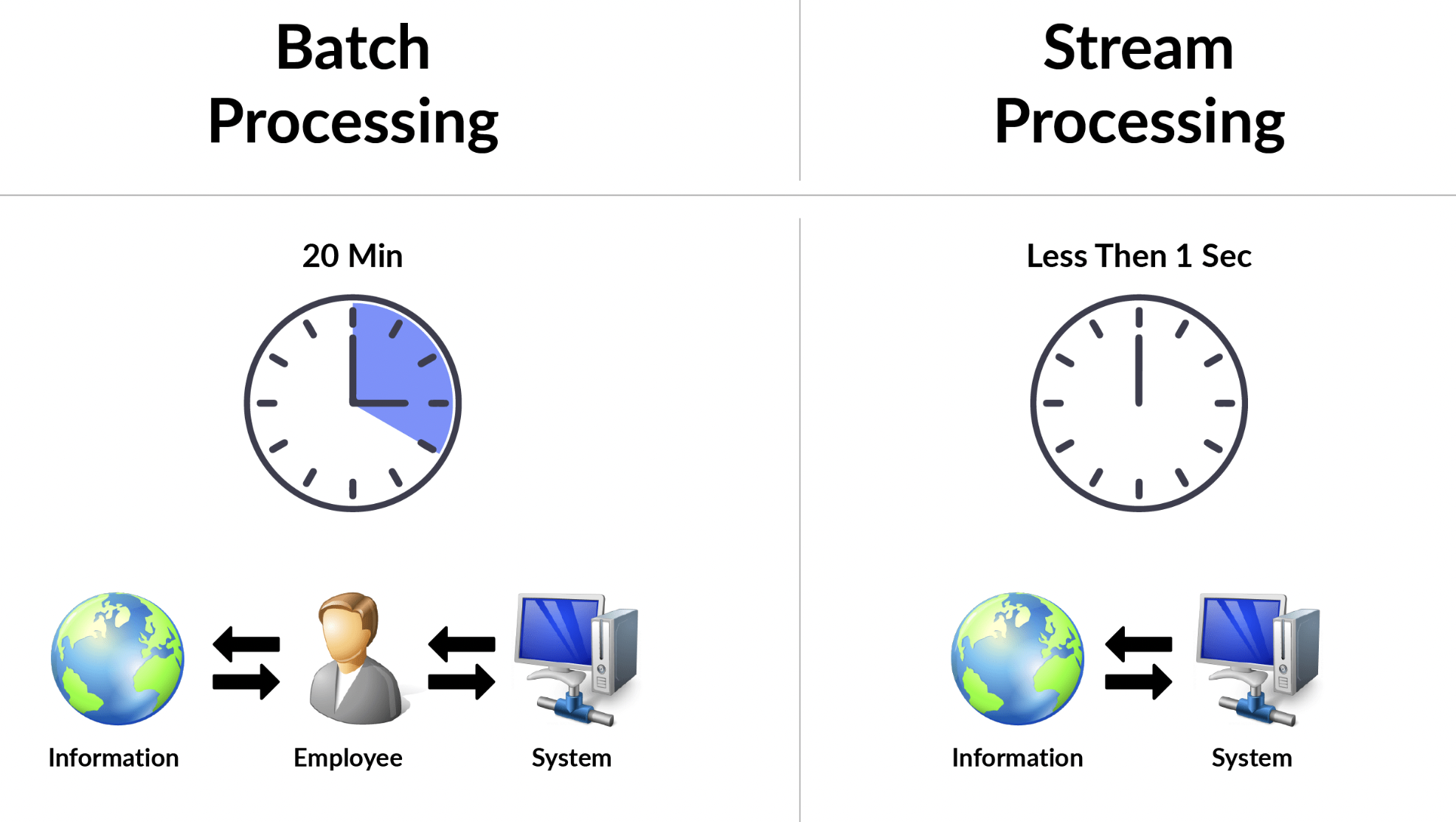
En revanche, le traitement en continu est le traitement de données en temps réel, au fur et à mesure de leur arrivée. Cette approche est souvent utilisée pour des tâches qui nécessitent une réponse en temps réel, comme la surveillance des données, les alertes et les notifications. Le traitement en continu peut être plus coûteux que le traitement par lot, car il nécessite des ressources en continu.
Le choix entre le traitement par lot et le traitement en continu dépendra des besoins de votre entreprise. Si vous avez besoin d’analyser de grands volumes de données historiques de manière régulière, le traitement par lot peut être une option plus économique. Si vous avez besoin d’une réponse en temps réel, le traitement en continu peut être plus approprié. Il est important de noter que certains services de data warehouse proposent des options hybrides combinant le traitement par lot et le traitement en continu. Ces options peuvent être utiles pour les entreprises qui ont besoin de répondre à des besoins variés.
Structure de prix des principaux Data Warehouses du marché
Tableau de synthèse
| Data Warehouse | Coût |
|---|---|
| Snowflake | |
| Google BigQuery | Système principalement "pay as you go", mais possibilité d'avoir une tarification mensuelle prévisible. |
| Amazon Redshift | |
| Azure Analytics |
Google BigQuery
BigQuery est un data warehouse basé sur le cloud qui fait partie de la Google Cloud Platform. L’un des principaux avantages de BigQuery est son modèle de tarification « pay-as-you-go », qui permet aux utilisateurs de ne payer que pour les ressources informatiques qu’ils utilisent. Il s’agit donc d’une option rentable pour les entreprises de toutes tailles. BigQuery propose également des tarifs forfaitaires pour les clients qui souhaitent une tarification mensuelle prévisible.
BigQuery offre plusieurs fonctionnalités qui en font un outil puissant pour l’analyse des données, notamment la prise en charge du langage SQL et le flux de données en temps réel. Il s’intègre également à d’autres services de Google Cloud Platform, tels que Google Cloud Storage, Dataflow et Dataproc. En outre, BigQuery offre plusieurs fonctions de sécurité, de contrôles d’accès et d’audit. Il est également conforme à plusieurs normes et réglementations du secteur, telles que SOC 2, HIPAA et GDPR.
Dans l’ensemble, le modèle de tarification « pay-as-you-go » de BigQuery, ses puissantes fonctionnalités et sa sécurité robuste en font un choix populaire pour l’entreposage et l’analyse de données dans le cloud. Son intégration avec d’autres services de Google Cloud Platform le rend facile à utiliser et offre une expérience utilisateur simple.
Snowflake
Snowflake est un data warehouse moderne basé sur le cloud qui offre une architecture distincte pour le stockage de masse et le calcul. Il propose une variété de fonctionnalités pour la gestion, l’analyse, le stockage et la recherche de données. L’un des principaux avantages de Snowflake est qu’il offre des ressources informatiques dédiées, ce qui garantit de meilleures performances et des temps de traitement des requêtes plus rapides. Ce datawarehouse est strcturé en 3 couches :
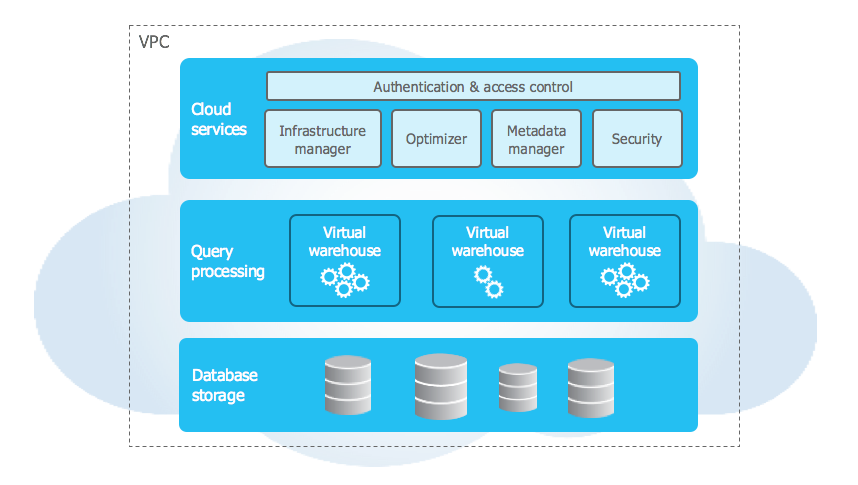
Snowflake propose plusieurs modèles de paiement, dont le stockage à la demande et le stockage de capacité, qui sont basés sur la quantité de données stockées dans l’entrepôt. En outre, il existe quatre modèles de tarification qui offrent différents niveaux de fonctionnalité : Standard, Enterprise, Business Critical et Virtual Private Snowflake.
Dans l’ensemble, les modèles de tarification flexibles et les ressources informatiques dédiées de Snowflake en font un choix populaire pour les besoins d’entreposage de données modernes. La plateforme offre une gamme de caractéristiques et de fonctionnalités qui peuvent répondre aux besoins des entreprises de toutes tailles et de tous secteurs, des startups aux grandes entreprises.
Amazon Redshift
Amazon Redshift est un entrepôt de données basé sur le cloud qui fait partie de la plateforme Amazon Web Services (AWS). Il s’agit d’une solution évolutive et entièrement gérée pour l’entreposage et l’analyse de données.
Redshift utilise un format de stockage et une architecture de traitement massivement parallèle qui lui permet de traiter rapidement et efficacement de grands ensembles de données. Il offre plusieurs fonctionnalités qui en font un outil puissant, notamment l’intégration avec d’autres services AWS tels que S3, Lambda et Glue. Redshift offre également plusieurs fonctionnalités de sécurité et la conformité à plusieurs normes et réglementations sectorielles telles que SOC 2, PCI DSS et HIPAA.
L’un des principaux avantages de Redshift est sa compatibilité avec un large éventail d’outils de BI et d’analyse, notamment Tableau, Power BI et Looker. Cela permet aux entreprises d’intégrer facilement Redshift dans leurs flux de travail analytiques existants.
Redshift propose plusieurs modèles de tarification, notamment la tarification à la demande, qui permet aux utilisateurs de ne payer que pour les ressources qu’ils utilisent, et la tarification des instances réservées, qui offre des réductions importantes aux clients qui s’engagent à utiliser Redshift pendant une certaine période. En outre, Redshift offre un éventail de types de nœuds, allant des petits nœuds avec quelques téraoctets de stockage aux grands nœuds avec des pétaoctets de stockage.
Dans l’ensemble, l’évolutivité de Redshift, sa flexibilité tarifaire et sa compatibilité avec les outils d’analyse les plus courants en font un choix populaire pour l’entreposage de données et l’analyse dans le cloud. Son intégration avec d’autres services AWS et sa conformité aux normes de l’industrie en font une solution sûre et fiable pour les entreprises de toutes tailles.
Microsoft Azure
Azure Synapse Analytics, anciennement connu sous le nom d’Azure SQL Data Warehouse, est une solution d’entreposage de données basée sur le cloud proposée par Microsoft Azure. Il s’agit d’un service entièrement géré et hautement évolutif qui s’intègre à d’autres services Azure et offre de bonnes performances sur de grands ensembles de données.
L’un des principaux avantages d’Azure Synapse Analytics est sa capacité à traiter des données structurées et non structurées, y compris des données provenant d’Azure Data Lake Storage. Il offre plusieurs options de tarification, notamment le paiement à l’utilisation, le calcul provisionné et les instances réservées, ce qui permet aux clients de choisir le modèle qui correspond le mieux à leurs besoins.
Azure Synapse Analytics permet l’intégration avec d’autres services Azure tels qu’Azure Data Factory, Azure Stream Analytics et Azure Databricks. Un autre avantage de ce data warehouse est son intégration avec Power BI, qui permet aux entreprises de créer facilement des tableaux de bord et des rapports interactifs pour mieux comprendre leurs données. Il prend également en charge plusieurs langages de programmation, notamment SQL, .NET et Python, ce qui le rend flexible et facile à utiliser pour les data scientist et engineer.
Dans l’ensemble, Azure Synapse Analytics est une solution puissante et flexible pour l’entreposage de données et l’analyse dans le nuage. Son intégration avec d’autres services Azure et sa compatibilité avec les outils d’analyse les plus courants en font un choix populaire pour les entreprises de toutes tailles. Ses options tarifaires et ses fonctions de sécurité en font une solution rentable et sûre pour la gestion et l’analyse de grands ensembles de données.
La gestion des coûts est un élément crucial lors de la mise en place d’un data warehouse pour les entreprises. Il est important de comprendre les différents postes de coûts associés à la construction, l’hébergement et la maintenance.
Les entreprises doivent choisir la bonne plate-forme de data warehouse en fonction de leurs besoins spécifiques, en tenant compte des coûts de licence, des frais de gestion et des coûts de stockage et de traitement des données.
Les options de pricing flexibles offertes par les fournisseurs de cloud computing peuvent aider les entreprises à s’adapter à l’évolution de leurs besoins en matière de données et à maîtriser leurs dépenses. En somme, une planification minutieuse, une évaluation des coûts et un choix judicieux de plate-forme peuvent aider les entreprises à améliorer leur efficacité et leur rentabilité en matière de gestion de données.